

La data cleaning non è più solo compito dei data analyst. Se lavori con una lista di prospect, usi dati scrappati nei tuoi processi o consolidi più fonti, conosci il valore di una pulizia dei dati fatta bene.
Google Sheets e Excel bastano per operazioni semplici, ma sono limitati quando si parla di consolidamento e deduplicazione.
In questa guida, scoprirai come usare Datablist, uno strumento online gratuito per pulire e normalizzare i tuoi dati.
Ecco un riepilogo veloce delle operazioni di pulizia presenti nell’articolo:
- Converti testo in Datetime, Number, Boolean
- Converti HTML in testo (rimuovi i tag HTML)
- Rimuovi spazi superflui dai testi
- Normalizza i tuoi dati
- Rimuovi simboli dai testi
- Dividi il Full Name in First Name e Last Name
- Deduplica gli elementi
- Estrai email, URL, ecc. dai testi
- Usa Regular Expressions per filtrare e validare i dati
- Scrivi trasformazioni custom con codice JavaScript
- Valida gli indirizzi Email
Importa da CSV o copia-incolla i dati
Datablist è perfetto per la pulizia dei dati. È un editor CSV online con funzionalità di cleaning, bulk editing ed enrichment. E scala fino a milioni di item per collezione.
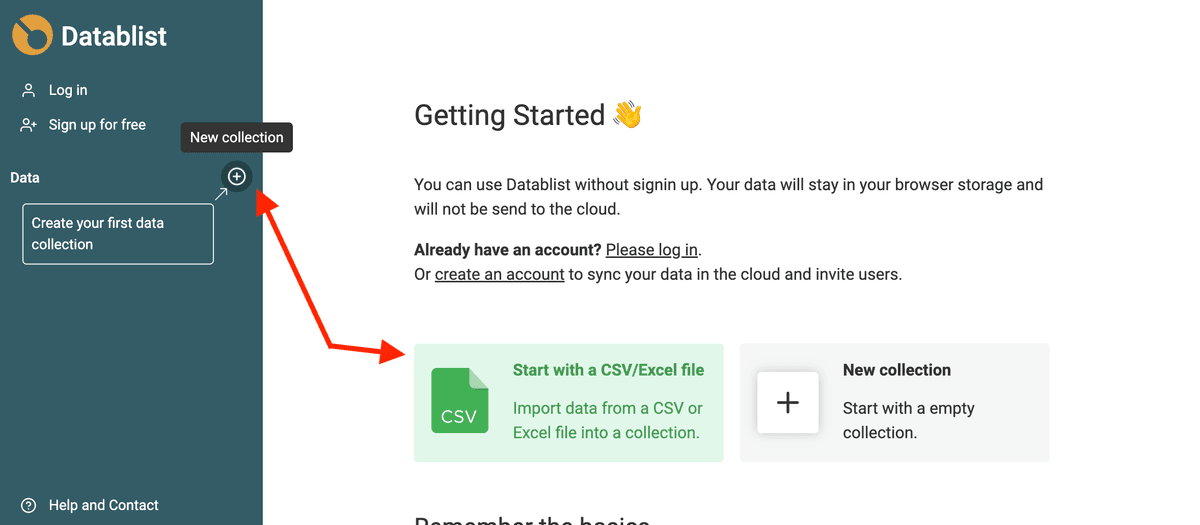
Apri Datablist e carica le collezioni con le tue fonti dati.
Per creare una nuova collection, clicca sul pulsante + nella sidebar. Poi clicca su "Import CSV/Excel" per caricare il file. In alternativa, usa lo shortcut dalla pagina di getting started per andare direttamente all’import.
Rilevamento automatico del formato
L’assistente di import di Datablist rileva automaticamente email, Datetime in ISO 8601, Boolean, Number, URL, ecc. quando sono ben formattati.
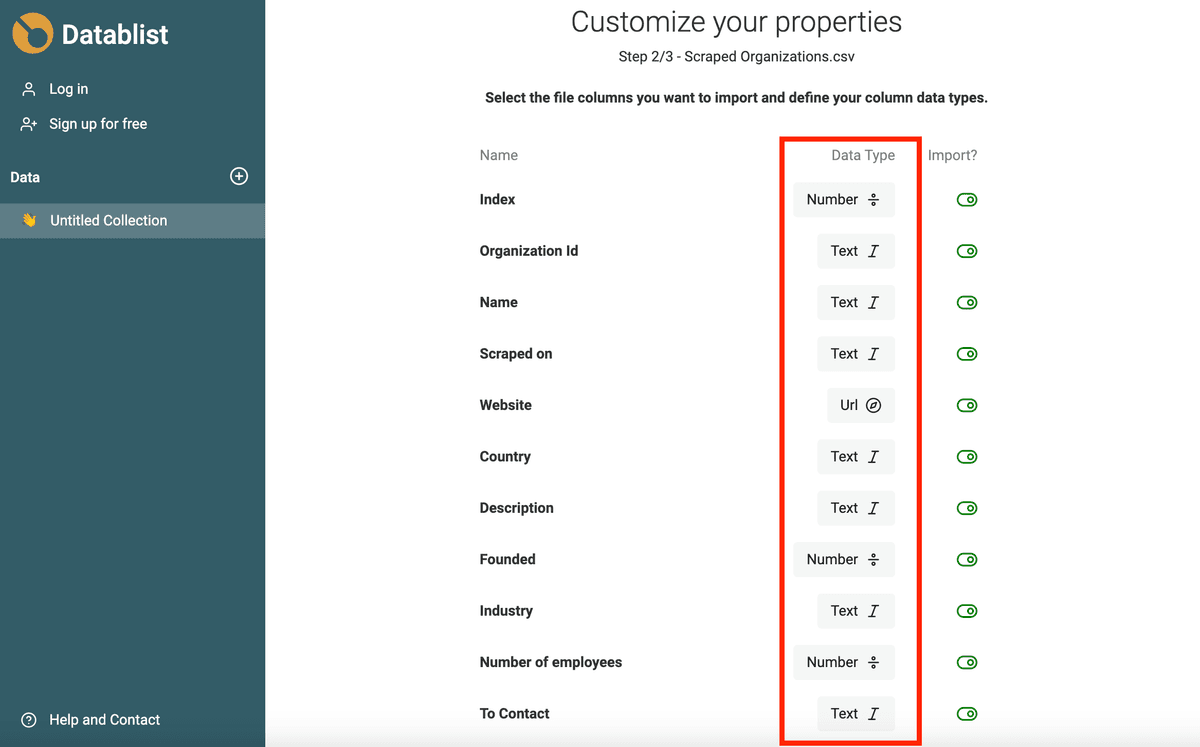
Se i tuoi dati richiedono un’analisi più complessa (formati data diversi, typo nelle URL o nelle email), importali come proprietà di tipo Text. Nella prossima sezione ti mostro come convertire le proprietà di tipo testo in Datetime, Boolean o Number.
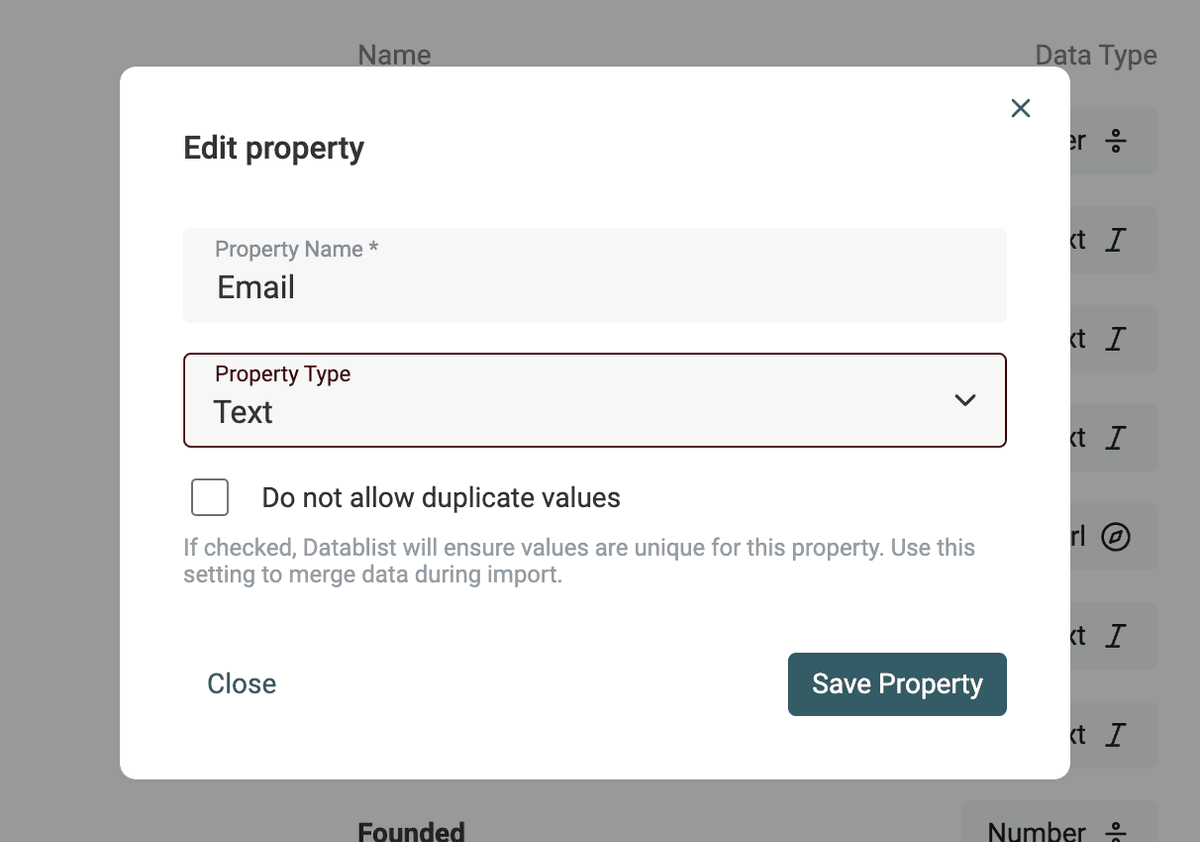
Converti testo in Datetime, Boolean, Number
Marie Kondo dice: "La vita inizia davvero quando metti in ordine la tua casa". Vale anche per i dati: "Le vendite iniziano davvero quando metti in ordine i tuoi dati"! 😅
Filtrare per una data (creation date, funding date, ecc.), un numero (prezzo, numero di dipendenti) o un boolean è molto più semplice quando sono tipi nativi e non solo testo.
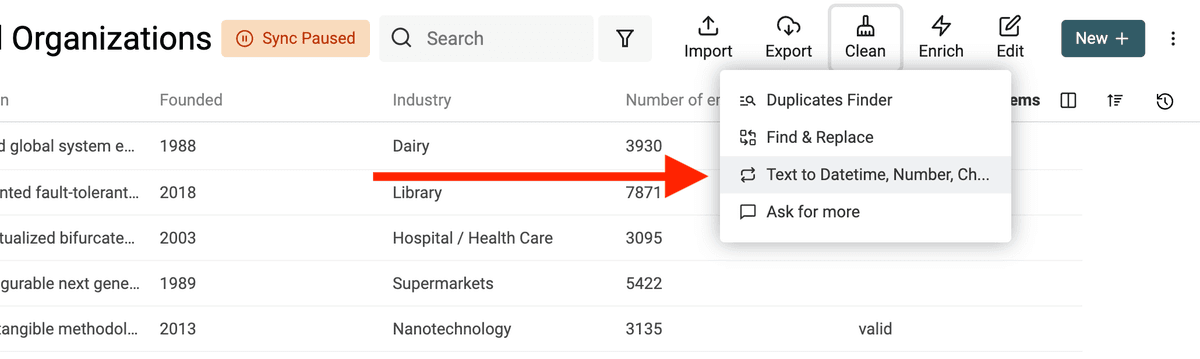
Apri lo strumento "Text to Datetime, Number, Checkbox" dal menu "Clean".
Converti qualsiasi testo in formato Datetime
Datetime ha un formato internazionale chiamato ISO 8601 con una struttura definita. Se i tuoi dati usano il formato ISO 8601, una proprietà Datetime verrà creata automaticamente in import per memorizzarli.
Per valori Date e Datetime in altri formati, devi specificare il formato usato così Datablist può convertirli in valori Datetime strutturati.
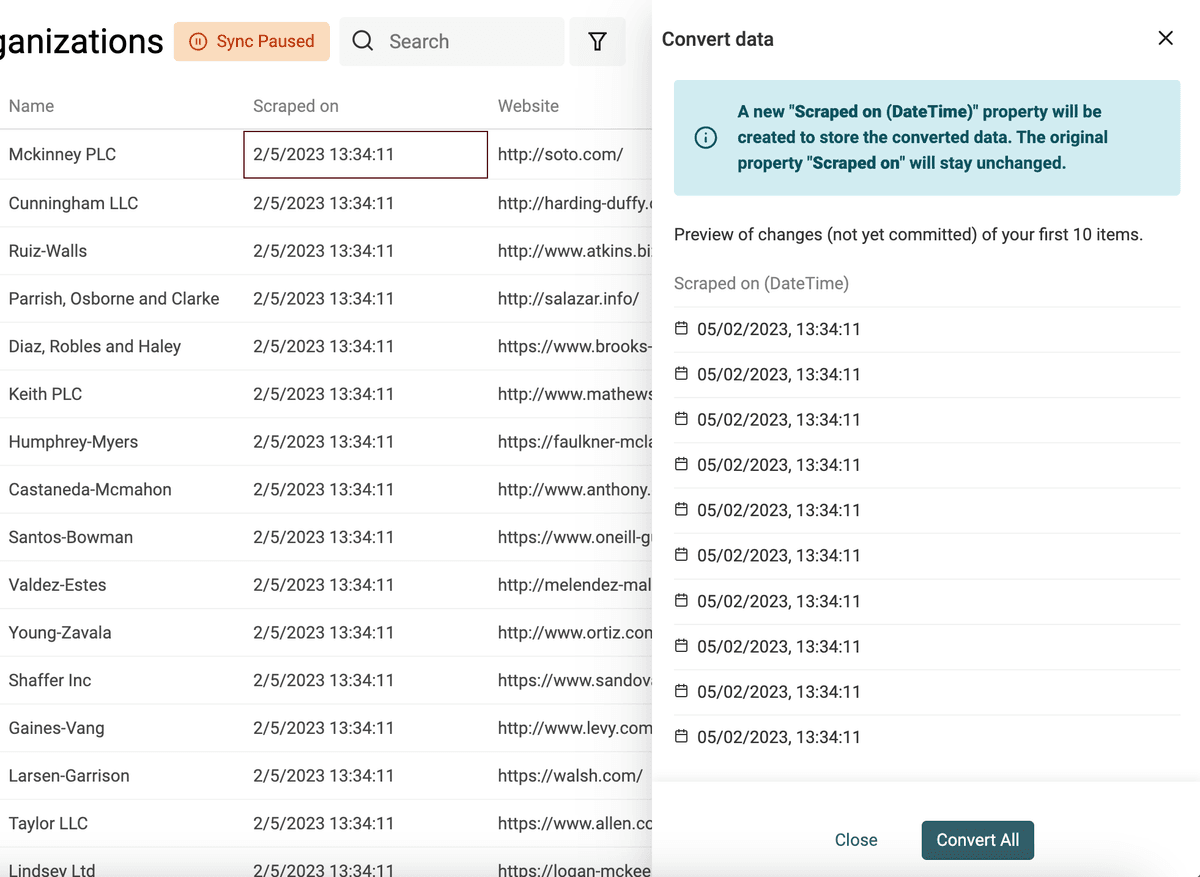
Seleziona la proprietà da convertire e scegli "Convert to Datetime".
