

Se crei liste prospect da dati ottenuti via scraping, ti imbatterai in questo problema: Come pulisco e normalizzo i miei dati?
Se hai provato a farlo con Google Sheets sai che non è lo strumento giusto.
I dati provenienti da LinkedIn hanno spesso un campo "full name", mentre altre fonti separano in "first name" e "last name". Le email possono contenere refusi dovuti allo scraping. Le date arrivano in formati diversi, ecc.
Con questa guida, imparerai a risolvere il 99% dei problemi tipici dei dati scrappati. Per l'1% rimanente, contattami e ti aiuto 👨💻
Ecco un rapido riepilogo delle principali operazioni di pulizia descritte in questo articolo:
- Converti testo in Datetime, Number, Boolean
- Converti HTML in testo (rimuovi tag HTML)
- Rimuovi spazi extra dai testi
- Normalizza i tuoi dati
- Rimuovi simboli dai testi
- Dividi Full Name in First Name e Last Name
- Deduplica gli elementi
- Valida gli indirizzi email
- Estrai nomi di persone o aziende dai testi
Importa da CSV o copia-incolla dati
Datablist è perfetto per fare data cleaning. È un online CSV editor con funzioni di pulizia, modifica massiva e arricchimento. E scala fino a milioni di item per collection.
Apri Datablist, crea una collection e carica il tuo file CSV con i dati scrappati.
Per creare una nuova collection, clicca sul pulsante + nella sidebar. Poi clicca "Import CSV/Excel" per caricare il file. In alternativa, usa lo shortcut dalla pagina iniziale per andare direttamente allo step di import.
Riconoscimento automatico del formato
L'assistente di import di Datablist rileva automaticamente email, Datetime in ISO 8601, Boolean, Number, URL, ecc. quando sono formattati correttamente.
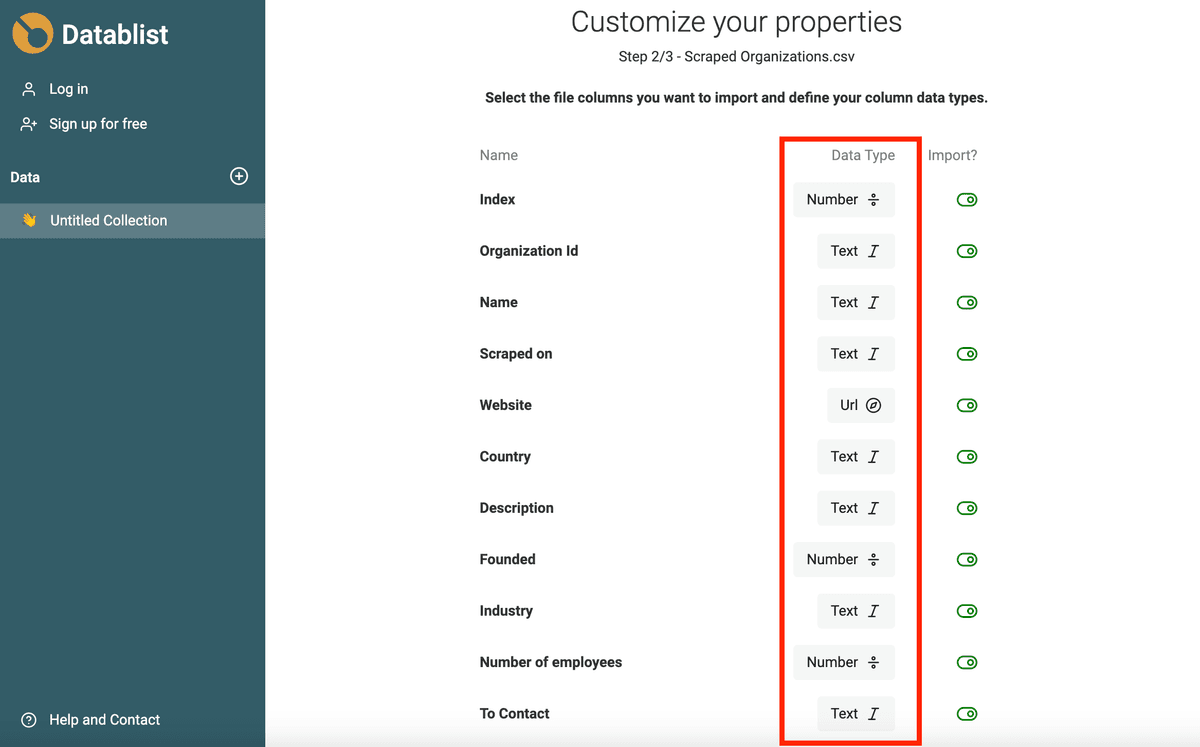
Se i tuoi dati richiedono un'analisi più complessa (formati data diversi, refusi in URL o email), importali come proprietà di tipo Text. Nella sezione seguente vedrai come convertirli in Datetime, Boolean o Number.
Converti testo in datetime, boolean, number
Marie Kondo dice: "La vita inizia davvero quando metti in ordine la tua casa". Con i dati scrappati è uguale: "Le vendite iniziano davvero quando metti in ordine i tuoi dati"! 😅
Filtrare per una data (creation date, funding date, ecc.), un numero (prezzo, numero di dipendenti) o un boolean è molto più semplice quando sono oggetti nativi e non testo.
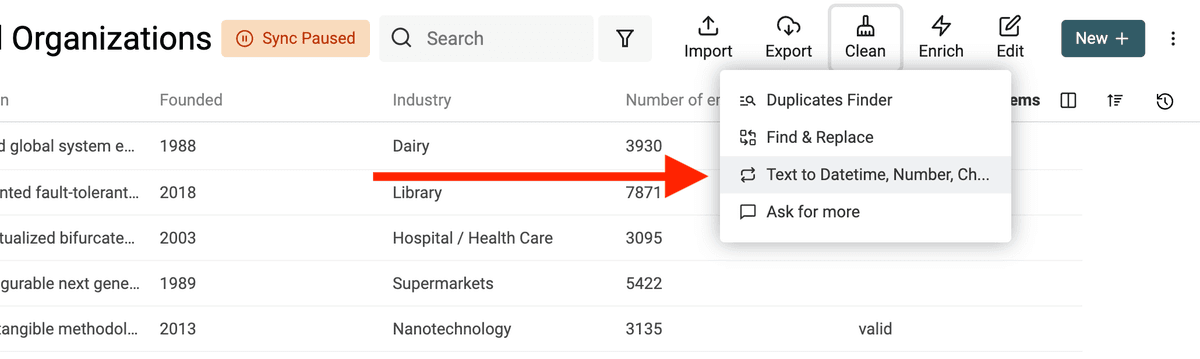
Apri lo strumento "Text to Datetime, Number, Checkbox" dal menu "Clean".
Converti qualsiasi testo in formato Datetime
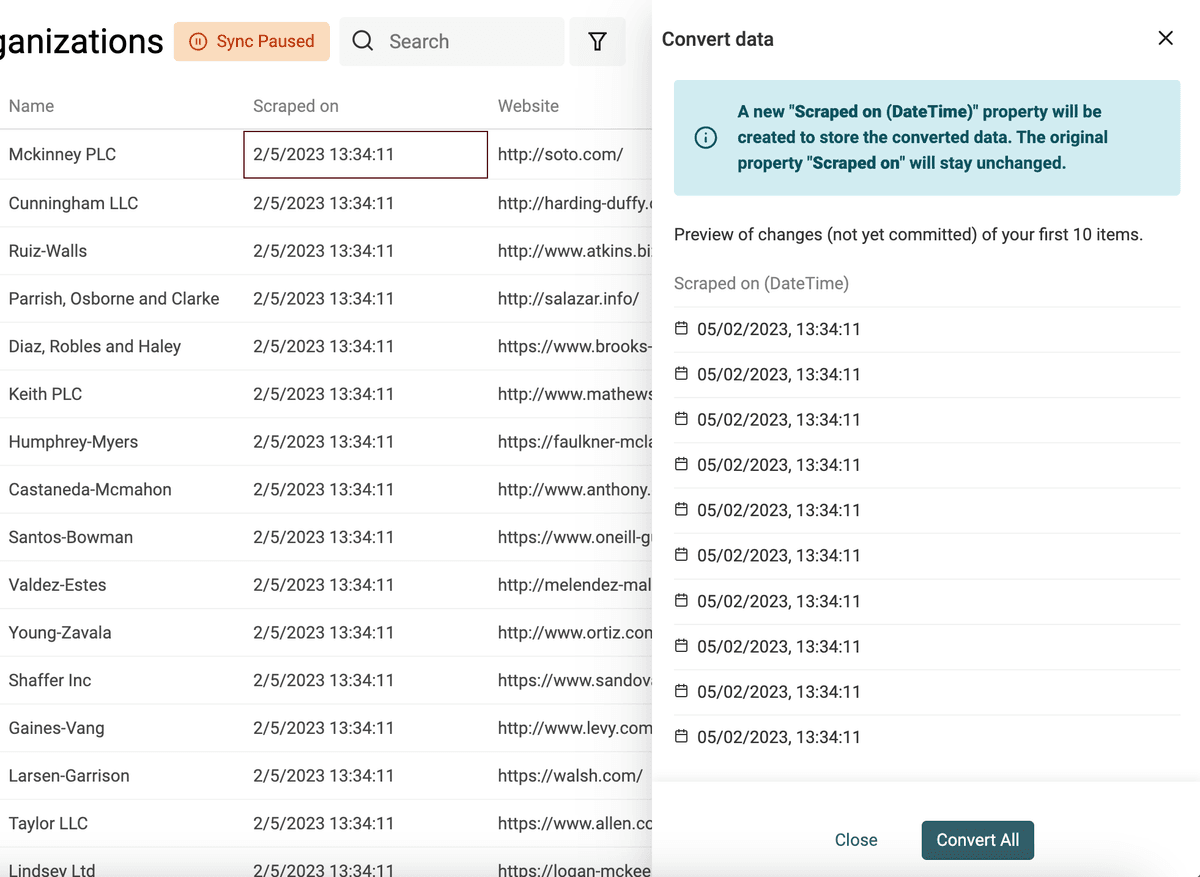
Datetime ha un formato internazionale chiamato ISO 8601 con una struttura definita. Se i tuoi dati usano l'ISO 8601, durante l'import verrà creata automaticamente una proprietà Datetime per conservarli.
Per date e datetime in altri formati, devi specificare il formato utilizzato così che Datablist possa convertirli in valori strutturati Datetime.
Seleziona la proprietà da convertire e scegli "Convert to Datetime".
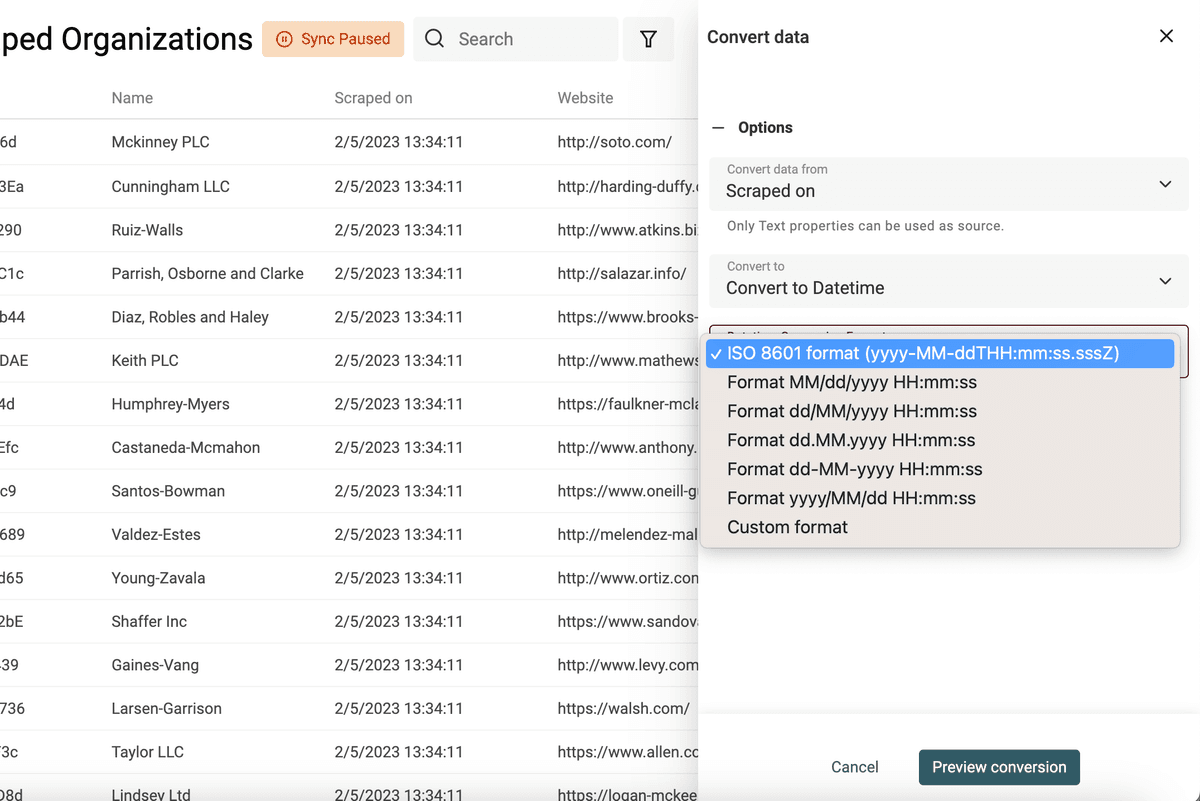
Troverai i formati più comuni (quelli usati da Google Sheets ed Excel) oppure seleziona "Custom format" per definire un formato personalizzato.
