
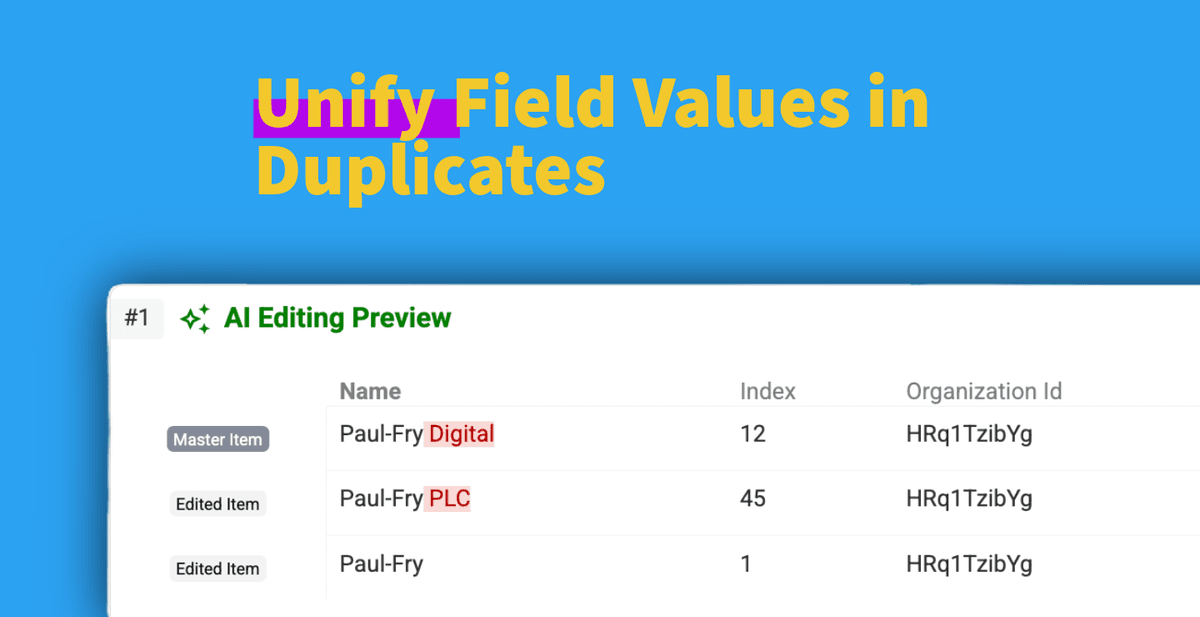
Dealing with duplicate records in your datasets is a common headache. While finding these duplicates is the first step, cleaning them up often presents another challenge.
Sometimes, you don't want to merge duplicate records fully yet.
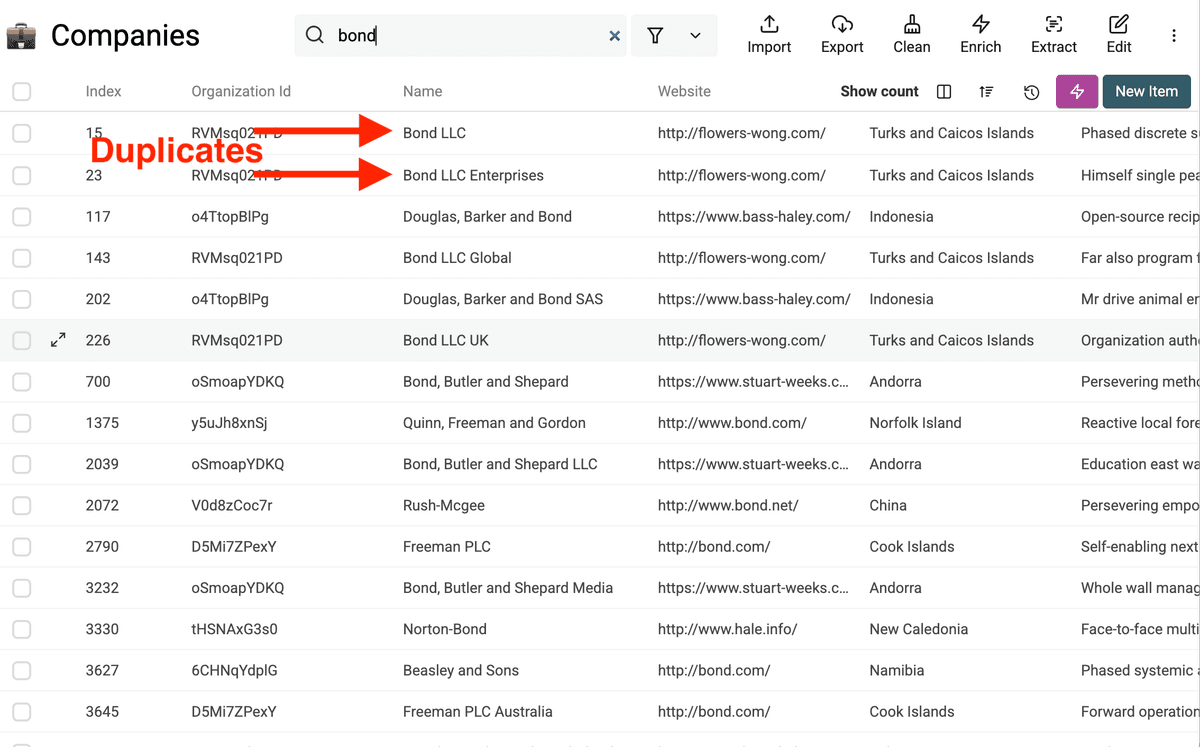
You might have the same company listed with slightly different names ("Innovate Corp", "Innovate Corporation", "Innovate Corp.") across several duplicate entries.
