Bezpłatne usuwanie duplikatów

Czym jest deduplikacja danych?
Deduplikacja danych, czyli deduping, to proces usuwania zduplikowanych rekordów z zestawu danych.
Deduplikacja jest konieczna, aby mieć listę unikalnych wpisów. W marketingu z listami mailingowymi, w lead generation lub zarządzaniu klientami. Albo w e‑commerce przy zarządzaniu katalogami produktów. Dwa wpisy są duplikatami, gdy odnoszą się do tej samej jednostki. Dwa leads z tym samym adresem email, lub dwa produkty z tym samym kodem kreskowym.
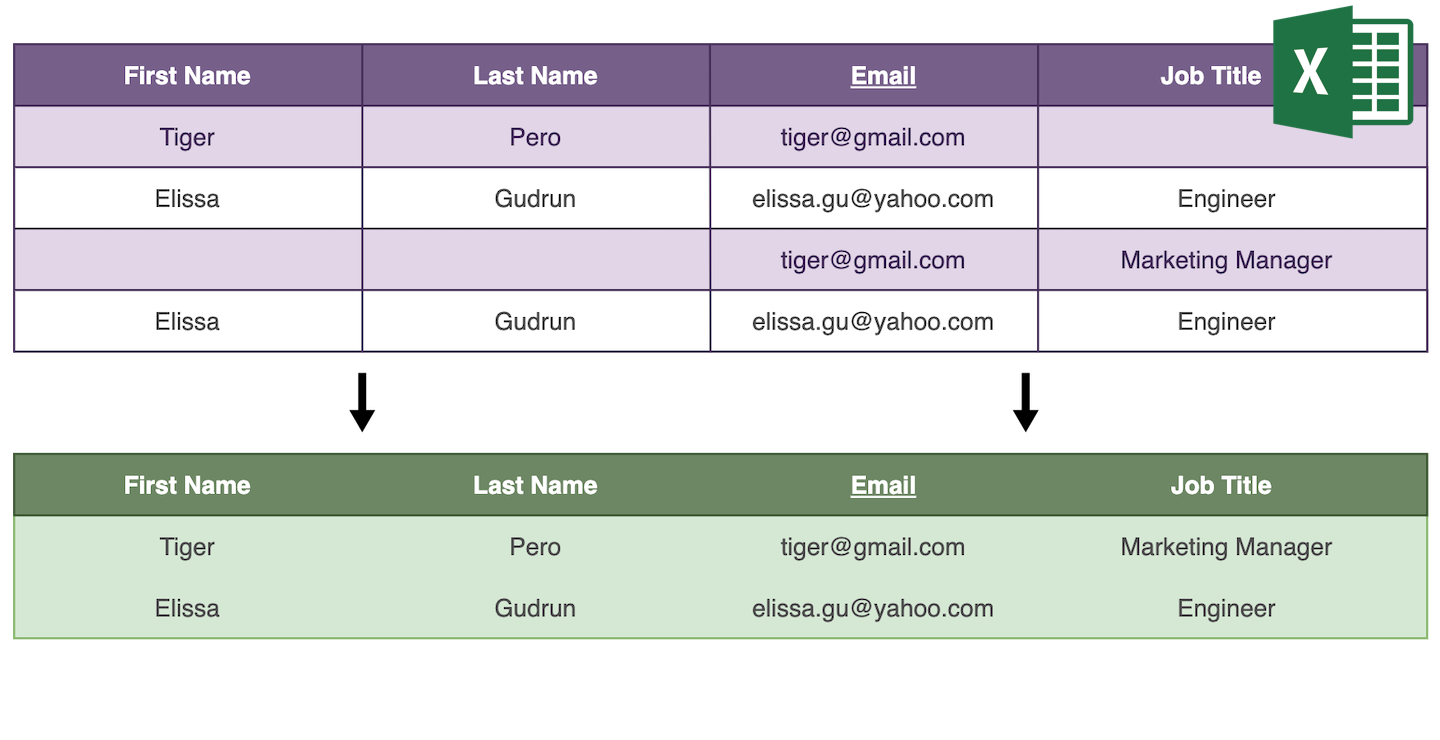
Duplikaty wpływają na jakość danych i obniżają produktywność. Istnieją dwa sposoby, aby się ich pozbyć: usunąć je lub scalić podobne wpisy w jeden.
