Gratis verktyg för att ta bort dubbletter

Vad är deduplicering av data?
Deduplicering av data, eller deduping, är processen att eliminera dubblettposter från ett dataset.
Deduping krävs för att ha en lista med unika poster. Inom marknadsföring med e-postlistor, i lead generation, eller kundhantering. Eller i e‑handel när produktkataloger hanteras. Två poster är dubbletter när de hänvisar till samma entitet. Två leads med samma emailadress, eller två produkter med samma streckkod.
Dubbletter påverkar kvaliteten på dina data och sänker din produktivitet. Det finns två sätt att bli av med dubbletter: ta bort dem, eller slå samman liknande poster till en enda.
Att ta bort dubbletter är enkelt, dedupliceringsalgoritmen hittar dubblettposterna och raderar alla utom en. Att slå samman dubbletter kräver att de analyseras för att kombinera dem till en enda huvudpost.


















Fullständig eller partiell analys av poster, på en eller flera datasamlingar
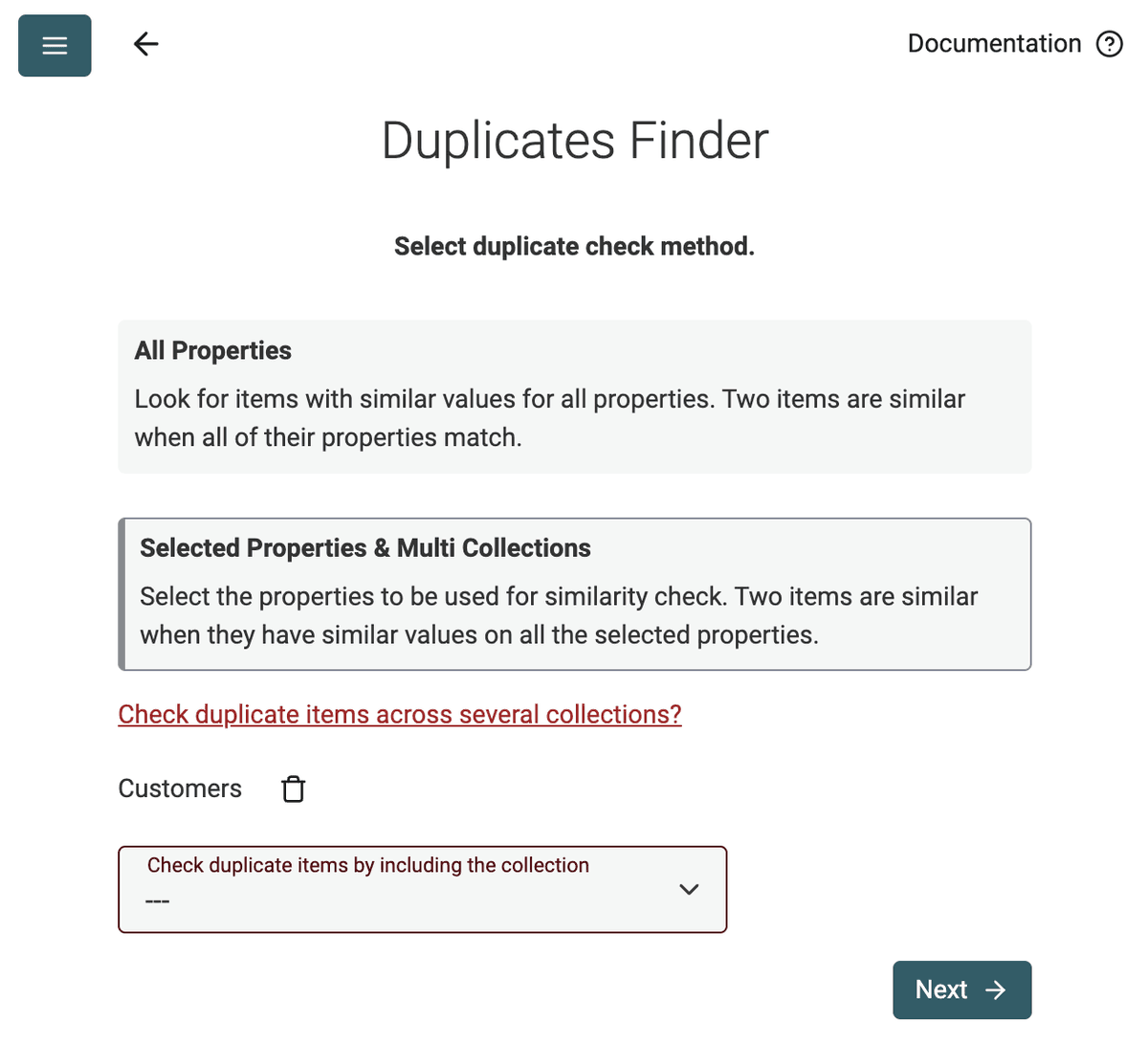
Datablist Duplicates Finder fungerar med fullständig jämförelse av poster eller med valda fält.
