Scrapes agency listings from Clutch.co including company names, ratings, services, pricing, and profile links
Como usar este prompt de IA
- Criar uma nova coleção: Comece criando uma coleção nova e vazia no Datablist onde os dados serão armazenados. Clique em "+ Create new collection" na barra lateral.
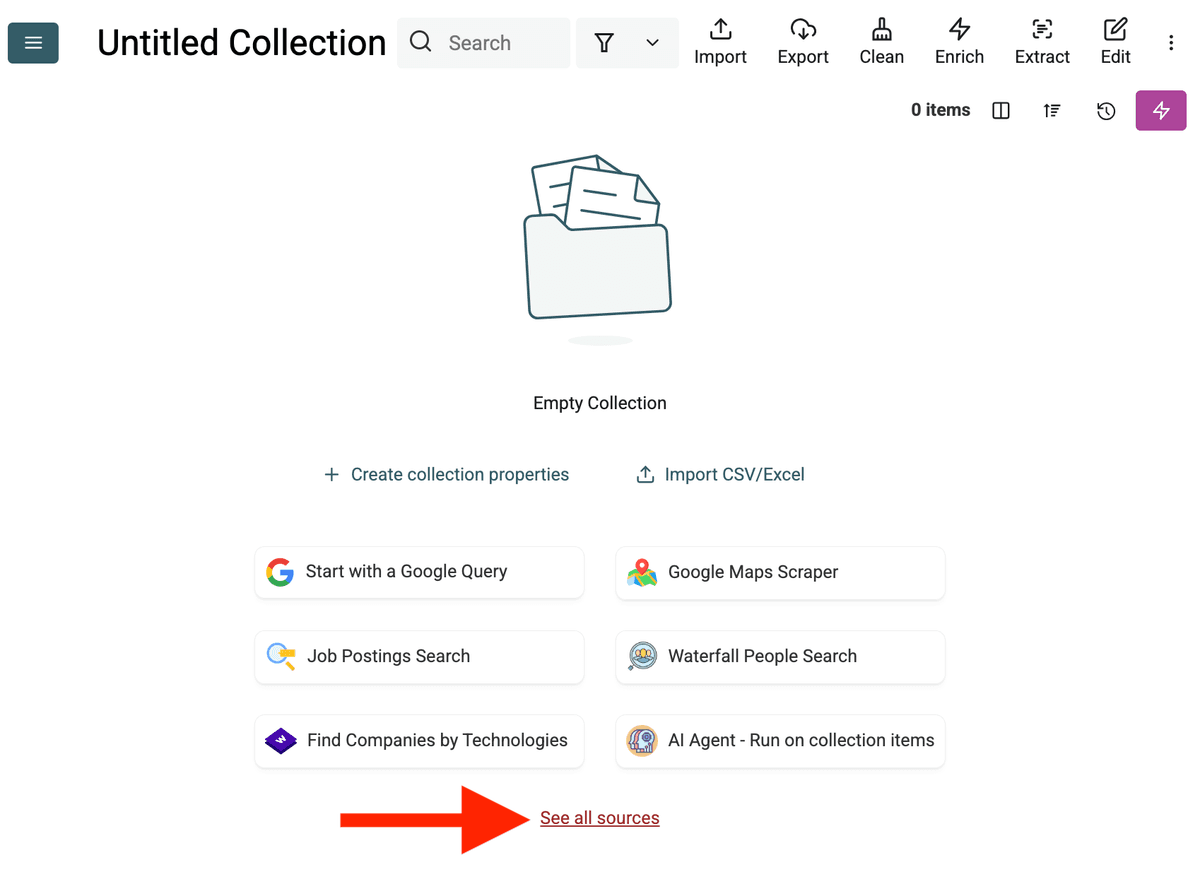
- Selecionar a Fonte do AI Agent: Clique em "See all sources" ou vá para "Import" -> "Import From Data Sources". Escolha "AI Agent - Site Scraper".
