
Facebook 群组是搭建 leads 数据库的宝藏渠道。 你可以去触达竞争对手群里的成员,或者抓取某个垂直主题群,快速找到潜在客户。
但问题也很明显:直接 scrape Facebook 群组,往往会得到一堆低质量 leads! 群里常见学生、实习生,或者各种你根本不想触达的人。
Facebook 群组很强,但成员必须先过滤。我的建议是:Facebook 群成员更适合作为“线索来源”,用来找到值得联系的人;但千万不要把整个群一股脑群发邮件! 关键在于先给 Facebook leads 做 enrichment(补全信息)、再分层分组(segmentation),最后只联系真正匹配的 prospects。
Facebook 是偏个人属性的社交网络,个人信息保护也更严格。有些找邮箱工具声称能从 Facebook profile 推出邮箱,但我实际用下来效果很一般。更高效的做法是用 Facebook profile 里的信息去反查 LinkedIn profiles。 LinkedIn 更适合做 cold messaging;而且它是偏商业的社交网络,用 LinkedIn profile 去做 email lookup(邮箱查找)通常更靠谱。
按这份 step by step 指南,你将学会:
- 如何把 Facebook 群成员导出成 CSV
- 如何把成员 enrich 成 LinkedIn Profile URL
- 如何从 LinkedIn URLs scrape 更完整的资料
- 如何查找 email addresses
- 如何持续把新进群成员更新进你的导出结果
- 如何用 Chrome Extension 快速调用脚本
Step 1: 从 Facebook 群成员提取 leads
Facebook 是个人社交网络,本身没有“导出群成员”的内置功能。想导出成员,你需要借助第三方工具。
通常有两种选择:
- 用 Phantombuster 这类云端 extraction 服务:在他们的服务器上用你的 Facebook 凭证跑脚本。
- 在你自己的浏览器里运行脚本/插件:你浏览 Facebook 的同时,直接 scrape 页面数据。
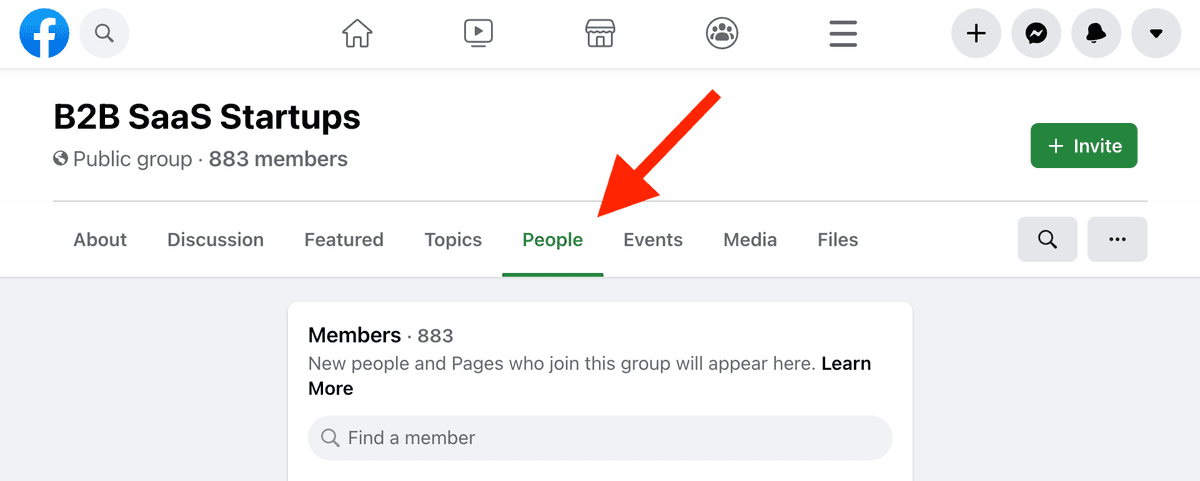
目前能稳定访问群成员列表的入口,是群组“People”tab 下的 “New members” 列表。 脚本和浏览器扩展会在你滚动页面时抓数据;云端服务本质上也是在服务器上模拟你的浏览行为。
Facebook 对 scraping 的对抗很强,会用各种机制检测自动化抓取。用云端 extraction 服务时,为了避免被封通常需要 proxy。即便如此,Facebook 的防护也在持续升级;所以做自动化抓取务必克制。
这篇指南会教你用浏览器脚本:当你在 “People”tab 正常浏览时,顺手把数据 scrape 下来。
注意事项
要能提取数据,群页面必须能看到 “People”tab。所以群要么是公开群,要么(私密群)你必须先加入群组。
将 Facebook 群成员导出为 CSV 文件
要提取 Facebook 群成员,只需要 把下面这段脚本复制到 Chrome Developer Console 里运行。
注意事项
Facebook group scraper 的源码在 Github。脚本会读取网页加载成员时触发的 API calls,从而提取成员数据。
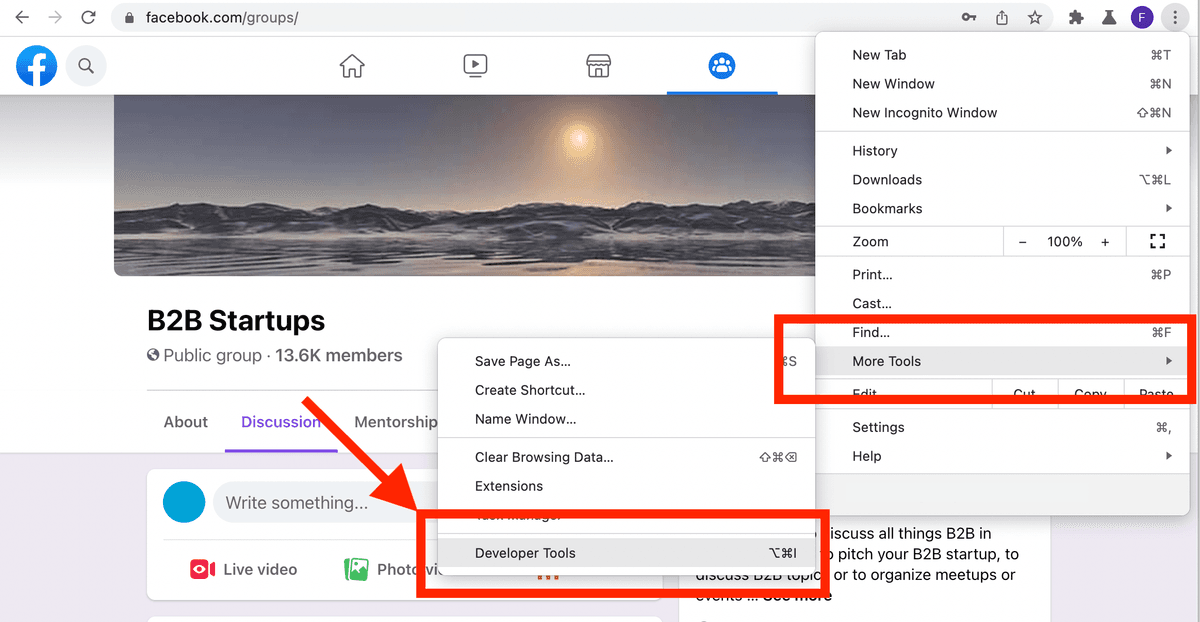
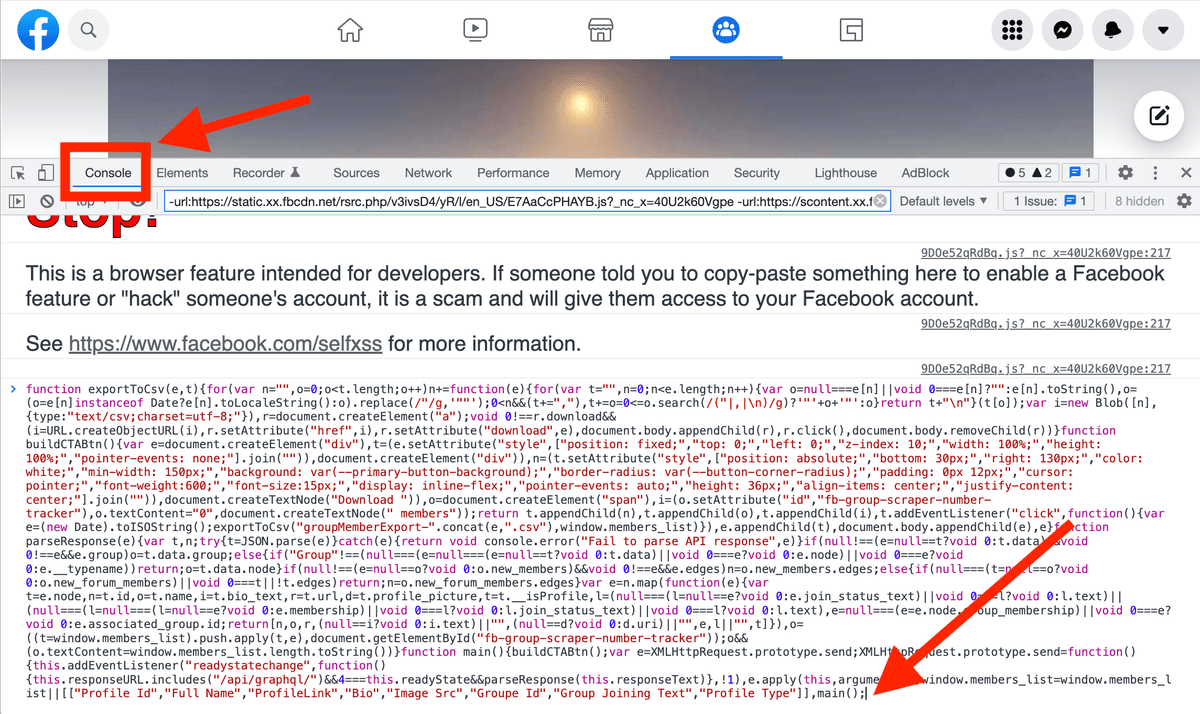
