Dealing with duplicates is an exhausting task with spreadsheet tools. Datablist provides a built-in deduplication feature to find duplicate values in your collections. Duplicates can then be removed or merged (automatically or using a merging assistant).
To find the duplicates in a collection, click on the "Duplicates Finder" button in your collection header.
Note:
Check Importing Data to learn how to load your datasets into Datablist.
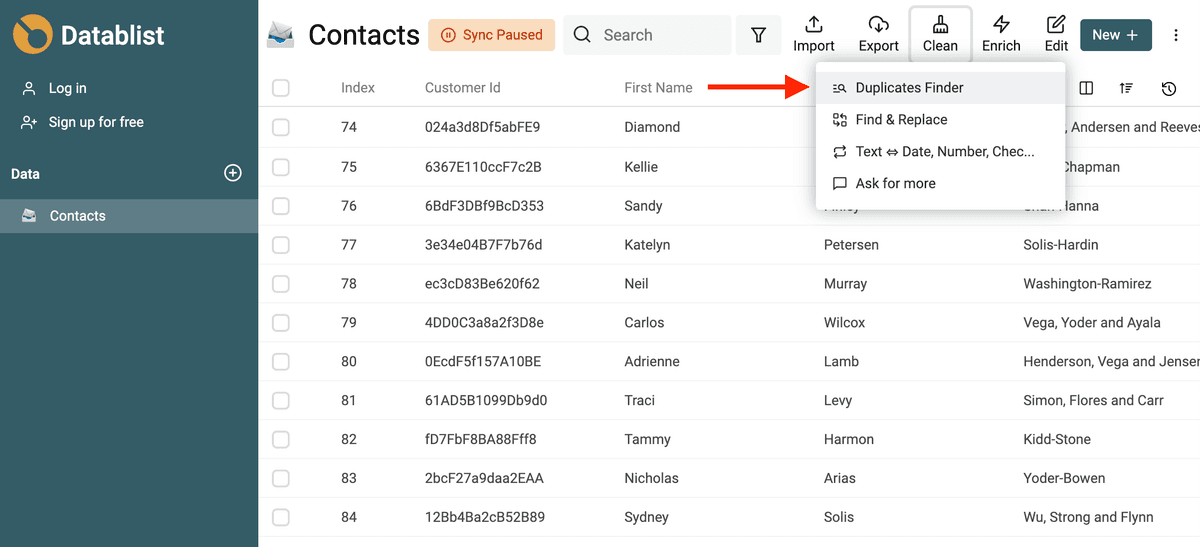
Select duplicate check method
The first step is to select how to compare items to find duplicate values. Two methods are available:
- All Properties - Look for items with similar values for all properties. Two items are considered similar when all of their properties match.
- Selected Properties & Multi Collection - With this mode, you can select the properties to be used for similarity check and select other collections to be included in the analysis. Two items are considered similar when they have similar values on the selected properties. Different algorithms are available to detect duplicate items with small variations
Most of the time, Selected Properties & Multi Collections is the best option. This is perfect to deduplicate contacts based on their email addresses and phone numbers, or companies using their website URLs. Use Selected Properties when you have one or several properties that identify a product, person, company, etc.
Find duplicates across several collections
If you select "Selected Properties & Multi Collections", you will be able to select other collections. In multi-collection mode, you will need to map the selected properties of your current collection with properties from the others. Datablist will create a single "computed" list with the items from all the collections and run the deduplication algorithm on it. If duplicates are found, you will be able to merge them to create consolidated items, or to remove the duplicate items to keep only one item for each duplicate group.
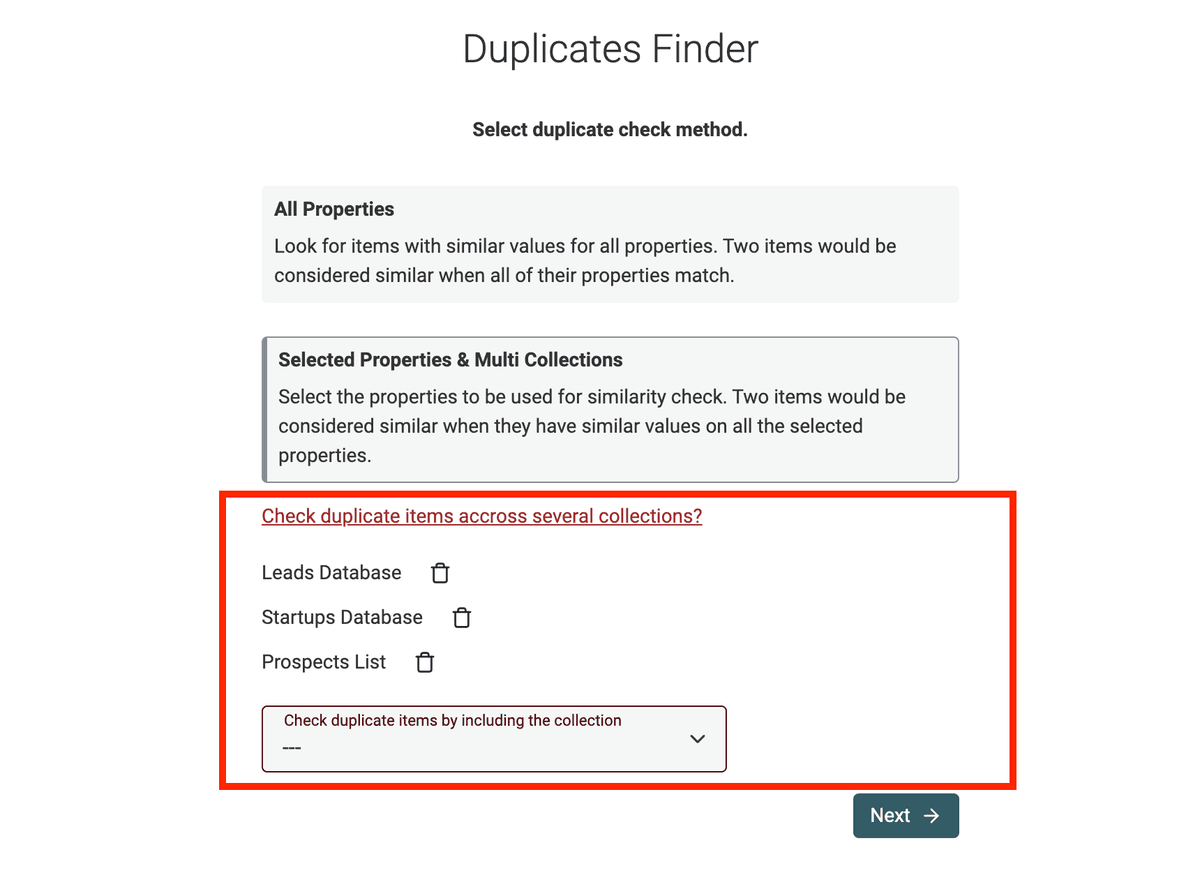
Configure Properties
Next, if you click on the Selected Properties method, you have to select which properties will be checked.
