

Le nettoyage de données (data cleaning) n'est plus l'affaire exclusive des data analysts. Si vous gérez une liste de prospects, si vous utilisez des données issues du scraping, ou si vous fusionnez différentes sources, vous connaissez l’importance du nettoyage pour exploiter vos données efficacement.
Google Sheets et Excel sont pratiques pour les opérations simples mais atteignent leurs limites quand il s'agit de consolider et de dédupliquer.
Dans ce guide, apprenez à utiliser Datablist, un outil gratuit en ligne pour nettoyer et normaliser vos données.
Résumé rapide des opérations traitées dans cet article :
- Convertir texte en Date, Nombre, Booléen
- Convertir du HTML en texte (retirer les balises)
- Retirer les espaces inutiles
- Normaliser vos données
- Supprimer les symboles dans les textes
- Séparer le nom complet en prénom et nom
- Dédupliquer les éléments
- Extraire des emails, URLs, etc. de textes
- Utiliser Regex pour filtrer, valider vos données
- Ecrire vos propres transformations en JavaScript
- Valider des adresses email
Importer depuis CSV ou collez vos données
Datablist est l’outil idéal pour nettoyer des données. Il fonctionne comme un éditeur CSV en ligne et propose des fonctionnalités de nettoyage, d’édition massive, et d’enrichissement. Il gère des collections allant jusqu’à plusieurs millions d’articles.
Ouvrez Datablist, et chargez vos collections de données sources.
Pour créer une nouvelle collection, cliquez sur le bouton + dans la barre latérale. Puis "Importer CSV/Excel" pour charger votre fichier. Ou passez par l’assistant de démarrage pour arriver directement à l’import de fichier.
Détection automatique du format
L’assistant d’import détecte automatiquement les adresses email, dates ISO 8601, booléens, nombres, URLs, etc. si vos données sont bien structurées.
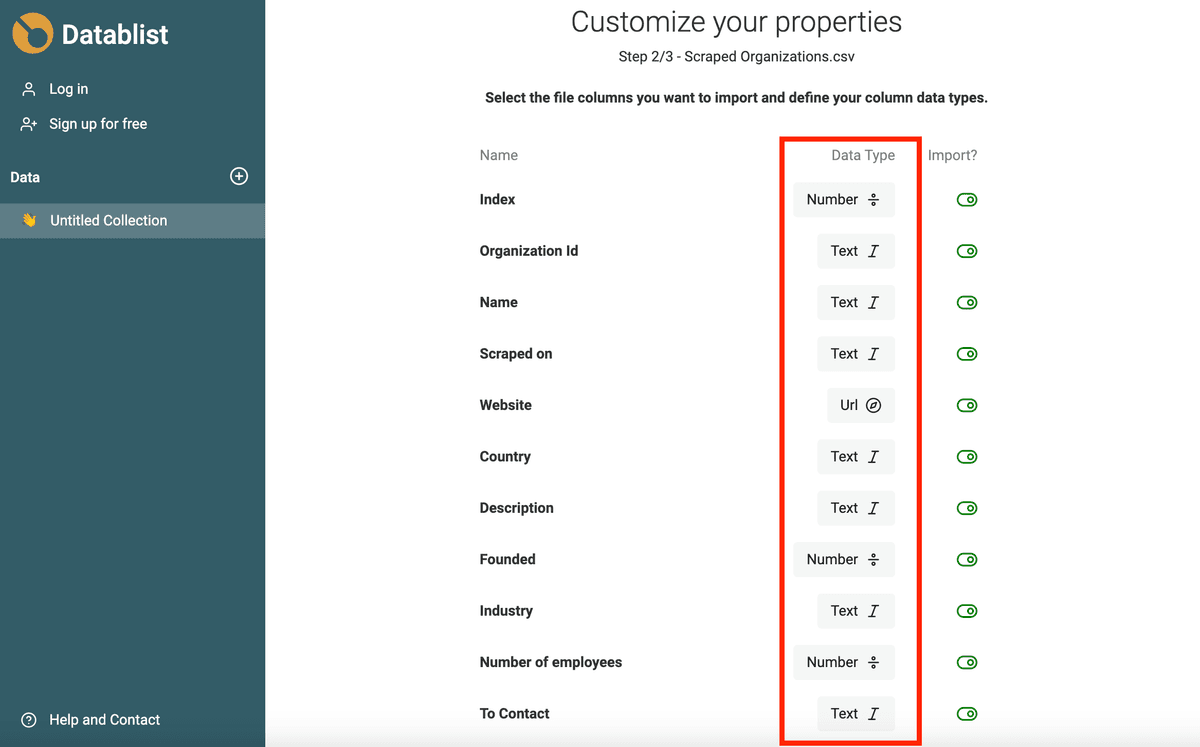
Si votre source nécessite plus d’analyse (formats de dates variés, erreurs de saisie dans les URLs ou adresses email), importez-les d’abord en propriété Texte. Retrouvez la méthode pour convertir en date/boolean/nombre dans la section suivante.
Convertir le texte en date, booléen, nombre
Marie Kondo dit "La vie commence vraiment après avoir mis de l’ordre chez soi". Pour la donnée, on pourrait dire : "La conversion commence après avoir mis tes données en ordre"
Filtrer sur une date (ex : date de création, de financement), un nombre (CA, nombre de salariés), ou un booléen est bien plus simple quand il s’agit d’objets natifs, pas de textes.
Ouvrez l’outil "Text to Datetime, Number, Checkbox" depuis le menu "Clean".
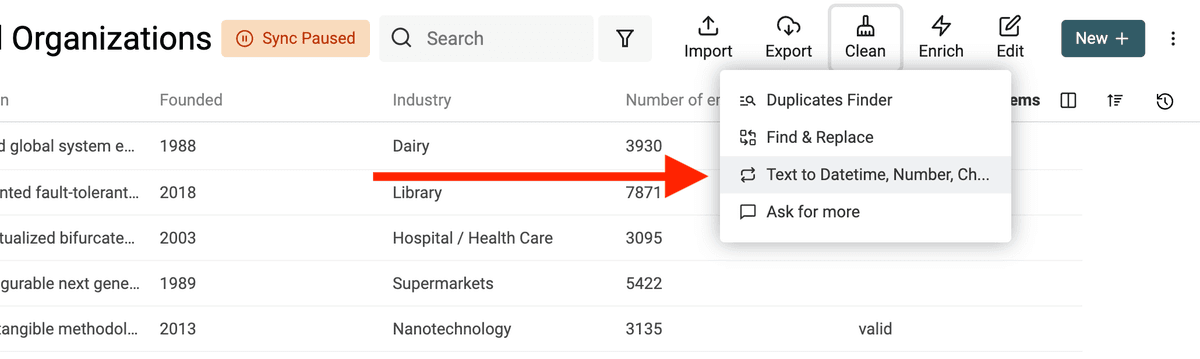
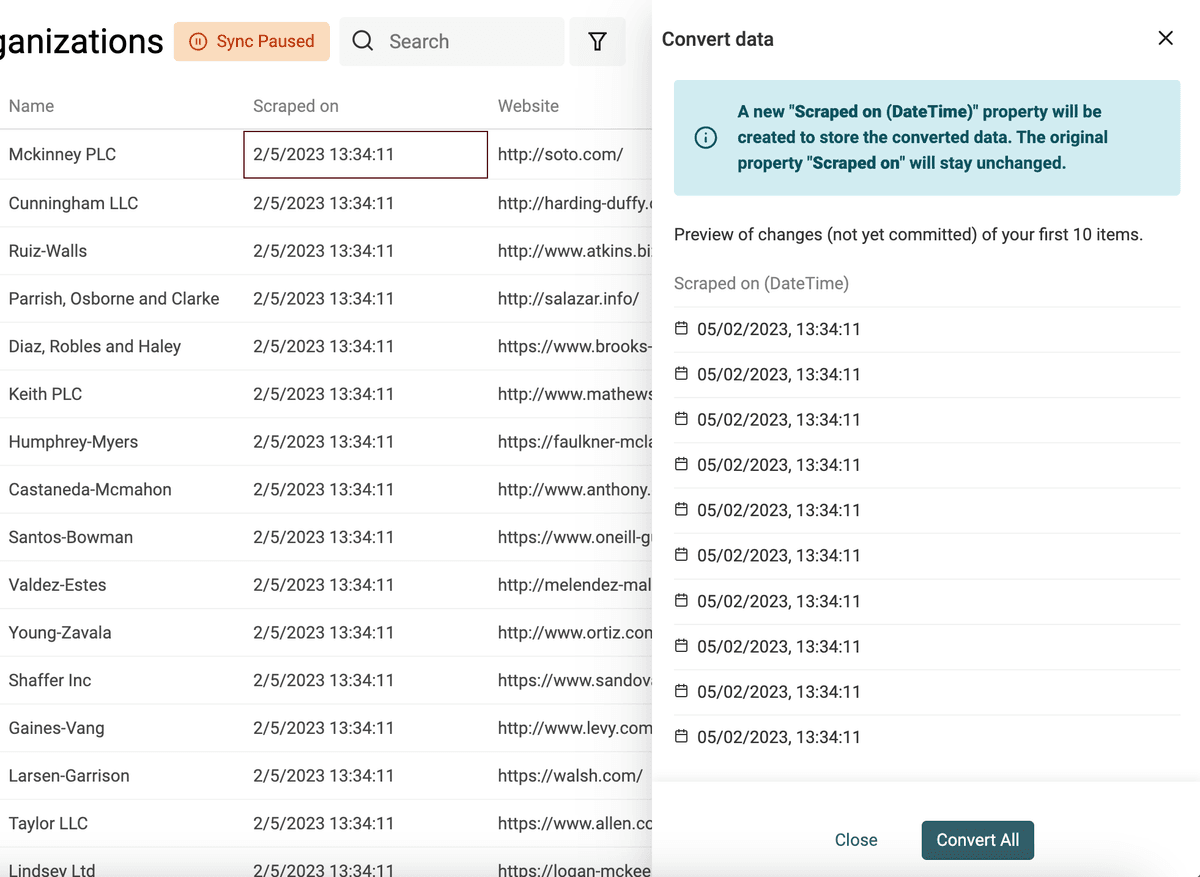
Convertir un texte en Date/Datetime
Le format standard international ISO 8601 est détecté automatiquement à l’import. Sinon, spécifiez le format de vos dates lors de la conversion.
Sélectionnez la propriété à traiter et choisissez "Convert to Datetime".
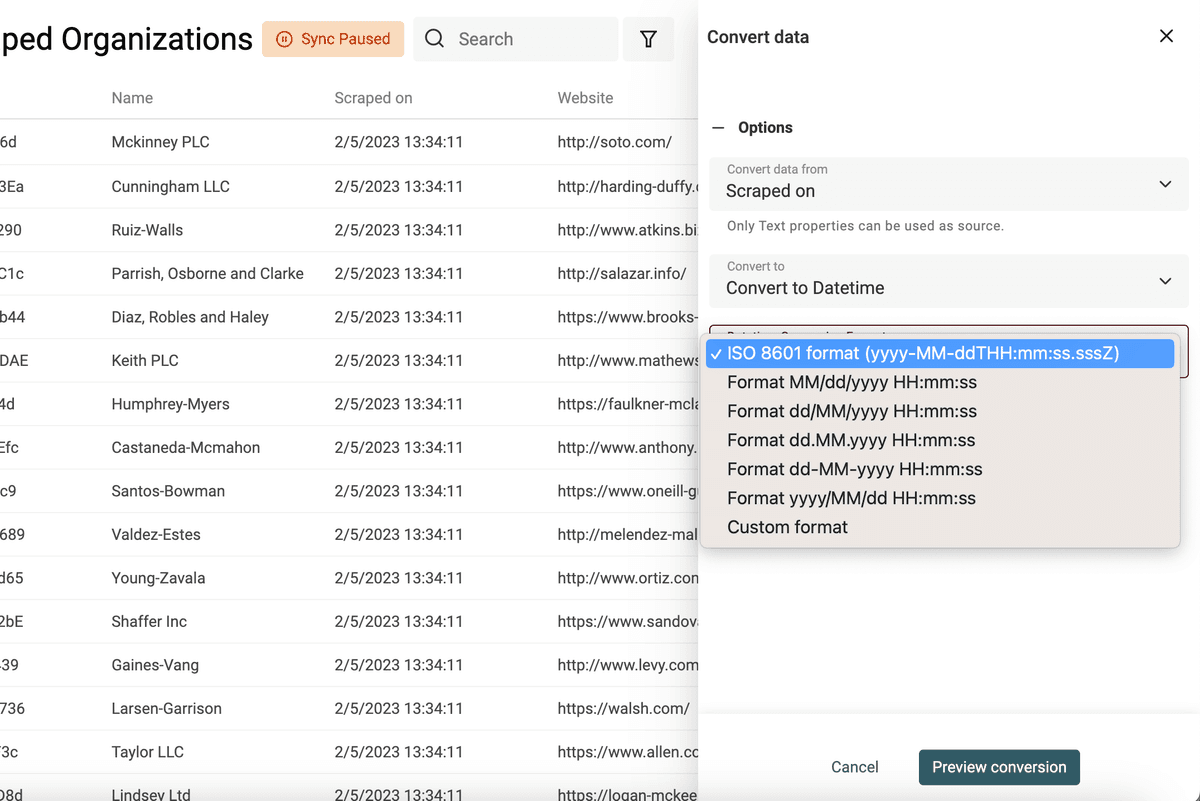
Formats communs proposés (Google Sheets, Excel...) ou personnalisez le format.
