Scrapes agency listings from Clutch.co including company names, ratings, services, pricing, and profile links
Comment utiliser ce prompt IA
- Créer une nouvelle collection : Commencez par créer une collection vide dans Datablist où seront stockées les données. Cliquez sur « + Create new collection » dans la barre latérale.
- Sélectionner la source Agent IA : Cliquez sur « See all sources » ou allez dans « Import » -> « Import From Data Sources ». Choisissez « AI Agent - Site Scraper ».
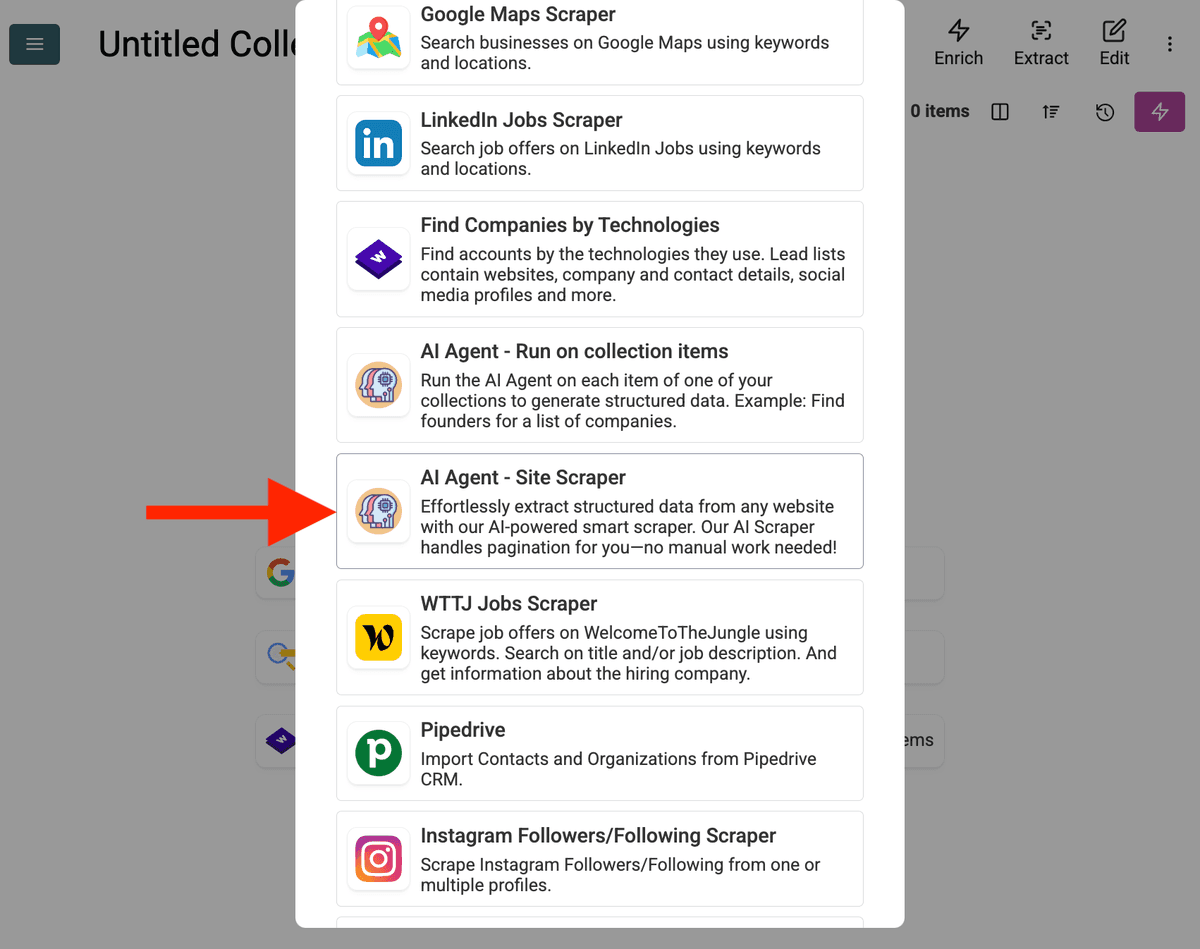
-
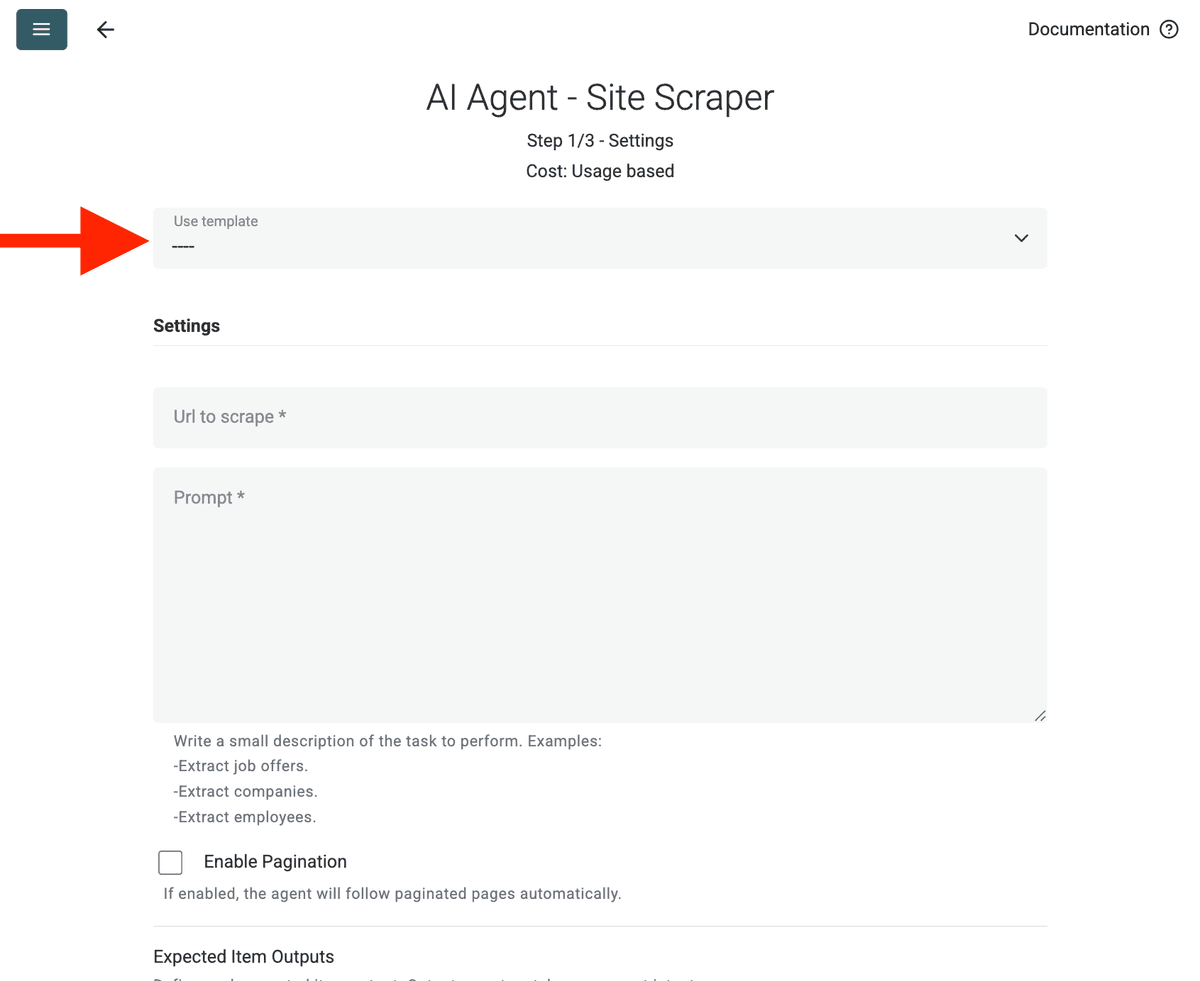
Configurer la source :
- Select Template : Trouvez et choisissez le prompt dans le menu déroulant « Template ». Le prompt ci-dessus sera chargé automatiquement.
- URL to Scrape : Entrez votre URL à scraper
- Enable Pagination (Optional) : Si les résultats sont sur plusieurs pages, cochez Enable Pagination et définissez une limite Max Pages raisonnable (ex. 10).
- Customize (Optional) : Vous pouvez ajuster le modèle IA (p. ex., GPT-4o mini est souvent économique), éditer le prompt selon vos besoins spécifiques ou modifier les Outputs attendus.
