

Si vous construisez des listes de prospects à partir de données issues du scraping, vous vous retrouvez très vite confronté à ce problème : Comment nettoyer et normaliser ces données ?
Si vous avez testé Google Sheets, vous savez que cet outil n’est clairement pas fait pour ça.
Des données issues de LinkedIn proposent un champ "full name", d’autres sources séparent prénom et nom. Les adresses email comportent parfois des fautes dues au scraping. Les dates sont dans des formats différents, etc.
Avec ce guide, vous allez pouvoir résoudre 99% des problèmes liés au nettoyage des données scrapées. Et pour le 1% restant, contactez-moi, je peux vous aider 👨💻
Voici un résumé des opérations de nettoyage abordées dans cet article :
- Convertir du texte en Date, Number, Boolean
- Convertir HTML en texte brut (suppression des balises HTML)
- Supprimer les espaces en trop
- Normaliser vos données
- Supprimer les symboles indésirables
- Scinder un nom complet en prénom et nom de famille
- Dédupliquer les enregistrements
- Valider les adresses email
- Extraire un nom de personne ou entreprise depuis un texte scrapé
Importer depuis un CSV ou coller vos données
Datablist est l’outil idéal pour nettoyer vos données. C’est un éditeur CSV en ligne doté de fonctions de nettoyage, d’édition en masse et d’enrichissements. Il gère des collections allant jusqu’à plusieurs millions de lignes.
Ouvrez Datablist, créez une collection et importez votre fichier CSV contenant vos données issues du scraping.
Pour créer une nouvelle collection, cliquez sur le bouton + dans la barre latérale. Puis cliquez sur "Importer CSV/Excel" pour charger votre fichier. Ou accédez rapidement à l’import depuis la page d’accueil.
Détection automatique du format
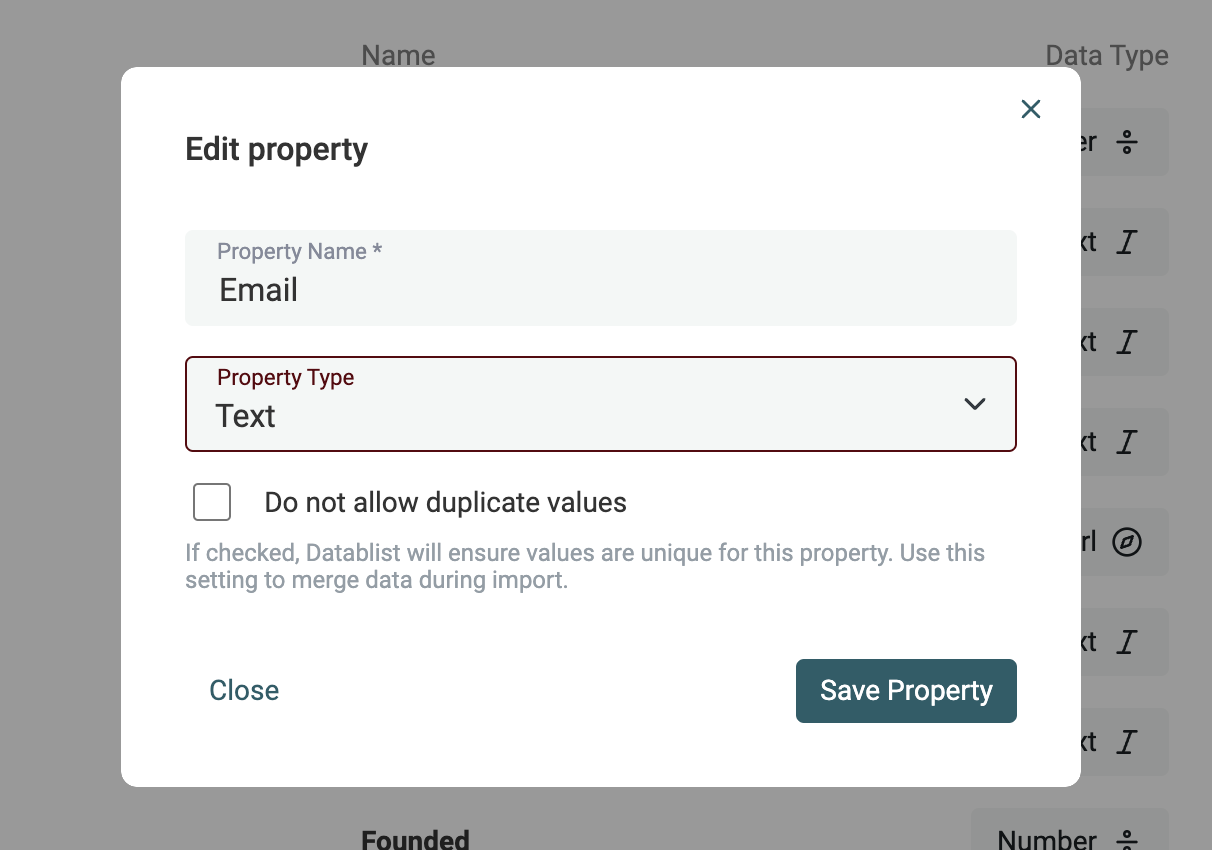
L’assistant d’import de Datablist détecte automatiquement les adresses emails, les Datetimes au format ISO 8601, les Booleans, les Numbers, les URLs, etc. dès qu'ils sont bien formatés.

Si vos données demandent une analyse plus poussée (format de date différent, erreurs dans les URLs ou adresses email), importez-les en tant que propriété Texte. Vous verrez dans la section suivante comment convertir vos propriétés texte en Datetime, Boolean ou Number.
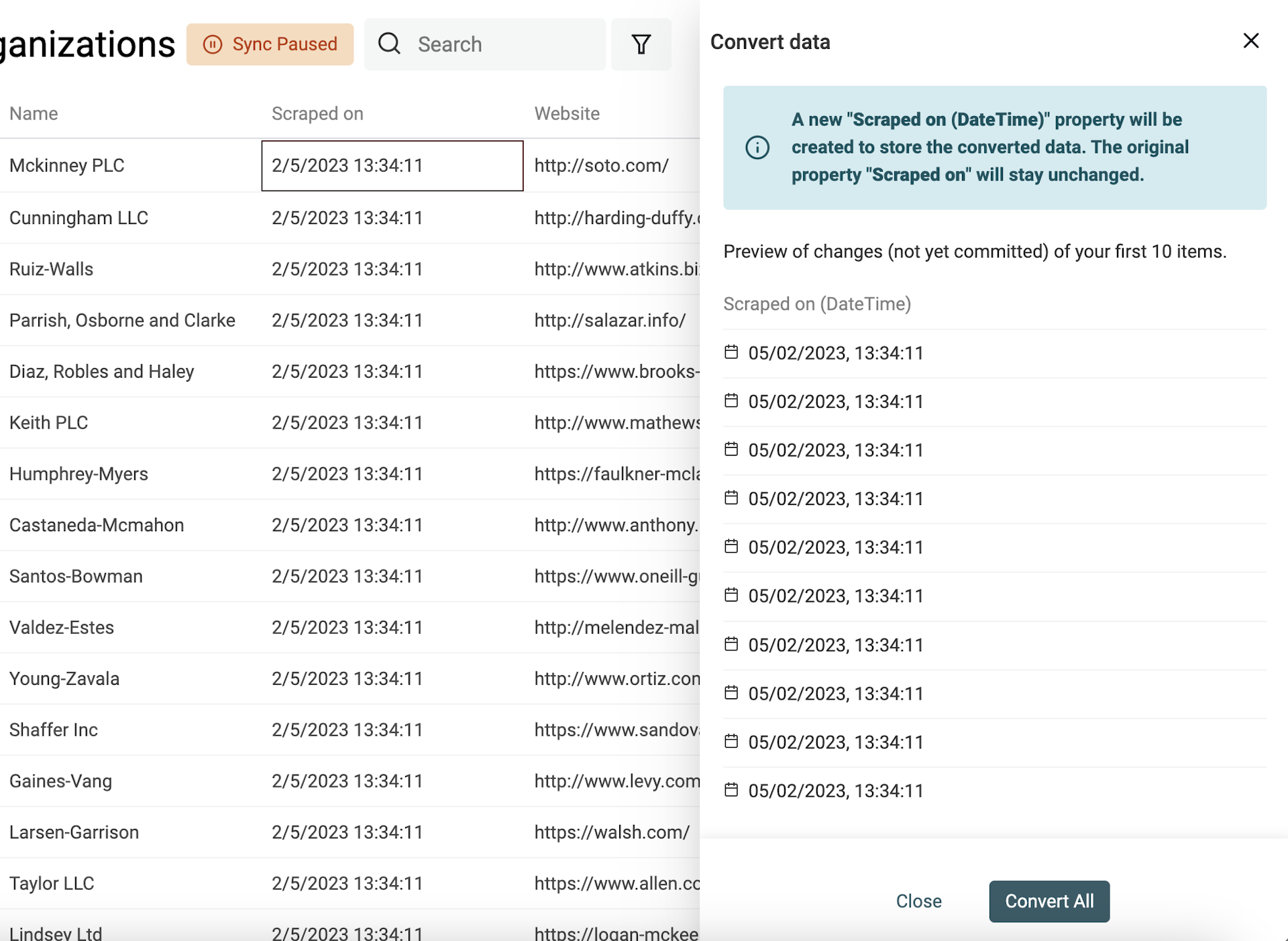
Convertir du texte en date, boolean, number
Marie Kondo disait « La vie commence dès que vous avez rangé la maison ». Pour la data, c’est pareil : « Le business commence quand vos données sont rangées ! » 😅
Filtrer selon une date (date de création, de levée de fonds…), un nombre (prix, effectif, etc.) ou un boolean est bien plus simple quand la donnée est au bon format, pas juste du texte.
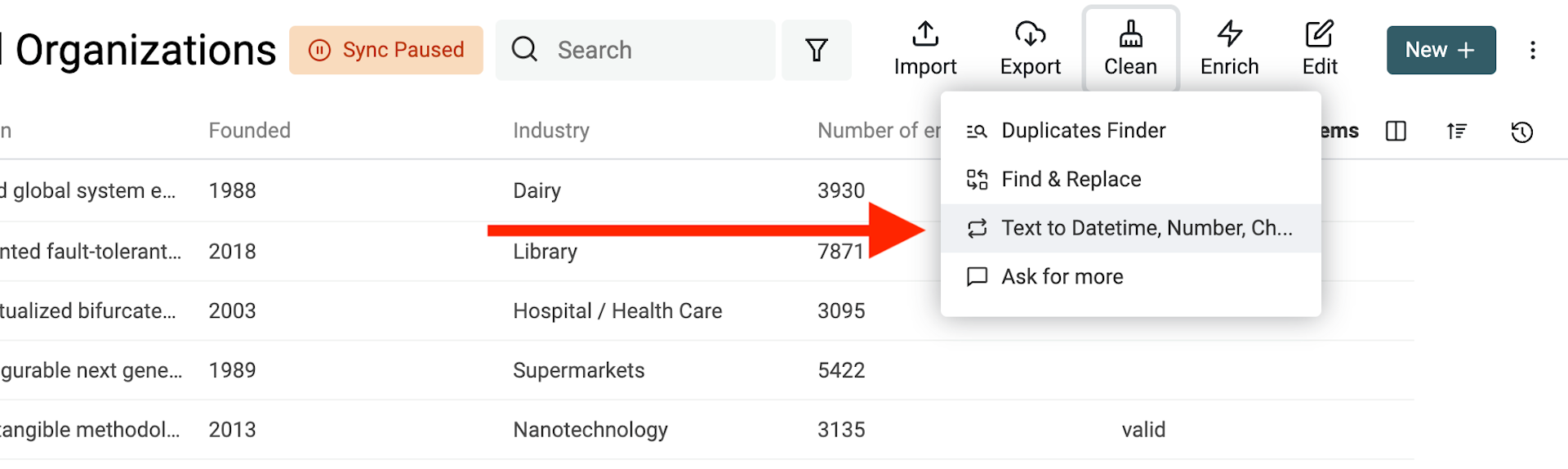
Ouvrez l’outil "Text to Datetime, Number, Checkbox" dans le menu "Clean".
Convertir n'importe quel texte en Date
La norme internationale des dates s’appelle ISO 8601. Si vos champs sont déjà dans ce format, l’import dans Datablist créera directement une propriété Datetime.
Pour les autres formats, vous devrez indiquer le format utilisé : Datablist convertit alors vos valeurs de date en valeurs Datetime structurées.
Sélectionnez la propriété à convertir, puis "Convert to Datetime".