Important - 如果你是第一次打开 Chrome Developer Console,可能会看到一个 Warning 提示,导致你无法直接 copy/paste。要允许粘贴,只要输入 "allow pasting",然后按 “Enter”。
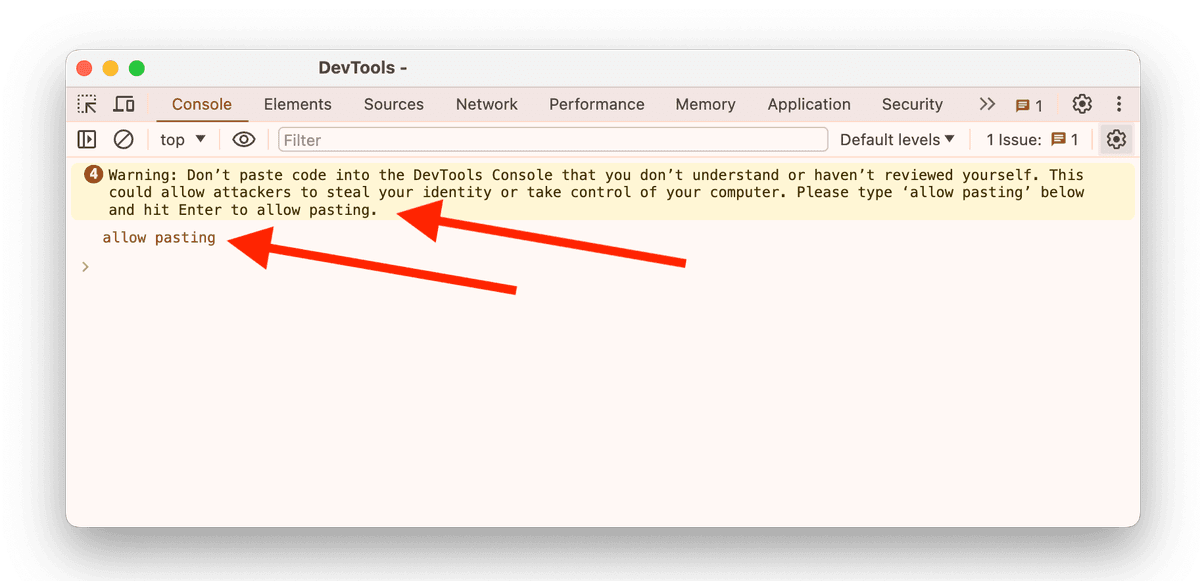
Scrape Facebook 群成员 profiles
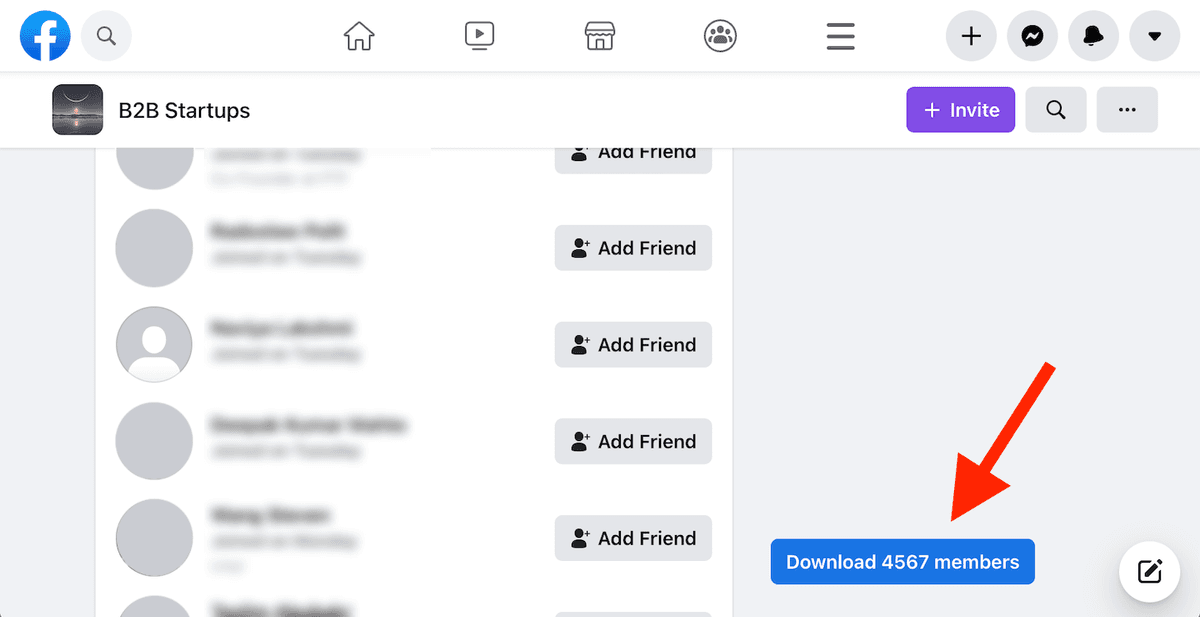
按键盘的 ‘Enter’ 运行脚本。 页面右下角会出现一个按钮:"Download X members"。
你现在可以关闭 Developer Console,脚本依然会在页面里运行 👍
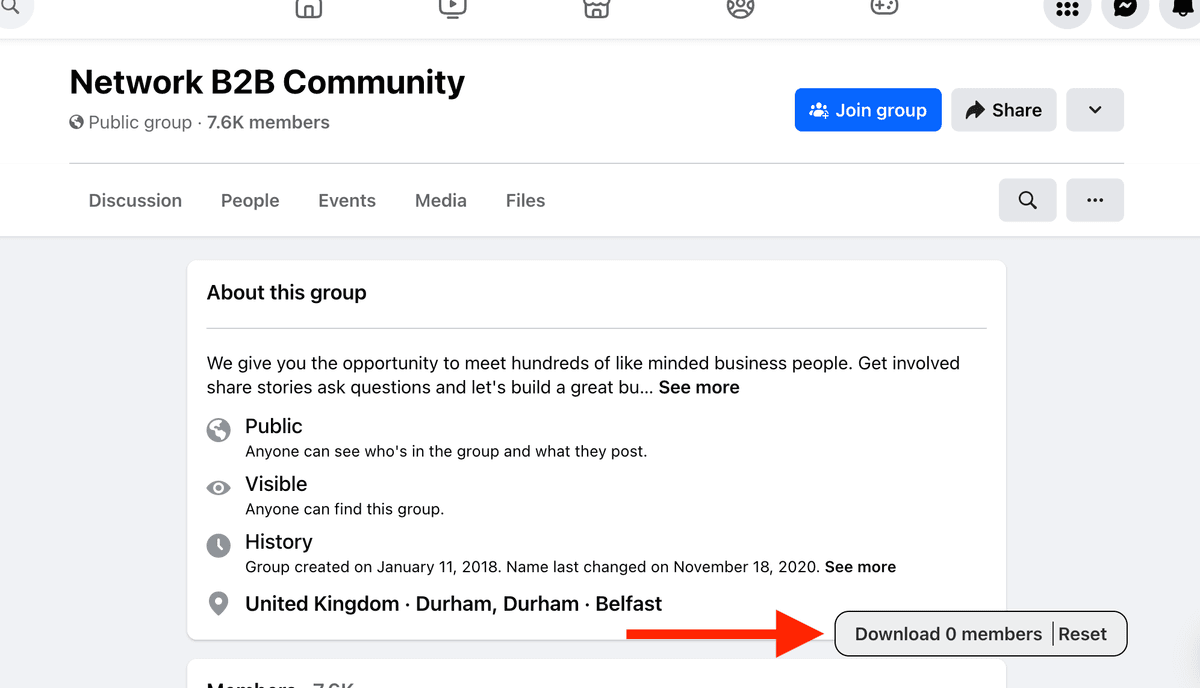
在较新的版本里,scrape 到的 leads 会先存到浏览器 cache。这样即使浏览器崩溃,数据也不会丢。你刷新页面、之后再粘贴脚本时,之前缓存的数据会自动恢复。你也会看到一个 “Reset” 按钮,用来清空 cache,从空列表重新开始。
接着回到群页面的 “People”tab。Facebook 会在你滚动时自动加载新成员。你只需要不断向下滚动来加载更多人。
你滚动的过程中,脚本会捕捉 Facebook API calls 并写入数据(能写 cache 的情况下会同步缓存)。
导出 Facebook members
点击 "Download x members" 按钮,就会把成员导出为 CSV。
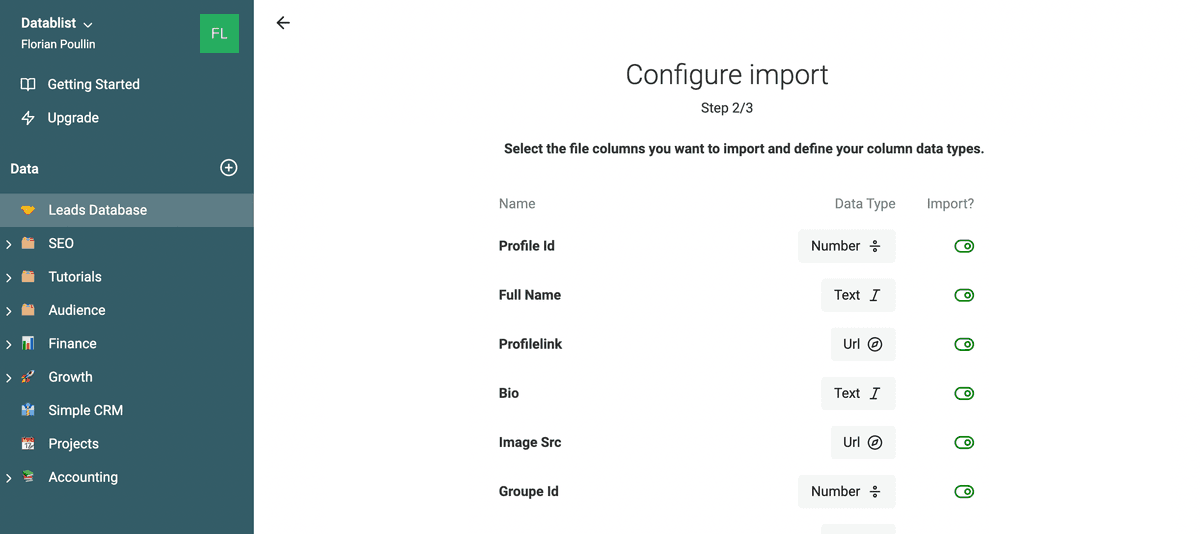
CSV 一共包含 8 列:
- Profile Id:Facebook 的唯一标识(多位数字)。
- Full Name:名 + 姓拼接。
- Profile Link:profile URI,格式 https://www.facebook.com/{{username}}。如果没有 username,则使用通用链接 https://www.facebook.com/profile.php?id={{profile_id}}
- Bio:成员 bio 文本。可能是职位、学校、城市,也可能为空。
- Image Src:头像图片 URL。
- Group Id:Facebook 群组标识(多位数字)。
- Group Joining Text:加入群的相对时间,格式类似:"Member since XX"。
- Profile Type:profile 类型,可能是 "User" 或 "Page"。
注意事项
想停止 scraping 并移除按钮,直接刷新网页即可。
清空 cache,从头开始
成员列表会一直存在 cache 里,直到你点击 “Reset”。你可以连续 scrape 多个 Facebook 群,之后再用 Group Id 做分组(segment)。
如果你更希望“每个群单独一个 CSV”,那就在进入 “People/Members”tab 之前先点一次 “Reset”。
FAQ
我最多能提取多少成员?
Facebook 在 “New members” 页面最多展示到 10k 成员,并按加入时间排序。建议你定期提取新成员并追加到你现有的 leads database。具体做法见:用新进群成员更新导出结果。
scrape 群成员需要多久?
脚本会在你滚动成员页时监听 Facebook API calls。API calls 是透明发生的,每次平均会加载 10 个新成员。通常你滚动几分钟,就能提取到几千个成员。
