Scrapes agency listings from Clutch.co including company names, ratings, services, pricing, and profile links
Så här använder du den här AI-prompten
- Create a New Collection: Börja med att skapa en ny, tom collection i Datablist där datan ska lagras. Klicka på '+ Create new collection' i sidomenyn.
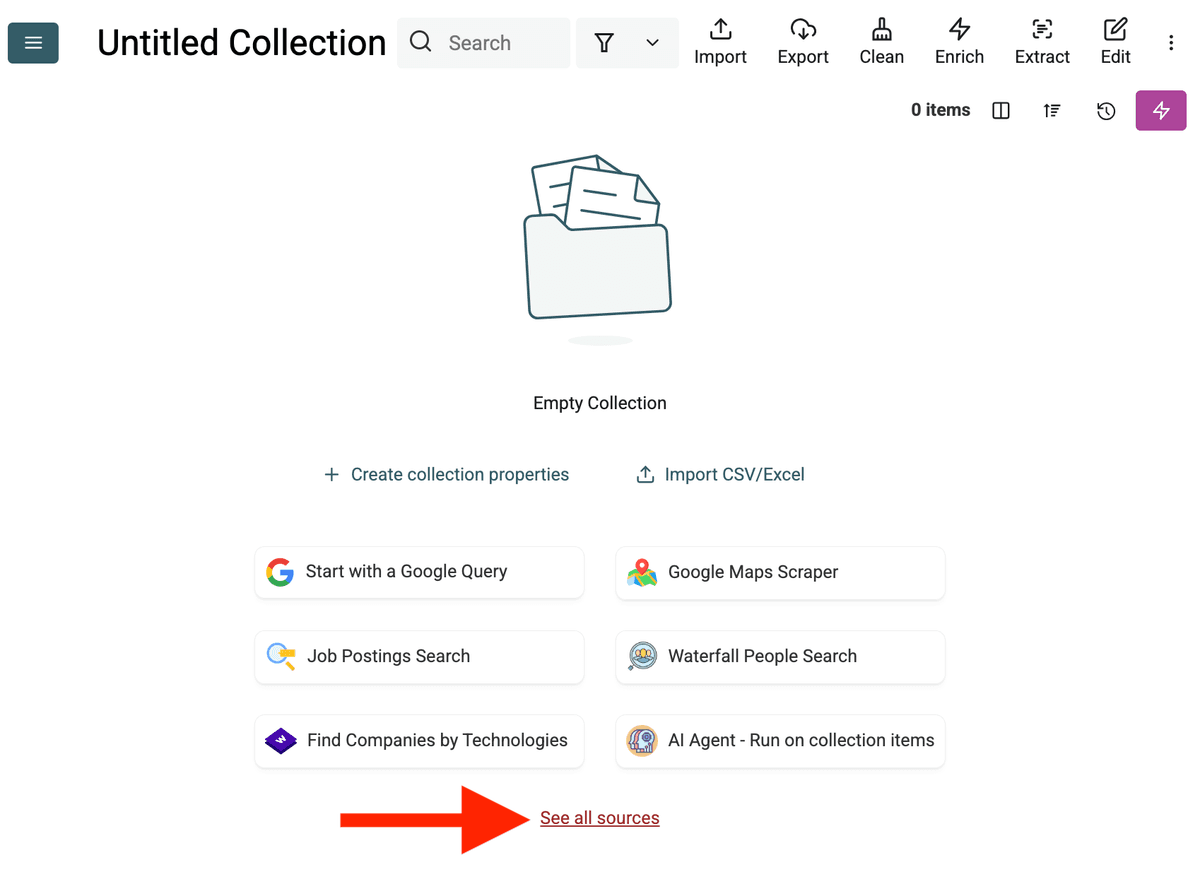
- Select the AI Agent Source: Klicka på "See all sources" eller gå till "Import" -> "Import From Data Sources". Välj "AI Agent - Site Scraper".
