

Je peux scraper des centaines d’études de cas en quelques minutes et vous pouvez le faire aussi.
Dans ce guide, je vous montre pas à pas comment scraper efficacement les études de cas et ainsi bâtir une base de données précieuse à des fins de vente, marketing ou de veille concurrentielle.
À la fin du tuto, vous saurez automatiquement extraire non seulement les liens d'études de cas, mais aussi les informations clés comme les détails clients, les données sectorielles et d'autres métriques, le tout proprement structuré.
Voici un workflow en 2 parties qui détaille le process en étapes actionnables :
- Dans la première partie, on scrape tous les liens des pages principales où se trouvent les customer stories
- Dans la seconde partie on scrape les informations spécifiques qu’on souhaite obtenir
Note : Ce guide montre comment scraper des dizaines ou centaines d’études de cas depuis un même site web. Si vous voulez en scraper 1 ou 2 sur beaucoup de sites, lisez plutôt : Comment scraper des études de cas à grande échelle avec l’IA.
Partie 1 : Scraper tous les liens d'études de cas sur un site web
Étape 1 - Démarrer le scraping des liens d’études de cas
Allez sur Datablist.com et inscrivez-vous.
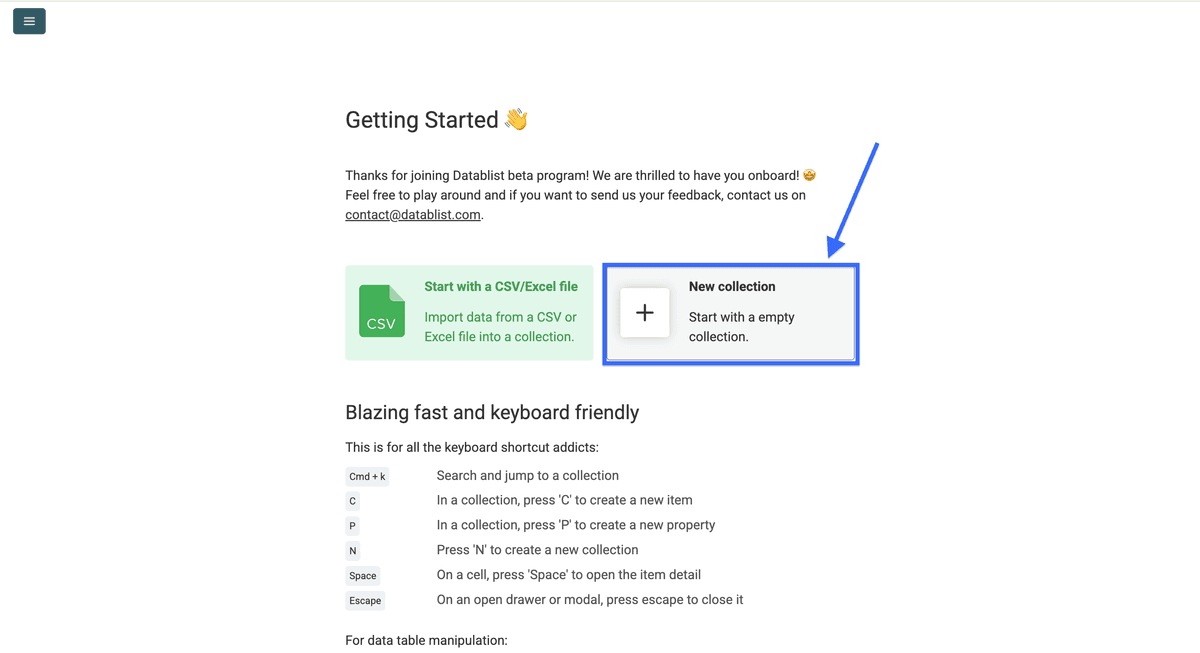
Créez une collection.
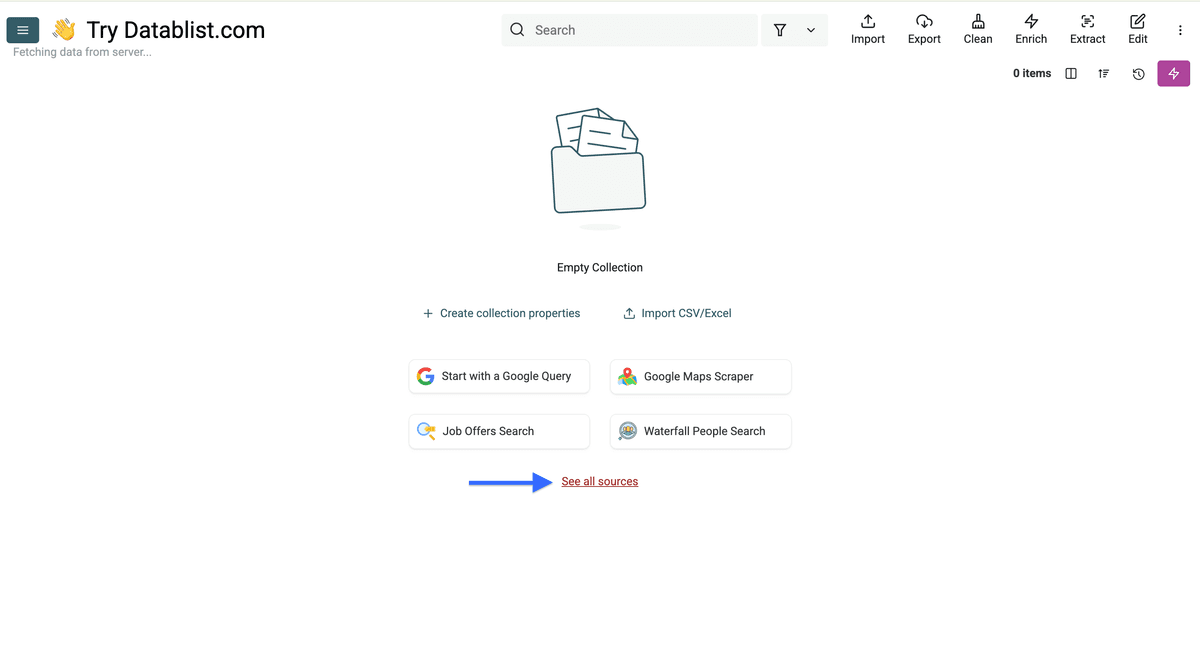
Cliquez sur “Voir toutes les sources”
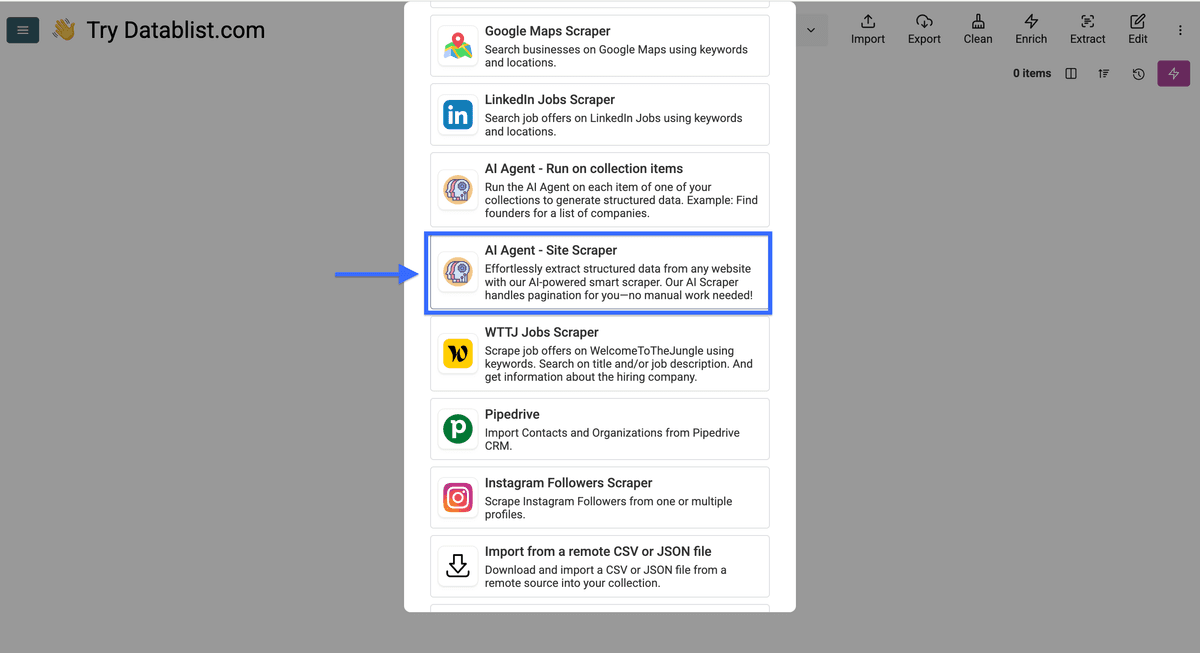
Choisissez "AI Agent - Site Scraper"
Étape 2 - Configurer l'extraction des liens d’études de cas
On configure notre AI Agent pour extraire tous les liens présents sur la page listant les études de cas.
Commencez par donner le lien vers la page qui regroupe les études de cas.
Ensuite, rédigez un prompt ou utilisez directement notre template :
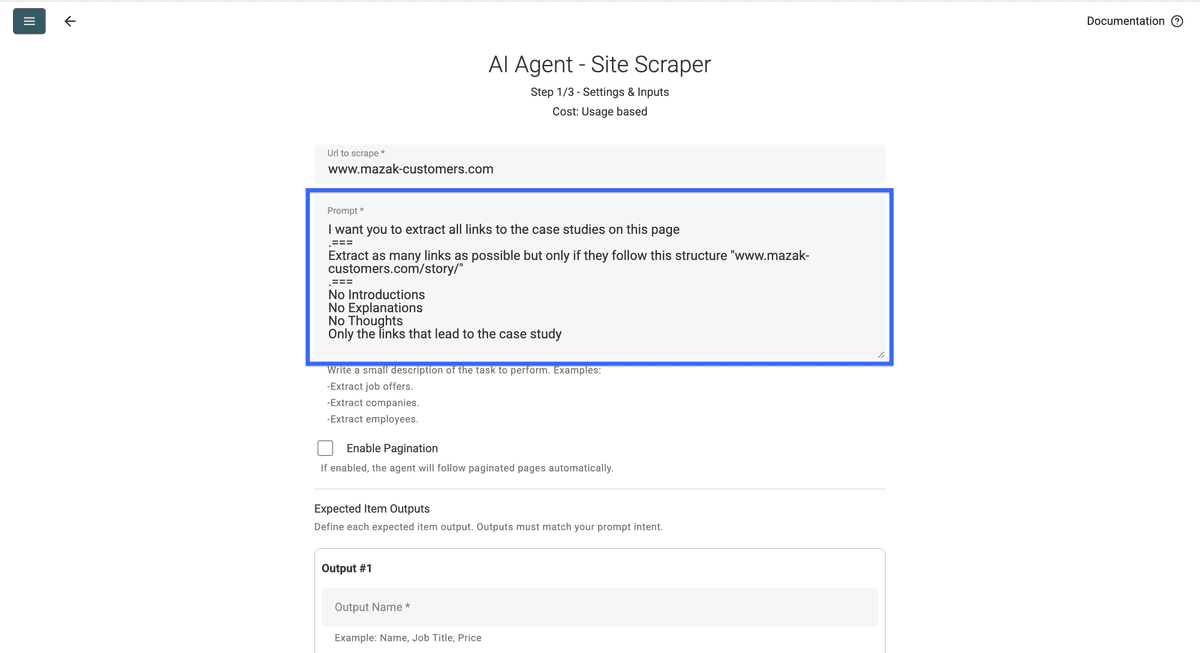
Voici mon prompt :
Je veux que tu extraies tous les liens vers les études de cas présentes sur cette page
===N’extrais que les liens qui suivent cette structure : "https://www.mazak-customers.com/story/story/......"
