
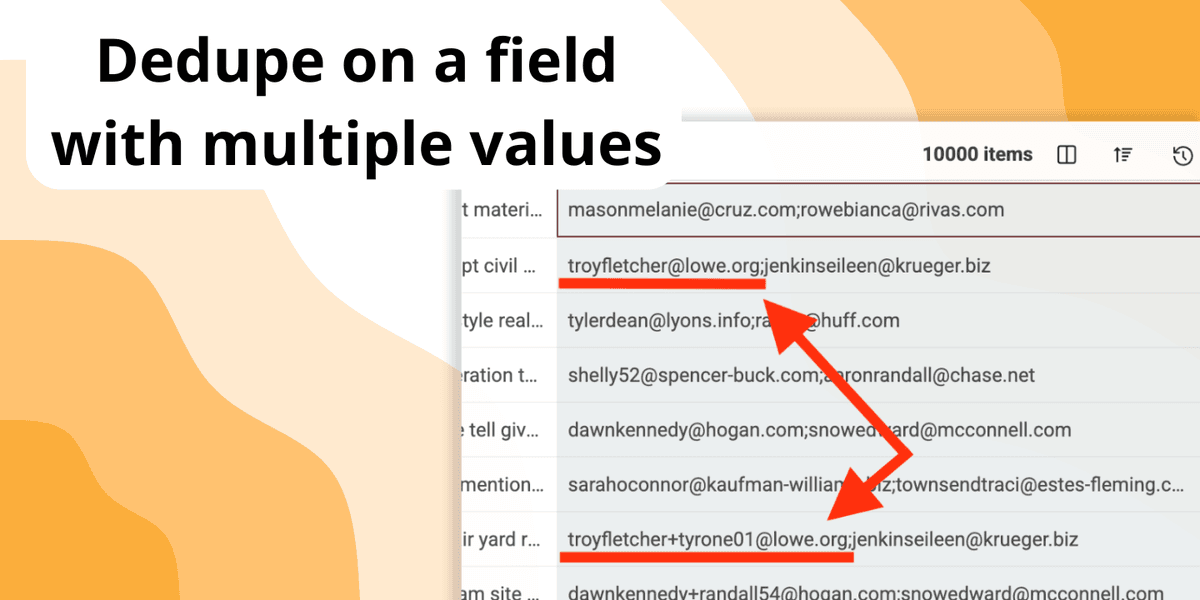
Deduplicating lists becomes significantly more complex when a single field contains multiple values.
Imagine a contact list where the "Emails" field holds several email addresses separated by commas, or a company database where the "URLs" column lists multiple links to website, social media pages.
Standard deduplication tools often struggle to recognize that two records might be duplicates if they share even one of these multiple values.
If you first need to normalize a multi-value column into one row per value, use Datablist's CSV Rows Splitter. It expands cells like email1, email2 into separate rows before cleaning or deduplication.
Datablist provides a robust solution for this advanced deduplication scenario.
In this article you will see how to dedupe list using a field that have multiple values:
- Importing your Data for Deduplication
- Identifying Duplicates with Multiple Value Matching
- Resolving Conflicts and Merging Duplicate Records
Step 1: Importing and Preparing Your Data for Deduplication
The first step is to bring your data into Datablist. This could involve importing a CSV or Excel file, or connecting to your CRM or other data sources.
