

A few months ago, we dropped a feature that we didn't expect to be so powerful.
Now, this feature is shaking up the no-code web scraping industry.
The feature I am talking about is our “AI Agent - Site Scraper” source. This AI scraping agent can go on any website to find, process, and extract the data you need.
Now, a few months later, I discovered 3 things:
- The entire no-code scraping industry is a big lie
- We built the best no-code scraper without knowing it
- AI scraping agents are more powerful, easier to use, and faster than any no-code scraping tool that existed before.
📌 Summary For Those In a Rush
This article covers everything you need to know about true no-code scraping, and shows that it doesn't require APIs, CSS selectors, or technical know-how. If you are in a rush, here is a summary:
Problem: "No-code" scraping tools still require technical knowledge, force you to understand website structures, watch tutorials, spend hours setting up, and when the website makes one minor update, everything breaks.
Why it's a problem: You shouldn't need to learn APIs, CSS selectors, or watch hours of tutorials just to extract data from websites. That defeats the entire purpose of "no-code."
Solution: Datablist’s AI-powered scraping using plain English instructions. You describe what you want, and the AI handles everything else.
What You'll Learn: This guide exposes the lies of the no-code scraping industry, shows you what true no-code scraping looks like, and provides practical use cases and prompting tips.
Why Use Datablist for No-Code Scraping: 3 Key Reasons
- Truly no-code, just describe what you want in plain English
- Handles complex websites with JavaScript, pagination, and dynamic content
- Adapts when websites change, unlike brittle CSS selector-based scrapers
What This Article Will Cover
- The No-Code Scraping Industry & Its Lies
- The Easy Solution: Use Words, Not APIs
- Use Cases & Usage Tips for AI-Powered Scraping
- Frequently Asked Questions About No-Code Scraping
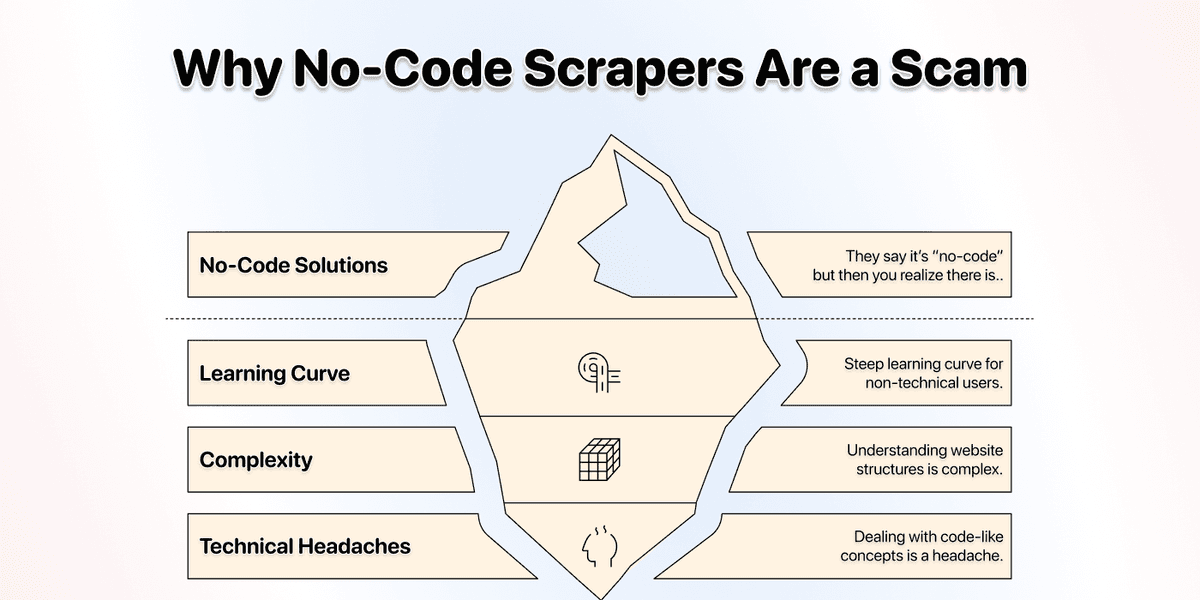
The No-Code Industry & Its Lies
This section is all about debunking the myths and tricks of the no-code scraping industry. The truth is, most "no-code" tools aren't really no-code at all. They just repackaged technical complexity into a slightly different format.