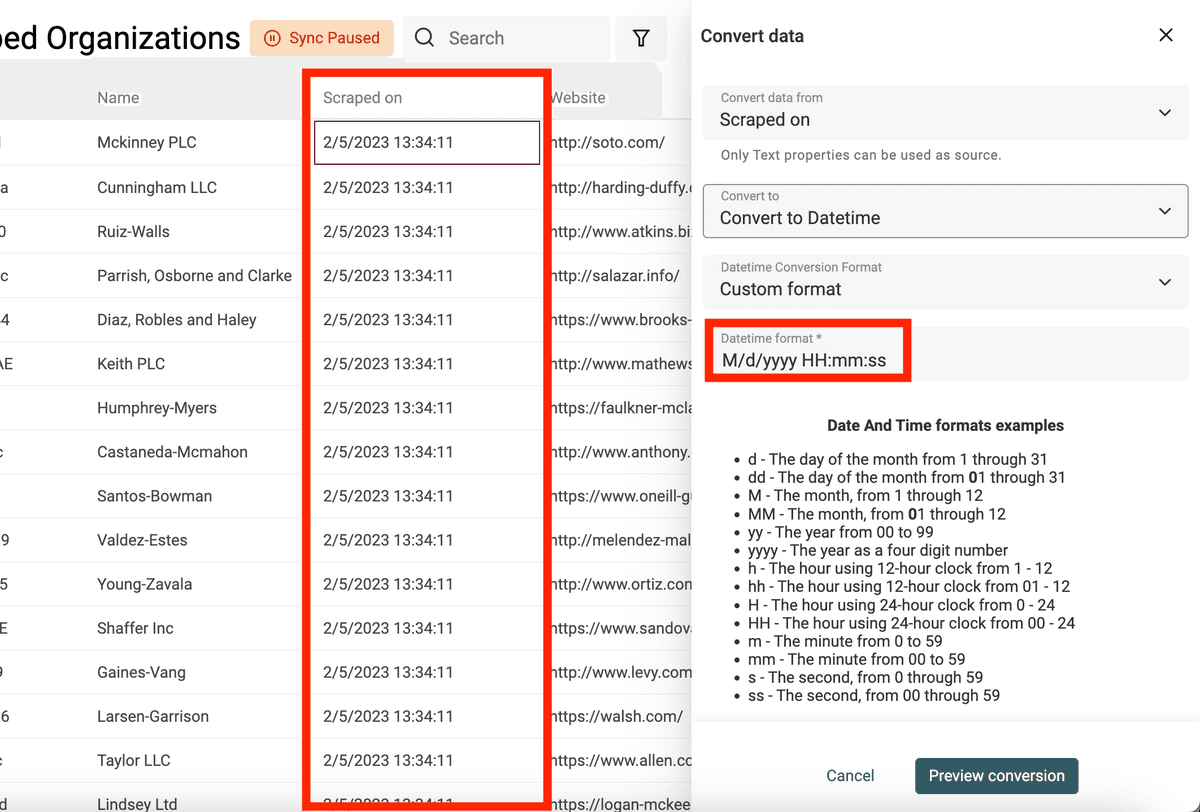
Pour les champs mélangeant plusieurs formats de date, cochez "Custom or multiple formats" et saisissez chaque format sur une ligne. Datablist testera chaque format jusqu’à trouver un match valide.
👉 Consultez notre documentation sur les formats personnalisés de date.
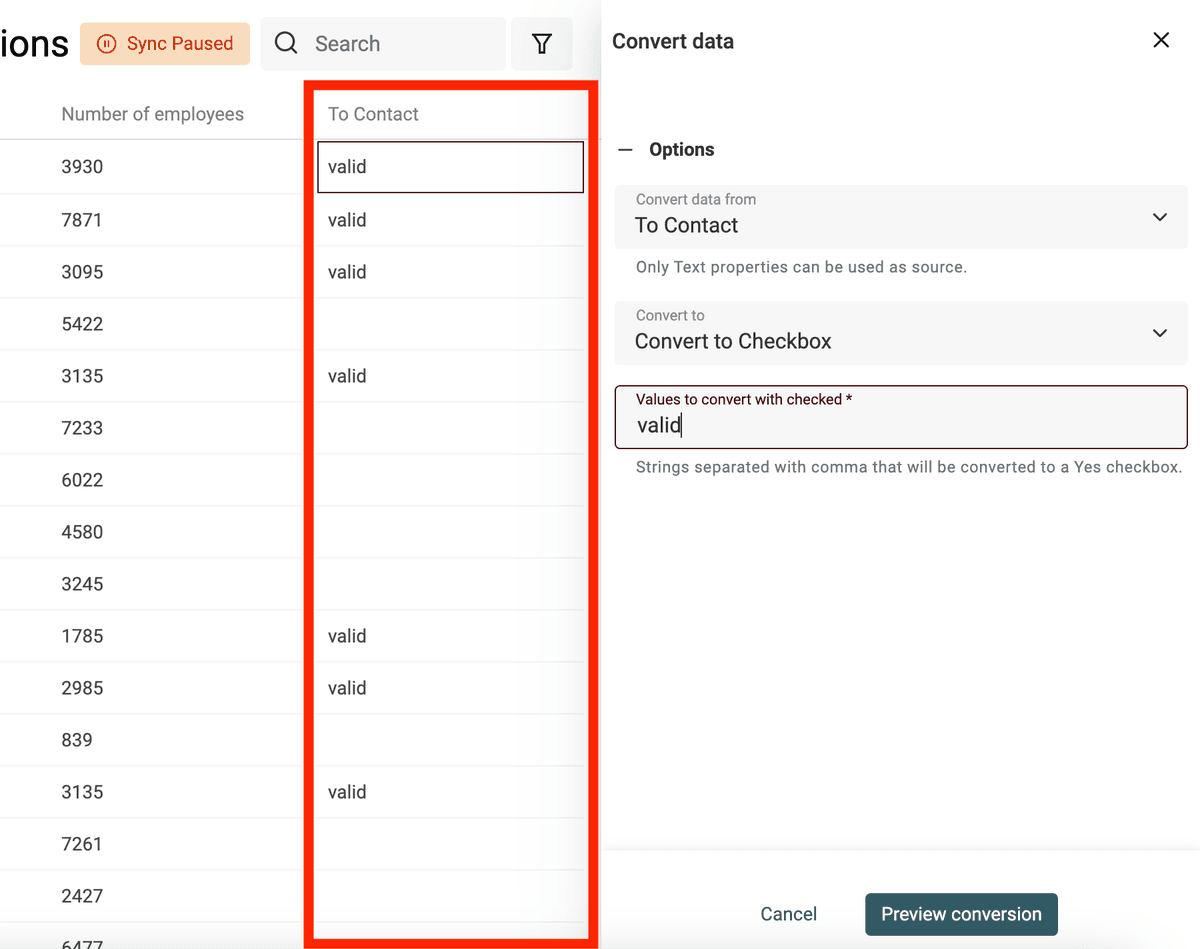
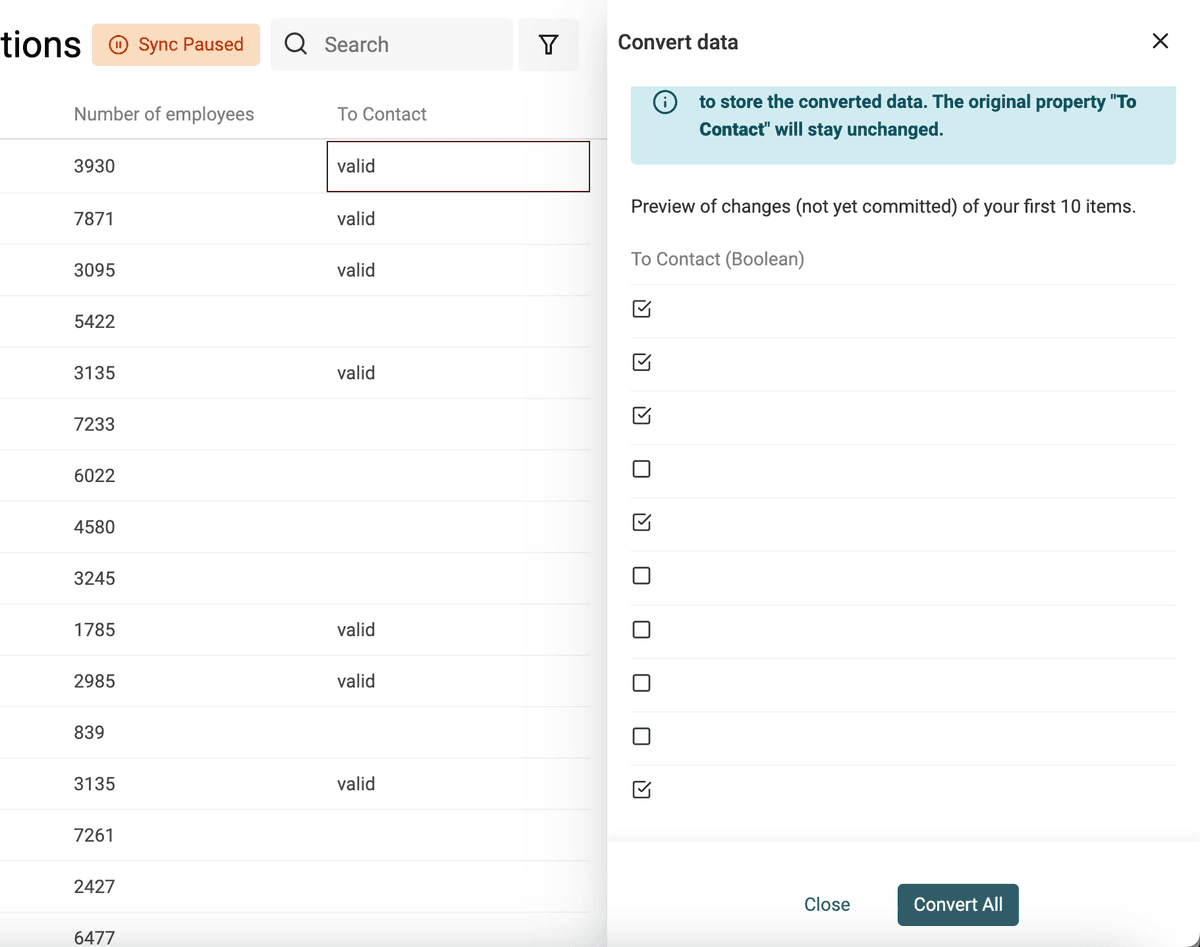
Transformer du texte en cases à cocher (booléens)
Datablist convertit automatiquement les colonnes "Oui, Non", "TRUE, FALSE", etc. en cases à cocher lors de l’import. Utilisez le convertisseur pour des cas plus complexes.
Définissez les valeurs (séparées par virgule) correspondant à « coché ». Les autres restent décochées.
Extraire les valeurs numériques des textes
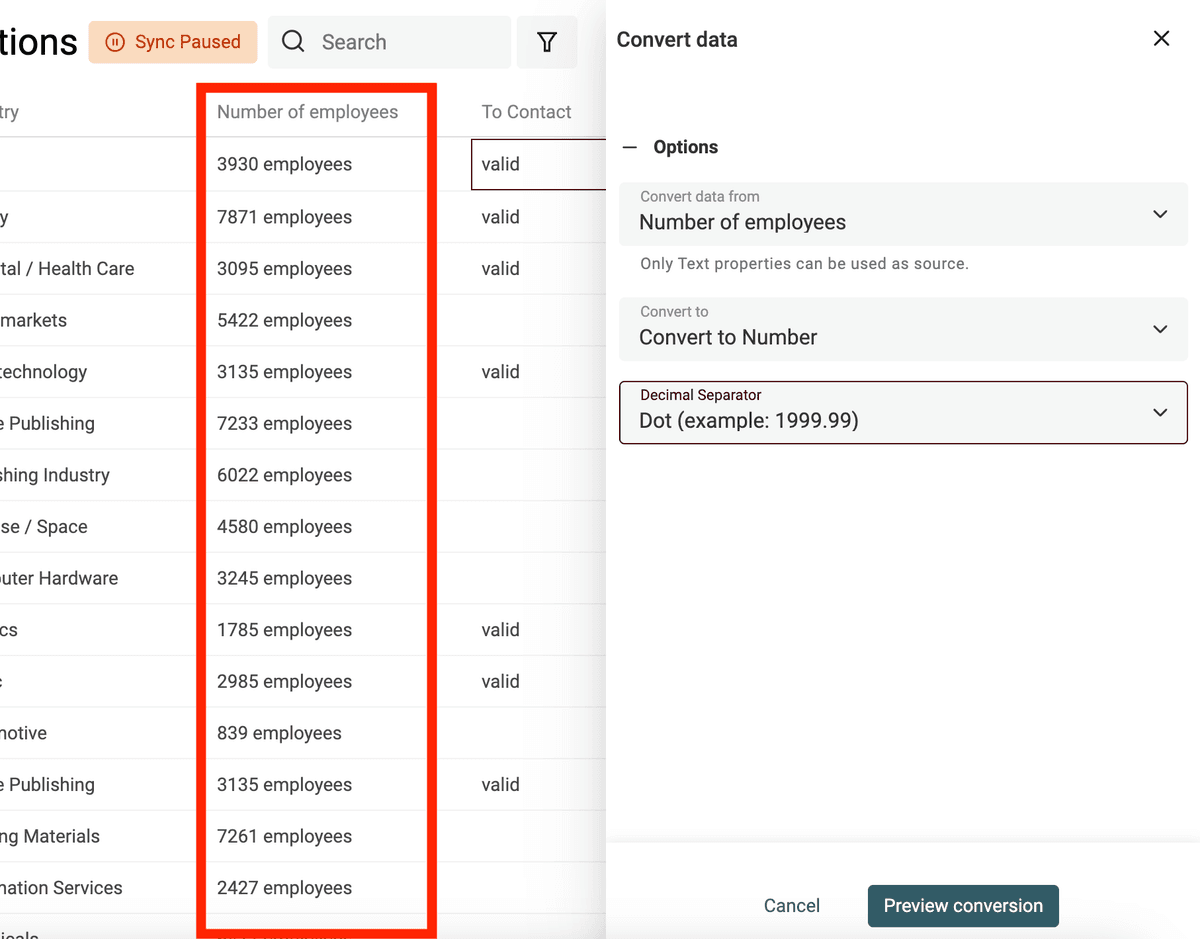
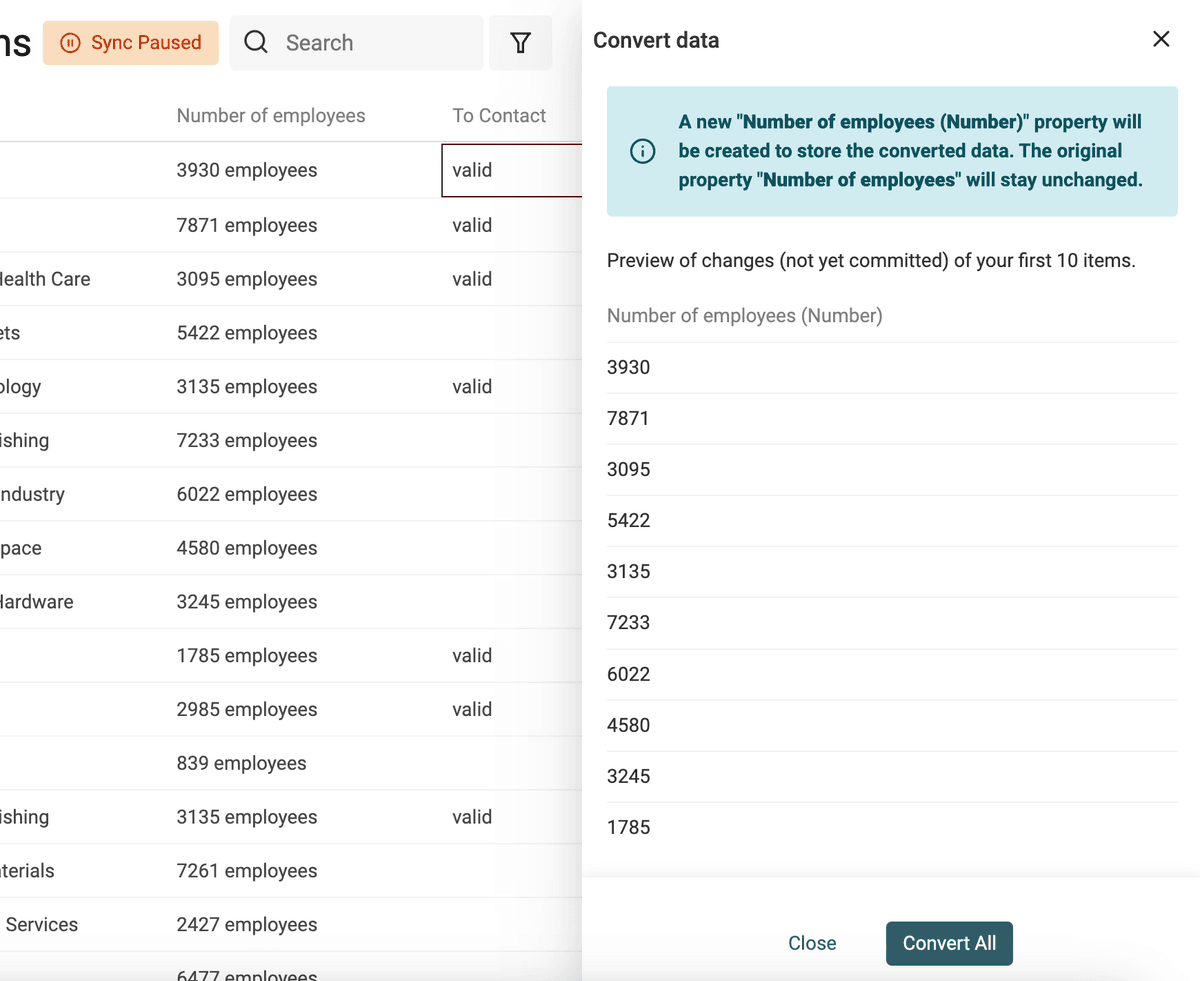
Utilisez le convertisseur "Text to number" pour :
- Normaliser les nombres avec les séparateurs voulus
- Extraire des nombres présents au sein de textes
👉 En savoir plus sur la conversion numérique dans notre documentation.