What if you could standardize a specific field, like the company name or job title, across all records within a duplicate group without merging the records themselves?
In this guide you will learn how to normalize specific field values across duplicate groups while keeping the individual records intact:
- What is Data Normalization?
- Introducing AI Processing in Duplicates Finder
- How to Normalize Data Across Duplicates (Step-by-Step)
What is Data Normalization?
Data normalization, in this context, means bringing data into a consistent format. When dealing with duplicates, inconsistencies often arise in specific fields. For example:
- Company Names: "Tech Solutions Inc.", "Tech Solutions, LLC", "Tech Solutions"
- Job Titles: "Software Engineer", "Software Dev.", "Eng., Software"
- Addresses: "123 Main St", "123 Main Street", "123 main st"
- Countries: "USA", "United States", "U.S.A."
Normalization aims to pick a single, standard value (like "Tech Solutions" or "United States") and apply it to the relevant field across all records identified as duplicates.
This makes your data cleaner, easier to analyze, and more reliable for filtering or reporting, even if the duplicate records themselves remain separate. It's a crucial step in data cleaning.
Introducing AI Processing in Duplicates Finder
Datablist's Duplicates Finder is already a powerful tool for identifying similar records. While it offers robust options for automatically or manually merging duplicates, the AI Processing mode provides an extra layer of flexibility.
Instead of predefined merging rules, AI Processing lets you define the logic using a natural language prompt. You can tell the AI exactly how to handle the duplicates. This includes tasks like:
- Selecting a master record based on specific criteria (e.g., the most recently updated).
- Merging specific fields while keeping others separate.
- Performing calculations during the merge (like summing values).
- 👉 And, crucially for this guide: Updating a specific field across all duplicates to a single, normalized value without merging the records.
It transforms the complex task of scripting data manipulation into a simple conversation with our AI.
How to Normalize Data Across Duplicates (Step-by-Step)
Let's walk through the process of using AI Processing to normalize a field (e.g., Company Name) across duplicate records.
Step 1: Prepare Your Data
First, you need your data in Datablist.
- Create a Collection: Click the '+' button in the sidebar to create a new collection.
- Import Data: Import your data from a CSV or Excel file. If your data comes from multiple files, import them into the same collection. Datablist will guide you through mapping columns to properties. Ensure the field you want to normalize (e.g., Company Name) and the fields you'll use to identify duplicates (e.g., Email, Website) are imported correctly.

In this sample data, we already see some duplicate company names that must be normalized.
Step 2: Find Duplicates
Now, identify the duplicate records.
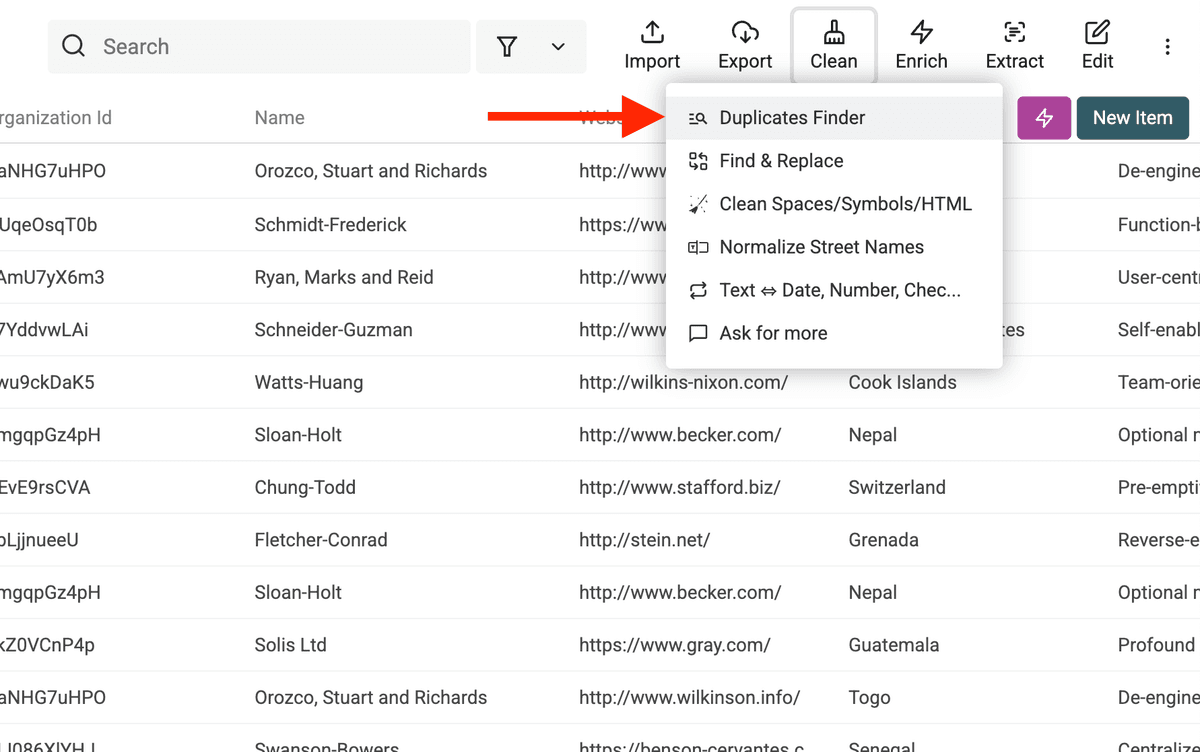
2.a. Open Duplicates Finder
Click on "Clean" in the header menu, then select "Duplicates Finder".