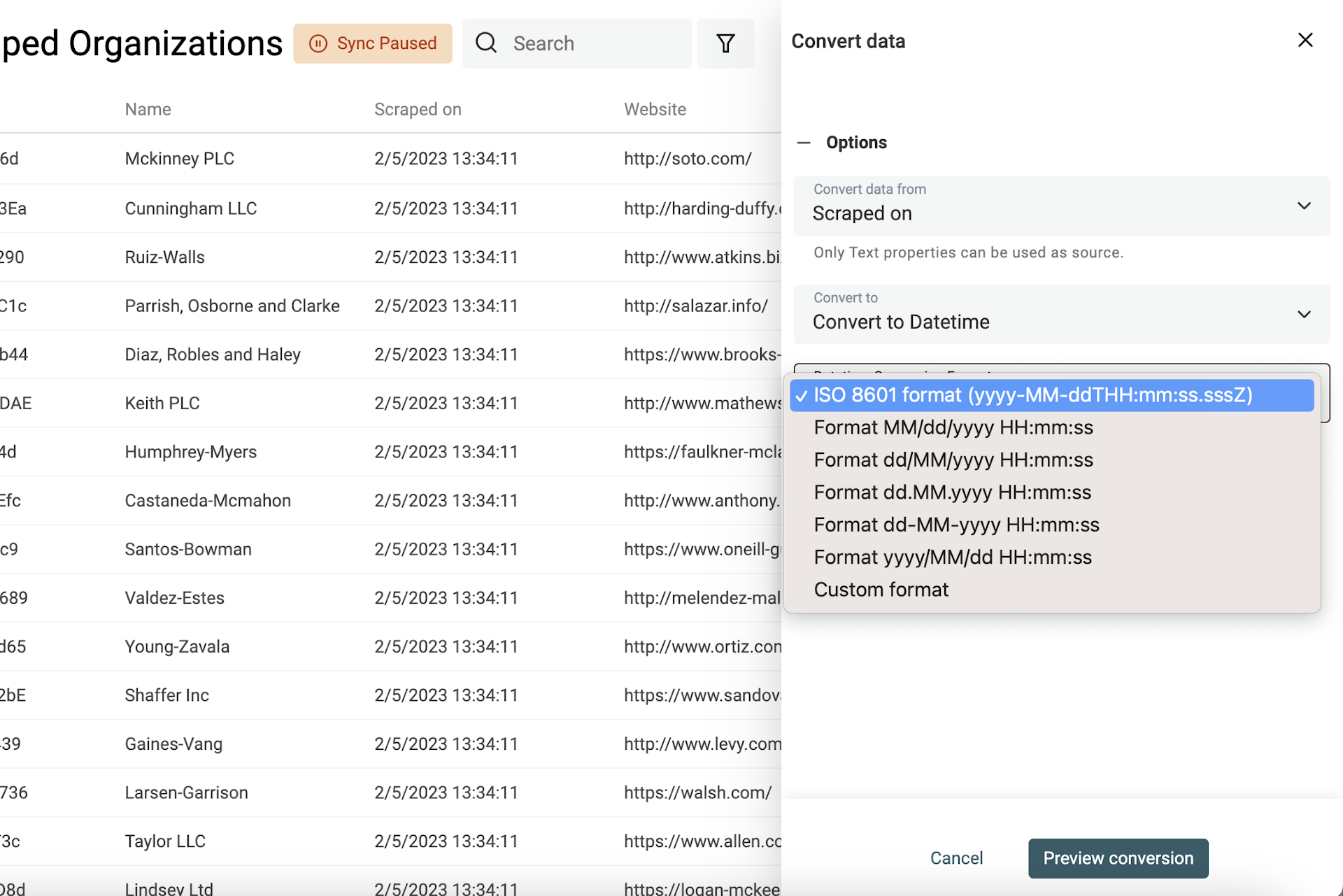
Les formats de dates courants (Google Sheets, Excel…) sont proposés, ou sélectionnez "Format personnalisé".

👉 Découvrez notre documentation sur les formats de date personnalisés.
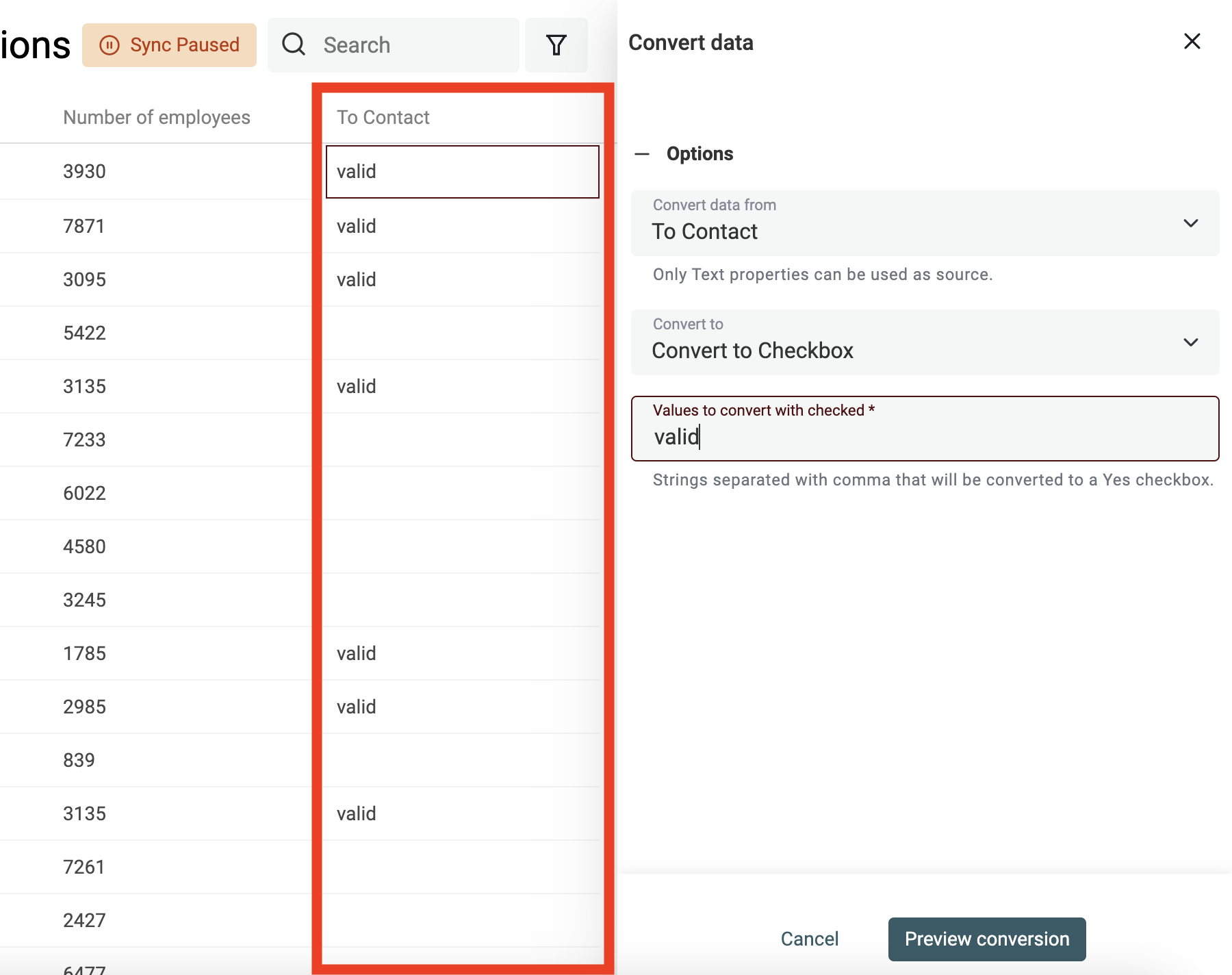
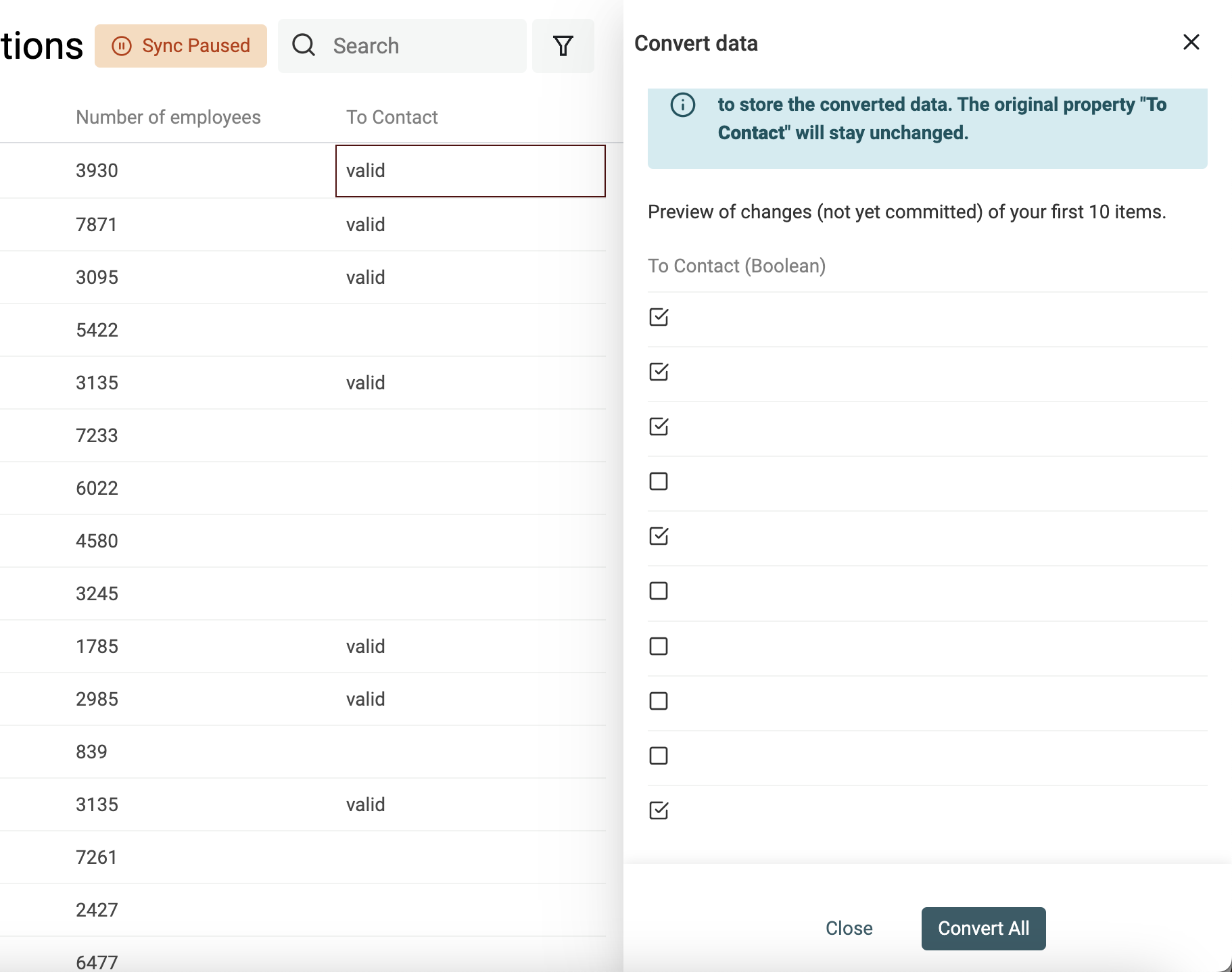
Créer des cases à cocher (Boolean) à partir de texte
Datablist convertit automatiquement les colonnes "Yes, No", "TRUE, FALSE", etc. en cases à cocher à l’import. Utilisez l’outil pour les cas complexes.
Indiquez les valeurs (séparées par une virgule) à convertir en case cochée. Les autres resteront décochées.
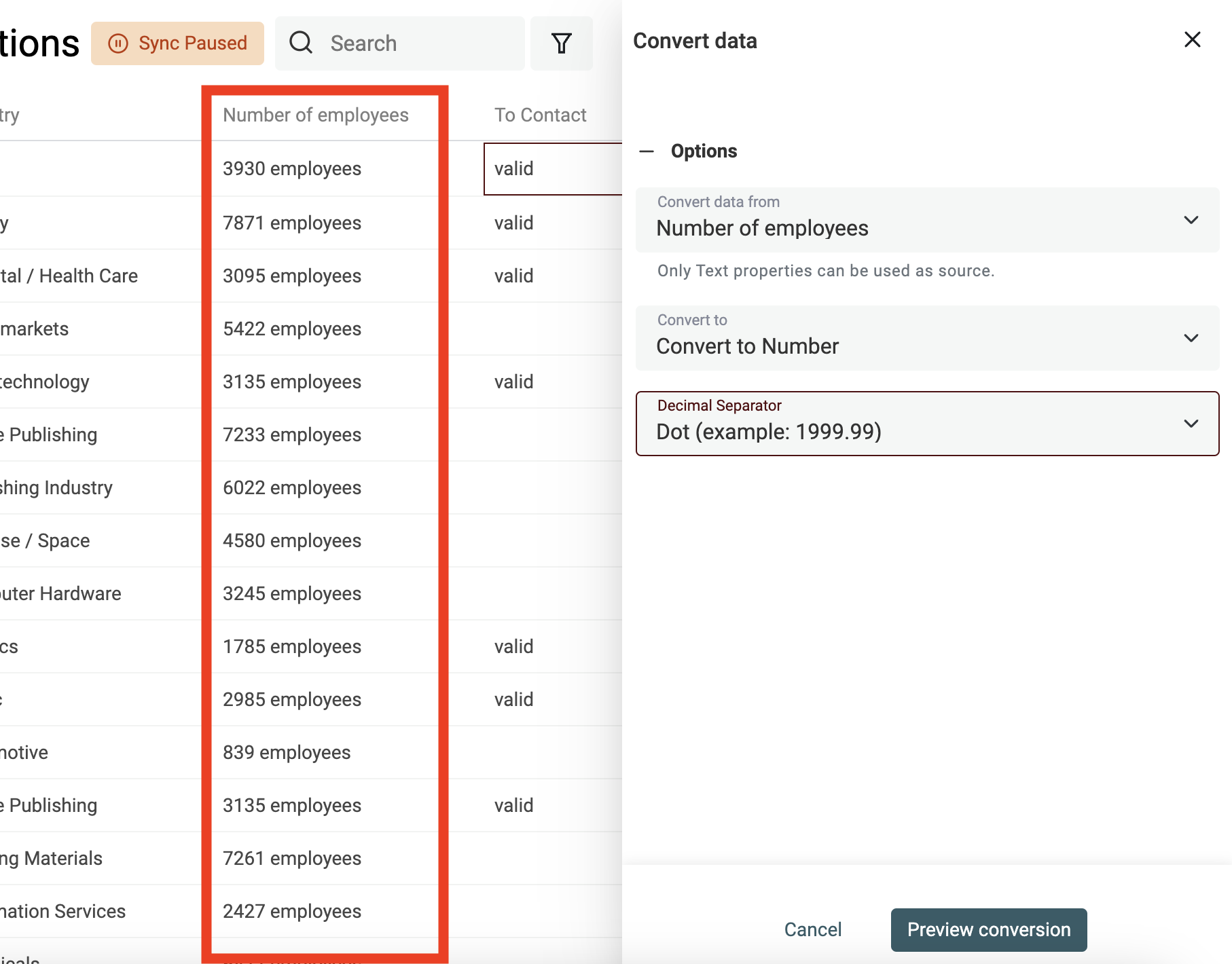
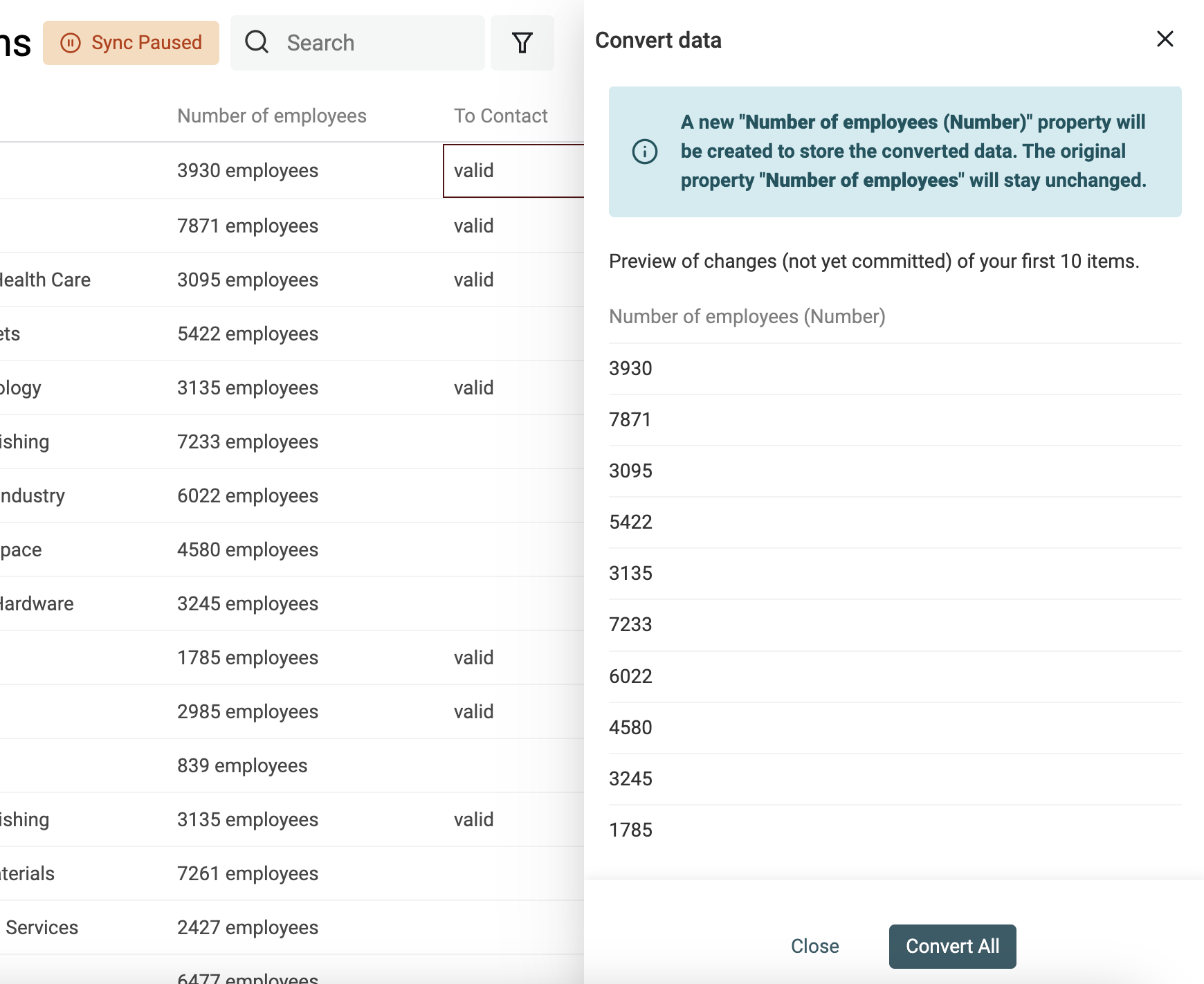
Extraire les valeurs numériques d'un texte
Utilisez le convertisseur "Texte en nombre" pour :
- Normaliser la saisie avec les bons séparateurs (virgule, point, espace)
- Extraire les chiffres d’un texte contenant aussi des lettres
👉 Consultez notre documentation détaillée sur la conversion des nombres.
