

数据清洗(Data Cleaning,也常叫 Data Cleansing)早就不只是数据分析师的专利了。只要你在处理一份 prospect list、在流程里用到 scraped data,或者需要把多个数据源汇总到一起,你就会非常清楚:数据清洗做得好,后面的增长、运营、Sales 才跑得动。
对于简单操作来说,Google Sheets 和 Excel 够用,但一涉及到汇总(consolidation)和去重(deduplication),它们就会明显吃力。
这篇指南会带你用 Datablist —— 一个免费的在线工具,帮你清洗并标准化数据。
下面先快速概览本文会讲到的清洗操作:
- 把文本转换成 Datetime、Number、Boolean
- 把 HTML 转成纯文本(移除 HTML 标签)
- 去掉文本里的多余空格
- 标准化数据(Find and Replace)
- 移除文本中的符号
- 把 Full Name 拆分成 First Name 和 Last Name
- 数据去重
- 从文本中提取 email、URL 等
- 用 Regular Expressions 做筛选与校验
- 用 JavaScript 编写自定义转换
- 验证 Email 地址
从 CSV 导入或直接复制粘贴数据
Datablist 非常适合做数据清洗。它本质上是一个带清洗、批量编辑和 enrichment 功能的在线 CSV editor。 而且单个 collection 可以扩展到上百万条数据。
打开 Datablist,然后加载你的数据集合(collections)。
要新建一个 collection,在侧边栏点击 + 按钮,然后点击 “Import CSV/Excel” 上传文件;你也可以从新手引导页点击快捷入口,直接进入导入步骤。
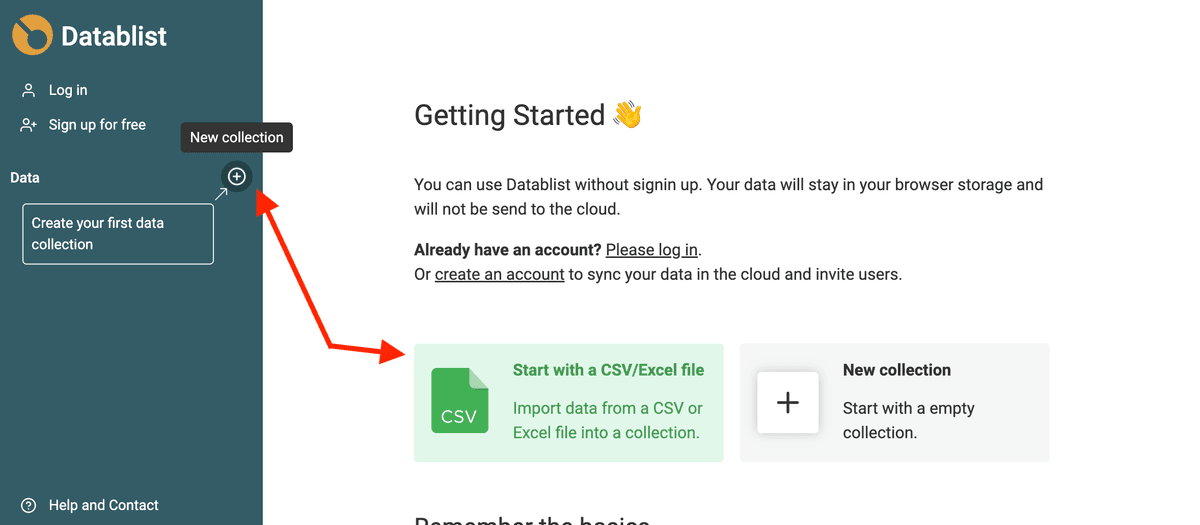
自动识别字段类型
Datablist 的导入助手会自动识别 email、ISO 8601 格式的 Datetime、Boolean、Number、URL 等,前提是数据格式足够规范。
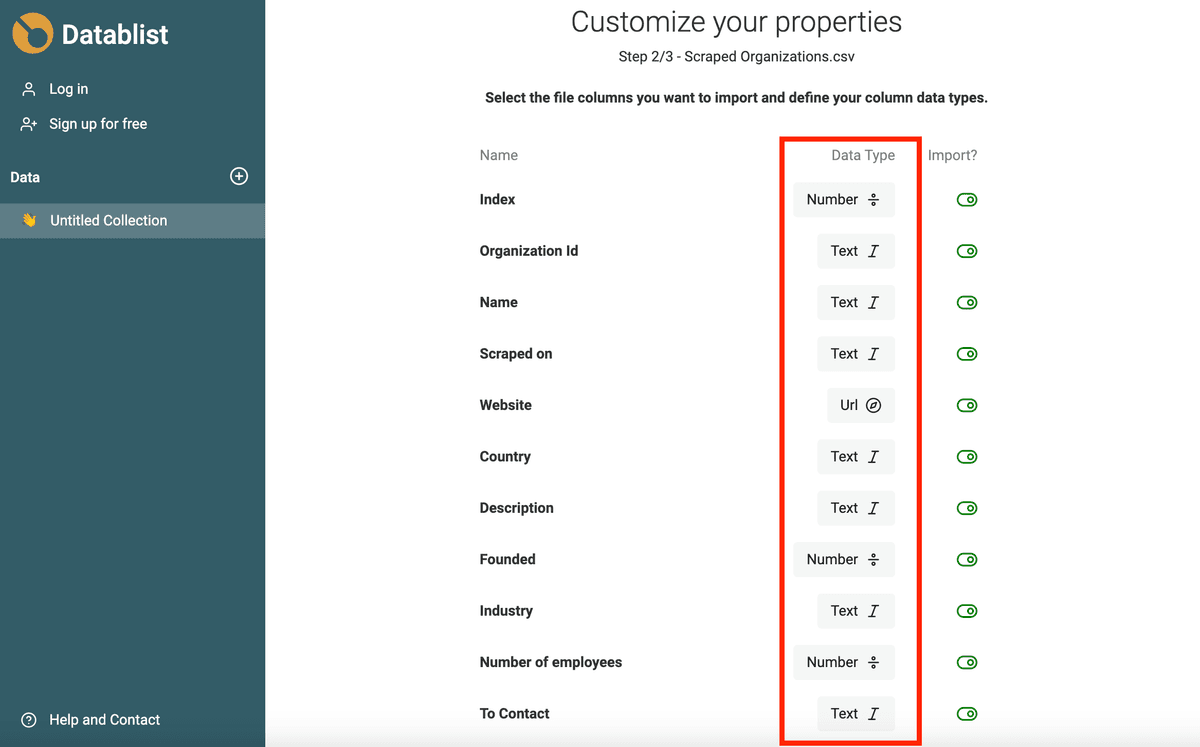
如果你的数据需要更复杂的判断(比如不同的日期格式、URL 或 email 有拼写错误),建议先按 Text 字段导入。下一节我会演示如何把 Text 字段再转换成 Datetime、Boolean 或 Number。
文本转换为 Datetime、Boolean、Number
Marie Kondo 说过:“人生真正开始于你整理好房间之后。”放到数据上也同理:Sales 真正开始于你把数据整理干净之后。(确实是这样)