2.b Choose Deduplication Identifier(s)
Select the property (or properties) that uniquely identify a duplicate.
For our example, we want to dedupe company names. So we select the name field.
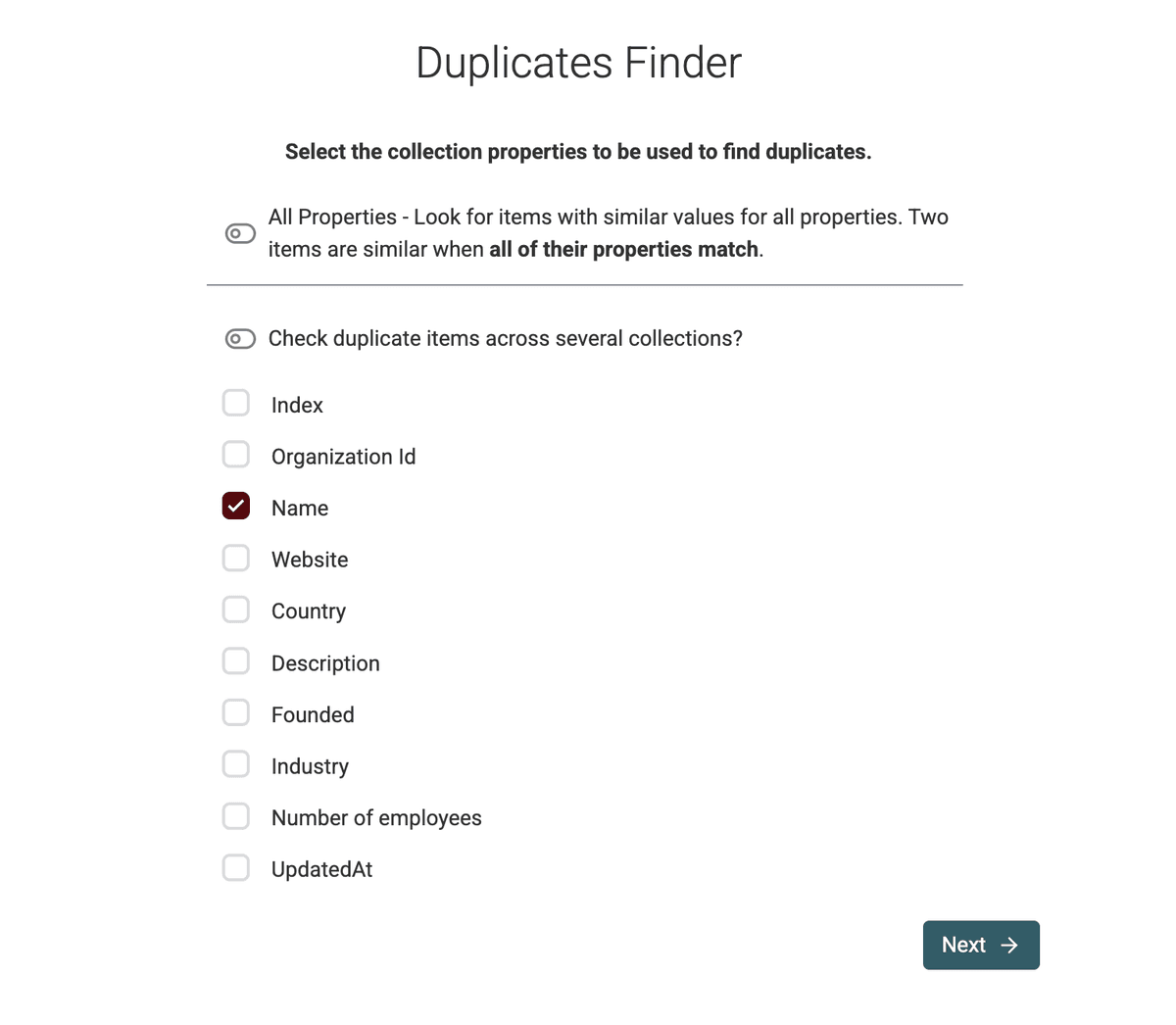
For companies, you could also use
Website URLorLinkedIn Company Page URL.For contacts,
Phone Numberare common choices.