Nettoyer les données
Convertir HTML en texte brut
Les outils de scraping extraient du code HTML et vos champs contiennent parfois des balises HTML.
Les codes HTML intègrent liens, images, listes à puces, paragraphes, etc.
Le but ? Garder la structure offerte par le HTML, mais transformer un code illisible en texte brut propre.
Le convertisseur HTML -> Texte de Datablist préserve les retours à la ligne, transforme les listes à puces en listes préfixées par -.
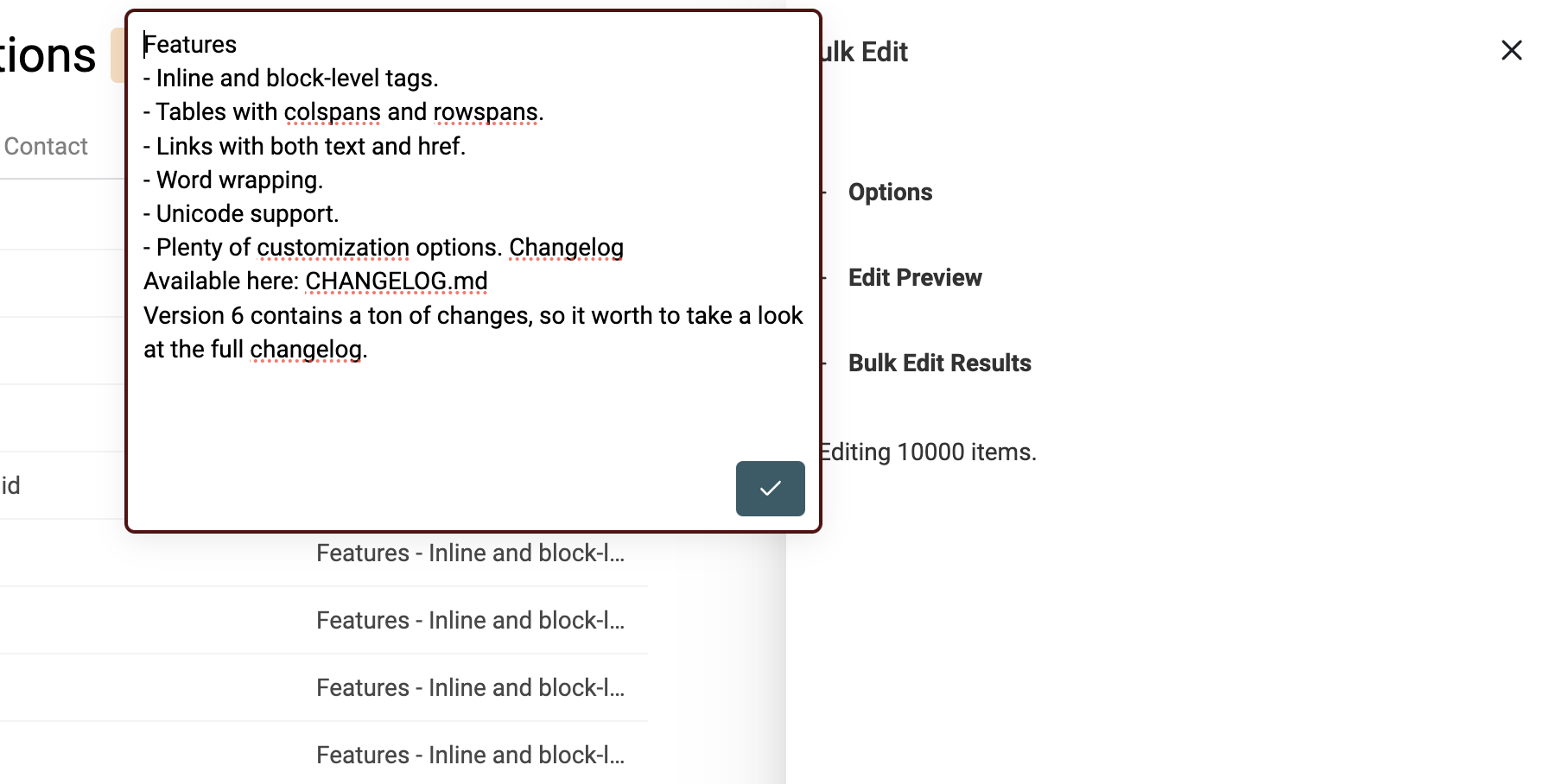
Pour transformer un texte HTML en texte lisible, ouvrez "Bulk Edit" dans le menu "Edit".
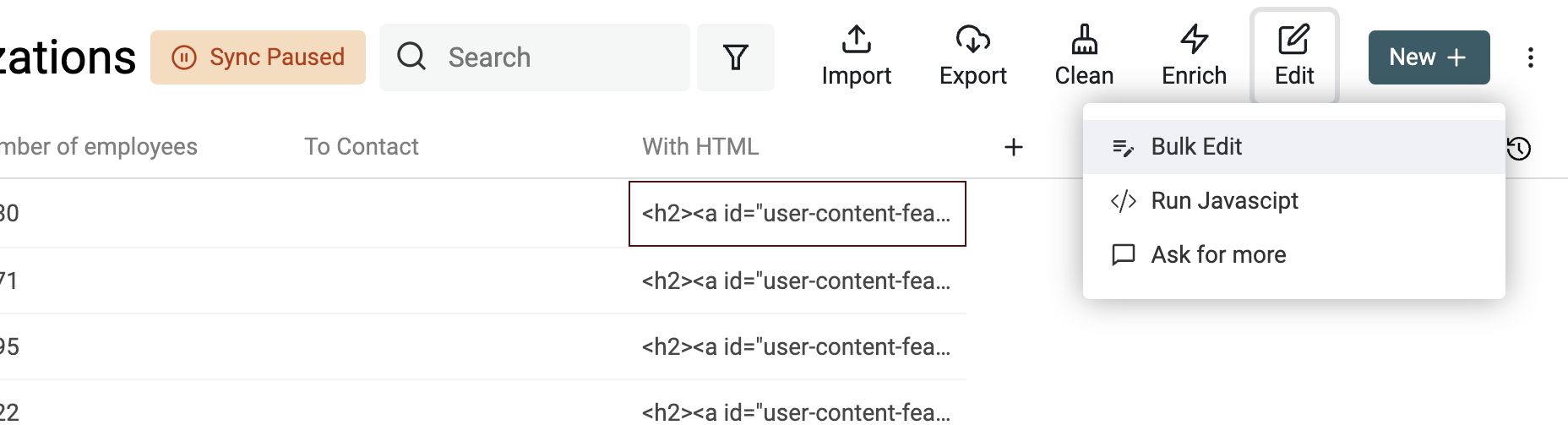
Sélectionnez la propriété à traiter puis l’option "Convert HTML into plain text".
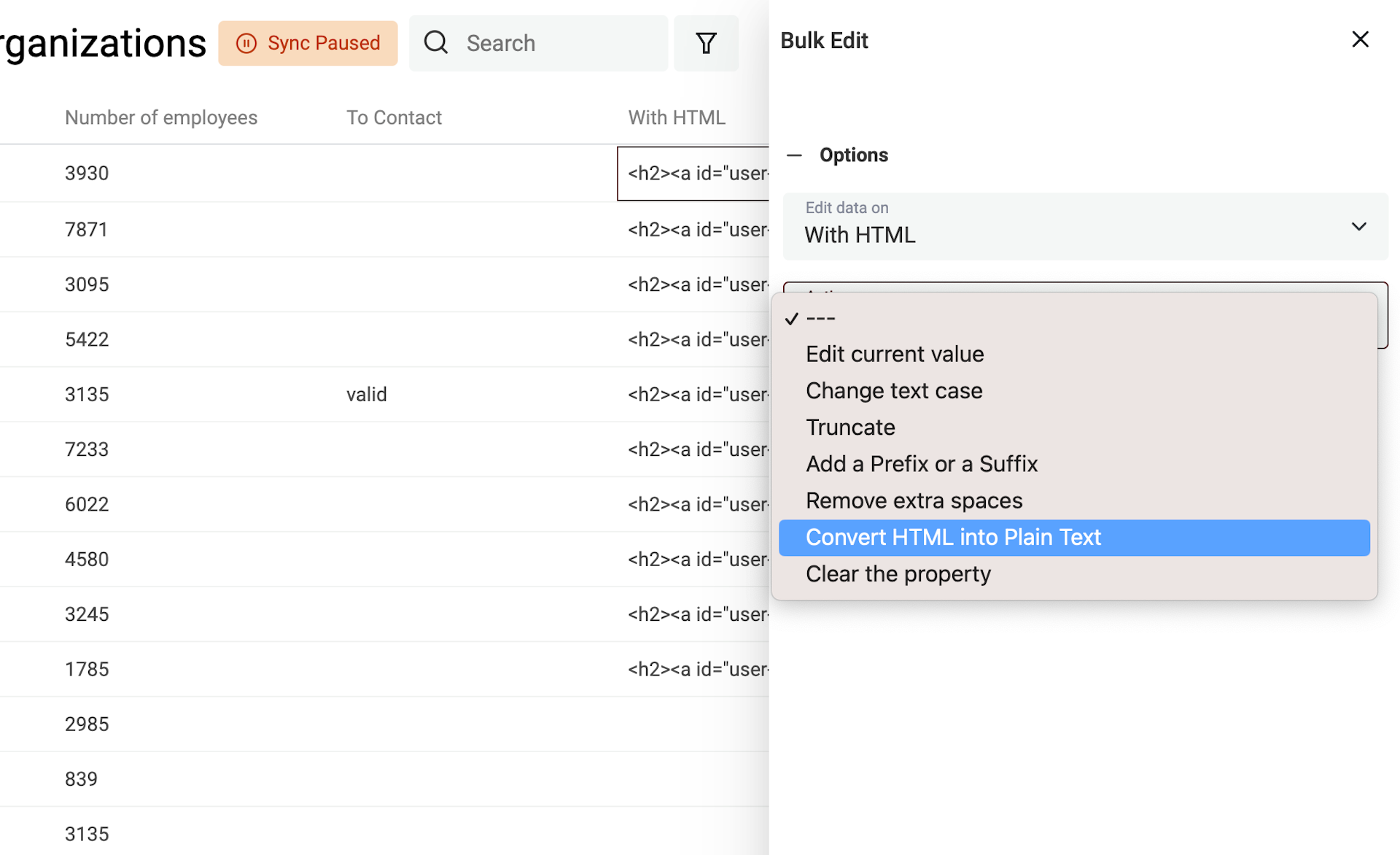