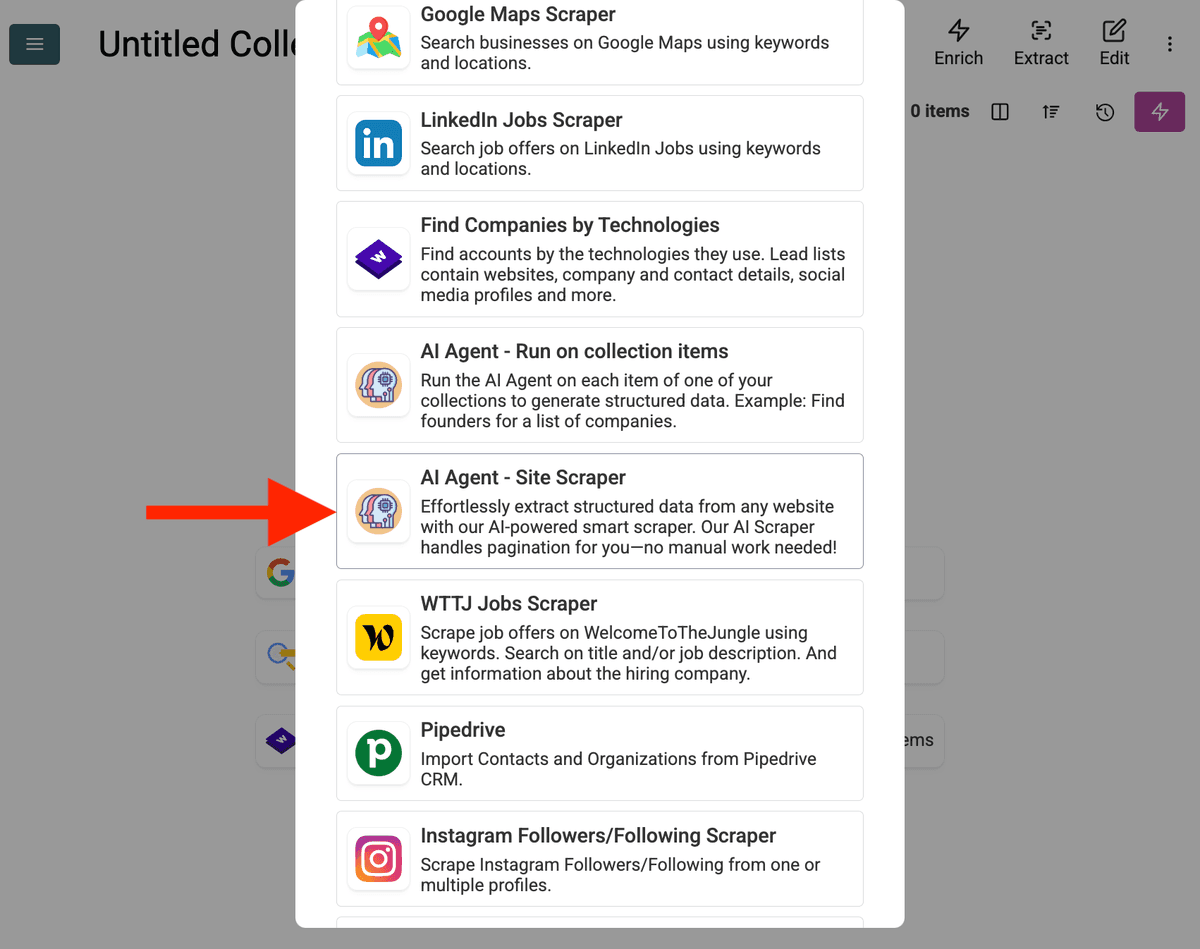
-
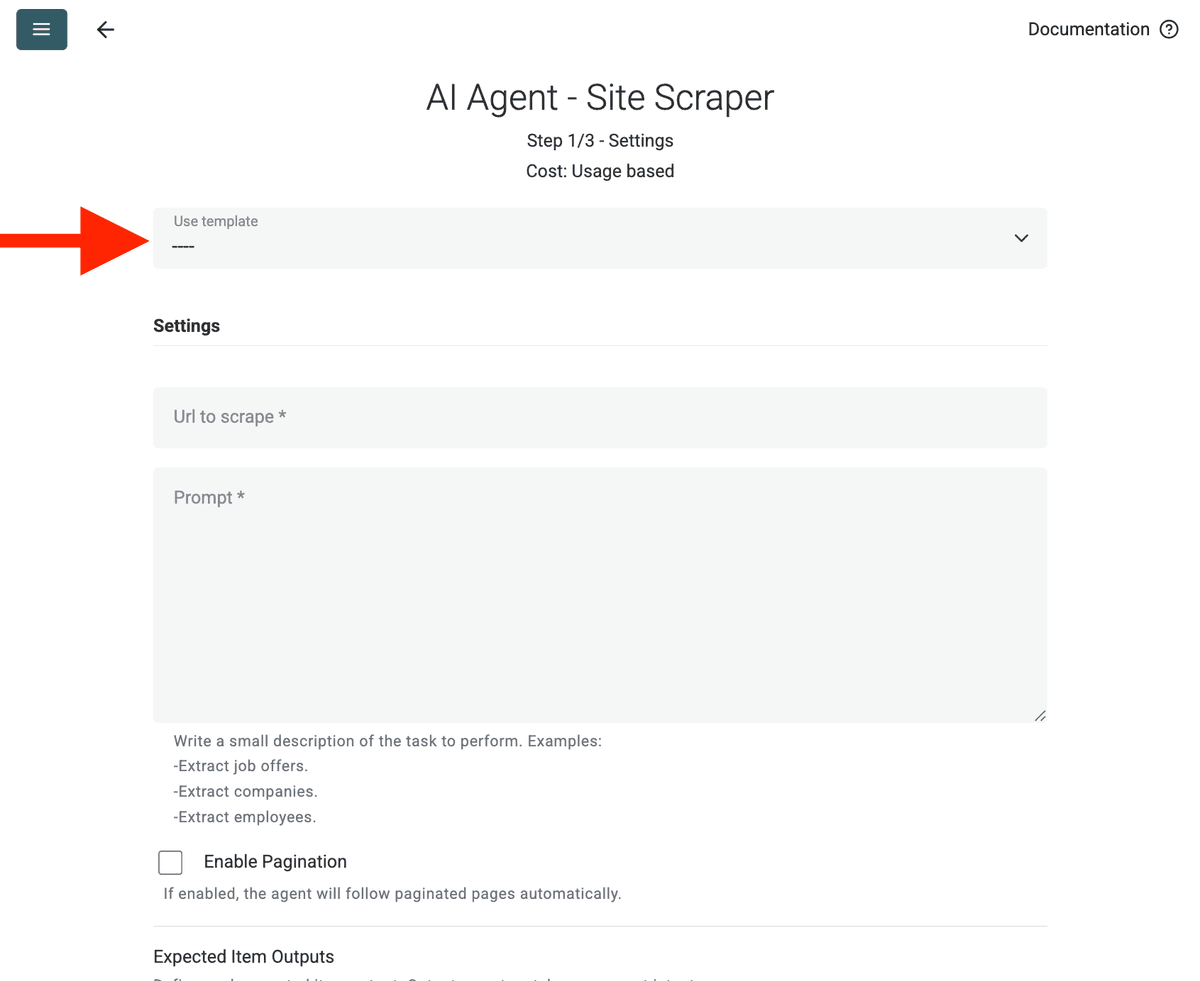
Konfigurera källan:
- Select Template: Leta upp och välj prompten i "Template"-rullgardinsmenyn. Prompten ovan laddas automatiskt.
- URL to Scrape: Ange din URL att skrapa
- Enable Pagination (Optional): Om resultaten finns på flera sidor, markera Enable Pagination och sätt en rimlig gräns för Max Pages (t.ex. 10).
- Customize (Optional): Du kan justera AI-modellen (t.ex. GPT-4o mini är ofta kostnadseffektiv), redigera prompten för specifika behov eller ändra förväntade Outputs.