===
Aucune introduction
Aucune explication
Aucune réflexion
Juste les liens qui mènent aux études de cas
Veillez à donner un exemple ou un modèle d’URL (ex : www.mazak-customers.com/story/ ou www.salesforce.com/customer-stories/), car parfois l’IA peut aussi retourner des PDF qui ne sont pas exploitées dans ce contexte.
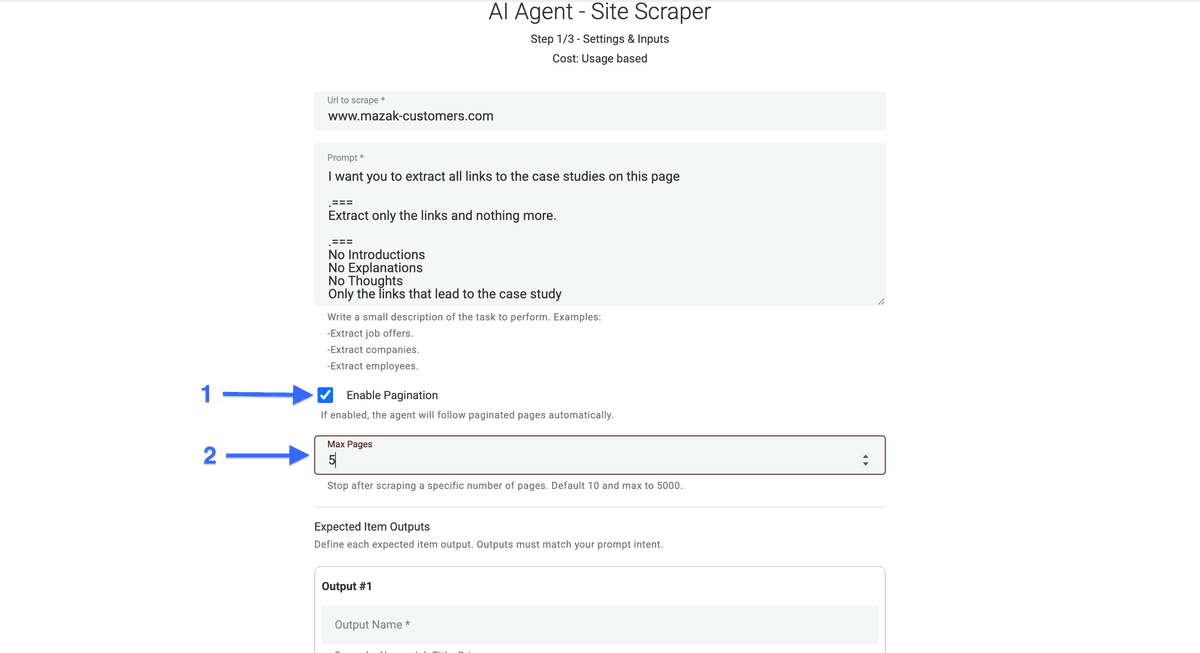
Cochez la case "Enable Pagination" à gauche et fixez un nombre limite de pages à visiter.
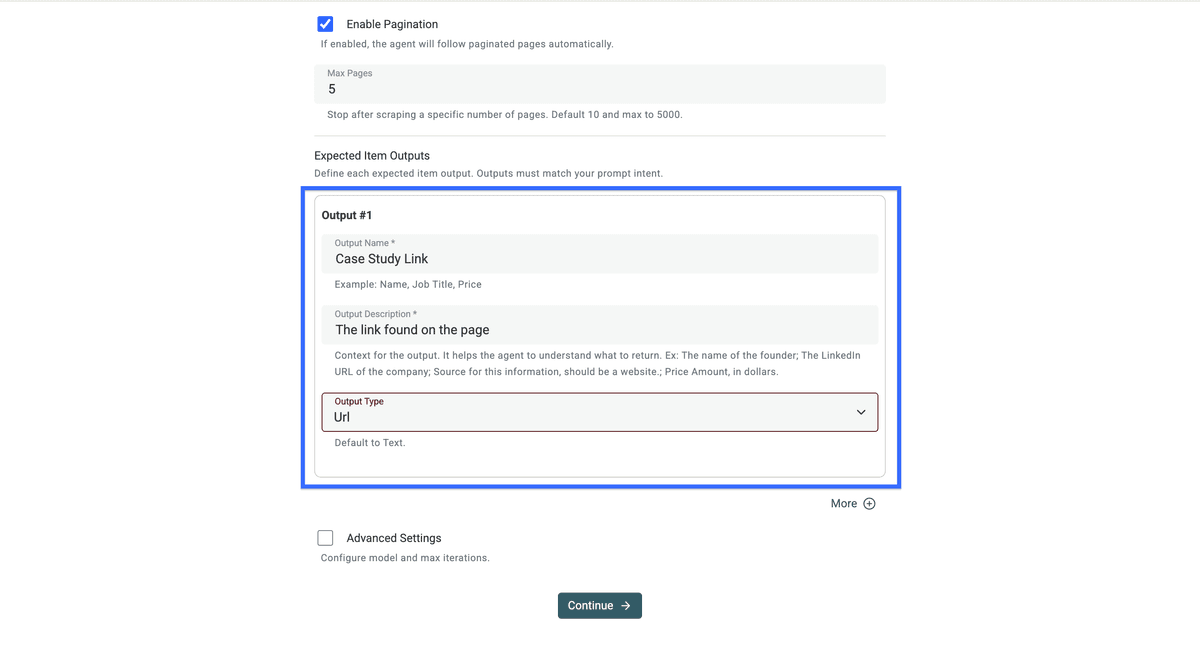
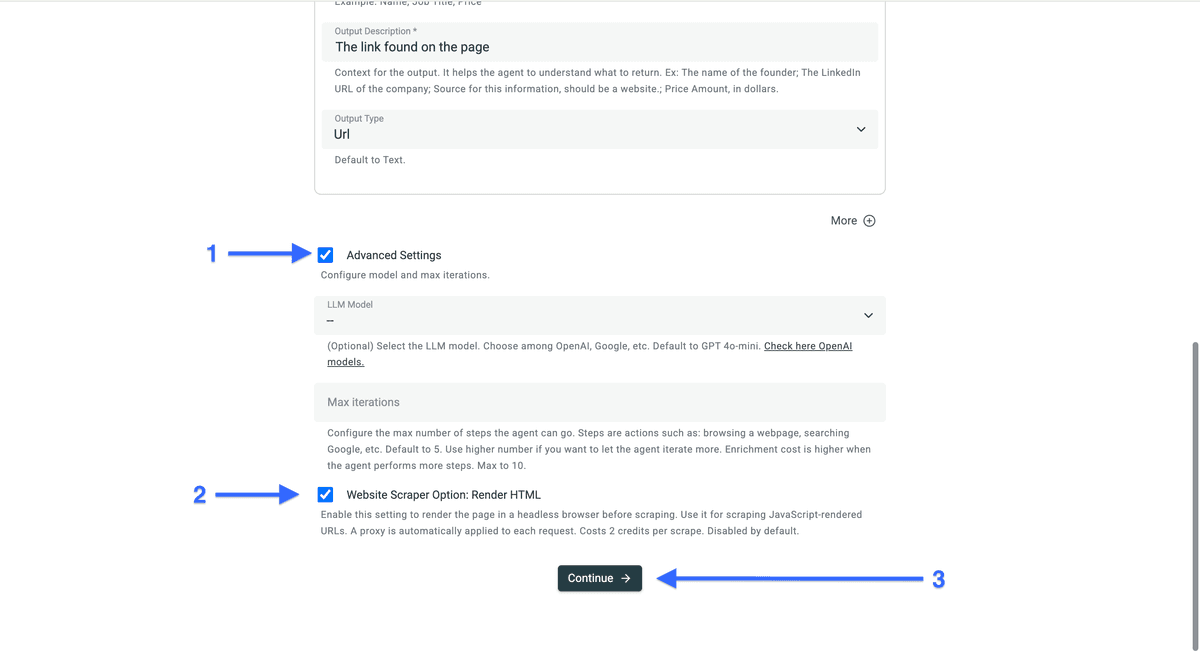
Configurez vos sorties comme ceci (ou copiez/collez ci-dessous) :
- Nom Sortie : Case Study Link
- Description Sortie : Lien trouvé sur la page
