
You have exported your data from an application in a CSV file and want to get rid of the duplicates? You have concatenated several CSV files into a big one and now need to clean it? Or maybe you have several sources of data no longer in sync and want to merge all those versions into a single listing. Microsoft Excel or Google Sheets will not help you with your problem because they don't allow you to set up a unique constraint on a column.
On a small CSV file, this task can be done manually. On bigger files, it would take hours to process the entries one by one. And you risk human errors.
What you need is a tool to automatically detect CSV entries with similar values in one or several columns. Then, once the duplicates are found, you can edit or merge them to consolidate their data and remove the duplicates.
Merge duplicates from CSV files

Datablist is great to perform data operations that are not possible with spreadsheets. Use it when you are looking for a great online CSV editor.
In this guide, we will work with 2 CSV files that contains thousands of entries. We will load them into a single collection and de-duplicate entries based on 1 of the 4 columns. Deduplication also works on a single CSV file.
To download the tutorial CSV files: CSV File 1 and CSV File 2
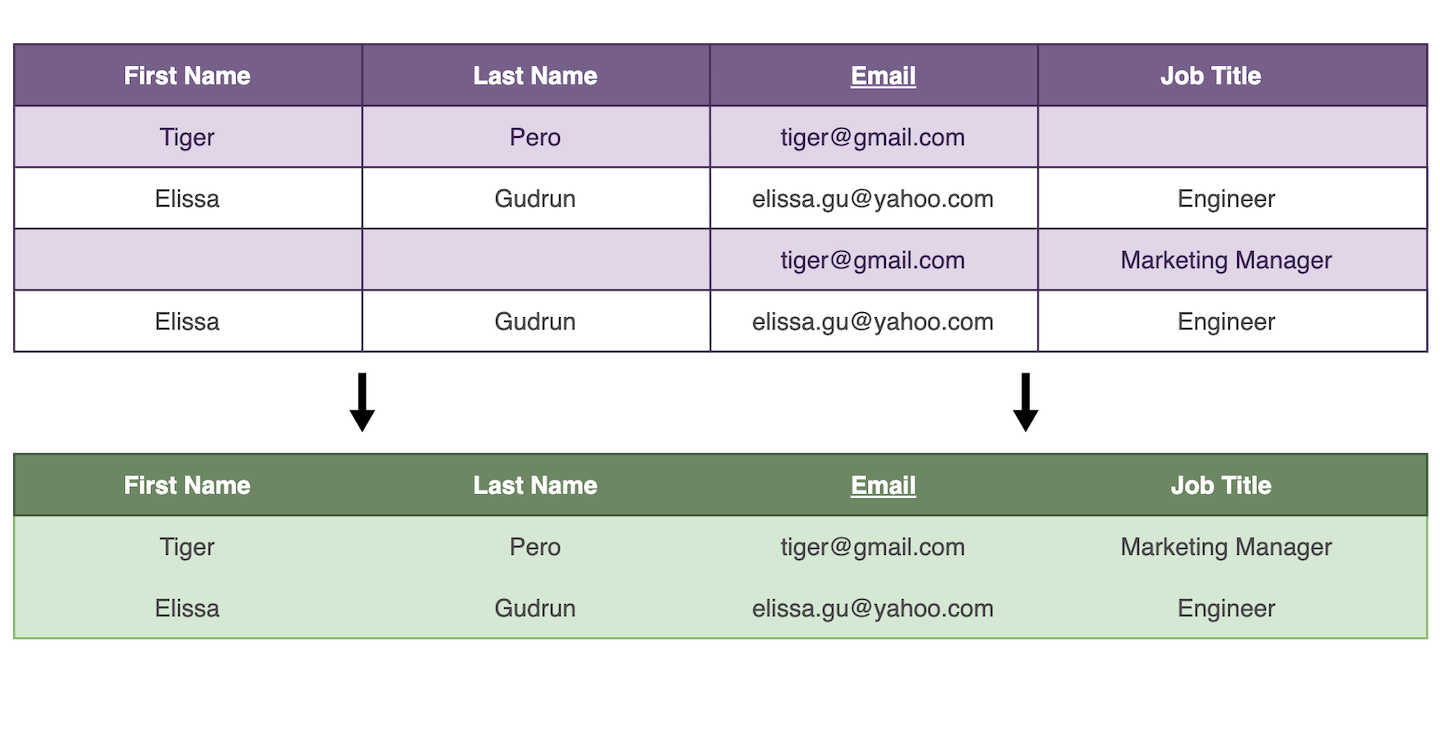
The CSV file contains 4 columns: First Name, Last Name, Email, Job Title. We want to merge entries that share the same email address.