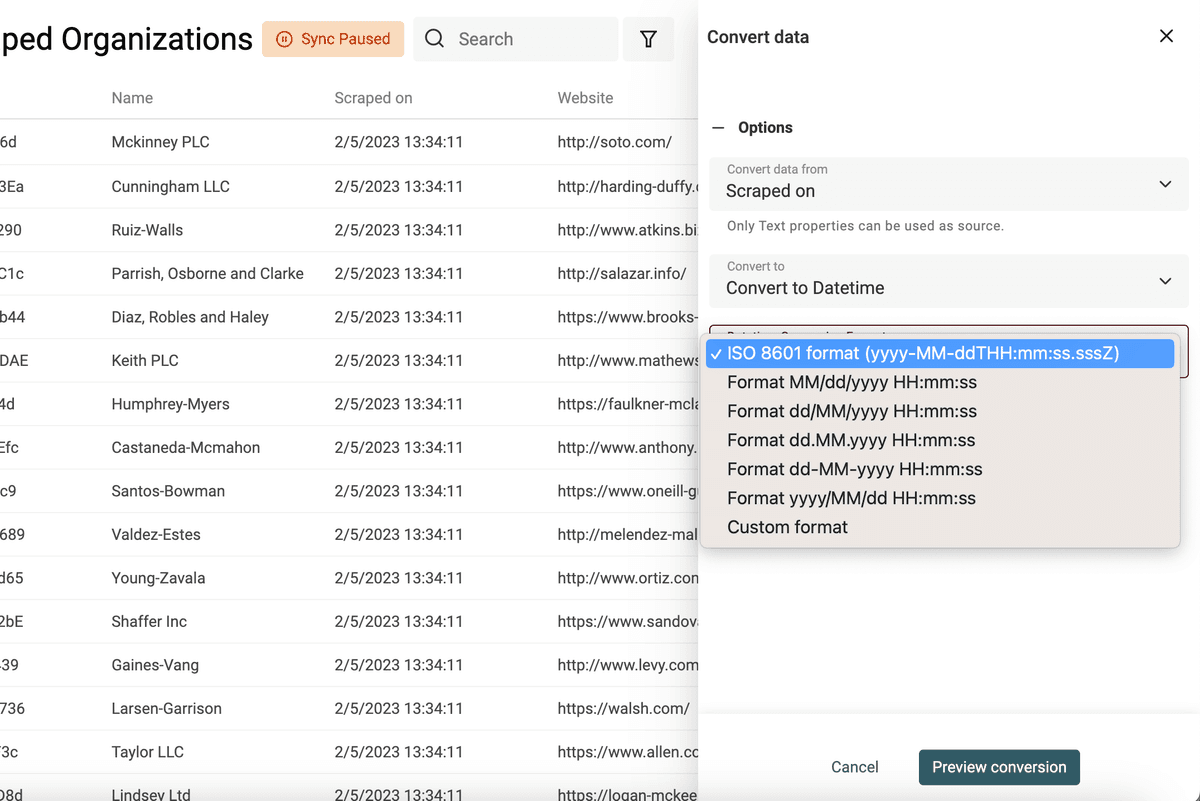
Sono elencati i formati comuni (quelli usati da Google Sheets ed Excel) oppure scegli "Custom format" per definire il tuo formato datetime.
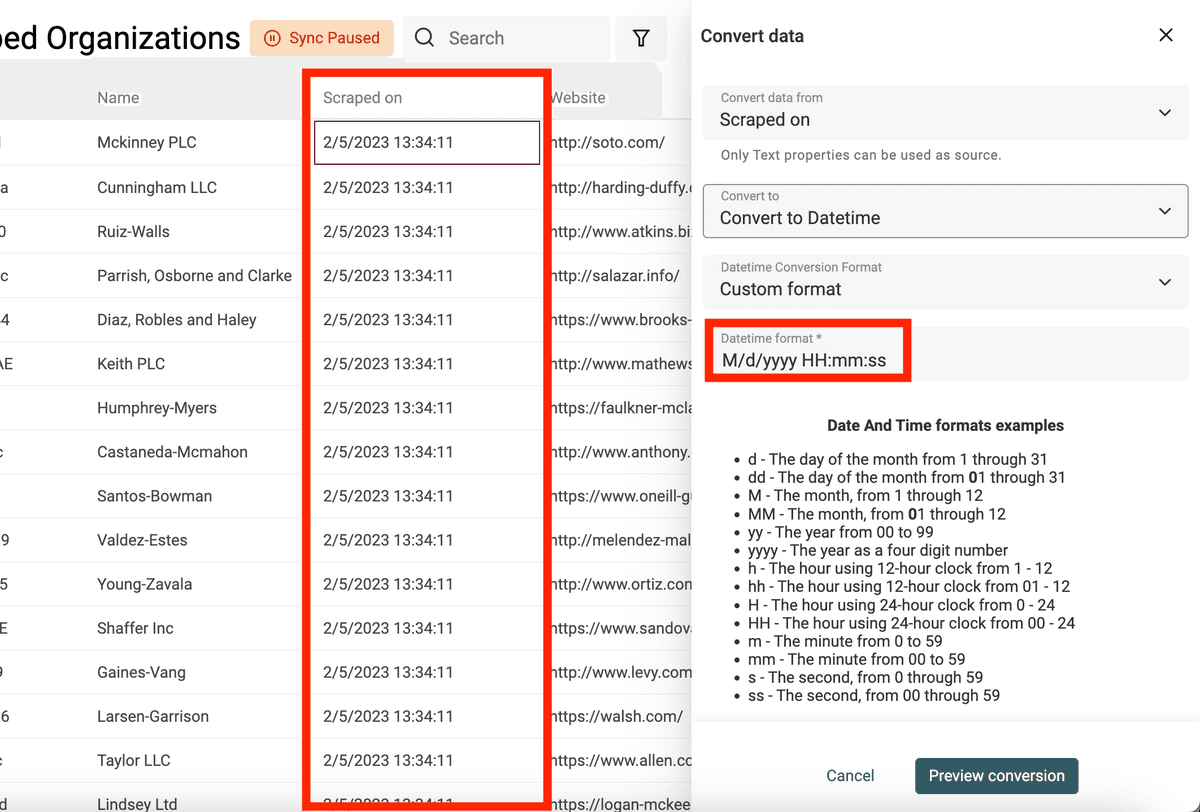
Se hai date e/o datetime in più formati per la stessa proprietà, seleziona "Custom or multiple formats" in "Datetime Conversion Format". Inserisci poi un formato per riga. Datablist proverà ogni formato partendo dal primo finché non ottiene una data valida.
👉 Visita la documentazione per saperne di più sui formati datetime custom.
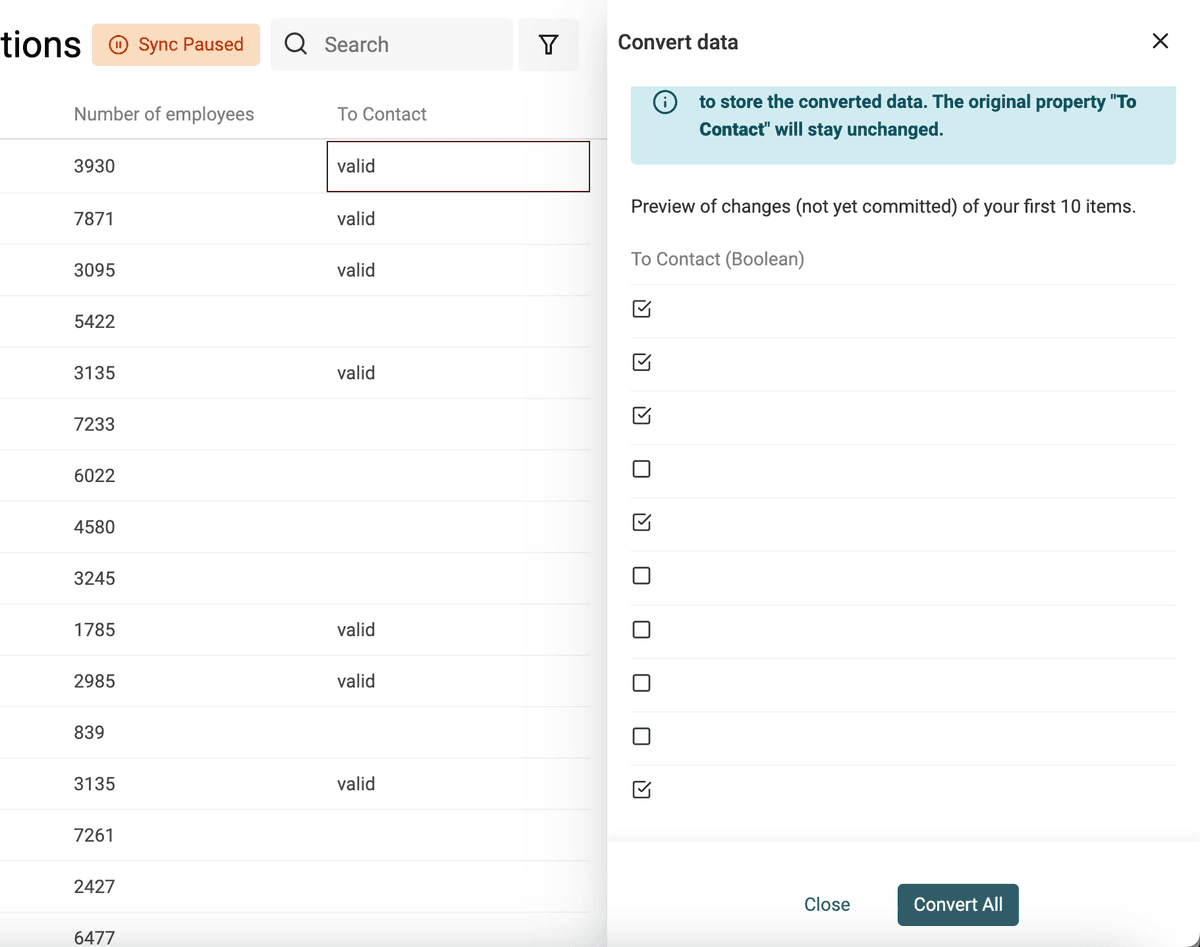
Crea Checkboxes (Boolean) da valori testuali
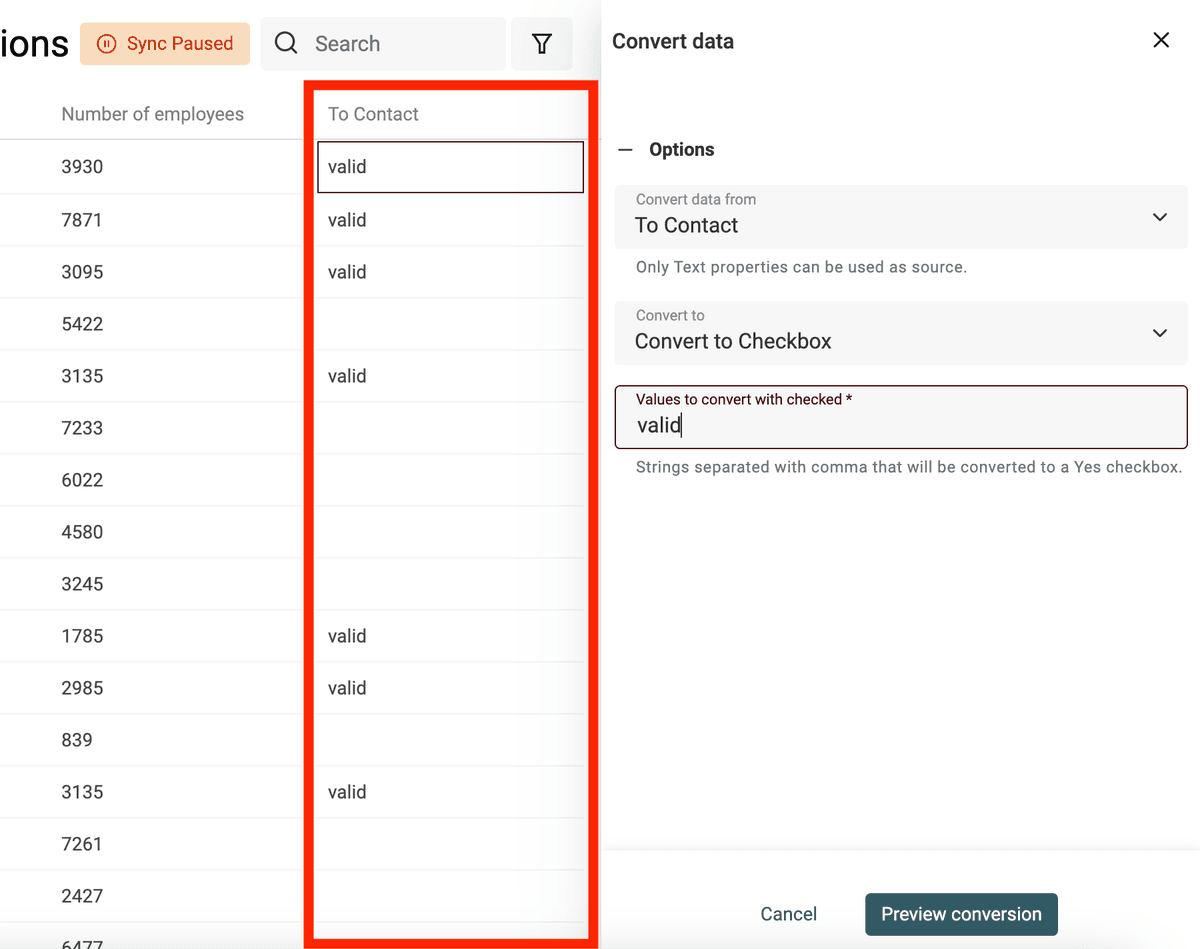
Datablist converte automaticamente colonne con "Yes, No", "TRUE, FALSE", ecc. in proprietà di tipo Checkbox in fase di import. Usa il converter per casi più complessi.
Definisci i valori (separati da virgola) da convertire in checkbox selezionata. Gli altri resteranno non selezionati.
