Calculations
You can now run calculations on property values. Calculations are accessible from a property column menu.
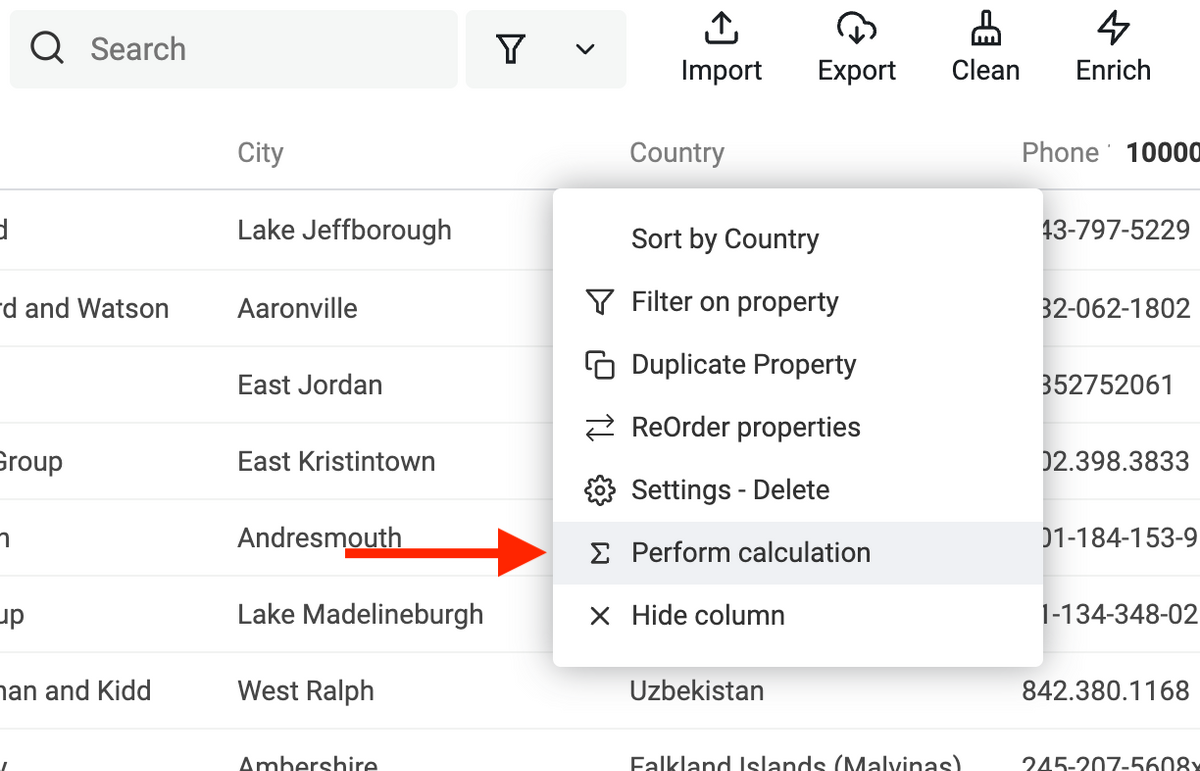
Datablist runs the calculation in the "current view". It takes the items in this order:
- If you have selected items in your collection, it will process them.
- If you have a filter or a full-text search term, it will process the filtered items.
- Otherwise, it will process all your collection items.
Calculations available for all data types:
- Count Empty - How many items with an empty value for the property.
- Count Filled - How many items with a value for the property.
Other calculations depend on the property data types such as Text or Number.
Calculation available for text-based data types:
- Characters count - Return the sum of all characters. Leading and trailing spaces are not counted. Spaces in between words are.
- Words count - Return the number of words found in the texts.
- Count distinct values - Return facets for a property with how many times each value appears. This is great for aggregation of limited choice values (countries, status, etc.).
For number-based data types:
- Min - Return the lowest value for the property.
- Max - Return the highest value for the property.
- Average - Return the sum of values divided by the number of non-empty values.
Check the calculations documentation to know more.
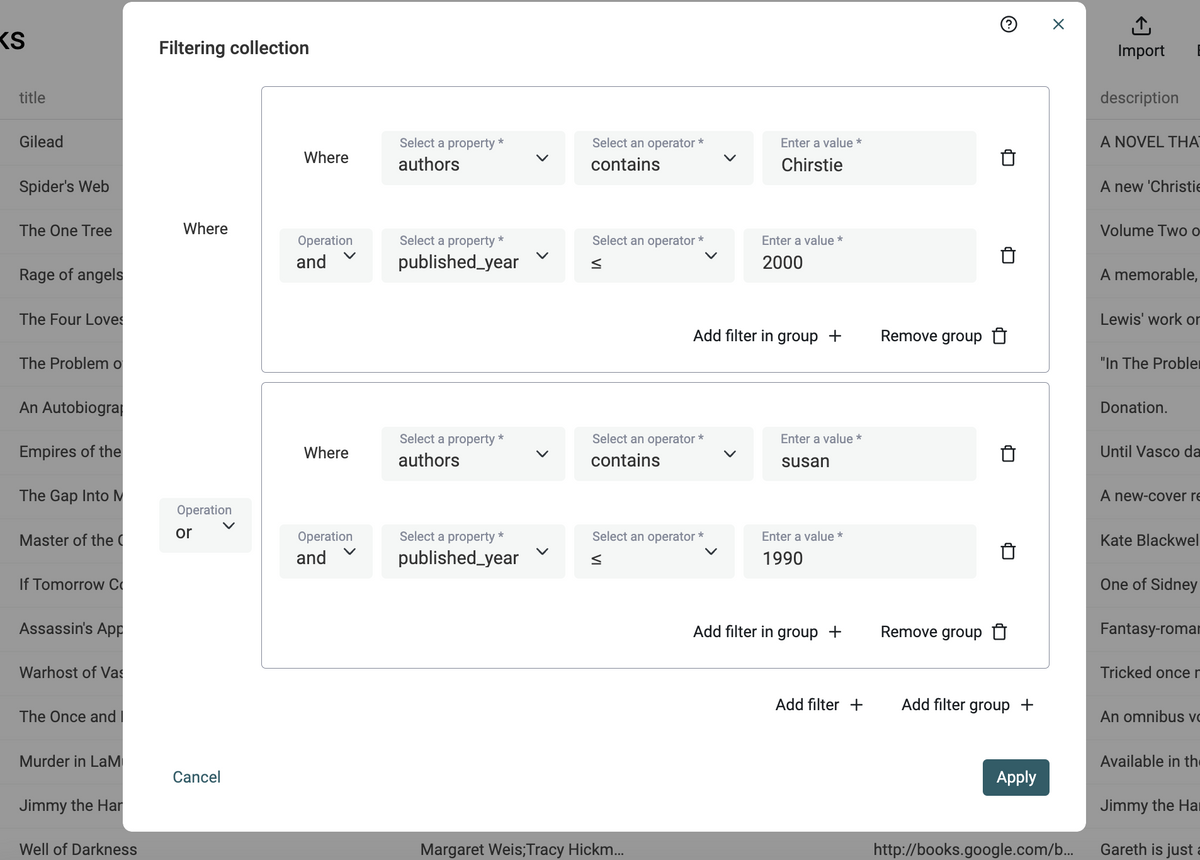
Filter Groups
Data Filtering has been improved with "Filter Groups".
With Filter Groups, you can create complex filters with different filtering operations. Filtering operations define how filters are combined. With "AND", an item must pass all conditions. With "OR", an item passes once one of the filters returns true.
Filter Groups are compatible with Saved Filters.
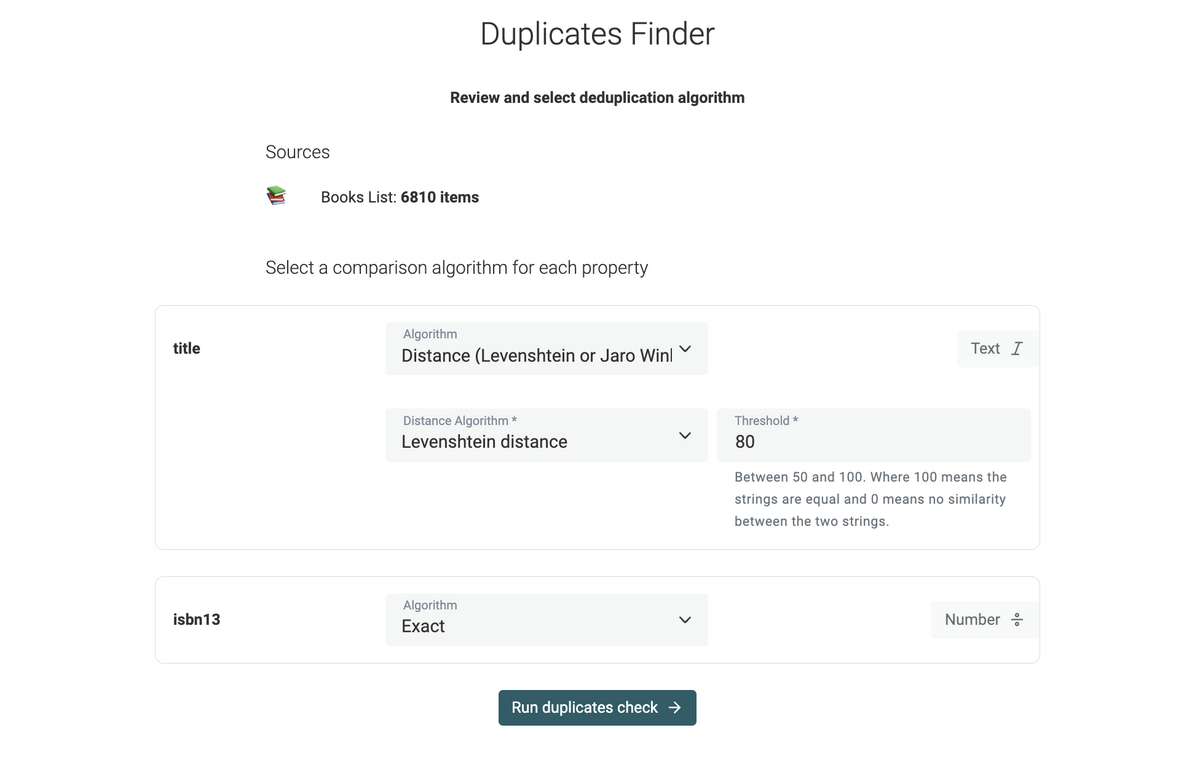
Duplicate Finder Improvements
Select a different algorithm for each property
Until now, a single data-matching algorithm was selected before the deduplication process. Internally, Datablist checked each property data type to apply the selected algorithm on compatible properties. And it fell back to Exact matching on the other properties (e.g. Date, Checkbox, Number).
Now, each property used for deduplication is listed in the data-matching algorithm step.
Compatible algorithms are listed according to their data type. And options only apply to the property.
For example, two properties might use a fuzzy matching algorithm and have different distance thresholds.
Ignore the case in the Exact algorithm
By default, Datablist Duplicates Finder is case-insensitive. But in some cases, you need to match duplicate values only when they have a similar case.
A new option is available for the "Exact" Algorithm to be case-sensitive.
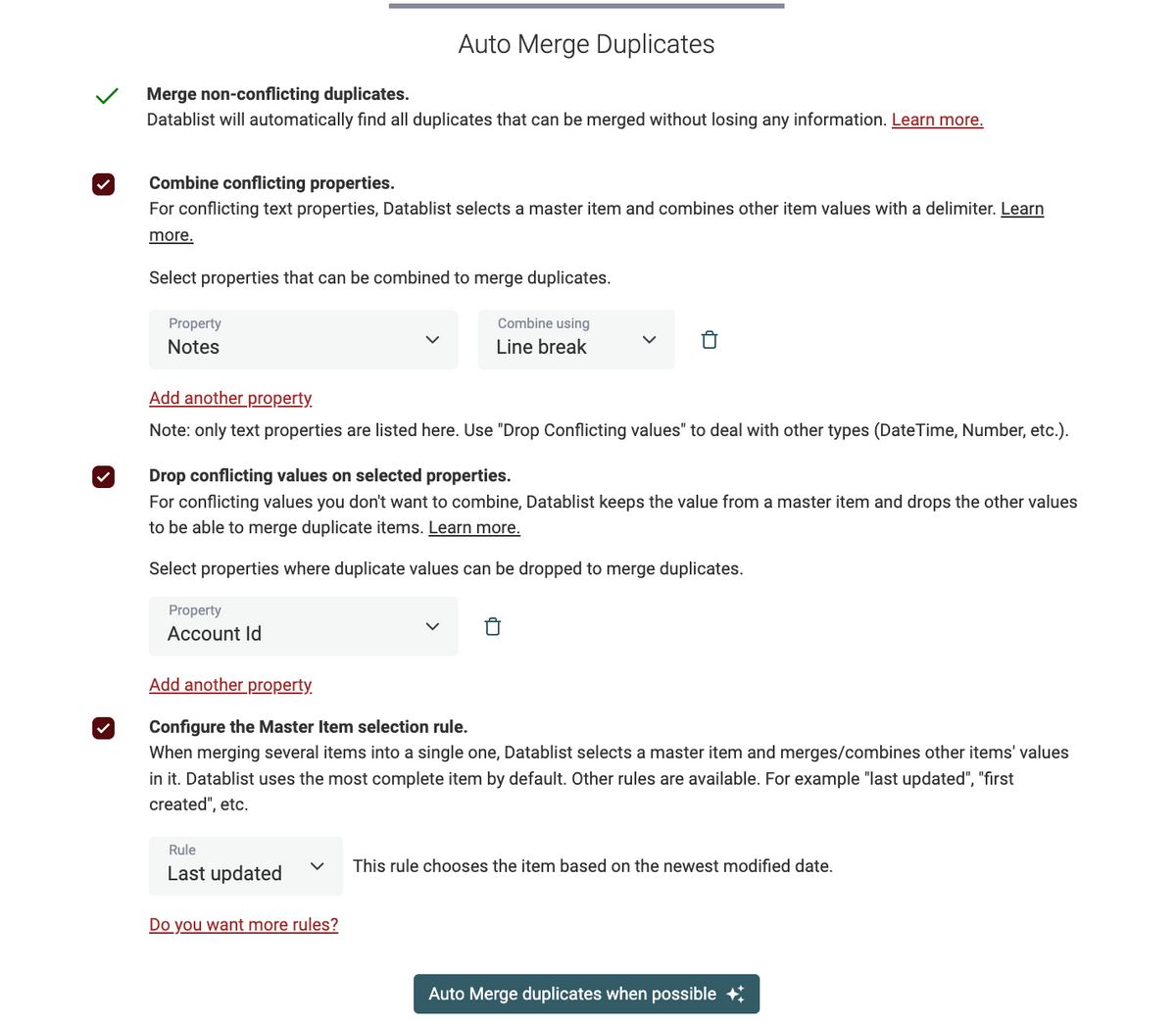
Master Item Rule selection
After the data matching step, an important part of deduplication is duplicate merging. With the auto-merge algorithm, Datablist selects a master item, merges the values from the other items in it, and deletes all but the master item.
By default, the elected master item is the one with the most data.
A new setting has been added in the auto-merging assistant to change this master item selection.
Two new rules are now available:
- Last Updated - This rule chooses the item based on the newest modified date.
- First Created - This rule chooses the item based on the oldest creation date.
During this development cycle, the "Most Complete" default rule has also been improved. Until now, the rule checked how many properties had data. When two items had the same number of properties with data, it took the last created item.
Now, for two items with the same number of properties with data, it also checks the text length.
For two items such as:
First Name | Last Name | Notes
John...... | Doe ..... | A great man.
John...... | Doe ..... | A great man. Remember to contact him.
The second one will be selected as the master item. The "Notes" text is longer for the second item.
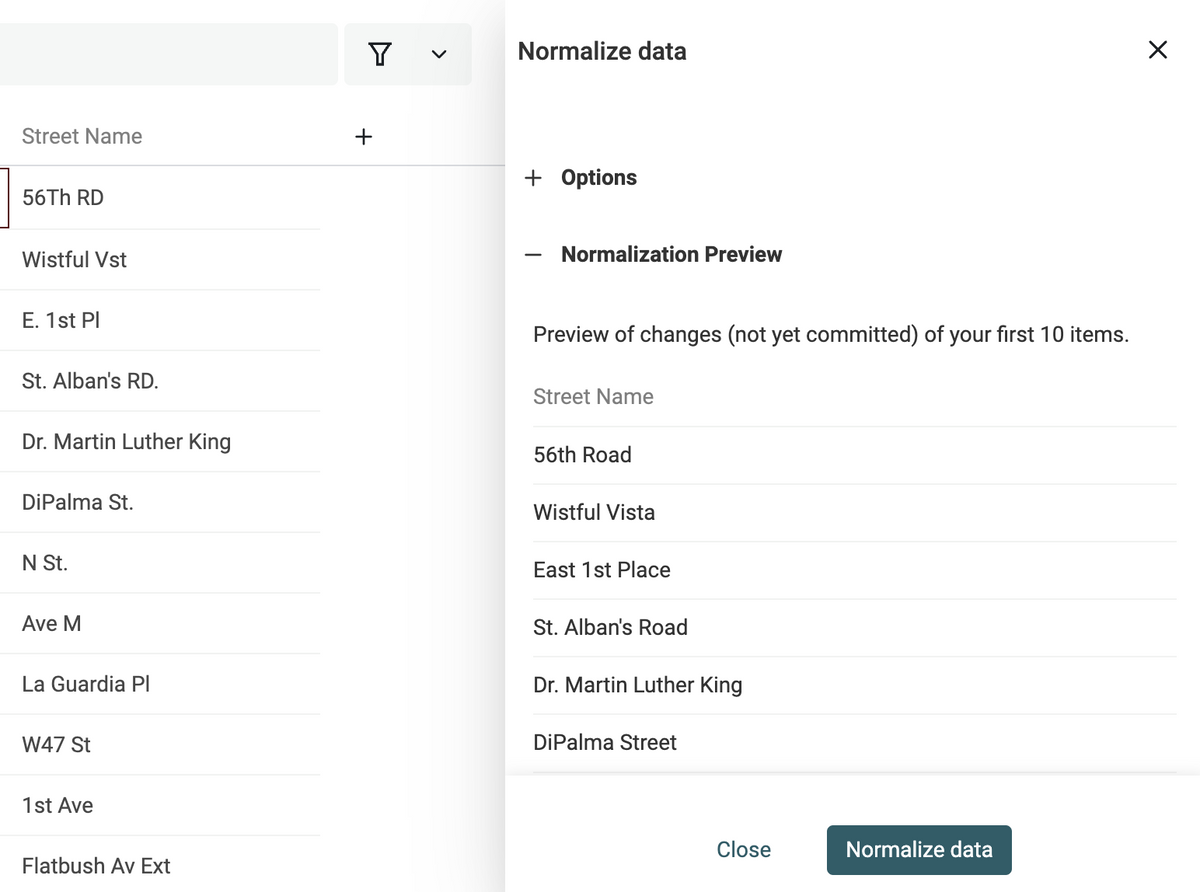
Normalize street names
In Data Cleaning, normalization ensures you have a uniform format across all your data. Normalization reduces errors during deduplication and you get a consistent view of your data.
I have several built-in normalizations in mind for later:
- Company name normalization to remove suffixes such as "Inc." or "GmbH".
- People name normalization to clean nicknames, deal with initials, etc.
Last month, I released the first normalization algorithm to deal with street names written in English.
The "Normalize Street Name" algorithm deals with abbreviations (St. == St == Street), directional words (N 45 == North 45), etc.
Other Improvements & Fixes
- Option to auto-generate column names during import for files without headers.
- Fix Excel export in selected items (and duplicate groups download).
- Fix auto merging on properties with punctuation differences.
- Show how many duplicate groups have been merged during the auto-merge process.
- Auto updated disposable provider domain list and added Stop Forum Spam as a new source.
- Fix anonymous collection import for collections with more than 10k items.
- Auto open Datetime picker on cell edition.
- Show data loss warning every 48 hours for collections not synced to the cloud (anonymous, or free account with more than 1000 items per collection).