我在滚动,但计数器不增长
Facebook Group scraper 会自动去重。如果某个成员已经被抓取过,就不会重复加入。
另外,脚本初始化时会从 cache 加载之前抓取过的成员。如果你在 scrape 一个以前抓过的群,或新群里包含了你之前抓过的人,那么只有“新 profile”才会增加计数。
我的账号会被 Facebook 封吗?
这个脚本只是在网页内部捕捉真实发生的 API calls,不会额外发请求,也不会做 bot click。整个过程发生在你正常浏览行为之内。相比那些在云端用 proxy + bots 跑的 scraping 工具,这种方式更安全。
但话说回来,任何 scraping 都要克制,不要滥用 Facebook,尽量避免全自动脚本。如果可以,建议用一个非个人主号的备用 Facebook 账号操作。
Step 2: 找到 LinkedIn Profile
你现在已经有一份包含大量 prospects 的 CSV 了?很好!接下来要把它变成真正可用的 leads database。
在 Facebook 上做 cold messaging 基本等同于骚扰。Facebook 是社交网络,你不希望天天收到业务询盘,你的潜在客户也一样。
只要有姓名 + 公司名(或 domain),你就能反查到 LinkedIn profile,用于 LinkedIn 私信,或进一步获取 business email address。
这一部分会教你如何用 Datablist 的 LinkedIn Profile Finder from name 给 Facebook prospects 做 enrichment,补全 LinkedIn Profile URL。这个 enrichment 会用 prospect 的姓名在 Google 上搜索,匹配可能的 LinkedIn profile。
创建 Datablist collection 并导入 CSV
Datablist 非常适合用来 查看和编辑 CSV,并对数据批量执行 actions。这篇指南里,我会带你用 "LinkedIn Profile Finder" 给你的 prospects 做补全:它接收 name + keyword,命中时返回 LinkedIn profile URL。
首先,注册 Datablist,并创建一个 collection。
点击侧边栏的 “+” 创建 collection,然后点击 “Import CSV/Excel”。
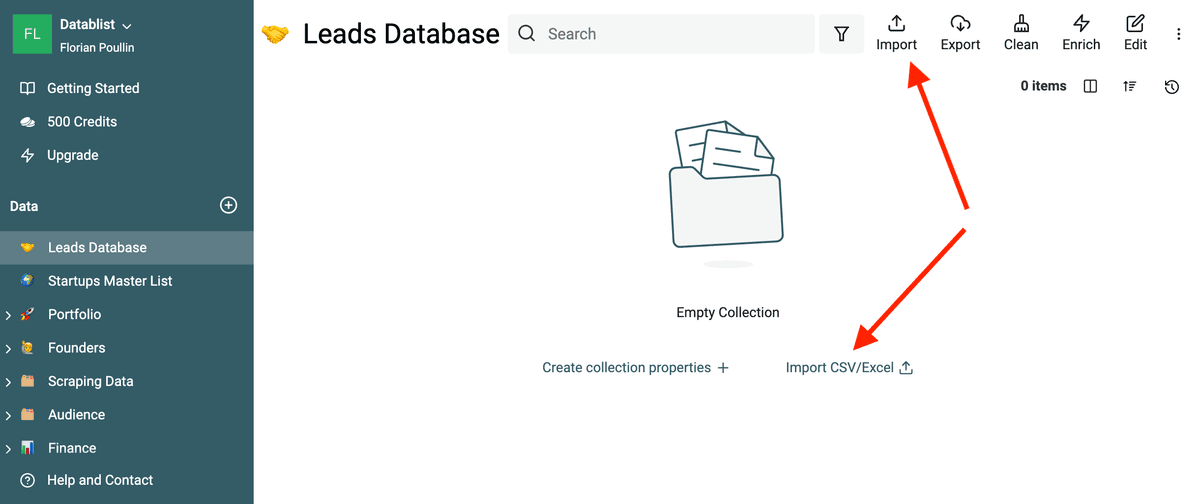
上传 CSV,为每一列创建对应 property 并启动导入。想看更细的操作步骤,可以参考 Import Data 文档。
清洗 leads 列表
先 filter 你的 collection,把 "Page" profiles 移除,只保留 profile type 为 "User" 的 leads。
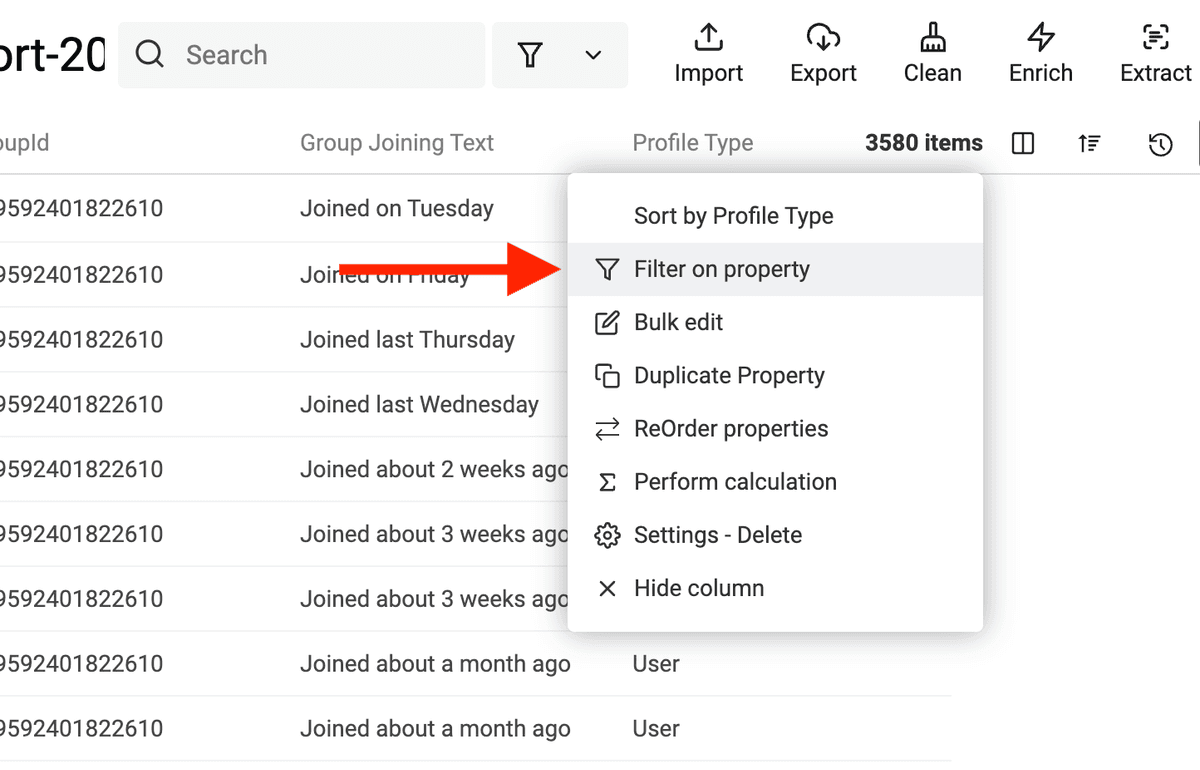
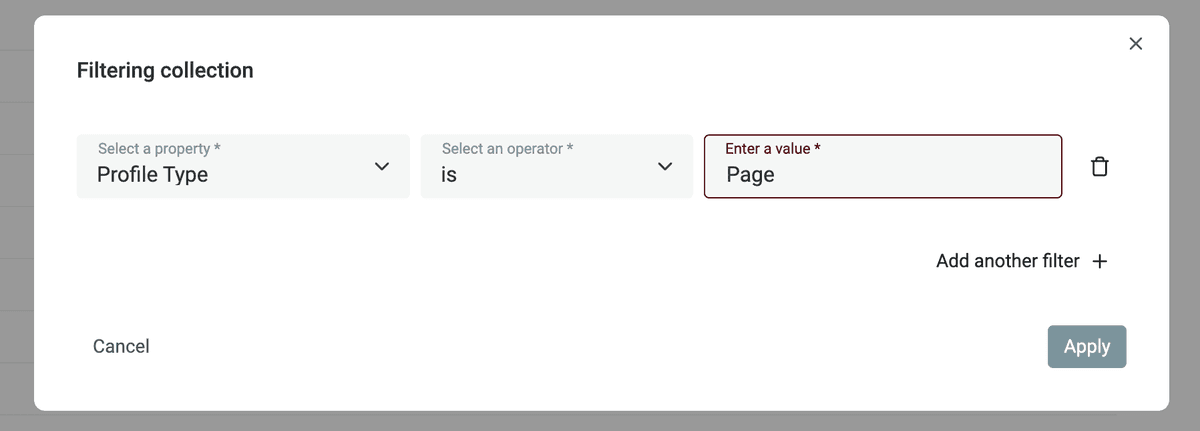
然后删除这些记录。
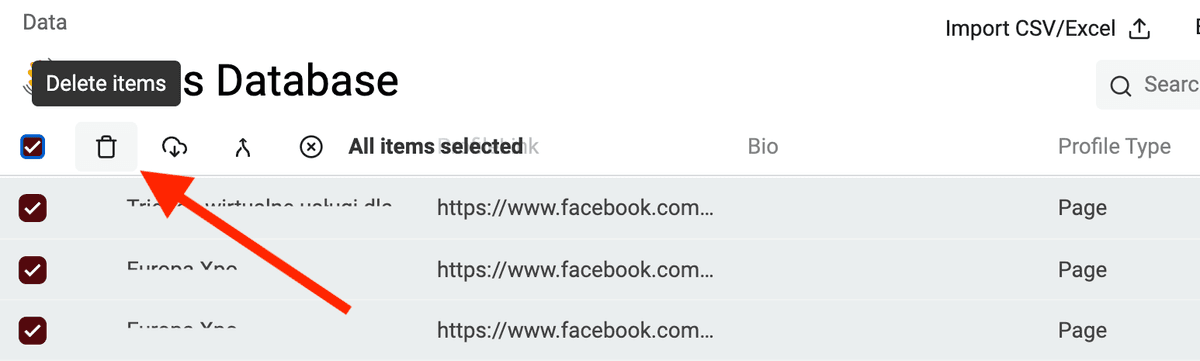
接着如果你和我一样喜欢极简视图,可以把不重要的 properties 隐藏掉:除了 "Full Name"、"ProfileLink" 和 "Bio" 以外都隐藏。
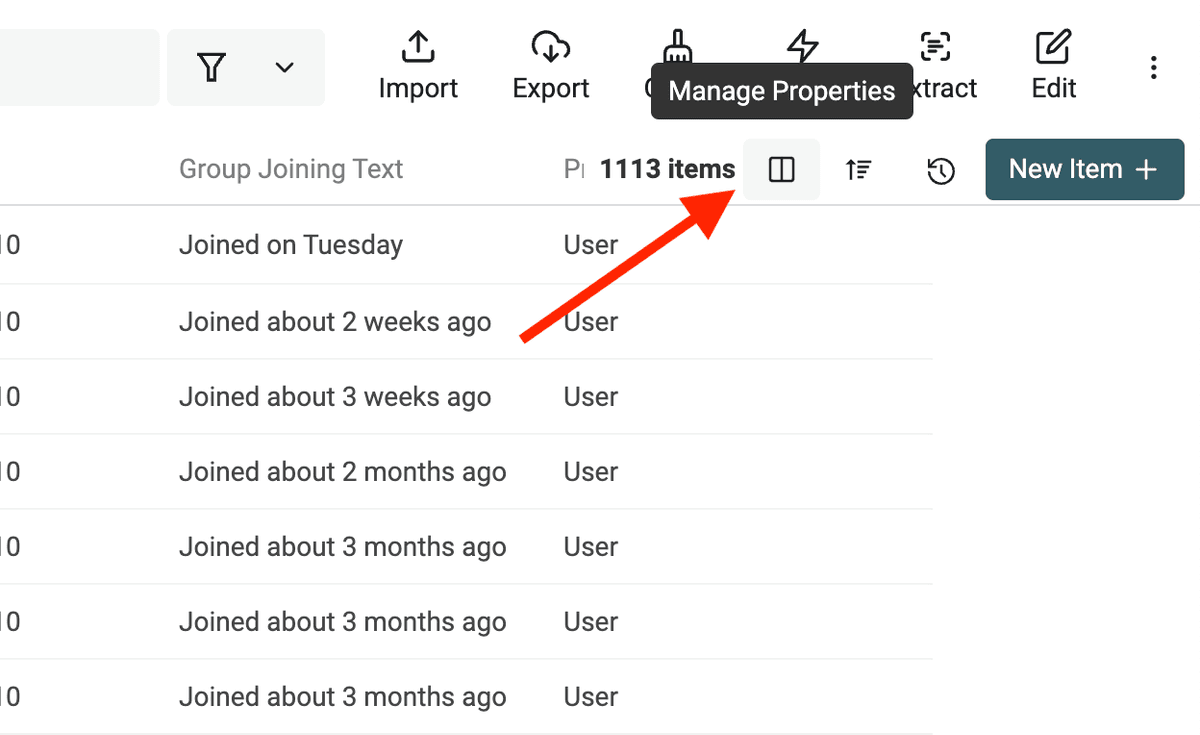