Estrai numeri dai testi
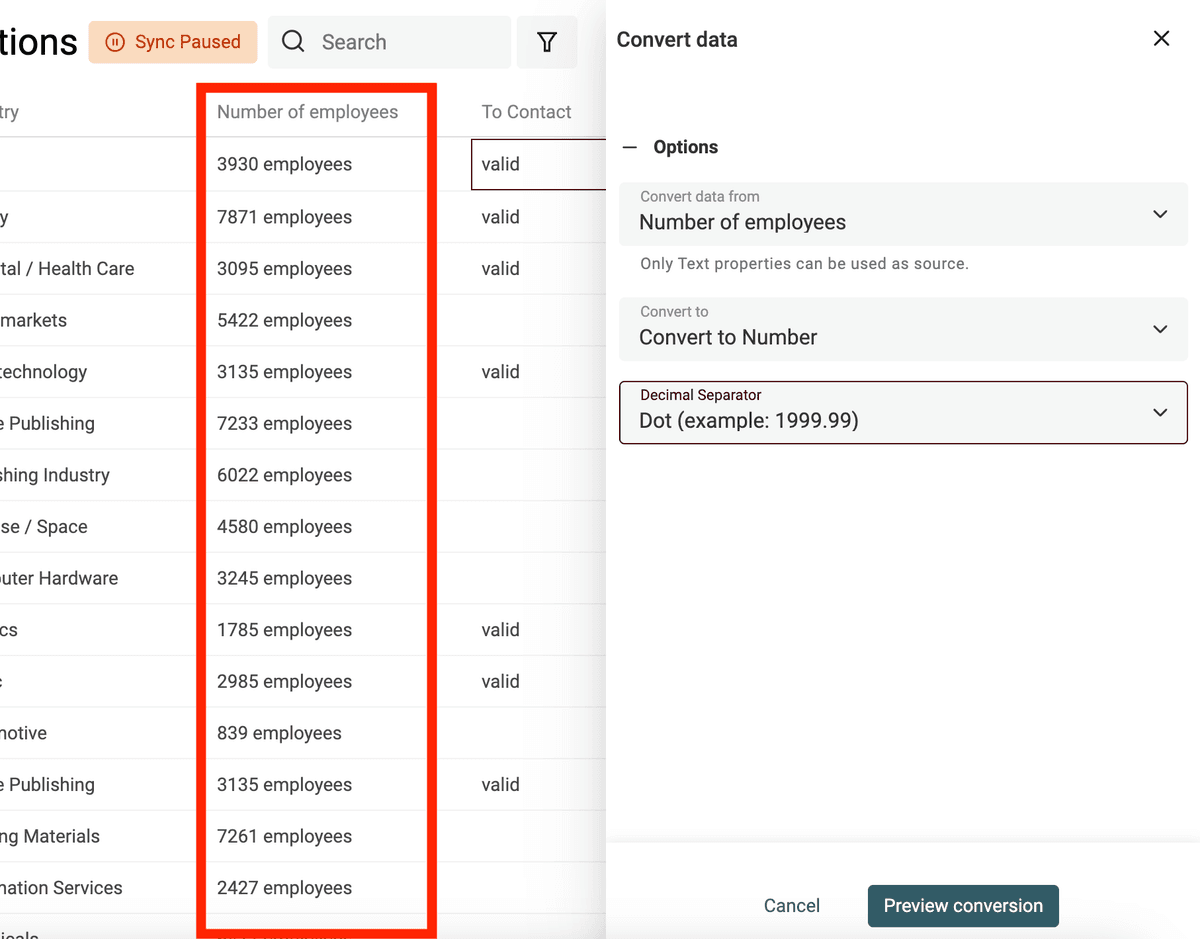
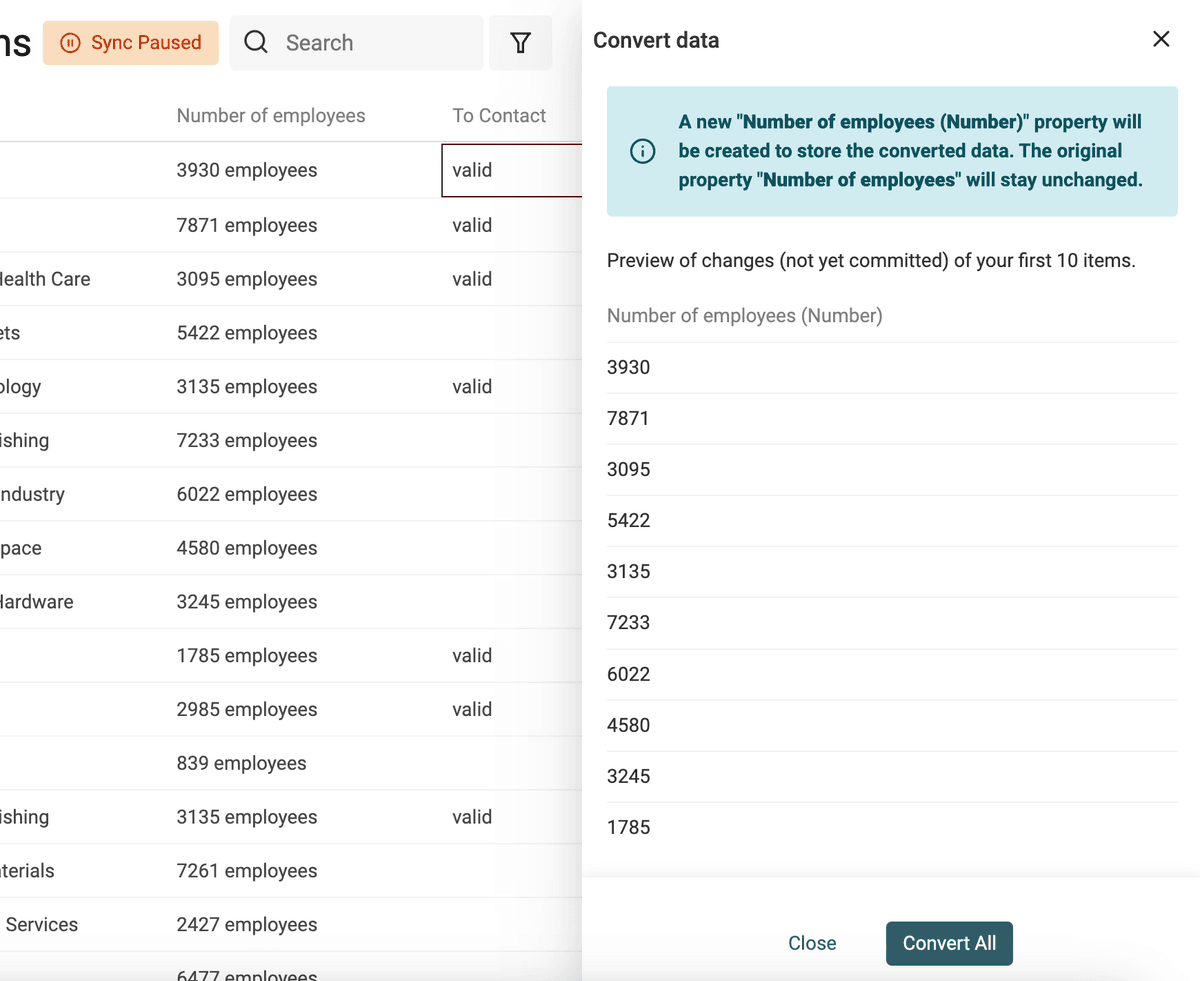
Usa il converter "Text to number" per:
- Normalizzare i numeri con separatori decimali e delle migliaia personalizzati
- Estrarre numeri da testi contenenti lettere
👉 Visita la documentazione per saperne di più sulla conversione dei numeri.
Pulizia dei dati
Converti HTML in testo
Gli strumenti di scraping leggono codice HTML e potresti ritrovarti tag HTML nei tuoi testi.
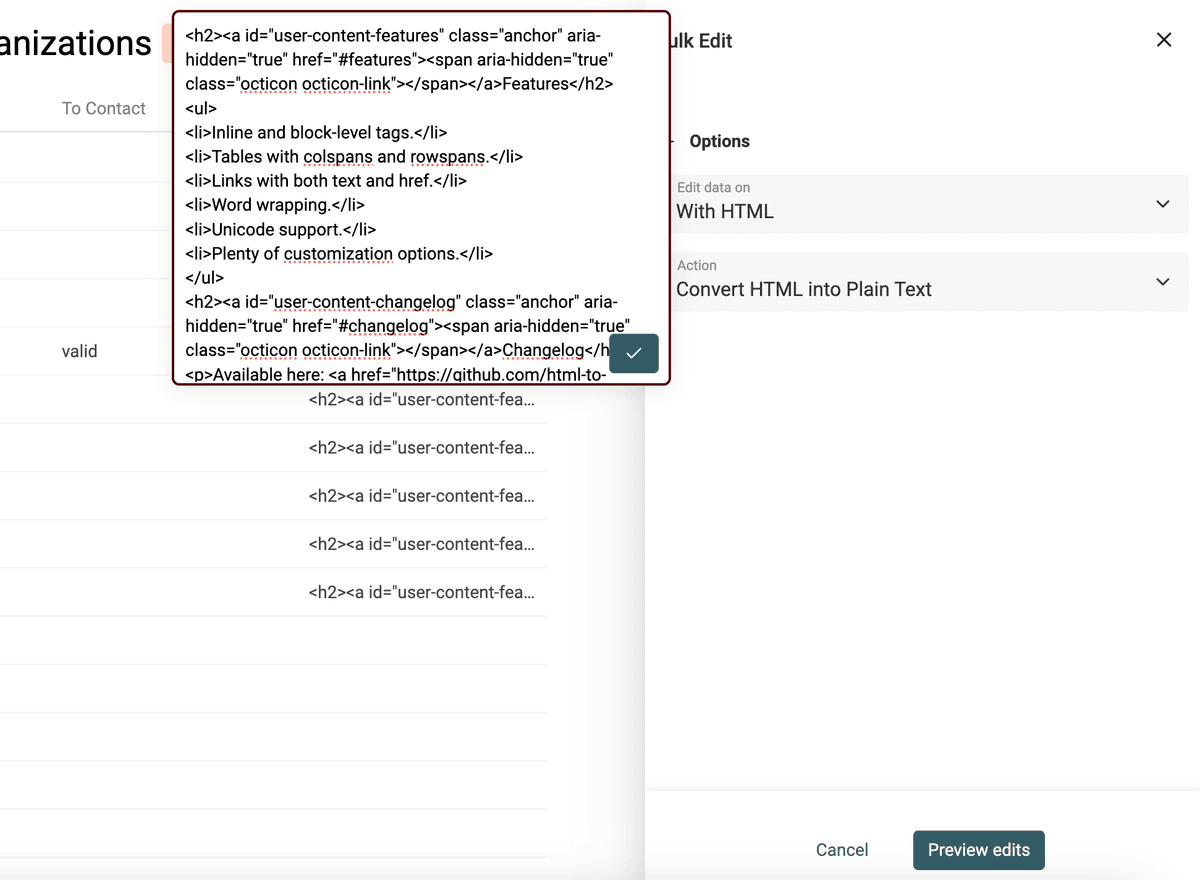
Il codice HTML include link, immagini e liste puntate. Ed è strutturato in paragrafi e multi-linea.
L’obiettivo è mantenere un po’ dell’ordine che l’HTML porta, ma trasformare un codice illeggibile in testo semplice.
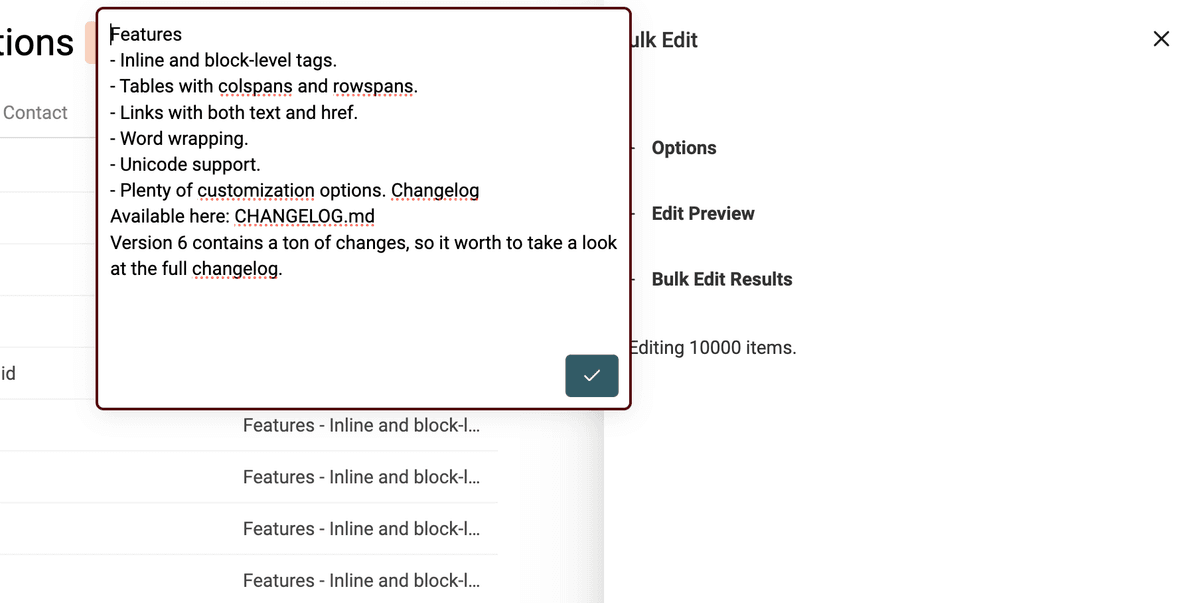
Il convertitore HTML to Text di Datablist mantiene le nuove linee e trasforma i bullet point in liste prefissate con -.
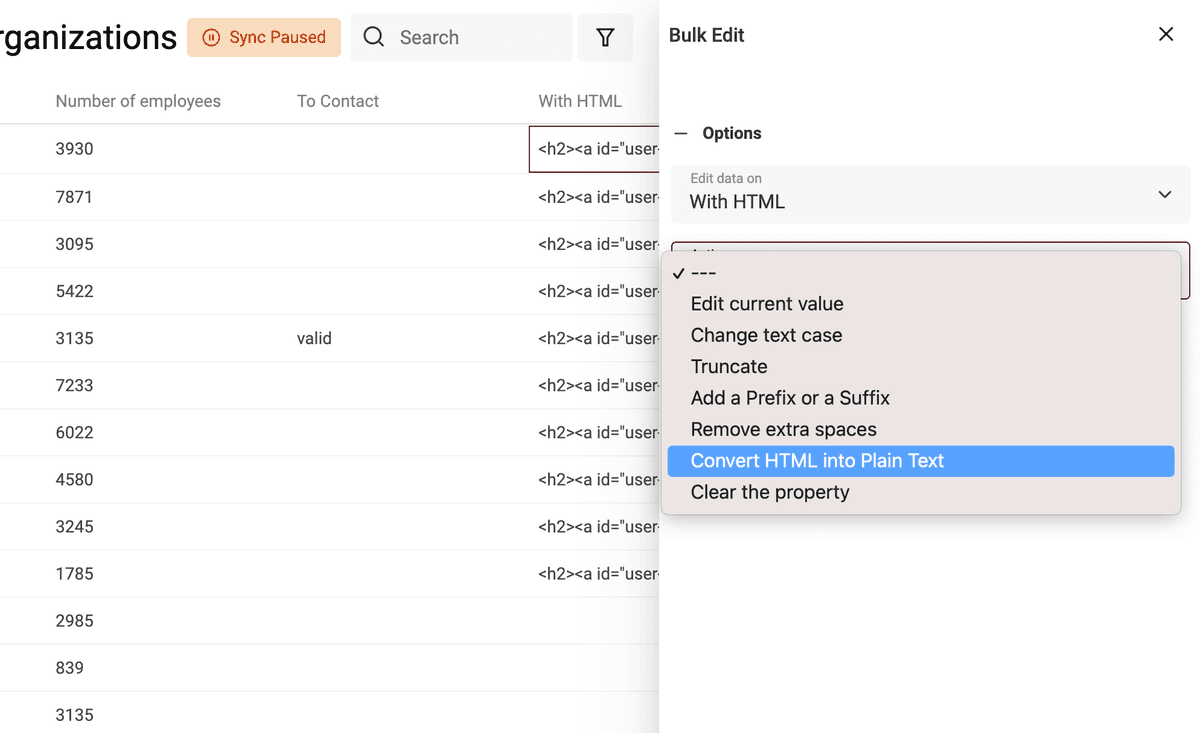
Per trasformare testi con tag HTML in plain text, apri lo strumento Bulk Edit nel menu Edit.
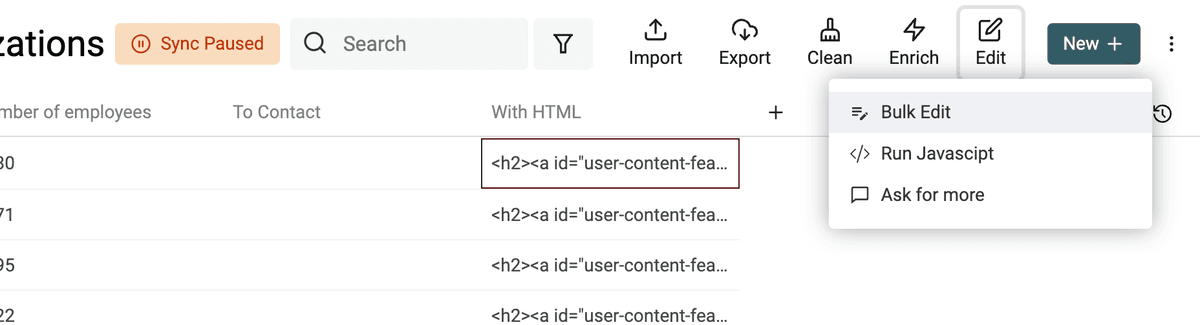
Seleziona la proprietà con i tag HTML. E scegli "Convert HTML into plain text".
Rimuovi spazi superflui
Un altro problema tipico dei dati disordinati sono gli spazi extra. Gli spazi arrivano da nuove linee, dal tasto Tab e da altri caratteri che rappresentano spazi in HTML.
Datablist include uno strumento di cleaning per eliminare gli spazi superflui.
Ha due modalità:
- Modalità 1: Rimuovi tutti gli spazi - Elimina tutti i caratteri di spazio. Utile per pulire numeri di telefono, prezzi, ecc., dove servono solo lettere, cifre, ecc.
- Modalità 2: Rimuovi solo gli "spazi extra".
