Import files up to 500k items
Another milestone in Datablist handling large collections. After moving the limit from 10k to 50k in April, I've been able to increase it ten-fold in May to 500k. From 10k to 500k in 4 months is a big step forward. When importing a data file (like a CSV file), the data is parsed, and stored in a local database. Datablist uses a database to filter, sort the data, and save edits. In my test, importing a 500k file takes less than 2 minutes. My goal is to import and edit files up to 1 million items.
Join big CSV files
In the process of increasing the number of items in a collection, I've rewrote some features. The algorithm to join several CSV files on a unique key has been improved to handle bigger collections and edge cases.
Joining two CSV files with hundred of thousand of items is now possible.
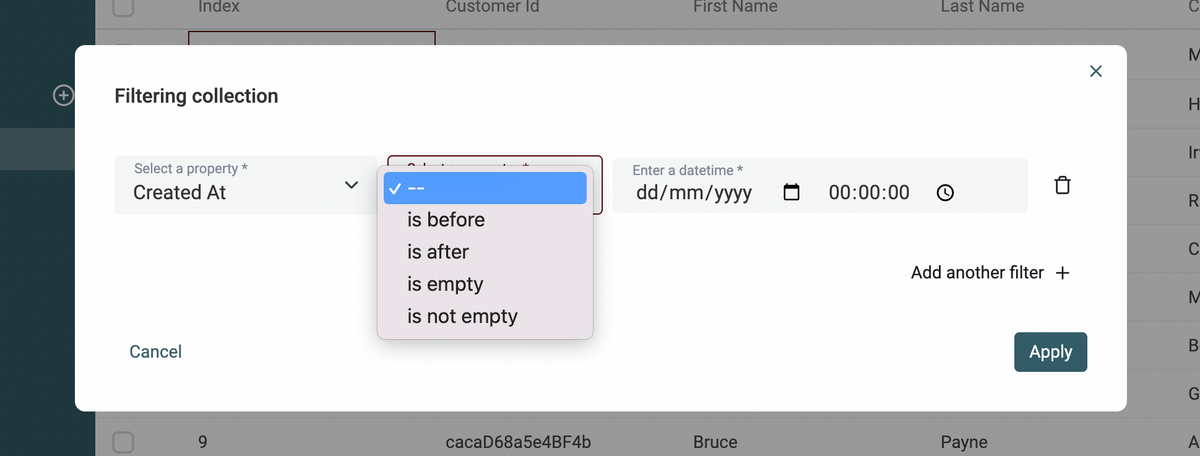
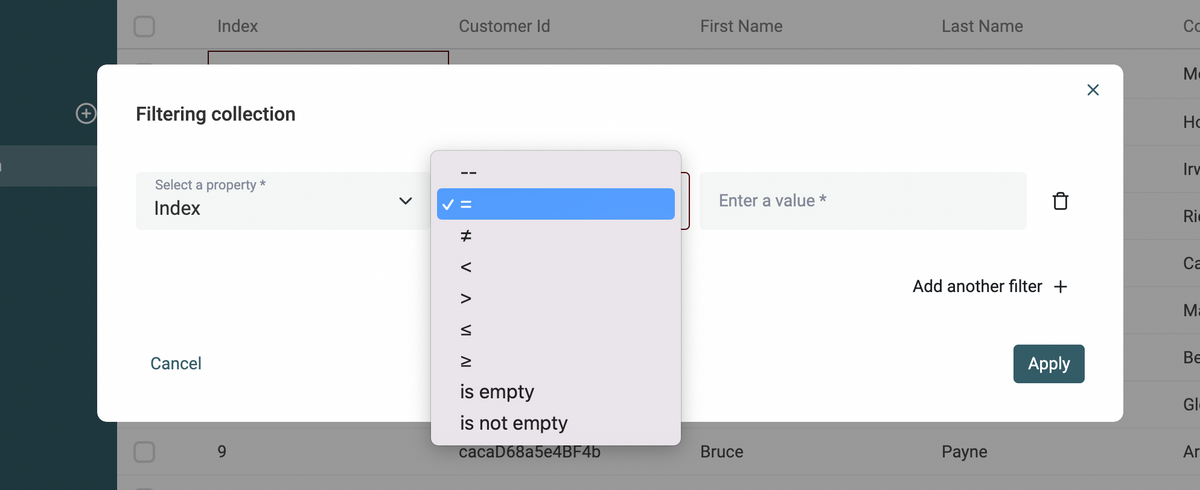
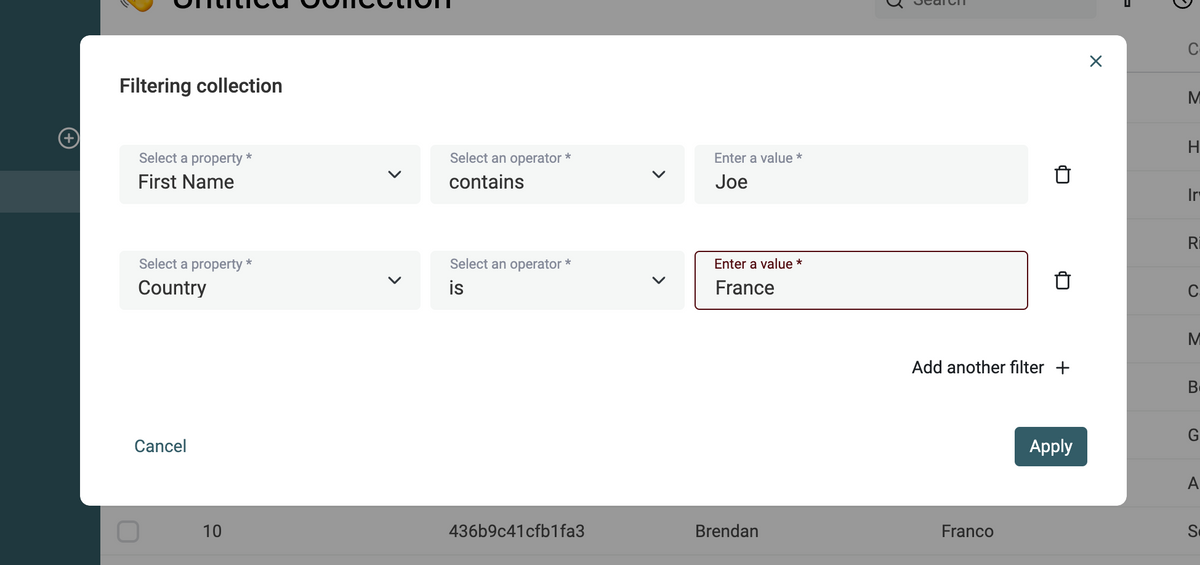
Collection Filters
Filtering data is finally available on Datablist. Select one or several filter conditions to show a subset of your collection items. Filtering conditions depend on your data types. Number properties can be filtered on numerical operators, DateTime values are filtered related to timestamps. To export your filtered view, select all items and click on "Export selected items".
Auto create properties during first import
Datablist is both used by regular users and users coming from Google who wants to perform a single task (like deduplicating a CSV file). The import process must be as straightforward as possible. On an empty collection, when importing a file, properties are auto-created using column names and detected data types. If the collection already has properties, the mapping process is shown.
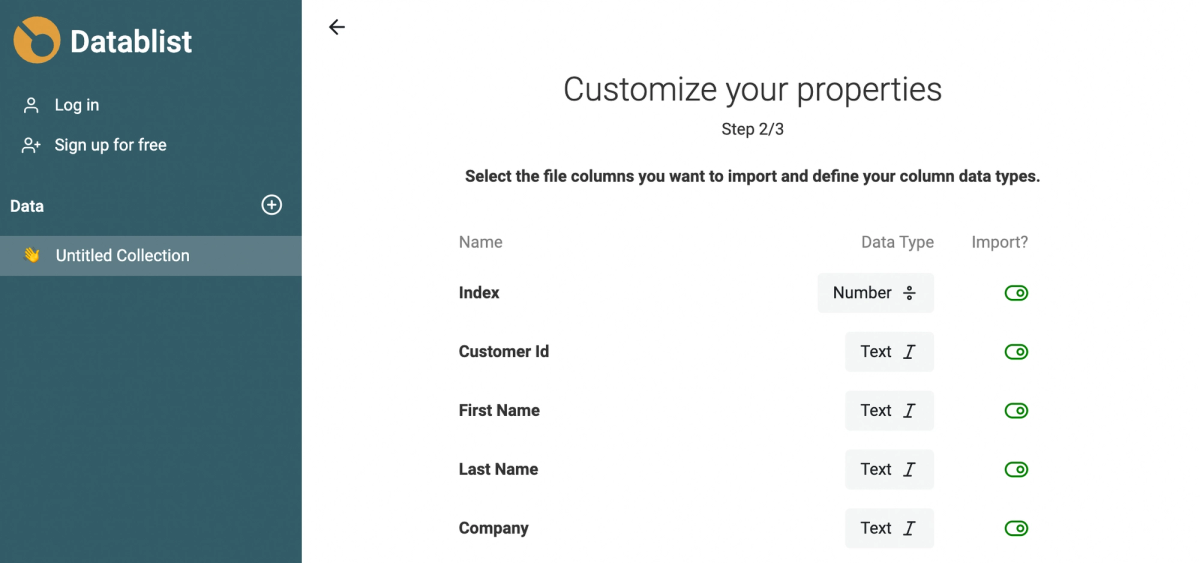
Clone collection
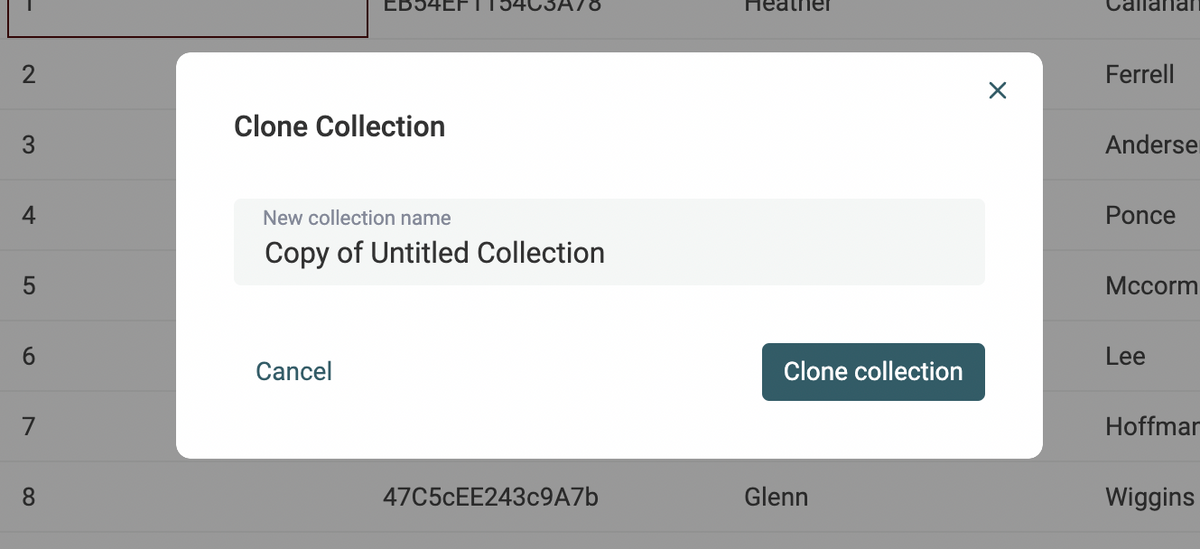
Instead of exporting a collection to a CSV file to re-import it in another collection, you can use the shortcut "Clone collection". All the properties and the collection items are duplicated in a new collection.