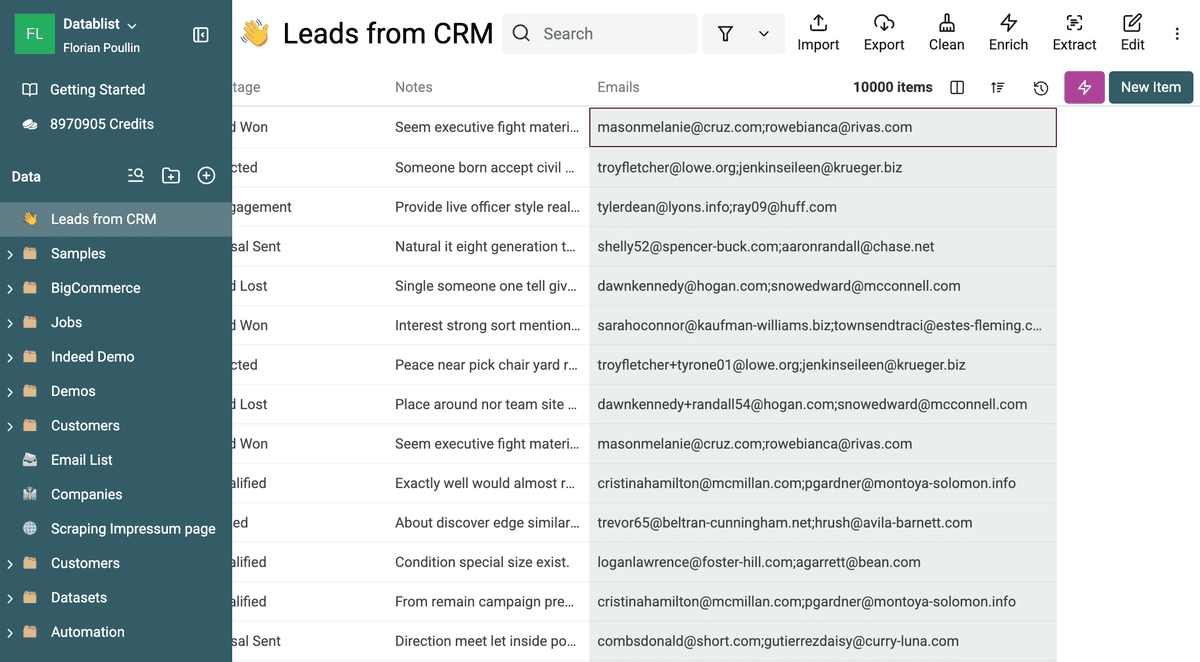
Once your data is imported, it's crucial to examine the field that contains multiple values. Datablist's "Multiple Values" feature is designed to work with values separated by a semicolon (;).
Example:
Consider an "Emails" field in a contact list. If the emails are listed as:
- Record 1:
john.doe@example.com; jane.doe@example.com; info@example.com - Record 2:
jane.doe@example.com; support@example.com; sales@example.com - Record 3:
john.doe@example.com; marketing@example.com
Datablist can recognize that Record 1 and Record 3 both include "john.doe@example.com", and Record 1 and Record 2 both include "jane.doe@example.com", even though these are within a single field.
Handling Different Separators:
If your multiple values are separated by a character other than a semicolon (e.g., comma, pipe, space), you'll need to normalize your data before using the Duplicates Finder. Datablist's powerful Find & Replace tool can be used for this purpose.
Here's how to use Find & Replace to standardize your separators to semicolons:
- Navigate to your Datablist collection.
- Select the column containing the multiple values.
- Go to the "Clean" menu and choose "Find & Replace".
- In the "Find" field, enter the current separator (e.g.,
,for comma-separated values). - In the "Replace with" field, enter a semicolon
;. - Click "Apply".
By ensuring that all your multi-value fields use a semicolon as the separator, you'll enable Datablist's "Multiple Values" feature to work accurately.