Använd läget Valda fält för att hitta dubblettkontakter baserat på deras emailadress eller för att upptäcka dubbletter i en företagslista med deras webbplats-URL.
Ta bort eller konsolidera dubbletter

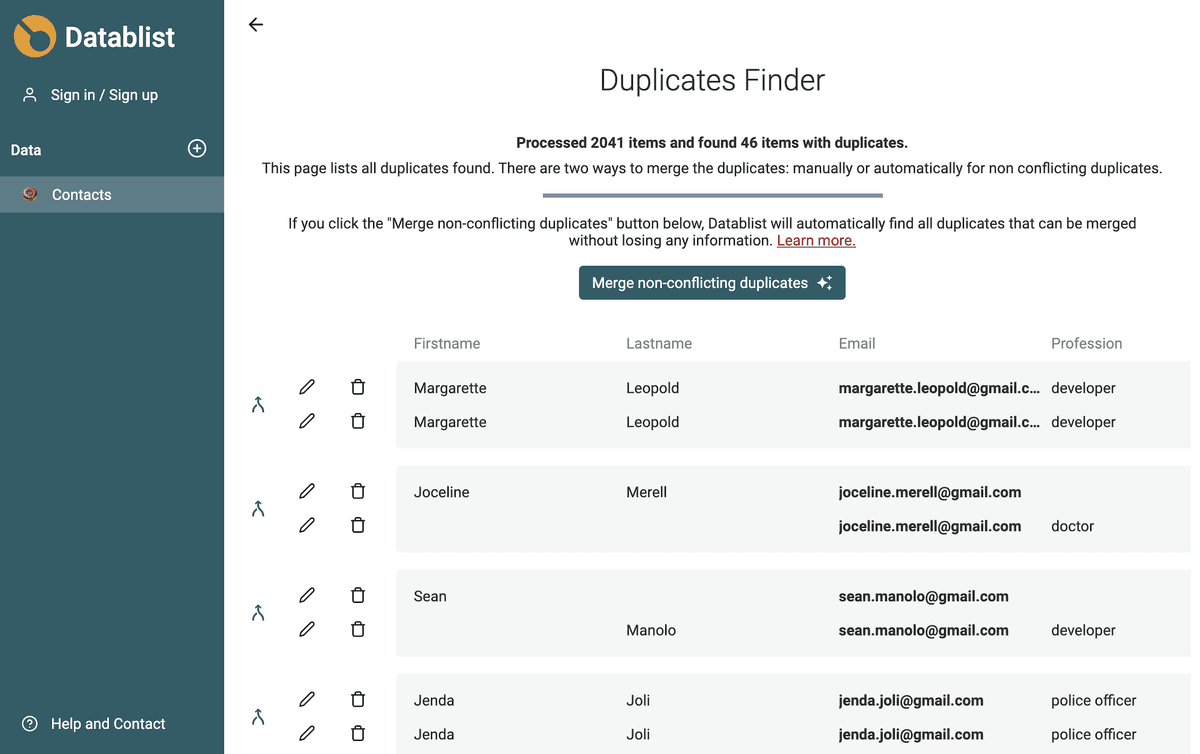
Slå samman icke-konfliktande dubbletter automatiskt
Datablist hittar automatiskt alla dubblettvärden som kan slås samman utan att förlora information.