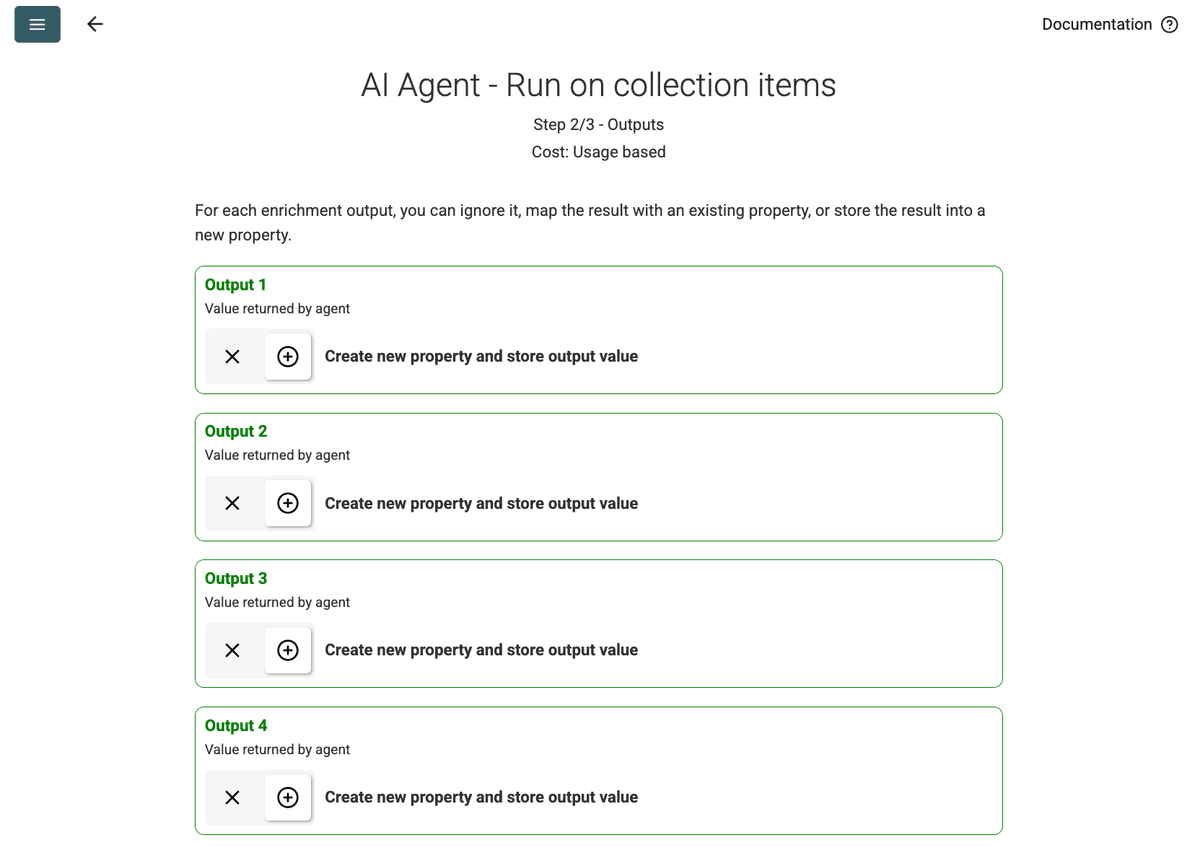
- Review Outputs : Cliquez sur Continue. Datablist affichera les champs de sortie définis dans le prompt (Project Name, Client Company Name). Cliquez sur l’icône + à côté de chacun pour créer les propriétés correspondantes (colonnes) dans votre collection.
- Run Import : Cliquez sur Run import now. L’Agent IA commencera à scraper le site web selon le prompt et alimentera votre collection.
Tarification
Cette source de données utilise des crédits Datablist à l’usage. Les coûts dépendent de la complexité du site web et du nombre de pages visitées.
Commencez par exécuter l’Agent IA sur une seule page afin d’estimer le coût.
FAQ
Comment lancer une autre exécution avec la même configuration ?
Une fois que vous avez exécuté votre Agent IA, cliquez sur le bouton rose en haut à droite de votre tableau de données pour le rouvrir avec vos derniers paramètres utilisés.
Que se passe-t-il si l’Agent IA tente d’accéder à un site protégé ou est bloqué ?
L’Agent IA utilise automatiquement des serveurs proxy au besoin pour accéder aux sites qui pourraient avoir des protections contre le scraping ou des restrictions géographiques. Cela augmente les chances d’extraction réussie, même si des sites très fortement protégés peuvent rester difficiles.
Combien de données puis-je traiter avec l’Agent IA ?
Lors de l’exécution de l’Agent IA (en enrichissement ou en source de données), les collections Datablist peuvent traiter jusqu’à 100 000 éléments (lignes). Pour des datasets plus volumineux, vous devrez peut-être scinder vos données en plusieurs collections.
En quoi l’Agent IA est-il différent des enrichissements ChatGPT/Claude/Gemini ?
Les enrichissements IA standard (ChatGPT, Claude, Gemini) traitent les données déjà présentes dans votre collection en s’appuyant sur les connaissances existantes de l’IA. L’Agent IA peut interagir activement avec le web en direct — effectuer des recherches Google, parcourir des sites et extraire de nouvelles informations selon votre prompt.
Quel est le niveau de précision des résultats ?
La précision dépend fortement de la clarté et de la spécificité de votre prompt, ainsi que de la complexité de la tâche et des informations disponibles en ligne. Fournir des instructions claires, des exemples et des règles de gestion des erreurs améliore les résultats. Datablist fournit souvent un score de confiance pour les sorties de l’Agent IA afin d’évaluer la fiabilité.