
As companies continue digitizing their operations, data is more valuable than ever. But as we wrote in our article Where enterprise software is heading?, the number of applications used in an organization keeps increasing. It is then not surprising to see businesses invest in data platforms to centralized their data.
Once all the data is in one place, it's possible to have a 360 view of the customer journey, control costs, and have real-time accounting. Data is also the fuel needed to run predictions. In the next years, artificial intelligence models will help companies run accurate finance forecasts and it could detect operational anomalies automatically.
However, building a data platform is complex. First, you need to extract the data from all the applications and store it as a single data model. The customer data coming from the CRM and the one coming from the accounting must have the same identifiers and attributes to be consolidated. This is known as Extract Transform Load (ETL). It is said that data engineers spend 80% of their time cleaning and organizing data.
Once the data is stored. Whether it's in a data warehouse or a database, the second step is to build analytic views and models on the data to get insights and create value over the raw data. This is heavy work. The tools at play are complex to configure and you need a data team to benefit from your data platform.
Every business deals with the same data models: Customers, Organizations, Invoices, etc. Yet, they need to redefine manually the data schemas to store their data and create analytics views almost from scratch. So, could this process be simplified?
At Datablist, we believe it's time to have common data models that define all those concepts (Customers, Organizations, Finance, etc.) independently of the applications that store them.
In the past months, the big players (Microsoft, Salesforce, AWS, and Google Cloud) have announced working on unified data models to federate an ecosystem of tools compatible with the same data schemas. Are all of them working on a single data model? No, they have decided to go on a separate road!
What is a data model and why does it matter?
First, we need to define what a data model is. It is made of:
- Entities - Classes that represent business concepts. For example Person, Organization, Product. Entities can be drill-down in nested levels. The entity "Person" can have sub-entities like Contact, Lead, Customer for example. Usually, a data model is composed of few root classes but each one has a nested tree of sub-entities.
- Properties - Entities are empty shells. They need Properties (or attributes) to store information. name is an example of property and the same property could be used in several entities: Person, Product, Organization. Properties are also defined in a hierarchical tree. We can imagine firstName and lastName as sub properties of name.
- Relationships - With the properties, it is possible to define relations. For example, a Product entity would have a brand property that is represented by an Organization value.
- Data validations - On a generic data model, data validation is loose to avoid imposing constraints on the input data. Nevertheless, a data model could define rules to validate mandatory properties or property value types.
Together, Entities, Properties and Relationships compose a data model. It is also called a vocabulary.
So, why is it important? Because it's the first step toward standardization!. Standardization of data organization and expected structure. Data cleaning, the most time-consuming task of any data engineer could be automated (at least partially). When you export data from different applications in a single data model, the consolidation will be automatic.
Then, once the data is stored and consolidated, come the analytics and data visualization parts. A unified data model would bring ready-to-use tools. Instead of building analytics views from scratch, generic views would be used to make dashboards that represent common concepts (revenues, customer churn rate, etc.).
Finally, a unified model would empower non-technical people to work with the data instead of relying on data scientists.
Microsoft and the Open Data Initiative
The first move was made by Microsoft with the "Open Data Initiative" in 2018. Microsoft was joined by SAP and Adobe to agree on a list of data schemas so their respective applications could speak the same language.
The Open Data Initiative has created the Common Data Model (CDM). When exporting customer data from SAP, Adobe, or Microsoft Dynamics 365, among the formats, the Common Data Model is now available.

The full Data Poster is available here and an interactive version here.
Microsoft Dynamics 365 internal data structure is the main source for this data model. It has the advantage of providing a complete and broad model. Entities for banking, education, medical fields are available. On the other hand, the model is very complex and the inner workings of Dynamics 365 are too visible.
This is a smart move from Microsoft and the Azure platform. All the data tools on the Azure platform will be compatible eventually. Obviously, the Azure Data Lake to store data but also the Artificial Intelligence tools that will benefit from standard data structures.
To read more, visit the Microsoft page on the Open Data Initiative: https://www.microsoft.com/en-us/open-data-initiative and the Github repository: https://github.com/microsoft/CDM.
Salesforce and the Cloud Information Model
Recently, at the end of 2019, Salesforce and Amazon Web Services decided to start their own initiative called the Cloud Information Model (CIM). Google Cloud, Twilio and other companies have joined the consortium since.
Unlike the Common Data Model, the Cloud Information Model is not a replication of an existing software data structure. Thus, it is lighter and the number of entities and properties is nothing to compare with the Open Data Initiative. It sounds like a weak point but it is not, in the long term. The project is at the beginning and it will grow slowly. In the end, the data model will be easier to understand and to implement.
