
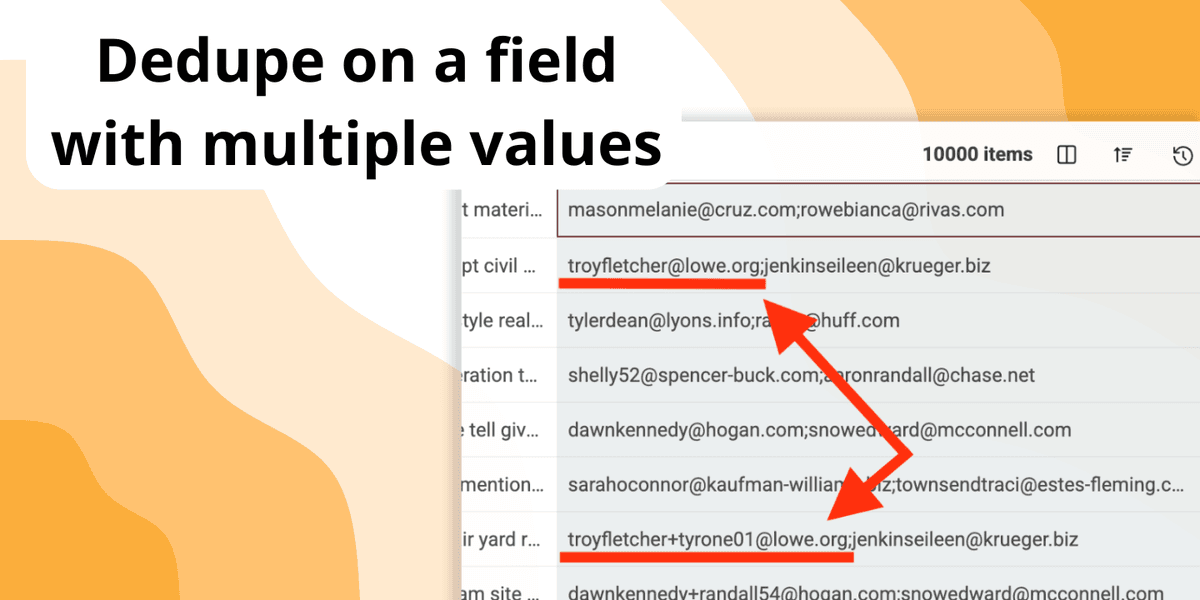
La deduplicazione delle liste si complica parecchio quando un singolo campo contiene più valori.
Immagina una lista contatti in cui il campo "Emails" raccoglie diversi indirizzi separati da virgole, oppure un database aziendale in cui la colonna "URLs" elenca più link al sito e ai profili social.
I tool di deduplica standard spesso faticano a riconoscere che due record possono essere duplicati anche se condividono uno solo di questi valori multipli.
Datablist offre una soluzione solida per questo scenario avanzato di deduplicazione.
In questo articolo vedrai come deduplicare una lista usando un campo che contiene più valori:
- Importazione e preparazione dei dati per la deduplicazione
- Identificare i duplicati con matching su valori multipli
- Risolvere conflitti e unire i record duplicati
Passo 1: Importazione e preparazione dei dati per la deduplicazione
Il primo step è importare i tuoi dati in Datablist. Puoi caricare un file CSV o Excel, oppure connetterti al tuo CRM o ad altre sorgenti dati.