Why Code Was Never The Problem
Think about it for a moment: code was never a problem. If you knew how to code, you would scrape using code and never search for a no-code solution in the first place.
You search for no-code solutions, because you don’t want learn to code just to scrape a website, but people are smart, so they sold you a semi-working solution; a solution that still involves:
- Steep learning curve
- Watching a bunch of tutorials
- Understanding website structures
And sometimes even working with code-like concepts like CSS selectors
The real problem was never about code versus no-code.
The real problem was always about learning curve, complexity, and technical headaches.
What They Tried to Sell You
The no-code scraping industry has three main approaches, and none of them truly solves the complexity problem.
API-Based Scrapers
These tools claim to be "no-code" because you're not writing Python or JavaScript. But there are some things they don't tell you.
You still have to deal with:
- Website DOM structures
- CSS selectors
- HTML tags
Technically speaking, you're not coding, but you're doing something just as technical. You're translating human needs into machine-readable selectors, which is basically programming with extra steps.

Click and Point Tools
This approach is easier, but it still requires you to understand how the website is built. They make it a bit easier by letting you click on elements, but it's still not headache-free.
The biggest issue? If the website structure changes, you have to set up everything completely from scratch. This means:
- Watch the tutorial again
- Reconfigure all your selectors
- Hope it works this time
Browser Extensions
These are basically click-and-point tools that operate in your browser instead of having a dedicated app. Many of them are free, like Instant Data Scraper.
The major issues with these tools:
- One website change, and you have to redo everything from scratch
- Limited functionality and scale
- Can get your IP blocked
📘 The Pattern You Should Notice
All three approaches force you to understand the technical structure of websites. They've simply repackaged technical complexity into different interfaces. That's not solving the problem; that's just moving it around. AI Scraping
What You Actually Want
Let's be honest about what you're really looking for: You want no-headache-based scraping, not no-code scraping. Here’s what no-headache based scraping actually means:
No Headaches
- Don't force me to understand CSS selectors
- Don't make me watch 3-hour tutorials
- Don't break when the website updates its design
No Learning Curve
- I should be able to start immediately
- I shouldn't need to learn a new technical skill
Essentially, you want to describe your goal in plain language and get the results. Everything else is just unnecessary friction that the industry has normalized.
The Solution: Replacing No-Code Scraping With AI Scraping
The solution to the no-code scraping problem isn't a better click-and-point interface or a cleaner API. The solution is removing the technical layer entirely and using natural language.
How AI Scraping Makes No-Code Scraping Actually No-Code
As the name suggests, AI scraping lets the AI scrape the website, not you. You become the manager, not the technical operator.
With no-code scraping powered by AI, you simply tell the system what to do, how to do it, and when to do it. The AI handles all the technical complexity behind the scenes.
No need to understand:
- CSS selectors or HTML structure
- Website DOM architecture
- API endpoints or technical documentation
You just give plain English instructions, and the AI scraping agent figures out the rest. This is how easy no-code scraping should have been working from the very beginning.