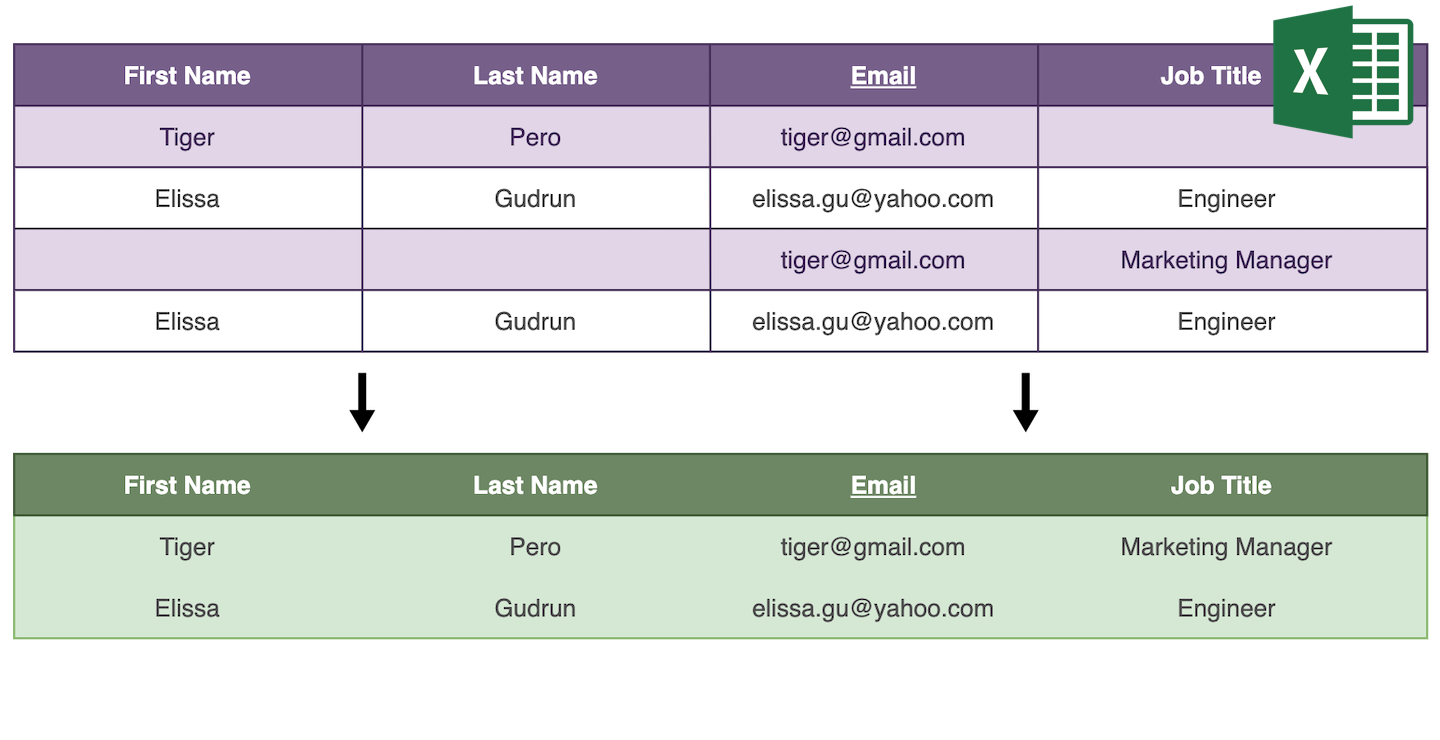
- När alla dubblettposter har samma fältvärden behålls endast en post och de andra raderas.