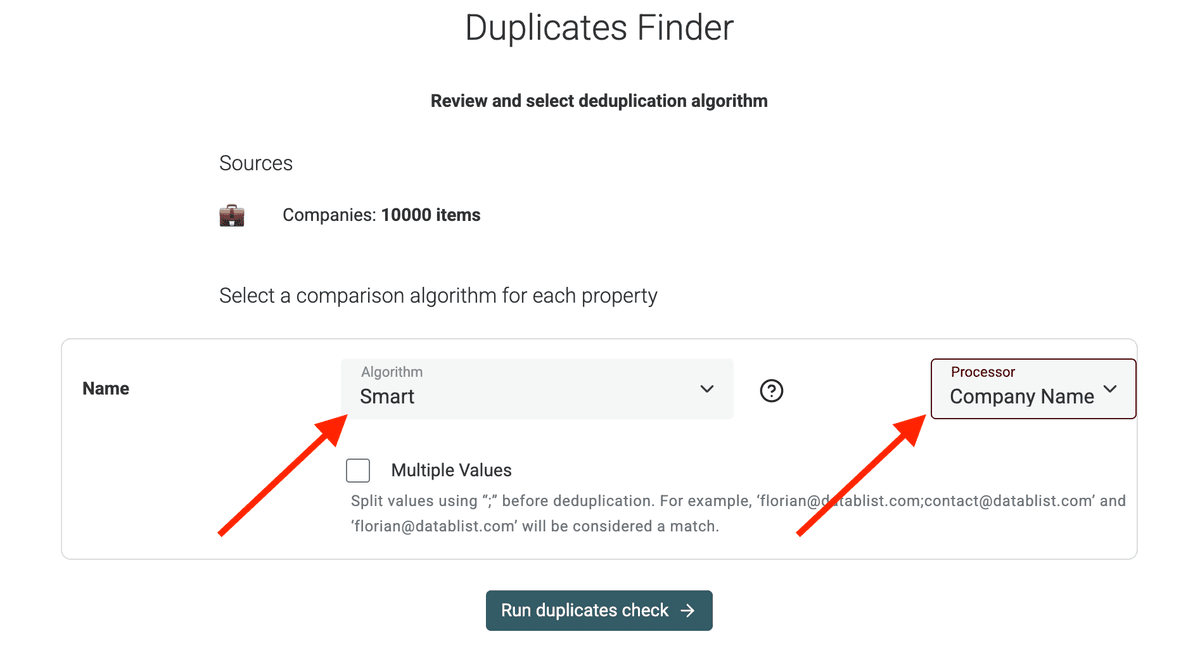
2.c Configure Algorithm
In the next step, choose the matching algorithm.
'Smart' often works well for URLs or emails, handling minor variations. 'Exact' is stricter. You can also use phonetic or fuzzy matching for names.
Select also the Processor that makes sense for your data.
Here, I select the Company Name processor to handle specific company name variations (business suffixes, geographical terms, etc.)
2.c Run Check
Click "Run duplicates check".
Datablist will analyze your data and present groups of potential duplicates.
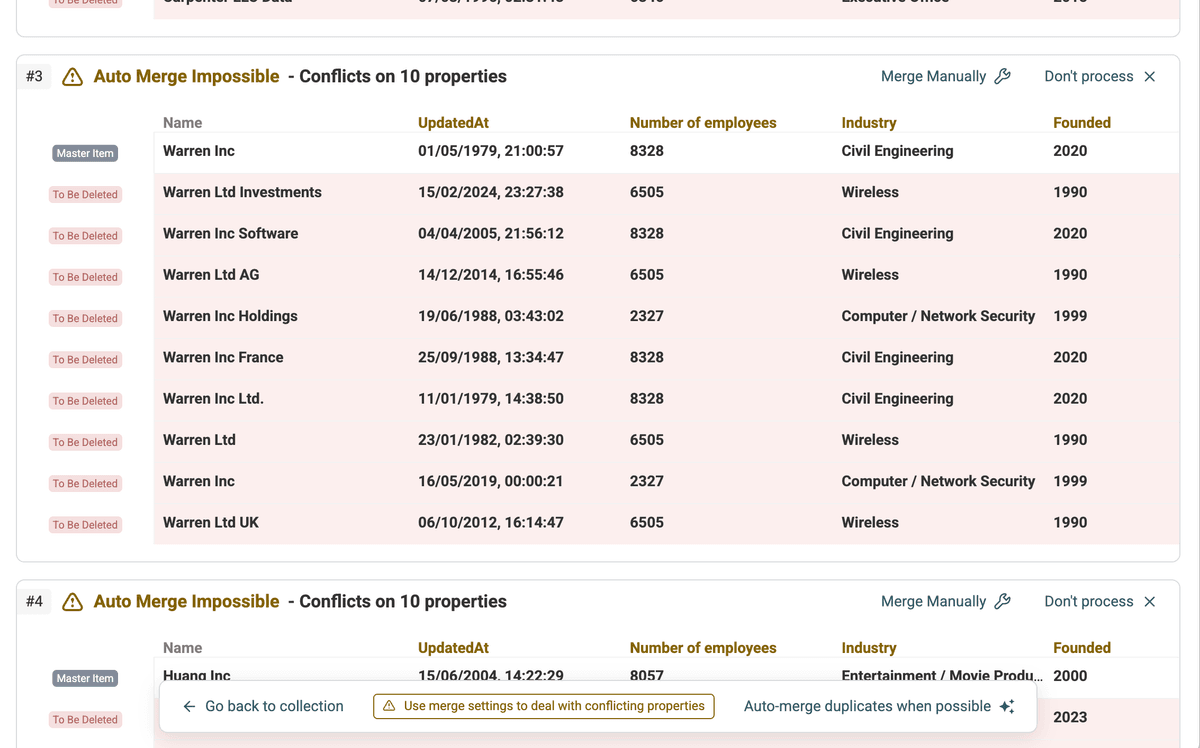
Step 3: Select AI Processing Mode
Instead of using the standard "Auto Merge" or manual merging options, click the AI Editing button on the duplicate results page. This activates the AI-driven processing mode.