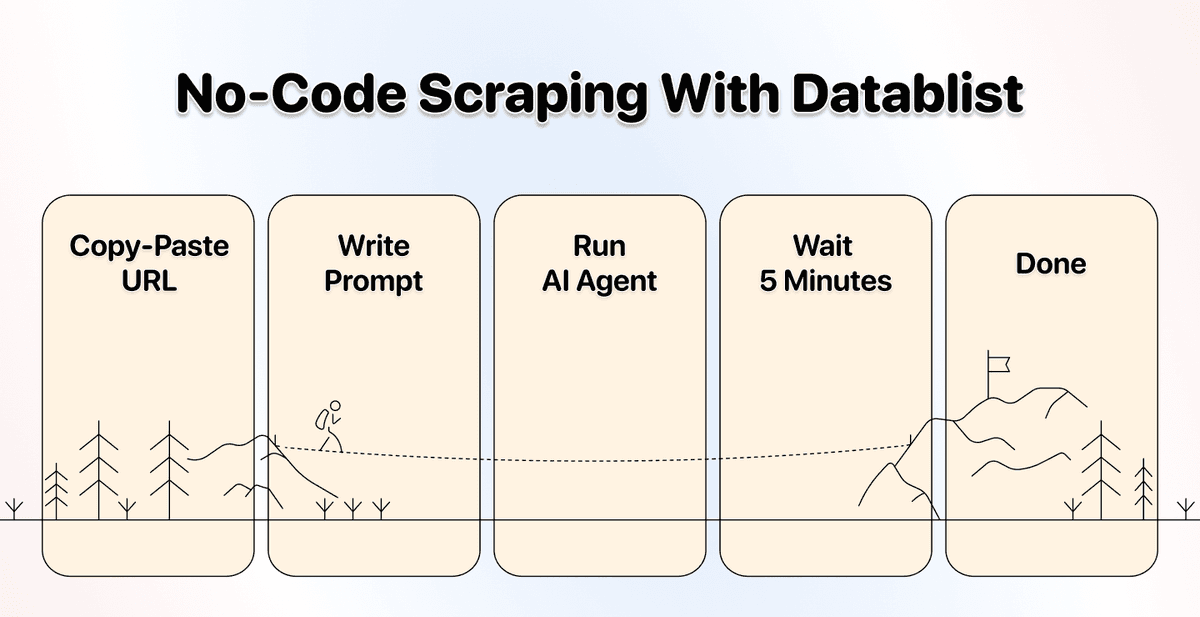
The Company That Brings You The Solution: Datablist.com
As I mentioned at the beginning, we didn’t plan to destroy the entire no-code industry; we did it by accident because one of our users needed to scrape a website, so we built them a solution
We built them an AI Agent that can:
- Understand instructions in plain English
- Navigate complex websites automatically
- Handle JavaScript-heavy pages
- Process paginated content
- Extract data intelligently
- ….
And the breakthrough wasn't in building a better scraper
It was in eliminating the need for technical know-how entirely.
You tell the AI what you want, and it figures out how to get it.
No CSS selectors. No DOM inspection. No tutorials.
What Is Datablist
Datablist is a platform for automation lead generation, data enrichment, and cleaning workflows built for non-technical users such as sales, marketing, and recruiting folks.
It allows you to find, clean, and enrich data using over 60 different tools from AI Agents to Email Finders, AI processors, Technology enrichments, and many more.

Additionally, Datablist allows you to build automated workflows that run on schedule or demand. A few practical use cases that many Datablist users love include:
- Building lead lists
- Personalizing emails with AI
- Cleaning and deduplicating CRMs
- Scraping job postings from 19 boards at once
- Scrape thousands of Business from Yellow Pages
- Scraping LinkedIn Sales Navigator searches without risking your account
I think the point is clear: if you need to get, clean, or enrich data, or automate workflows involving data, and you need it to be easy, fast, and reliable, Datablist is the place to go.
On top of all that, Datablist accidentally solved the no-code web scraping problem.
💡 Datablist Summarized in 35 Words
Datablist is a platform for automating lead generation workflows, which offers a suite of over 60 tools, including AI Agents, Waterfall Enrichment to find emails and phone numbers, data cleaning tools for deduplication, and more.
Why Choose Datablist
Datablist's approach to no-code scraping is different from the rest on the market, because we never sold well-packaged tech-headaches; we went for AI scraping instead.
Here’s what that means for you:
Real No-Code Solution
- Zero technical knowledge required
- No understanding of HTML or CSS needed
- Your automations don’t break with each website update
You Just Need to Prompt
- Write what you want in plain English
- The AI understands context and intent
Templates for Many Scrapers
- Pre-built prompts for common use cases
- Directory scraping templates
- E-commerce scraping templates
- Case study extraction templates
The Easiest Solution to Scrape a Directory
- Works on Yellow Pages, Yelp, TripAdvisor, Alibaba
- Handles pagination automatically
You Don't Need to Play Export-Import with 10 Tools
- Data goes straight into a spreadsheet interface
- Edit, filter, and enrich data in one place
- Access to an entire lead-generation ecosystem
Use Cases & Usage Tips
Using Datablist to scrape websites, directories, or even scale AI search is easy; the approach is very simple, and remains always the same: Describe what you want as precisely as possible.
