November 2024
Hi Folks, it’s been an incredible month of putting our heads down and working relentlessly to improve Datablist for you. Here’s what we did:
We pushed new features such as:
- Impressum Scraper
- Indeed Scraper
- Waterfall people search
- Waterfall email verification
- Waterfall Email Finder
- Import filter
We improved:
- Templates
- Collection view
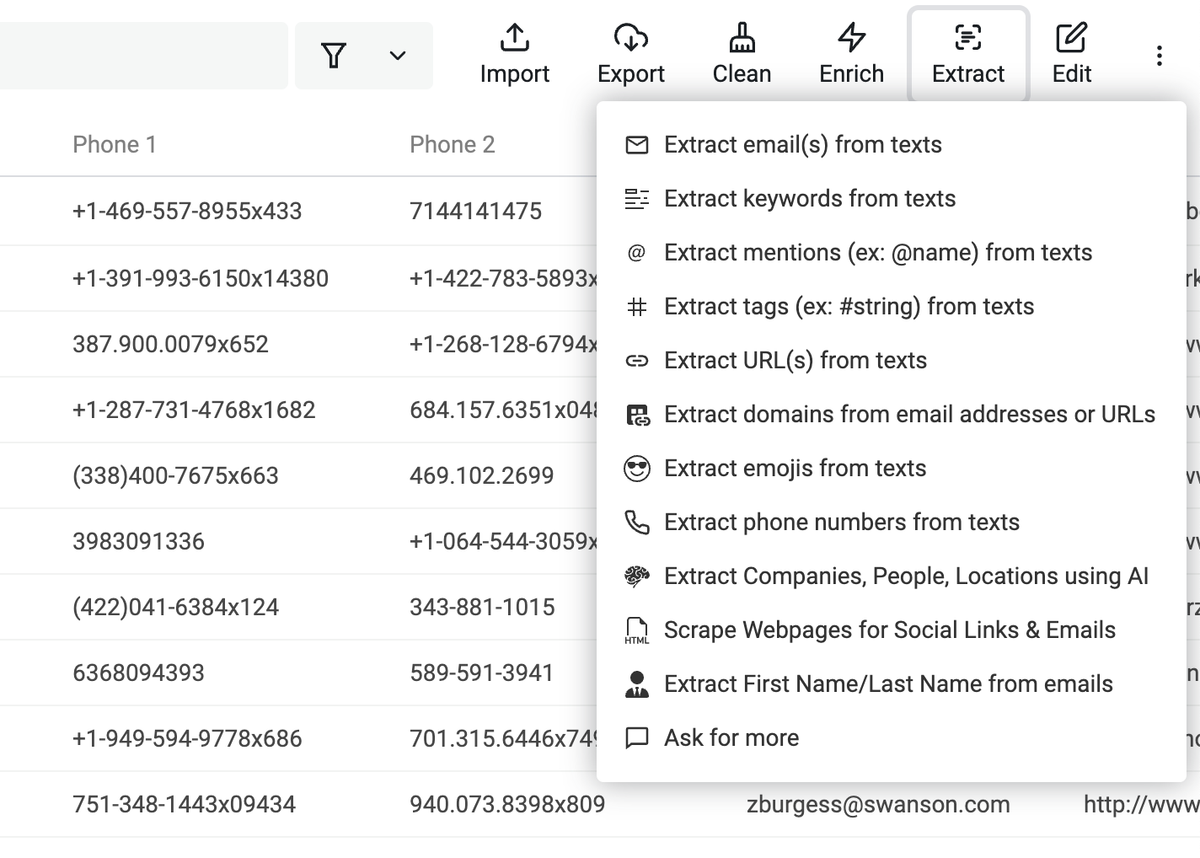
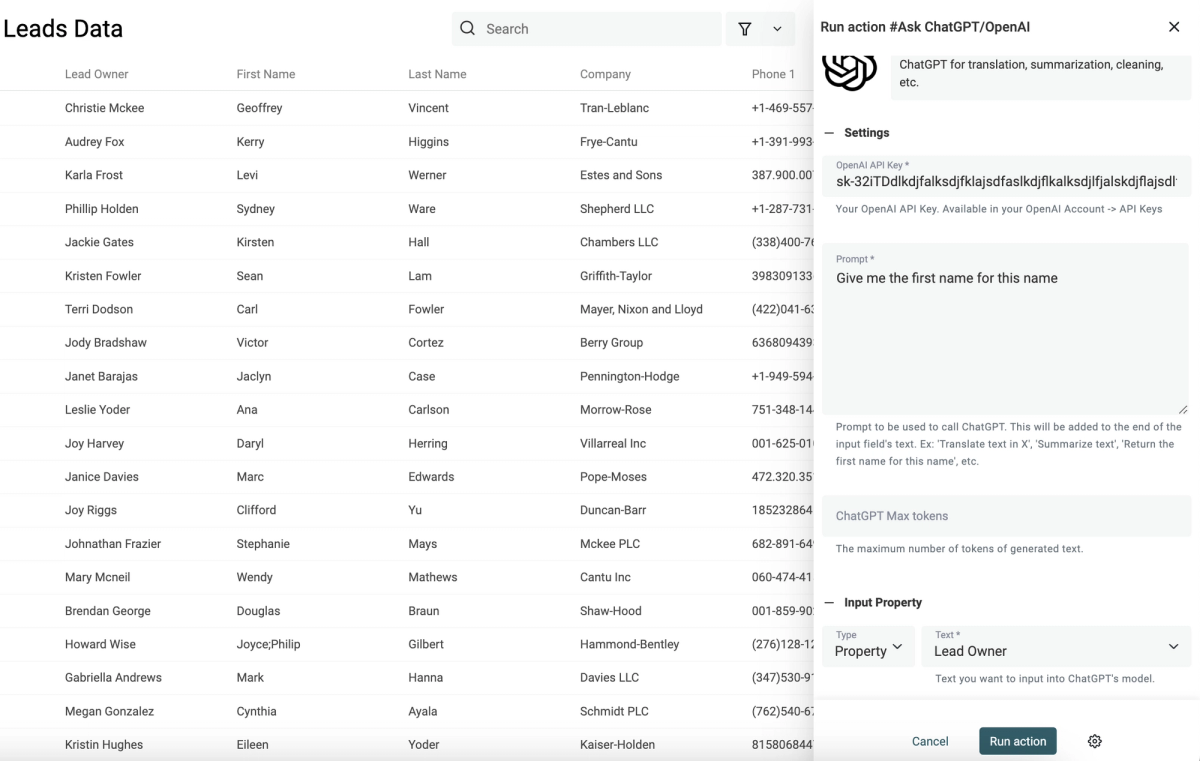
New Enrichment: Impressum Scraper
The Impressum Scraper is particularly valuable for sales teams and business developers working in German-speaking markets, as they can extract valuable data from companies' Impressum pages.
How it Works:
We use AI to visit the Impressum pages of German, Austrian, and Swiss businesses and extract all the data from their Impressum.
This automated process saves hours of manual data gathering and ensures accurate, up-to-date information for your business contacts.
How To Use It
- Upload a CSV with website URLs or domains
- Click "Enrich" in the top menu
- Go to "AI" and select "Impressum Scraper"
- Map the column with the URLs as Input Property and click on "Continue to outputs configuration"
- Click on the ⊕ icons to add a new column for each returned data point
- Click on "Instant Run" or schedule your task
- Configure your preferred "Run Settings" and start scraping
Returned Data
- Company name
- Managing directors
- Phone numbers
- Emails
- Addresses
- Legal registration numbers
Related Resources:
Für die, die Videos lieber mögen
New Data Source: Indeed Scraper
Since many recruiters and HR professionals are struggling with inefficient methods of manually gathering job posts to identify potential clients, we had to build this one.
This Indeed scraper makes it simple to extract vacancies at scale, allowing you to make data-backed decisions without the manual effort of browsing countless job listings.
How It Works
You provide an Indeed search URL or configure your search in Datablist using keywords, locations, and time based filtering and we scrape all the job listings matching your search criteria for you.
How to use it
- Provide keywords & locations or Indeed search URLs
- Define country, time of publication, and set result limit per search
- Click on "Continue" to configure your outputs
- Click on the ⊕ icons to add a new column for each piece of information
- Click on "Import Data" to start scraping!