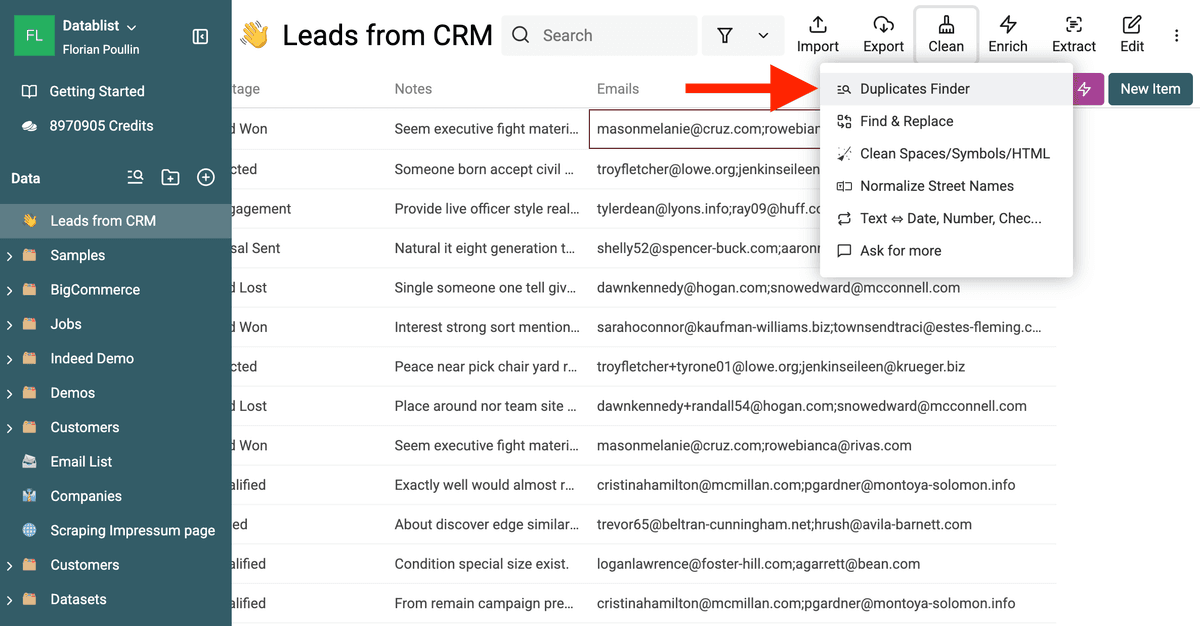
Step 2: Identifying Duplicates with Multiple Value Matching
With your data imported and the multi-value fields prepared (using semicolons as separators), you can now proceed to find duplicates.
-
Navigate to the "Clean" menu and select "Duplicates Finder".
Open Duplicates Finder Tool -
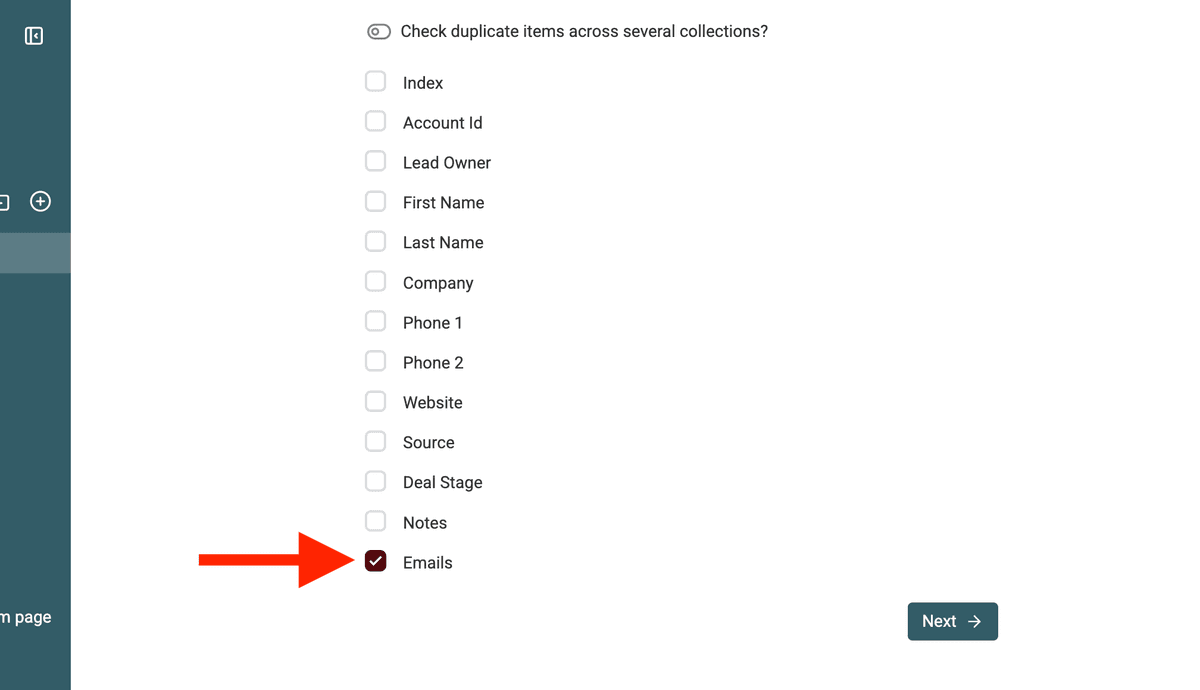
In the Duplicates Finder, select the column that contains the multiple values you want to use for matching. Let's say you select the "Emails" column from our previous example.
Select the Property -
Crucially, enable the "Multiple Values" checkbox. You should see a field appear where you can confirm or specify the separator. Ensure it is set to
;(semicolon).Enable Multiple Values Option -
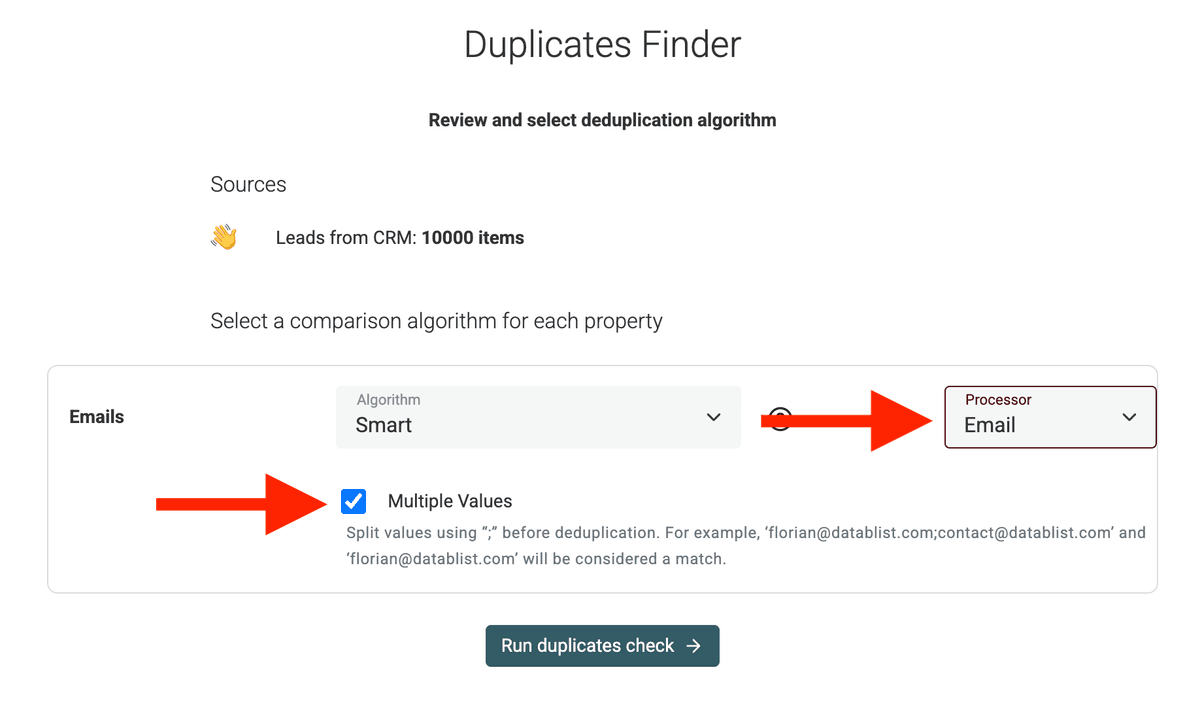
Choose your matching algorithm and the Processor
Datablist comes with different deduplication algorithms. Here are the two main ones:
- Smart Algorithm: This is generally a good starting point. It will analyze the individual emails within each record and identify records that share one or more common emails.
- Distance Algorithm: If you expect slight variations or typos within the emails (e.g., "john.doe@exmaple.com" vs. "john.doe@example.com"), the Distance Algorithm can be helpful. You'll need to set a similarity threshold to define how close the values need to be to be considered a match.
Datablist also comes with "Processor" that normalize your data before identifying duplicates. If you dedupe on URLs, select
URL, for Emails, selectEmails, etc.For example, the Email processor will match the two following email addresses:
john@datablist.comandjohn+spam@datablist.com. -
Run the duplicates check. Datablist will now process your data, treating each email within the "Emails" field as a separate entity for comparison. Records that share at least one email (or have similar emails based on the Distance Algorithm) will be grouped as potential duplicates.
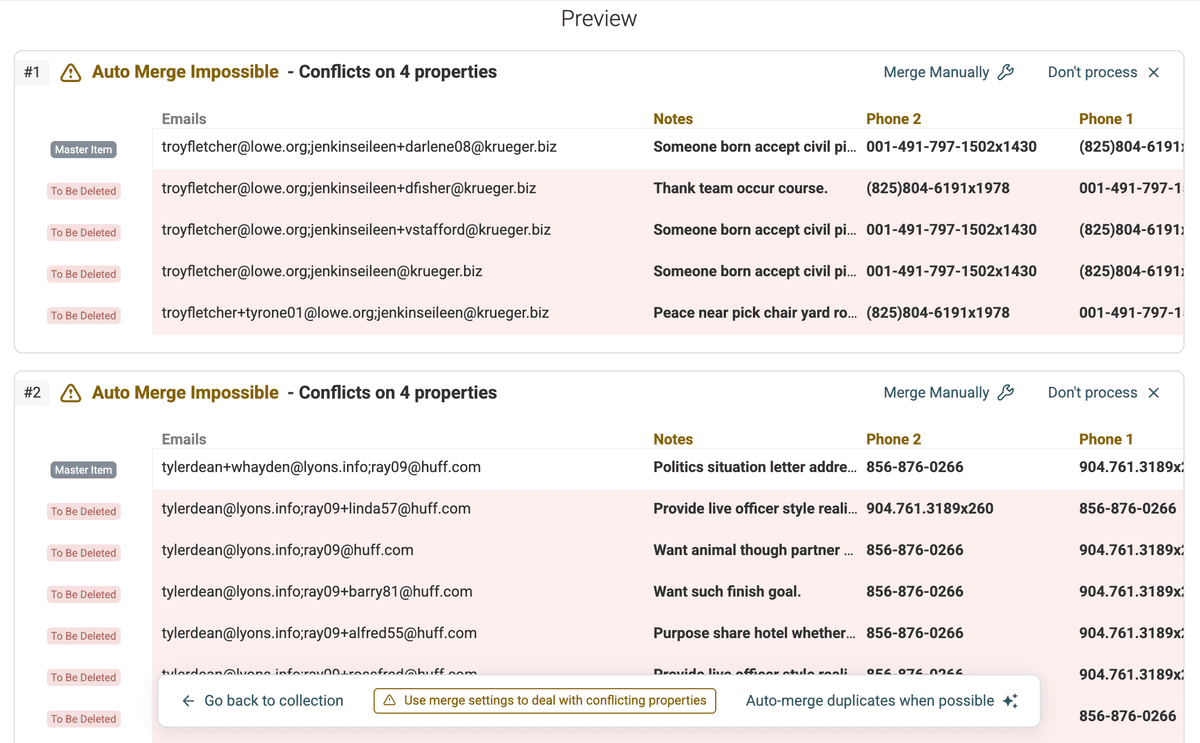
Duplicates Preview -
Carefully review the detected duplicate groups. You'll see how the records are matched based on the shared values in the multi-value field. For instance, in our "Emails" example, records 1 and 3 would likely be grouped because they both have "john.doe@example.com". Records 1 and 2 would also be grouped due to the shared "jane.doe@example.com" email.
Step 3: Resolving Conflicts and Merging Duplicate Records
Once you've identified the duplicate groups, the next step is to define how these records should be merged, especially concerning the multi-value field and any other potential conflicts.
-
For each duplicate group, Datablist will highlight any fields where the values differ – these are considered conflicting properties. This might include other contact information like phone numbers, email addresses (if you deduplicated based on emails), or job titles.
-
When it comes to the multi-value field (in our example, "Emails"), you'll have specific merging options:
-
Combine Values: This is often the most desirable option. Datablist will gather all the unique values from the duplicate records and merge them into a single value using a concatenation character. For example, merging Record 1 (
john.doe@example.com; jane.doe@example.com; info@example.com) and Record 3 (john.doe@example.com; marketing@example.com) would result in a master record withjohn.doe@example.com; jane.doe@example.com; info@example.com; marketing@example.com. -
Drop Conflicting Values: If one contact is clearly more complete, and you want to discard the other, select "Drop conflicting values...".
Select a master record
You can also configure how Datablist selects the master record. When merging duplicate records, Datablist keeps one record, updates its fields, and deletes the other records to end up with only one record.
You can control how Datablist selects this Master Record by choosing from several rules:
- Most Complete: Picks the record with the most populated fields.
- Last Updated: Picks the most recently modified record.
- First Created: Picks the oldest record based on the creation date.
- Highest Value: Picks the record with the highest value for a selected property. If multiple records have the same value, it selects the most recent one.
- Lowest Value: Picks the record with the lowest value for a selected property. If multiple records have the same value, it selects the most recent one.
- Matching Value: Picks the record that contains a specific value in a selected property. If no record matches, they won’t be merged.
-
-
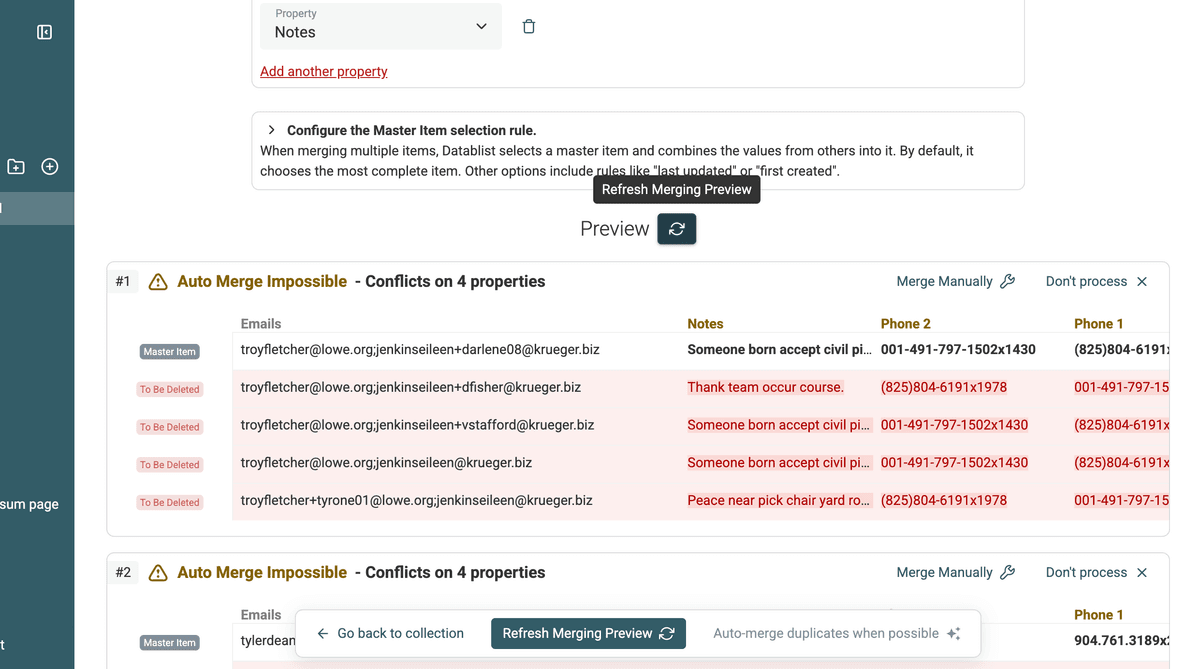
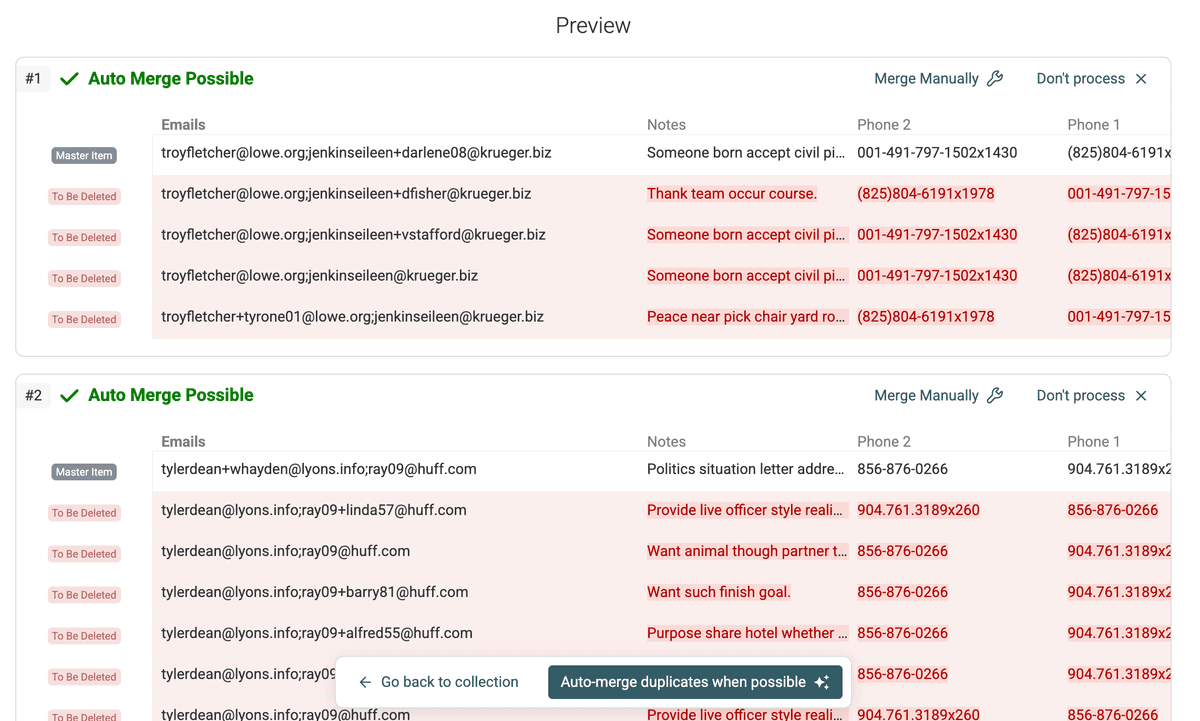
After setting your merging rules for all conflicting properties, refresh the preview. This will show you exactly how the merged record will look for each duplicate group. Pay close attention to how the multiple values have been combined.
Update Merging Result Preview -
Review the merging preview carefully to ensure the outcome aligns with your expectations. Once you are satisfied, you can proceed with the merging process. Click on "Auto-merge duplicates when possible" or manually merge specific groups if needed.
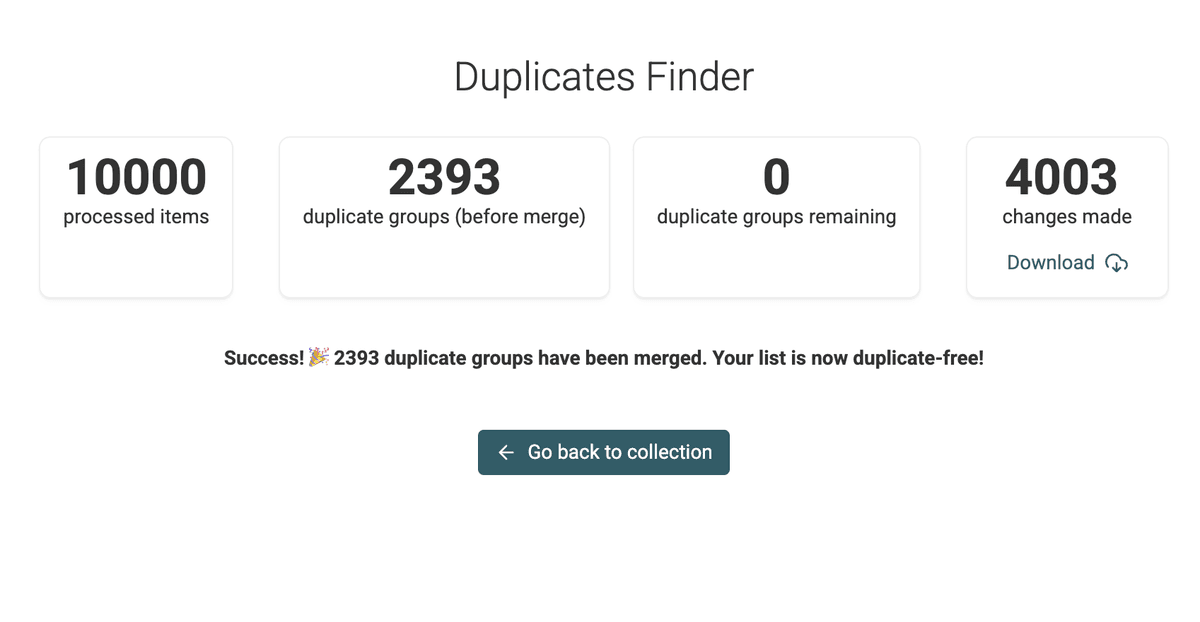
Successful Merging Preview -
Once the merge is complete, Datablist will provide a summary of the actions taken.