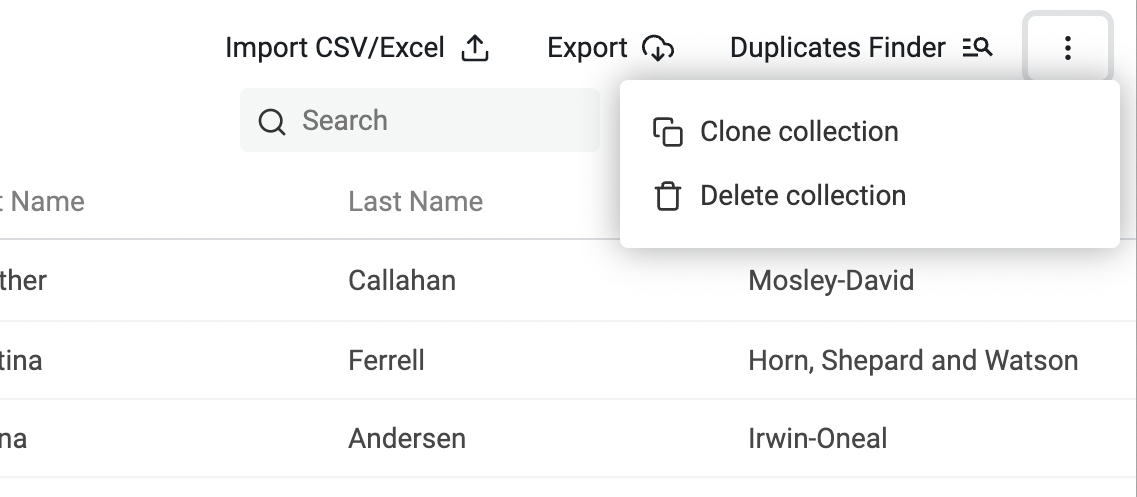
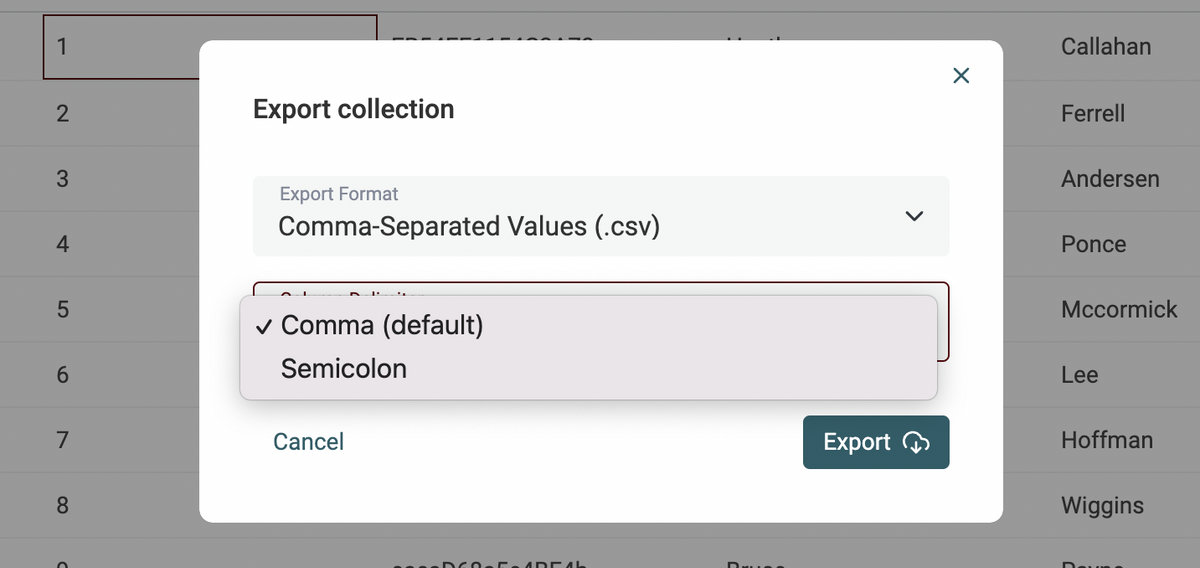
Select CSV Export separator
When exporting your data to a CSV file, a new option to select the separator character is available. Choices are "comma" (default) and "semicolon".