
Vous avez exporté vos données d'une application dans un fichier CSV et vous souhaitez vous débarrasser des doublons ? Vous avez concaténé plusieurs fichiers CSV en un seul gros fichier et vous avez maintenant besoin de le nettoyer ? Ou alors, vous disposez de plusieurs sources de données qui ne sont plus synchronisées et souhaitez fusionner toutes ces versions en une seule liste. Microsoft Excel ou Google Sheets ne résoudront pas votre problème car ces outils ne permettent pas d'imposer une contrainte d'unicité sur une colonne.
Sur un petit fichier CSV, cette tâche peut se faire manuellement. Sur des fichiers plus volumineux, cela prendrait des heures ligne par ligne, avec un risque important d'erreur humaine.
Ce qu'il vous faut, c'est un outil capable de détecter automatiquement les lignes CSV ayant des valeurs similaires sur une ou plusieurs colonnes. Une fois les doublons identifiés, vous pouvez les éditer ou les fusionner pour consolider leurs données et supprimer les doublons.
Fusionner les doublons de fichiers CSV

Datablist est l'outil idéal pour réaliser des opérations sur vos données impossibles avec les tableurs classiques. Utilisez-le lorsque vous recherchez un éditeur CSV en ligne efficace.
Dans ce guide, nous allons utiliser 2 fichiers CSV contenant chacun des milliers d'entrées. Nous allons les charger dans une seule collection et dédupliquer les lignes selon l'une des 4 colonnes. Ce processus fonctionne également sur un seul fichier CSV.
Pour télécharger les fichiers CSV de ce tutoriel : Fichier CSV 1 et Fichier CSV 2
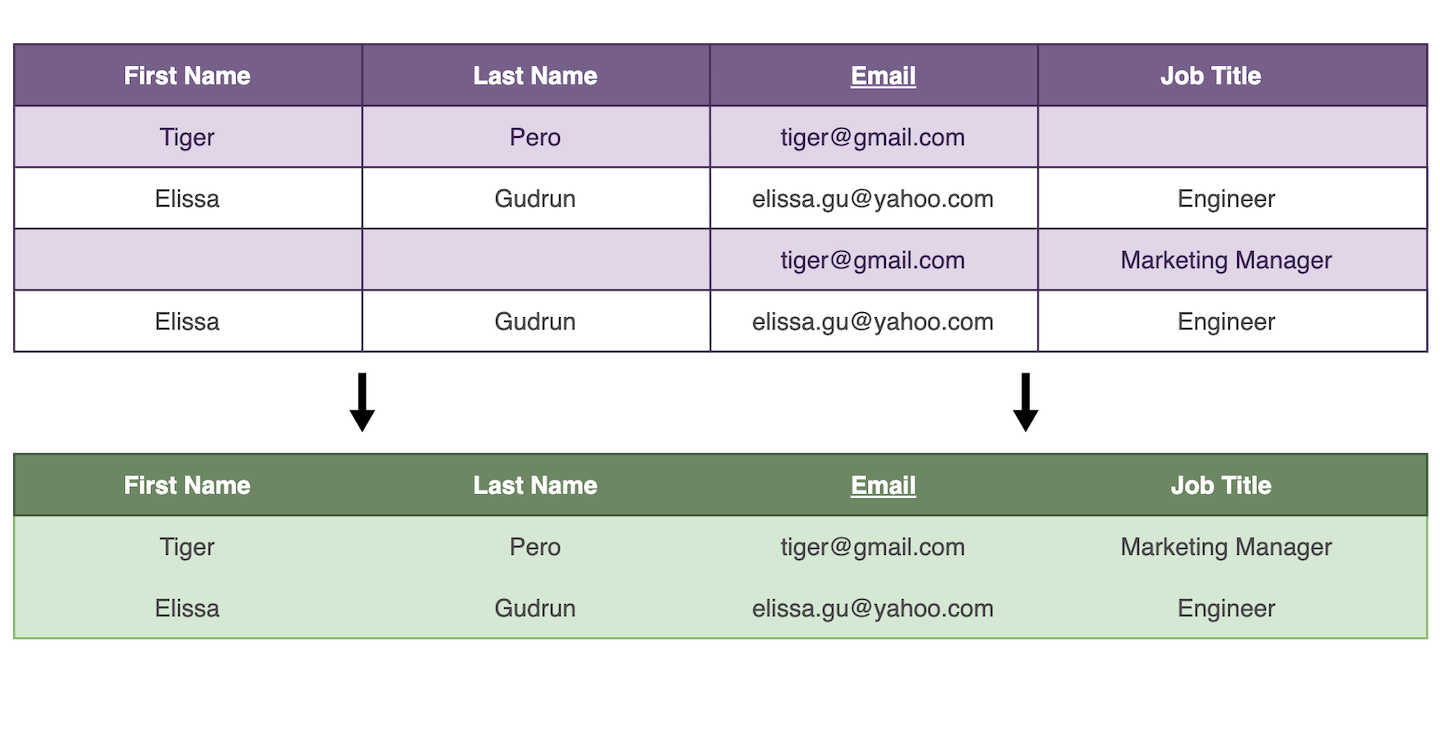
Chaque fichier CSV contient 4 colonnes : First Name, Last Name, Email, Job Title. Nous voulons fusionner les entrées qui partagent la même adresse email.
Le processus de fusion des doublons se résume ainsi :
- Importez vos fichiers CSV dans une collection Datablist
- Sélectionnez les propriétés pour l'identification des doublons