- Type : URL
Activez ensuite "Advanced Settings" et là, activez "Website Scraper Option: Render HTML".
Cliquez sur "Continue" pour lancer le scraping.
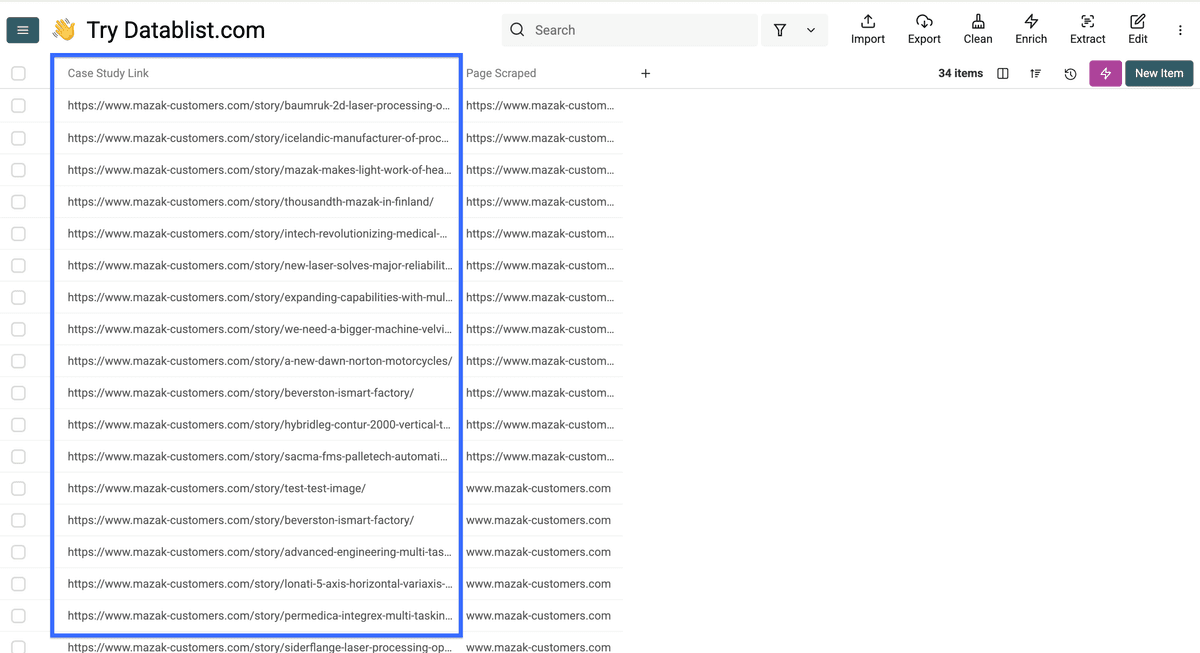
Une fois le run terminé, votre collection ressemblera à ceci :
Résultat : Vous voyez chaque lien d’étude de cas dans la colonne "Case Study Link" et la page d’origine dans "Page Scraped".
Maintenant qu’on a tous les liens, passons à l’extraction du contenu de chaque étude de cas.
Partie 2 : Extraire les informations pour chaque étude de cas
Ce workflow est un peu plus avancé mais vous fera gagner beaucoup de temps comparé au manuel — suivez les étapes pas à pas et vous êtes tranquille !