Step 4: Write the Normalization Prompt
This is where you tell the AI what to do. You need to instruct it to:
- Identify the most common value for the target property within each duplicate group.
- Update all records in that group to use this common value for that specific property.
- Explicitly state not to delete any records.
Here’s an example prompt to normalize the /Company Name property:
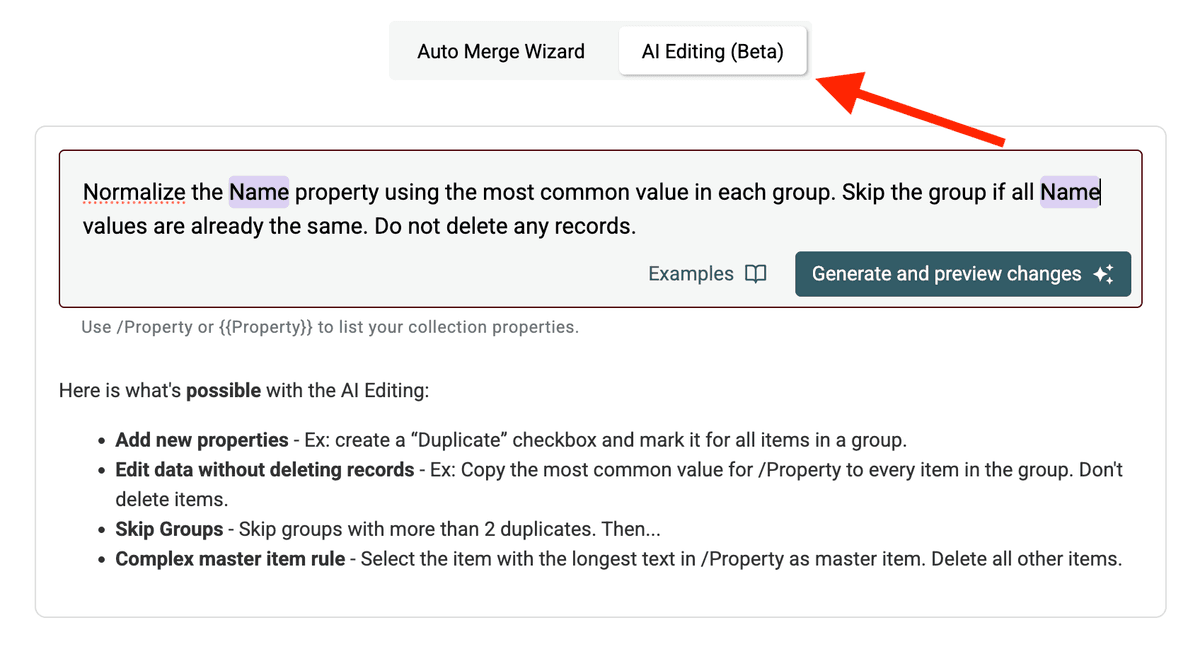
Breaking down the prompt:
Normalize the /CompanyName property...: Specifies the target field. Use/PropertyNameor{{PropertyName}}to reference your columns....using the most common value in each group.: Defines the logic for choosing the standard value. You could also use other criteria like "longest value", "shortest value", or even reference another field (e.g., "use the value from the record with the latest /UpdatedAt date").Skip the group if all /CompanyName values are already the same.: An efficiency instruction to avoid unnecessary processing.Do not delete any records.: This is crucial to ensure we only update fields, and no records are merged or removed.
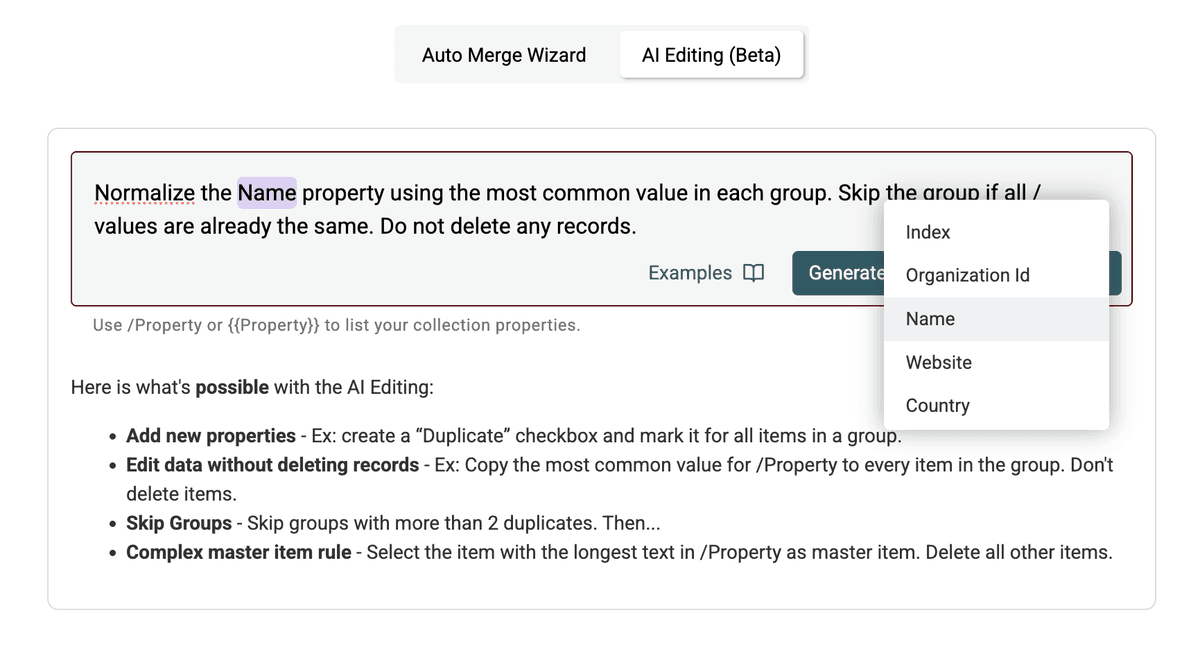
Step 5: Generate & Preview the Script
Click Generate and preview changes. Datablist's AI will interpret your prompt and generate a script to perform the action.
Don't worry, you don't need to write or edit any script.
- Script Explanation: A plain English summary of what the script will do. Verify this matches your intent.
- Result Preview: A table showing exactly how the script will modify a sample of your duplicate groups before any changes are made. Check the target field (e.g.,
/Company Name) in the preview to ensure it reflects the intended normalized value across the sample duplicates.
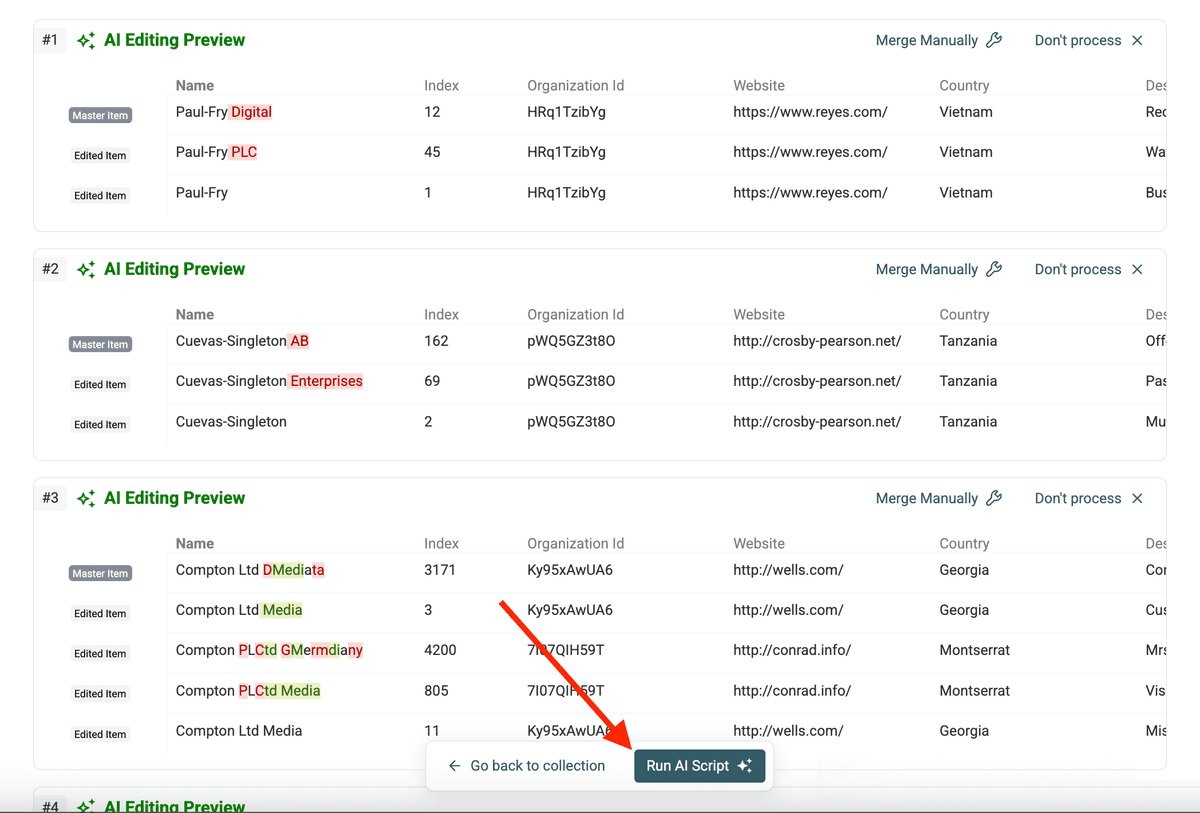
Step 6: Run the Script
If the explanation and preview look correct, click Run AI Script. Datablist will execute the generated script on all the identified duplicate groups.
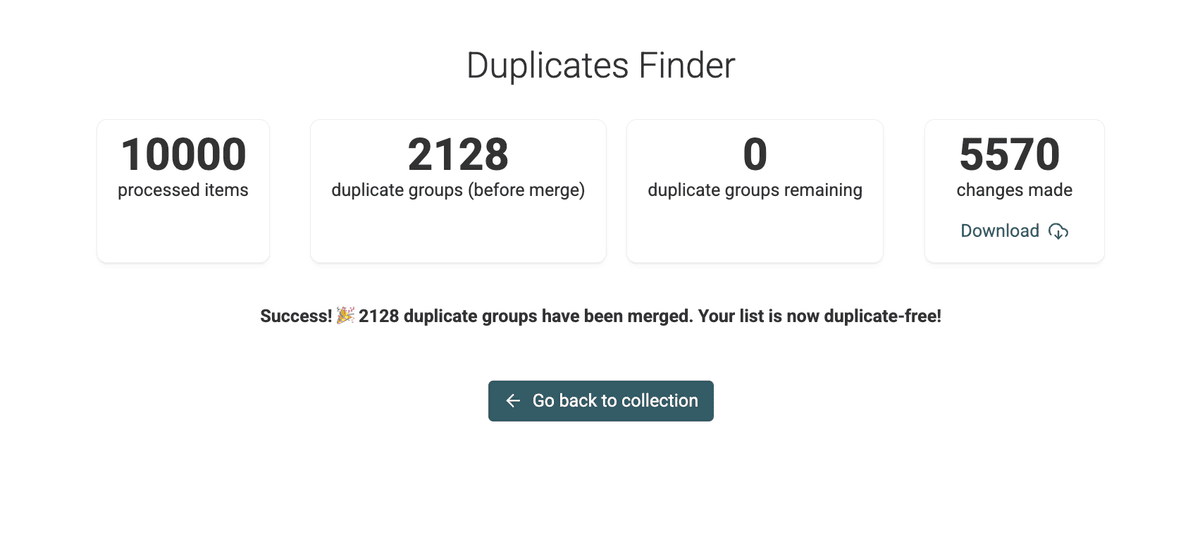
Step 7: Review Changes
Once the script finishes, Datablist provides a summary and a downloadable Changes List.
This is useful when you need to replay the changes in an external system (for example to edit CRM leads, etc.)
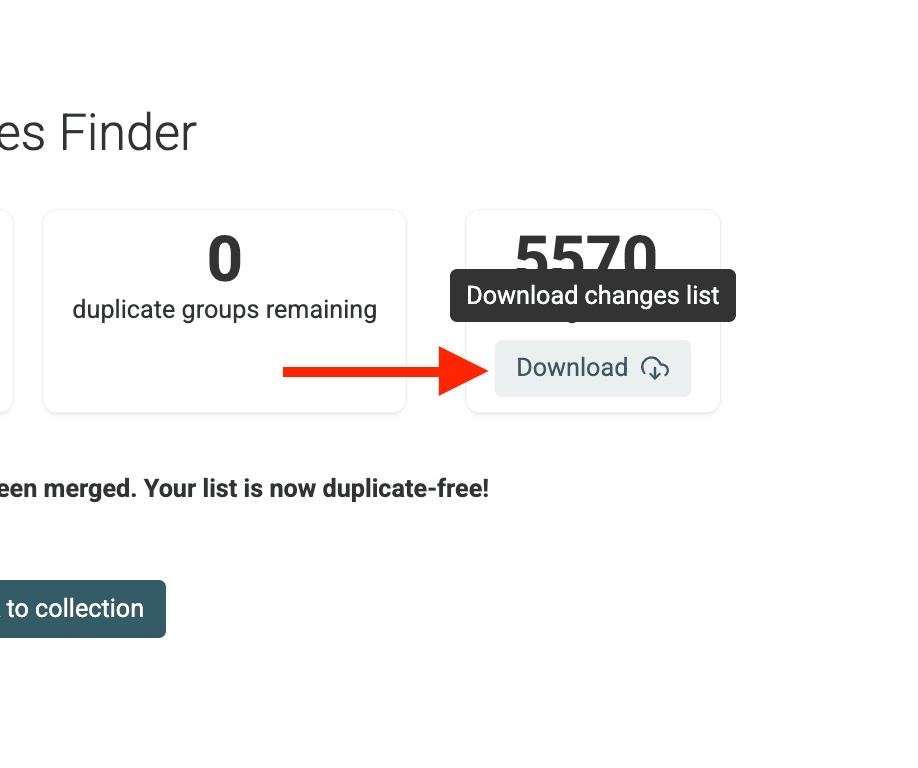
Go back to your main collection view. You'll see that the target field (e.g., /CompanyName) is now consistent across the records within the duplicate groups, while the records themselves remain separate.