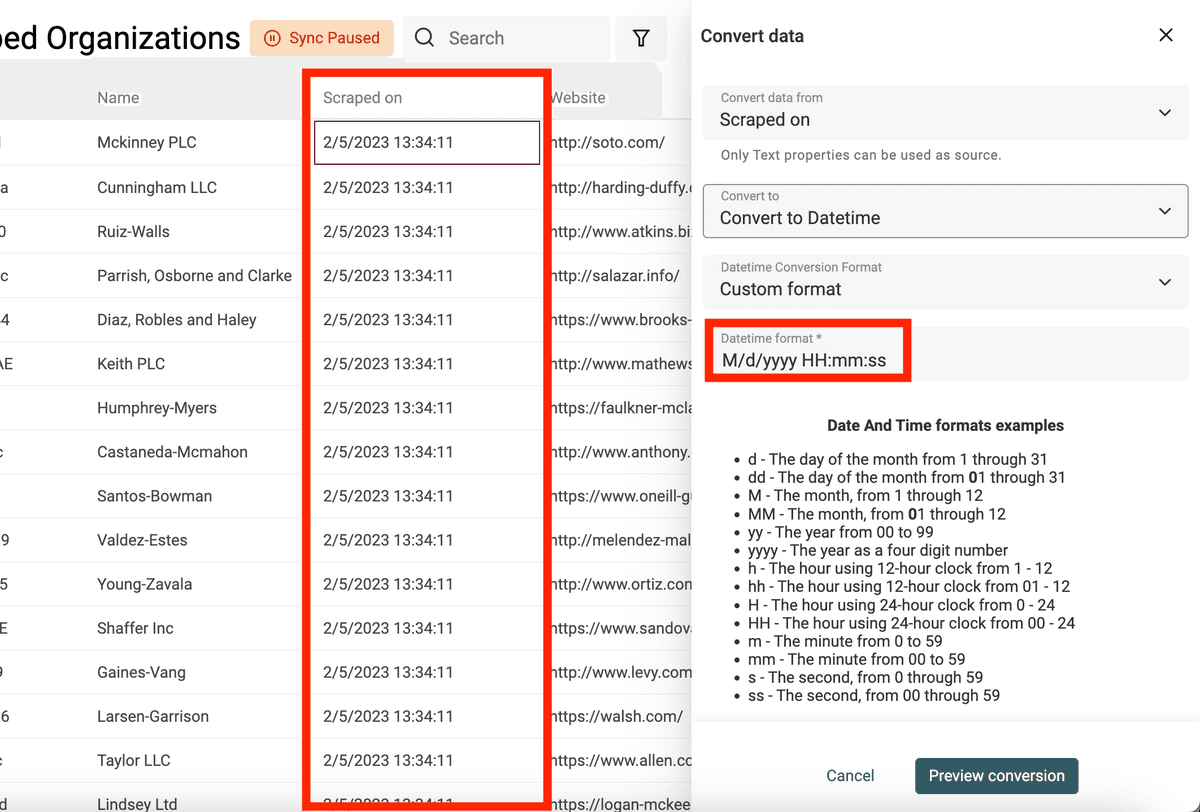
👉 Visita la documentazione per i formati datetime personalizzati.
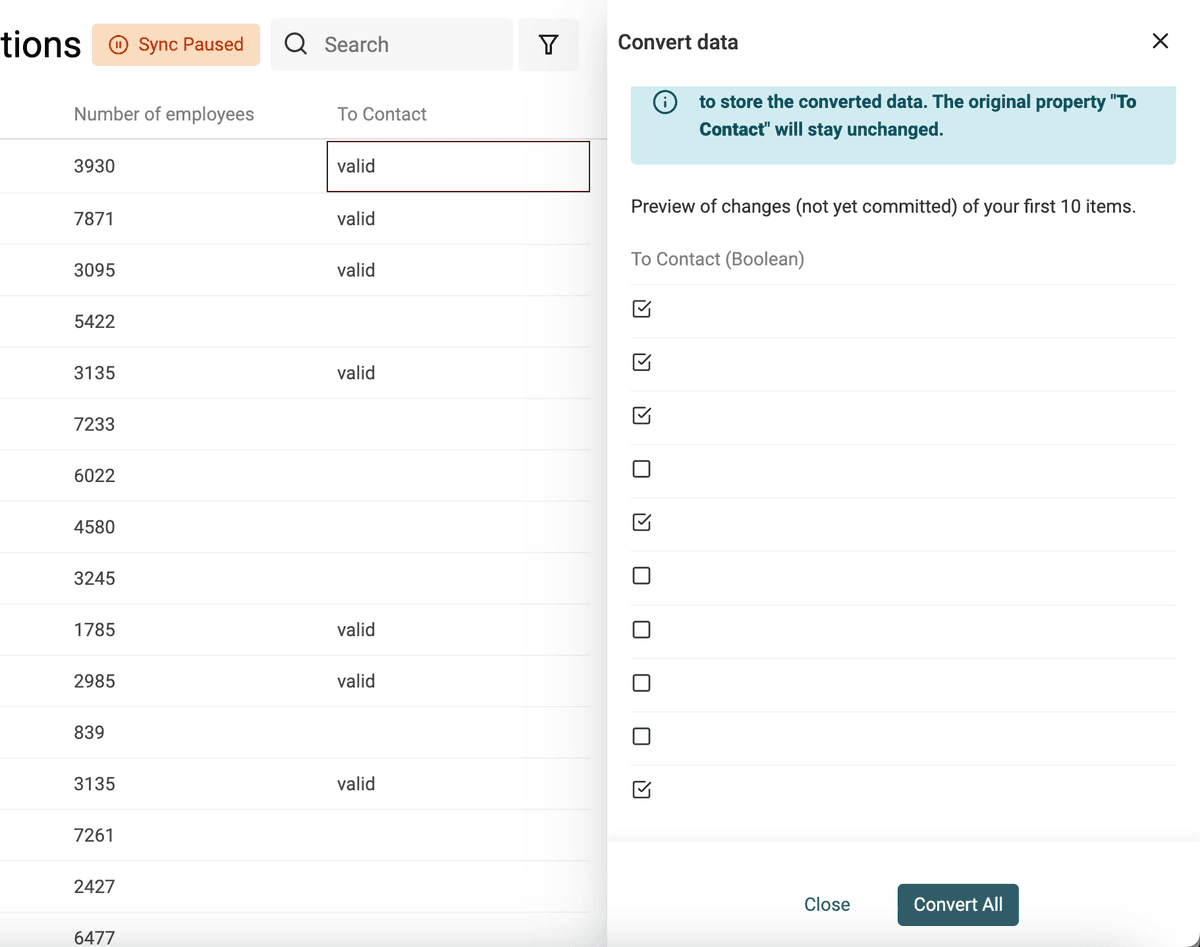
Crea Checkboxes (Boolean) dai valori di testo
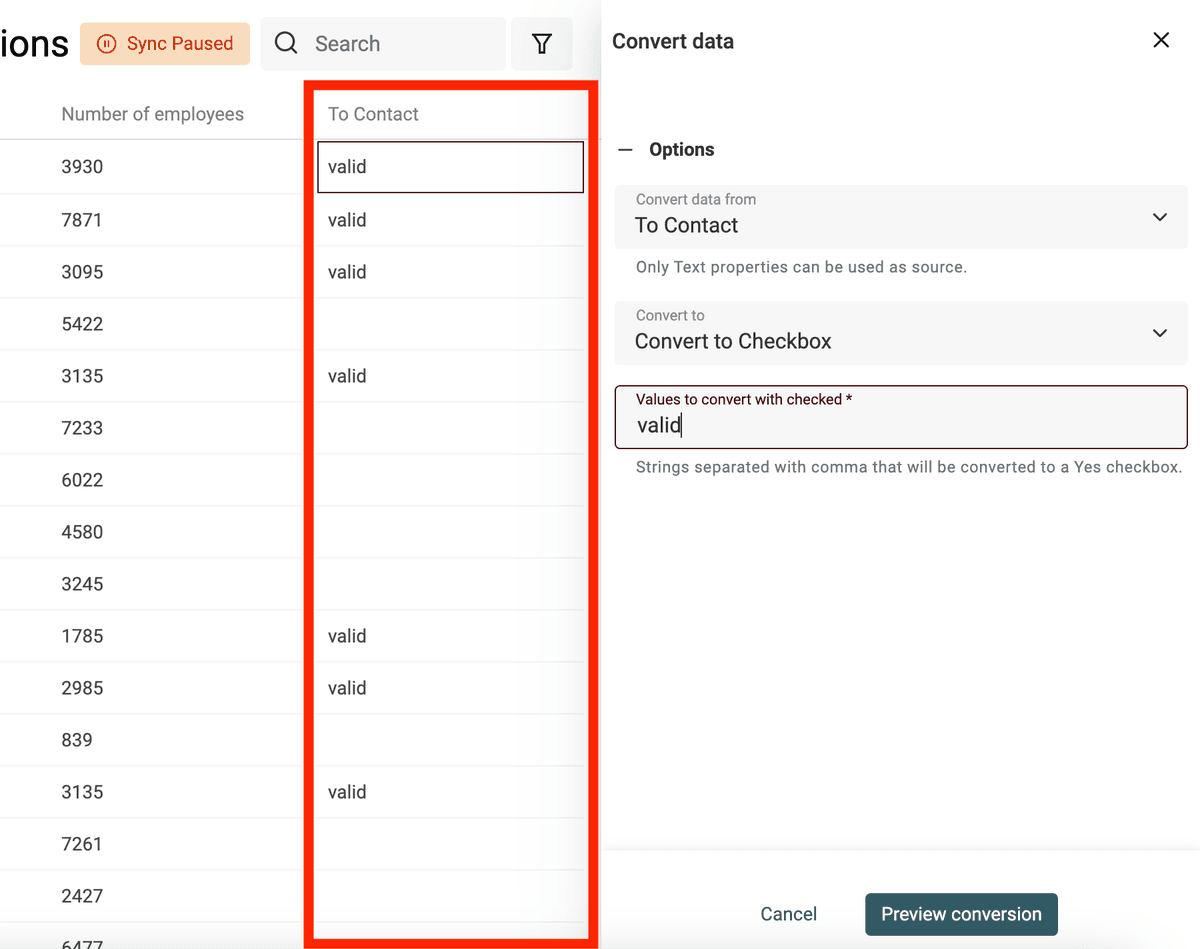
Datablist converte automaticamente colonne con "Yes, No", "TRUE, FALSE", ecc. in proprietà Checkbox all'import. Usa il converter per casi più complessi.
Definisci i valori (separati da virgole) da convertire in checkbox selezionata. Gli altri resteranno deselezionati.