Voici les étapes à suivre :
- Visitez 1 ou 2 pages pour analyser la structure des études de cas
- Créez un tag pour chaque information à extraire
- Rédigez un prompt en donnant des exemples à l’IA
- Configurez les sorties recherchées
- Lancez l’AI agent pour scraper le contenu de chaque étude de cas
Étape 1 - Analyser et taguer les informations des études de cas
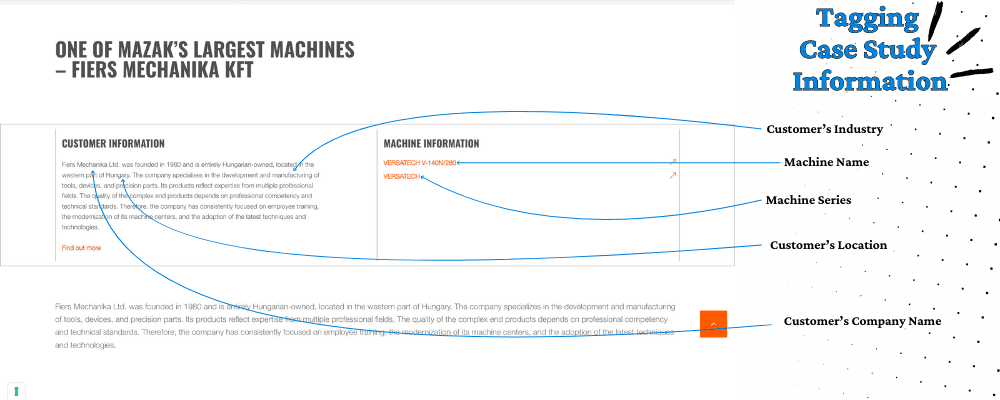
D’abord, visitez une ou deux pages collectées précédemment et définissez les infos que vous voulez (structure, patterns). Ensuite, créez un tag pour chaque info souhaitée, donnez des exemples à l’IA et indiquez où trouver l’info : L’IA sera bien plus performante ainsi.
Parfois, survolez les éléments pour déceler des informations cachées dans les liens (utile pour affiner vos sorties). Par exemple, "VERSATECH" pourrait être une série machine.
💡 Astuce :
Donner des exemples triple la qualité des résultats en sortie
Étape 2 - Configurer le scraping d’infos sur les pages études de cas
Dans cette étape, on configure l’AI agent pour extraire les infos depuis chaque page : prêt ?
Ouvrez votre collection avec les liens d’études de cas (on peut masquer la colonne "Scraped Page" ici). Cliquez ensuite sur "Enrich".
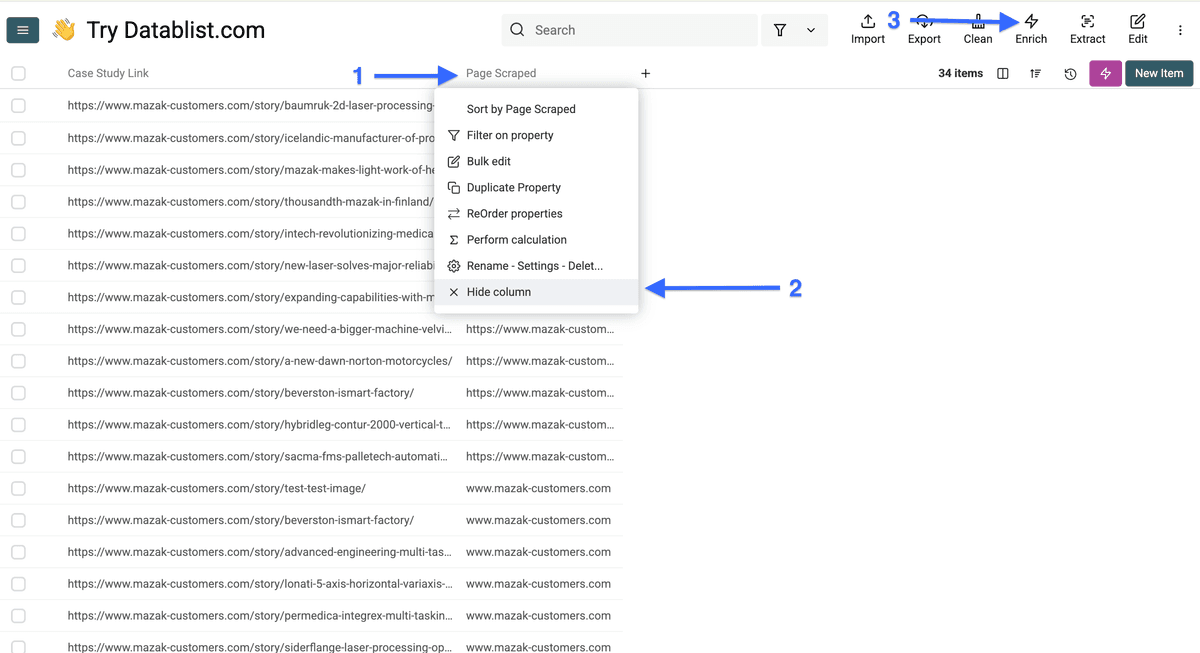
Rendez-vous dans “AI” et sélectionnez "AI Agent".
