Scrapes agency listings from Clutch.co including company names, ratings, services, pricing, and profile links
Slik bruker du denne AI-prompten
- Create a New Collection: Start med å opprette en ny, tom collection i Datablist der dataene skal lagres. Klikk '+ Create new collection' i sidepanelet.
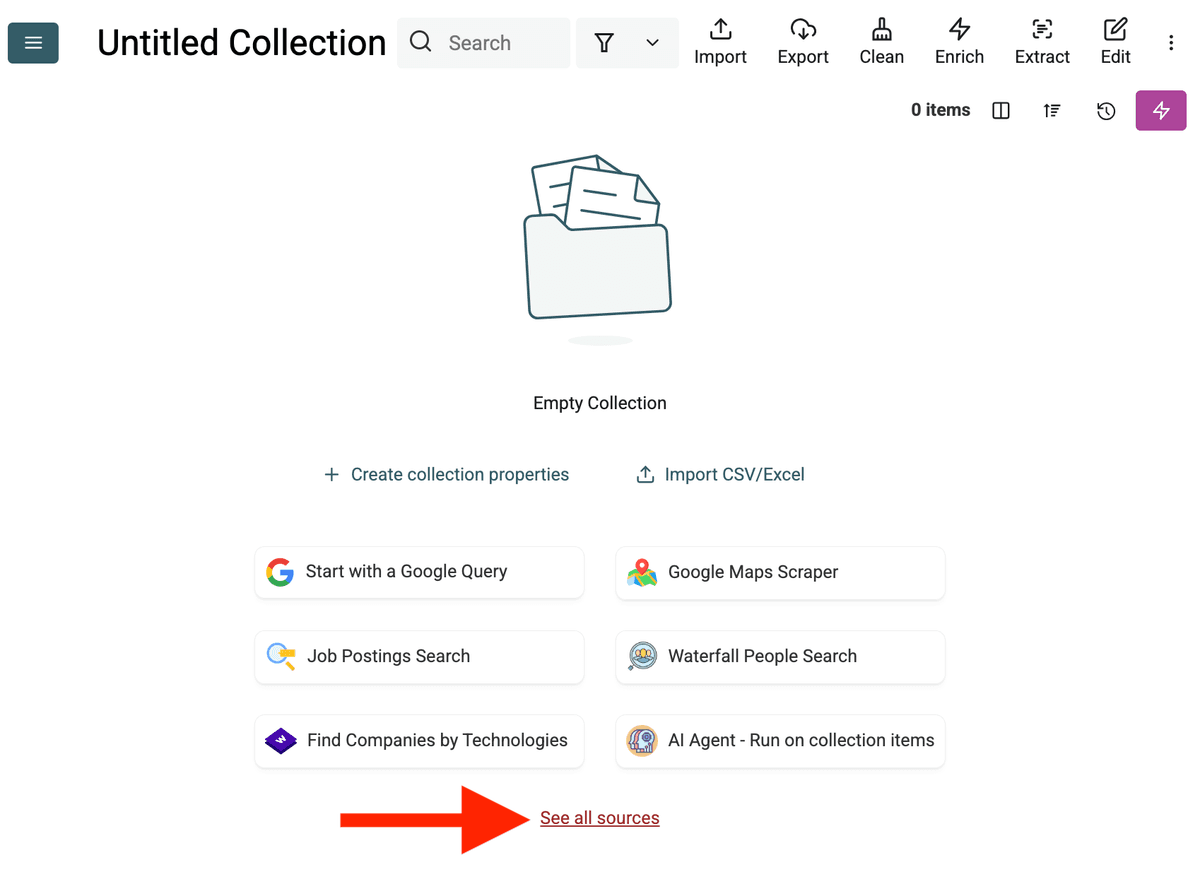
- Select the AI Agent Source: Klikk "See all sources" eller gå til "Import" -> "Import From Data Sources". Velg "AI Agent - Site Scraper".
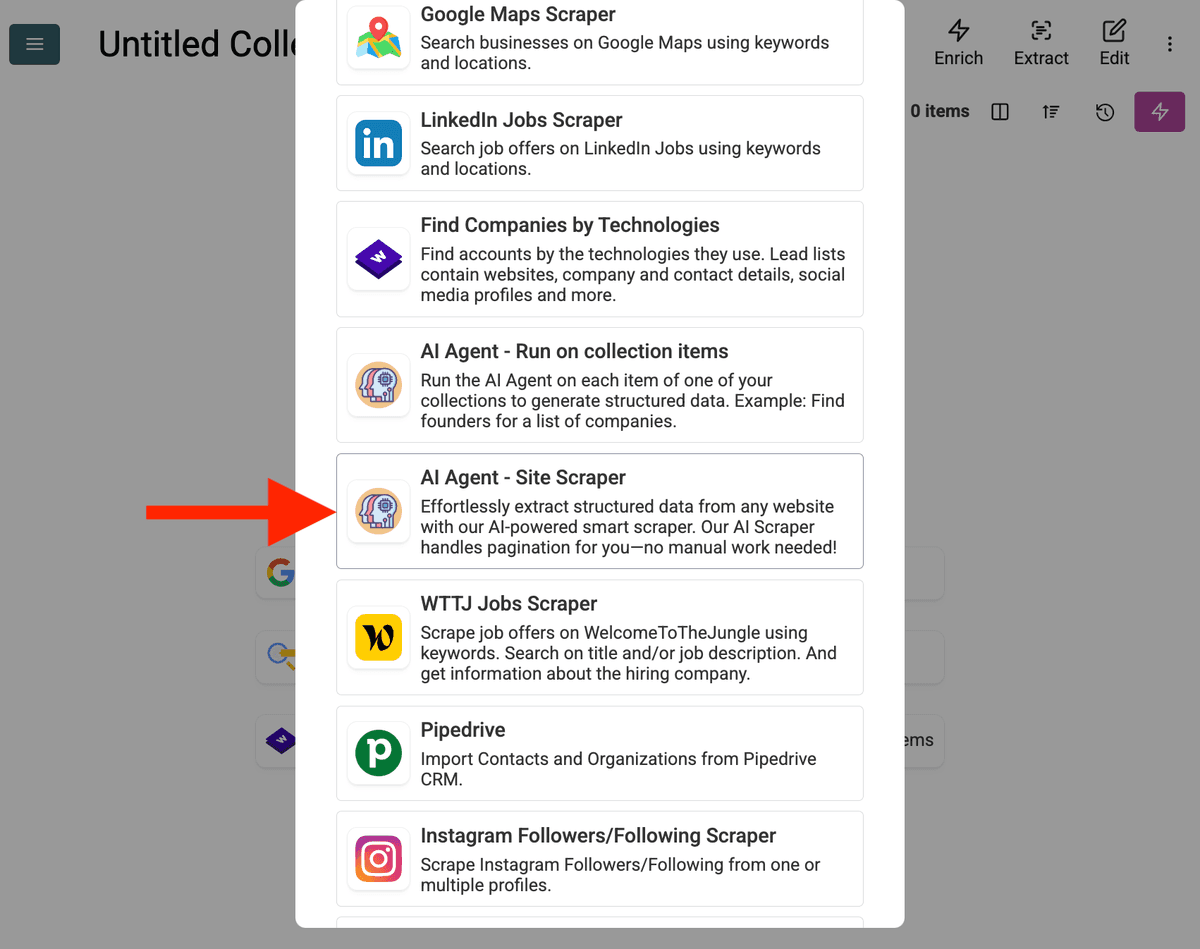
-
Konfigurer Source:
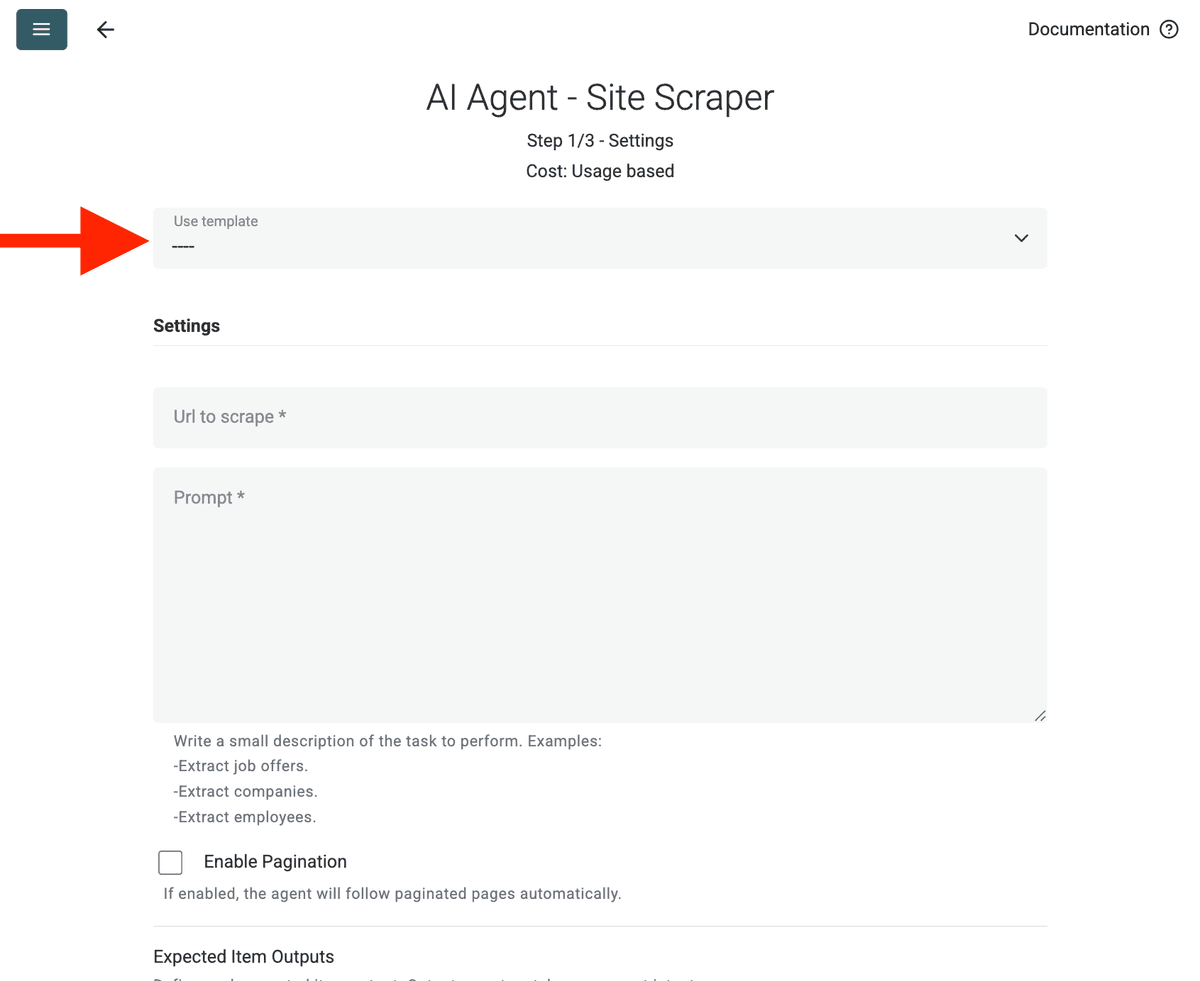
- Select Template: Finn og velg prompten fra "Template"-nedtrekksmenyen. Prompten over lastes inn automatisk.
- URL to Scrape: Skriv inn URL-en du vil skrape
- Enable Pagination (valgfritt): Hvis resultatene er på flere sider, huk av for Enable Pagination og sett en fornuftig Max Pages-grense (f.eks. 10).
- Customize (valgfritt): Du kan justere AI-modellen (f.eks. GPT-4o mini er ofte kostnadseffektiv), redigere prompten for spesifikke behov, eller endre forventede Outputs.
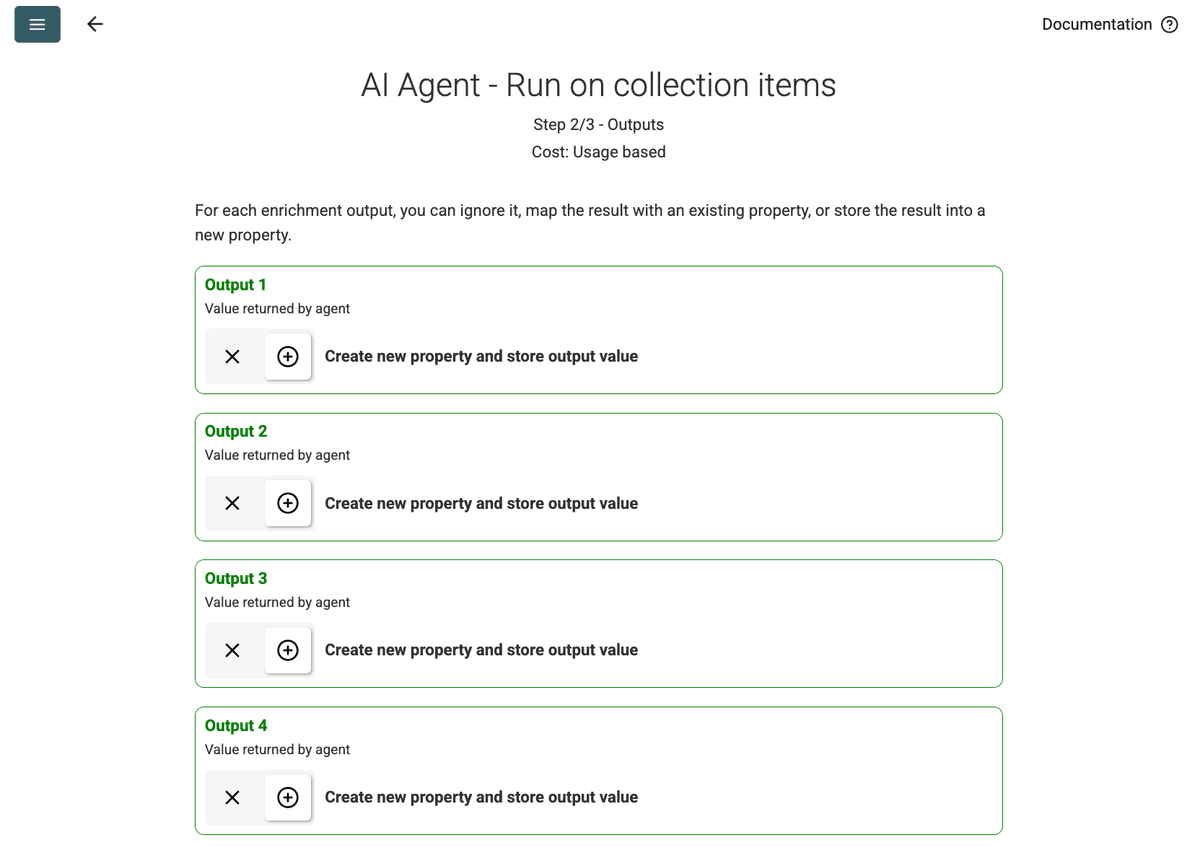
- Review Outputs: Klikk Continue. Datablist viser output-feltene definert i prompten (Project Name, Client Company Name). Klikk +-ikonet ved siden av hvert for å opprette tilsvarende properties (kolonner) i samlingen din.
- Run Import: Klikk Run import now. AI Agent vil starte skraping av nettstedet basert på prompten og fylle samlingen din.
Priser
Denne datakilden bruker Datablist credits basert på forbruk. Kostnadene avhenger av nettstedets kompleksitet og antall sider som besøkes.
Test ved å kjøre AI Agent på én side først for å få et kostnadsestimat.
FAQ
Hvordan starte et nytt kjør med samme konfigurasjon?
Når du har kjørt AI Agent, klikk på den rosa knappen øverst til høyre i datatabellen for å åpne den igjen med dine sist brukte innstillinger.
Hva skjer hvis AI Agent prøver å få tilgang til et beskyttet nettsted eller blir blokkert?
AI Agent bruker automatisk proxy-servere ved behov for å få tilgang til nettsteder som kan ha scraping-beskyttelser eller geografiske begrensninger. Dette øker sjansen for vellykket datauttrekk, men svært tungt beskyttede nettsteder kan fortsatt være utfordrende.
Hvor mye data kan jeg behandle med AI Agent?
Når du kjører AI Agent (enten som en beriking eller en datakilde), kan Datablist-samlinger håndtere behandling for opptil 100 000 elementer (rader). For større datasett må du kanskje dele dataene i flere samlinger.
Hvordan er AI Agent forskjellig fra ChatGPT/Claude/Gemini-berikelsene?
De standard AI-berikingene (ChatGPT, Claude, Gemini) prosesserer data som allerede ligger i samlingen din ved å bruke AI-ens eksisterende kunnskap. AI Agent kan aktivt samhandle med det levende nettet—utføre Google-søk, bla gjennom nettsteder og hente ny informasjon basert på prompten din.
Hvor nøyaktige er resultatene?
Nøyaktigheten avhenger i stor grad av hvor tydelig og spesifikk prompten din er, samt oppgavens kompleksitet og informasjonen som er tilgjengelig på nettet. Å gi klare instrukser, eksempler og regler for håndtering av feil forbedrer resultatene. Datablist gir ofte en confidence score for AI Agent-outputs for å hjelpe med å vurdere pålitelighet.