- Om dubblettposterna är kompletterande väljs posten med mest information som primärpost och dess fältvärden fylls på med värden från de andra posterna. Därefter raderas alla poster utom primärposten.
- Om dubblettposter har konfliktande fältvärden hoppas de över för manuell sammanslagning.
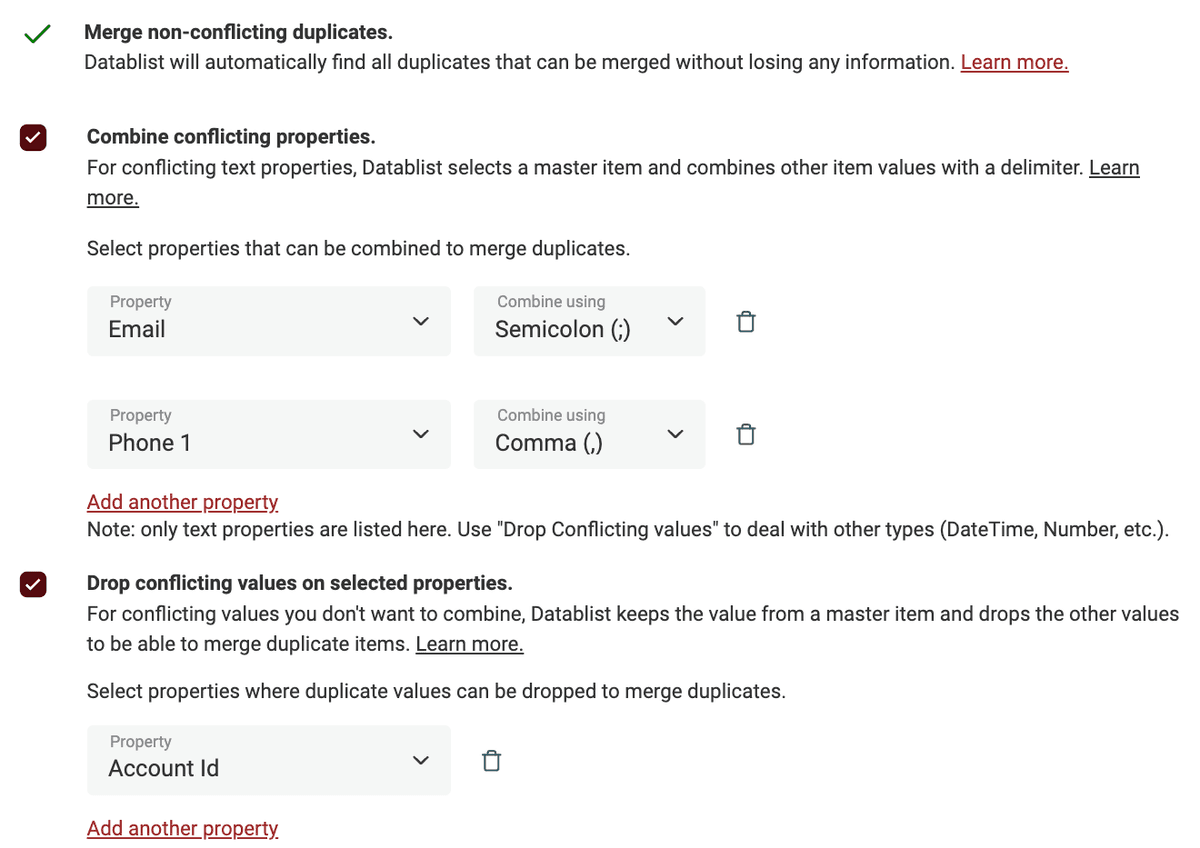
Konsolidera dubbletter för att behålla en enda post
När en enkel sammanslagning inte räcker använder du de avancerade funktionerna: kombinera eller ta bort dubblettvärden för att konsolidera dina dubblettposter.