The process to merge duplicates can be summed up with:
- Load your CSV files into a Datablist collection
- Select the properties to perform the duplicates check
- Merge automatically non conflicting duplicates
- Merge manually remaining duplicates
Step 1: Load your CSV files into a Datablist collection
Create a new collection
The first step in our process is to load the CSV file into Datablist. Open Datablist (No signup required) to get started.
To create a new collection, click the "New collection" button with the +. Once the collection is created, give it a name and an icon.
Then click on the Import CSV button.
Create properties for your CSV file
With the CSV file now loaded, you can create properties for your collection using the CSV column names. Datablist lists every column found in the CSV so you can create a property for each of them.
CSV data is not typed. When reading a CSV file, everything is a text. To provide better filtering and sorting features, Datablist tries to detect data types by looking at the first 100 lines. For example, when it finds only numbers, it set the property data type to number. Same with date, email, checkboxes (true or false values), etc.
Review and import
In the review step, the CSV rows will be listed directly from the CSV file. Be sure the data is well formatted and is consistent. Then click the "Import items" button and you are done! 💪
Do it again for your other CSV files
Now you have a collection with properties configured, perform the "Import CSV/Excel" process to import your other CSV files or Excel files into the same collection.
Step 2: Find duplicates
After loading the CSV files, the second step is to search for duplicate values. In the collection data listing, click the "Duplicates Finder" button in the "Clean" menu (top right).
