

Il Data Matching, noto anche come record linkage o deduplicazione, è il processo di identificare e collegare record correlati tra più dataset. È la “salsa segreta” che trasforma dati grezzi e disordinati in un asset prezioso per marketing, sales o analisi dati.
Gran parte dei tool software disponibili sono complessi e costosi. Datablist è un'applicazione online, compatibile con Mac OS, Microsoft Windows e Linux, per fare Data Matching in modo rapido. Integra exact match, phonetic e avanzati fuzzy matching algorithms.
In questa guida, semplifichiamo le complessità del Data Matching. Che tu sia alle prime armi o un professionista dei dati, qui trovi suggerimenti pratici per migliorare il tuo flusso di lavoro.
Ecco un riepilogo veloce dei punti che troverai nell'articolo:
- Caricare i tuoi dataset
- Preparazione dei dati con Cleaning e Normalization
- Abbina i record nella stessa collection o tra più collections
- Deduplica: rimuovi o unisci i gruppi di match
Inizia a usare il nostro tool di Data Matching online in pochi secondi. Niente call commerciali o slide su PowerPoint.
Step 1: Carica i tuoi dataset
Il primo passo è caricare i tuoi dataset su Datablist. Datablist è un tool online per la gestione di liste. Puoi visualizzare e modificare file CSV e file Excel. È lo strumento ideale per gestire le liste di Lead, pulire i dati dei clienti o ripulire dati scrappati.
Per iniziare, crea una collection e carica il tuo primo dataset.
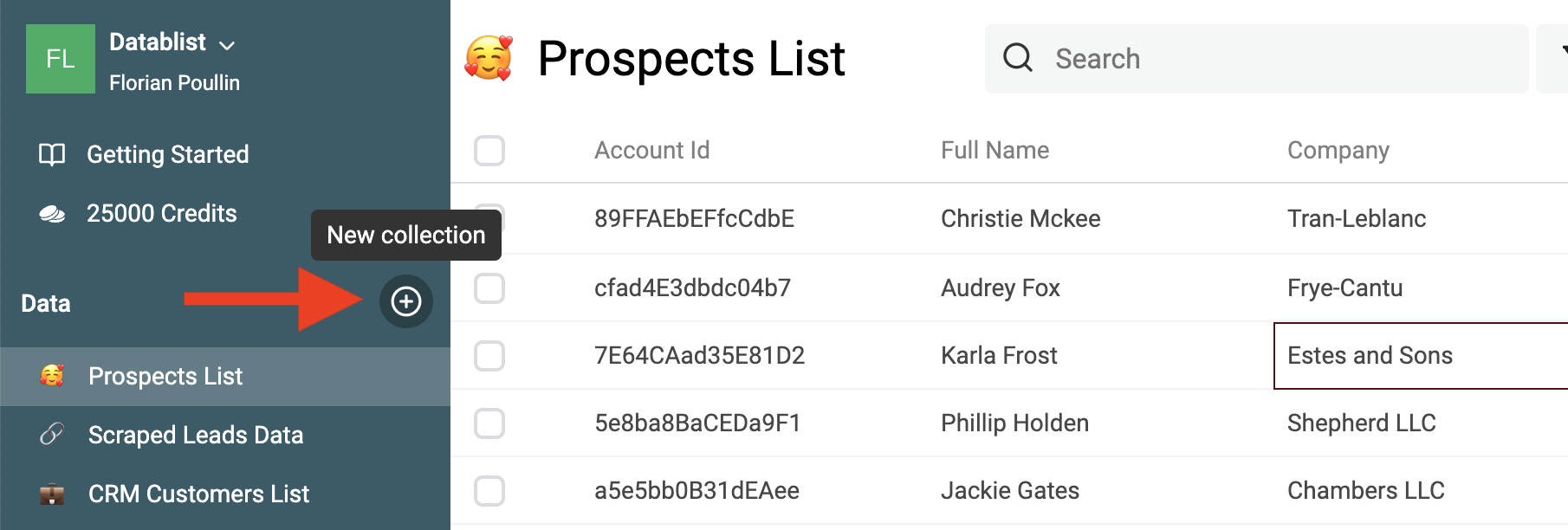
Poi clicca il bottone Import.
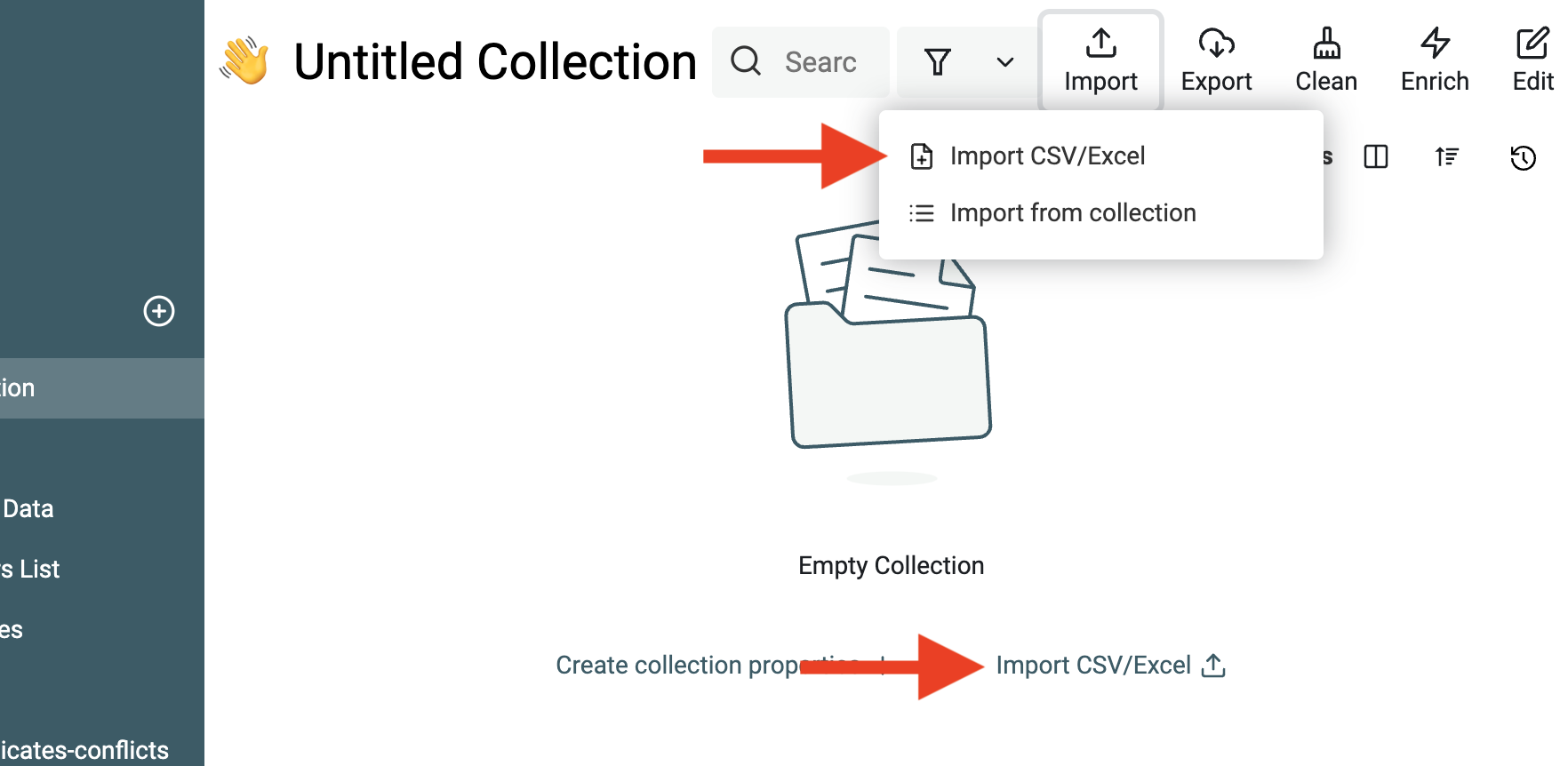
Una volta importato il primo dataset, puoi:
- Importare altri dataset con struttura dati simile nella stessa collection.
- Importare dataset con strutture dati diverse in nuove collections.
Il Duplicates Finder di Datablist trova record corrispondenti all'interno di una singola collection o tra collections con strutture dati diverse.
Step 2: Pulisci i dati se necessario
Il secondo passo è il Data Cleansing. La pulizia dei dati è un prerequisito essenziale per il Data Matching: garantisce accuratezza e affidabilità nel processo. Dati sporchi o incoerenti portano a match errati e risultati poco affidabili. In sintesi, il data cleaning apre la strada a un Data Matching di successo.
Quando compaiono nei nomi (di persone o aziende), alcuni elementi non aggiungono valore e possono impedire all'algoritmo di deduplicazione di rilevare i duplicati.
Datablist include una serie di data-cleaning tools:
- Remove symbols and punctuation - I testi scrappati possono contenere emoji e simboli ASCII, o nomi con punteggiatura. L'algoritmo di matching di Datablist li ignora durante il Data Matching, ma impediranno il merge automatico nella fase di deduplicazione.
- Remove extra spaces - Uno spazio in più tra le parole basta a rendere due stringhe diverse. Gli algoritmi di Datablist pre-processano i testi rimuovendo gli spazi extra, ma anche qui potrebbero impedire il merge automatico nella deduplicazione.
- Extract email addresses, URLs, etc. from texts - Se hai testo non strutturato con email, URL, menzioni, tag, ecc. usa il nostro Data Extractor per estrarre queste entità e strutturare i dati. Il Data Matching è più semplice con entità strutturate da confrontare.
- Remove HTML tags - Un'altra funzione di cleaning è ottenere plain text da stringhe con tag HTML. Così puoi mettere in match liste scrappate con HTML con i tuoi altri dataset.