Returned Data
- Basic Information: Job Title, Location, Country, Type
- Job Content: Description, Benefits, Salary Range, Date Posted
- Application: Indeed Offer URL, Apply Link
- Basic Company Data: Company Name, Website, Description, Industry
- Company Metrics: Staff Range, Revenue, Rating, Reviews Count
- Company Location: Address
- Company Links: Indeed Link
- Source Information: Job Source
Related Resources:
Indeed Scraping Video Tutorial
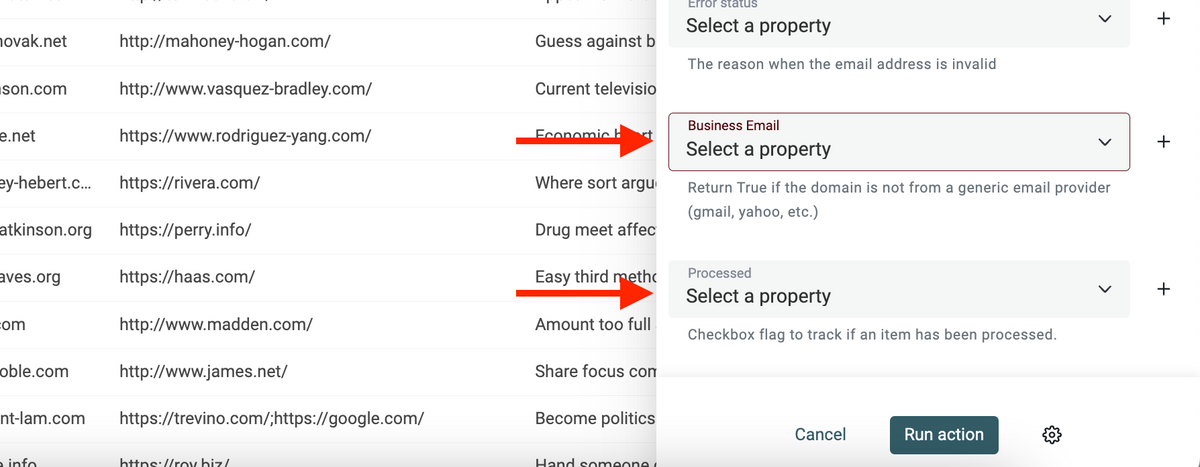
New Enrichment: Waterfall Email Verification
This email verification allows you to take existing email lists and check if there’s an actual inbox behind that email or not which is crucial for having healthy inboxes, effective growth campaigns, and newsletters that convert people.
How It Works:
Here's how our email verification process works:
- First, we scan MX records to check if the domain can receive emails
- If no MX records exist, the email is marked as undeliverable (this check is free)
- If MX records exist, we perform an SMTP check to verify if the inbox exists