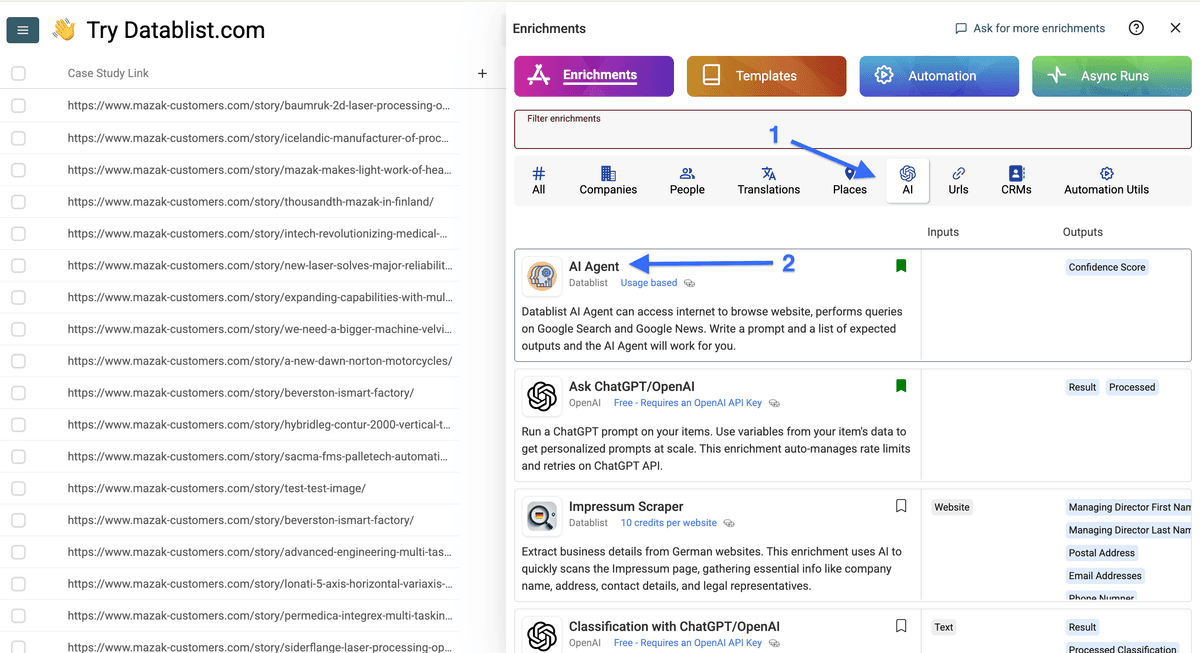
Copiez ce template de prompt et adaptez-le à votre use case :
Contexte : J'ai besoin d’informations concernant l'étude de cas sur la page web
===Ce que je veux : Visite la page (je vais te donner le lien) et extrais les données demandées. Je te décris chaque info tout de suite.
===
Les données à récupérer (avec exemples) :
[Tag info 1] ex : [Exemple 1, Exemple 2, Exemple 3]
[Tag info 2] ex : [Exemple 1, Exemple 2, Exemple 3]
[Tag info 3] ex : [Exemple 1, Exemple 2, Exemple 3]
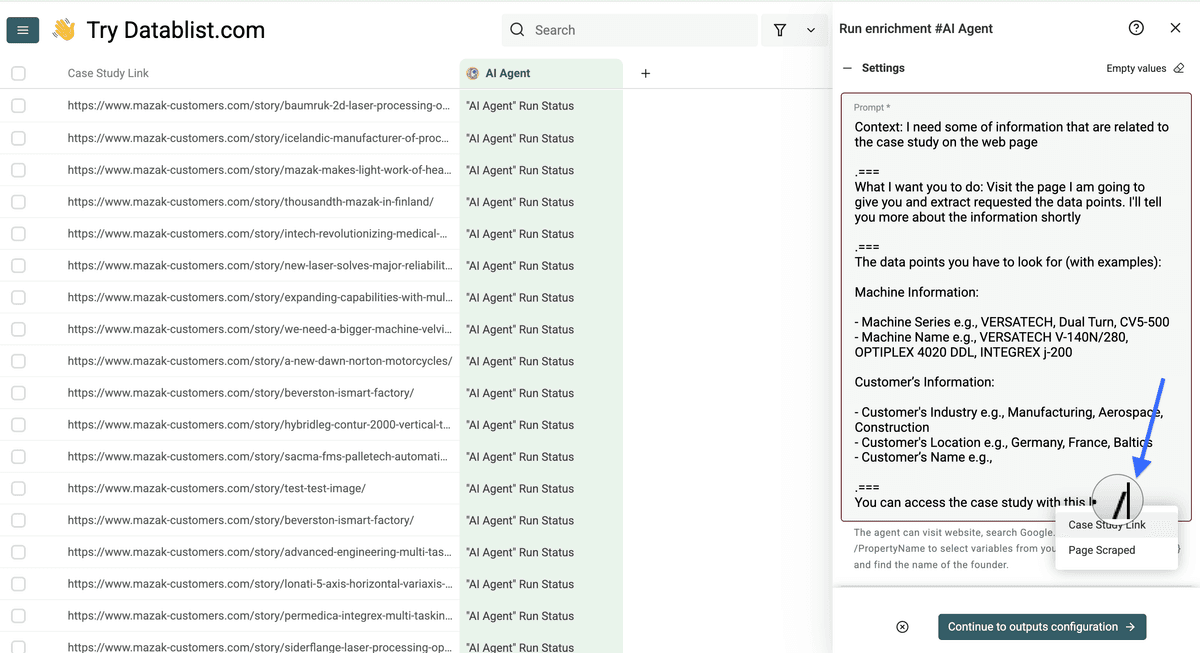
Tu peux accéder à l'étude de cas via ce lien : /Votre colonne
Voici le template avec des exemples :
Contexte : J'ai besoin d’informations concernant l'étude de cas sur la page web
===Ce que je veux : Visite la page (je vais te donner le lien) et extrais les données demandées. Je te décris chaque info tout de suite.
===
Les données à récupérer (avec exemples) :
Informations Machine :
- Série machine ex : VERSATECH, Dual Turn, CV5-500
- Nom machine ex : VERSATECH V-140N/280, OPTIPLEX 4020 DDL, INTEGREX j-200
Informations Client :
- Secteur client ex : Industrie, Aéronautique, BTP
- Pays client : Allemagne, France, Pays baltes
- Nom client :
Tu peux accéder à l'étude de cas via ce lien : /Case Study Link
💡 Pour info : L’AI agent suit très bien les instructions… mais avoir des exemples concrets triple la qualité des résultats.