- Convert text to DateTime, Number, Boolean, etc. - Datablist offre veri tipi di dato con formati nativi per DateTime, Number, Boolean, ecc. Un passaggio importante è convertire il testo grezzo in un formato nativo. DateTime, numeri, ecc. nativi sono cruciali per regole di merge avanzate quando devi scegliere un record master basandoti sul confronto di valori (per esempio la data più recente).
- Change text case to get consistent formatting - La trasformazione del case è semplice ma necessaria. Datablist include diverse trasformazioni del case).
- Split o merge properties - Perfetto per dati multi-valore. Se una proprietà contiene più email separate da virgole/punto e virgola/spazi, lo strumento Split Property creerà più proprietà con una singola email ciascuna.
- Rimuovere o sostituire valori vuoti - Usa le funzioni di Filtering di Datablist per filtrare valori o righe vuote.
Consulta la nostra guida al data cleaning per altri esempi e istruzioni.
Normalizza i nomi delle persone
Lavorare con dataset di persone è comune nella Data Deduplication. Customer, Leads e prospects datasets sono buoni esempi. Nel caso ideale, il matching su persone si basa su identificatori univoci come email o numeri identificativi. Senza questi, o per mettere in match persone tra dataset diversi, dovrai usare i nomi.
Il pre-processing dei nomi garantisce un formato uniforme e riduce gli errori durante la deduplicazione.
Rimuovi il rumore dai nomi
I nomi possono variare molto. Nickname, abbreviazioni, grafie alternative e l'uso di caratteri speciali sono variazioni comuni.
Usa il potente Find & Replace tool per rimuovere prefissi, suffissi, stop-word, indicazioni regionali e altre parole inutili.
Per esempio, per rimuovere i titoli dal nome, puoi usare questa espressione regolare:
^\s*(mr|mrs|dr|miss|ms|sir|madam|m).?\s
E sostituirla con una stringa vuota.
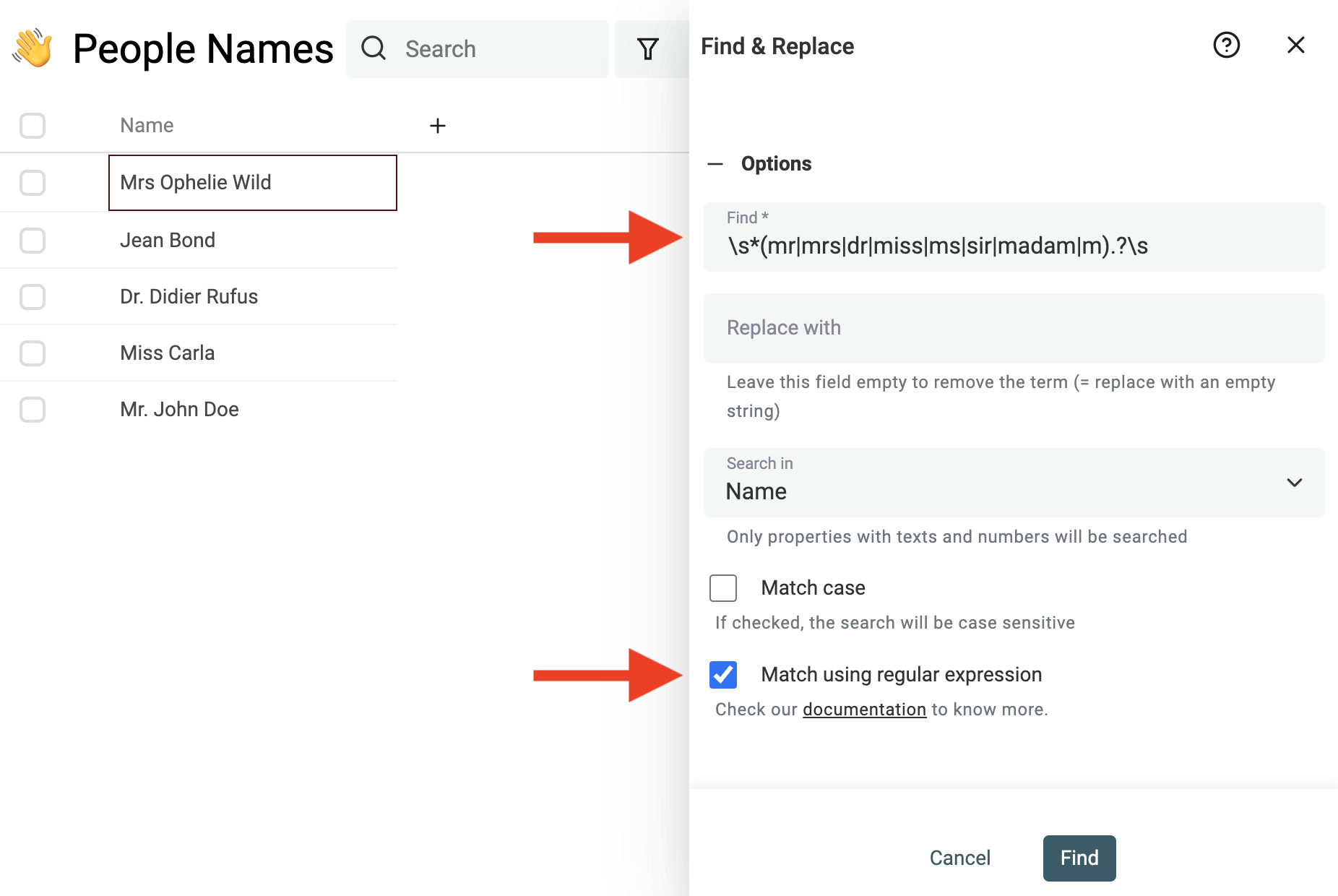
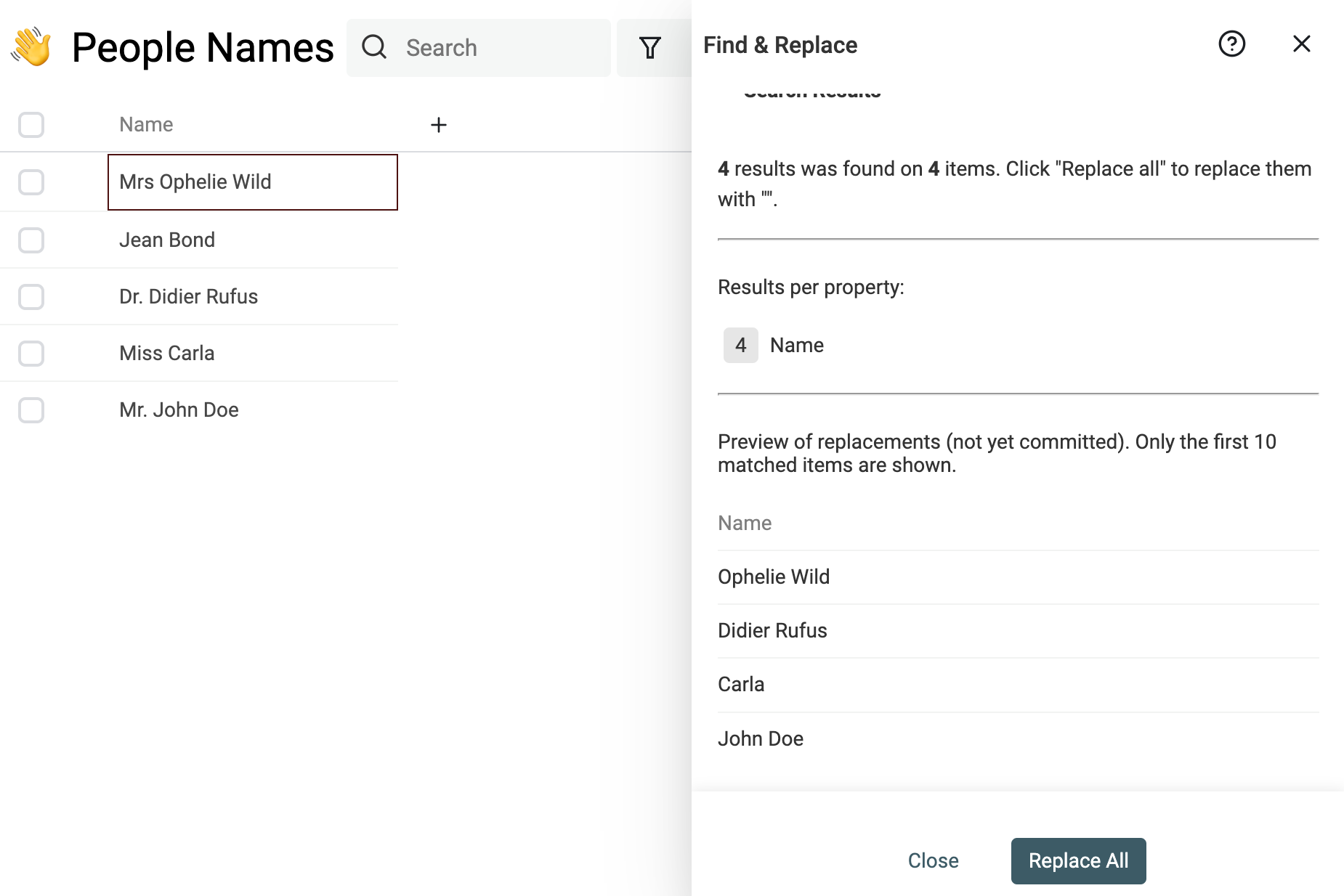
Note Se non hai familiarità con le Regular Expressions, contattaci e ti aiutiamo a pulire i dati.
Scomponi il nome completo in parti
Datablist è più di un semplice strumento di cleaning e offre data enrichment. Esempi di enrichment sono i lead enrichments o traduzioni di CSV con Deepl.