Per la seconda modalità, l’algoritmo funziona così:
- Rimuove gli spazi extra fra le parole
- Rimuove le righe vuote
- Rimuove spazi iniziali e finali su ogni riga
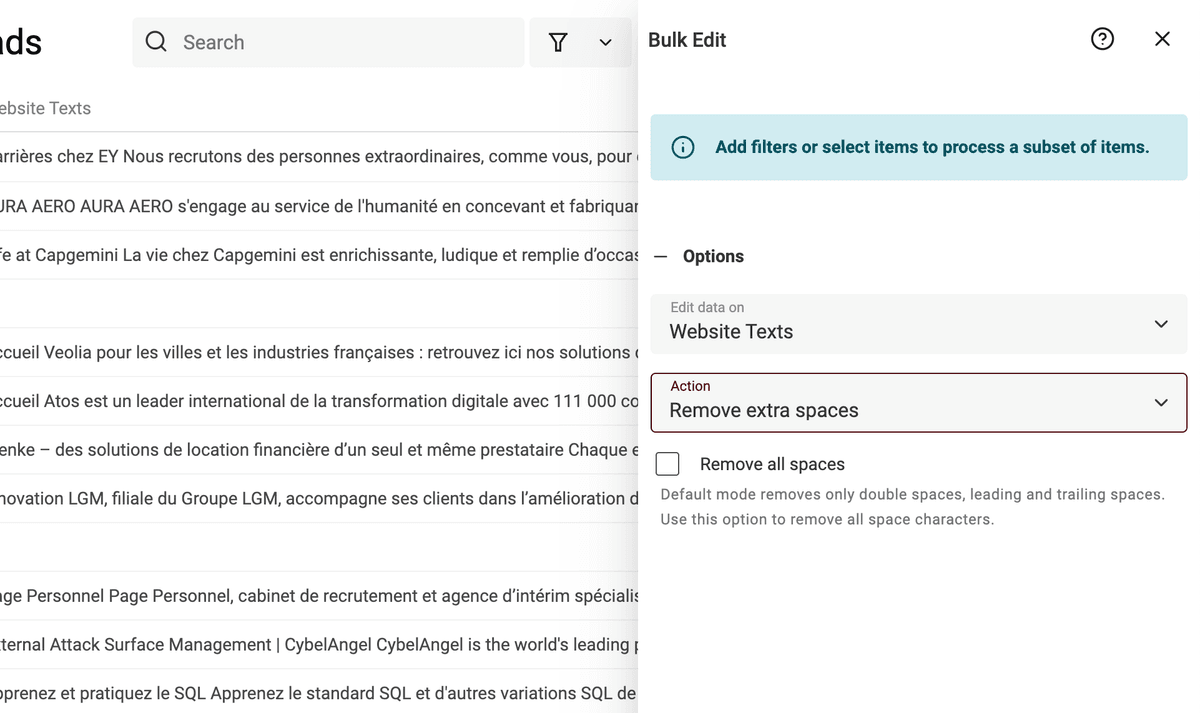
Per rimuovere gli spazi extra, apri lo strumento "Bulk Edit" dal menu "Edit". Seleziona la proprietà e l’azione "Remove extra spaces".
Spunta l’opzione "Remove all spaces" per eliminare tutti gli spazi. Lasciala disattivata per rimuovere solo gli "spazi extra".
Ecco un esempio con l’algoritmo che rimuove gli spazi:
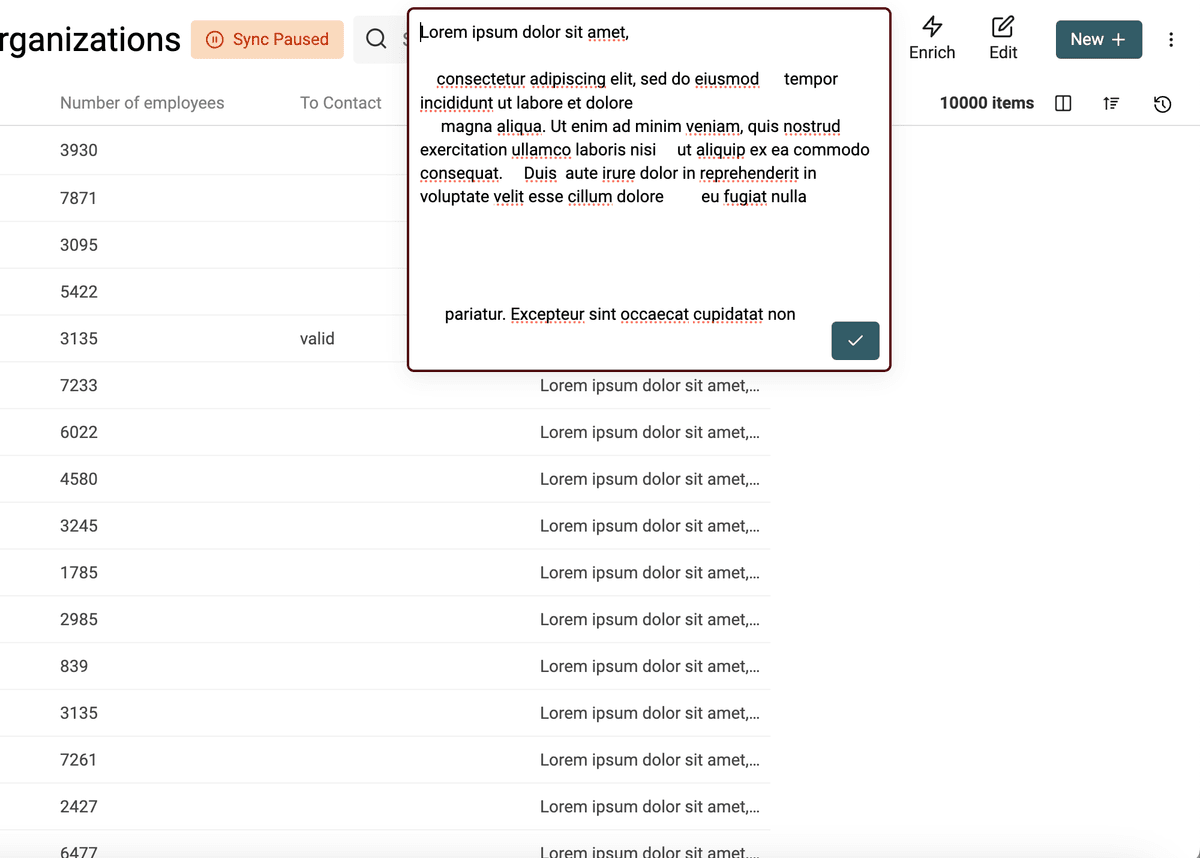
Dopo la pulizia, senza spazi superflui:
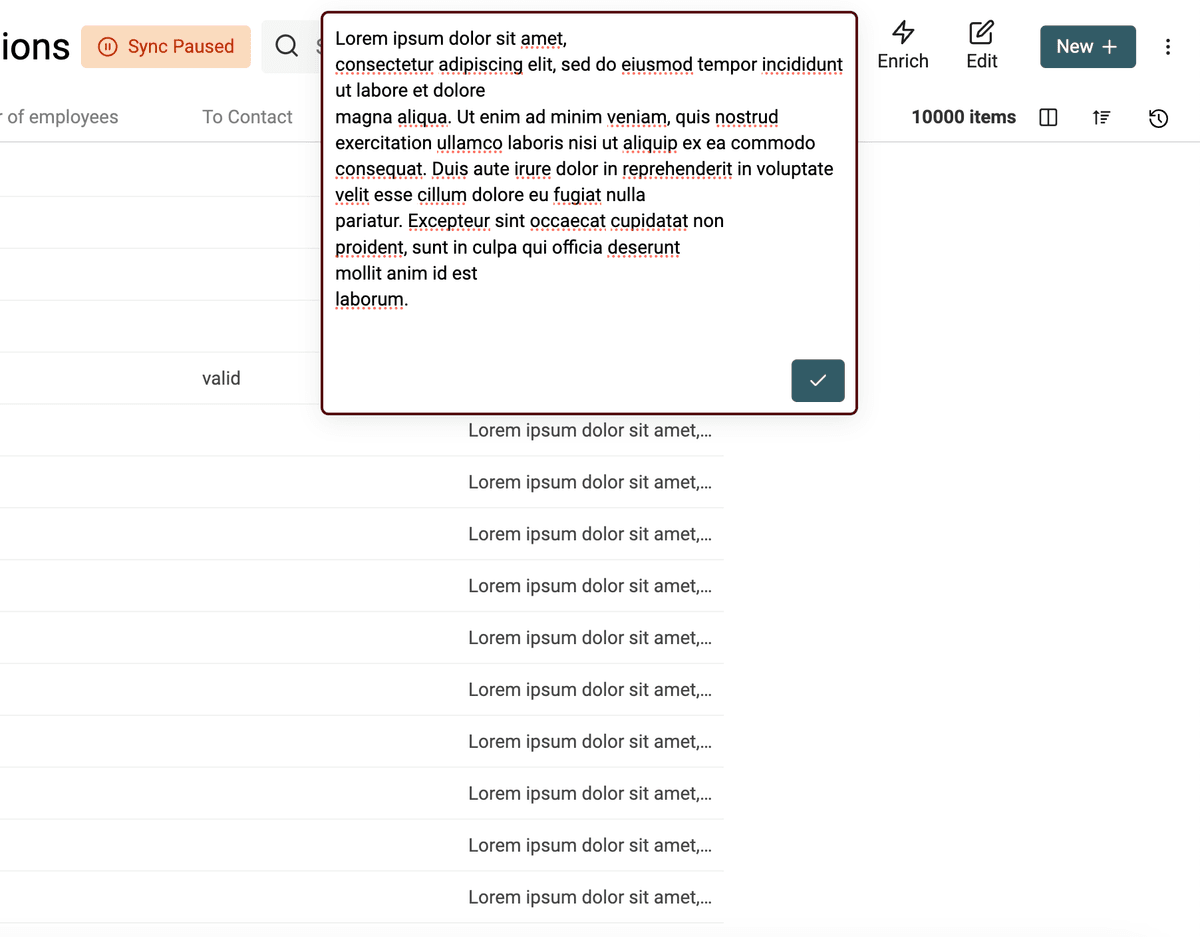
Uniforma maiuscole/minuscole
Cambiare il case del testo è semplice. Apri lo strumento "Bulk Edit" nel menu "Edit".
Seleziona la proprietà da processare e usa l’azione "Change text case".
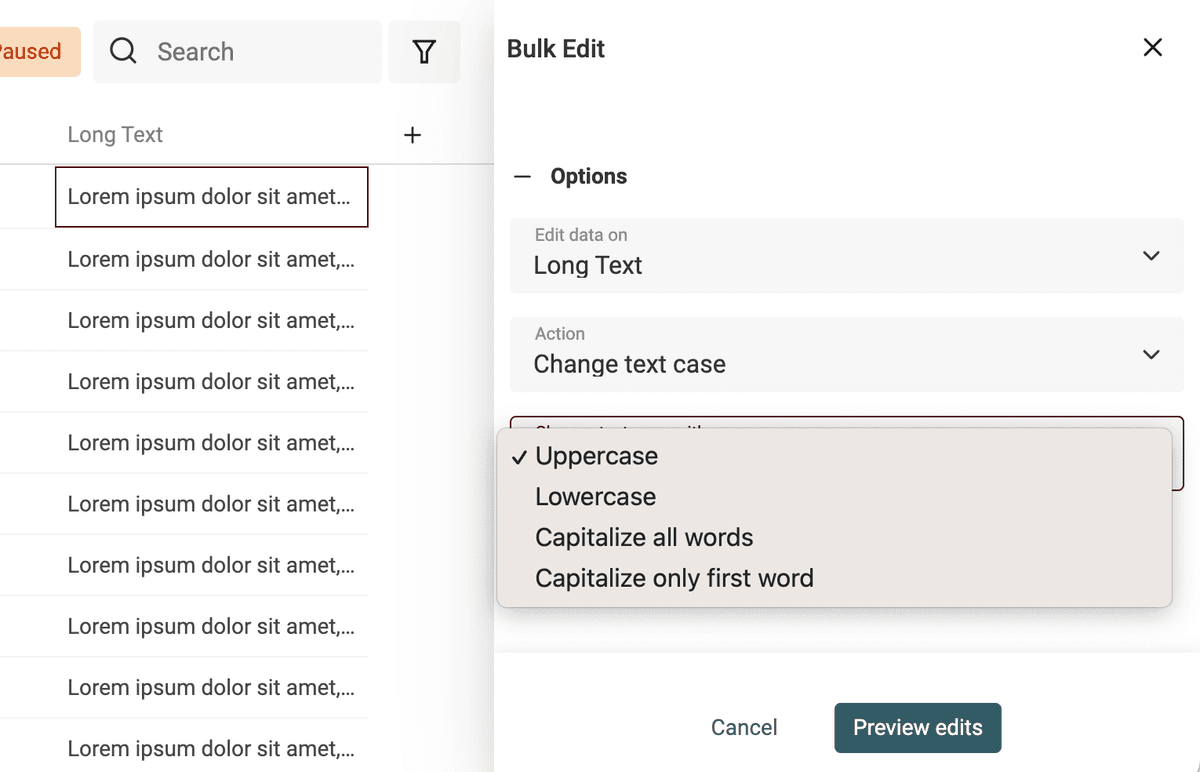
3 modalità disponibili:
- Uppercase - Tutte le lettere diventano maiuscole. Es:
john=>JOHN - Lowercase - Tutte le lettere diventano minuscole. Es:
API=>api - Capitalize - La prima lettera di ogni parola diventa maiuscola. Es:
john is a good man=>John Is A Good Man - Capitalize only the first word - Solo la prima lettera della prima parola diventa maiuscola. Es:
john is a good man=>John is a good man
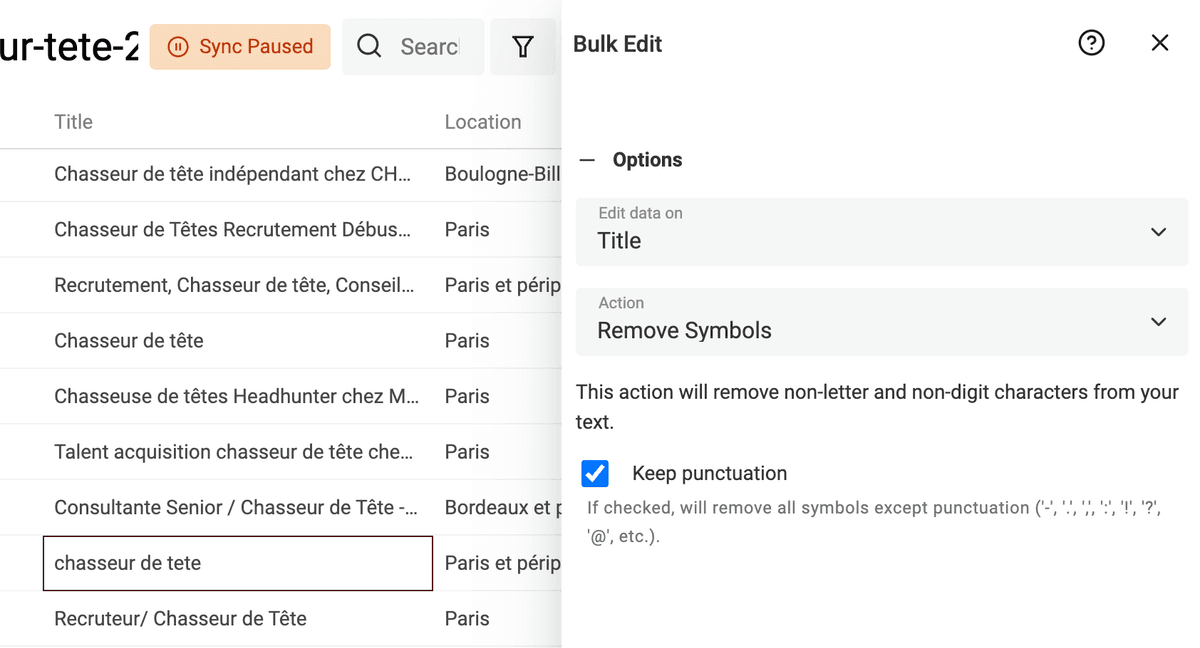
Rimuovi simboli dai testi
Testi scrappati da pagine HTML o inseriti dagli utenti (per esempio i titoli dei profili LinkedIn) possono contenere simboli: emoji e altri caratteri che impattano l’elaborazione dei dati. Una semplice emoji alla fine di un nome può impedire a un algoritmo di deduplicazione di riconoscerlo.