Estrai valori numerici dai testi
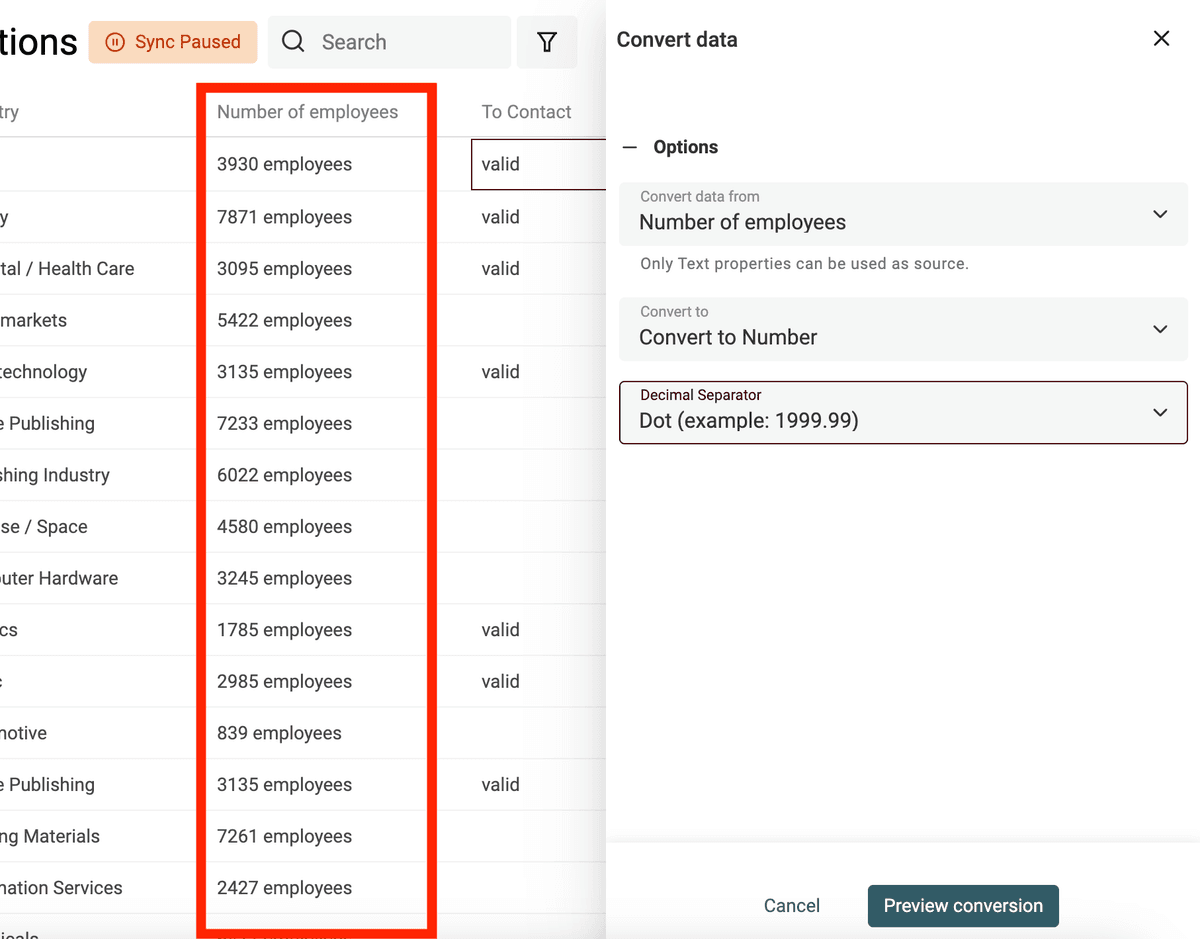
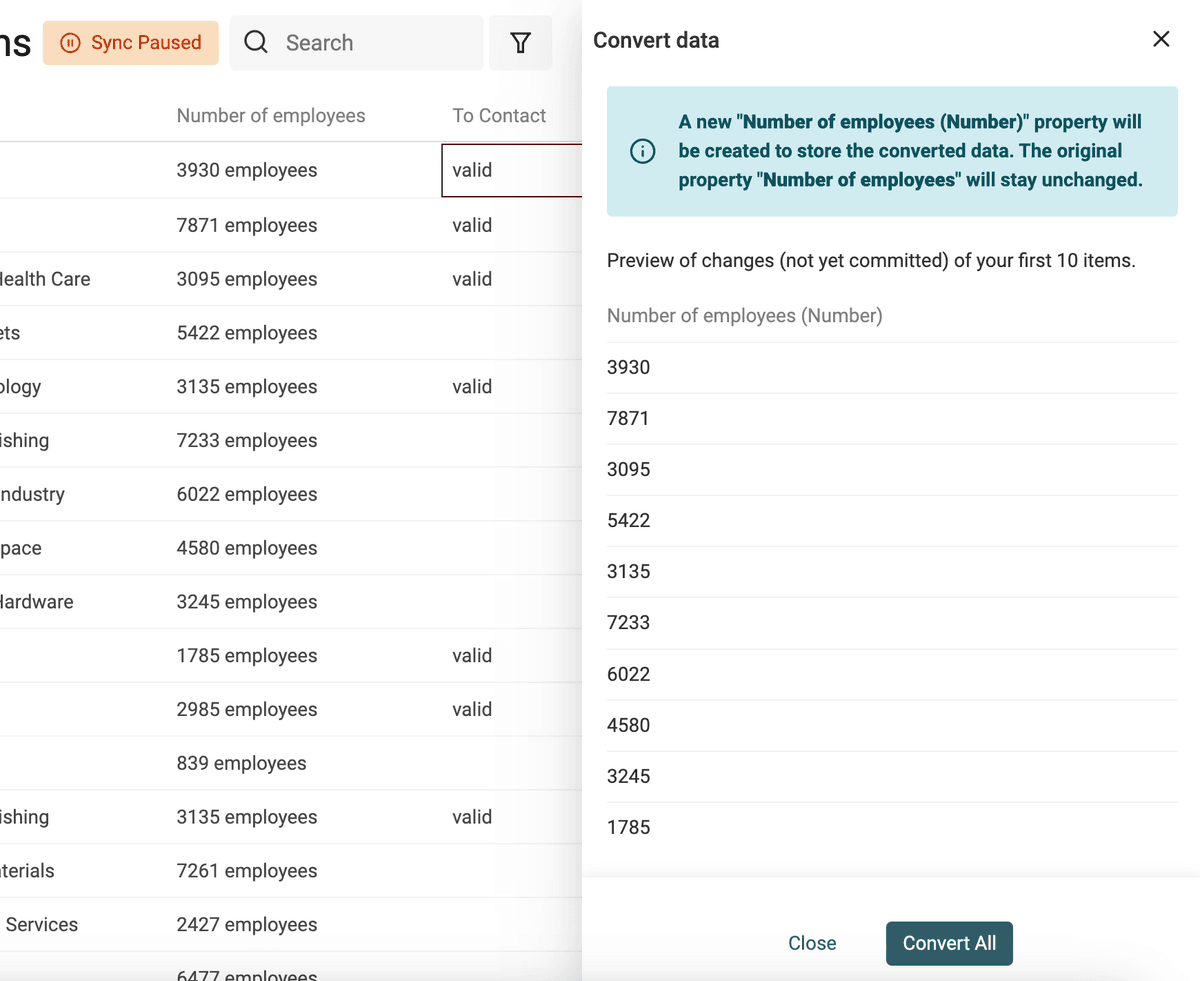
Usa il converter "Text to number" per:
- Normalizzare numeri con separatori decimali e migliaia personalizzati
- Estrarre numeri da testi che contengono lettere
👉 Scopri di più sulla conversione dei numeri nella documentazione.
Pulisci i dati
Converti HTML in testo
Gli strumenti di scraping analizzano il codice HTML e potresti ritrovarti tag HTML dentro i tuoi testi.
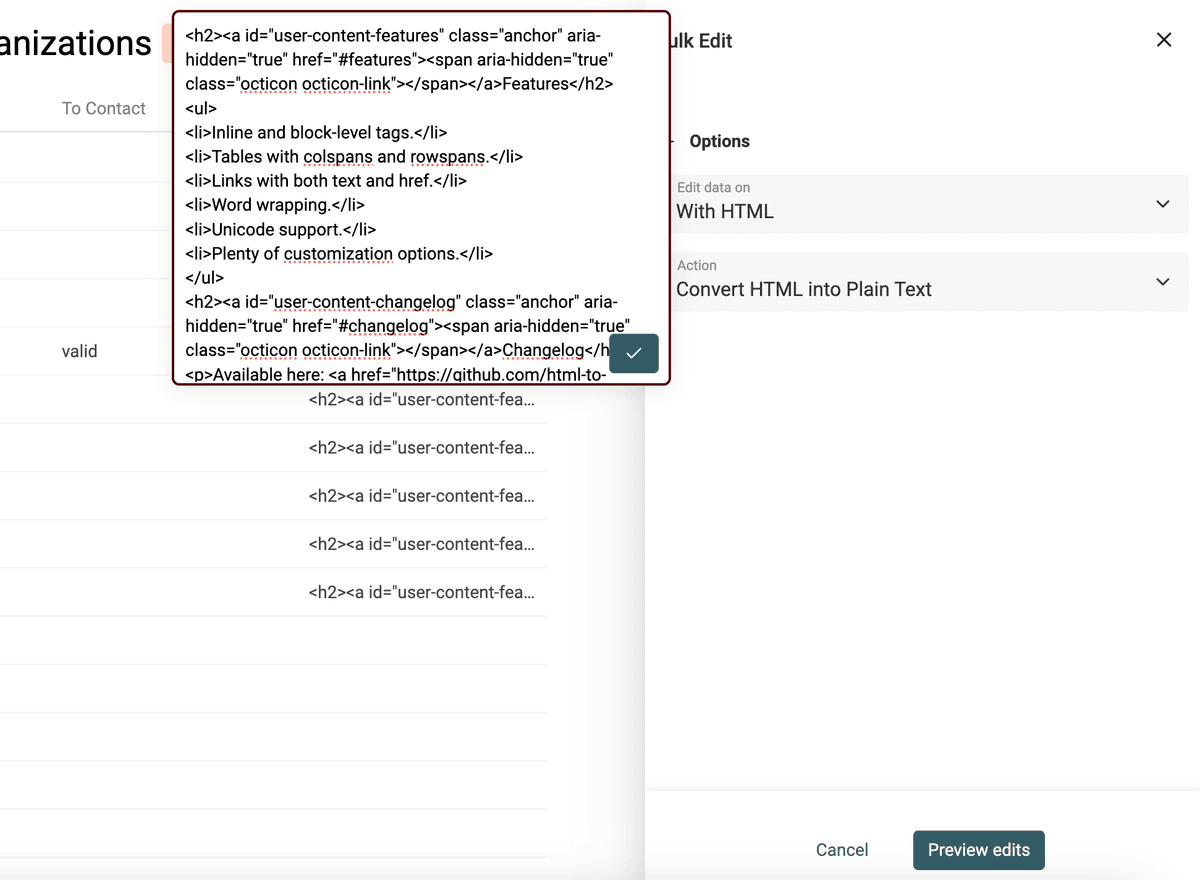
L'HTML contiene link, immagini e liste con bullet point. Ed è spesso strutturato in paragrafi su più righe.
L'obiettivo è mantenere parte dell'ordine che l'HTML offre ma trasformare un codice poco leggibile in testo semplice.
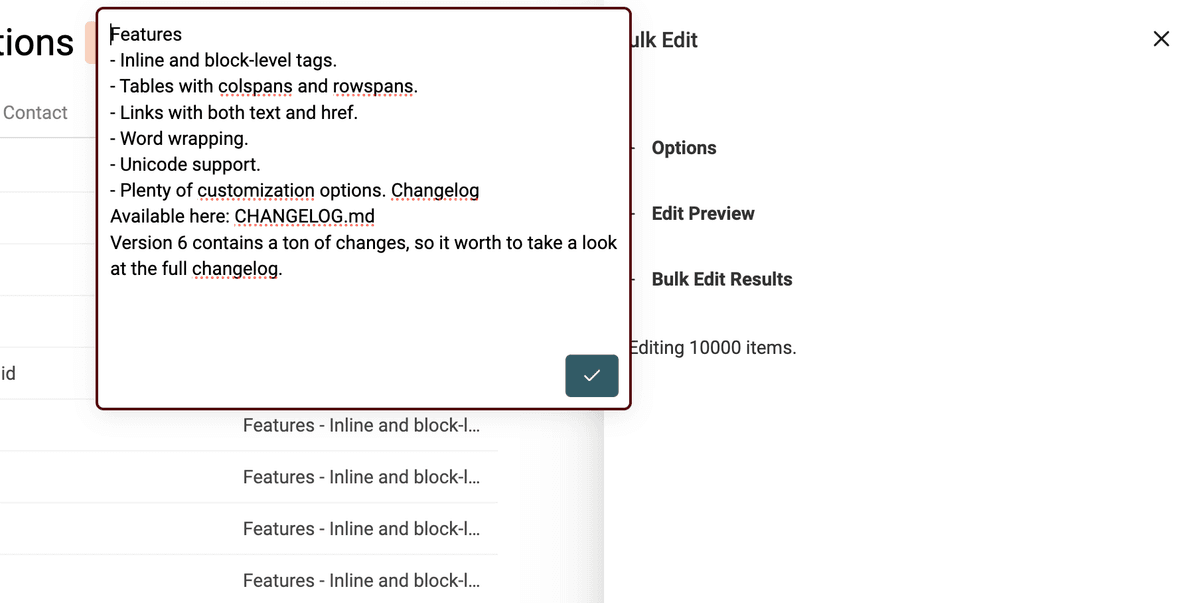
Il convertitore HTML to Text di Datablist mantiene gli a capo e trasforma i bullet point in liste prefissate da -.