Datablist listar dina konfliktfält och låter dig välja hur du ska hantera dem. Använd Kombinera värden för datasammanfogning. Och Ta bort värden för att behålla värdet från en vald huvudpost.
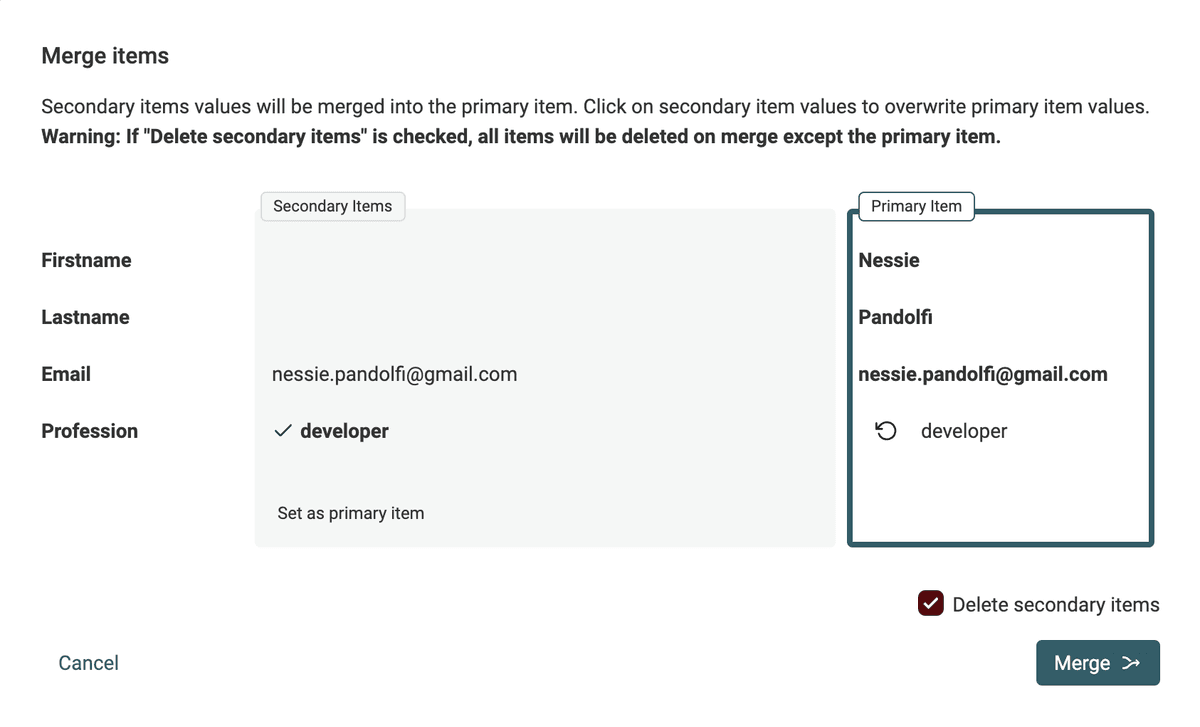
Eller granska konfliktande värden manuellt med sammanslagningsassistenten
När automatisk sammanslagning inte är möjlig använder du Datablists sammanslagningsassistent för att välja vilket värde som ska behållas och konsolidera dina poster.
Posten med mest information väljs som huvudpost och får kompletterande värden från sekundära poster.
AI-bearbetning av dubbletter
När ska du använda deduplicering av data?
- Deduplicering av e-postlistor
Med tiden kommer flera källor att matas in i din e‑postlista. Med webbinariedeltagare, köpare, freemium‑användare osv. kan en emailadress förekomma flera gånger i din e‑postlista.
Dubbletta emailadresser påverkar dina marknadsföringskampanjer med extra kostnader, spamliknande beteende och risken för frustration hos användare om de fortsätter få utskick efter att de avslutat prenumerationen på en kampanj.- Hur du rensar en e‑postlista
- Deduplicering i Microsoft Excel
Google Sheets, Microsoft Excel och andra kalkylbladsverktyg erbjuder grundläggande dedupliceringsfunktioner. De markerar dubblettvärden i en kolumn eller tar bort dem. Använd Datablists automatiska sammanslagning och den manuella sammanslagningsassistenten för att hantera komplexa dubblettposter.
