Gratis værktøj til at fjerne dubletter

Hvad er deduplikering af data?
Deduplikering af data, eller deduping, er processen med at fjerne dublerede poster fra et datasæt.
Deduping er nødvendigt for at have en liste med unikke poster. I marketing med mailinglister, i lead generation eller kundehåndtering. Eller i e‑handel ved håndtering af produktkataloger. To poster er dubletter, når de refererer til den samme enhed. To leads med samme email-adresse, eller to produkter med samme stregkode.
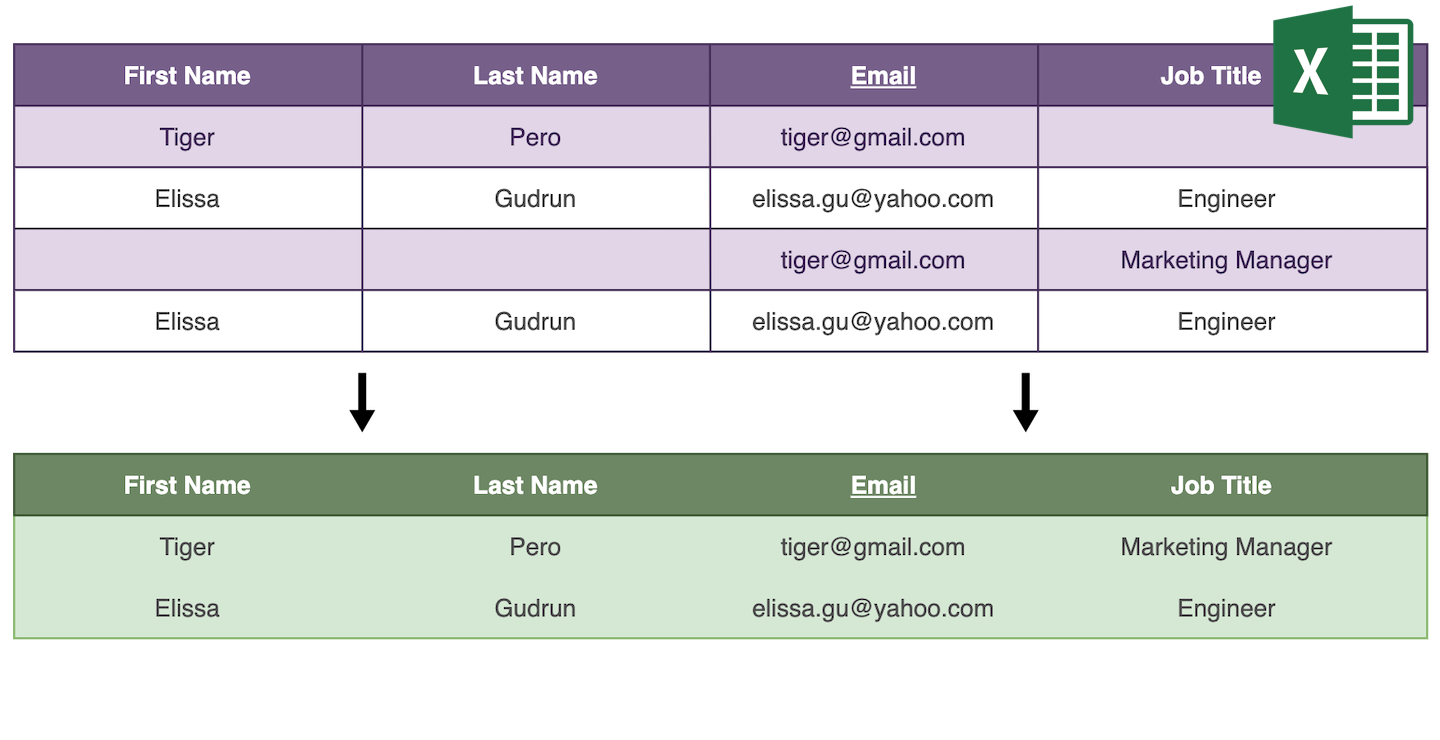
Dubletter påvirker kvaliteten af dine data og sænker din produktivitet. To løsninger findes for at slippe af med dubletter: slet dem, eller flet lignende poster til én.