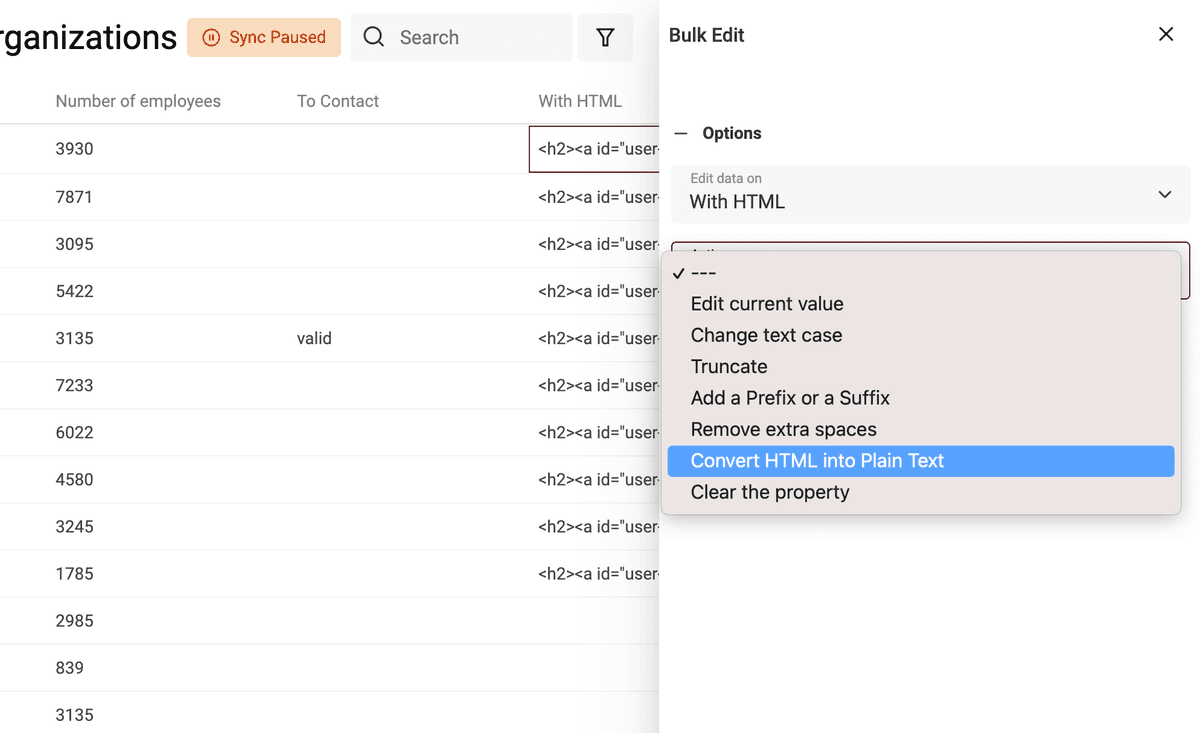
Per trasformare in testo semplice i contenuti con tag HTML, apri lo strumento Bulk Edit nel menu Edit.
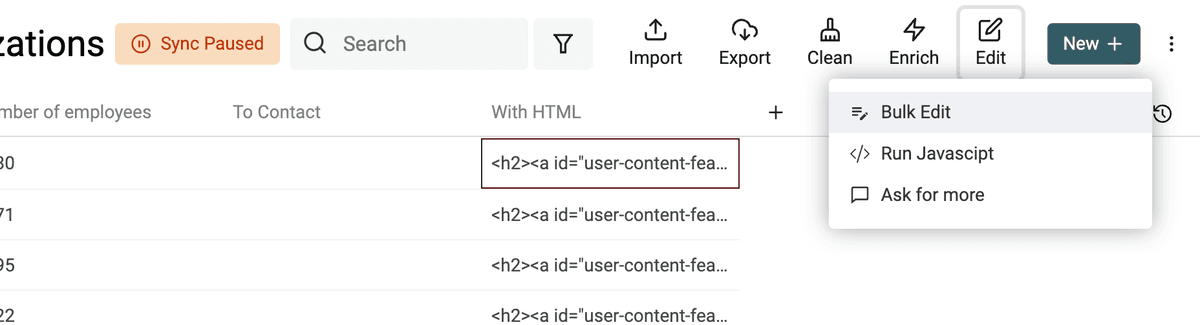
Seleziona la proprietà con i tag HTML e scegli "Convert HTML into plain text".
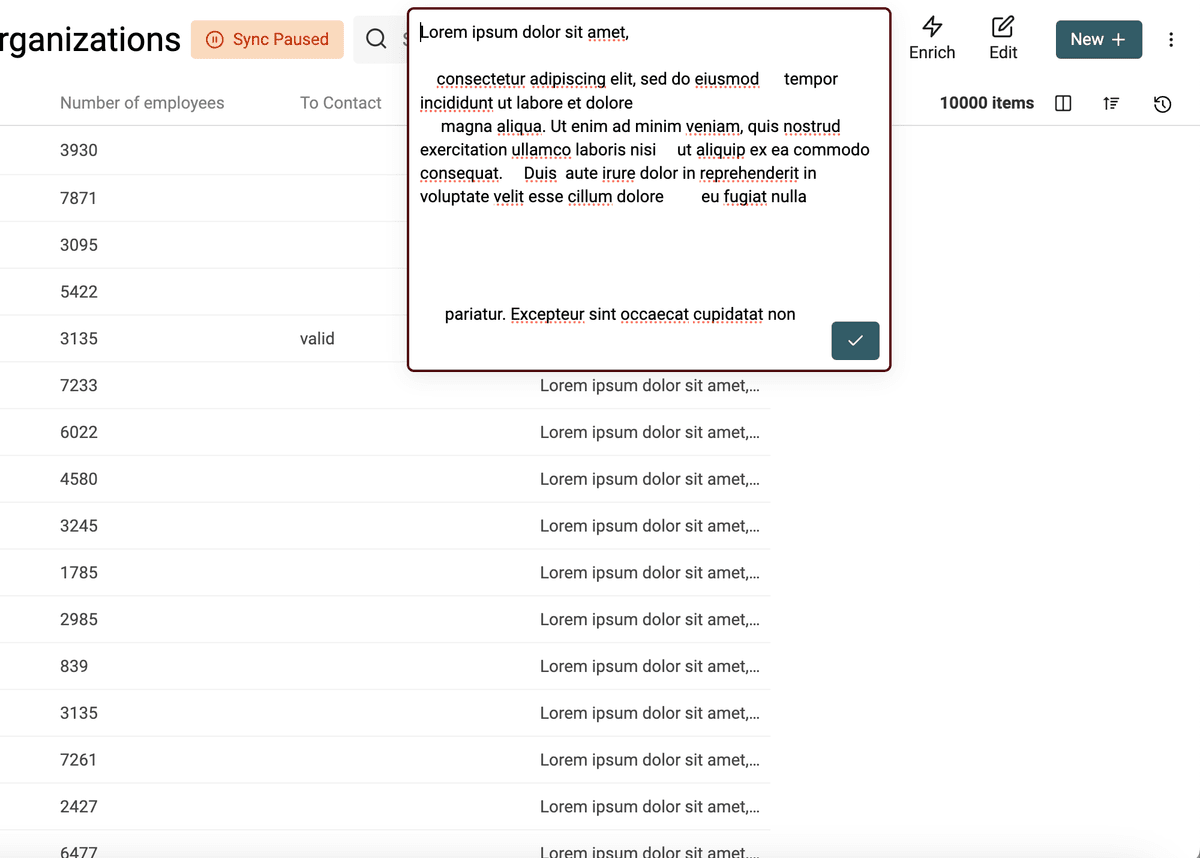
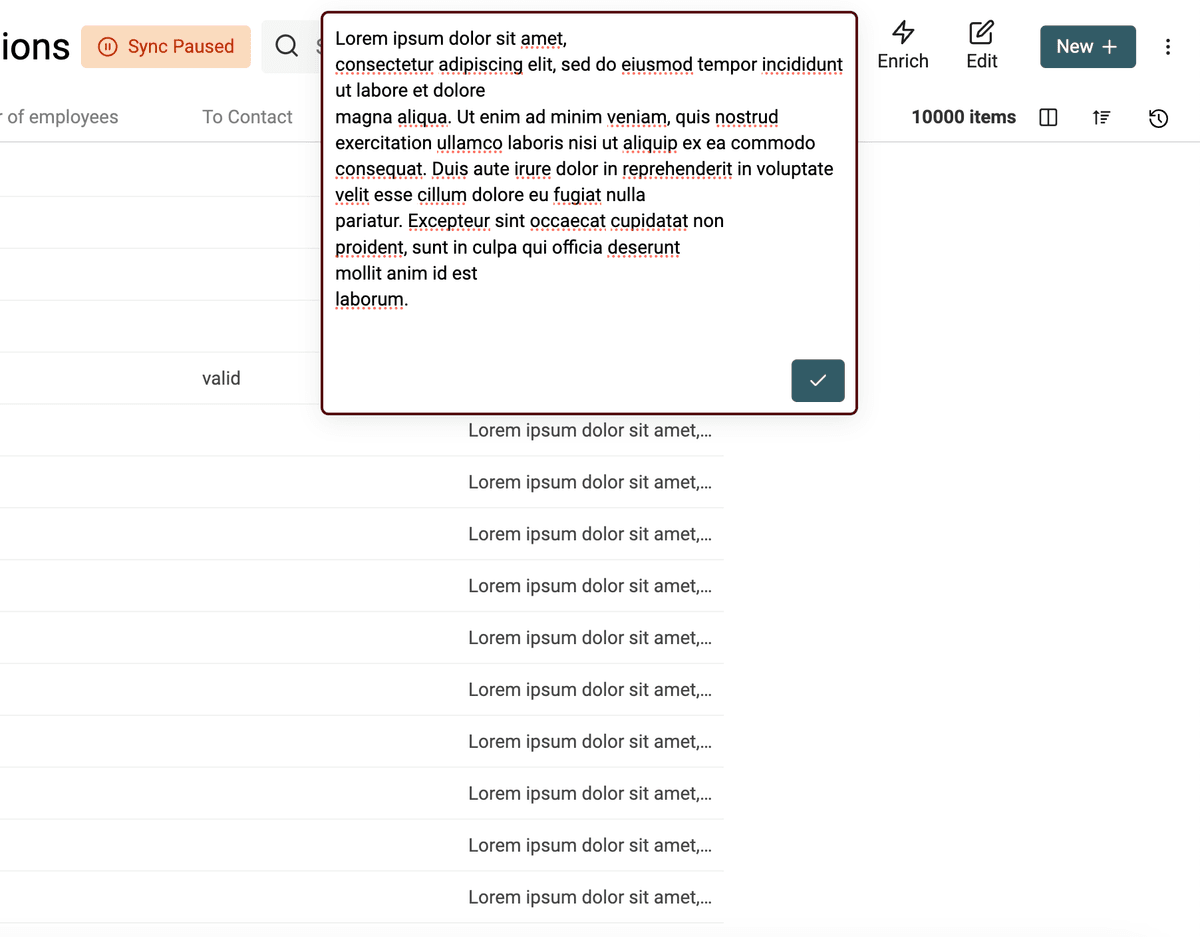
Rimuovi spazi extra
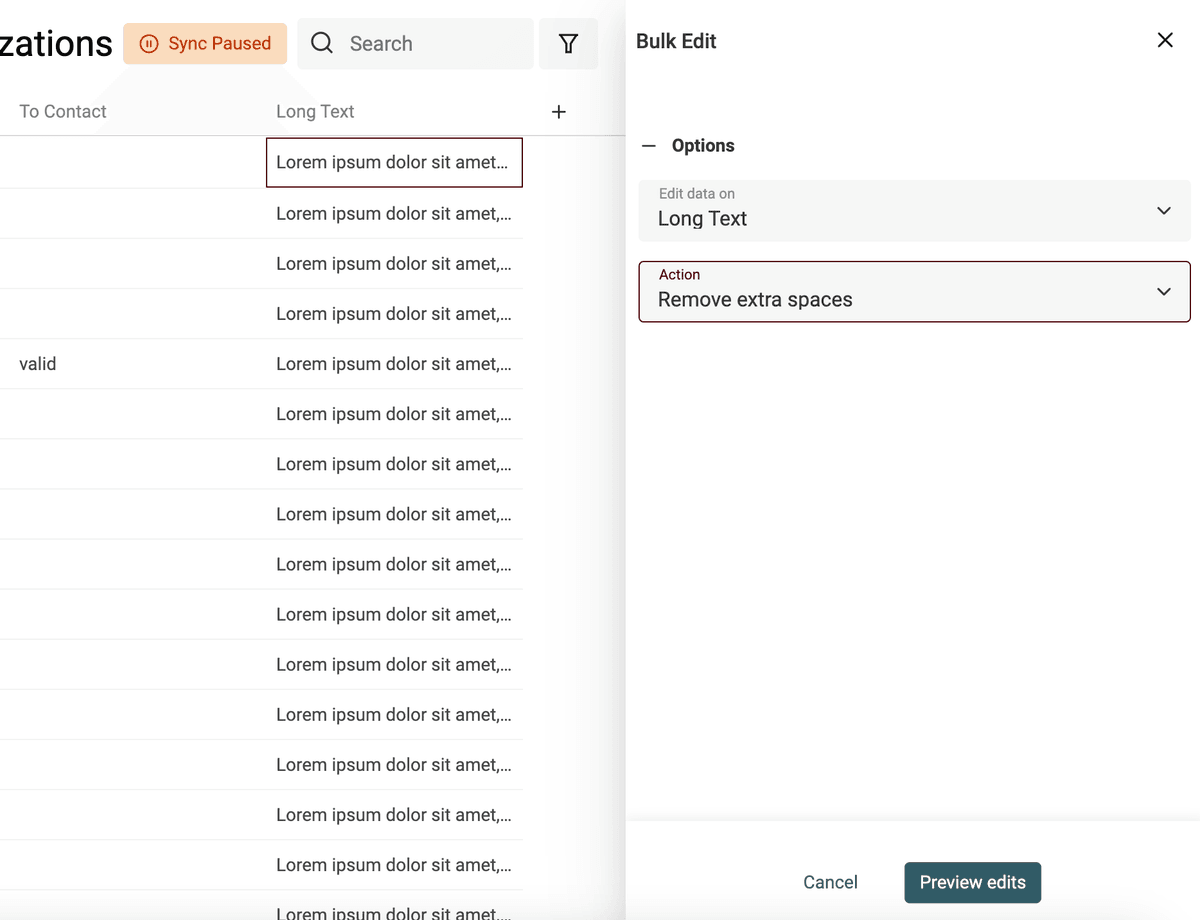
Un altro problema tipico dei dati scrappati sono gli spazi extra. Possono arrivare da nuove righe, dal carattere Tab e da altri caratteri che rappresentano spazi in HTML.