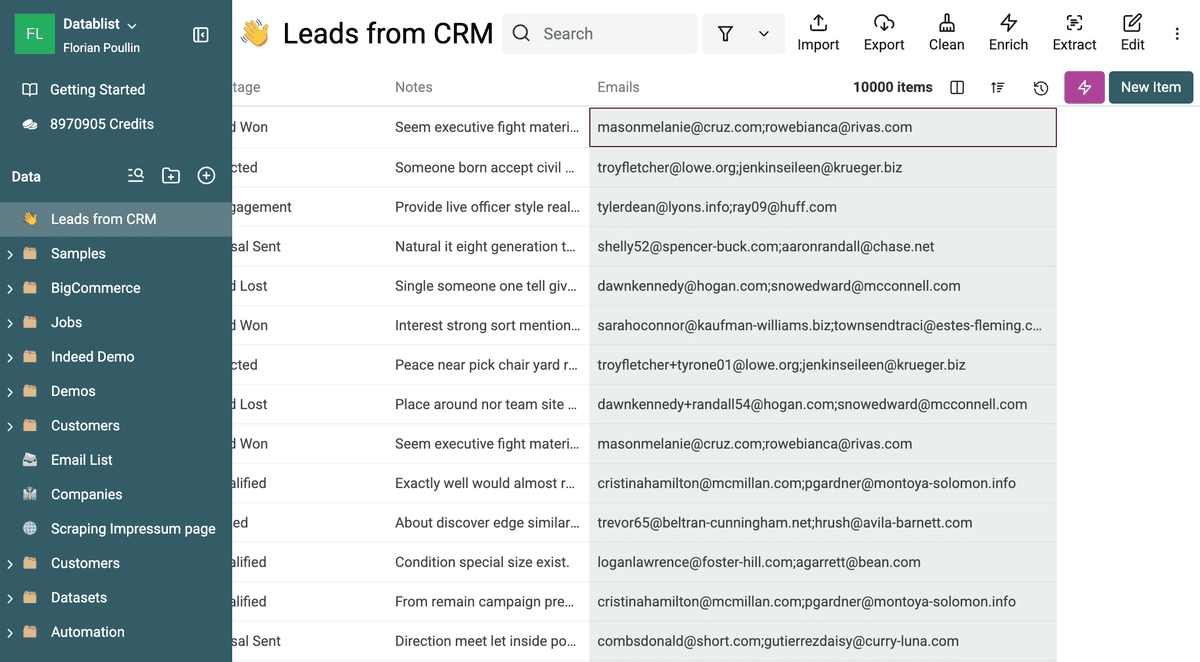
Una volta importati, è fondamentale esaminare il campo che contiene valori multipli. La funzione "Multiple Values" di Datablist è progettata per funzionare con valori separati da punto e virgola (;).
Esempio:
Considera un campo "Emails" in una lista contatti. Se le email sono elencate così:
- Record 1:
john.doe@example.com; jane.doe@example.com; info@example.com - Record 2:
jane.doe@example.com; support@example.com; sales@example.com - Record 3:
john.doe@example.com; marketing@example.com
Datablist è in grado di riconoscere che il Record 1 e il Record 3 includono entrambi "john.doe@example.com", e che il Record 1 e il Record 2 condividono "jane.doe@example.com", anche se sono nello stesso campo.
Gestire separatori diversi:
Se i tuoi valori multipli sono separati da un carattere diverso dal punto e virgola (ad es. virgola, pipe, spazio), dovrai normalizzare i dati prima di usare il Duplicates Finder. Il potente strumento Find & Replace di Datablist è perfetto per questo.
Ecco come usare Find & Replace per standardizzare i separatori al punto e virgola:
- Vai alla tua collection in Datablist.
- Seleziona la colonna che contiene i valori multipli.
- Apri il menu "Clean" e scegli "Find & Replace".
- Nel campo "Find", inserisci l’attuale separatore (es.
,per valori separati da virgola). - Nel campo "Replace with", inserisci un punto e virgola
;. - Clicca su "Apply".
Assicurandoti che tutti i campi multivalore usino il punto e virgola come separatore, abiliterai la funzione "Multiple Values" di Datablist a lavorare in modo accurato.
Passo 2: Identificare i duplicati con matching su valori multipli
Con i dati importati e i campi multivalore preparati (usando i punti e virgola come separatori), puoi procedere a trovare i duplicati.