- Fusionnez automatiquement les doublons sans conflit
- Fusionnez manuellement les doublons restants
Étape 1 : Importez vos fichiers CSV dans une collection Datablist
Créez une nouvelle collection
La première étape consiste à charger le fichier CSV dans Datablist. Ouvrez Datablist (aucune inscription requise) pour débuter.
Pour créer une nouvelle collection, cliquez sur le bouton "New collection" avec le +. Une fois la collection créée, donnez-lui un nom et une icône.
Cliquez ensuite sur le bouton Import CSV.
Créez les propriétés pour votre fichier CSV
Une fois le fichier CSV chargé, vous pouvez créer les propriétés de votre collection à partir des noms de colonnes du CSV. Datablist liste chaque colonne trouvée dans le fichier afin que vous puissiez vous assurer qu'une propriété correspondante est bien créée.
Le format CSV n'impose pas de type de données. Lors de la lecture du CSV, tout est lu comme du texte. Pour permettre un meilleur filtrage et tri, Datablist tente de détecter les types de données sur les 100 premières lignes. Par exemple, s'il ne trouve que des chiffres, il définit le type sur nombre. Idem pour les dates, emails, cases à cocher (valeurs true ou false), etc.
Vérification et import
Dans l'étape de vérification, les lignes du CSV sont listées directement à partir du fichier. Vérifiez que les données sont correctement formatées et cohérentes. Puis cliquez sur le bouton "Import items" pour terminer l'import ! 💪
Recommencez pour les autres fichiers CSV
Votre collection est maintenant prête avec ses propriétés configurées. Effectuez à nouveau la procédure "Import CSV/Excel" pour importer vos autres fichiers CSV ou Excel dans la même collection.
Étape 2 : Identifier les doublons
Après avoir chargé les fichiers CSV, la seconde étape consiste à rechercher des valeurs en double. Depuis la liste des données de la collection, cliquez sur le bouton "Duplicates Finder" dans le menu "Clean" (en haut à droite).