Datablist include uno strumento di pulizia per rimuovere gli spazi superflui.
- Rimuove gli spazi multipli tra le parole
- Rimuove le righe vuote
- Rimuove gli spazi iniziali e finali su ogni riga
Per eliminare gli spazi extra, apri lo strumento "Bulk Edit" dal menu "Edit". Seleziona la proprietà e l'azione "Remove extra spaces".
Uniforma maiuscole/minuscole
Cambiare il case del testo è semplice. Apri lo strumento "Bulk Edit" nel menu "Edit".
Seleziona la proprietà da processare e usa l'azione "Change text case".
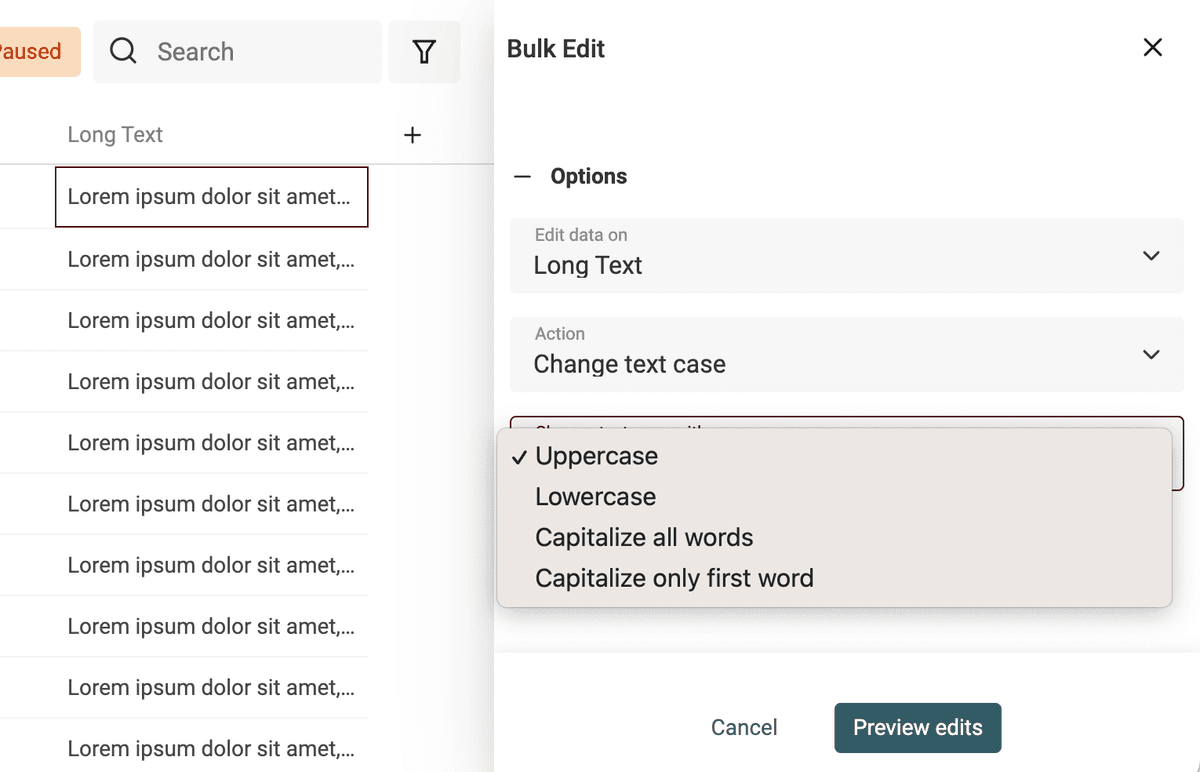
Sono disponibili 4 modalità:
- Uppercase - Tutte le lettere vengono trasformate in maiuscolo. Es:
john=>JOHN - Lowercase - Tutte le lettere vengono trasformate in minuscolo. Es:
API=>api - Capitalize - La prima lettera di ogni parola viene maiuscolata. Es:
john is a good man=>John Is A Good Man - Capitalize only the first word - Solo la prima lettera della prima parola viene maiuscolata. Es:
john is a good man=>John is a good man
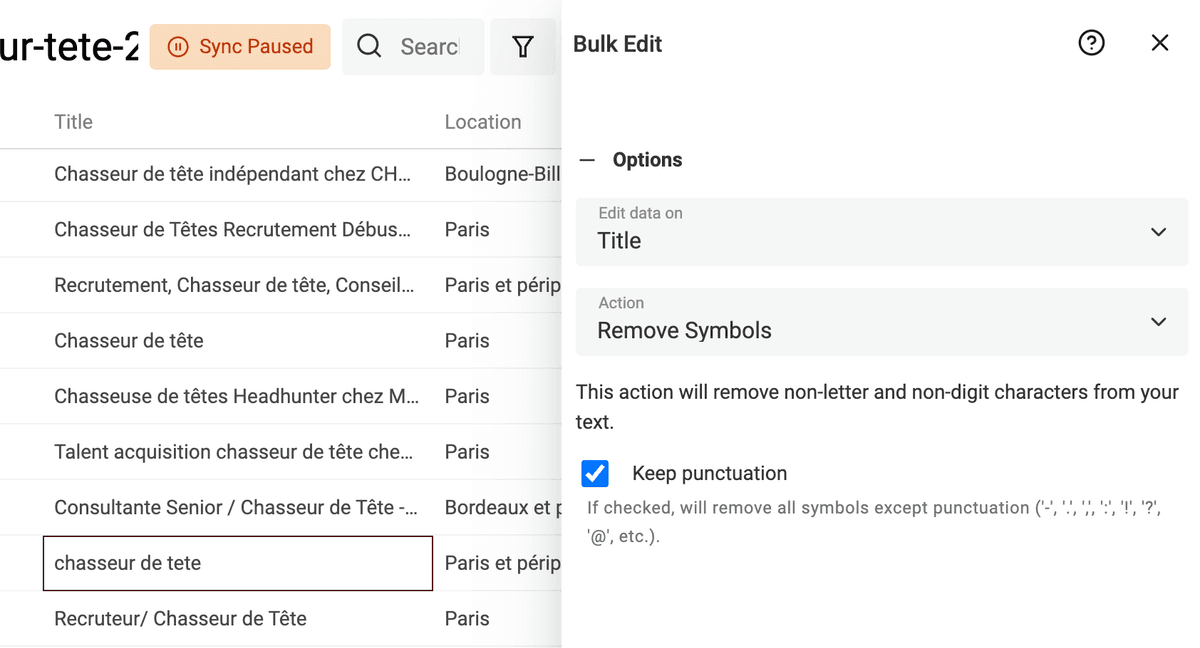
Rimuovi simboli dai testi
Testi scrappati da pagine HTML o inseriti dagli utenti (ad esempio i titoli profilo su LinkedIn) possono contenere simboli: emoji e caratteri non testuali che complicano l'elaborazione. Una semplice emoji a fine nome può impedire il rilevamento da parte di un algoritmo di deduplicazione.
Datablist ha un processor integrato per rimuovere qualsiasi simbolo non testuale dai tuoi dati.
Clicca su "Bulk Edit" dal menu "Edit", seleziona una proprietà di tipo testo e scegli la trasformazione "Remove symbols".
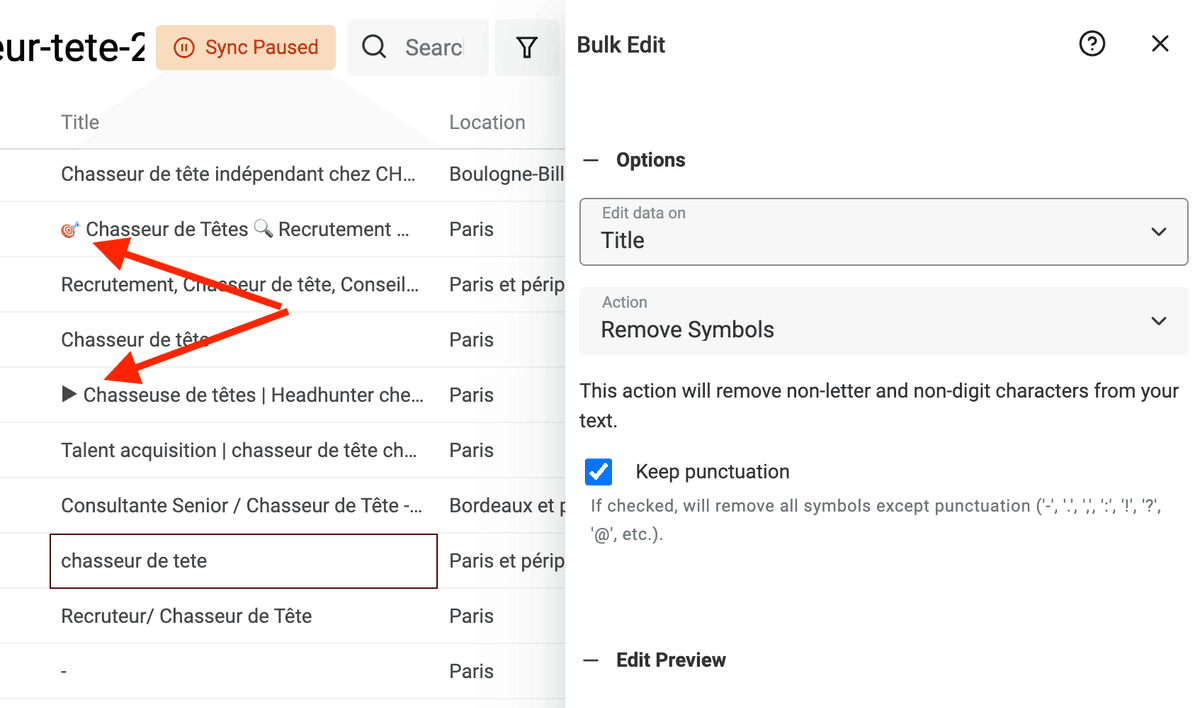
Se l'anteprima è corretta, esegui la trasformazione per processare gli item.
Normalizza con Find and Replace
Per segmentare le tue prospect lists, devi normalizzare i dati.
- Normalizzare i job title
- Normalizzare paesi e città
- Normalizzare le URL
- Etc.
L'obiettivo è ridurre una proprietà a testo libero in una con scelte limitate. Oppure trasformare i testi in una versione più semplice (es. URL con path in un semplice dominio).
Datablist include un potente Find and Replace. Funziona sia con testo semplice sia con espressioni regolari.
Le Regular Expressions sono complesse ma molto potenti.
Ecco alcuni esempi di come usare le RegEx per pulire i dati.
Rimuovi i parametri di query da un URL
Le URL scrappate hanno spesso parametri di tracking o marketing inutili. Rimuoverli rende le URL pulite e ti aiuta con la deduplicazione usando la URL per trovare i duplicati.
Per rimuovere i query parameter dalle URL, seleziona l'opzione "Match using regular expression" e usa questa regex con testo di sostituzione vuoto:
\?.*$
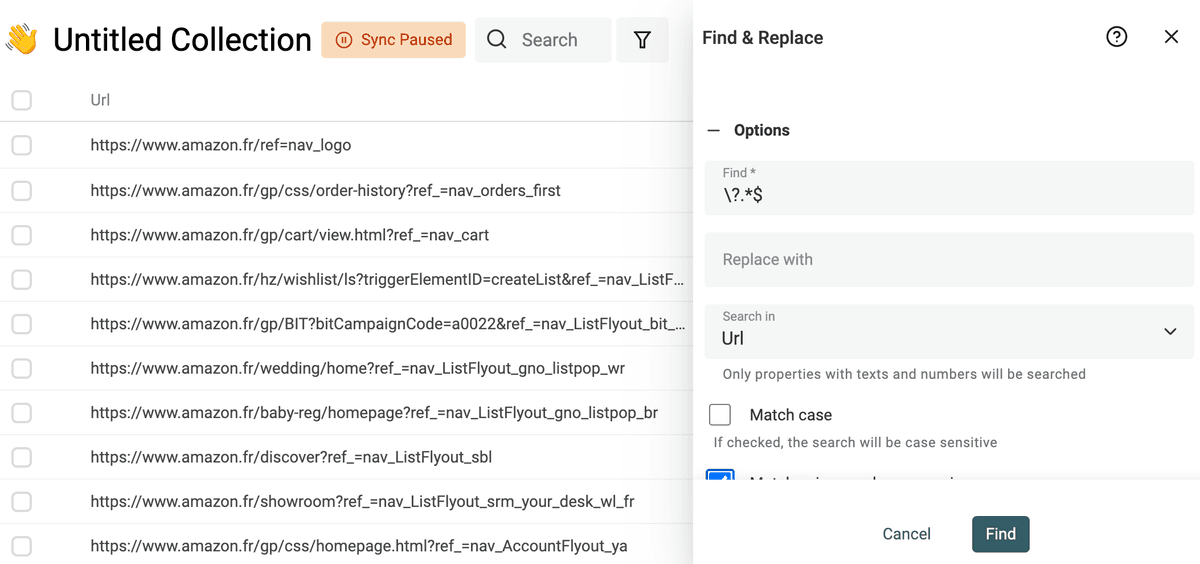
Applicala sulla proprietà con le URL.
