Import files up to 50k items
In April, I released a first step toward managing a higher number of items with Datablist. From 10k items per collection, the limit has been increased to 50k items.
A lot has changed just to multiply the limit by five. Instead of loading all the data in memory (like all spreadsheet tools), Datablist now loads it on demand from a local database. The user interface is still responsive and easy to use. And this stack will scale well to millions of items (at least it does in my head 🤞).
Performance Improvements
Faster file import
Importing files (CSV/Excel) into a collection for registered users has been improved. Previously, items were saved in the cloud during the file import process. For big files with thousands of items, this leads to frustrating seconds/minutes waiting for cloud sync before accessing the data.
Cloud sync is now asynchronous. Access and manage your data instantly after importing a file while the data is being synced to the cloud in the background.
Faster duplicates finder
Duplicates finder algorithm has been improved. It is now faster with big collections.
Also:
- Duplicates comparison is now case insensitive.
- DateTime values are now compared
- Duplicates on empty values are skipped
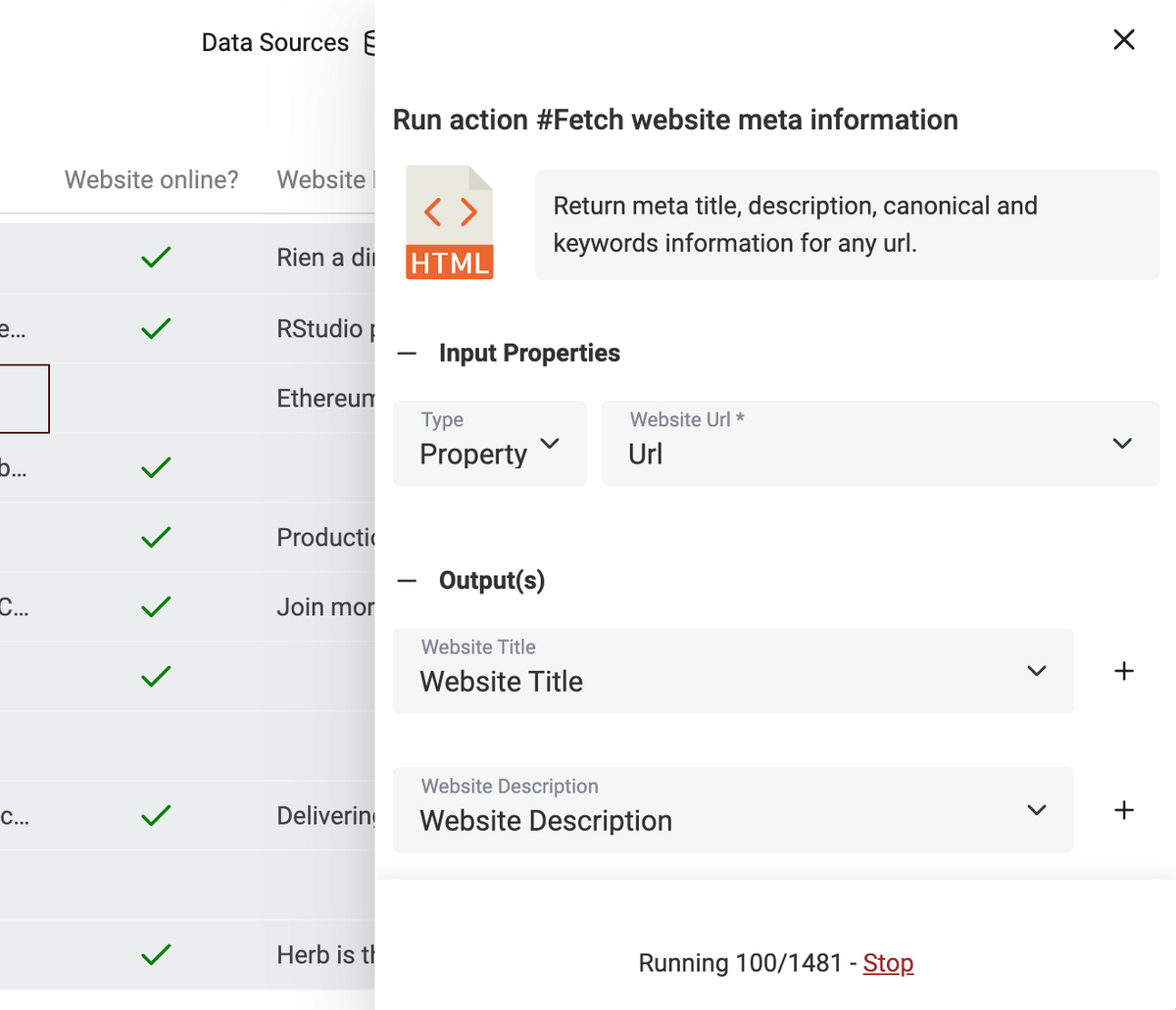
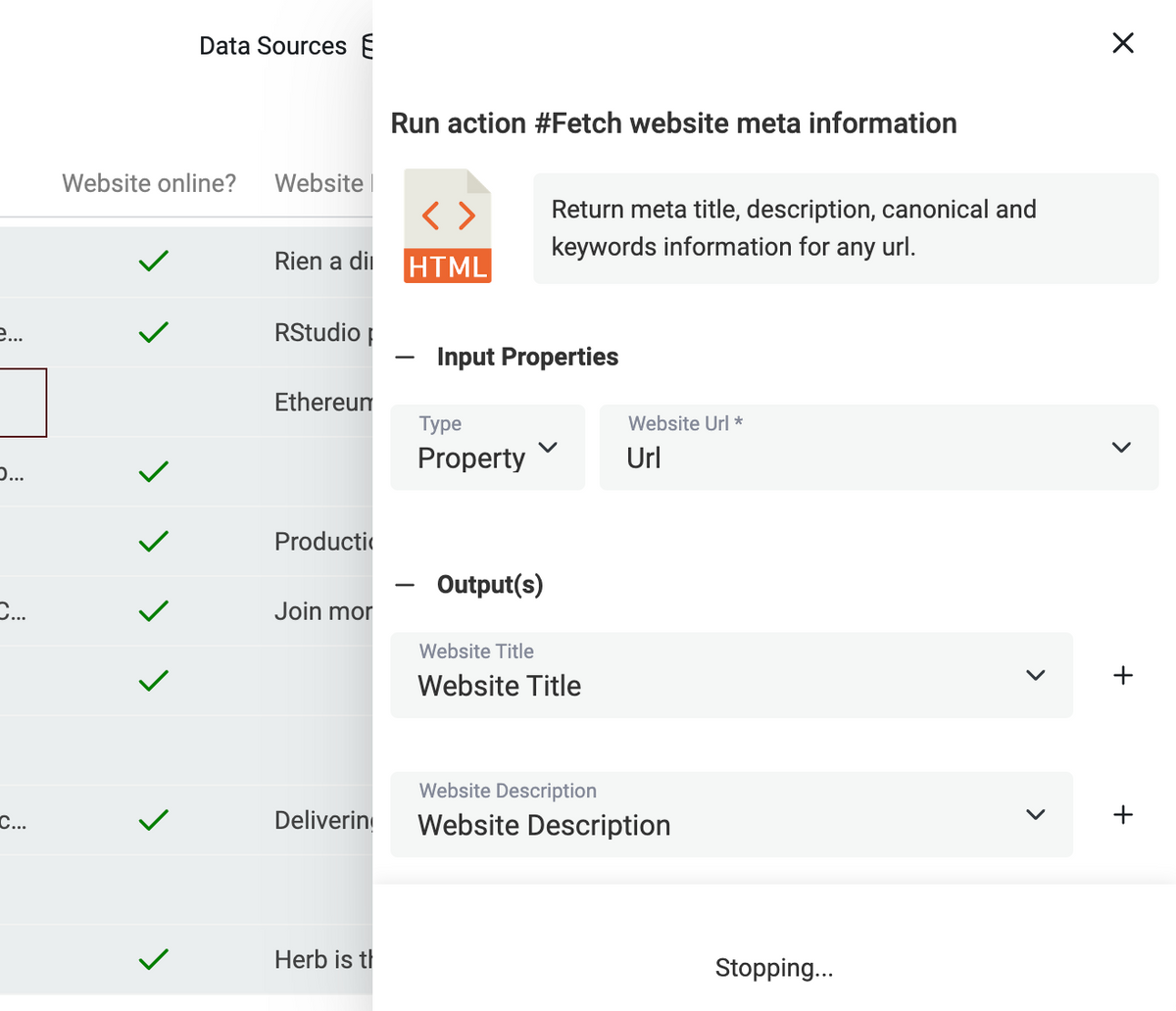
Action Runner for big collection
Running actions (verify email addresses, find a LinkedIn profile for an email address, etc.) on thousands of items was challenging. The action runner now split the collection into small parts (chunks) and sends them in sequence. A stop button is available to stop the action before processing all the items.
Better errors handling
A lot can happen in a web application. Internet can be lost, servers might have intermittent issues, etc. Shit happens 🤷♂️
I continue to improve how Datablist web client deals with any errors. Retries, showing feedback, etc.