-
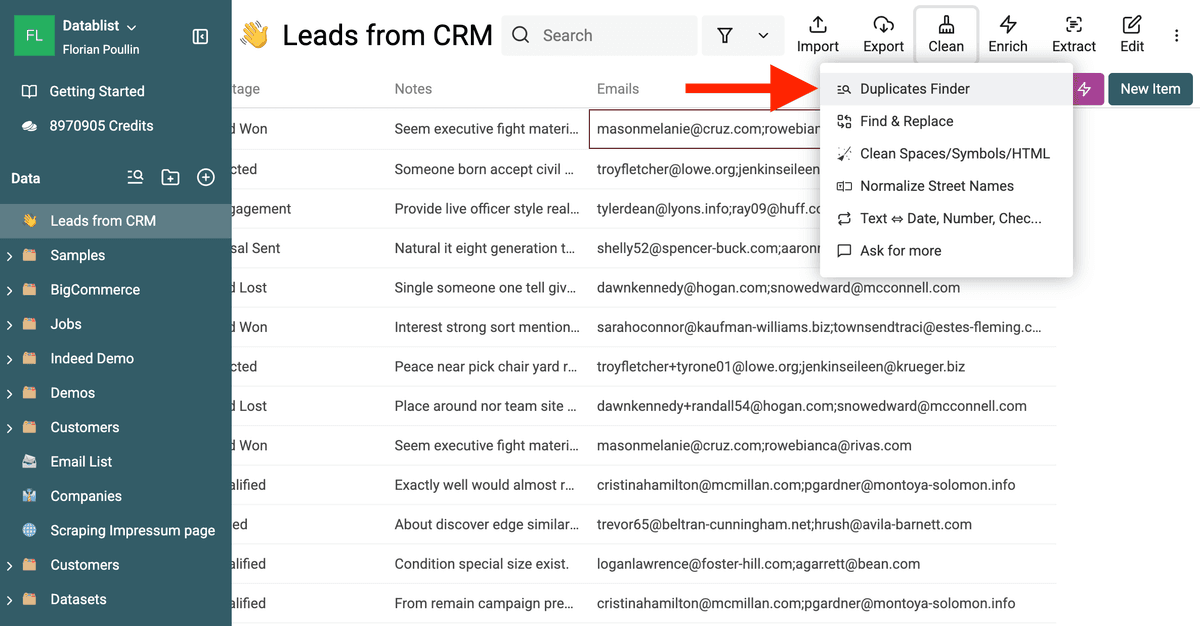
Apri il menu "Clean" e seleziona "Duplicates Finder".
Apri Duplicates Finder -
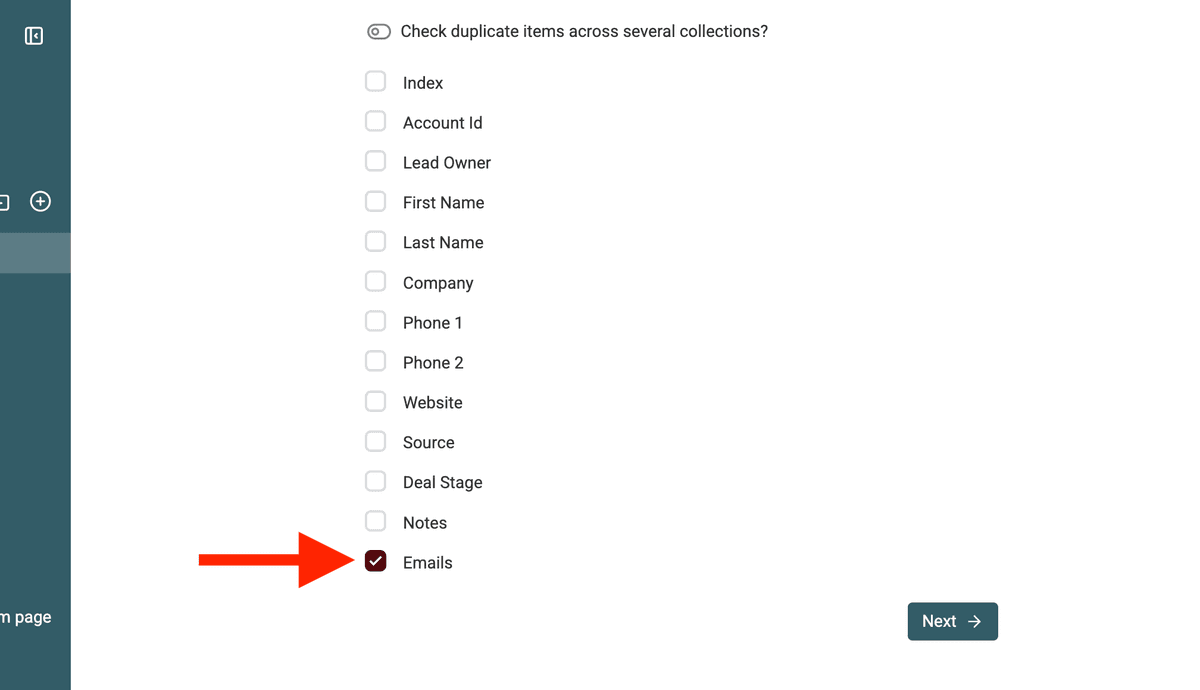
In Duplicates Finder, seleziona la colonna che contiene i valori multipli su cui vuoi effettuare il matching. Ad esempio, scegli la colonna "Emails" del nostro esempio.
Seleziona la proprietà -
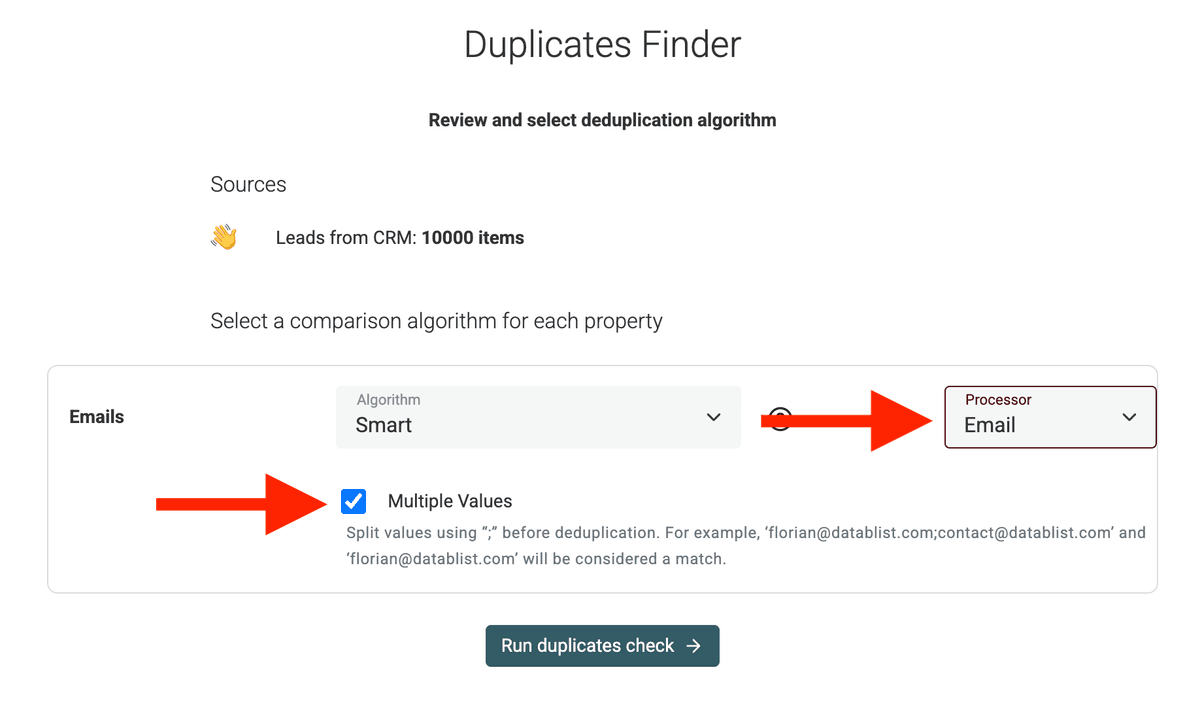
Fondamentale: abilita la checkbox "Multiple Values". Vedrai apparire un campo per confermare o specificare il separatore. Assicurati che sia impostato su
;(punto e virgola).Abilita l’opzione Multiple Values -
Scegli l’algoritmo di matching e il Processor
Datablist include diversi algoritmi di deduplicazione. Ecco i due principali:
- Smart Algorithm: in genere è un ottimo punto di partenza. Analizza le singole email all’interno di ogni record e identifica i record che condividono una o più email in comune.
- Distance Algorithm: se ti aspetti piccole variazioni o typo nelle email (es. "john.doe@exmaple.com" vs. "john.doe@example.com"), il Distance Algorithm può aiutare. Dovrai impostare una soglia di similarità per definire quanto devono essere vicini i valori per considerarli un match.
Datablist offre anche i "Processor" per normalizzare i dati prima di trovare i duplicati. Se deduplichi sugli URL, seleziona
URL; per le email, selezionaEmails, ecc.Ad esempio, l’Email processor farà combaciare questi due indirizzi:
john@datablist.comejohn+spam@datablist.com. -
Avvia il controllo dei duplicati. Datablist elaborerà i tuoi dati trattando ogni email nel campo "Emails" come entità separata per il confronto. I record che condividono almeno una email (o hanno email simili in base al Distance Algorithm) verranno raggruppati come potenziali duplicati.
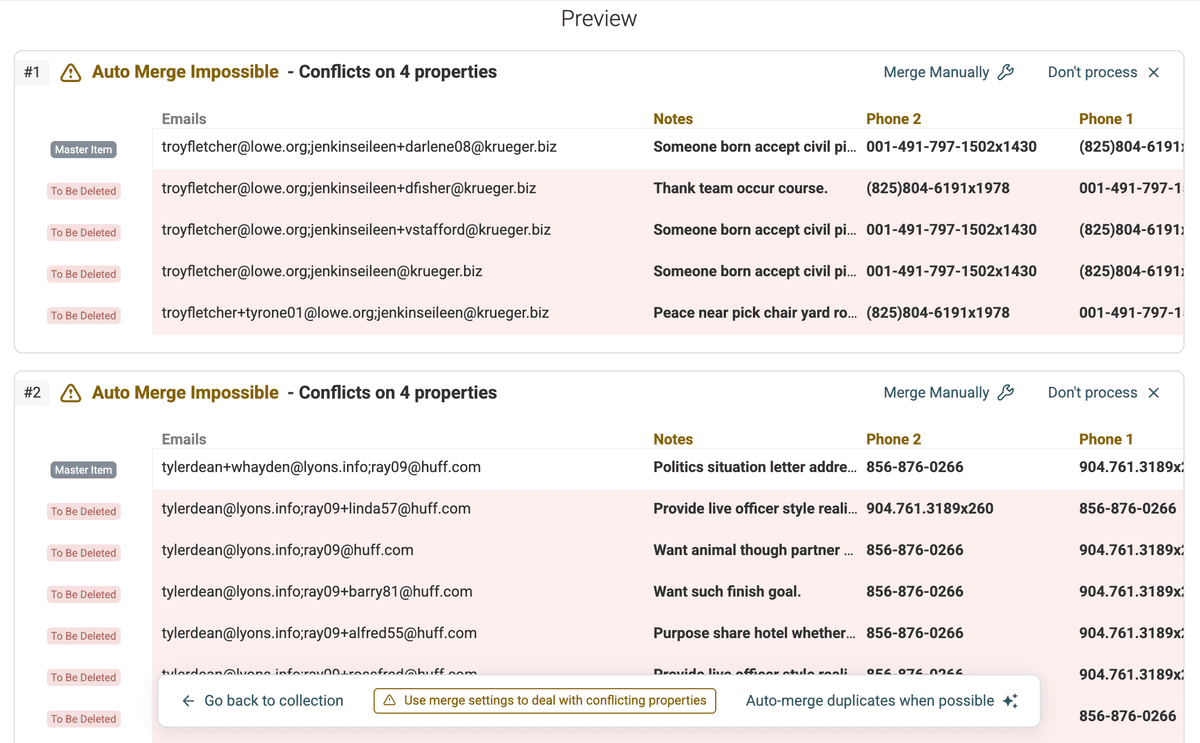
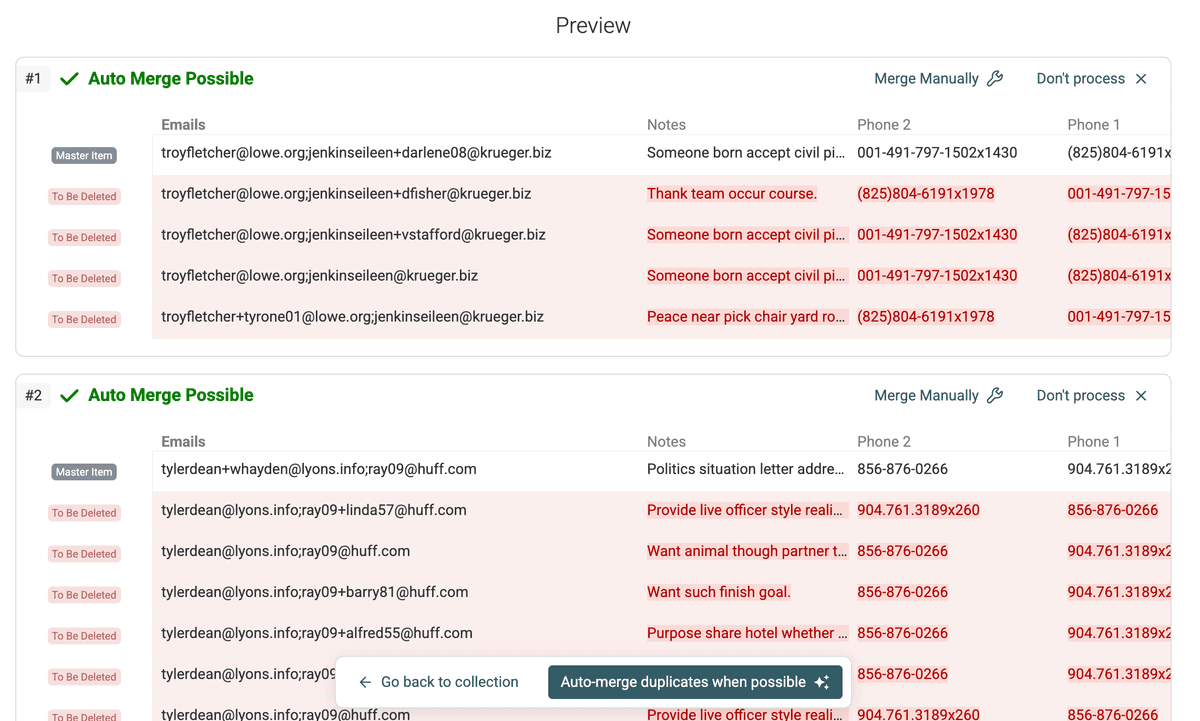
Anteprima duplicati -
Rivedi con attenzione i gruppi di duplicati rilevati. Vedrai come i record sono stati abbinati in base ai valori condivisi nel campo multivalore. Nel nostro esempio, i record 1 e 3 saranno probabilmente nello stesso gruppo perché hanno entrambi "john.doe@example.com". I record 1 e 2 saranno raggruppati per la email condivisa "jane.doe@example.com".
Passo 3: Risolvere conflitti e unire i record duplicati
Identificati i gruppi di duplicati, il passo successivo è definire come unire questi record, con particolare attenzione al campo multivalore e ad altri possibili conflitti.
-
Per ogni gruppo, Datablist evidenzia i campi in cui i valori differiscono: sono le conflicting properties. Questo può includere altre informazioni di contatto come numeri di telefono, indirizzi email (se hai deduplicato sulle email) o job title.
-
Per il campo multivalore (nel nostro esempio, "Emails"), hai opzioni specifiche di merging:
-
Combine Values: spesso è l’opzione migliore. Datablist raccoglie tutti i valori unici dai record duplicati e li unisce in un solo valore usando un carattere di concatenazione. Ad esempio, unendo il Record 1 (
john.doe@example.com; jane.doe@example.com; info@example.com) e il Record 3 (john.doe@example.com; marketing@example.com) otterrai un record master conjohn.doe@example.com; jane.doe@example.com; info@example.com; marketing@example.com. -
Drop Conflicting Values: se un contatto è chiaramente più completo e vuoi scartare l’altro, seleziona "Drop conflicting values...".
Seleziona il master record
Puoi anche configurare come Datablist sceglie il master record. Quando unisci duplicati, Datablist mantiene un record, ne aggiorna i campi e elimina gli altri per arrivare a un solo record.
Puoi controllare la selezione del Master Record scegliendo tra varie regole:
- Most Complete: sceglie il record con più campi compilati.
- Last Updated: sceglie il record modificato più di recente.
- First Created: sceglie il record più vecchio in base alla data di creazione.
- Highest Value: sceglie il record con il valore più alto per una proprietà selezionata. Se più record hanno lo stesso valore, sceglie il più recente.
- Lowest Value: sceglie il record con il valore più basso per una proprietà selezionata. Se più record hanno lo stesso valore, sceglie il più recente.
- Matching Value: sceglie il record che contiene un valore specifico in una proprietà selezionata. Se nessun record corrisponde, non verranno uniti.
-
-
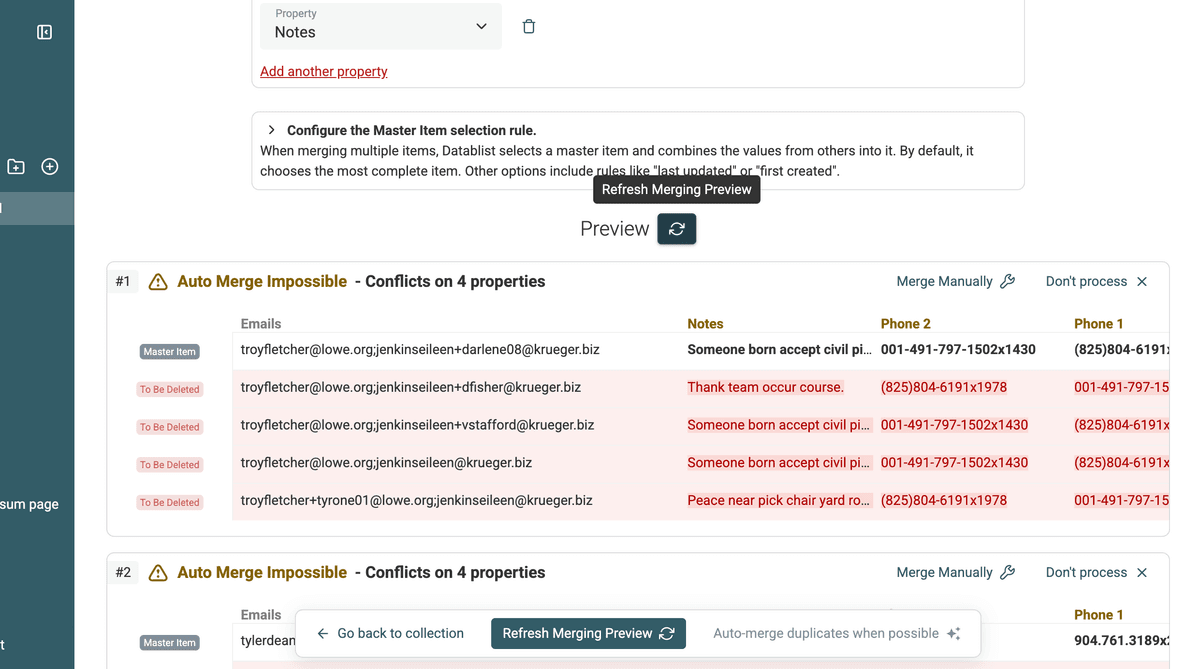
Dopo aver impostato le regole di merging per tutte le proprietà in conflitto, aggiorna l’anteprima. Vedrai esattamente come apparirà il record finale per ogni gruppo di duplicati. Fai attenzione a come sono stati combinati i valori multipli.
Aggiorna anteprima merge -
Controlla l’anteprima con cura per assicurarti che il risultato sia in linea con le aspettative. Quando sei soddisfatto, procedi con il merge. Clicca su "Auto-merge duplicates when possible" oppure unisci manualmente i gruppi desiderati.
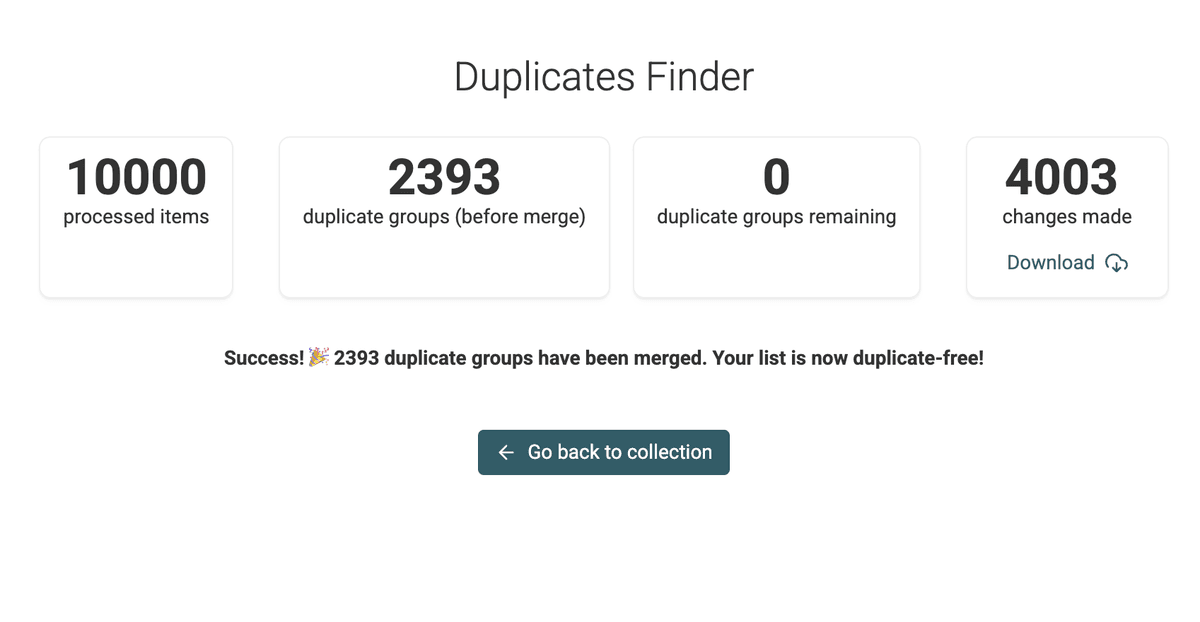
Merge eseguito con successo -
Al termine, Datablist mostrerà un riepilogo delle azioni eseguite.
Schermata di completamento merge
Infine, puoi esportare la tua lista pulita e deduplicata, che ora contiene informazioni consolidate anche per i record che avevano più valori nello stesso campo.
Seguendo questi passaggi, sfrutti al meglio la funzione "Multiple Values" di Datablist per una deduplicazione avanzata su liste in cui informazioni chiave sono memorizzate in un formato strutturato e multivalore. Ricorda di standardizzare i separatori con il punto e virgola per risultati ottimali.