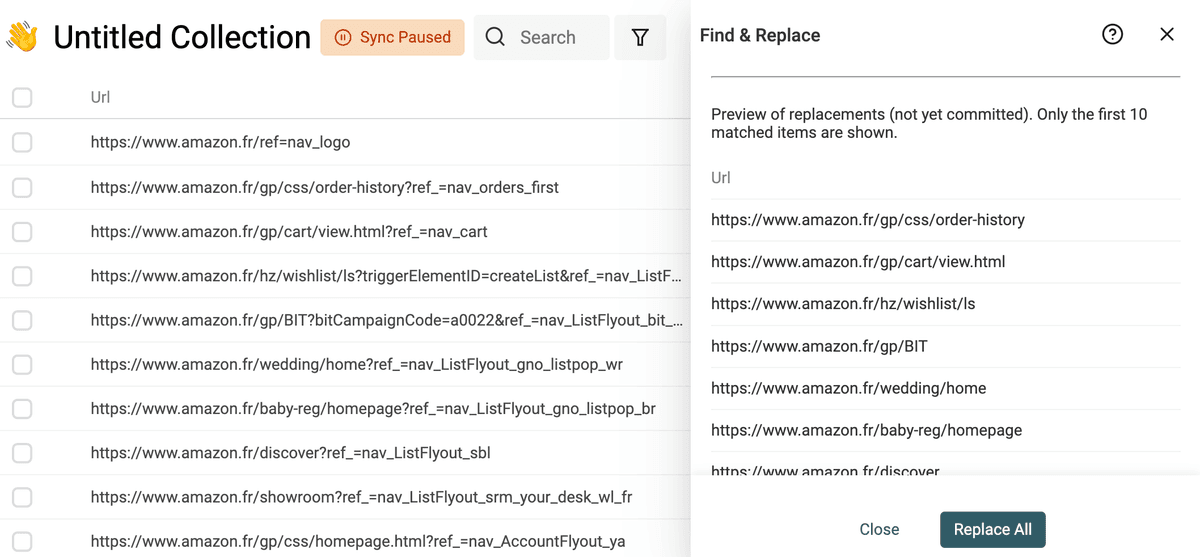
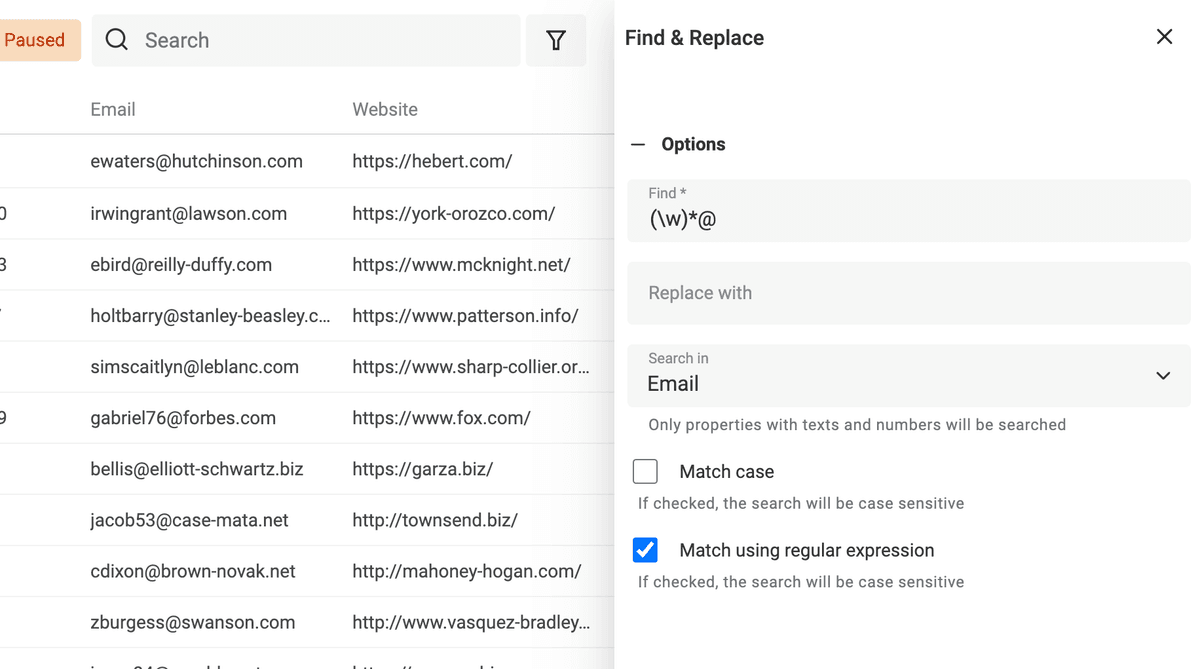
Estrai il dominio dagli indirizzi email
Un altro uso di Find and Replace con RegEx è ottenere il dominio del sito dalle email.
Duplica la proprietà email per preservare i dati originali e usa questa regex con testo di sostituzione vuoto:
^(\w)*@
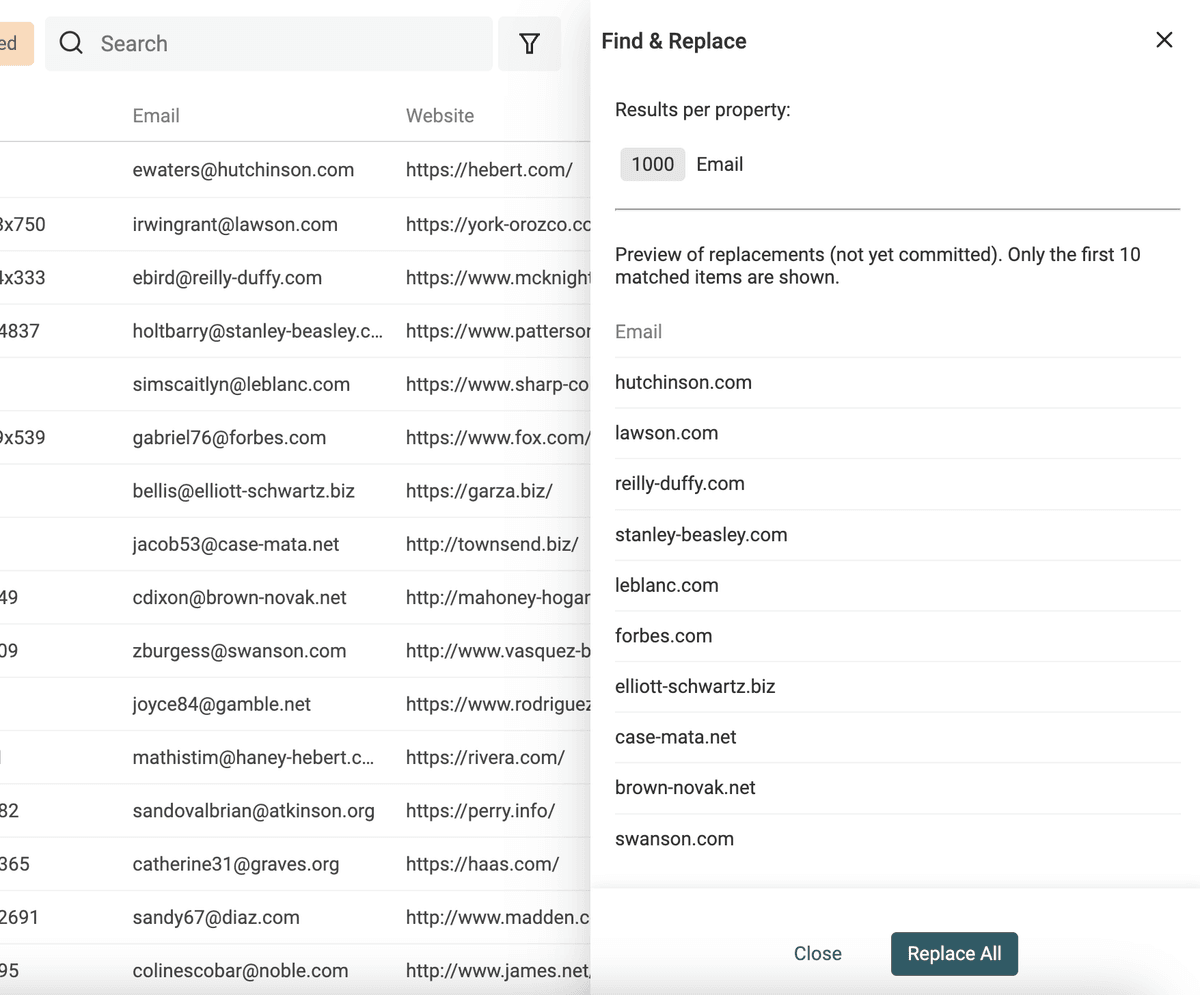
👉 Per saperne di più, leggi la documentazione su Find and Replace.
Dividi Full Name in First Name e Last Name
Quando fai scraping di lead list, spesso ottieni contatti con "Full Name" da dividere in "First Name" e "Last Name". Saper fare il parsing accurato del nome è un passaggio chiave.
Separare first name e last name è utile per personalizzare le campagne di cold emailing, dedurre il gender del contatto e recuperare il titolo accademico.
Dividere i nomi può essere complicato. Per fortuna, Datablist offre un tool semplice per dividere "Name" in due valori usando lo spazio come delimitatore.
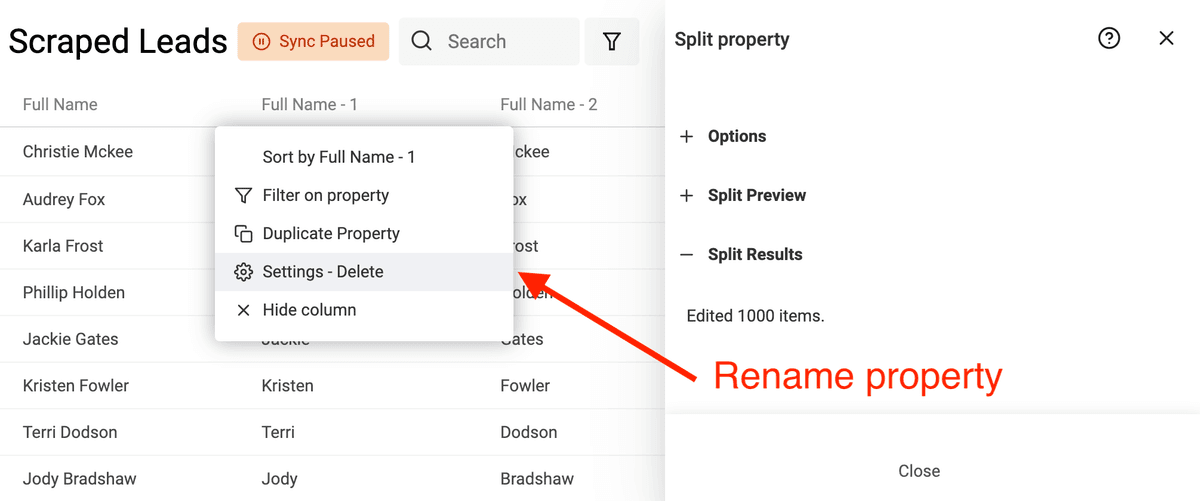
Per iniziare, apri lo strumento "Split Property" nel menu "Edit".
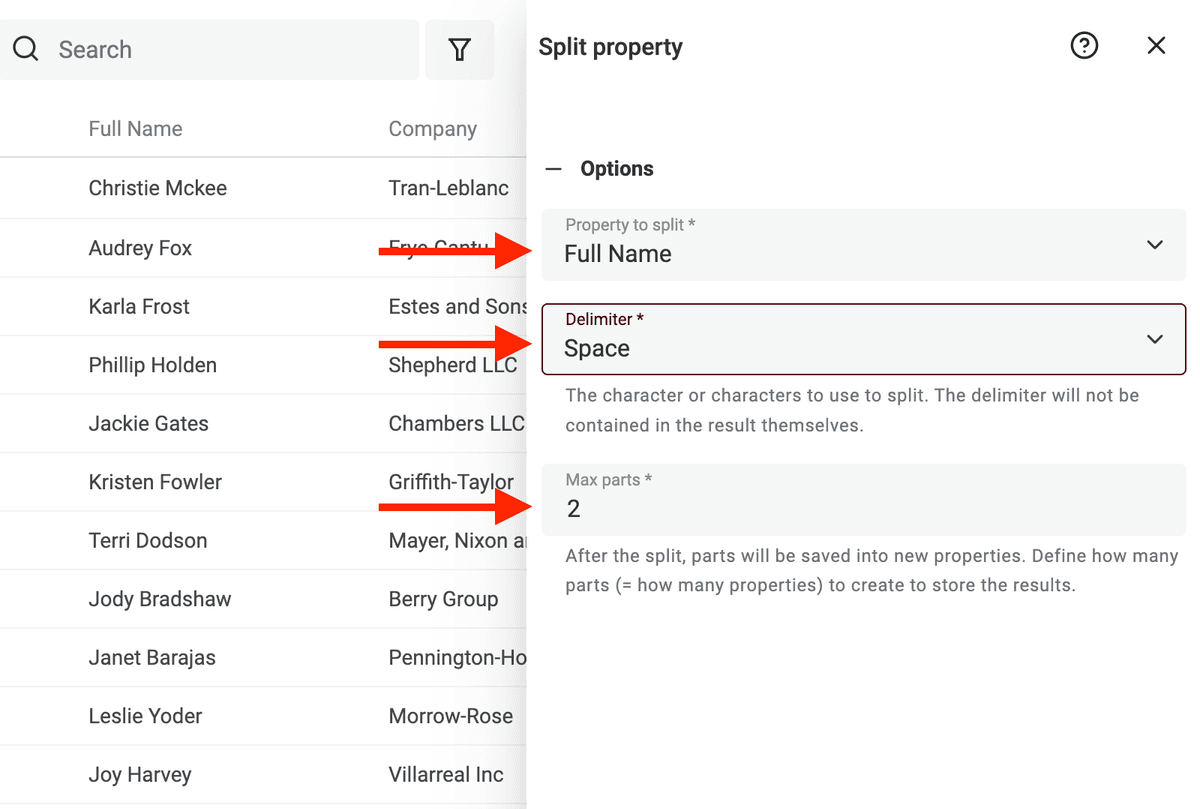
Seleziona poi la proprietà con i nomi da analizzare. Scegli Space come delimitatore e imposta il numero massimo di parti a 2.
Avvia l'anteprima. Datablist analizzerà i primi 10 item per mostrarti un preview. Se il risultato è corretto, clicca "Split Property" per eseguire l'algoritmo su tutti gli item correnti.
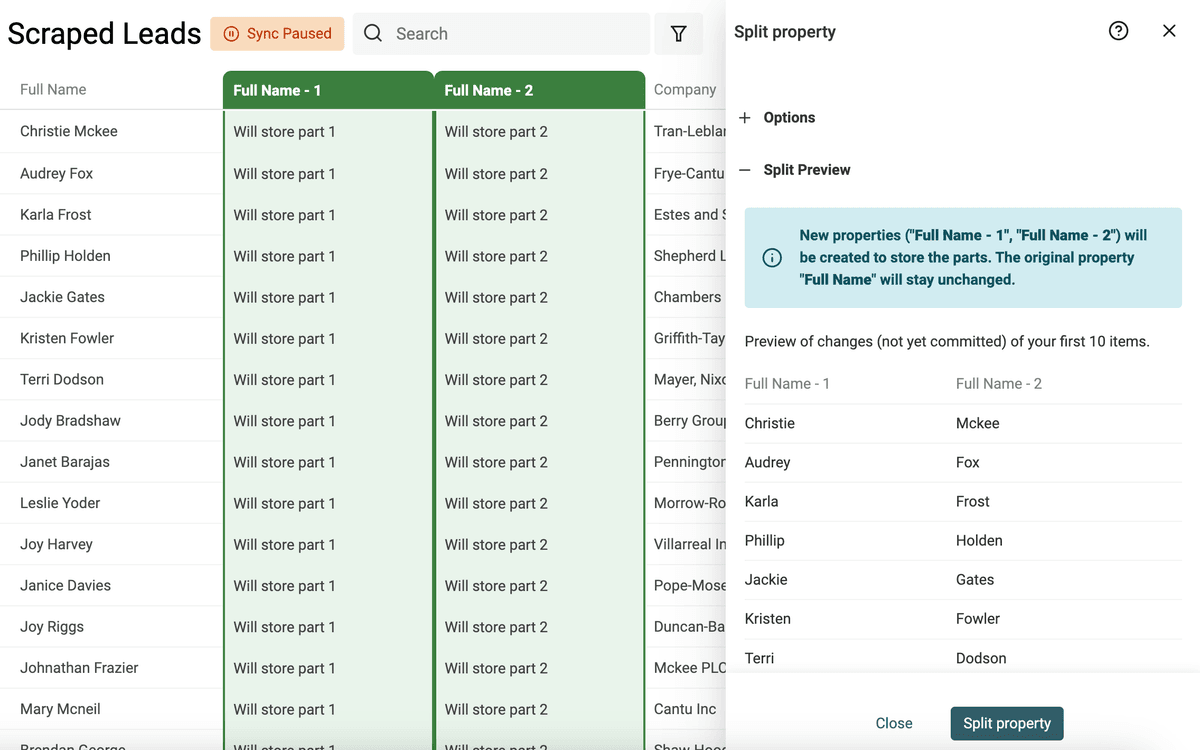
Dopo la divisione, rinomina le due proprietà create in "First Name" e "Last Name".
Questo esempio si concentra sulla convenzione occidentale, che prevede tipicamente first name e last name. Diventa più complesso con nomi non occidentali, con più given name o surname, oppure quando sono presenti titoli o suffissi.
Deduplicazione dei dati
Datablist ha un potente algoritmo per dedupe records. Trova item simili usando una o più proprietà e dispone di un algoritmo automatico per fonderli senza perdere informazioni.
Per avviare la deduplicazione, clicca "Duplicate Finder" nel menu "Clean".
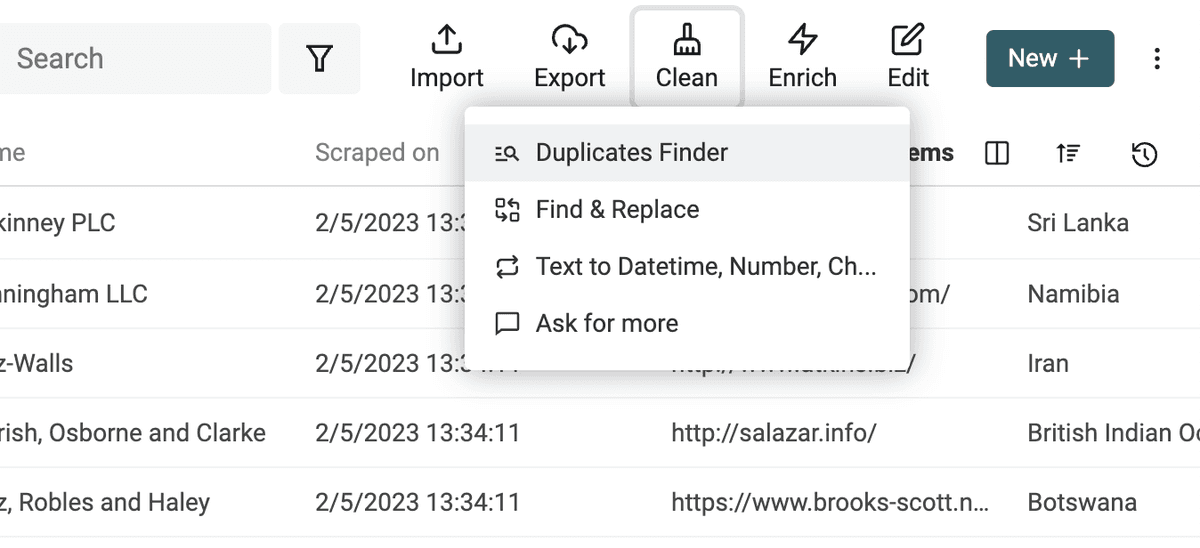
Seleziona le proprietà da usare per il matching.
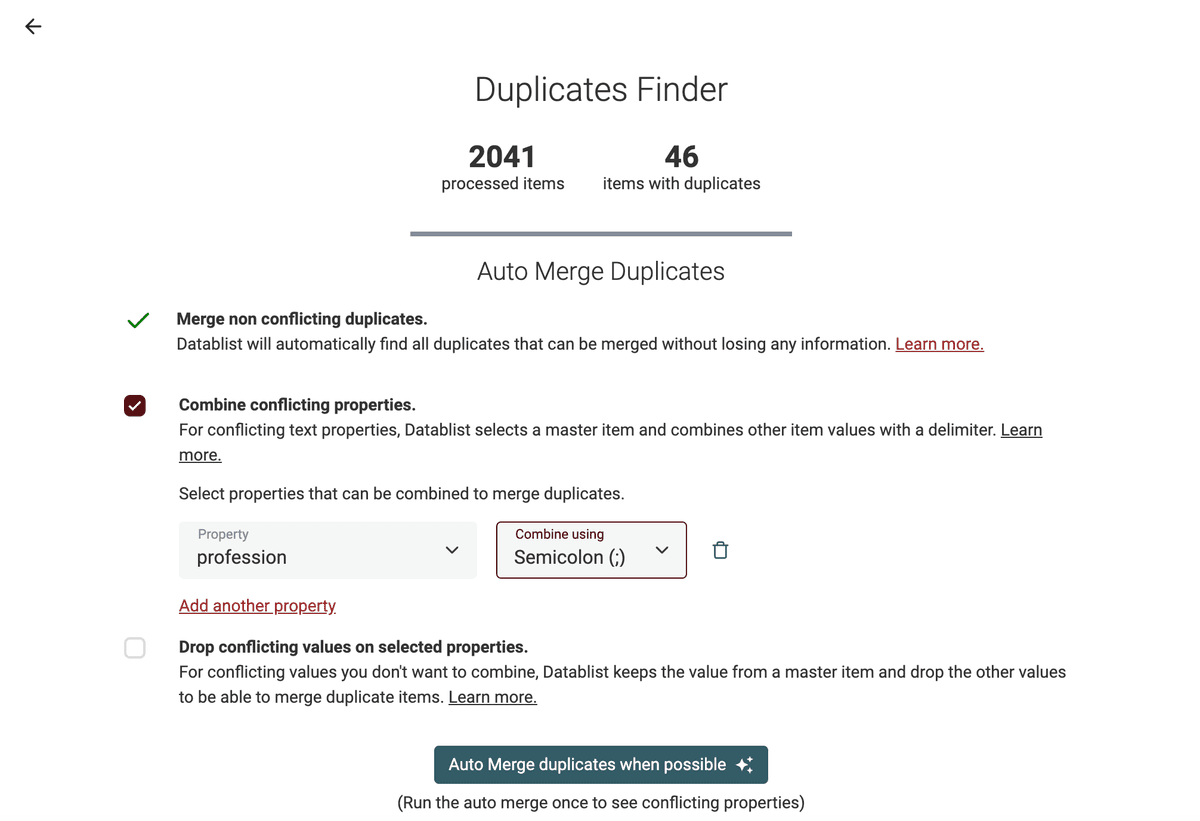
Nella pagina dei risultati, esegui l'algoritmo "Auto Merge" una prima volta con l'opzione "Merge non-conflicting duplicates". Fonderà automaticamente i duplicati semplici e ti mostrerà le proprietà in conflitto.
L'algoritmo di dedupe ha due opzioni per gestire i conflitti. Puoi "Combine conflicting properties" usando un delimitatore, oppure scartare i valori in conflitto e mantenere un solo master item.
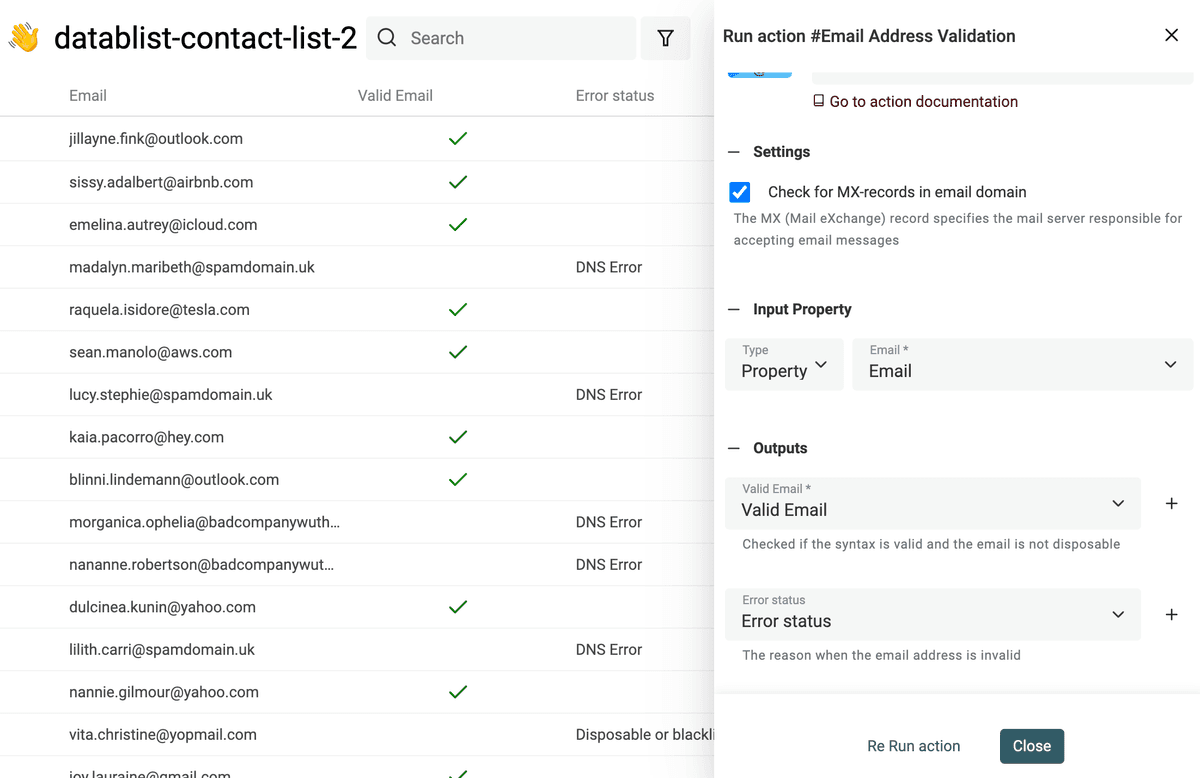
Valida gli indirizzi email
I dati da scraping possono essere vecchi, avere refusi o risultare non validi. Questo vale soprattutto per gli indirizzi email ottenuti via scraping.
Quando i dati sono user-generated, troverai email fasulle nel database o email da provider temporanei.
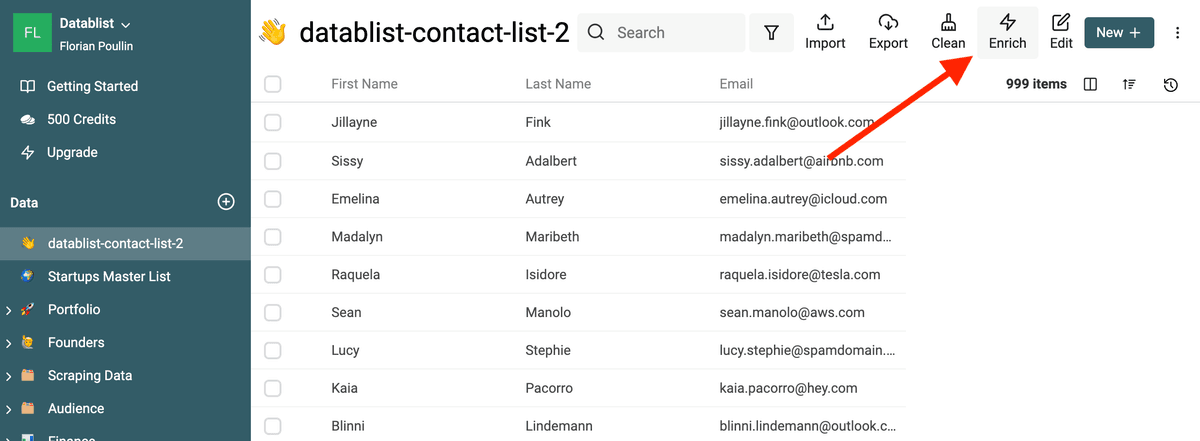
Datablist ha un tool integrato di email validation per convalidare migliaia di indirizzi in pochi clic.
Il servizio di validazione offre:
- Email syntax analysis - Primo controllo: verifica la conformità allo standard IETF e un'analisi sintattica completa. Segnala indirizzi senza chiocciola (@), con domini non validi, ecc.
- Disposable providers check - Rileva email temporanee. Il servizio individua domini appartenenti ai provider di Disposable Email Address (DEA) come Mailinator, Temp-Mail, YopMail, ecc.
- Domain MX records check - Un'email valida deve avere un dominio con record MX configurati. I record MX specificano i mail server che ricevono i messaggi per quel dominio. L'assenza di record MX indica un'email non valida. Per ogni dominio, il servizio interroga i DNS e verifica i record MX. Se il dominio non esiste, l'email è segnata come non valida. Se esiste ma senza MX validi, è comunque non valida.
- Business and Personal Email addresses Segmentation - Per prospect da lead magnet o per segmentare la user base, potresti voler distinguere tra email business e personali. Il servizio di validazione ti fornisce questa informazione per arricchire i contatti.
Estrai nomi di persone o aziende dai testi
Quando fai scraping di testi da siti o altre fonti, è spesso utile estrarre i nomi di persone o aziende. Queste informazioni servono per varie attività, dalla lead generation alla competitor analysis. Tuttavia l'estrazione da testo non strutturato è complessa, perché i nomi assumono molte forme e possono essere immersi in blocchi più ampi di testo.
Una delle principali difficoltà è l'enorme varietà di convenzioni e formati dei nomi nelle diverse culture e lingue. In alcune culture il cognome precede il nome, in altre è il contrario. Alcune persone hanno più given name, altre nessuno. Inoltre, i nomi possono essere scritti male, abbreviati o in formati non standard, rendendo difficile identificarli con semplici pattern.
Un approccio comune è usare la Named Entity Recognition (NER), una tecnica di NLP che identifica e classifica le entità nominate nel testo. I modelli NER riconoscono persone, organizzazioni, luoghi, ecc., e possono essere adattati a convenzioni e varianti diverse.
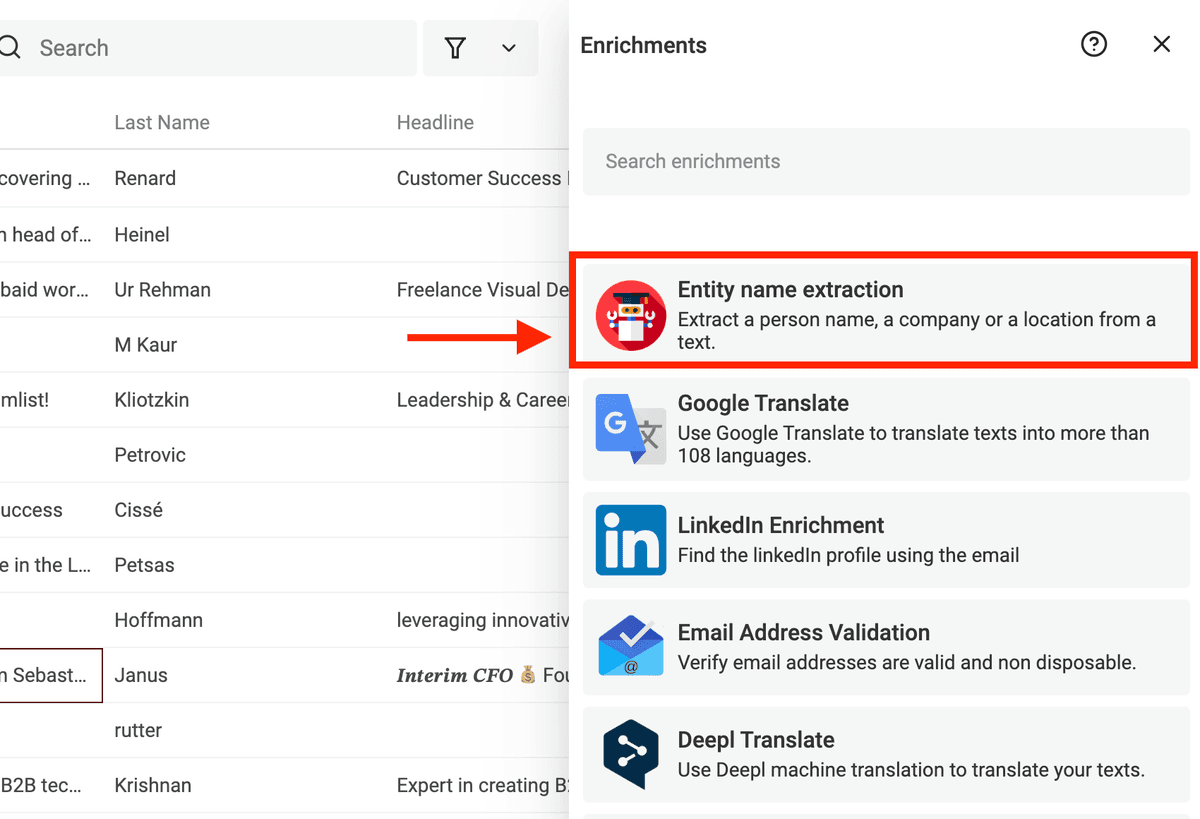
Datablist include un potente modello di "Named Entity Recognition" (NER) eseguibile direttamente sui tuoi testi. È addestrato in arabo, tedesco, inglese, spagnolo, francese, italiano, lettone, olandese, portoghese e cinese.
Seleziona "Entity name extraction" dal menu "Enrichments".
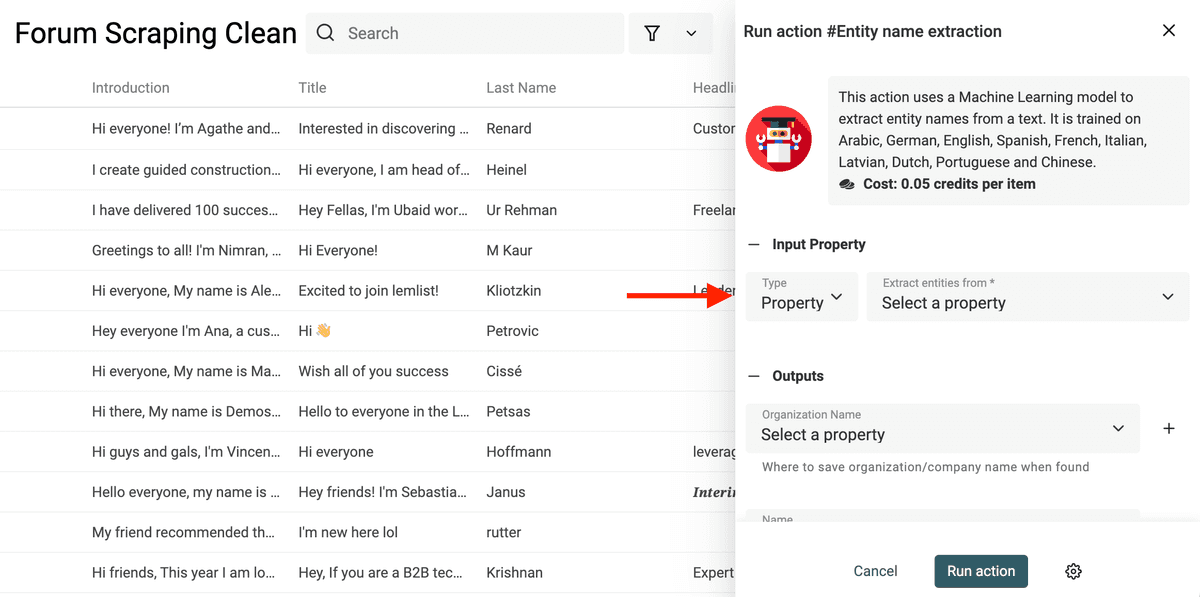
Nelle opzioni di input, seleziona la proprietà con il testo da cui estrarre i nomi.
Negli output, clicca sul pulsante "Create a new property" per ogni tipo di nome che vuoi estrarre.
Il Datablist Entity Name extractor cerca:
- Organization Name: ad esempio aziende.
- Person Name: Full name oppure First Name/Last Name
- Location: città, paese e luoghi
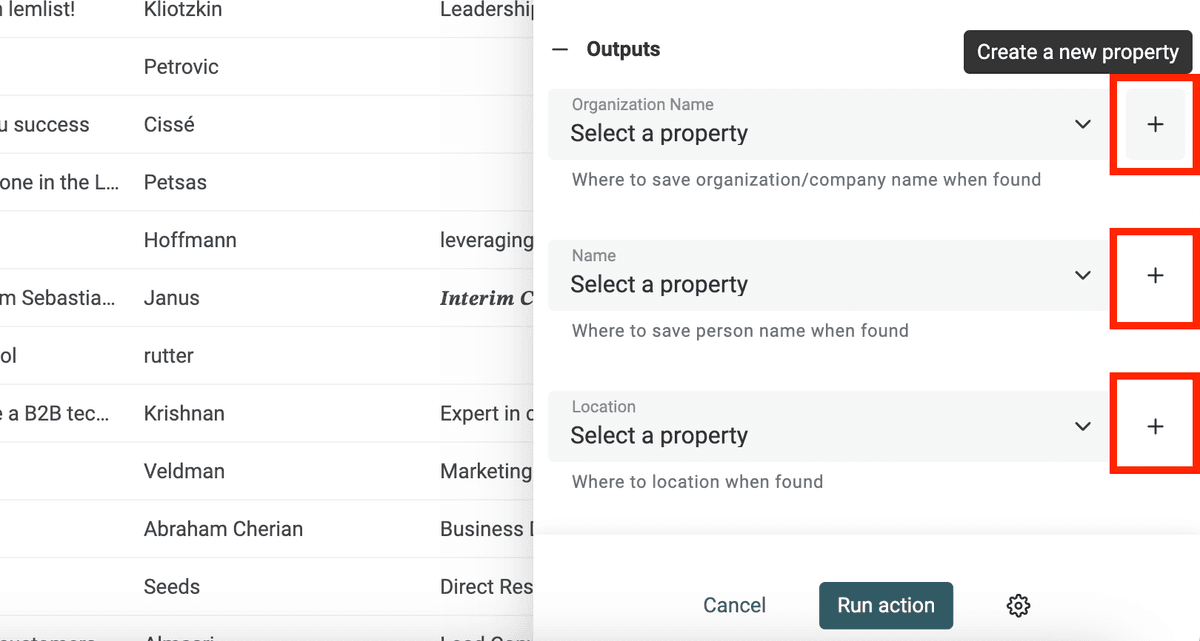
Poi avvia l'enrichment.
Ti serve aiuto con il data cleaning?
Cerco sempre feedback e casi reali di data cleaning da risolvere. Per favore contattami e raccontami il tuo use case.