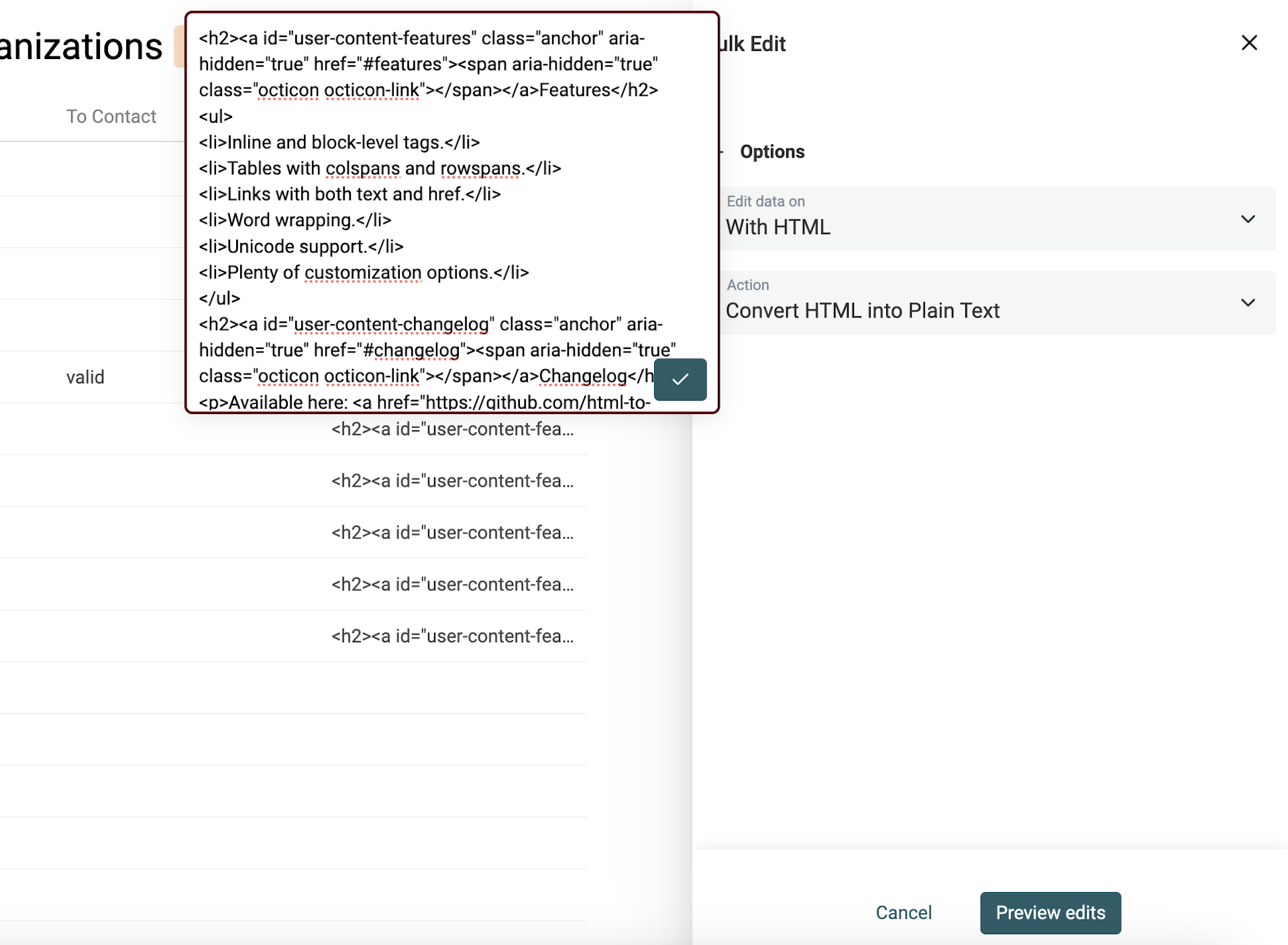
Supprimer les espaces superflus
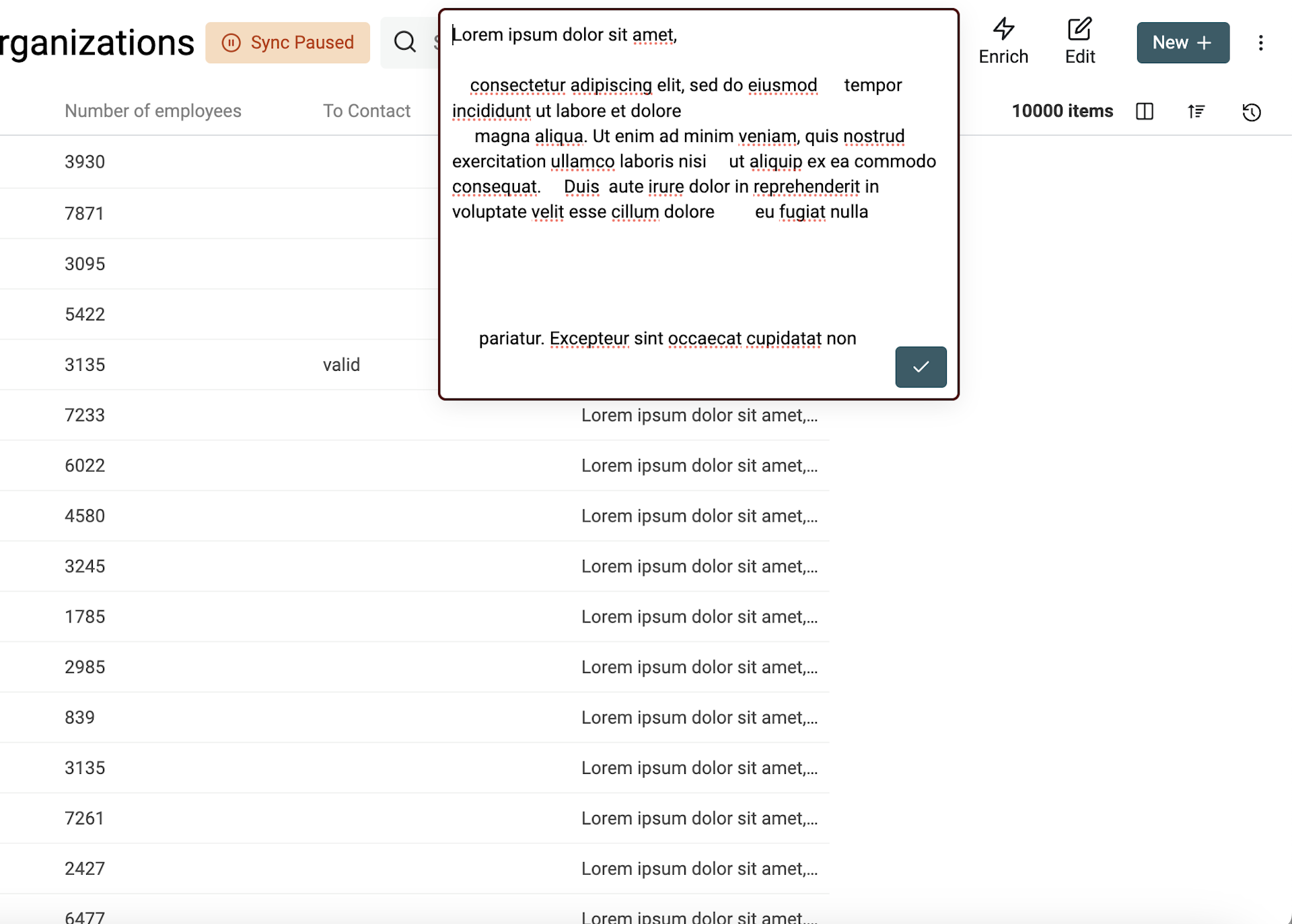
Autre souci typique du scraping : les espaces ou lignes vides. Tabulations, espaces, nouveaux paragraphes…
Datablist propose un outil de nettoyage pour supprimer les espaces inutiles :
- Suppression des espaces en trop entre les mots
- Suppression des lignes vides
- Suppression des espaces devant/derrière chaque ligne
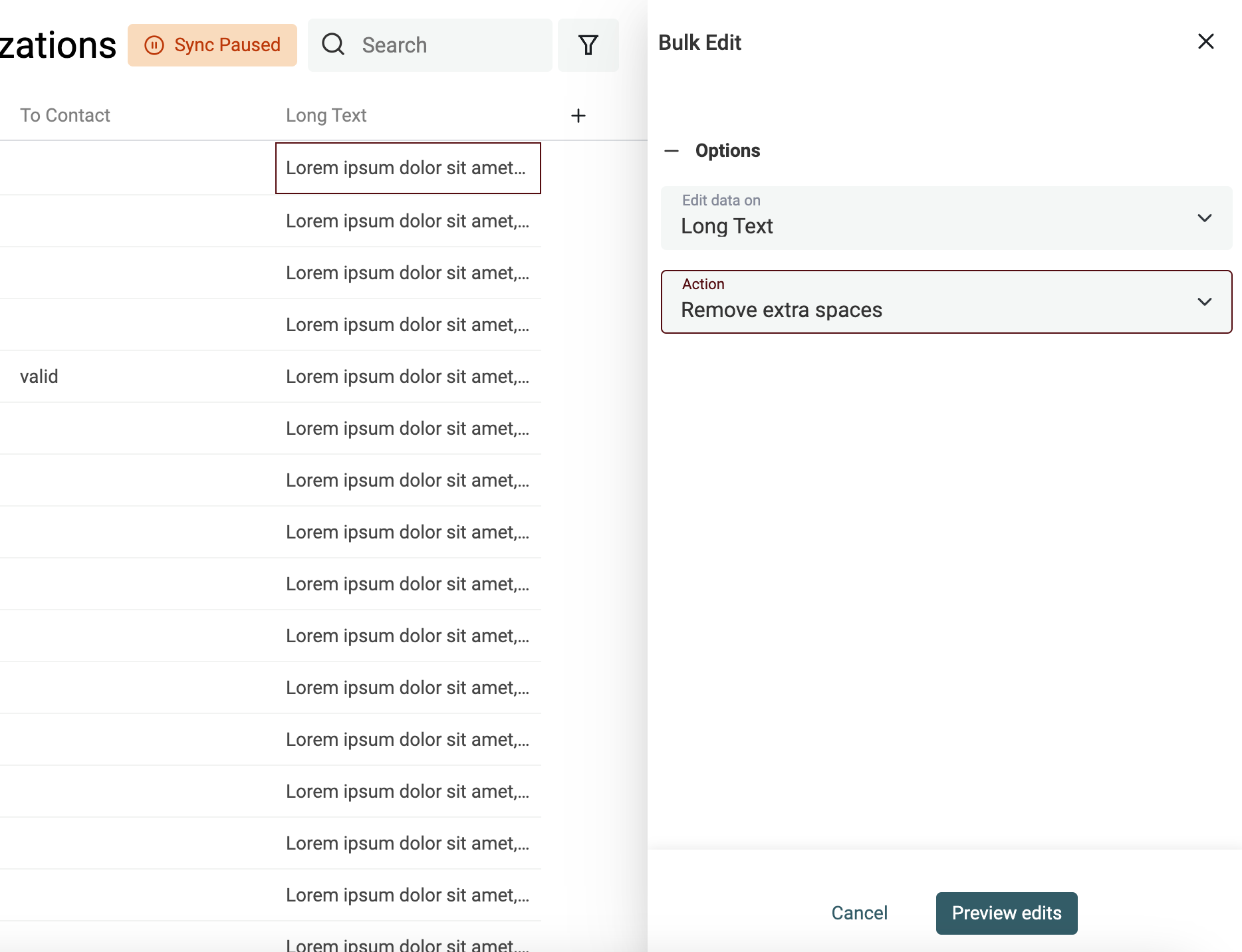
Ouvrez "Bulk Edit" via le menu "Edit". Sélectionnez votre propriété et l’action "Remove extra spaces".

Nettoyer la casse d’un texte
Pour gérer la casse (majuscule/minuscule), ouvrez "Bulk Edit" dans "Edit".
Sélectionnez la propriété à traiter puis l’action "Change text case".
