

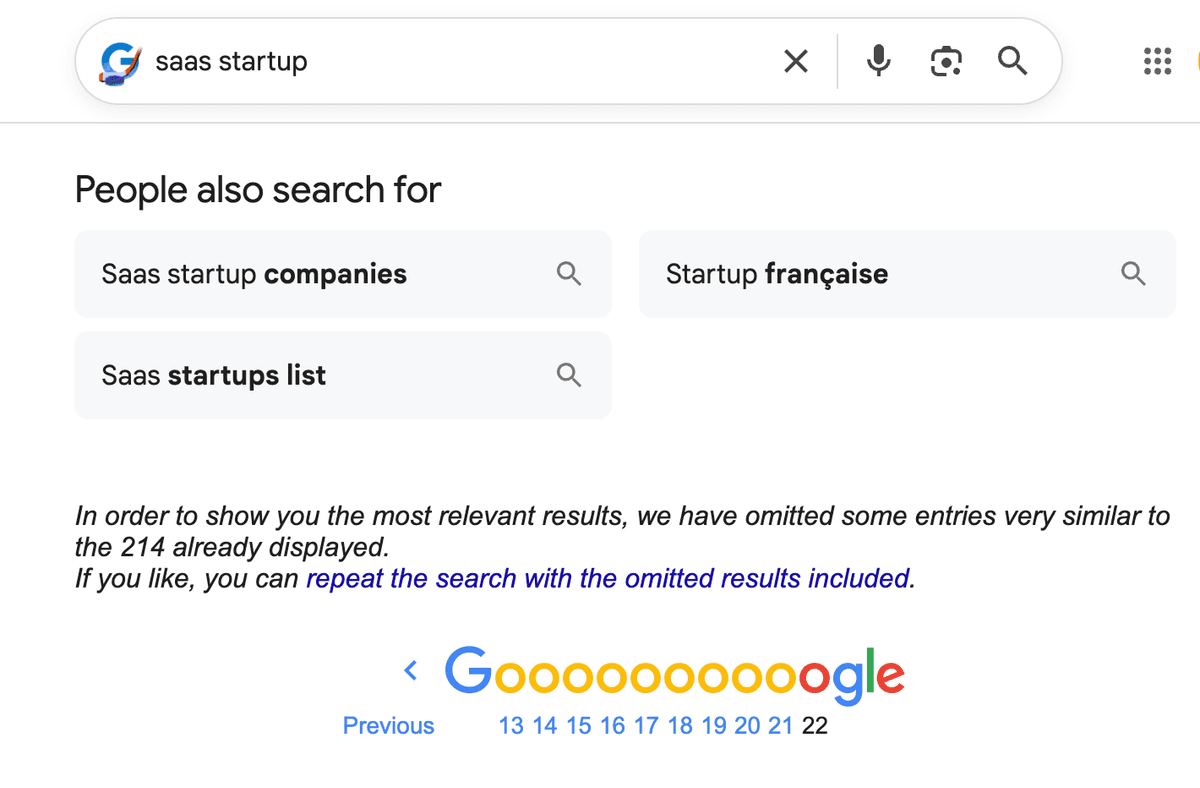
Fare scraping dei risultati Google è uno dei modi più convenienti per costruire una lista di lead. Ma quasi tutti si scontrano presto con lo stesso limite: Google smette di mostrare risultati dopo i primi 250 o 300 elementi.
Anche se ci sono milioni di pagine pertinenti alla tua ricerca, andando avanti trovi semplicemente pagine vuote.
Datablist risolve questo limite con la source "Start with Google Search Queries".
Invece di lanciare una sola ricerca e ottenere appena 200 risultati, puoi eseguire decine o centinaia di varianti in una volta sola.
Puoi ottenere circa 4.000 risultati con appena $1.
In questa guida vedrai come automatizzare il processo per estrarre migliaia di risultati di alta qualità senza scrivere neanche una riga di codice.
📌 Esempi di casi d’uso
- Creare una lista di lead con profili LinkedIn
- Cercare profili Instagram con parole chiave
- Targettizzare aziende in base a specifiche tecnologie web
- Costruire database di aziende locali su centinaia di città
Link rapidi alle sezioni:
- Capire il limite dei 300 risultati
- La strategia multi-query & usare l’AI per creare varianti delle query
- Guida passo passo allo scraping Google con Datablist
- Pulire e deduplicare i dati
- Arricchire i risultati di ricerca
- Analisi dei costi: scraping low budget
Capire il limite dei 300 risultati
Google ottimizza il suo motore di ricerca per la navigazione umana. La maggior parte delle persone trova ciò che cerca già nella prima pagina.
Per Google non ha senso mostrare migliaia di risultati a un singolo utente, anche per limitare gli abusi di scraping.
Se provi ad arrivare fino a pagina 40, spesso compare un messaggio che dice che Google ha omesso risultati simili, oppure le pagine risultano direttamente vuote.
Per la lead generation, questo è un grosso problema. Se cerchi "avvocato Italia" potresti trovare 250 prospect interessanti. Ma migliaia di altri restano invisibili perché si trovano tra la posizione 301 e la 10.000. Con una keyword troppo generica, semplicemente non ci arrivi.
L’unico modo per accedere a questi risultati nascosti è rendere la ricerca più specifica. Restringendo il campo, costringi Google a mostrarti i primi 300 risultati di una nicchia più piccola. Se ripeti questo processo su decine di nicchie, alla fine ricostruisci praticamente l’intera lista.
La strategia multi-query
Lo scraping multi-query consiste nel suddividere una ricerca ampia in tante query più piccole e parzialmente sovrapposte. Invece di cercare "avvocati in Italia", cerchi "avvocati Milano", "avvocati Roma", "avvocati Napoli", "avvocati Torino" e "avvocati Bologna".
Ogni ricerca su una città specifica restituisce un nuovo set di 200-300 risultati. Se fai ricerche sulle 50 città principali in Italia, puoi arrivare a raccogliere fino a 15.000 risultati. Ci sarà qualche sovrapposizione (uno studio legale potrebbe comparire per due città vicine), ma i risultati unici saranno comunque molti di più rispetto a una sola query generica.
Questa strategia funziona perché cambia l’"intent" della ricerca dal punto di vista di Google. Usando varianti geografiche o altri schemi di variazione, sposti i prospect dalla posizione 5.000 di una ricerca ampia alla posizione 1 di una ricerca più specifica.
Usare l’AI per creare varianti delle query
Creare a mano 100 varianti di una query richiede tempo. Ma i moderni LLM come ChatGPT, Gemini o Claude possono farlo in pochi secondi. Basta fornire un prompt e l’AI restituisce una lista di query ben formattata, pronta da usare.
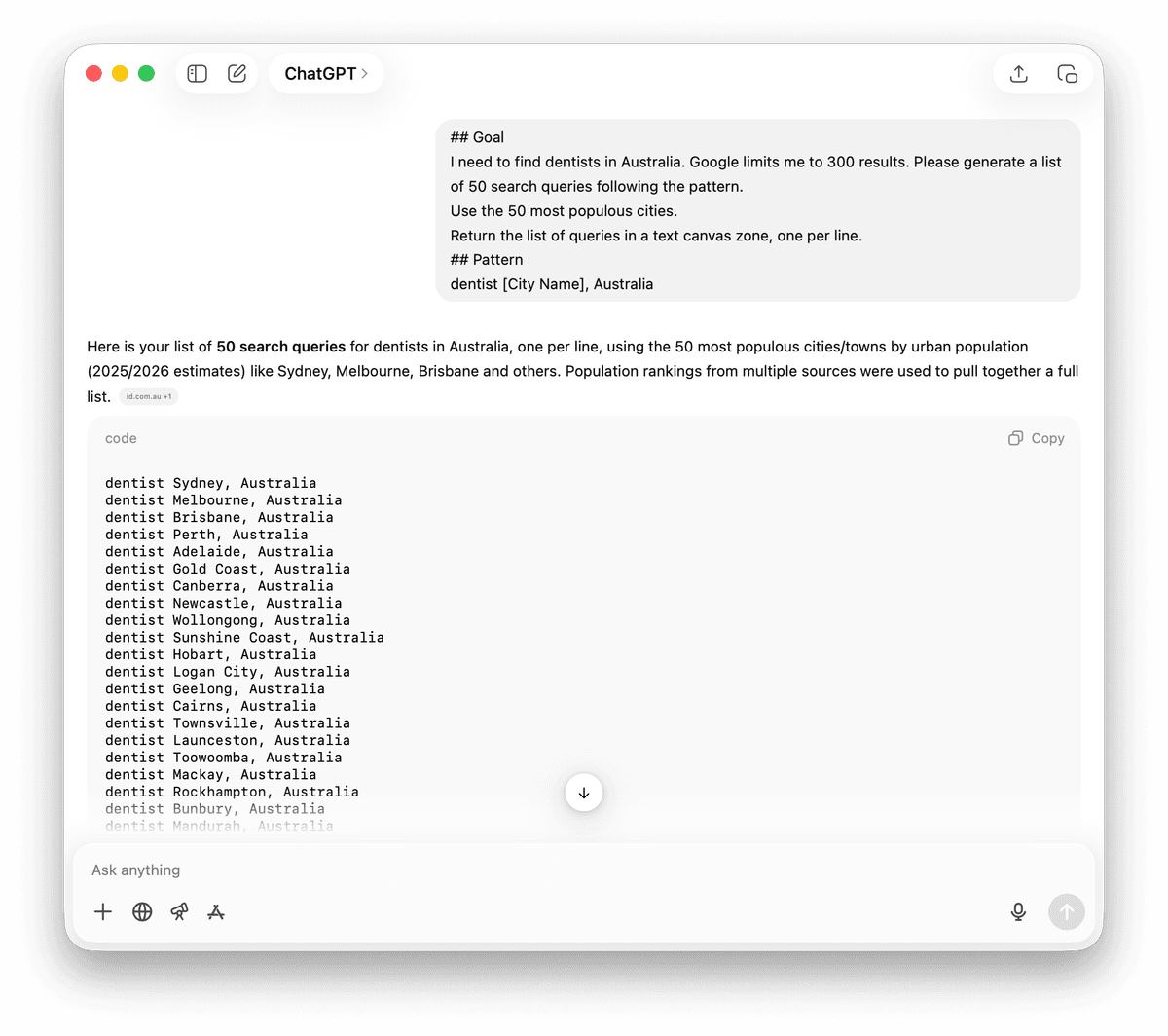
La strategia geografica
La localizzazione è il modo più semplice per moltiplicare i risultati. Ogni Paese ha elenchi di città, regioni o province.
Devo trovare dentisti in Italia. Google mi limita a 300 risultati. Genera un elenco di 50 query di ricerca seguendo questo pattern.
Usa le 50 città più popolose.
Restituisci la lista delle query in un'area di testo, una per riga.
## Pattern
dentista [Nome Città], Italia
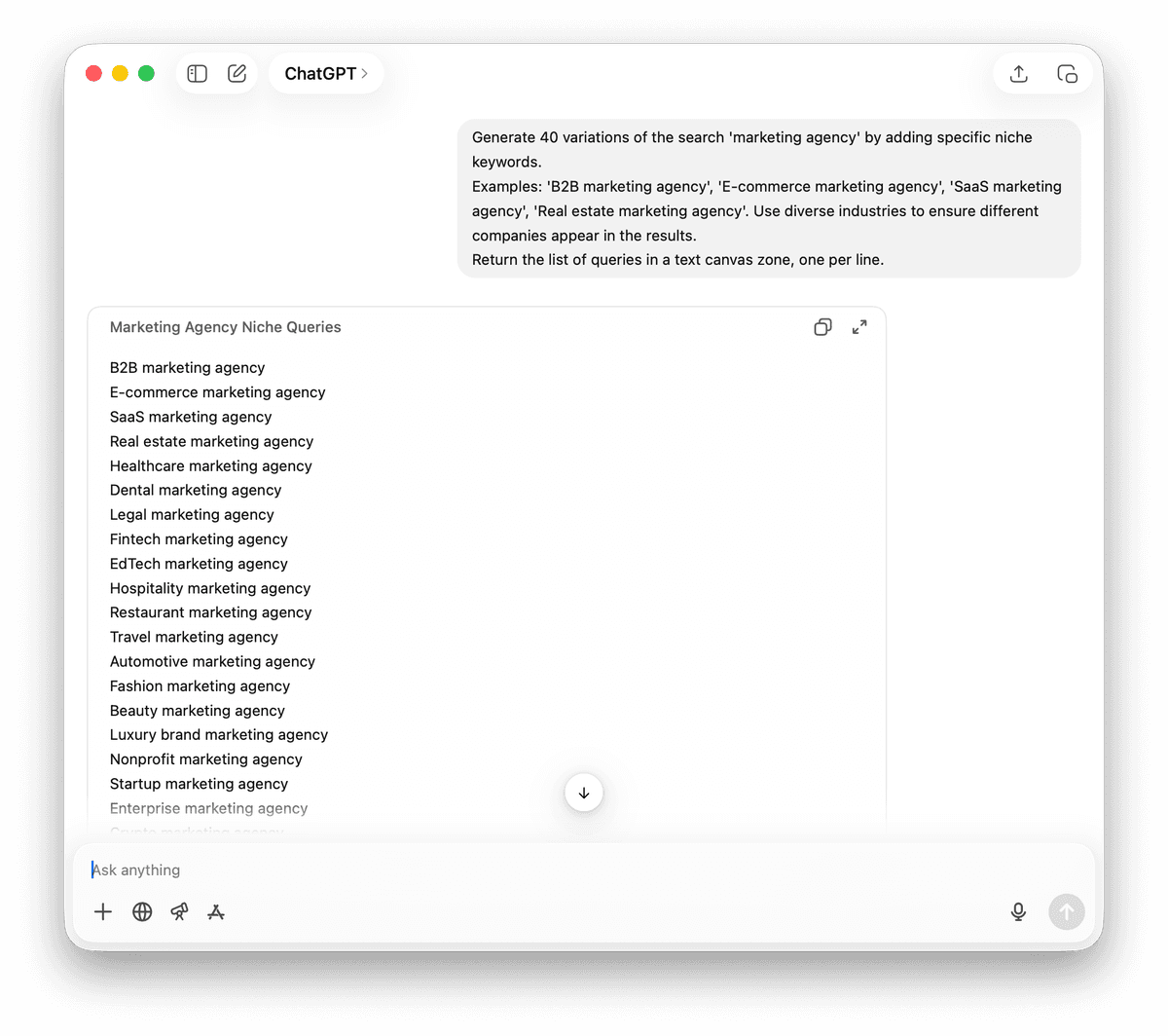
La strategia delle varianti keyword
A volte la variabile geografica non basta o non è adatta. Se stai cercando "Remote Marketing Agencies", ad esempio, può avere più senso variare le keyword.
Esempi: 'B2B marketing agency', 'E-commerce marketing agency', 'SaaS marketing agency', 'real estate marketing agency'. Usa settori diversi per fare in modo che nei risultati compaiano aziende differenti.
Restituisci la lista delle query in un'area di testo, una per riga.
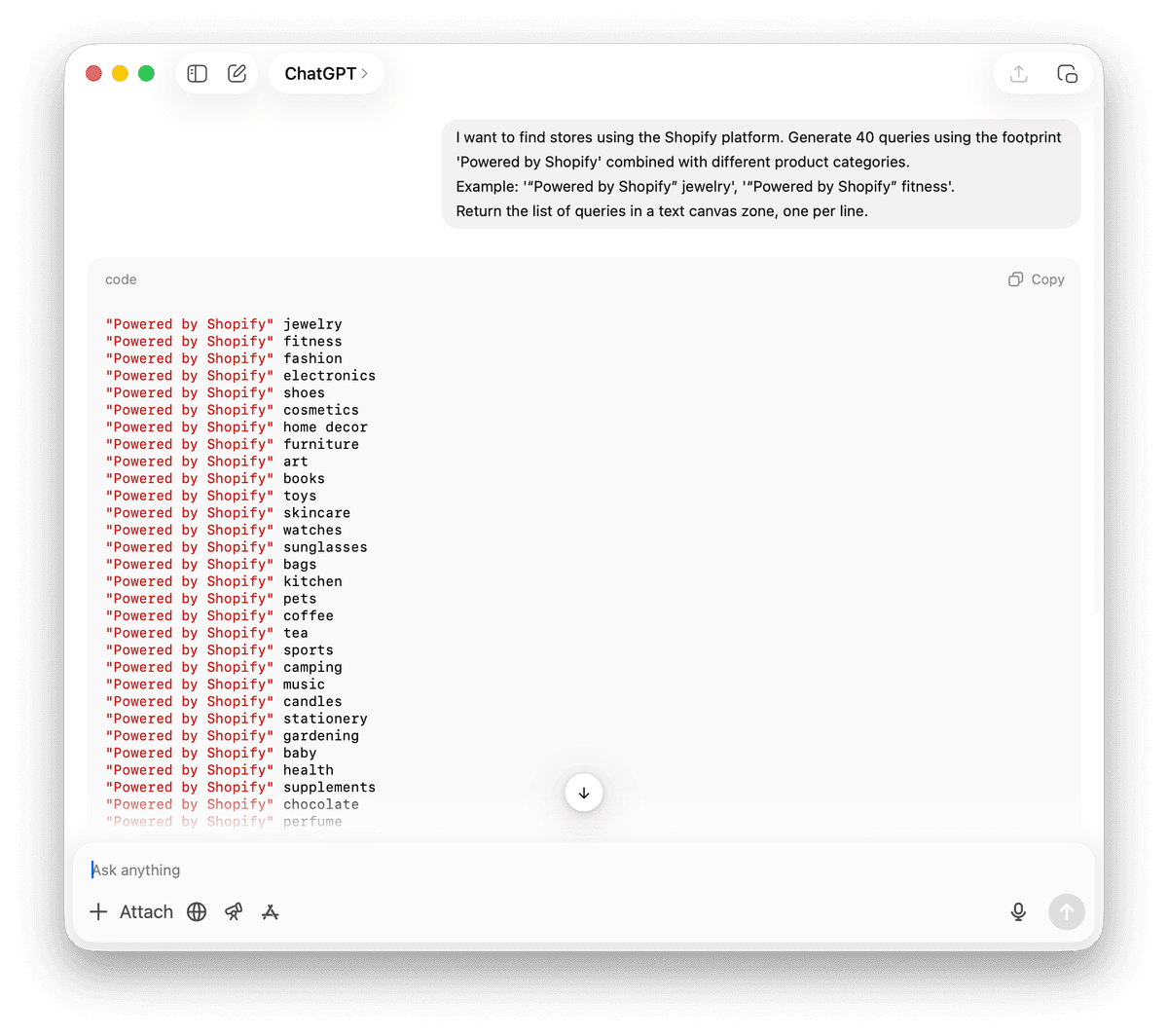
La strategia del "fingerprint"
Molti siti web utilizzano software specifici. Spesso questi strumenti lasciano una traccia nel codice HTML o nel footer del sito. Google indicizza anche questo testo.
Esempio: '“Powered by Shopify” gioielli', '“Powered by Shopify” fitness'.
Restituisci la lista delle query in un'area di testo, una per riga.
Guida passo passo allo scraping Google con Datablist
Una volta pronta la lista di query, Datablist rende invisibile tutta la parte tecnica dell’esecuzione in parallelo. Non devi preoccuparti di rotating proxies, browser headless o estrazione dati dall’HTML.
1. Accedi alla Data Source
Apri Datablist e clicca su "Start from a data source" nella barra laterale.
Cerca la data source "Start with Google Search Queries". È pensata appositamente per l’estrazione ad alto volume.
2. Incolla le query e configura i parametri di ricerca
Copia la lista di varianti generata dal tuo AI. Incollala nel campo query di Datablist. Puoi incollare decine o centinaia di righe tutte insieme.
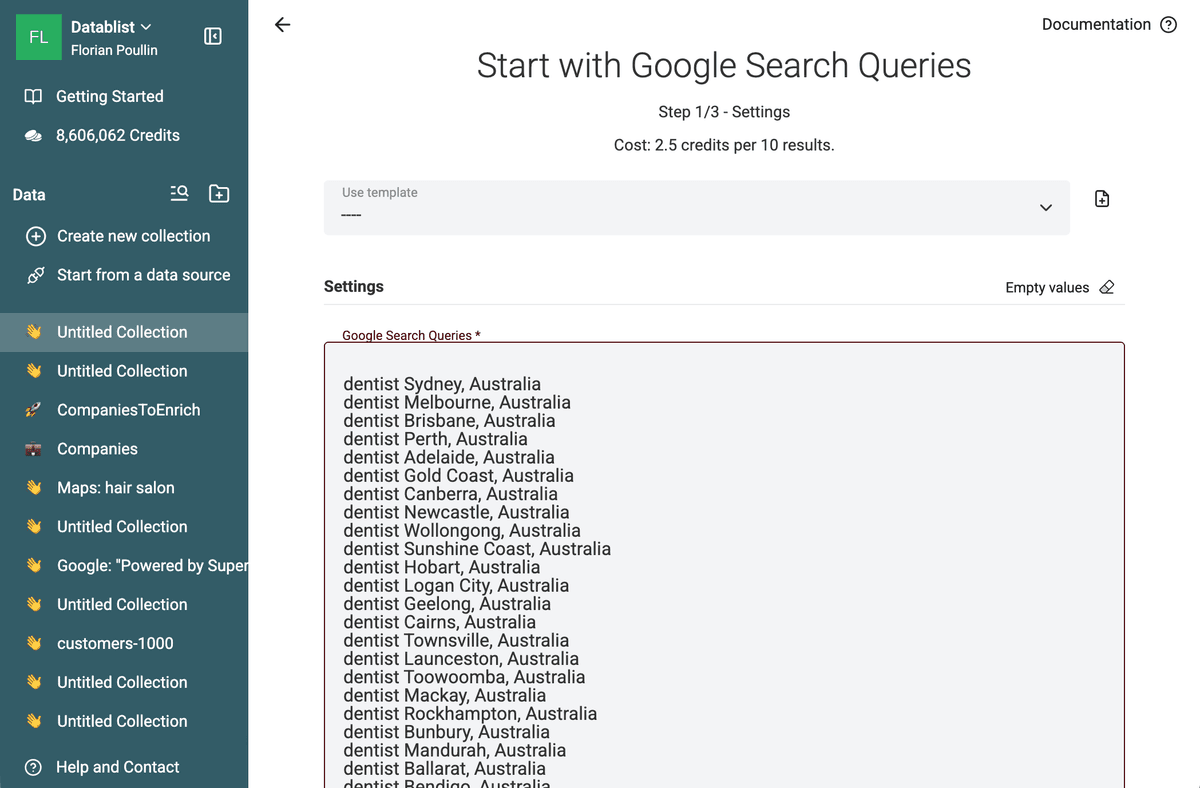
Imposta Paese e lingua di destinazione. È un passaggio fondamentale. Se cerchi avvocati in Italia ma imposti come Paese gli Stati Uniti, Google restituirà risultati diversi e probabilmente poco rilevanti. Puoi anche specificare un intervallo temporale se vuoi solo risultati indicizzati nell’ultimo mese o nell’ultimo anno.
4. Esegui e aspetta
Clicca sul pulsante di esecuzione. Datablist elaborerà le query per te. Dato che lo scraping su Google richiede una gestione attenta per evitare blocchi, il sistema si occupa automaticamente dei timing.
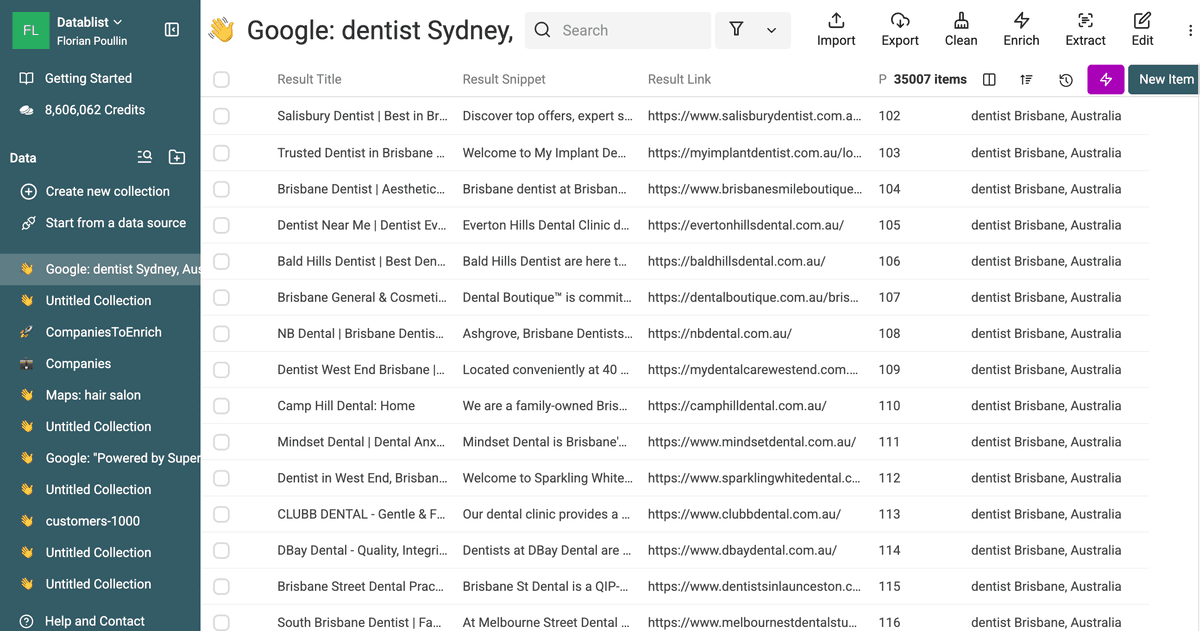
Puoi vedere gli elementi che popolano la collection in tempo reale.
Pulire e deduplicare i dati
Deduplica
Un effetto collaterale inevitabile quando esegui 50 query simili è la presenza di duplicati. Uno studio legale ben posizionato potrebbe comparire per "avvocato Milano", "avvocato Italia" e "avvocato societario". Quando unisci tutti questi risultati in un’unica collection Datablist, ti ritrovi con tre righe per la stessa azienda.
Prima di iniziare qualsiasi attività di outreach, devi deduplicare i dati. Datablist include un potente strumento chiamato Duplicates Finder.
- Apri il menu "Clean".
- Seleziona "Duplicates Finder".
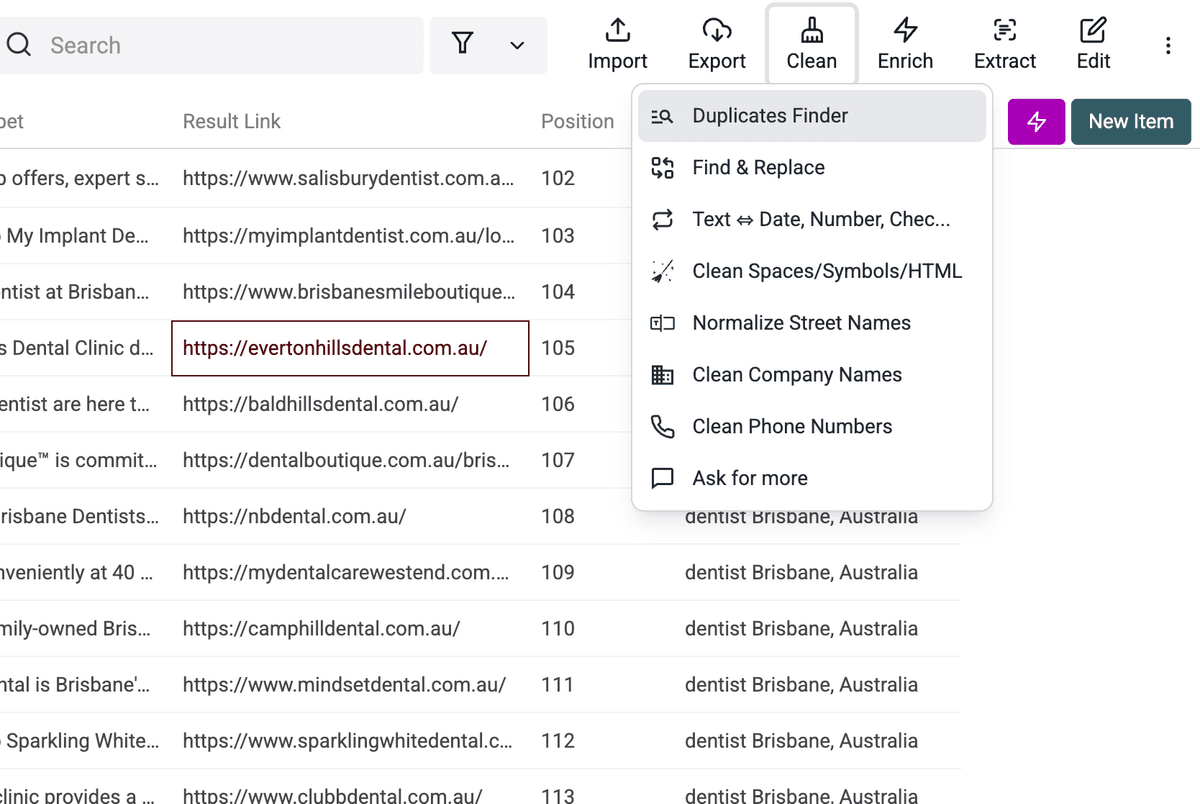
- Scegli la proprietà da confrontare. Nei risultati Google, "Result Link" è in genere la scelta migliore.
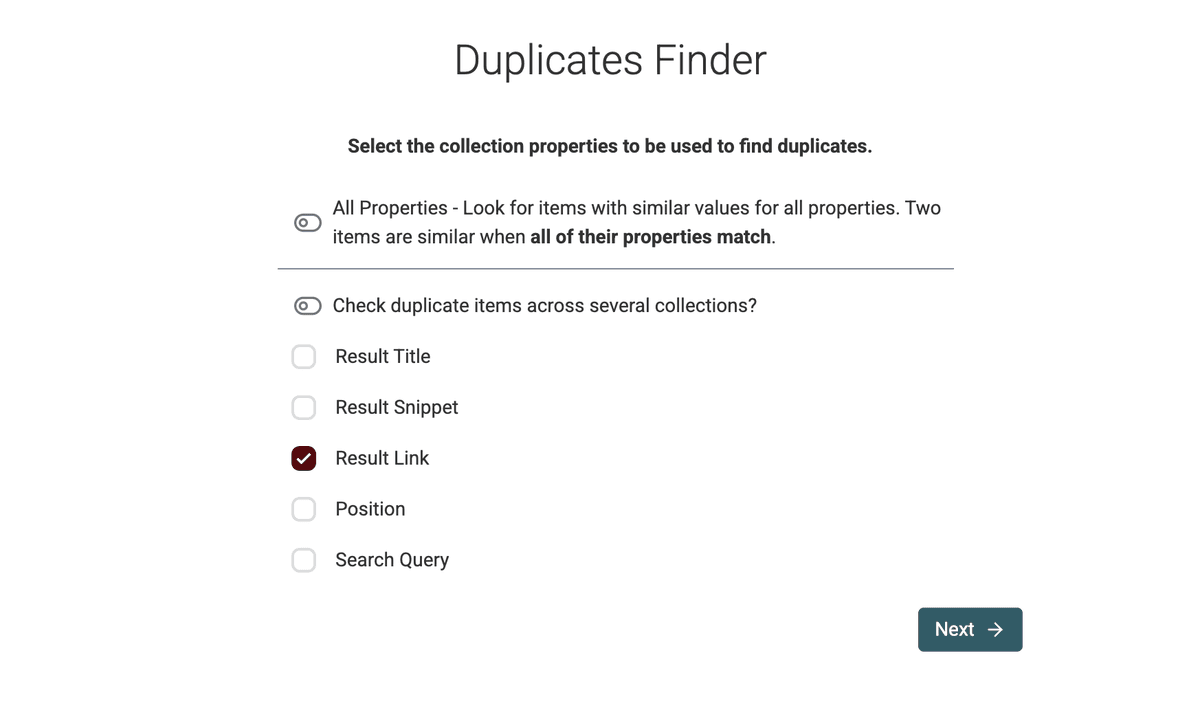
- Seleziona il preprocessor "URL" per ignorare path, query params, ecc. durante il processo di deduplica.
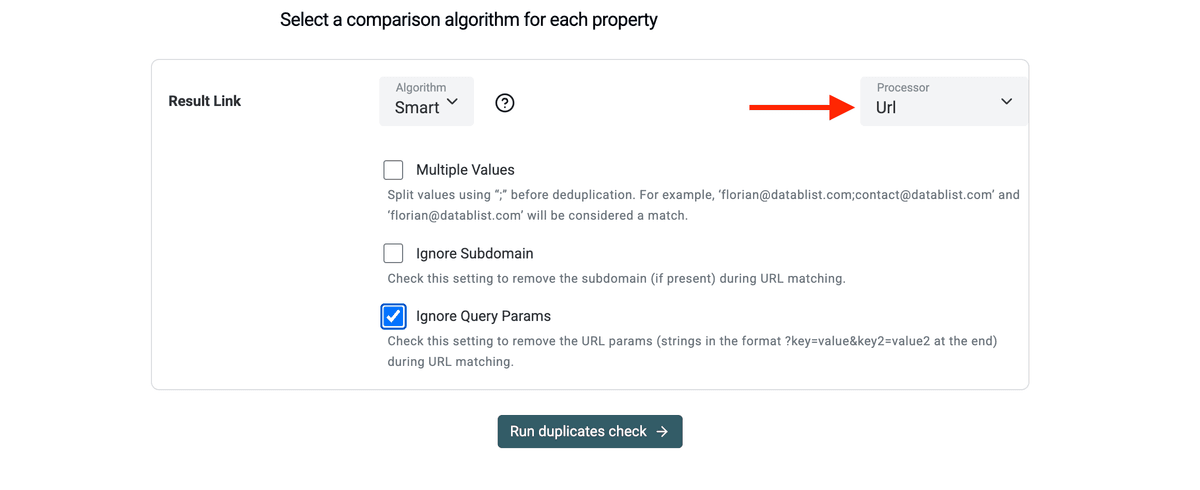
- Lascia che il tool identifichi le righe corrispondenti e uniscile oppure elimina i duplicati in eccesso.
Rimuovere il rumore
Pulire i dati significa anche eliminare il rumore. Alcuni risultati Google saranno "aggregatori" come Pagine Gialle, Yelp o Tripadvisor. Nella maggior parte dei casi conviene escluderli per concentrarti sui siti web diretti delle aziende.
Usa le funzionalità di filtro per escludere i domini delle directory più comuni. Se vuoi approfondire, trovi una guida dettagliata qui: data cleaning this guide.
Arricchire i risultati di ricerca
Un URL o il titolo di una pagina raramente bastano per una campagna sales. Una volta ottenuta una lista unica di siti web, ti servono informazioni di contatto. Datablist funziona come un hub di enrichment, permettendoti di inviare i dati estratti verso altri servizi.
Trovare email
-
Trovare email partendo dai domain aziendali
Se il tuo scraping restituisce i domain delle aziende, usa l’enrichment Datablist "Waterfall People Search". Trova persone che lavorano in quelle aziende e restituisce dettagli del profilo insieme a email verificate. È ideale per costruire liste contatti B2B molto targettizzate. -
Trovare email da URL di profili LinkedIn
Se il tuo scraping restituisce link a profili LinkedIn, usa il Datablist Waterfall Email Finder. Trova l’email professionale usando solo l’URL del profilo LinkedIn. Puoi seguire la guida passo passo qui: Find email addresses from a LinkedIn Profile URL.
Ottenere le LinkedIn Company Page dai domain
Se parti dai siti web aziendali, puoi trasformarli in asset LinkedIn con un click. Usa l’enrichment "LinkedIn Company Page Matcher". Trova la LinkedIn Company Page ufficiale per ogni azienda della tua lista.
È molto potente. Un semplice risultato Google si trasforma in un profilo aziendale ricco di dati su settore, dimensioni e attività.
Una volta ottenuta la corrispondenza, puoi recuperare informazioni aziendali dettagliate con:
Passi rapidamente da URL grezzi a dati B2B strutturati.
Usare AI Agent per visitare i siti
A volte un sito web nasconde le informazioni più utili. È qui che entra in gioco AI Agent.
AI Agent visita ogni sito per te. Legge le pagine come farebbe una persona.
Può:
- Categorizzare le aziende in base ai contenuti del sito
- Etichettare i lead come "High Priority" o "Low Priority"
- Estrarre dettagli di contatto dalle pagine Contact o About Us
Invece di aprire 500 tab e leggerle una per una, lasci fare il lavoro pesante all’agent.
Casi studio e casi d’uso
Case Study: l’agenzia di nicchia
Un’agenzia di marketing specializzata in veterinari voleva espandersi in tutta Italia. Una singola ricerca come "veterinario Italia" restituiva 300 risultati. Generando una lista delle 500 città italiane più grandi e lanciandola in Datablist, ha raccolto 85.000 risultati grezzi.
Dopo la deduplica per domain, erano rimaste 42.000 cliniche veterinarie uniche. A quel punto hanno arricchito il dataset con le informazioni di contatto.
Case Study: il recruiter tech
Un recruiter doveva trovare CTO di startup a Milano. Ha usato questa query:
site:linkedin.com/in/ "CTO" "Milano" "startup"
Poi ha creato varianti sostituendo "Milano" con altri hub tech italiani come Roma, Torino e Bologna. Ha variato anche il job title: "VP Engineering", "Technical Co-founder" e "Head of Development". Con questo approccio multi-livello ha costruito un pool di 4.000 profili executive, ben oltre i limiti di una ricerca standard su LinkedIn.
Case Study: trovare rivenditori online
Il titolare di un brand cosmetico voleva trovare boutique online indipendenti che potessero distribuire una nuova linea di oli viso biologici. Invece di cercare manualmente, ha puntato sul footprint "Powered by Shopify", molto comune tra i retailer indipendenti.
Ha usato la strategia "fingerprint":
"organic face oil" "powered by shopify"
Usando un LLM per generare varianti per ogni categoria prodotto ("natural beauty boutique", "vegan skincare", "botanical serum"), ha identificato oltre 1.200 store online unici in linea con il suo profilo ideale di distributore.
Ha importato i risultati in Datablist, rimosso i duplicati e usato AI Agent di Datablist per trovare le informazioni di contatto.
Analisi dei costi: scraping low budget
Lo scraping web tradizionale è costoso. Assumere uno sviluppatore per creare uno scraper custom costa spesso migliaia di euro. Anche usare scraping API dedicate richiede in genere un abbonamento mensile e competenze tecniche per gestire gli output JSON.
Datablist semplifica anche l’equazione economica. Il sistema a crediti significa che paghi solo per i dati che riesci davvero a estrarre.
- Tariffa: 2,5 crediti ogni 10 risultati Google.
- Valore: con pacchetti crediti a partire da $1 per 20.000 crediti, il calcolo è semplice.
- Risultato: ottieni circa 4.000 risultati per circa $1.
Rispetto all’acquisto di liste lead "stale" da broker, che possono costare anche $0,50 per lead, fare scraping di dati freschi da Google è enormemente più conveniente. Hai tu il controllo su filtri, tempi e nicchie.
Consigli: usa gli operatori di ricerca Google
Per massimizzare la qualità dei dati estratti, ecco alcuni operatori di ricerca Google che puoi usare per costruire le tue query.
Questi simboli indicano a Google esattamente dove cercare le keyword.
- site: Usalo per fare scraping dei risultati da una piattaforma specifica. Per trovare profili LinkedIn, usa
site:linkedin.com/in/. - inurl: Cerca parole all’interno dell’URL. Per trovare pagine contatti, usa
inurl:contact. - intitle: Trova parole nel titolo della pagina.
intitle:"Index of"individua spesso directory aperte. - filetype: Usalo per cercare documenti.
filetype:pdf "marketing plan"trova documenti strategici pubblici. - - (segno meno): Esclude parole. Se cerchi avvocati ma non agenzie di recruiting, usa
avvocato -recruiting.
Combinati con lo scraping multi-query, questi operatori diventano uno strumento estremamente preciso. Ad esempio:
site:instagram.com "concept store" -inurl:/p/
Questa ricerca trova pagine profilo Instagram di concept store, escludendo i singoli post (il path /p/). Se la esegui per 50 Paesi o nicchie diverse, puoi costruire un database globale di influencer o competitor.
📘 Scopri di più
Consulta la nostra guida Search and Scrape Instagram Profiles by Category and Keywords per approfondire la ricerca di profili Instagram con Google
FAQ
Perché Google limita i risultati a 300?
Google punta a offrire la migliore user experience possibile. Presume che se non hai trovato ciò che ti serve entro la trentesima pagina, le successive difficilmente saranno utili. Questo serve anche a proteggere i suoi server dai bot automatici che tentano di scaricare l’intero web.
Fare scraping su Google è legale?
Lo scraping di dati pubblicamente accessibili è generalmente legale per finalità di business come ricerca o lead generation. Tuttavia, quando gestisci dati personali devi rispettare normative come il GDPR. Inoltre, è sempre buona prassi verificare i termini di servizio dei siti specifici che visiti dai risultati di ricerca.
Posso fare scraping di Google Maps con questo tool?
La source "Start with Google Search Queries" è focalizzata sul motore di ricerca standard. Se ti servono dati di attività locali, comprese recensioni, orari di apertura e coordinate precise sulla mappa, dovresti usare uno scraper dedicato a Google Maps. I risultati Search sono più adatti per siti web e profili digitali; i risultati Maps sono migliori per location fisiche.
Come gestisco i CAPTCHA?
Quando usi Datablist, non devi farlo tu. La piattaforma gestisce header delle richieste e rotazione dei proxy. Se una query incontra una challenge, il sistema gestisce automaticamente anche la logica di retry. Tu vedi solo i dati finali nella tua collection.
Posso usare questi risultati nel mio CRM?
Sì. Datablist ti permette di esportare i dati puliti e arricchiti in formato CSV o Excel. La maggior parte dei CRM, come HubSpot, Salesforce o Pipedrive, consente di importare direttamente questi file. Pulendo prima i dati in Datablist, mantieni il tuo CRM libero da duplicati e record inutili.