A Quick Prompting 101
Before we talk about all the use cases you could use the AI scraping agent for, let me first show you how easy it is to instruct it.
Prompting Rules:
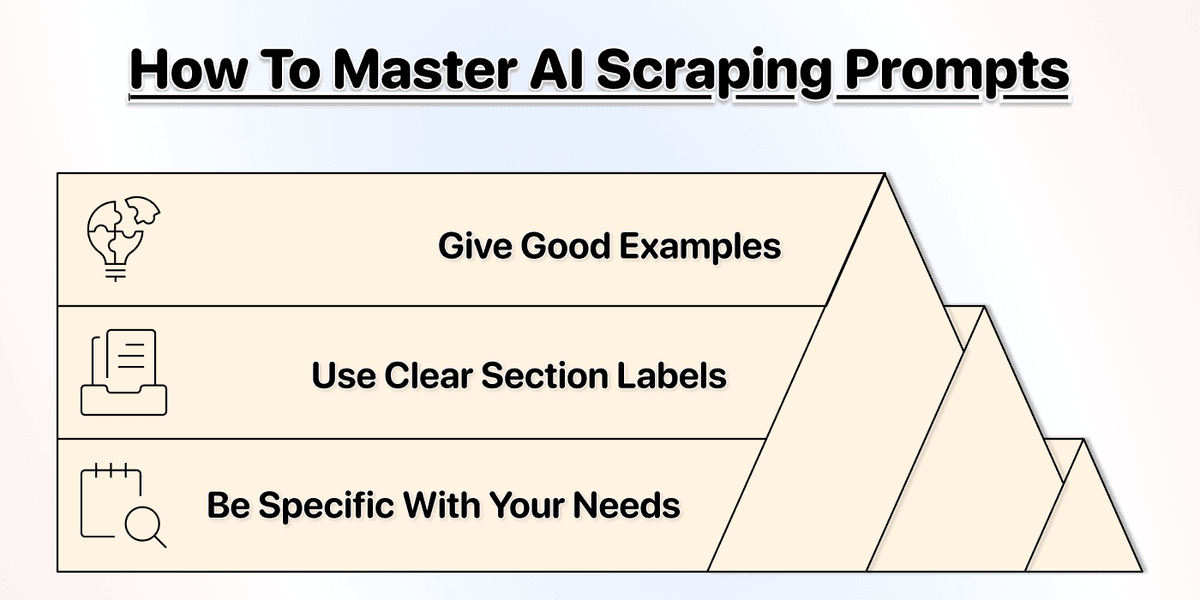
Good prompting is simple. You don't need to be an expert. You just need to be clear about what you want. Here are a few tips that will help you write better prompts:
Be Specific
- Don't say "get product info"
- Say "get product name, price, and availability status"
- Include examples when possible
This ensures you get the data you want without the AI agent interpreting something wrong.
Use Section Labels
- Organize your prompt with clear sections
- Goal: What you're trying to accomplish
- Data Points: What specific information do you need
- Format: How you want the data structured
- Constraints: What to avoid or include
Section labels help the AI agent understand what you’re asking it about. This isn’t a requirement; we just found that it increases the accuracy by a lot.
Give Examples
The AI agent doesn’t know everything. Some websites are very complex. By giving examples, you avoid getting false positives, increase accuracy, and decrease cost.
Here’s a detailed guide on how write a prompt for an AI agent 👈🏽
💡 Pro Tip: Pagination Handling
Datablist's AI Agent can automatically handle paginated content. Just enable pagination in the settings and set the maximum number of pages. The agent will navigate through all pages and extract data from each one.
===
Data Points I Need:- Product Name (example: "Classic T-Shirt")
- Price (example: "$29.99")
- Product URL (full link)
- Availability (In Stock / Out of Stock)
===
Format:- Return one row per product
- Use "N/A" if data is missing
===
Constraints:- Skip promotional banners
- Only get actual products, not category pages
No-Code Scraping Use Cases
The possibilities for no-code scraping are nearly endless. Here are the most popular and effective AI scraping use cases we've seen so far:
Directories
- Scraping businesses from Yellow Pages
- Scraping Yelp restaurant data
- Scraping properties from AirBnB
- Scraping TripAdvisor hotel information
- Scraping Alibaba supplier catalogs
- Scraping properties from Zillow
- Scraping Realtors from Zillow
E-Commerce Websites
Other
- Scrape all case studies from a website
- Extract exhibitors from fair websites
📘 How To Scrape Multiple Websites
If you have many similar websites you need to scrape, you can also use Datablist's AI Research Agent to scrape a list of websites. This agent also has some additional capabilities that allow you to run AI search at scale.
Conclusion: No-Code Scraping Should Be Renamed
No-code scraping should be renamed to "No-tech-headache" scraping because that's what people actually want. You don't search for no-code scraping because you can't code; you search for it because you don't want to learn technical skills just to extract data.
So if scraping is not a big money-making activity for you, then you should not be required to waste hours on it, and the solution isn't a better API or cleaner click-and-point interfaces.
The solution is removing the technical layer entirely, a.k.a. AI scraping
And with Datablist, you can do exactly this, and:
- Get results in minutes, not hours
- Scale from one website to thousands
- Describe what you want in plain English
- Adapt to website changes automatically
The no-code scraping problem is finally solved. And we did it by accident.

Frequently Asked Questions About No-Code Scraping
Can Datablist Scrape Directories?
Yes, Datablist’s AI Scraping Agent can scrape directories efficiently, and tagent handles pagination automatically, so you can extract thousands of listings without manual configuration.
For example, we've successfully scraped data from:
- TripAdvisor reviews, hotels, restaurants, and more.
- Yellow Pages business listings
- Airbnb property catalogs
- Alibaba supplier databases
- Yelp business information
- … and many more
Can I Scrape Data From Multiple Pages Automatically?
Yes, Datablist's AI Scraping Agent supports automatic pagination. Set the maximum number of pages in the configuration, and the agent will navigate through all pages, extracting data from each one without manual intervention.
This works for:
- E-commerce product catalogs
- Directory listings across multiple pages
- Search results with pagination
- Blog archives
- …
How Much Does It Cost to Use Datablist's Scraping Agent?
The pricing for Datablist’s AI agents is usage-based based varies based on the complexity of the scraping task. For directories like Yellow Pages, costs are much lower, and scraping 1000 listings would end up between 800-1000 credits. For scraping JavaScript-heavy sites like Shopify stores, costs can be higher.
What Is No-Code Scraping?
No-code scraping is the process of extracting data from websites without writing code or using technical skills. True no-code scraping means you can describe what you want in plain English and get results, without understanding HTML, CSS selectors, or APIs.
Can Datablist Handle JavaScript-Heavy Websites?
Yes, Datablist's AI Agent can scrape JavaScript-heavy websites. Enable the "Render HTML" option in the advanced settings to ensure the agent waits for JavaScript to load before extracting data.
This is essential for modern websites built with React, Vue, or Angular that dynamically load content after the initial page load.
What Is the Difference Between No-Code Scraping and Traditional Web Scraping?
Traditional web scraping requires coding knowledge (Python, JavaScript) or technical skills (CSS selectors, XPath). No-code scraping eliminates this requirement by providing visual interfaces or, in Datablist's case, natural language understanding.
How Does AI Scraping Work Differently From CSS Selector-Based Scraping?
CSS selector-based scrapers rely on the exact structure of a website's HTML. If the website changes its layout, the scraper breaks.
AI scraping understands the meaning of content, not just its location. It can identify "this is a product price" even if the HTML class names change. This makes AI scraping more resilient and requires zero maintenance.
Is No-Code Scraping Legal?
Web scraping legality depends on what you scrape and how you use it. Scraping publicly available data is generally legal, but you should:
- Respect robots.txt files
- Avoid scraping behind login walls
- Use the data ethically and comply with privacy laws
- Do not overload servers with excessive requests