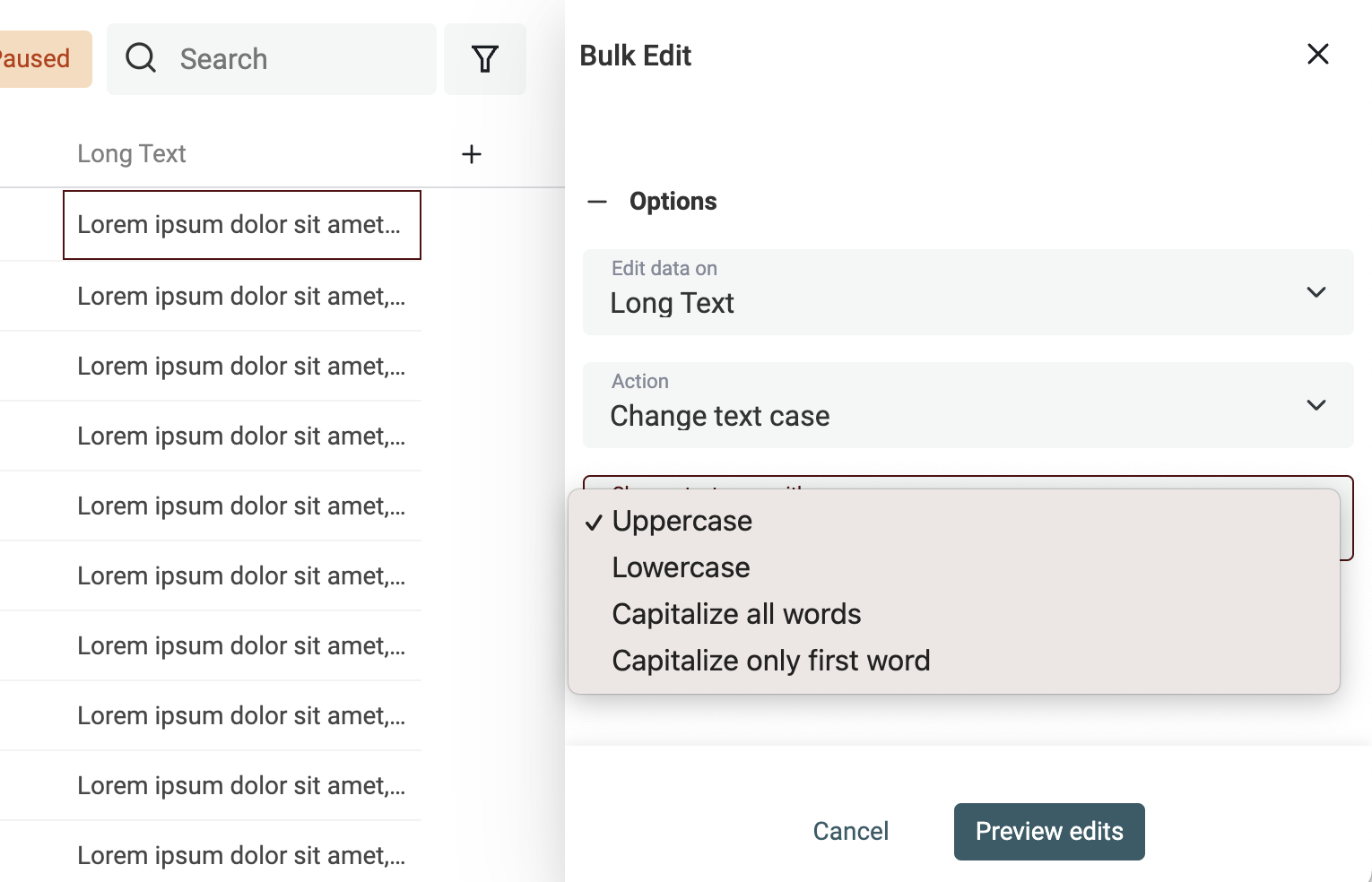
4 modes :
- Majuscules – Tout le texte est en MAJUSCULES. Ex :
john→JOHN - Minuscules – Tout le texte passe en minuscule. Ex :
API→api - Capitalisation – Toutes les premières lettres de chaque mot sont en majuscule. Ex :
john is a good man→John Is A Good Man - Première lettre – Seule la première lettre du premier mot est en majuscule. Ex :
john is a good man→John is a good man
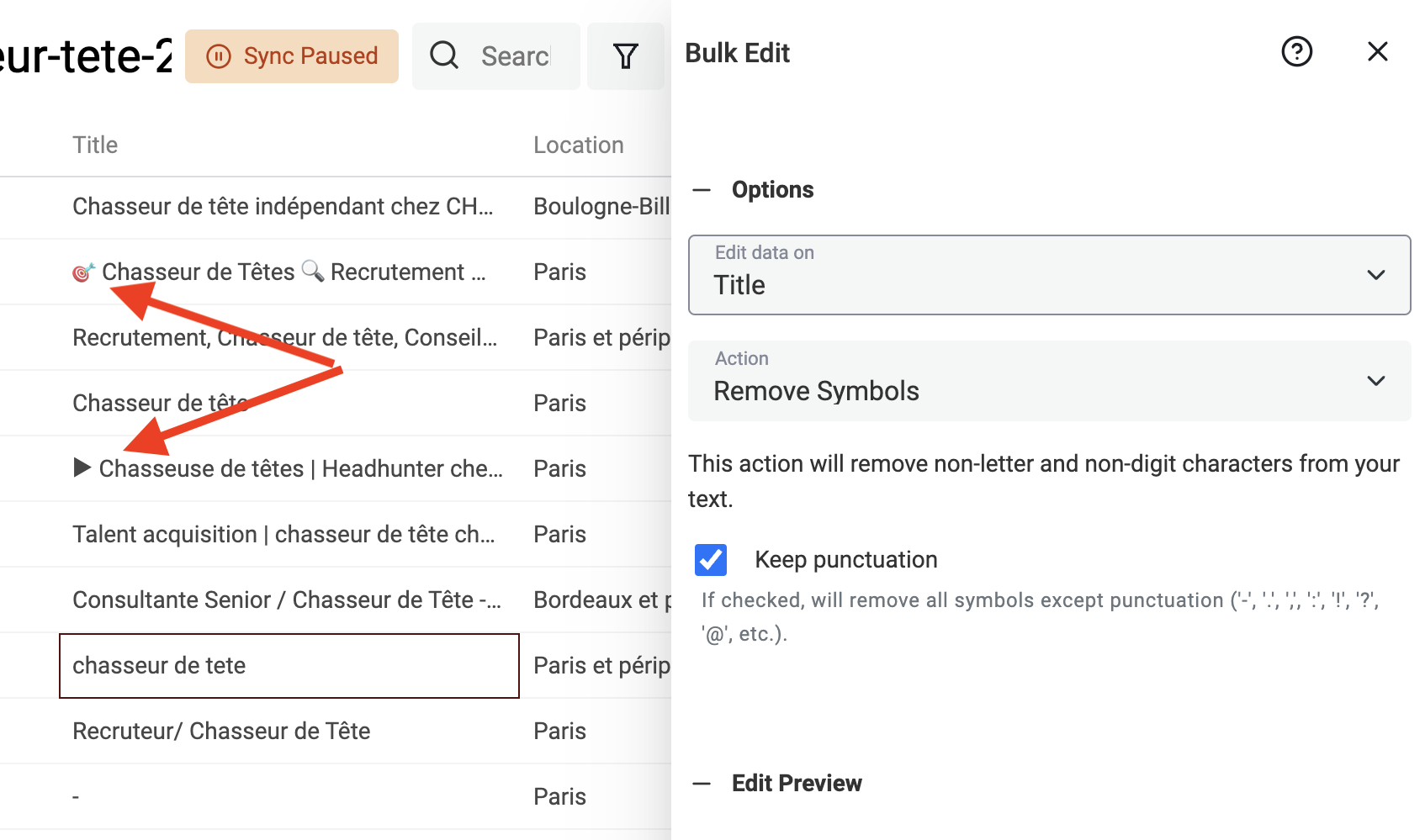
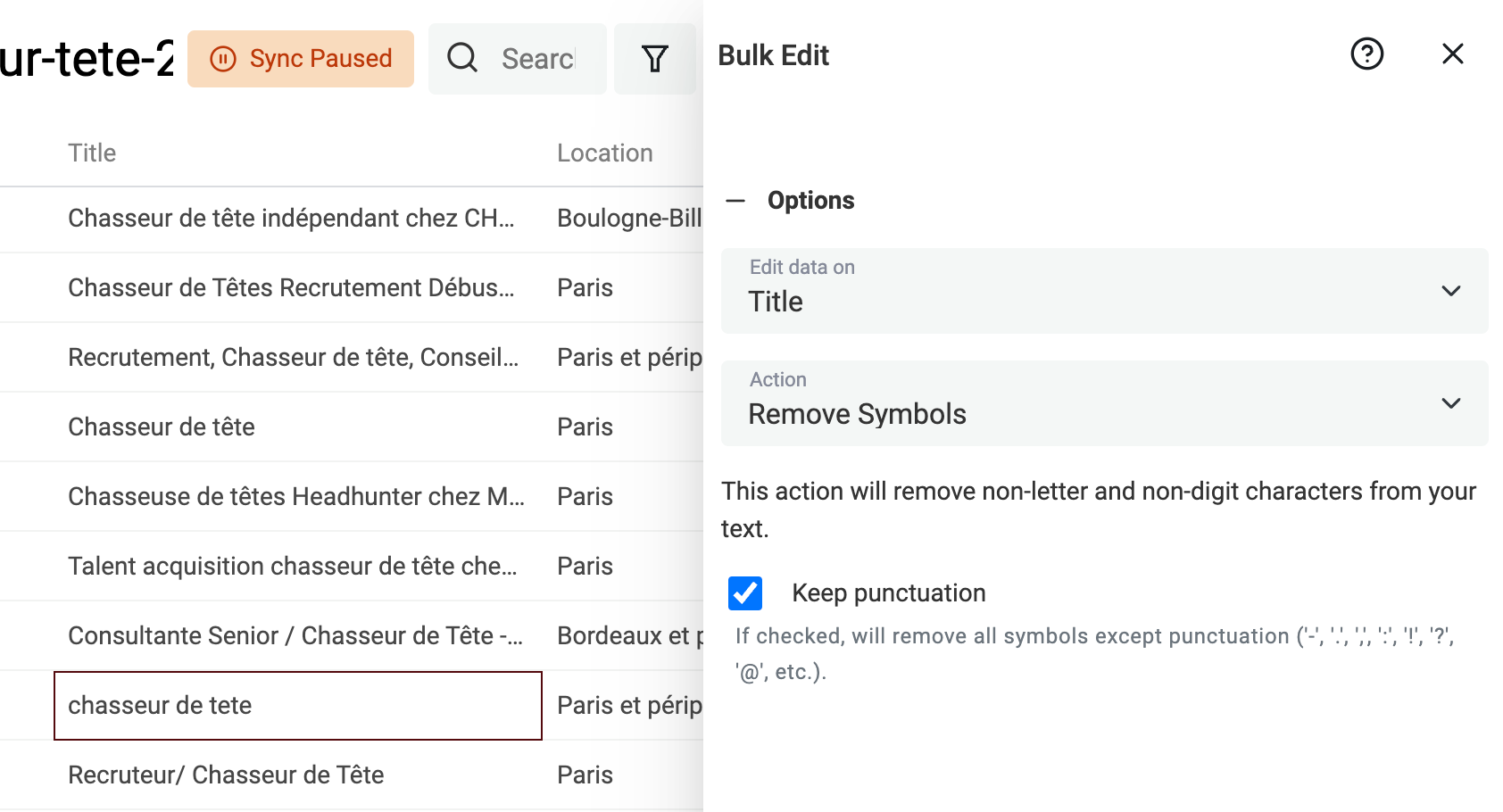
Supprimer les symboles indésirables des textes
Des textes scrapés, ou des saisies utilisateurs (ex : titres LinkedIn) contiennent parfois des symboles, emojis ou caractères spéciaux qui polluent votre traitement. Un simple smiley à la fin d’un nom peut bloquer votre algorithme de déduplication.
Datablist intègre une fonction native pour supprimer tous les symboles non textuels.
Cliquez sur "Bulk Edit" dans "Edit", choisissez une propriété texte puis "Remove symbols".
Si l’aperçu vous convient, lancez la transformation.
Normaliser avec Recherche & Remplacement (Find and Replace)
Pour travailler vos listes de prospects, il faut normaliser vos données :
- Normaliser les intitulés de poste
- Normaliser pays, villes
- Uniformiser les URLs
- Etc.
L’objectif : transformer un champ texte libre en un champ normalisé, ou transformer des textes complexes (URL complètes) en version standardisée (domaine principal).
Datablist propose pour ça une fonction Recherche & Remplacement avancée, compatible avec les regex (expressions régulières).
Quelques exemples pour nettoyer vos données :
Supprimer les paramètres d’URL (query params)
Les URL scrapées comportent souvent des paramètres inutiles. Les enlever vous permet d’obtenir des URL propres et facilite la déduplication par URL.
Pour les supprimer, cochez "Match using regular expression" puis utilisez cette regex avec une valeur de remplacement vide :
\?.*$
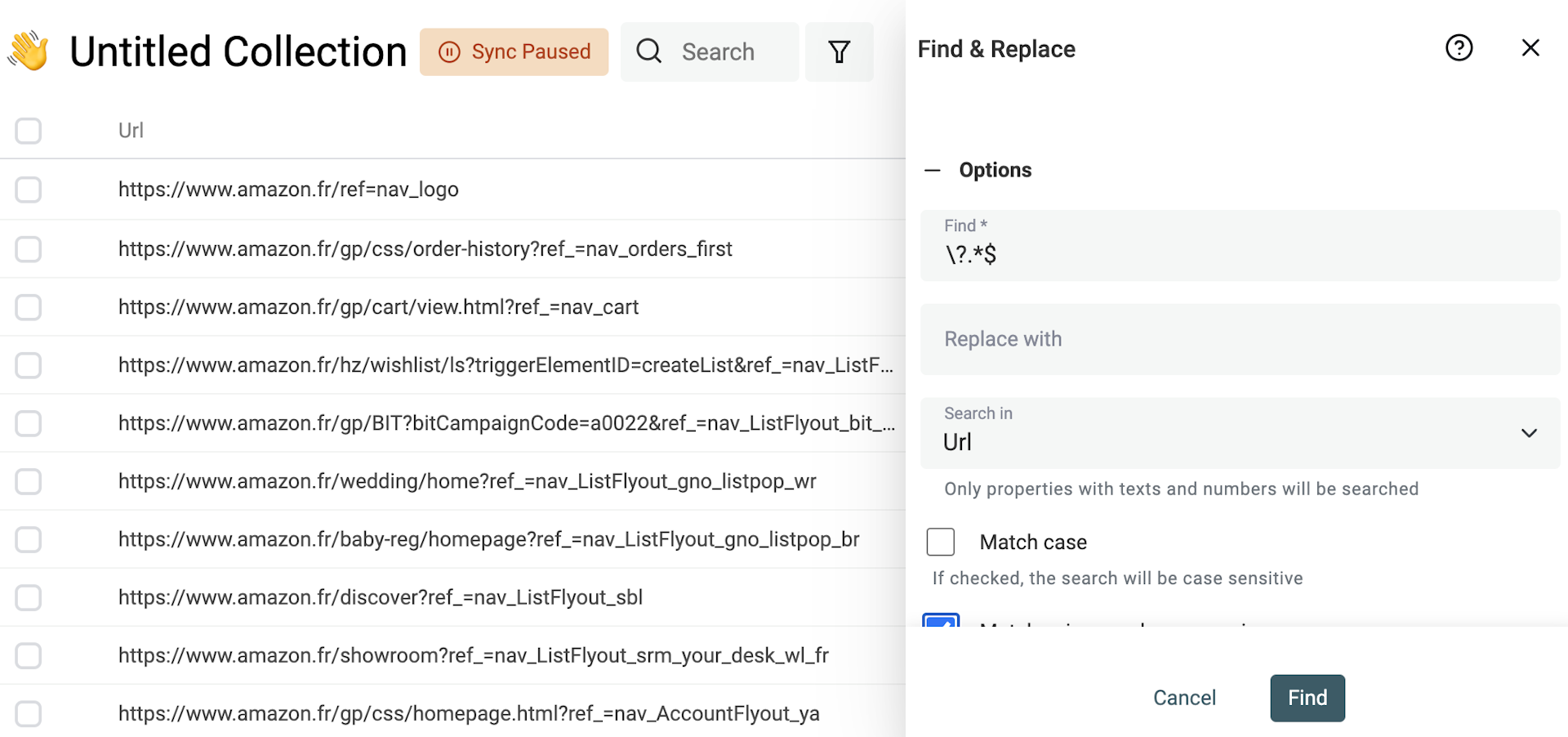
Appliquez sur vos propriétés d’URL.