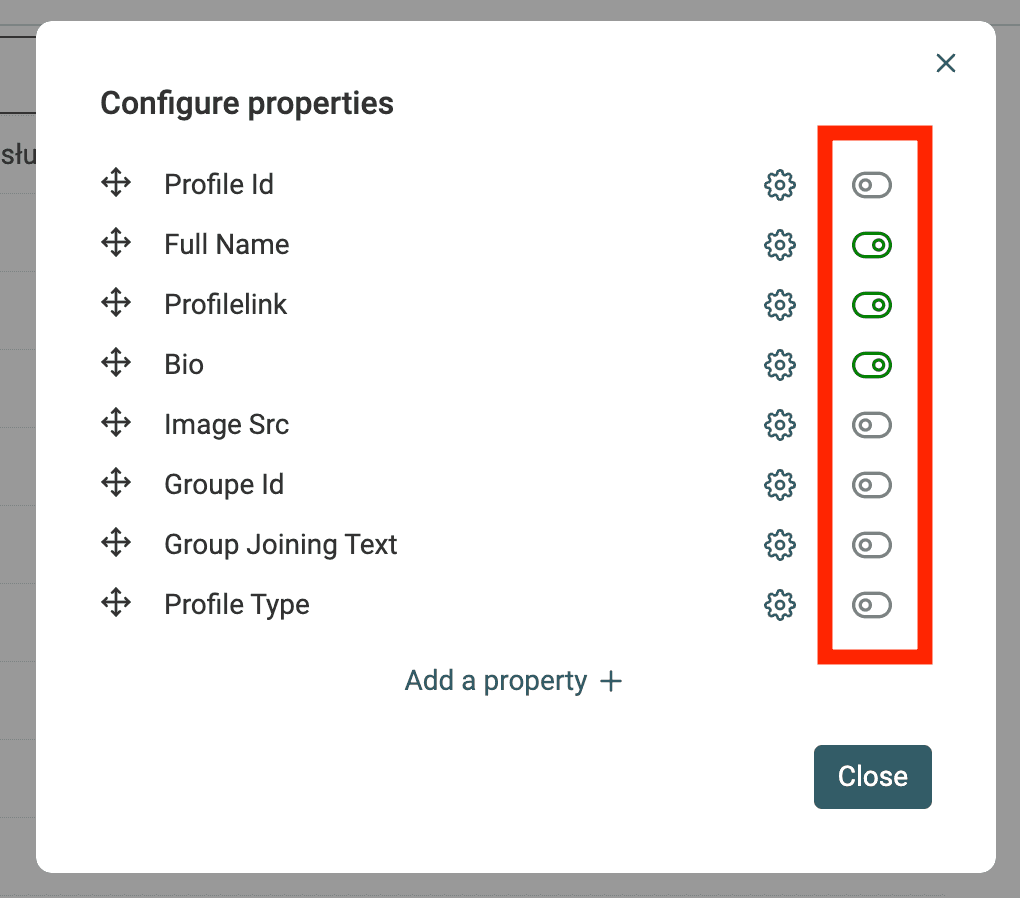
再进一步 filter,移除明显不职业的 leads。你可以用 Datablist search 或 filters 搜索这些关键词:"school"、"university"、"student"、"college"。
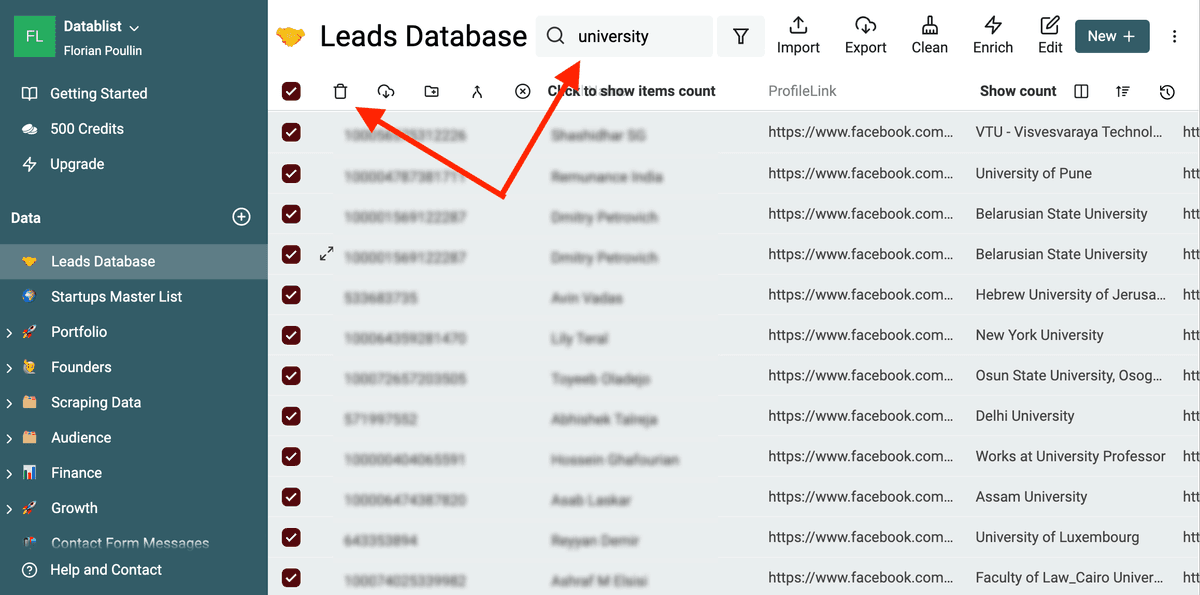
如果你做的是本地生意,也可以筛选 bio 包含你的城市/国家的记录。
注意事项
Facebook bio 有时会误导你。比如学生的 bio 可能写成 "Works at {学校名}"。建议你抽样浏览一下 leads,把 bio 里明显是学校的记录删掉。
提取职业信息
对于只有名字、没有任何工作信息的群成员,你只能更依赖手动搜索并人工 enrich。最有效的方法是去 Google 搜索:"{full name} site:linkedin.com/in/",然后查看 Google 返回的 profiles。
只用名字找 LinkedIn profile 很容易遇到重名。你需要通过 location、job title、头像等信息,确认哪个才是你的目标 prospect。
理想情况下,一部分 Facebook profiles 的 bio 能帮你自动缩小范围。
只保留带公司信息的 leads
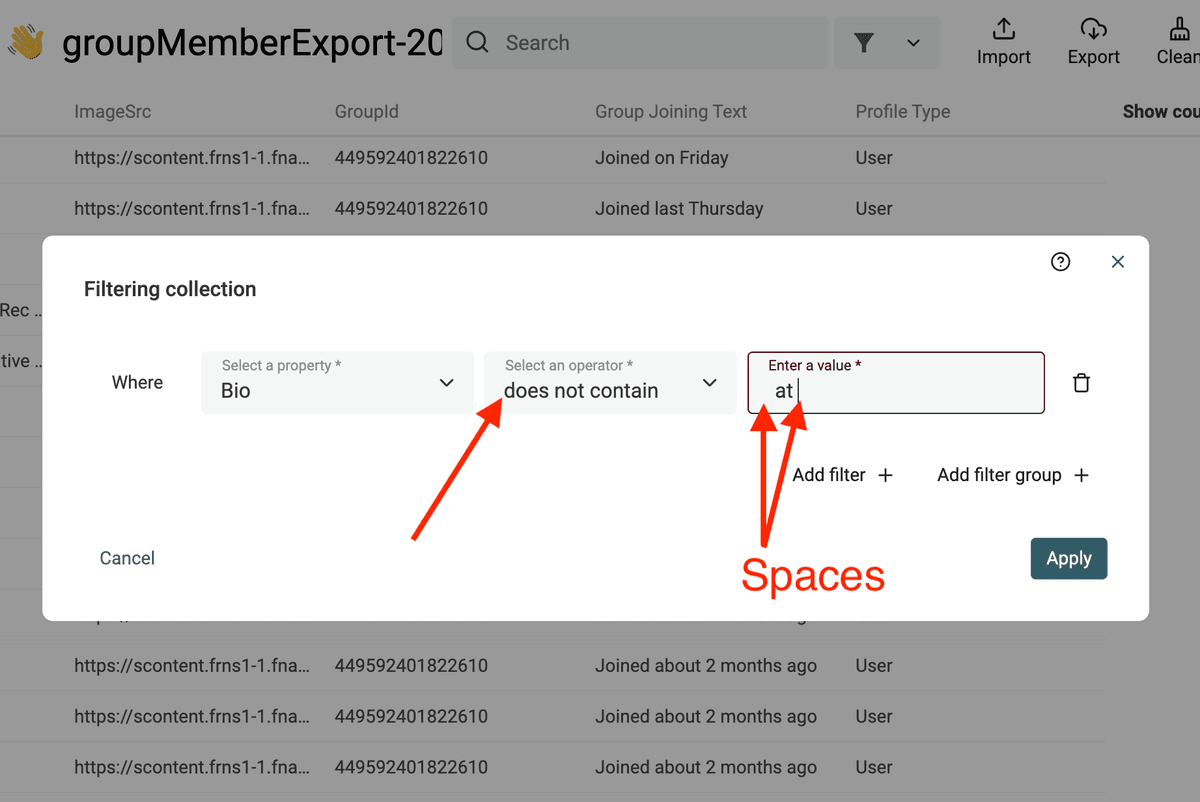
想聚焦 B2B leads,一个简单策略是只保留 bio 里带公司名的 profile。做法是:对 bio property 过滤,排除掉不包含 at 的成员。
B2B leads 的 bio 常见格式是:Works at XX、CEO at XX、Founder at XX。
Important:at 前后要加空格。否则任何包含字母 at 的词都会被误匹配。
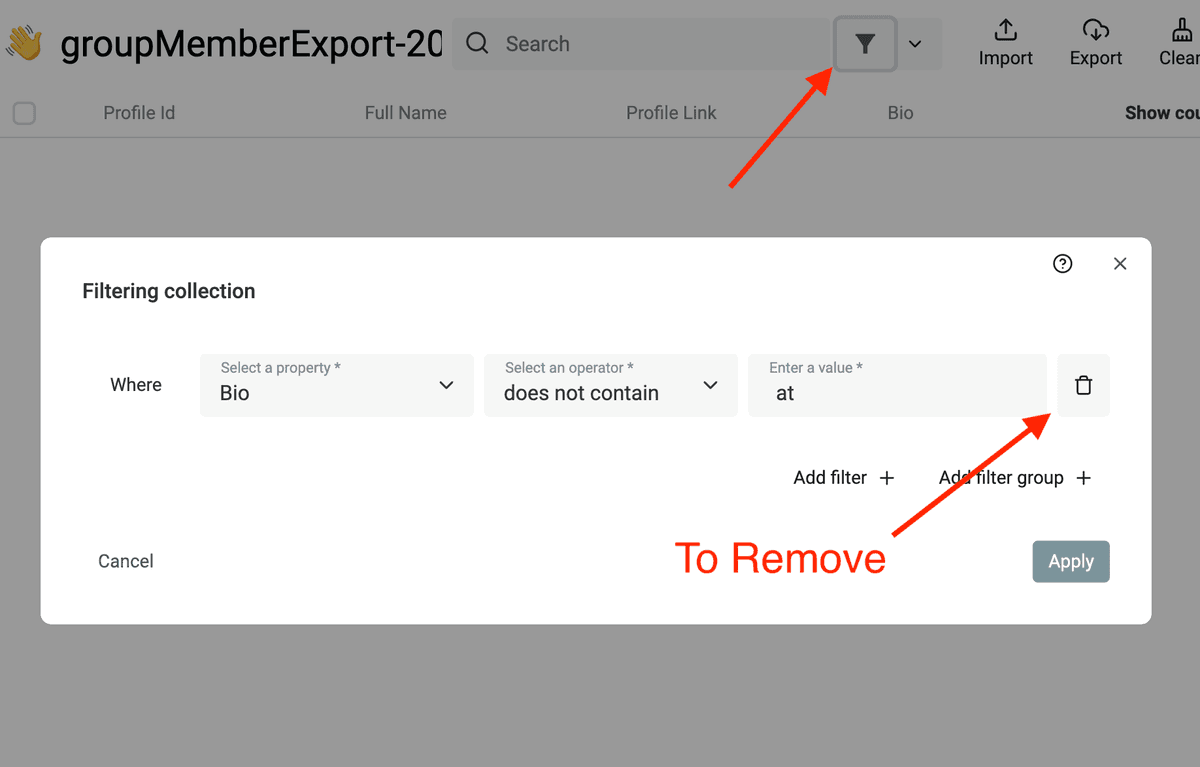
然后删除筛出来的非目标 leads。再移除 filter,回到你的干净列表。
Notes: 这一步会让你的 leads 数量大幅下降,这是正常的。Lead Generation 往往就是这样:从一个巨大列表开始 -> 缩小到少量但高价值的目标。 想要更多 leads,就去 scrape 更多 profiles,加入更多相关群组。
现在你已经把列表缩小到:bio 里有公司信息的 Facebook leads。接下来需要 从 “Bio” 里提取公司名,以便跑 Datablist 的 "LinkedIn Profile Finder from name"。
自动提取公司名
现在我们从 bio 中提取公司名。有了联系人姓名 + 公司名,你就可以运行 Datablist 的 "LinkedIn Profile Finder from name"(见下文)。
在 "Edit" 菜单里点击 "AI Editing"。
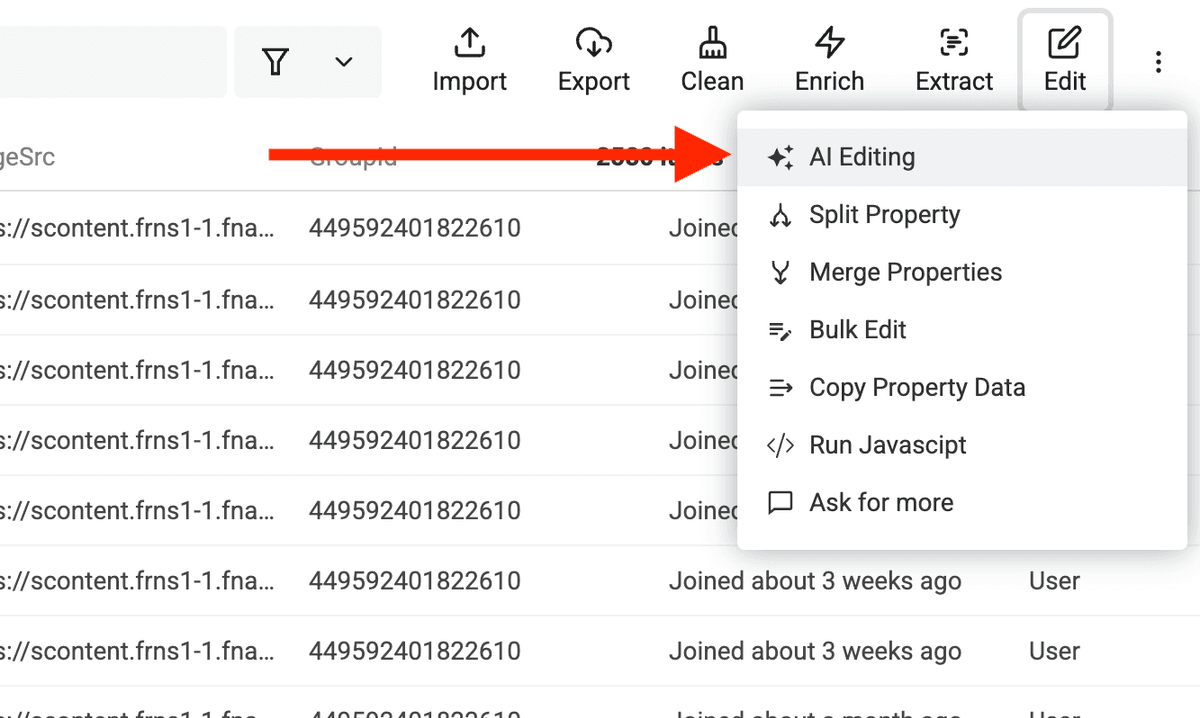
输入下面的 prompt:
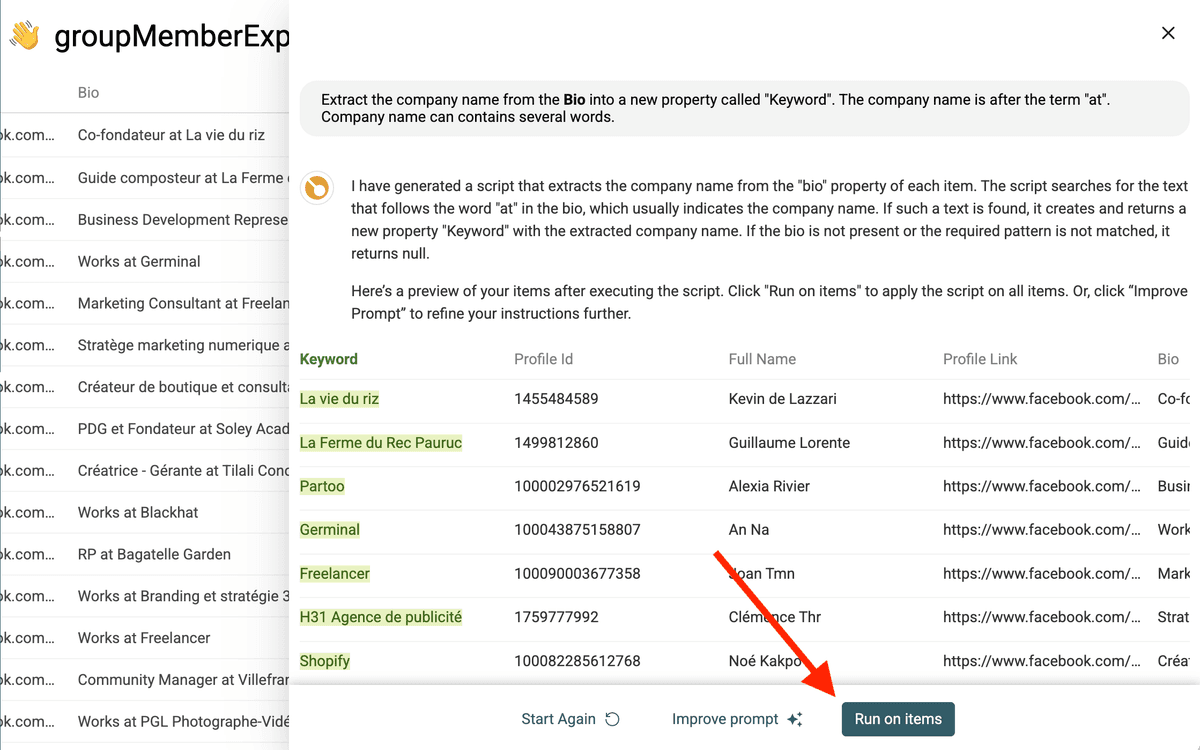
Extract the company name from the Bio into a new property called "Keyword".
The company name is after the term "at".
Company name can contains several words.
