Scrapes agency listings from Clutch.co including company names, ratings, services, pricing, and profile links
Jak używać tego AI promptu
- Utwórz nową kolekcję: Zacznij od utworzenia nowej, pustej kolekcji w Datablist, w której zostaną zapisane dane. Kliknij „+ Create new collection” w panelu bocznym.
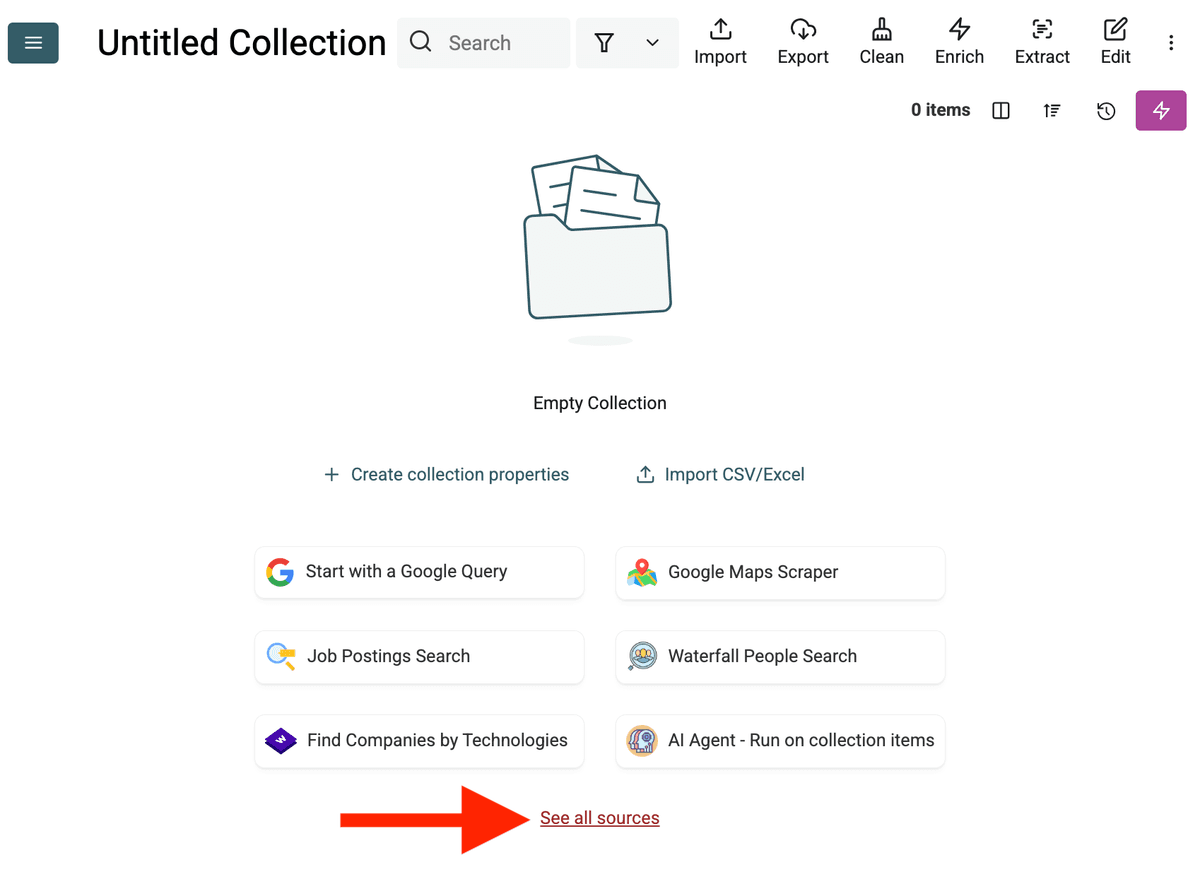
- Wybierz źródło AI Agent: Kliknij „See all sources” lub przejdź do „Import” -> „Import From Data Sources”. Wybierz „AI Agent - Site Scraper”.
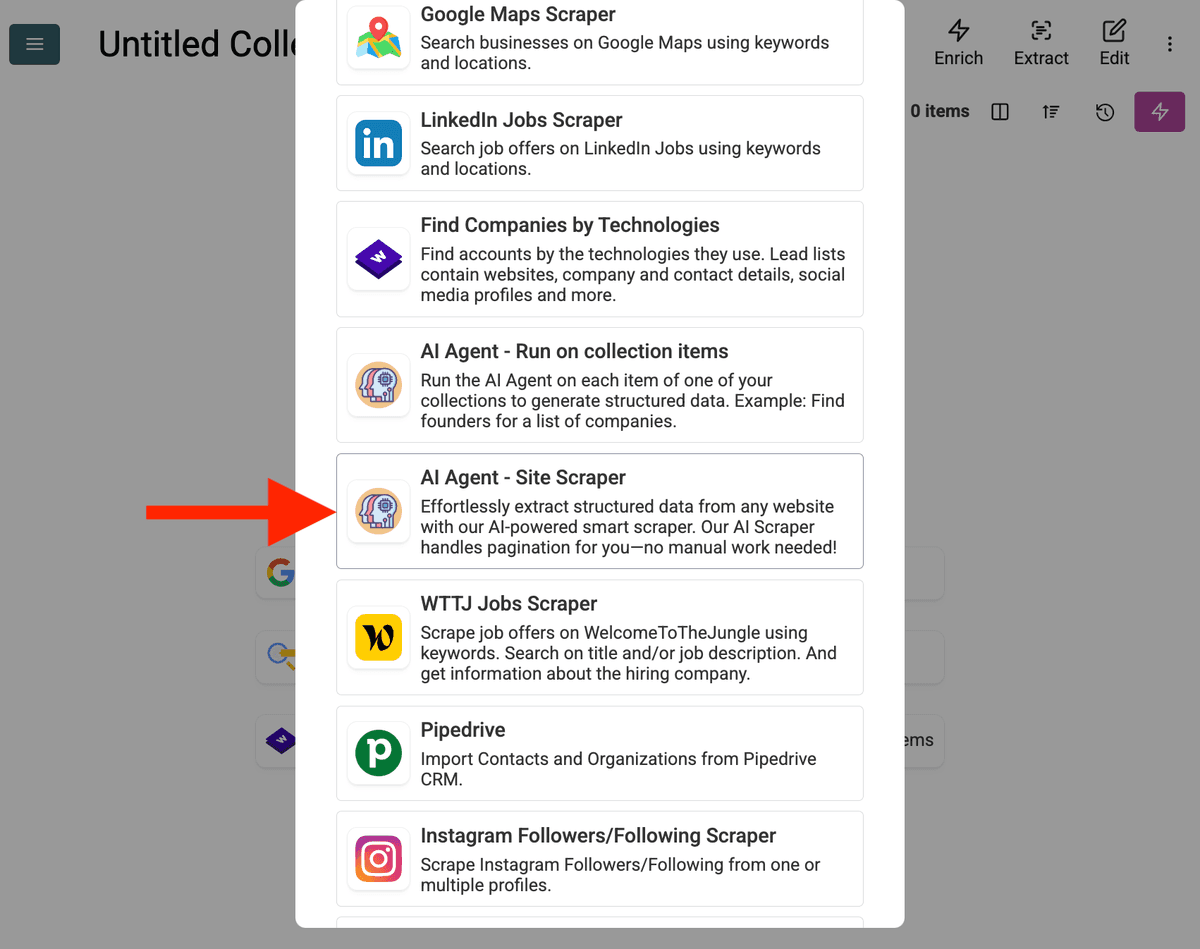
-
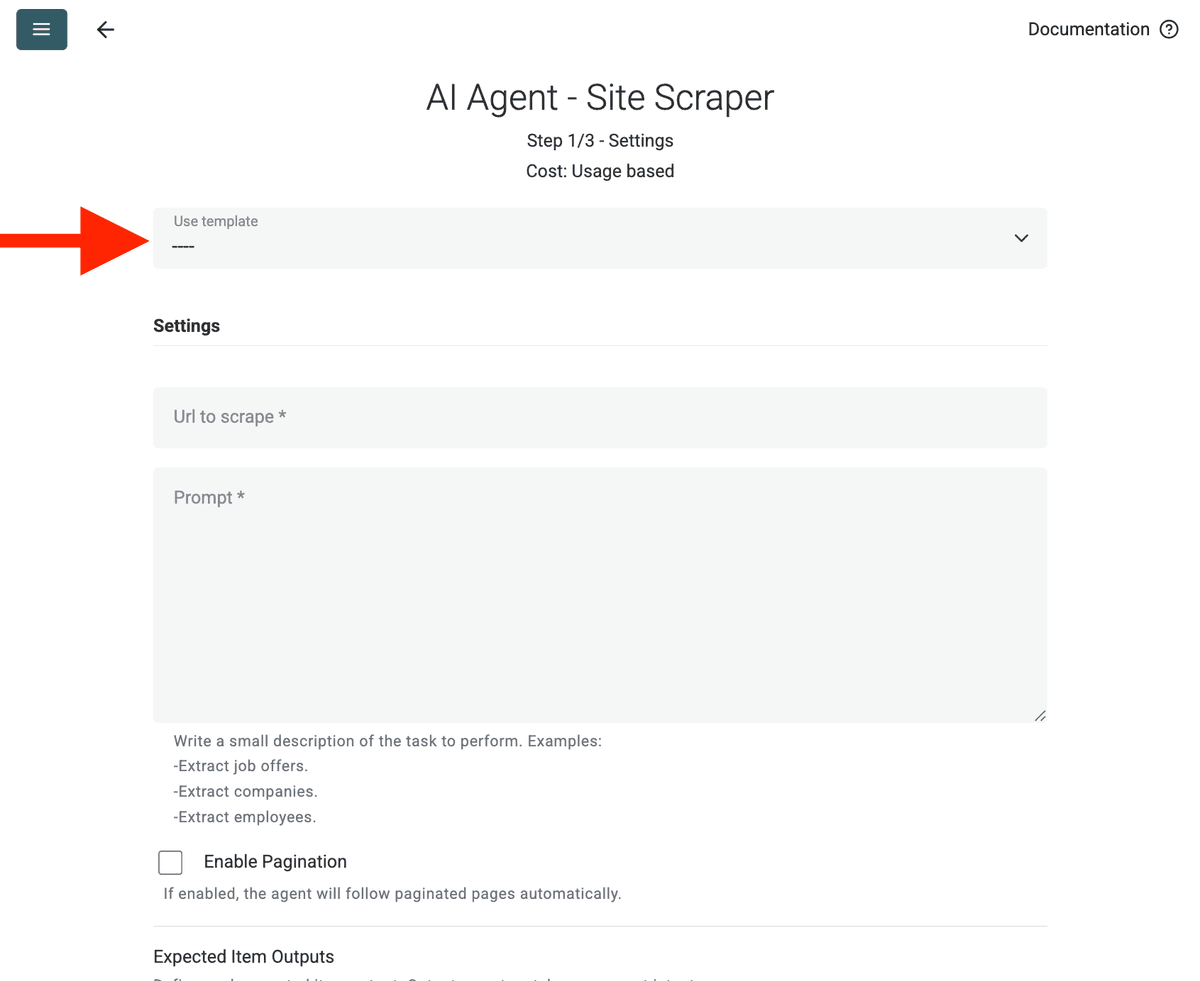
Skonfiguruj źródło:
- Select Template: Znajdź i wybierz prompt z listy „Template”. Powyższy prompt zostanie załadowany automatycznie.
- URL to Scrape: Wprowadź URL do scrapingu
- Enable Pagination (Optional): Jeśli wyniki są na kilku stronach, zaznacz Enable Pagination i ustaw rozsądny limit Max Pages (np. 10).
- Customize (Optional): Możesz dopasować model AI (np. GPT-4o mini bywa korzystny kosztowo), edytować prompt pod konkretne potrzeby lub zmienić oczekiwane Outputs.
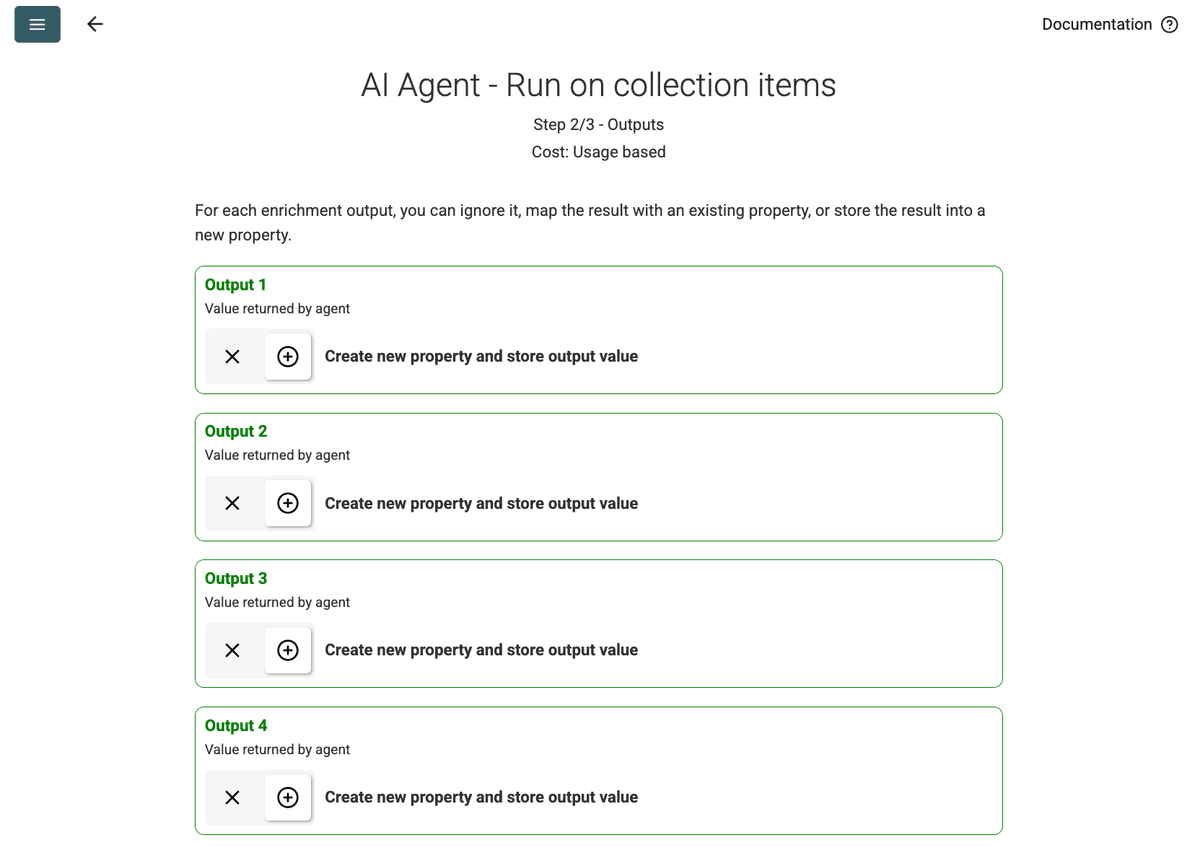
- Review Outputs: Kliknij Continue. Datablist pokaże pola wyjściowe zdefiniowane w prompt (Project Name, Client Company Name). Kliknij ikonę + obok każdego, aby utworzyć odpowiednie właściwości (kolumny) w Twojej kolekcji.
- Run Import: Kliknij Run import now. AI Agent rozpocznie scraping strony zgodnie z promptem i zapełni Twoją kolekcję.
Cennik
To źródło danych korzysta z kredytów Datablist w modelu rozliczeń za użycie. Koszt zależy od złożoności strony i liczby odwiedzonych stron.
Przetestuj uruchomienie AI Agent najpierw na pojedynczej stronie, aby oszacować koszt.
FAQ
Jak uruchomić kolejne zadanie z tą samą konfiguracją?
Po uruchomieniu AI Agent kliknij różowy przycisk w prawym górnym rogu tabeli danych, aby otworzyć go ponownie z ostatnimi ustawieniami.
Co się stanie, jeśli AI Agent spróbuje uzyskać dostęp do chronionej strony lub zostanie zablokowany?
AI Agent automatycznie używa serwerów proxy, gdy to konieczne, aby dotrzeć do stron z zabezpieczeniami przed scrapingiem lub ograniczeniami geograficznymi. Zwiększa to szanse na skuteczną ekstrakcję danych, choć bardzo silnie chronione witryny nadal mogą stanowić wyzwanie.
Ile danych mogę przetworzyć za pomocą AI Agent?
Podczas uruchamiania AI Agent (zarówno jako wzbogacenie, jak i źródło danych) kolekcje Datablist mogą przetwarzać do 100 000 elementów (wierszy). W przypadku większych zbiorów danych możesz potrzebować podzielić je na kilka kolekcji.
Czym AI Agent różni się od wzbogaceń ChatGPT/Claude/Gemini?
Standardowe wzbogacenia AI (ChatGPT, Claude, Gemini) przetwarzają dane już znajdujące się w Twojej kolekcji, korzystając z istniejącej wiedzy AI. AI Agent potrafi aktywnie działać w sieci — wykonywać wyszukiwania w Google, przeglądać strony i pozyskiwać nowe informacje na podstawie Twojego promptu.
Jak dokładne są wyniki?
Dokładność w dużej mierze zależy od klarowności i precyzji Twojego promptu oraz złożoności zadania i dostępności informacji online. Dostarczenie jasnych instrukcji, przykładów i zasad obsługi błędów poprawia wyniki. Datablist często podaje ocenę pewności (confidence score) dla wyników AI Agent, aby pomóc ocenić wiarygodność.