当你要按 date(创建时间、融资时间等)、按 number(价格、员工数),或者按 boolean 来筛选时,如果它们是“原生类型”而不是一段文本,效率会高很多。
在 “Clean” 菜单里打开 “Text to Datetime, Number, Checkbox” 工具。
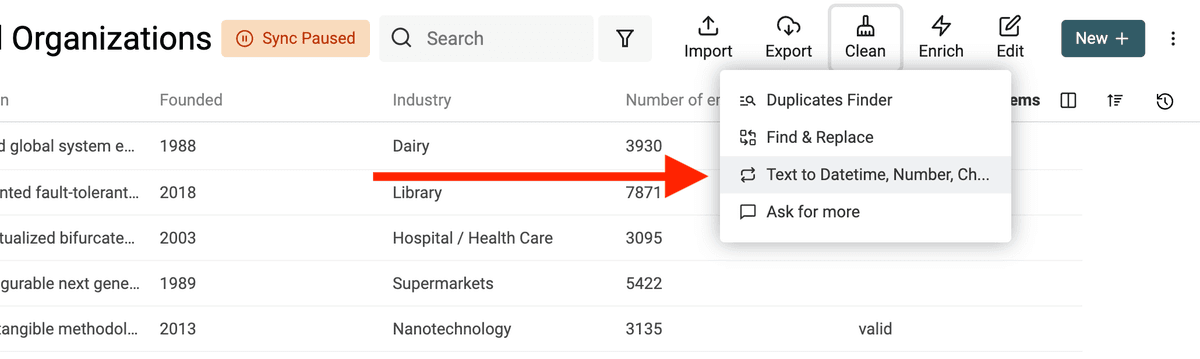
将任意文本转换为 Datetime 格式
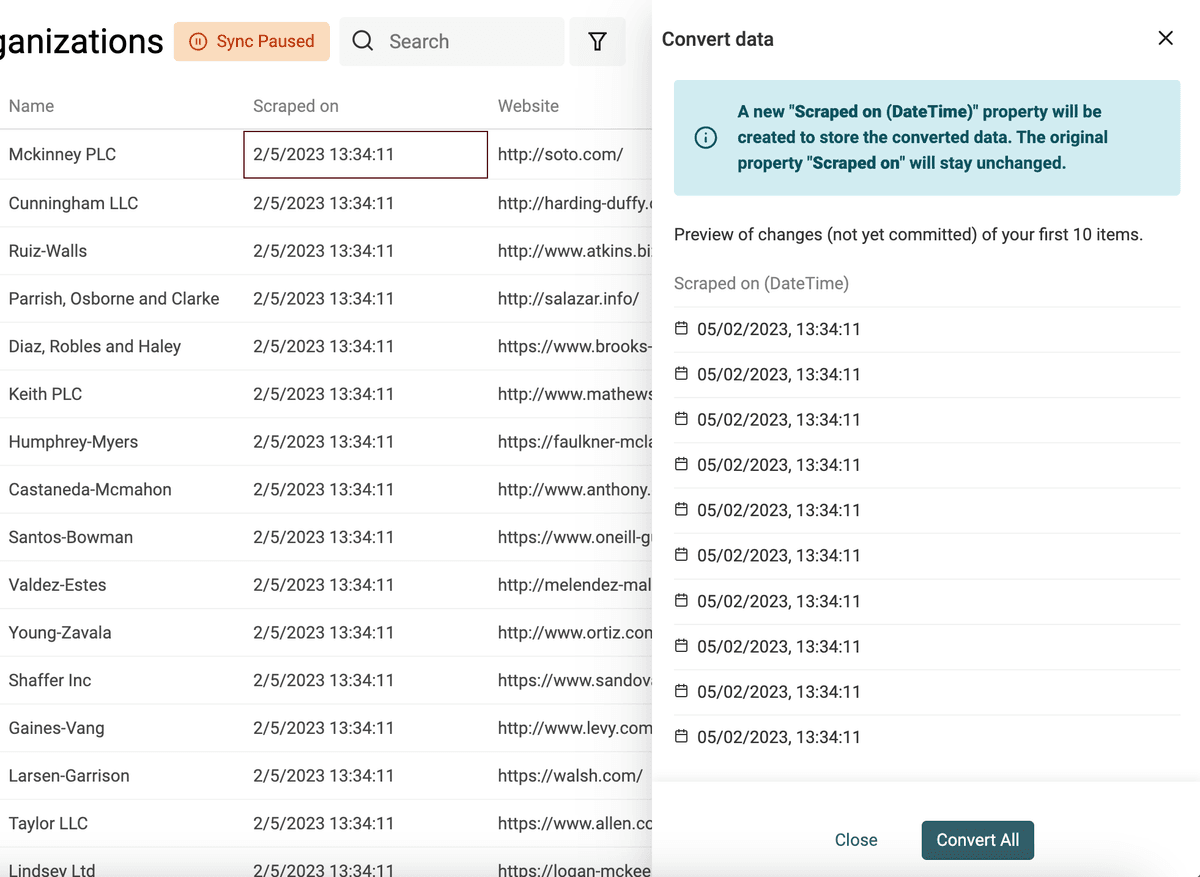
Datetime 有一个国际通用格式:ISO 8601,结构是固定的。如果你的数据本身就是 ISO 8601,导入时 Datablist 会自动创建 Datetime 字段来存储。
但如果你的日期/时间是其它格式,就需要你告诉 Datablist 具体格式,它才能把文本正确转换为结构化的 Datetime。
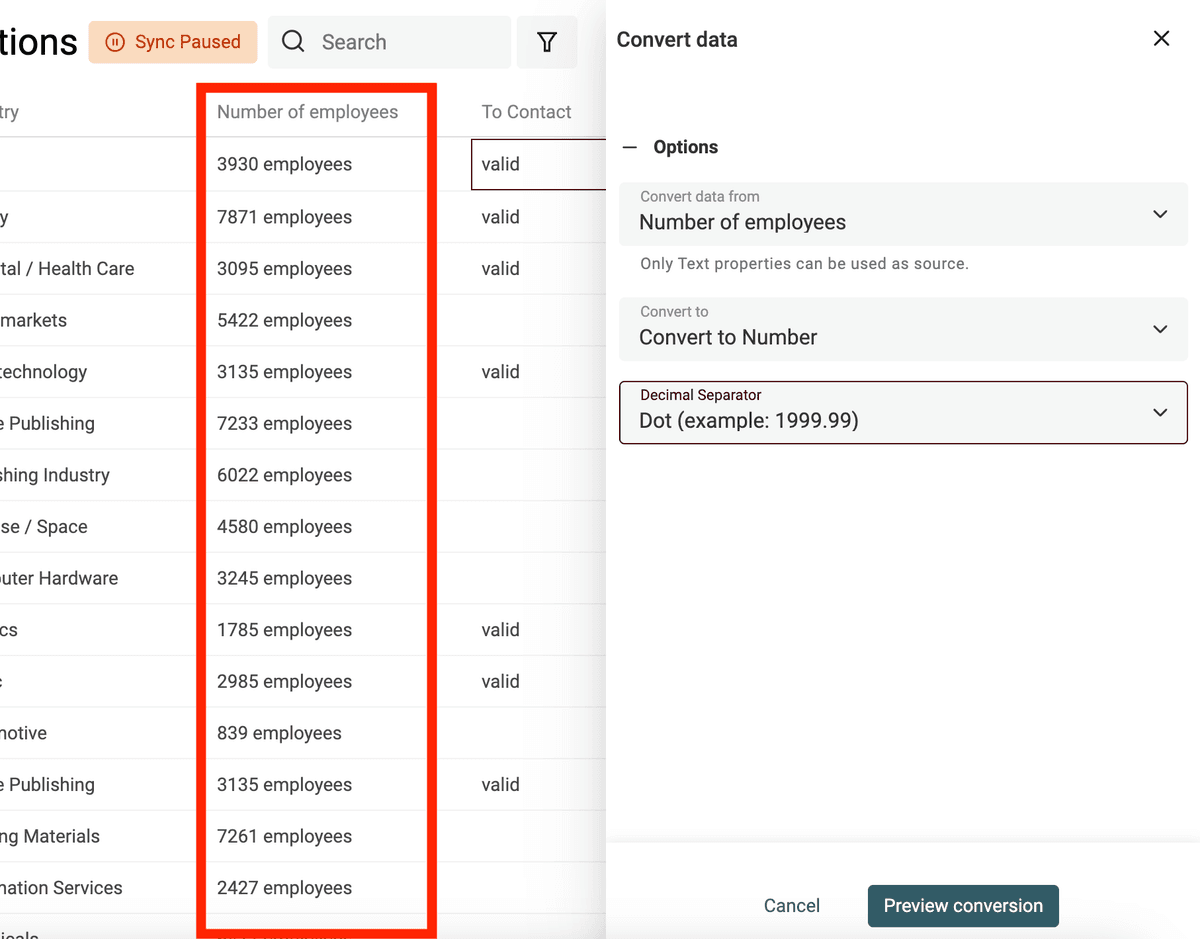
选择要转换的字段,然后选择 “Convert to Datetime”。
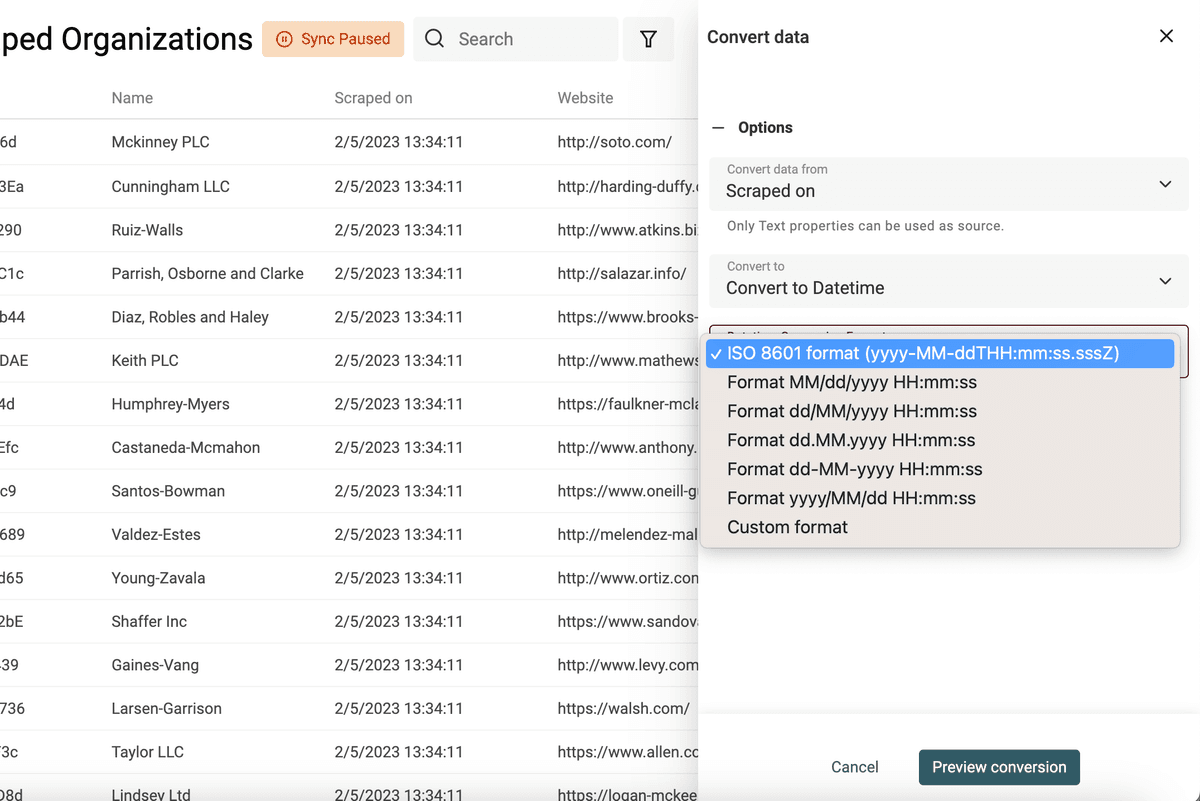
你可以直接选择常见格式(Google Sheets / Excel 常用格式),也可以选择 “Custom format” 自定义日期时间格式。
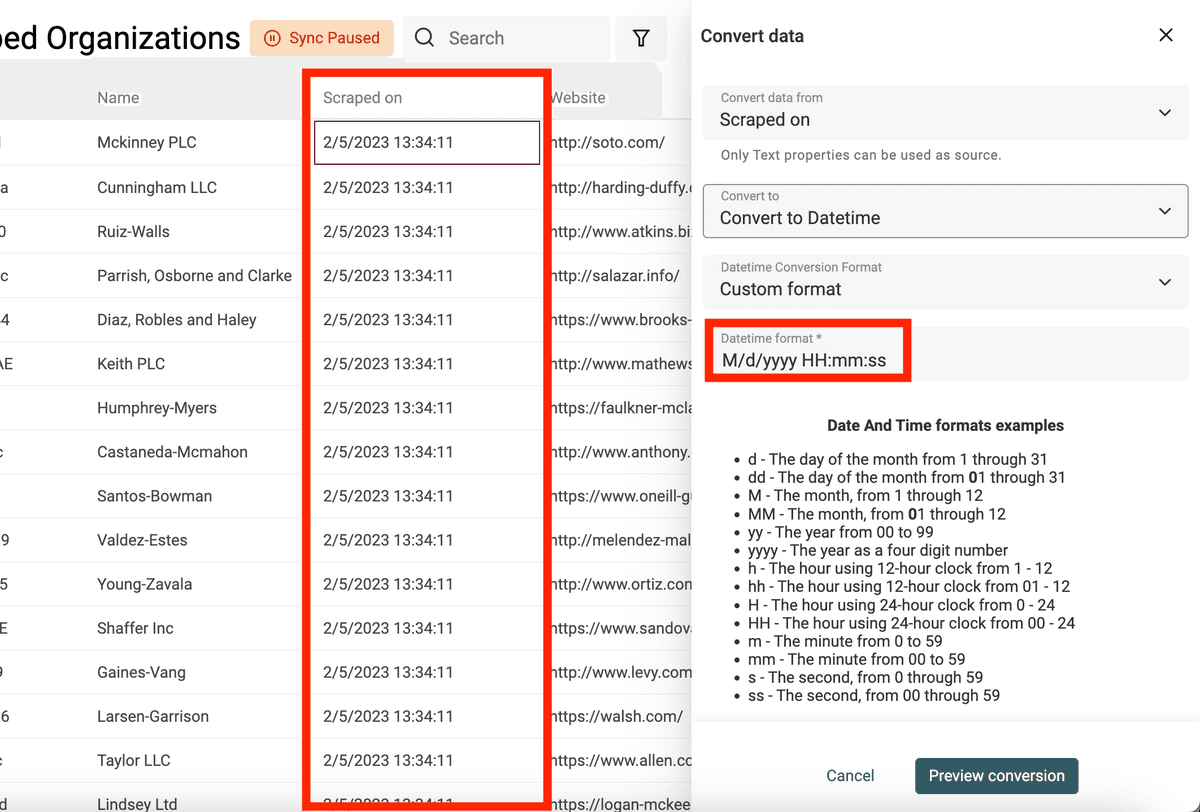
如果同一个字段里混用了多种日期/时间格式,可以在 “Datetime Conversion Format” 里选择 “Custom or multiple formats”,然后每行填一种格式。 Datablist 会从第一行开始依次尝试,直到解析出有效日期为止。
从文本值创建 Checkbox(Boolean)
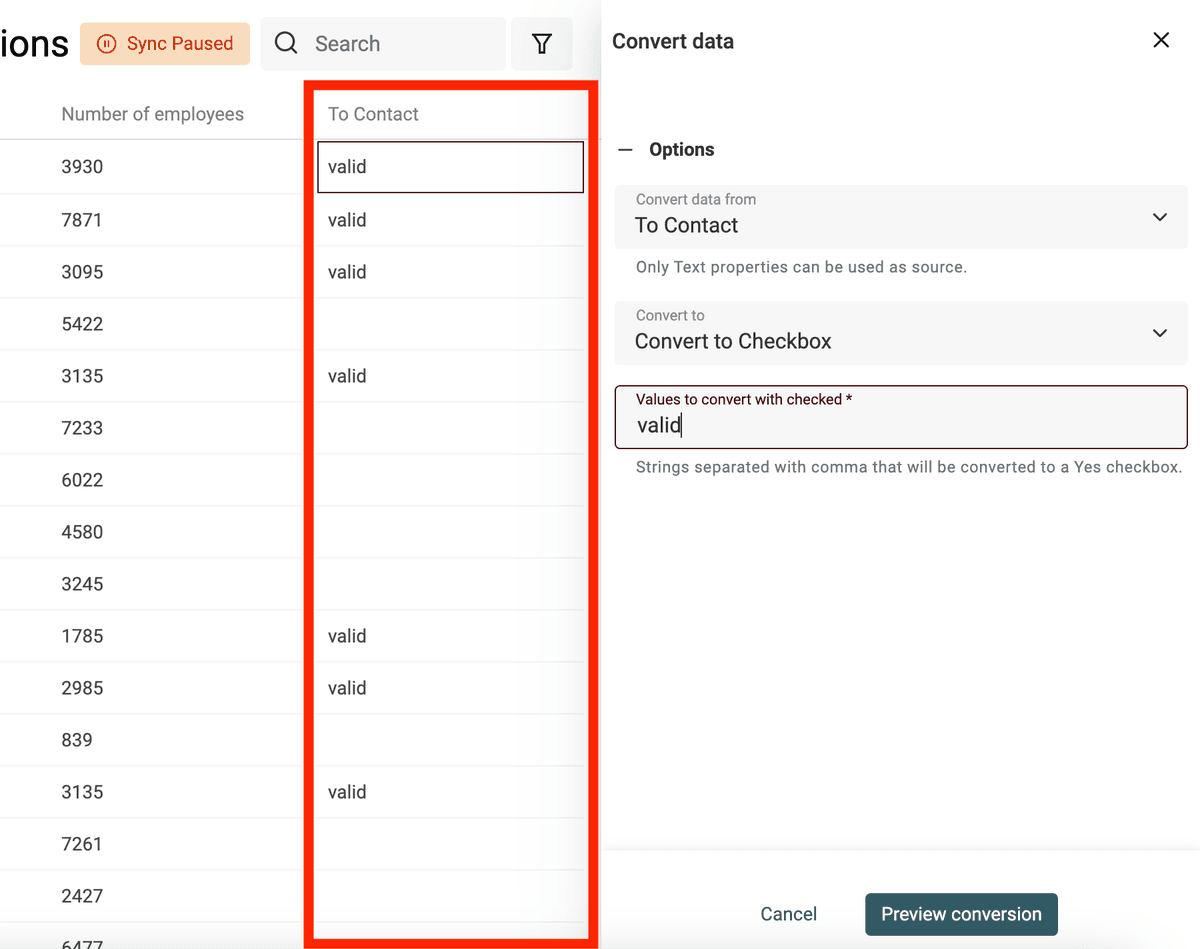
Datablist 在导入时会自动把 “Yes/No”、“TRUE/FALSE” 这类列识别成 Checkbox 字段。更复杂的情况就用转换器来处理。
你需要定义哪些值(用逗号分隔)会被转换为 checked;其它值会保持 unchecked。
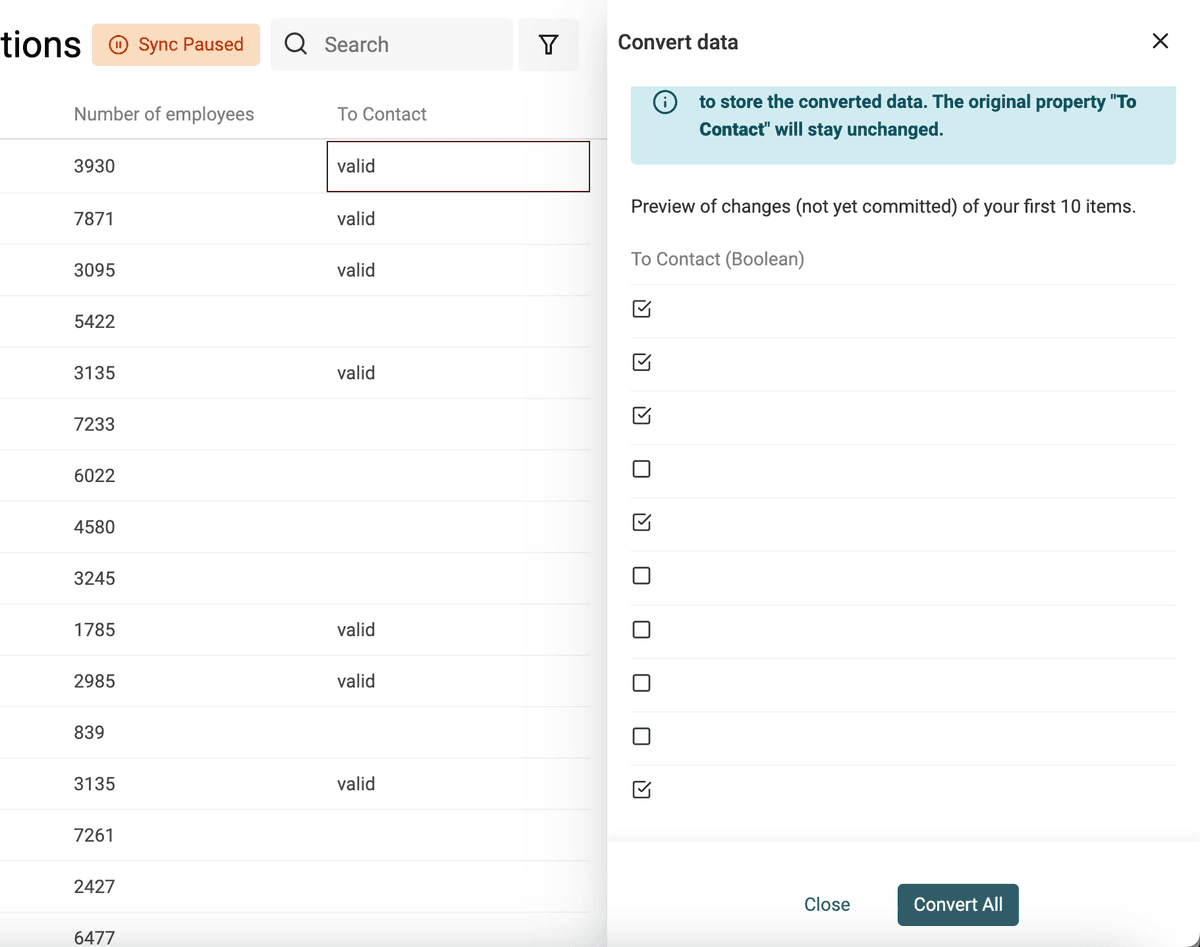
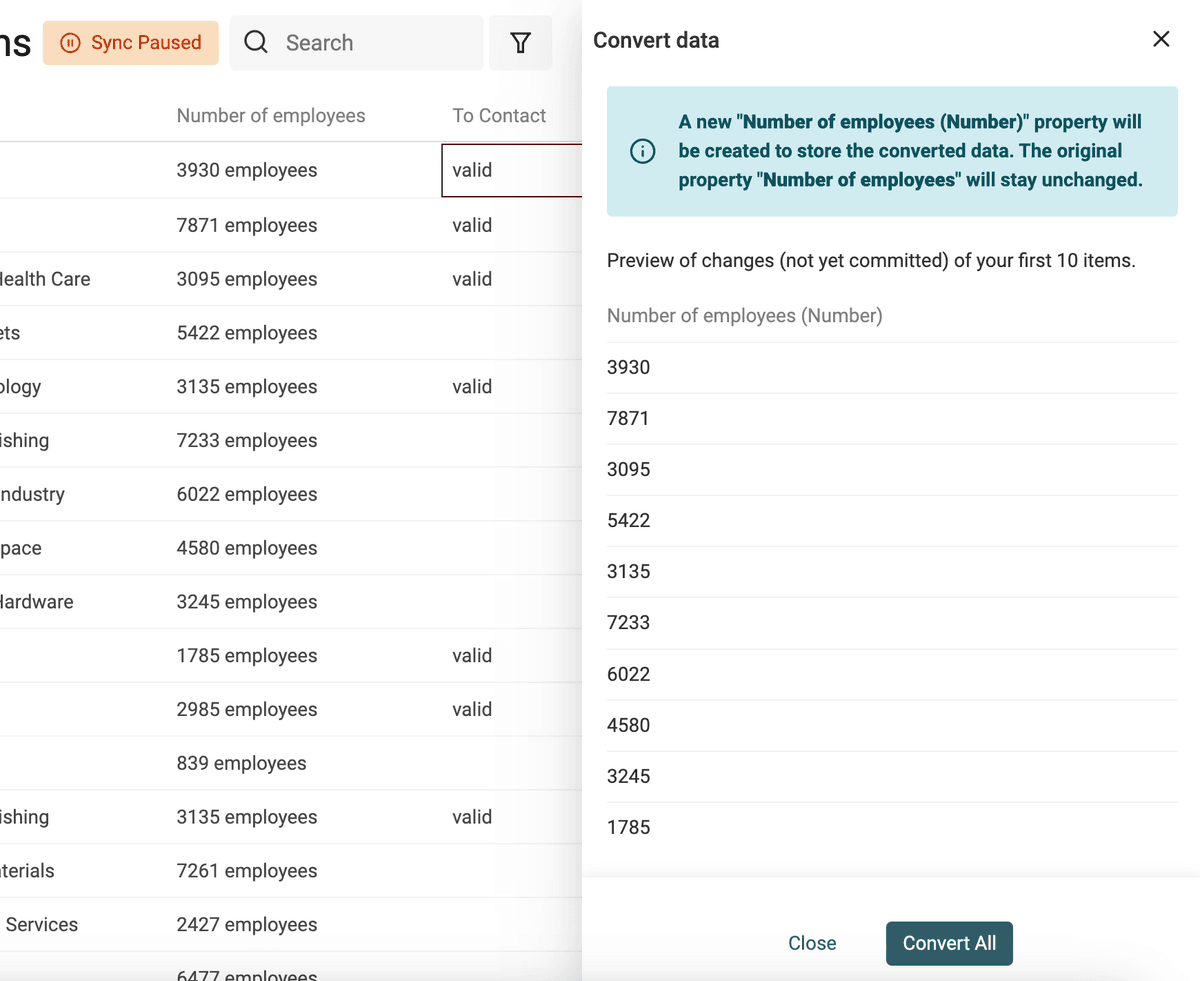
从文本中提取数值(Number)
用 “Text to number” 转换器可以:
- 用自定义的小数位/千分位分隔符来规范化数字
- 从包含字母的文本里提取出数字
数据清洗技巧与实操
将 HTML 转为纯文本