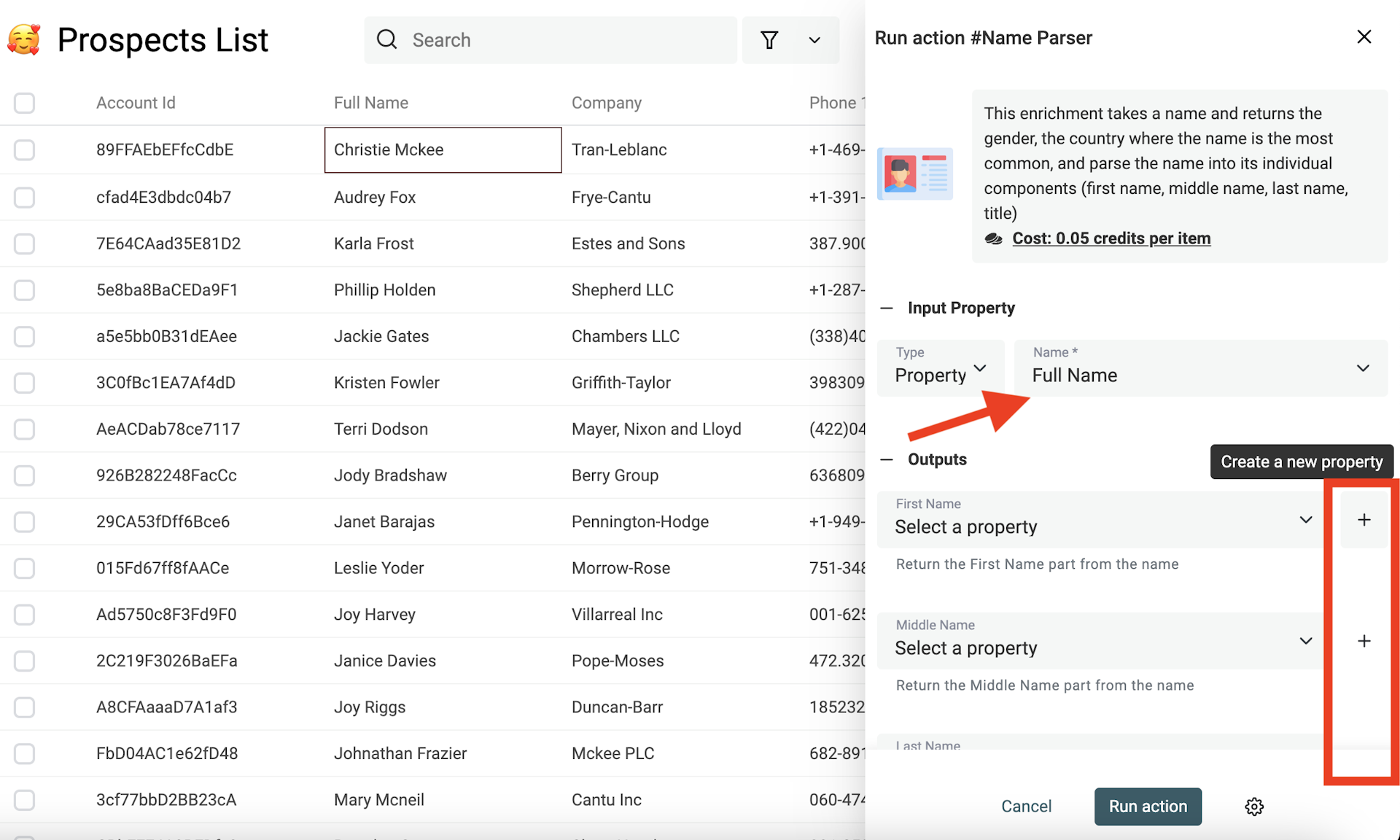
Il Name Parser è un enrichment perfetto per ripulire i nomi delle persone. Prende un nome completo e restituisce le parti: first name, middle name, last name. E propone il gender e il paese più probabili per quel nome.
Usa dati statistici per scomporre i nomi completi.
Per usarlo, apri l'"Enrich Menu" dai pulsanti in alto.
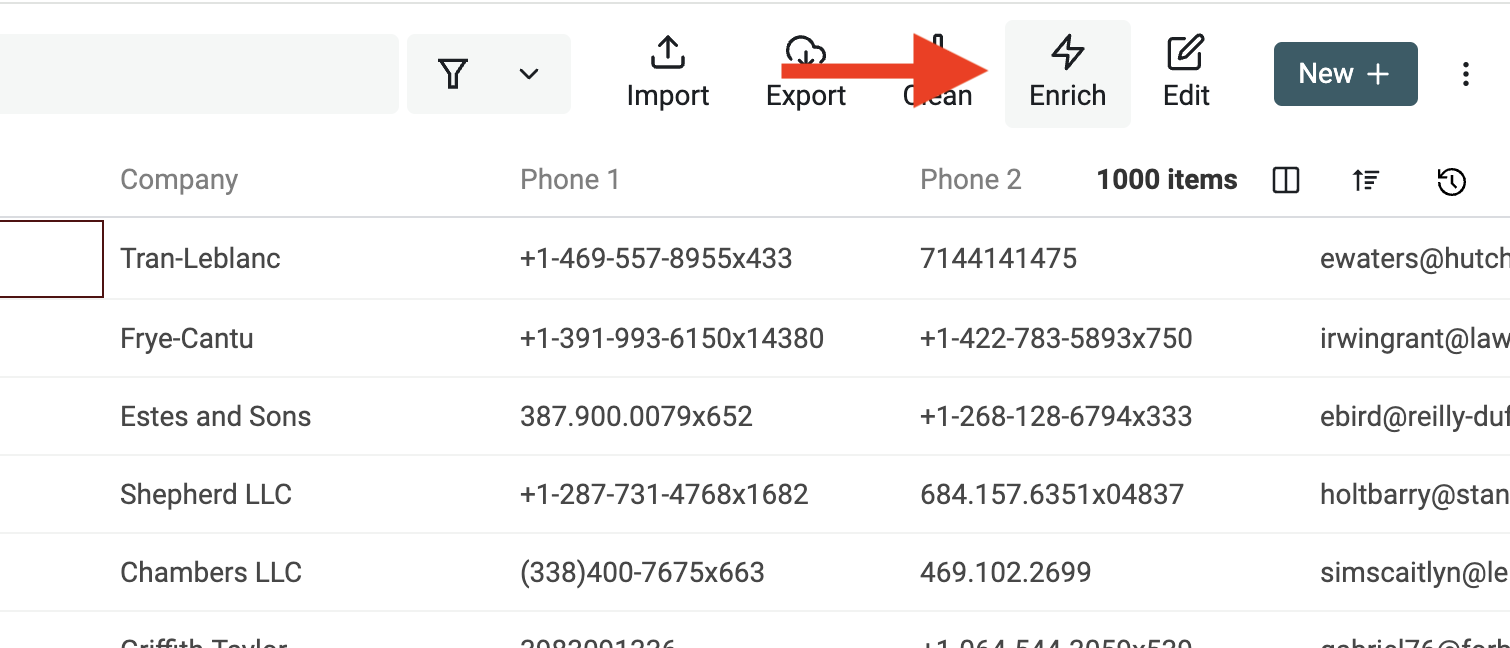
Poi seleziona "Name Parser".

Quindi seleziona la proprietà con i valori del nome e mappa o crea nuove proprietà in cui salvare i risultati del parsing. La proprietà con il nome completo non verrà modificata: solo le proprietà di output saranno aggiornate con i risultati.
Normalizza i nomi delle aziende
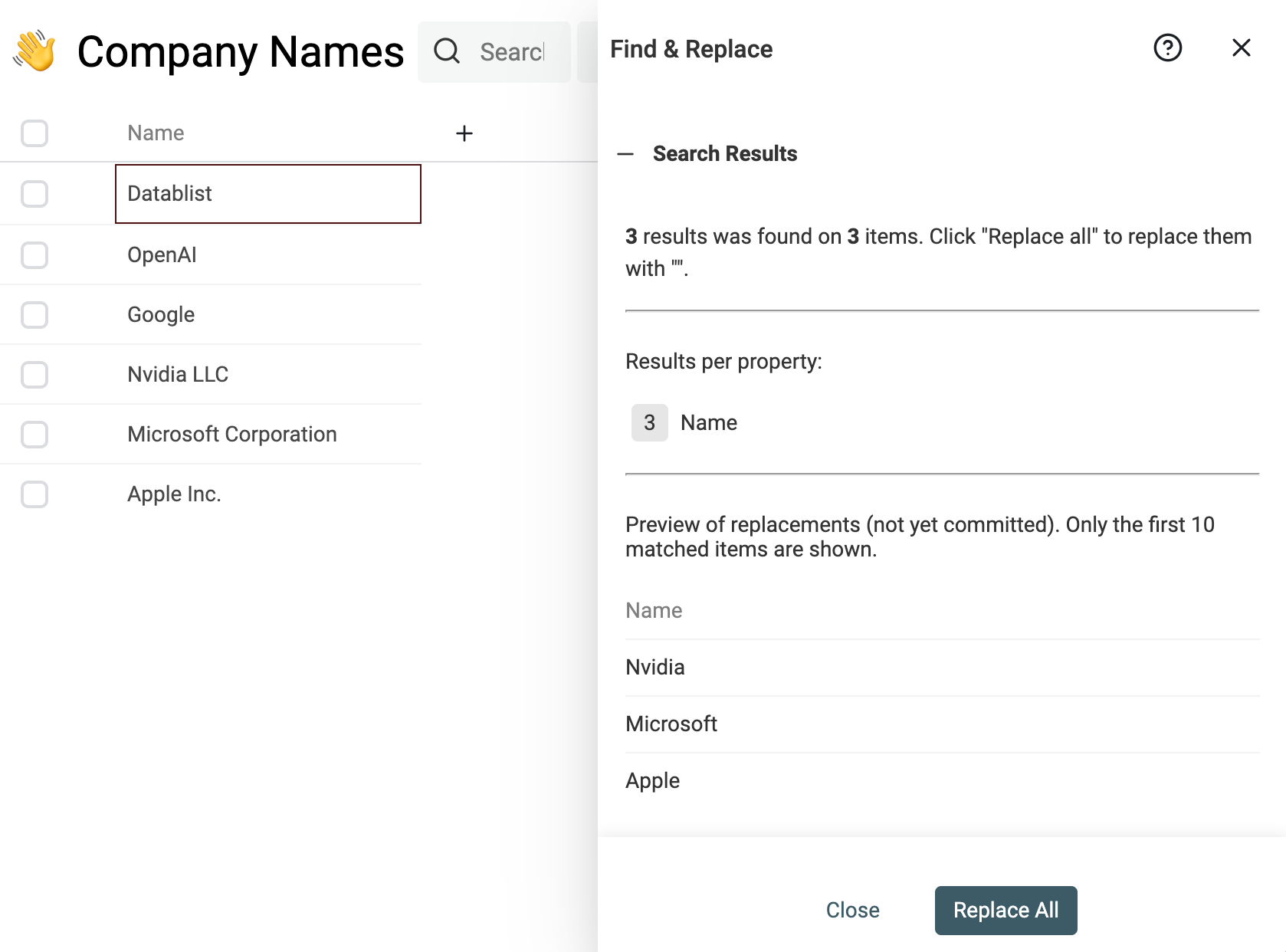
Puoi rimuovere il rumore anche dai nomi delle aziende. Se hai prefissi, suffissi, stop-word, indicazioni regionali o altro che ostacola il matching.
Un esempio è rimuovere suffissi come "Inc." o "GmbH".
Usa questa espressione regolare nel tool Find & Replace:
,?\s(llc|inc|incorporated|corporation|corp|co|gmbh|ltd).?$
E sostituiscila con una stringa vuota.

Normalizzare i nomi aziendali e gli indirizzi su tutti i dataset è importante per portarli a un formato standard.
Normalizza i nomi delle strade
Se stai facendo Data Matching sugli indirizzi postali, la normalizzazione dei nomi delle strade è fondamentale. Gli indirizzi possono essere scritti con abbreviazioni, prefissi direzionali o suffissi numerici. Senza normalizzazione, la stessa strada può apparire più volte in rappresentazioni diverse, complicando il matching.
Per esempio: Main 9 St, Main 9TH St., e Main 9th Street si riferiscono alla stessa via. O Washington Blvd e Washington Boulevard.
Usare algoritmi fuzzy per gestire queste differenze è inefficiente. Servono diverse modifiche di lettere tra Washington Blvd e Washington Boulevard. E la distanza di similarità calcolata con fuzzy-matching algorithms sarebbe alta.
Un modo migliore è normalizzare i nomi delle strade. Un formato coerente garantisce consistenza.
Datablist offre la normalizzazione dei nomi delle strade per formati in inglese. Normalizza abbreviazioni, numeri civici, ecc.
Note
La normalizzazione dei nomi delle strade funziona con indirizzi suddivisi. Le informazioni sulla via devono essere in una proprietà distinta. Valori con indirizzo completo non funzionano.
Clicca su "Normalize Street Names" dal menu "Clean".
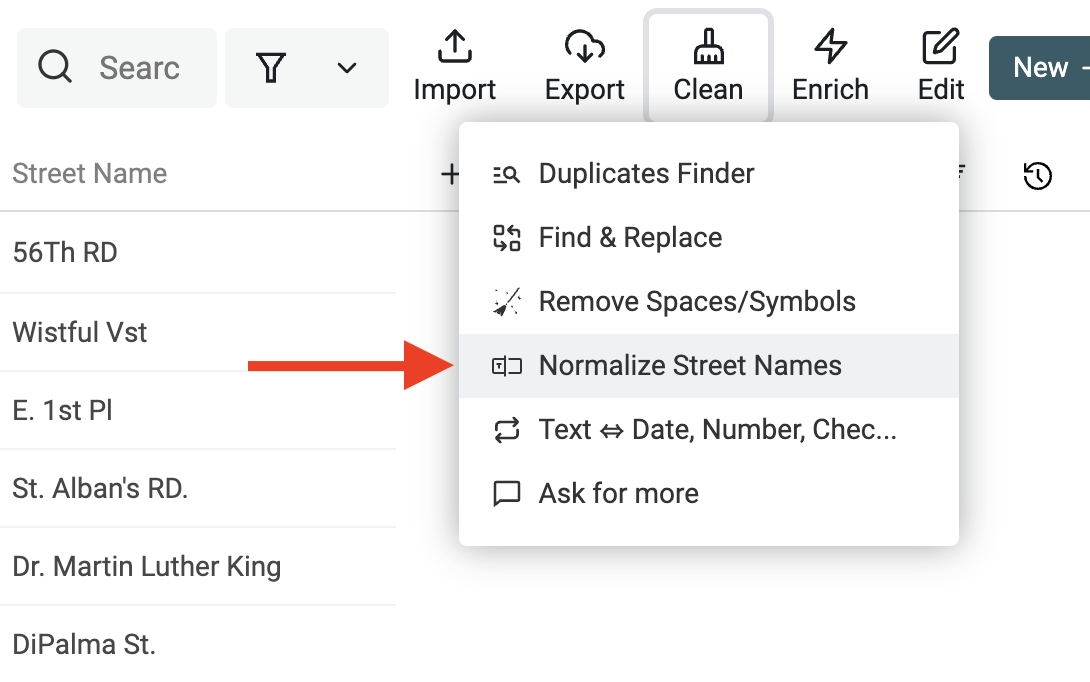
Poi seleziona la proprietà con i nomi delle vie e scegli "Normalize english street names".
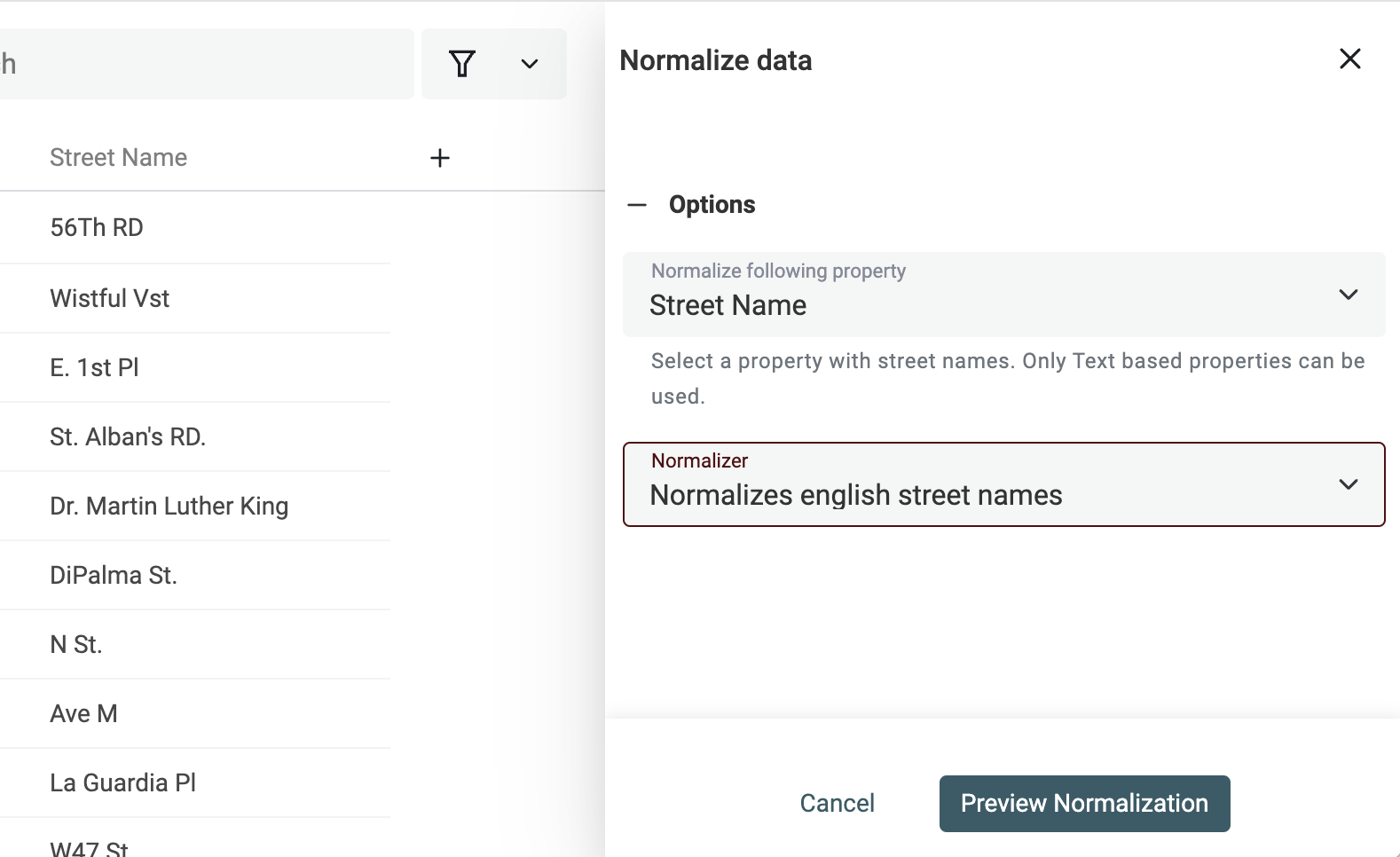
Controlla l'anteprima delle modifiche e clicca "Run".
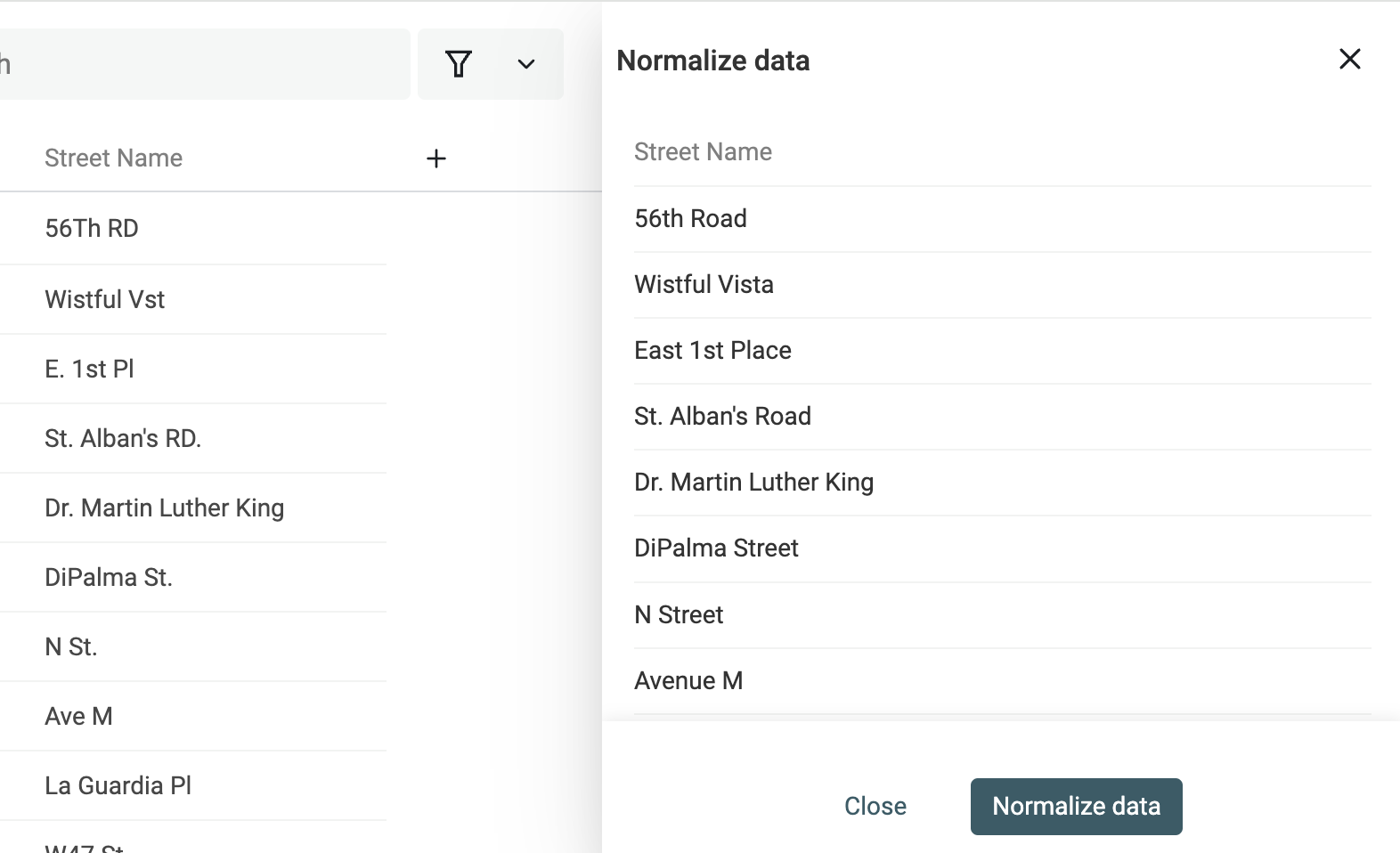
Step 3: Abbina i record nella stessa collection o tra più collections
Ora che i tuoi dati sono puliti e normalizzati, è il momento del Data Matching. In questo step vogliamo raggruppare insieme i record simili.

Datablist ha due modalità per confrontare i record:
- Selected properties comparison - È la modalità più usata. Definisci le proprietà da confrontare. Questa modalità è compatibile con il matching multi-collection.
- All Properties comparison - In questa modalità, il Duplicates Finder identifica e rimuove i record esattamente identici. Devono avere gli stessi dati per le stesse proprietà. Se una proprietà è vuota, i record non verranno messi in match.
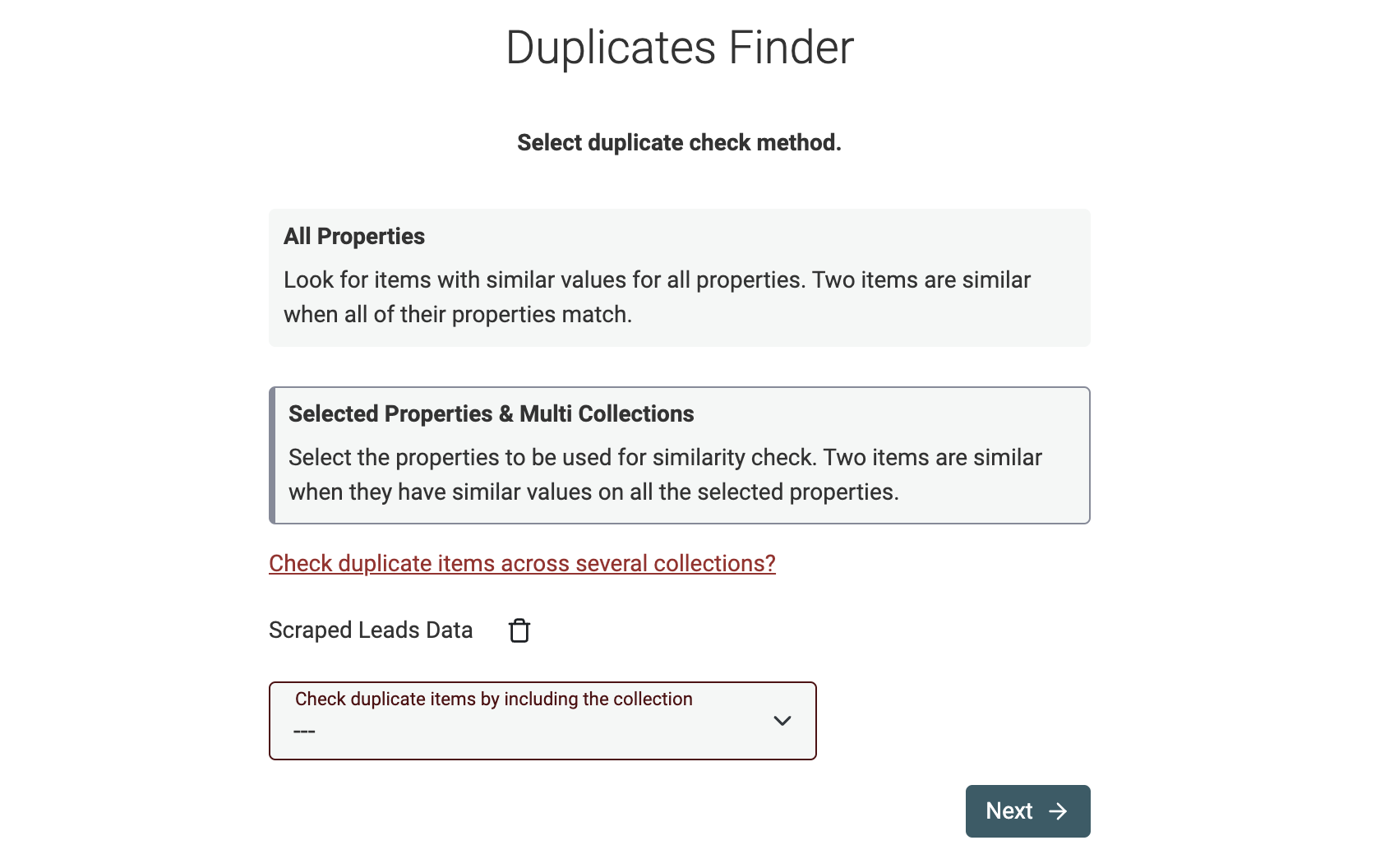
Seleziona le proprietà da confrontare
Per il resto della guida useremo la modalità "Selected Properties & Multi Collections".
Il passo successivo è selezionare le proprietà da usare per il Data Matching. Se nel passo precedente hai selezionato più collections, ti verrà chiesto di scegliere una proprietà di mapping per ciascuna collection.
Note
Datablist proverà a mappare automaticamente le proprietà tra le collections usando il loro nome.
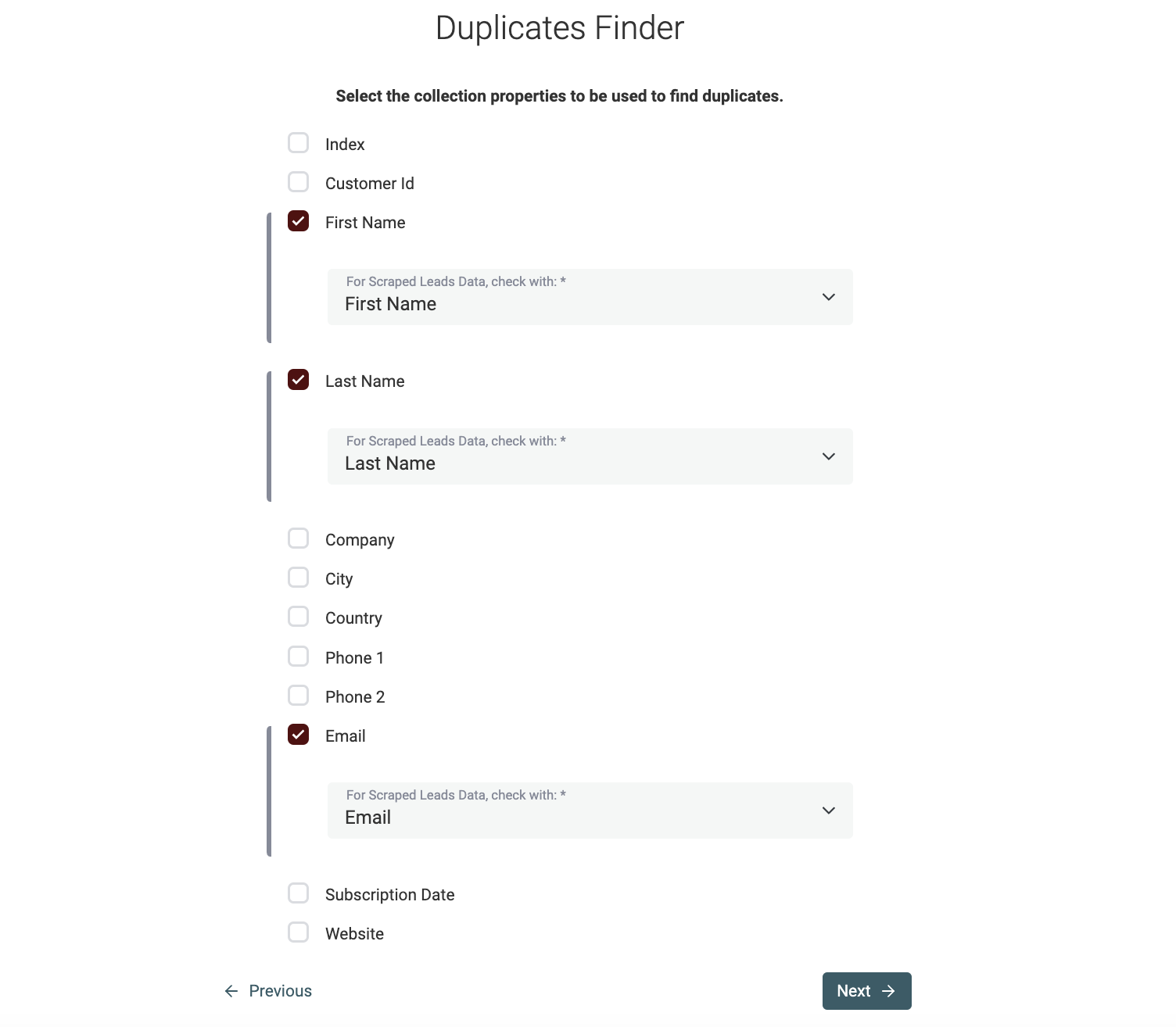
Scegli l'algoritmo di matching
Nel passo seguente, le proprietà selezionate vengono elencate e devi configurare gli algoritmi di confronto.
Datablist implementa i seguenti algoritmi di matching:
-
Exact - L'algoritmo exact è consigliato per proprietà non testuali come DateTime, Number, Boolean, ecc. Sulle proprietà testuali, un'opzione ti permette di decidere se il confronto deve essere case-sensitive. L'algoritmo exact rimuove gli spazi iniziali e finali dai testi.
-
Smart - L'algoritmo smart pre-processa gli elementi per mettere in match dati con leggere variazioni. Mette in match URL con protocolli diversi. Gestisce anche ordine delle parole e punteggiatura. "John-Doe" e "Doe John" verranno messi in match.
-
Phonetic con algoritmo Double Metaphone - Datablist implementa l'algoritmo Double Metaphone per il matching fonetico. Converte le parole in codici che rappresentano la pronuncia. Due parole con suono simile otterranno lo stesso codice Double Metaphone.
-
Fuzzy matching con algoritmi di distanza - Datablist implementa anche il fuzzy matching con le distanze Jaro-Winkler e Levenshtein. Quando selezionati, devi impostare una soglia di similarità. Più alta è la soglia, minore è la variazione consentita.
Consulta la documentazione per maggiori dettagli sugli algoritmi.
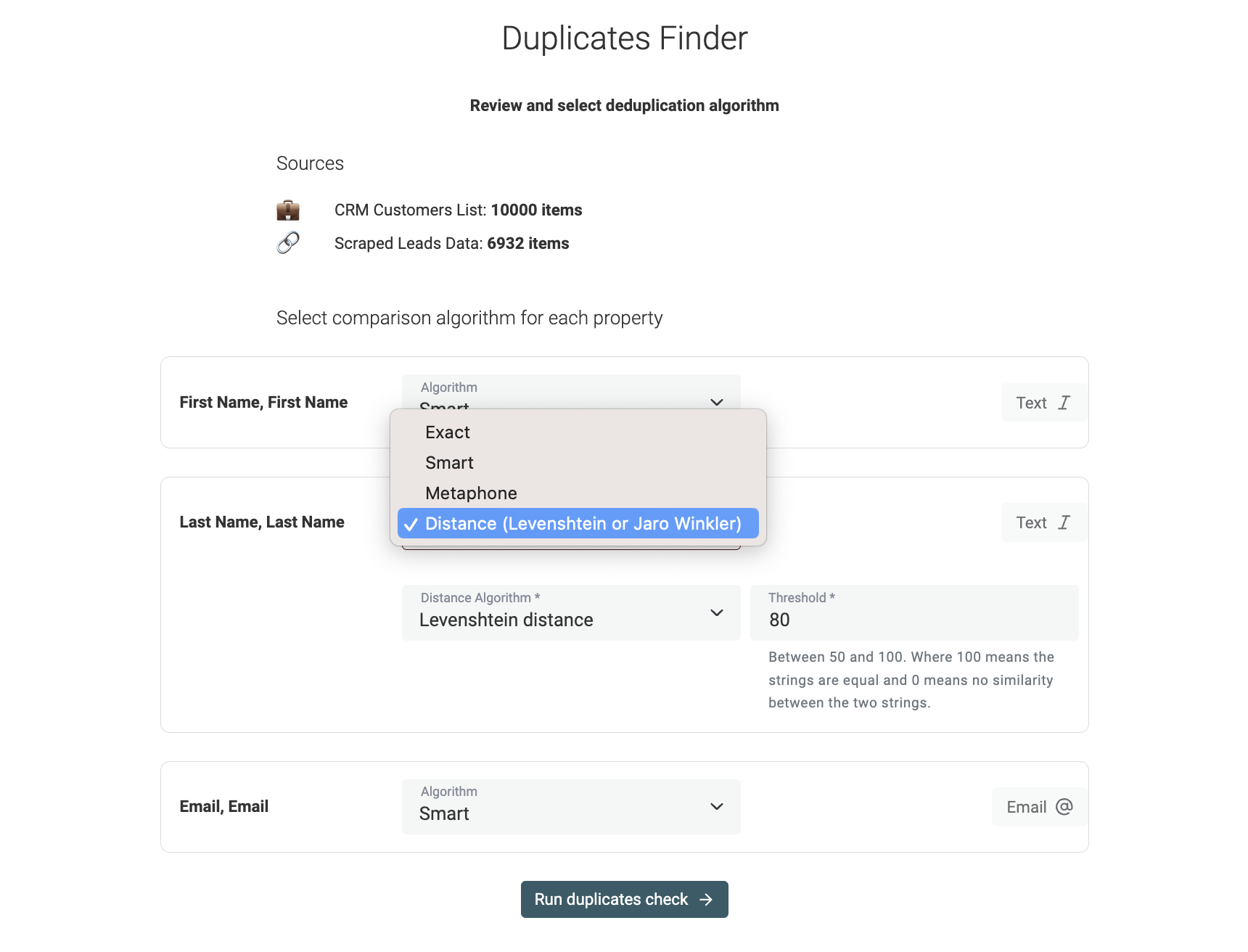
Note
- Gli algoritmi Smart, Phonetic e fuzzy si applicano solo a proprietà testuali (inclusi Email, Text, LongText).
- Le proprietà URL sono compatibili solo con gli algoritmi Exact e Smart.
Step 4: Deduplica: rimuovi o unisci i gruppi di match
Il Duplicates Finder di Datablist restituisce in pochi secondi l'elenco dei gruppi di duplicati.
Unione automatica per deduplicazione su singola collection
Il Data Matching tool di Datablist offre un algoritmo avanzato per unire i duplicati. Sono disponibili due modalità di merge dei doppioni:
- Non-conflicting items merging. (vedi sotto)
- Merge con conflitti usando concatenazione o scarto valori (vedi sotto)
Note:
Questa funzionalità è disponibile solo nella deduplicazione su singola collection. Con deduplicazioni multi-collection, la struttura dati può essere diversa tra le collections.
Auto-Merging senza conflitti di dati
Datablist trova automaticamente tutti i duplicati che possono essere uniti senza perdita di informazioni.
Funziona così:
- Se tutti i duplicati hanno gli stessi valori di proprietà, verrà mantenuto un solo item e gli altri saranno eliminati.
- Se gli item duplicati sono complementari, l'item con più informazioni verrà selezionato come Primary Item e i suoi valori verranno completati usando le proprietà degli altri item. Poi tutti gli item tranne il Primary Item verranno eliminati.
- Se gli item duplicati hanno valori in conflitto su qualche proprietà, gli item verranno saltati per un merge manuale.
Auto-Merging con risoluzione dei conflitti
Durante l'Auto-Merging, il Duplicates Finder rileva automaticamente le proprietà in conflitto. C'è conflitto quando due item hanno valori diversi sulla stessa proprietà. Per poterli unire, devi scegliere tra due opzioni:
- Combine properties values - L'opzione combine consente di concatenare i valori con un delimitatore. Ad esempio, se esistono due valori "Phone" diversi per lo stesso record, puoi concatenarli usando un punto e virgola. Perfetto per email, numeri di telefono, note, ecc.
- Drop properties values - Per proprietà non testuali è possibile mantenere un solo valore e scartare quello in conflitto. Per esempio, con due valori DateTime non è possibile concatenarli: devi sceglierne uno. Utile anche con identificativi esterni. Se stai pulendo i dati per il tuo CRM, l'external account ID deve identificare un record univoco e non può essere una stringa concatenata.