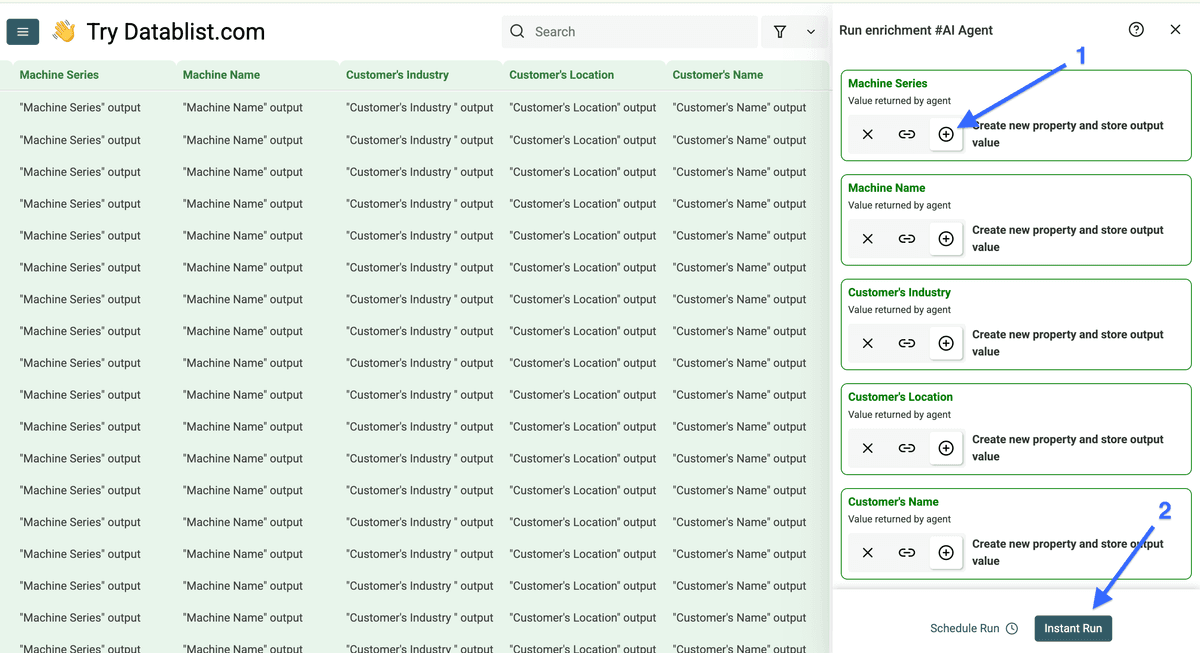
Après la configuration du prompt (grâce à notre template), configurez vos sorties :
- Utilisez le nom du tag comme "Output Name"
- Ajoutez une description claire en "Output Description" (mettez des exemples)
- Choisissez le bon "Output Type"
- Cliquez sur "More" pour ajouter d’autres sorties
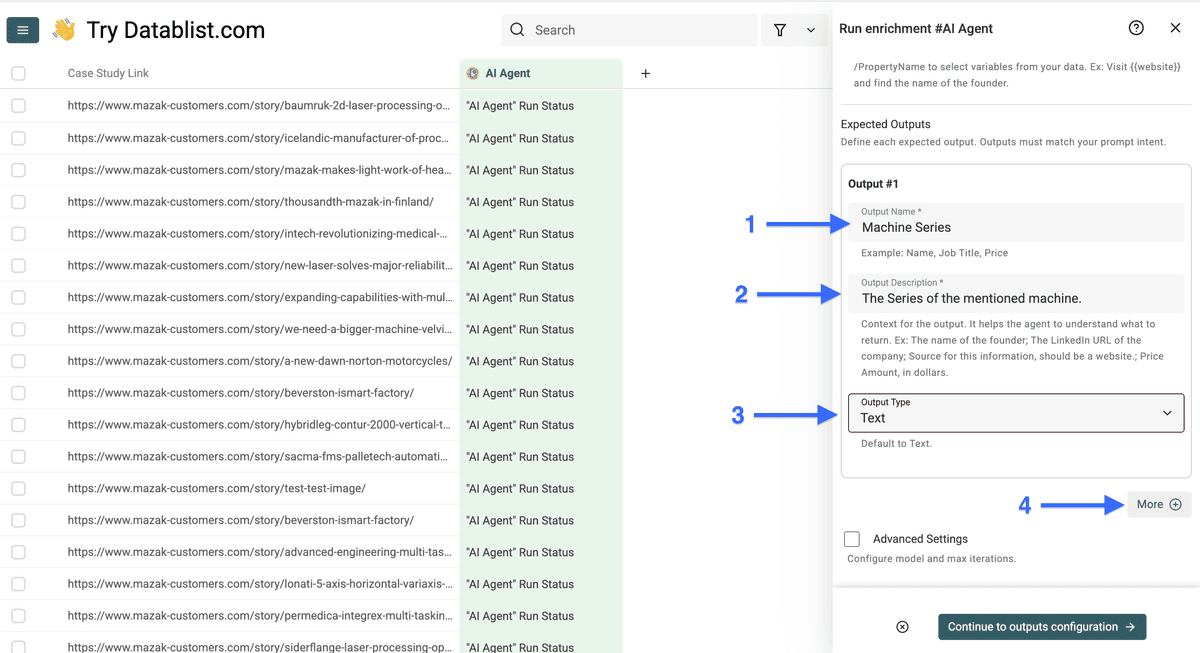
Quand vous avez tout configuré, cliquez sur "Continue to outputs configuration".