Datablist ha un processore integrato per rimuovere i simboli non testuali dai tuoi dati.
Clicca su "Bulk Edit" dal menu "Edit", seleziona una proprietà di tipo testo e scegli la trasformazione "Remove symbols".
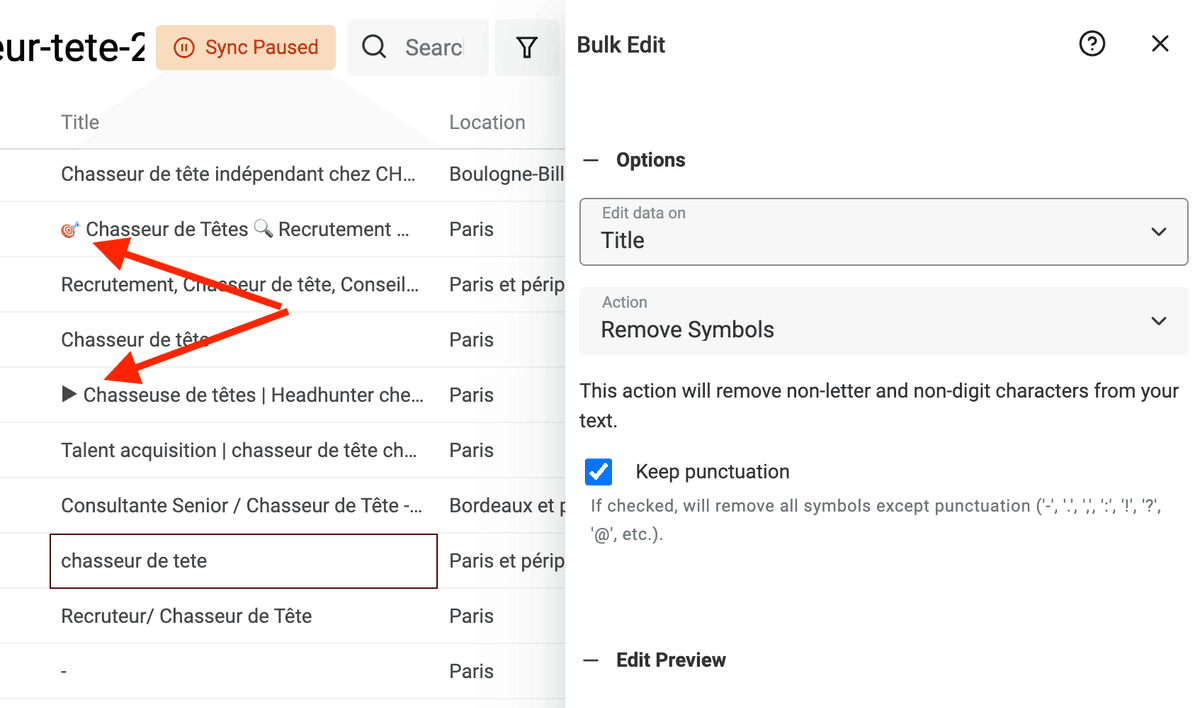
Se l’anteprima è corretta, esegui la trasformazione per processare gli item.
Normalizzazione con Find and Replace
Per creare segmenti nelle tue prospect lists, devi normalizzare i dati.
- Normalizzare i job title
- Normalizzare paesi, città
- Normalizzare le URL
- Etc.
L’obiettivo è ridurre una proprietà con testo libero a un insieme di scelte limitate. Oppure trasformare i testi in una versione più semplice (URL con path in un semplice dominio).
Datablist include un potente strumento di Find and Replace. Funziona sia con testo semplice sia con Regular Expressions.
Le Regular Expressions sono complesse ma molto potenti.
Ecco alcuni esempi su come usare le RegEx per pulire i dati.
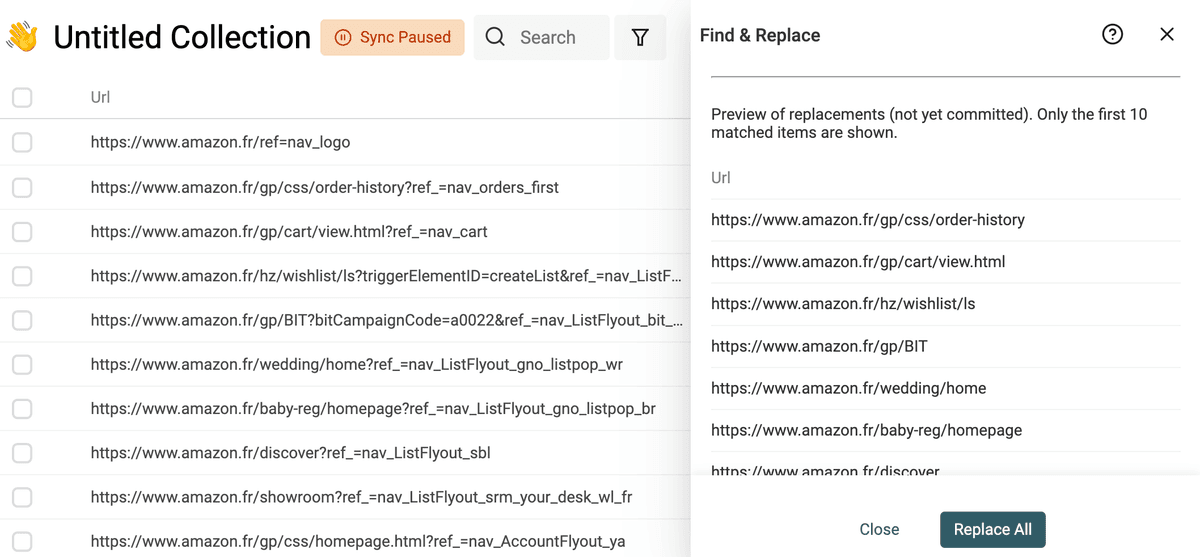
Rimuovi i parametri query da un URL
Le URL scrappate includono spesso query parameter inutili per tracking o motivi di marketing. Rimuoverli dalle URL ti darà indirizzi puliti. E ti aiuterà nella deduplicazione usando la URL per trovare duplicati.
Per rimuovere i parametri dalle URL, attiva l’opzione "Match using regular expression". Usa poi la seguente espressione regolare con testo di sostituzione vuoto:
\?.*$
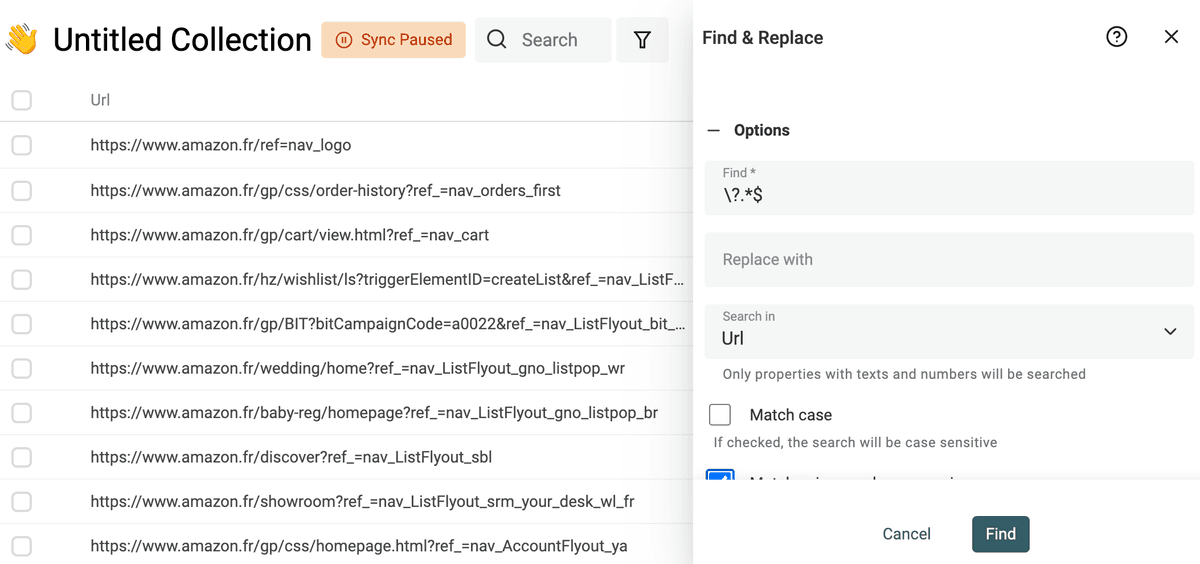
E applicala alla tua proprietà URL.
Estrai il dominio dalle email
Un altro uso di Find and Replace con Regular Expressions è estrarre il dominio del sito dalle email.
Duplica la proprietà email per preservare il dato sorgente. Poi usa questa RegEx con sostituzione vuota:
^(\w)*@
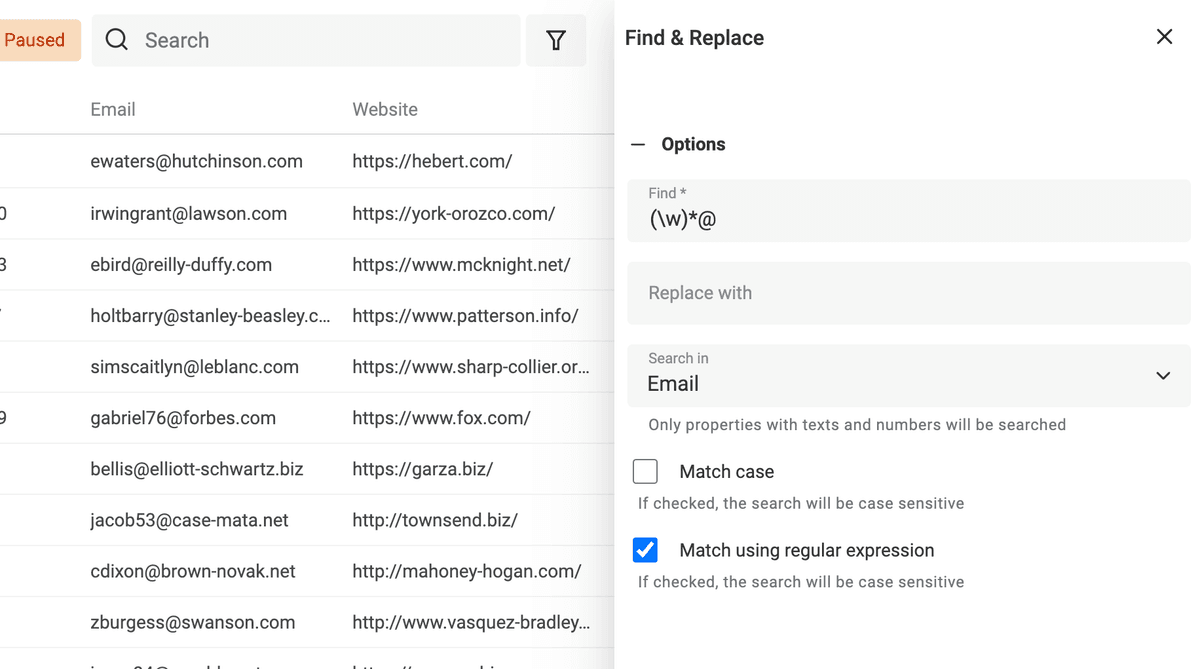
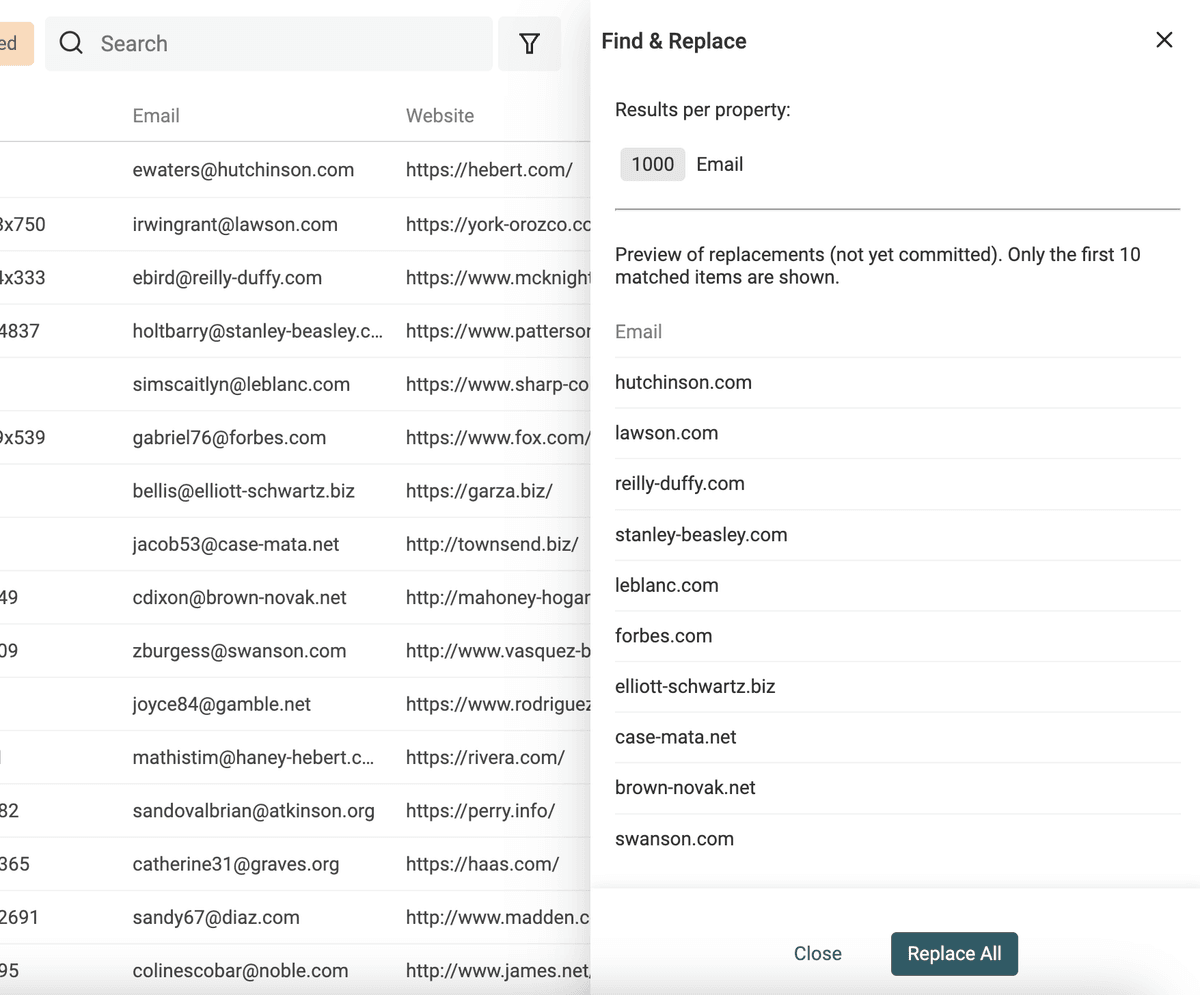
👉 Per saperne di più, visita la documentazione su Find and Replace.
Dividi il Full Name in First Name e Last Name
Quando fai scraping di lead list, ottieni contatti con "Full Name" che vanno divisi in "First Name" e "Last Name". Saper fare il parsing accurato del nome è un passaggio fondamentale.
Separare First Name e Last Name è utile per personalizzare i messaggi nelle campagne di cold emailing, per identificare il gender del contatto e per ottenere eventuali titoli accademici.
Il task può essere complicato. Per fortuna, Datablist offre uno strumento semplice per dividere "Name" in due valori usando lo spazio come delimitatore.