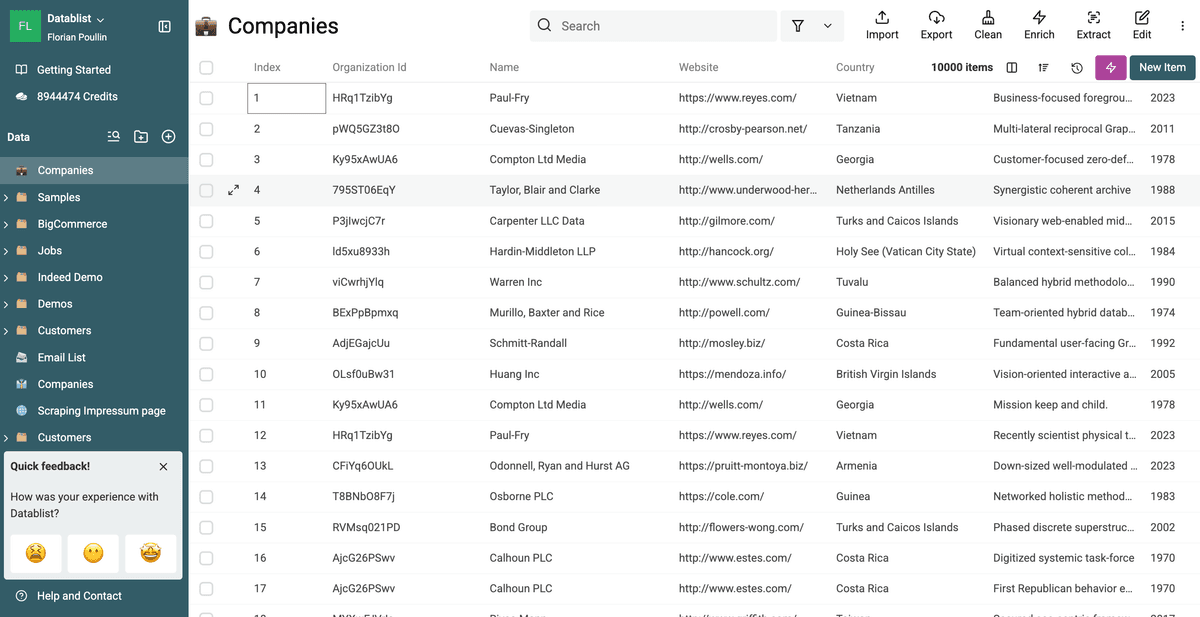
You've successfully normalized a field across duplicates without merging! 🚀
Use Cases for Normalizing Without Merging
When might you choose to normalize a field instead of doing a full merge?
- Standardizing Company or Contact Names: Clean up variations like "Example Ltd," "Example Limited," or "Jon Doe," "Jonathan Doe" across duplicates before deciding on a final merge strategy.
- Cleaning Job Titles: Unify titles like "VP Marketing," "Vice President Marketing," "Marketing VP" for consistent reporting or analysis.
- Normalizing Locations: Ensure consistent country names ("UK," "United Kingdom") or state abbreviations ("CA," "California") across duplicate address records.
- Preparing for CRM Import/Update: Standardize key fields before importing data into a CRM that might have strict validation rules, even if you keep the duplicates temporarily.
- Data Auditing: Preserve original duplicate records for auditing or historical tracking but standardize key identifiers for easier analysis.
- Incremental Cleaning: Normalize one field at a time as part of a larger data cleaning workflow before committing to a full merge or deletion.
Why Normalize Instead of Merging?
- Preserves Record Granularity: Keeps individual duplicate records intact, which might be necessary for tracking origins, specific interactions, or historical data associated with each record.
- Handles Uncertainty: Useful when duplicates aren't perfect matches. Normalizing a key field provides consistency without forcing a potentially incorrect merge of records with other differing data points.
- Staged Approach: Allows for a more controlled data cleaning process. Normalize first, then review and decide on merging or deleting later.
- Simplicity: It's a focused action. You target one field for consistency without affecting the rest of the data in the duplicate records.
Conclusion
Datablist's AI Processing feature in the Duplicates Finder offers a flexible and powerful way to manage duplicate data. Allowing you to normalize specific fields across duplicate groups without merging the records, it provides a crucial intermediate step in many data-cleaning workflows. Using simple natural language prompts, you can achieve data consistency quickly and efficiently, saving hours of manual effort and reducing the risk of errors. Whether you're standardizing company names, job titles, or locations, this feature empowers you to take control of your data quality.
FAQ
-
Is AI Processing included in my Datablist plan? AI Processing, including generating and running scripts for normalization, is available on Datablist's paid plans. Check our Pricing Page for details.
-
Can I normalize multiple fields with one prompt? Yes, you can write a prompt to normalize multiple fields simultaneously. For example: "Normalize the /Company Name property using the most common value in each group. Normalize the /Country property using the most common value in each group. Do not delete any records."
-
What if the AI misunderstands my prompt? Always carefully review the script explanation and the preview results before running the script. If the preview isn't correct, refine your prompt to be clearer and more specific, then regenerate the script.
-
Can I undo the changes made by the AI script? Once the script is run, the changes are applied directly. While Datablist has an undo feature for recent actions within the session, it's always best practice to clone your collection before running significant data transformations like this, allowing you to revert if needed.
-
How does this differ from the standard "Combine conflicting properties" merge option? The standard "Combine" option merges duplicate records into one master record and concatenates conflicting text values into a single field. AI Processing, with the right prompt, updates the field across all duplicate records to a single chosen value and keeps all records separate. It doesn't merge records or concatenate values unless specifically prompted to do so.