用 {{X}} 选择你 collection 里的 "Bio" property。
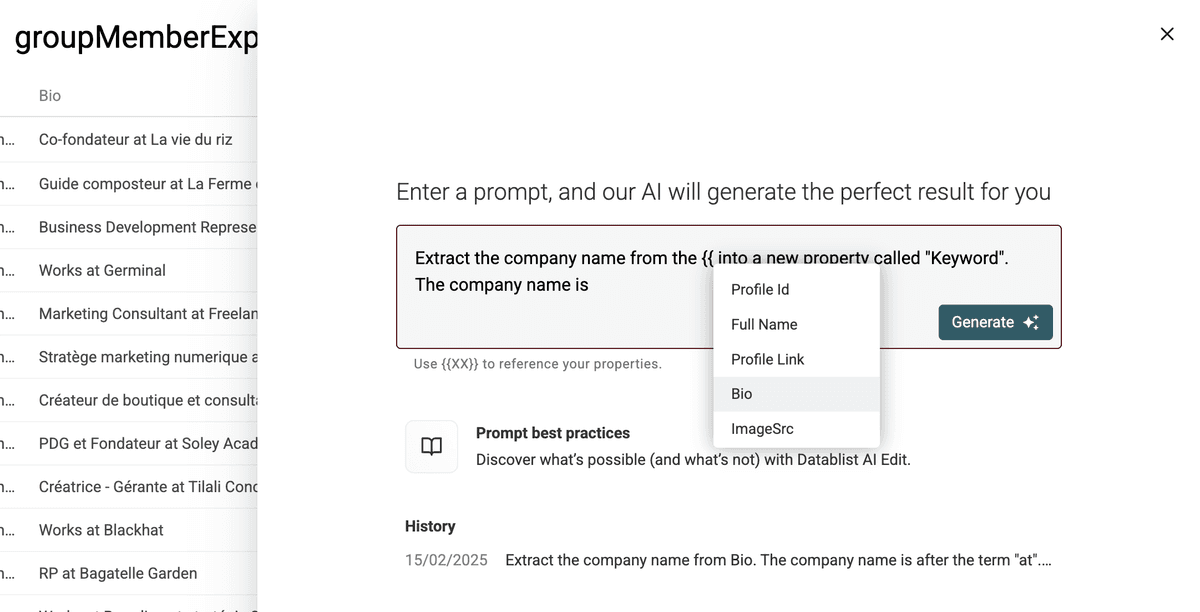
这是点击 "Generate" 前的完整 prompt:
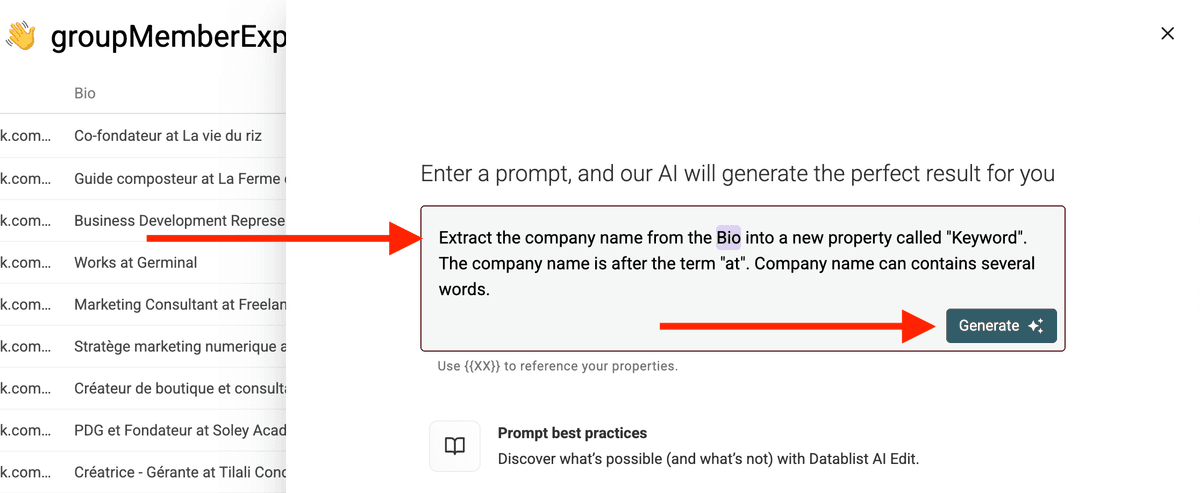
然后点击 "Generate" 生成脚本。你会看到结果预览;如果效果不错,点击 "Run on items"。
手动补齐剩余 keywords
如果你想尽量多拿到 leads,可以处理最初那份完整列表,针对某些特定词来找更“职业”的 bio。比如:"works"、"founder"、"CEO"、"marketing" 等。你可以按自己的业务和 Facebook 使用语言做调整。
注意事项
想编辑某个单元格,点击后按 “Enter” 进入编辑模式。

运行 "LinkedIn Profile Finder from name" enrichment
"LinkedIn Profile Finder from name" 会通过搜索引擎自动匹配 LinkedIn profiles。该 enrichment 在 Datablist "Standard" plan 可用。 需要的话可以点这里升级。
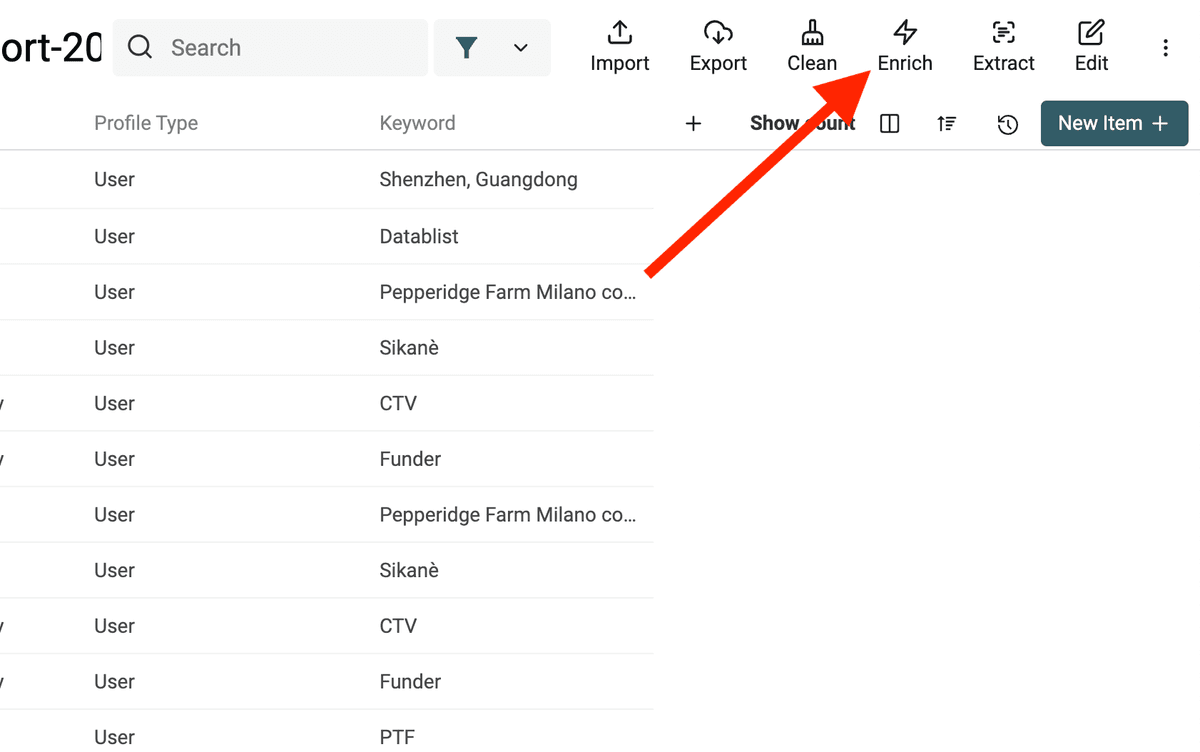
先 filter 你的 collection,只显示 "Keyword" 已填写的 leads。然后点击 "Enrich" 打开 Enrichments 面板,选择 "LinkedIn Profile Finder from name",进入配置抽屉。

Important
"LinkedIn Profile Finder from name" 的准确率和 keyword 质量强相关。相比大而泛的群,更建议你优先抓小而精准、成员质量更高的 Facebook 群组。
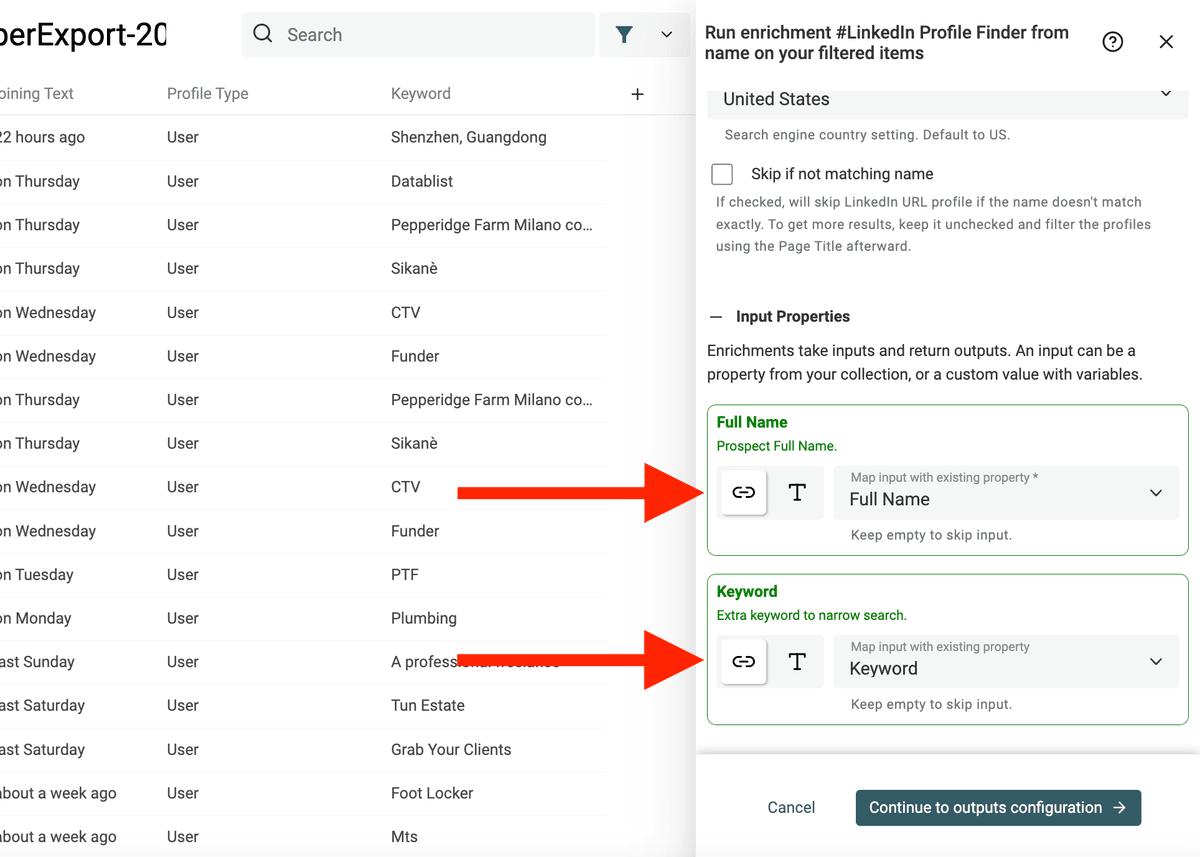
点击 "Continue to outputs configuration"。enrichment 会基于输入生成输出。这里会返回 LinkedIn Profile Url、LinkedIn Profile Title 和 LinkedIn Profile Summary。
点击 “+” 把这些 properties 添加到你的 collection。
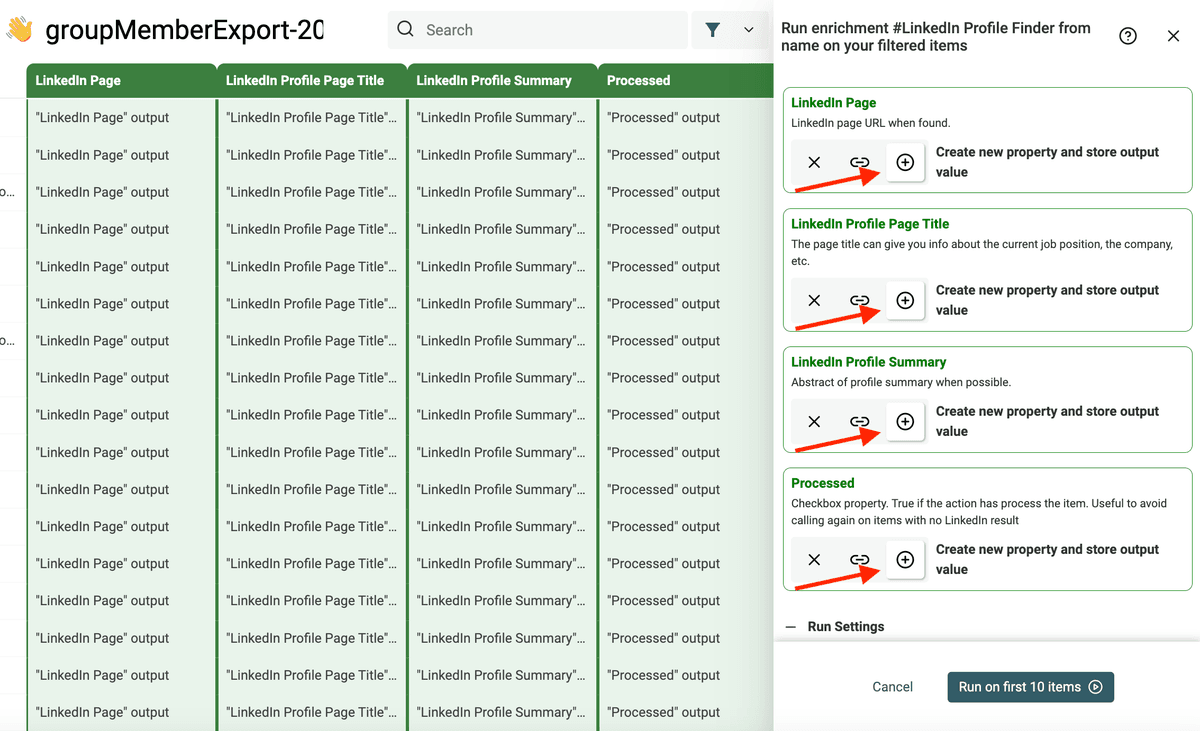
点击 "Run on first 10 items" 先跑前 10 条预览效果;满意后,点击 "Run enrichment on all items" 处理全部 leads。这个 enrichment 会以每批 30 条来处理你的 Leads Database。
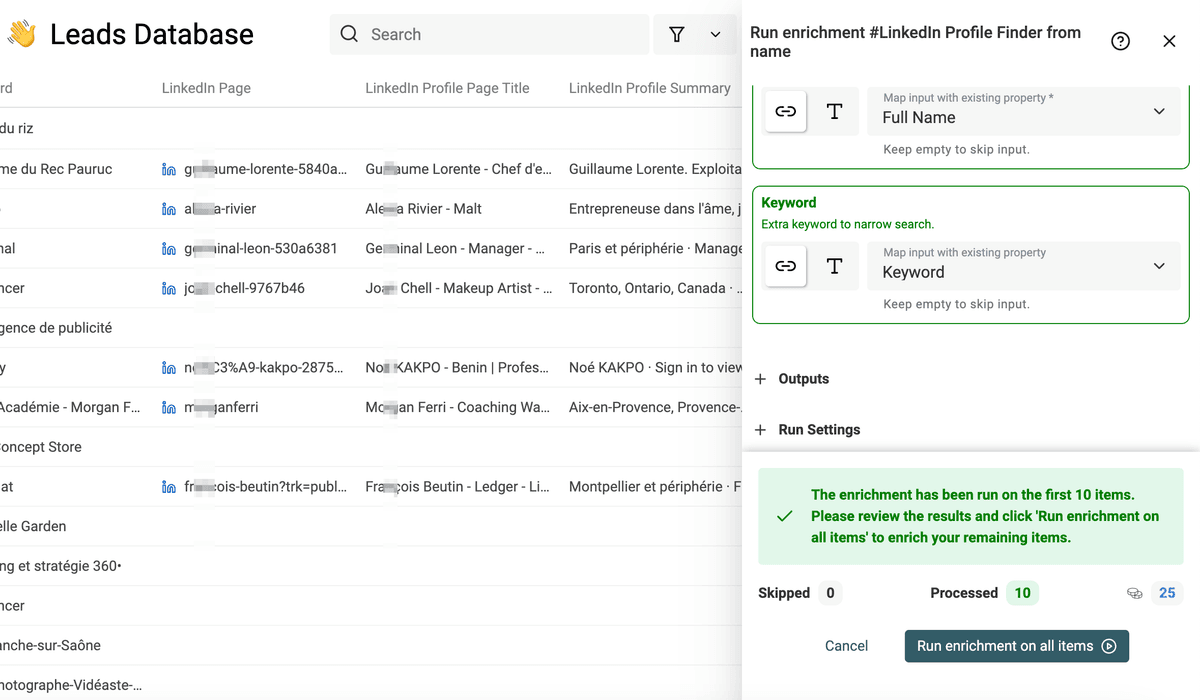
获取更高质量 leads 的小技巧
LinkedIn 在北美和欧洲更普及,在亚洲相对弱一些。为了提高 LinkedIn profiles 的命中率,建议优先定位到区域性更强的群组,比如包含 "European",或国家/地区关键词如 "French"、"Canadian" 等。
Step 3 (可选): 从 LinkedIn URL 获取完整资料
通过 "LinkedIn Profile Finder from name" 返回的 Google 搜索结果信息是有限的。
Datablist 还提供另一个 enrichment,用于从 LinkedIn Profile URL scrape 完整 LinkedIn 数据!