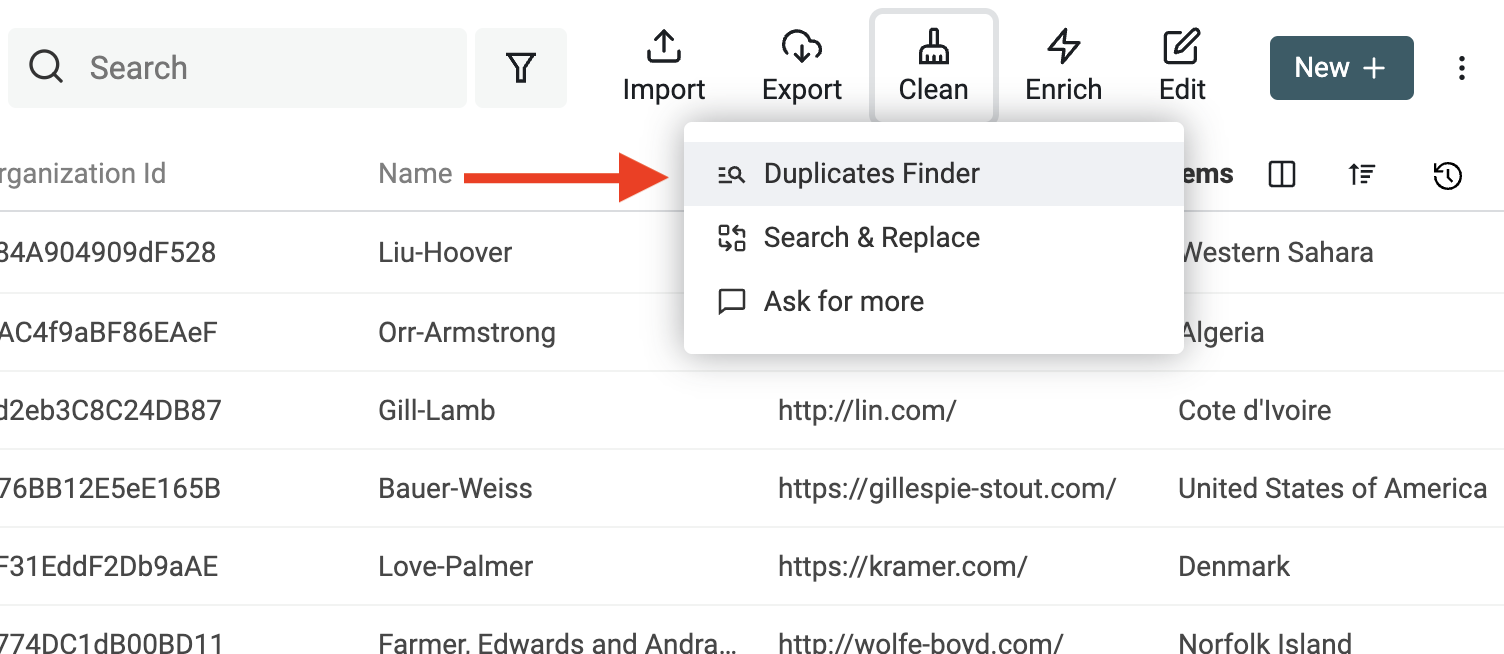
Two modes are available:
- All Properties - In this mode, Datablist looks for items with similar values for all properties. Two items would be considered similar when all of their properties match.
- Selected Properties - For this second mode, you will select the properties to be used for similarity check. Two items would be considered similar when they have similar values on all the selected properties.
Here, the email property is enough to identify a contact, so you can select the Selected Properties mode with the email property.
Once the analysis is done, Datablist lists all your duplicate items based on the email property. For each items with one or more duplicates, you can:
- Edit the item - Use values from incomplete items to merge the data into a single item.
- Merge duplicates - Merge values from secondary items to a selected primary item.
- Delete the extra items - When duplicates don't bring value, just remove the duplicates
Step 3: Merge and combine duplicates automatically
Usually, you want to merge all your CSV duplicate rows into a single item and consolidate the data. Thus, merging duplicates without losing data in the process.
Datablist comes with an automatic algorithm to merge most of the duplicates without data loss. For the remaining duplicate rows, a manual merging assistant is available.
Deduping big lists can be time-consuming. Datablist Auto Merger processes your duplicates in bulk and merges them automatically when possible.
Three merging algorithms are available: Merging non-conflicting rows, Combining duplicate values and Dropping conflicting values. Check our documentation on finding duplicates to learn more.
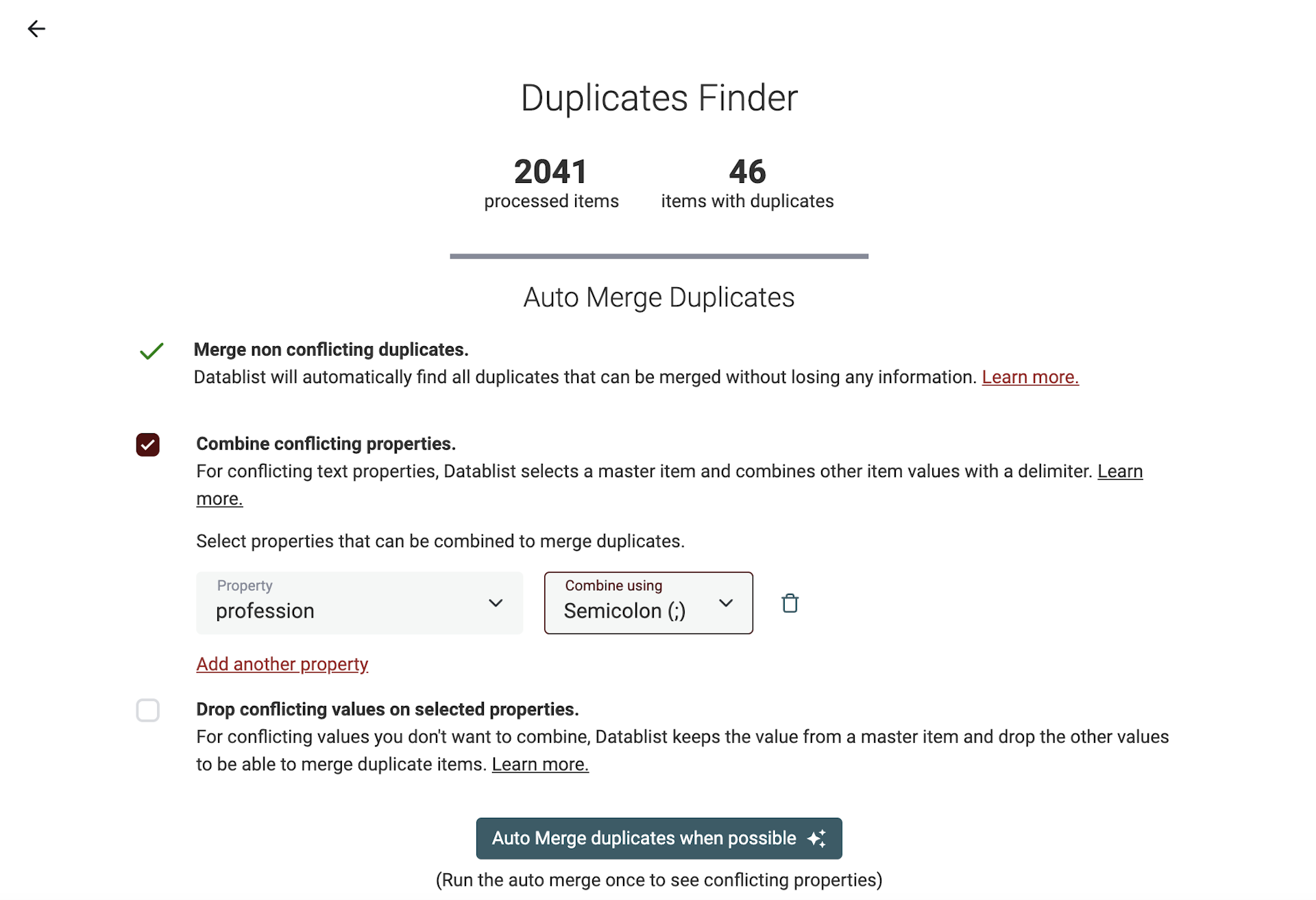
Run with the "Merge non conflicting duplicates" algorithm first to see properties with conflicting values.

Merging non-conflicting rows
The "Merge non-conflicting duplicates" algorithm run a "smart merge". It works by merging records with similar or complementary values.
For example, the following duplicates:
email | First Name | Last Name
james@gmail.com | James
james@gmail.com | | Bond
Will be merged into:
email | First Name | Last Name
james@gmail.com | James | Bond
Combining duplicate values
Combining (or consolidating) duplicate values is perfect when your duplicates have conflicting values but you still want to merge them without losing data.
For example, combining the Phone property with a semi-colon:
email | Phone | First Name | Last Name
james@gmail.com | +33 1 34 65 23 | James |
james@gmail.com | 06 13 42 78 23 | | Bond
Will be merged into:
email | Phone | First Name | Last Name
james@gmail.com | +33 1 34 65 23;06 13 42 78 23 | James | Bond
Any property containing text can be combined. The available delimiters are line break, semi-colon, comma, and space. One or more properties can be combined during the merging.
Merging duplicate items and combining values is ideal for leads and CRM cleaning. Merge all your duplicate leads and combine the Phone, Email, Notes properties to have a clean list. And after exporting your clean lead CSV, just reimport it into your CRM.
Drop Conflicting Values
This algorithm keeps the value from a master item and deletes other conflicting values to merge leads into a single record.
The item with the most properties with data is selected as the master.