Nettoyer les données
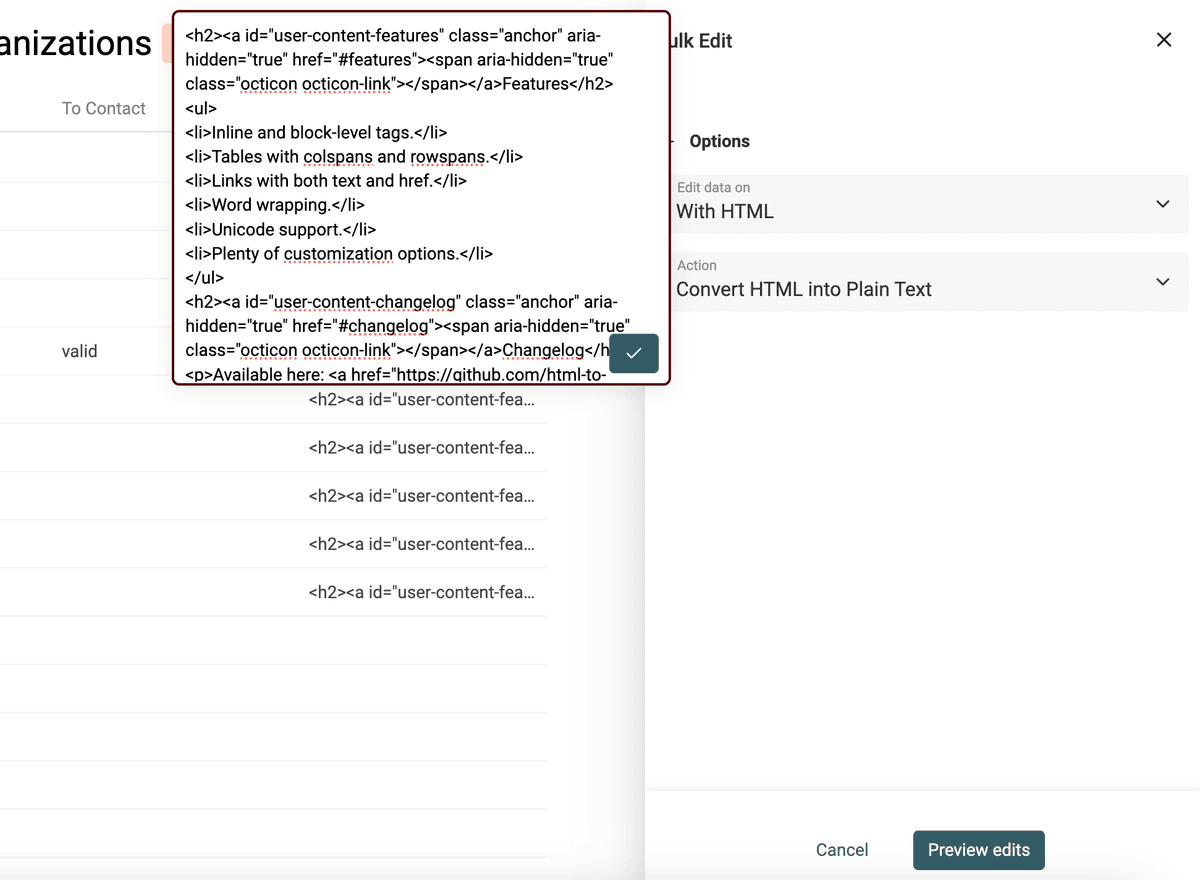
Convertir le HTML en texte
Les outils de scraping extraient le HTML et incluent souvent des balises dans vos textes.
L’objectif est de protéger une partie de la structure (paragraphes, listes à puces) tout en produisant du texte brut et lisible.
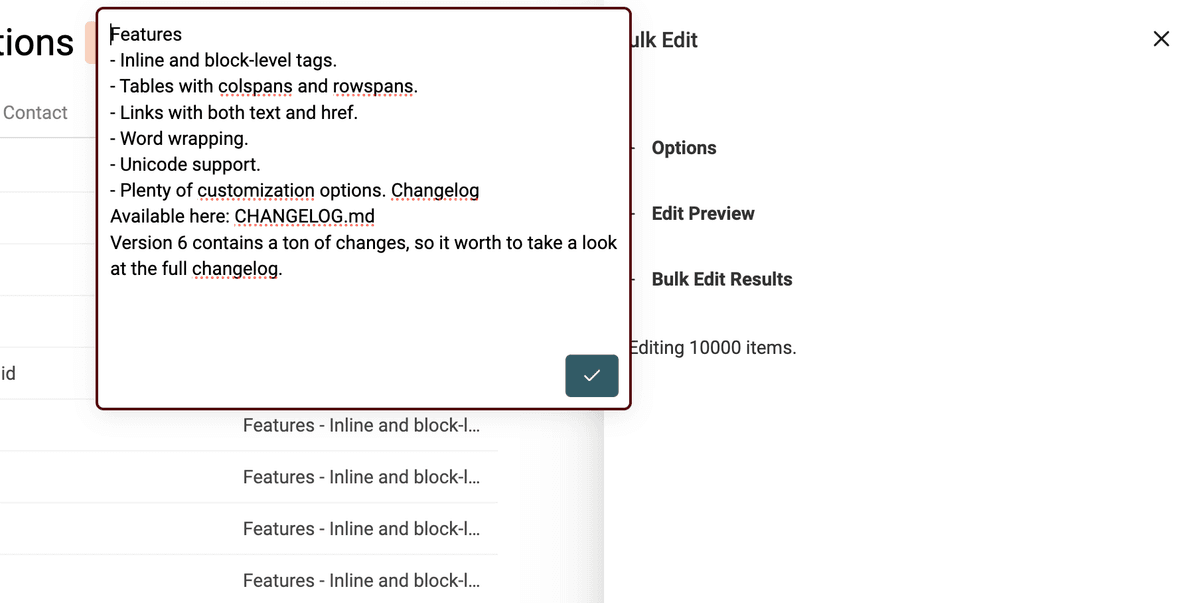
L’outil Datablist de conversion HTML en texte conserve les retours à la ligne et transforme les listes à puces avec un -.
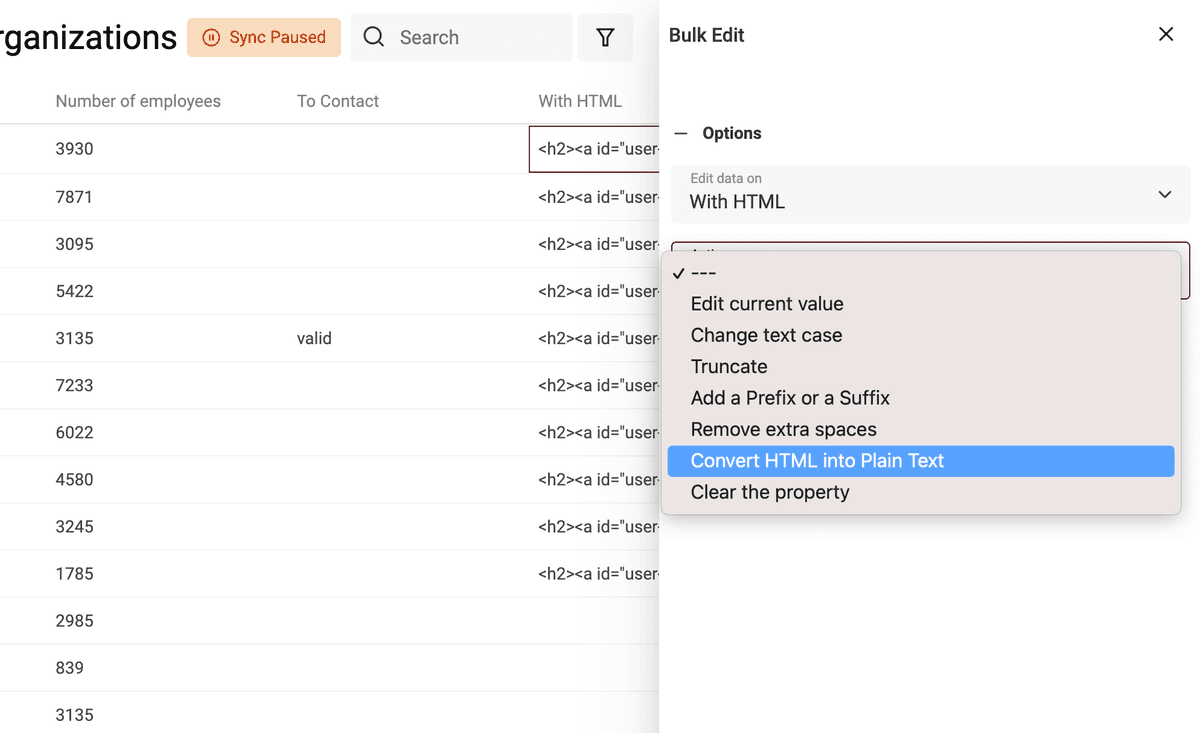
Ouvrez l’outil Bulk Edit du menu Edit.
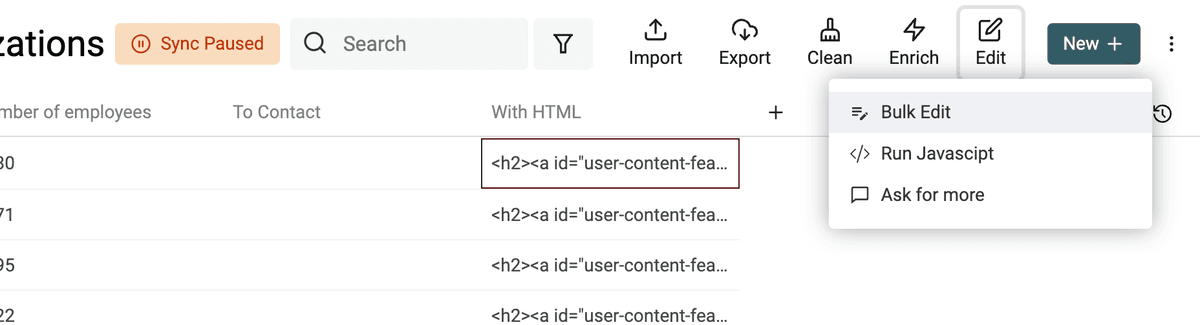
Sélectionnez la colonne concernée, puis l’action "Convert HTML into plain text".