At slette dubletter er let; deduplikeringsalgoritmen finder dublerede poster og sletter alle undtagen én. At flette dubletter kræver, at man analyserer dublerede poster for at kombinere dem til én masterpost.


















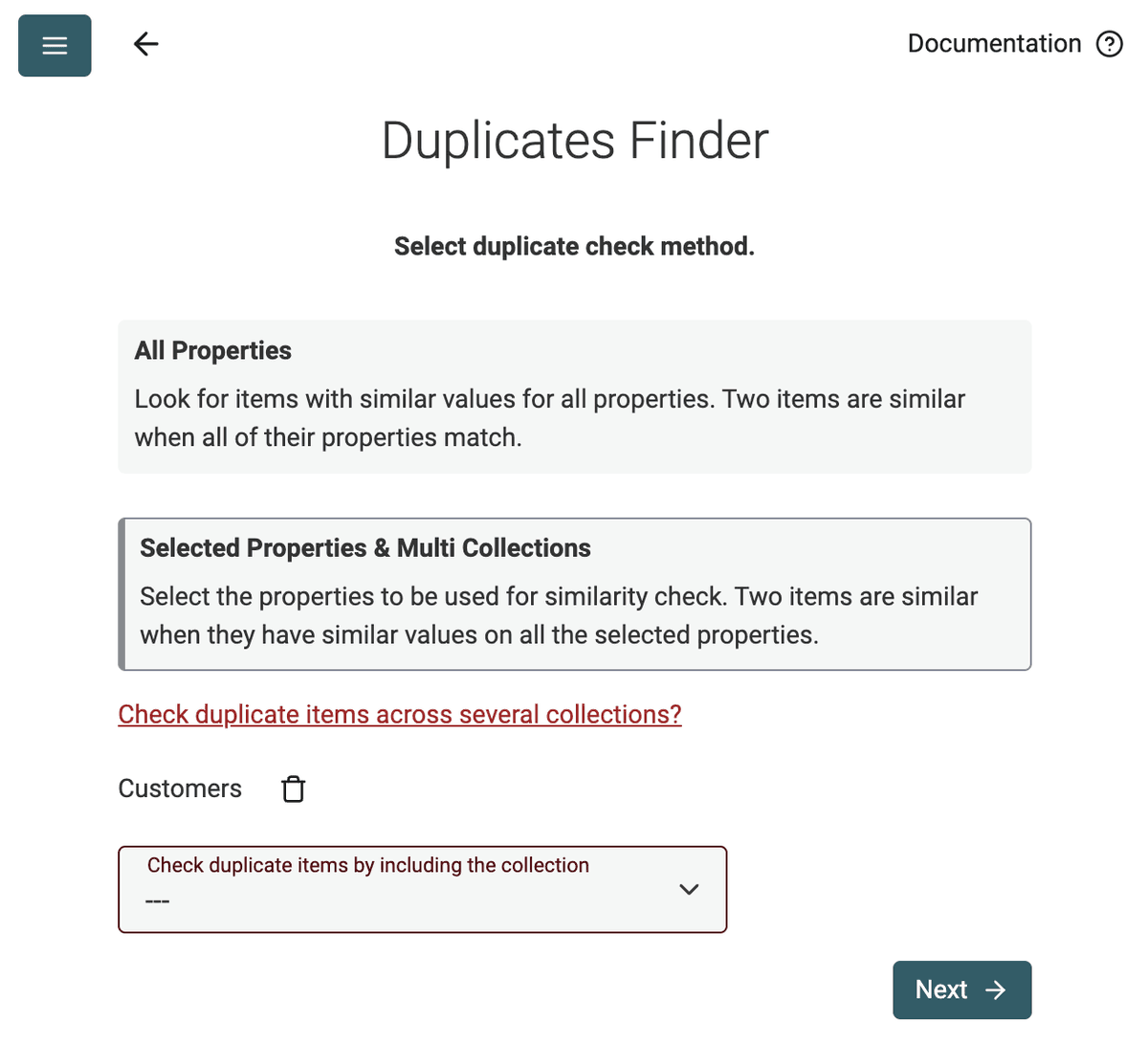
Fuld eller delvis analyse af poster i én eller flere datasamlinger
Datablist Duplicates Finder virker enten med fuld post-sammenligning eller baseret på udvalgte felter.
