

Gestire record duplicati su più file Excel è un incubo che porta via tempo, crea incoerenze nei dati ed errori costosi.
Senza un processo di deduplica affidabile, rischi di inviare più email allo stesso contatto, prendere decisioni sbagliate basate su dati duplicati e sprecare ore a confrontare i record manualmente.
Scopri come deduplicare in modo efficiente i dati su più file Excel con tecniche e tool collaudati che ti fanno risparmiare tempo, mantengono l’integrità dei dati e prevengono future duplicazioni.
In questa guida vedrai come rimuovere record duplicati su più liste anche con strutture diverse:
- Come importare i tuoi file Excel
- Come fare matching dei duplicati tra più liste
- Come rimuovere automaticamente i duplicati
Step 1: Importa i file da deduplicare su Datablist
Registrati a Datablist e importa almeno due file.
Assicurati di avere almeno un identificatore univoco nei tuoi file.
Nota: il Duplicates Finder di Datablist funziona con qualsiasi numero di file Excel/CSV. Possono avere strutture diverse: serve solo un identificatore di matching in ciascun file/lista.
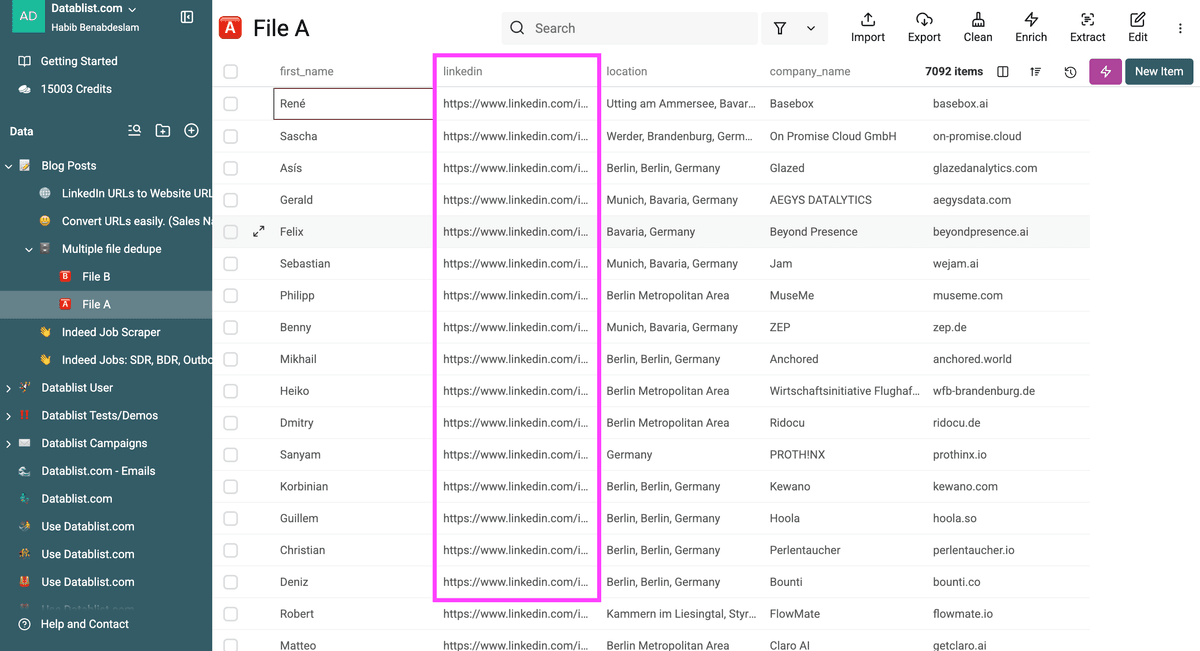
Ho scelto l'URL LinkedIn dei miei prospect come identificatore univoco.
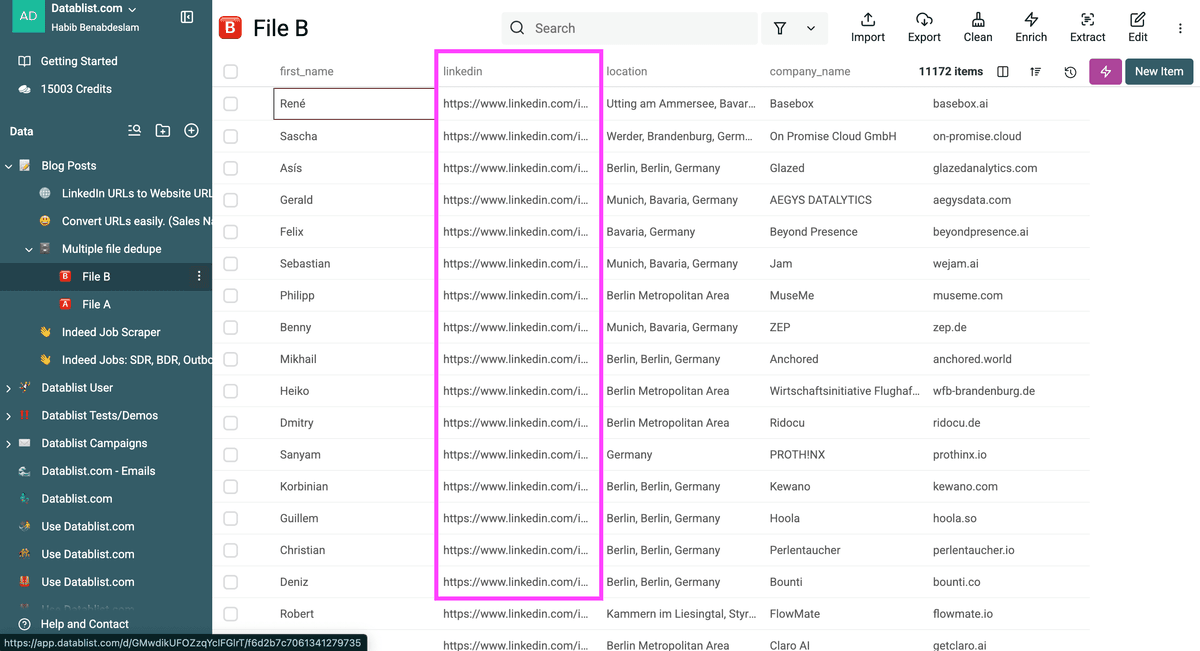
Un identificatore univoco non deve essere “assolutamente” unico: può essere anche il nome azienda o un nome proprio, purché lo definisci come tuo identificatore univoco.
Step 2: Trova i duplicati tra le tue liste
Poi, clicca su “Clean” e seleziona “Duplicates finder”.
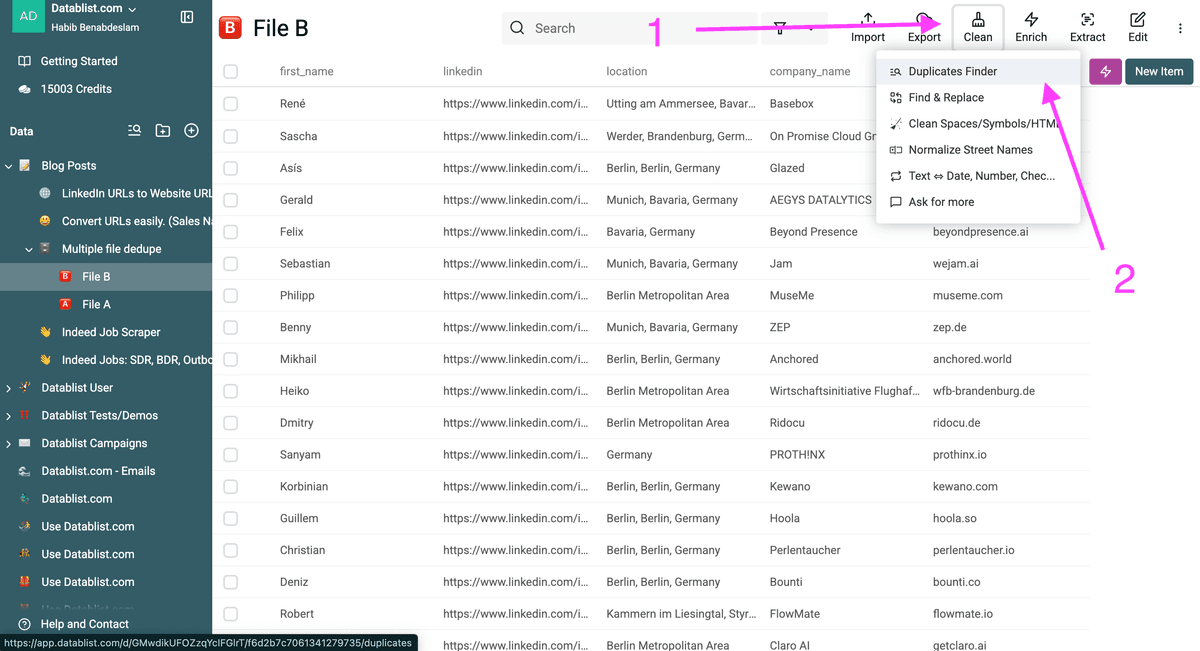
Nota: puoi partire dal file che preferisci. Il processo e i risultati saranno gli stessi.
