

清理重复数据,不只是点一下“delete”这么简单。
有些记录完全一致。有些记录字段互相冲突。还有很多记录是互补的,应该合并,而不是直接删除。
根据你的工作流,你可能需要合并记录、更新主记录,或者只是把重复项标记出来供后续审核。
普通工具通常只会删除整行,不理解字段优先级,也不理解你的业务规则。这种做法很容易删掉有价值的数据。
可靠的去重需要清晰的逻辑:如何选择主记录,如何处理冲突字段,以及如何处理次级记录。
本文会讲清楚在 CSV 文件、Excel 表格和 CRM 中合并、更新、删除重复记录的实用方法。
开始吧!
📌 赶时间先看这里
本文会覆盖电子表格去重时你需要知道的核心内容,包括如何用正确方式合并、更新和删除重复项。
问题: 如果不了解优先级规则和批量处理方式,处理重复数据时,你很容易丢掉重要信息,或者保留下错误记录。
解决方案: Datablist 提供三种去重方式:简单合并与删除、用 AI 处理复杂规则,以及跨多个文件去重。
本文会讲到的去重方法:
接下来 10 分钟你会学到什么
为什么听我们讲去重
Datablist 是一个用于搭建 lead generation workflows 的平台。目前有 26000 名用户通过它使用超过 60 种工具 来查找、enrich 和清洗数据,包括 AI Agents、Email Finders、AI processors、Technology enrichments 等。
另外,Datablist 内置了一套完整的 deduplication 工具,无需写代码,只需点击几下,就能合并、更新、删除或标记重复项。
了解去重基础
在开始讲如何给名单去重之前,我们先看不同去重技术背后的基本原则。
本节会讲:
- 重复数据类型的简短说明
- 处理冲突记录时的去重基础
- 帮你更快确定目标的问题
你需要理解的去重基础
下面这些内容主要适用于单文件去重。 如果是多文件去重,你通常只能从某些文件中删除副本,不能合并或更新记录。所以这些原则对多文件场景有帮助,但不是必需。
默认情况下,Datablist 会尝试自动合并重复记录。但在实际场景中,这并不总是可行,因为大多数用户的数据里都有冲突重复项。
当存在冲突时,流程依赖两个概念:
- 用优先级规则在重复组中选择主记录
- 用批量操作处理这个重复组里的次级记录
重复数据有哪些类型
我们会根据字段相似程度来分类重复项。
- 完全重复项:所有列的值都完全一样。通常来自重复导入或误复制粘贴。
- 冲突重复项:记录指向同一个实体,但某些字段存在冲突,比如电话、职位或营收。
- 互补重复项:每条记录都包含不同的有用信息,应该合并。比如一条记录有 email address,另一条重复记录有电话号码,这就是互补关系。

第一步:确定优先级规则
你必须决定哪条记录成为参考记录。我们把它叫做 Master Item Rule。记住这个词,后面还会用到。
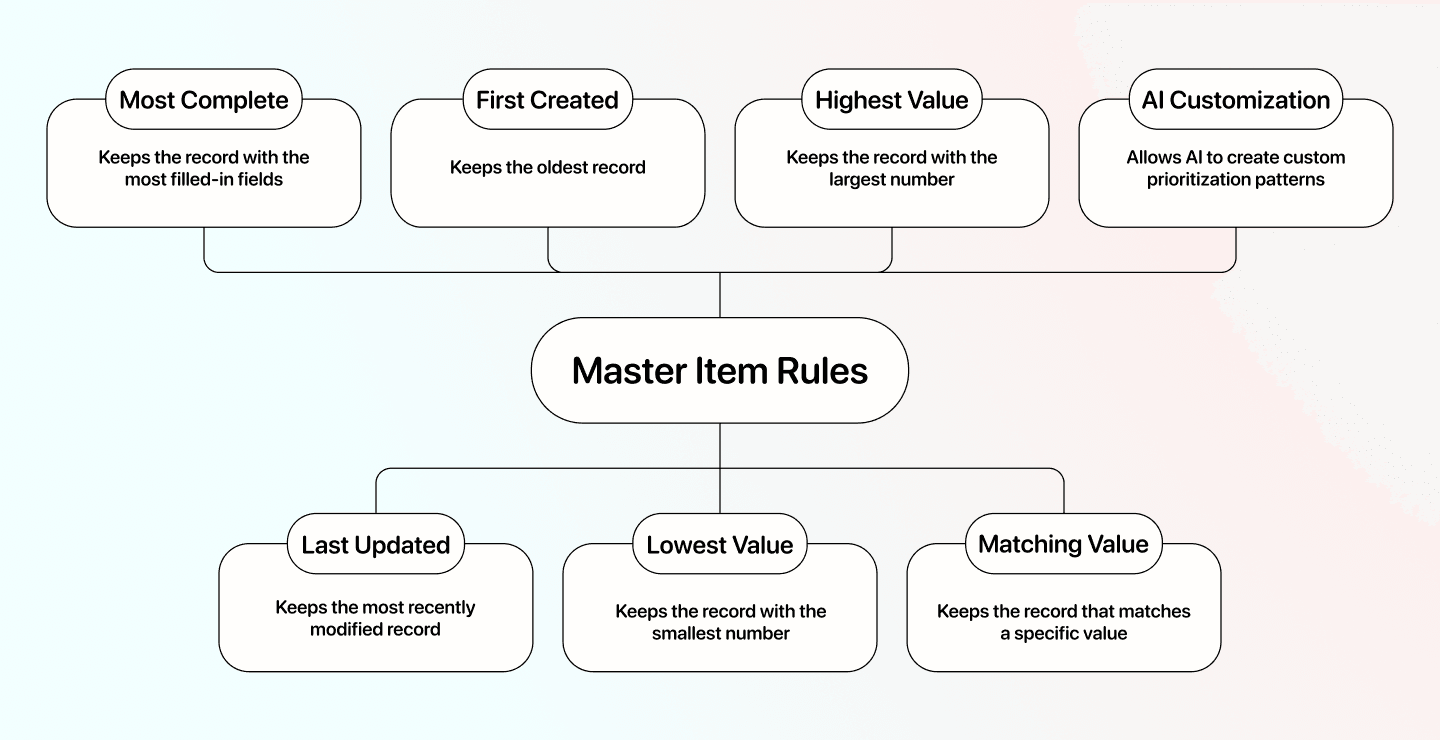
常见规则 / Master Item Rules:
- Most complete: 保留字段填写最完整的记录
- Last updated: 保留最近修改过的记录
- First created: 保留最早创建的记录
- Lowest value: 保留某个指定列中数值最小的记录
- Highest value: 保留某个指定列中数值最大的记录
- Matching value: 保留某个属性中匹配指定值的记录
📘 Master Item Rules
重要: “Last updated”和“First created”只适用于在 Datablist 中长期管理过的数据。如果你只是刚上传文件,这两个选项不会生效,因为导入的电子表格不包含这类元数据。
如果你不确定该选哪个 Master Item rule,我们建议先选择“Most complete”,或者使用本节第二部分介绍的方法。
对于复杂场景,Datablist 支持用 AI 创建自定义优先级规则。例如:当 A 列包含“Hello people”,且 B 列包含“of Germany”时,按你的自定义逻辑选择记录。
这部分会在后面的分步教程第二种方法中详细说明。
第二步:选择批量操作
选好优先级规则后,下一步是决定如何处理那些不符合规则的记录。
处理重复项的常见批量操作:
- 删除次级记录
- 将 Master Item 和次级记录合并成一条记录
- 将次级记录的指定属性合并到 Master Item,并删除其余内容
- 用次级记录的值更新 Master Item 的指定属性
- 只标记重复项,不删除它们。如果你在大型组织中工作,并且次级记录需要用于合规留痕,这种方式尤其有用
- ……以及任何你能清楚描述出来的处理方式
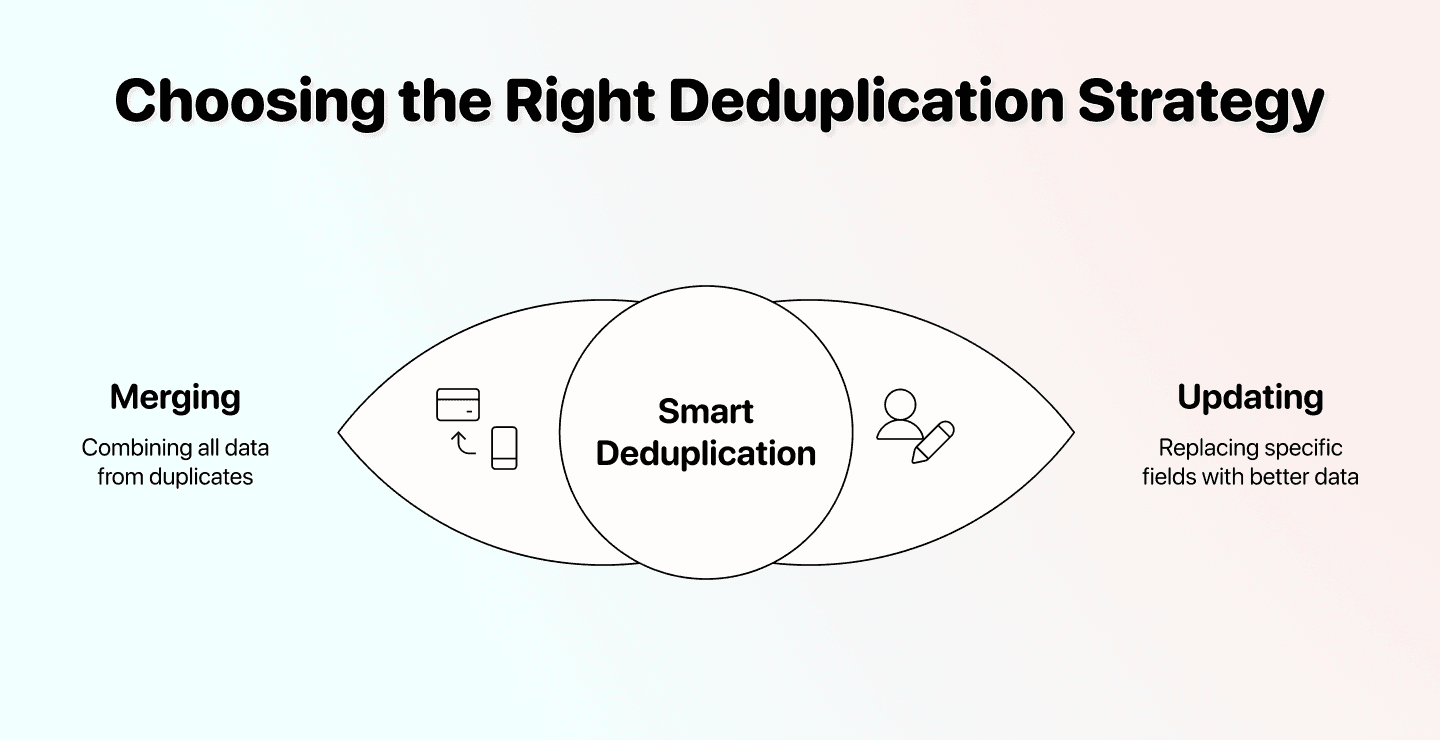
📘 理解合并重复项和更新重复项的区别
合并是把两条记录的值组合起来。 这特别适合重复的 CRM 联系人,例如两条记录里都有备注。
更新是用另一个来源中更好的数据替换指定字段。 当每条重复记录都有部分正确信息时使用它。比如保留联系人 A,但用联系人 B 中更准确的职位来修正它。
去重前需要问自己的问题
现在你已经理解了优先级规则和批量操作,可以用下面这些问题快速判断该选哪种规则,以及其余记录该怎么处理。
哪条记录应该作为 Master Item?
这个问题能帮你确定优先级规则。想一想,是什么让某条重复记录比另一条“更好”。
问问自己:
- 是否有一条记录比其他记录更完整?
- 是否有一条记录来自更可靠的数据源?
- 是否有一条记录更新、更近期?
- 是否有一条记录包含某个特定值,因此它才是“正确”版本?
你的答案决定 Master Item rule:
- 如果完整度最重要 → 使用“Most complete”
- 如果新旧程度最重要 → 使用“Last updated”或“First created”
- 如果某个指定值决定谁胜出 → 使用“Matching value”
- 如果逻辑更复杂 → 使用 AI Editing(方法 2)
非 Master 记录应该怎么处理?
这个问题能帮你确定批量操作。选出胜出的记录后,你要怎么处理其他记录?
问问自己:
- 其他记录里是否有值得保留的数据?
- 我是否需要把多条记录的信息合并到一条记录中?
- 我是否只需要删除多余记录,然后继续下一步?
- 我是否需要先标记重复项供审核,而不是直接删除?
你的答案决定批量操作:
- 如果其他记录没有价值 → 直接丢弃所有冲突值 / 删除它们
- 如果其他记录有有用数据 → 合并冲突值或更新 Master Item
- 如果需要合规留痕 → 只标记重复项,不删除
- 如果需要挑选特定字段值 → 使用 AI Editing(方法 2)
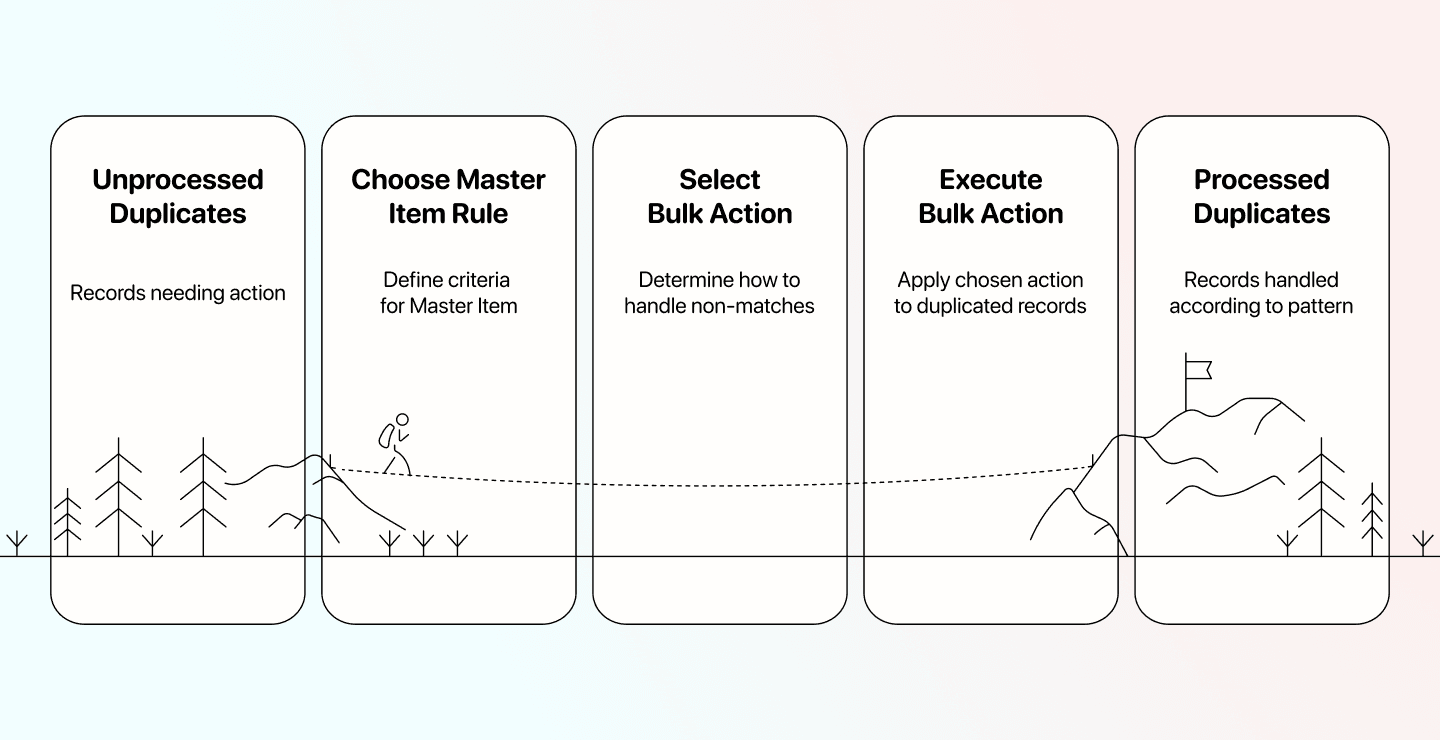
数据去重:清理重复记录
Datablist 的去重工具可以覆盖从简单删除重复项到跨文件去重的完整流程。 所以本节会介绍 3 个不同工作流:
开始操作。
Datablist 如何处理重复项:快速回顾
如果你已经读过上一节,可以跳过这里; 如果还没读,这个简短总结能帮你理解接下来具体要做什么。
- Datablist 会扫描你的数据,并在你指定的列中查找信息匹配的行。
- 找到重复项后,如果是完全匹配,它会允许你自动合并。
- 如果存在冲突重复项,它会让你选择一种规则,用来决定哪条记录优先于另一条记录(我们称为“Master Item Rule”)。
- 定义 Master Item Rule 后,你可以合并、更新、标记或删除这一组中的第二条重复记录。
在单个文件中简单合并和删除重复项
这是删除重复项最简单的方法。你的名单里有一些条目出现了不止一次,而你只想为每条记录保留一个副本。
适用场景
- 你不小心导入了同一个 CSV 文件两次
- 你的 CRM 导出文件包含重复联系人
- 抓取数据因为分页错误出现重复条目
第 1 步:注册并上传数据
- 注册 Datablist
- Upload 你的 CSV 或 Excel
第 2 步:进入 Duplicates Finder
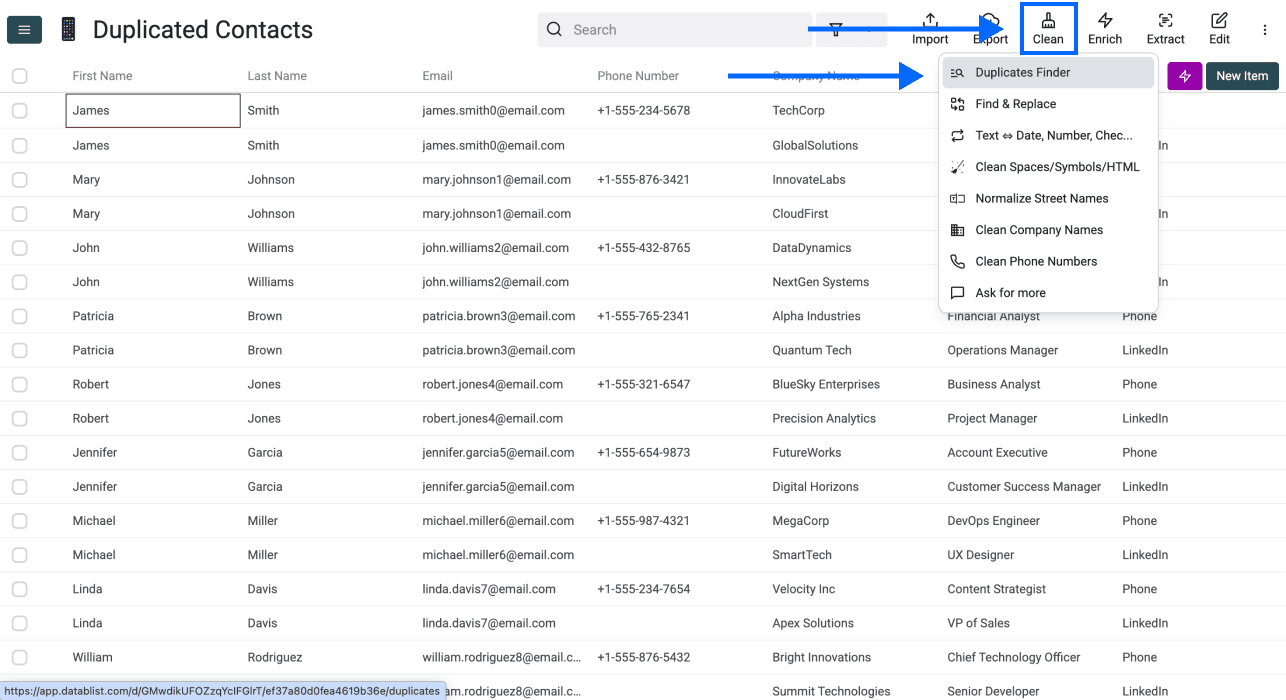
点击应用顶部菜单中的 Clean,然后选择 Duplicates Finder。
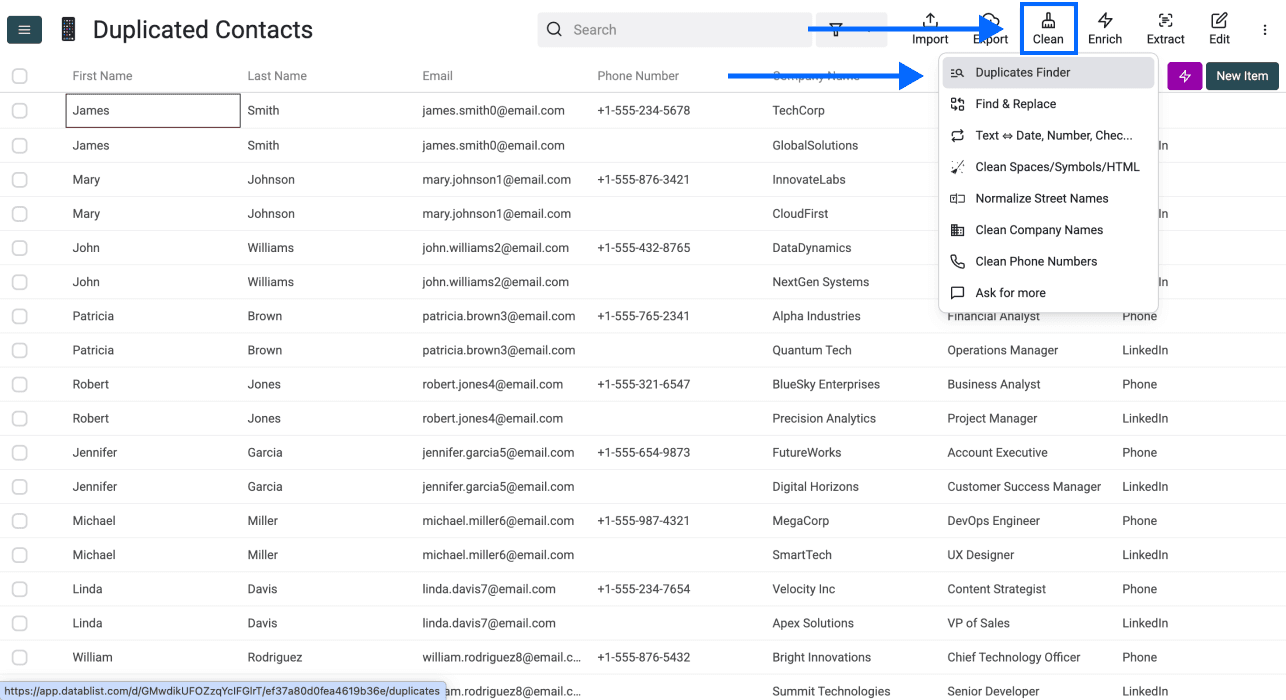
第 3 步:选择唯一标识符
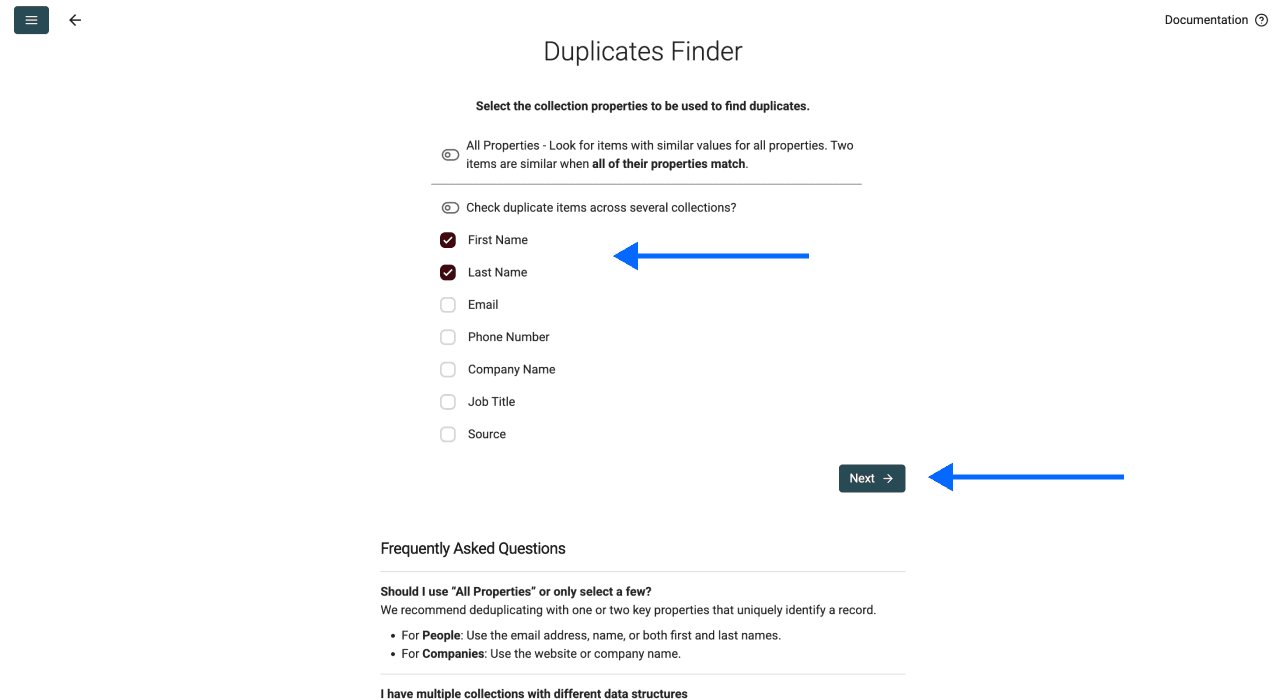
在这一步,你有两个选项:
选项 1: 选择一个或几个列作为唯一标识符 - 推荐
你可以把唯一标识符理解为让每条记录“独一无二”的信息。例如:
- 使用一个列: 如果你选择“Email”作为唯一标识符,那么 john@example.com 会被视为唯一,即使其他字段也匹配
- 使用多个列: 如果你把“First Name”+“Company”一起作为标识符,那么“Microsoft 的 John”和“Google 的 John”就是两条不同记录
你选择的列越多,匹配条件就越严格。我们建议先从一到两个真正能识别唯一记录的列开始。
选项 2: 基于所有属性去重 - 不推荐
这个选项会检查一行中的每一列是否都和另一行完全一致。也就是说,只有当两行的所有数据都相同时,它们才会被视为重复项。
为什么不推荐: 在真实数据里,重复项很少在所有列上完全一致。比如同一个人可能有略有不同的职位,同一家公司也可能因为数据源不同而有不同的员工数。如果使用这个选项,你会漏掉大多数重复项。
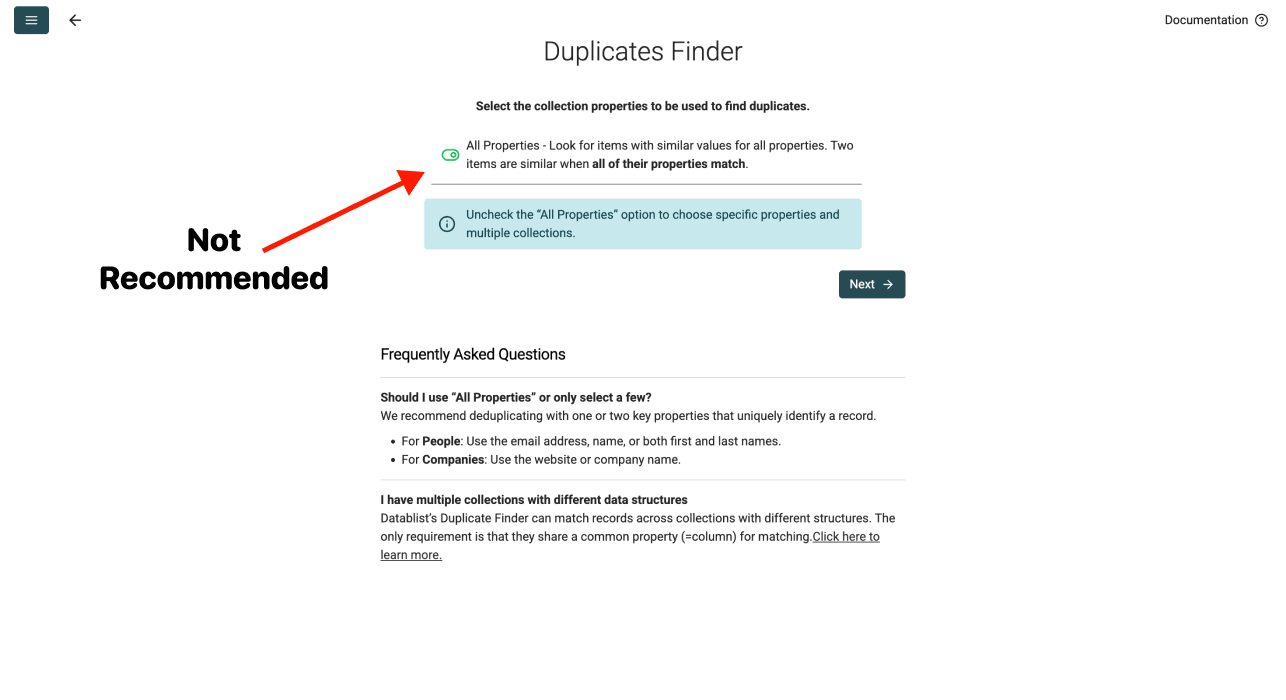
第二个选项什么时候有用: 只有在你要查找因误导入两次而产生的完全重复行,并且每个字段都完全一致时,才使用它。
选择好用于去重的属性后,向下滚动并点击 Next。
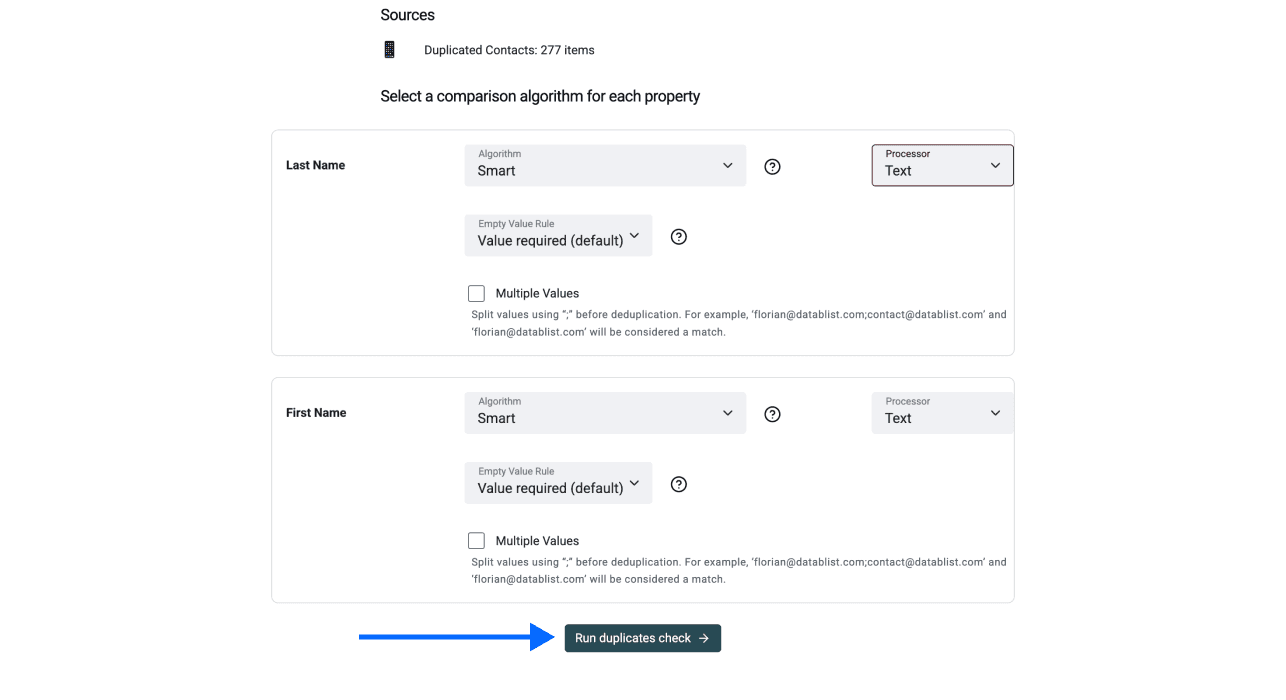
第 4 步:选择比较算法
在这一步,你需要为每个用于去重的属性选择比较算法和处理器。除公司名称外,我们建议保留默认设置。
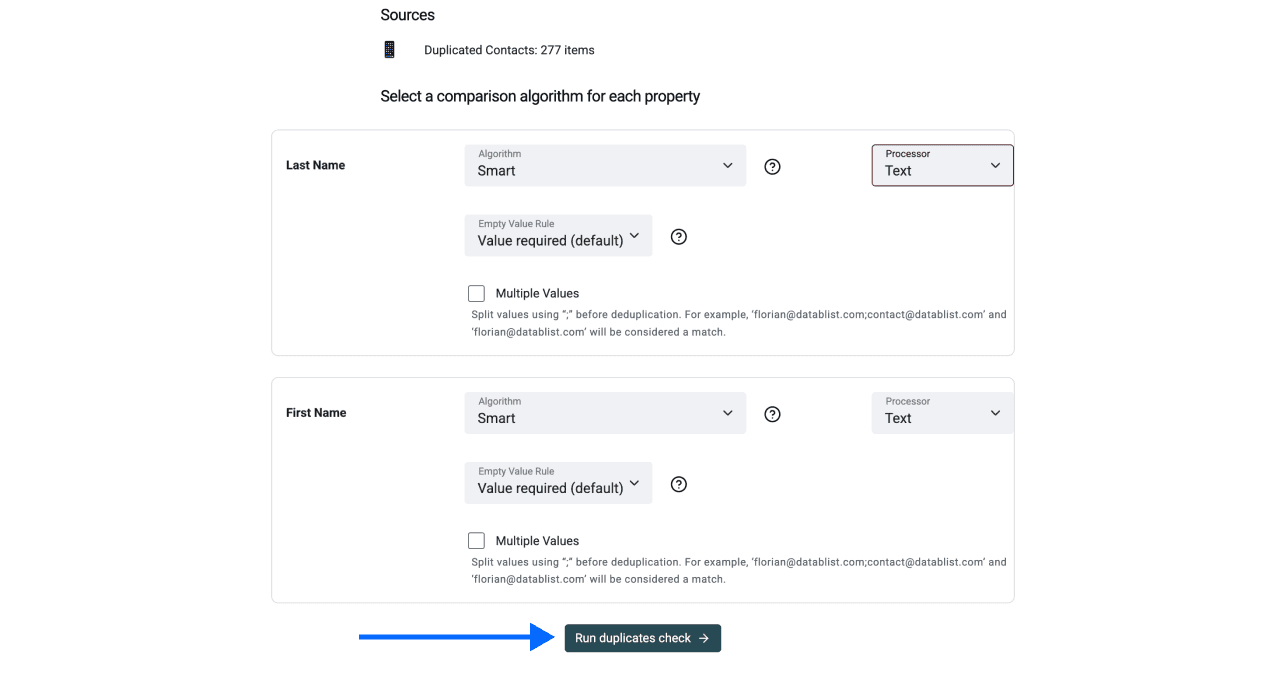
如果你基于公司名称去重: 请选择公司名称处理器,因为这是 Datablist 目前无法自动检测的唯一情况。
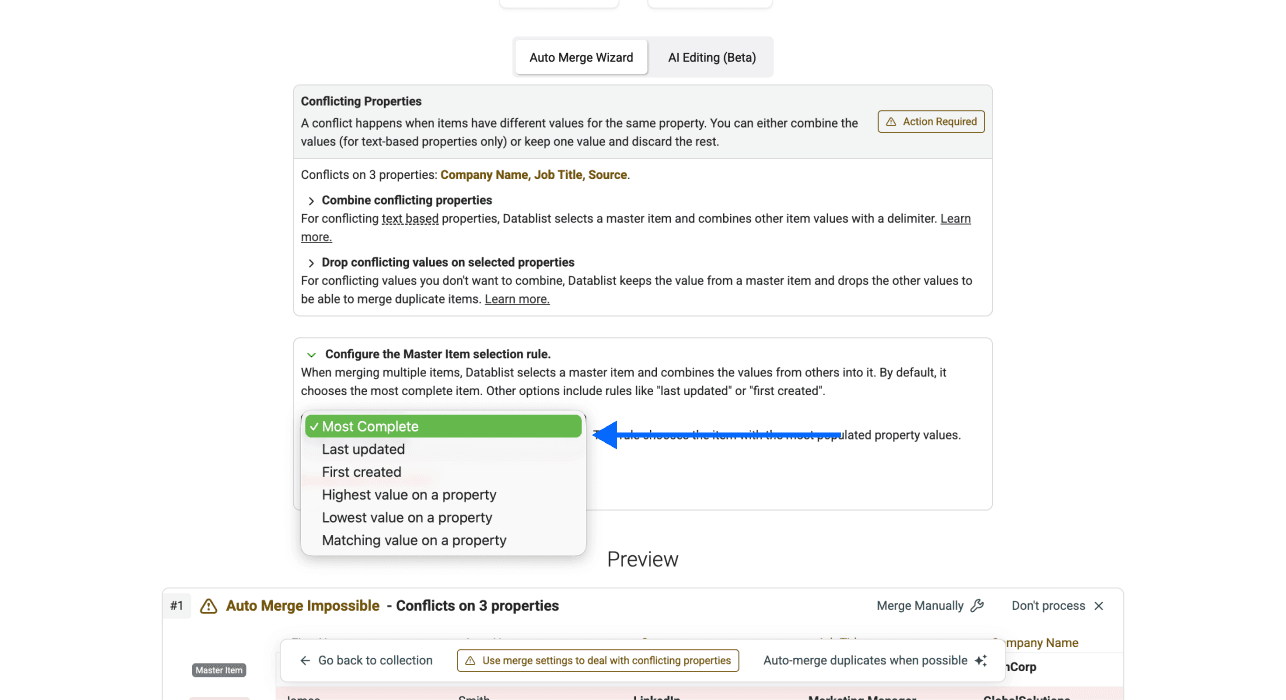
第 5 步:选择 Master Item,检查并解决冲突
- 选择 master item rule:如第一部分所说,Datablist 总会要求你指定一个 Master Item rule。默认规则是“Most Complete”,但你也可以选择其他规则。
-
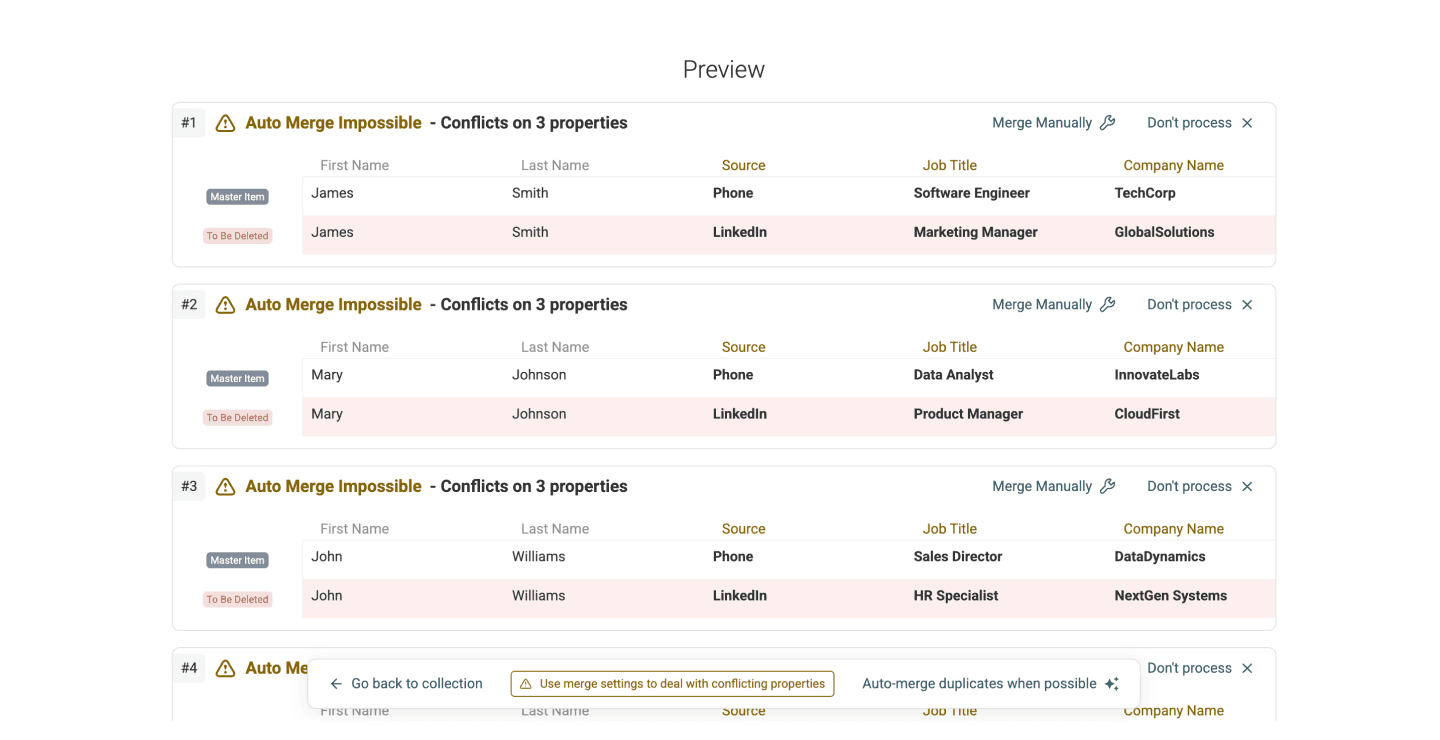
必要时检查并解决冲突:很多时候,重复项并不是所有属性都完全一致。这也是我们要求你指定 Master Item 的原因。
为了解决冲突,你可以选择 combine 或 drop 冲突值。不过,combine 只适用于文本类属性。如果你的字段是数字、日期时间等,就需要组合使用 combine 和 drop 两种规则。
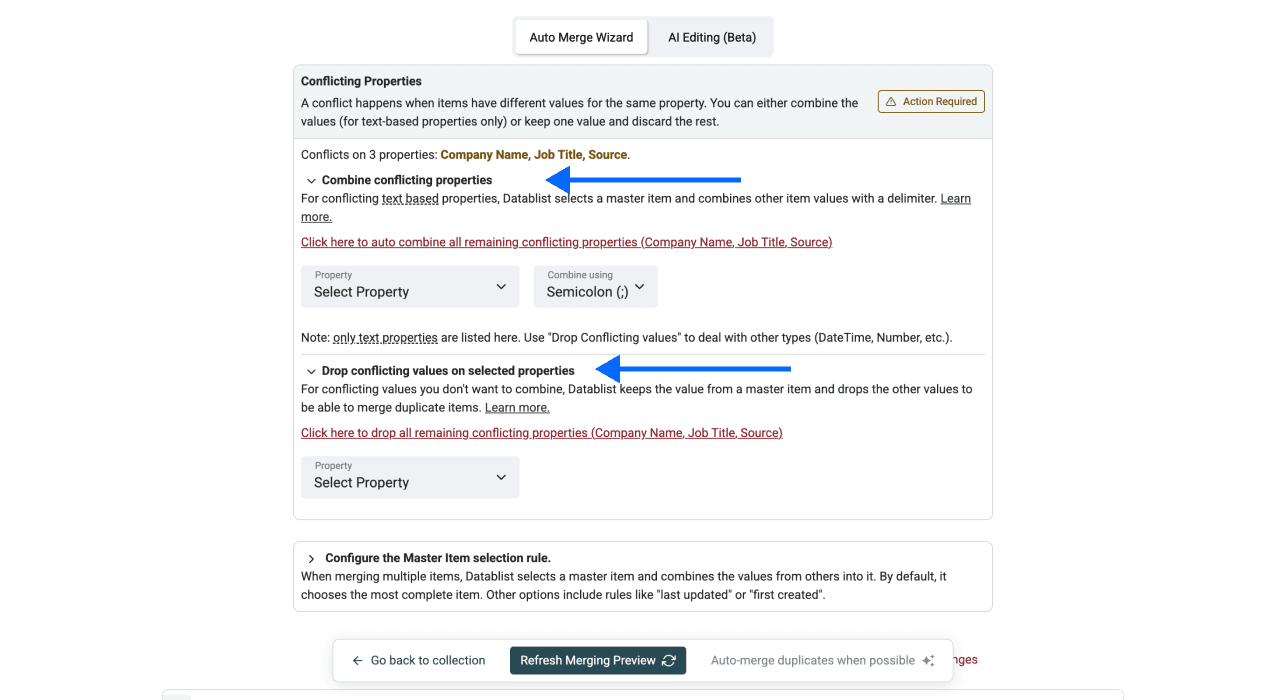
- 点击 Refresh Merging Preview,查看即将产生的变更。
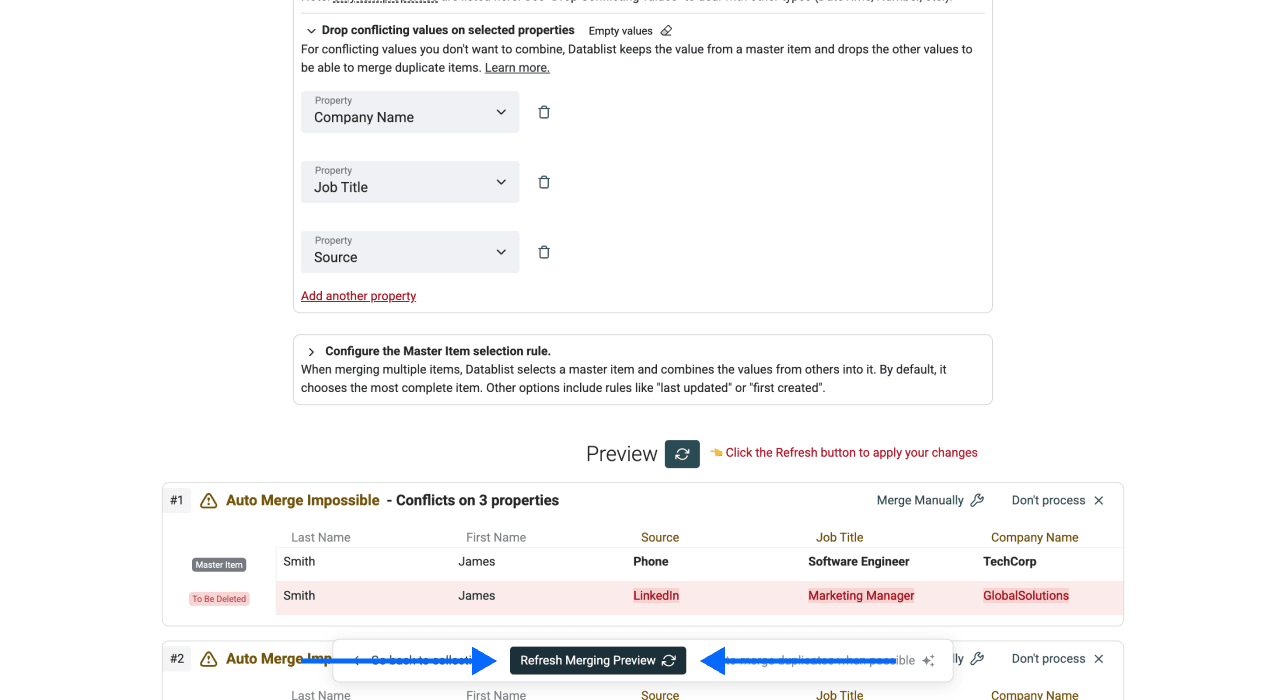
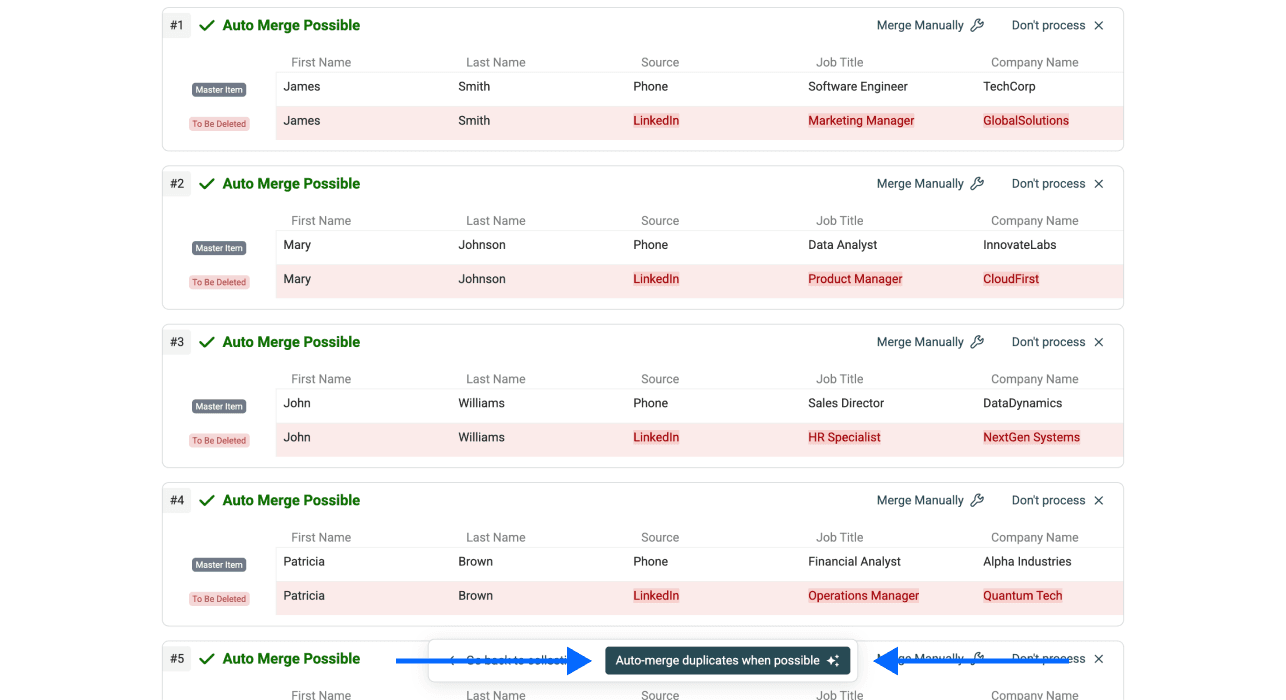
第 6 步:运行并检查结果
现在你只需要点击 Auto-merge when possible。
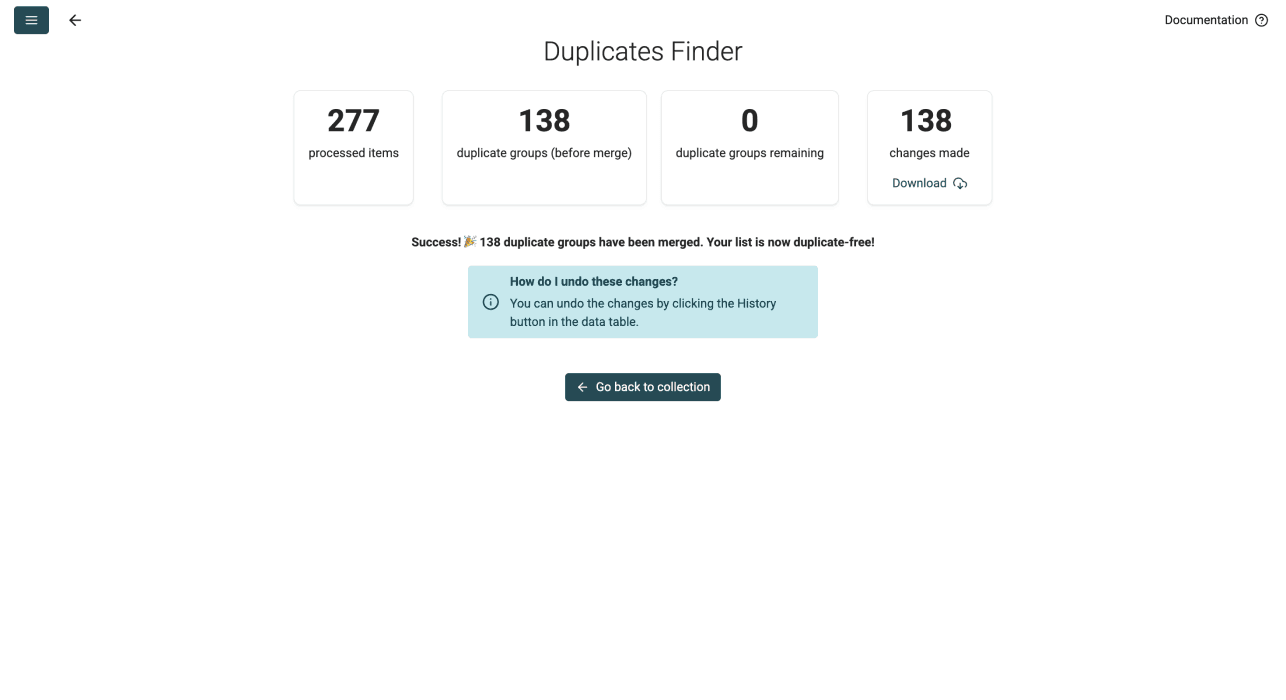
合并重复项后,Datablist 会让你以 CSV 格式下载本次变更记录。文件会包含:
- 文件中所有重复项
- 这些重复项被合并到哪些记录中
- 实际产生的变更
- Datablist record ID
下载这个文件是可选的。
💡 如果你操作错了
回到表格视图后,你也可以点击 history 按钮撤销刚才的操作,恢复之前的变更。
删除前先编辑重复项
有时简单的 master item rules 不够用。比如,你想保留一条记录里的电话号码,但使用另一条记录里的职位。这时就需要 AI Editing。
工作原理: 你不再选择预设规则,而是用自然语言准确描述你想要的结果。Datablist 的 AI 会读取你的指令,生成脚本,并把你的自定义逻辑应用到每个重复组。
适用场景
- 你的联系人来自多个来源(CRM、LinkedIn、电话名单),想把每个来源中最好的数据合并起来
- 重复项填写了不同字段,你想逐个字段挑选最佳值
- 你需要的自定义逻辑不适合标准 master item rules
- 你想在删除前先更新记录,而不是只选一个胜出者
- 出于合规原因,你想标记重复项,而不是删除它们
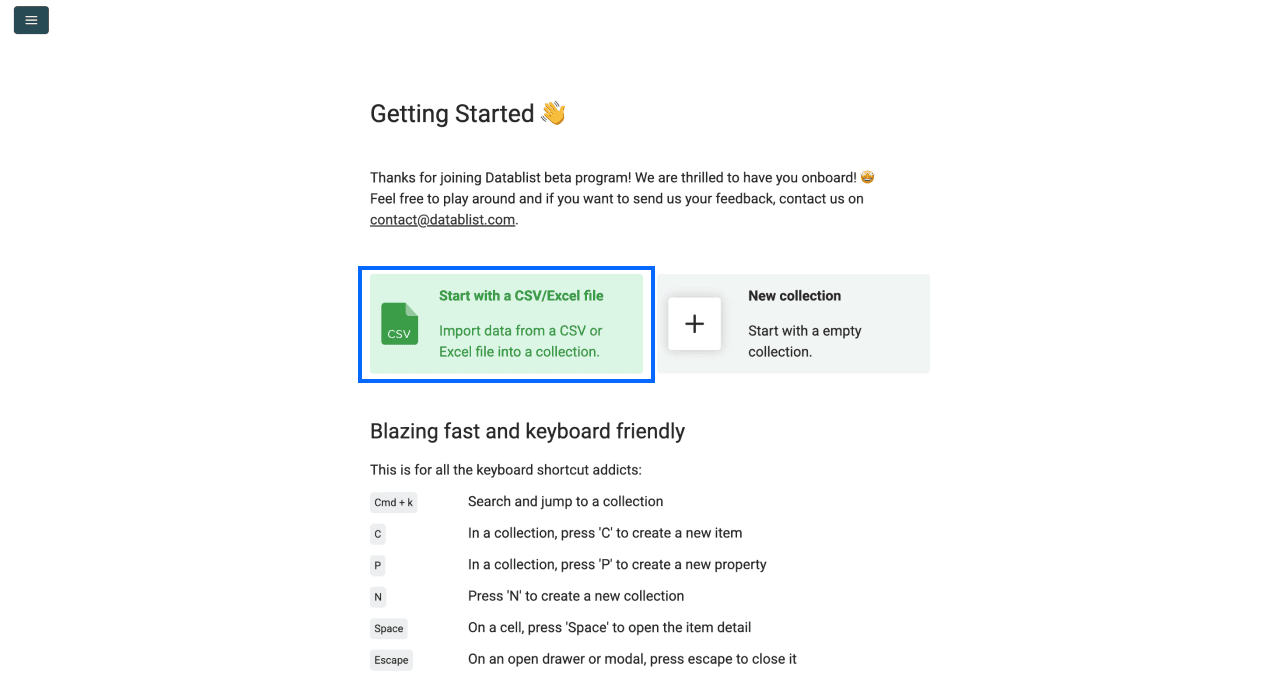
第 1 步:注册并上传数据
- 注册 Datablist
- Upload 你的 CSV 或 Excel
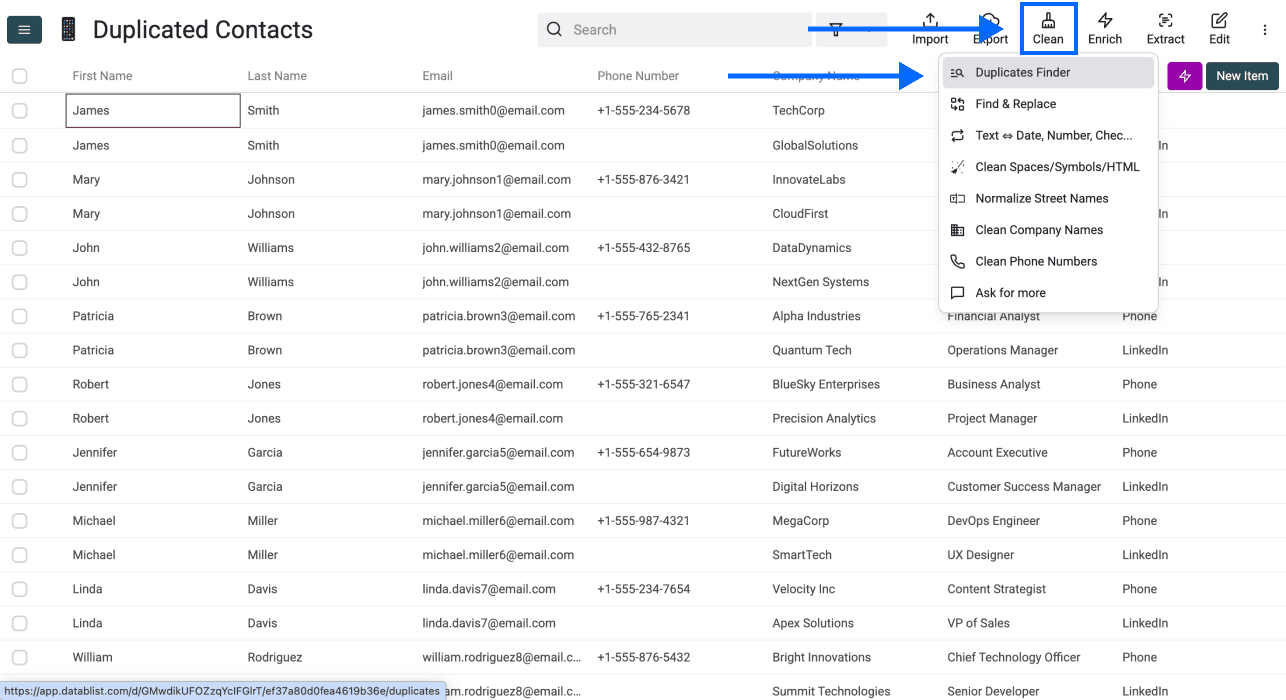
第 2 步:进入 Duplicates Finder
点击应用顶部菜单中的 Clean,然后选择 Duplicates Finder。
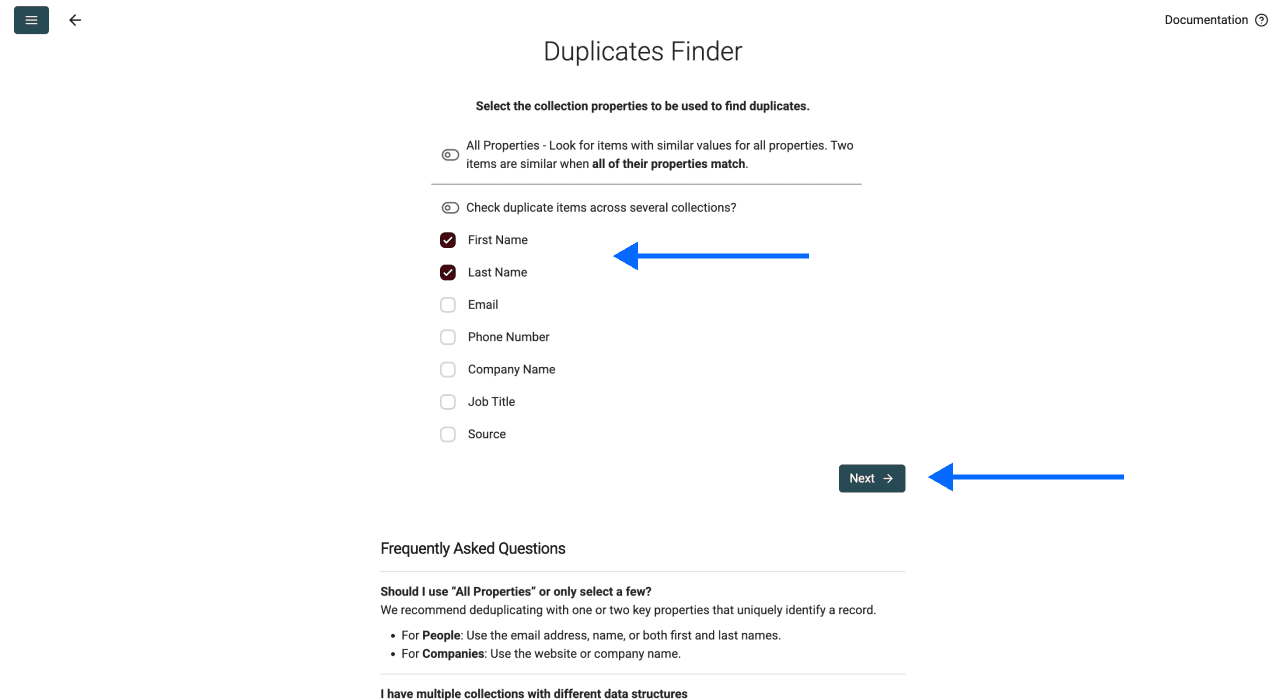
第 3 步:选择唯一标识符
选择你想用于匹配重复项的列。选好后,向下滚动并点击 Next。
第 4 步:选择比较算法
为每个用于去重的属性选择比较算法和处理器。除公司名称外,我们建议保留默认设置。
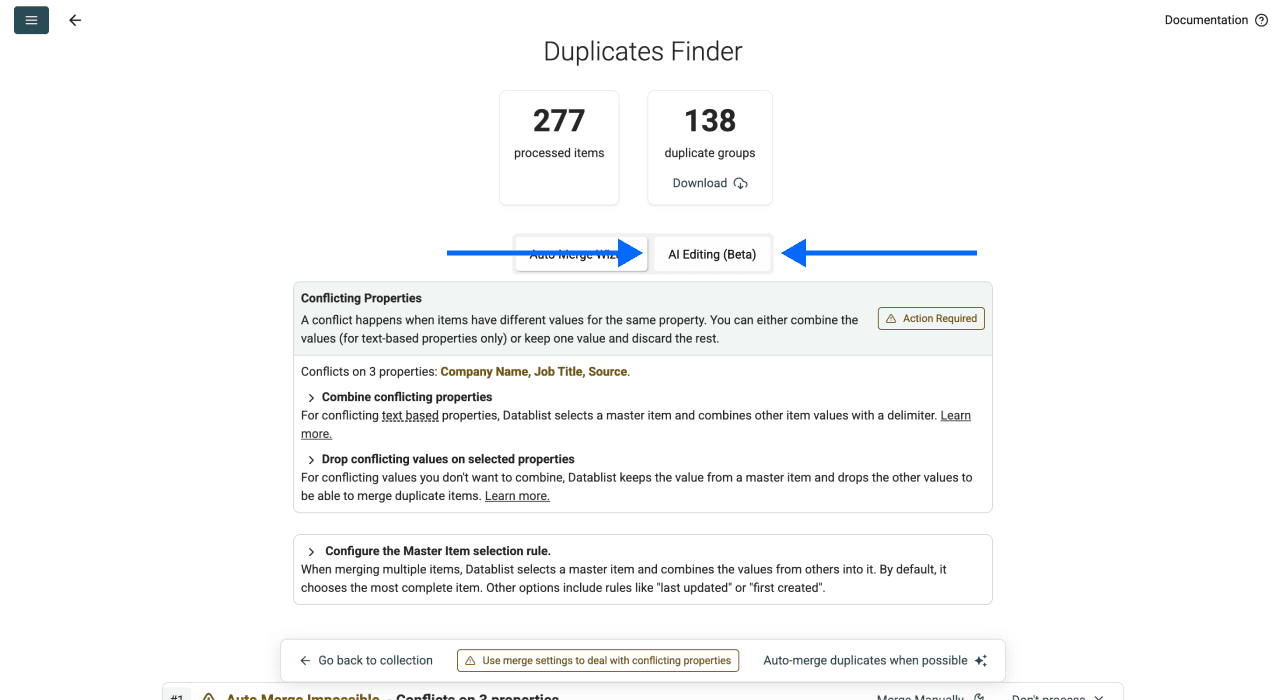
第 5 步:打开 AI Editing
不要选择 master item rule,而是在去重面板中点击 AI Editing。
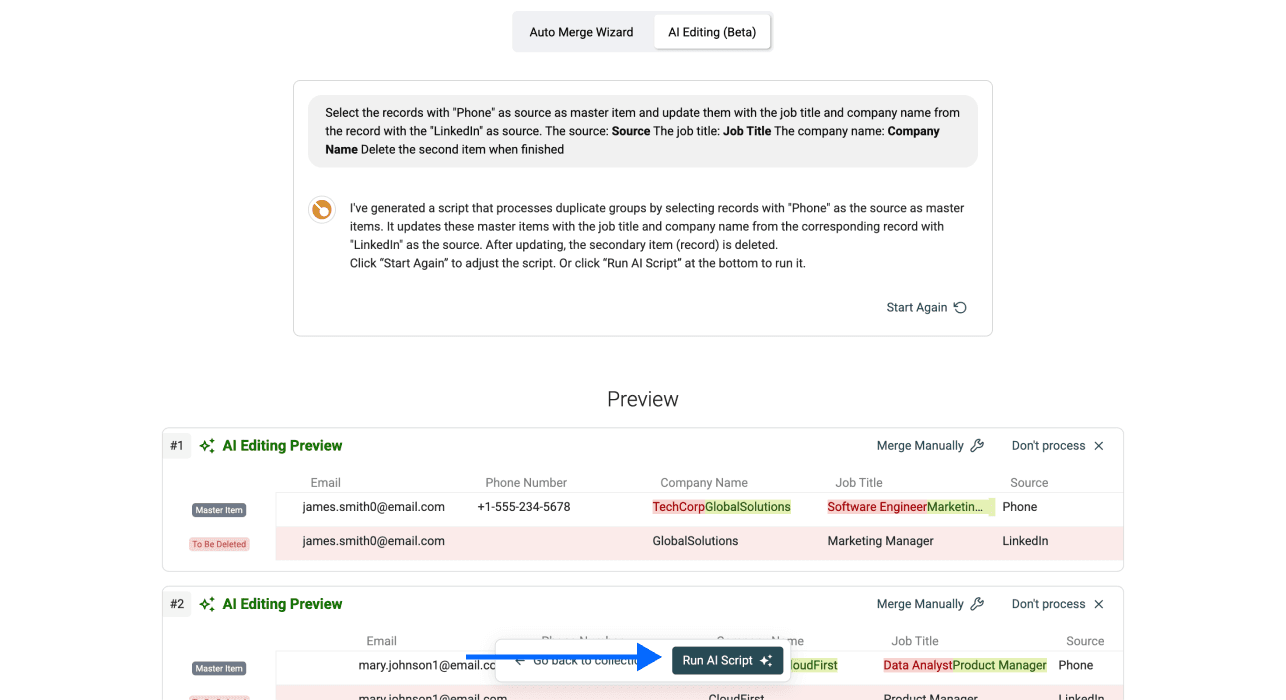
第 6 步:编写 Prompt
用自然语言描述你想要的结果。下面是一个实用例子:
假设你有两个来源的联系人数据:电话验证和 LinkedIn 抓取。电话记录有已验证号码,但 LinkedIn 记录有更新的职位和公司名称。你想保留电话记录作为 master,同时用 LinkedIn 数据更新它。
这是我使用的 prompt:
Select the records with "Phone" as source as master item and update them with the job title and company name from the record with the "LinkedIn" as source.