很多 scraping 工具会解析 HTML,所以你拿到的数据里经常会混入 HTML 标签。
HTML 里会包含链接、图片、带项目符号的列表,也常常是多段落、多行的结构。
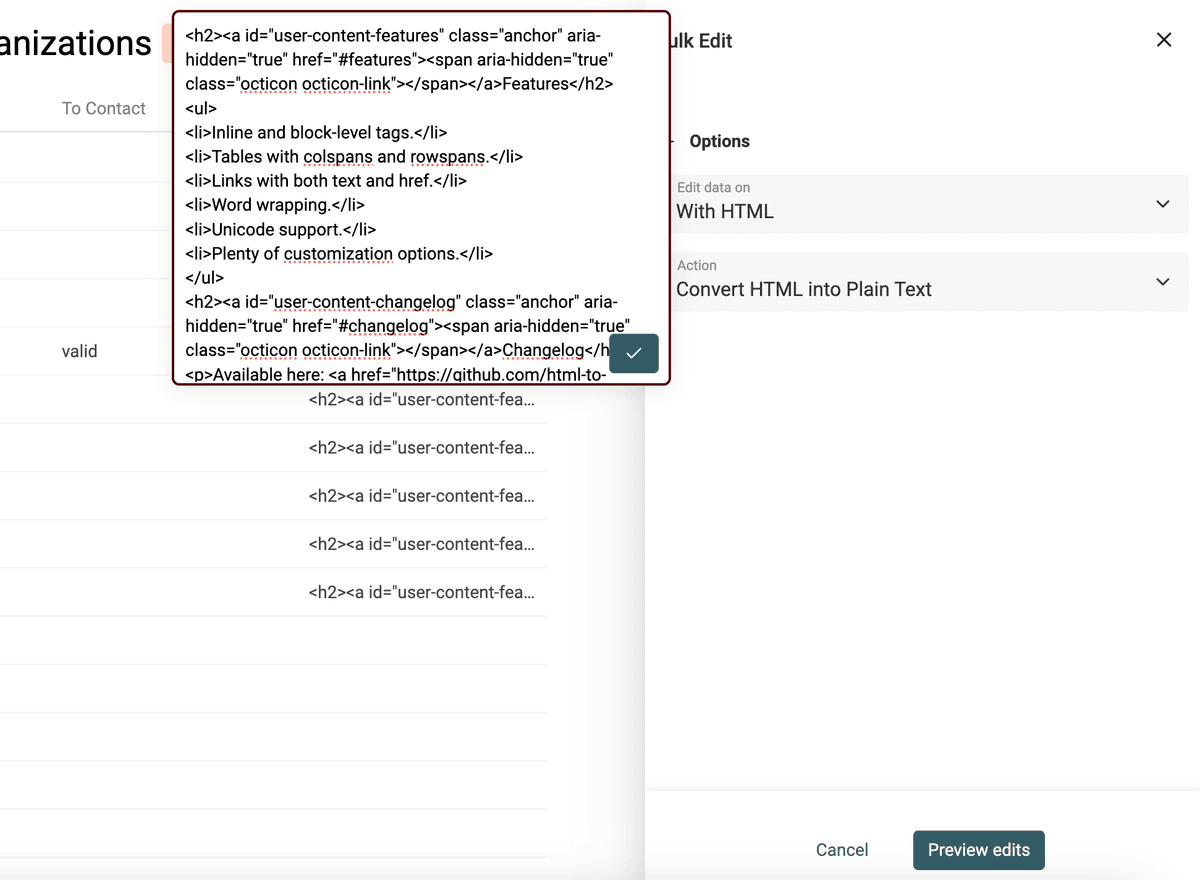
我们的目标是尽量保留 HTML 的“排版顺序”,但把不可读的代码变成纯文本(plaintext)。
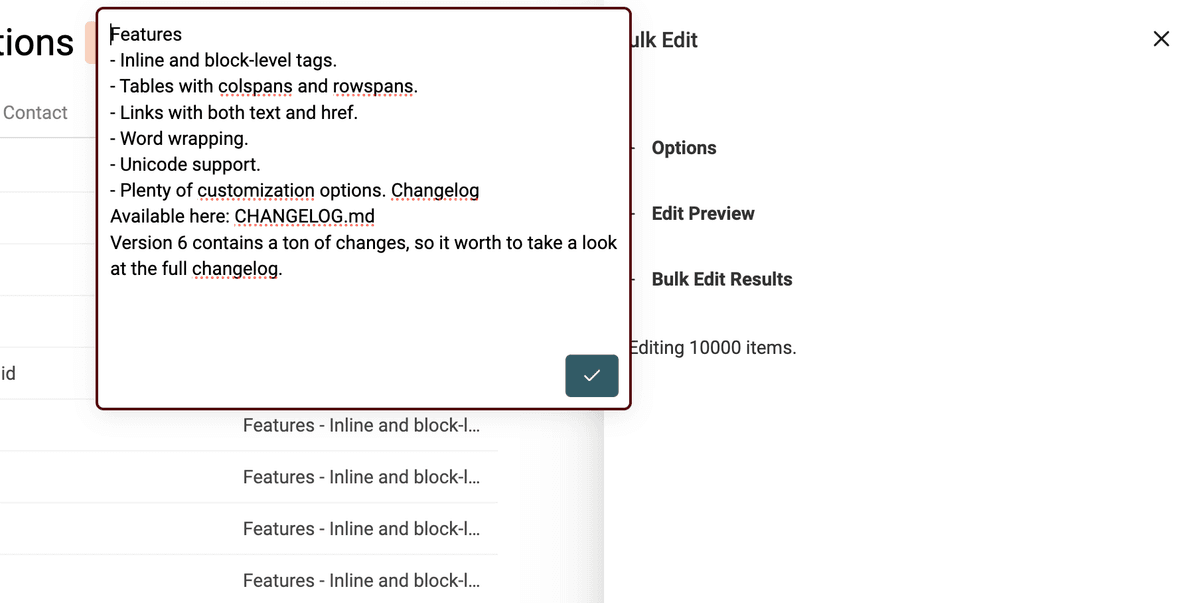
Datablist 的 HTML to Text 转换器会保留换行,并把项目符号列表转换成以 - 开头的列表。
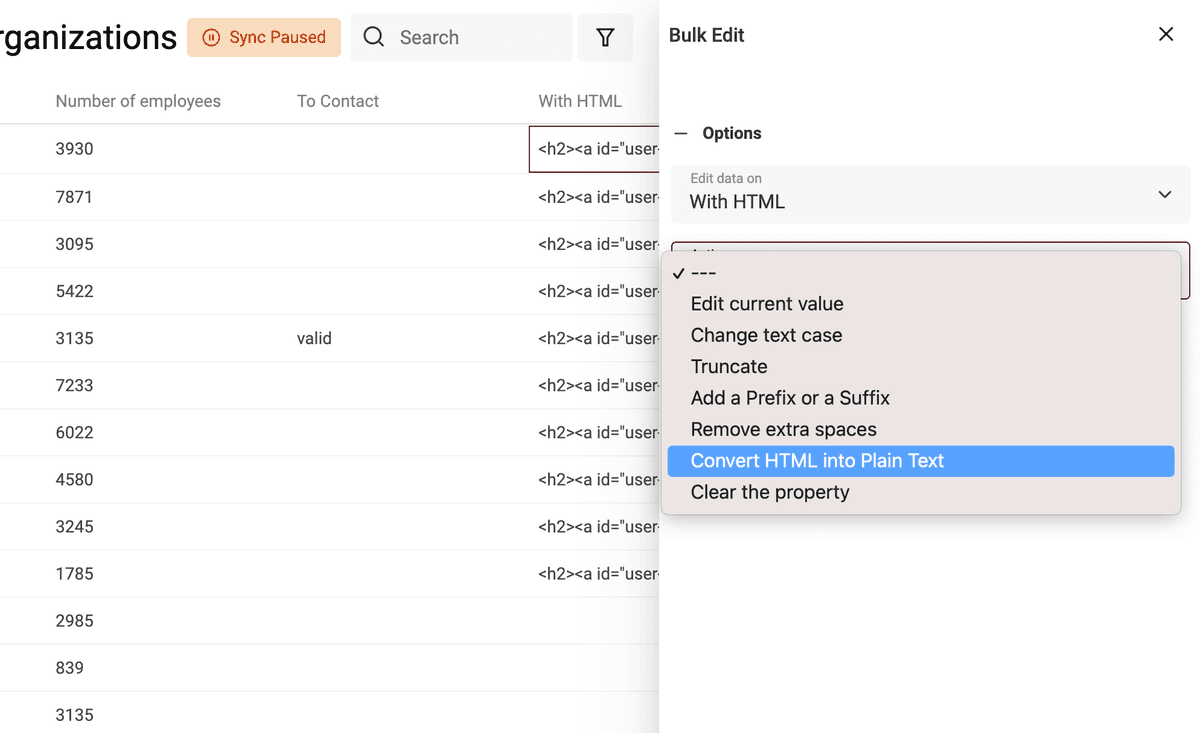
要把包含 HTML 标签的文本转换为纯文本,在 Edit 菜单中打开 Bulk Edit。
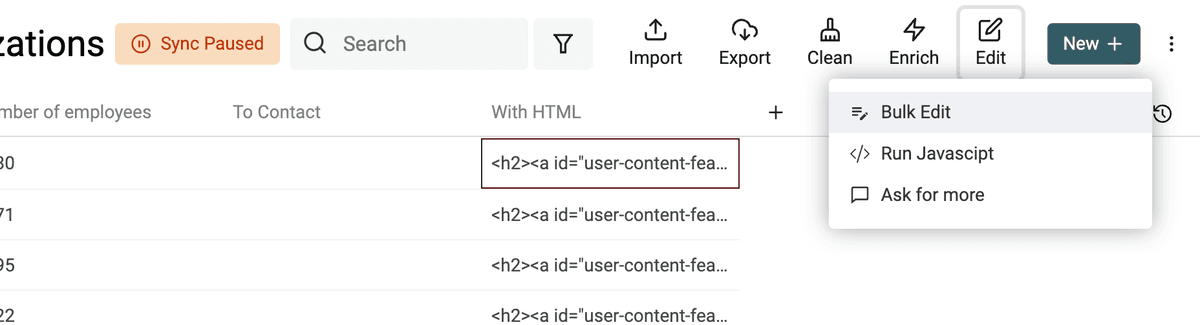
选择包含 HTML 的字段,然后选择 “Convert HTML into plain text”。
移除多余空格
脏数据里另一个常见问题就是“多余空格”。这些空格可能来自换行、Tab,或者 HTML 里各种代表空格的字符。
Datablist 内置了一个专门的清洗动作来处理多余空格。
它有两种模式:
- Mode 1:Remove all spaces —— 移除所有空格字符。适合清洗手机号、价格等(你希望只保留字母/数字等)。
- Mode 2:只移除“多余空格”。
第二种模式的算法逻辑是:
- 删除单词之间多余的空格
- 删除空行
- 删除每行的首尾空格
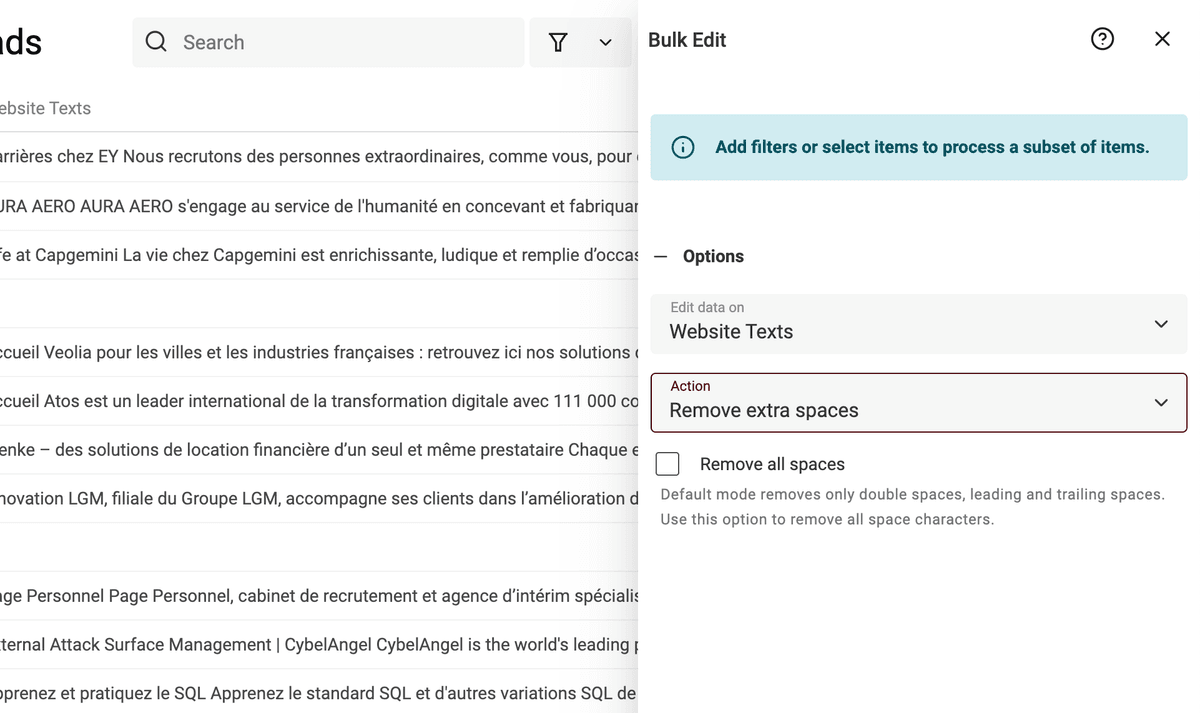
要移除多余空格,在 Edit 菜单打开 “Bulk Edit”,选择字段并使用 “Remove extra spaces”。
如果勾选 “Remove all spaces”,会移除所有空格;不勾选则只清理“多余空格”。
下面是一个示例(算法清理前):
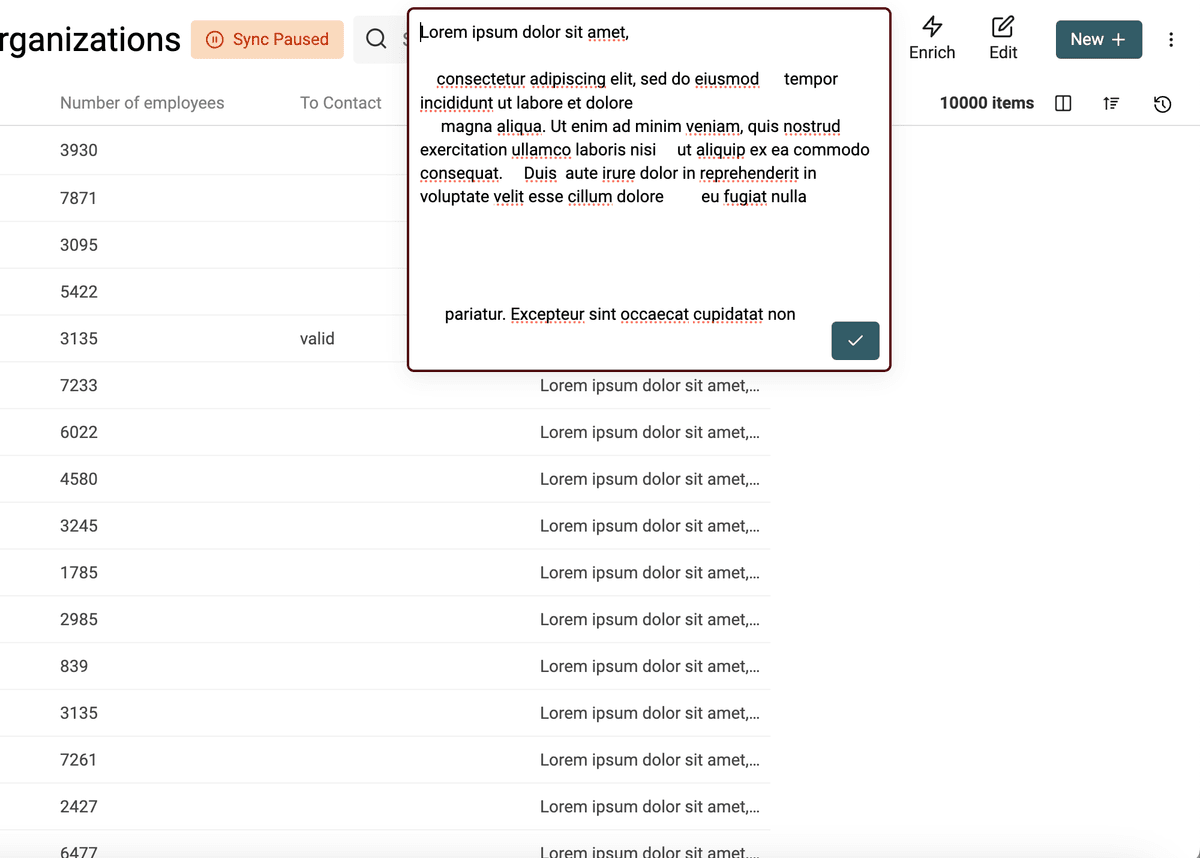
清理后(多余空格被移除):
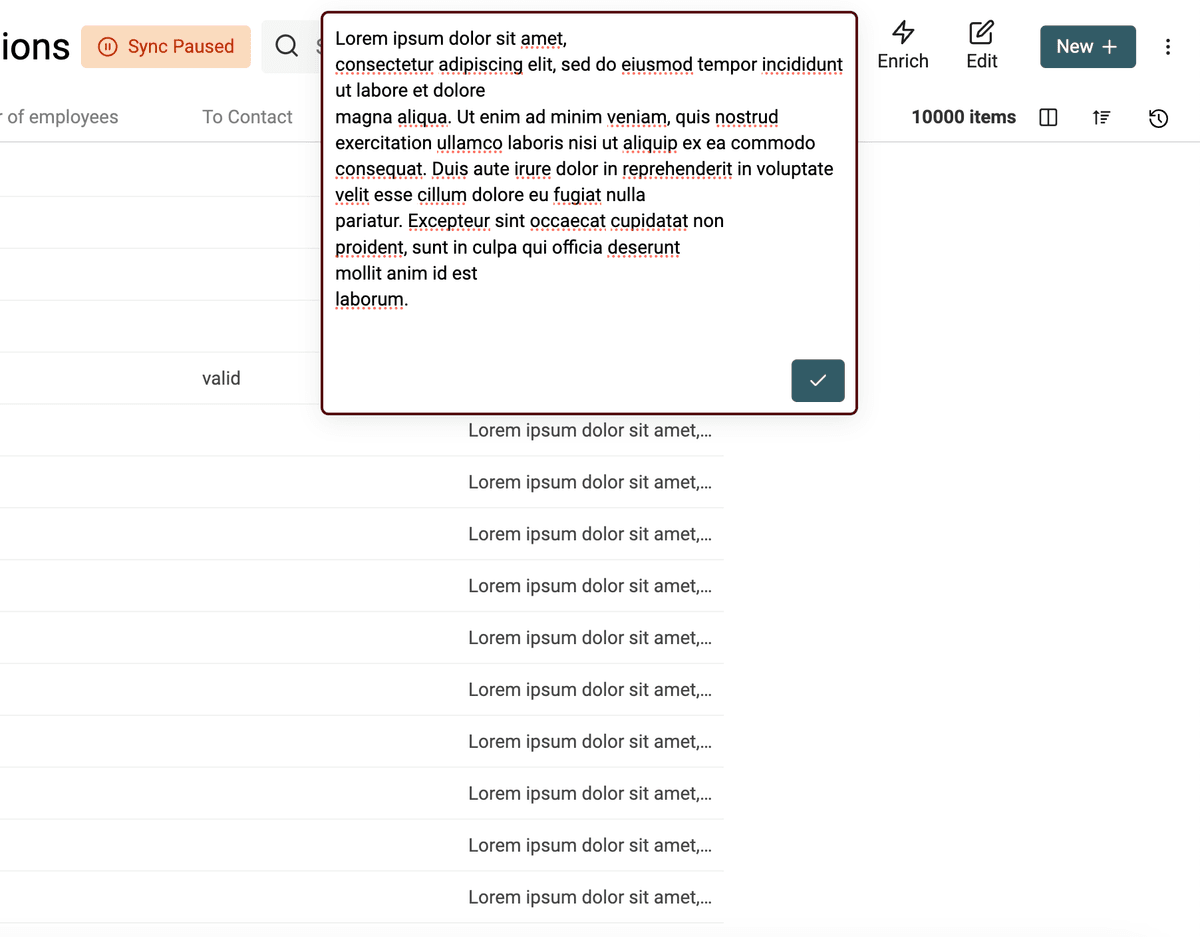
统一文本大小写
要调整文本大小写很简单:在 Edit 菜单打开 “Bulk Edit”。
选择要处理的字段,然后使用 “Change text case”。
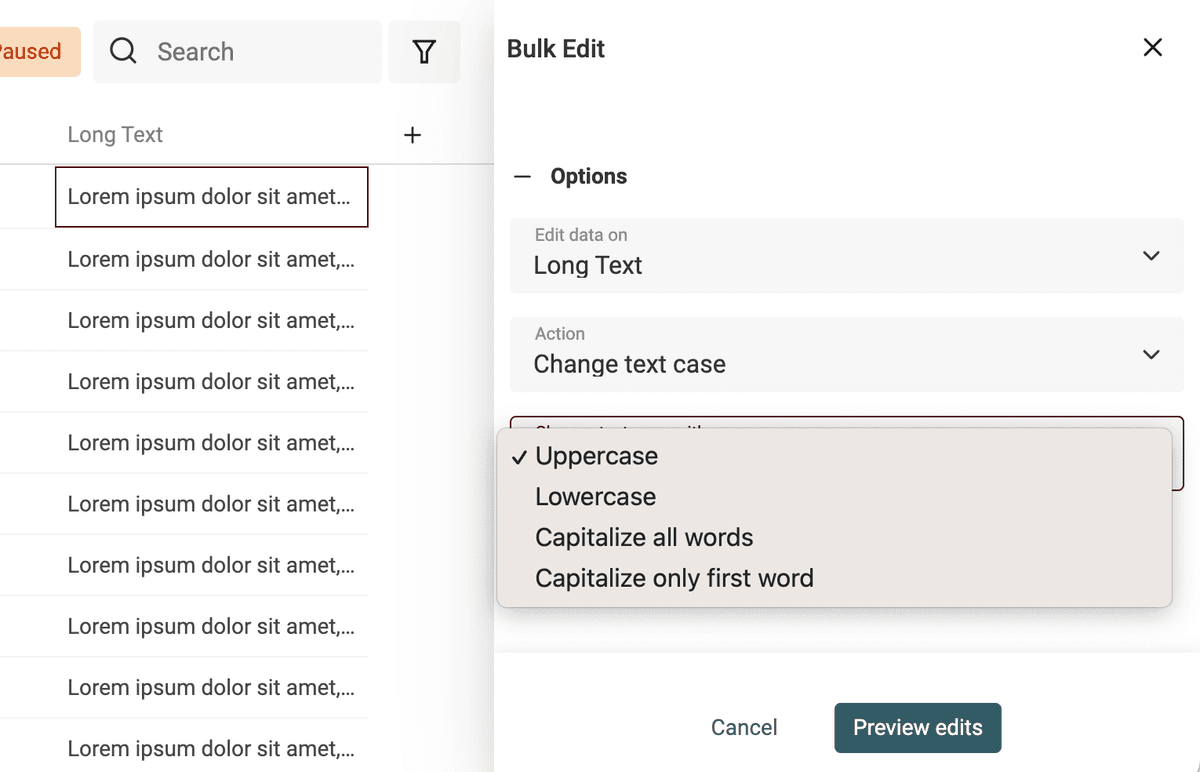
提供 4 种模式:
- Uppercase - 全部转换为大写。例如:
john=>JOHN - Lowercase - 全部转换为小写。例如:
API=>api - Capitalize - 每个单词首字母大写。例如:
john is a good man=>John Is A Good Man - Capitalize only the first word - 只把第一个单词首字母大写。例如:
john is a good man=>John is a good man
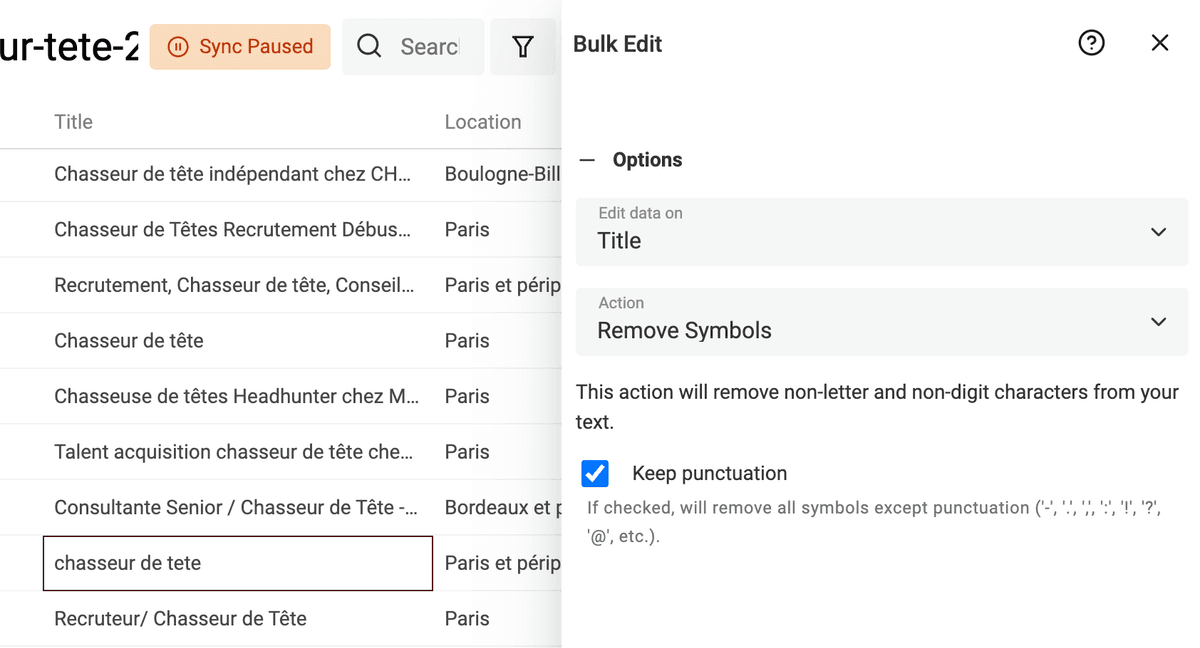
移除文本中的符号
从 HTML 抓取的文本、或者用户输入(比如 LinkedIn profile 的 title)里,经常会带一些符号:表情、特殊字符等,这些都会干扰后续处理。 比如名字末尾多了一个表情,就可能让它无法被去重算法识别。
Datablist 内置处理器,可以移除数据中的非文本符号。
在 Edit 菜单点击 “Bulk Edit”,选择一个文本字段,然后选择 “Remove symbols”。
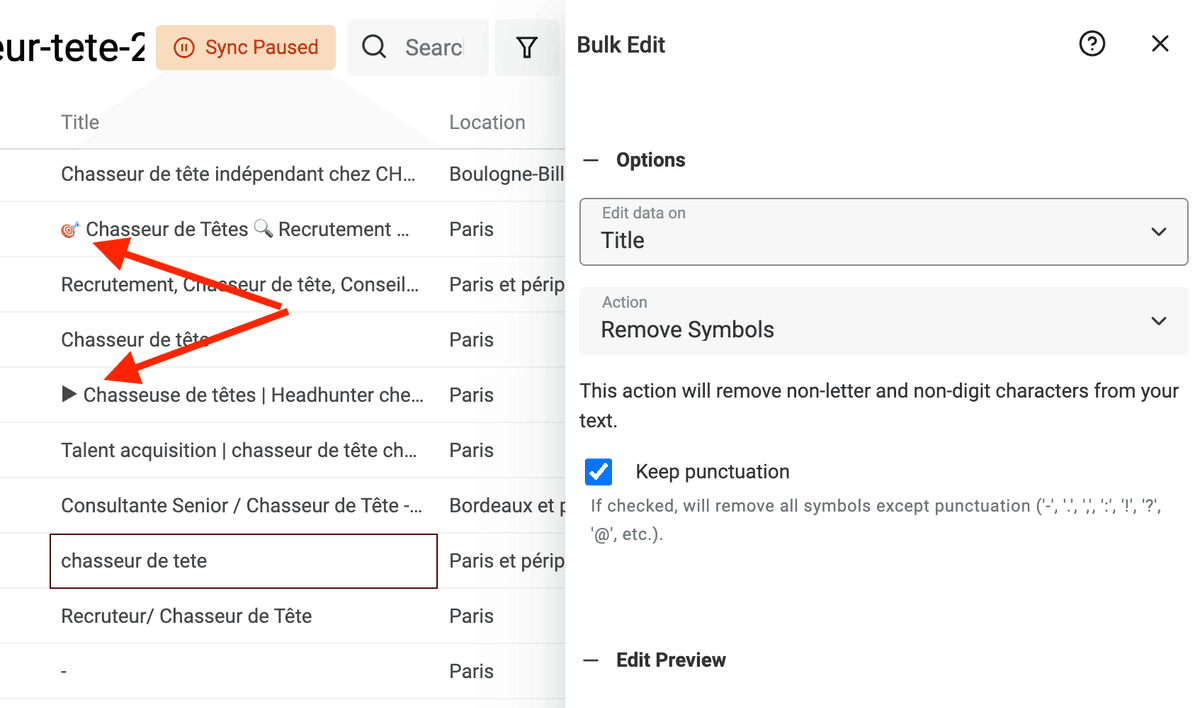
预览结果没问题的话,直接运行转换即可。
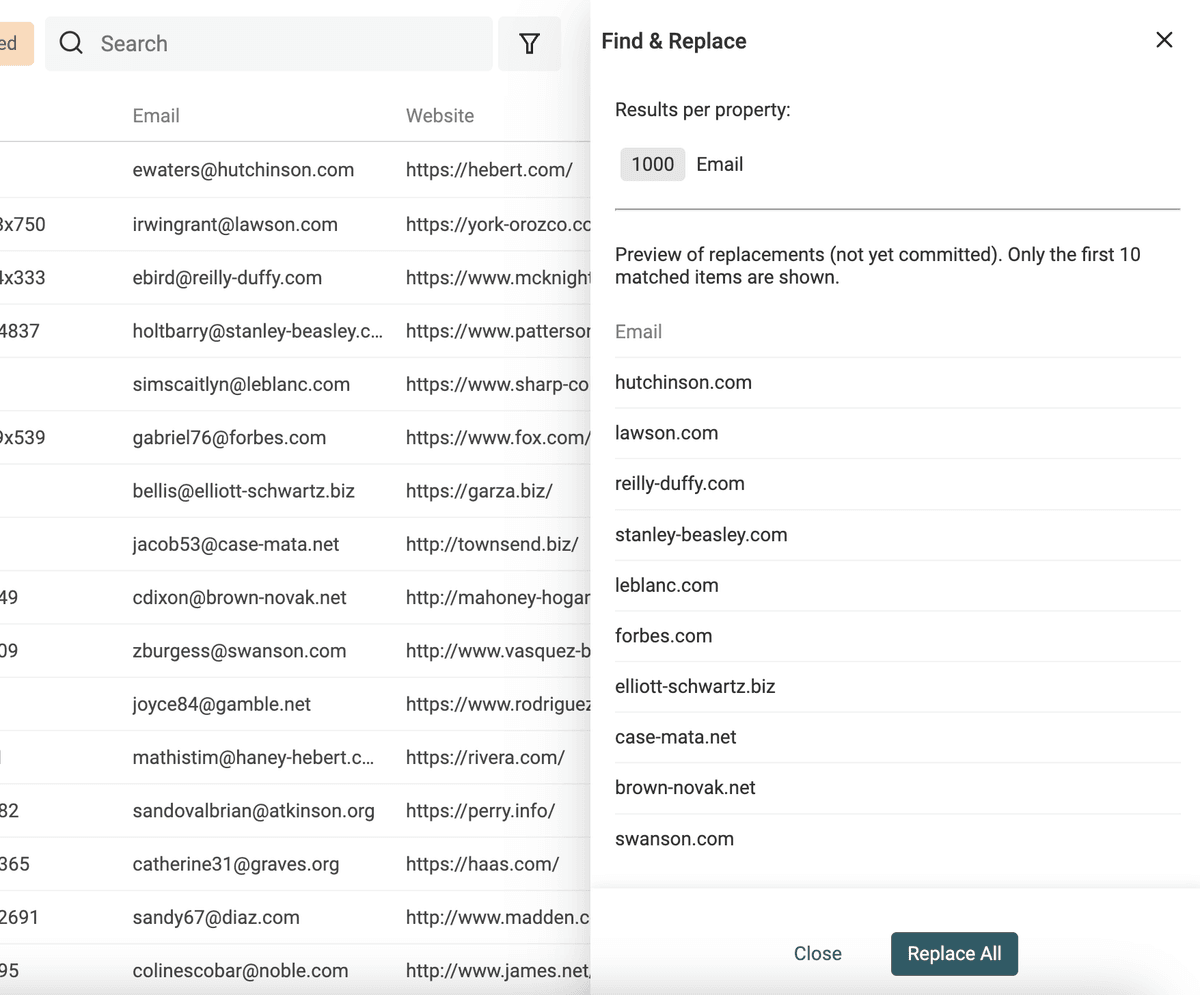
使用 Find and Replace 进行标准化
如果你要对prospect lists做分组/分层(segmentation),数据标准化几乎是必做项。
- 标准化 job titles
- 标准化国家、城市
- 标准化 URL
- 等等
核心目标是:把“自由输入的文本”变成“可控的有限选项”;或者把文本转换成更基础、更统一的形式(比如把带路径的 URL 变成纯域名)。
Datablist 自带强大的 Find and Replace 工具,既支持普通文本,也支持 regular expressions。
Regular Expressions 上手有门槛,但能力非常强。
下面给你两个常见的 RegEx 清洗示例。
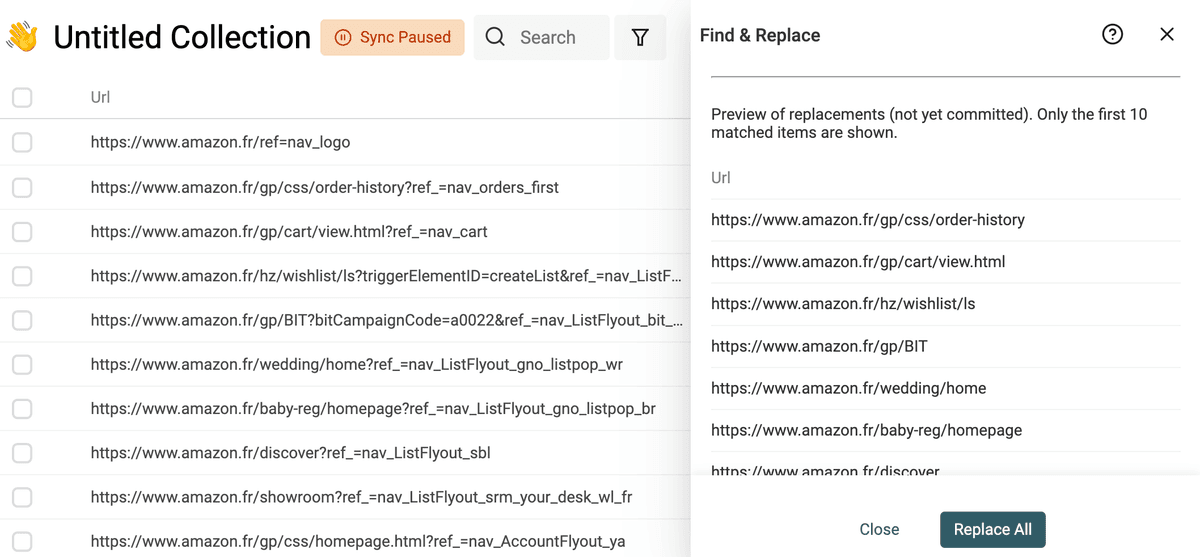
移除 URL 的 query params
scraped URLs 经常带一些用于 tracking/marketing 的 query parameters。把它们删掉后,URL 更干净,也更利于用 URL 来查找重复项。
要移除 query parameters,勾选 “Match using regular expression”,然后使用下面的正则表达式,并把替换内容留空:
\?.*$
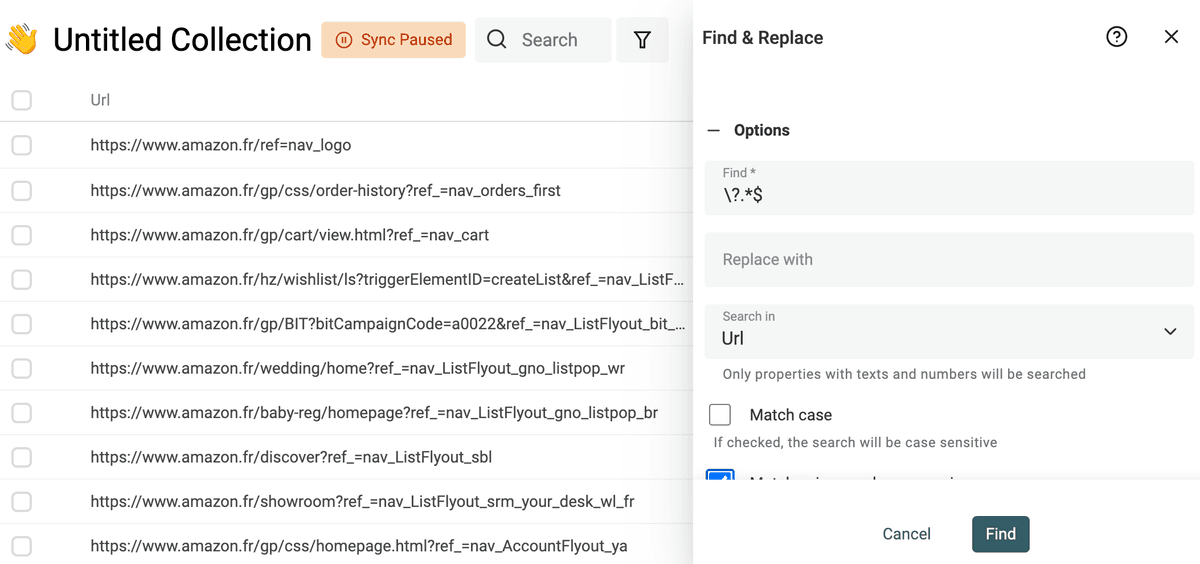
然后应用到你的 URL 字段上。
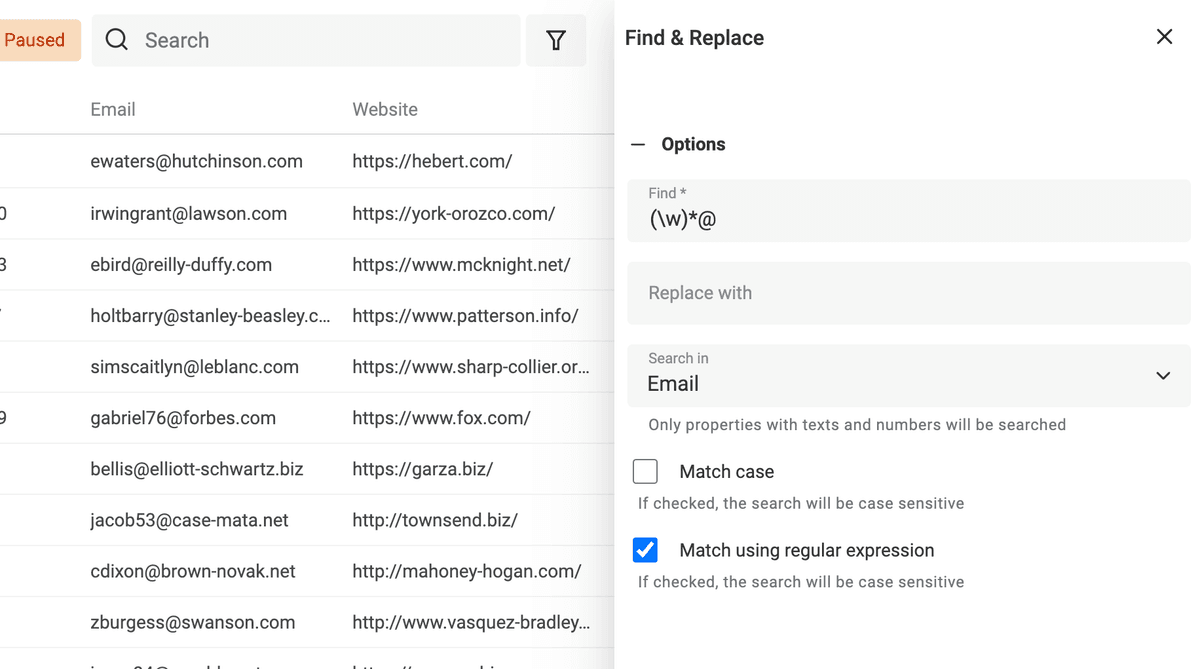
从 email 地址提取 domain