Use the drop conflicting values option for:
- Technical properties such as
Account Idthat require a single value. - Properties that are "Relation" and can't have multiple values. For example
Lead owner,Account. - Non-text properties that can't be combined. For example datetime such as
Last Activity,Contacted on, and checkboxes.
Step 4: Manual Merging Assistant
When duplicates remains after the Auto Merge, use the Merging Assistant. To merge duplicates, click on the "Manual Merging assistant" button on the left of every duplicates group.
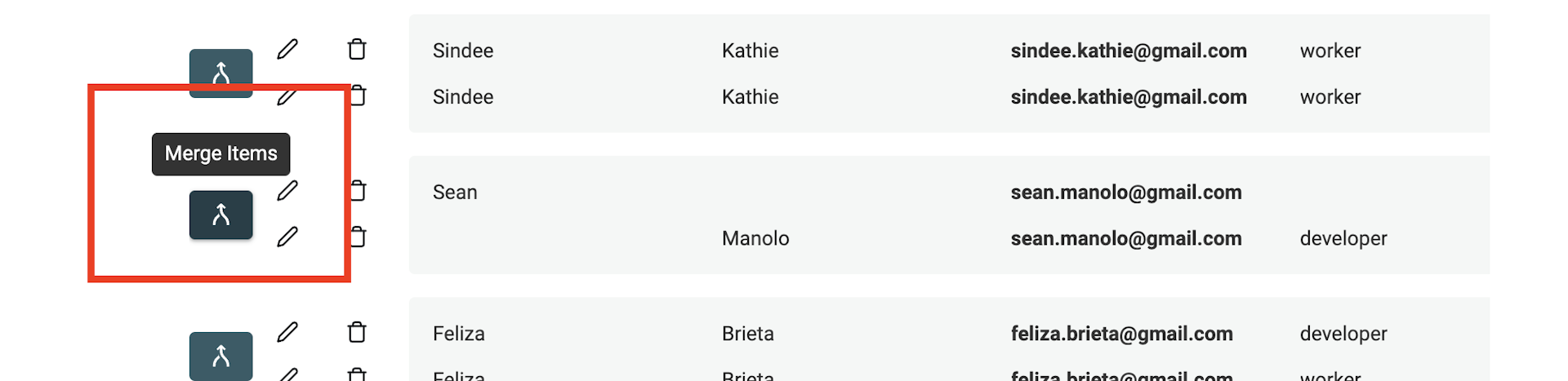
It opens a merging tool. On the right, a "Primary Item" is shown and on the left the remaining duplicate items are called "Secondary Items". Datablist elects the item with the most data as "Primary item".
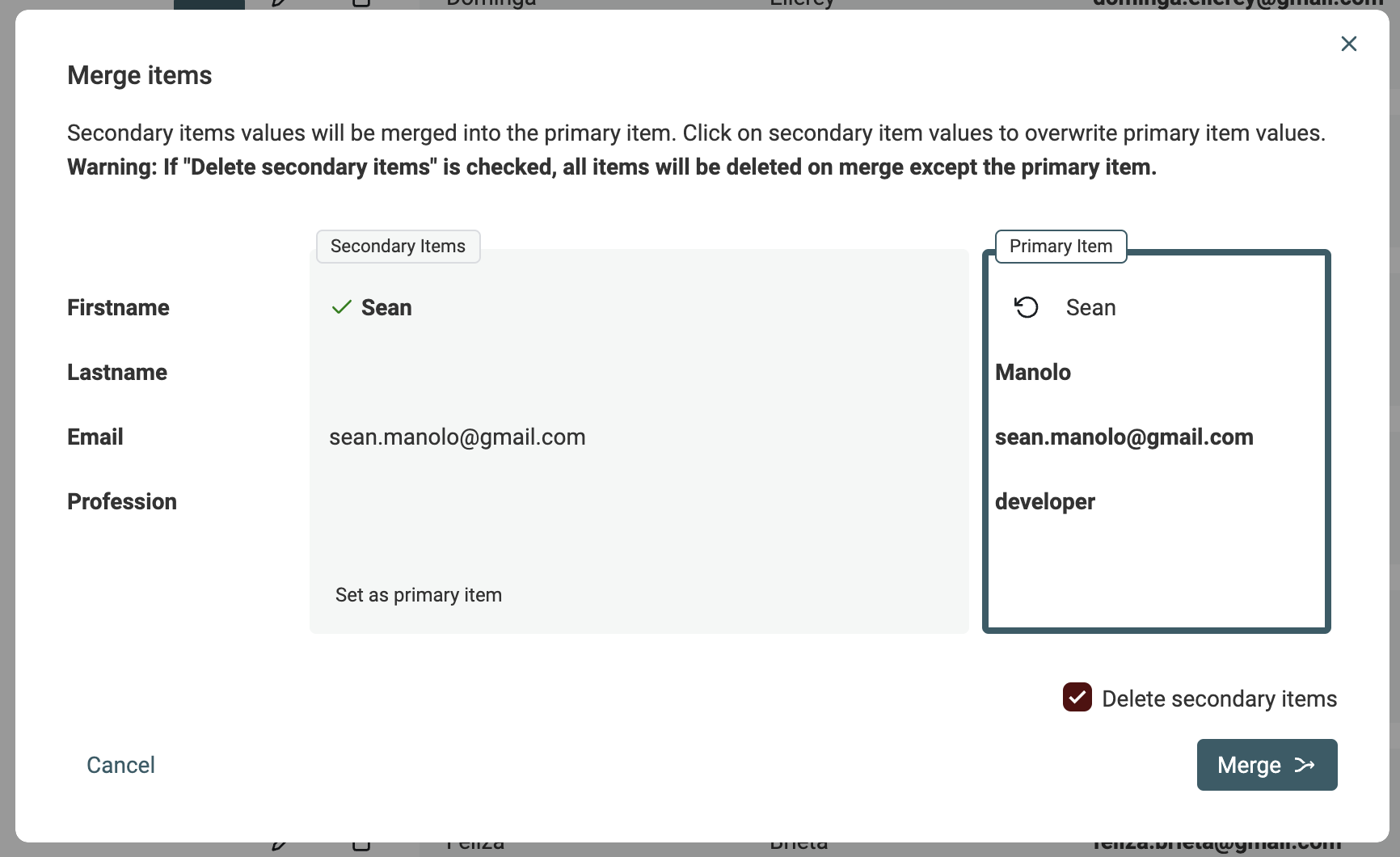
When possible, property values from secondary items are auto selected to be merged into the primary items. If several values conflict, you will have to make a decision and select which value to keep.
If the resulting "Primary item" suits you, click the Merge button to confirm the merge process. All the secondary items will be deleted to keep only one combined item.
Export to CSV if needed
Congrats, you have successfully deduped your CSV files! If you need to use the result in another tool, click on the "Export" button to export the collection as another CSV file.
FAQ
What are the other data manipulations available with Datablist?
CSV files are everywhere to define structured data for software applications or data sets. Despite being ubiquitous, CSV manipulation is hard and often requires technical knowledge.
For simple manipulations, spreadsheets are enough. However, they are limited when it comes to:
If you have several CSV files that you want to join together using a unique column, go to the join CSV files guide.
Can Datablist handle big CSV files?
Datablist handles CSV files with up to 1.5 million of rows. Datablist is built not only to open CSV files but to edit them. To view bigger files, you can use analytics solutions. To edit big CSV files, Datablist is still one of the best solutions.
Is the deduplication algorithm better than Microsoft Excel and Google Sheets "remove duplicates" features?
Spreadsheet tools (Microsoft Excel, Google Sheets) have a deduplication tool. It works by removing similar rows. For business use cases, simply removing rows is not ideal.
Datablist deduplication algorithm merges duplicate records. First by doing smart merging, then by combining values, and the last option is to merge records by electing a master record.
If you have any questions, please contact us.