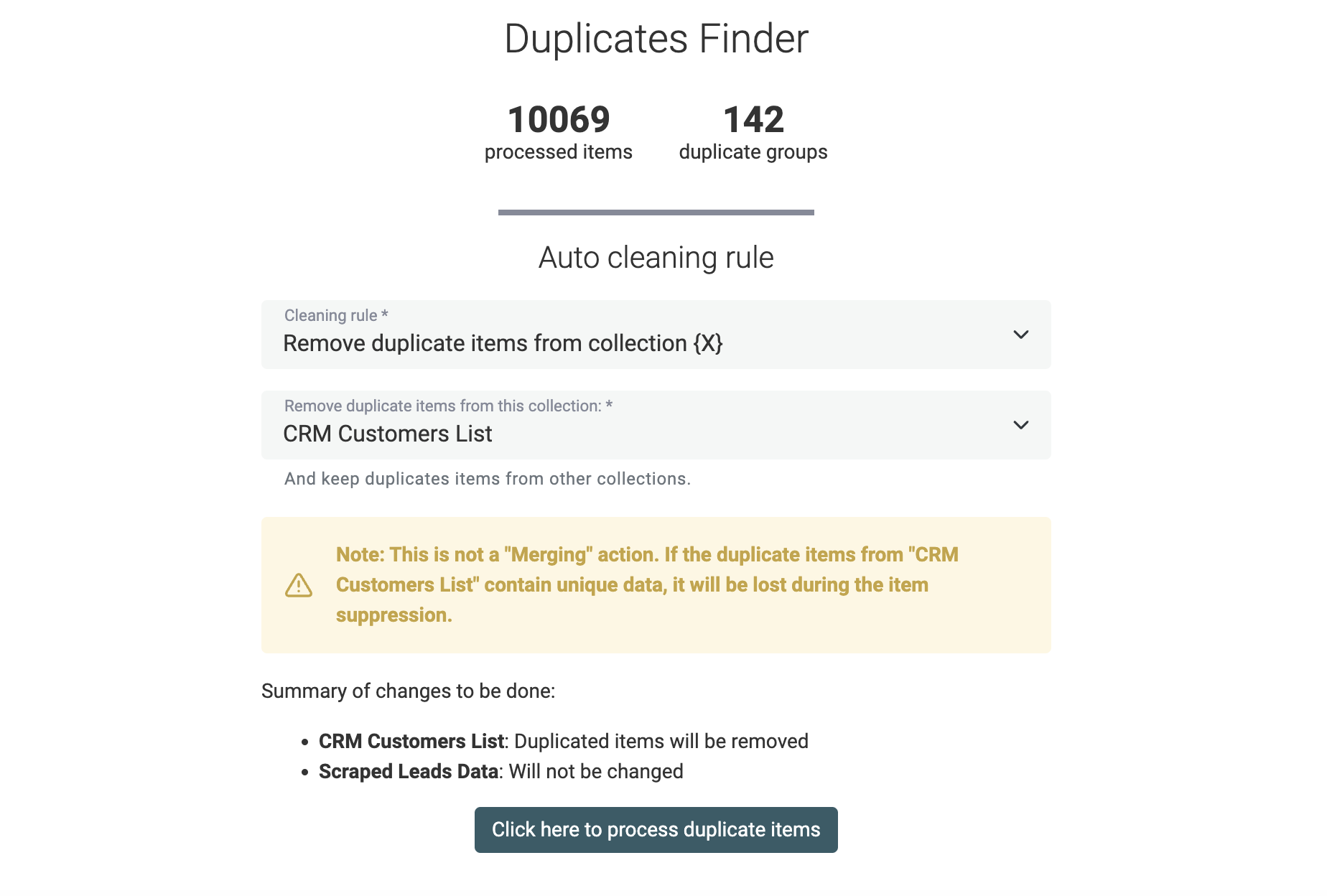
Regole di cleaning per il Data Matching multi-collection
Quando esegui il Data Matching su più dataset, l'auto-merging non è disponibile. Le tue collections possono avere strutture dati diverse con proprietà differenti.
In alternativa, Datablist offre una funzione di cleaning per rimuovere i duplicati in tutte le collections tranne una. Usa questo strumento per garantire l'unicità degli item tra i tuoi dataset.
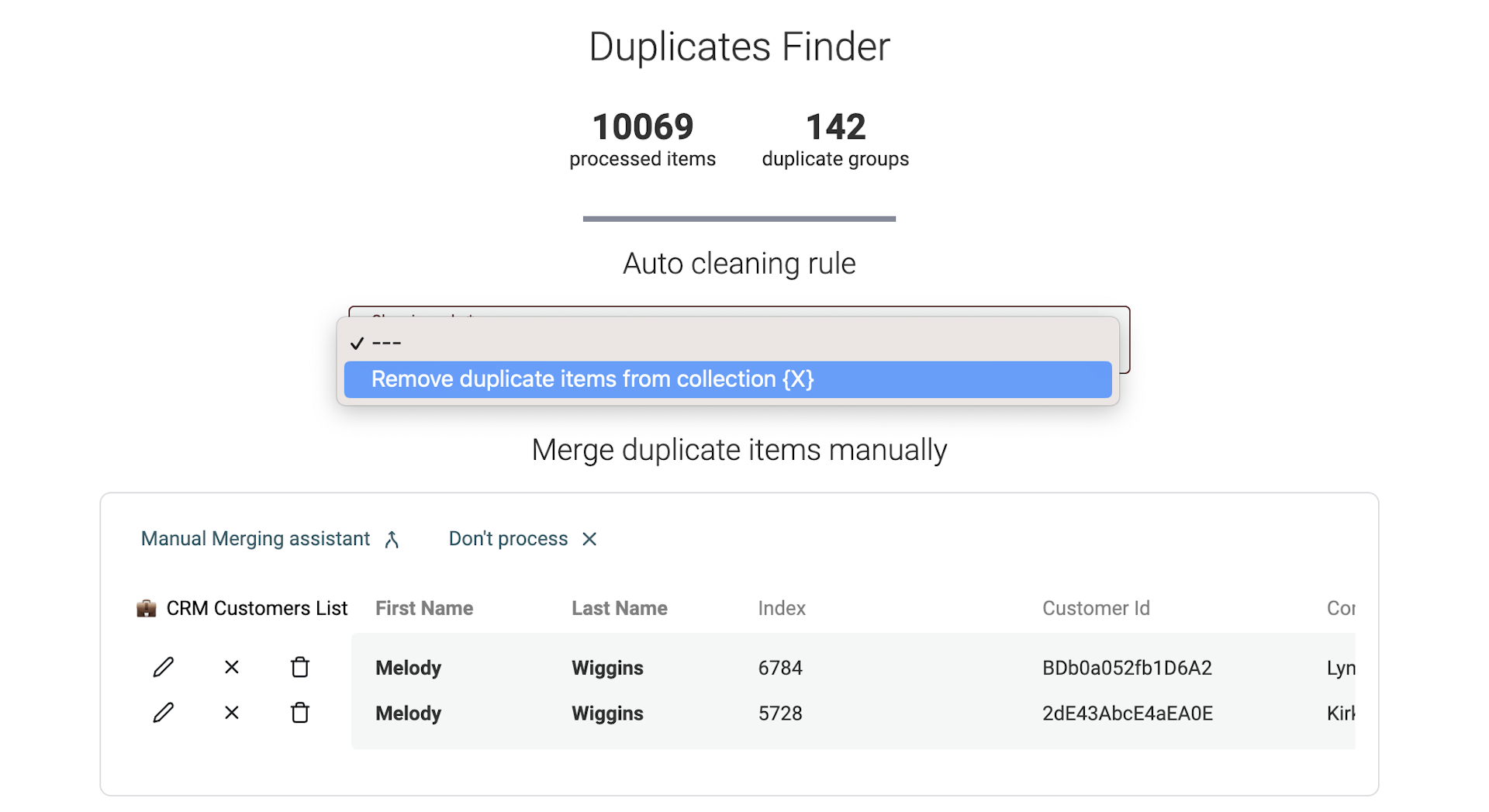
Viene mostrata un'anteprima delle modifiche prima di avviare l'algoritmo di cleaning.
Unione manuale con il Merging Assistant
Per i duplicati restanti è disponibile un assistente per il merge manuale.
Per unire i duplicati, clicca sul pulsante "Manual Merging Assistant" a sinistra di ogni gruppo di duplicati.
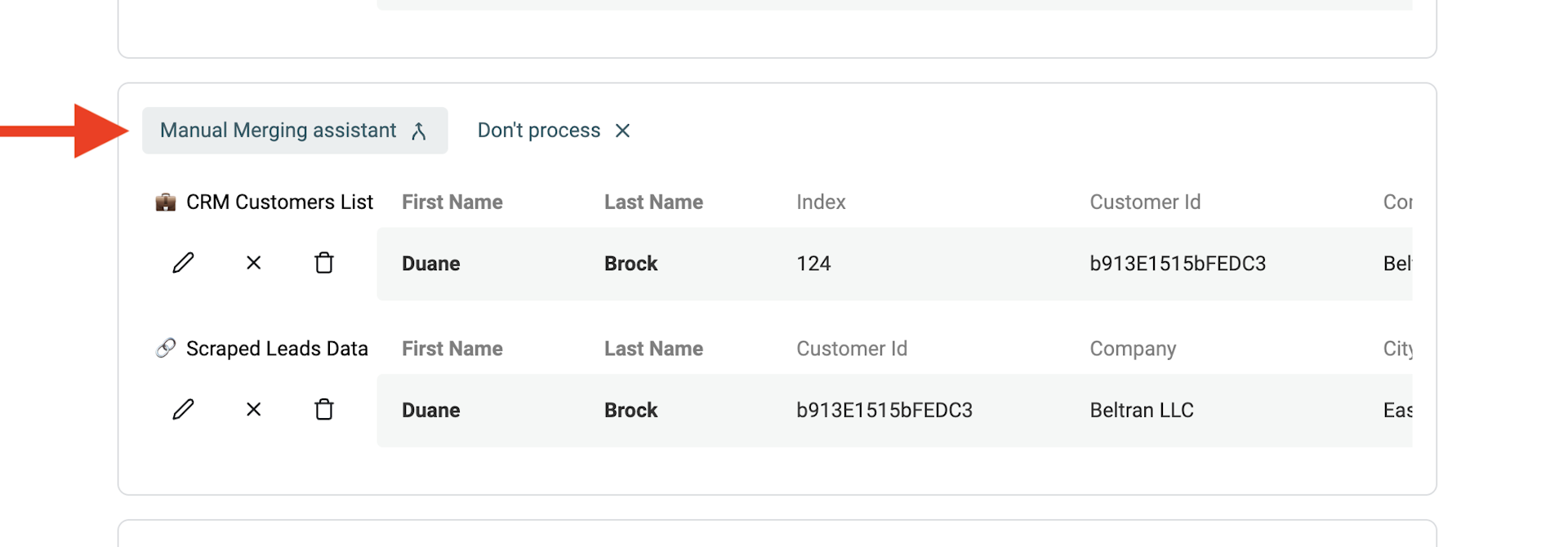
Si apre lo strumento di merge. A destra è mostrato il "Primary Item" e a sinistra i duplicati rimanenti, detti "Secondary Items". Datablist elegge come "Primary item" quello con più dati.
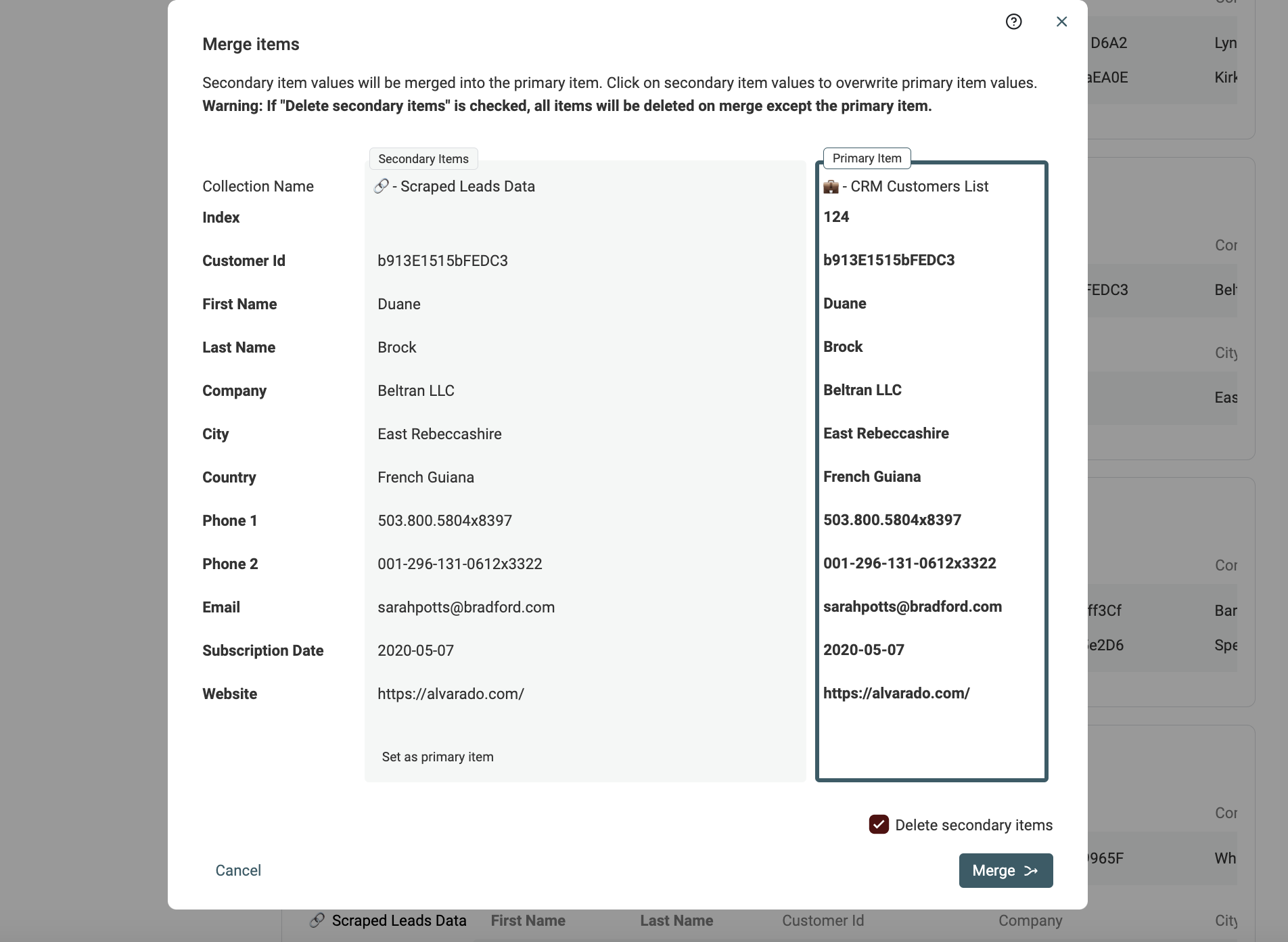
Quando possibile, i valori delle proprietà dei secondary items sono selezionati automaticamente per essere fusi nel primary item. Se alcuni valori sono in conflitto, dovrai decidere quale mantenere.
Se il "Primary item" risultante ti soddisfa, clicca il pulsante Merge per confermare. Tutti i secondary items verranno eliminati mantenendo un solo item combinato.
Note Il Merging Assistant è disponibile in multi-collection se le collections hanno una struttura dati simile (stesse proprietà).
Scarica i gruppi duplicati per unirli con uno strumento esterno
Infine, il Data Matching tool di Datablist permette l'export dei gruppi di duplicati rilevati. Puoi esportare un file CSV o Excel con tutti i duplicati elencati consecutivamente.
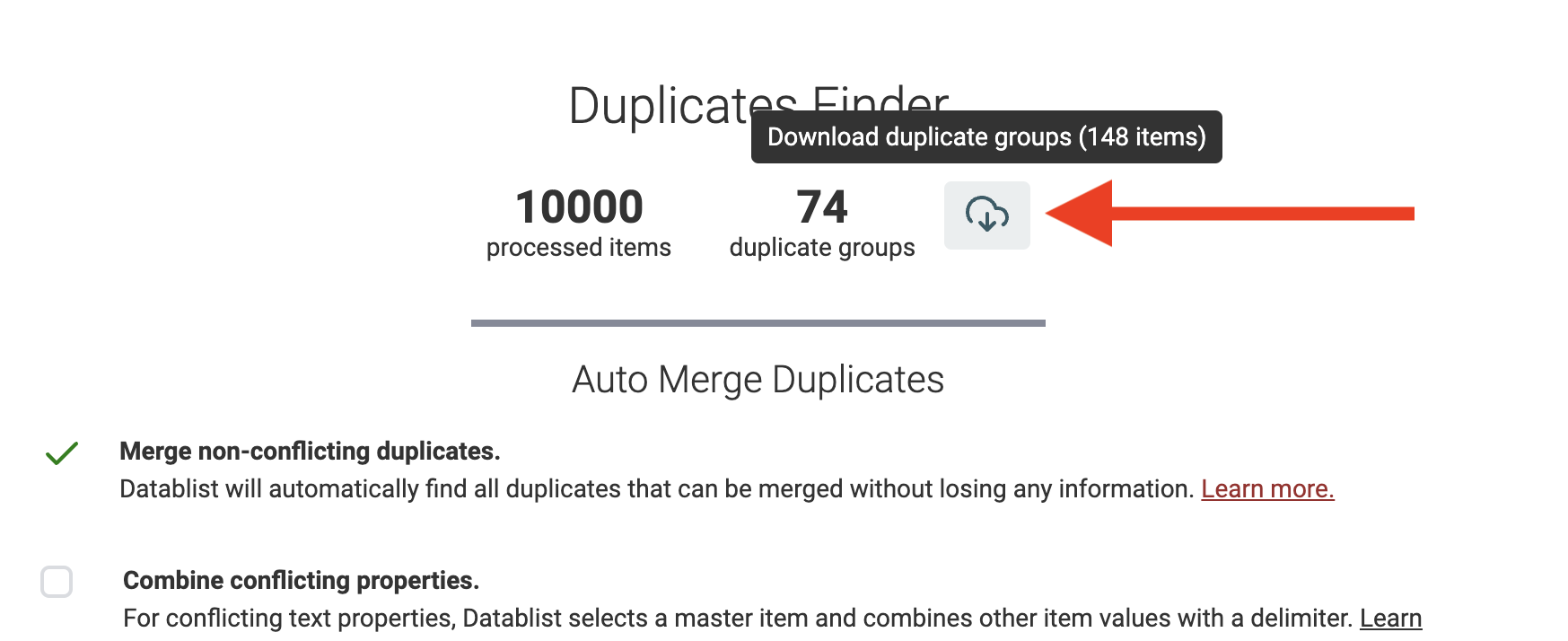
Usa l'export per ripulire i record con un altro strumento (ad esempio un foglio di calcolo) o per analisi più complesse.
FAQ
Che cos'è il Data Matching?
Il Data Matching, noto anche come record linkage o deduplicazione, è il processo di identificare e collegare record correlati all'interno o tra dataset diversi. L'obiettivo è migliorare qualità, accuratezza e coerenza dei dati riconoscendo e consolidando voci duplicate o simili che rappresentano le stesse entità, persone o oggetti.
È utile per ripulire dataset in cui, nel tempo, si accumulano duplicati oppure per combinare più dataset con campi simili o sovrapposti.
Il Data Matching può usare campi discriminanti come email, URL del sito o stringhe/numeri identificativi. Oppure una combinazione di attributi non unici (come nome, data di nascita, nome azienda o località) per generare uno score di similarità tra record.
Quanto è veloce il tool di Data Matching di Datablist?
Il Data Matching tool di Datablist carica i dataset in memoria per effettuare l'analisi. È adatto a dataset fino a 1 milione di record e completa la maggior parte delle analisi di matching in pochi minuti.
Servono competenze tecniche per fare Data Matching?
No. Datablist è una soluzione no-code pensata per tutti: da data analyst a team marketing o sales.
Quando usare il Data Matching?
Il Data Matching ha applicazioni diffuse in vari ambiti, tra cui finance, healthcare, marketing e customer management, dove servono dati affidabili per decisioni informate o per integrazione con altri tool.
Questo processo facilita attività come rilevamento frodi, consolidamento dei profili utente e data enrichment da più fonti.
Cosa leggere dopo?
Se ti interessa il data cleansing, potrebbero piacerti queste guide: