

Pipedrive is great for managing leads and sales. However, like any CRM, duplicate contacts and organizations pile up over time.
The built-in Pipedrive deduplication tool has major limitations (see all Pipedrive Merge Duplicate Limitations):
- It only detects exact matches using the persons/organization names - No matching of company names with legal suffixes (Google LLC == Google), no fuzzy matching, or deduplication using the website, email address, etc.
- It doesn’t let you bulk merge duplicates.
If you’re dealing with duplicate People or Organizations in Pipedrive, you need a better solution.
That’s where Datablist Duplicates Finder comes in to dedupe your Pipedrive data. In this guide, I'll show you how:
- Import your Pipedrive People and/or Organizations in Datablist
- Find and merge duplicates using advanced algorithms
- Sync Merges in bulk back to Pipedrive
- Pipedrive Built-in Merge Duplicates Limitations
Step 1: Import Your Pipedrive Contacts
The first step to cleaning up your Pipedrive duplicates is to import your data into Datablist. This allows you to use advanced deduplication tools that Pipedrive doesn’t offer. Follow these steps to import your contacts and organizations:
1. Create a New Datablist Collection
A collection in Datablist is like a spreadsheet where you store and clean your data. Each collection will hold your Pipedrive contacts (People) or companies (Organizations).
- If you want to deduplicate People, create a collection for People.
- If you want to deduplicate Organizations, create a collection for Organizations.
- If you need to clean both, create two separate collections: one for People and one for Organizations.
2. Select “Source → Pipedrive”
Datablist connects directly to your Pipedrive account through the API.
In your Datablist collection, go to Import → Select Source → Choose Pipedrive. Or directly from the "See all sources" link in the collection start screen.
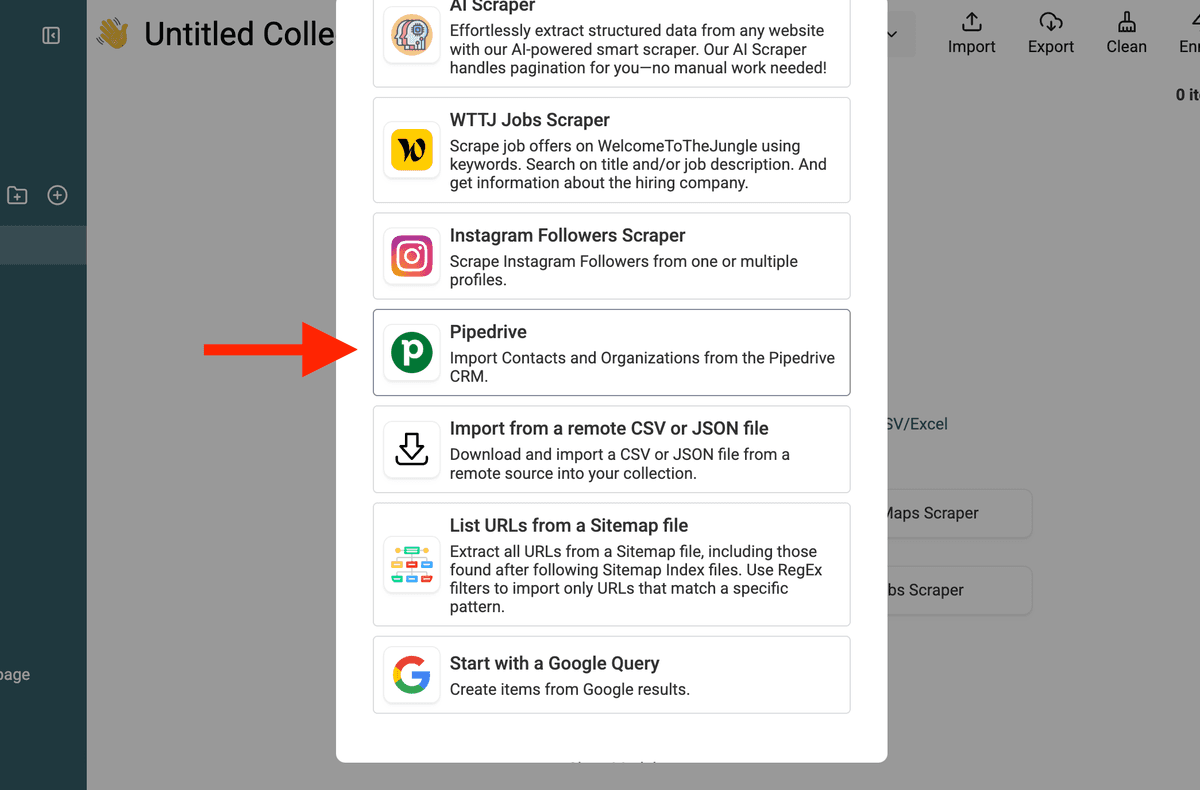
3. Find Your Pipedrive API Key
You’ll be prompted to enter your Pipedrive API key.
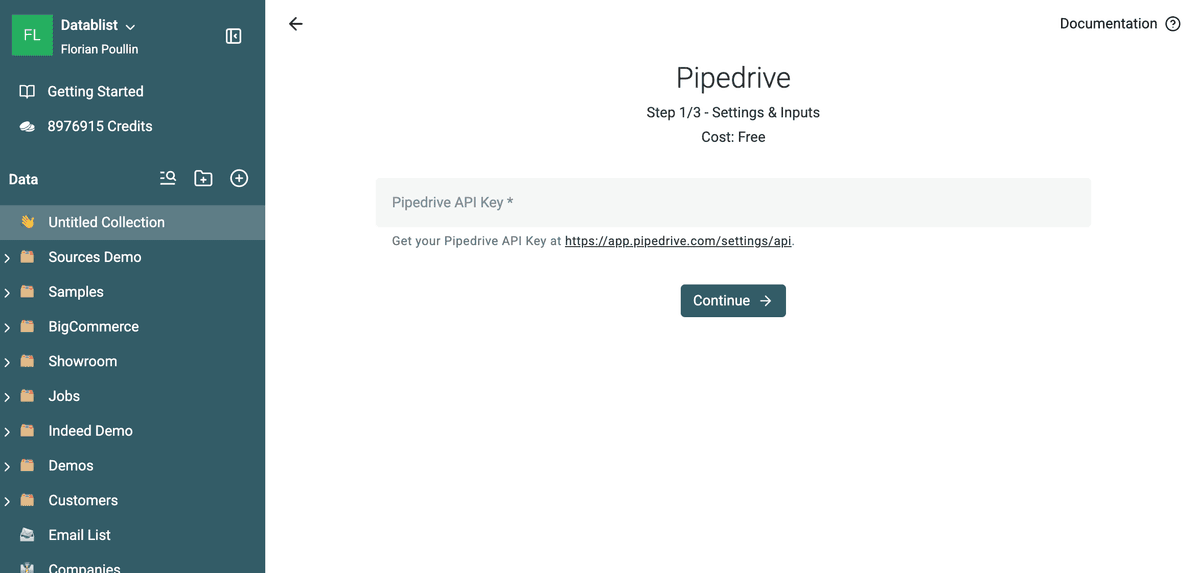
Your Pipedrive API key is required to link Datablist with your Pipedrive account. Go to Pipedrive API Settings and copy your personal API key. Paste it into Datablist.
4. Choose People or Organizations
Once connected, decide what you want to import:
- If you’re cleaning duplicate contacts, select People.
- If you’re cleaning duplicate companies, select Organizations.
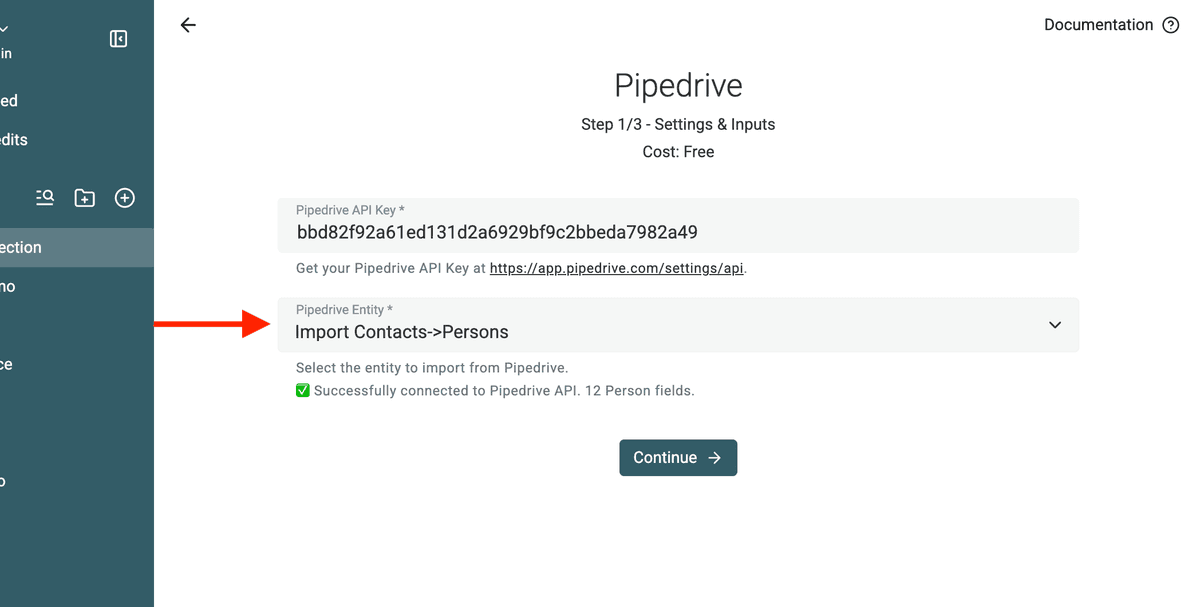
Note: If you need both, import them separately into two different collections.
Why separate collections? - Pipedrive stores People and Organizations differently. You can’t deduplicate a mix of both at the same time. Keeping them separate ensures accurate results.
5. Datablist Fetches All Pipedrive Fields
Once you select People or Organizations, Datablist will pull in:
- Standard Pipedrive fields (Name, Email, Phone, Website, etc.).
- Custom fields you’ve created in Pipedrive.
This ensures that all relevant data is available for deduplication.
6. Run the Import
Click Import to start fetching your data. The time it takes depends on the number of records.
Datablist processes your contacts and structures them for deduplication.
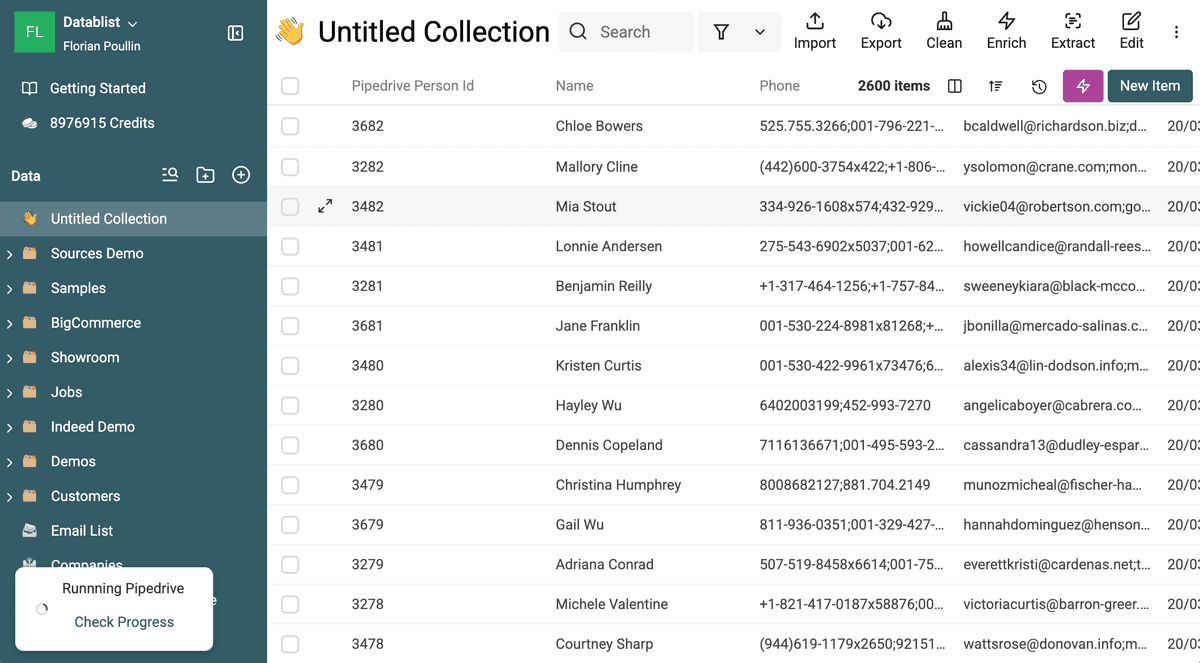
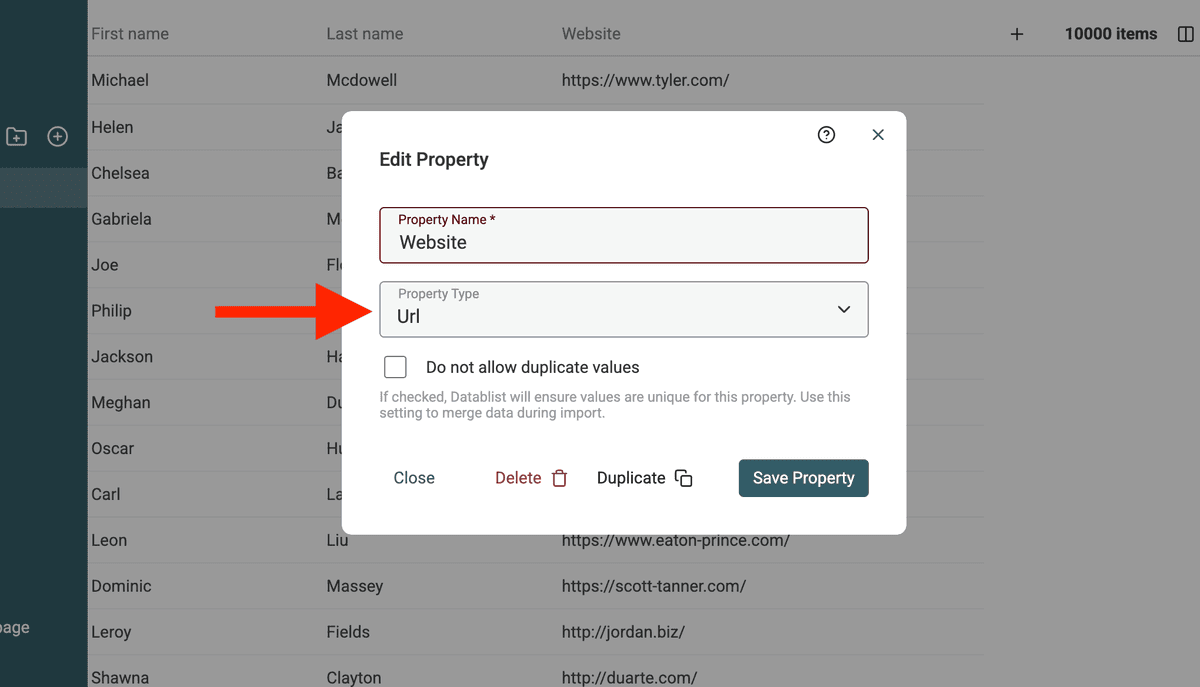
Change data types for URLs
Datablist Duplicates Finder has special processor to deal with Emails, URLs, etc. If your data has websites, change their property type to URL.
Multiple Email Addresses & Phone Numbers
If a contact has multiple emails or phone numbers in Pipedrive, they are concatenated into a single field, separated by a semicolon ;.
Example:
- John Doe has two emails in Pipedrive:
john@company.comandj.doe@gmail.com. - In Datablist, he appears as: Email:
john@company.com;j.doe@gmail.com
This allows Datablist to handle multiple values correctly during deduplication.
If you later need one email or phone number per CSV row, use the CSV Rows Splitter after exporting your cleaned file.
Once the import is complete, your data is ready for deduplication. Next, we’ll find duplicates using advanced matching techniques.
Step 2: Find Duplicates in Pipedrive People and Organizations
Now that your Pipedrive contacts or organizations are in Datablist, it’s time to find duplicates. Unlike Pipedrive’s built-in tool, Datablist uses advanced matching algorithms to detect similar records—even when names are slightly different or contact details are incomplete.
Here’s how to do it:
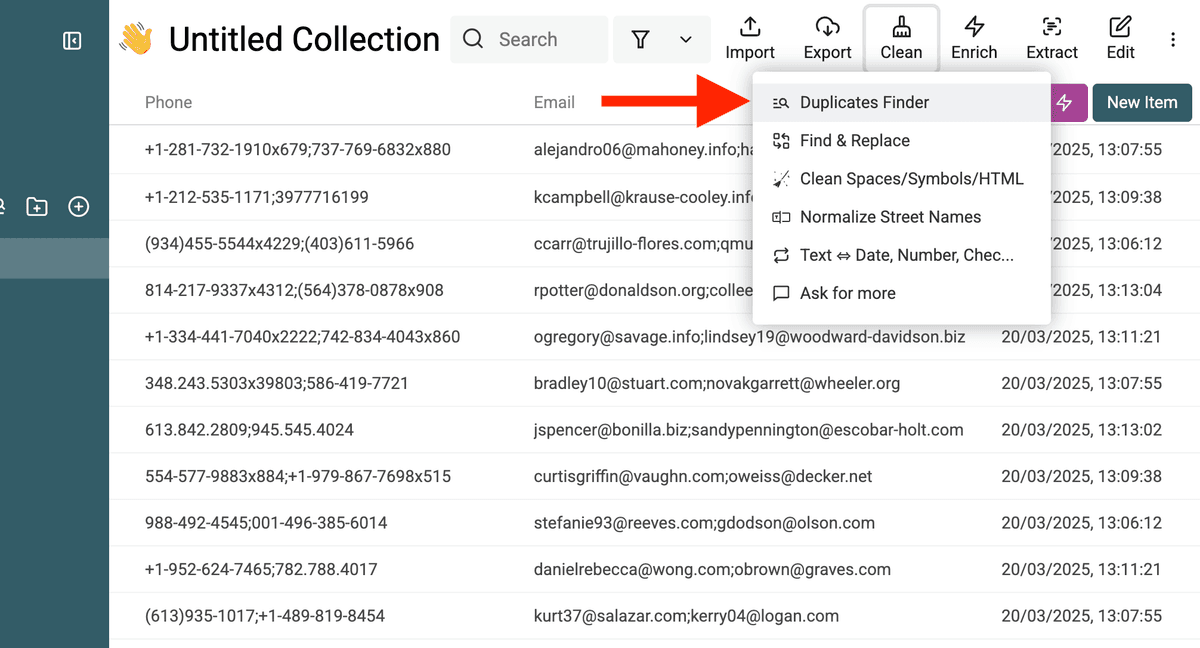
1. Open the Duplicates Finder and choose a Deduplication Property
In your Datablist collection, go to Clean → Duplicates Finder.
A deduplication property is the field Datablist will use to find duplicates. The best one depends on the type of data:
- For People: Use Email (most reliable) or Name (if emails are missing or inconsistent).
- For Organizations: Use Website (best) or Name (if no website is available).
💡 Example:
- If "Google" has two records: one with
Google LLCand another withGoogle, Datablist will detect them as duplicates because their names are similar.
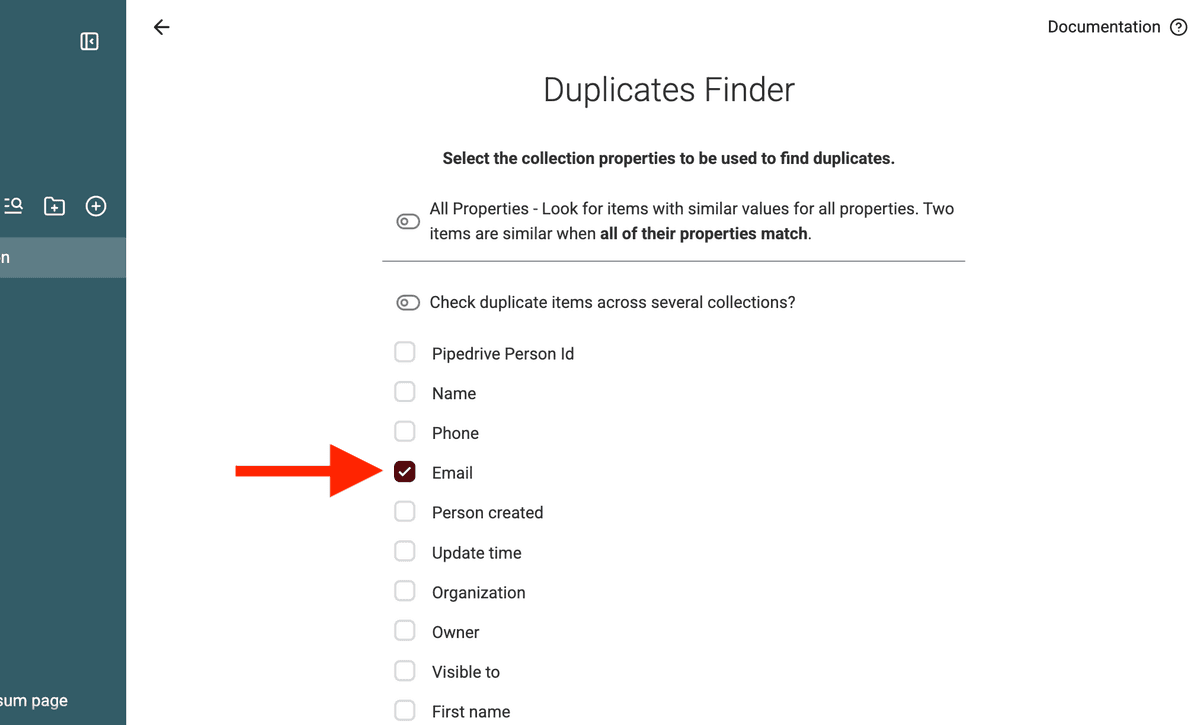
2. Run Deduplication
For best results, don’t merge everything at once. Run deduplication in iterations:
1️⃣ First pass: Match on Email (for People) or Website (for Organizations). This finds clear duplicates.
2️⃣ Second pass: Match on Name (for People or Organizations) to catch duplicates that may have different emails but refer to the same entity.
🔹 Why two steps?
- If you merge on Email + Name together, minor name variations (like "John Doe" vs. "Johnathan Doe") might prevent matches.
- Doing an email-first pass ensures exact email matches are handled first, avoiding errors.
Special care for multiple Emails and Company Names
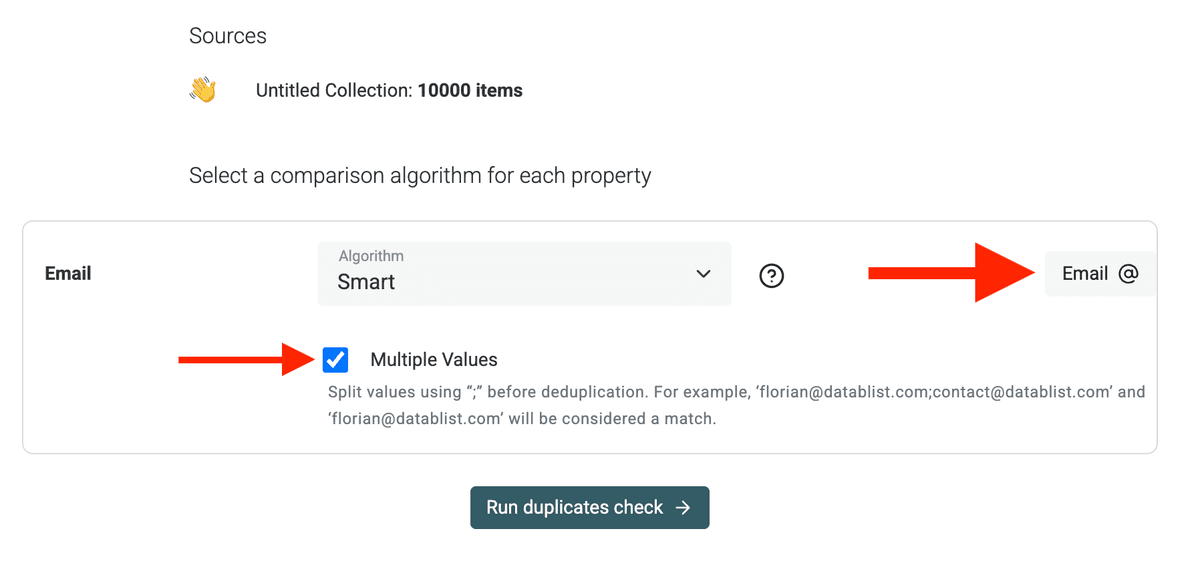
Some Pipedrive fields contain multiple values, like Emails and Phones.
If you are deduping on fields such as Emails or Phones that have multiple values (separated with ;), enable "Multiple Values" mode in Datablist. This ensures that if a contact has john@company.com; j.doe@gmail.com on a record, and just john@company.com on another, it still gets correctly matched.
If you are deduping on Company Names, Datablist Duplicates Finder has a dedicated processor to deal with legal suffixes and clutter words.
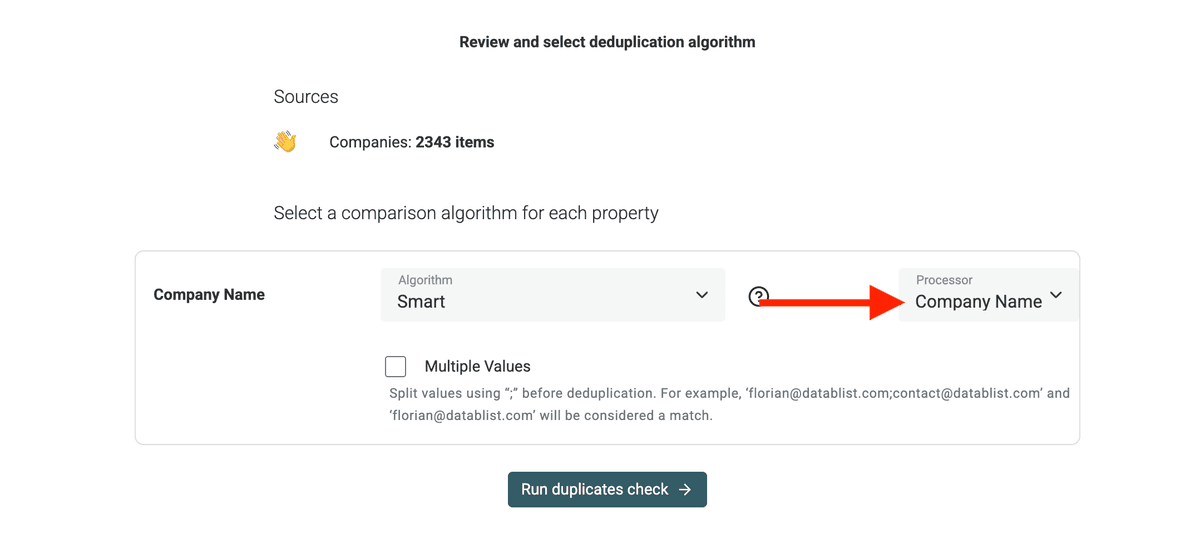
If your are deduping on websites, use the
URLprocessor.
3. Review the Detected Duplicates and Conflicting values
Once the scan is complete, Datablist groups duplicates together.
- You’ll see clusters of similar People or Organizations. We call them "Duplicate Groups".
- Each group will show how they match (by email, name, or website) and if they have conflicting data.
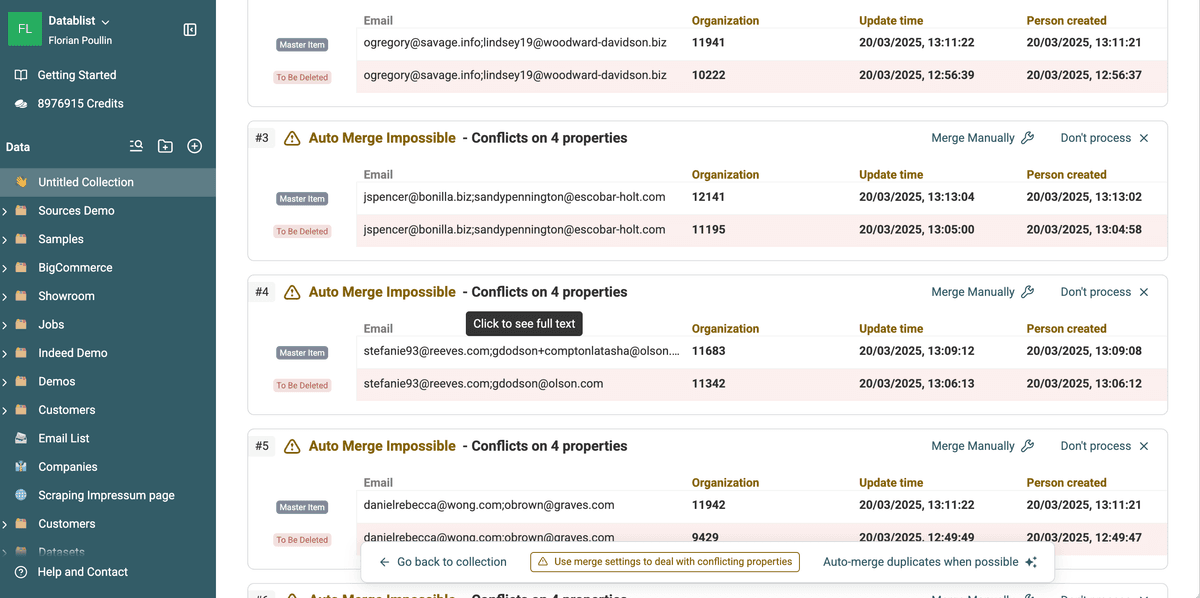
3.a. Understand Duplicate Groups
Each duplicate group contains multiple records that are considered the same entity.
- Some groups can be merged automatically because they have identical or complementary data.
- Others require manual review because they have conflicting information.
💡 Example:
- If two records for “John Doe” have the same email but different phone numbers, Datablist will detect them as duplicates but flag the phone number as a conflicting field.
3.b. Set Up Merging Rules for conflicting values
Understanding Conflicts
Conflicts happen when duplicate contacts have different values for the same field. For example, two records might have different job titles or phone numbers. Datablist highlights these conflicts so you can decide which value to keep.
How to Deal with Conflicts
Datablist provides an intuitive interface to resolve conflicts efficiently, ensuring you maintain clean and accurate data.
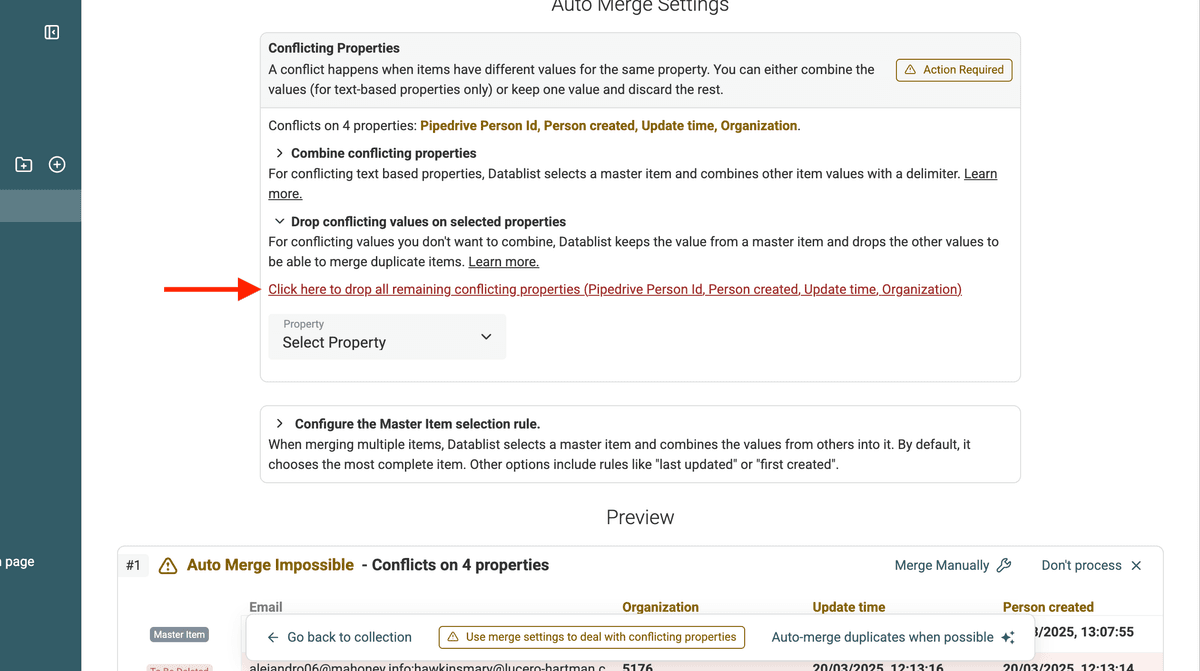
- Combine Values: If the values are complementary (e.g., multiple phone numbers, notes), combine them.
- Keep One Value and delete the others: If one contact is clearly more complete, and you want to discard the other, select "Drop conflicting values...".
For the Combine conflicting values and Drop conflicting values settings, you have a shortcut link to automatically select all conflicting properties.
Select a master record
You can also configure how Datablist selects the master record. When merging duplicate records, Datablist keeps one record, updates its fields, and deletes the other records to end up with only one record.
You can control how Datablist selects this Master Record by choosing from several rules:
- Most Complete: Picks the record with the most populated fields.
- Last Updated: Picks the most recently modified record.
- First Created: Picks the oldest record based on the creation date.
- Highest Value: Picks the record with the highest value for a selected property. If multiple records have the same value, it selects the most recent one.
- Lowest Value: Picks the record with the lowest value for a selected property. If multiple records have the same value, it selects the most recent one.
- Matching Value: Picks the record that contains a specific value in a selected property. If no record matches, they won’t be merged.
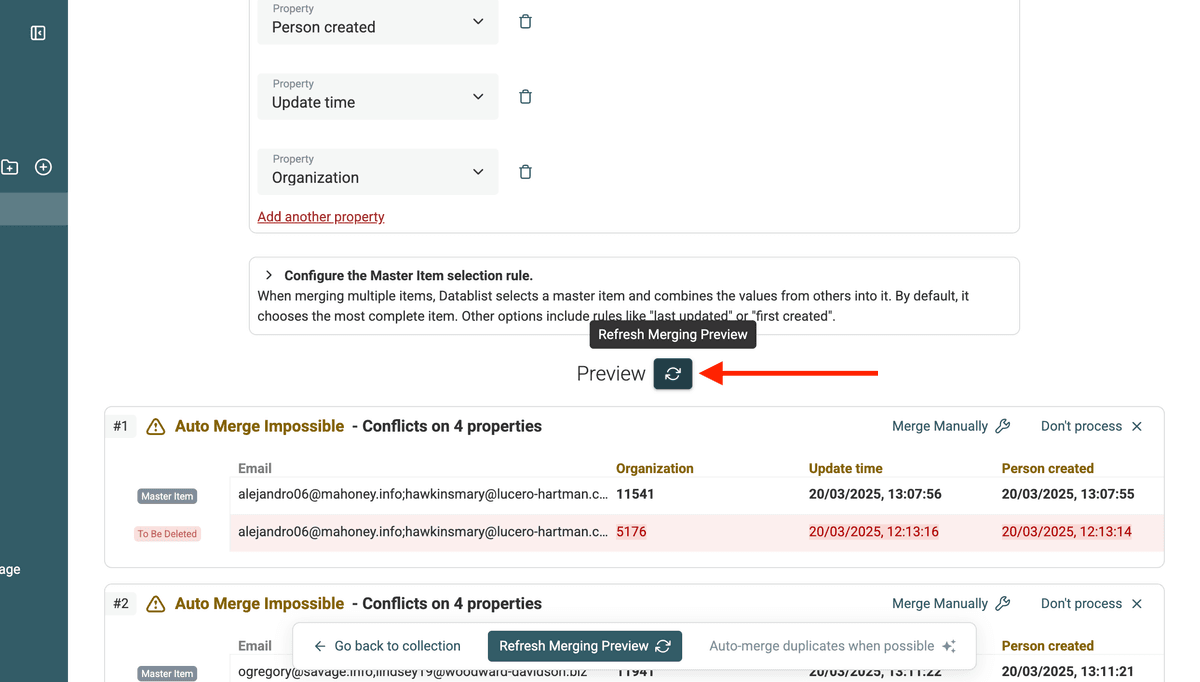
Datablist shows a preview listing of the changes to be made. You see which records will be deleted, which values will be combined, etc.
Click on the "Refresh" preview once you have finished defining the merge settings.