Merging Done Screen
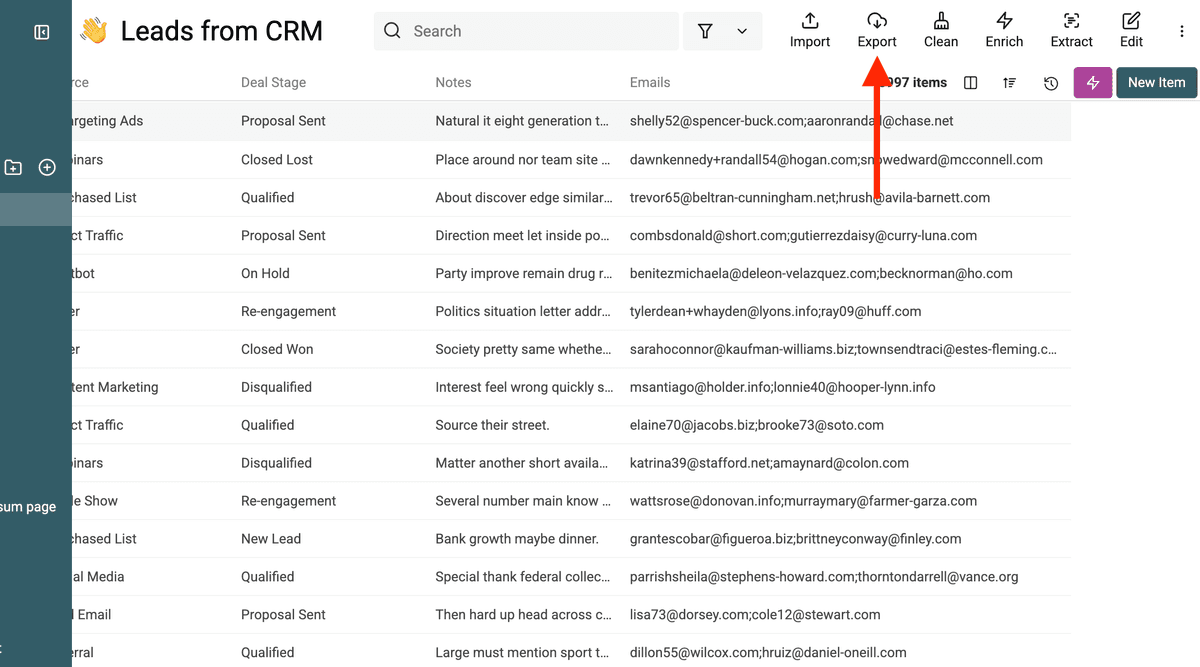
Finally, you can export your cleaned and deduplicated list, now containing consolidated information even for records that had multiple values in a single field.
By following these steps, you can effectively leverage Datablist's "Multiple Values" feature to perform advanced deduplication on lists where key information is stored in a structured, multi-value format. Remember to standardize your separators to semicolons for optimal results.