拿到 Step 2 的结果后,先 filter,只保留成功匹配到 LinkedIn profile 的成员。
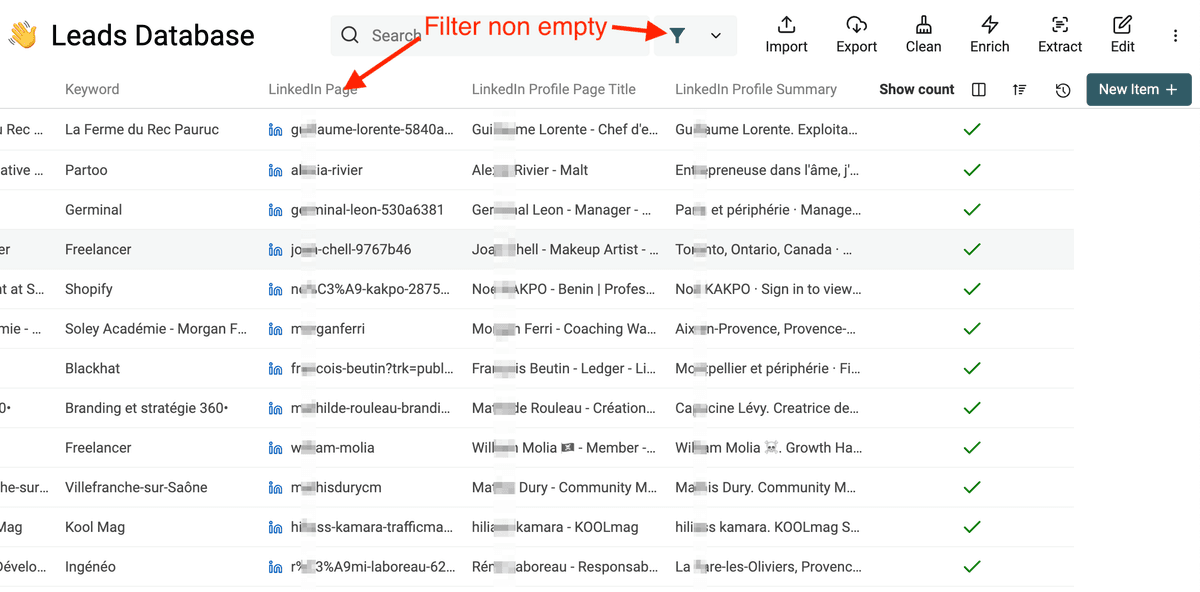
然后选择 "LinkedIn Profile Scraper"。
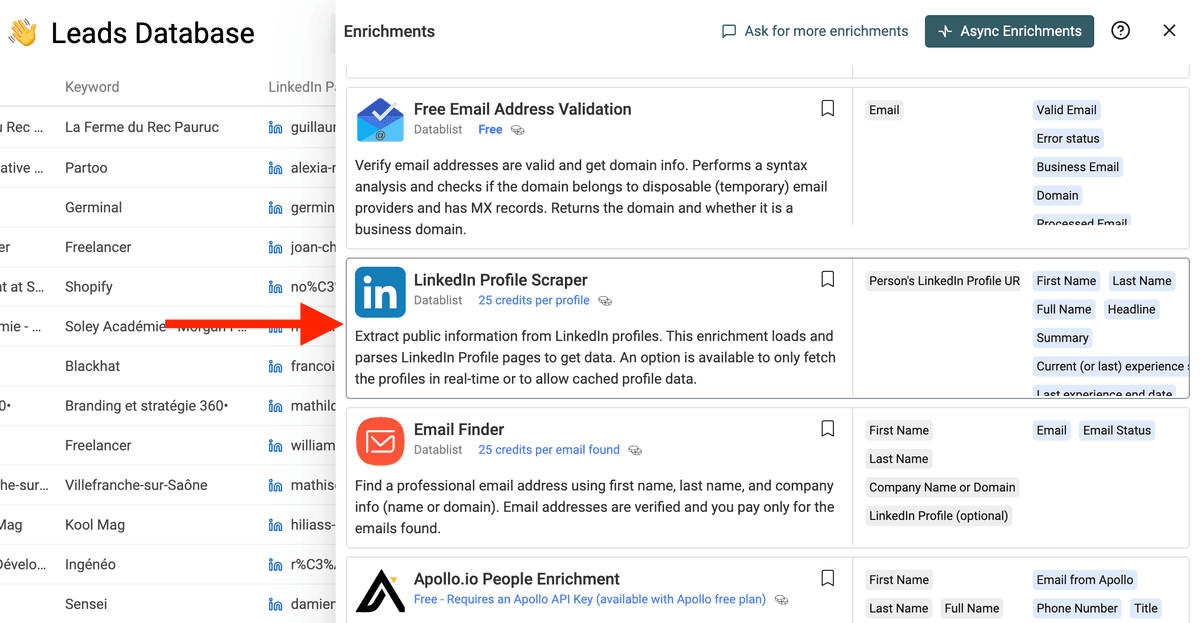
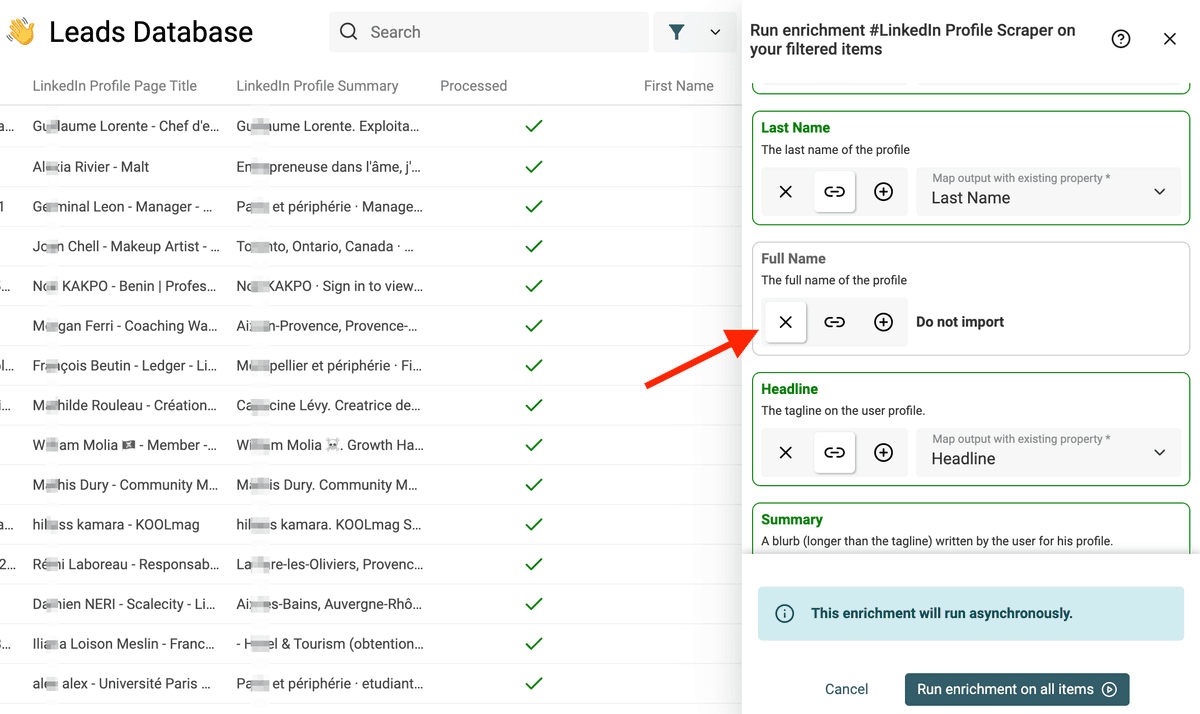
把输入映射到 LinkedIn Profile URL(通常是 LinkedIn Page)。Datablist 会做 auto-mapping,但它也可能把 Facebook URL 当成链接字段映射进去……请务必确认映射的是正确的 property。
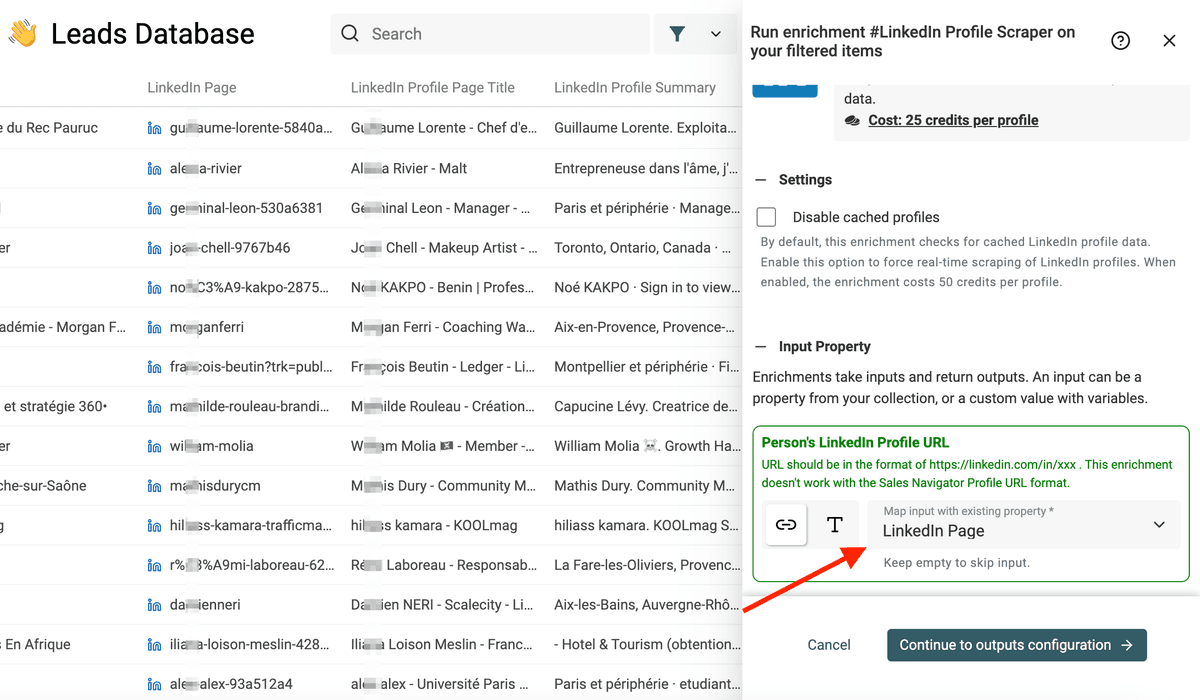
下一步的 outputs 配置里,点击 “+” 用 enrichment 结果创建新 properties。
建议至少提取这些字段:
- First Name
- Last Name
- Current (or last) experience company name
- Current (or last) experience company page URL - 这个对 Step 3 - Bis: 从 LinkedIn Company Pages 获取公司域名 非常关键
Warning
不要把 "Full Name" 映射到 Facebook 抓取出来的 Full Name。 否则 Datablist 可能会为了避免覆盖数据而跳过 items。你可以点 “X” 忽略该 output,或点 “+” 新建一个空 property。
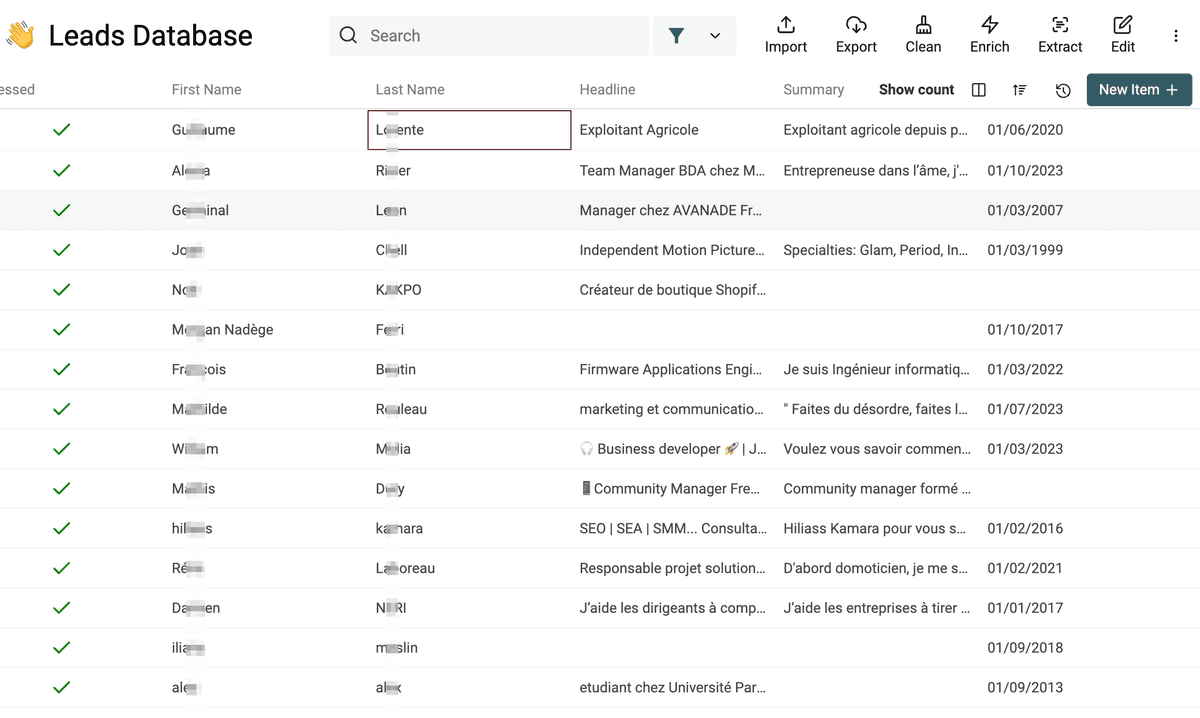
完成后,你会拿到更完整的 leads 属性集,可以用来继续筛掉不合格 leads,或者做更个性化的开场白。
Step 3 - Bis: 从 LinkedIn Company Page 获取公司域名
Step 3 会给你一个 "Current (or last) experience company page URL"。Datablist 提供了一个很直接的方法,可以从 LinkedIn Company Page 反查 Company Domain。
Company domain 对 Step 4:查找邮箱 很重要!