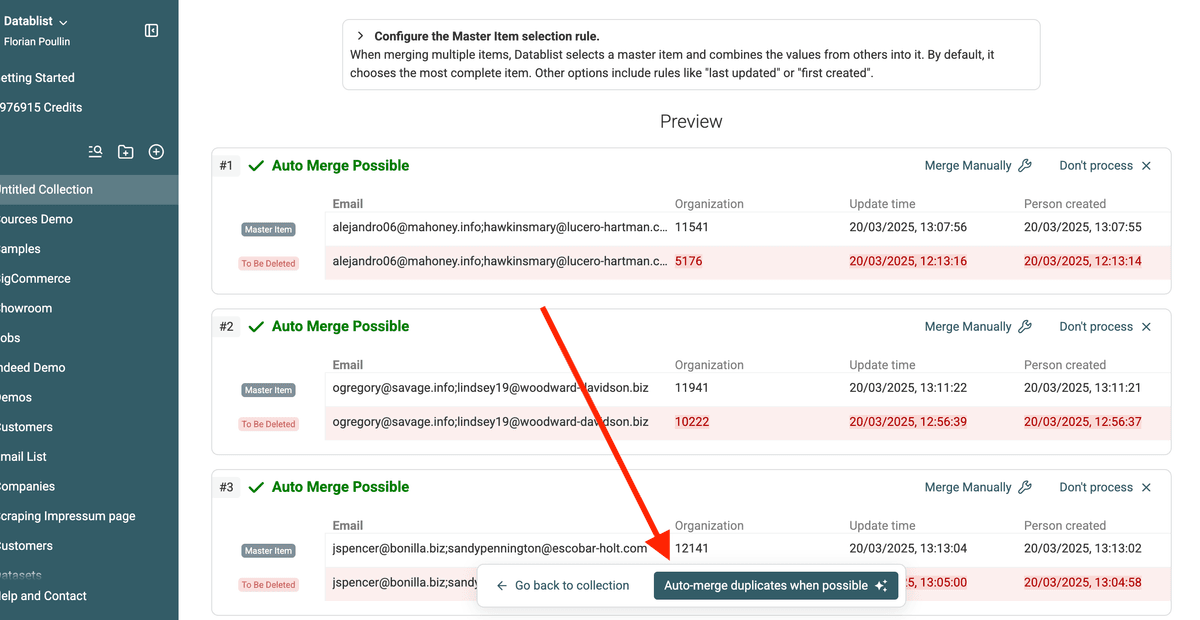
🔹 Example: Merging Two Contacts
The following example shows the result of the merging rules:
- Drop Conflicting values on the
Namefield. - Combine Conflicting values on the
Phonefield.
| Field | Contact 1 | Contact 2 | Merged Result |
|---|---|---|---|
| Name | John Doe | Johnathan Doe | John Doe |
| john@company.com | john@company.com | john@company.com | |
| Phone | 555-1234 | 555-5678 | 555-1234; 555-5678 |
3.c. Merge Duplicates Automatically
When you are happy with the preview, click on "Auto-merge duplicates when possible". to Datablist will apply the merging rules across all duplicate groups.
3.d. Download Changes File
⚠️ You NEED this changes file to merge and update the records in your Pipedrive CRM.
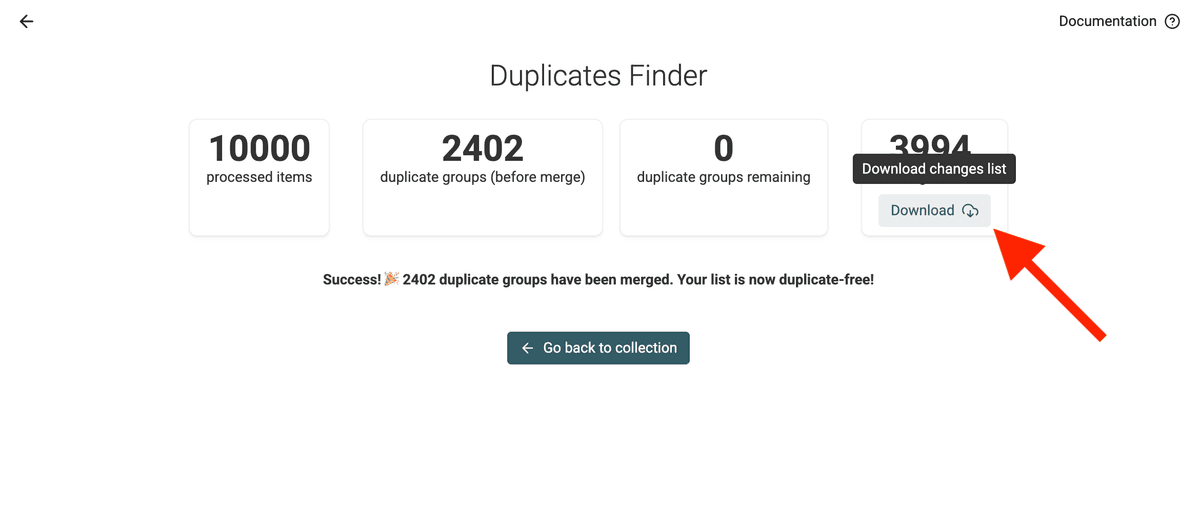
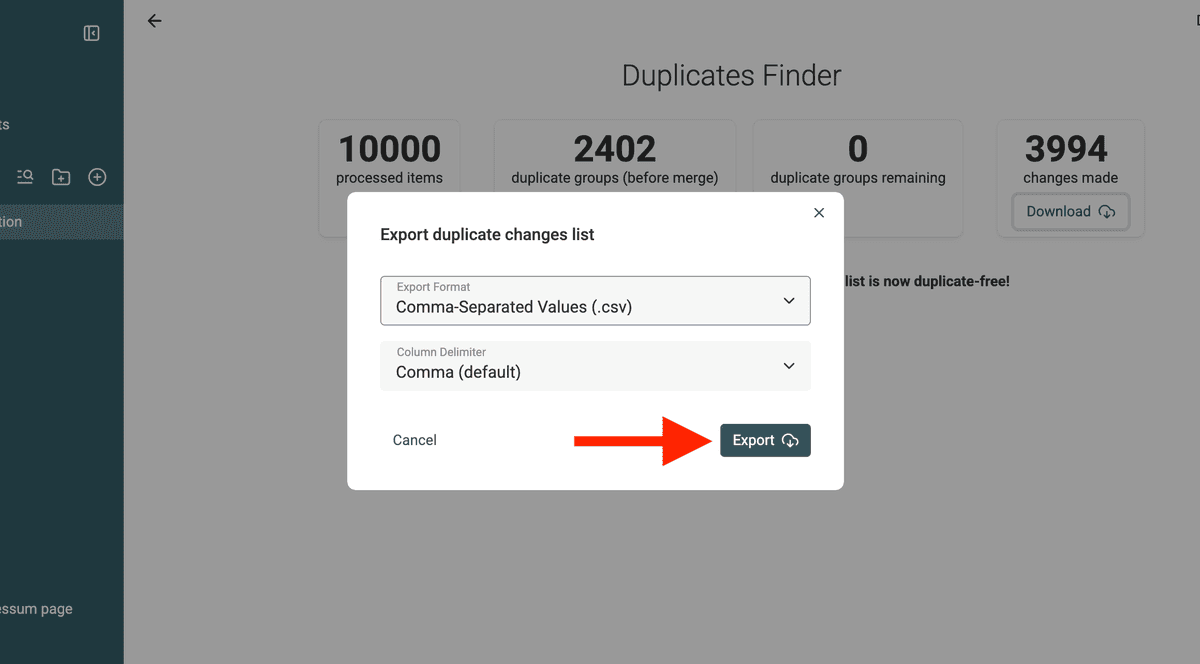
Step 3: Sync Merges in bulk back to Pipedrive
Your duplicates are now merged in Datablist. The final step is to sync the cleaned data back to Pipedrive so your CRM stays up to date.
For that, we will use the Changes File downloaded in the last step (See 4.d. Download Changes File). This file lists all merged records, deleted duplicates, and updated fields.
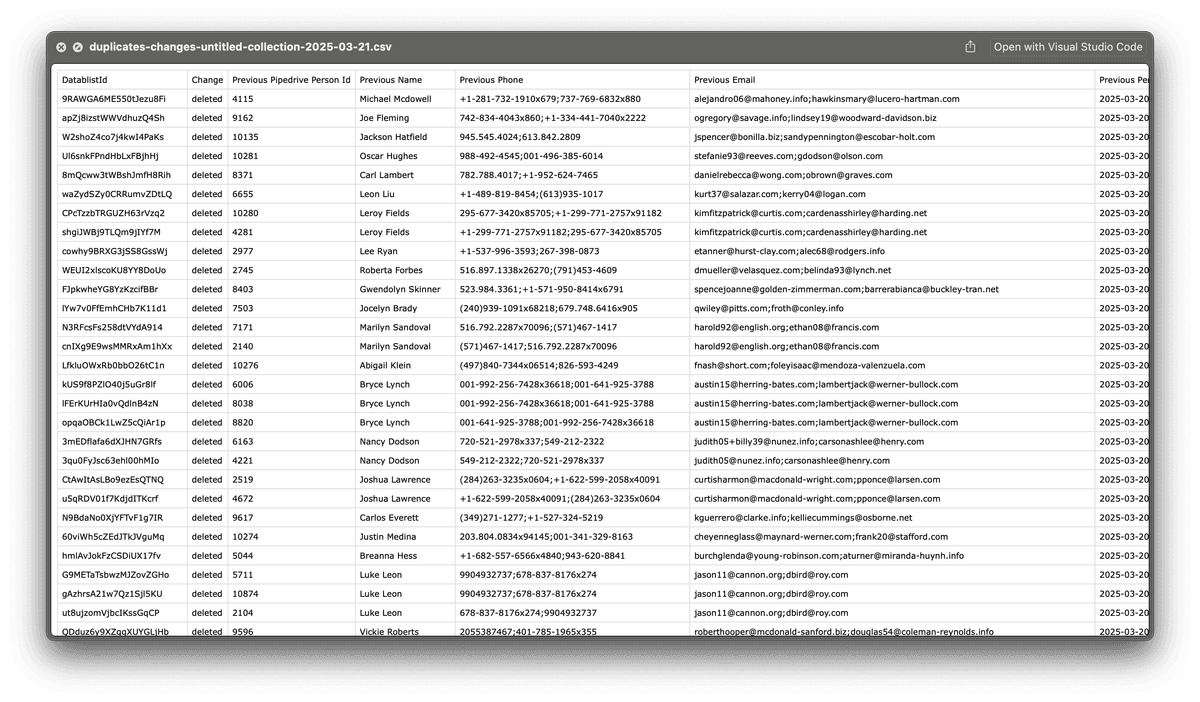
In this Changes Log file, you can see:
✅ Updated Records → Contacts or Organizations that were modified (e.g., combined emails, phone numbers, or names). With the previous data, and the new updated data.
✅ Deleted Records → Duplicate records that were merged into a master record. With the id of the record deleted and the id of the master record that replaced it. Those records need to be deleted in Pipedrive.
3.a Import the Duplicates Changes File into a new collection
To apply those changes in your Pipedrive, create a new collection, and upload the Changes File.
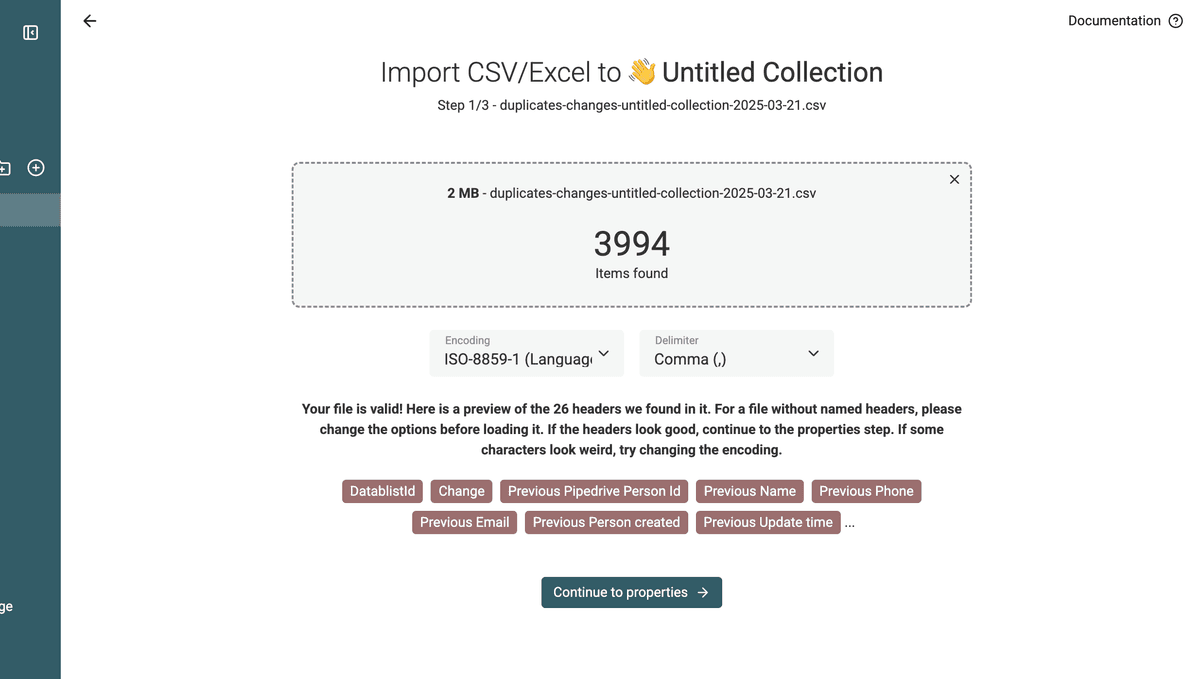
You will have a collection with the merging operations.
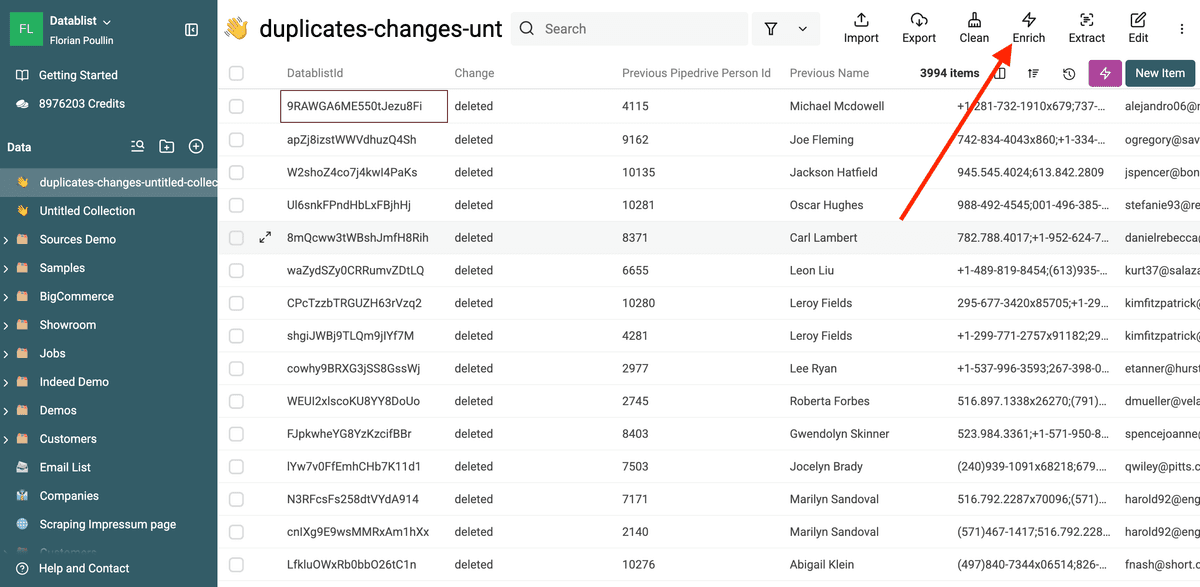
3.b. Merge and Delete Duplicate Records
The first step to apply those changes to Pipedrive is to tell Pipedrive to merge the "deleted" records into the "master" ones.
Pipedrive provides a merge API to consolidate duplicate records. We will use it.
For the technical people, here is how the Pipedrive API works:
- Use the
/organizations/:id/mergeendpoint for Organizations. - Use the
/persons/:id/mergeendpoint for People. - The duplicate record is deleted, and its data is transferred to the master record.
💡 Example API Request:
PUT https://api.pipedrive.com/v1/persons/{duplicate_id}/merge?api_token=YOUR_API_KEY
{
"merge_with_id": "{master_record_id}"
}
🔹 Why Use the Merge API?
- It ensures all linked deals, activities, and notes stay attached to the master record.
- Non-conflicting data (like extra phone numbers or emails) is automatically retained.
Don't panic - Datablist has a native enrichment that calls this Pipedrive endpoint for you.
The first step is to select only the items with a deleted change operation.
Then, in the Enrich menu, select Pipedrive Merge Duplicates.
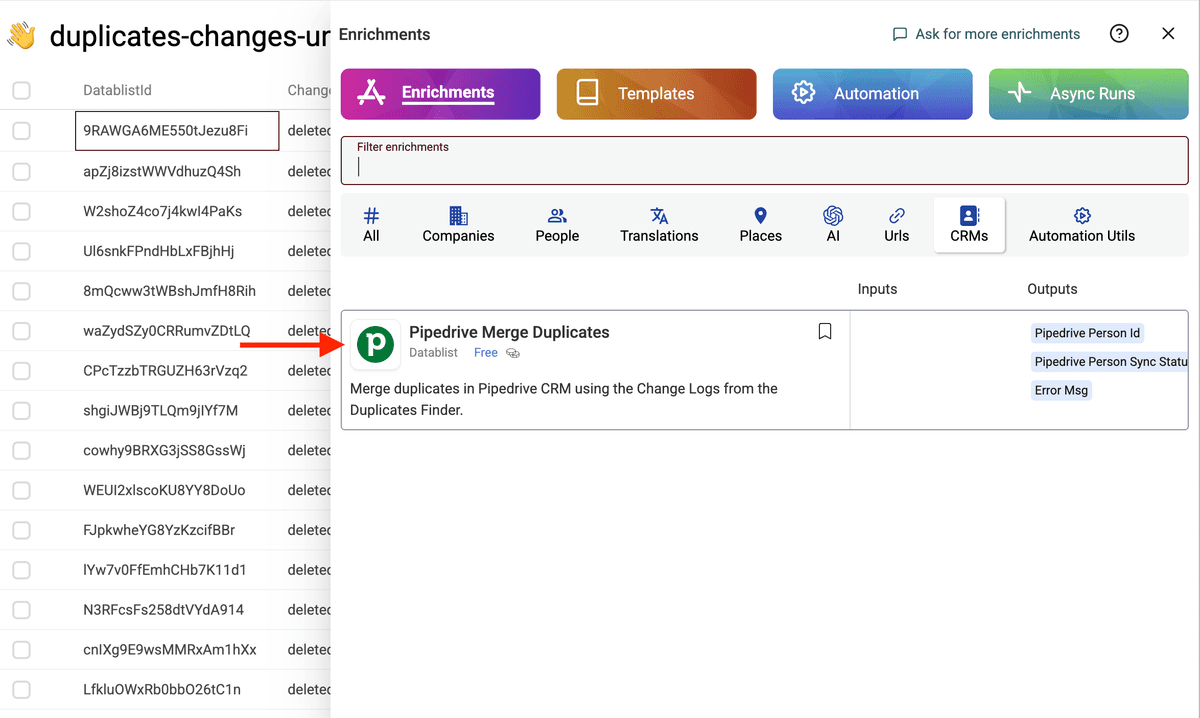
Be sure to only see "deleted" in the change column before running the Pipedrive Merge Duplicates enrichment.
Enter your Pipedrive API key, and configure the Pipedrive entity to merge.
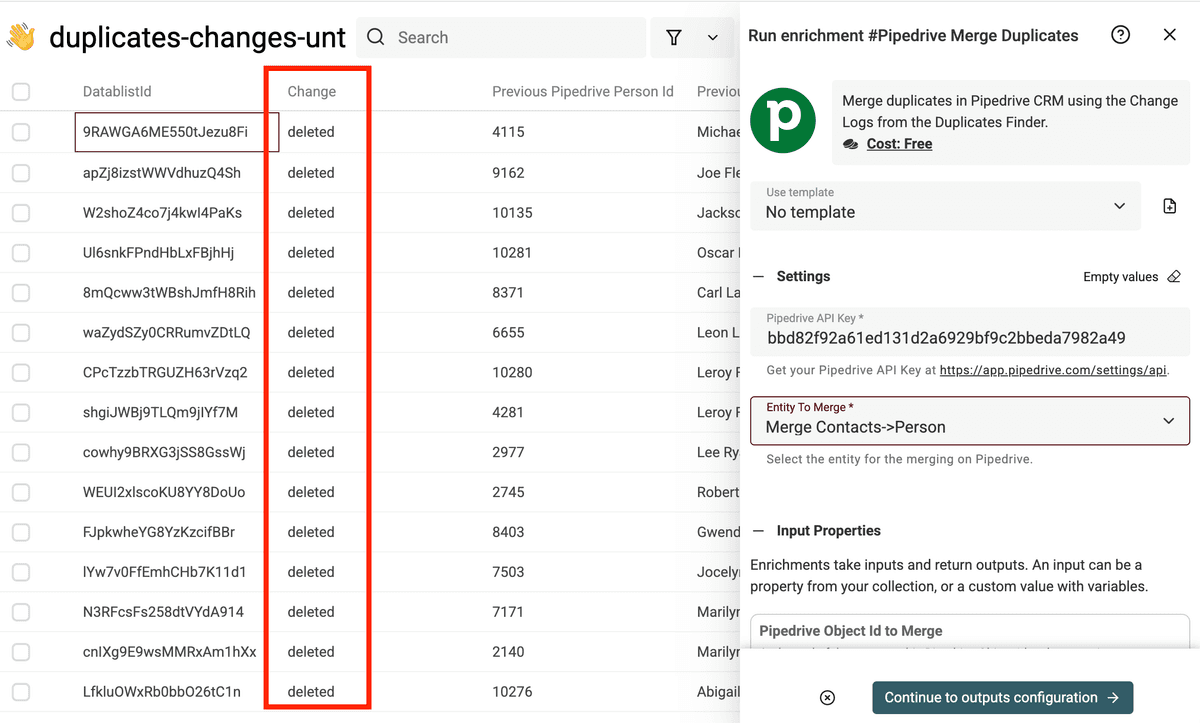
Then, in the inputs, for Pipedrive Object Id to Merge, map with the Previous Pipedrive Person Id field.
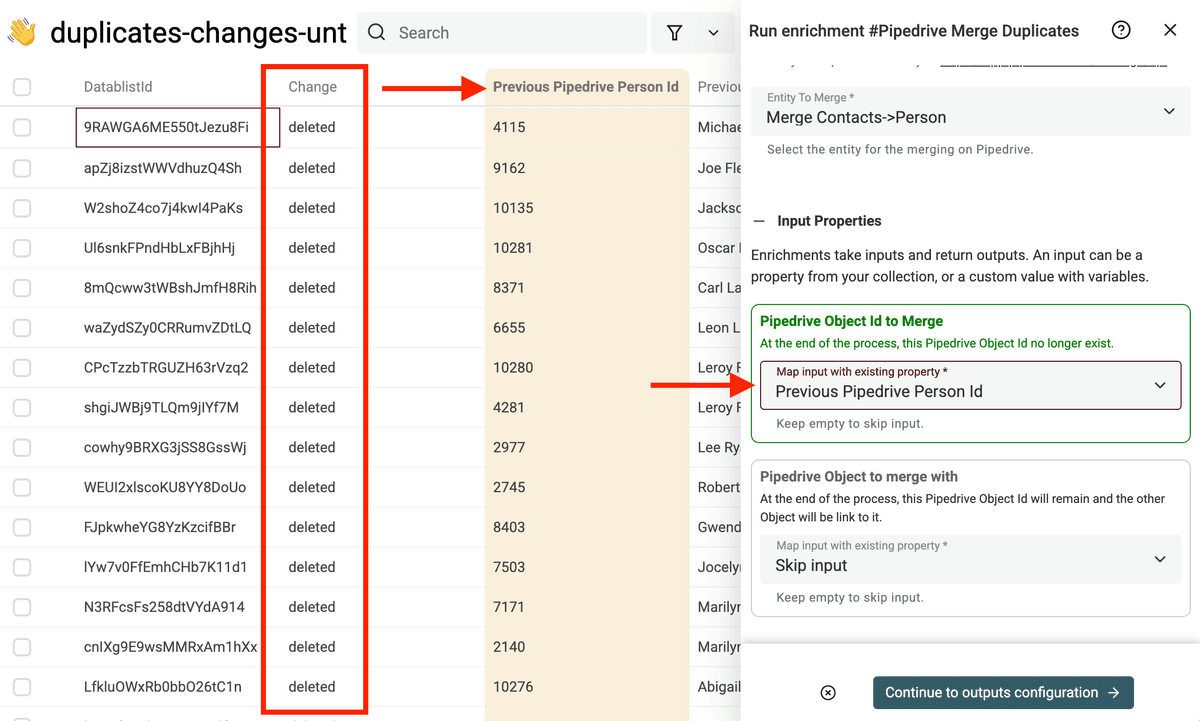
For the Pipedrive Object to merge with, map with the Destination Pipedrive Person Id field.
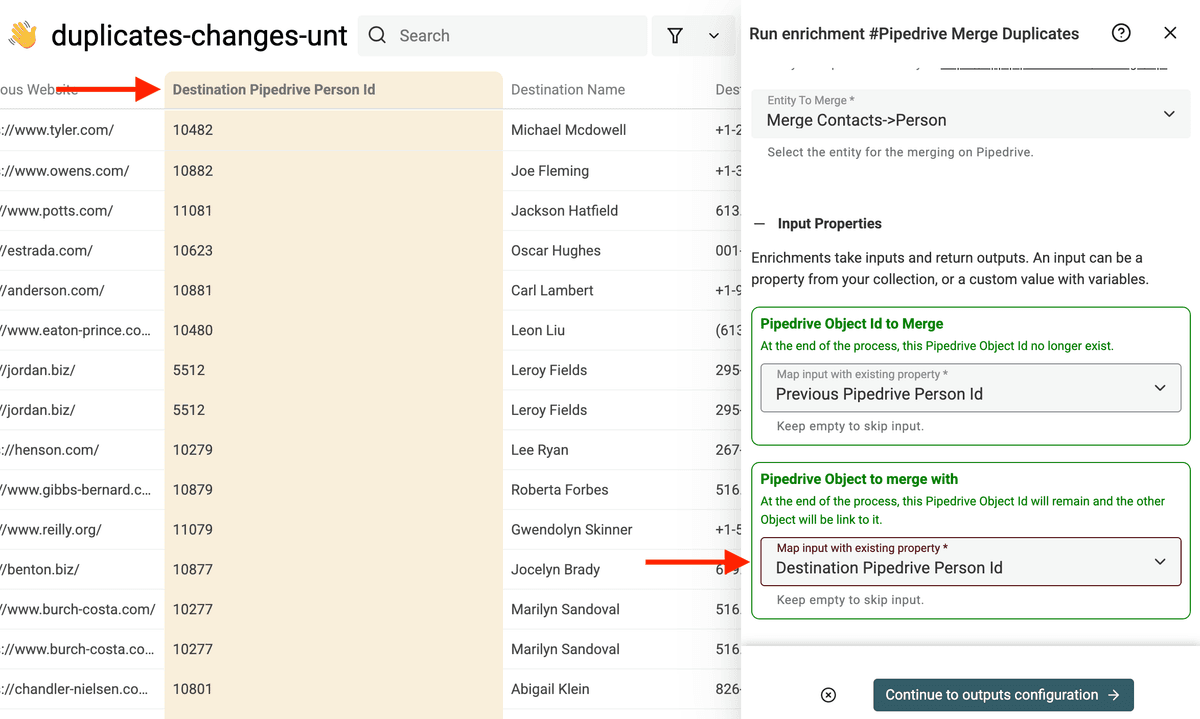
Then, start the merging process.
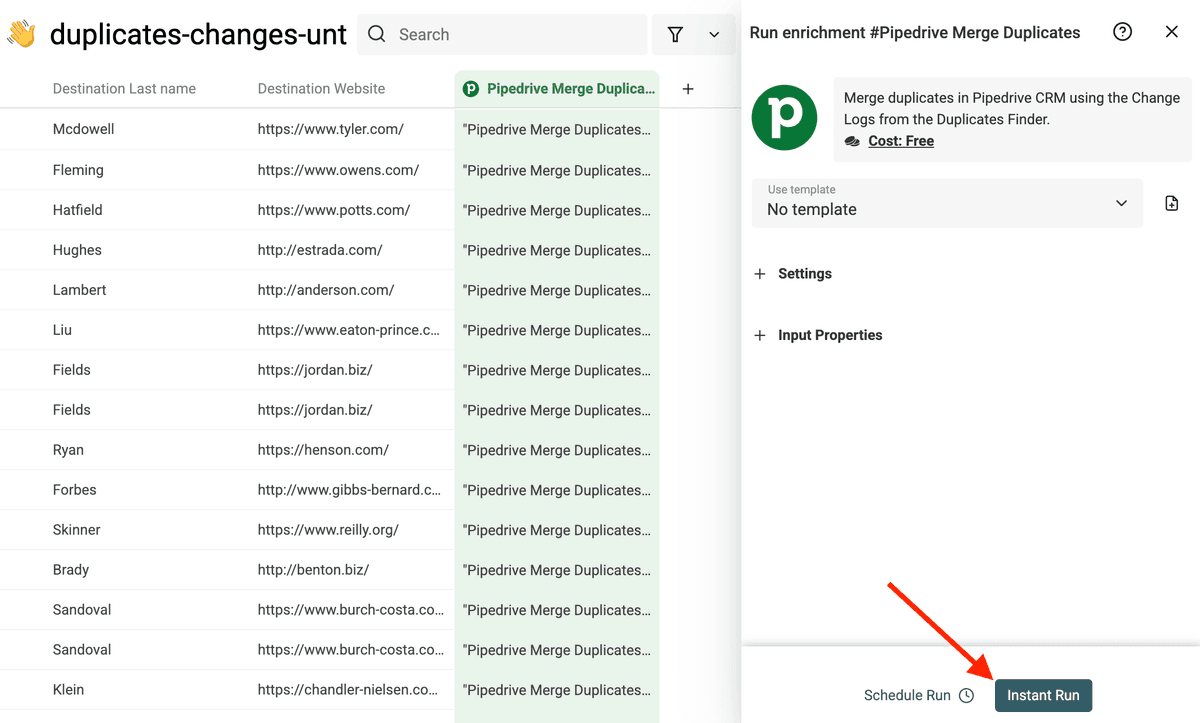
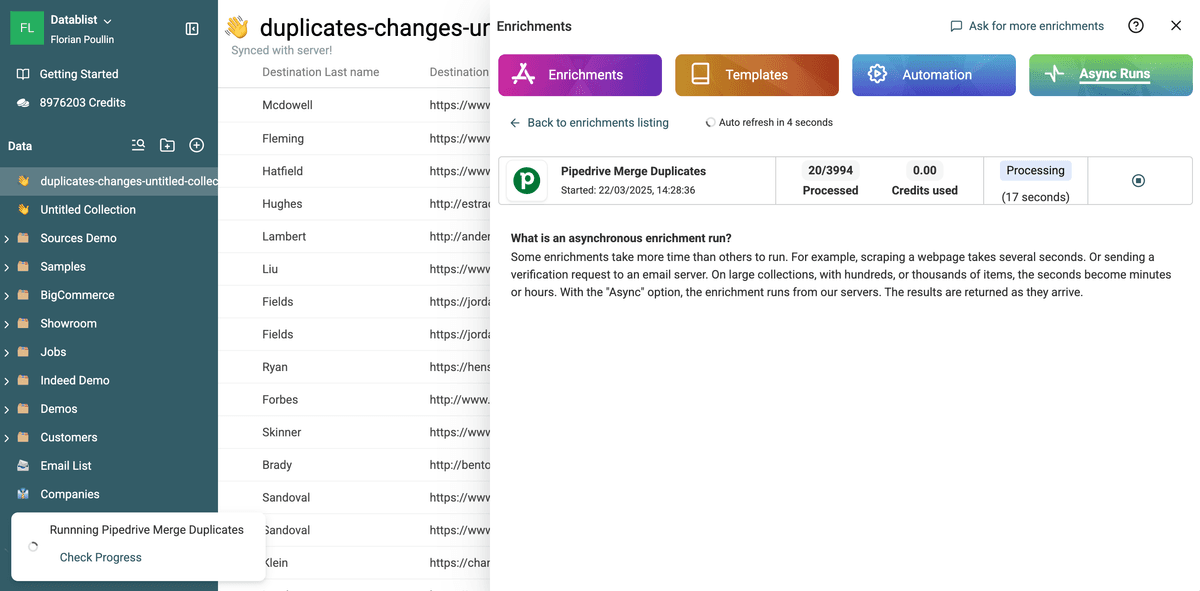
You can see the progress directly in Datablist.
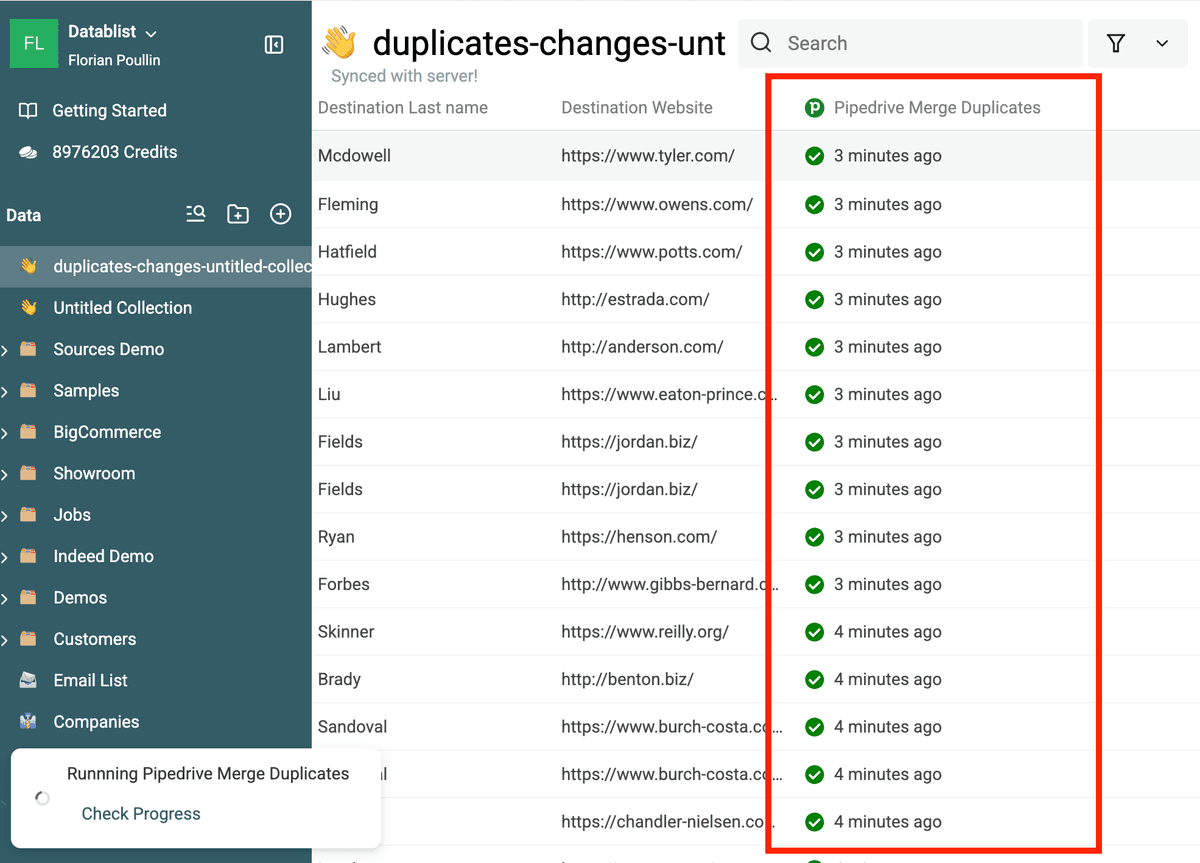
For each line in the collection, you have the status for the merging.
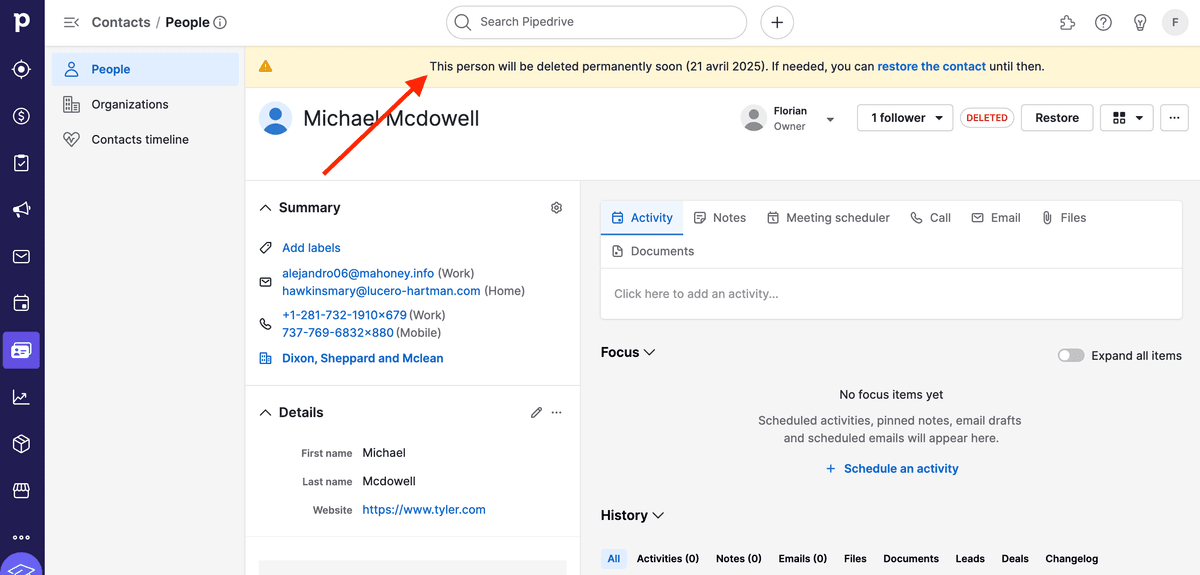
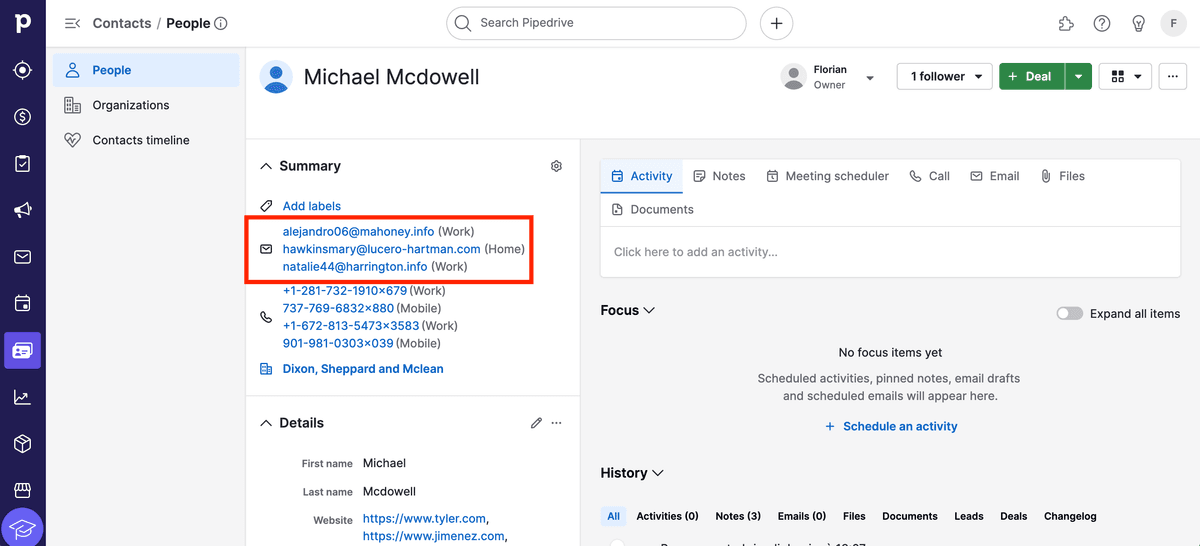
You can check the Pipedrive record that will be deleted. Go to the record (for People, the URL is https://app.pipedrive.com/person/:ID). A message will appear at the top of the screen.
In the master records, you will also see merged data.
3.c. Sync Updated Records in Pipedrive
During the previous step, we used the Pipedrive merging API to merge our duplicate records with the master one.
Unfortunately, during this merging process, Pipedrive adds the duplicate record values to the master one. You might end up with multiple similar websites, etc.
To deal with that, we will update the remaining master records with the clean data we got after the merging on Datablist.
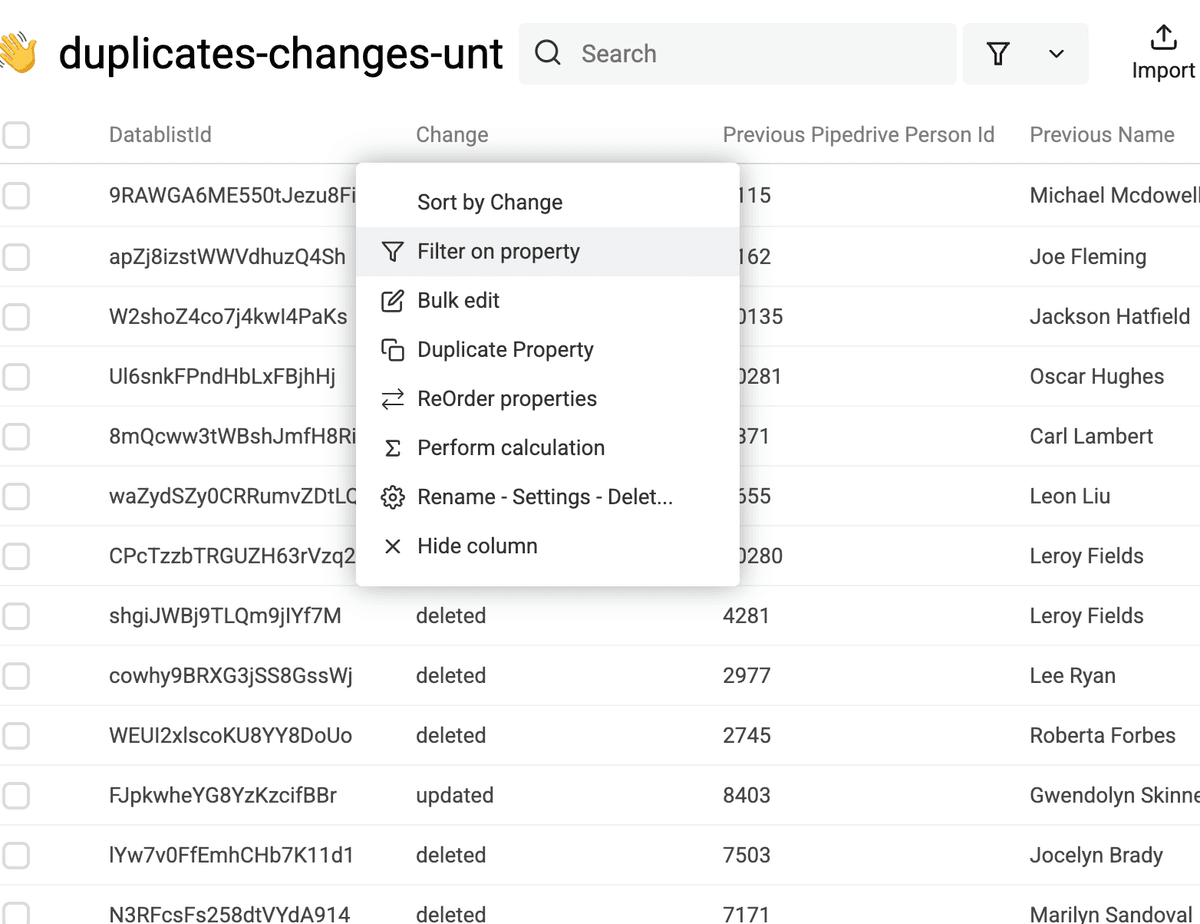
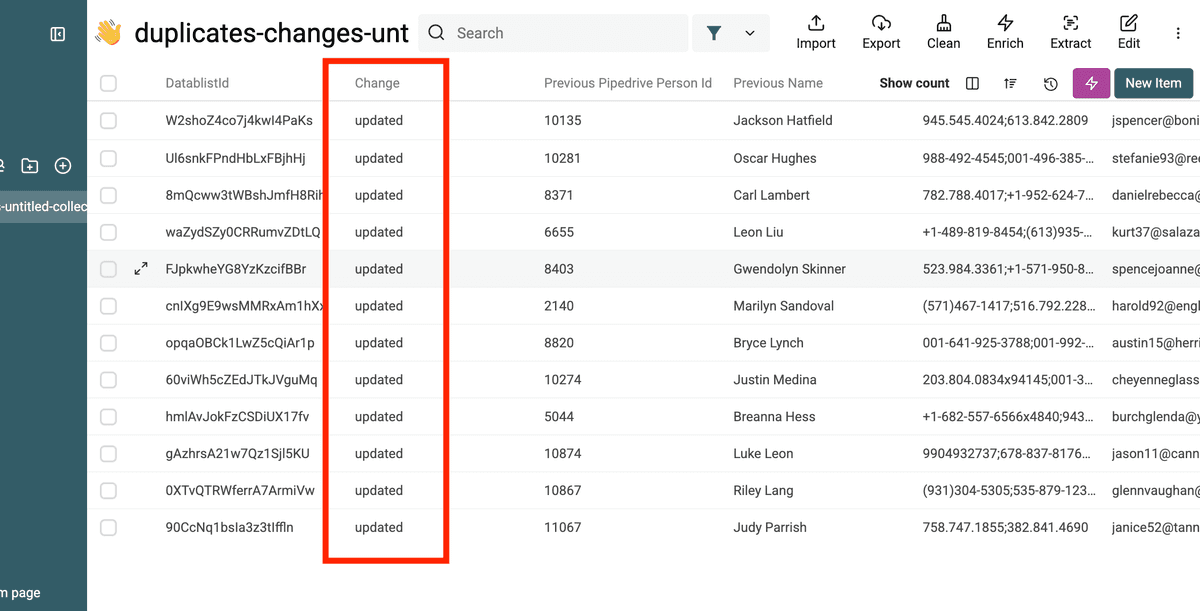
In the same "Changes File" collection, filter on the change column to see only the updated operation.
Then, click Export -> Send to external tool.
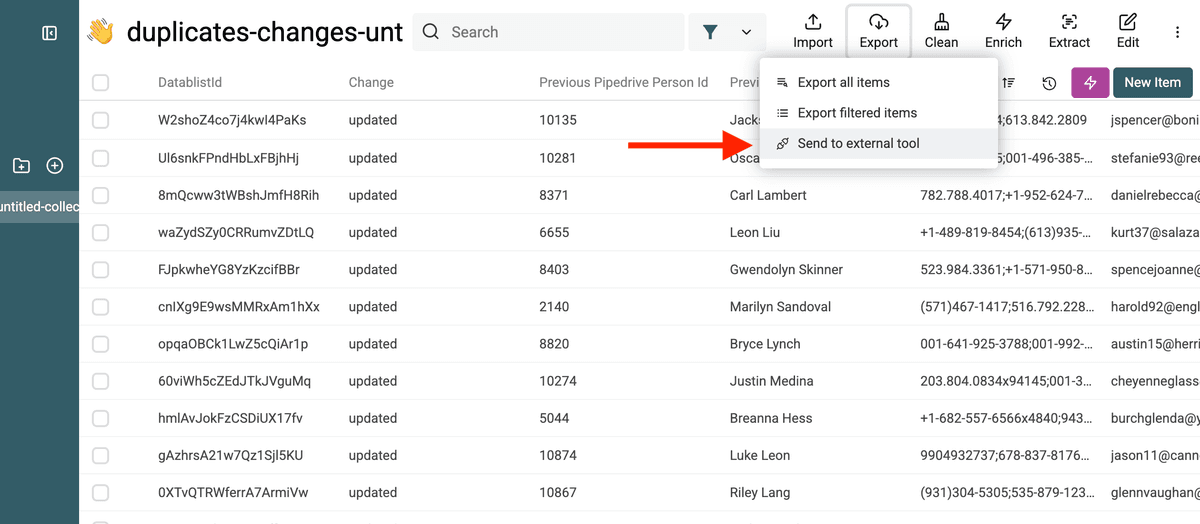
And select Sync with Persons/Organizations in Pipedrive.
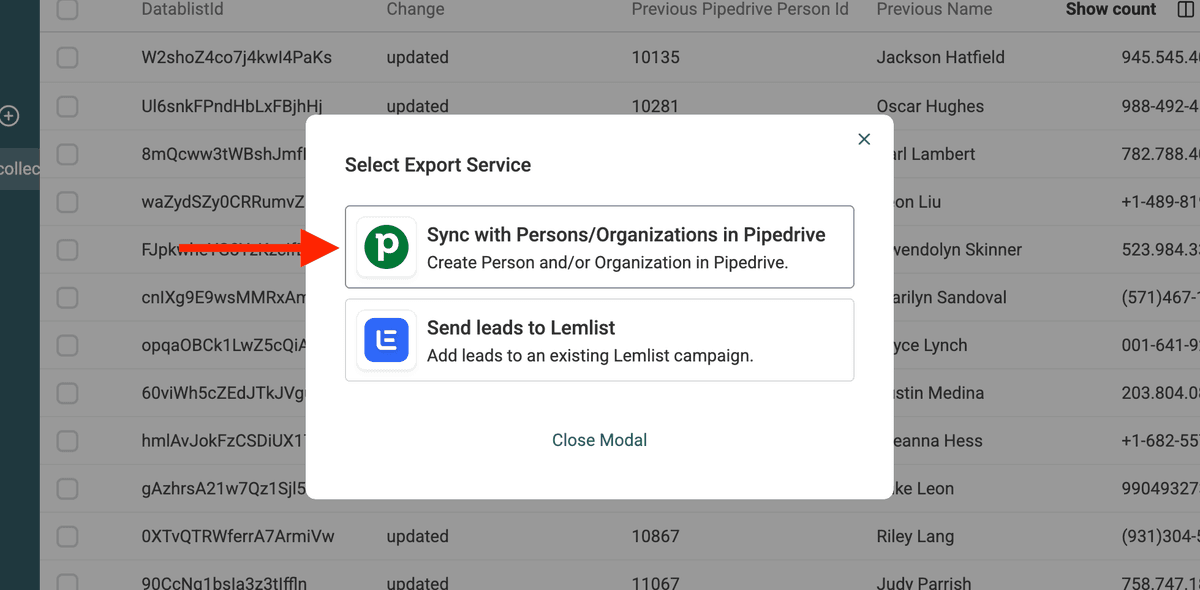
Enter your Pipedrive API Key, and select the entity you are updating (People or Organizations).
Select the ID field and the fields you want to update with clean values.
Important - You must select the
IDfield to update the data, and not create new records.
In this example, I will only update the website field. So I select ID and Website.
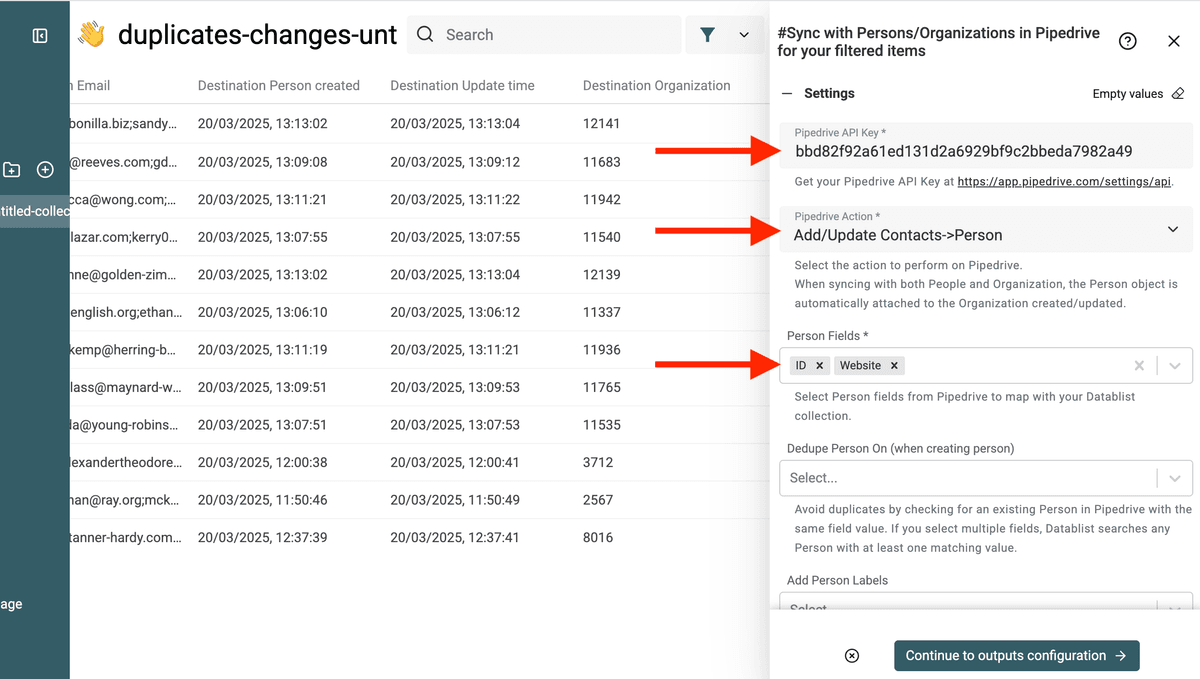
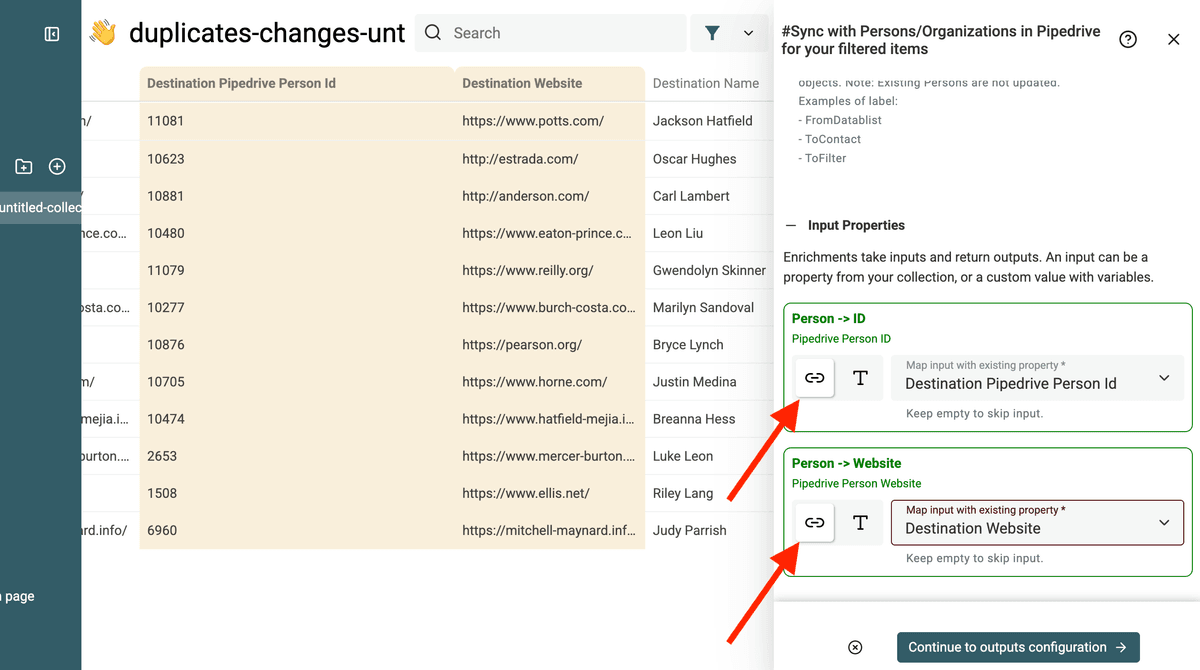
In the Inputs sections, map with the Destination XX fields.
Configure the outputs to have the status of the update.
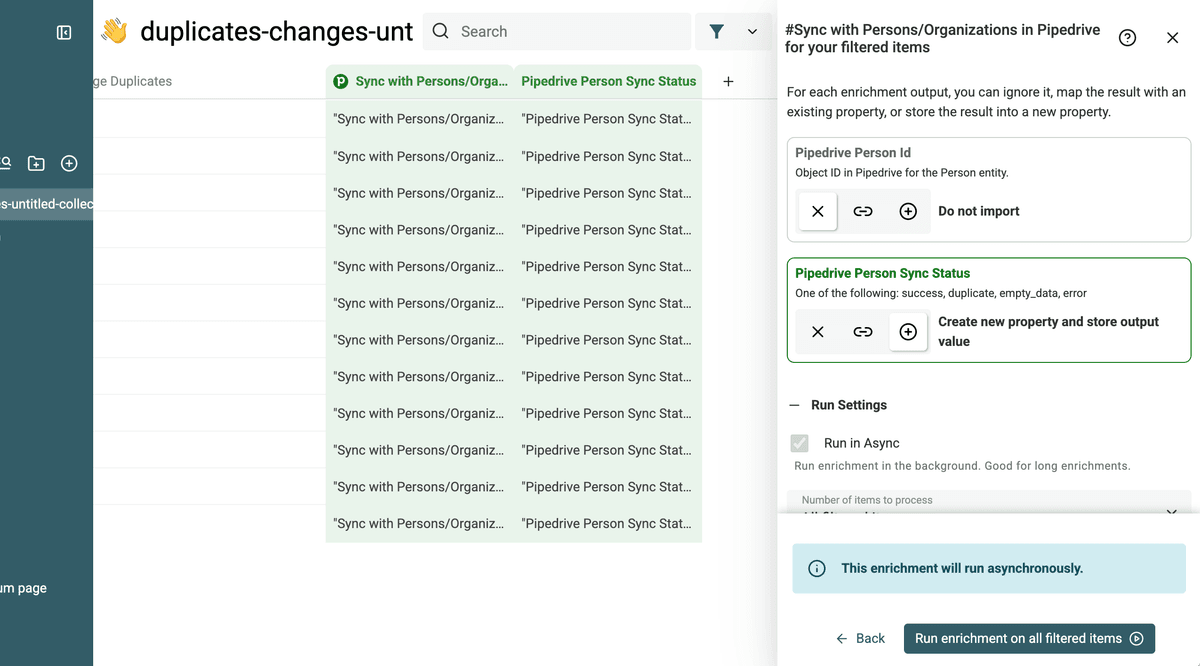
Then run the process.
You can check the result by going in the Changelog listing in your Pipedrive record.
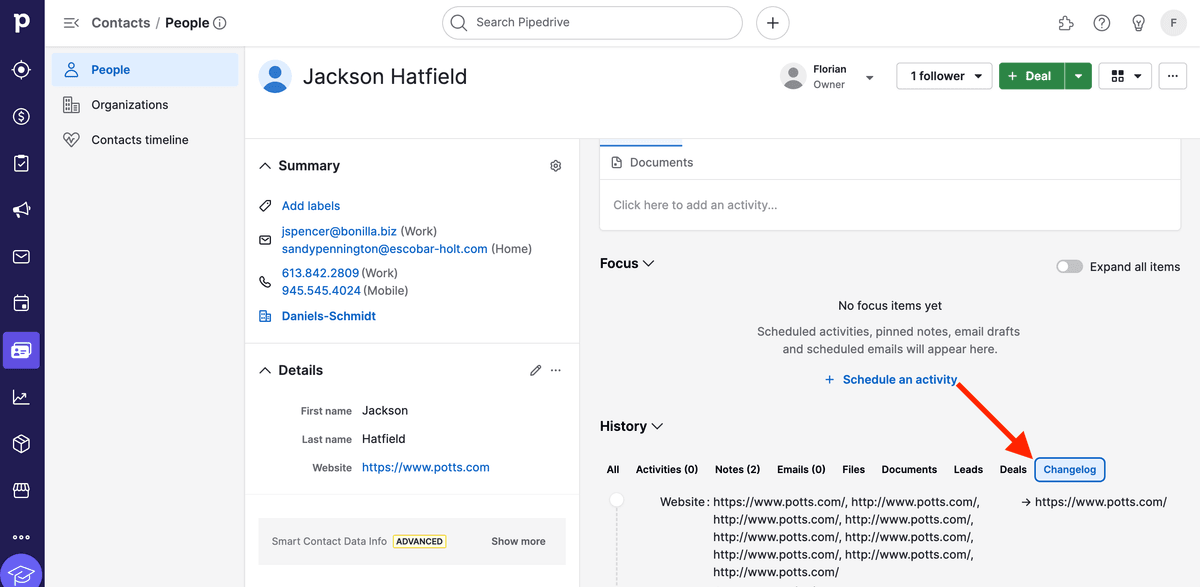
3.d. Done! Your Pipedrive CRM is Now Clean
That’s it! You’ve successfully:
✅ Imported data into Datablist.
✅ Found and merged duplicates with smart algorithms.
✅ Synced the cleaned data back to Pipedrive.
Your CRM is now deduped and organized, making it easier to manage your sales and contacts. 🚀
Pipedrive Built-in Merge Duplicates Limitations
Pipedrive offers a basic deduplication tool, but it has serious limitations that can leave your CRM cluttered with duplicates. Here’s why Datablist is the better solution:
1. Pipedrive Only Finds Exact Matches
Pipedrive’s duplicate detection is too strict. It only matches records with identical names. This means:
- "Google LLC" and "Google" won’t be flagged as duplicates.
- Emails, phone numbers, or websites aren’t considered for deduplication.
✅ Datablist Advantage: Uses fuzzy matching to catch duplicates even when names, emails, or websites are slightly different.
2. No Bulk Merging in Pipedrive
Pipedrive forces you to merge duplicates one by one, which is time-consuming if you have hundreds of duplicates.
✅ Datablist Advantage: Bulk merging with full control over how fields are combined, ensuring clean and complete data.
3. No Control Over Merging Rules
When merging in Pipedrive:
- You can’t choose which fields to keep or combine.
- Some data might get lost if the system picks the wrong master record.
✅ Datablist Advantage: Define custom merging rules, combine multiple values, and ensure no important data is lost.
4. No Merge History or Change Log
Pipedrive doesn’t track what was merged or which records were deleted. If a mistake happens, there’s no undo.
✅ Datablist Advantage: Change Log keeps track of every merge, so you always know what changed.
Pipedrive is great for managing sales, but when it comes to deduplication, Datablist is the smarter choice. Try it today and clean up your CRM effortlessly! 🚀