Datablist öppnar både CSV- och Excel-filer.- Hur du tar bort dubbletter i en Excel-fil
- Deduplicering av leads och prospekt
Inom B2B‑marknadsföring påverkar kvaliteten på din prospektdatabas resultaten av dina kampanjer. En smutsig datalista med dubblett‑leads ökar lagringskostnaderna, minskar effektiviteten i leadspårning och skapar frustration i säljteamet.
Hantera dina lead generation-processer med Datablist. Eller importera dina CRM‑data eller leadlistor till Datablist för att rensa dem.- Hur du deduplicerar leadlistor
- Deduplicera CSV-filer
Att rensa CSV‑data är tidskrävande. Data engineers använder programmeringsspråk som Python för att parsa och rensa CSV‑data. Datablist erbjuder ett No-Code‑verktyg för att utföra datarensning med dina CSV-filer för icke-tekniska användare. Öppna CSV‑filer med hundratusentals rader och deduplicera poster snabbt.
- Hur du tar bort dubbletter i en CSV-fil
Vanliga frågor
Ja, du kan hitta och slå samman dubbletter online gratis. Grundfunktioner som exakt och smart matchning är tillgängliga utan konto. För avancerade algoritmer som fuzzy eller fonetisk matchning krävs en betald plan.
Excel raderar permanent dubblettrader, vilket gör att du kan förlora potentiellt värdefull data från de posterna. Datablist slår samman poster och kombinerar intelligent kompletterande information från alla dubbletter till en enda komplett huvudpost. Du förlorar ingen data.
Datablist är byggt för att hantera stora filer. Du kan bearbeta listor med upp till 1 miljon rader på gratisplanen och upp till 1,5 miljoner rader på våra betalda planer, långt över gränserna för traditionella kalkylbladsverktyg.
Absolut. Vårt verktyg använder avancerade fuzzy‑matchningsalgoritmer, som Levenshtein- och Jaro‑Winkler‑avstånd, för att identifiera liknande poster även med felstavningar eller små formateringsskillnader.
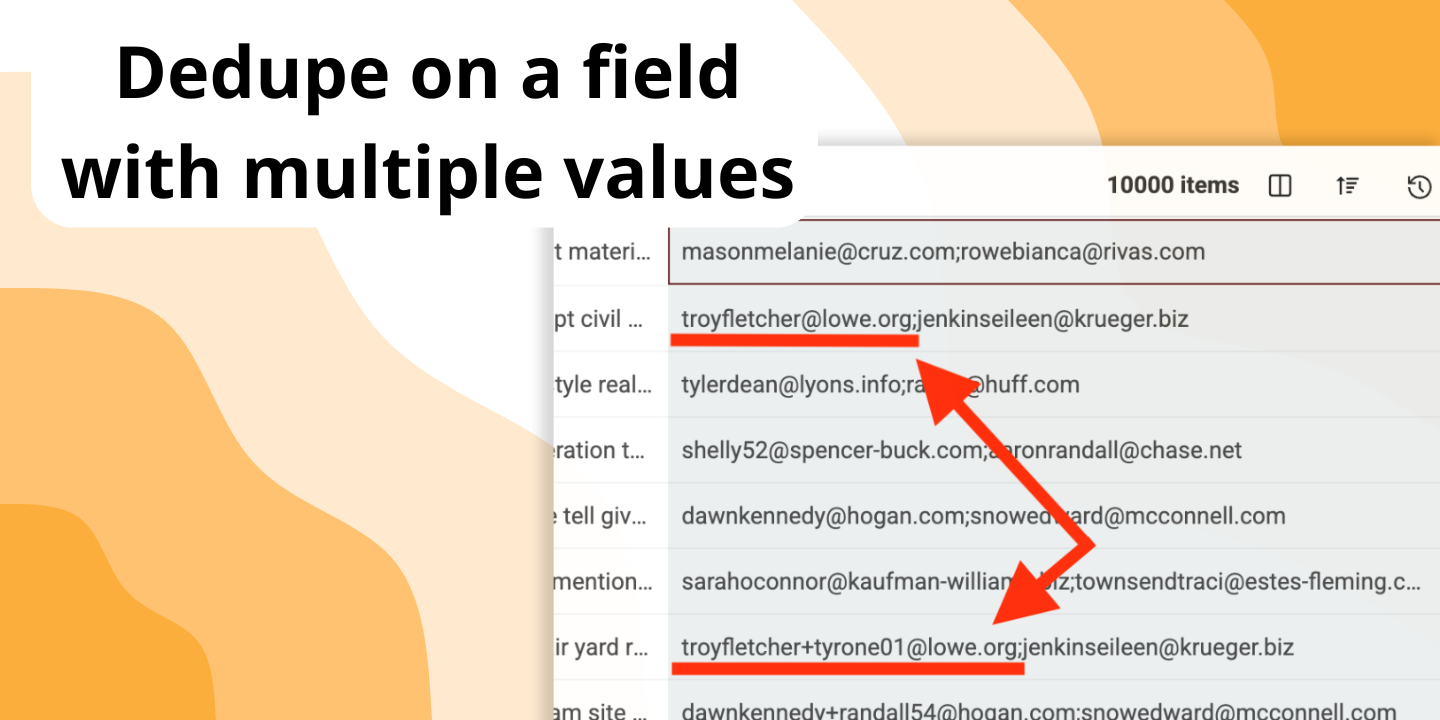
Det är byggt för just det. Du kan aktivera "Multiple Value Matching" för att behandla varje värde i en cell (avgränsade med semikolon) som en separat post för jämförelse. Den hittar en träff om minst ett av värdena är en dubblett.