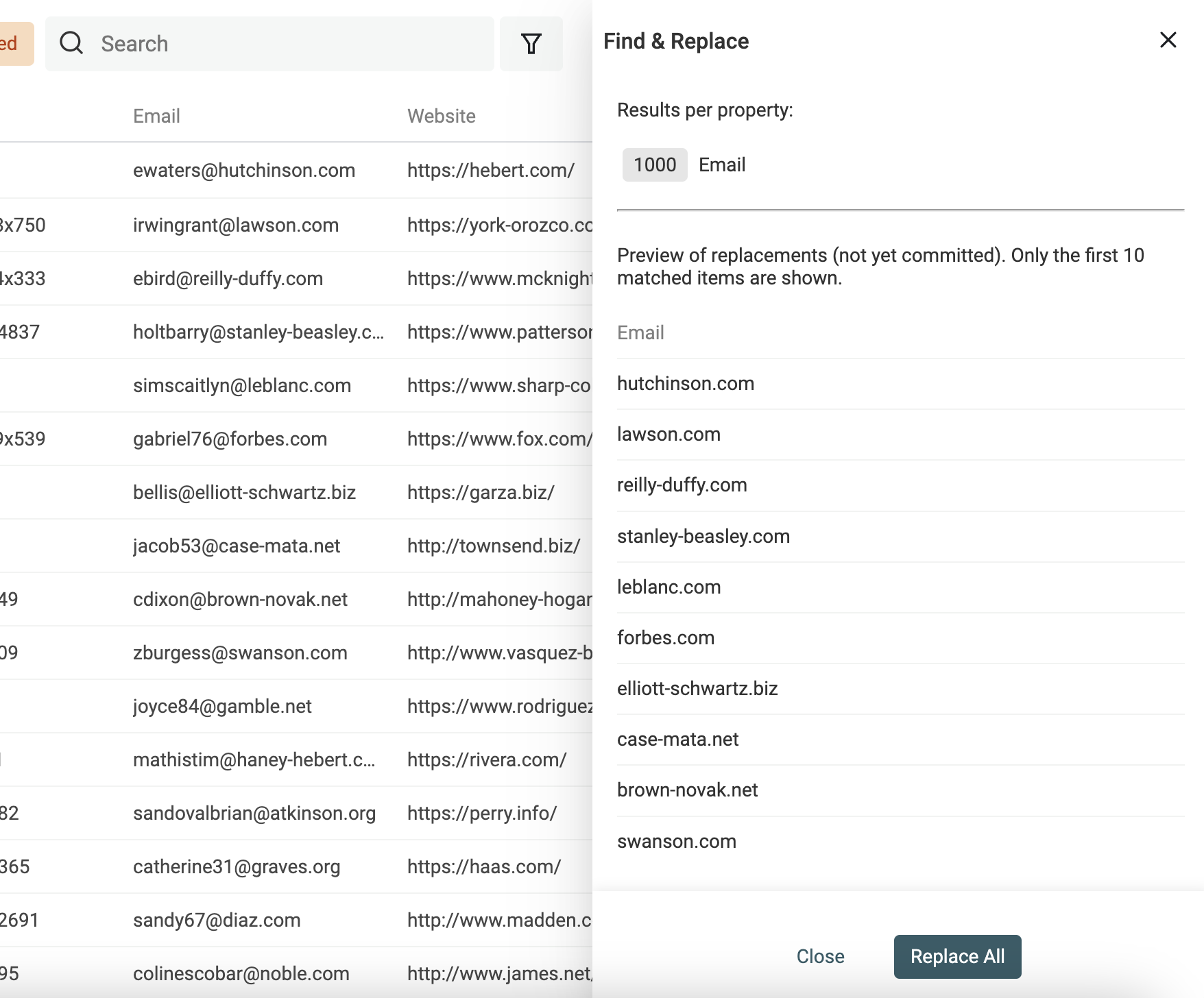
Extraire un domaine d’email
Un autre usage : obtenir le domaine d’un email avec une regex.
Dupliquez d’abord la propriété email. Puis :
^(\w)*@

Scinder un nom complet en prénom et nom de famille
Lorsque vous scrapez des listes de leads, vous obtenez un champ "Full Name" qu’il faut séparer en "Prénom" et "Nom". Faire ce découpage correctement est crucial.
Séparer prénom/nom permet d’être plus personnel en cold emailing, de trouver le genre du contact, ou d’obtenir un titre académique.
La séparation n’est pas toujours simple. Heureusement, Datablist intègre un outil qui découpe "Name" en deux valeurs selon l’espace.
Démarrez l’outil "Split Property" du menu "Edit".
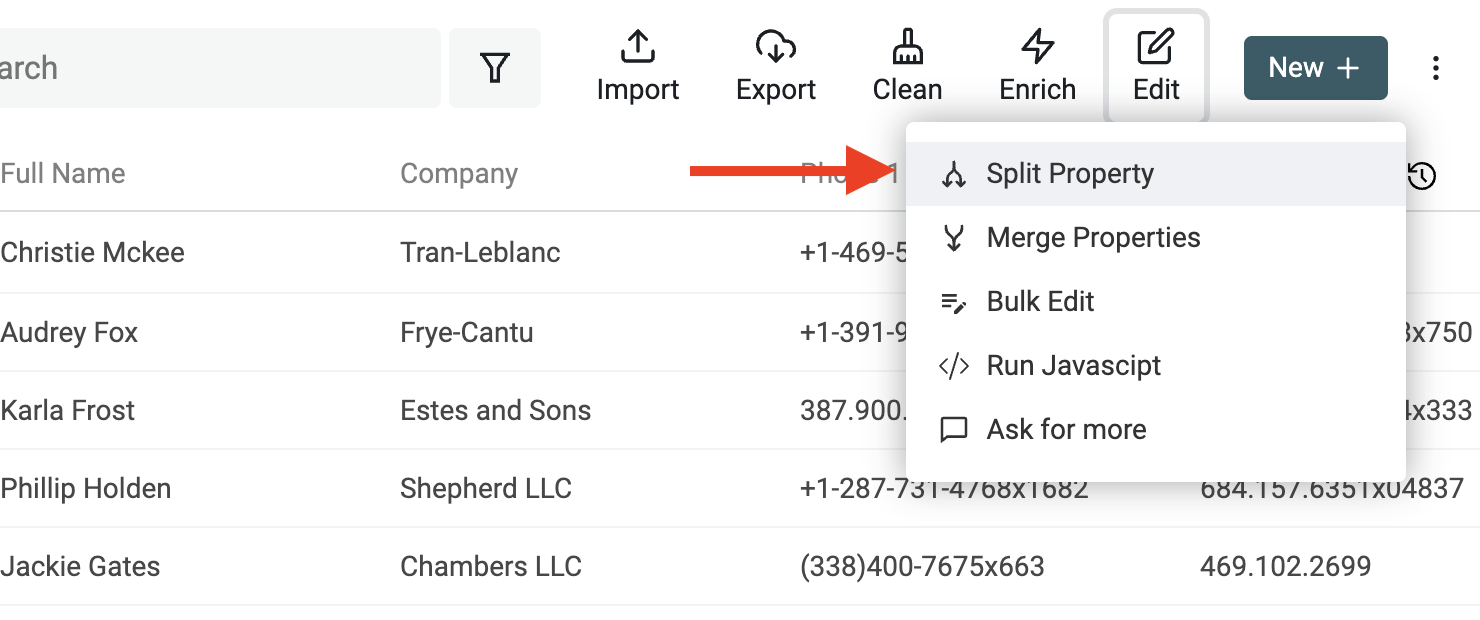
Sélectionnez la propriété à parser. Indiquez Espace comme séparateur. Saisissez 2 pour le nombre maximum de parties.
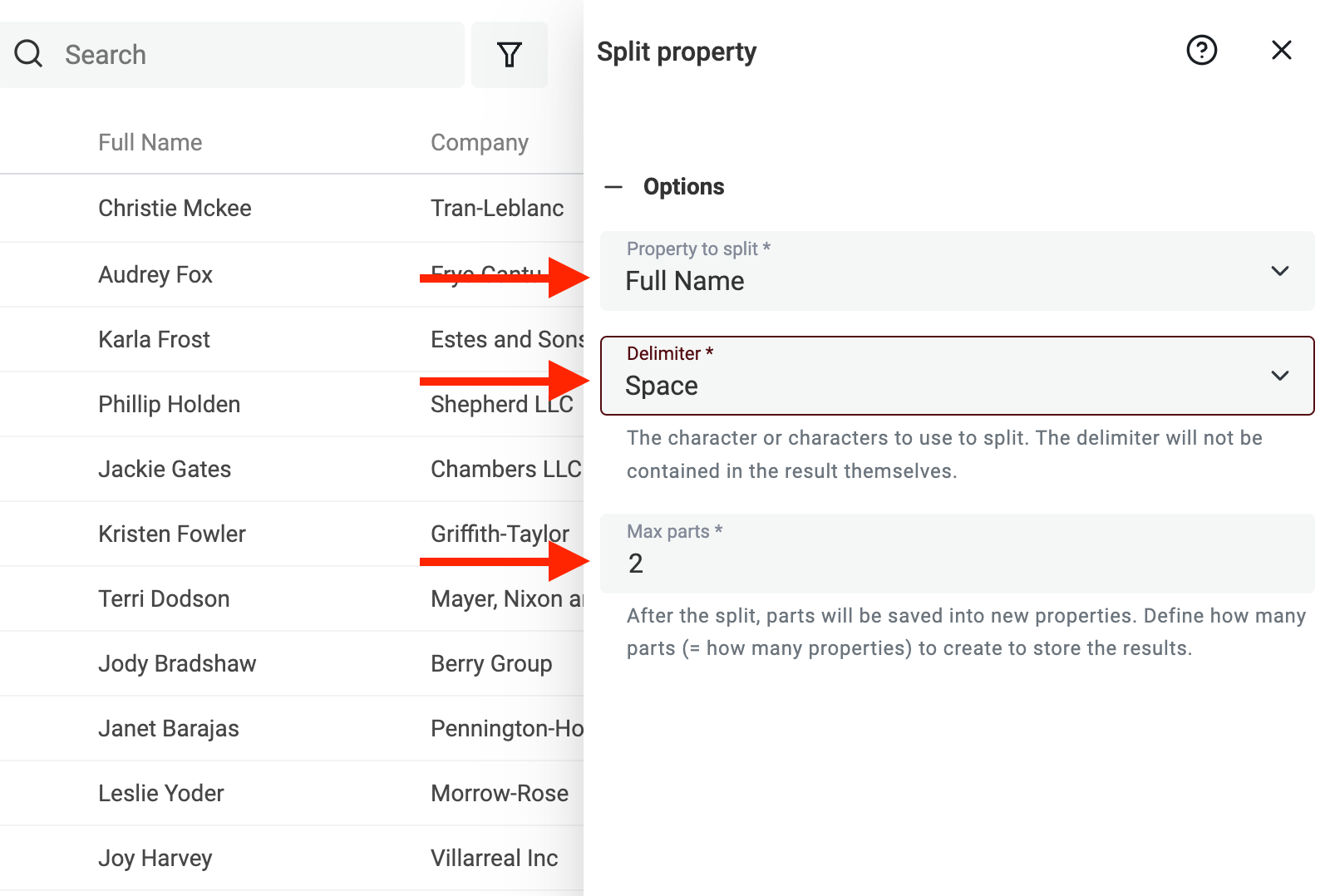
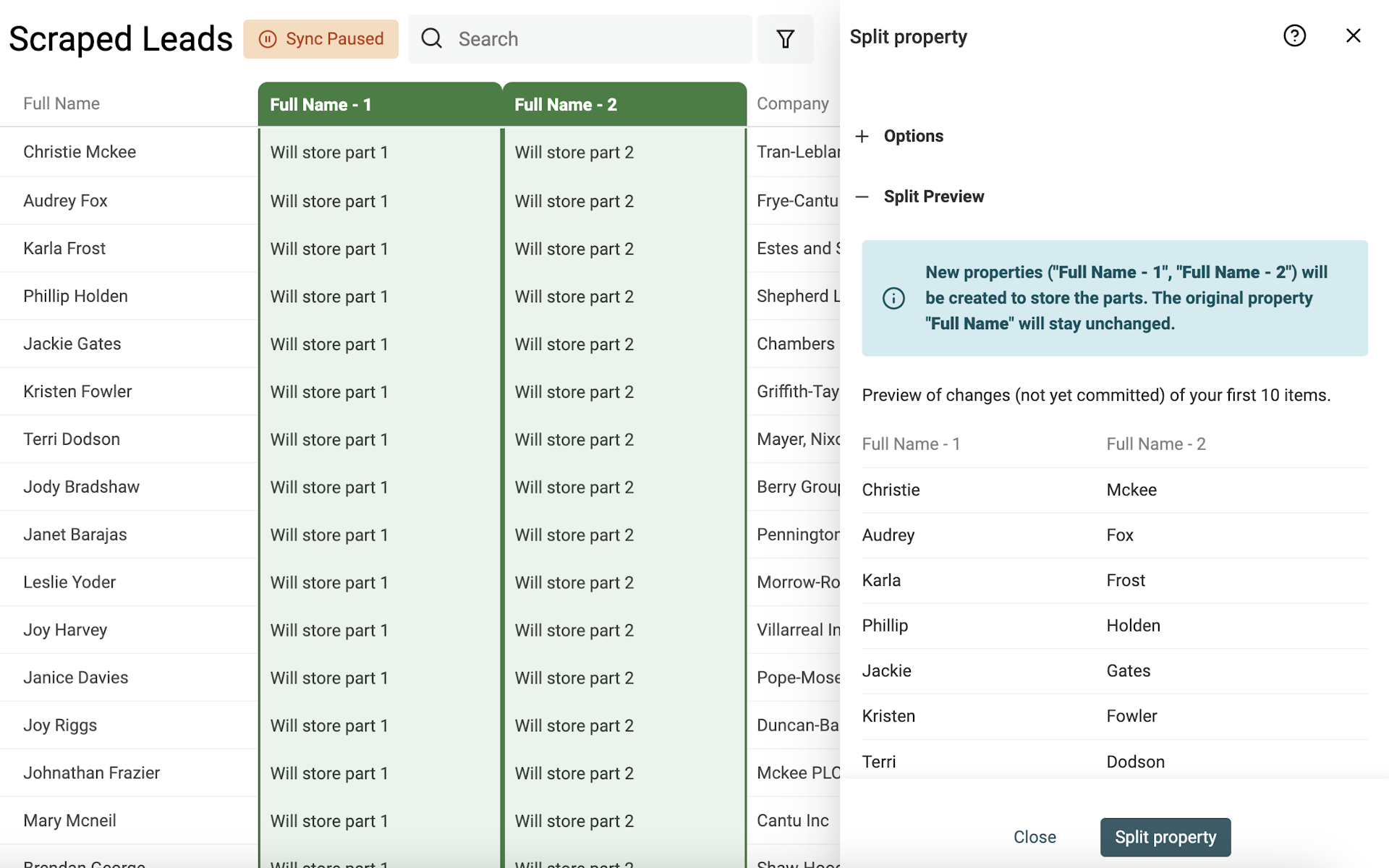
Lancez l’aperçu. Datablist traite les 10 premières entrées. Si le résultat est OK, cliquez "Split Property".
Renommez les deux propriétés créées en "First Name" & "Last Name".
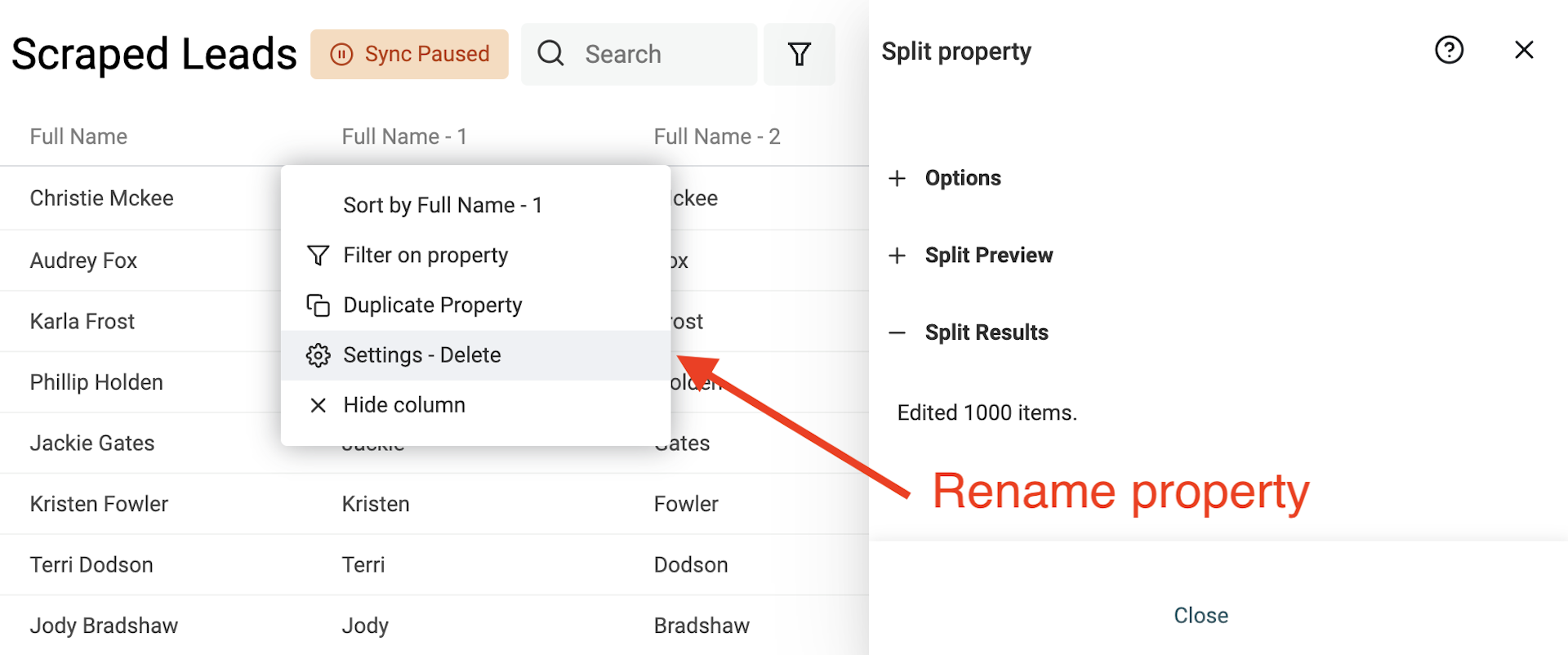
Cet exemple part d’un nom typiquement occidental (prénom puis nom). Si vos données comportent d’autres conventions (plusieurs prénoms, titres, suffixes), il faudra adapter l’algorithme.
Dédoublonnage des données
Datablist propose un moteur de déduplication hyper efficace. Vous pouvez détecter des lignes similaires sur une ou plusieurs colonnes, et fusionner automatiquement sans perdre de données.
Pour lancer la déduplication, cliquez sur "Duplicate Finder" dans le menu "Clean".
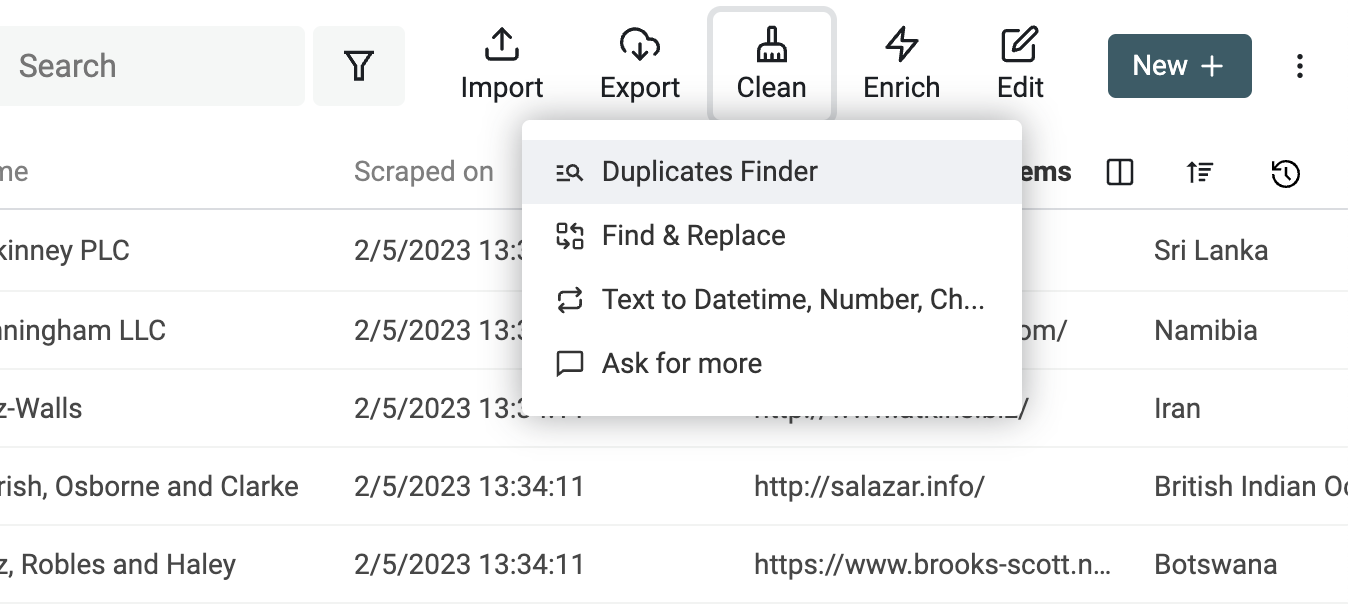
Choisissez les propriétés de comparaison.
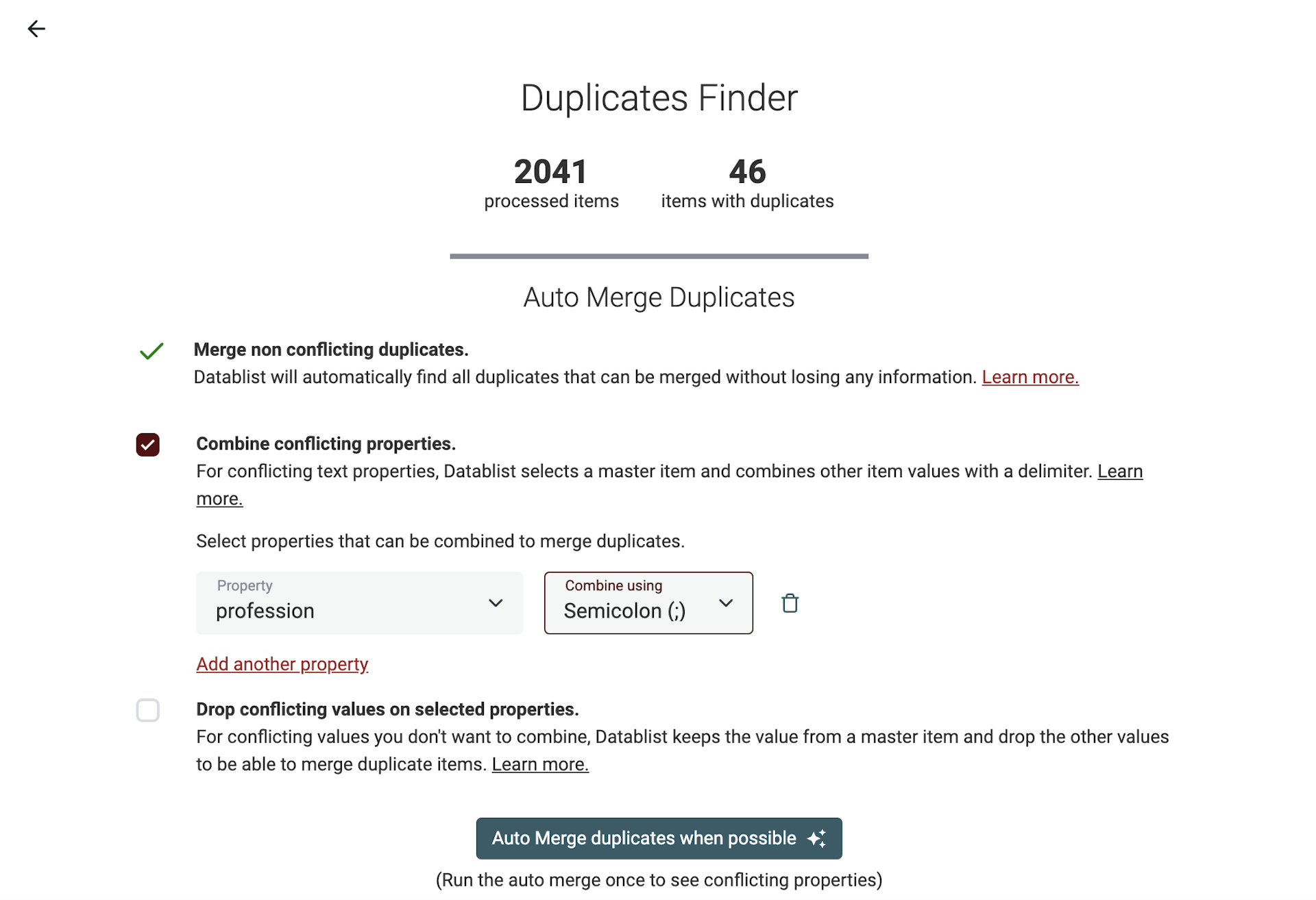
Dans les résultats, lancez l’"Auto Merge" avec l’option "Merge non-conflicting duplicates". Les doublons faciles sont fusionnés, et les conflits sont listés.
L’algorithme propose deux options pour les conflits : "Combine conflicting properties" (valeurs séparées par un délimiteur) ou suppression au profit du master item.
Valider les adresses email
Les données scrapées sont parfois anciennes, erronées, ou invalides. C’est spécialement vrai pour les adresses email.
Lorsque la donnée est saisie par l’utilisateur, vous pouvez avoir des emails fake, ou des adresses de fournisseurs temporaires.
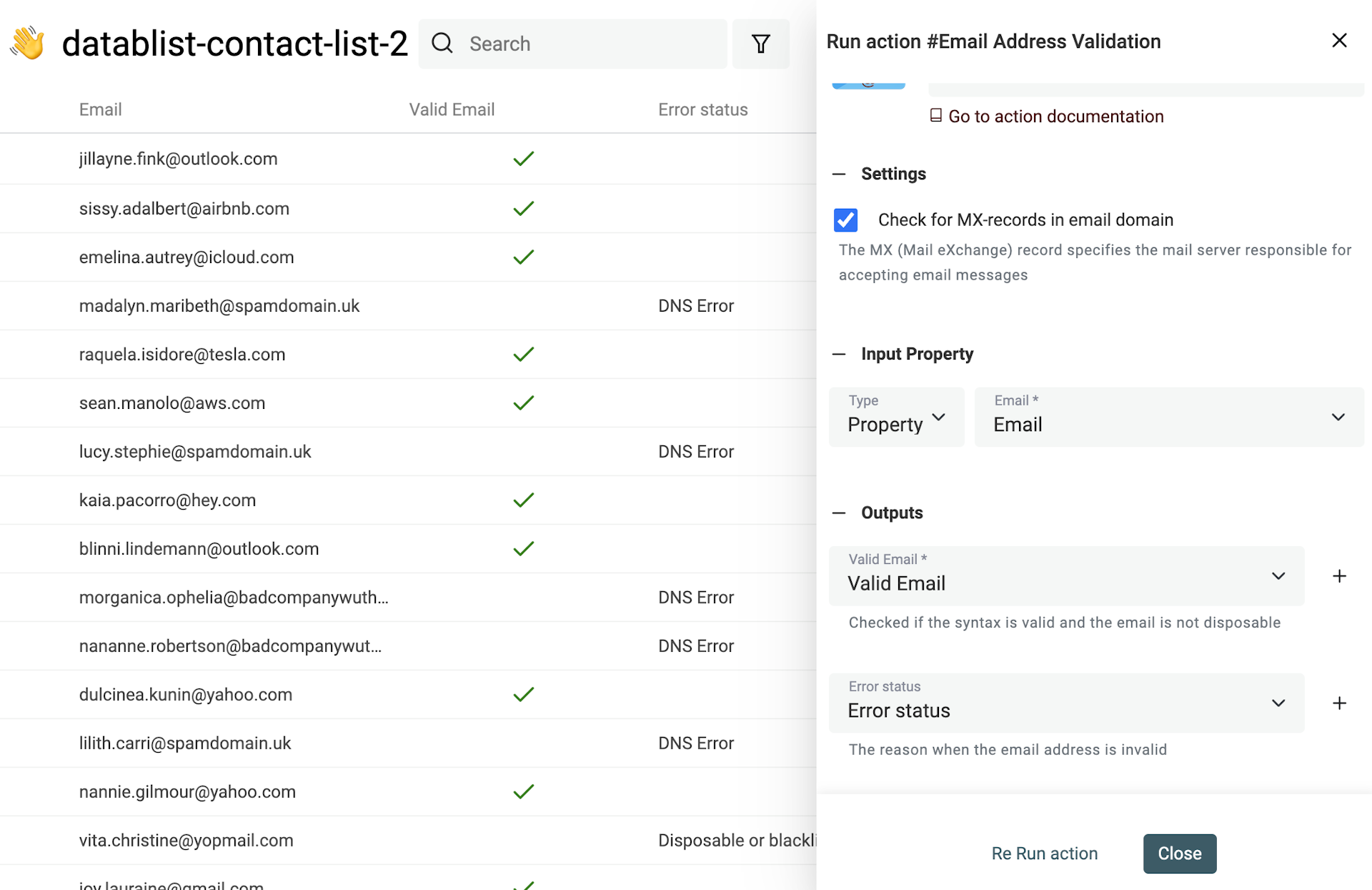
Datablist intègre une validation d’emails qui vérifie des milliers d’emails en un clic.

La vérification propose :
- Analyse syntaxique de l’email – Vérifie la conformité avec la norme IEFT et analyse la structure (présence du @, domaine valide, etc.)
- Détection des fournisseurs jetables – Identifie les emails de type Mailinator, Temp-Mail, YopMail…
- Vérification des MX du domaine – Vérifie si le domaine est existant et possède bien des enregistrements MX (serveur mail). En cas d’absence, l’email est déclaré invalide.
- Segmentation email pro/perso – Pour distinguer business emails et emails personnels parmi vos leads ou utilisateurs.
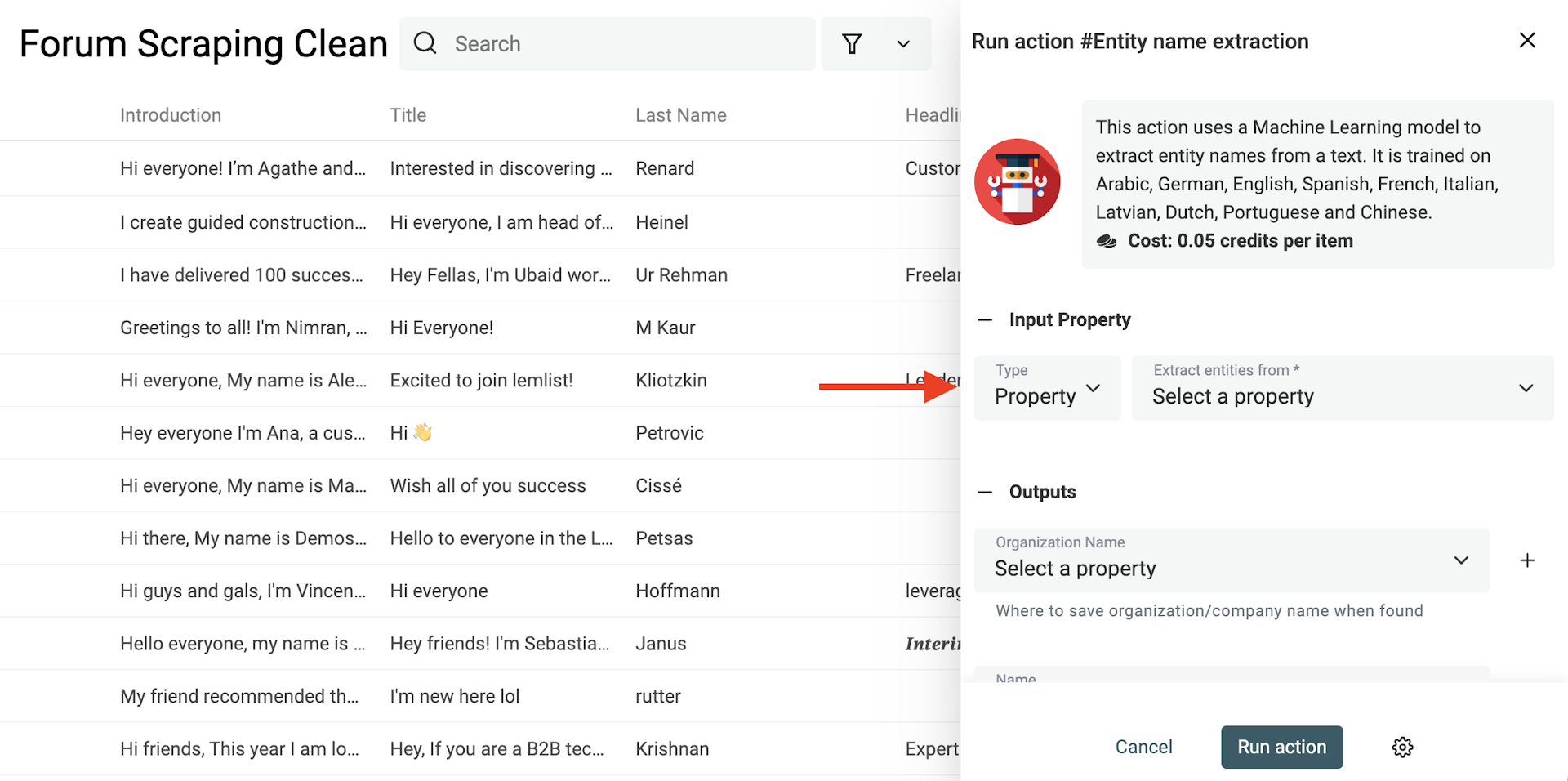
Extraire des noms de personne ou d’entreprise de textes scrapés
En scrapant des textes, il est très utile de pouvoir isoler des noms de personnes ou d’entreprises. Ces infos permettent d’enrichir vos leads, d’analyser la concurrence… Mais extraire des noms dans du texte libre est complexe : conventions de nom différentes selon les pays, abréviations, titres, fautes, etc.
Une méthode consiste à utiliser la reconnaissance d’entités nommées (Named Entity Recognition ou NER), une technique IA/NLP qui repère et classe les entités (personne, entreprise, lieu…). Les modèles NER sont entraînés pour gérer plusieurs langues et variations.
Datablist propose un enrichment "Named Entity Recognition" (NER) directement sur vos textes. Il est entraîné en arabe, allemand, anglais, espagnol, français, italien, letton, néerlandais, portugais et chinois !
Choisissez "Entity name extraction" dans le menu "Enrichments".
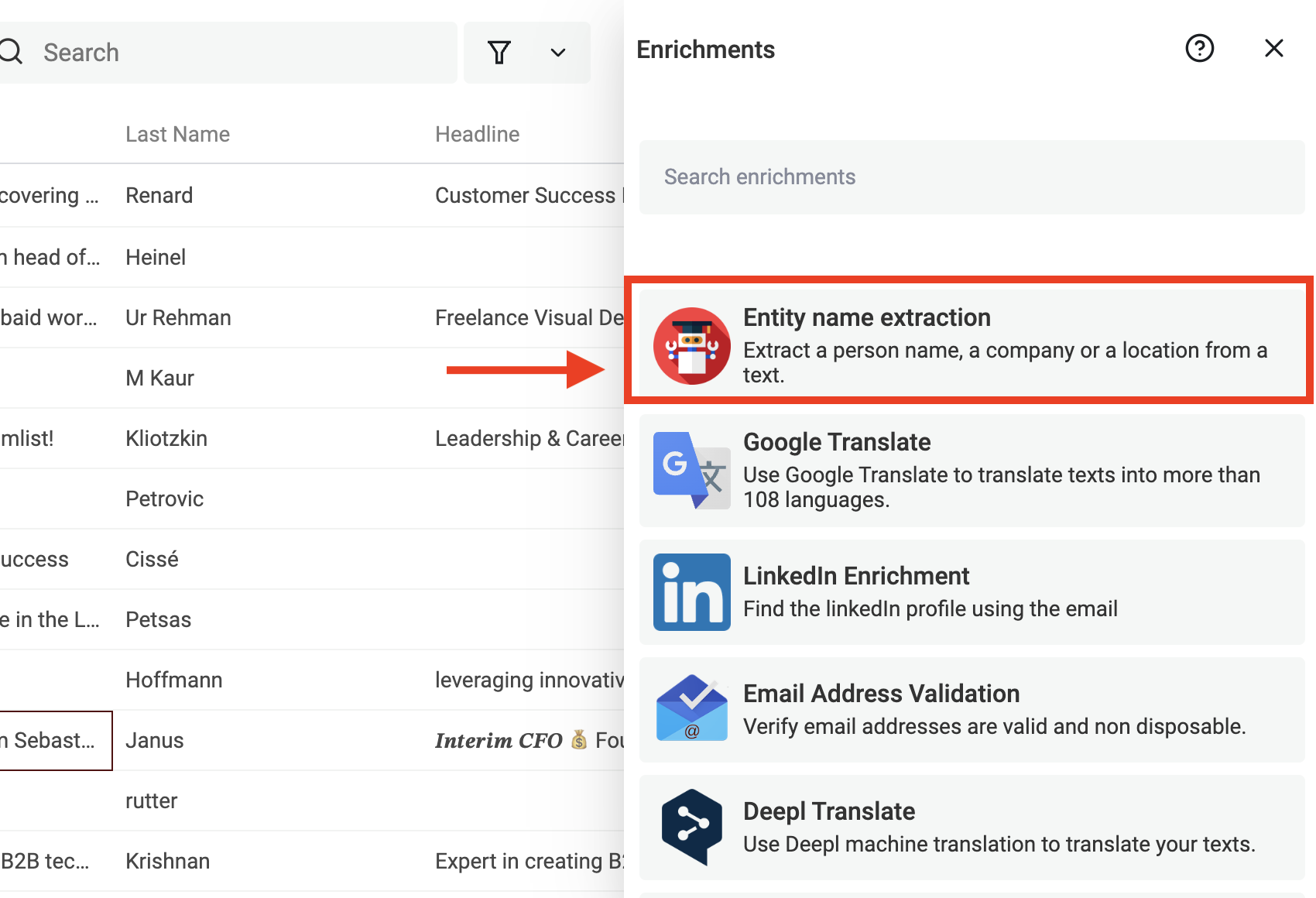
Dans l’input, sélectionnez la colonne texte à analyser.
Pour chaque type de nom extrait, cliquez sur "Create a new property".
L’extracteur NER Datablist détecte :
- Organization Name : Entreprises, organismes...
- Person Name : Noms ou prénoms et noms combinés
- Location : Villes, pays, lieux
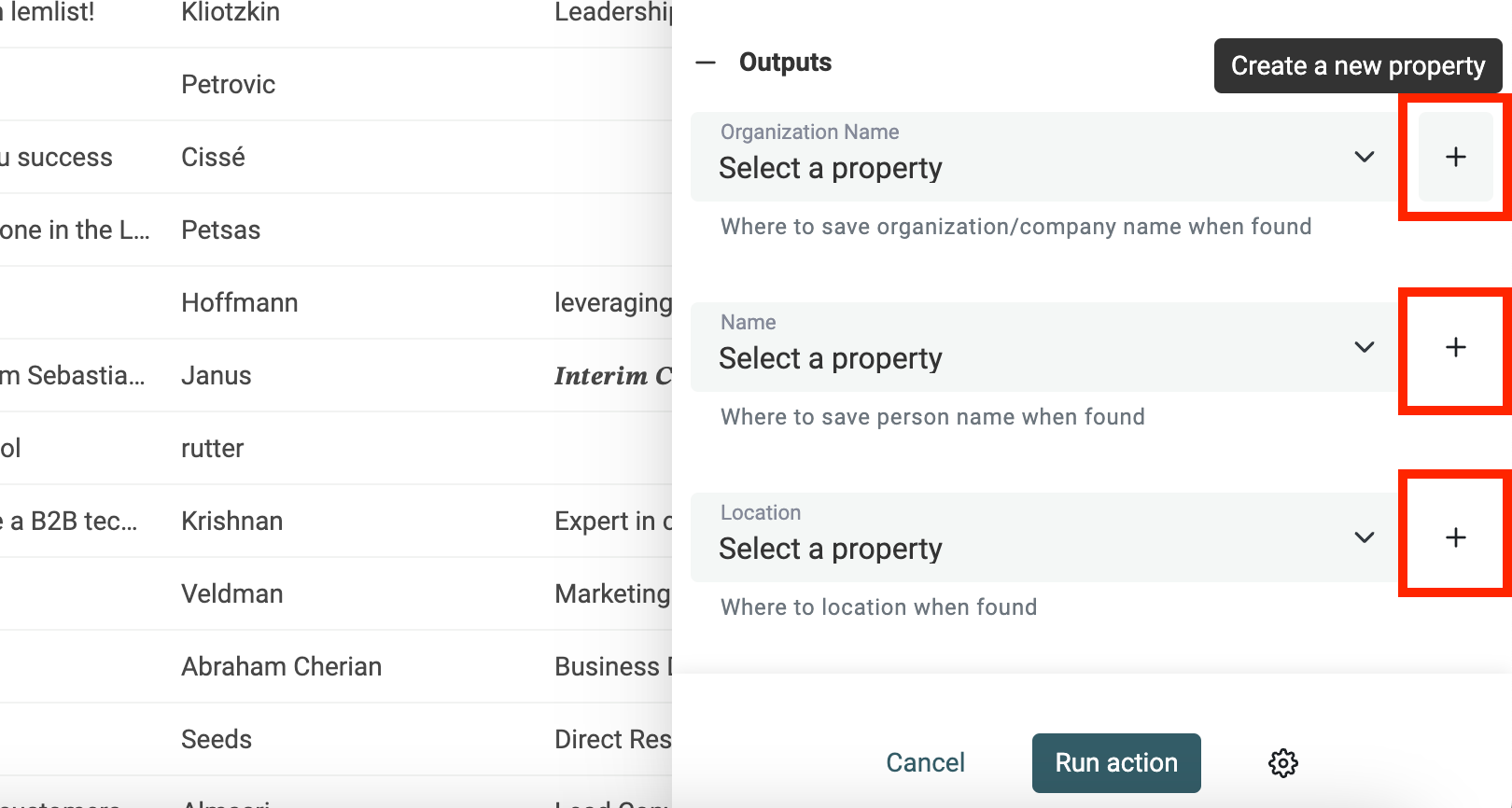
Lancez l’enrichment.
Besoin d’aide pour nettoyer vos données ?
Je cherche toujours des cas d’usage ou problèmes à traiter. Contactez-moi pour partager vos besoins.