For additional accuracy, emails marked as "unknown" or "catch_all" undergo a more sophisticated verification process to determine their safety status.
For each stage, we use specialized providers.
How to Use It
- Upload a list of emails
- Click on “Enrich”
- Go to “People” and select “Advanced Waterfall Email Address Verification”
- Keep the “Default Settings” or configure a “Custom Waterfall” and use your API keys
- Map the column with the emails as “Input property”
- Click on “Continue to outputs configuration”
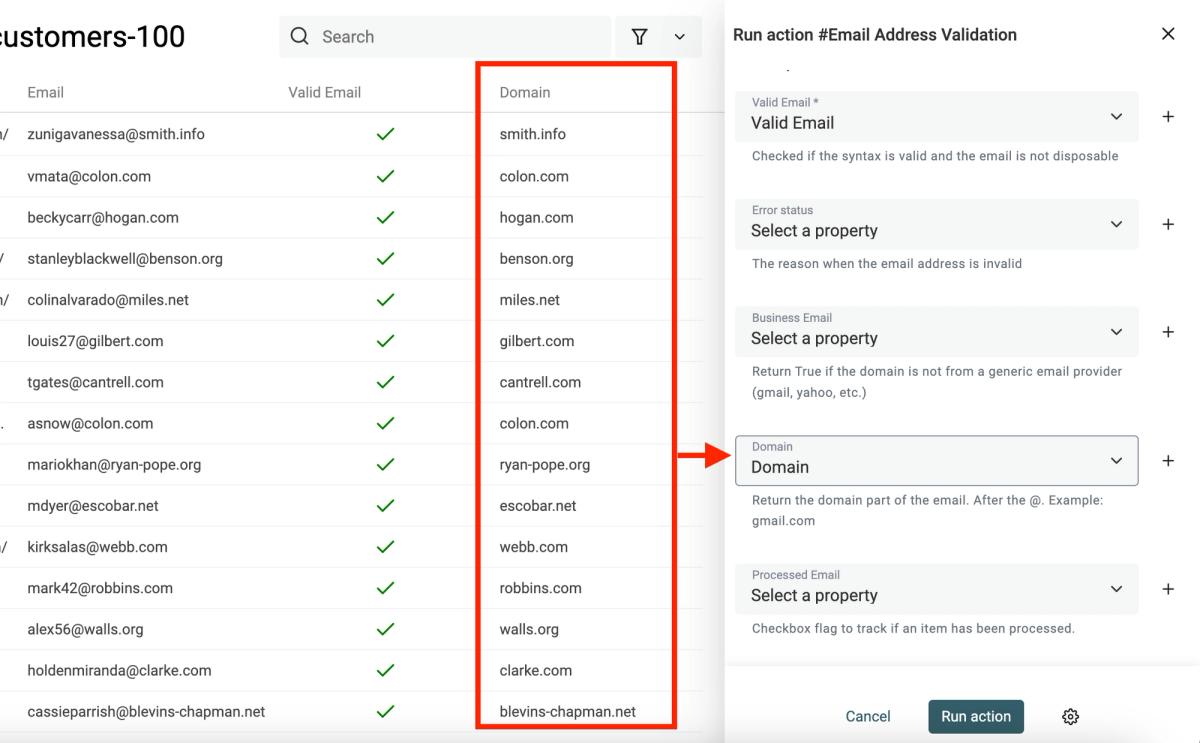
Returned Data:
- Email Status – valid, invalid, risky, catch_all, unknown
- Reason – Additional context to explain the status.
- Suggested Email – If the address is invalid and we found a likely repaired version
- Free Provider – Return True if the domain is from a free email provider (Gmail, Yahoo, Hotmail, etc.)
- Role Account – Return True if the email address is a role address (support@, team@, etc.)
- Domain – Return the domain part of the email. After the @. Example: gmail.com