Imposta tutto per deduplicare tra i tuoi file CSV.
- Clicca su "Selected Properties and Multi Collections" e
- Clicca su "Check Duplicate Items Across Several Collections"
- Seleziona le collections su cui deduplicare — puoi scegliere due o più file, senza limiti.

Scegli la proprietà su cui fare la deduplica.
Una proprietà analoga deve esistere su ciascuno dei tuoi file. Per ogni proprietà da usare nella deduplica, seleziona la proprietà corrispondente in ogni collection.
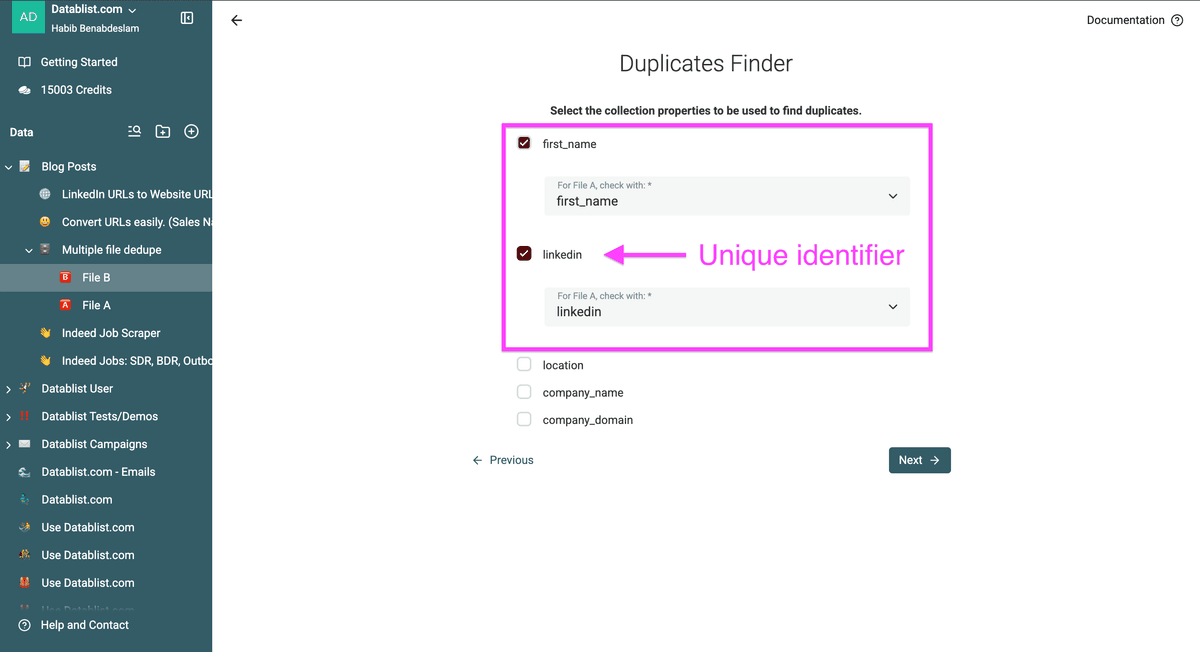
Nel mio esempio, rimuoverò tutti i prospect presenti in "File A" da "File B" in base all'URL LinkedIn.
Puoi selezionare più proprietà per il matching dei duplicati. In questo caso, i record dovranno avere valori corrispondenti su tutte le proprietà. Se vuoi trovare duplicati su una proprietà OPPURE su un’altra, esegui il processo due volte, una per ciascuna proprietà.
Seleziona i meccanismi di confronto con cui vuoi lavorare.
Per gli ID (ID CRM, ID interni) uso sempre "Exact". Per proprietà testuali come URLs, Emails, ecc. scelgo l'algoritmo "Smart" per la massima accuratezza quando deduplico più file.
Se hai Names che potrebbero avere refusi o leggere variazioni, usa uno degli algoritmi di distanza (Levenshtein Distance o Jaro-Winkler Distance).

Clicca su “Run duplicates check” quando hai scelto l’opzione più adatta alla tua deduplica.
Step 3: Scegli le operazioni di pulizia per i duplicati
Imposta le regole di pulizia scegliendo tra:
- Rimuovere gli elementi duplicati dalla collection X
- Tenere gli elementi duplicati solo nella collection X (opzione disponibile solo quando si deduplica su 3 o più collections)

Clicca su "Process duplicate items" per continuare.
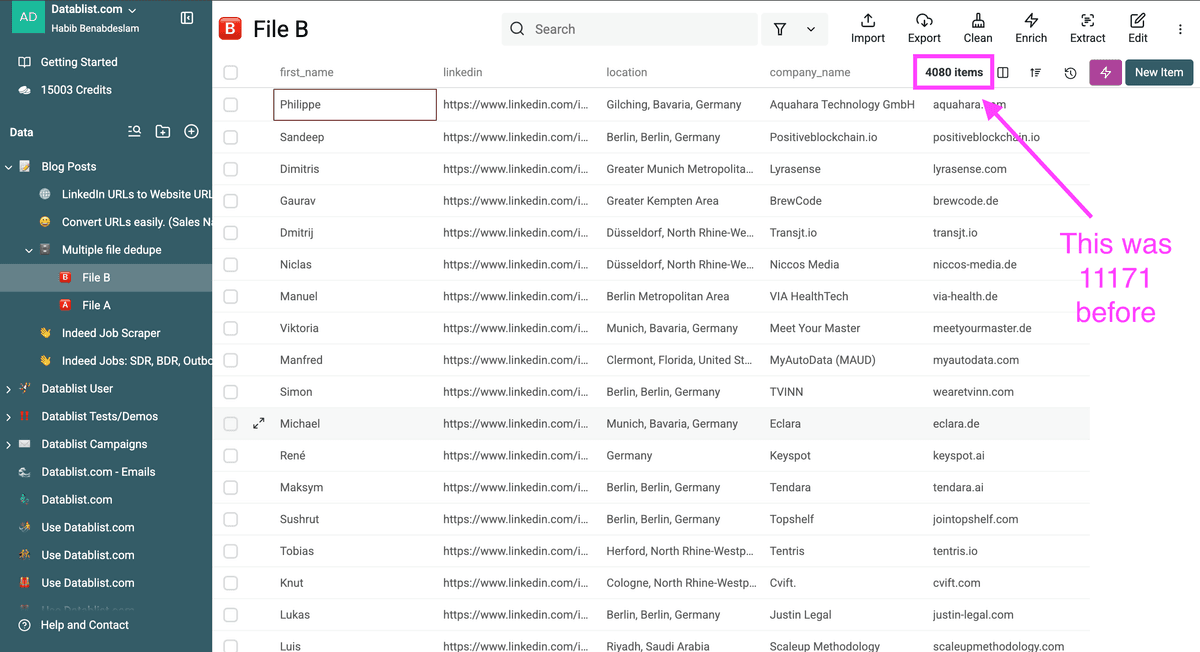
Il mio file pulito ora contiene solo nuovi prospect, senza duplicati.
Importante - Quando fai deduplica su più liste, l'algoritmo non rimuove i duplicati all'interno di un singolo file. Se esistono duplicati dentro un file, inizia eseguendo la deduplica su ciascun file.
Casi d'uso per questo workflow
- Evitare di contattare lo stesso prospect due volte.
- Evitare di contattare più persone della stessa azienda.
- Consolidare i dati dei clienti da vari reparti o sedi.
- Pulire e unire più liste contatti da diverse campagne di vendita.
- Consolidare feedback dei clienti o risposte a survey da più fonti.