Ja. Du kan importera flera filer till Datablist och köra Duplicates Finder över alla. Den kan matcha poster baserat på en gemensam identifierare, även om filerna har olika kolumner eller strukturer.
Inte alls. Datablist är en helt no-code-lösning. Duplicates Finder guidar dig genom en enkel steg‑för‑steg‑process där du väljer dina kolumner och matchningsregler via ett användarvänligt gränssnitt.
Vår AI Editing‑funktion ger dig obegränsad flexibilitet. Istället för standardregler för sammanslagning kan du skriva instruktioner på enkel engelska. Be till exempel att summera försäljningssiffror från dubblettposter eller välja huvudposten baserat på det senaste datumet. Det omvandlar komplex logik till en enkel begäran.
Datablist konsoliderar dina data till en enda huvudpost. Den fyller automatiskt i saknad information från andra dubbletter och ger alternativ för konfliktande data: du kan kombinera text från olika rader eller välja vilket värde som ska behållas. De redundanta posterna raderas sedan.
Vi erbjuder flera algoritmer för olika behov: 'Exact' för identiska träffar, 'Smart' för variationer som ordföljd eller URL‑protokoll, 'Phonetic' för namn som låter lika och 'Fuzzy Matching' för stavfel och misskrivningar.
Ja. Efter att Datablist har identifierat alla dubblettgrupper kan du exportera dem till en CSV- eller Excel‑fil innan du gör några ändringar. Den här filen listar alla dubblettposter i följd, med varje grupp listad efter varandra, vilket gör det enkelt att granska dem externt eller bearbeta dem i ett annat verktyg.
När du är klar med sammanslagningen tillhandahåller Datablist en nedladdningsbar 'Changes List'. Den här filen fungerar som en logg och visar varje post som uppdaterades eller raderades under processen. Du kan använda filen för att enkelt replikera ändringarna i ditt externa system, till exempel ett CRM, så att dina data förblir perfekt synkade.
See Also