- MX Provider – Return the email provider. Examples: google, microsoft, ovh, etc.
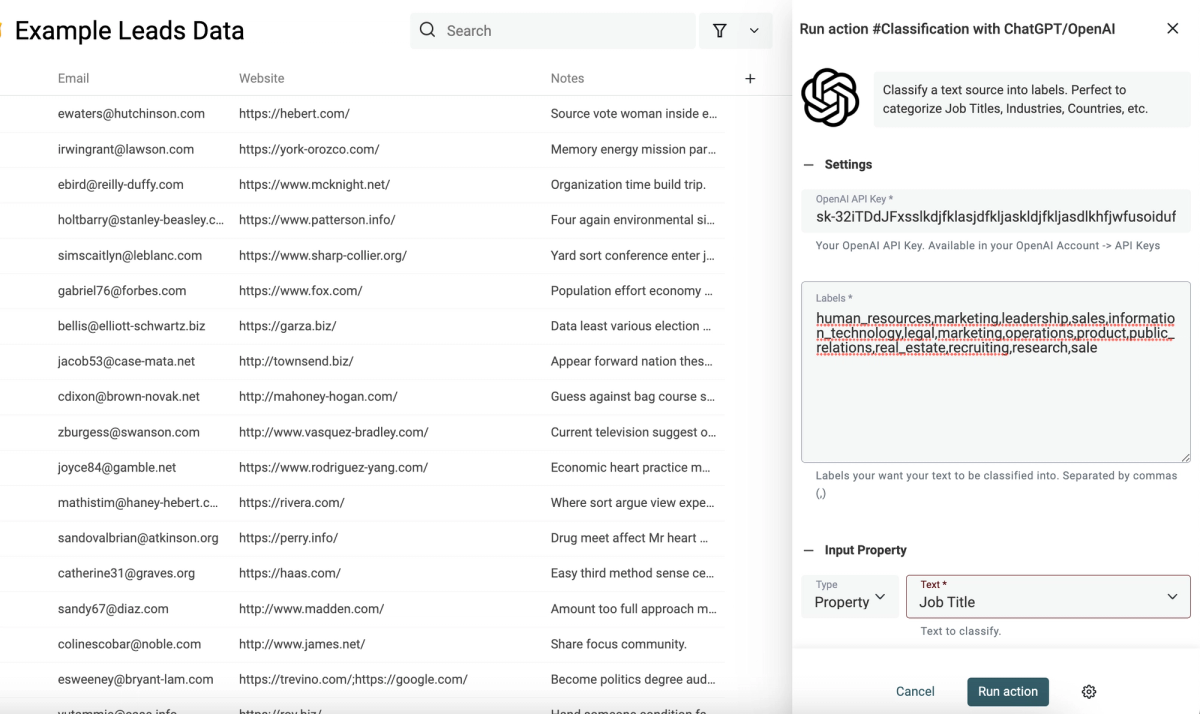
New Enrichment: Waterfall People Search
Until now if you had a list of accounts and wanted to find prospects within those companies you had to export your list, use a tool like Apollo or Lusha to upload the list there, search for prospects, export the list, and import it back to Datablist. Here’s why this was a problem:
- Adds more (and manual) steps to your workflow
- You get outdated contact information
- You had to manage multiple subscriptions
We fixed all that with our new Waterfall People Search, now you can create prospect lists directly in Datablist!
How It Works:
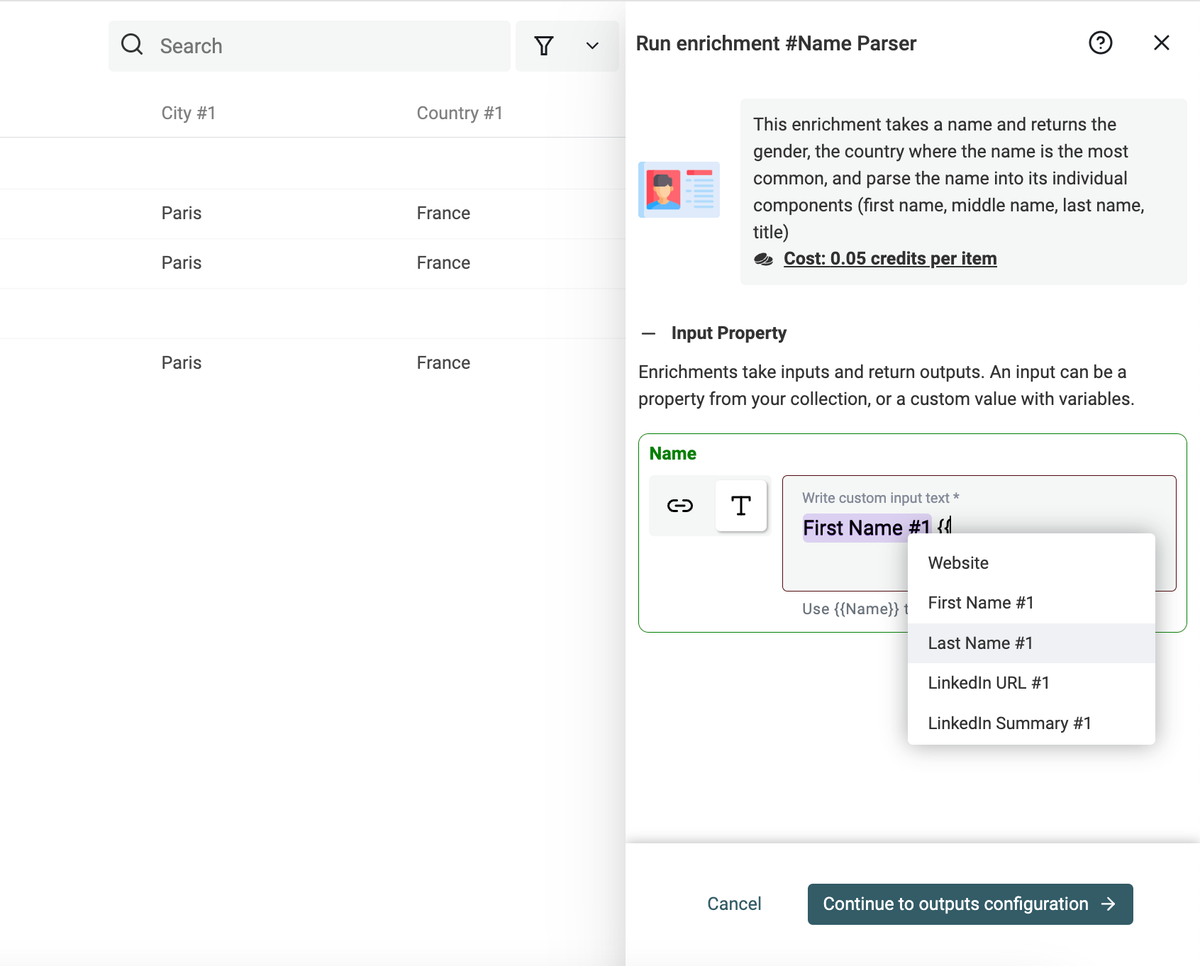
You configure a search using the company domain, job title, department, and seniority. Then you can set up a fallback in case our database doesn't contain the contact you're looking for. Once a contact is found, you'll get their contact information with fresh LinkedIn data.