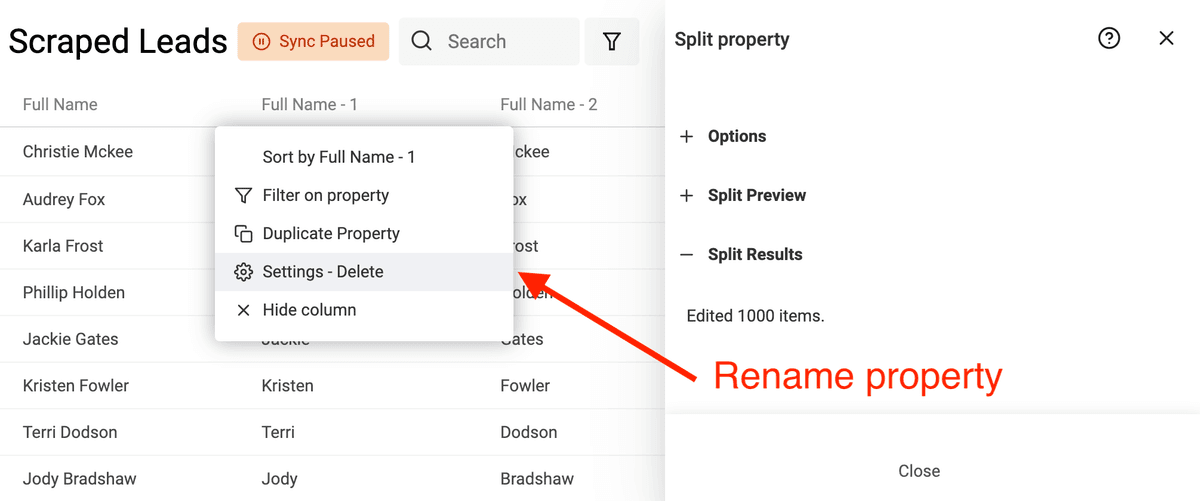
Per iniziare, apri "Split Property" dal menu "Edit".
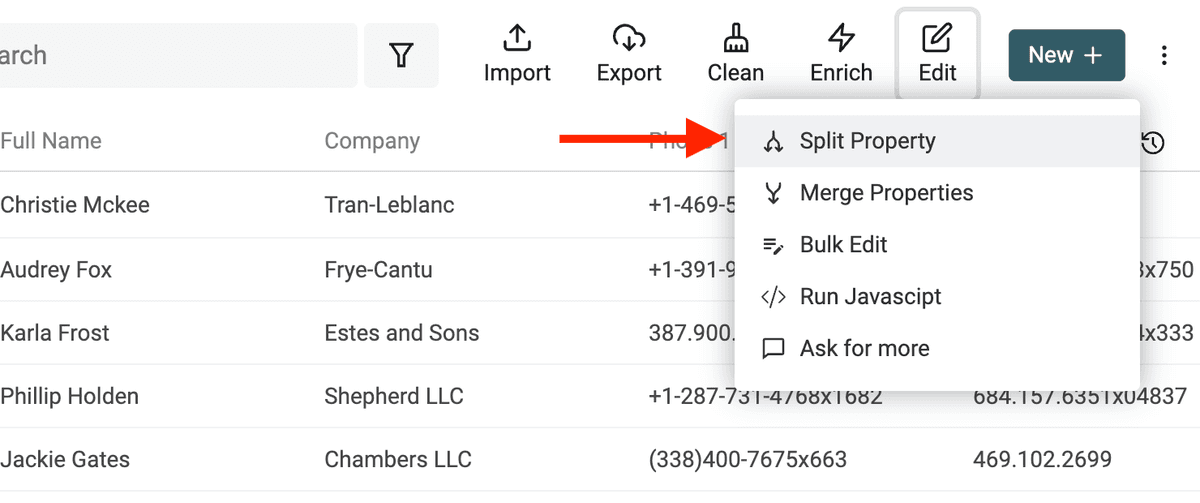
Poi seleziona la proprietà con i nomi da analizzare. Scegli Space come delimitatore e imposta il numero massimo di parti su 2.
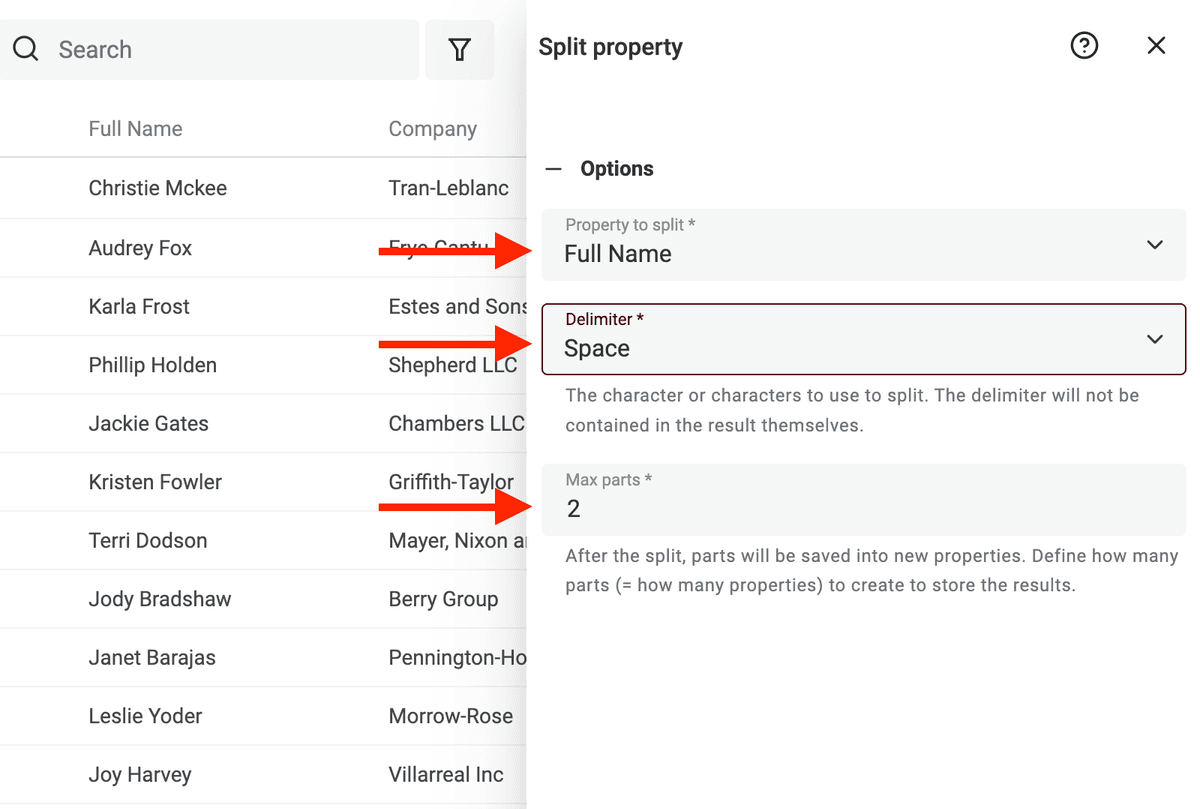
Esegui la preview. Datablist analizzerà i primi 10 item per generare l’anteprima. Se i risultati sono ok, clicca "Split Property" per lanciare l’algoritmo su tutti gli item correnti.
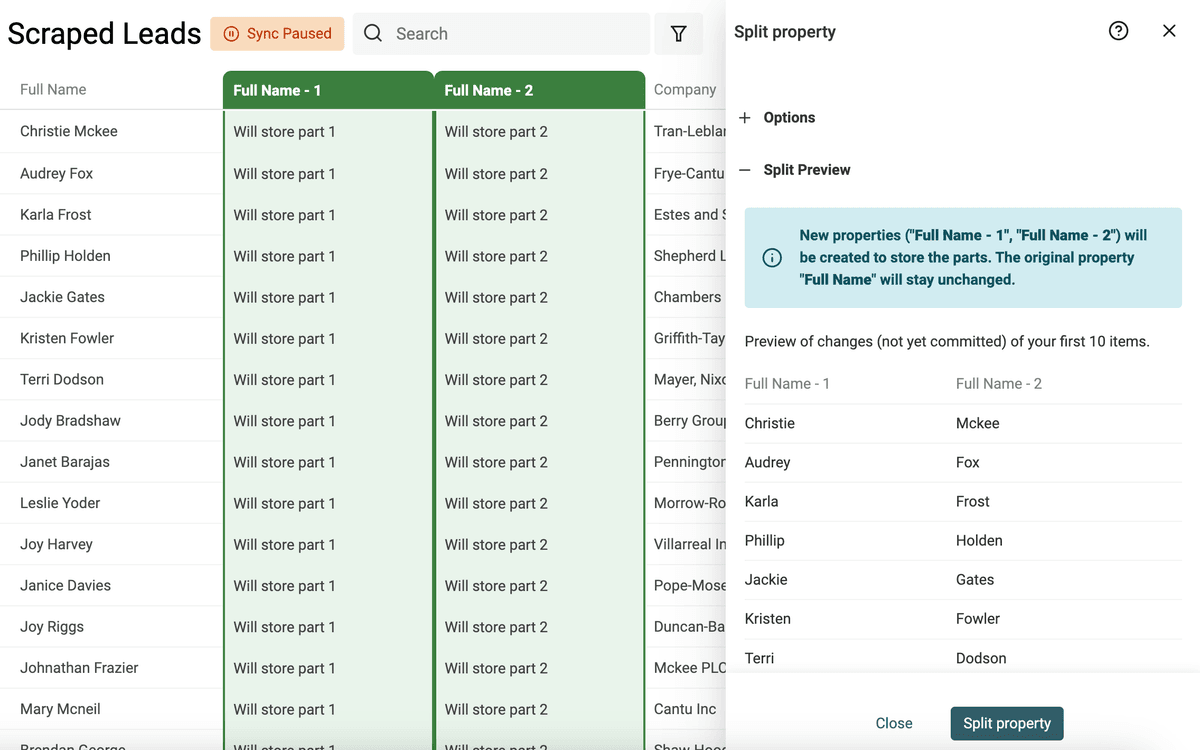
Dopo la divisione, rinomina le due proprietà create in "First Name" e "Last Name".
Questo esempio si concentra sulla convenzione occidentale (first name + last name). La cosa può complicarsi con nomi non occidentali, nomi composti o con titoli/suffissi.
Deduplicazione dei dati
Datablist ha un potente algoritmo per dedupe records. Trova item simili usando una o più proprietà e dispone di un algoritmo automatico per unirli senza perdere dati.
Per avviare la deduplicazione, clicca su "Duplicate Finder" nel menu "Clean".
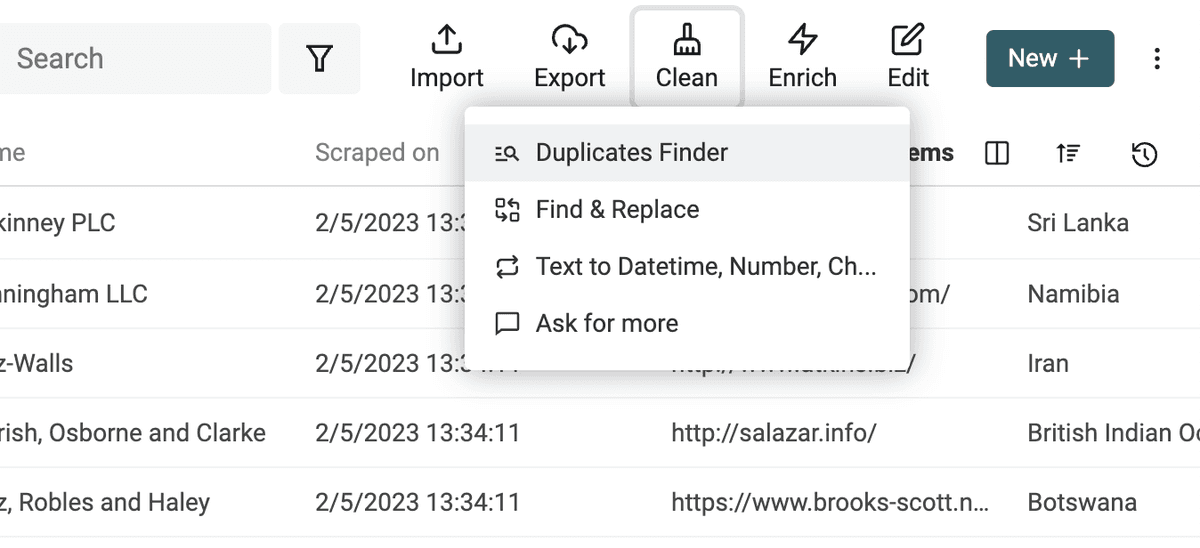
Seleziona le proprietà da usare per il matching.
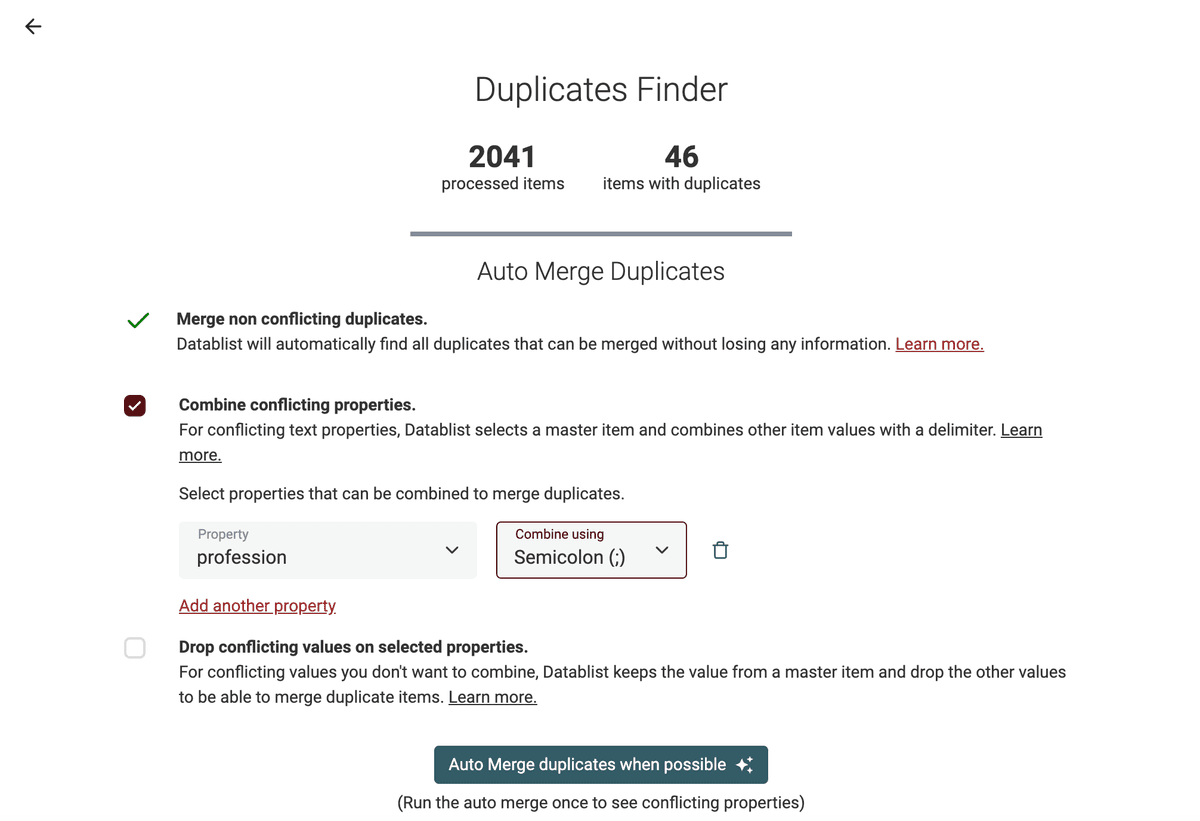
Nella pagina dei risultati, esegui l’algoritmo "Auto Merge" una volta con l’opzione "Merge non-conflicting duplicates". Unirà i duplicati facilmente unificabili e ti elencherà le proprietà con conflitti.
L’algoritmo di dedupe offre due opzioni per i conflitti: puoi "Combine conflicting properties" usando un delimitatore, oppure scartare i valori in conflitto per mantenere un solo master item.
👉 Visita la guida su come unire i duplicati nei file CSV. e la nostra guida per trovare e unire i duplicati usando i nomi aziendali.