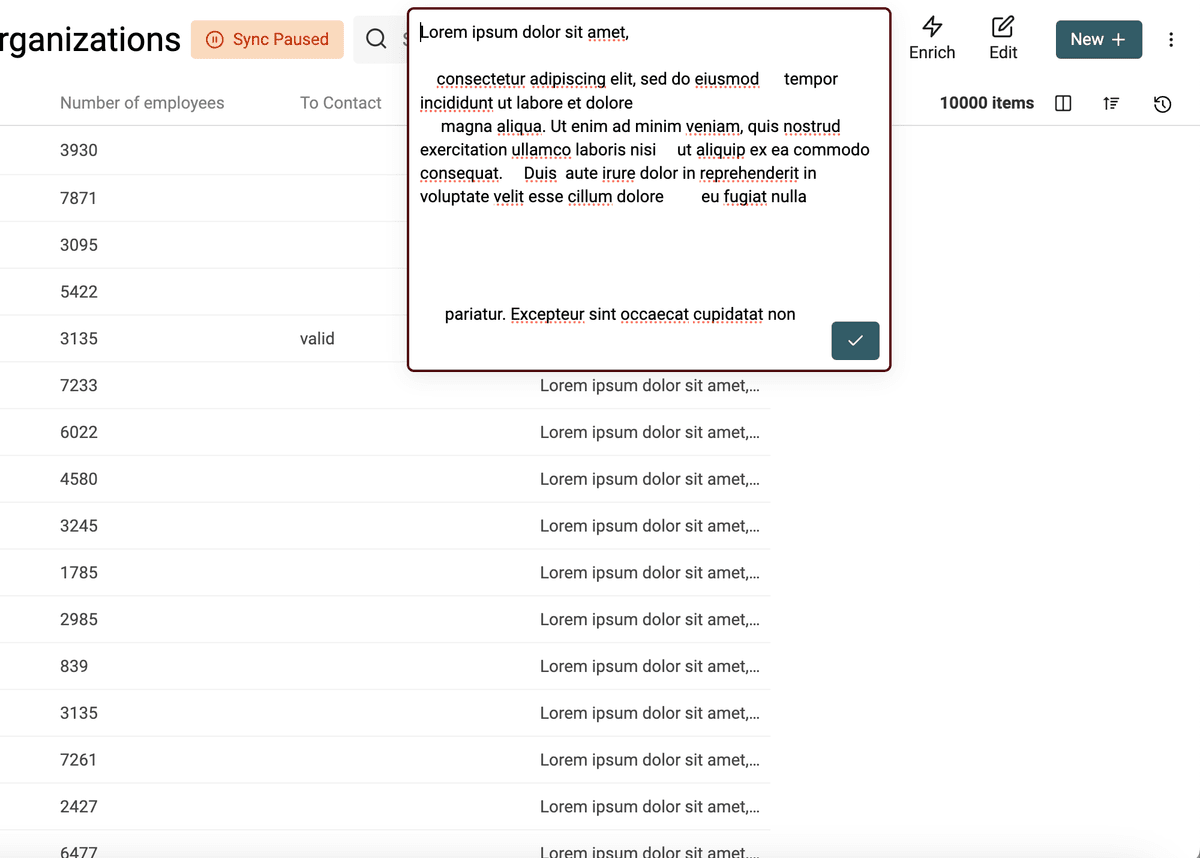
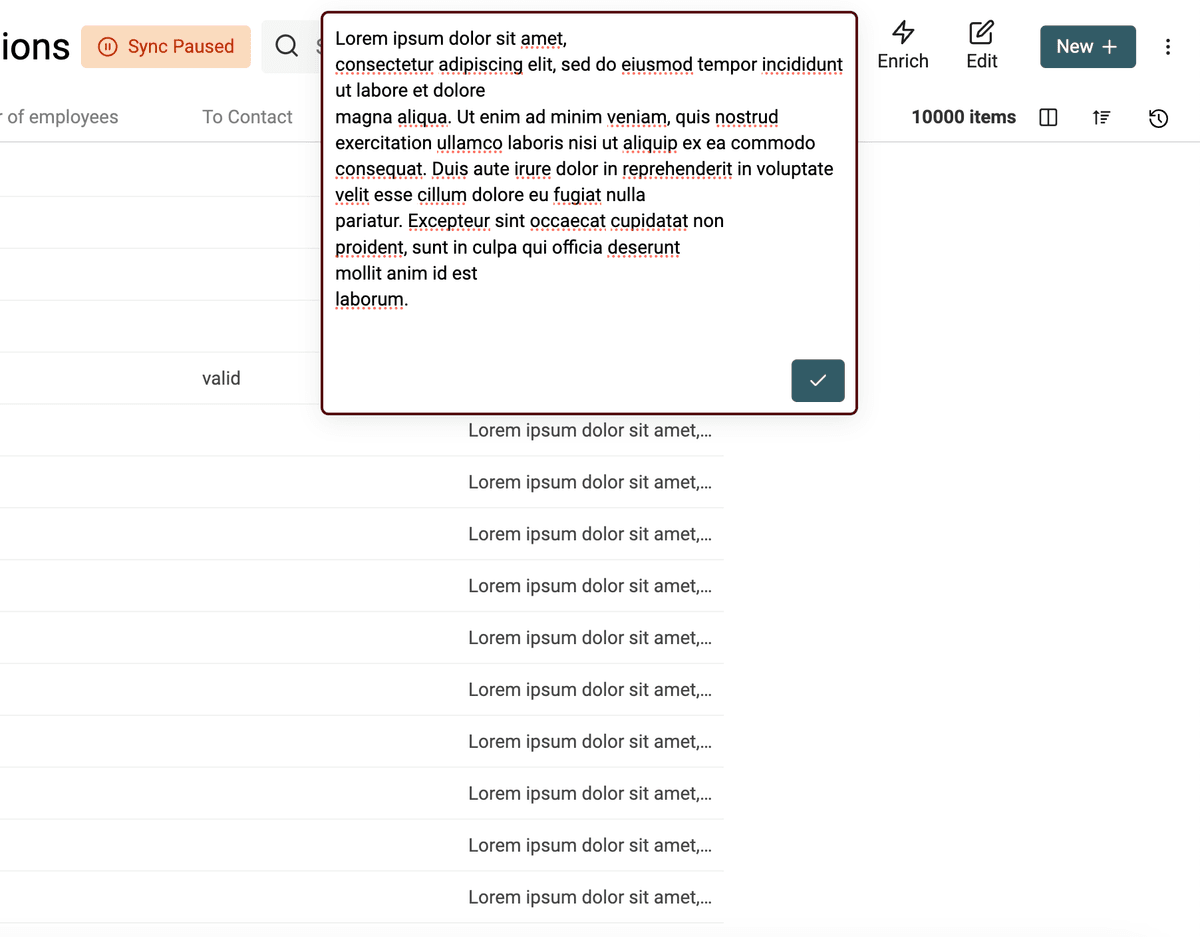
Retirer les espaces inutiles
Autre souci fréquent : les espaces superflus (sauts de ligne, Tabulations, espaces multiples, etc.).
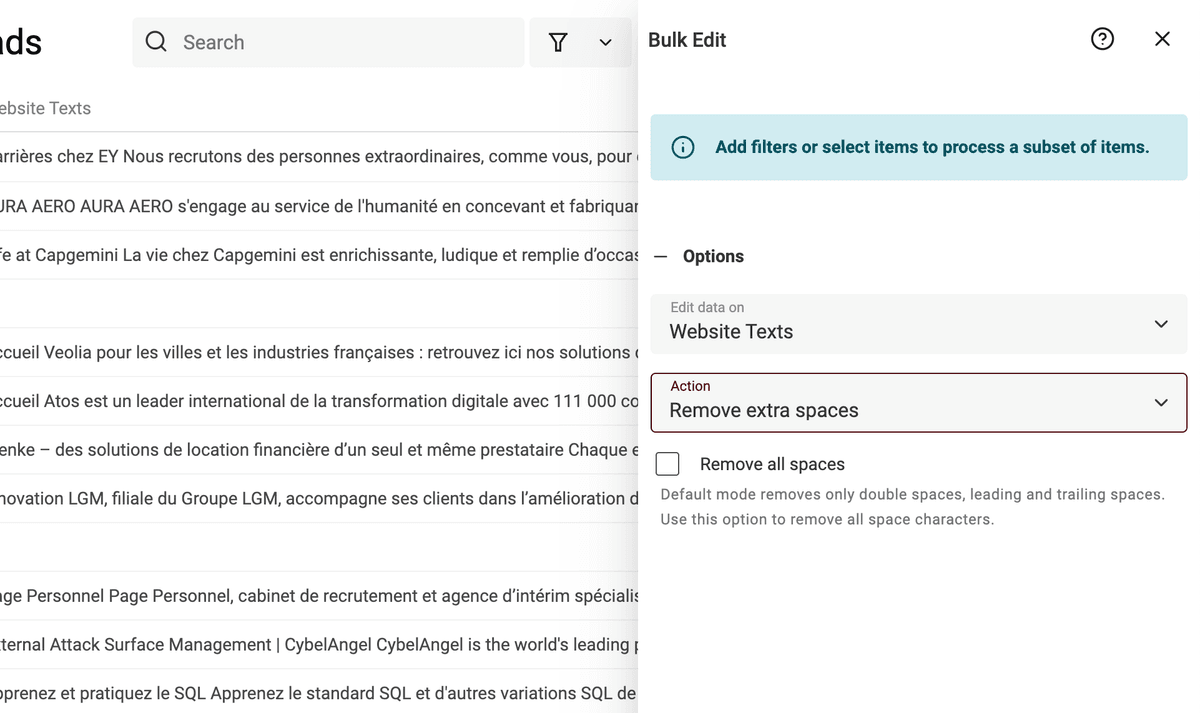
Datablist propose un outil de nettoyage d’espaces avec deux modes :
- Mode 1 : Retirer tous les espaces (pratique pour nettoyer les numéros, prix…)
- Mode 2 : Retirer uniquement les espaces en trop (dans un texte)
Ce second mode :
- supprime les espaces répétés entre mots,
- retire les lignes vides,
- supprime les espaces en début/fin de ligne.
Utilisez "Bulk Edit" dans "Edit" pour accéder à l’action "Remove extra spaces". Cochez "Remove all spaces" pour supprimer absolument tous les espaces.
Exemple avant/après :
Après nettoyage, sans espaces inutiles :
Changer la casse des textes
Changer la casse est simple. Ouvrez "Bulk Edit" dans "Edit".
Sélectionnez votre propriété cible puis "Change text case".
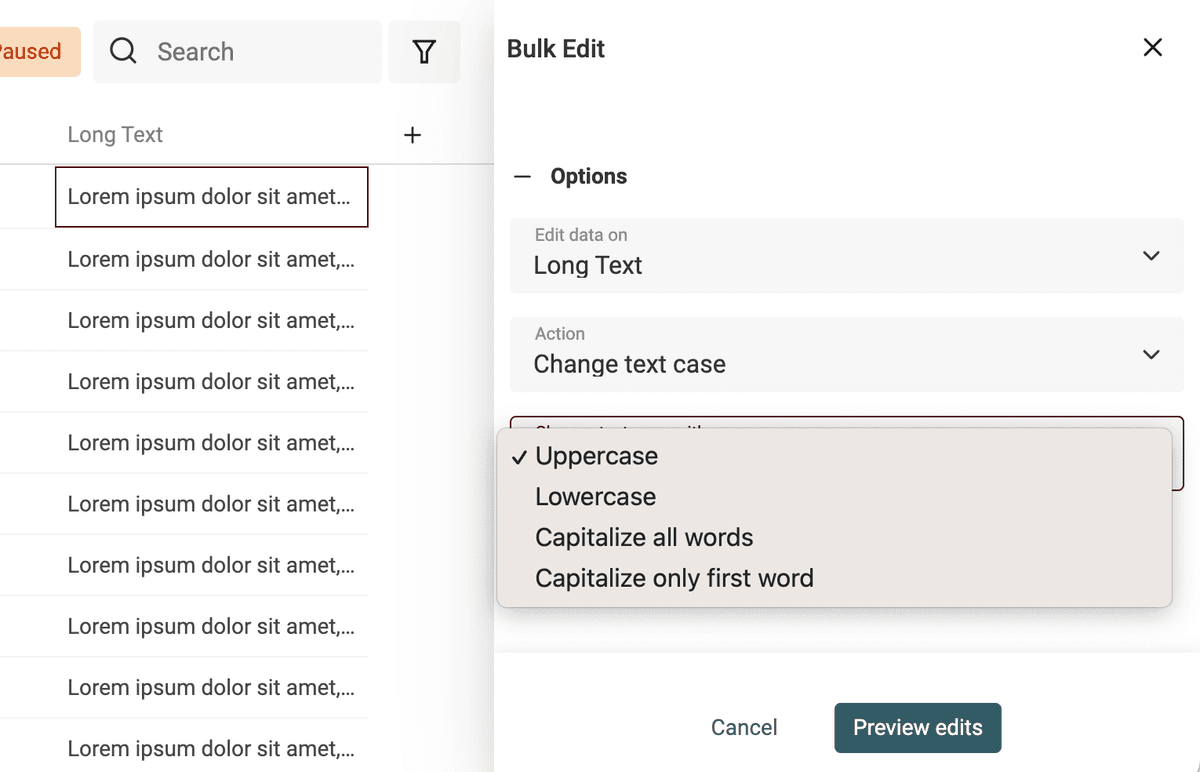
Modes proposés :
- Majuscule
- Minuscule
- Capitaliser chaque mot
- Capitaliser uniquement le premier mot
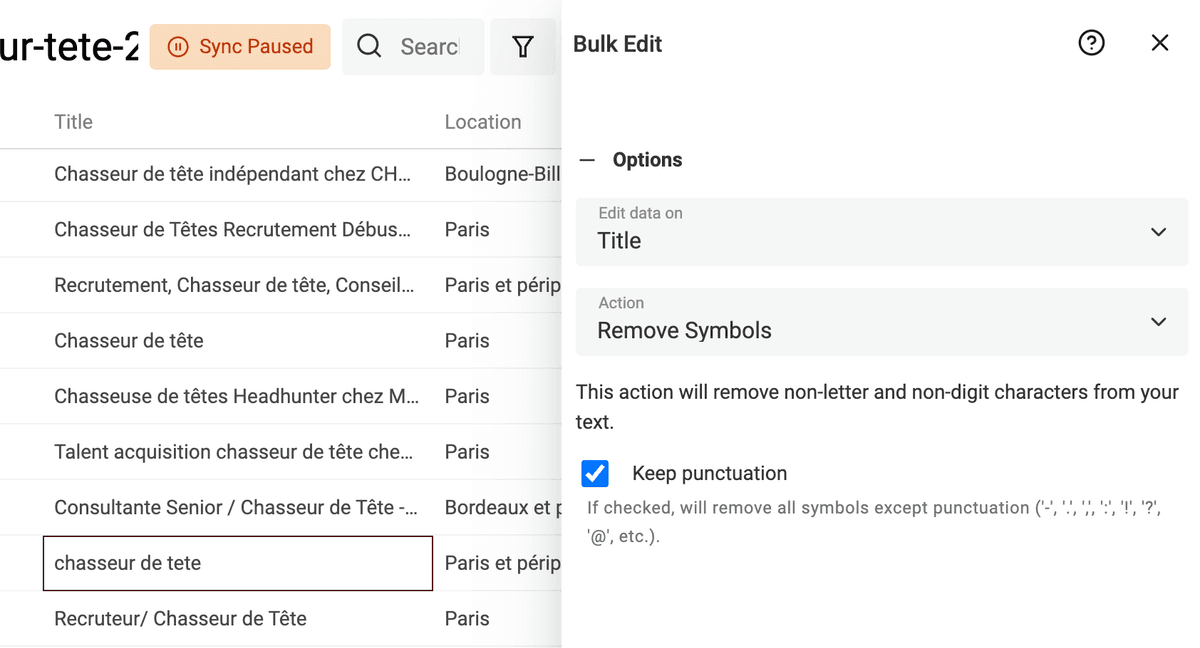
Supprimer les symboles dans les textes
Les textes extraits (scraping ou saisie utilisateur, titres LinkedIn, etc.) contiennent parfois des symboles parasites (smileys, caractères spéciaux…). Un simple symbole dans un nom peut empêcher la détection des doublons par un algorithme de déduplication.
Datablist propose un nettoyeur qui supprime tous les symboles non-textuels.
Sélectionnez "Bulk Edit" puis la colonne à traiter, action "Remove symbols".