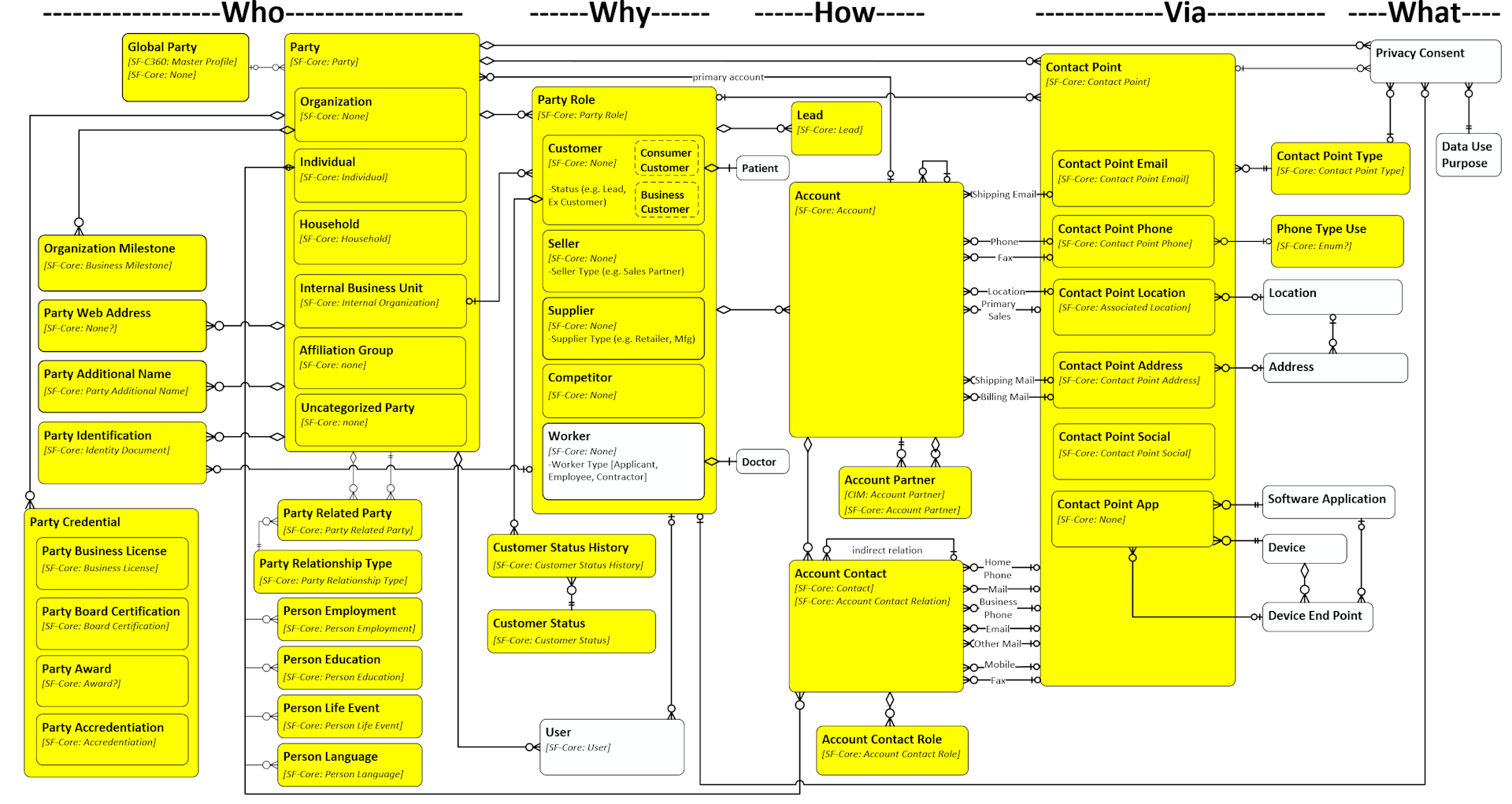
Another difference with the Microsoft data model is the governance of the project. It is open-source and claims to welcome any company that wants to contribute.
On the negative side, the project is less active than the Common Data Model. Salesforce has announced it would be available on Salesforce Customer 360 and Salesforce Mulesoft solution is compatible, but that's all. The ecosystem doesn't exist yet.
With AWS and Google Cloud on board, we will see if they implement it on their big data tools.
To read more, visit the Cloud Information Model website and the Github repository https://github.com/cloudinformationmodel.
Do we need several data models?
One can ask why Salesforce, AWS, and the other members of the Cloud Information Model haven't joined the Microsoft initiative and decided instead to go alone. Clearly, this has to do with having control over the course of the project and be at the center of the future ecosystem.
But it doesn't matter. Both models share common entities and properties. A property from one will have a matching property on the other. We might see data format converters to translate data from a vocabulary to another one, in the same way, we have PNG, JPEG, etc. to store images and converters to go from one format to the other. Competition has always been an accelerator for innovation.
What about Datablist?
At Datablist, we are building our own data model using the W3C standard JSON-LD. The Cloud Information Model (CIM) also uses JSON-LD to structure its data model. Technologically speaking, our data model is quite similar to CIM. Unfortunately, at the moment, the CIM model has a narrow list of business domains (basically Customer, Payment, Product, Order) and is not stable. To move fast, we will continue building our own data model.
Data interoperability is coming. The 2020 decade will be all about data!