Brug Valgte felter-tilstand til at finde dubletkontakter baseret på deres email-adresse eller til at opdage dubletter i en liste over virksomheder via deres website‑URL.
Slet eller konsolider dubletter

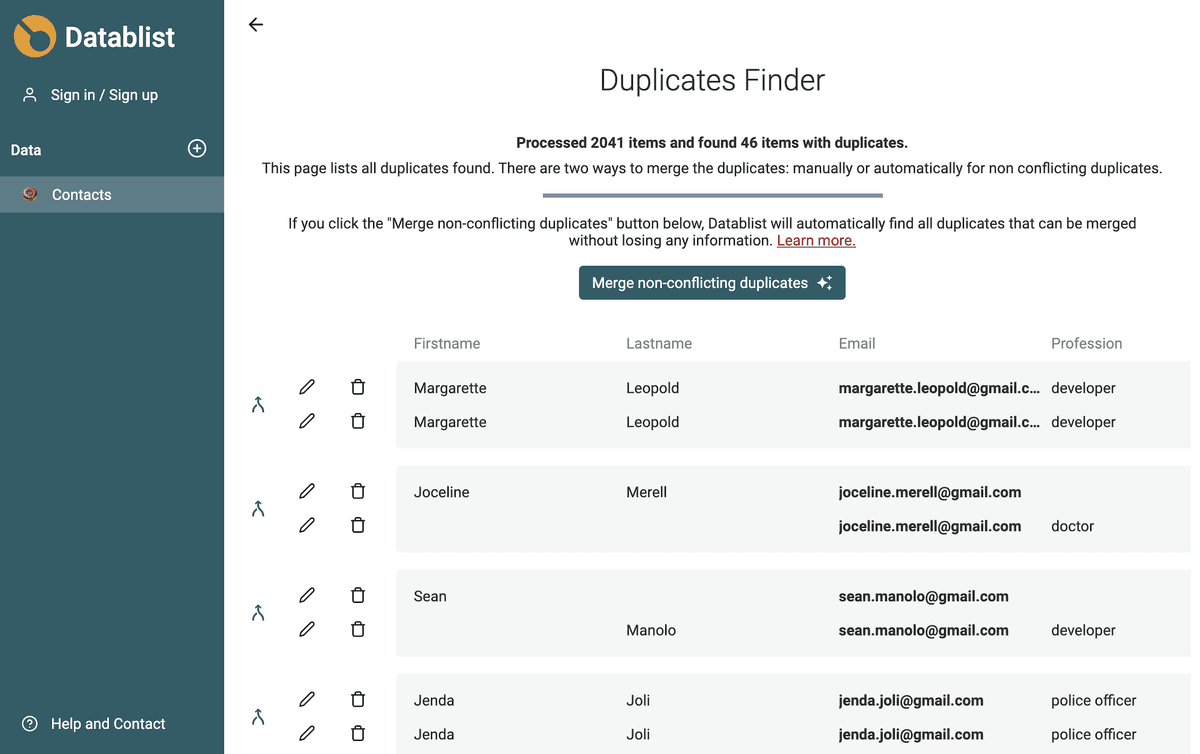
Flet automatisk ikke-konfliktende dubletter
Datablist finder automatisk alle dubletværdier, der kan flettes uden at miste information.
- Når alle dubletposter har de samme feltværdier, beholdes kun én post og de andre slettes.
- Hvis dubletposterne supplerer hinanden, vælges posten med mest information som primær, og dens feltværdier udfyldes ved hjælp af andre posters værdier. Derefter slettes alle poster undtagen den primære.
- Hvis dubletposter har modstridende feltværdier, springes de over til manuel fletning.
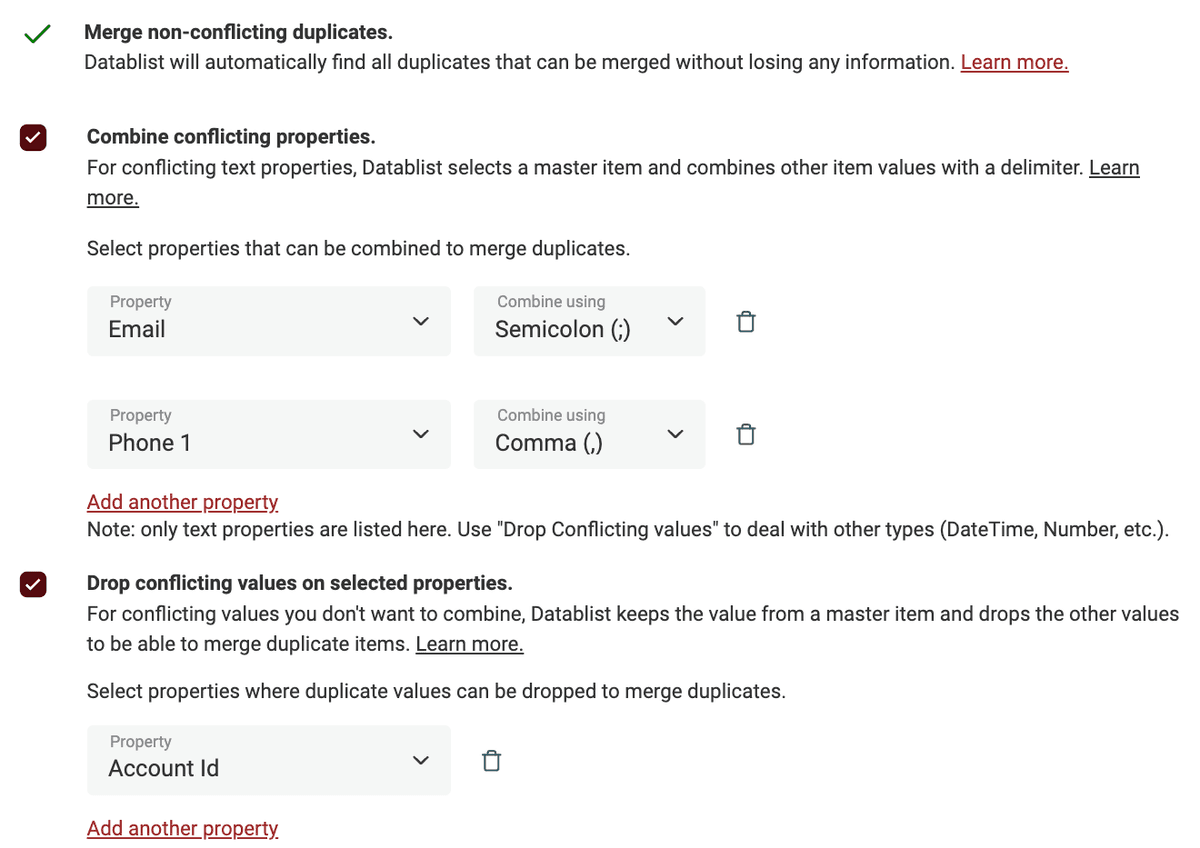
Konsolider dubletter for at beholde én post
Når en simpel fletning ikke er nok, brug de avancerede funktioner: kombinér eller drop dubletværdier for at konsolidere dine dubletposter.
Datablist viser dine konfliktfelter og lader dig vælge, hvordan du vil håndtere dem. Brug Combine values til sammenkædning af data. Og Drop values for at beholde værdien fra én masterpost.
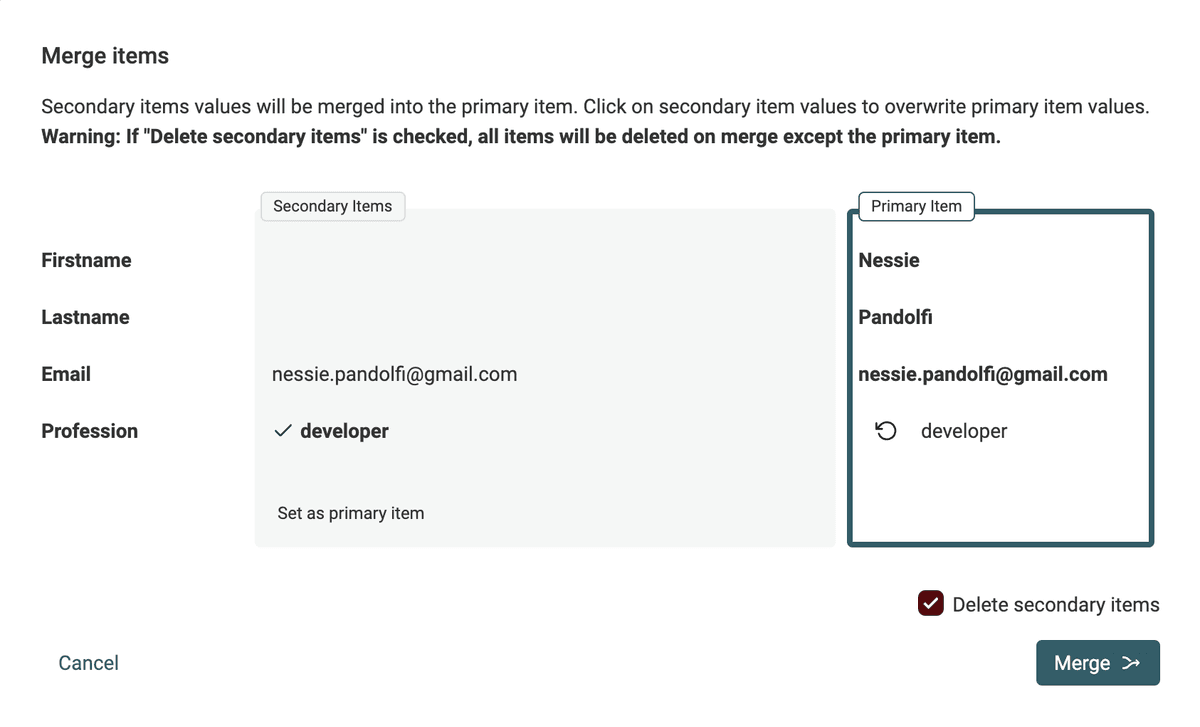
Eller gennemgå konfliktværdier manuelt med fletteassistenten
Når automatisk fletning ikke er mulig, kan du bruge Datablists fletteassistent til at vælge, hvilken værdi der skal bevares, og konsolidere dine poster.
Posten med mest information vælges som masterpost og modtager supplerende værdier fra sekundære poster.
AI-behandling af dubletter
Hvornår skal man bruge deduplikering af data?
- Deduplikering af mailinglister
Over tid vil flere kilder flyde ind i din mailingliste. Med webinar-deltagere, købere, freemium-brugere osv. kan en email-adresse optræde flere gange på din mailingliste.
Dublette email-adresser påvirker dine marketingkampagner med ekstra omkostninger, spamagtig adfærd og risiko for brugerfrustration, hvis de fortsætter med at modtage emails efter afmelding fra en kampagne.- Sådan rydder du op i en mailingliste
- Deduplikering i Microsoft Excel
Google Sheets, Microsoft Excel og andre regnearksværktøjer tilbyder basale deduplikeringsfunktioner. De fremhæver dubletværdier i en kolonne eller sletter dem. Brug Datablists automatiske fletning og den manuelle fletteassistent til at håndtere komplekse dubletposter.
Datablist åbner både CSV- og Excel-filer.- Sådan deduplikerer du en Excel-fil
- Værktøj til deduplikering af leads og prospects
I B2B marketing påvirker kvaliteten af din prospect-database resultaterne af dine kampagner. En rodet dataliste med duplicate leads øger lagringsomkostningerne, reducerer effektiviteten af lead-tracking og skaber frustration i dit salgsteam.
Styr dine lead generation-processer med Datablist. Eller importér dine CRM-data eller lead-lister til Datablist for at rense dem.- Sådan deduplikerer du lead-lister
- Dedupliker CSV-filer
Rensning af CSV-data er tidskrævende. Dataingeniører bruger programmeringssprog som Python til at parse og rense CSV-data. Datablist tilbyder et No-Code-værktøj til at udføre datarensningsprocesser med dine CSV-filer for ikke-tekniske brugere. Åbn CSV-filer med hundredtusindvis af rækker og dedupliker poster hurtigt.
- Sådan deduplikerer du en CSV-fil
Ofte stillede spørgsmål
Ja, du kan finde og flette dubletter online gratis. Basisfunktioner som exact og smart matching er tilgængelige uden en konto. For avancerede algoritmer som fuzzy eller fonetisk matching kræves en betalt plan.
Excel sletter permanent dubletrækker, hvilket kan få dig til at miste potentielt værdifulde data fra disse poster. Datablist fletter poster og kombinerer intelligent supplerende information fra alle dubletter til én komplet masterpost. Du mister ingen data.
Datablist er bygget til at håndtere store filer. Du kan behandle lister med op til 1 million rækker på gratisplanen og op til 1,5 millioner rækker på vores betalte planer, langt ud over begrænsningerne i traditionelle regnearksværktøjer.
Absolut. Vores værktøj bruger avancerede fuzzy matching-algoritmer, såsom Levenshtein- og Jaro‑Winkler‑afstand, til at identificere lignende poster selv med misspellings, tastefejl eller små formateringsforskelle.
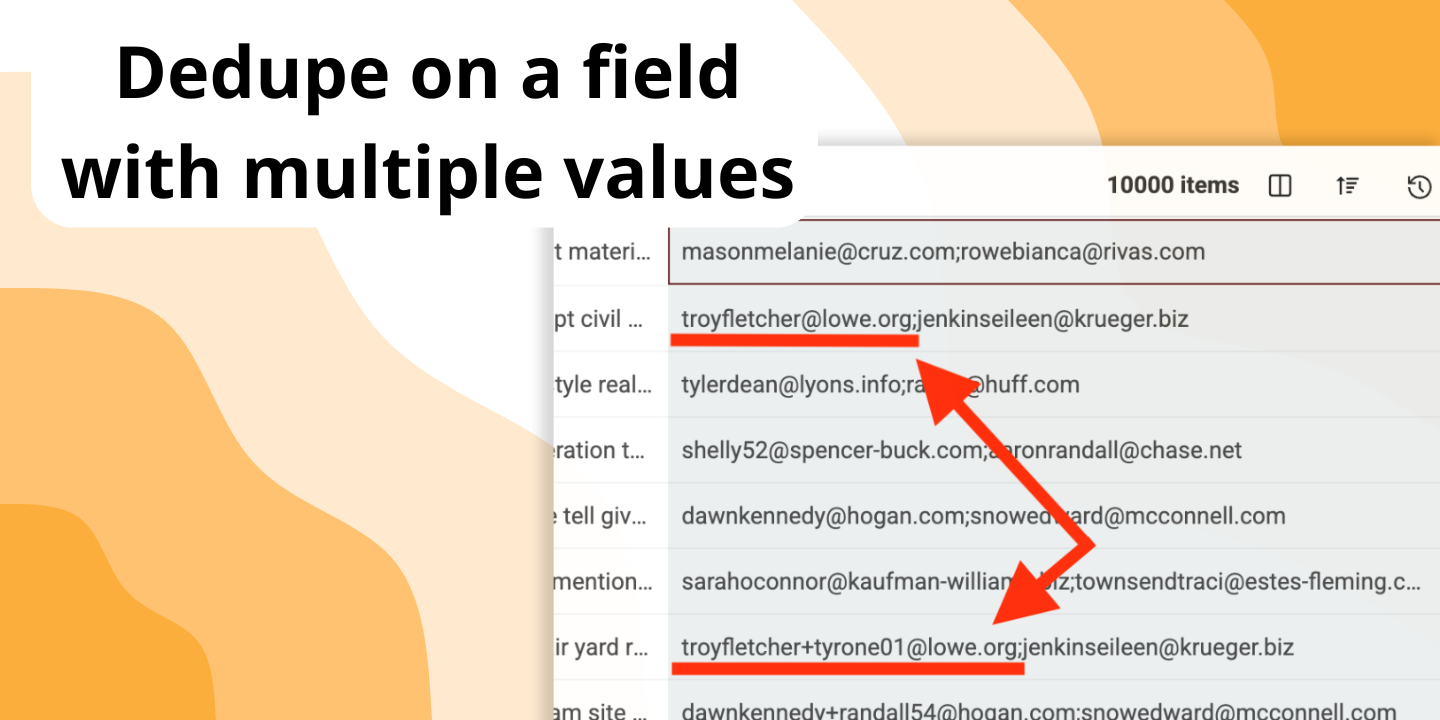
Det er den designet til. Du kan aktivere "Multiple Value Matching" for at behandle hver værdi i en celle (separeret med et semikolon) som en separat post til sammenligning. Den finder et match, selv hvis blot én af værdierne er en dublet.
Ja. Du kan importere flere filer til Datablist og køre Duplicates Finder på tværs af dem alle. Den kan matche poster baseret på en fælles identifikator, selvom filerne har forskellige kolonner eller strukturer.
Slet ikke. Datablist er en helt no-code løsning. Duplicates Finder guider dig gennem en enkel, trin-for-trin proces, hvor du vælger dine kolonner og matchregler fra en brugervenlig grænseflade.
Vores AI Editing-funktion giver dig ubegrænset fleksibilitet. I stedet for standard fletningsregler kan du skrive instruktioner på almindeligt engelsk. For eksempel kan du bede den om at summere salgstal fra dubletposter eller vælge masterposten baseret på den seneste dato. Det omsætter kompleks logik til en simpel forespørgsel.
Datablist konsoliderer dine data i én masterpost. Den udfylder automatisk manglende information fra andre dubletter og giver dig muligheder for konflikter: du kan kombinere tekst fra forskellige rækker eller vælge, hvilken værdi der skal bevares. De redundante poster slettes derefter.
Vi tilbyder flere algoritmer til forskellige behov: 'Exact' til identiske matches, 'Smart' til variationer som ordorden eller URL-protokoller, 'Phonetic' til navne, der lyder ens, og 'Fuzzy Matching' til tastefejl og stavefejl.
Ja. Når Datablist har identificeret alle dubletgrupperne, kan du eksportere dem til en CSV- eller Excel-fil før du foretager ændringer. Denne fil lister alle dubletposter fortløbende, med hver gruppe angivet efter hinanden, så de er nemme at gennemgå eksternt eller behandle med et andet værktøj.
Når du er færdig med at flette, giver Datablist en downloadbar 'Changes List'. Denne fil fungerer som en log, der beskriver hver post, der blev opdateret eller slettet under processen. Du kan bruge filen til nemt at replikere ændringerne i dit eksterne system, f.eks. et CRM, så dine data forbliver helt synkroniserede.
See Also