Levenshtein Distance, often referred to as edit distance, is a fundamental concept in string comparison and analysis. It quantifies the difference or similarity between two strings by calculating the minimum number of single-character edits required to transform one string into another. These edits can be in the form of insertions, deletions, or substitutions of individual characters.
How does Levenshtein Distance work?
Imagine comparing the words "kitten" and "sitting." The Levenshtein Distance between these words is 3, as three operations are needed to change "kitten" into "sitting": substitute 'k' with 's,' insert 'i' after 'k,' and substitute 'e' with 'g.' This distance value provides a numerical measure of the similarity between the two words, considering variations like typos, misspellings, and other minor changes.
Why is Levenshtein Distance important?
Levenshtein Distance has various practical applications. It serves as the basis for spell checkers, suggesting corrections for misspelled words. It's integral in fuzzy string matching, where data may have slight variations.
In bioinformatics, it helps analyze DNA sequences. By offering a systematic way to measure string differences, Levenshtein Distance plays a vital role in studying genetic variations and pattern recognition.
What are the limitations of Levenshtein Distance?
While effective, Levenshtein Distance may not capture complex semantic differences between strings. Long strings can lead to larger computation times and memory usage. For more nuanced comparisons, other similarity metrics, like Jaccard similarity or cosine similarity, might be more suitable.
How to use Levenshtein Distance to find duplicate records?
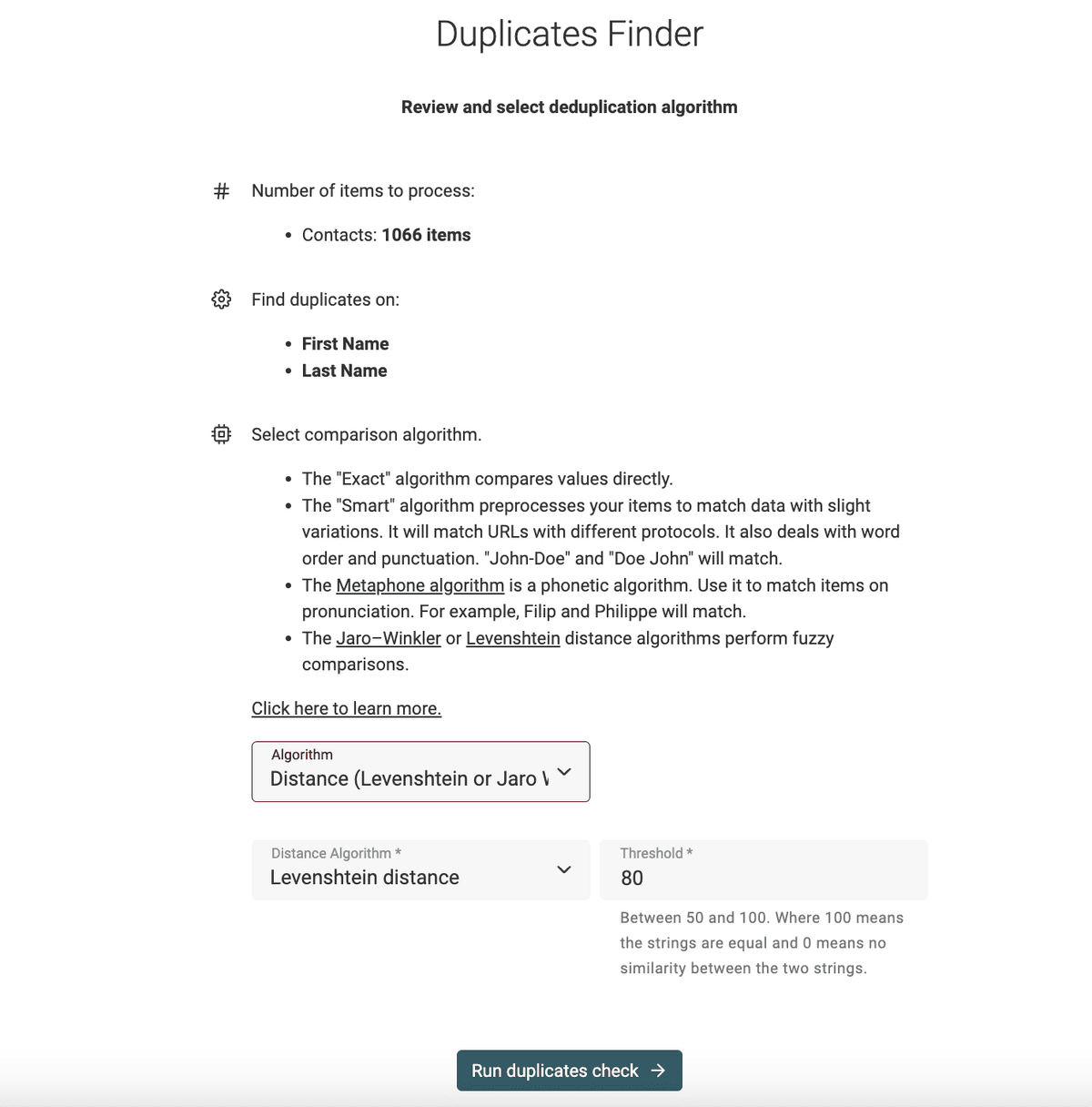
The Levenshtein distance is suited for Fuzzy Matching and data deduplication. This algorithm can be used to compute similarity in names, addresses, or any text fields. Using a threshold value, records with a similarity distance above the threshold are considered as duplicate records.
Datablist is a free data editor with powerful data-cleaning features. Datablist Duplicates Finder implements the Leventshtein distance to detect duplicate records across your datasets.