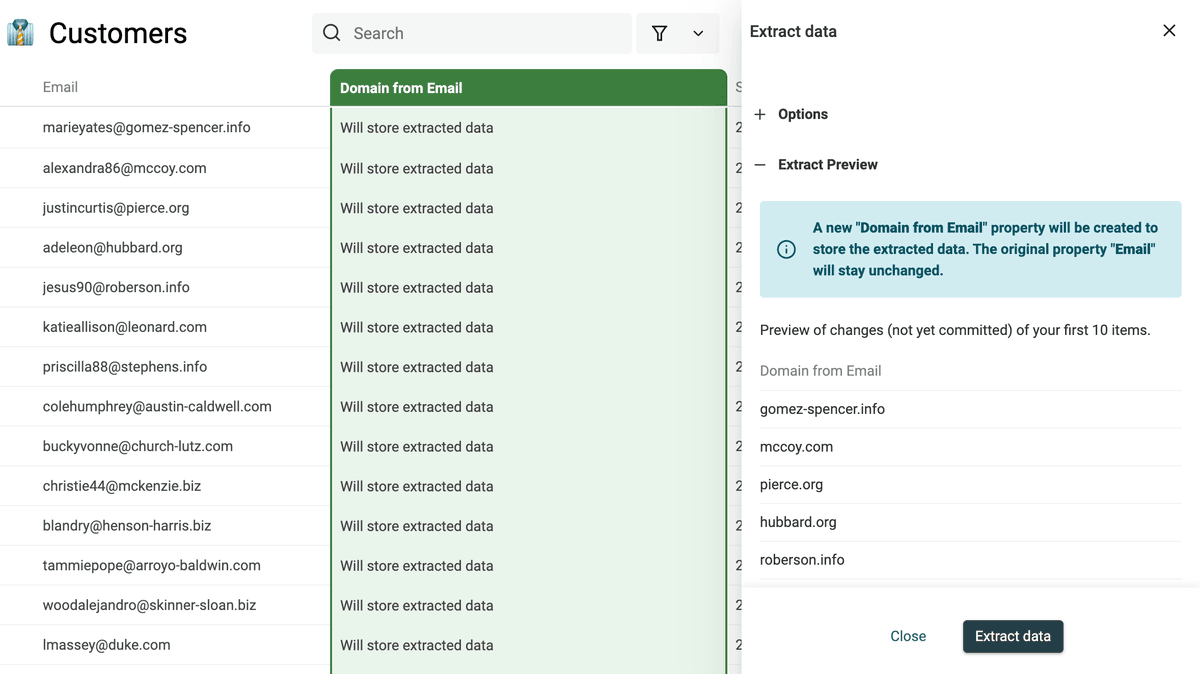
Estrai email, URL, ecc. dai testi
Il Data Extractor di Datablist è uno strumento per analizzare testi non strutturati ed estrarre entità.
Riconosce pattern per rilevare:
- Indirizzi email da un testo
- URL da un testo
- Dominio da URL
- Dominio da email
- Menzioni (es. @name) da un testo
- Tag (es. #tag) da un testo
Il Data Extractor è perfetto per l’analisi e per dare struttura ai dati. Con email e URL ben formattate puoi collegare i dati ad altri tool e creare flussi automatici.
Per esempio, una volta ottenute le email, potrai arricchirle per trovare informazioni di contatto. Oppure, usando il dominio dalle URL, puoi recuperare il ranking del traffico con, ad esempio, Similarweb.
Il Data Extractor è disponibile dal menu "Edit -> Extract url, email, tag, etc.".
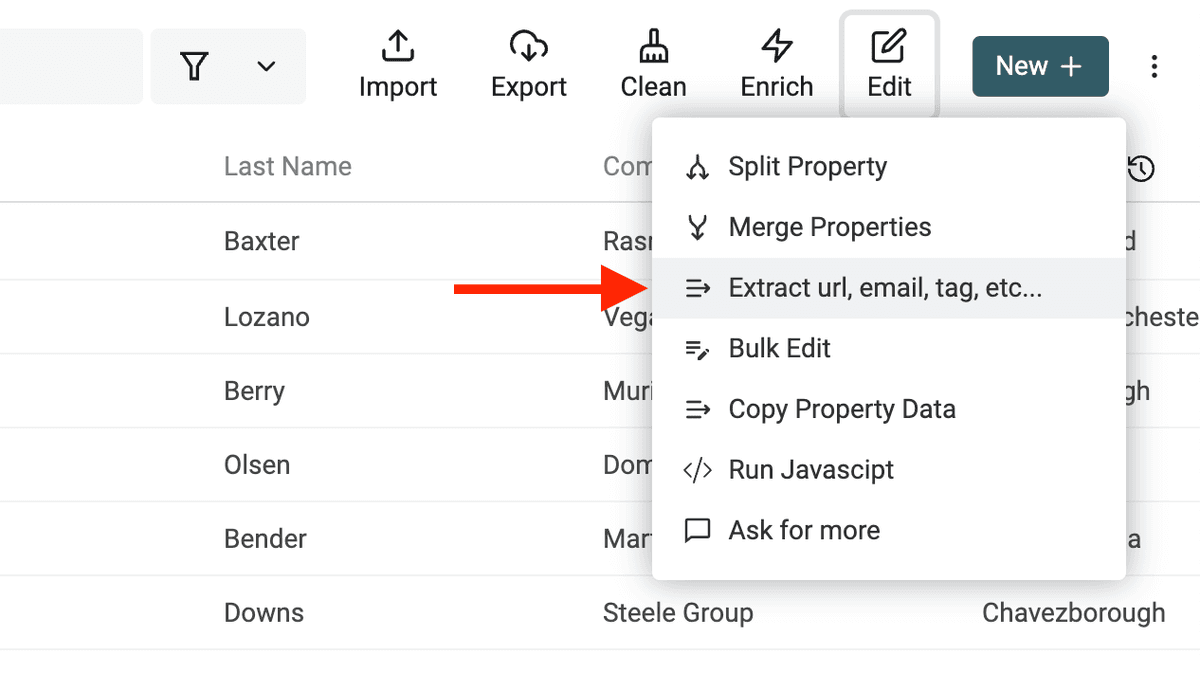
Seleziona la proprietà con testo non strutturato e scegli un parser.
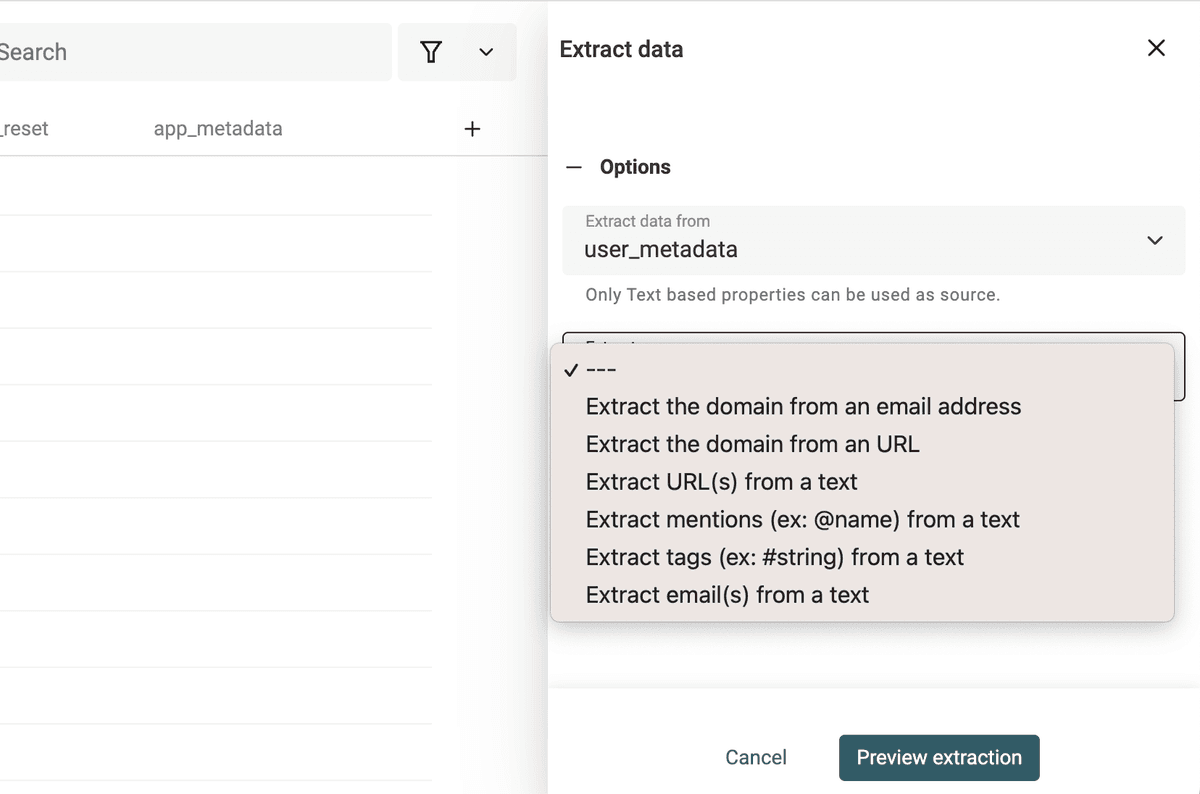
Esegui il parser per vedere la preview. Se è tutto ok, clicca "Extract" per processare gli item.
Usa Regular Expressions per filtrare e validare dati
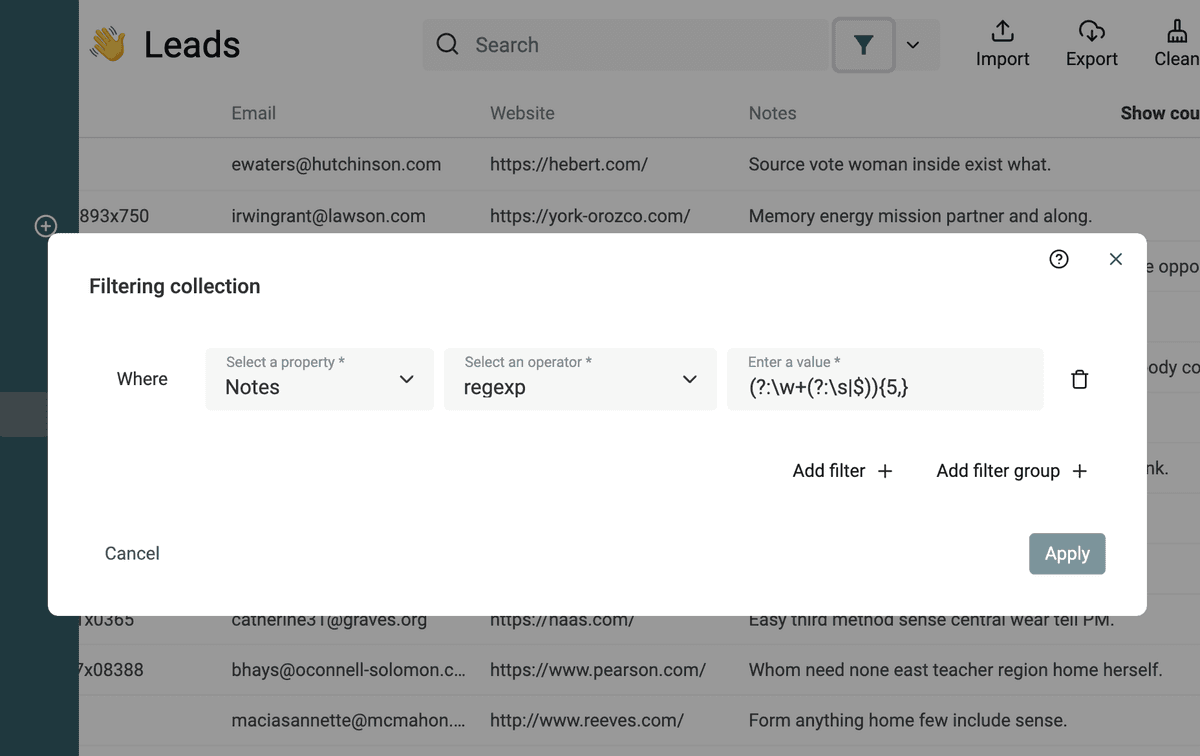
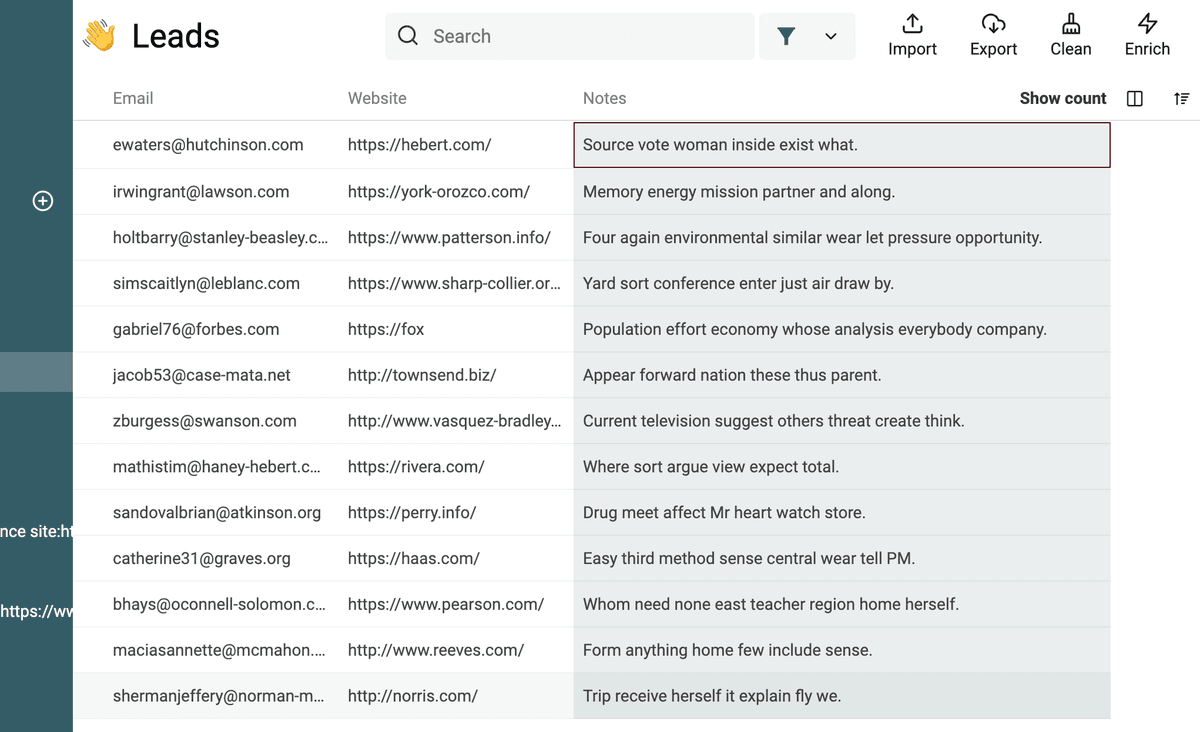
Datablist ti permette di usare Regular Expression per filtrare i dati.
Filtra testo in base al numero di parole
Con questa Regular Expression puoi filtrare i testi con almeno {n} parole:
(?:\w+(?:\s|$)){5,} (sostituisci 5 con il numero desiderato)
Altre varianti di questa RegEx:
(?:\w+(?:\s|$)){,5}: Testi con meno di 5 parole (incluse 5)(?:\w+(?:\s|$)){5,10}: Testi tra 5 e 10 parole
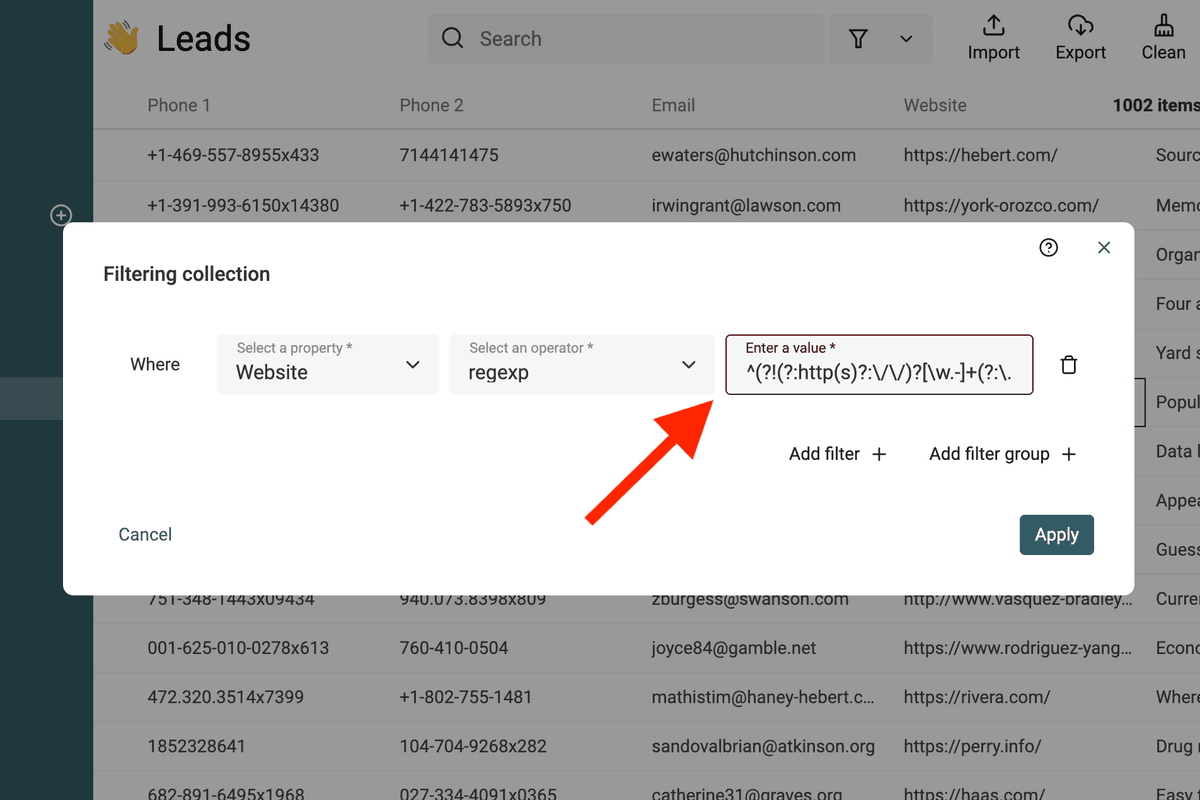
Filtra URL non validi
Questa RegEx intercetta URL non valide:
^(?!(?:http(s)?:\/\/)?[\w.-]+(?:\.[\w\.-]+)+[\w\-\._~:\/?#[\]@!\$&'\(\)\*\+,;=.]+).*$
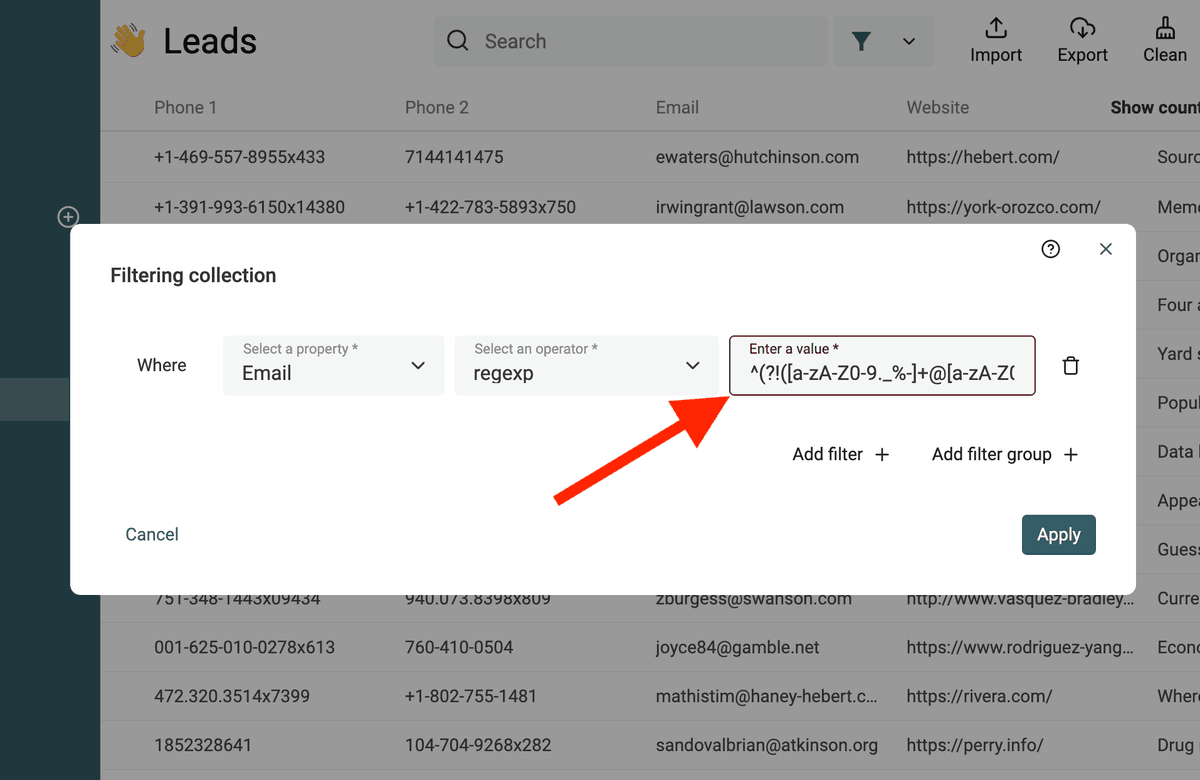
Filtra email non valide
Questa RegEx intercetta email non valide:
^(?!([a-zA-Z0-9._%-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,})).*$
Trasformazioni custom con JavaScript
Datablist ti consente di eseguire codice JavaScript custom sui tuoi dati. Con questa possibilità puoi affrontare sfide uniche, gestire formati speciali, fare calcoli complessi e applicare trasformazioni sofisticate.
Questa funzionalità potente ti permette di liberare creatività ed esperienza nella manipolazione dei dati. Hai la flessibilità di applicare logiche custom, creare loop, condizioni e usare un’ampia gamma di funzioni JavaScript per le attività di cleaning più complesse.
Apri l’editor JavaScript cliccando su "Run JavaScript" dal menu "Edit".
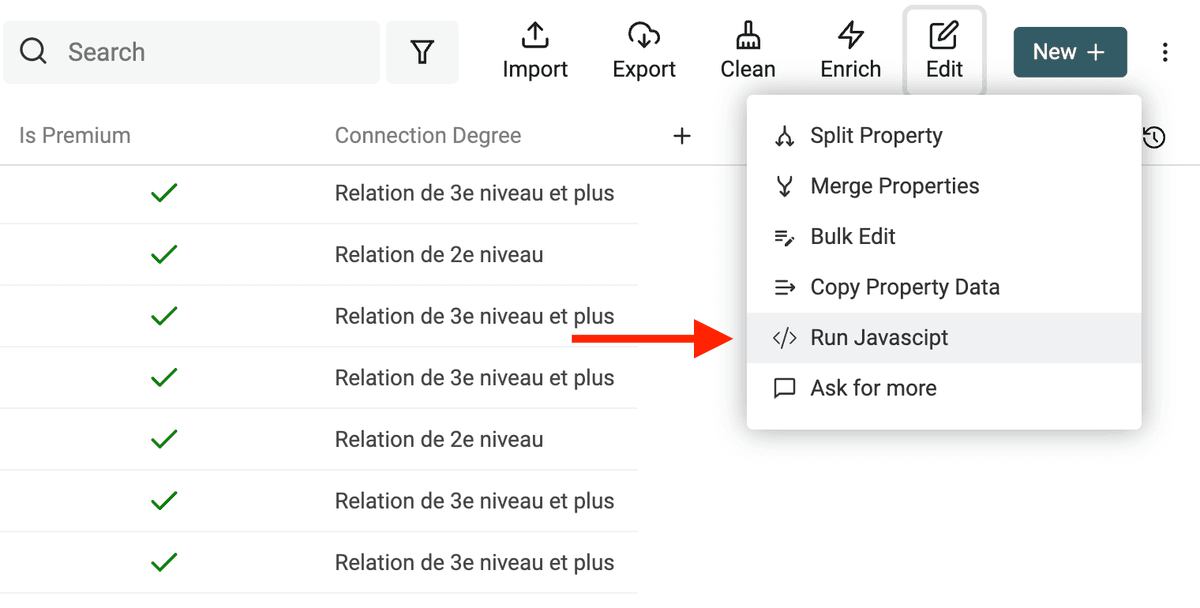
👉 Visita la documentazione per imparare a scrivere codice JavaScript.
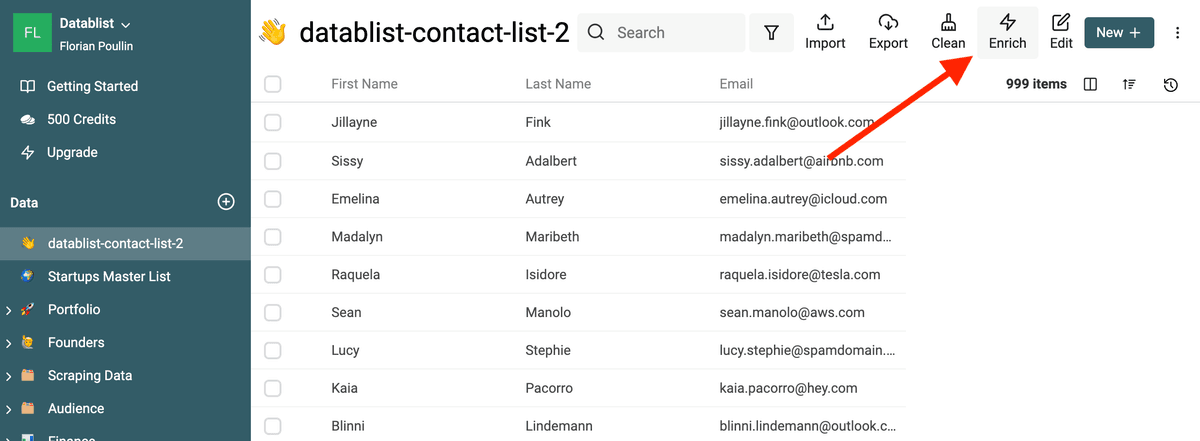
Valida gli indirizzi Email
I dati da scraping possono essere vecchi, avere typo o essere invalidi. Questo è particolarmente vero per gli indirizzi email ottenuti tramite scraping.
Con dati user-generated, potresti ritrovarti email fake nel database. O indirizzi di provider usa e getta.
Datablist include un tool di email validation per validare migliaia di email in blocco.
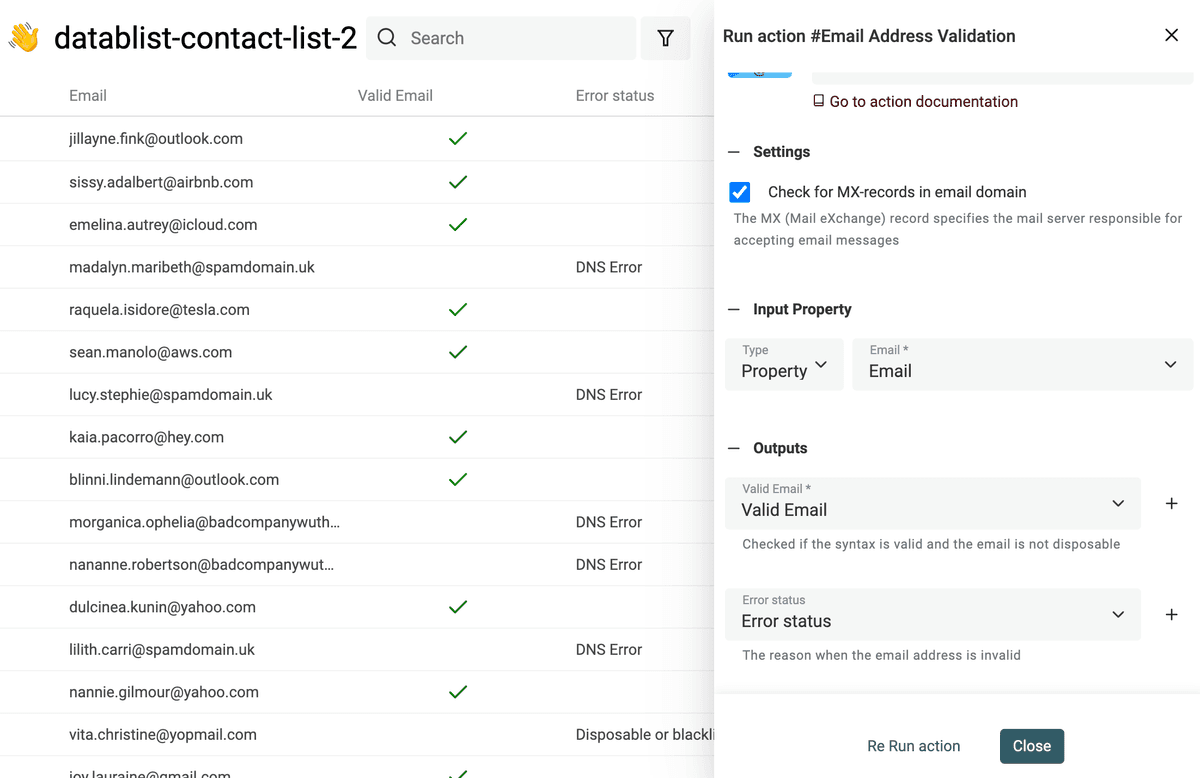
Il servizio di validazione verifica:
- Email syntax analysis - Primo check: l’email rispetta lo standard IETF e supera un’analisi sintattica completa. Vengono segnalati indirizzi senza la @, con domini non validi, ecc.
- Disposable providers check - Secondo check: rileva email temporanee. Il servizio cerca domini appartenenti a provider di Disposable Email Address (DEA) come Mailinator, Temp-Mail, YopMail, ecc.
- Domain MX records check - Un’email valida deve avere un dominio con MX record configurati. Gli MX indicano il mail server che accetta i messaggi per il dominio. MX mancanti = email non valida. Per ogni dominio, il servizio interroga i DNS e cerca gli MX. Se il dominio non esiste, l’email è invalid. Se esiste ma senza MX validi, è comunque invalid.
- Business vs Personal Email Segmentation - Con prospect da lead magnet o per segmentare la user base, potresti voler separare email business e personali. Il servizio fornisce questa informazione per arricchire i contatti.
FAQ
Che cos'è la data cleaning e perché è importante?
La data cleaning, nota anche come data cleansing o data scrubbing, è il processo di identificazione e correzione o rimozione di errori, incoerenze e inesattezze in un dataset. Include il rilevamento e la correzione di problemi come valori mancanti, record duplicati, errori di formattazione, outlier e incoerenze nella rappresentazione dei dati.
La pulizia dei dati è un passaggio cruciale perché garantisce che i dati siano accurati, affidabili e adatti all’analisi o all’uso in varie applicazioni.
Quali sono gli altri tool gratuiti per la Data Cleaning?
Il panorama della data cleaning va da tool generici come i fogli di calcolo ad applicazioni specializzate. Ecco alcuni tool gratuiti consigliati, oltre a Datablist, per le tue operazioni di pulizia dei dati.
OpenRefine
OpenRefine (in passato Google Refine) è un tool open-source focalizzato sull’esplorazione, pulizia e trasformazione di dati disordinati e inconsistenti.
OpenRefine è un’app desktop standalone compatibile con file tabellari (CSV, TSV), file Microsoft Excel e altri formati strutturati come JSON e XML.
OpenRefine è molto utile per gestire CSV non validi:
- Gestisce molto bene i problemi di encoding dei CSV
- Offre opzioni per risolvere errori di formato CSV
Tra i punti deboli, OpenRefine ha una curva di apprendimento ripida e manca di alcune funzionalità business. Non ha deduplicazione integrata né workflow semplici per unire un dataset con un’altra lista per aggiornare o consolidare i dati. Mancano anche funzionalità di collaborazione e enrichment/integrations orientate al business.
Microsoft Excel and Google Sheets
Microsoft Excel e Google Sheets sono potenti spreadsheet che puoi usare per cleaning e preparazione dei dati. Pur con differenze, entrambi offrono tante funzioni utili per pulire e trasformare.
Puoi usare formule per trasformazioni e manipolazione. E con il conditional formatting evidenziare valori non validi che richiedono gestione manuale.
Hai bisogno di aiuto con la tua data cleaning?
Cerco sempre feedback e casi reali di data cleaning da risolvere. Per favore contattami e raccontami il tuo use case.