The source: /source
The job title: /job title
The company name: /company
Delete the second item when finished
注意: 别忘了用 / 把你的属性映射到 prompt 中。
准备好后,点击 Generate and preview changes。

第 7 步:检查并应用变更
Datablist 会在应用变更前,清楚展示 AI 将执行哪些修改。先检查预览,确认它符合你的预期。
确认没问题后,点击 Run AI Script,把变更应用到所有重复组。然后导出清洗后的数据。
💡 写好 Prompt 的技巧
尽量具体说明你的期望。你越清楚地描述想让它做什么,结果就越稳定。
你还可以这样用
- 标记重复项,而不是删除: 写一个 prompt,例如“Add 'DUPLICATE' to the status column for all non-master items instead of deleting them”
- 合并文本字段: “Merge all notes from duplicate records into the master item's notes field, separated by line breaks”
- 按数据源质量排序: “Use Salesforce records as master when available, otherwise use HubSpot, then spreadsheet imports”
- ……或者任何你能清楚描述的规则。
跨两个或更多表格删除重复项
如果你有两个不同的 CSV 文件,想找出两个文件里都出现的记录,或者想用现有 CRM 导出文件来给新的 lead list 去重,Datablist 可以把流程简化很多。
工作原理: 和单文件去重不同,这个工作流会跨多个文件比较记录,并删除分布在不同数据源中的重复项。你可以选择两个或更多文件,没有数量限制。
适用场景
- 你正在导入新 Leads,想避免和现有联系人重复
- 你正在合并多个供应商或来源的数据
- 你需要找出两个客户名单之间的重叠部分
- 你想避免重复联系同一个潜在客户
- 你需要整合不同部门或分支机构的客户数据
- ……以及更多 data cleaning 工作流
📘 与单文件去重的重要区别
跨多个文件去重时,Datablist 会直接删除重复项,而不是合并它们。
第 1 步:注册并上传文件
- 注册 Datablist
- Import 你的第一个 CSV 或 Excel 文件
- 将第二个文件 Import 到另一个 collection 中(以及任何你想参与跨文件去重的其他文件)
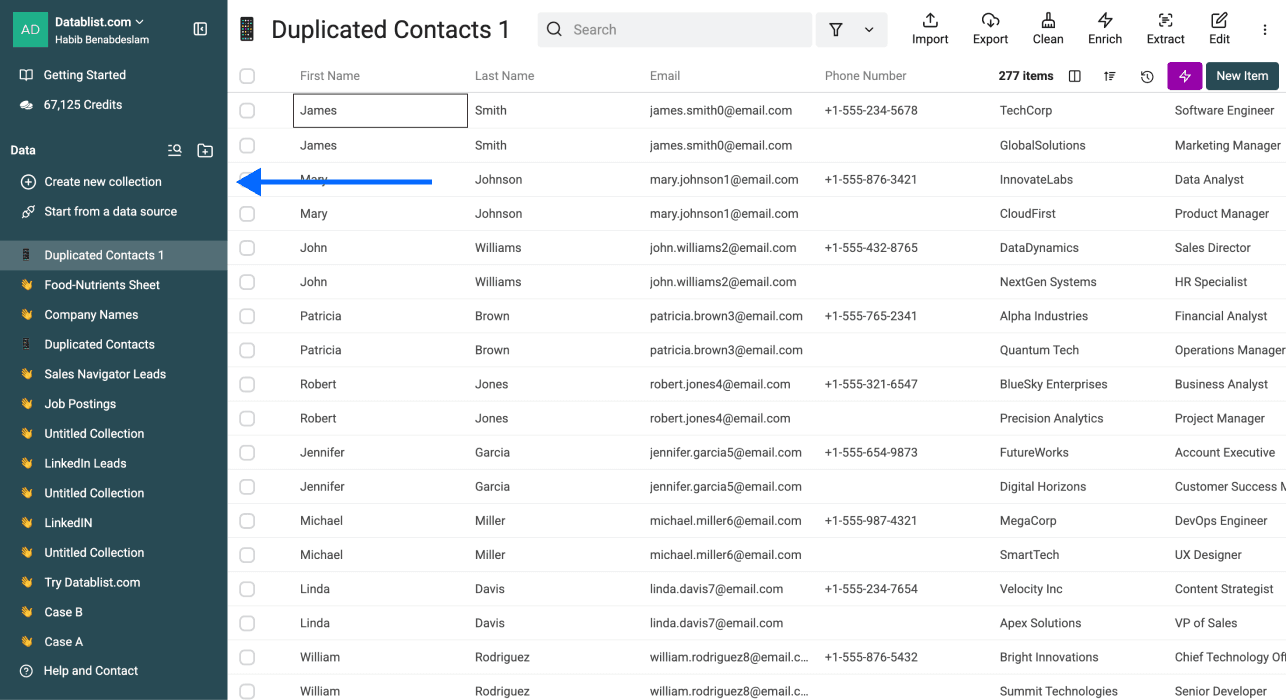
- 确保你有唯一标识符
继续之前,确认所有文件至少共享一个可作为唯一标识符的公共列。可以是:
- Email address
- LinkedIn URL
- Company domain
- Phone number
- 任何其他能唯一识别记录的字段
第 2 步:进入 Duplicates Finder
点击应用顶部菜单中的 Clean,然后选择 Duplicates Finder。
第 3 步:启用 Multi-Collection Deduplication
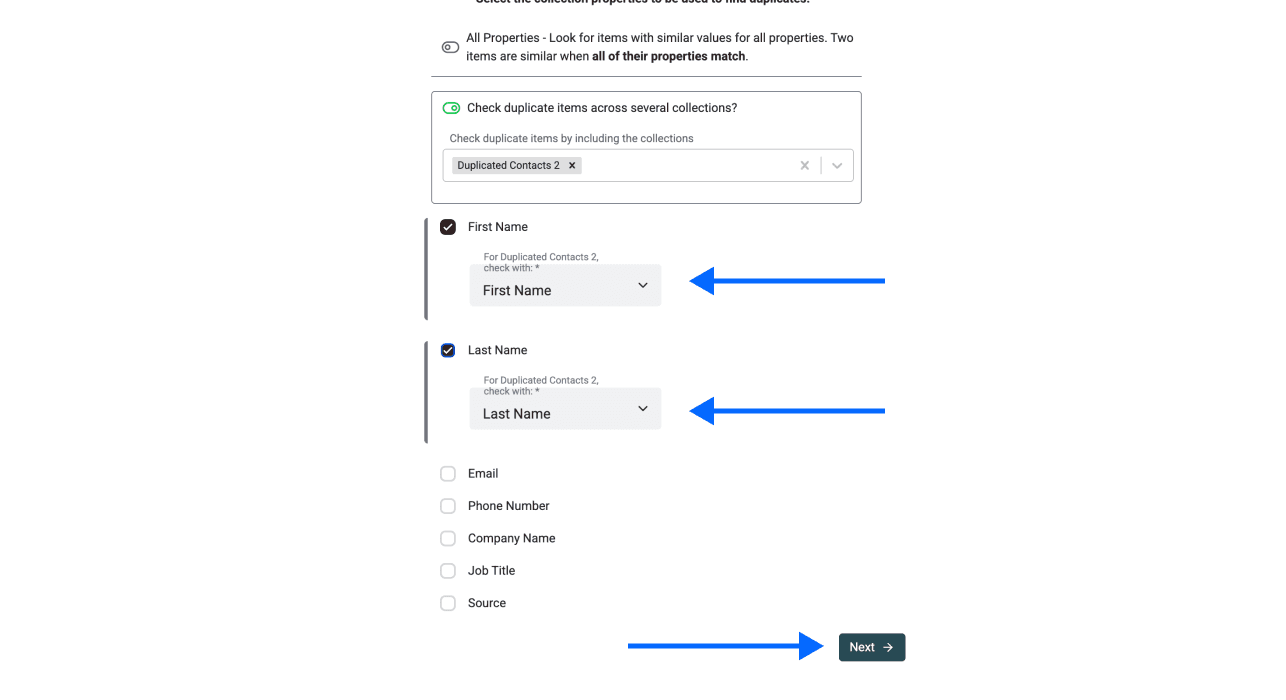
- 勾选 Check Duplicate Items Across Several Collections
- 选择你刚导入的 collection(s) / file(s)
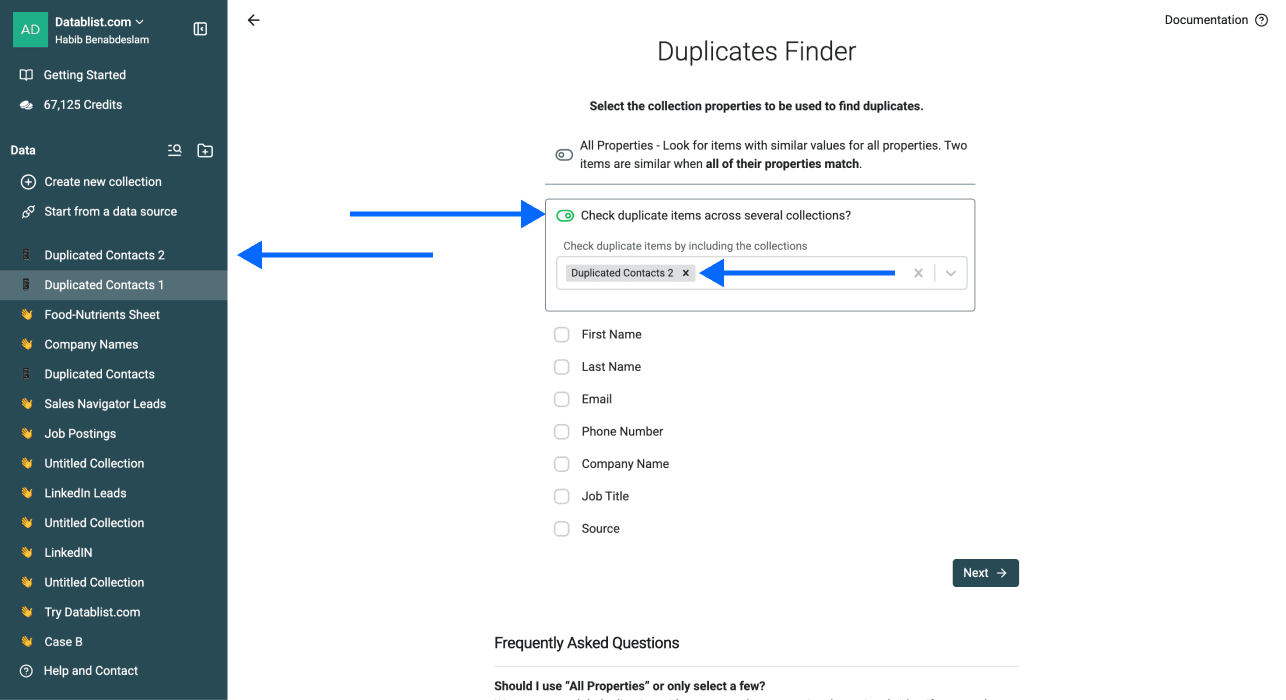
第 4 步:选择唯一标识属性
选择用于跨文件匹配重复项的属性。你可以选择多个属性,但要确保所有文件都包含这些属性,这样去重结果才准确。
第 5 步:选择比较算法
选择适合你数据的比较机制:
- Exact: 适合 URL、域名或 ID 等必须完全匹配的字段
- Smart: 适合文本类属性,能够处理轻微差异
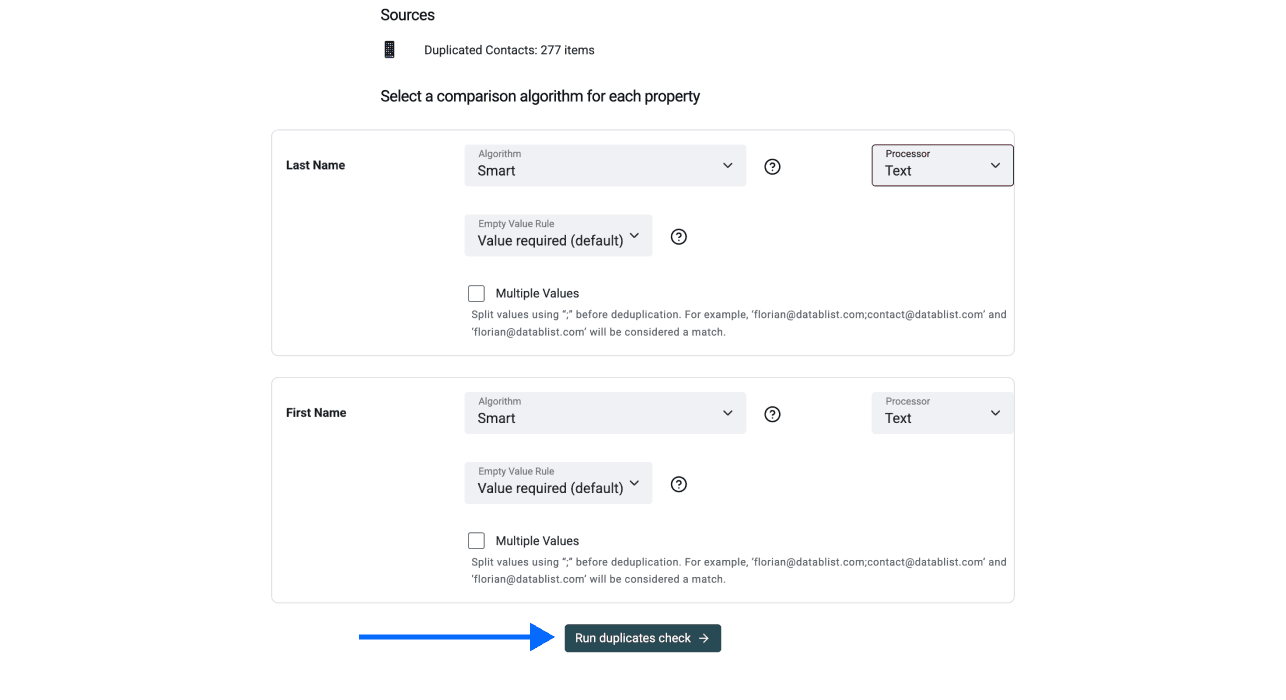
选择比较方法后,点击 Run duplicates check。
第 6 步:设置清洗规则
选择你想如何处理重复项:
- Remove duplicate items from collection X: 从你选定的文件中删除重复项
- Keep duplicate items only in collection X: 只在跨 3 个或更多 collection 去重时可用
点击 Process duplicate items 继续。
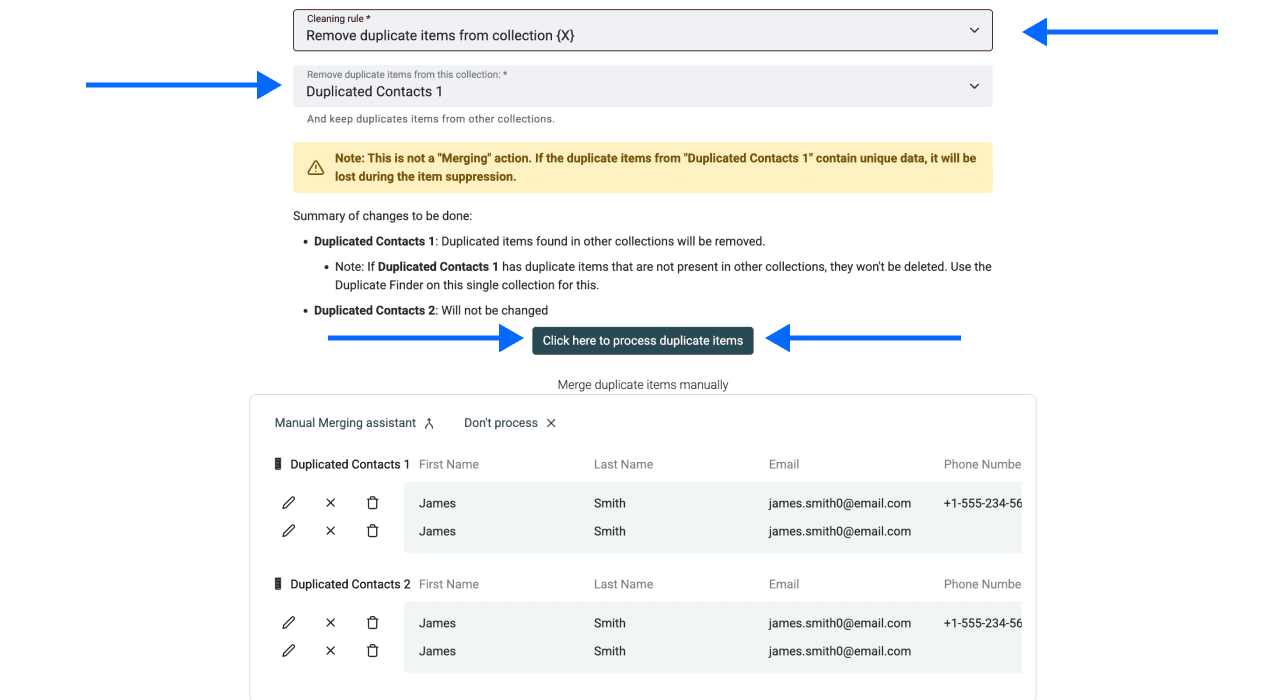
就这么简单!
结论
恭喜,你已经读到最后,现在你对 deduplication 的理解,已经超过大多数人会接触到的程度。快速回顾一下今天最重要的几点:
- 重复项并不都一样, 知道自己面对的是哪种类型,会直接影响处理方式
- 选对 Master Item 和批量操作,可以节省数小时的手动清理时间
- 不像很多工具会把你限制在固定流程里,Datablist 允许你按自己的规则处理重复项
无论你是在合并混乱 CRM 中的联系人,用 AI 应用自定义逻辑,还是用现有数据库清洗新 Leads,现在你都有了正确处理重复数据的工具和方法。
常见问题
Datablist 如何决定保留哪条重复记录?
Datablist 不替你决定,决定权在你。你选择一个 Master Item Rule(比如“Most complete”或“Last updated”),告诉 Datablist 哪条记录优先。如果你的逻辑更复杂,可以用 AI Editing 用自然语言定义自定义规则(我们的 AI assistant 会处理剩下的工作)。
Datablist 的 Deduplication And Matching Suite 和其他产品有什么不同?
三个关键词:灵活性、AI-powered customization 和 价格。大多数工具只能删除重复项。Datablist 可以根据你定义的规则合并、更新、标记或删除记录。AI Editing 能处理其他工具无法覆盖的复杂逻辑。而同类企业级产品通常每年要花费数千美元。
如果我不想删除重复项怎么办?
你可以只标记它们。使用 AI Editing,并写一个 prompt,比如:“Add 'DUPLICATE' to the status column for all non-master items instead of deleting them.” 这在合规场景下尤其有用,也适合你需要先审核重复项再删除的情况。
如果 Master Item Rules 不适合我的场景怎么办?
使用 AI Editing。你不需要选择预设规则,而是用自然语言描述你的逻辑,Datablist 的 AI 会为你创建自定义脚本。例如:“Keep the record from Salesforce, but use the job title from LinkedIn.”
我可以创建自定义 Master Item Rules 吗?
可以。Datablist 的 AI Editing 允许你写下任何可以清楚描述的优先级规则。想保留 A 列包含某个特定值的记录?或者基于多个条件排序?直接输入你的需求,AI 会处理剩下的部分。
去重中的唯一标识符是什么?
唯一标识符是能让每条记录彼此区分的列(或列组合)。例如,如果你用“Email”作为唯一标识符,两行只要 email 相同,即使其他字段不同,也会被视为重复项。你也可以组合“First Name”+“Company”等列,让匹配更严格。
如何处理带有冲突值的名单去重?
冲突重复项指的是两条记录代表同一个实体,但某些字段的值不同。处理方式是:(1) 选择一个 Master Item Rule,决定哪条记录胜出;(2) 决定是合并、丢弃还是更新冲突值;(3) 使用 Datablist 的 deduplication suite 批量应用你的选择。 对复杂场景,AI Editing 可以让你从不同记录中挑选指定字段值。
如何只标记重复项而不删除?
你可以在 Datablist 的 Deduplication and Matching Suite 中使用 AI Editing。只需要写一个 prompt,例如:“Add 'DUPLICATE' to the status column for all non-master items instead of deleting them.” 这样会保留所有数据,并把重复项标记出来供审核。它很适合合规场景,或者需要人工批准后再删除的流程。
如何在不删除的情况下更新重复记录?
更新重复项的意思是,用另一个来源中更好的数据替换 master record 的指定字段。为此,你可以使用 Datablist 的 AI Editing,它位于 Deduplication and Matching Suite 中。你唯一需要做的就是描述想要的结果,例如: “Keep records from Source A, but update the job title and company name using values from Source B.” AI 会把你的逻辑应用到所有重复组,之后你可以删除多余记录,也可以保留并标记它们。