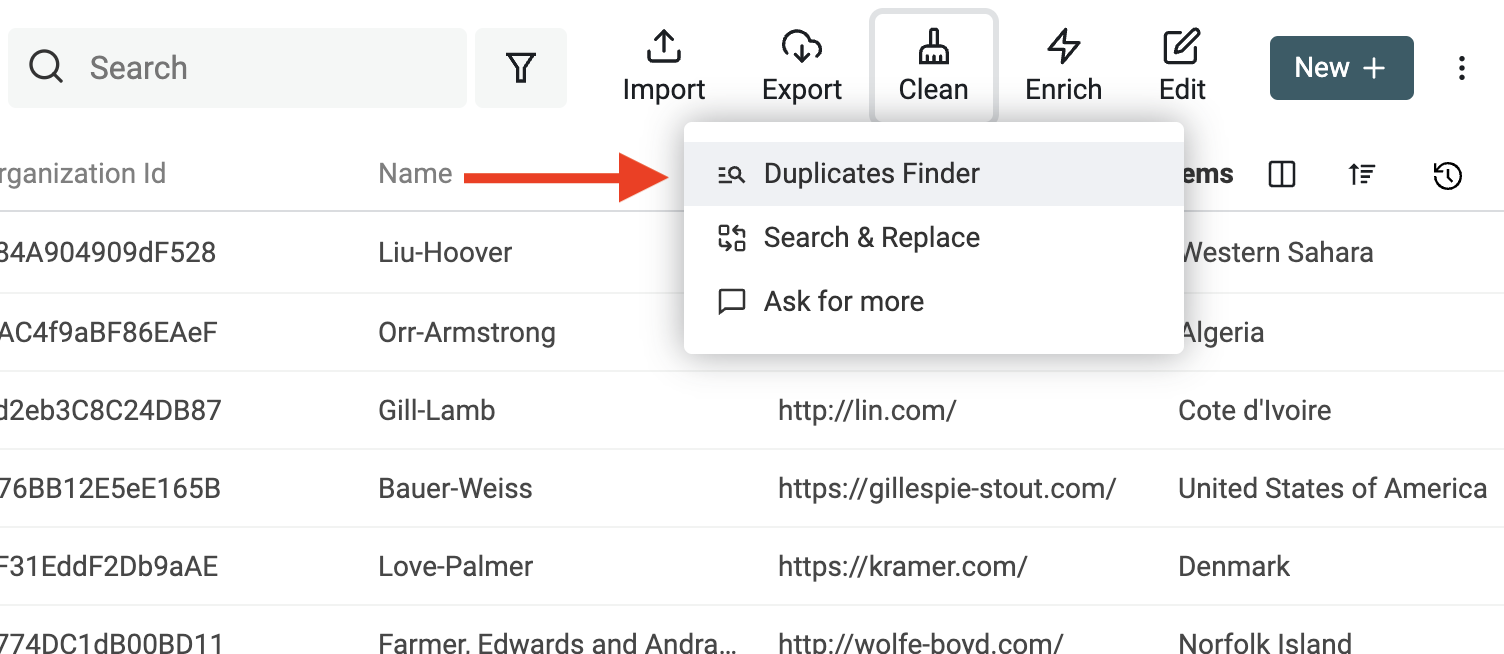
Deux modes sont possibles :
- All Properties : Dans ce mode, Datablist recherche les éléments ayant des valeurs similaires pour toutes les propriétés. Deux éléments seront considérés comme semblables si l'ensemble de leurs propriétés concordent.
- Selected Properties : Avec ce mode, vous sélectionnez précisément les propriétés utilisées pour identifier les similitudes. Deux éléments seront considérés comme semblables si toutes les propriétés sélectionnées présentent des valeurs similaires.
Ici, la propriété email suffit à identifier un contact : optez pour le mode Selected Properties avec la propriété email.
Une fois l’analyse terminée, Datablist liste tous les doublons basés sur le champ email. Pour chaque entrée ayant un ou plusieurs doublons, vous pouvez :
- Éditer l'élément : Utilisez les valeurs issues des entrées incomplètes pour fusionner les données en un seul élément.
- Fusionner les doublons : Fusionnez les valeurs des éléments secondaires vers un élément principal.
- Supprimer les éléments superflus : Quand les doublons n’apportent aucune valeur, supprimez-les simplement.
Étape 3 : Fusionner et combiner les doublons automatiquement
En général, il est souhaitable de fusionner toutes les lignes dupliquées du CSV en un seul élément pour consolider les informations, sans perdre aucun champ au passage.
Datablist intègre un algorithme automatique pour fusionner la plupart des doublons sans perte de données. Pour les doublons restants, un assistant de fusion manuel est disponible.
Dédupliquer de grandes listes prend souvent du temps. Datablist Auto Merger traite vos doublons en masse et les fusionne automatiquement lorsque cela est possible.
Trois algorithmes de fusion sont à votre disposition : Fusion des lignes sans conflit, Combinaison des valeurs en double et Suppression des valeurs en conflit. Consultez notre documentation sur l'identification des doublons pour approfondir.
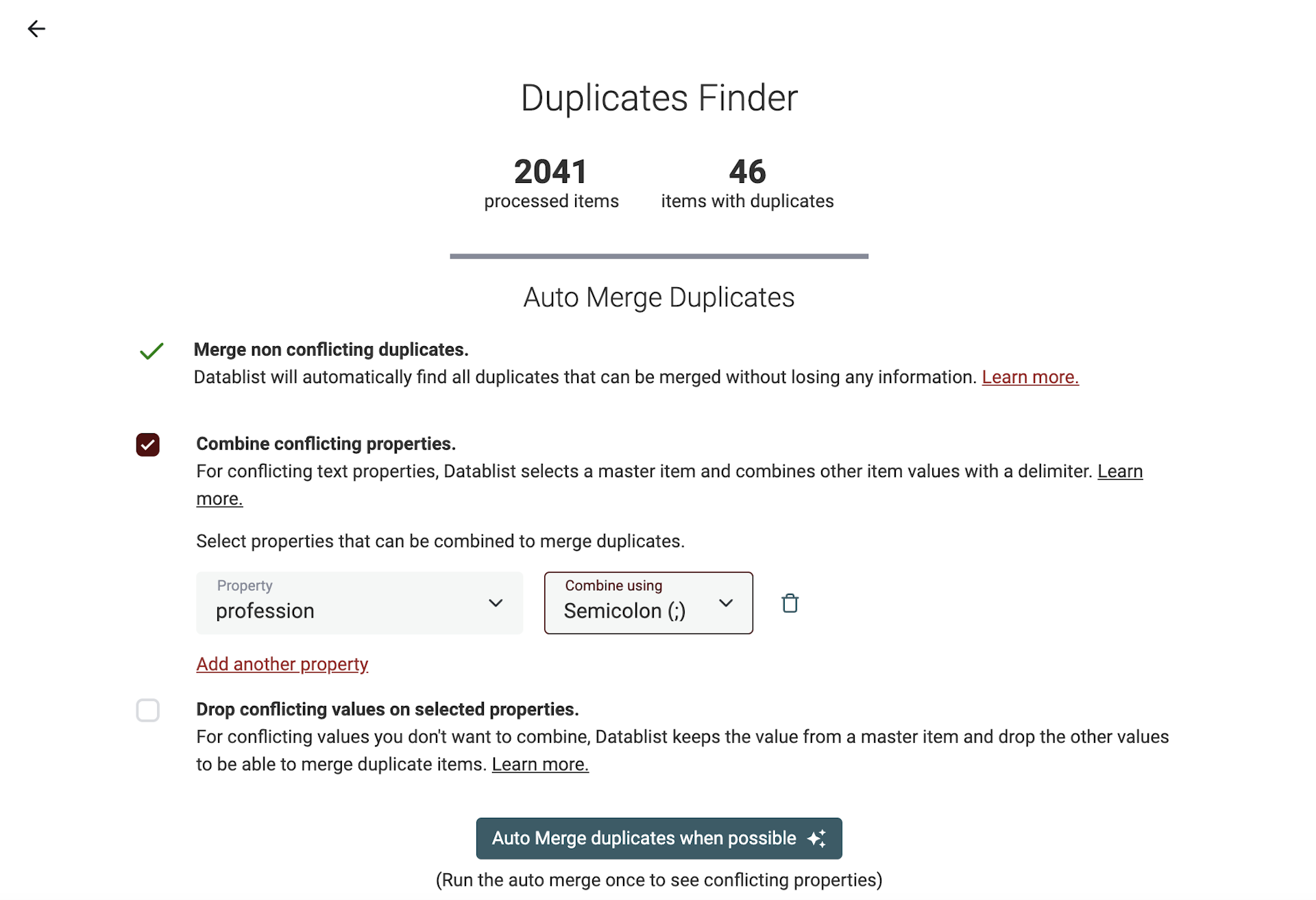
Commencez par lancer "Merge non conflicting duplicates" pour visualiser les propriétés qui sont en conflit.

Fusion des lignes sans conflit
L'algorithme "Merge non-conflicting duplicates" effectue une fusion intelligente. Il regroupe les enregistrements ayant des valeurs similaires ou complémentaires.
Par exemple, pour les doublons suivants :
email | First Name | Last Name
james@gmail.com | James
james@gmail.com | | Bond
Sera fusionné en :
email | First Name | Last Name
james@gmail.com | James | Bond
Combiner les valeurs en double
La consolidation (ou combinaison) des valeurs en double est idéale lorsque vos doublons comportent des valeurs discordantes tout en souhaitant n'en perdre aucune lors de la fusion.
Exemple de combinaison du champ Phone avec un point-virgule :
email | Phone | First Name | Last Name
james@gmail.com | +33 1 34 65 23 | James |
james@gmail.com | 06 13 42 78 23 | | Bond
Sera fusionné en :
email | Phone | First Name | Last Name
james@gmail.com | +33 1 34 65 23;06 13 42 78 23 | James | Bond
Toute colonne contenant du texte peut être consolidée. Les délimiteurs disponibles sont : saut de ligne, point-virgule, virgule et espace. Une ou plusieurs propriétés peuvent être combinées lors de la fusion.
Fusionner les éléments en double et combiner les valeurs est parfaitement adapté au nettoyage de leads et CRM. Fusionnez tous vos leads dupliqués et combinez les propriétés Phone, Email, Notes pour obtenir une liste propre. Après l'export de votre CSV nettoyé, il ne vous reste plus qu'à le réimporter dans votre CRM.
Supprimer les valeurs en conflit
Cet algorithme conserve la valeur provenant de l'élément principal (master) et supprime les autres valeurs conflictuelles pour regrouper vos leads en un seul enregistrement.
L'élément ayant le plus de données est automatiquement désigné comme master.
Utilisez l'option drop conflicting values pour :
- Les propriétés techniques comme
Account Idqui nécessitent une valeur unique. - Les propriétés de type "Relation" qui ne peuvent avoir plusieurs valeurs (ex:
Lead owner,Account). - Les propriétés non textuelles qui ne sont pas combinables (ex : dates telles que
Last Activity,Contacted on, ou cases à cocher).
Étape 4 : Assistant de fusion manuel
Quand il reste des doublons après l'auto fusion, utilisez l'Assistant de Fusion. Pour fusionner, cliquez sur le bouton "Manual Merging assistant" à gauche de chaque groupe de doublons.
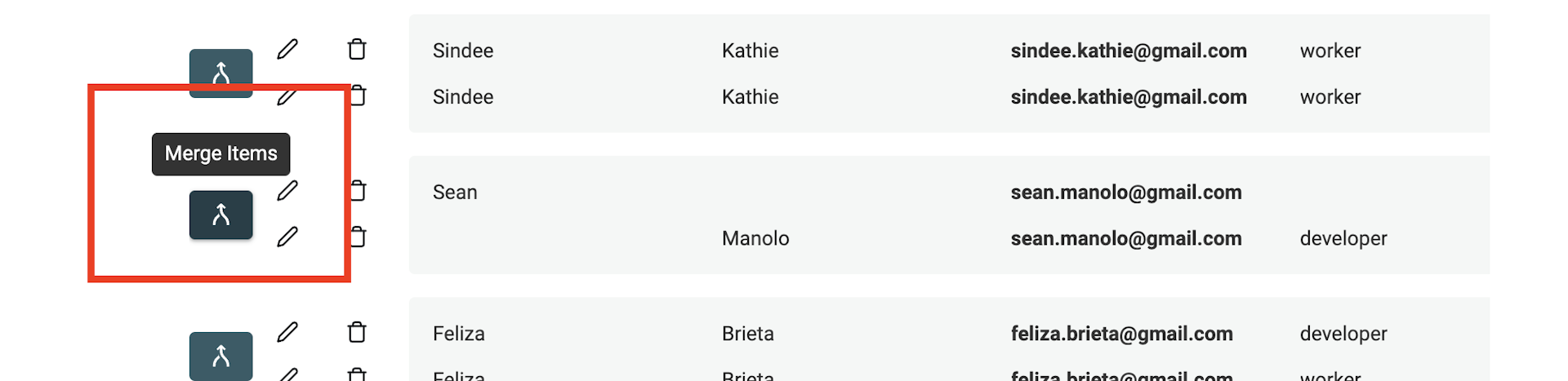
L'assistant affiche un "Primary Item" à droite et, à gauche, les "Secondary Items". Datablist choisit celui contenant le plus de données comme "Primary item".
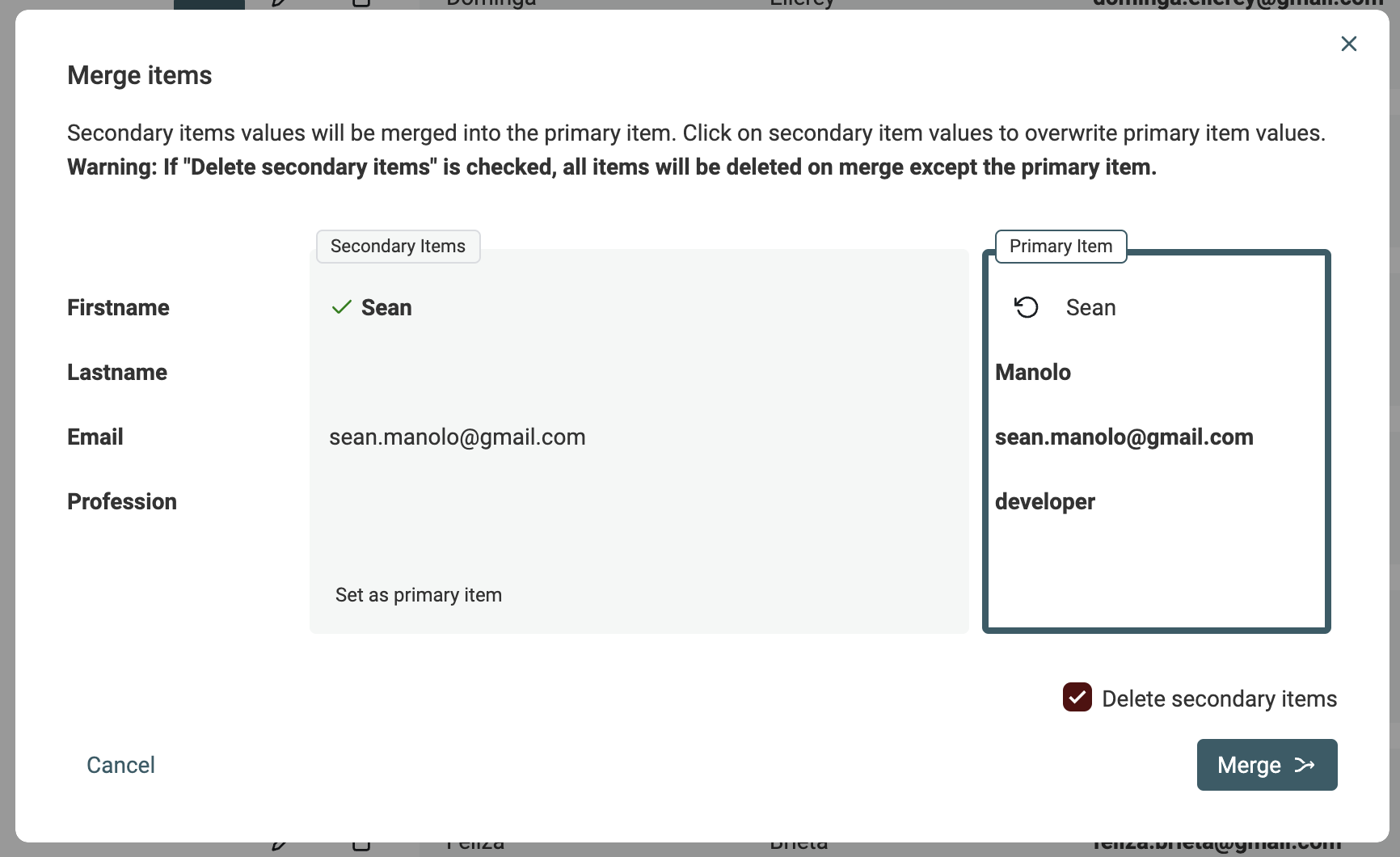
Quand cela est possible, les valeurs des secondaires sont automatiquement sélectionnées pour fusionner vers le principal. Si plusieurs valeurs sont en conflit, il vous faudra choisir laquelle conserver.
Lorsque le résultat du "Primary item" vous convient, cliquez sur le bouton Merge pour lancer la fusion. Tous les éléments secondaires seront supprimés et il ne restera qu'un élément combiné.
Exporter au format CSV si besoin
Félicitations, vous avez dédoublonné vos fichiers CSV ! Pour réutiliser le résultat dans un autre outil, cliquez sur le bouton "Export" pour exporter la collection dans un nouveau fichier CSV.
FAQ
Quelles autres manipulations de données sont possibles avec Datablist ?
Les fichiers CSV sont omniprésents pour structurer les données dans les applications ou les jeux de données. Mais la manipulation de CSV reste complexe et demande souvent des compétences techniques.
Pour des modifications simples, les tableurs suffisent. Mais leurs limites apparaissent vite pour :
Si vous souhaitez joindre plusieurs fichiers CSV sur une colonne unique, consultez le guide de jointure de fichiers CSV.
Datablist gère-t-il les gros fichiers CSV ?
Datablist prend en charge les fichiers CSV jusqu'à 1,5 million de lignes. Il est conçu non seulement pour ouvrir mais aussi pour éditer les CSV volumineux. Pour consulter des fichiers encore plus gros, privilégiez une solution d'analyse. Pour éditer de gros fichiers CSV, Datablist reste l'une des meilleures solutions.
L'algorithme de déduplication est-il meilleur que les fonctions "supprimer les doublons" de Microsoft Excel ou Google Sheets ?
Les tableurs (Microsoft Excel, Google Sheets) intègrent un outil pour supprimer les doublons. Celui-ci élimine simplement les lignes similaires. Dans les cas professionnels, supprimer sans consolidation n'est pas adapté.
L'algorithme Datablist fusionne les enregistrements dupliqués. Il commence par une fusion intelligente, puis combine les valeurs, et, en dernier recours, fusionne les enregistrements en élisant un master.
Pour toute question, contactez-nous.