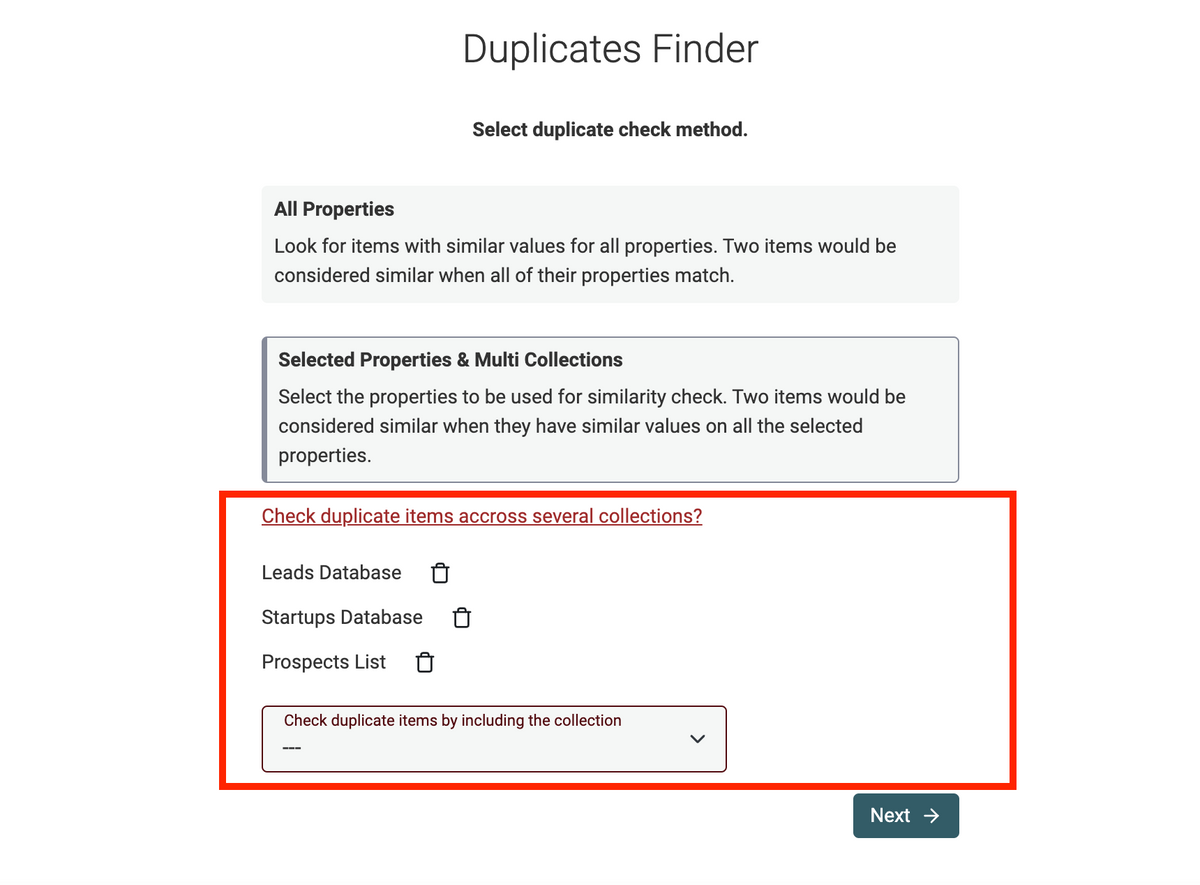
Deduplicate items across collections
I use Datablist to create lists of prospects. I have lists of companies from LinkedIn, a list from my user base, lists from scraping, company databases, etc.
All those lists have different properties. So, it doesn't make sense to create a single list to manage all my prospects. I like to keep them in different collections.
Until now, I couldn't check duplicate leads across all of my prospect's collections. From all the feedback I received, I was not alone to have this issue.
In April, I made big changes to the Duplicates Finder. I enabled deduplication across multiple collections and I moved the Duplicates Finder from an exact match algorithm to a probabilistic one.
I'm very confident this feature will help you deal with your lists of contacts the way it helps me. It's great to find engaged leads who appear in several communities. And to cross-check it with your user base.
You can check our updated Duplicates Finder documentation to learn more.
Improved deduplication algorithm
Match duplicate items that have empty values
Building a deduplication algorithm is complex. A brut force algorithm doesn't scale well. A list of 200 000 items generates 200 000*199 999/2 = 19 999 900 000 unique item pairs.
The previous "Duplicates Finder" algorithm was fast but worked only for exact matches. If you had a collection with leads and you ran the algorithm on the "names", "email addresses" and "company websites". It found duplicate items that had the same values.
If a lead had an empty company website, or no email address, the lead was often ignored.
With the new deduplication algorithm, the Duplicates Finder finds duplicate items even with some empty values. It computes a similarity score between items that work with incomplete data.
You can check our updated Duplicates Finder documentation to learn more.
Probabilistic similarity score
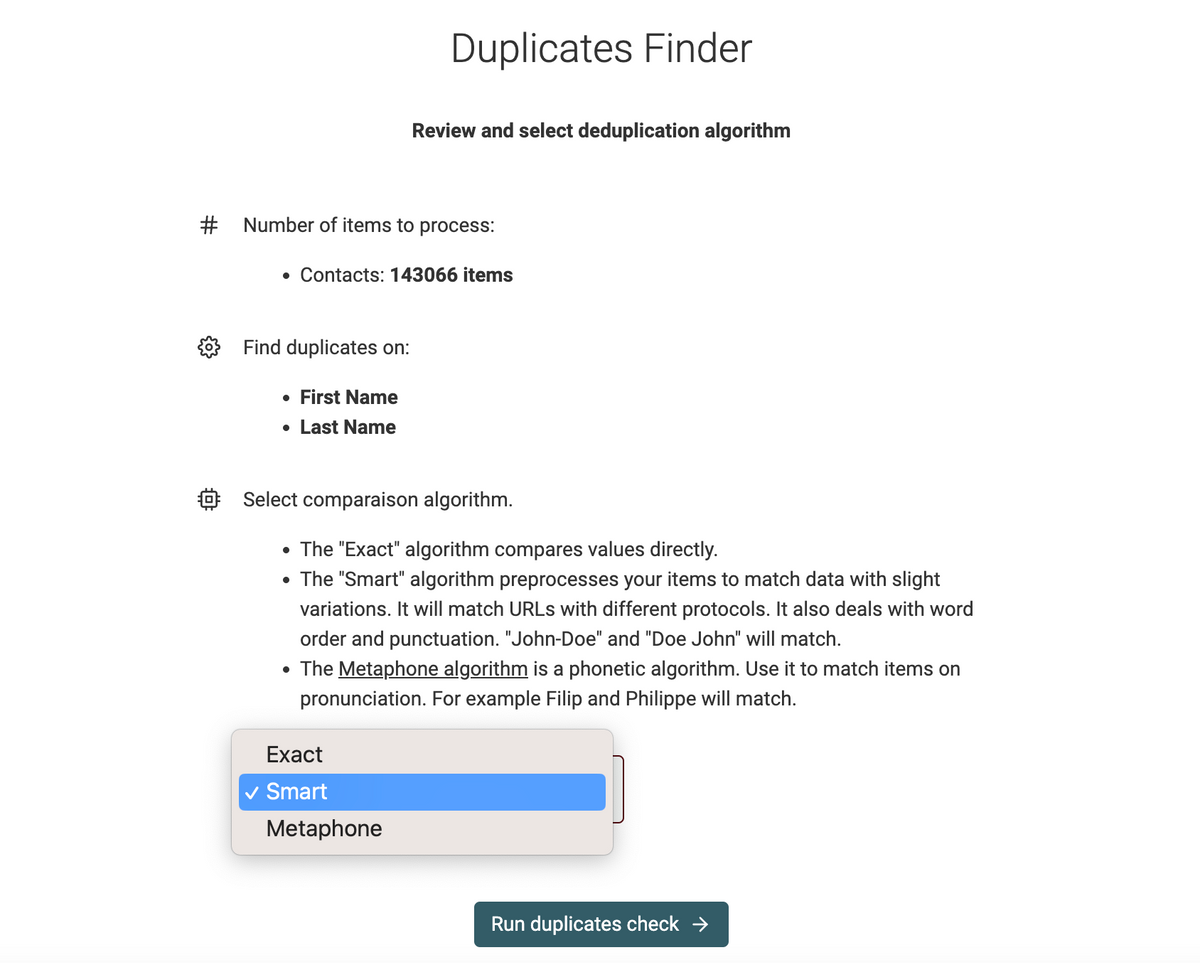
As I said above, the Duplicates Finder now uses a similarity score to find duplicate items. Datablist takes two items and calcules the similarity between them.
It opens a lot of possibilities to compare items that are not 100% similar. I've released two new algorithms to find duplicate items with minor differences.
The first one is the "Smart Algorithm":
- It removes all spaces and punctuation characters (before, after, between words)
- It matches words in different orders
- It removes URL protocol for URL comparaison
For example:
Item Id | Full Name | Company Website
00001 | James-Bond | https://www.acme.com
00002 | bond james | http://www.acme.com
00003 | james bond |
Would all pop up as duplicate items.
The second algorithm uses the "Metaphone" phonetic algorithm. It converts texts to codes to match similar-sounding words.
For example:
Item Id | Full Name | Company
00001 | Filip Dupon | google
00002 | Dupont-Philip | GOOGL
00003 | Dupond philippe | gogle
Would be flagged as duplicate items.
You can check our updated Duplicate Finder documentation to learn more.
Optimized duplicate group listing and merging for large lists
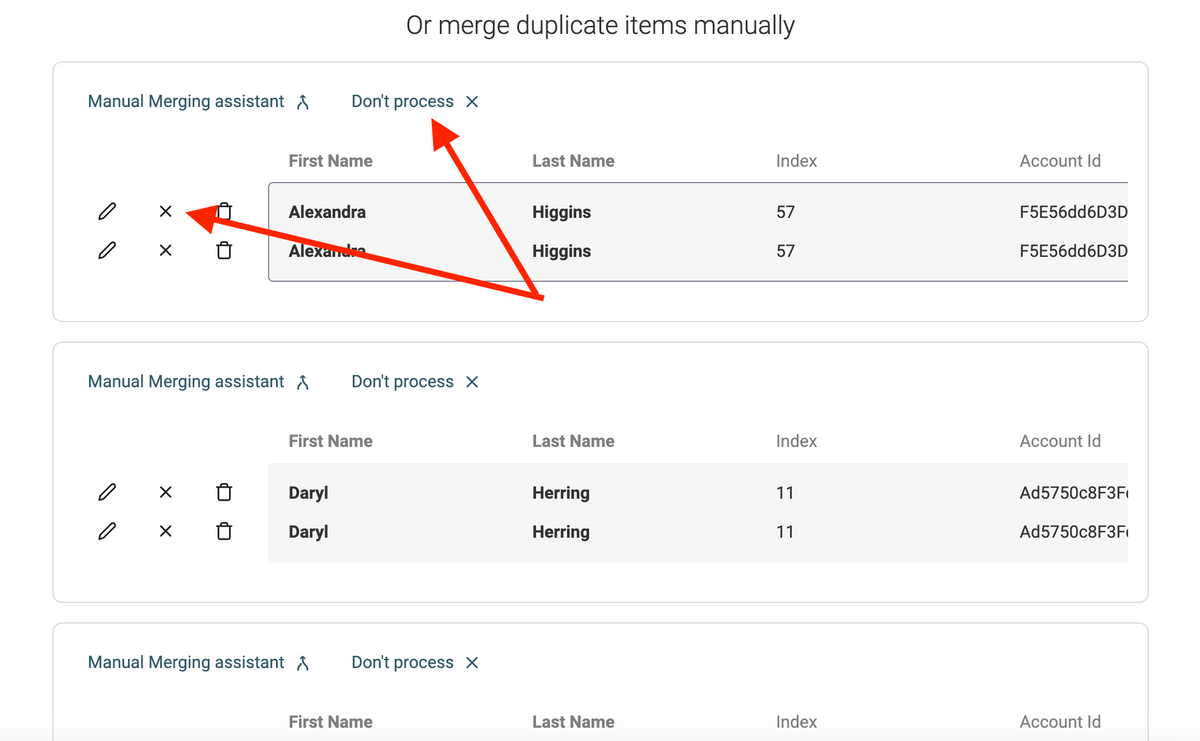
And one more thing, I've improved the Duplicate Finder results page to scale with thousands of duplicate groups. The page could freeze before when you had a lot of items flagged in duplicate groups.
The new page load the items on demand so it scales up to thousands of items.
A new "Don't process" action was added. It removes the duplicate group from the results listing. Skipped groups are ignored during the "Auto Merge" action.
New enrichments
Name Parser
Return the gender, country, and all name parts (First Name, Last Name, Title, etc.) from a person's full name.
Extract the name from an email address
Use probabilistic analysis to parse an email address and extract a first name and a last name.
Location Lookup
Return the City, Country, Latitude, and Longitude for a location. Read our new guide to extract the City and Country from a list of addresses.
Improvements & Fixes
- Fix auto detect of data type for numbers with more than 22 digits. They will now be imported as Text.
- Fix the issue with running enrichments before the credits balance is loaded
- Fix the issue with running enrichments before the enrichment options are loaded
- Change Payment Method and Password directly in your Datablist account