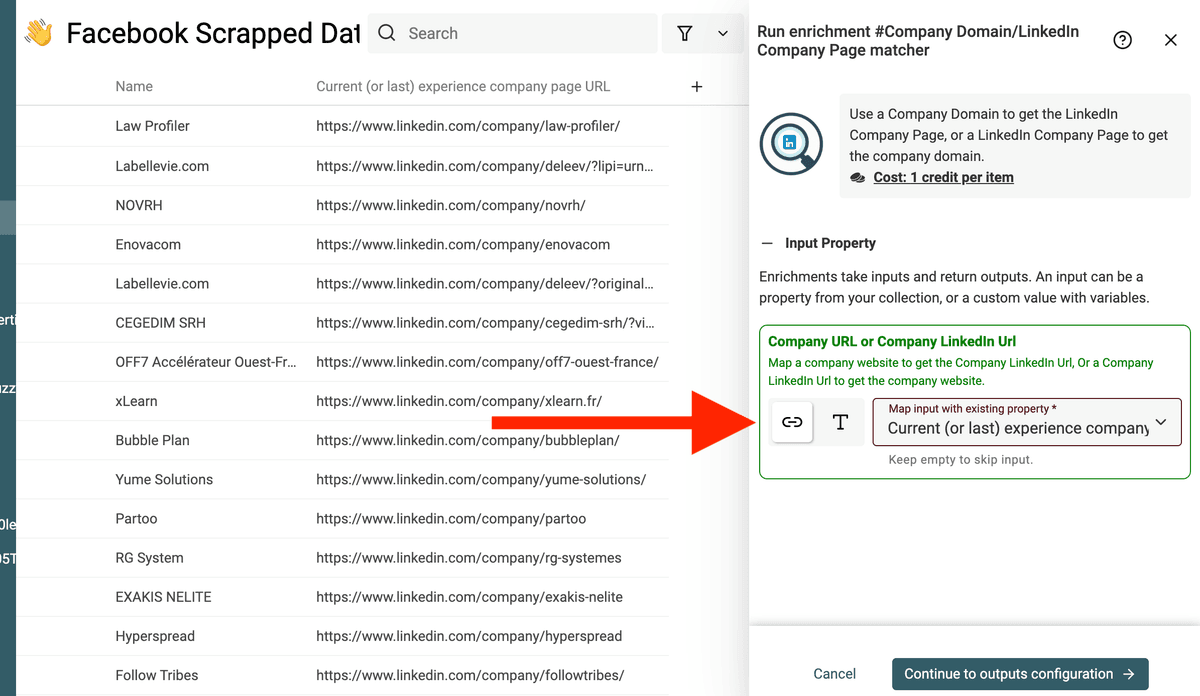
点击 "Enrich",选择 "Company Domain/LinkedIn Company Page Lookup"。

输入选择 "Current (or last) experience company page URL"。
创建一个新 property 用来存 domain。
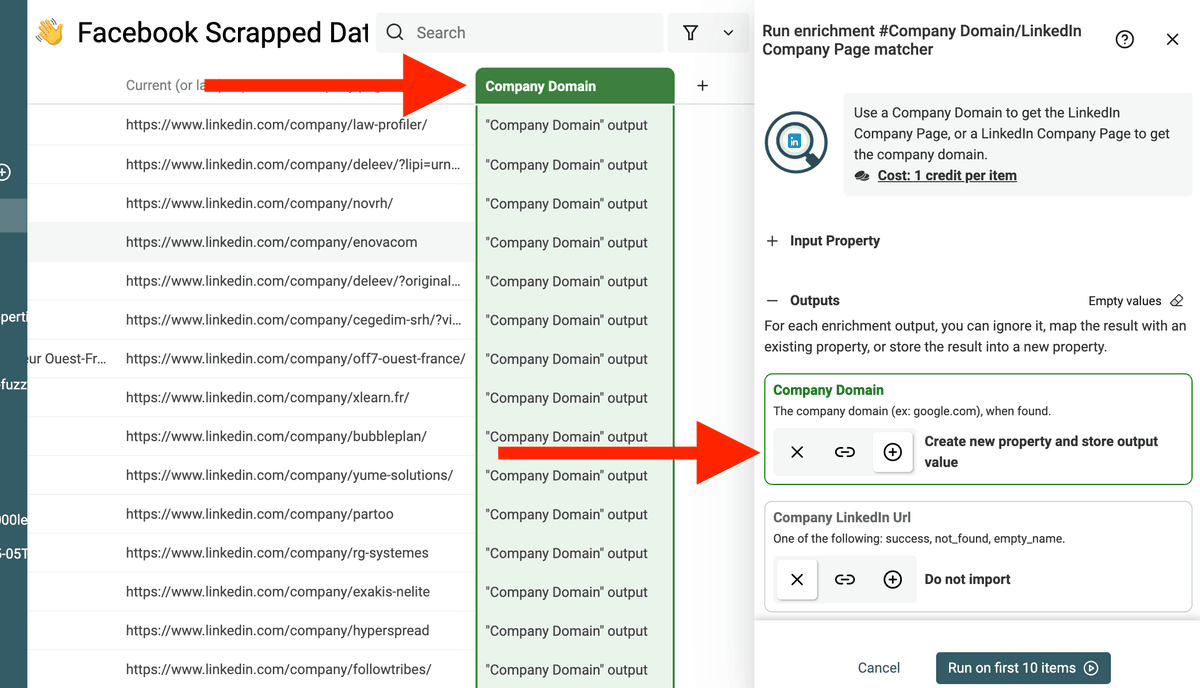
然后运行 enrichment,就能拿到 leads 对应的 domains。
Step 4: 为 Facebook 群成员找到邮箱
如果你要做 email marketing,那 email address 就是必需品。先说明白:从 Facebook 直接拿到邮箱,基本没有可靠的方式。
但我们可以利用姓名、公司名/domain、或者 LinkedIn Profile URL 去找邮箱。
这就是 "Email Finder" enrichment 的用途。
点击 "Enrich",搜索 "Email Finder"。
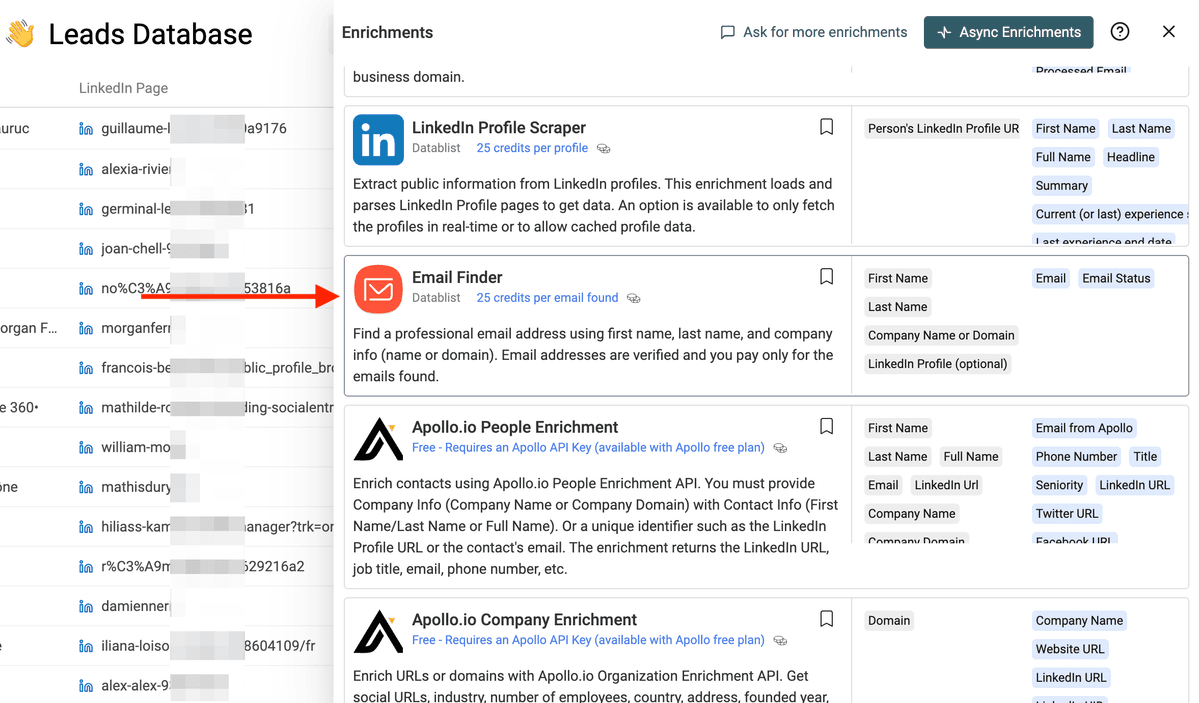
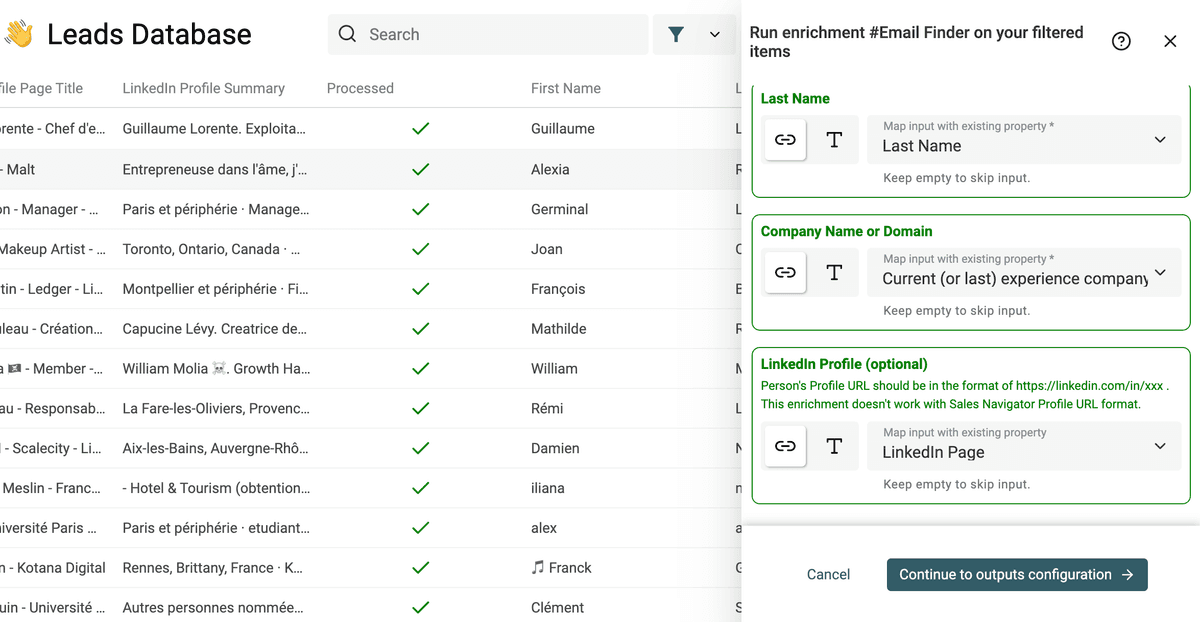
在 Inputs 里,映射 First Name、Last Name、Company Name(来自这一步)或 Company Domain(来自 LinkedIn Profile Scraper)。
⚠️ Notes
当你有真实的 First Name/Last Name + Company domain 时,Email Finder 的命中和准确度会明显更好。 如果你还没做 Step 3,建议回去补一下:Step 3:从 LinkedIn URL 获取完整资料。
如果你只有 Full Name,可以先用 Name Parser enrichment,把姓名拆成 First Name、Last Name 等组件。
LinkedIn Profile 的输入则映射为你从 "LinkedIn Profile Finder from name" 得到的 LinkedIn URL。
然后创建新 properties 来存结果。这个 enrichment 会返回两个字段:
- Email - 邮箱地址
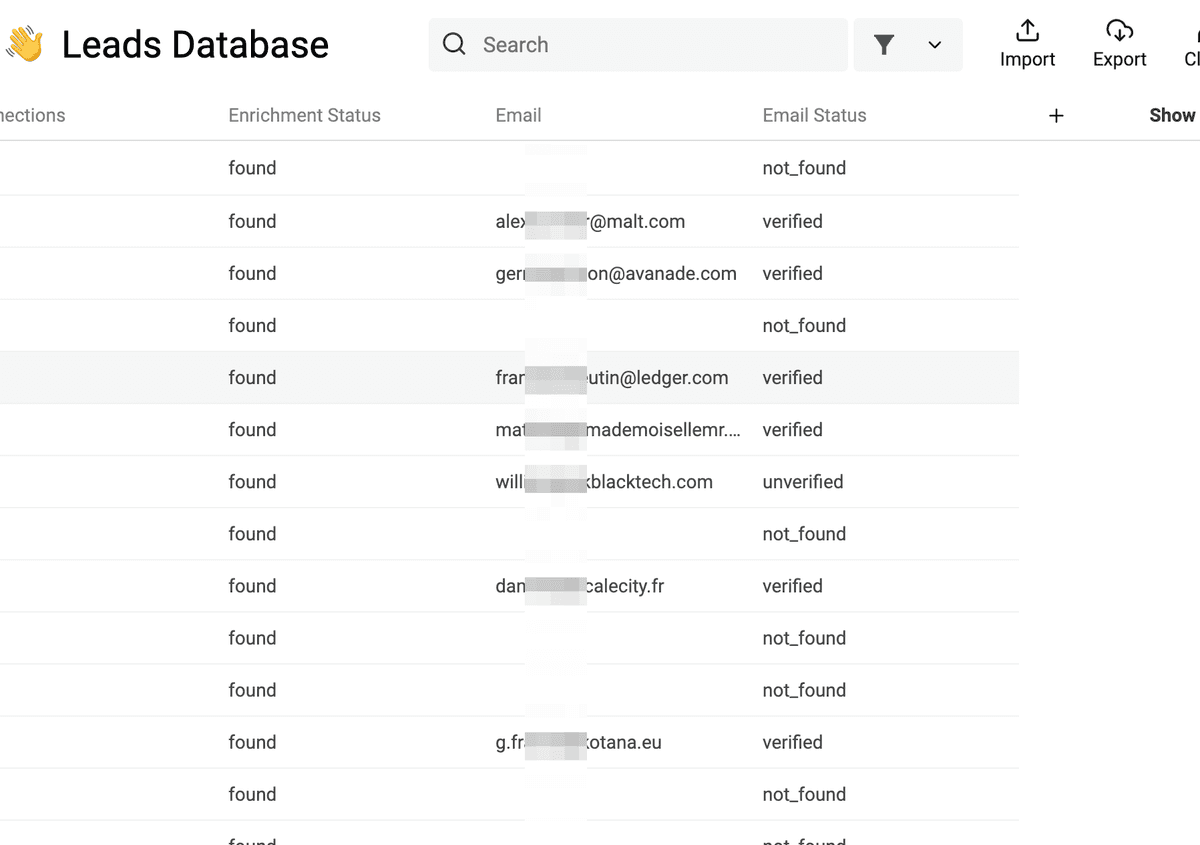
- Email Status - 邮箱可投递性信息;如果没找到则显示 'not_found'
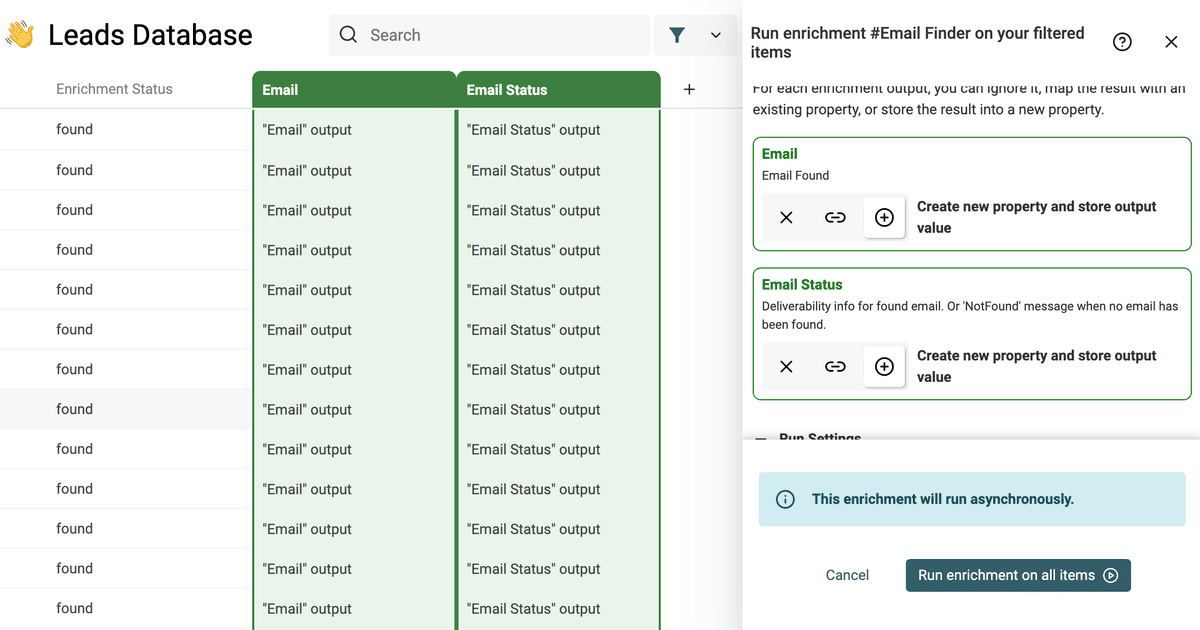
接着运行 "Email Finder"。
Pricing Info
Email Finder 的费用是每个 成功找到 的邮箱 25 credits。没找到邮箱不收费。