另一个典型用法:用 Find and Replace + RegEx 从 email 地址里提取网站域名。
建议先复制一列 email 字段,保留原始数据。然后用下面的正则表达式,并把替换内容留空:
^(\w)*@
将 Full Name 拆分为 First Name 和 Last Name
在抓取 lead lists 时,你通常会拿到联系人 “Full Name”,但很多场景需要拆成 “First Name” 和 “Last Name”。能把人名尽可能准确地解析成不同部分,是非常关键的一步。
把名和姓拆开后,你可以在 cold emailing 里更个性化地称呼对方,也更方便做性别推断、识别学术头衔等。
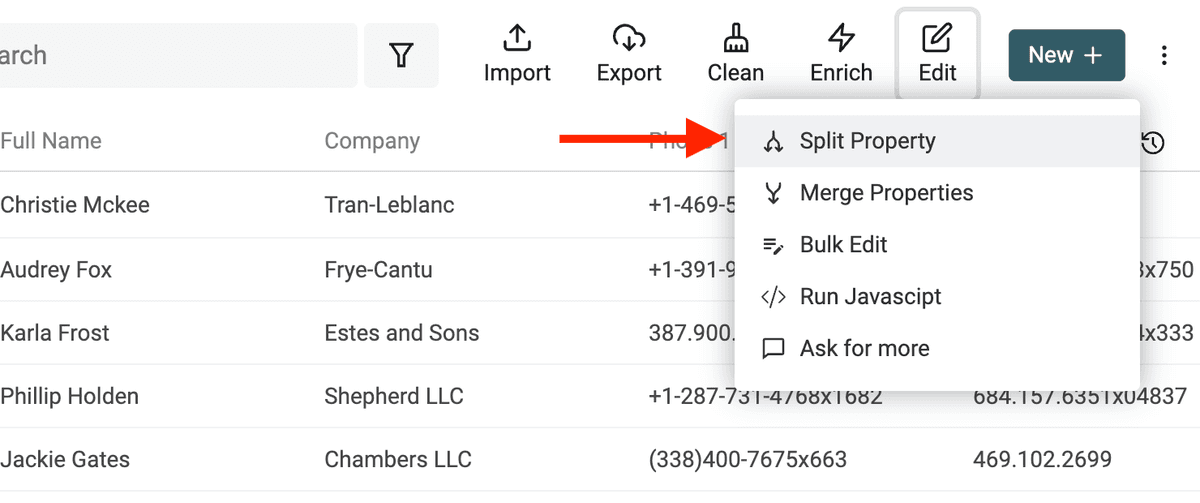
人名拆分这件事本身并不总是简单。好在 Datablist 提供了一个易用工具,可以用空格作为分隔符,把 “Name” 拆成两段。
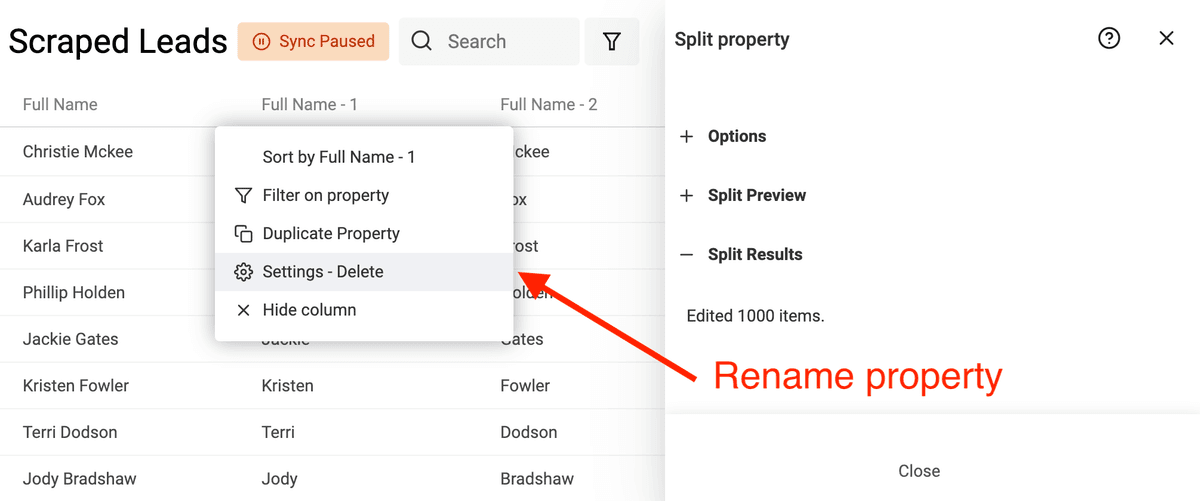
首先,在 Edit 菜单打开 “Split Property”。
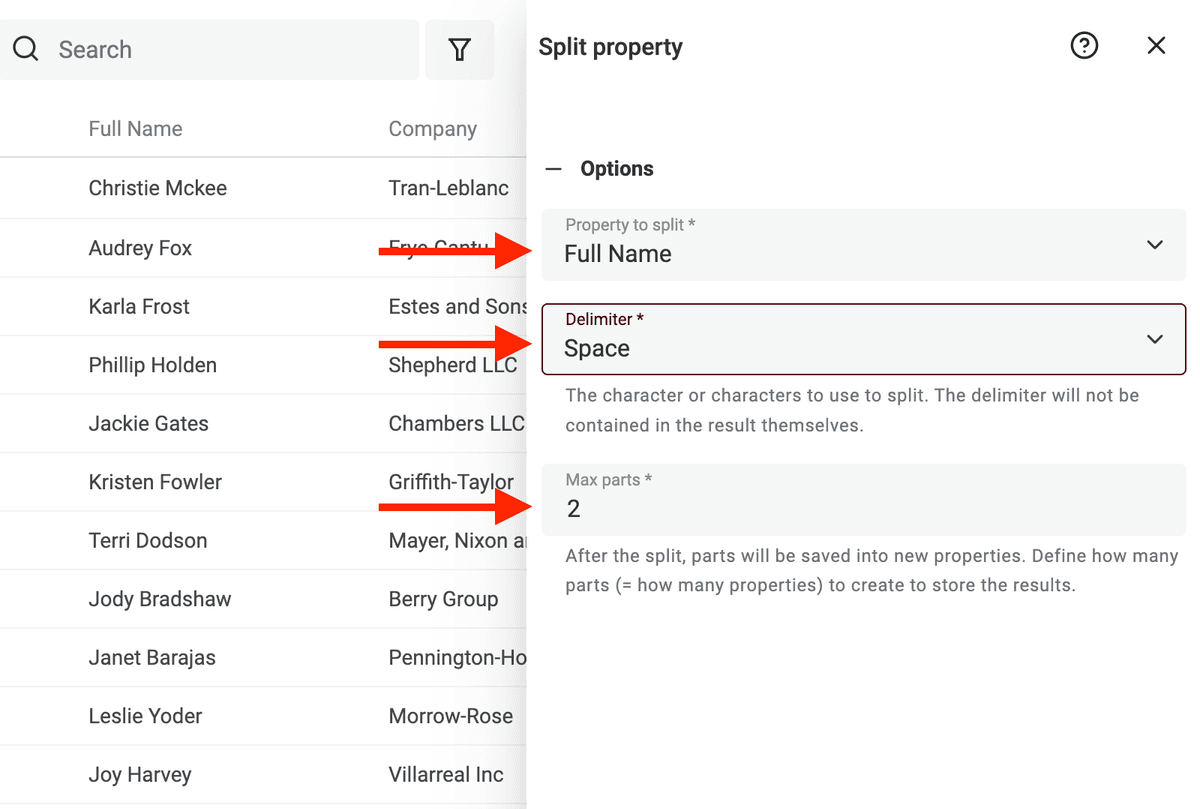
然后选择要解析的字段,分隔符选 Space,并把最大分段数(max number of parts)设为 2。
运行预览后,Datablist 会解析前 10 条生成 preview。结果没问题就点击 “Split Property”,对当前所有数据执行拆分。
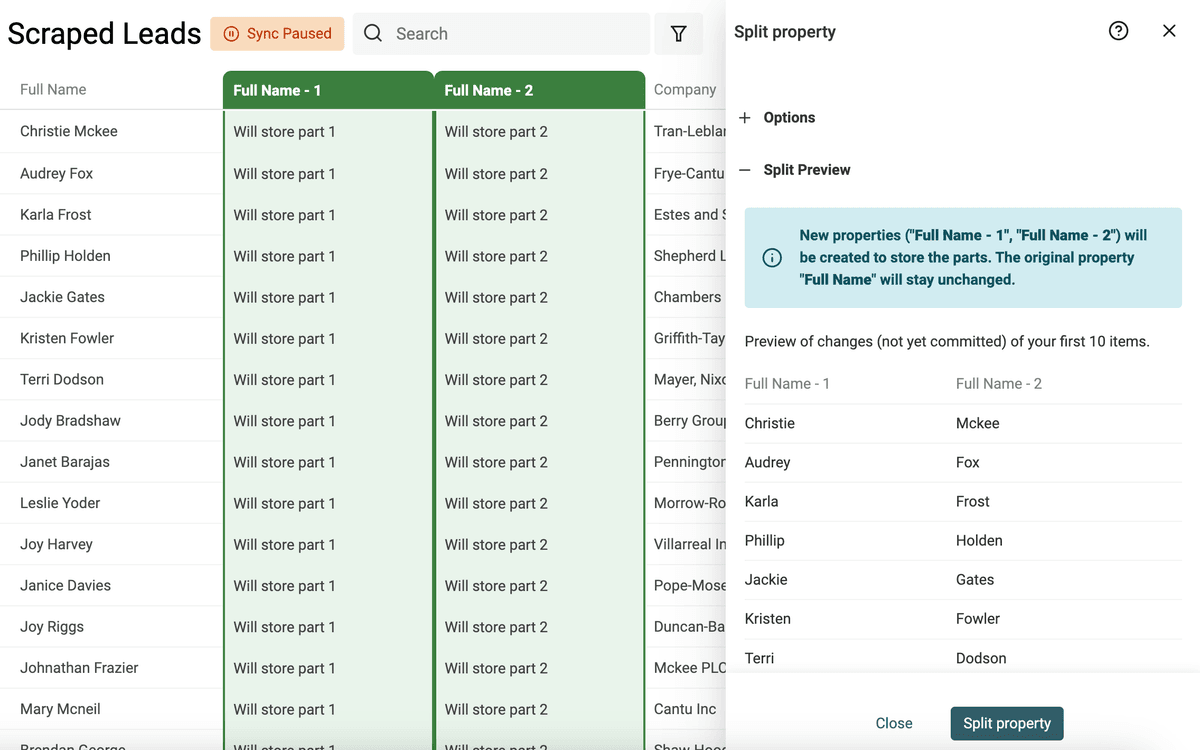
拆分完成后,把新生成的两个字段重命名为 “First Name” 和 “Last Name”。
这个示例主要针对西方命名习惯(通常是名 + 姓)。如果要处理非西方姓名(比如多名、多姓)、或包含 title/suffix 的姓名,情况会更复杂一些。
数据去重
Datablist 提供了强大的去重算法,可以用来dedupe records。它支持用一个或多个字段来判断相似项,并且能自动 merge,尽量不丢数据。
要运行去重,在 “Clean” 菜单点击 “Duplicate Finder”。
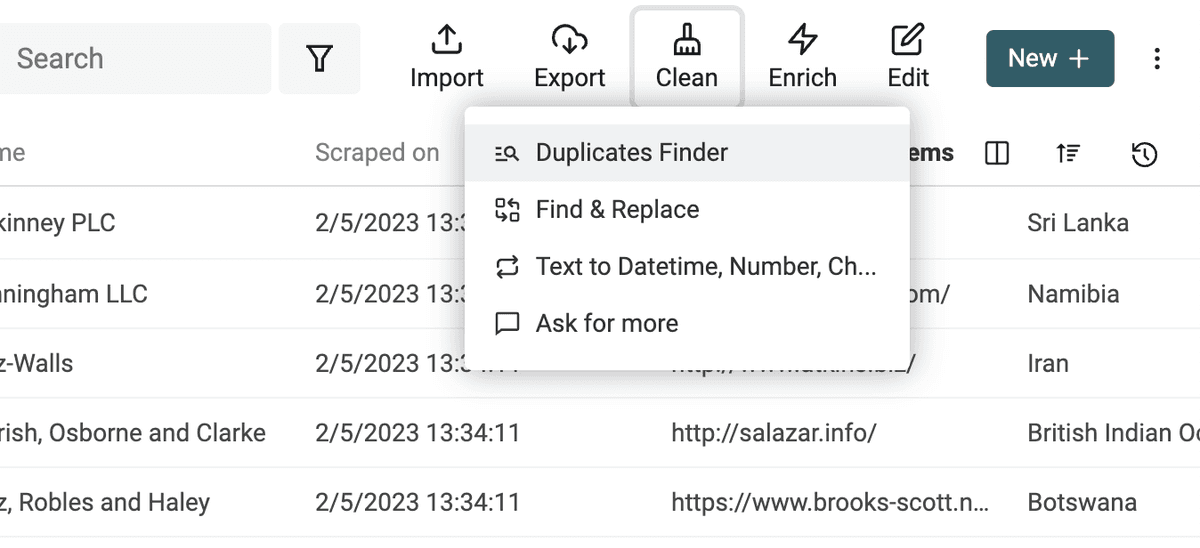
选择用来匹配的字段。
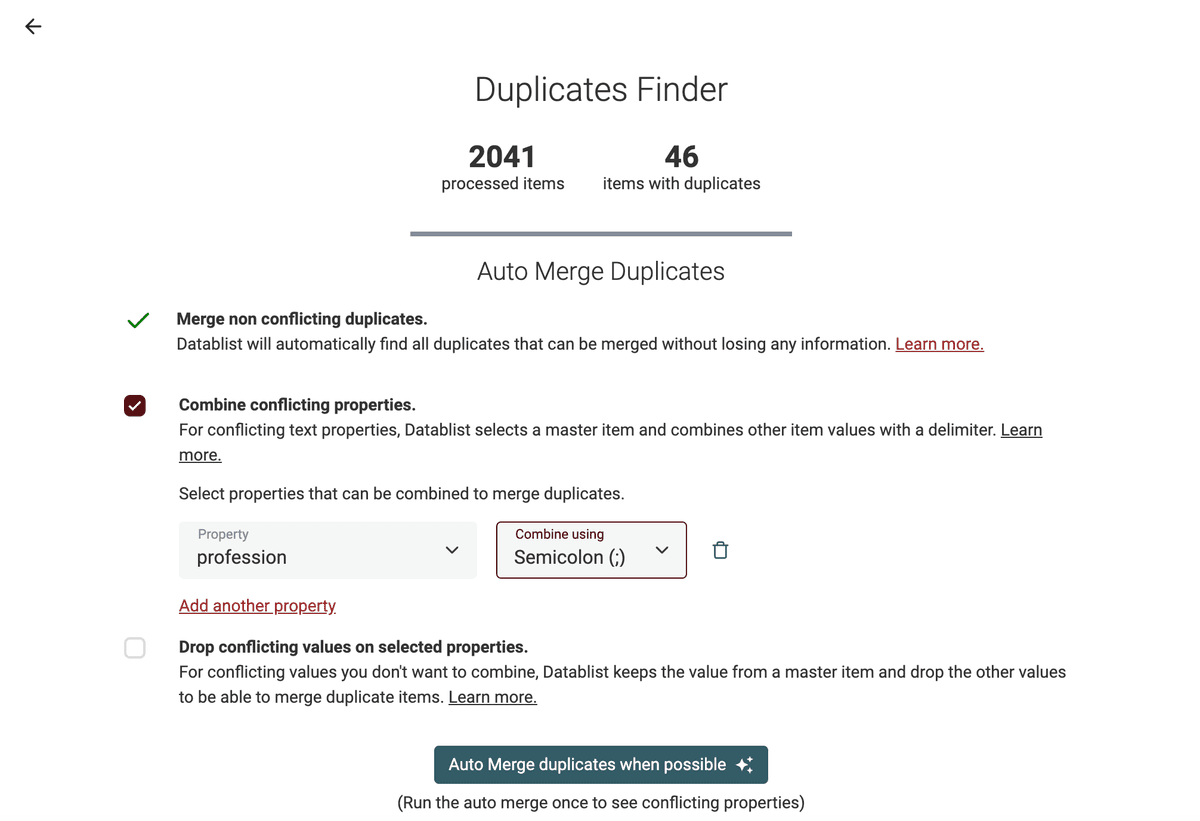
进入结果页后,建议先只勾选 “Merge non-conflicting duplicates”,运行一次 “Auto Merge”。它会先合并那些“无冲突、好合并”的重复项,同时把有冲突的字段列出来。
这个dedupe algorithm还提供两种处理冲突数据的方式:你可以选择用分隔符 “Combine conflicting properties”,或者丢弃冲突值,只保留一个主记录(master item)。
从文本中提取 email、URL 等
Datablist Data Extractor 用来解析非结构化文本,从中提取可用实体(entities)。
它基于模式识别(pattern recognition),可以检测并提取:
- 从文本提取 Email addresses
- 从文本提取 URLs
- 从 URL 提取 Domain
- 从 email 提取 Domain
- 从文本提取 Mentions(例如 @name)
- 从文本提取 Tags(例如 #tag)
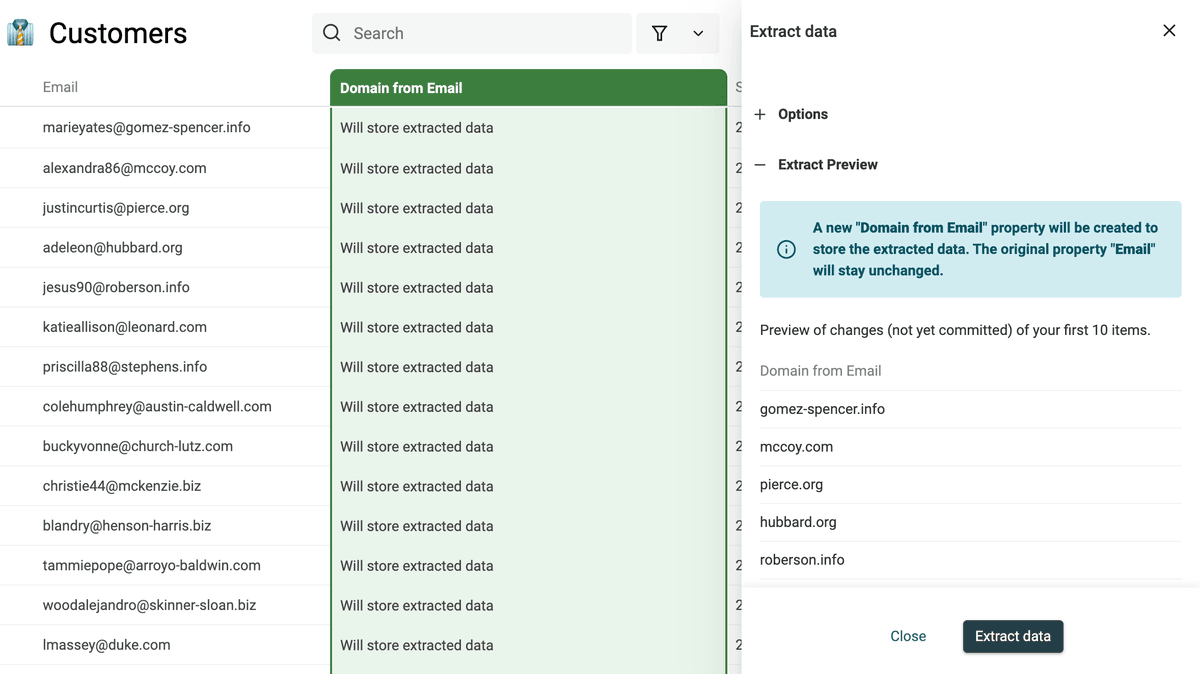
Data Extractor 特别适合做数据分析和结构化。拿到规范的 email、URL 之后,你就能更顺畅地对接其它工具(比如通过 API 串联自动化流程)。
举个例子:当你提取出 email 后,就可以进一步做 enrichment 来补全联系人信息;或者用 URL 的 domain 去查网站的流量排名(例如 Alexa 这类工具——当然现在也有很多替代服务)。
Datablist Data Extractor 在 “Edit Menu -> Extract url, email, tag, etc.” 里。
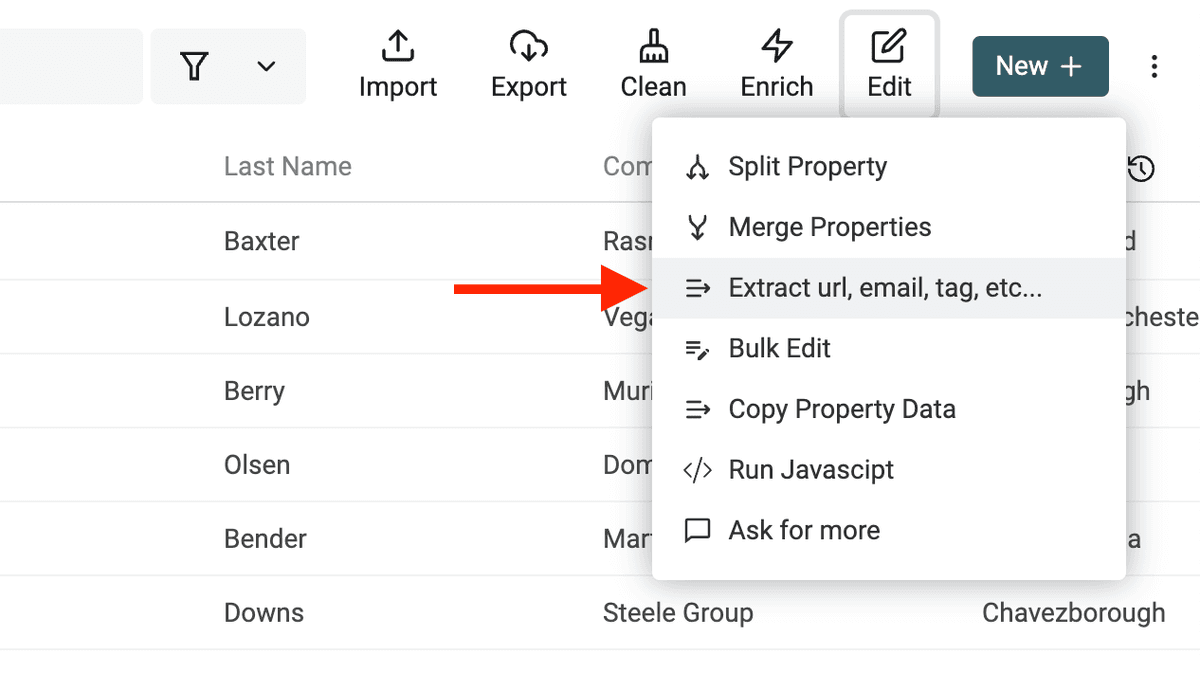
选择包含非结构化文本的字段,然后选择解析器(parser)。
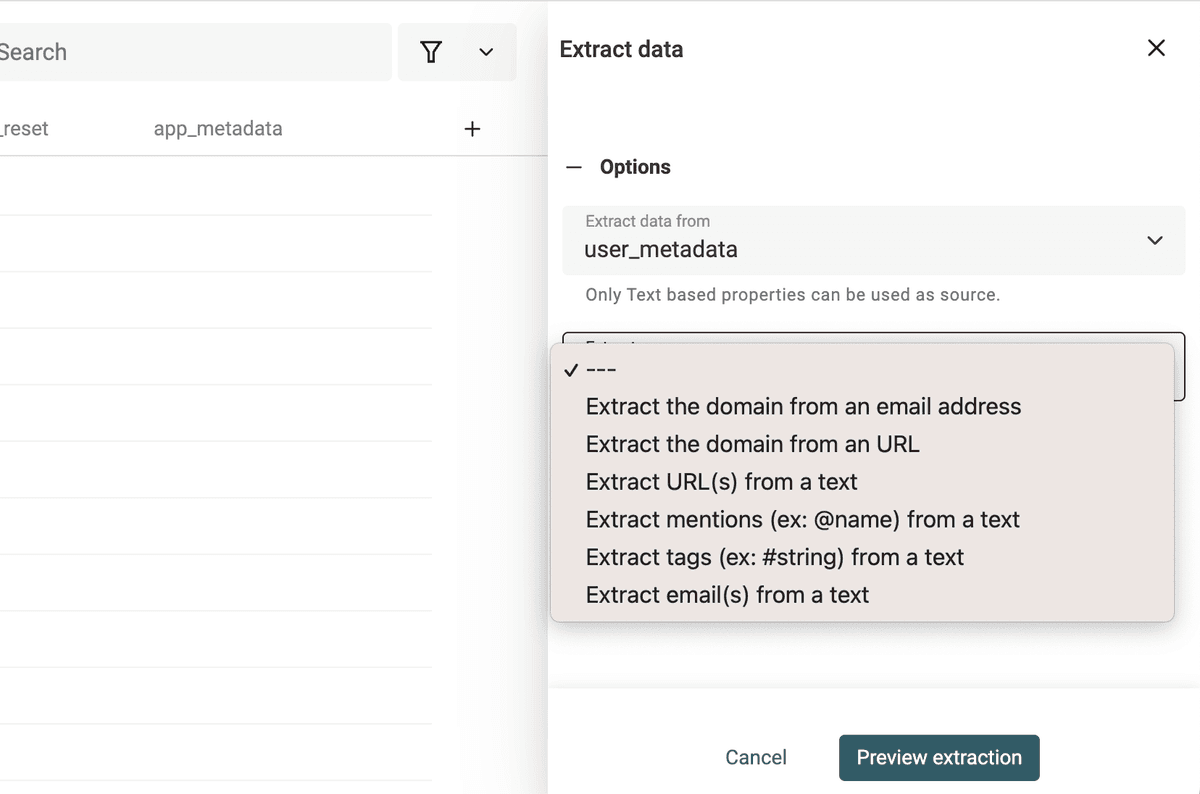
运行 parser 查看预览。预览结果OK的话,点击 “Extract” 处理全部数据。
使用 Regular Expressions 进行筛选与验证
Datablist 支持用 Regular Expression 来筛选数据。
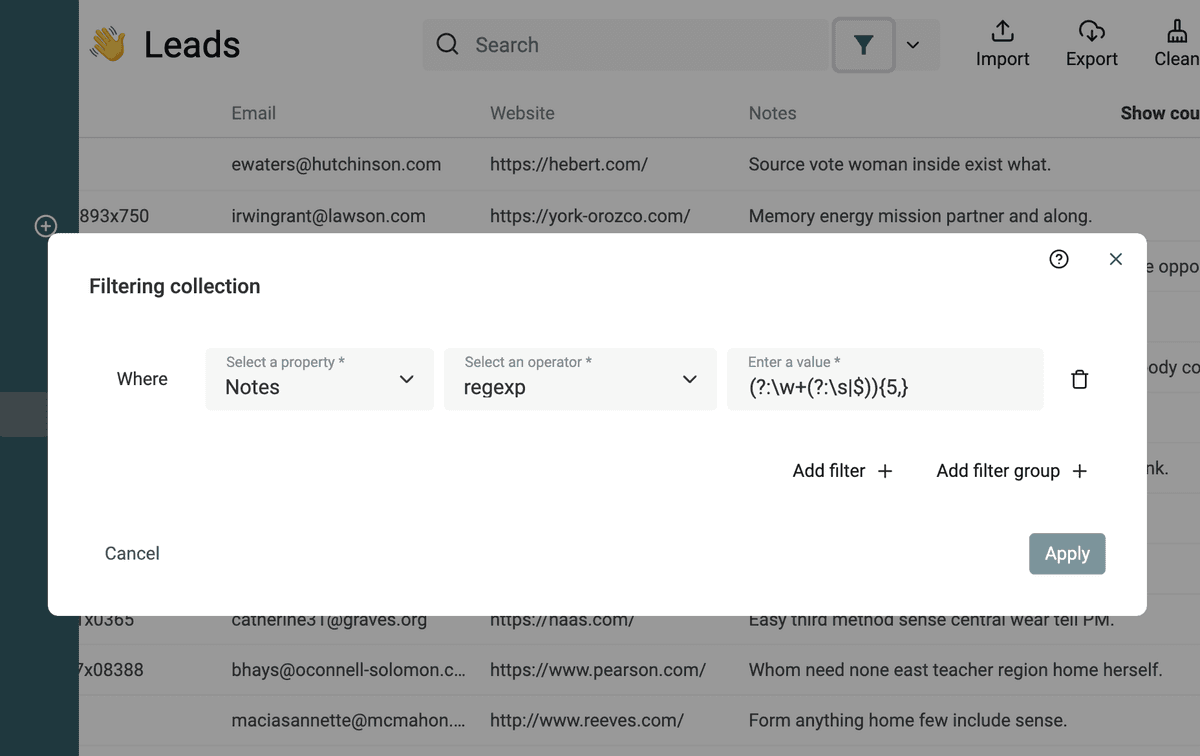
按单词数量筛选文本
使用下面的正则表达式,你可以筛选“至少包含 {n} 个单词”的文本:
(?:\w+(?:\s|$)){5,}(把 5 替换成你想要的数字)
它的其它变体:
(?:\w+(?:\s|$)){,5}:少于 5 个单词(包含刚好 5 个)(?:\w+(?:\s|$)){5,10}:单词数量在 5 到 10 之间
筛选无效 URL
下面这个 RegEx 用来匹配无效 URL:
^(?!(?:http(s)?:\/\/)?[\w.-]+(?:\.[\w\.-]+)+[\w\-\._~:/?#[\]@!\$&'\(\)\*\+,;=.]+).*$