Usuwanie duplikatów jest proste — algorytm deduplikacji znajduje zduplikowane wpisy i usuwa wszystkie poza jednym rekordem. Scalanie duplikatów wymaga analizy zduplikowanych wpisów, aby je połączyć w jeden rekord nadrzędny.


















Pełna lub częściowa analiza elementów – w jednej lub wielu kolekcjach
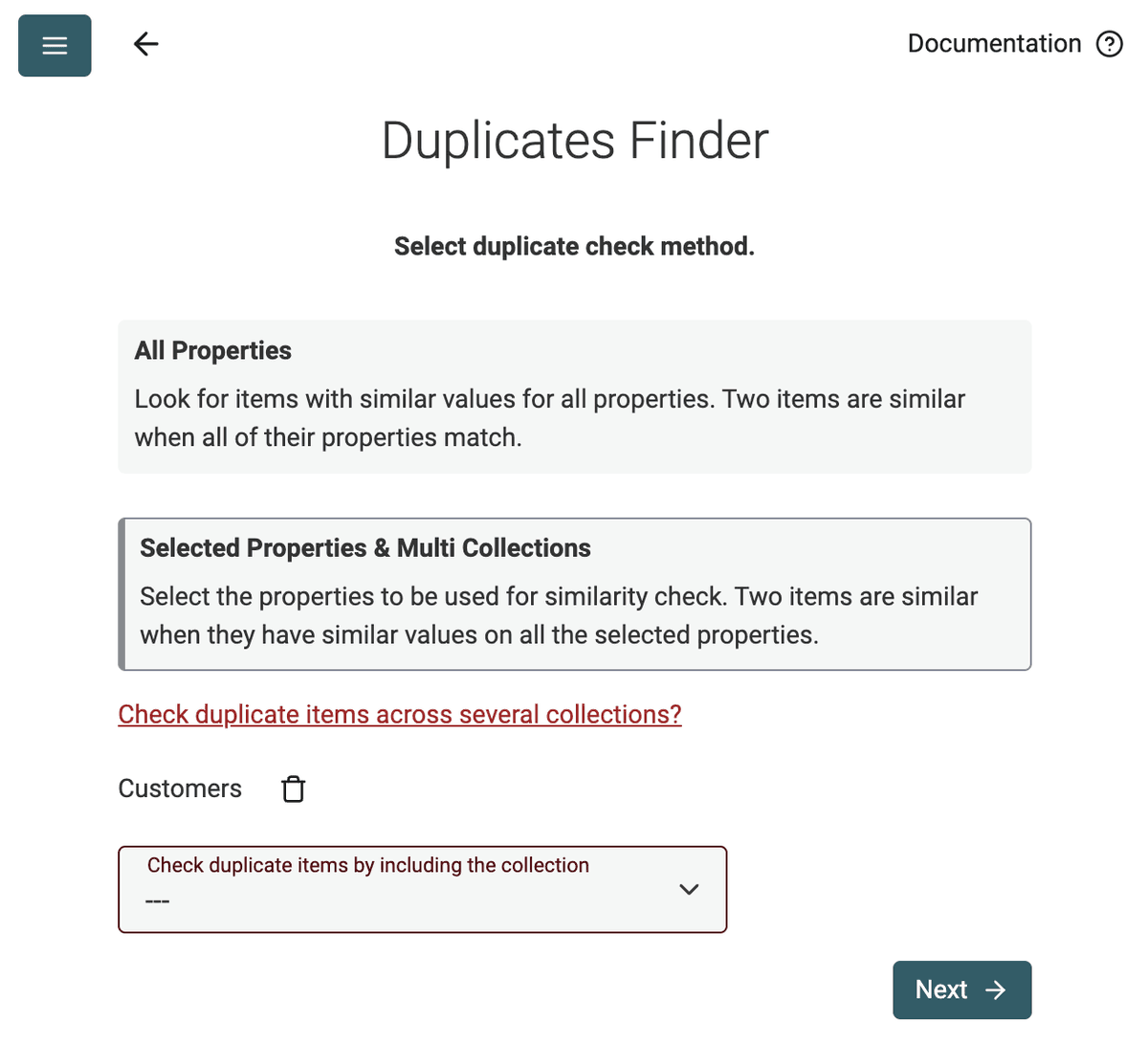
Datablist Duplicates Finder działa zarówno z pełnym porównaniem elementów, jak i na wybranych właściwościach.
Użyj trybu Selected Properties, aby znaleźć zduplikowane kontakty na podstawie ich adresu email lub wykryć duplikaty na liście firm przy użyciu adresu URL ich strony.
Usuwaj lub konsoliduj duplikaty

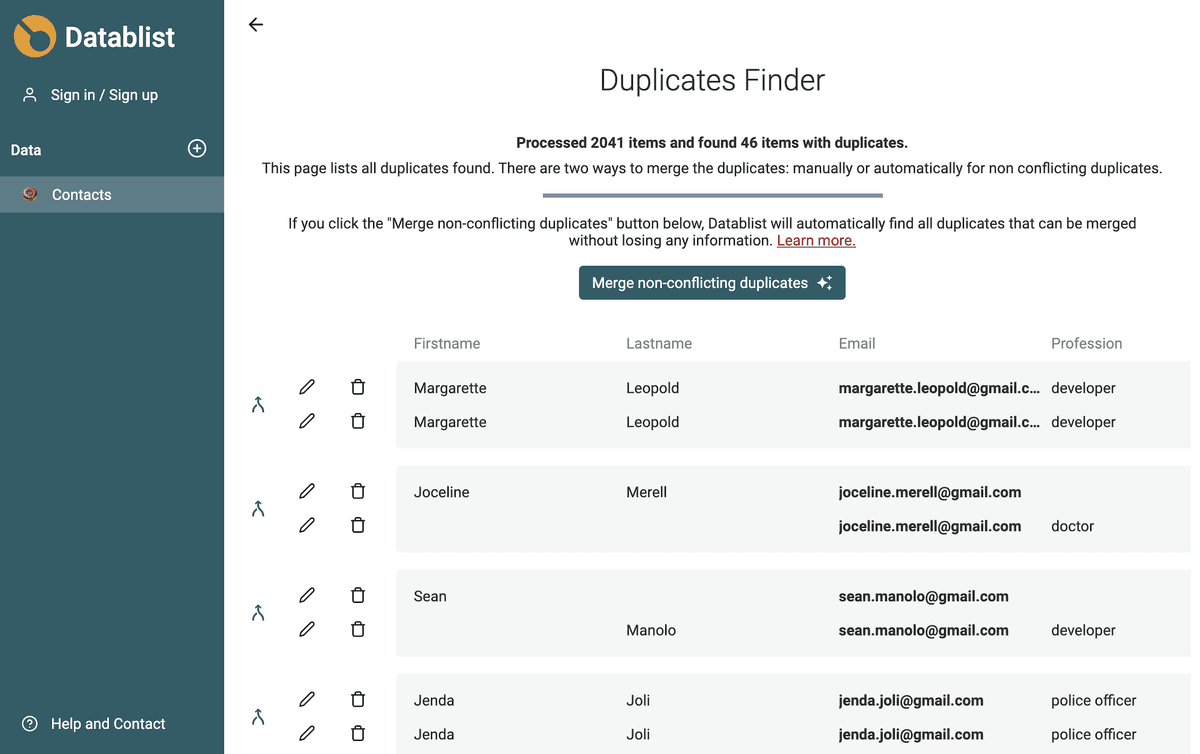
Automatyczne scalanie niekonfliktowych duplikatów
Datablist automatycznie znajduje wszystkie duplikaty, które można scalić bez utraty informacji.
- Gdy wszystkie zduplikowane elementy mają takie same wartości pól, zachowywany jest tylko jeden element, a pozostałe są usuwane.
- Jeśli zduplikowane elementy się uzupełniają, element z największą liczbą informacji jest wybierany jako główny, a jego wartości pól są uzupełniane danymi z pozostałych elementów. Następnie wszystkie elementy poza głównym są usuwane.
- Jeśli zduplikowane elementy mają sprzeczne wartości pól, są pomijane i kierowane do ręcznego scalania.
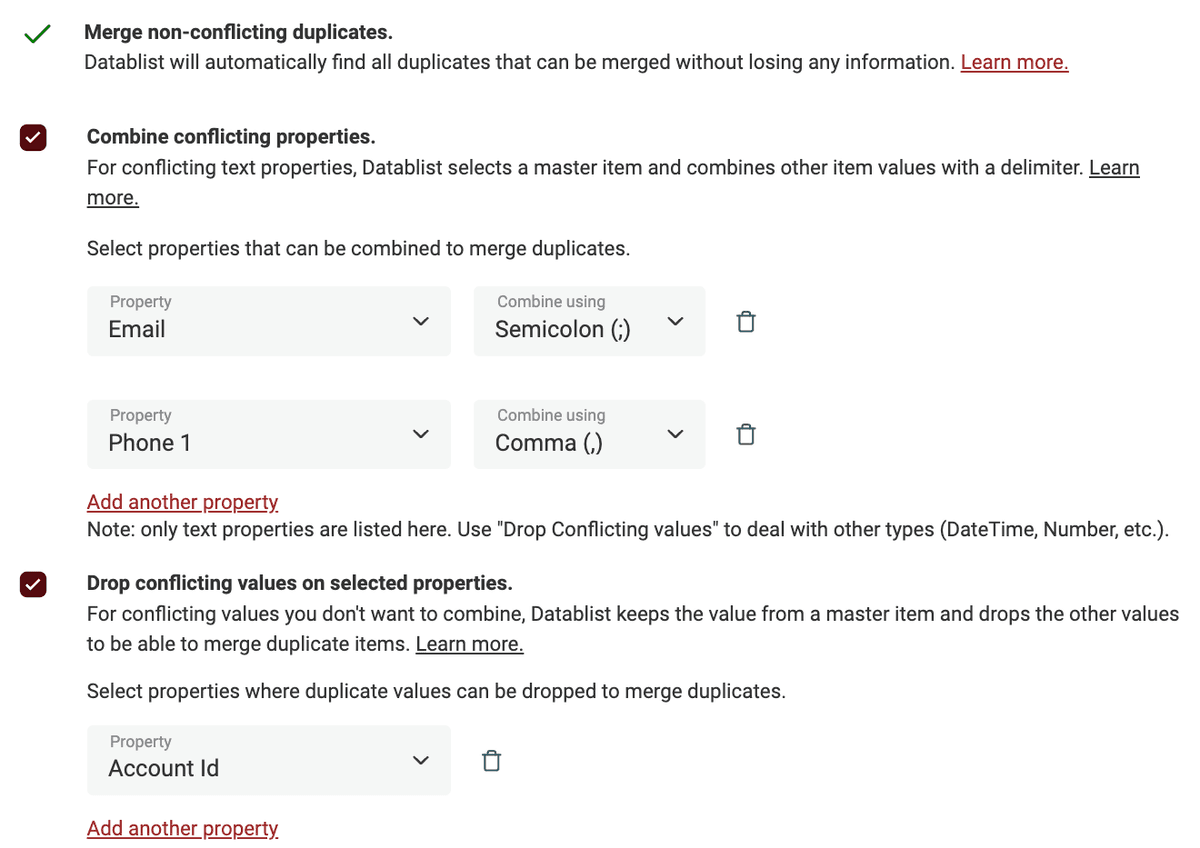
Konsoliduj duplikaty, aby zachować jeden rekord
Gdy proste scalanie nie wystarcza, skorzystaj z funkcji zaawansowanych: łącz lub odrzucaj duplikujące się wartości, aby skonsolidować swoje zduplikowane rekordy.
Datablist wyświetla pola w konflikcie i pozwala wybrać, jak sobie z nimi poradzić. Użyj Combine values do konkatenacji danych. A Drop values, aby zachować wartość z jednego rekordu nadrzędnego.
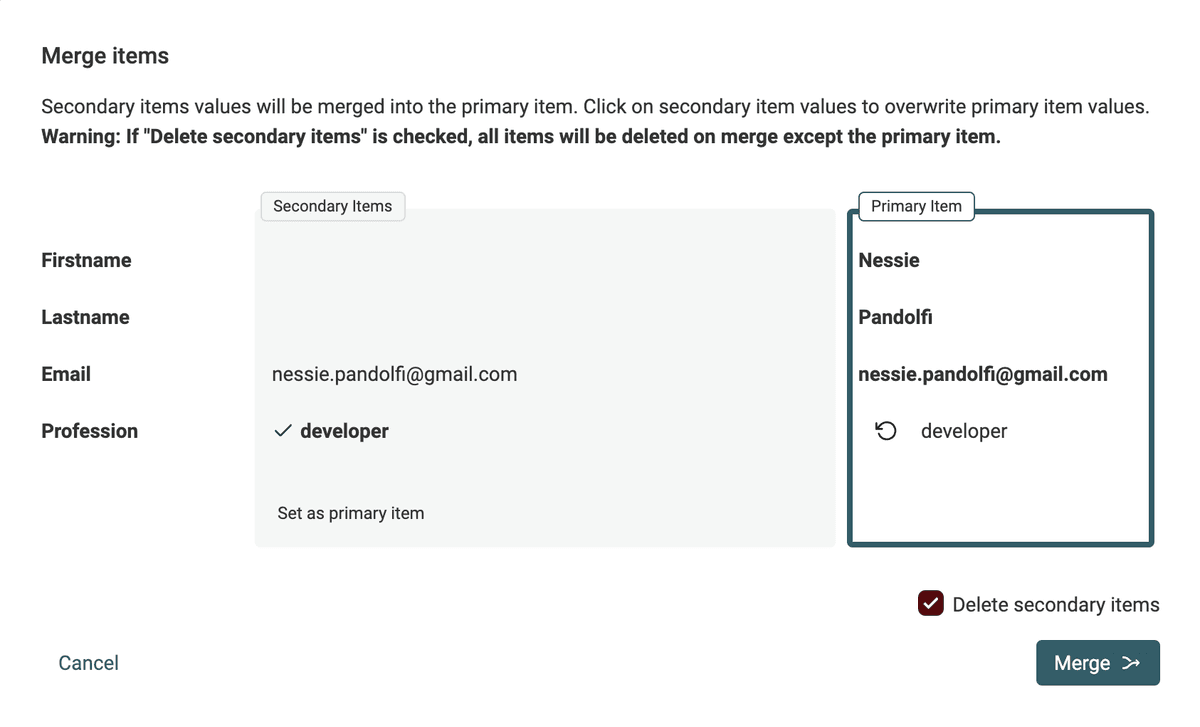
Lub sprawdź wartości w konflikcie ręcznie, korzystając z asystenta scalania
Gdy automatyczne scalanie nie jest możliwe, użyj asystenta scalania Datablist, aby wybrać, którą wartość zachować i skonsolidować elementy.
Element z największą ilością informacji jest wybierany jako rekord nadrzędny i otrzymuje wartości uzupełniające z elementów podrzędnych.
Przetwarzanie duplikatów z użyciem AI
Kiedy używać deduplikacji danych?
- Deduplikacja list mailingowych
Z czasem do listy mailingowej spłynie wiele źródeł. Z uczestnikami webinarów, nabywcami, użytkownikami freemium itp. adres email może pojawić się na liście wielokrotnie.
Zduplikowane adresy email wpływają na kampanie marketingowe dodatkowymi kosztami, spamowymi zachowaniami i ryzykiem frustracji użytkowników, jeśli wciąż otrzymują wysyłki po wypisaniu się z kampanii.- Jak wyczyścić listę mailingową
- Deduplikacja w Microsoft Excel
Google Sheets, Microsoft Excel i inne arkusze kalkulacyjne oferują podstawowe funkcje deduplikacji. Podświetlają duplikaty w kolumnie lub je usuwają. Skorzystaj z automatycznego scalania Datablist i ręcznego Asystenta scalania, aby poradzić sobie ze złożonymi zduplikowanymi rekordami.
Datablist otwiera zarówno pliki CSV, jak i Excel.- Jak deduplikować plik Excel
- Narzędzie do deduplikacji leads i potencjalnych klientów
W marketingu B2B jakość bazy prospektów wpływa na wyniki kampanii. Brudna lista danych ze zduplikowanymi leads zwiększa koszty przechowywania, obniża efektywność śledzenia leadów i frustruje zespół sprzedaży.
Zarządzaj procesami lead generation z Datablist. Albo zaimportuj dane z CRM lub listy leadów do Datablist, aby je wyczyścić.- Jak deduplikować listy leadów
- Deduplikacja plików CSV
Czyszczenie danych CSV jest czasochłonne. Inżynierowie danych używają języków programowania, takich jak Python, do parsowania i czyszczenia danych CSV. Datablist oferuje narzędzie No‑Code do wykonywania procesów czyszczenia danych na plikach CSV dla użytkowników nietechnicznych. Otwieraj pliki CSV liczące setki tysięcy wierszy i szybko deduplikuj rekordy.
- Jak deduplikować plik CSV
Najczęściej zadawane pytania
Tak, można bezpłatnie wyszukiwać i scalać duplikaty online. Podstawowe funkcje, takie jak exact i smart matching, są dostępne bez konta. Do zaawansowanych algorytmów, jak fuzzy lub phonetic matching, potrzebny jest plan płatny.
Excel trwale usuwa zduplikowane wiersze, przez co można utracić potencjalnie cenne dane z tych wpisów. Datablist scala rekordy, inteligentnie łącząc uzupełniające się informacje ze wszystkich duplikatów w jeden, kompletny rekord nadrzędny. Nie tracisz żadnych danych.
Datablist jest zbudowany do obsługi dużych plików. Na planie bezpłatnym przetworzysz listy do 1 miliona wierszy, a na planach płatnych do 1,5 miliona wierszy — znacznie powyżej limitów tradycyjnych arkuszy kalkulacyjnych.
Zdecydowanie. Nasze narzędzie wykorzystuje zaawansowane algorytmy fuzzy matching, takie jak odległość Levenshteina i Jaro‑Winkler, aby identyfikować podobne rekordy nawet przy błędach pisowni, literówkach lub drobnych różnicach formatowania.
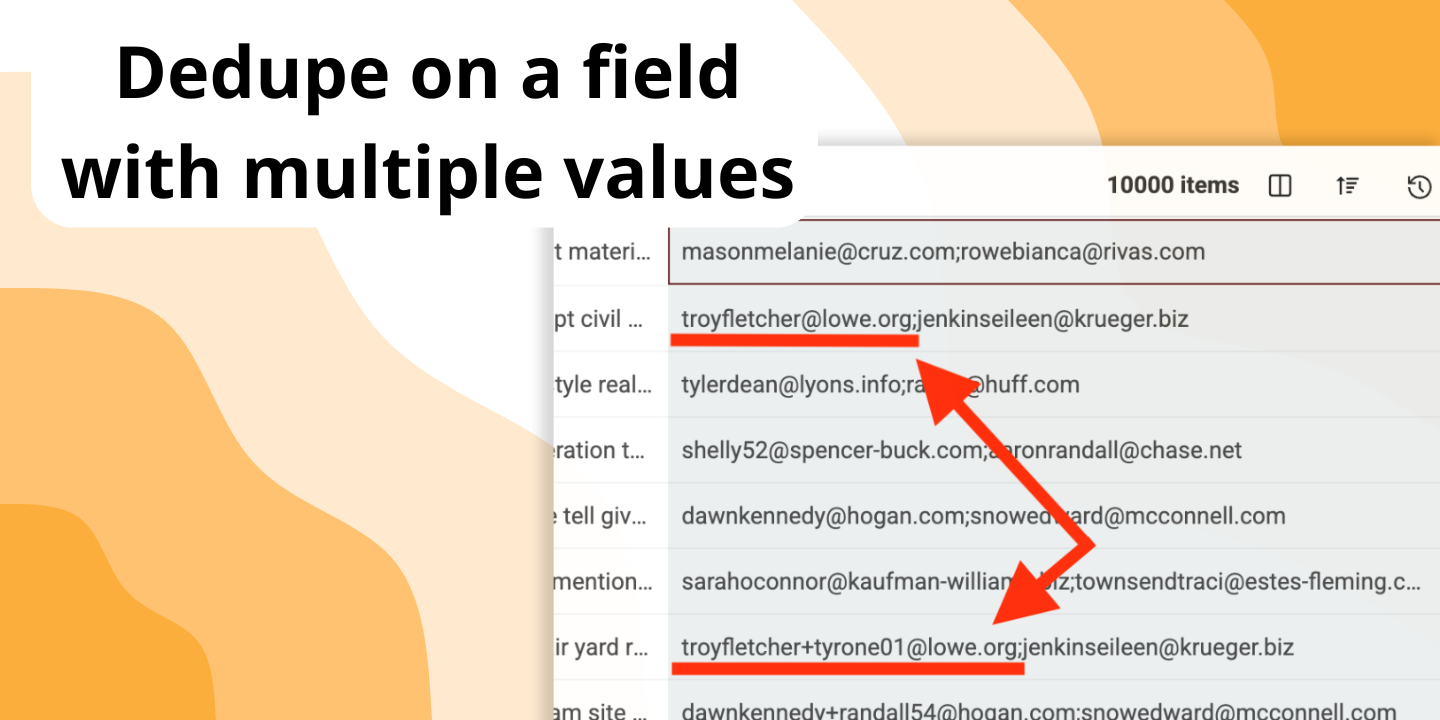
Zostało do tego zaprojektowane. Można włączyć „Multiple Value Matching”, aby traktować każdą wartość w komórce (oddzieloną średnikiem) jako osobny wpis do porównania. Narzędzie znajdzie dopasowanie, jeśli choć jedna z wartości jest duplikatem.
Tak. Można zaimportować wiele plików do Datablist i uruchomić Duplicates Finder na wszystkich. Narzędzie dopasuje rekordy na podstawie wspólnego identyfikatora, nawet jeśli pliki mają różne kolumny lub strukturę.
Wcale nie. Datablist to w pełni no‑code. Duplicates Finder prowadzi przez prosty, krok‑po‑kroku proces, w którym wybiera się kolumny i reguły dopasowania w przyjaznym interfejsie.
Funkcja AI Editing daje nieograniczoną elastyczność. Zamiast standardowych reguł scalania możesz pisać instrukcje prostym językiem angielskim. Na przykład poproś o zsumowanie wartości sprzedaży ze zduplikowanych wpisów lub wybór rekordu nadrzędnego na podstawie najnowszej daty. Złożoną logikę zamienia w proste polecenie.
Datablist konsoliduje dane w jeden rekord nadrzędny. Automatycznie uzupełnia brakujące informacje z innych duplikatów i daje opcje dla danych w konflikcie: można łączyć tekst z różnych wierszy lub wybrać, którą wartość zachować. Zbędne rekordy są następnie usuwane.
Oferujemy kilka algorytmów do różnych potrzeb: „Exact” dla identycznych dopasowań, „Smart” dla wariantów jak kolejność słów lub protokoły URL, „Phonetic” dla nazw brzmiących podobnie oraz „Fuzzy Matching” dla literówek i błędów.
Tak. Po zidentyfikowaniu wszystkich grup duplikatów można je wyeksportować do pliku CSV lub Excel przed wprowadzeniem zmian. Plik wymienia wszystkie zduplikowane elementy kolejno, grupa po grupie, co ułatwia zewnętrzny przegląd lub przetwarzanie w innym narzędziu.
Po zakończeniu scalania Datablist udostępnia plik „Changes List” do pobrania. Ten plik działa jak dziennik, pokazując każdy rekord zaktualizowany lub usunięty w procesie. Można go użyć do łatwego odtworzenia zmian w zewnętrznym systemie, np. CRM, aby dane pozostały idealnie zsynchronizowane.
See Also