How To Use It:
- Upload an account list
- Click on “Enrich”
- Go to “People” and select “Waterfall People Search”
- Configure your search using: Job titles, departments and seniorities
- Map the company domain as “Input Property”
- Click on “Continue to outputs configuration”
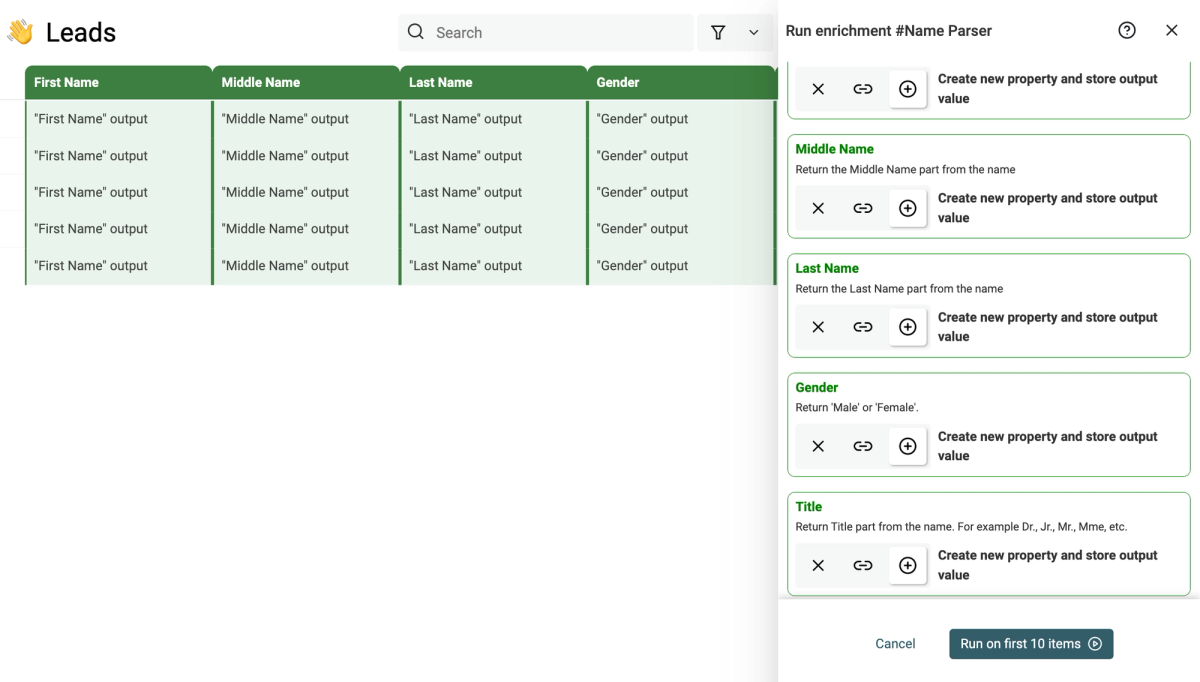
- Click on the ⊕ icons to add a new column for each output
- Click on “Instant Run”
- Configure your “Run Settings” and click on “Run enrichment on X items”
Returned Data
- First Name - Contact's first name
- Last Name - Contact's last name
- Full Name - Complete name
- LinkedIn URL - Profile URL
- LinkedIn Summary - Profile description
- Job Title - Current position
- Job Start Date - When they started their current role
- Work Email - Business email address
- Seniority - Level (owner, CXO, VP, director, manager, senior, entry, intern)
- City - Current city
- Region - State/province
- Country - Current country
- Company LinkedIn - Company's LinkedIn page
Use Cases:
- Build a prospect list
- Find a colleague of a prospect
And anything else that you creativity allows
Related Resources:
How to find a prospect colleagues
New Enrichment: Waterfall Email Finder
Many of you were frustrated about the fact that we only had one email finder and didn't allow using API keys. We heard your feedback and implemented not only one but two new email finders, and yes, you can use your own API keys.
To our existing provider Icypeas, we've added Enrow and Prospeo, which are both considered to be among the top 1% of email providers.
How It Works:
The new Waterfall Email Finder discovers email addresses using algorithmic patterns based on first name, last name, and company domain. Each of the providers has its unique strengths, and the good thing with Datablist's Waterfall Email Finder is that you're only charged for found emails.
How To Use It
- Upload a list of prospects
- Click on “Enrich”
- Go to “People” and select “Waterfall Email Finder”
- Configure your own “Waterfall” or keep the default settings
- Map the columns with the first names, last names and domains of your prospects as “Input properties”
- Click on “Continue to outputs configuration”
- Click on the ⊕ icons to add a new column for each output and click on “Instant Run”
- Configure your “Run Settings” and click on “Run enrichment on X items”
Use Cases:
- CRM enrichment
- Prospecting
Related Resources:
How to clean and refresh CRM data
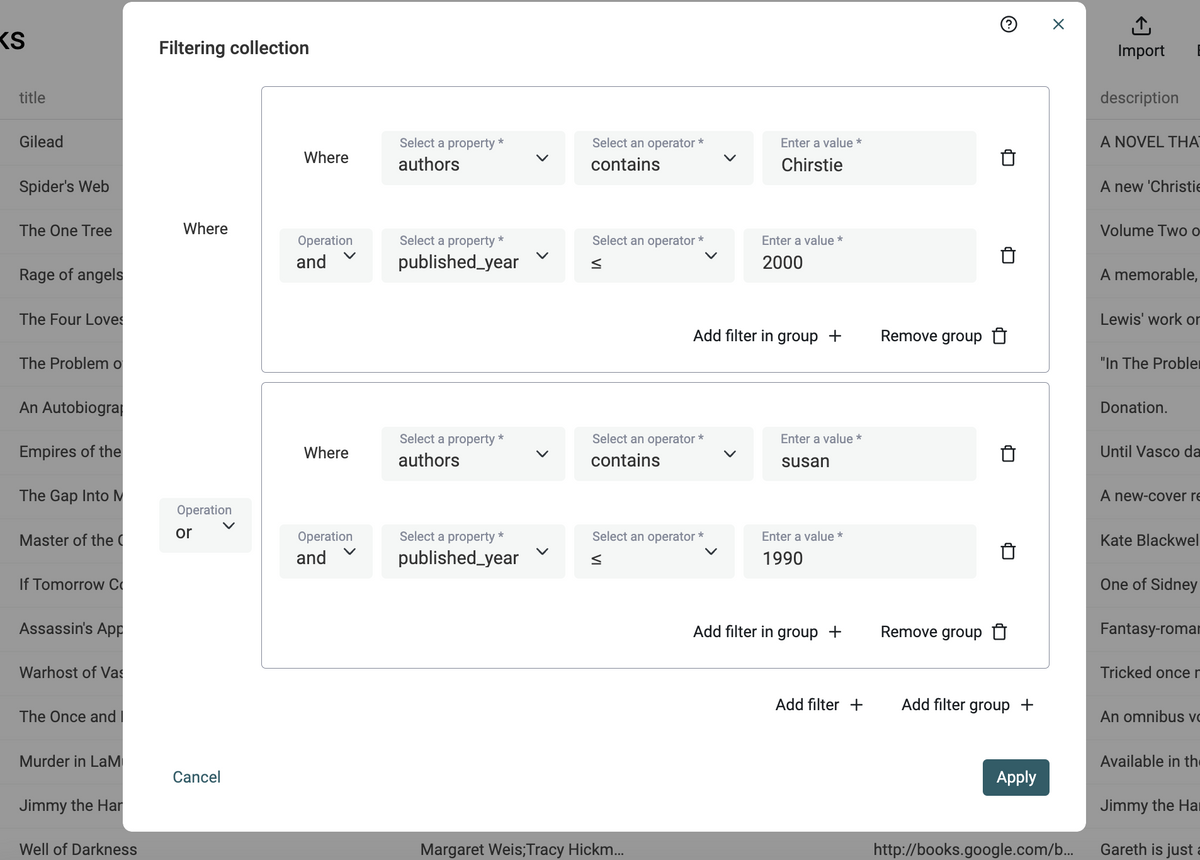
New Feature: Import Filter
When you have a file with non-matching records, you don't want to import the file as a whole — you want to filter only for matching records and delete the rest. With this feature, you can control which records get imported by applying custom filters, letting you work smarter, not harder.
How It Works:
You import your file, select the filters and we import only the records that match your filters.
How To Use It:
- Import a CSV or Excel
- Click on "Continue to properties"
- Select the file columns you want to import and define your column data types
- Click on "Continue"
- Switch the toggle to start filtering
- Set up your filters and click "Process X items with filters"
Use Cases:
- Filter before importing
- Create subsets of huge CSV files
- Remove duplicates before importing
- Import only records matching specific criteria (e.g., job titles, locations)
Improvement: Update Your Templates
We added this feature to let you keep your template library simple and clean and make adjustments based on the new learnings that you get from using them. Even if you just want to update your API key, you can easily do it.
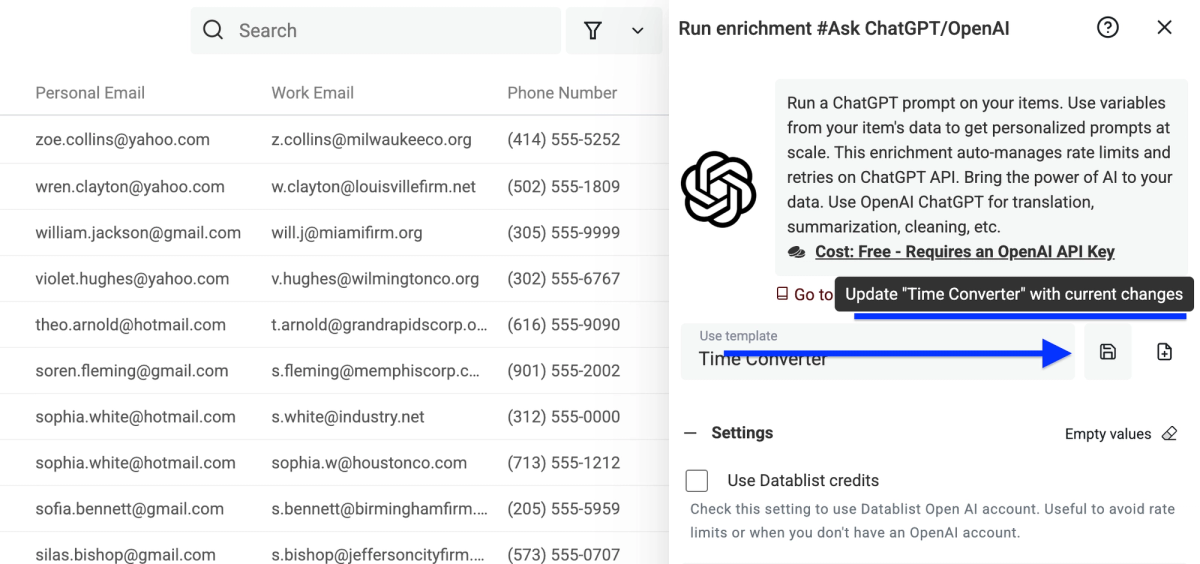
How It Works:
You add or remove parts of your template and click the update icon.
Improvement: Full Screen View
Toggle between full-screen and compact views by closing or opening the sidebar, making it easier to focus on what matters most to you.
Removed: Email finder
The legacy email finder is now the waterfall email finder.