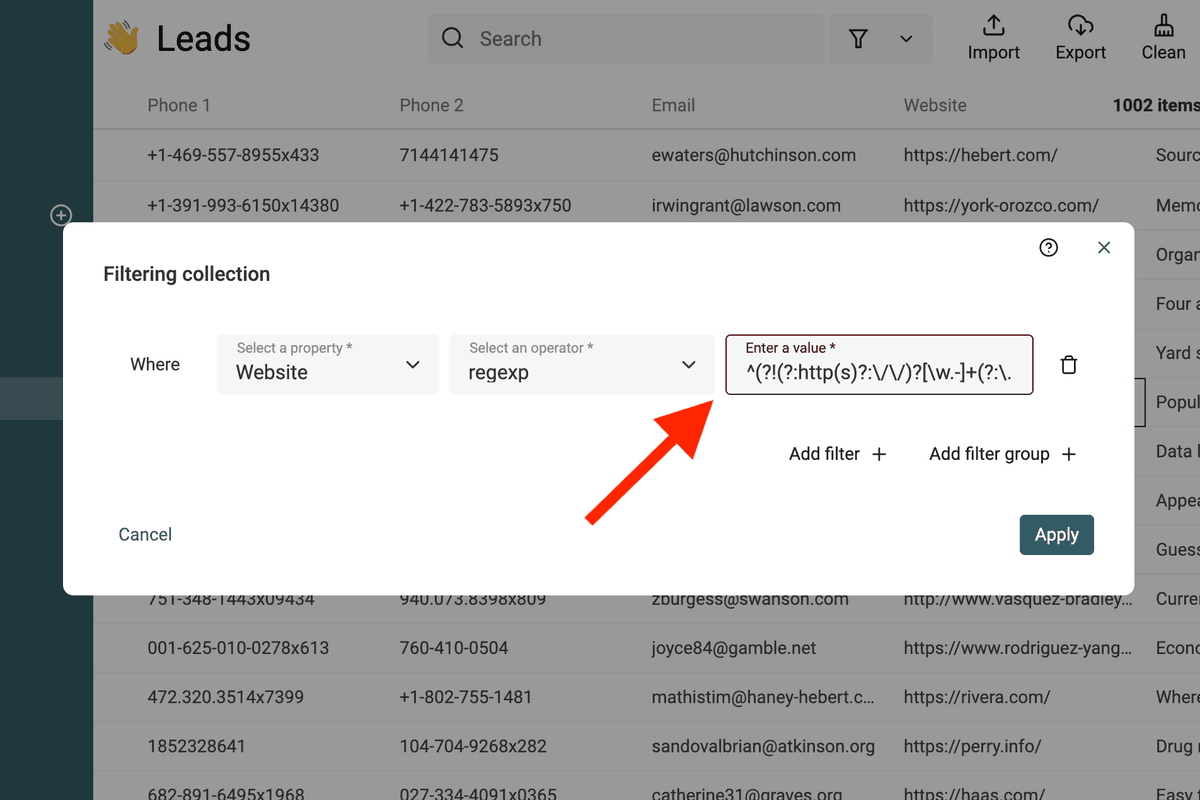
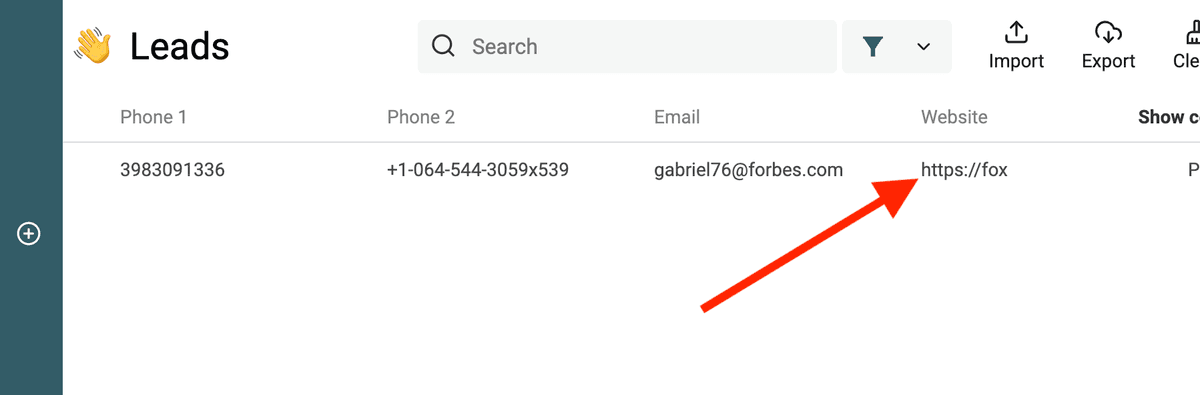
筛选无效 email 地址
下面这个 RegEx 用来匹配无效 email 地址:
^(?!([a-zA-Z0-9._%-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,})).*$
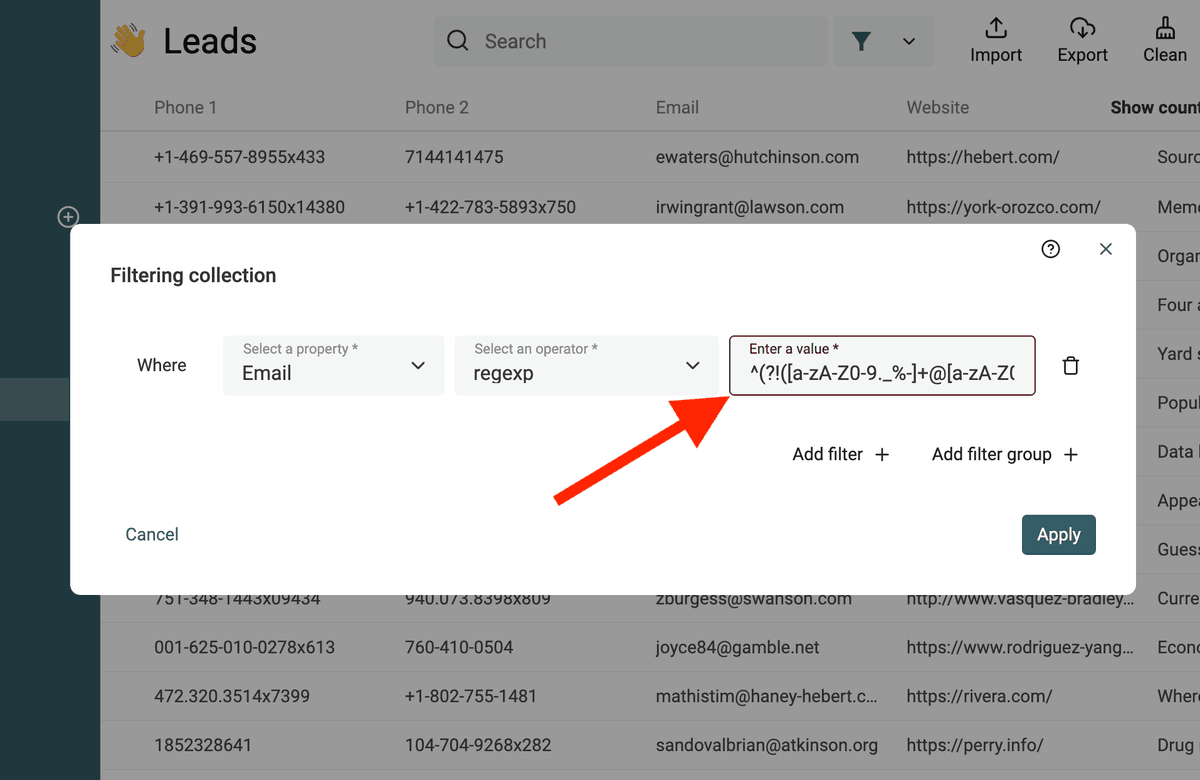
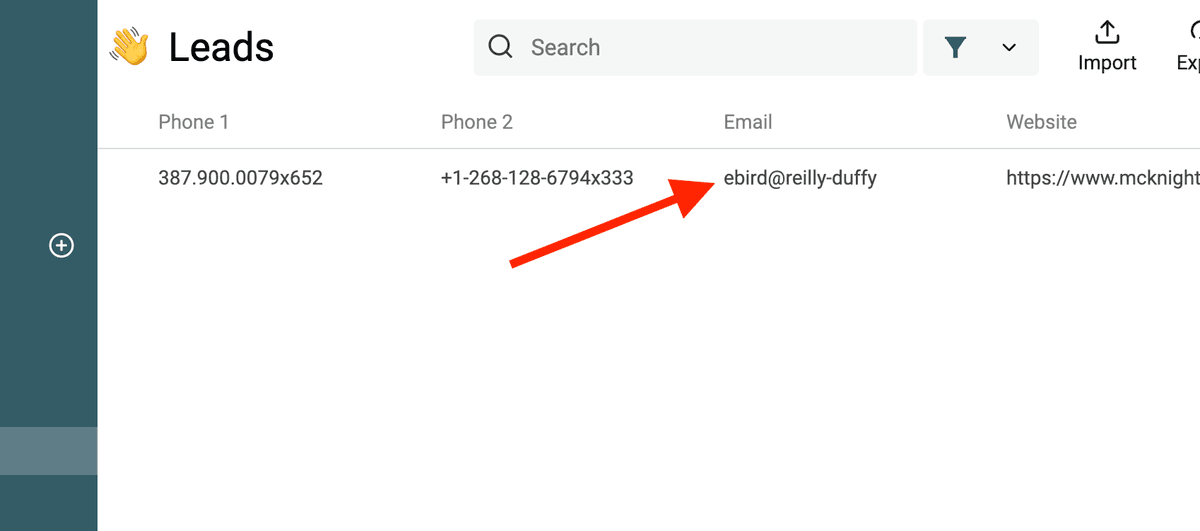
使用 JavaScript 编写自定义转换
Datablist 允许你对数据运行自定义 JavaScript 代码。有了自定义代码能力,你就能应对更独特的数据问题:处理特殊格式、做复杂计算、实现更高级的清洗与转换逻辑。
这个功能非常强,你可以自由写自定义规则、循环、条件判断,并调用各种 JavaScript 函数,把复杂的数据清洗任务自动化。
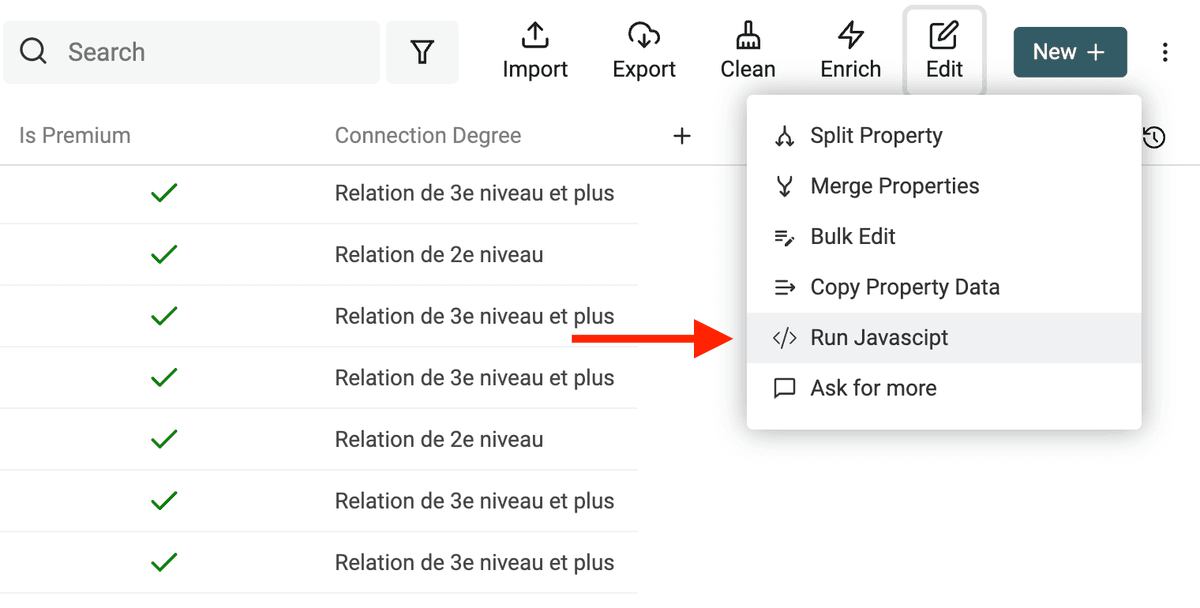
在 Edit 菜单点击 “Run JavaScript” 打开 JavaScript editor。
验证 Email 地址
scraping 得到的数据可能很旧、可能有拼写错误,也可能本身就是无效的。 Email 地址尤其如此。
如果数据来源是用户填写(user generated),你的数据库里还可能混入 fake email,或者来自一次性邮箱服务商(disposable provider)的地址。
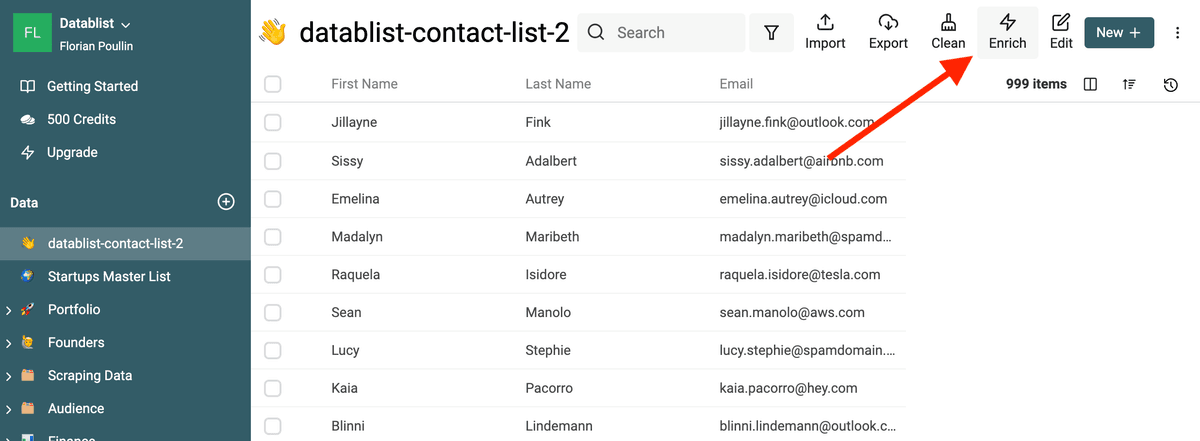
Datablist 内置 email validation 工具,可以一次性验证成千上万条 email。
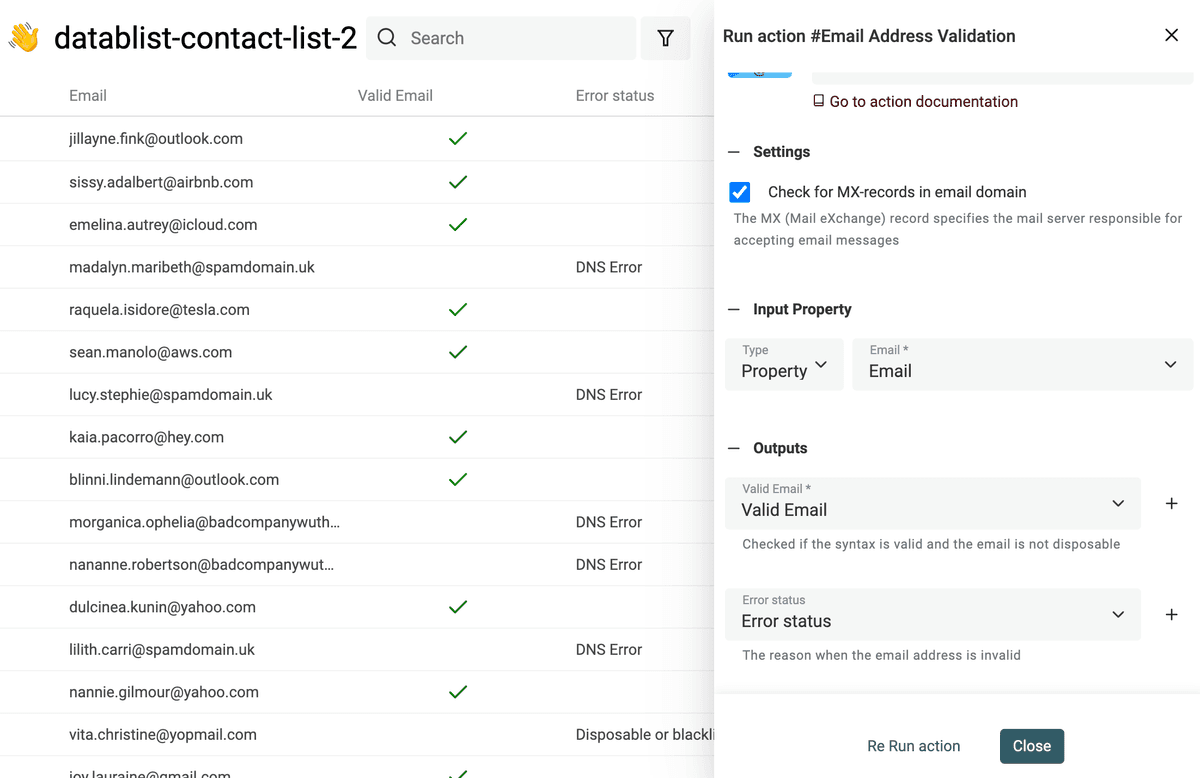
Email 验证服务包含:
- Email syntax analysis - 第一层检查是语法校验:确保 email 符合 IEFT 标准并进行完整的语法解析。比如缺少 @、domain 不合法等都会被标记。
- Disposable providers check - 第二层检查用于识别临时邮箱。服务会检测 domain 是否属于 Disposable Email Address(DEA)服务商,例如 Mailinator、Temp-Mail、YopMail 等。
- Domain MX records check - 有效的 email domain 必须配置 MX records,用来指定接收邮件的服务器。缺失 MX records 通常意味着 email 无效。 对每个 email 的 domain,服务会检查 DNS 记录并查找 MX 记录:domain 不存在会被判定为 invalid;domain 存在但没有有效 MX 记录也会被判定为 invalid。
- Business and Personal Email addresses Segmentation - 如果你的线索来自 lead magnets,或者你希望对用户做分层,你可能需要区分 business email 和 personal email。email validation 会把这个信息返回,用于 enrichment 联系人数据。
FAQ
什么是数据清洗?为什么重要?
数据清洗(data cleaning,也叫 data cleansing 或 data scrubbing)指的是在数据集中识别并修正或移除错误、不一致和不准确数据的过程。它通常包括:处理缺失值、重复记录、格式错误、异常值,以及不同表达方式带来的不一致。
数据清洗是数据处理里非常关键的一步,能确保数据更准确、更可靠,也更适合用于分析或在各种业务场景中直接使用。
还有哪些免费的数据清洗工具?
数据清洗工具从通用的表格工具到更专业的应用都有。除了 Datablist 之外,下面是一些常见的免费工具推荐。
OpenRefine
OpenRefine(原名 Google Refine)是一个开源工具,专注于探索、清洗和转换杂乱、不一致的数据。
OpenRefine 是独立桌面应用,支持表格文件(CSV、TSV)、Microsoft Excel,以及 JSON、XML 等结构化文件。
在处理不规范 CSV 方面,OpenRefine 特别有优势:
- 对 CSV 编码问题处理得很好
- 提供修复 CSV 格式错误的选项
不足之处是:学习成本相对高,并且偏“数据处理”而不是“业务工作流”。它不擅长做去重合并,缺少把一个数据集与另一个列表 join 来更新/汇总的简单流程;同时也缺少协作能力,以及面向业务的 enrichments 和 integrations。
Microsoft Excel 和 Google Sheets
Microsoft Excel 和 Google Sheets 都是非常强的 spreadsheet 工具,也常用于数据清洗与准备。虽然两者有一些差异,但都提供了不少清洗与转换能力。
你可以用公式做转换和数据处理,也可以用条件格式(conditional formatting)标记无效值,方便后续人工处理。
需要我们帮你处理数据清洗吗?
我一直在收集反馈,也在持续优化各种数据清洗问题的解决方案。欢迎你联系我分享你的 use case。