Scrapes agency listings from Clutch.co including company names, ratings, services, pricing, and profile links
Sådan bruger du denne AI-prompt
- Opret en ny Collection: Start med at oprette en ny, tom collection i Datablist, hvor dataene gemmes. Klik på '+ Create new collection' i sidepanelet.
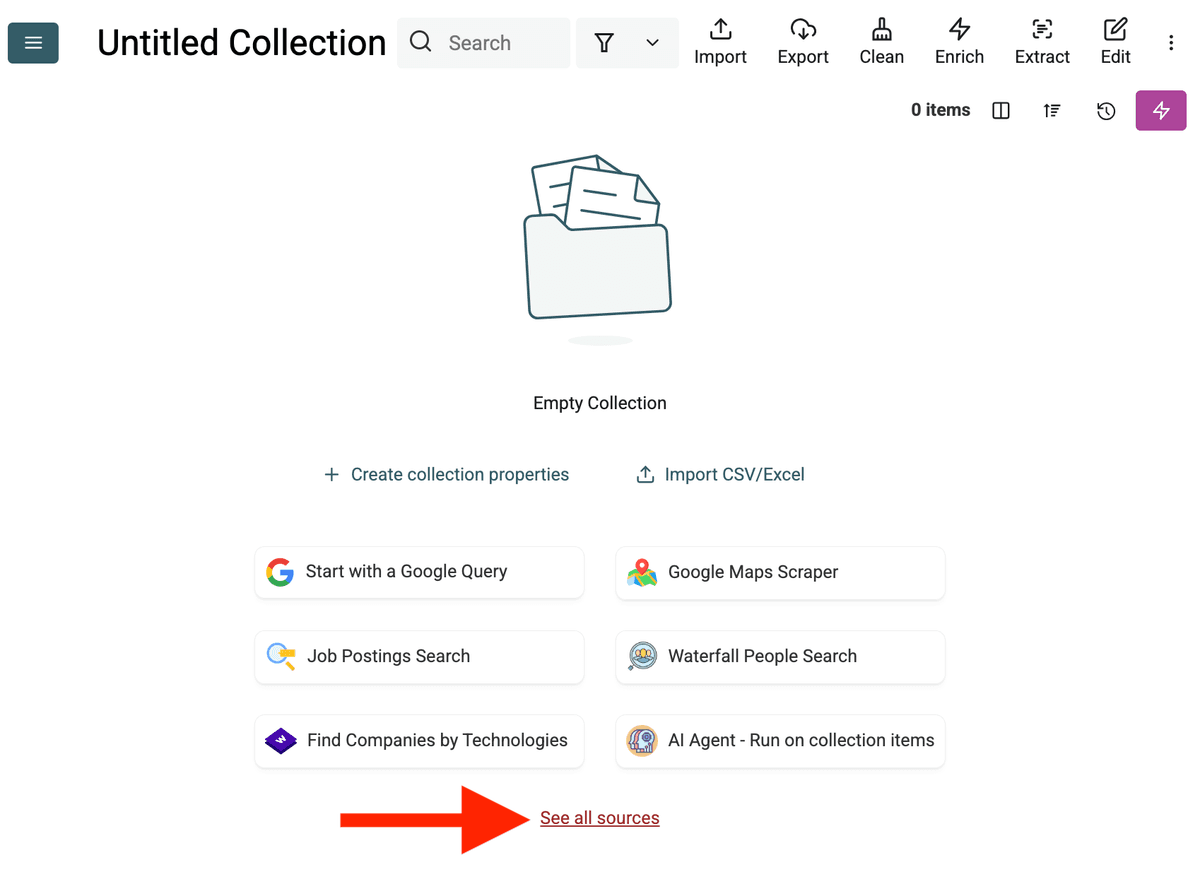
- Vælg AI Agent-kilden: Klik "See all sources" eller gå til "Import" -> "Import From Data Sources". Vælg "AI Agent - Site Scraper".
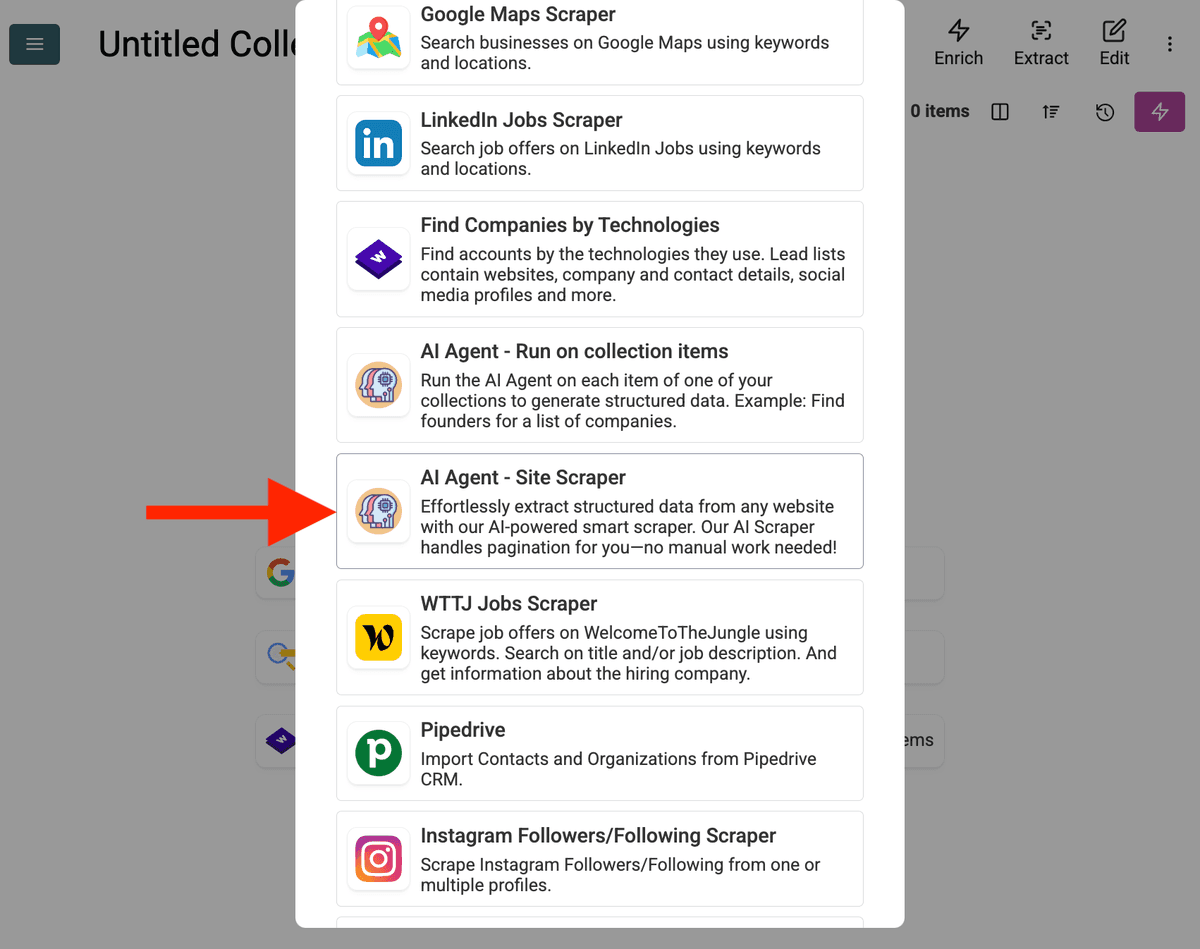
-
Konfigurer kilden:
- Select Template: Find og vælg prompten fra "Template"-dropdown-menuen. Prompten ovenfor bliver automatisk indlæst.
- URL to Scrape: Indtast din URL, der skal scrapes
- Enable Pagination (Optional): Hvis resultaterne er på flere sider, markér Enable Pagination og angiv en fornuftig grænse for Max Pages (fx 10).
- Customize (Optional): Du kan justere AI-modellen (fx er GPT-4o mini ofte omkostningseffektiv), redigere prompten til specifikke behov eller ændre de forventede Outputs.
- Gennemse Outputs: Klik Continue. Datablist viser de outputfelter, der er defineret i prompten (Project Name, Client Company Name). Klik på +-ikonet ved hver for at oprette de tilsvarende properties (kolonner) i din collection.
- Kør import: Klik Run import now. AI Agenten begynder at scrape websitet baseret på prompten og udfylder din collection.
Priser
Denne datakilde bruger Datablist credits efter forbrug. Omkostningerne afhænger af websitets kompleksitet og antallet af besøgte sider.
Test ved først at køre AI Agenten på en enkelt side for at få et estimat af omkostningen.
FAQ
Hvordan starter jeg endnu en kørsel med samme konfiguration?
Når du har kørt din AI Agent, skal du klikke på den lyserøde knap øverst til højre i din datatabel for at åbne den igen med dine senest brugte indstillinger.
Hvad sker der, hvis AI Agenten forsøger at tilgå et beskyttet website eller bliver blokeret?
AI Agenten bruger automatisk proxyservere, når det er nødvendigt, for at tilgå websites med scraping-beskyttelse eller geografiske begrænsninger. Det øger chancen for vellykket dataudtræk, men meget tungt beskyttede sider kan stadig give udfordringer.
Hvor meget data kan jeg behandle med AI Agenten?
Når du kører AI Agenten (enten som en berigelse eller en datakilde), kan Datablist collections håndtere behandling af op til 100.000 items (rækker). For større datasæt kan du have brug for at splitte dataene i flere collections.
Hvordan adskiller AI Agenten sig fra ChatGPT/Claude/Gemini-enrichments?
Standard AI-enrichments (ChatGPT, Claude, Gemini) behandler data, der allerede er i din collection, ved hjælp af AI'ens eksisterende viden. AI Agenten kan aktivt interagere med det live web—lave Google-søgninger, browse websites og udtrække ny information baseret på din prompt.
Hvor præcise er resultaterne?
Nøjagtighed afhænger i høj grad af klarheden og specificiteten i din prompt samt opgavens kompleksitet og den tilgængelige information online. Tydelige instruktioner, eksempler og regler for fejl-håndtering forbedrer resultaterne. Datablist giver ofte en confidence score for AI Agent-outputs for at hjælpe med at vurdere pålideligheden.