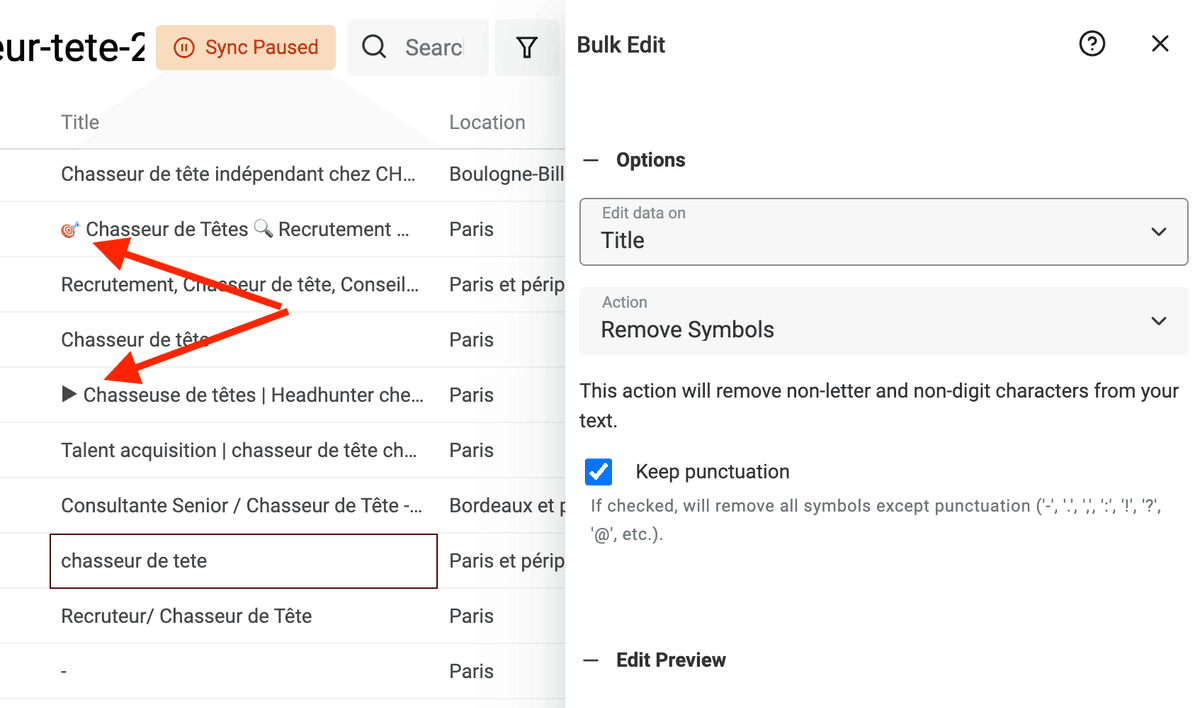
Validez si l’aperçu vous convient, lancez la transformation.
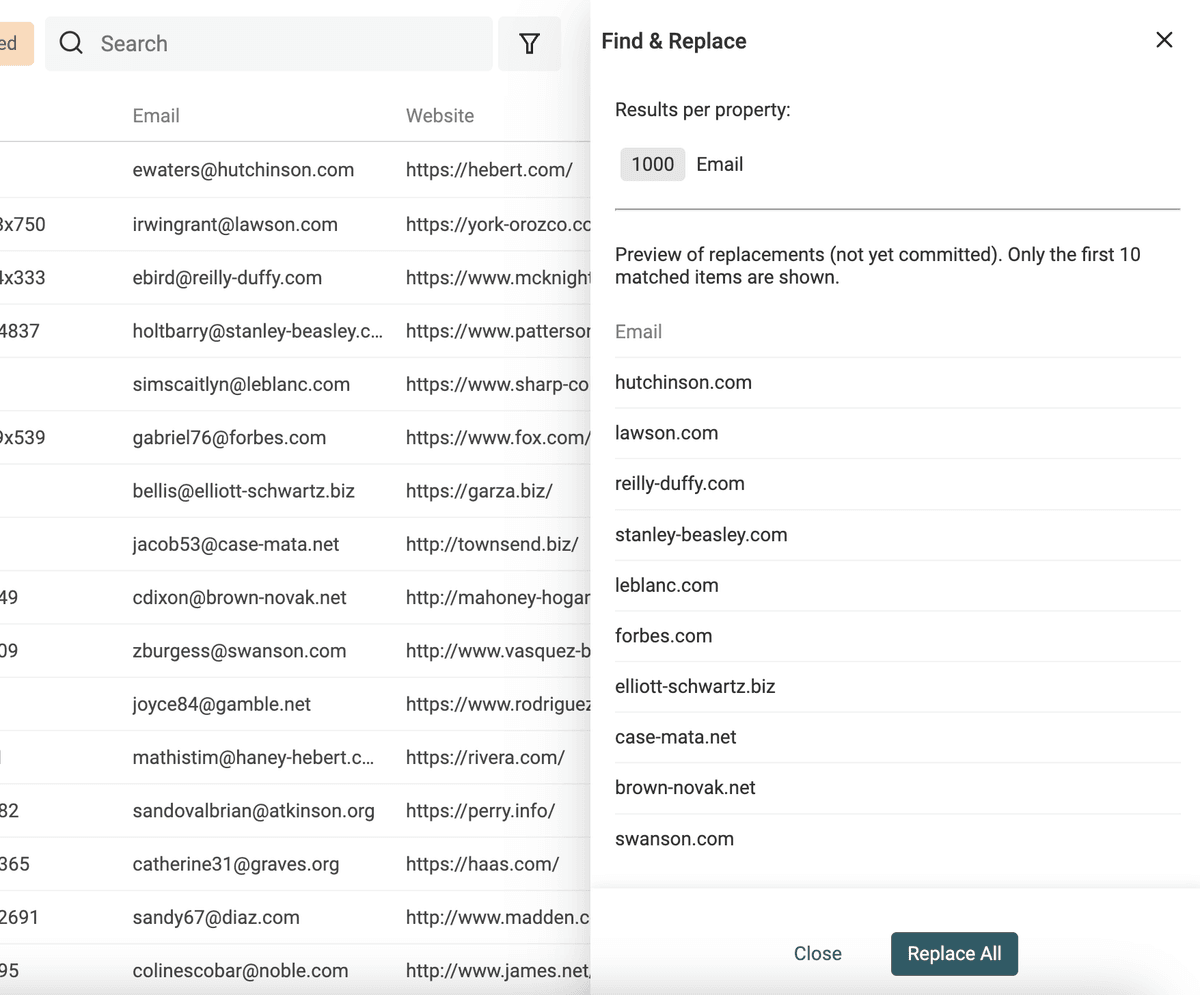
Normalisation avec Trouver et Remplacer
Pour segmenter vos listes de prospects, la normalisation est essentielle :
- Harmonisez les intitulés de poste
- Uniformisez pays, villes
- Normalisez URLs, etc.
L’objectif : réduire le texte libre à une liste limitée de choix ou à un format homogène.
Datablist propose "Find and Replace", fonctionnant en texte simple ou avec expressions régulières.
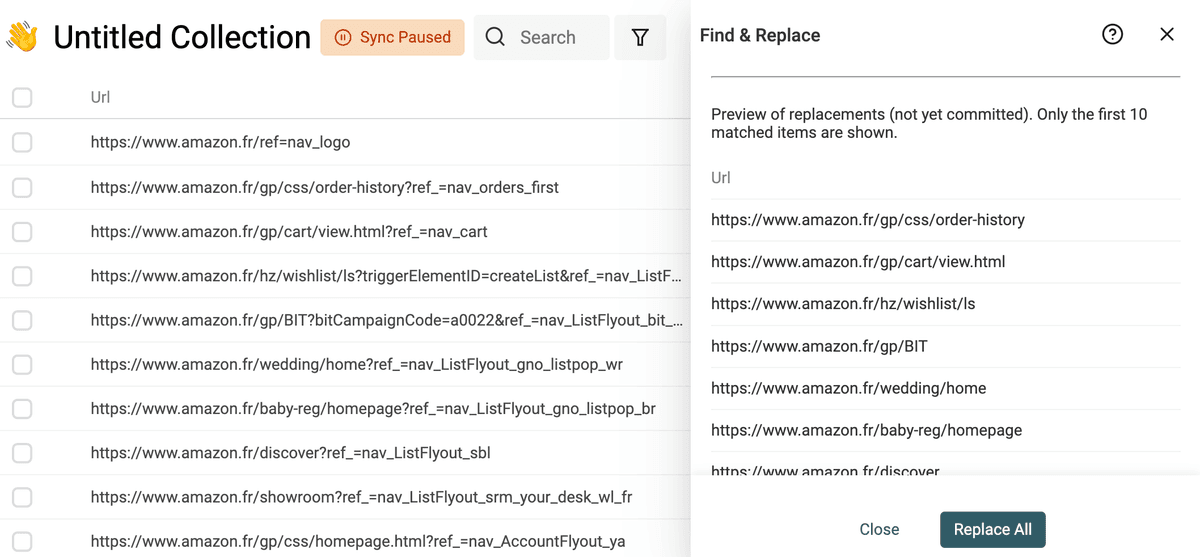
Retirer les paramètres d’URL
Supprimez facilement les paramètres inutiles ou de tracking dans vos URLs. Utilisez l’option RegEx avec l’expression :
\?.*$
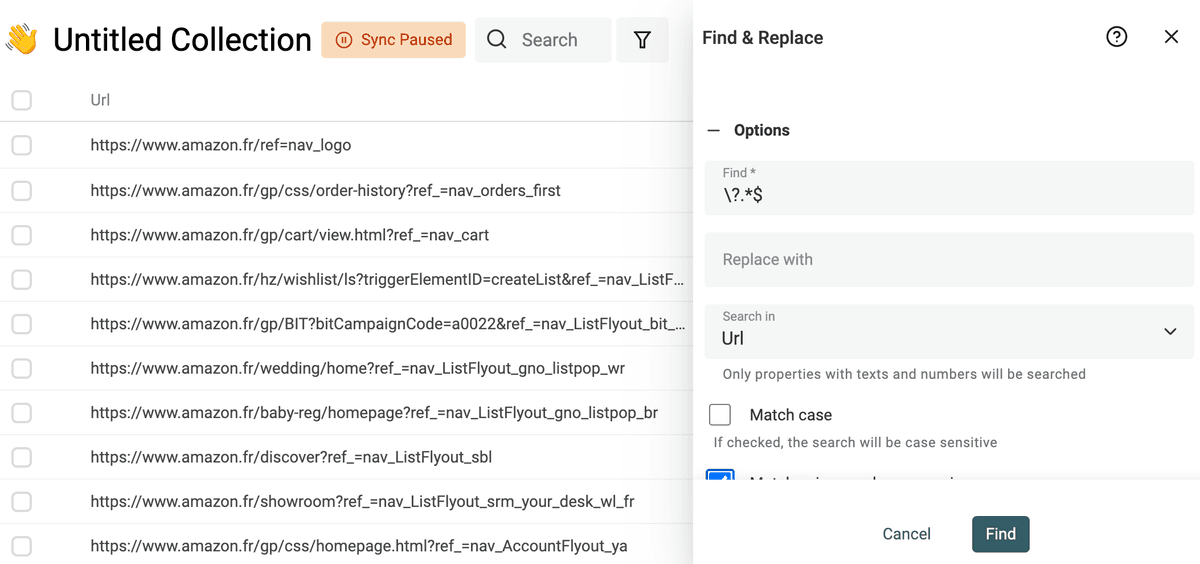
Appliquez ça sur la propriété concernée.
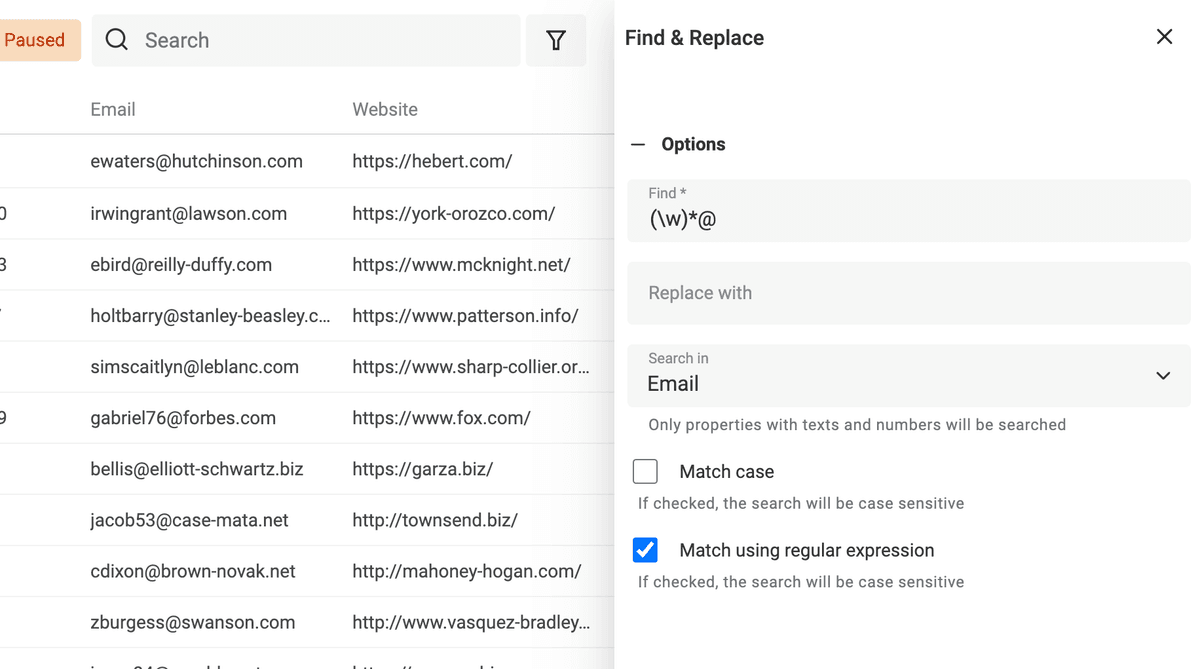
Extraire les domaines d’e-mails
Autre astuce : récupérer le domaine d’un e-mail avec Find and Replace (toujours via RegEx). Dupliquez d’abord la colonne. Utilisez :
^(\w)*@
Séparer nom complet en prénom et nom
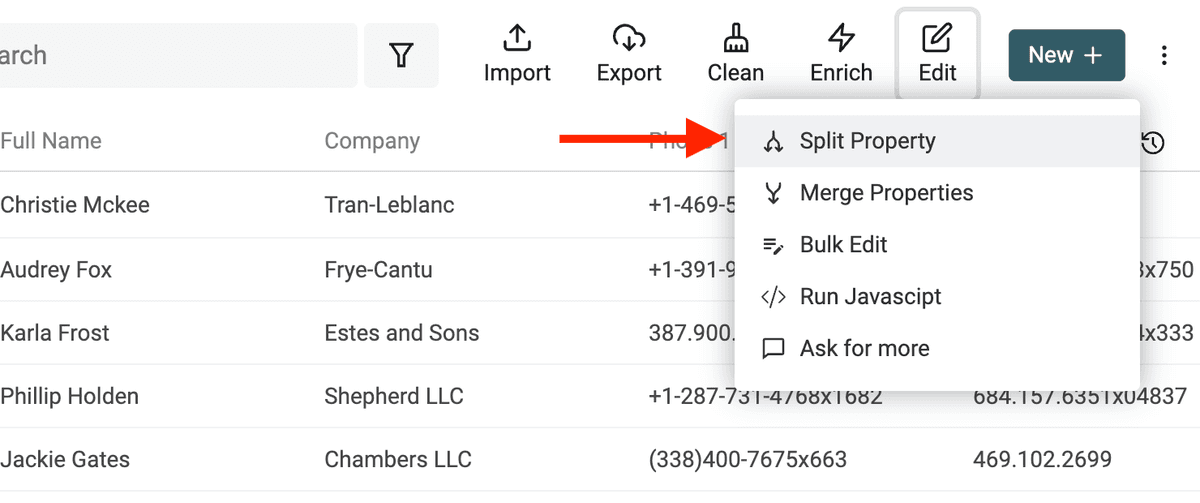
Quand on scrap des listes de leads, on récupère parfois un champ "Full Name" à séparer en "Prénom" et "Nom". Savoir séparer précisément les deux est utile pour personnaliser ses messages (Cold Emailing), détecter le genre, ou extraire un titre académique.