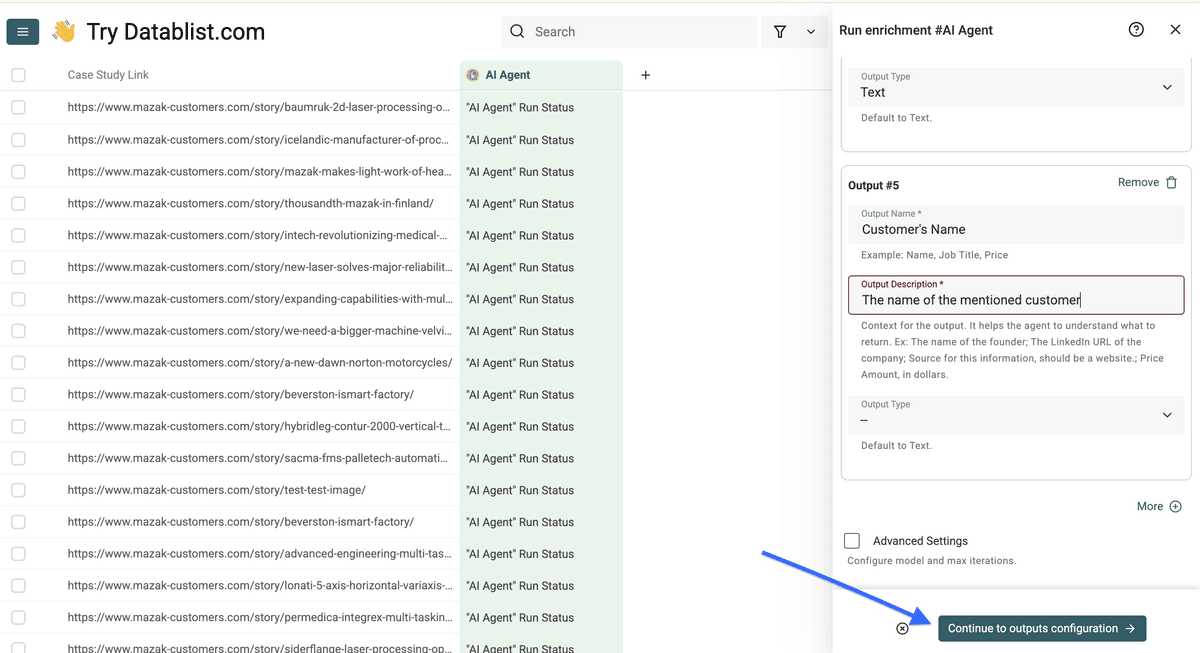
Cliquez sur les "+" pour ajouter une colonne par sortie, puis "Instant Run" pour lancer le scraping.
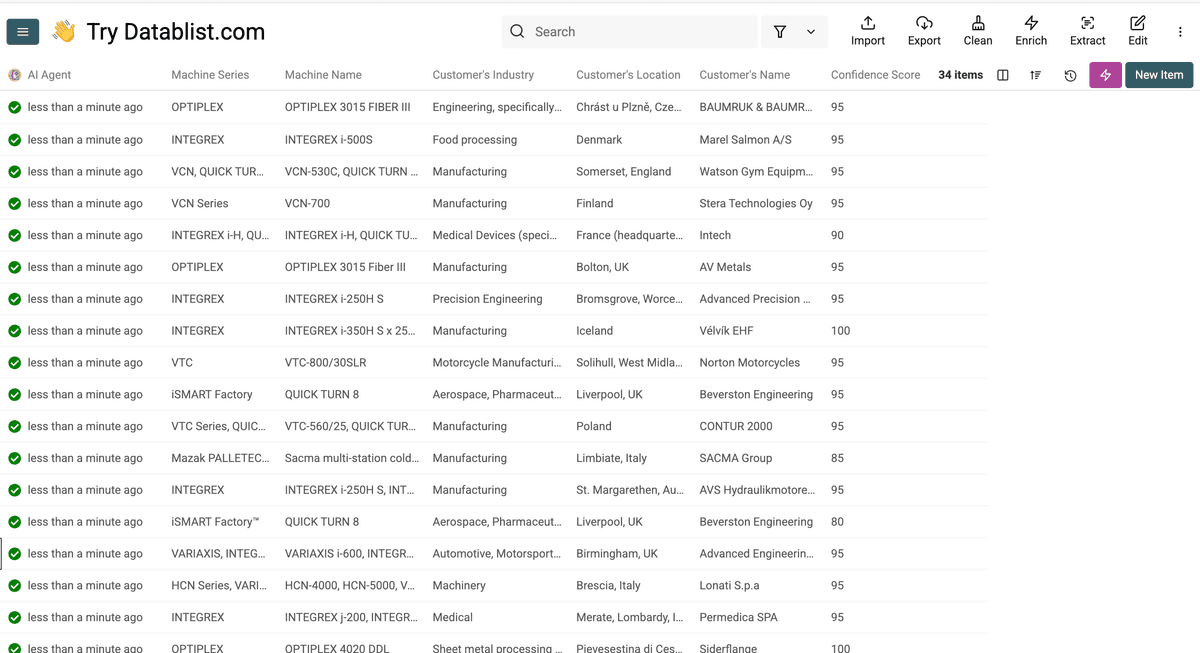
Voici le résultat final : toutes les études de cas enrichies !
Foire Aux Questions sur le Scraping d’Études de Cas
Comment scraper légalement des études de cas sur un site ?
Le scraping de données publiques est légal tant que vous respectez le droit d’auteur et ne violez pas les conditions d’utilisation du site.
Quels outils pour scraper les études de cas ?
Des outils no-code comme Datablist font le travail sans besoin de coder.
Combien de temps ça prend de scraper un site ?
Avec Datablist, comptez quelques minutes à quelques heures pour des centaines d’études de cas. La configuration initiale (comprendre le site) prend 15-30mn.
Puis-je scraper n’importe quel site ?
Non, certains sites protègent leurs contenus (anti-bot, conditions strictes).
Quelles infos extraire d’une étude de cas ?
Tout : noms clients, secteurs, défis, solutions, résultats, témoignages, dates, métriques… L’essentiel est d’identifier des patterns sur la page pour automatiser l’extraction.