Step 5: 用新成员更新 collection
第一次 scrape 完 Facebook 群成员之后,建议你隔一段时间就去抓一次新成员,并更新你的 Datablist collection。
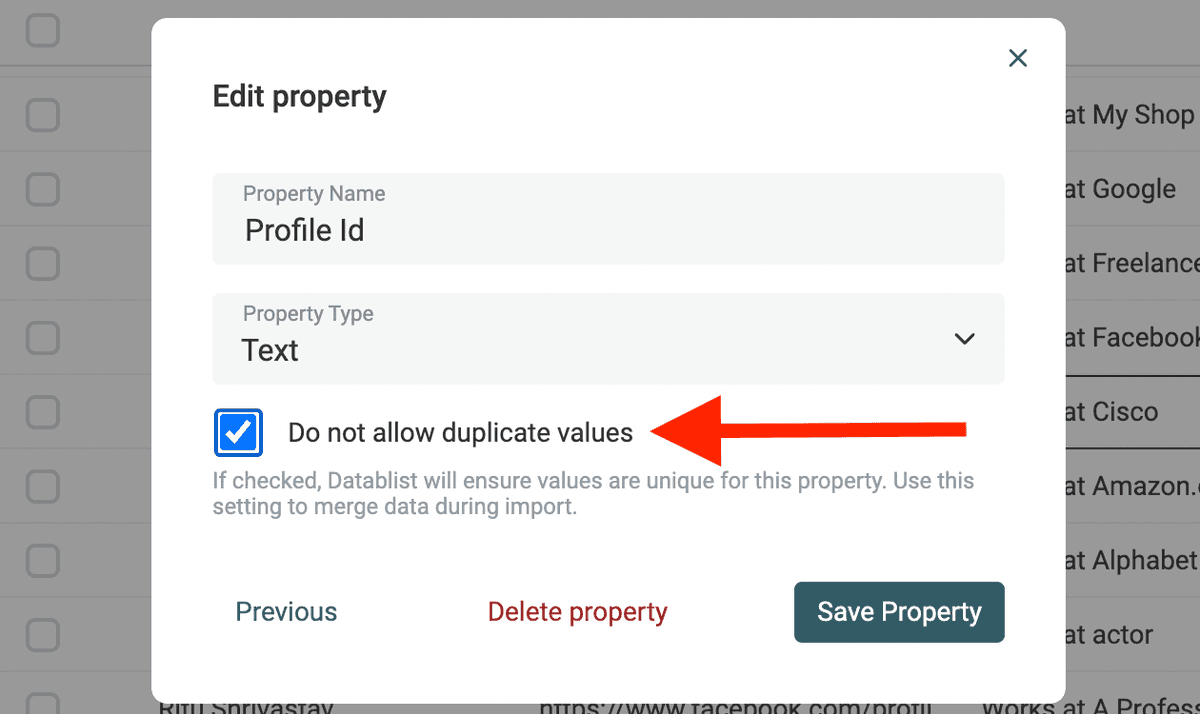
Datablist 支持给任意 property 设置 unicity constraint。当开启 "Do not allow duplicate values" 后,你在导入 CSV 时遇到重复行会自动跳过(或合并)。
给你的 "Profile Id" property 开启 "Do not allow duplicate values"。因为它对每个 Facebook profile 都是唯一且不会变化的。
导出结果到 Excel 文件(可选)
如果你需要用 Microsoft Excel 进一步处理 Facebook 群成员数据,点击 "Export",然后在导出格式里选择 "Microsoft Excel"。
把 scrape 脚本存到 Chrome Extension 里
每次都在 Chrome Console 里 copy/paste 脚本确实挺耗时间。好消息是:你可以用 Chrome Extension 一键把脚本注入到页面里。 你可以设置为在 Facebook 页面自动注入,也可以点击扩展菜单时再注入。
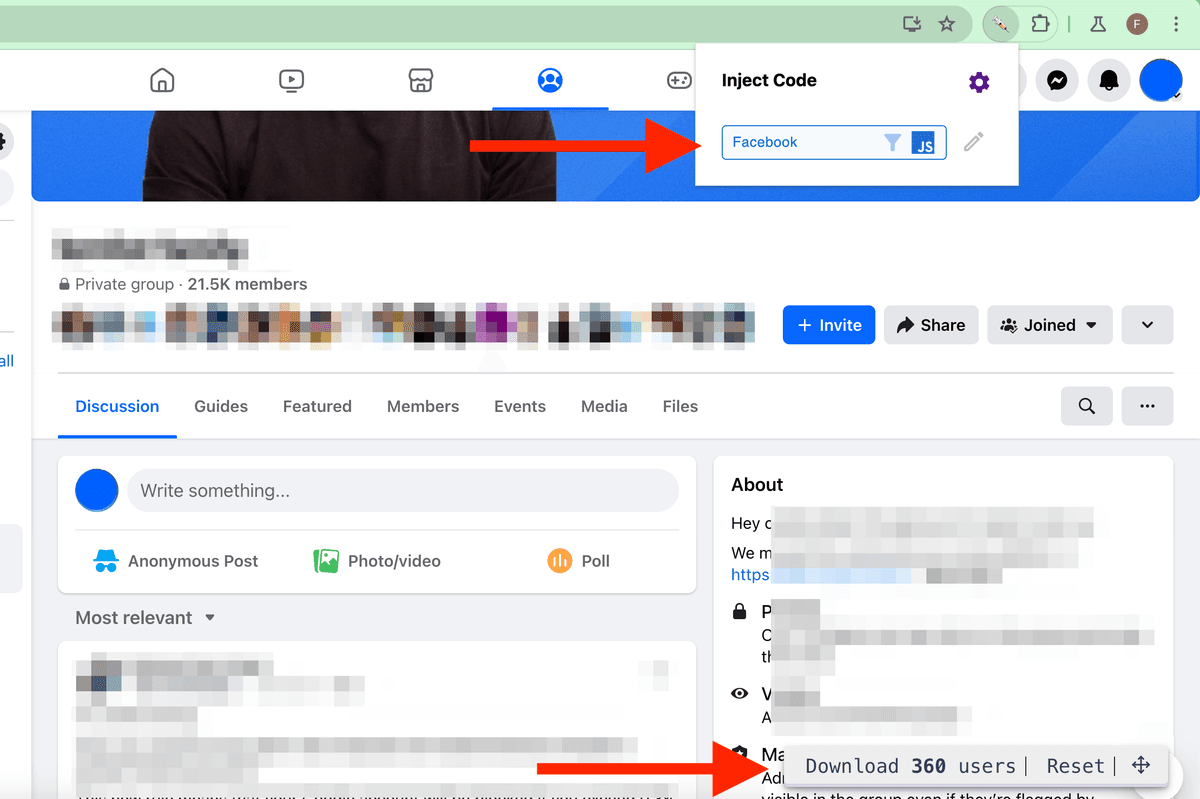
这个 Chrome Extension 叫 "Inject Code",在 Chrome Web Store 可以安装: https://chromewebstore.google.com/detail/inject-code/jpbbdgndcngomphbmplabjginoihkdph
安装完成后,点击配置一个新的 script。
点击 “+” 创建一个 "Snipper (script)"。
然后在配置页使用如下设置:
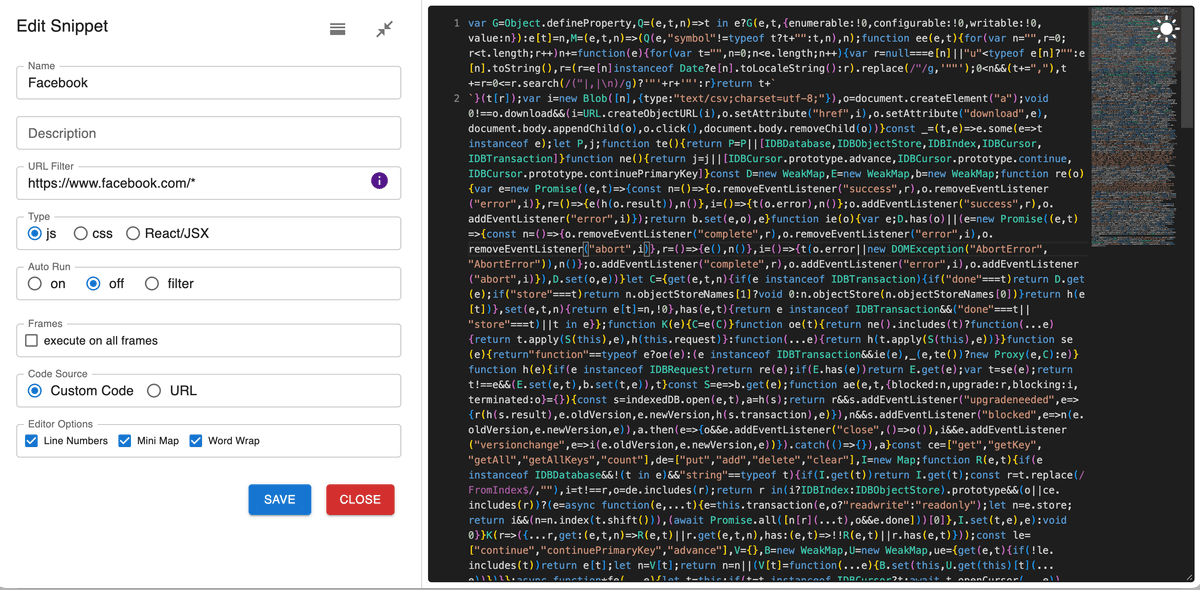
- Name:
Facebook - URL Filter:
https://www.facebook.com/* - Type:
js - AutoRun: 选择
on表示在 Facebook 页面自动注入脚本;或选off表示从 extension 菜单点击后再注入。 - CodeSource:
Custom Code
点击 "Save"。
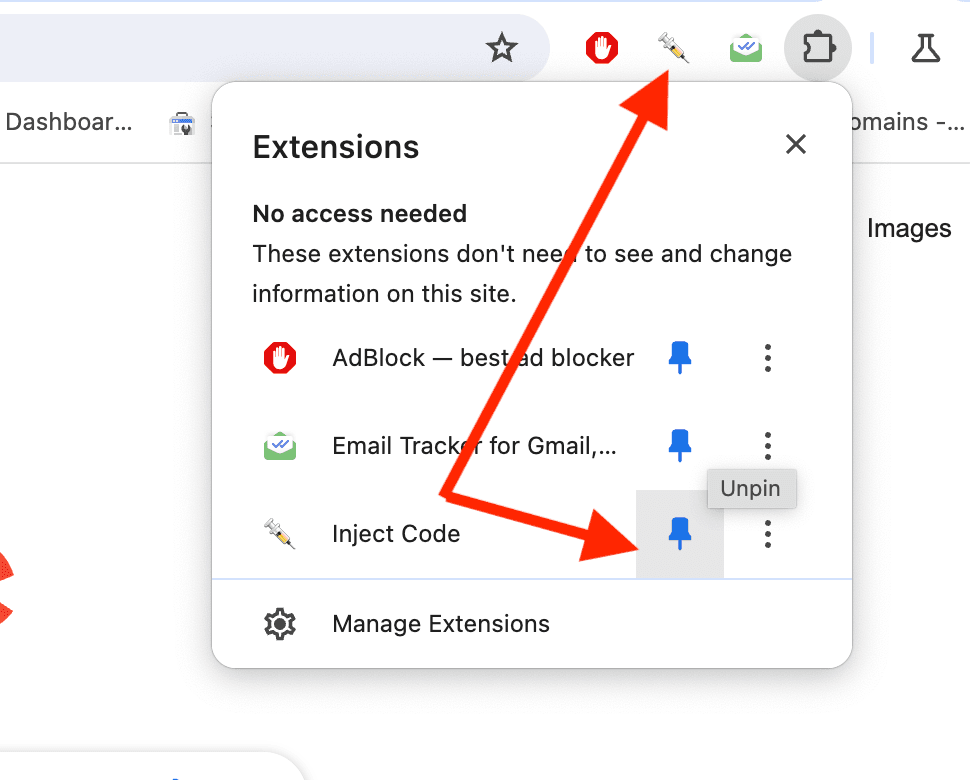
把扩展 pin 到浏览器导航栏,这样就能随时使用了。搞定!祝你 scrape 顺利。
其他 Scrapers
如果你对这份指南有任何反馈,或有问题想问,欢迎联系我们。