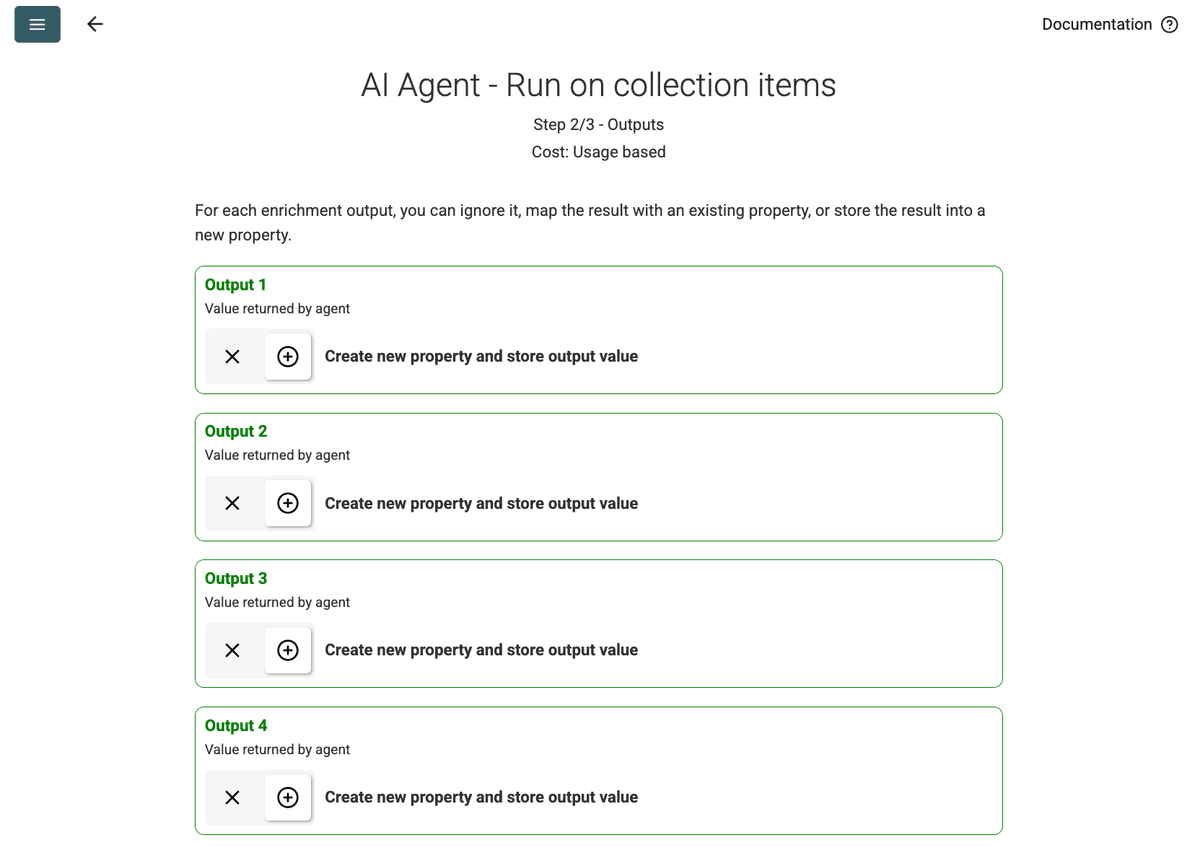
- Granska Outputs: Klicka på Continue. Datablist visar de output-fält som definieras i prompten (Project Name, Client Company Name). Klicka på +-ikonen bredvid varje fält för att skapa motsvarande egenskaper (kolumner) i din collection.
- Run Import: Klicka på Run import now. AI Agent börjar skrapa webbplatsen baserat på prompten och fyller din collection.
Prissättning
Den här datakällan använder Datablist Credits baserat på användning. Kostnaden beror på webbplatsens komplexitet och antalet besökta sidor.
Testa att köra AI Agent på en enda sida först för att uppskatta kostnaden.
FAQ
Hur startar jag en ny körning med samma konfiguration?
När du har kört din AI Agent klickar du på den rosa knappen längst upp till höger i din datatabell för att öppna den igen med senast använda inställningar.
Vad händer om AI Agent försöker komma åt en skyddad webbplats eller blir blockerad?
AI Agent använder automatiskt proxyservrar vid behov för att komma åt webbplatser som kan ha skydd mot scraping eller geografiska begränsningar. Det ökar chansen för lyckad datautvinning, men mycket hårt skyddade sajter kan fortfarande vara en utmaning.
Hur mycket data kan jag bearbeta med AI Agent?
När du kör AI Agent (antingen som berikning eller som en datakälla) kan Datablist-collections hantera upp till 100�a0000 poster (rader). För större dataset kan du behöva dela upp datan i flera collections.
Hur skiljer sig AI Agent från ChatGPT/Claude/Gemini-berikningarna?
Standard-AI-berikningar (ChatGPT, Claude, Gemini) bearbetar data som redan finns i din collection med AI:ns befintliga kunskap. AI Agent kan aktivt interagera med det levande webben—göra Google-sökningar, surfa på webbplatser och extrahera ny information baserat på din prompt.
Hur exakta är resultaten?
Noggrannheten beror i hög grad på hur tydlig och specifik din prompt är, samt på uppgiftens komplexitet och tillgänglig information online. Tydliga instruktioner, exempel och regler för felhantering förbättrar resultaten. Datablist tillhandahåller ofta en konfidenspoäng för AI Agent-utdata för att hjälpa dig bedöma tillförlitligheten.