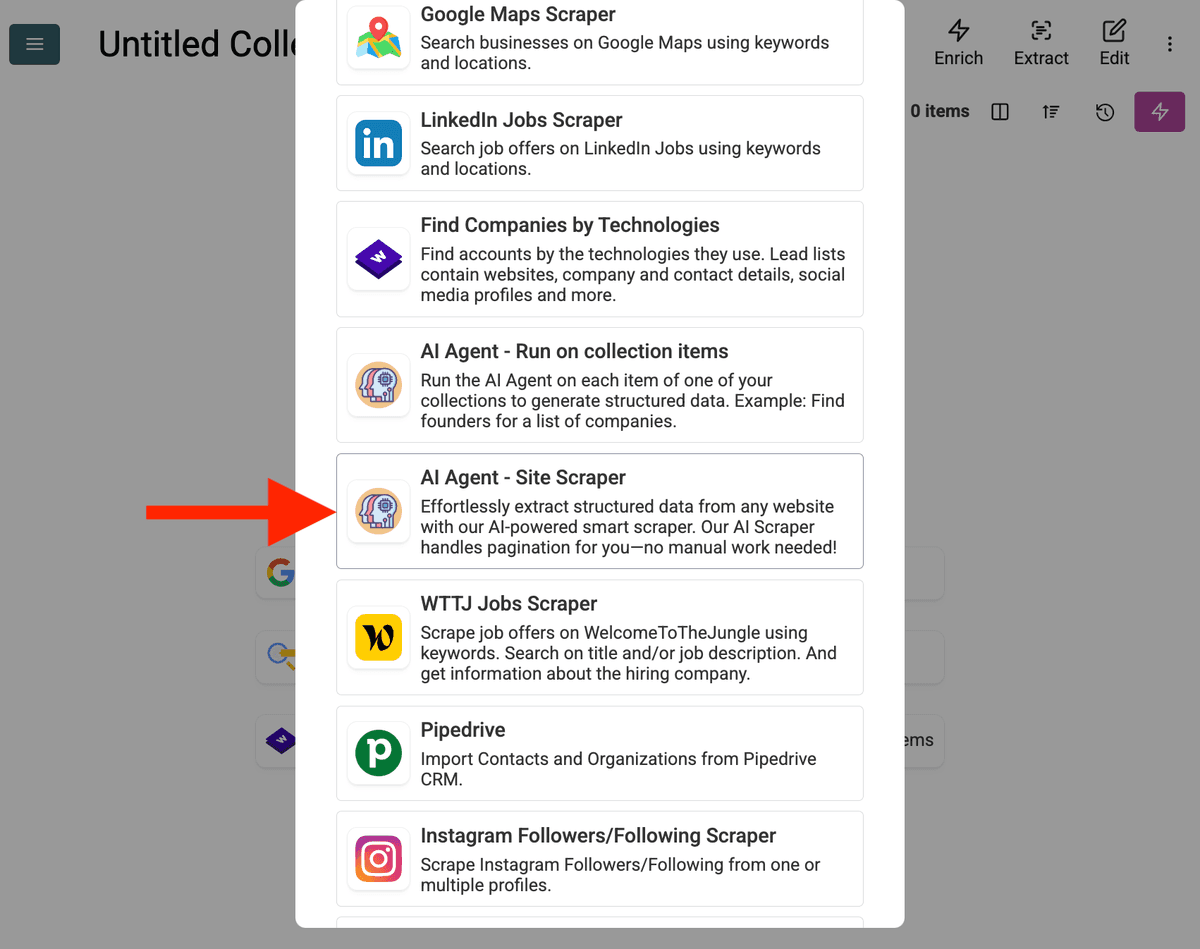
-
Configurar a fonte:
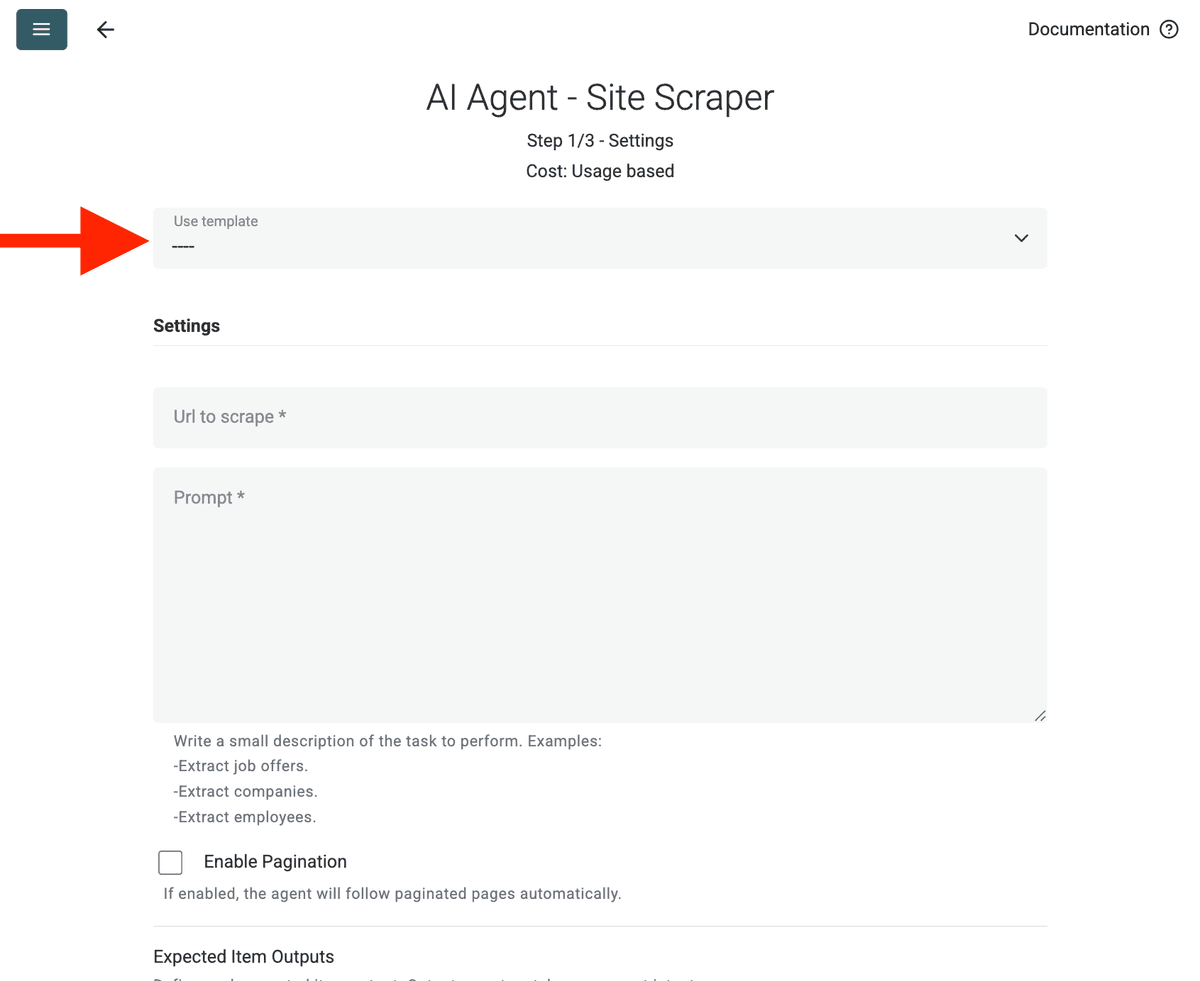
- Selecionar Template: Encontre e escolha o prompt no menu suspenso "Template". O prompt acima será carregado automaticamente.
- URL para Scraping: Insira a sua URL para fazer scraping
- Habilitar Paginação (Opcional): Se os resultados estiverem em várias páginas, marque Enable Pagination e defina um limite razoável de Max Pages (por exemplo, 10).
- Personalizar (Opcional): Você pode ajustar o modelo de IA (por exemplo, GPT-4o mini costuma ser econômico), editar o prompt para necessidades específicas ou modificar os Outputs esperados.
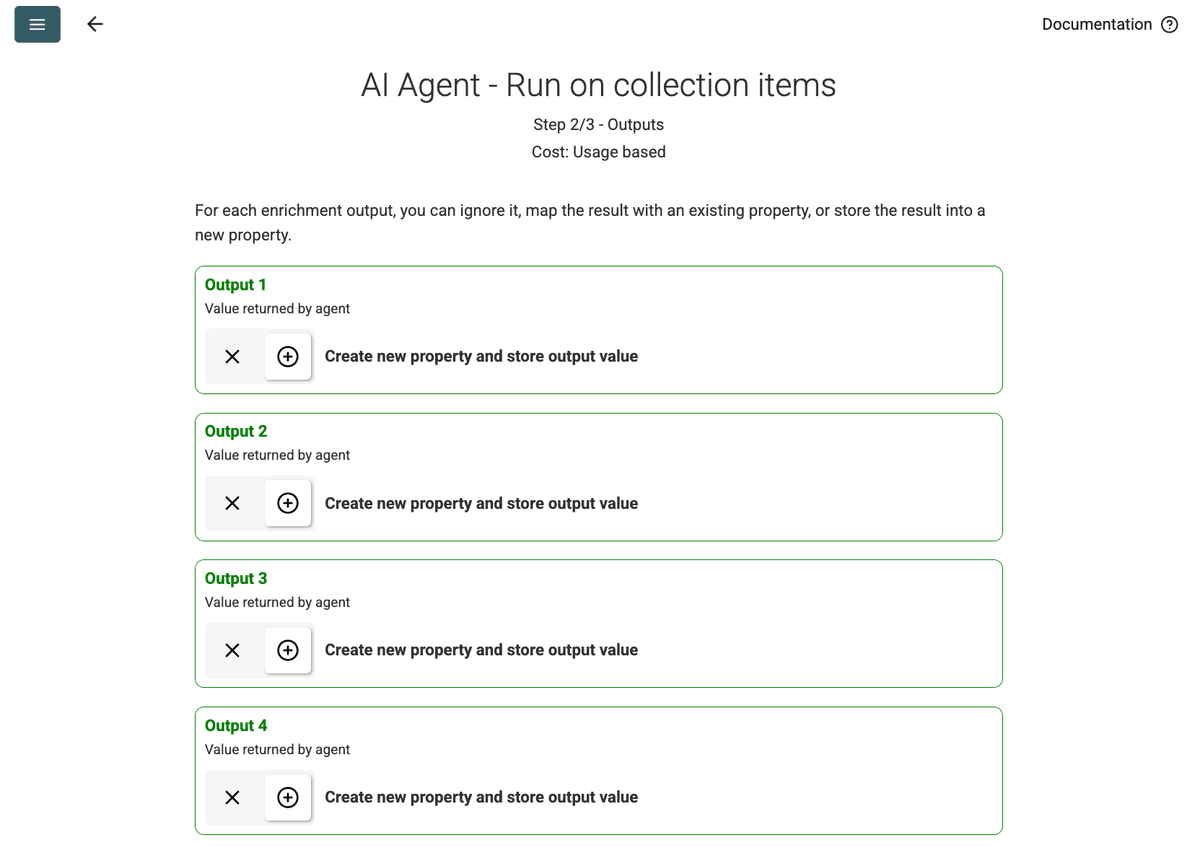
- Revisar Outputs: Clique em Continue. O Datablist mostrará os campos de output definidos no prompt (Project Name, Client Company Name). Clique no ícone + ao lado de cada um para criar as propriedades correspondentes (colunas) na sua coleção.
- Executar Importação: Clique em Run import now. O AI Agent começará a fazer scraping do site com base no prompt e preencherá a sua coleção.
Preços
Esta fonte de dados usa créditos do Datablist conforme o uso. Os custos dependem da complexidade do site e do número de páginas visitadas.
Faça um teste executando o AI Agent em uma única página primeiro para obter uma estimativa do custo.
FAQ
Como iniciar outra execução com a mesma configuração?
Depois de executar o seu AI Agent, clique no botão rosa no canto superior direito da sua tabela de dados para abri-lo novamente com as últimas configurações usadas.
O que acontece se o AI Agent tentar acessar um site protegido ou for bloqueado?
O AI Agent usa automaticamente servidores proxy quando necessário para acessar sites que possam ter proteções contra scraping ou restrições geográficas. Isso aumenta as chances de extração bem-sucedida de dados, embora sites muito protegidos ainda possam representar desafios.
Quanto de dados posso processar com o AI Agent?
Ao executar o AI Agent (seja como enriquecimento ou como fonte de dados), as coleções do Datablist podem processar até 100.000 itens (linhas). Para conjuntos de dados maiores, talvez seja necessário dividir os dados em várias coleções.
Qual a diferença entre o AI Agent e os enriquecimentos ChatGPT/Claude/Gemini?
Os enriquecimentos de IA padrão (ChatGPT, Claude, Gemini) processam dados já na sua coleção usando o conhecimento existente da IA. O AI Agent pode interagir ativamente com a web ao vivo — realizando buscas no Google, navegando por sites e extraindo novas informações com base no seu prompt.
Quão precisos são os resultados?
A precisão depende fortemente da clareza e especificidade do seu prompt, bem como da complexidade da tarefa e das informações disponíveis online. Fornecer instruções claras, exemplos e regras para lidar com erros melhora os resultados. O Datablist frequentemente fornece uma pontuação de confiança para os outputs do AI Agent para ajudar a avaliar a confiabilidade.