For example, in a collection with people items, you would select the Email property.
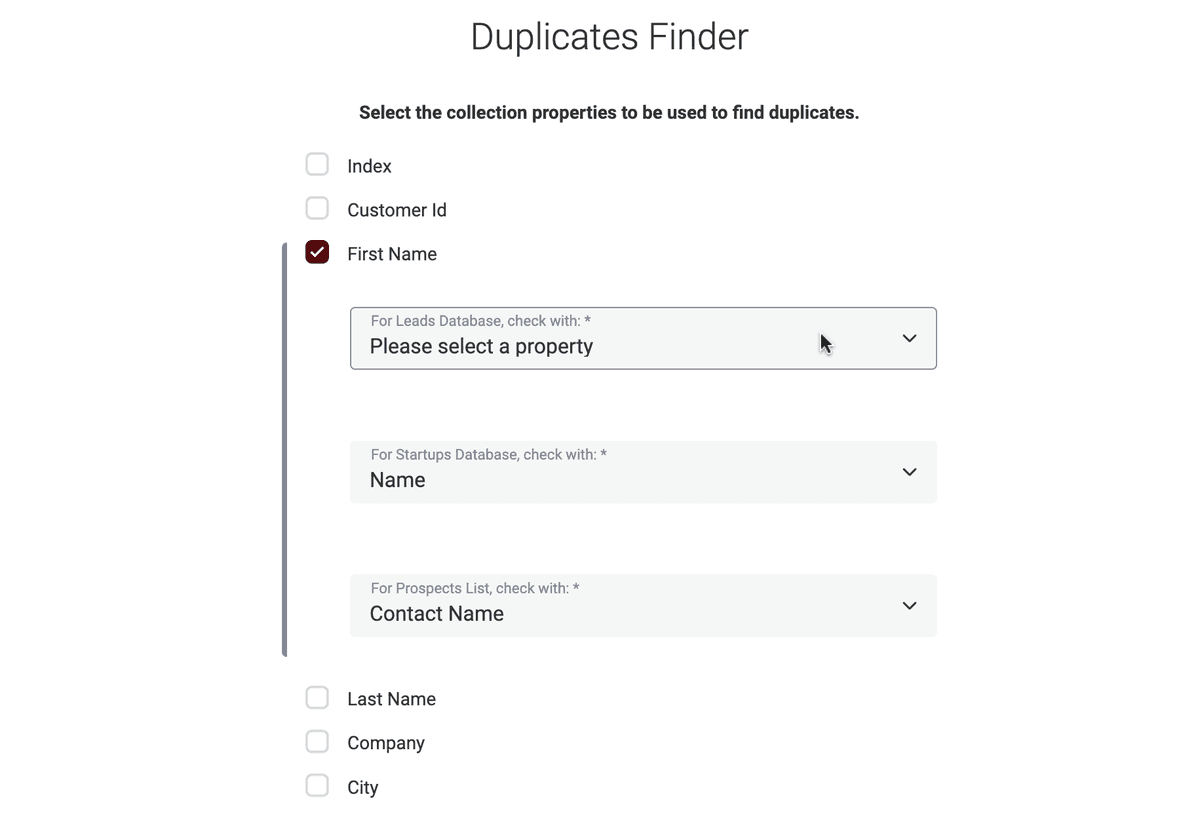
Mapping other collection properties
For multi-collection deduplication, an extra step is required: the mapping of the properties. For each property you select, you have to select a matching property in each of the collections you have added. This step is mandatory.