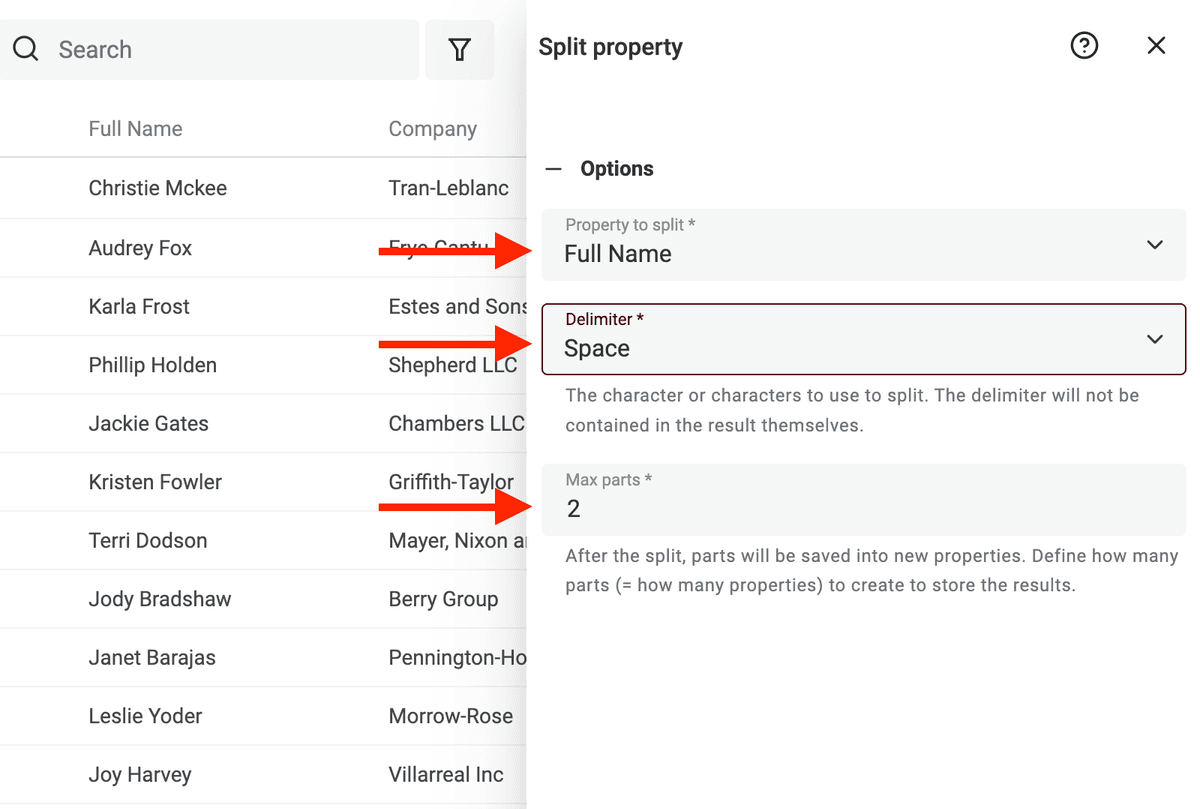
La tâche se complexifie dans certains cas, mais pour la méthode occidentale prénom/nom, c’est simple avec Datablist : ouvrez "Split Property" dans le menu "Edit".
Sélectionnez la colonne cible, puis "Space" comme délimiteur. Limitez à 2 parties.
Lancez l’aperçu : si le résultat convient, cliquez "Split Property" pour appliquer sur toutes les lignes.
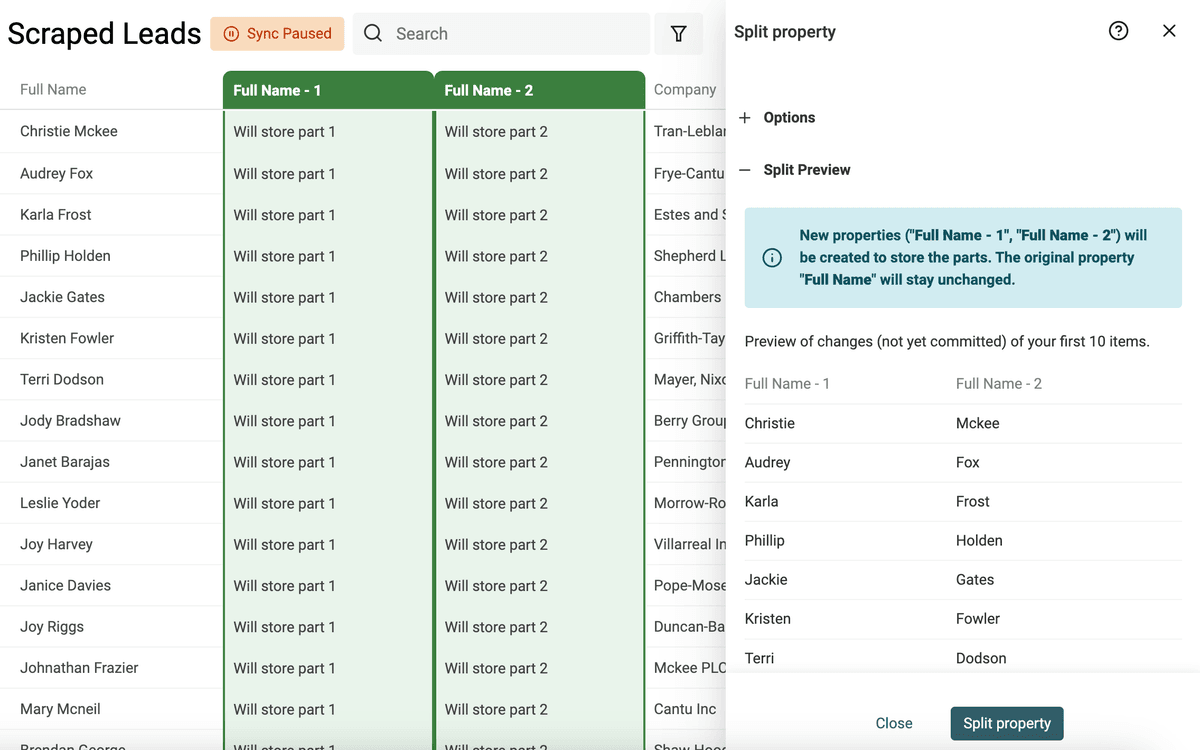
Renommez ensuite les deux nouvelles propriétés, par exemple "Prénom" et "Nom".
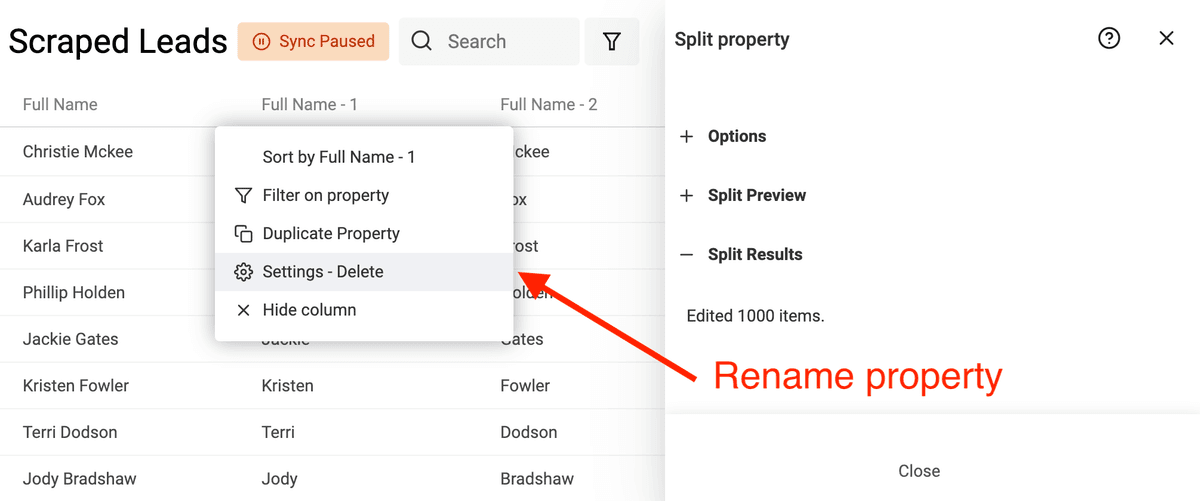
Ce cas est adapté aux noms occidentaux standards. Pour des cas complexes (double nom, titres…), affinez manuellement.
Déduplication des données
Datablist propose un super algorithme pour dedoublonner vos données. Il détecte automatiquement les éléments similaires sur une ou plusieurs propriétés et propose un algorithme de fusion automatique sans perte d’information.
Cliquez sur "Duplicate Finder" dans le menu "Clean".
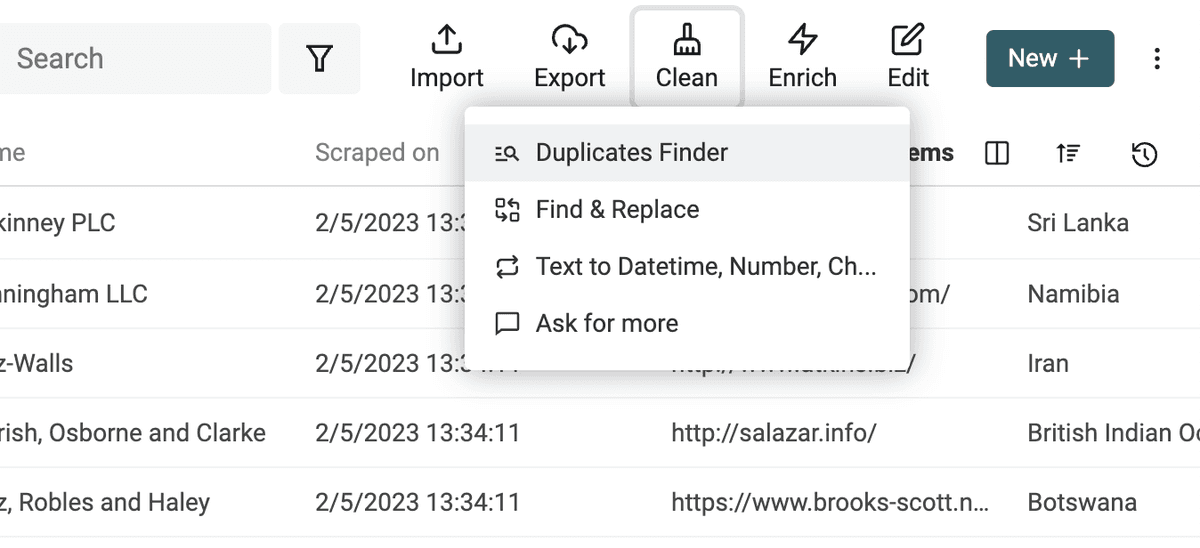
Sélectionnez les propriétés à utiliser pour la correspondance.
Sur la page de résultat, lancez "Auto Merge" avec l’option "Merge non-conflicting duplicates". Seuls les éléments fusionnables seront traités — les doublons avec conflit seront listés.
Le dedupe algorithm propose deux options pour les conflits : combiner les valeurs séparées par un délimiteur, ou conserver uniquement la plus pertinente.
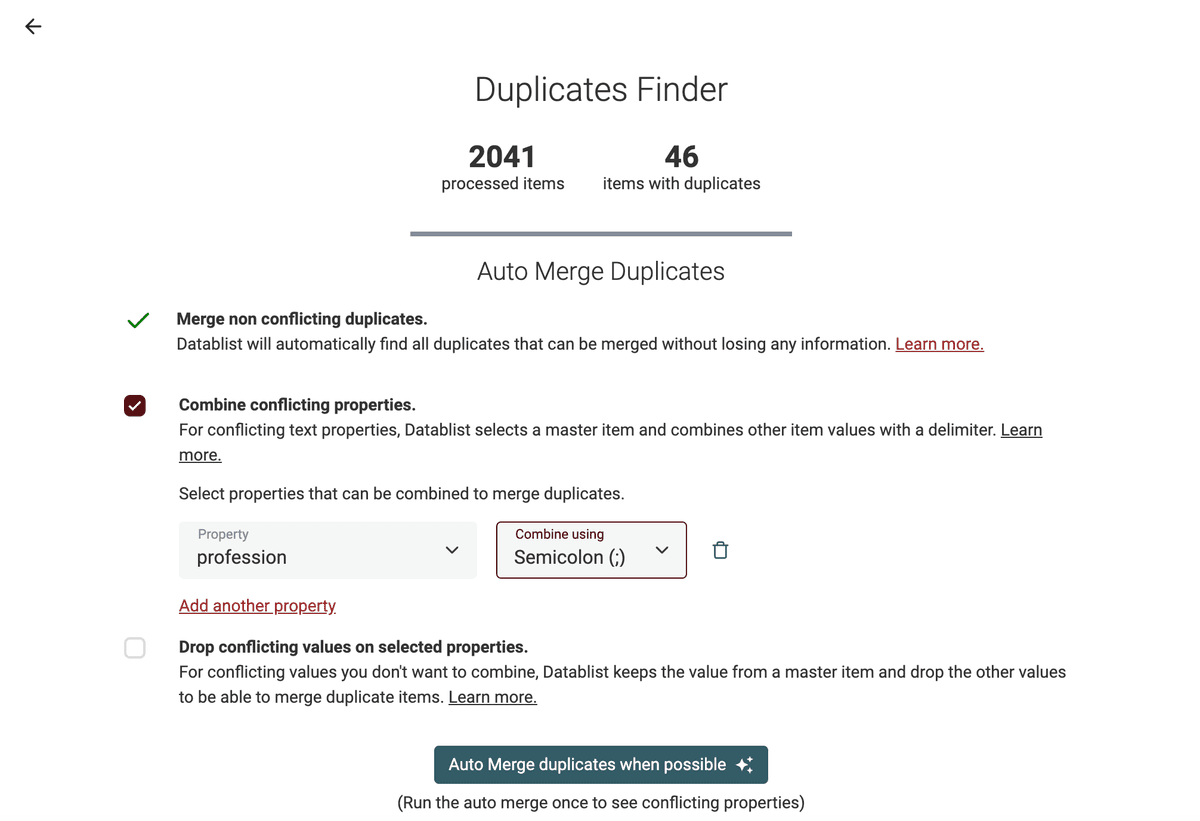
👉 Voir notre guide pour fusionner des doublons dans un CSV. et pour dédupliquer par nom d’entreprise.
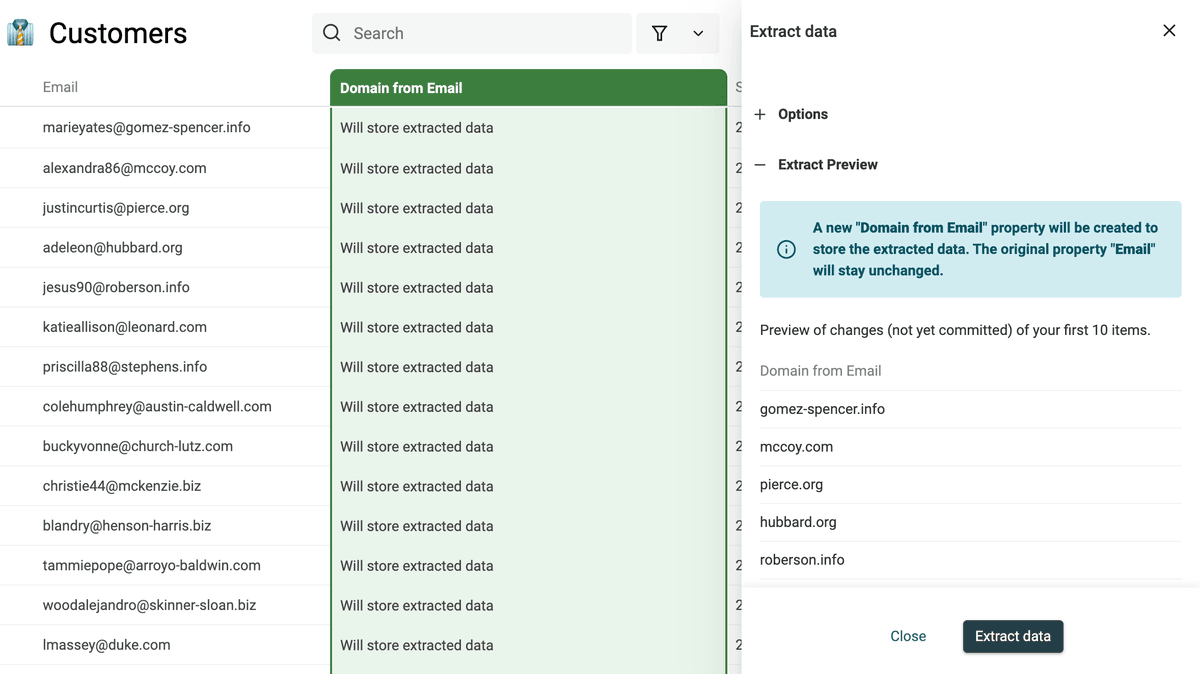
Extraire les adresses email, URLs, etc. des textes
Le "Data Extractor" permet de parser des textes non structurés et d’en sortir des entités :
- Emails
- URLs
- Domaine depuis une URL
- Domaine depuis un email
- Mentions (@nom)
- Tags (#tag)
C'est idéal pour segmenter et relier vos données à d’autres outils (enrichissement, automatisation, scoring…)
Dans le menu "Edit Menu -> Extract url, email, tag, etc.".
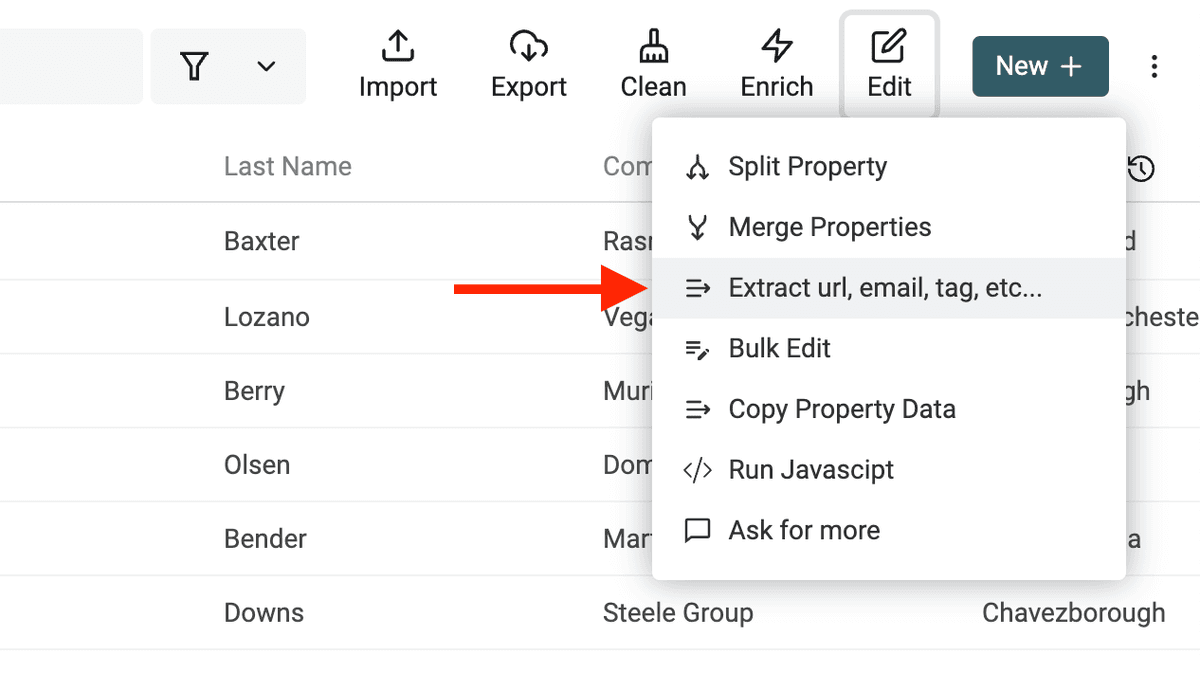
Sélectionnez la colonne cible et choisissez un parser.
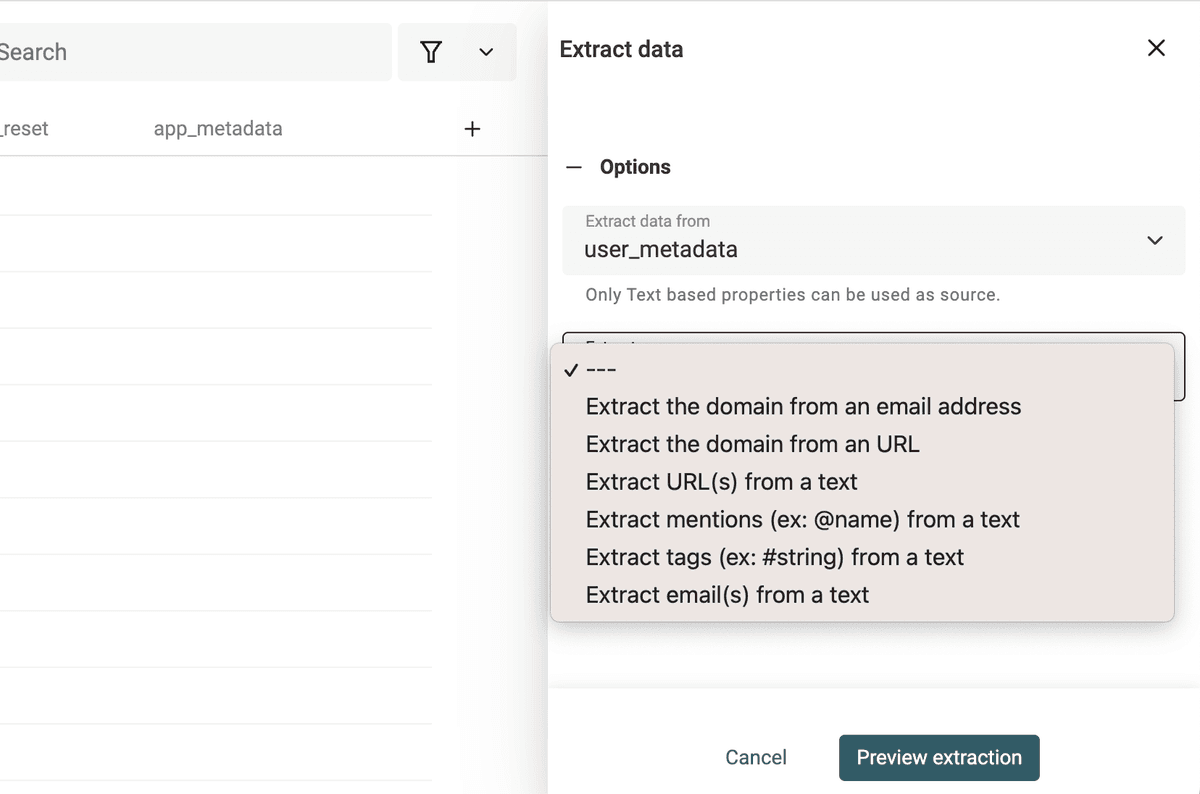
Lancez l'extraction pour prévisualiser le résultat, puis appliquez.
Utiliser les expressions régulières pour filtrer et valider les données
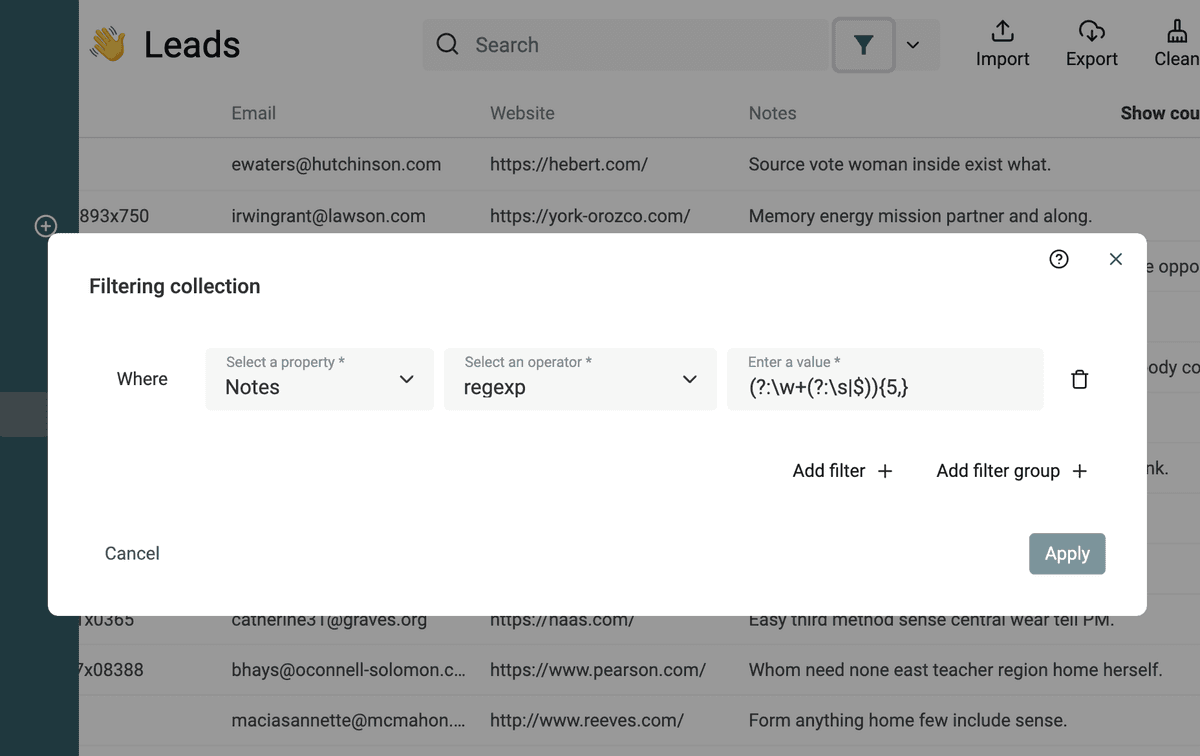
Datablist accepte les expressions régulières (Regex) pour filtrer ou valider vos données.
Filtrer par nombre de mots dans un texte
Pour filtrer les textes ayant au moins {n} mots :
(?:\w+(?:\s|$)){5,} (remplacez 5 par le nombre souhaité)
Variantes :
(?:\w+(?:\s|$)){,5}: moins de 5 mots (inclus)(?:\w+(?:\s|$)){5,10}: entre 5 et 10 mots
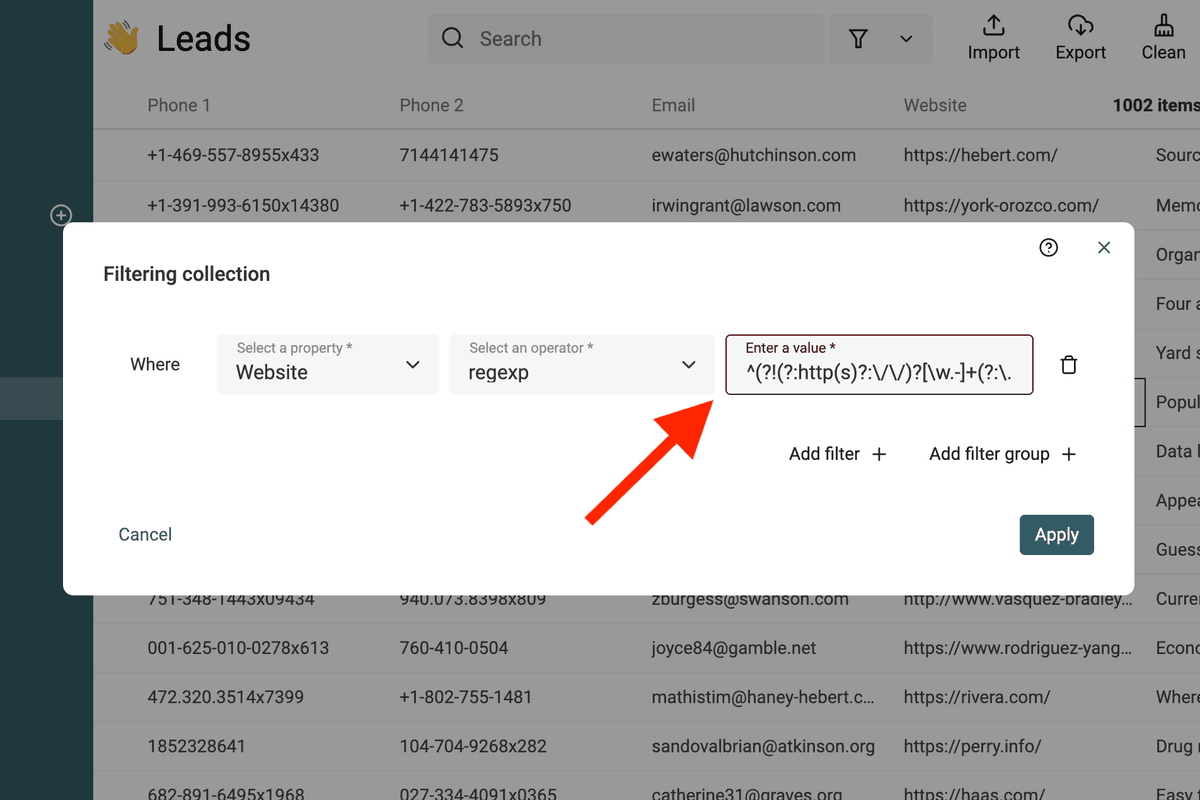
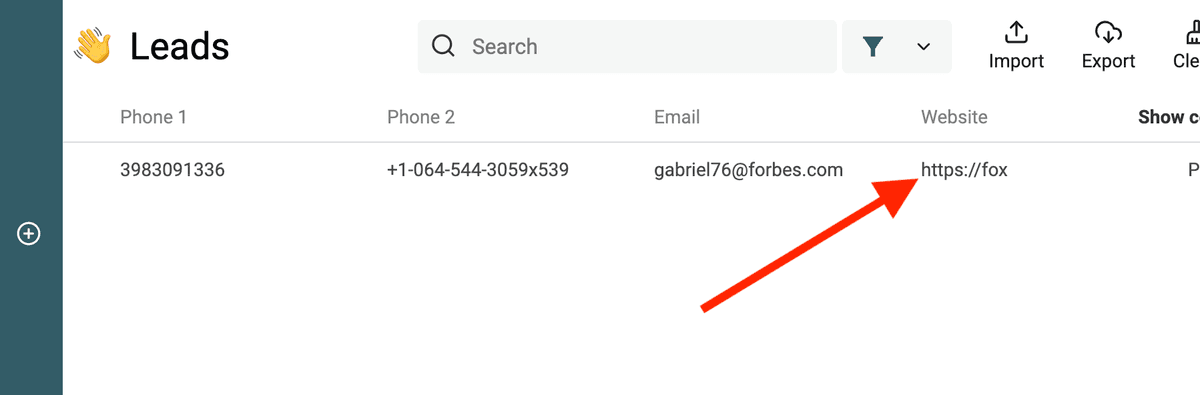
Filtrer les URLs invalides
Regex URL invalide :
^(?!(?:http(s)?:\/\/)?[\w.-]+(?:\.[\w\.-]+)+[\w\-\._~:/?#[\]@!\$&'\(\)\*\+,;=.]+).*$
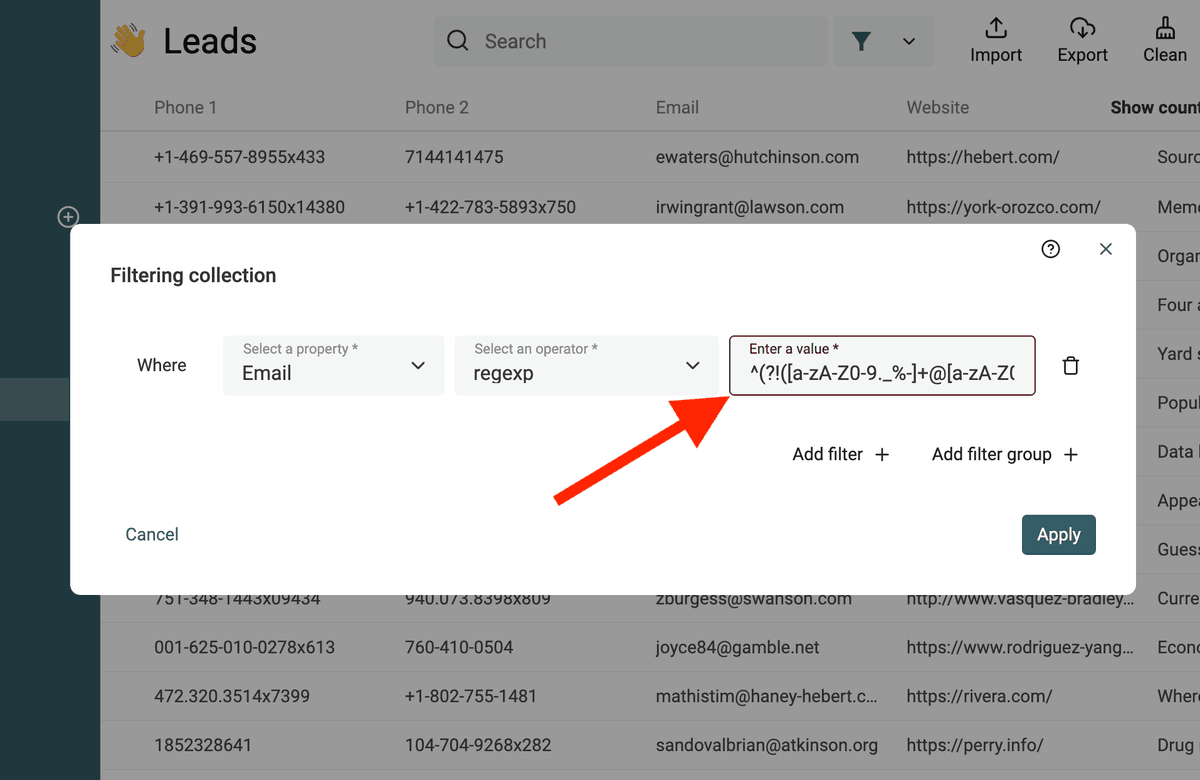
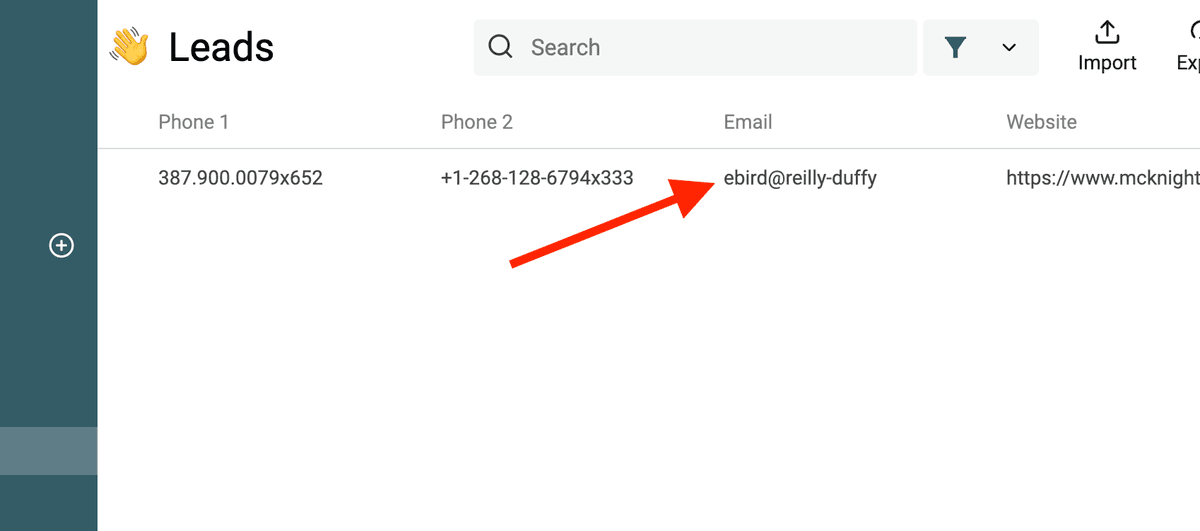
Filtrer les emails invalides
Regex emails invalides :
^(?!([a-zA-Z0-9._%-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,})).*$
Écrire des transformations sur-mesure en JavaScript
Datablist permet d’exécuter votre propre code JavaScript sur vos données. Extrêmement pratique pour traiter des formats personnalisés, des calculs ou des transformations avancées.
Éditeur accessible via "Run JavaScript" dans le menu "Edit".
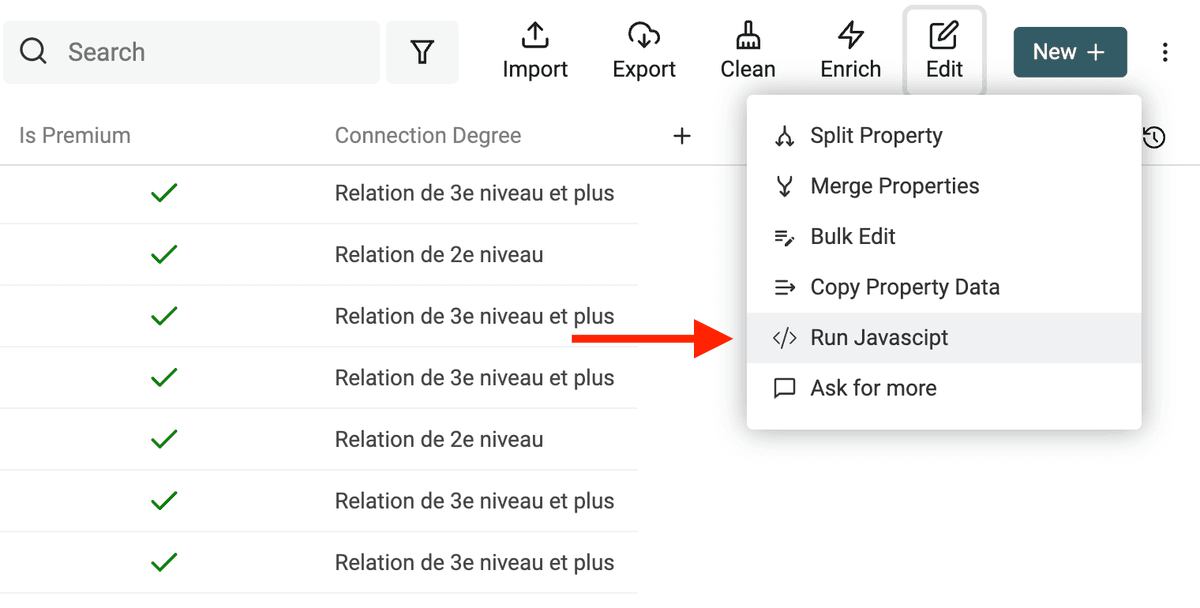
👉 Consultez la doc pour en savoir plus sur l’écriture de code JavaScript.
Valider les adresses email
Les emails issus de bases extraites peuvent être obsolètes, erronés ou temporaires.
Quand vos données proviennent de l’utilisateur final, attendez-vous à trouver des emails factices ou jetables.
Datablist intègre un outil pour valider en masse les adresses email :
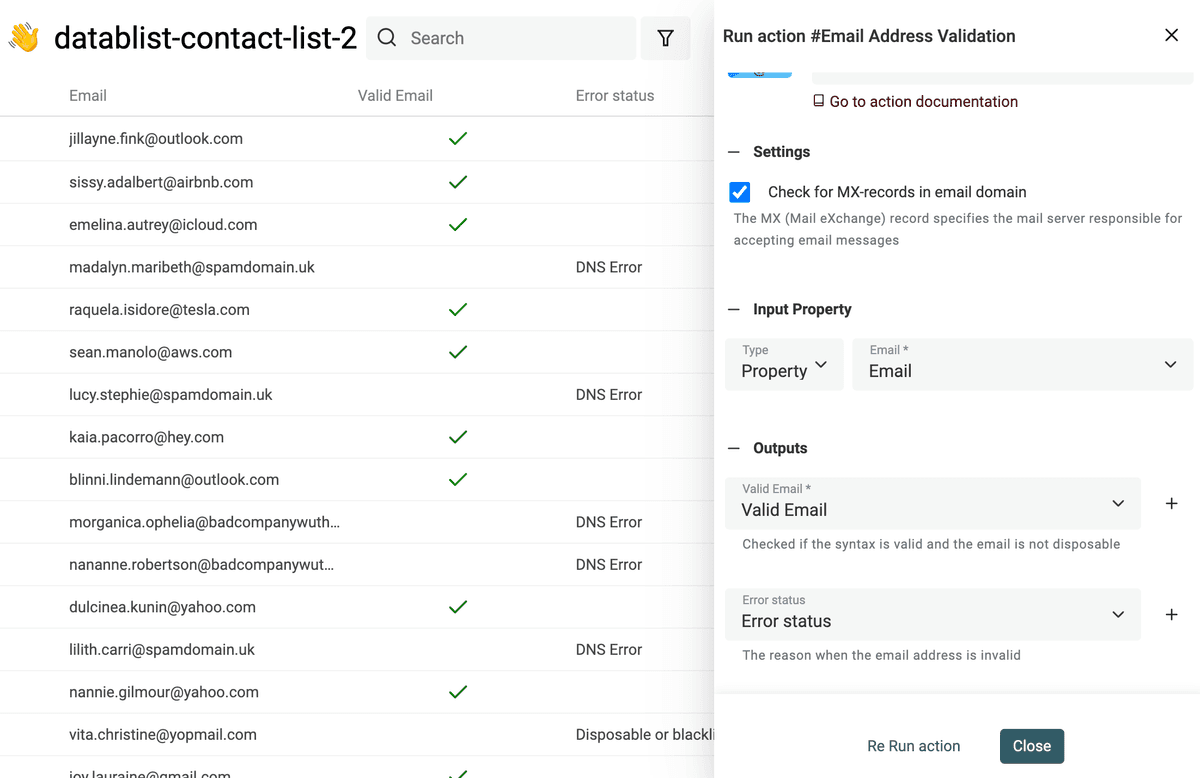
Les vérifications comprennent :
- Analyse syntaxique – Validation selon la norme IEFT, détection des @ manquants, domaines invalides, etc.
- Détection des emails jetables – Recherche des domaines Mailinator, YopMail, etc.
- Vérification des MX – Test des enregistrements DNS du domaine, absence de MX = email invalide.
- Segmentation pro/perso – Idéal pour segmenter vos contacts et adapter vos campagnes.
FAQ
Qu'est-ce que le nettoyage de données et pourquoi est-ce important ?
Le nettoyage de données (data cleaning, cleansing ou scrubbing) consiste à identifier et corriger ou supprimer les erreurs, incohérences, et valeurs erronées d’un jeu de données. Cela inclut la gestion des valeurs manquantes, des doublons, des formats incorrects et des incohérences de saisie.
Nettoyer ses données est primordial pour garantir la fiabilité des analyses, la précision des résultats et la qualité globale de vos traitements.
Quels outils gratuits alternatifs pour le data cleaning ?
L’univers du data cleaning s’étend des tableurs généralistes aux plateformes spécialisées. Voici quelques alternatives gratuites à Datablist :
OpenRefine
OpenRefine (ex Google Refine) est un outil open source pour explorer et nettoyer de grands volumes de données non structurées.
C’est une application de bureau compatible CSV, Excel, JSON, XML, etc. Elle gère bien les problèmes d’encodage et propose plusieurs options de réparation du format CSV.
Points faibles : prise en main complexe, peu de fonctions business prêtes à l’emploi (pas de déduplication native, pas de fusion simple avec d’autres listes, peu d’intégrations collaboratives).
Microsoft Excel et Google Sheets
Excel et Google Sheets, encore incontournables pour de nombreuses tâches de nettoyage et de préparation des données. Utilisez les formules pour transformer et manipuler les données ; la mise en forme conditionnelle pour repérer rapidement les valeurs à corriger.
Besoin d’aide pour le nettoyage de vos données ?
Je suis toujours à l’écoute pour recueillir vos retours et vos enjeux concrets sur le data cleaning. Contactez-moi ici pour partager votre cas d’usage !