Records deduplication, also known as data deduplication or record matching, is the process of identifying and eliminating duplicate records or entries within a database or dataset. It's a critical data cleansing technique used to ensure data accuracy and consistency.
How does Record Deduplication work?
Record deduplication typically involves two steps:
- Identifying duplicate records or Data Matching: The first step is to identify duplicate records in the dataset. This can be done using a variety of methods, such as comparing unique identifiers (e.g., customer IDs, product IDs), or using phonetic/fuzzy algorithms to identify records that are similar to each other.
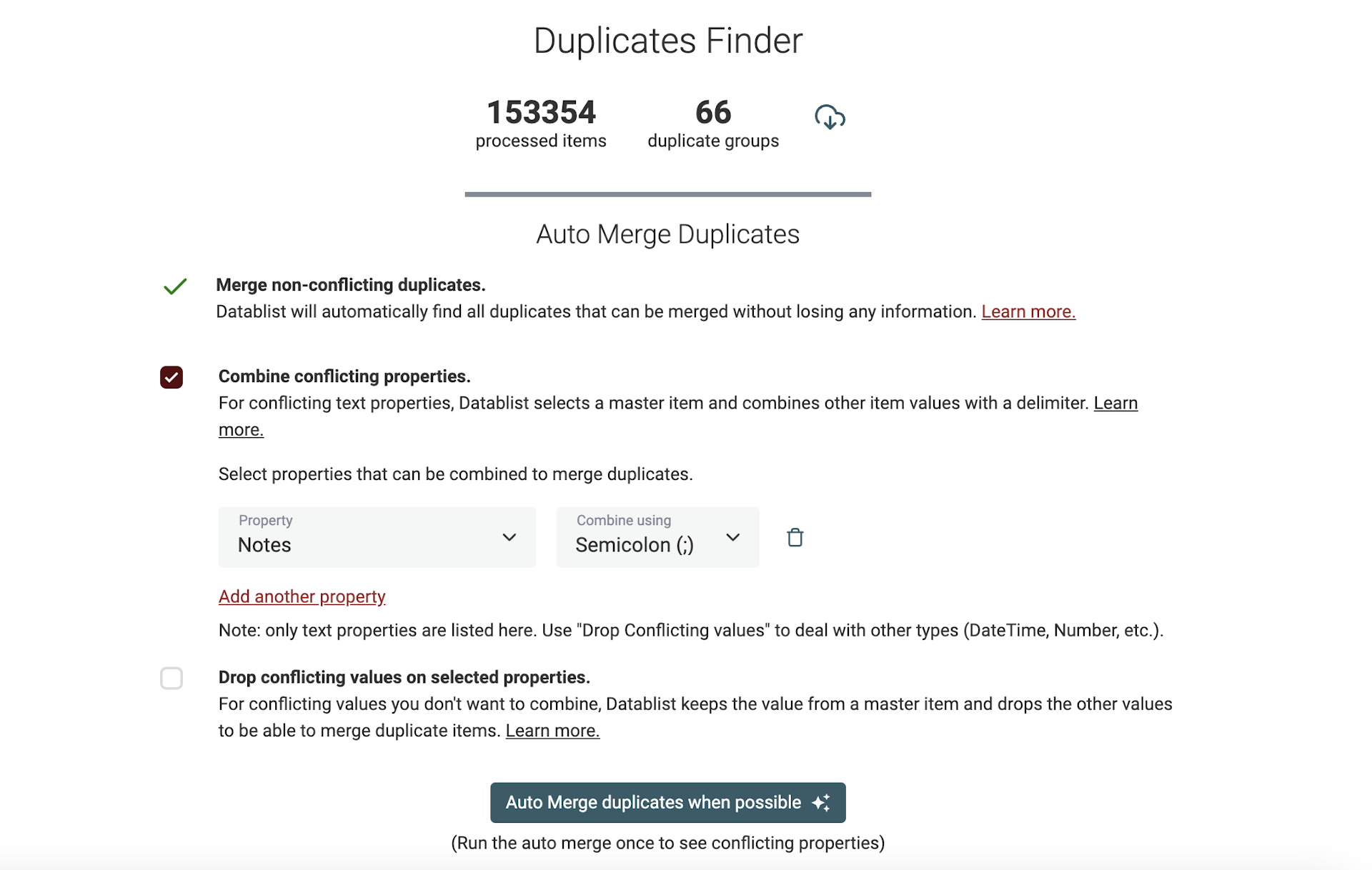
- Removing duplicate records: Once duplicate records have been identified, they can be removed from the dataset. This can be done manually, or using automated tools. When record data is similar or complementary, the merging process is a nondestructive step. When duplicate records have conflicting data, the merging process must offer text concatenation or a rule to drop conflicting data to be able to merge all fields into a single record.
How to identify duplicate records?
There are two main types of data matching:
- Exact record matching: Exact deduplication identifies and removes records that are exactly the same. This is the simplest type of deduplication.
- Field-specific matching: This is a more complex type of deduplication. It requires the use of algorithms to identify similar records by focusing on specific fields like names, addresses, or phone numbers.
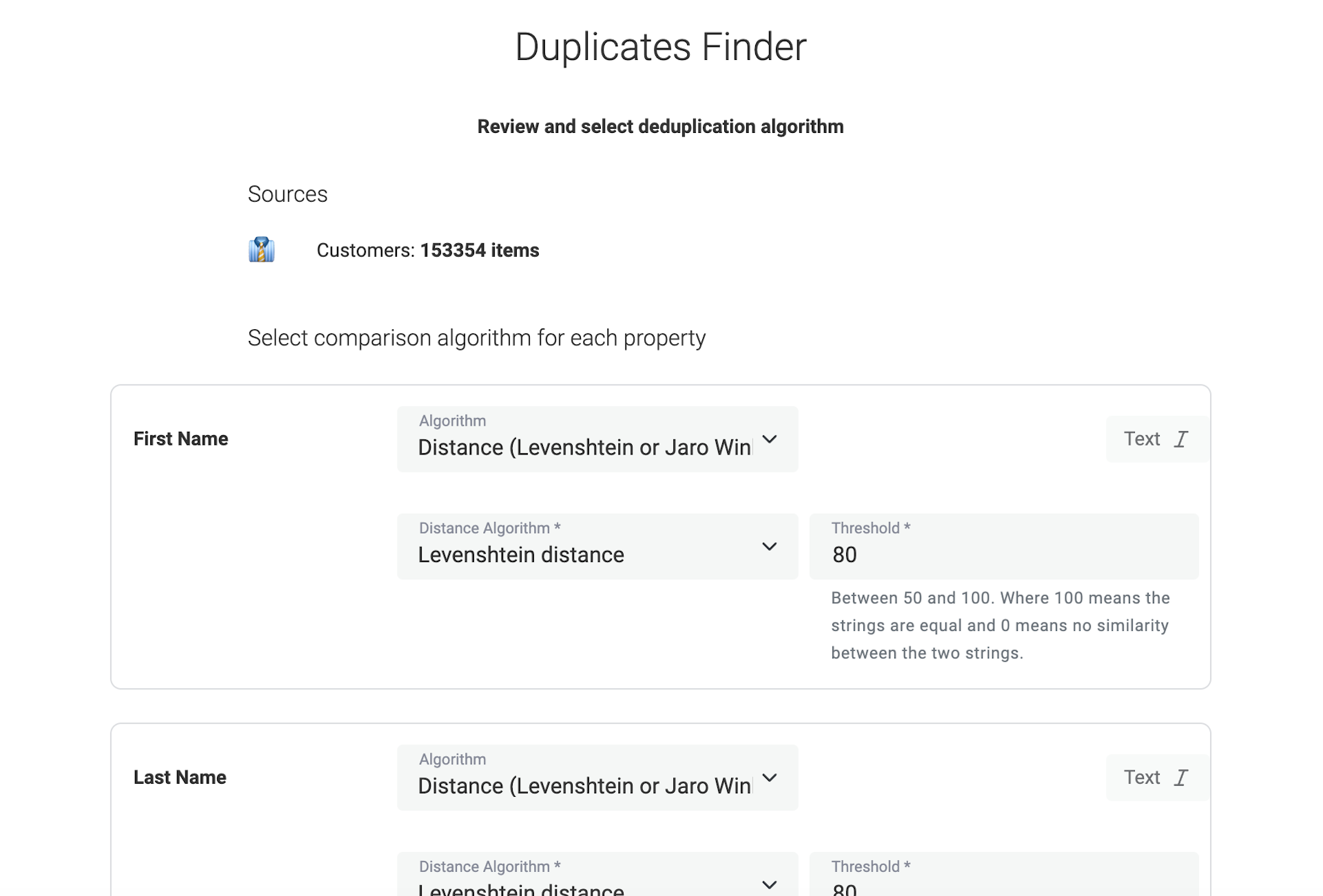
For field-specific matching, several algorithms exist:
- Exact matching: Identifies records that have identical values for the specific fields.
- Phonetic matching: Algorithm to match values by their pronunciation. Most phonetic algorithms work best with English words. The Soundex and Double Metaphone are among the best-known phonetic algorithms.
- Fuzzy Matching: Uses algorithms to find records that are similar but not necessarily identical, accommodating variations in spelling, formatting, or other data discrepancies. Two famous fuzzy matching algorithms are the Levenshtein Distance and Jaro-Winkler Distance.
For practical workflows, read about multi-column deduplication, cross-list deduplication, company deduplication, email deduplication, and URL deduplication.
Why is Record Deduplication Important?
Data or record deduplication is crucial for several reasons:
- Data Quality: Removing duplicates improves data accuracy, integrity, and consistency, preventing errors and confusion.
- Efficient Operations: It reduces the storage space required, speeds up data retrieval, and optimizes database performance.
- Compliance: In industries with regulatory requirements, deduplication helps maintain data integrity and meet compliance standards.
What tool is best to perform records deduplication?
Datablist is a free csv editor with powerful data cleansing features. Datablist Duplicates Finder implements Exact, Phonetic, and Fuzzy Matching algorithms to detect duplicate records across your datasets.