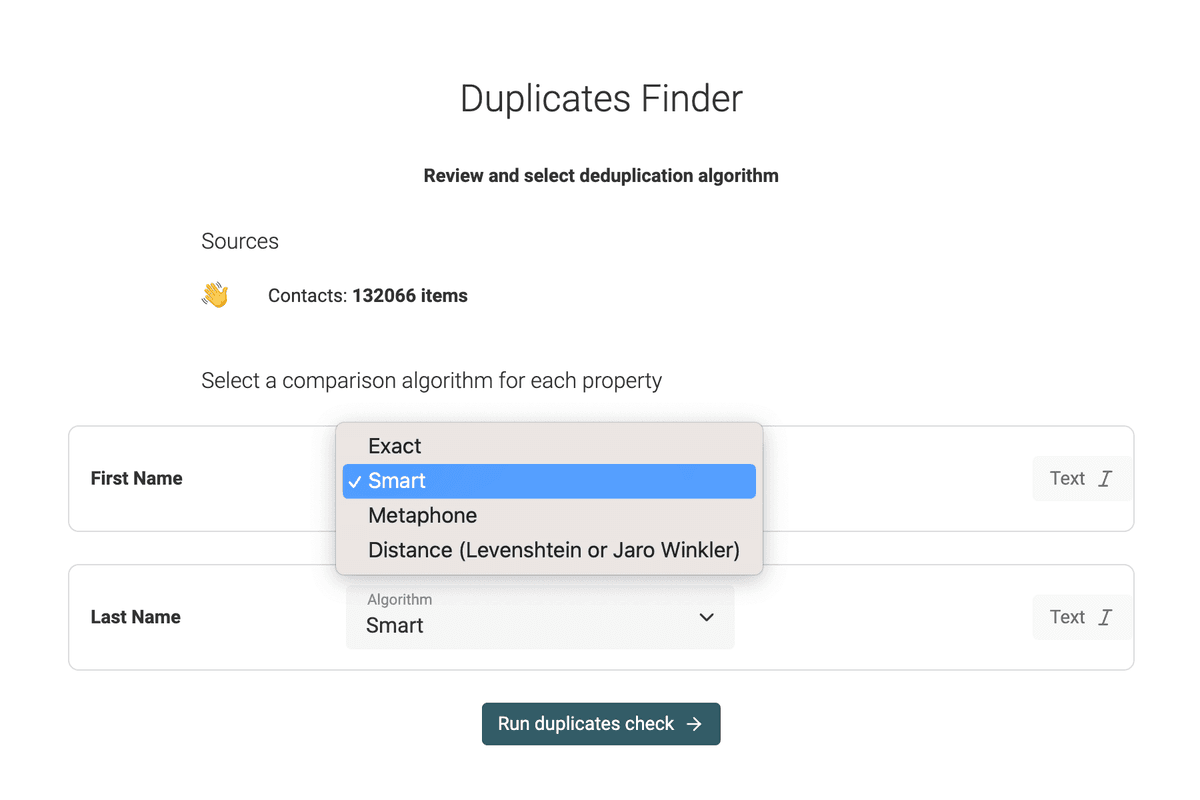
Select the comparison algorithm and run the deduplication check
Then, a review screen is shown with the duplicate mode and the number of items in your collection. For "Selected Properties & Multi Collections", you can configure the deduplication algorithm to be used on each property.
The deduplication analysis is a read-only operation. It will not perform any changes in your collection items until you decide to merge items.
How does Datablist deal with empty values?
Finding duplicate items is a probabilistic calculation. Datablist creates pairs of items to compare. Then, it computes a "similarity" score for each pair.
When the score passes a threshold, the items are put into a duplicate group.
The similarity score between two items is the average similarity across all compared properties.
For a defined property, when both items have empty values, the similarity is 100%. And if only one item has an empty value, the similarity is set to 50%.
For all algorithms except the fuzzy ones, the threshold is set at 80%.
For example, for the following two items:
Item id | First Name | Last Name
0001 | John | Doe
0002 | John |
The similarity score will be (1+0,5)/2 = 0,75 => 75%.
This is less than the threshold of 80%, so they will not be matched.
Now, with another property:
Item id | First Name | Last Name | Company
0001 | John | Doe | Acme
0002 | John | | Acme
The similarity score will be (1+1+0,5)/3 = 0,83 => 83%.
This time, the result is above the threshold. They will be matched.
Notes: When running the Duplicate Finder on just 2 properties, an empty value on one of the properties will prevent a match if other items have value. To be able to set a custom threshold and match below the default 80%, please use fuzzy matching.
How does the "Exact" algorithm work?
The "Exact" algorithm performs a few changes when it compares two items:
- It removes spaces before and after the text (but not in between words)
- It is case insensitive by default. Check the "Case sensitive" option if you need to differentiate by text case.
If you have three items such as:
Item Id | First Name | Last Name | Company
00001 | James | Bond | Acme-Corp
00002 | james | BOND | Acme-Corp
00003 | james | | acme-Corp
And you run the "Exact" algorithm on the properties "First Name", "Last Name" and "Company". The three items will be flagged as duplicates.
Because:
- The algorithm compares the text without case (uppercase or lowercase are the same)
- The algorithm removes leading and trailing spaces
- The similarity average with the empty value for item id
0003on "Last Name" is still above 80%:(1+1+0.5)/3 => 83%. See how Datablist deals with empty values.
How does the "Smart" algorithm work?
The "Smart" algorithm goal is to find duplicate items, even with small changes:
- It is case insensitive
- It removes all spaces and punctuation characters (before, after, between words)
- It removes symbols (smileys, etc.)
- It matches words in different orders
- It removes URL protocol for URL comparaison
If you have three items such as:
Item Id | Full Name | Job Title | Company Website
00001 | James-Bond | Head of Sales | https://www.acme.com
00002 | bond james | Head of Sales 🔥 | http://www.acme.com/
00003 | james bond 🚀 | head of Sales |
And you run the "Smart" algorithm on the "Full Name", and "Company Website" properties. The three items will be flagged as duplicates.
Because:
- The algorithm compares texts without symbols, case, punctuation, and word order
- The algorithm remove the protocol (
httpsandhttp) and trailing slash for URL comparaison - The similarity average with the empty value for item id
0003on "Company Website" is still above 80%:(1+1+0.5)/3 => 83%. See how Datablist deals with empty values.
How does the Metaphone algorithm work?
The "Metaphone" algorithm is a phonetic algorithm. It converts texts to codes to match similar-sounding words. Datablist uses the "Double Metaphone" algorithm.
It is built on top of the smart algorithm. It is useful to find duplicate items with typos.
If you have three items such as:
Item Id | Full Name | Company
00001 | Filip Dupon | google
00002 | Dupont-Philip | GOOGL
00003 | Dupond philippe | gogle
And you run the "Metaphone" algorithm on the "Full Name", and "Company" properties. The three items will be flagged as duplicates.
Because:
- The algorithm compares texts without case, punctuation, and word order
- "Filip Dupon", "Philip Dupont", and "philippe Dupond" sound similar
- "google", "googl", and "gogle" sound similar
Once you have selected the algorithm, click "Run duplicates check" to continue.
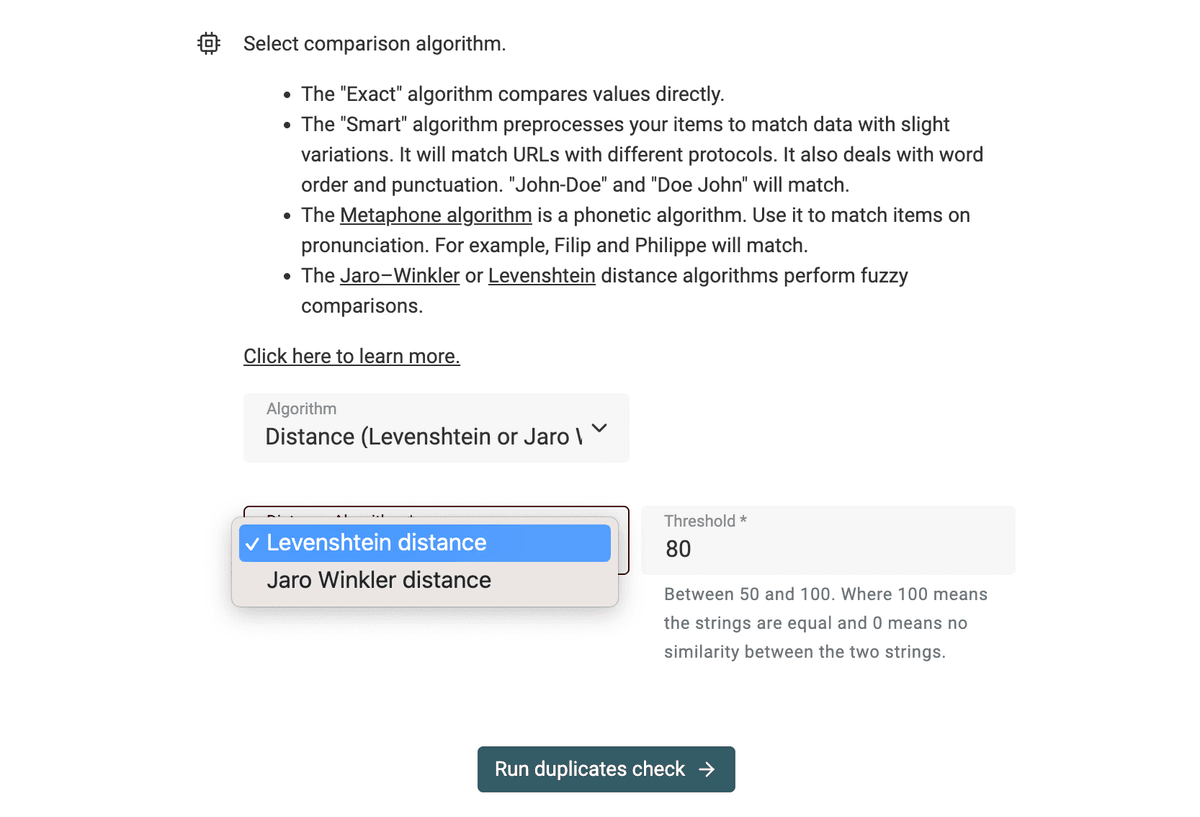
How do the Fuzzy Matching algorithms work?
Datablist implements fuzzy matching for deduplication. Fuzzy matching works by calculating the distance between two items. This distance is then converted to a similarity ratio. Items with a similarity above a configured threshold are considered similar.
After selecting "Distance Algorithms" in the Duplicates Finder, a select input lets you choose between two distance algorithms:
And a configurable threshold value is shown. The threshold ranges from 50 and 100. 100 is for an exact match. The default value is 80. You can start with a high value and re-run the deduplication algorithm with a lower value.
Fuzzy Matching process
Step 1: Blocking to reduce the number of comparisons
Fuzzy matching compares two records together to get a similarity ratio. Doing a comparison for each record pair in a dataset is computationally intensive.
For 200 000 records, it means 200 000*199 999/2 = 19 999 900 000 pairs.
To solve this, Datablist searches for records that could be similar. And discard the pairs that are very different.
This is called the blocking step. Datablist analyzes the properties selected for deduplication and looks for the most discriminative one. Then the algorithm creates potential similar pairs using the discriminative property when records have similar values for this property.
For properties with exact, smart, Metaphone algorithm, similar values means the values must be the same after being processed by those algorithms.
For a property with a fuzzy matching algorithm used, it compares the first three characters of each record property value and creates record pairs with the records sharing the same three characters.
Once the pairs of potentially similar records are generated, Datablist Duplicate Finder computes a similarity ratio for each pair.
Step 2: Compute a ratio for each property
Datablist needs a similarity ratio to compare it with the defined threshold.
The Jaro-Winkler algorithm returns by default a ratio.
However, the Levenshtein algorithm returns a distance value (the number of changes needed to transform a string into another string). Datablist converts the calculated distance to a ratio using this formula:
1 - LevenshteinDistance / ( (StringALength + StringBLength) / 2 )
Step 3: Get the average ratio between two items
A final ratio is calculated using the average for all the properties compared.
For example, if you search for duplicate items on two properties: First Name, and Last Name.
Item Id | First Name | Last Name
00001 | Filip | Richu
00002 | Failip | Richo
The similarity between the item "00001" and "00002" is calculated with:
(Similarity(Filip, Failip) + Similarity(Richu, Richo))/2
Step 4: Compare the similarity with the threshold
Then, the similarity is compared to the defined threshold. If the similarity is greater than or equal to the threshold, the items are marked as similar.
Step 5: Group items into Duplicate Groups
Finally, Datablist processes all the duplicate pairs to create duplicate groups.
For example, if Item1 and Item2 are similar, and Item2 and Item5 are also similar, then a group will be created with "Item1", "Item2", and "Item5".
Duplicates Listing
After running through all your items for duplicate items, Datablist will list all the duplicate groups found.
From this page, two actions are available:
The recommended way to deal with duplicates is to run auto merge duplicates first (1 in the screenshot below) and then pursue with Datablist merging assistant for conflicting items (2 in the screenshot below).
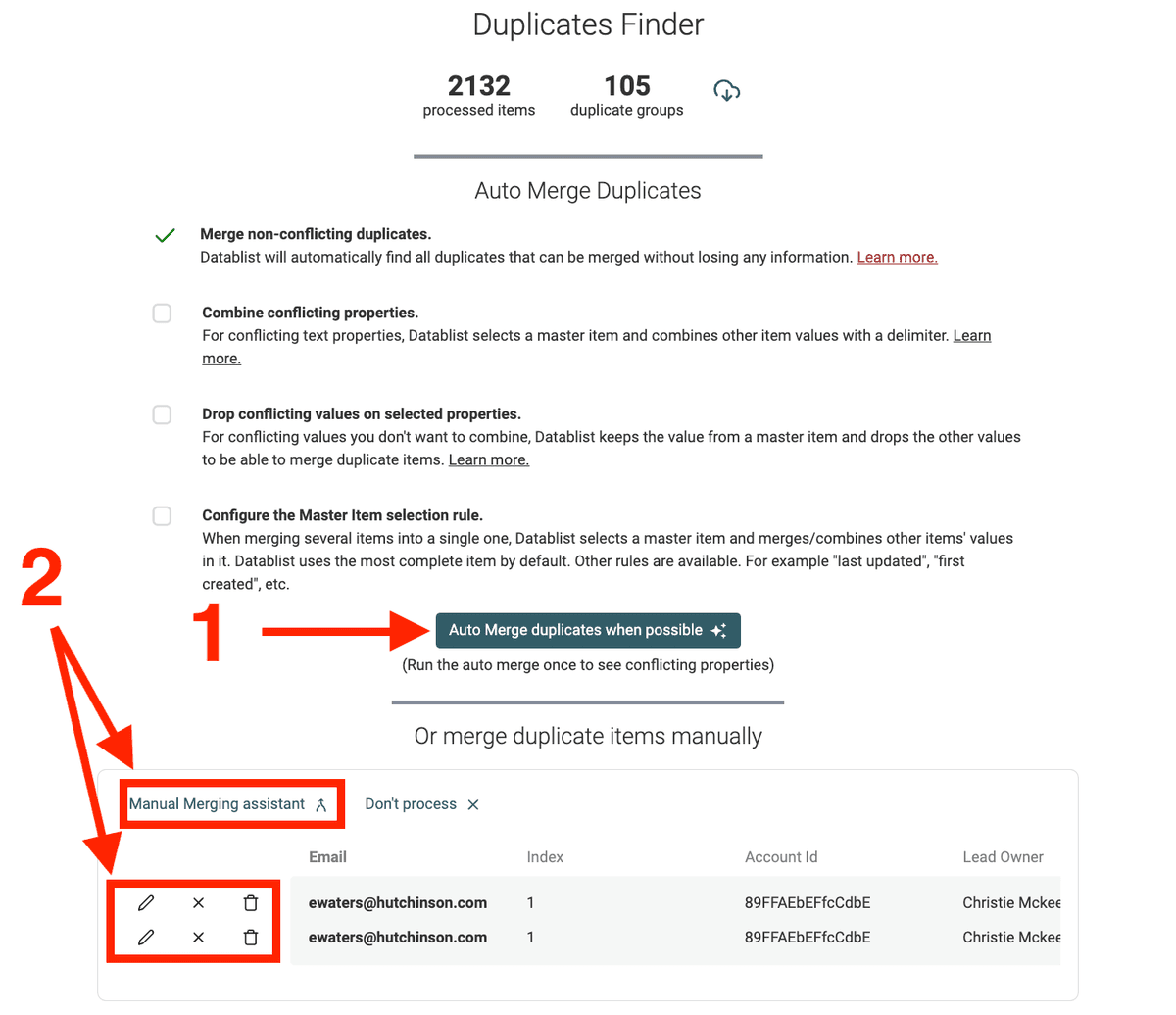
Automatically merge duplicates
To save you time, Datablist provides an "Auto Merge" algorithm. With "Auto Merge", most of the merging cases are possible. It handles merging non-conflicting items, combining duplicate values into a single item, and dropping duplicate values during the merging. The auto merge is triggered by clicking on the "Auto Merge duplicates when possible" button.
The merging non-conflicting items algorithm is always activated. Other merging algorithms need to be switched on to be activated.
Merge non-conflicting items
Datablist is able to merge non-conflicting items automatically without losing any information. It works as follows:
- If all the duplicate items have the same property values, only one item will be kept and the others will be deleted.
- If the duplicate items are complementary, the item with the most information will be selected as the primary item and its property values will be filled using other item property values. Then all items except the primary item will be deleted.
- If duplicate items have conflicted property values, items will be skipped for manual merging (or to be combined with the combining duplicates algorithm, or dropped)
For example, the following duplicates:
email | First Name | Last Name
james@gmail.com | James
james@gmail.com | | Bond
Will be merged into:
email | First Name | Last Name
james@gmail.com | James | Bond
Combine conflicting properties
The Auto Merge algorithm comes with a second option to combine values from duplicates into a single text property. It keeps the data from all the duplicate items and merges them with a delimiter into a single item.
One or more properties can be combined and 4 delimiters are available: Line Break, Semicolon, Comma and Space.
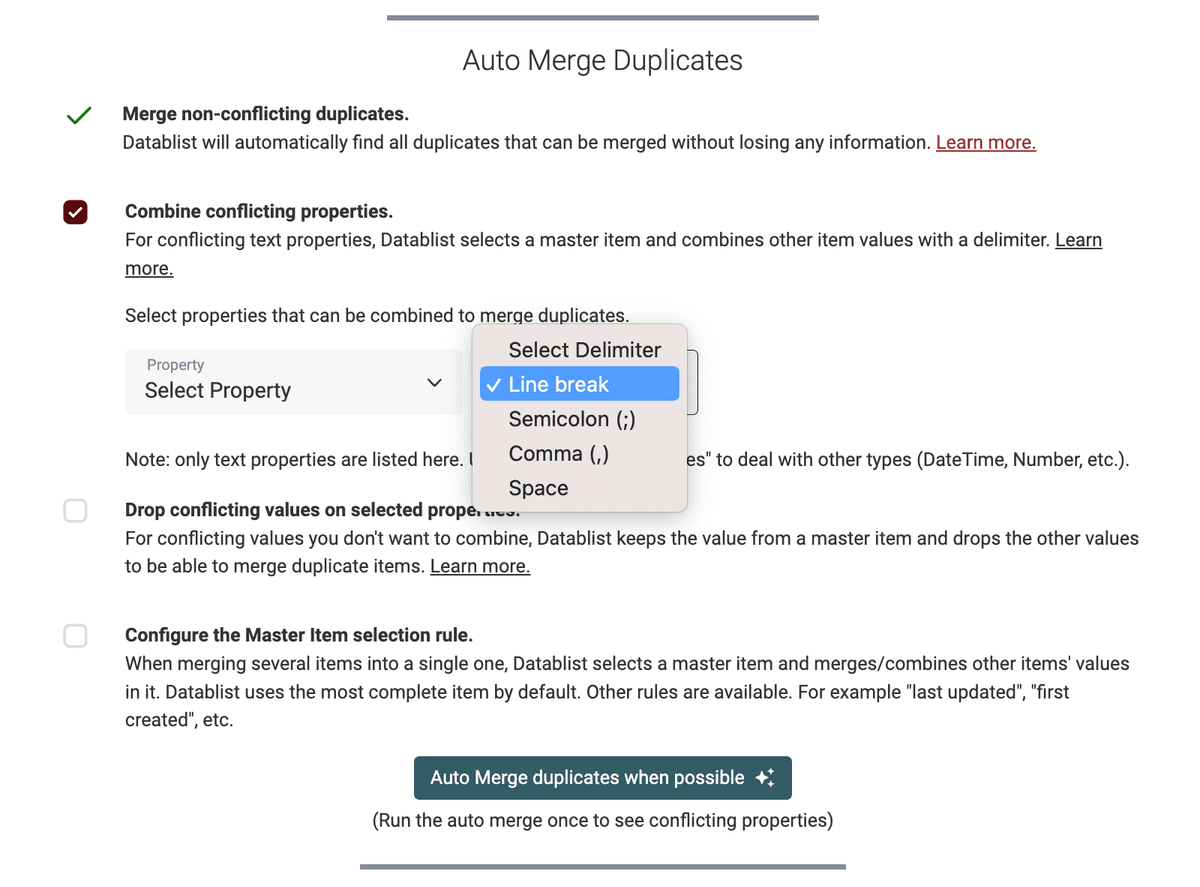
For example, combining the Phone property with a semi-colon:
email | Phone | First Name | Last Name
james@gmail.com | +33 1 34 65 23 | James |
james@gmail.com | 06 13 42 78 23 | | Bond
Will be merged into:
email | Phone | First Name | Last Name
james@gmail.com | +33 1 34 65 23;06 13 42 78 23 | James | Bond
This is useful when merging a list of leads or companies. If you have two leads with the same email address but different "Notes" and "Phone Number" values, combining them will create a consolidated lead.
Note: The algorithm only combines text values. If the property you want to combine is a Checkbox, Number, Datetime, etc. (see full data types list), it will not be combined.
Drop conflicting values
The last option available when merging duplicate items is to drop conflicting values.
Use this option:
- When the property must be a single value.
- For example, if you are cleaning a CRM lead list. You will have an external CRM "record id". To re-import your cleaned data back into your CRM, the "record id" must be a single value.
- When it doesn't make sense to keep several values.
- For example, if you have a "last activity" property with conflicting values. Date, Checkbox, and Number can't be combined so you can drop conflicting data to keep only one value.
Important
Datablist selects one of the duplicate items to be a master item. When conflicts exist to merge items, the value from the master item is kept. The item with the most properties containing data is selected as the master. If two items have the same number of properties with data, the item with the highest rank (last added in Datablist) is selected.
For example, configuring the algorithm to drop conflicting values on AccountId:
AccountId | email | First Name | Last Name | Job Title
934DSFG39FGDS | james@gmail.com | James | |
ODFJSDK123aSD | james@gmail.com | | Bond | CEO
Will be merged into:
AccountId | email | First Name | Last Name | Job Title
ODFJSDK123aSD | james@gmail.com | James | Bond | CEO
Algorithm Explanation
- The second item has 4 properties with data (
AccountId,Last Name,Job Title). It is the master item.First Name,Last Name, andJob Titleare merged without conflict.AccountIdhas a conflict. So the value from the master item is kept.
Master Item Selection
When merging several items into a single one, Datablist selects a master item and merges the data from the other items into it.

Three rules are available:
Master Item Rule: Most Complete
This is the default rule. The algorithm selects the item with the most properties containing values. If items have the same number of properties with data, it selects the one with the longest text. And when they still have the same text length, it selects the last created.
Example 1 with Most Complete:
ItemId | email | Name | Job Title
SDFASDCSXCAER | james@gmail.com | James Bond |
ODFJSDK123aSD | james@gmail.com | James Bond | Spy
For this first example, the algorithm will select the second item (ItemId: ODFJSDK123aSD). It has a value for the Job Title property, while the first has an empty value.
Example 2 with Most Complete:
ItemId | email | Name | Notes
SDFASDCSXCAER | james@gmail.com | James Bond | He is a fictional British Secret Service agent created in 1953 by writer Ian Fleming
ODFJSDK123aSD | james@gmail.com | James Bond | A spy
In this second example, both have value for every property, but the first one has a longer Notes value. So the master item rule selects the first item (ItemId: SDFASDCSXCAER)
Master Item Rule: Last updated
Datablist keeps two internal values for each item: CreatedAt and UpdatedAt. The UpdatedAt value is automatically updated after a change.
The "Last updated" master item rule, keeps the last item updated.
Master Item Rule: First created
The "First created" master item rule, keeps the first item created in Datablist.
Manually merge conflicting items
For some duplicate items, conflicting values prevent them to be merged without losing data. For example, imagine two items that store contact information with the following data:
# Contact A
Name: John Doe
Job Title: Marketing Manager
Email: johndoe@company.com
# Contact B
Name: John D.
Job Title: Business Development
Email: johndoe@company.com
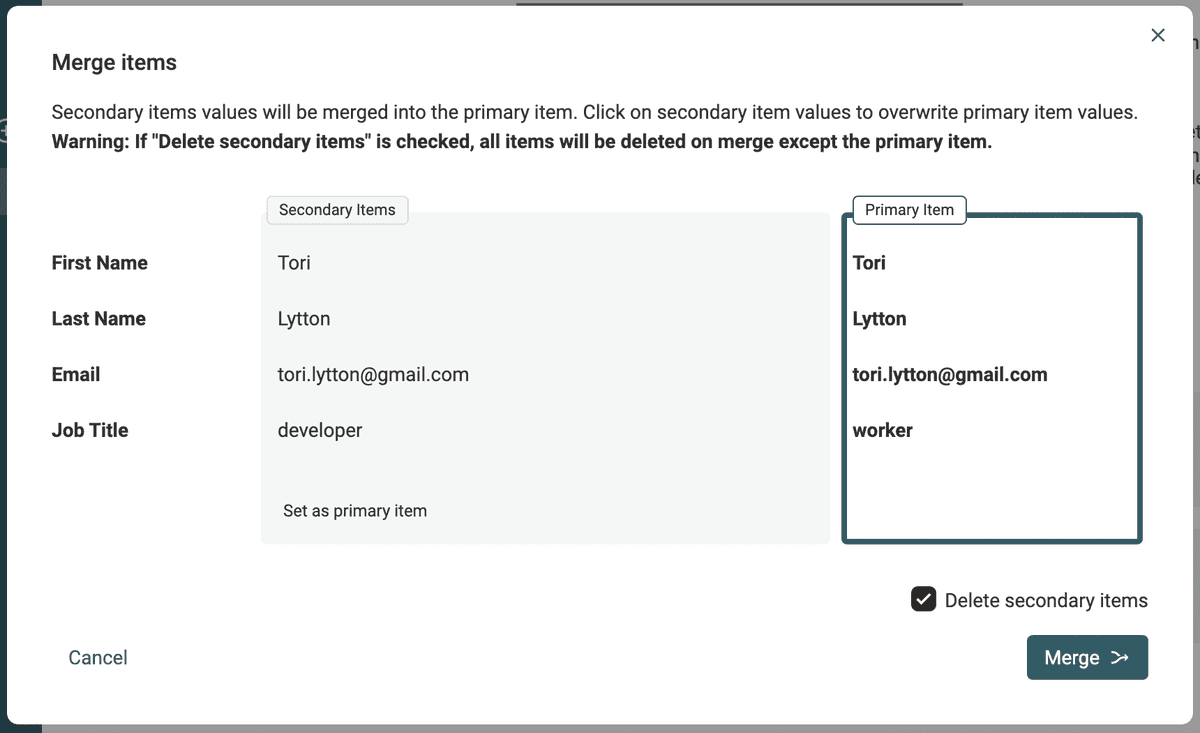
We know they represent the same person because they have similar email addresses. Unfortunately, they have two different job titles, the name is not the same, and merging them into a single item means choosing which data to keep.
This is where to use Datablist Merging Assistant. A "merge" button is available on the left of every duplicates group.
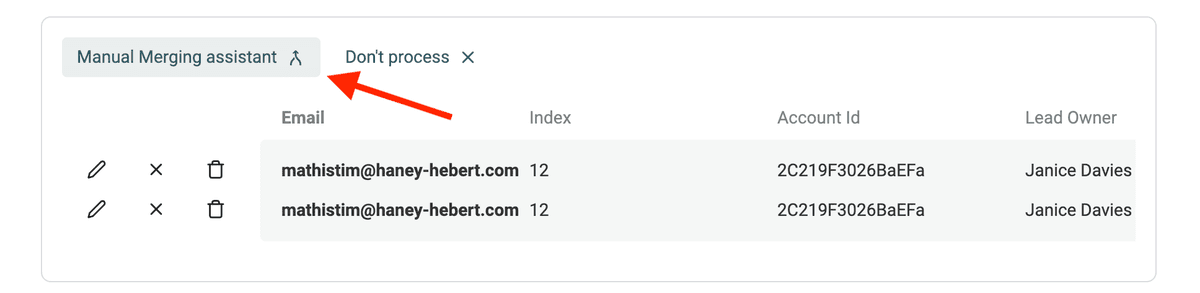
It opens the merging assistant for the items. On this modal, you can select which value to keep for each conflicting property. After merging them, all except one (the master item) will be deleted.
Please check our Datablist Merging Assistant documentation page to learn more.
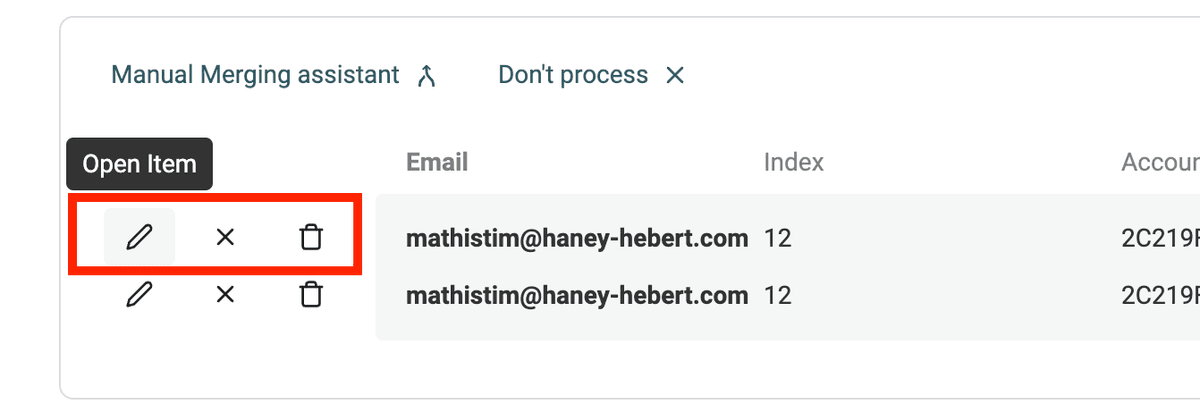
Edit or delete items
Another way to deal with duplicate values is to directly edit an item's data or delete unnecessary items. You can directly perform those actions with the buttons listed on each item.
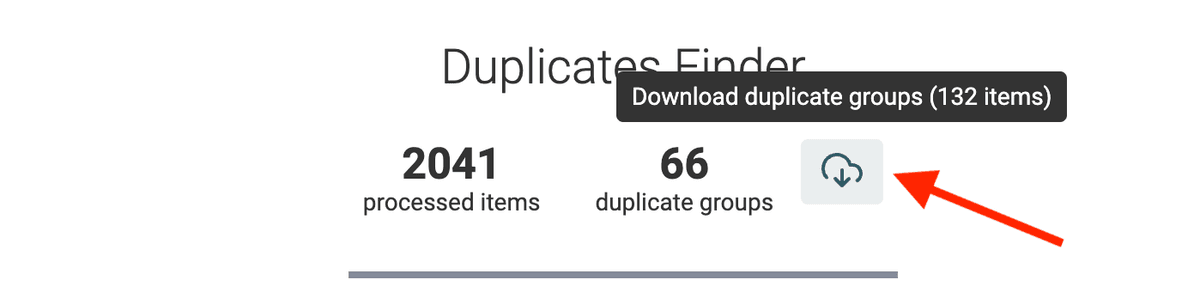
Export duplicate groups
In some use cases, you might want to export the list of duplicate items to process them externally. An export button is available to export the duplicate groups to a CSV or Excel file.
Duplicate groups are listed one after the other.
For example, for two duplicate groups:
Item Id | First Name | Last Name
00001 | Filip | Richu
00002 | Failip | Richo
And
Item Id | First Name | Last Name
00005 | John | Richu
00006 | Jaun | Richu
The export listing will be:
Item Id | First Name | Last Name
00001 | Filip | Richu
00002 | Failip | Richo
00005 | John | Richu
00006 | Jaun | Richu
Note: Duplicate group export is only available for single-collection deduplication.
FAQ
Can Datablist miss some duplicates?
Analysis of large lists of items is time consuming and resource intensive. For example, a list of 1000 items generates 1000*999/2 = 499 500 unique pairs of items.
This is manageable.
But a list of 200 000 items generates 200 000*199 999/2 = 19 999 900 000 pairs. This is not possible to return results in a few seconds.
To get results fast, Datablist doesn't compare all items between them. It uses an algorithm to create a list of "potential duplicate pairs". Those "potential duplicate pairs" are then compared with the similarity algorithm. A similarity score is calculated for each. When the similarity score is higher than the threshold, a duplicate group is returned.
This algorithm to find "potential duplicate pairs" is enough most of the time. For some rare cases, your items will need more analysis to find all the duplicate groups. This happens when your data doesn't have enough distinct values. Datablist will not be able to discard enough pairs.
This case is highlighted with an icon next to the processed items.
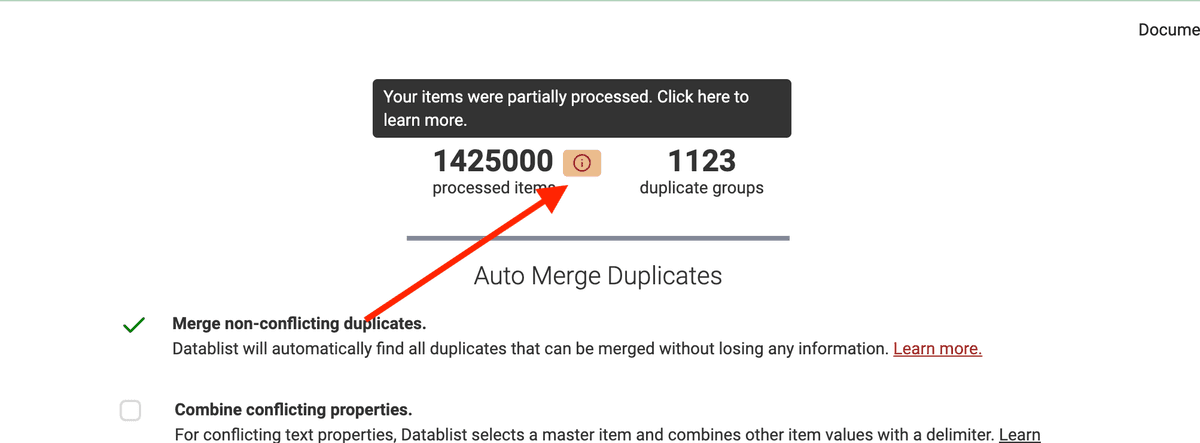
When this happens, you can process the duplicate groups found. And then restart another deduplication process to find other duplicates.
To learn more
Read our guides for step by step tutorials on how to deal with duplicates for CSV and Excel files: