

清理并 Enrich CRM 数据,是投入产出比最高的工作之一,原因很简单:
- 你给 CRM 做 enrichment 之后,销售能更高效地跟进,约到更多会议。
- 你把 CRM 清干净之后,市场能更清晰地看全局,campaign 做得更准。
- 你把 CRM 数据结构化之后,RevOps 和 GTM 团队能更快看出哪些有效、哪些无效。
当然,干净的 CRM 还有 99+ 个好处,但我们不展开了——下面直接带你从头到尾把 CRM 清理和 enrichment 跑一遍。
开始吧!
本篇 CRM 数据清理指南大纲
这份指南分为 4 个核心模块,每一块都对保持 CRM 数据干净、实时更新至关重要。在开始前,先快速看下我在文中提供的 CRM cleanup 工作流:
简单来说:我们会先 全量去重 → 再 验证剩余数据是否仍然有效 → 然后 结构化/提取 → 最后再 用新数据做 enrichment。
你可以直接跳到你最需要的部分,也可以跟着我完整走一遍。
❗️ 保留你的 Record ID
这篇示例里我没有展示 Record ID(比如 contact ID、note ID、account ID 等),但你在实际操作时一定要保留它们;否则你就无法把清理后的数据 import 并正确 map 回 CRM。
如何给 CRM 联系人与客户去重
当你要给 CRM 里的 contacts 和 accounts 去重时,在 Datablist 里通常有 3 种做法:
这里的“列表”可以是 account list、contacts list 或 deals list——不管是什么内容,流程都一样。
方法 1:使用所有列对单一列表去重
有时候你会多次从 LinkedIn 抓取联系人 或其他来源采集数据,结果同一个联系人被重复抓了好几次。这个场景下,最快的做法就是用所有列一键去重:去重联系人。操作如下:
Step 1:用所有列对列表去重
第一步,注册 Datablist.com
第二步,把你的列表 import 为 CSV 或 Excel。
Step 2:用所有列对列表去重
点击 Clean,选择 Duplicates Finder。
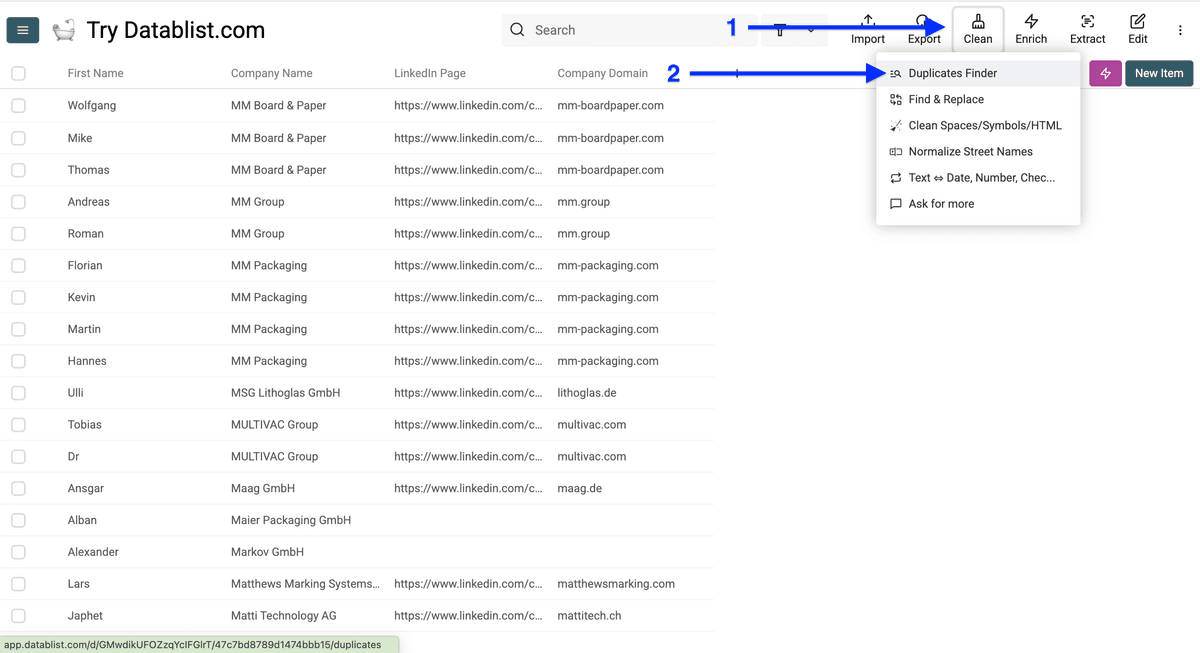
然后打开 All Properties 旁边的开关。
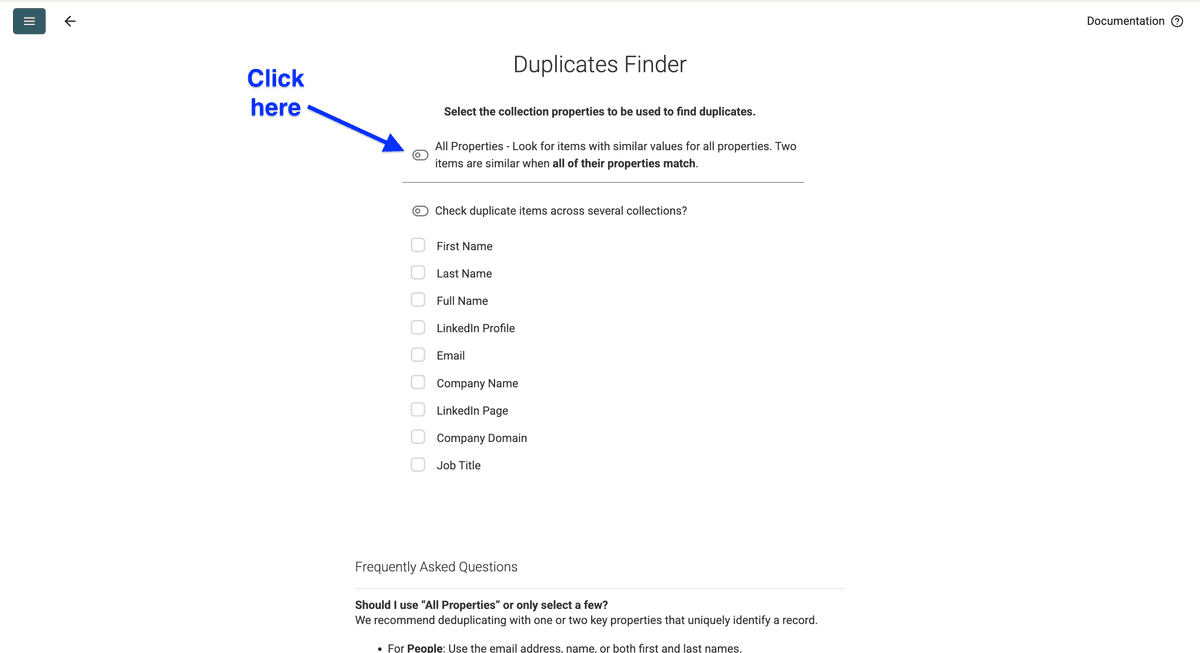
点击 Next。

点击 Run duplicates check。

现在你可以 review 结果,然后点击 Auto-merge duplicates when possible。
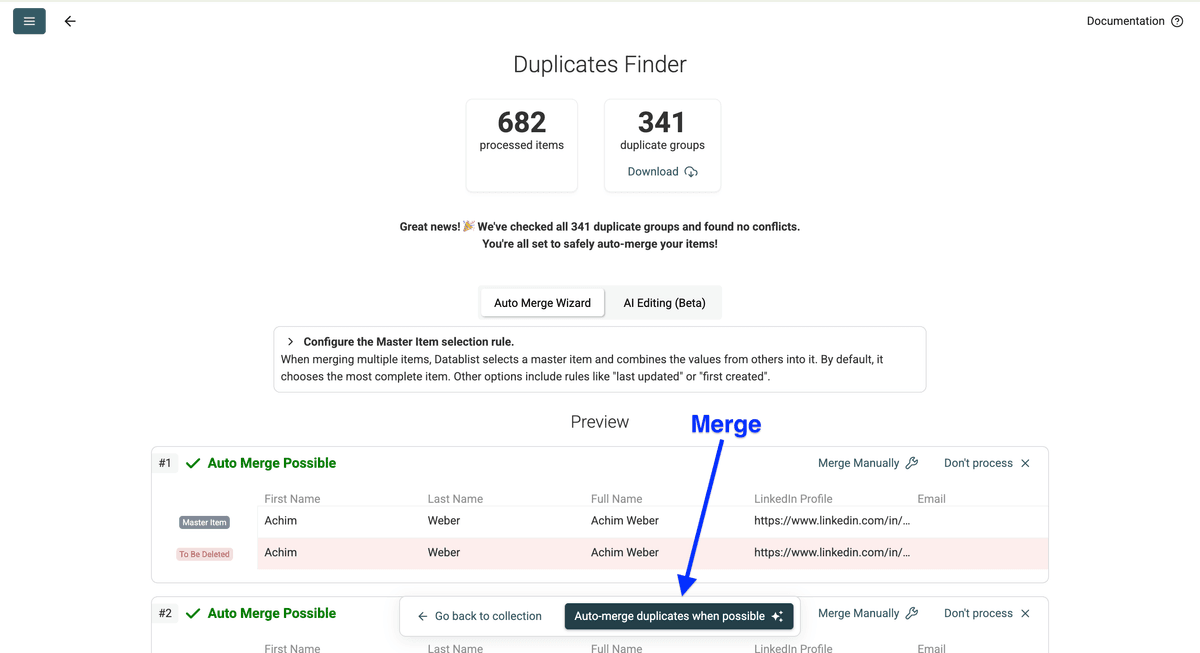
CRM 联系人去重就是这么简单!
下面我们来看第二种去重方式。
方法 2:使用指定列对列表去重
当你要去重的列表里,同一个联系人存在“轻微差异” 时,这就是最推荐的方法。
举个例子:同一个联系人出现两次,email 和姓名相同,但备注 notes 不同——那你就应该只用两三列作为去重依据,而不是全列。
我们把这种列叫做 unique identifier(唯一标识),而且你可以有多个。
Step 1:用指定列对列表去重
第一步,注册 Datablist.com。
第二步,把你的列表 import 为 CSV 或 Excel。
Step 2:用指定列对列表去重
点击 Clean,选择 Duplicates Finder。
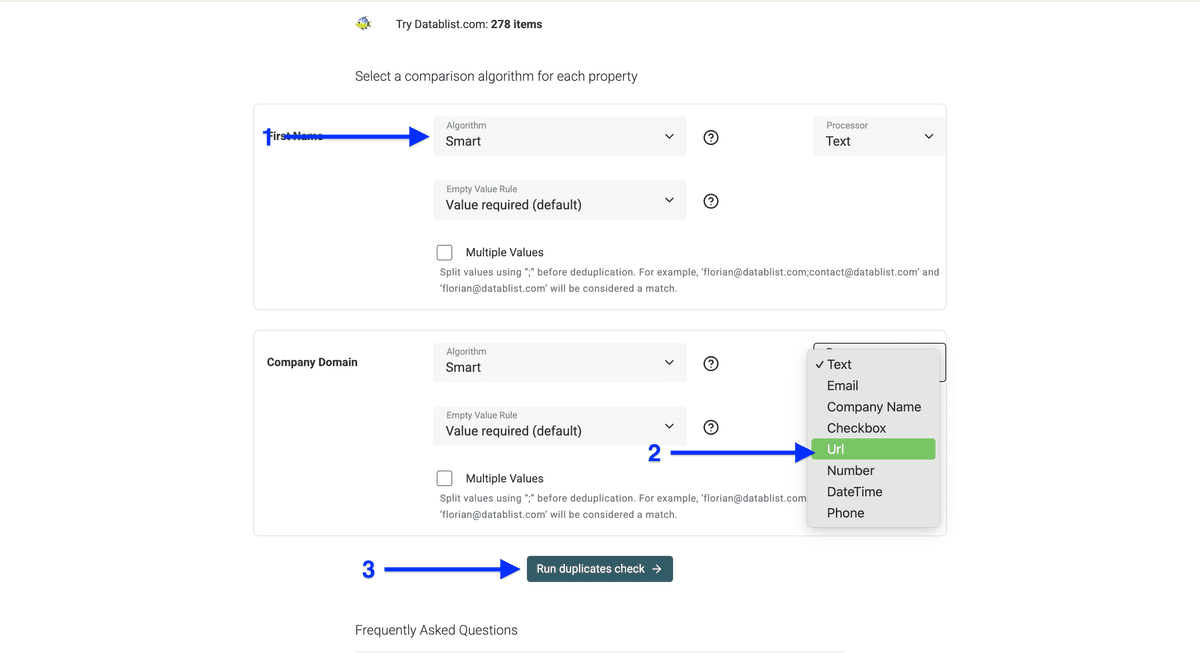
然后勾选你要作为去重依据的列。比如我这里想用 Company Domain 和 First Name 来对比联系人。
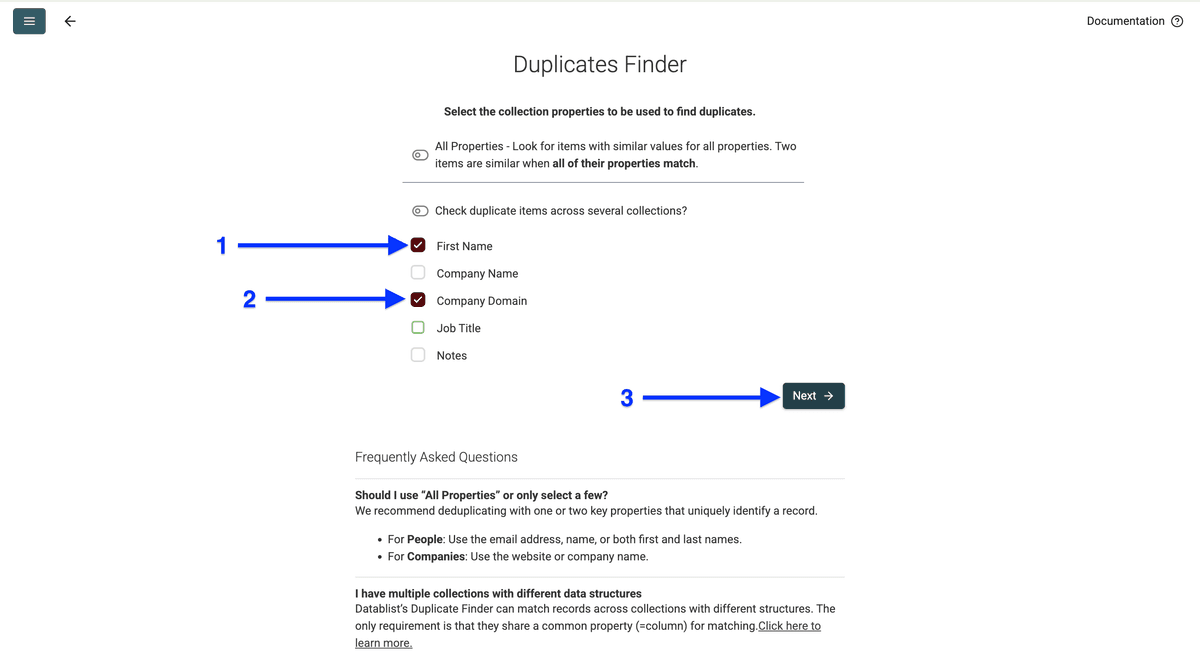
选择列后,也要确保 processor 选对了。
除非你用的是 ID、URL 或者必须严格一致的字段,否则 Algorithm 一般保持默认。
比如:domain 选 URL,公司名选 Company Name,以此类推。
最关键的一点:processor 一定要和你用于去重的列内容匹配。
设置好后,点击 Run duplicates check。
Step 3:用指定列对列表去重
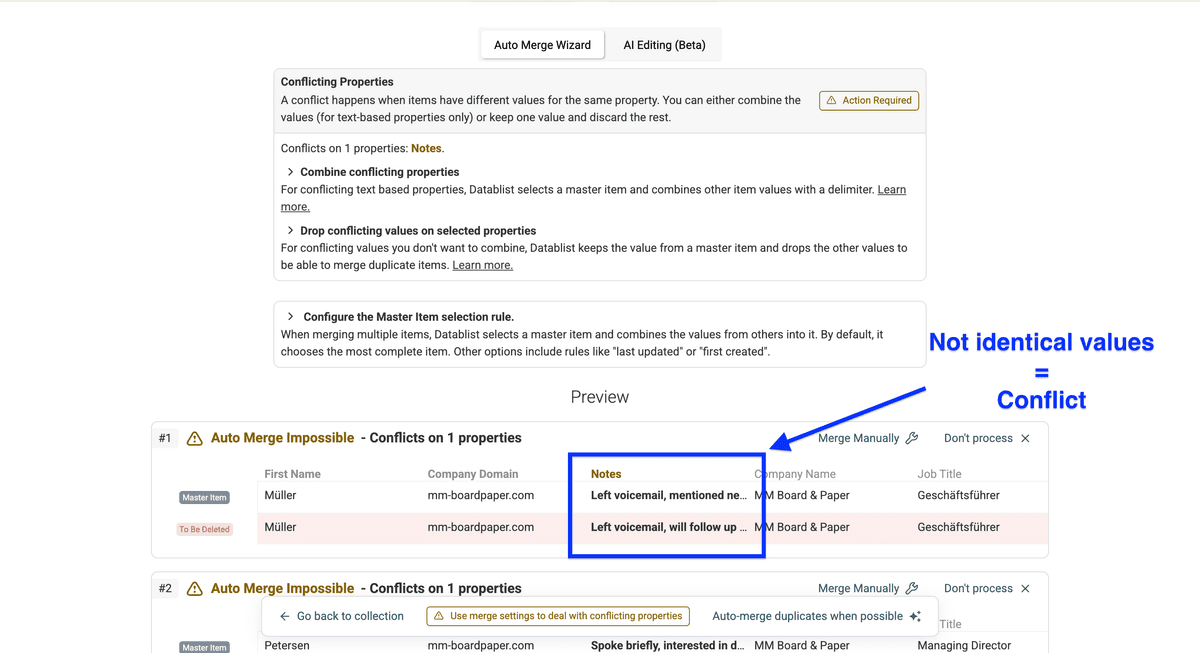
因为 notes 不完全一致,你会看到冲突(conflict)。你可以选择:
- 丢弃冲突项的值
- 合并冲突字段
接着点击 Combine conflicting properties,选中有冲突的列,用 Line break 作为分隔符,然后点击 Refresh Merging Preview。
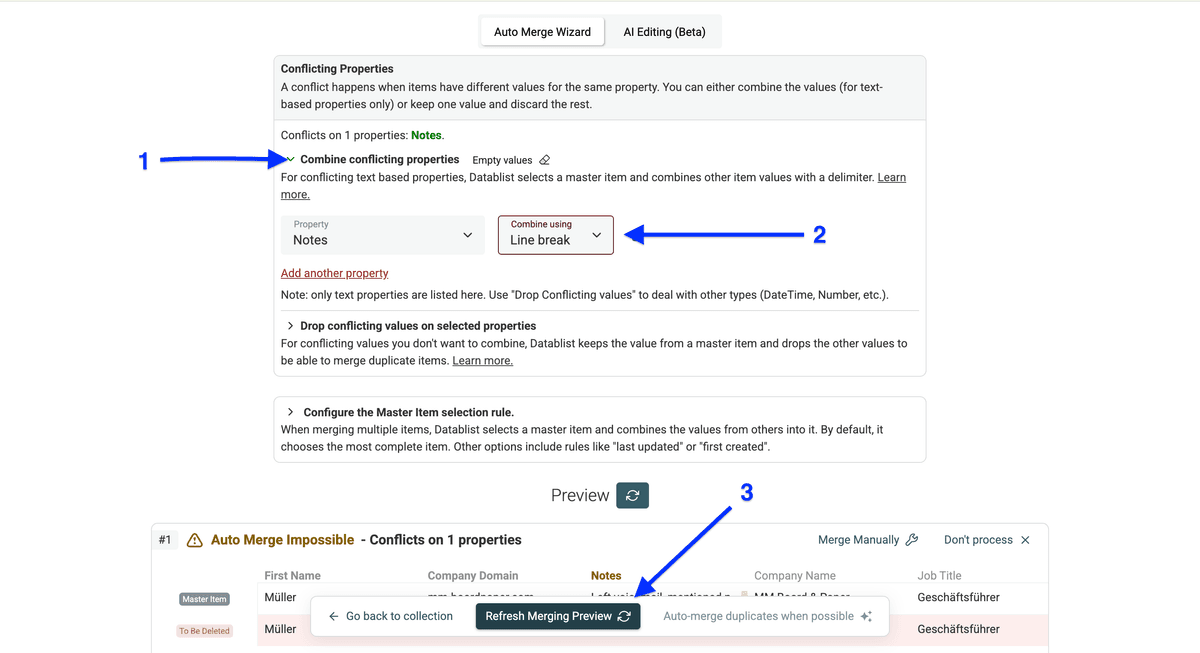
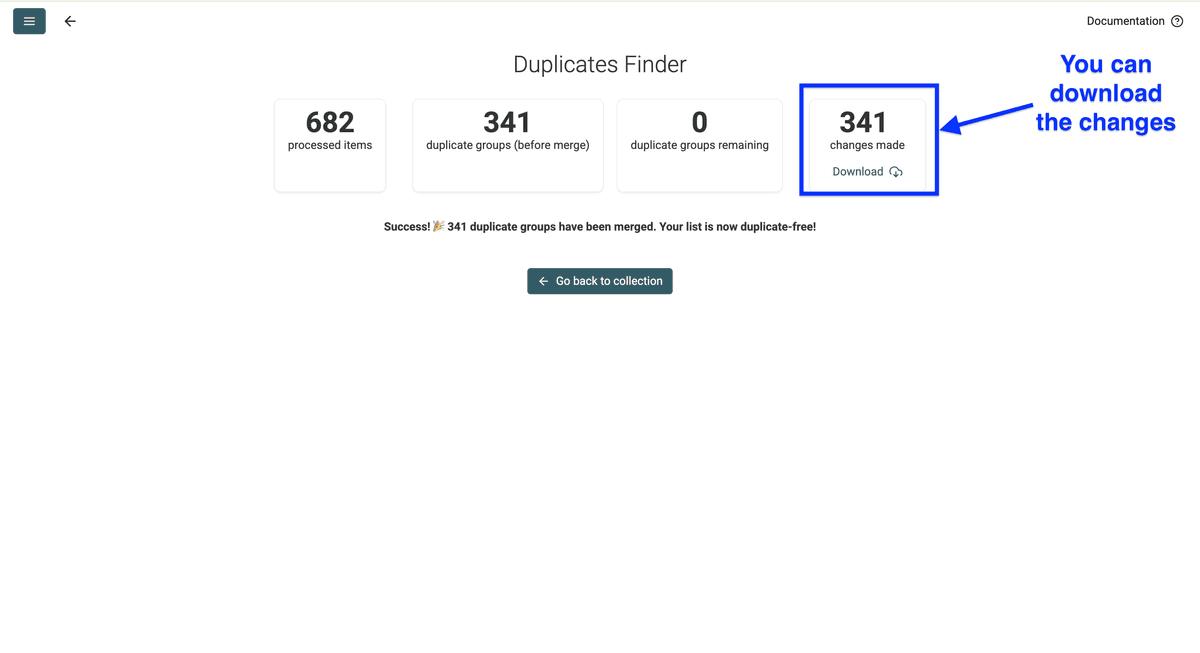
现在你可以预览 Datablist 会如何在删除重复项前把两条 notes 合并。确认无误后,点击 Auto-merge when possible。

这就是去重后的列表效果。

👉 你也可以读读这些文章,了解更多去重用法:Mac/iOS Contacts 去重、Multi-Values Column 去重、列表里匹配相似公司名、合并 Pipedrive duplicates。
下面进入第三种:跨多个列表/集合去重。
方法 3:跨多个列表/集合去重
这是一个典型的跨列表去重场景:
目标: 做一个 ABM campaign,只 targeting 真正的新 accounts(Q1 已经触达过的不算)
流程:
- 对比两份列表:Q1 accounts 与新 accounts
- 从新列表里移除 Q1 已触达 accounts
结果: 你会得到一份只包含“真正新 account”的干净名单。
开始!
Step 1:跨多个列表去重
第一步,注册 Datablist.com
第二步,在侧边栏点击 folder icon 创建一个文件夹。
然后在该文件夹里点击 three dots,选择 New collection 创建一个 collection。
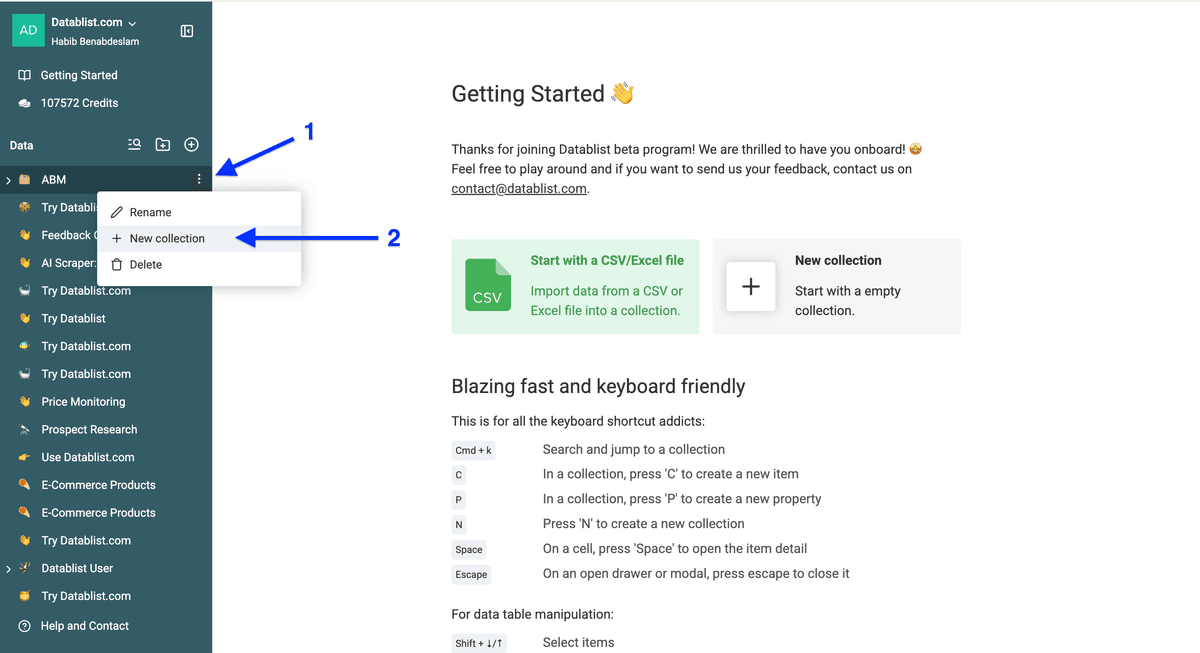
创建完成后是这样。接下来,把第一份列表 upload 到 Datablist,再重复一次把第二份列表也 upload 进来。
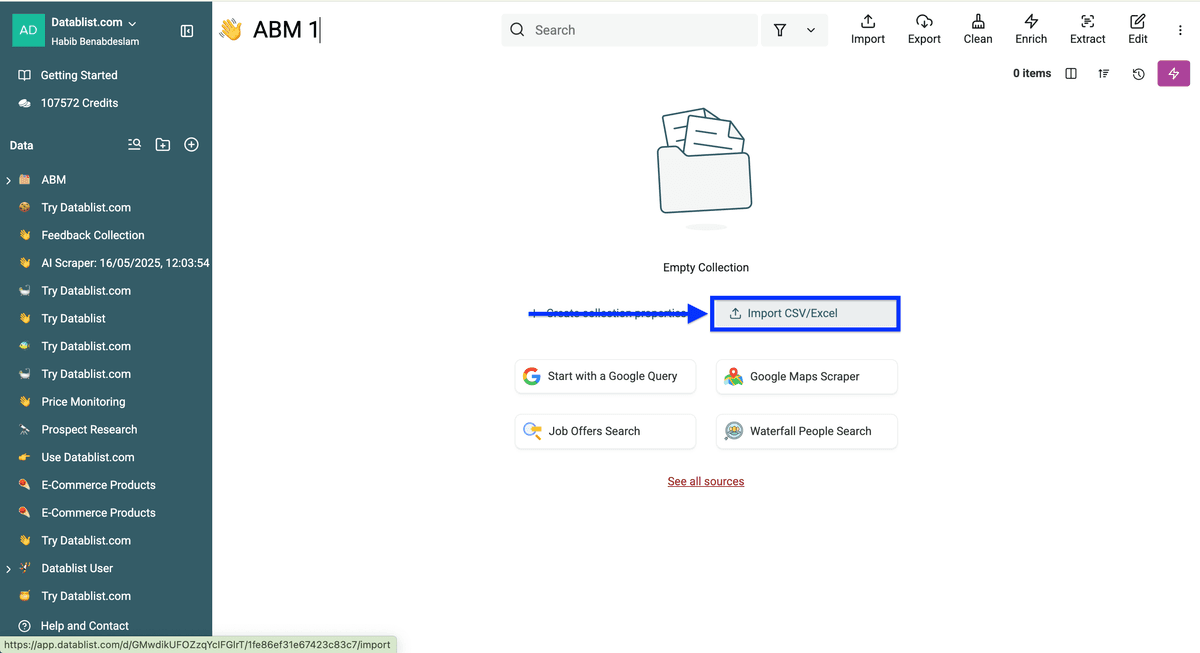
Step 2:跨多个列表去重
两份列表都上传后,先进入你的 Q2 列表(也就是更新、更“新”的那份)。
点击 Clean,选择 Duplicates finder。
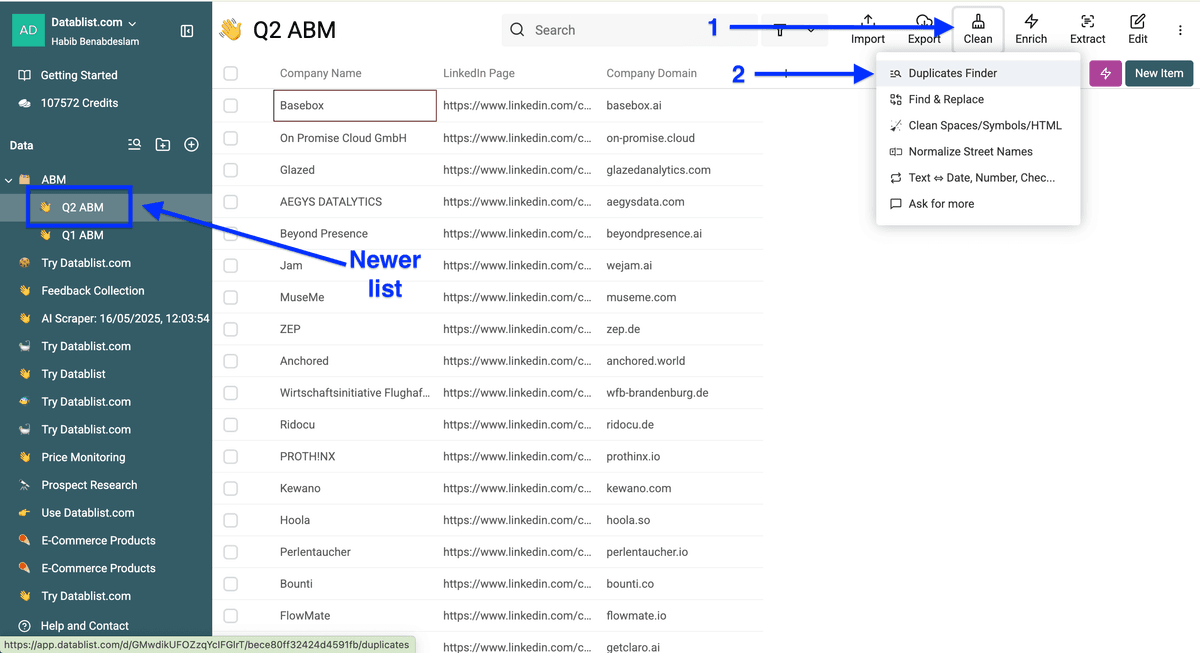
打开 Check deduplicates across several collections? 左侧的开关。

选择要对比的 collection——我这里是 “Q1 ABM”。
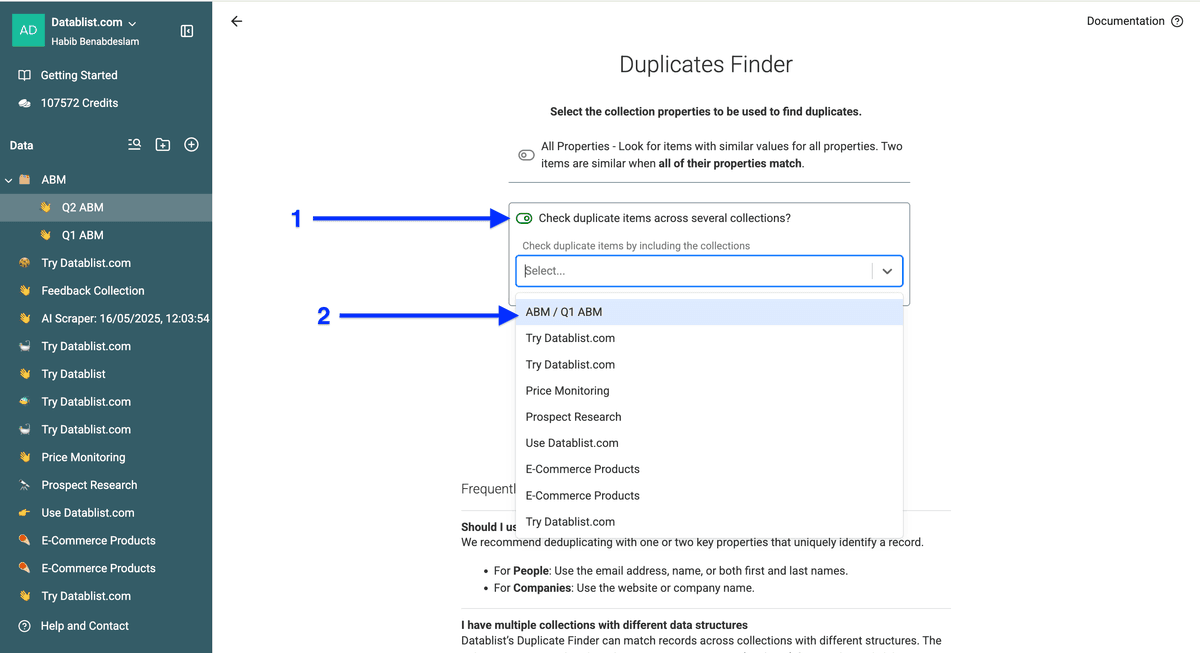
选择用于对比的 property 并点击 Next。一般建议:accounts 用 domain;contacts 用 email 或 LinkedIn profile。
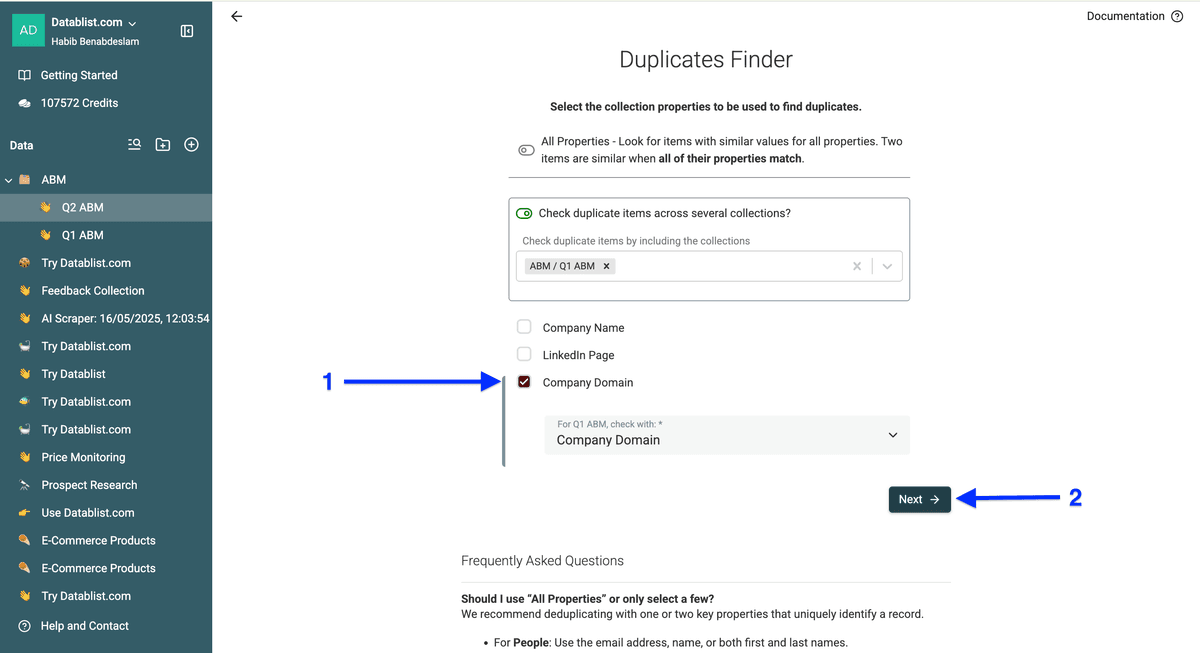
如果你选了 company domain 或其他链接作为唯一标识,processor 选 URL,然后点击 Run duplicates check。
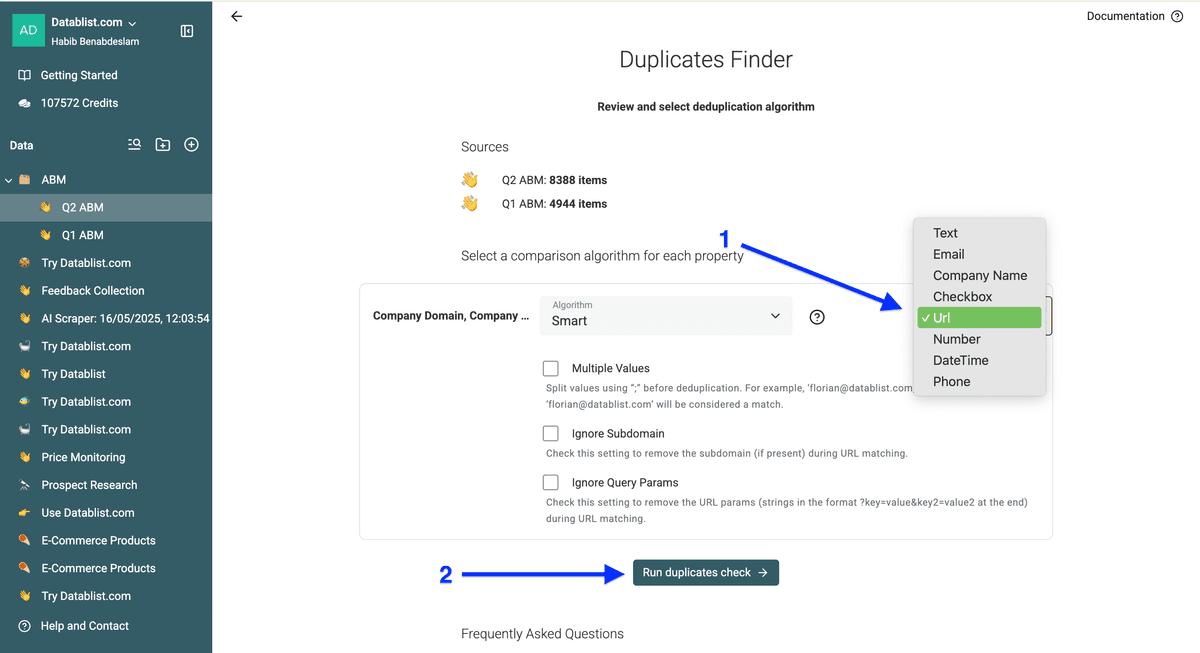
接下来会出现两份 collection 共享 duplicates 的预览。
点击 Auto cleaning rule 下方字段,选择一个规则——目前只有一个选项:Remove duplicate items from collection X。
如果你对比的是 3 个或更多 collection,还会出现第二个选项:Keep duplicate items only in collection X。
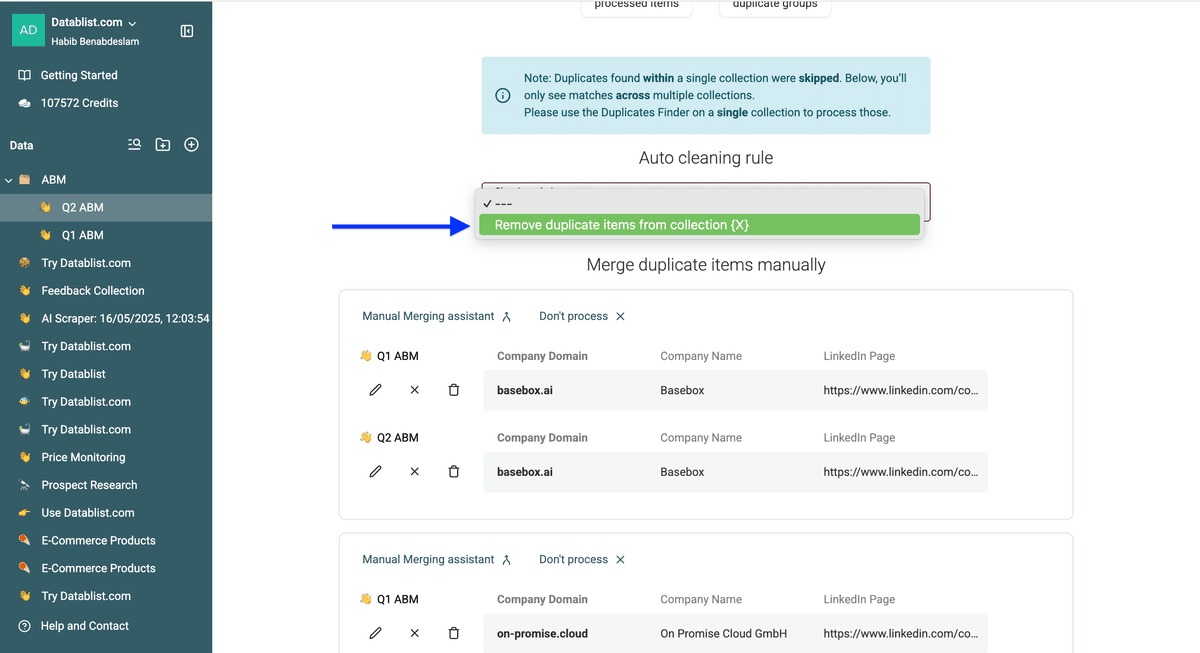
然后你可以选择 从哪个 collection 删除 duplicates(务必记住:通常应该从“新数据”里删除“旧数据”,而不是反过来)。
最后点击 Click here to process duplicated items。
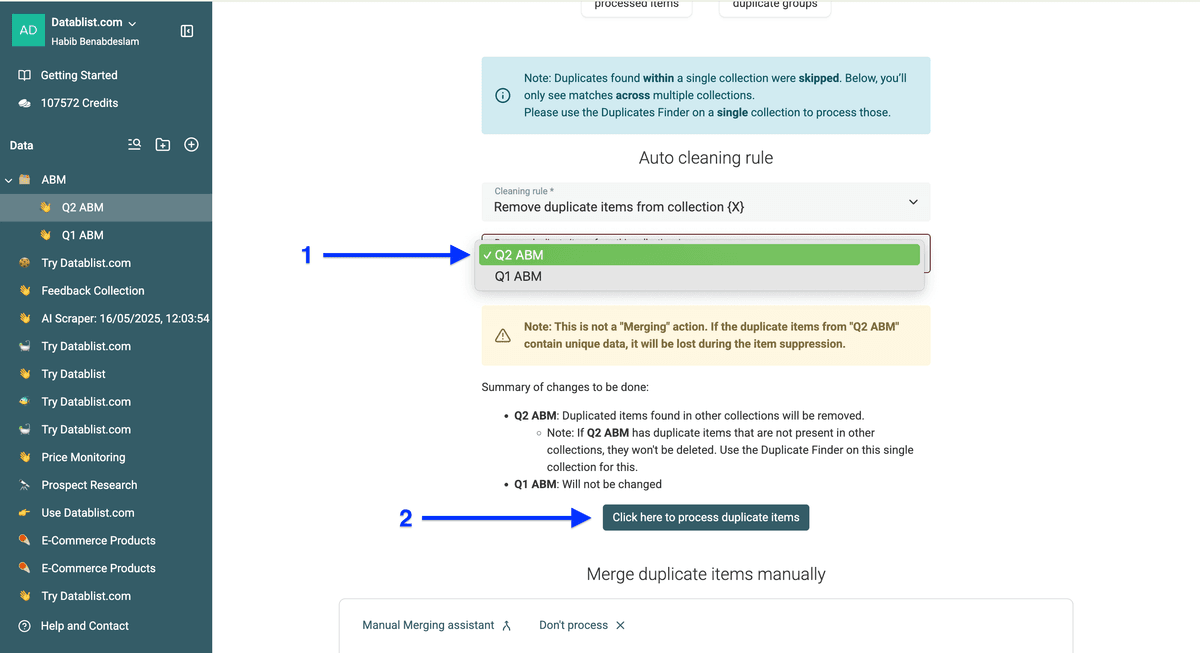
📘 如何拿到最好的结果
把 Q1 contacts 从 Q2 列表里删掉(而不是把 Q2 从 Q1 里删)。例如:
✅ Q1 list:100 contacts → 全部保留
✅ Q2 list:200 contacts → 移除与 Q1 重复的 → 最终得到 100 个独立 contacts
❌ Q1 list:100 contacts → 移除与 Q2 重复的
❌ Q2 list:150 contacts → 全部保留
这样做可以确保:
- Q1 的历史数据保持完整
- Q2 campaign 不会再次触达已联系账户
- 避免同一批 accounts 被重复 targeting
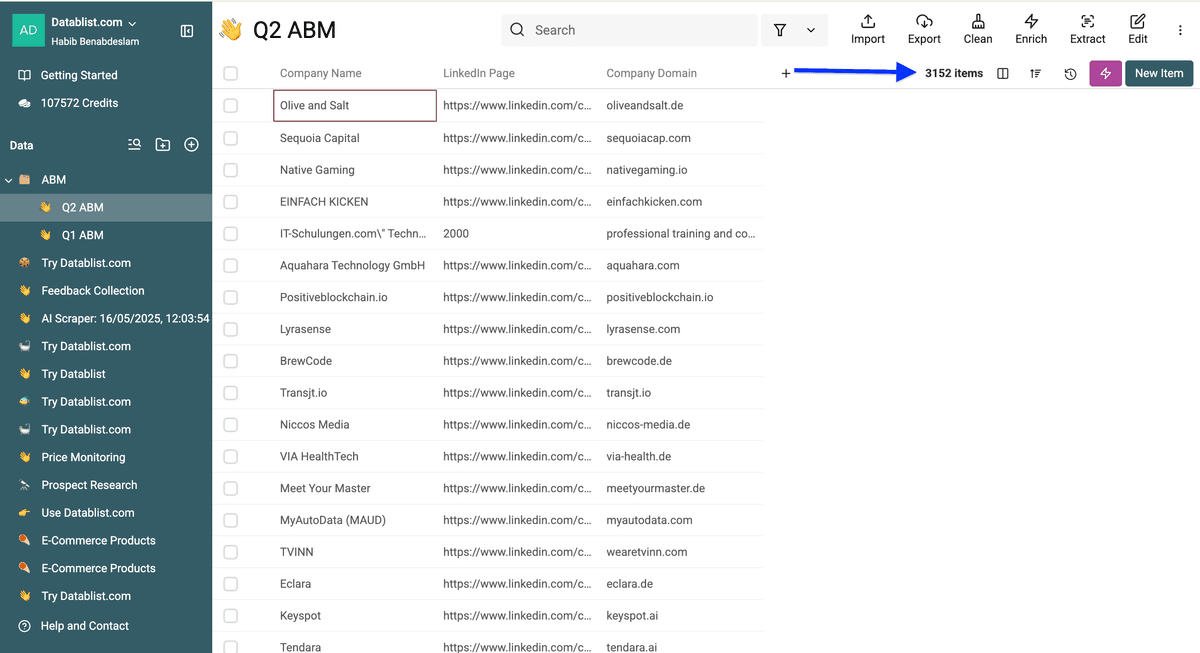
我这里从 Q2 列表里删掉了 5236 个重复 accounts,最后剩下 3152 个唯一 accounts。
👉 想深入了解跨数据集去重,可以看这篇:How to Deduplicate Across Several Excel Files
去重就到这里,下面进入 CRM 数据有效性校验。
如何判断你的 CRM 数据是否还是最新
检查 CRM 数据是否仍然 up-to-date,是很多人在做 CRM cleaning 时会忽略的一步——因为大家默认“只要当时是 valid,之后就一直 valid”。但 这是个很大的误区。
这一部分我会带你做:
开始!
如何免费判断 Email 是否有效
如果你曾经通过表单、lead magnet 或免费资源收集过邮箱,你一定见过:很多人会用非企业邮箱注册。
这种情况建议你先把“邮箱是否有效(valid)”当作第一道筛选,再决定要不要投入更贵的 deliverability 检查(尤其是你要发邮件 campaign 的时候)。
❗ 先搞清楚:Valid Email vs Deliverable Email
这个功能不告诉你邮箱是否 deliverable;它只会通过检查 MX records 来判断:邮箱背后的 domain 是否具备收信能力。
快速例子:
邮箱
habibi@datablist.com不存在,但 domain 的 MX 记录有效,所以它在 domain 层面仍然是 valid(即使没有真实 inbox)。邮箱
habib@datablist.ai不存在且 domain 没有有效 MX 记录,所以它是 invalid。邮箱
habib@datablist.com存在且 domain 的 MX 记录有效,所以它既 valid 也 deliverable。TL;DR
Email validation = Domain 级别
Email deliverability = Inbox 级别
Validated email = domain 能收信,但具体邮箱地址仍可能写错
Deliverable email = 有真实 inbox 能收信
不是所有 valid email 都能真正收信。
Step 1:免费检查 Email 是否有效
第一步,注册 Datablist.com
注册后,把你的 CRM accounts/contacts 列表 import 进来。
Step 2:免费检查 Email 是否有效
接下来我们会用 Datablist 的一个 免费功能:查出负责接收邮件的 MX provider。如果一个 domain 没有有效 MX Records,它就无法收信,也就 必然不可投递(undeliverable)。
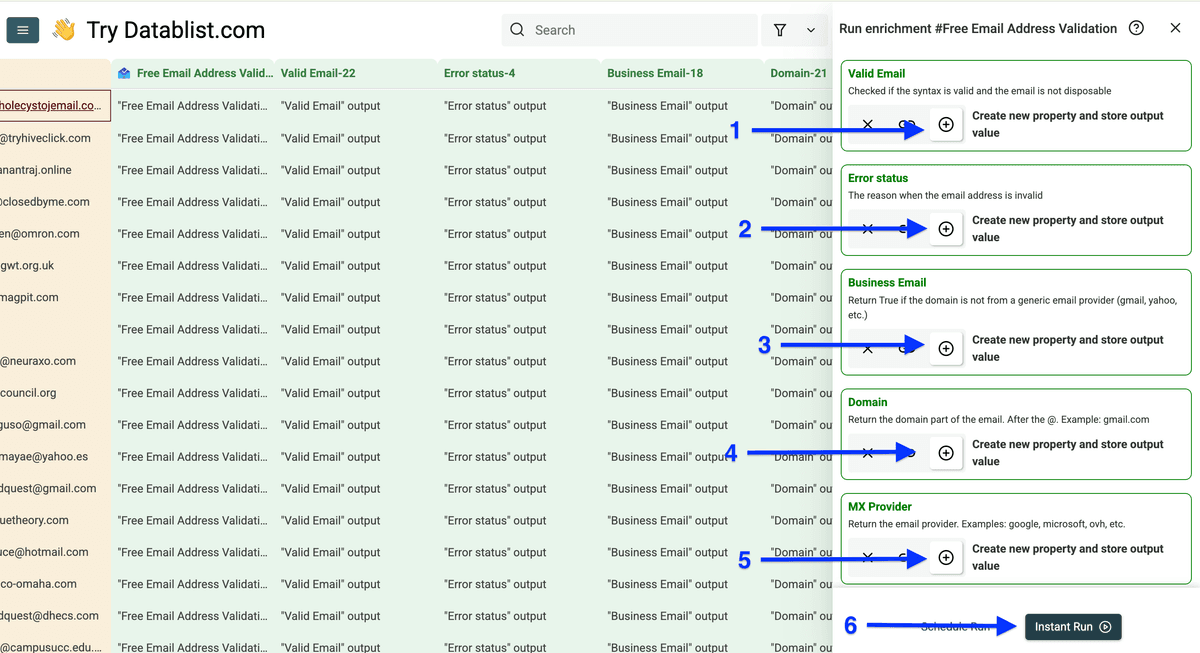
点击 Enrich。
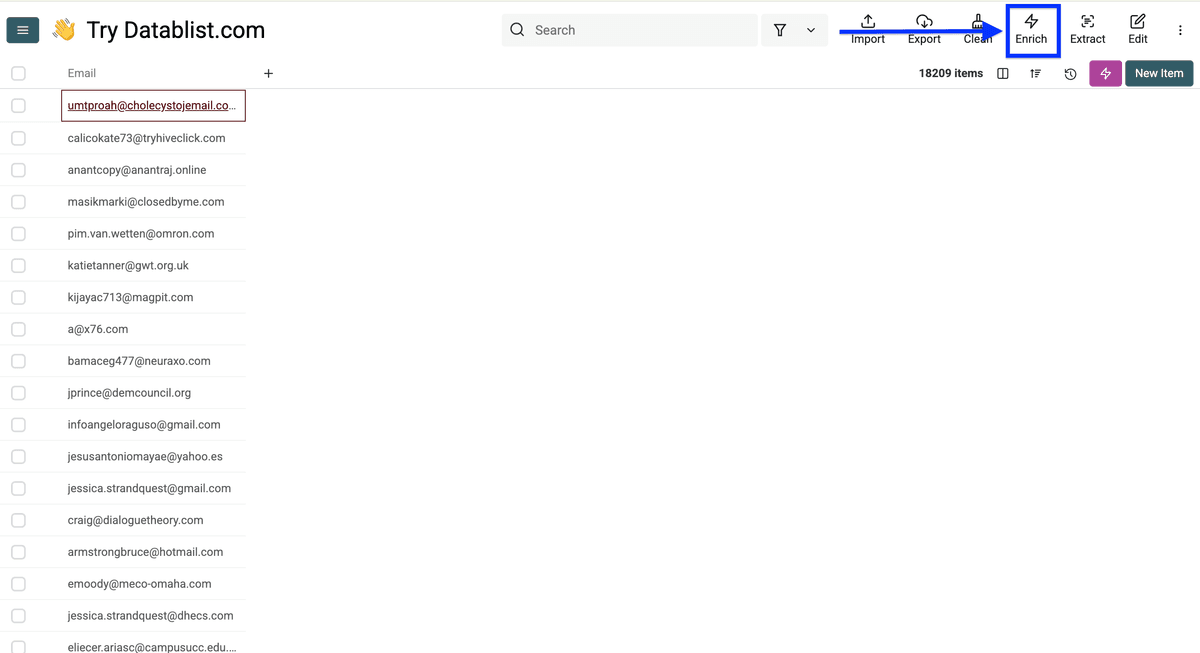
进入 People,选择 Free Email Address Validation。
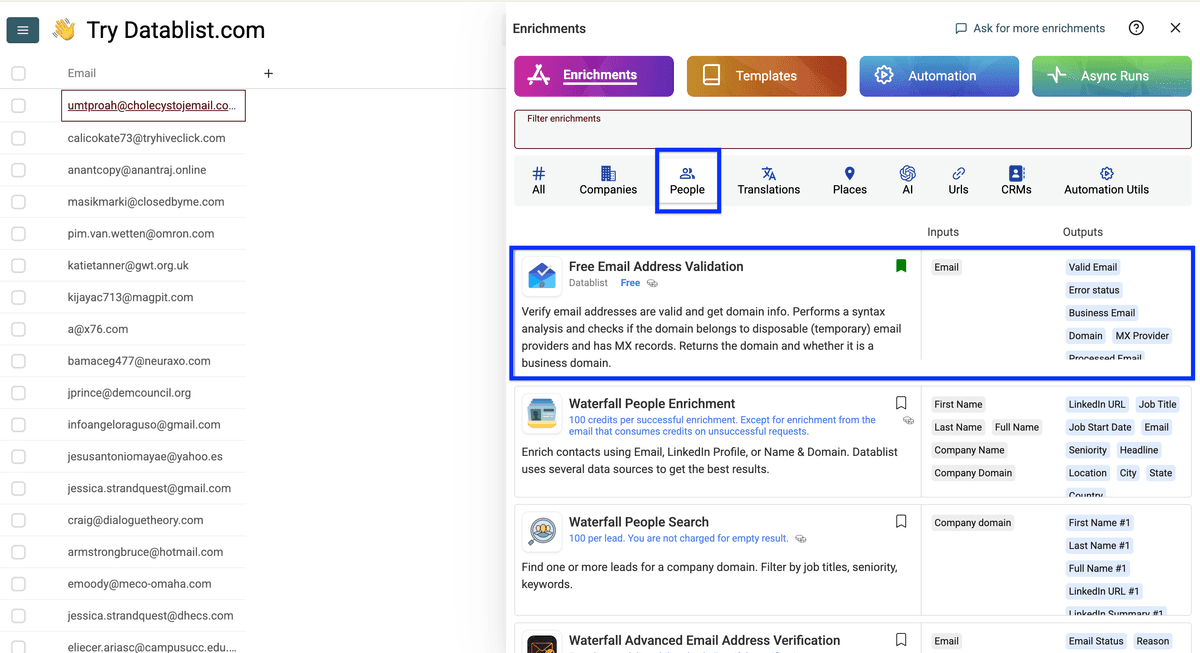
把邮箱字段 map 为 input property,然后点击 Continue to output configuration。
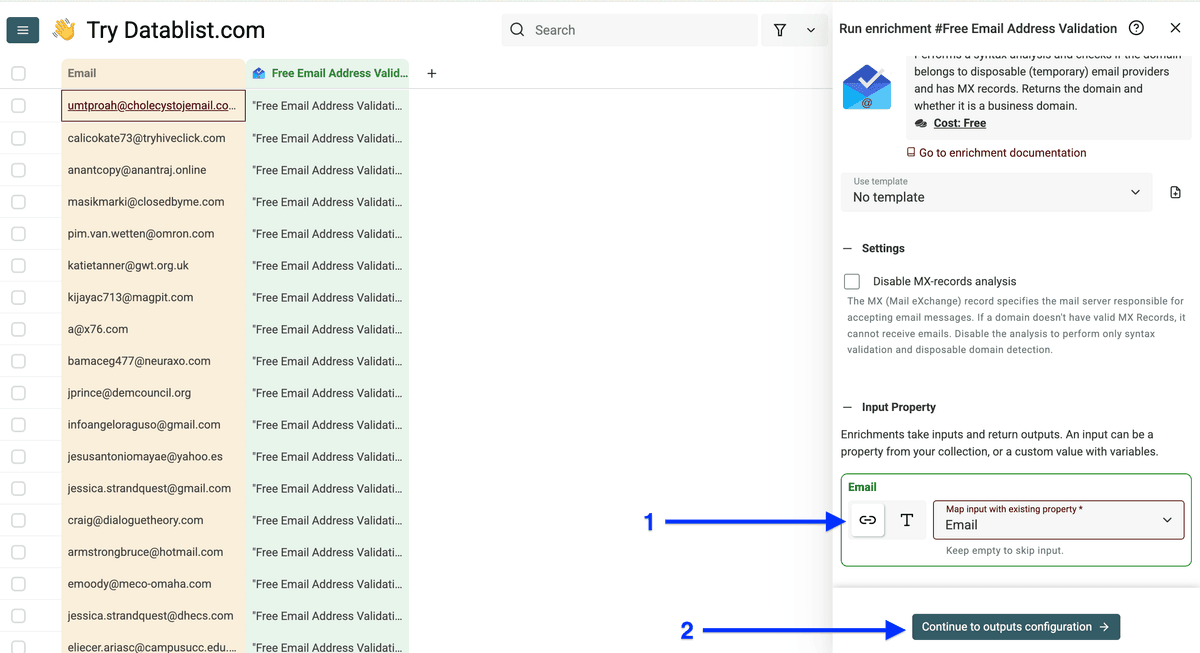
点击 plus icons 创建输出列,然后点击 Instant Run。
这就是运行 Datablist Free Email Validator 后得到的结果。
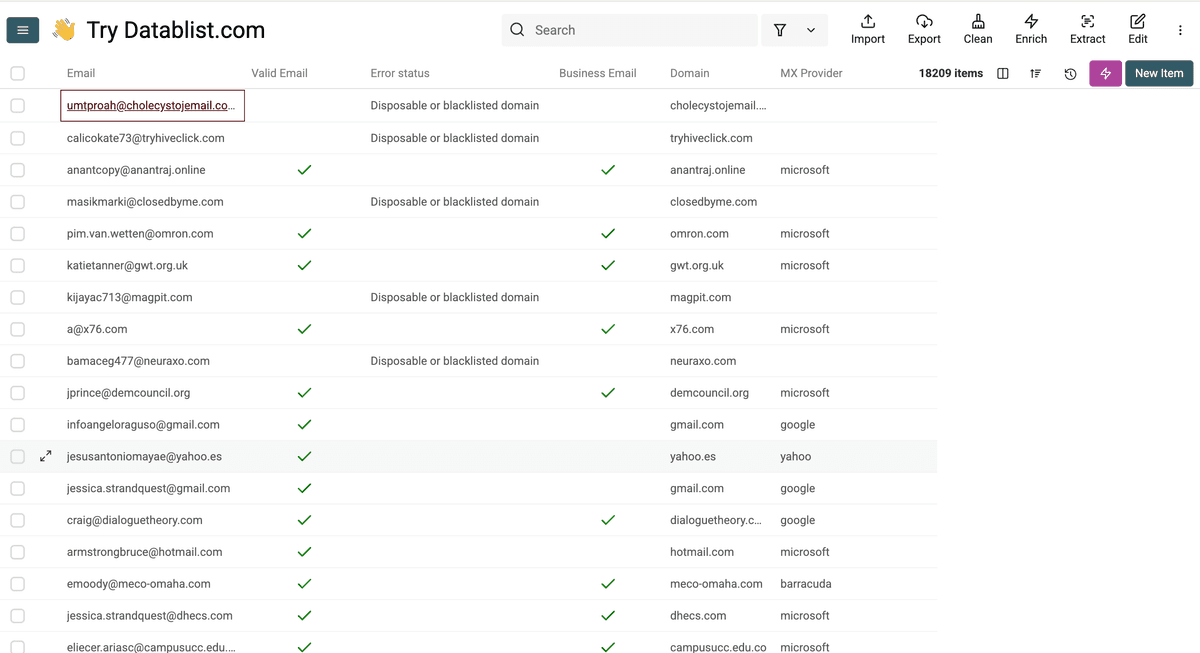
这些结果能告诉你:
- 这个 email 是否是 business email
- 这个 email 的 domain 是否能收信(不管是 business 还是 personal)
- 该 domain 的 MX 服务由哪个 provider 托管。为什么重要?因为在 cold emailing 时,你不希望把邮件发到某些 provider(尤其是 Microsoft)上,这可能会影响你的发信账号健康度。
👉 想系统了解可以看:Free Email List Validation Guide
现在我们已经确认邮箱在 domain 层面有效,下面继续检查它是否真的可投递。
如何判断 Email 是否可以收到邮件
如果你刚做完上一步: 先从结果里筛选出 valid emails——invalid emails 自动就是不可投递的——我下面会演示。
如果你从这一段开始:你有 2 种选择:
- 回去先跑上一段的工作流。
- 注册 Datablist、import 你的列表,然后直接从 Step 2 开始。
Step 1:筛选出有效 Email
点击 Valid Email,选择 Filter on property。
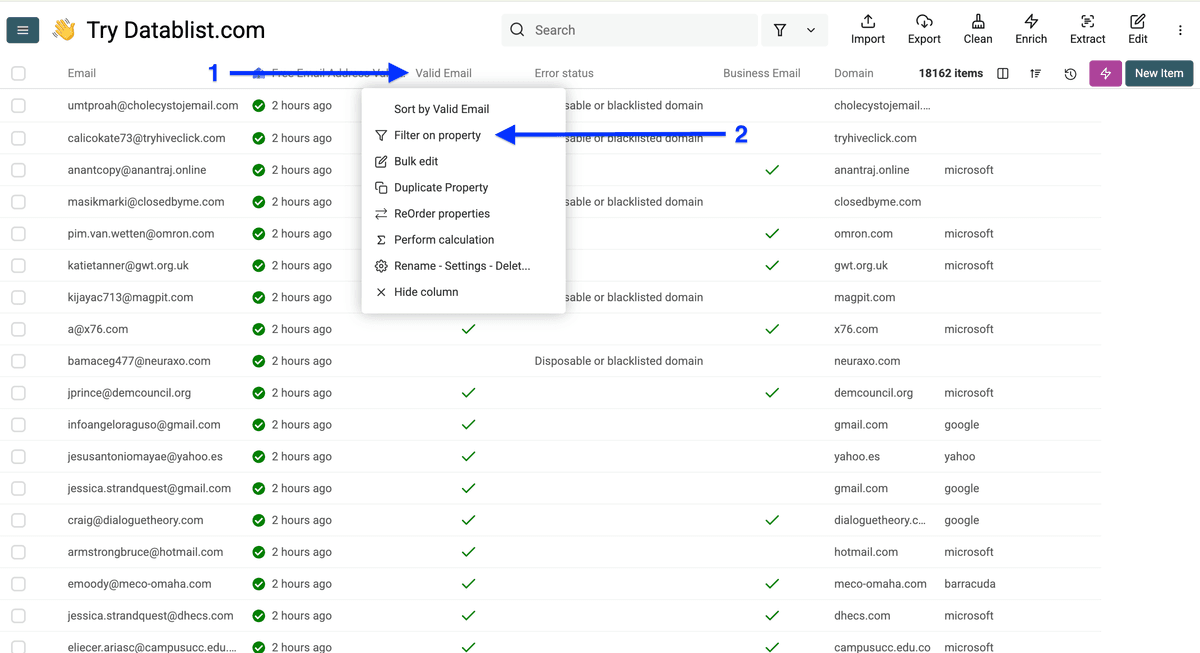
确保这个 checkbox 被勾选,然后点击 Apply。
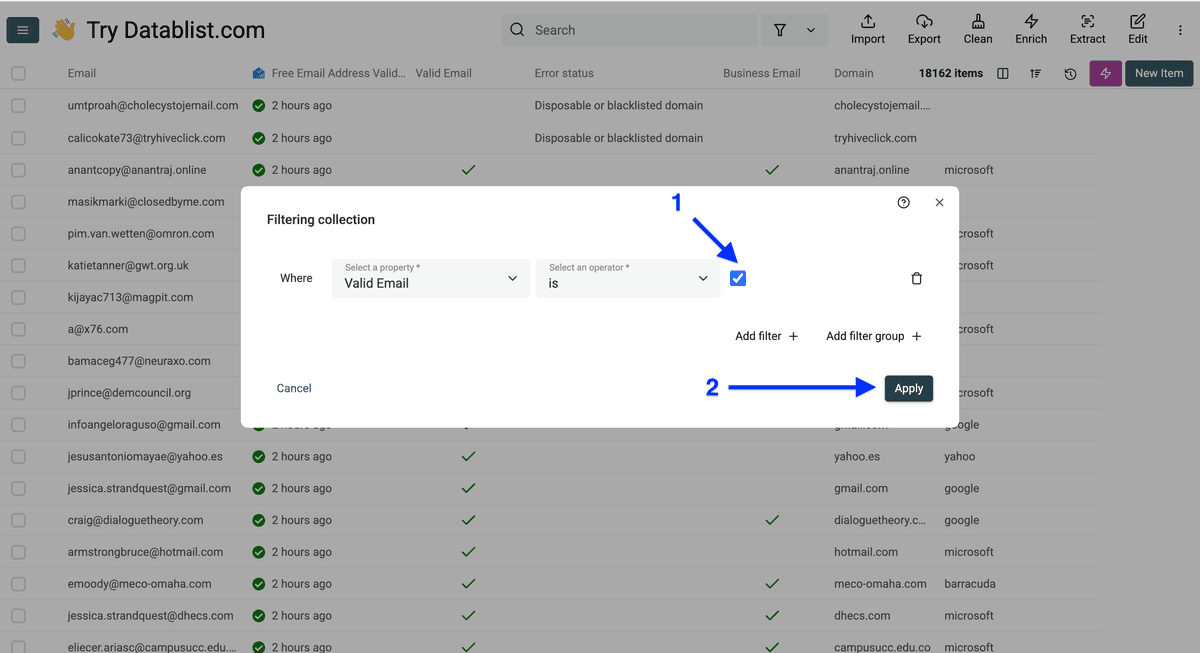
💡 给 B2B 的小建议
如果你只做 B2B,建议筛选 “Business Email” 列而不是 “Valid Email”。这里我们用更通用的例子,是因为也有很多 B2C 公司在用 Datablist。
Step 2:验证 Email 是否可投递
点击 Enrich。
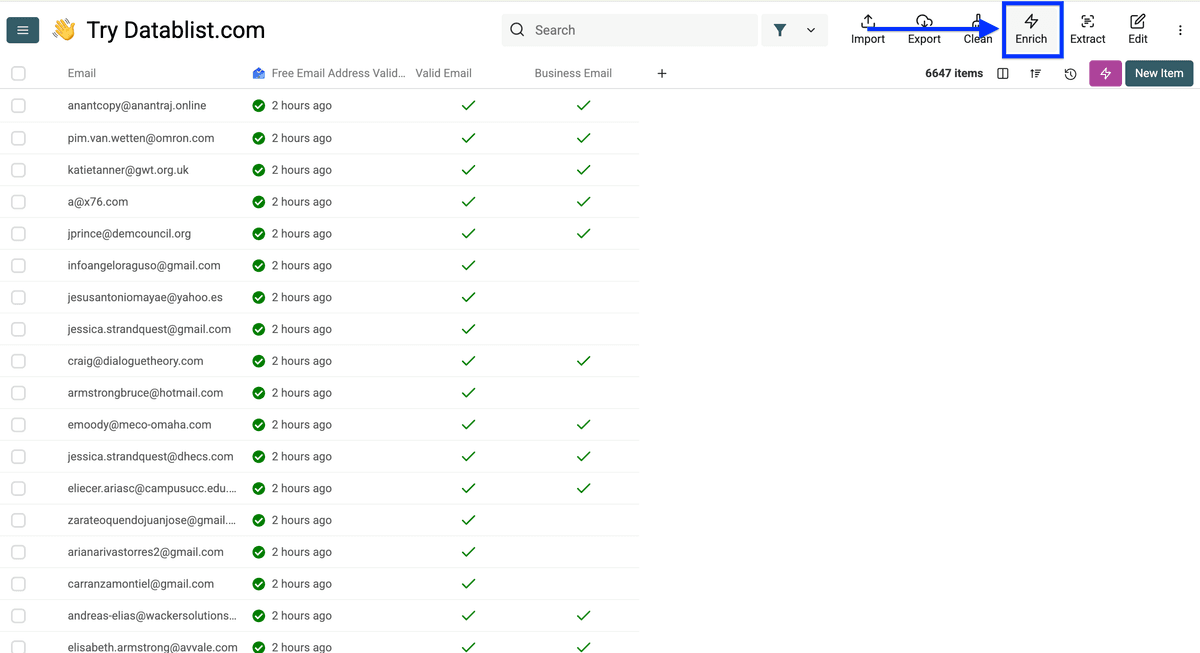
进入 People,选择 Waterfall Advanced Email Address Verification。
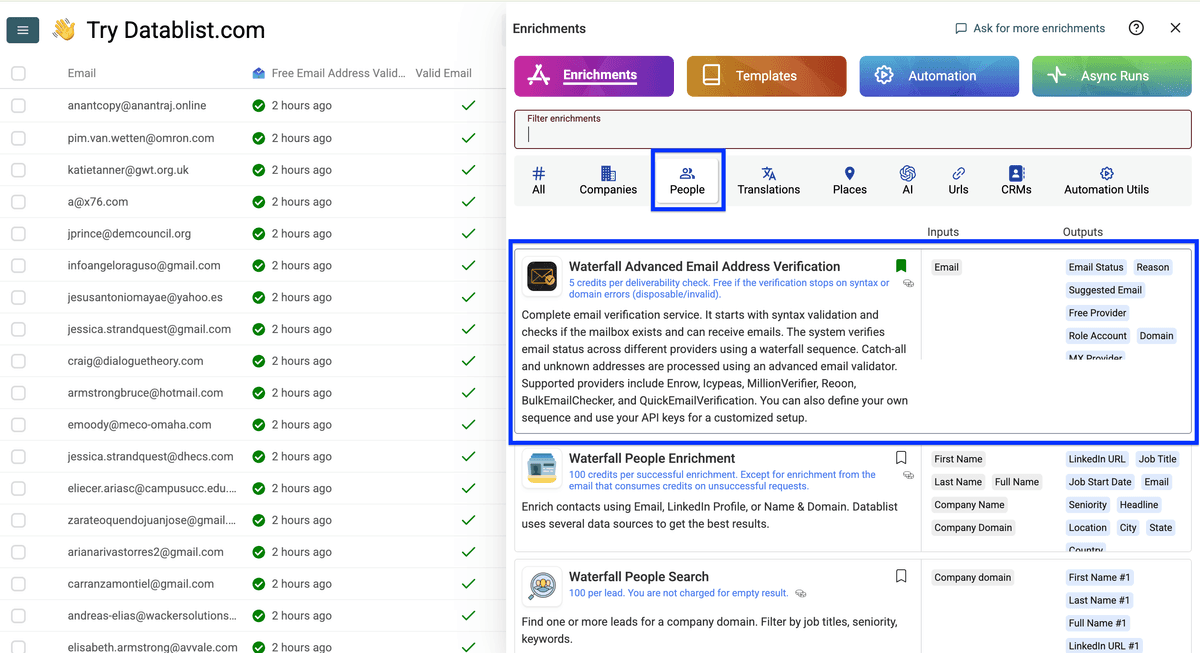
把 email 列 map 为 input property,点击 Continue to output configuration。
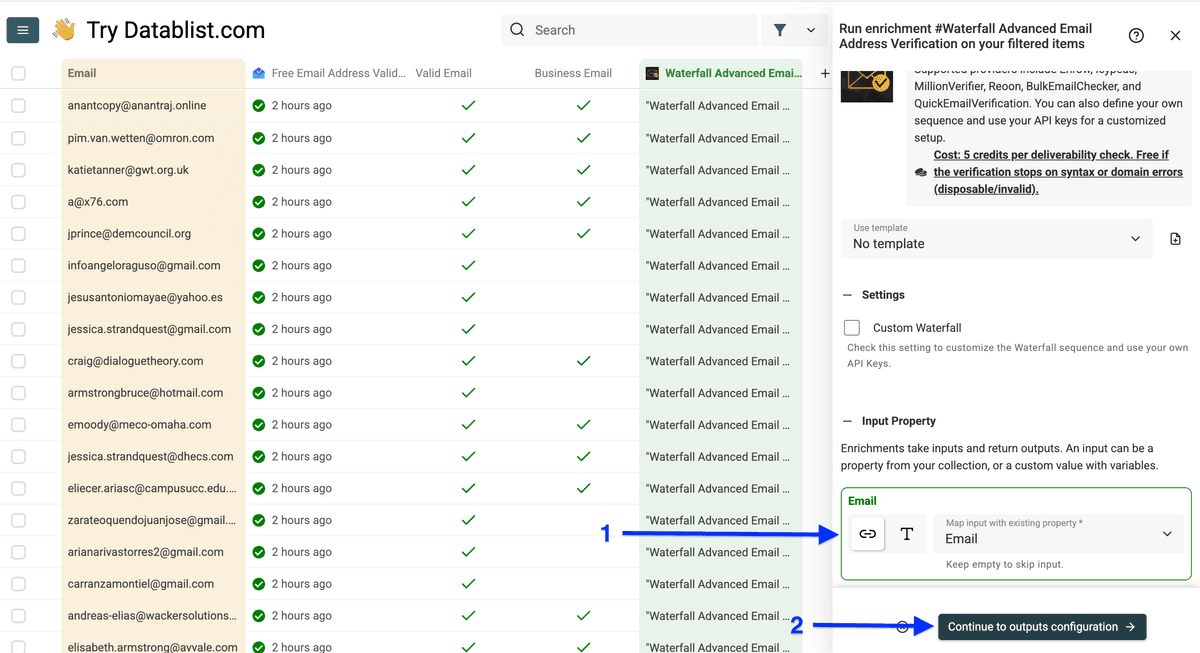
点击 plus icon 只创建两个输出列:Email Status 和 Role Account,然后点击 Instant Run。
为什么只要这两项: 其他输出会让表更复杂;如果你的目标只是清理 CRM,这两列就够用了。
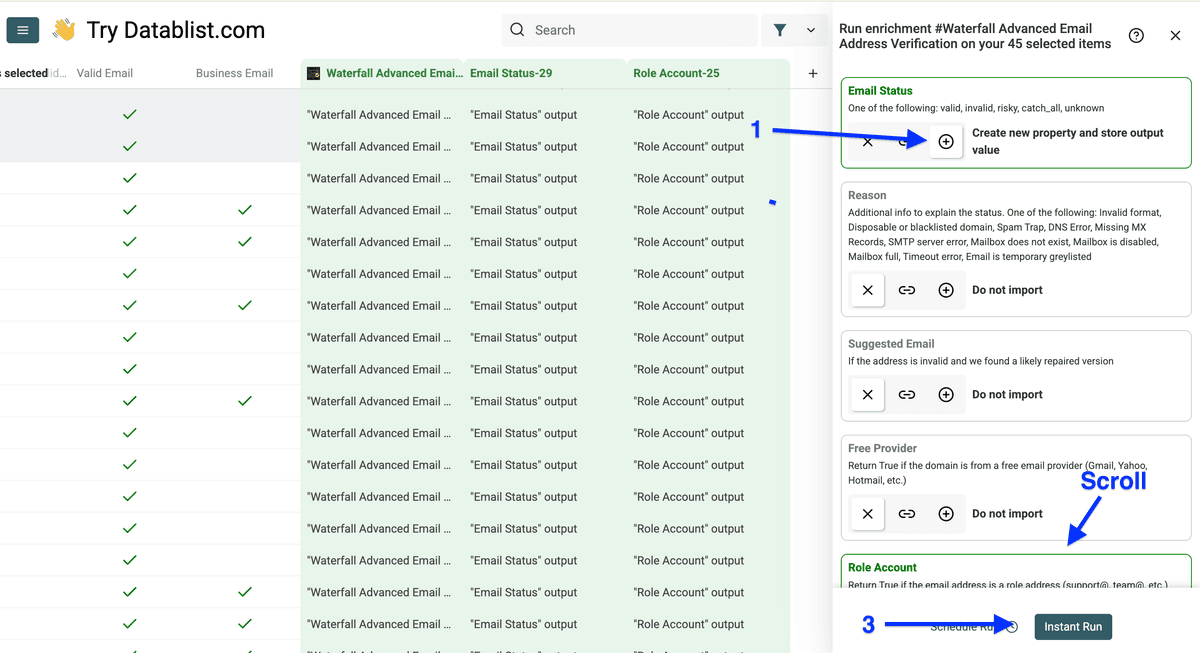
你会得到如下结果:
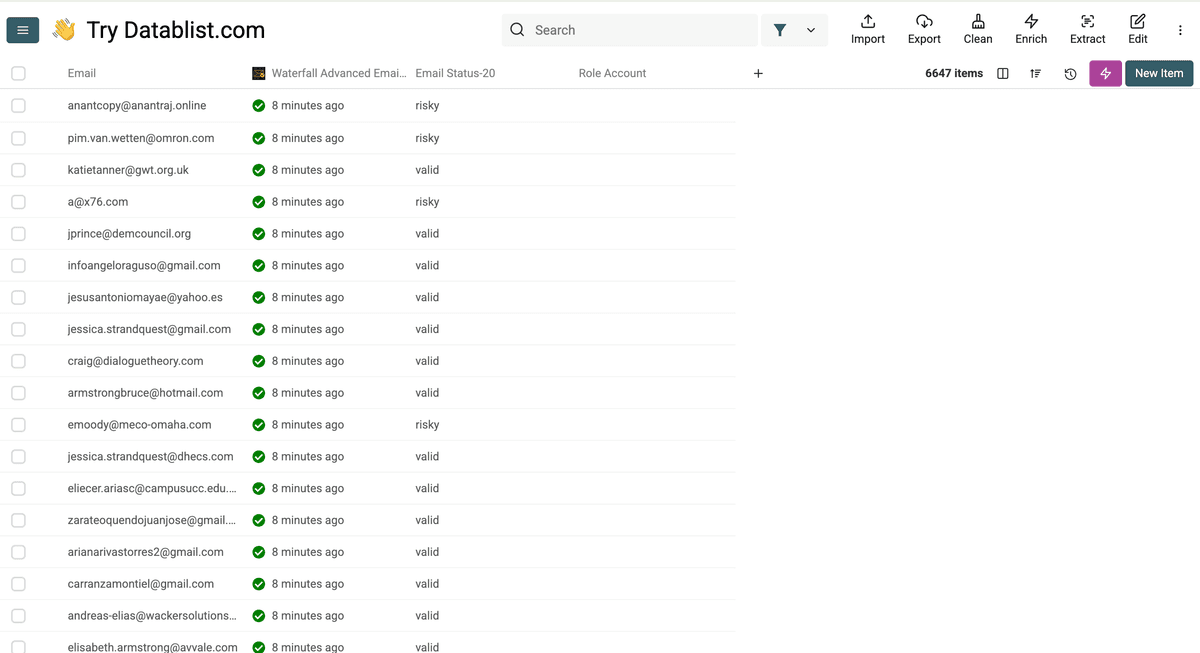
Valid: 这些邮箱背后有真实 inbox,可以收信。
Risky 邮箱通常有两类:
- 当时无法验证(临时原因导致验证失败)
- catch-all 邮箱:服务器设置为“全部接收”,即使具体邮箱账号不存在
Invalid: 该邮箱账号不存在(不要用)。
如何批量判断一个人是否还在原公司
你可能也发现了:现在大家换工作更频繁了。你发邮件时也可能越来越常收到类似 “This person doesn’t work at XYZ anymore” 的提示。
如果你也遇到这个问题,别担心——下面我带你 批量确认联系人是否还在原公司。
先明确你需要什么:
- 这个人的 LinkedIn profile(必需)
- 他“应该在”的公司 email 或 domain
我们要做的事:
- 抓取 LinkedIn profile,找出他现在在哪家公司
- 找到他现公司的 domain
- 让 AI 对比两个 domain
注意: 这套方法也适用于“公司 LinkedIn 页面”的场景。
Step 1:准备数据
注册 Datablist.com。
把列表 import 到 Datablist。
Step 2:抓取 LinkedIn profile
这一步我们会 抓取 LinkedIn profile。
点击 Enrich。
进入 People,选择 LinkedIn People Profile Scraper。
把 LinkedIn profile URL 列 map 为 input property,点击 Continue to output configuration。
点击 plus icons 创建以下输出列:Company Name、Company page URL、Company website,然后点击 Instant Run。
其他输出你也可以一起加,但这条工作流里不需要——除非你还想顺便拿更多 LinkedIn 数据(这样就不用为同一次抓取付两次费)。
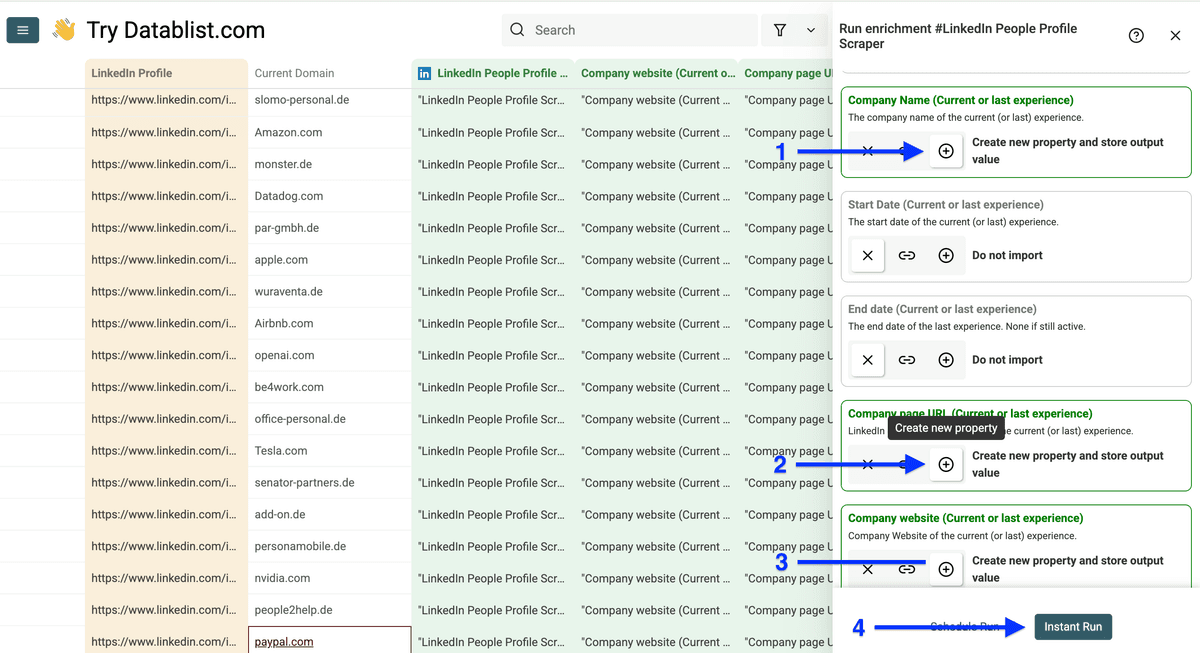
这是抓取结果。下一步我们需要 为剩余记录补齐 domain。
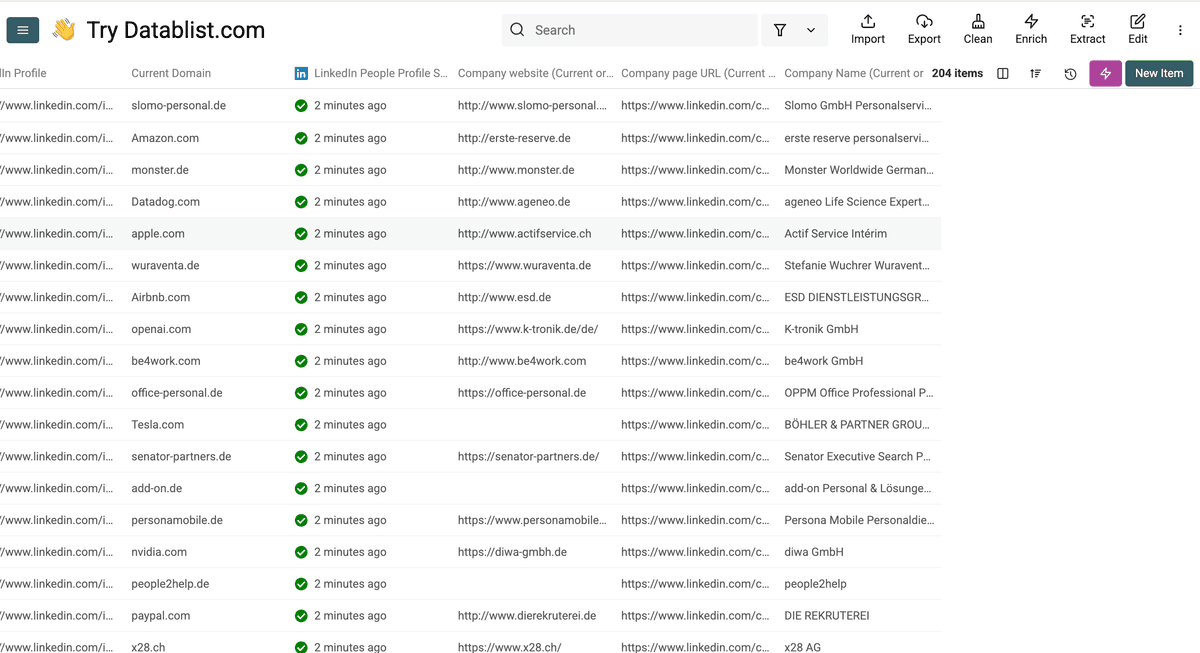
Step 3:从公司 LinkedIn 页面找回官网域名
点击 Enrich。
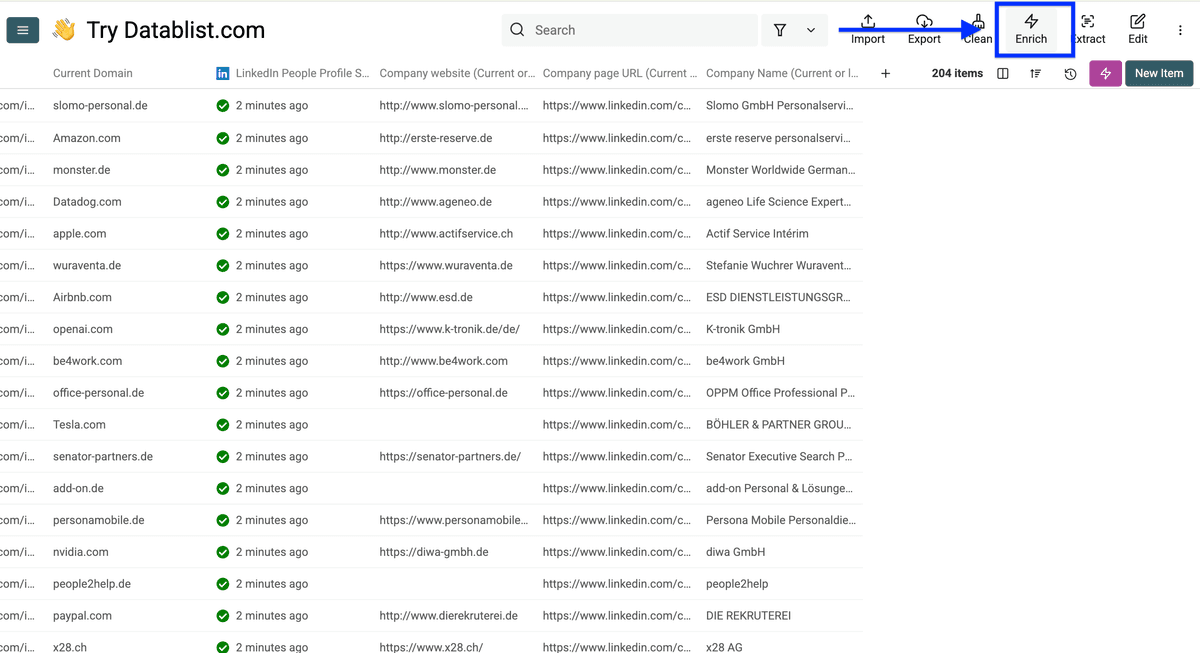
进入 Companies,选择 Company Domain/Website and LinkedIn Company Page Matcher。
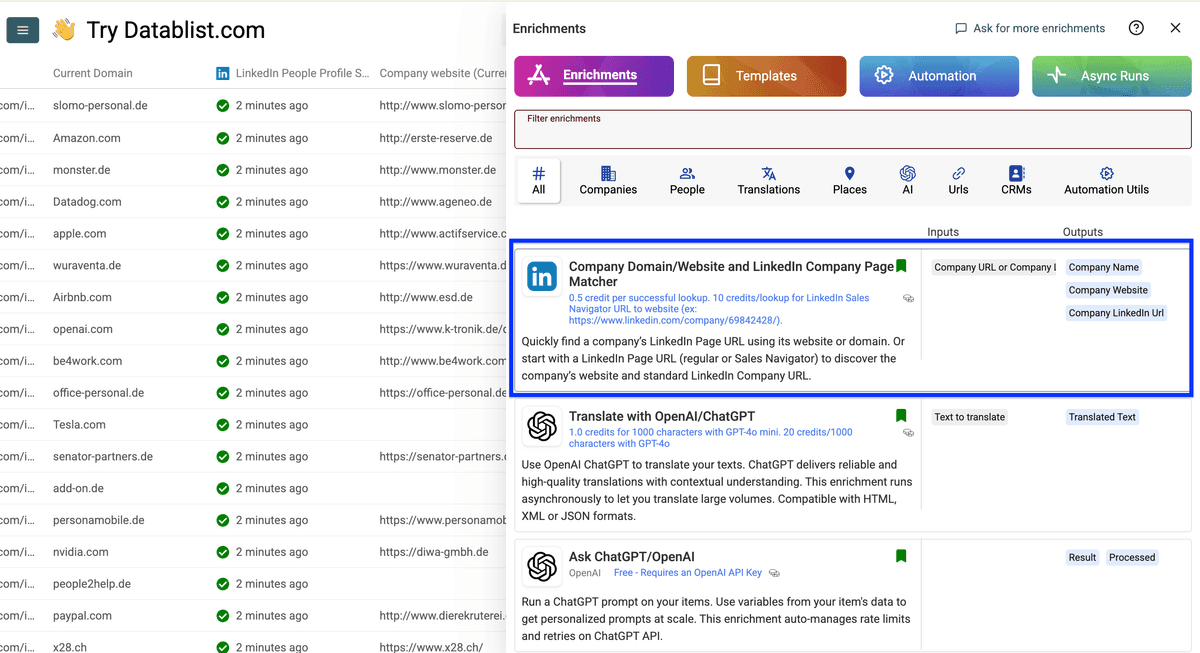
把 Matching Type 设为 Get the company website from the LinkedIn page URL。
然后把 LinkedIn page URL map 为 input property,点击 Continue to output configuration。
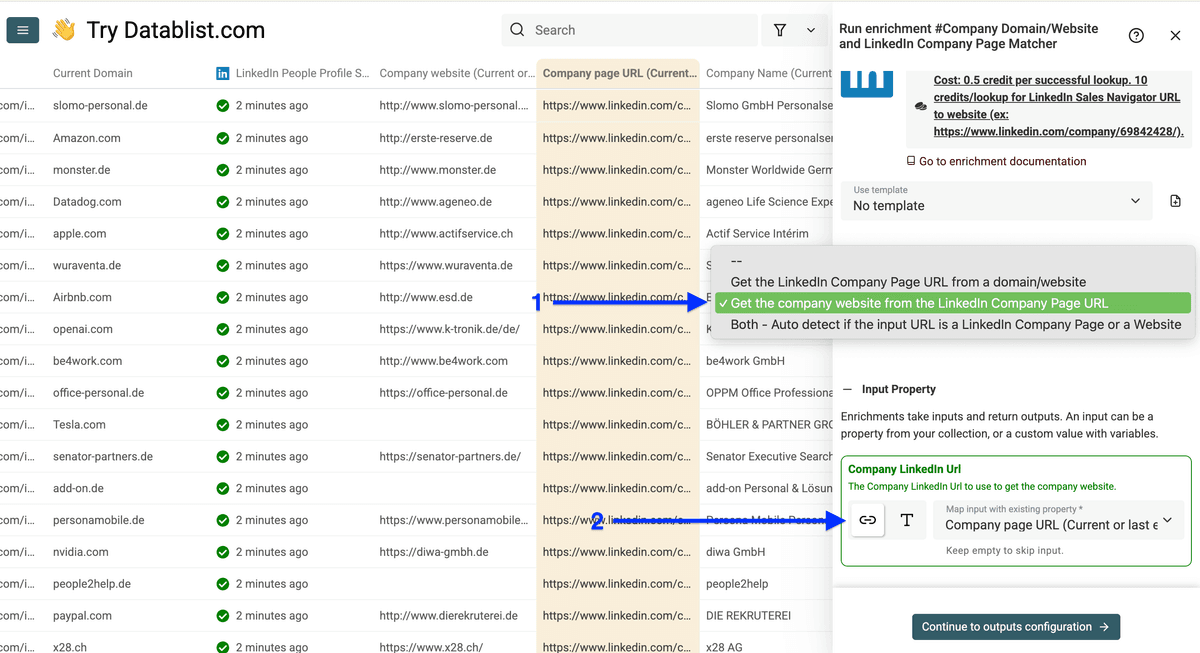
把 “Company website” output map 到你新建的公司网站列。
注意: 千万别 map 到你旧 domain 的那一列。
点击 Instant Run。
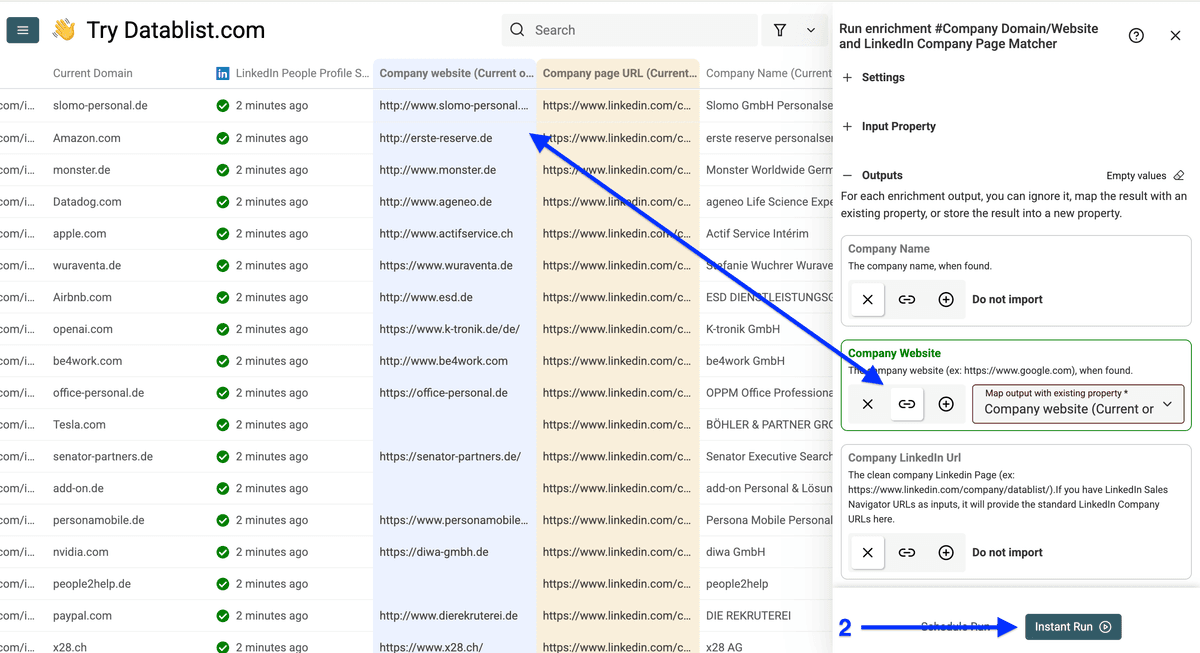
你会看到这些选项:
- Run in Async: 勾选后在云端跑,适合大列表,你可以同时做别的事
- Test on the first 10 items: 先小范围测试效果
Select number of items to process: 只处理前 10/100/自定义数量。
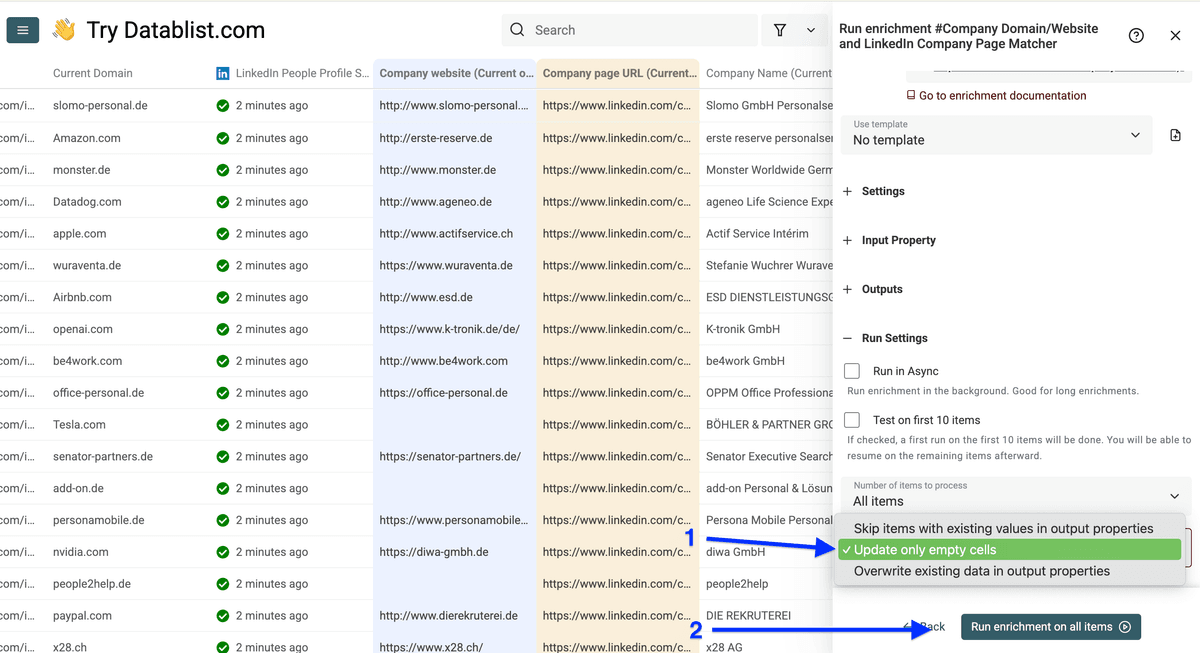
Existing data rule:告诉 Datablist 如何处理已有数据——选第二个:Update only the empty cells。
设置好后点击 Run enrichment on all items。
Step 4:用 AI 对比 domain,判断是否换公司
现在我们有了旧域名和新域名,可以对比它们是否一致,从而 判断联系人是否已经换公司。
点击 Enrich。
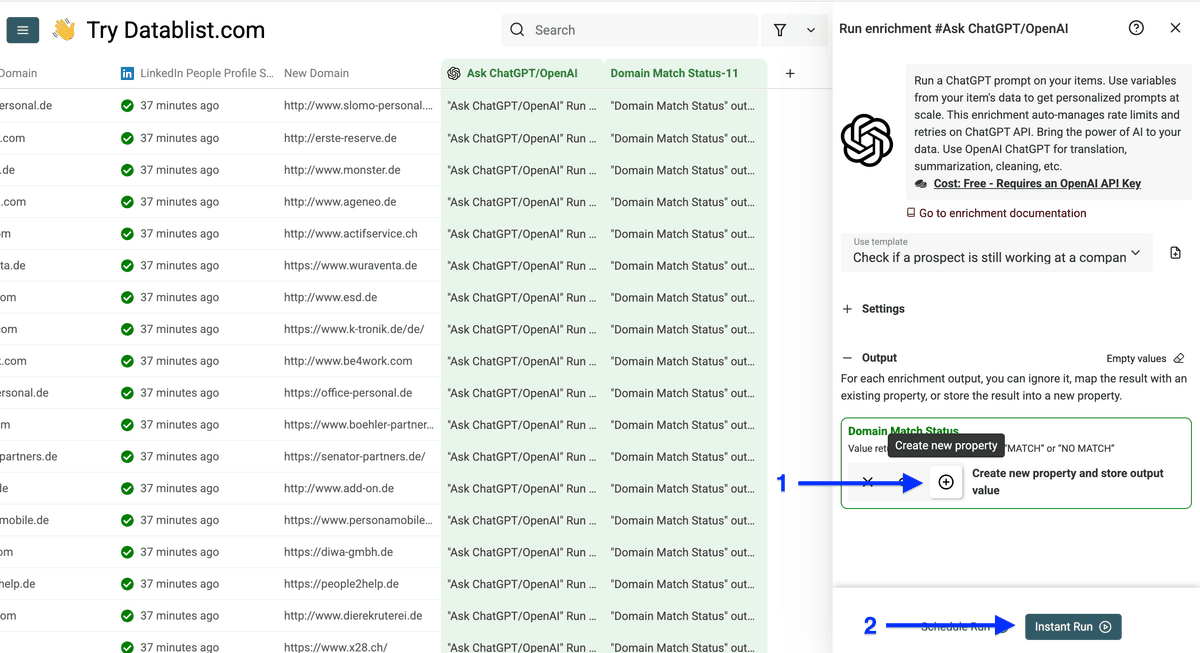
进入 AI,选择 Ask ChatGPT/OpenAI。
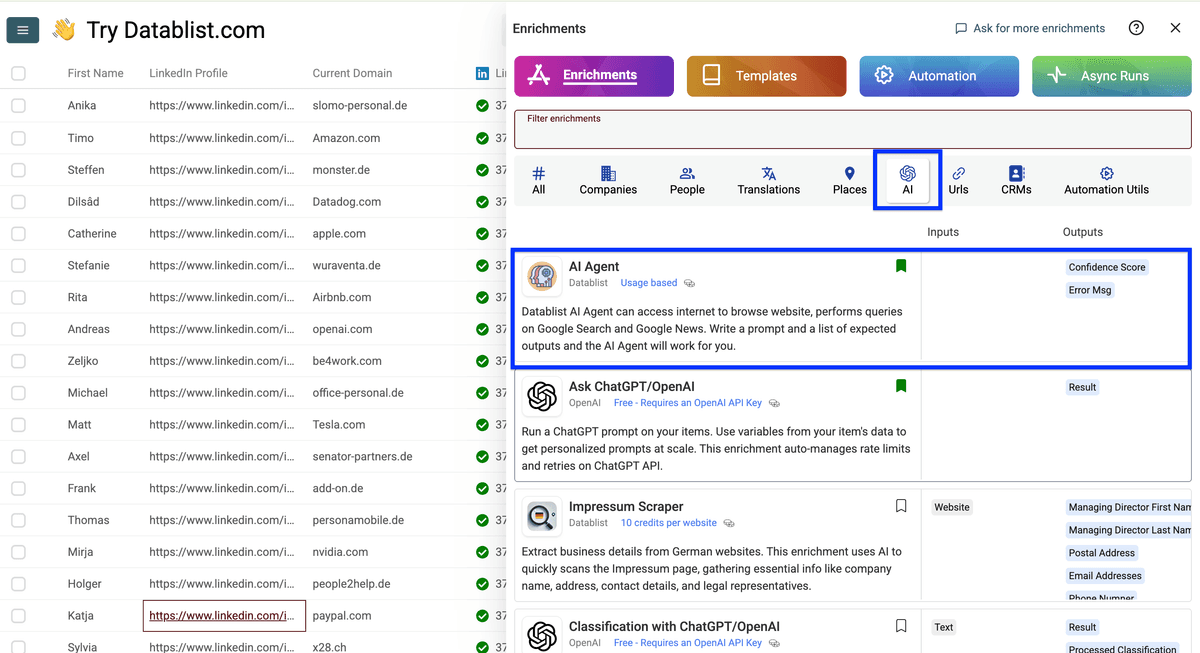
勾选使用 Datablist credits,或填写你的 OpenAI API key,然后点击 Use template。
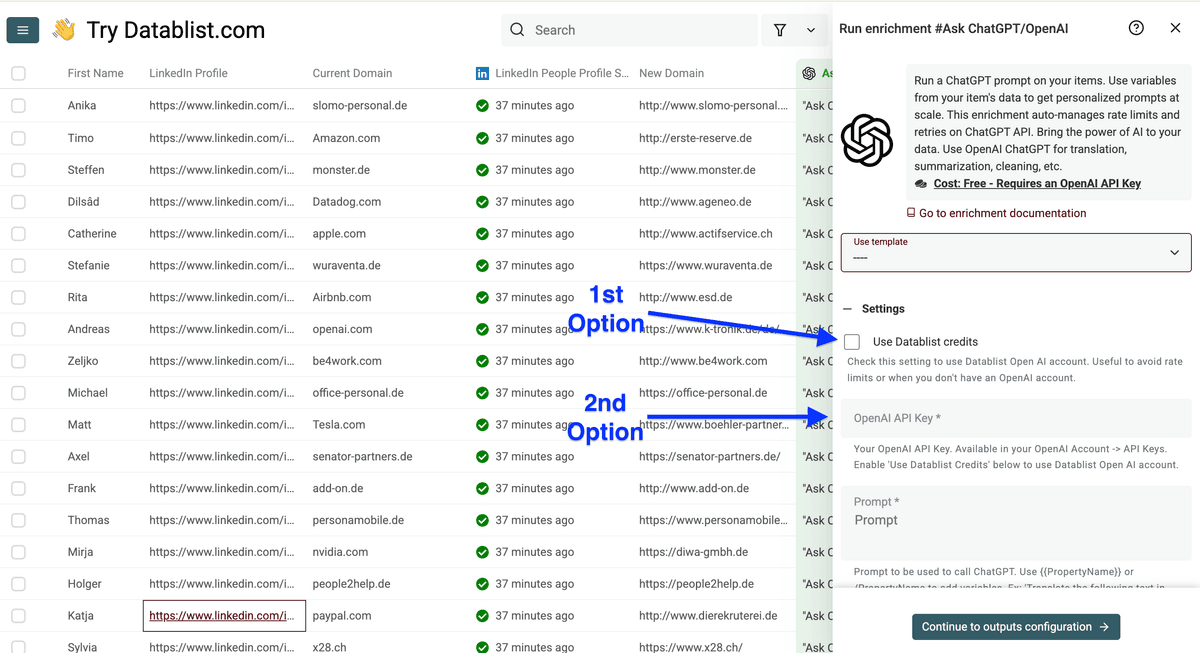
向下滚动,选择 Check if prospect is still working at a company。
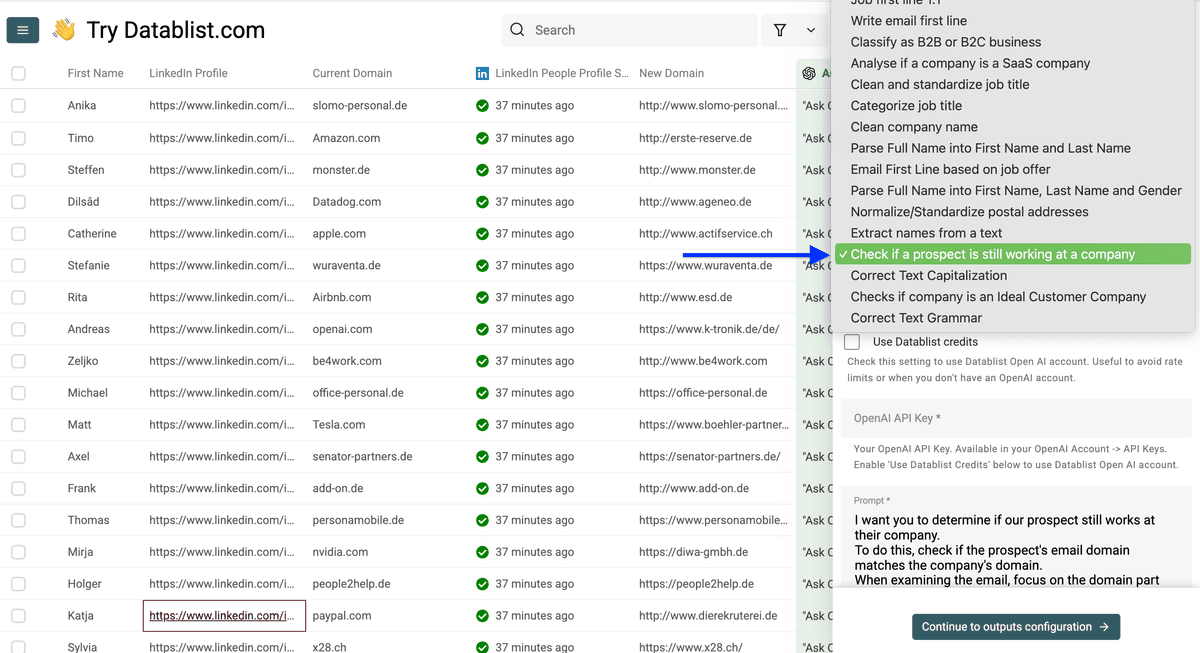
把你 collection 里的列 map 进模板:
用 “/” 可以弹出列名列表,把旧 domain map 到第一个字段。
第二个字段 map 新 domain。
然后点击 Continue to output configuration。
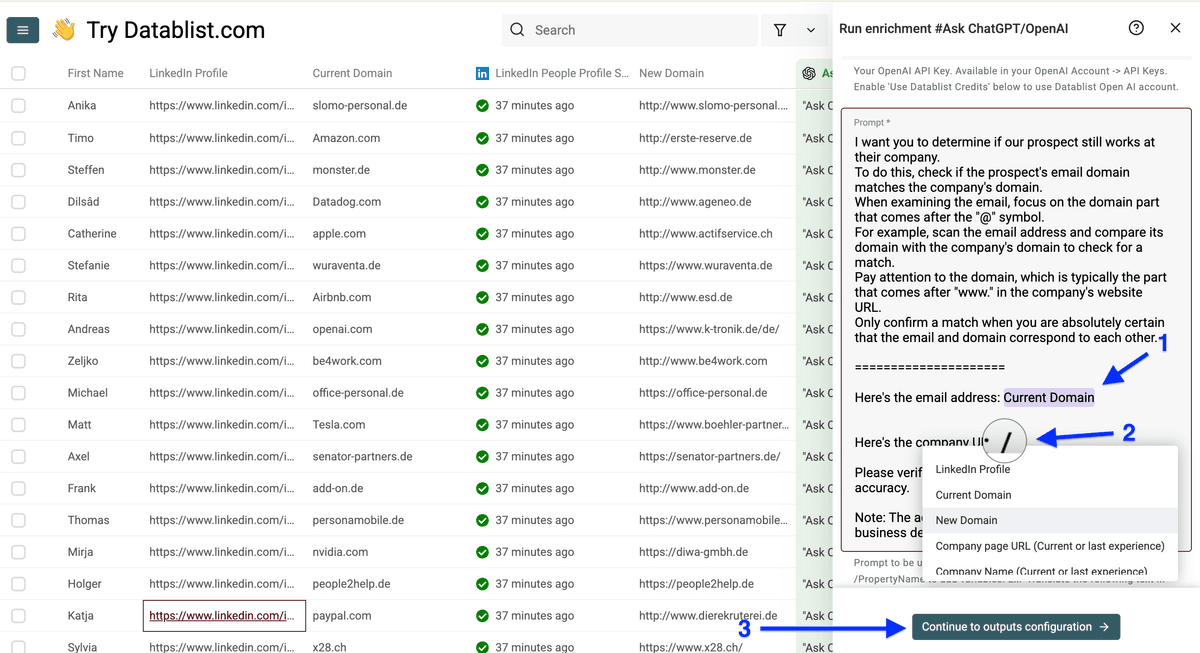
点击 plus icon 新建输出列,然后点击 Instant Run。
这就是批量判断结果:
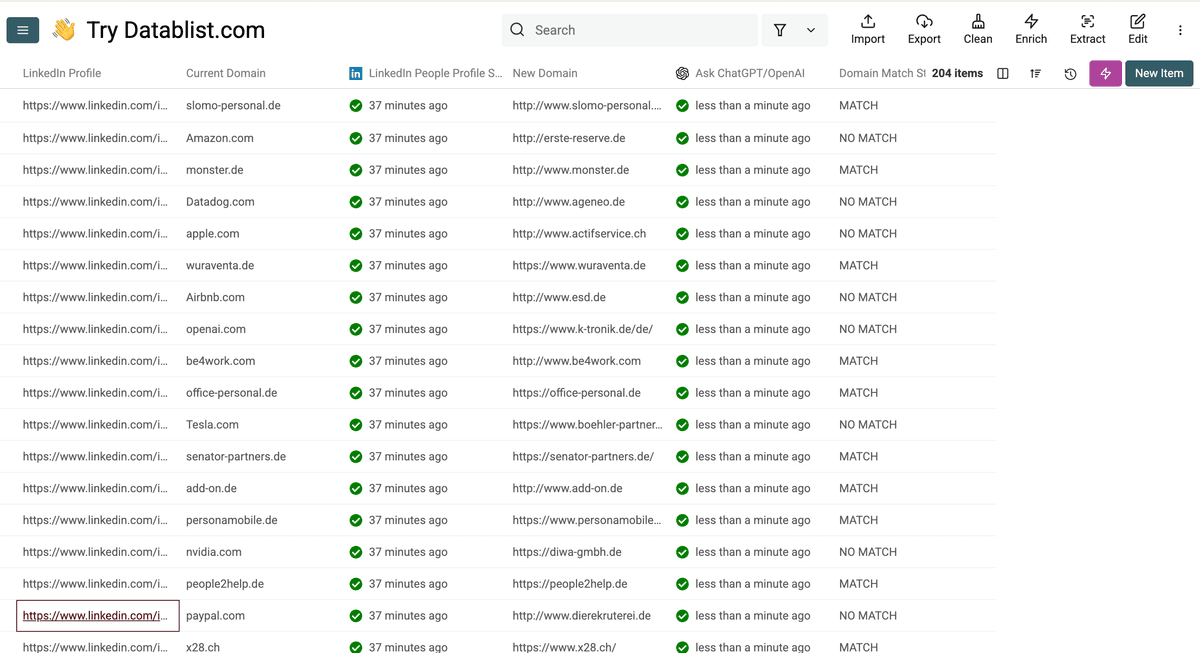
这样你就能确认 CRM 数据是否仍然 up-to-date 了!
你也可以顺便用 AI 给 accounts 做 lead scoring。
如何对 CRM 数据结构化与格式化
清理 CRM 时,结构化与格式化同样关键——它决定了后续销售和市场如何使用这些数据。为了把 CRM 数据统一到一个“干净格式”,我会带你做:
把数据统一格式只是第一步——真正长期维护好 CRM 的关键,是让数据持续保持干净、结构化。这里有几种常用做法:
- 定义标准化输入格式——比如统一 call notes 的记录框架
- 限制某些列只能输入特定类型(例如手机号列只允许数字)
- 设定必填字段——例如要求销售必须填写 “Last Contact Date”,确保数据完整
如何拆分姓名 first/last
CRM 清理里最常见的问题之一就是:姓和名经常被写在同一列里。这样一来,你做邮件个性化时很容易出现“把全名当名字叫”的尴尬情况。
Step 1:拆分姓名
注册 Datablist.com。
Import 一个包含联系人姓名的 CSV 或 Excel。
Step 2:用 Name Parser 拆分
点击 Enrich。
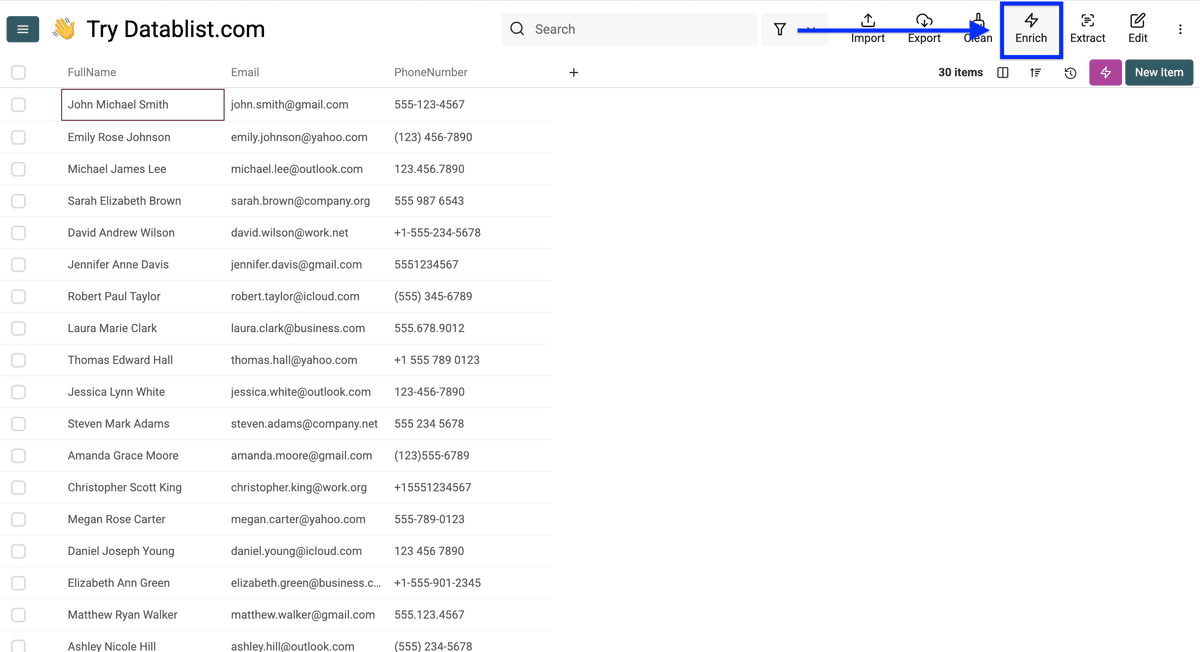
进入 People,选择 Name Parser。
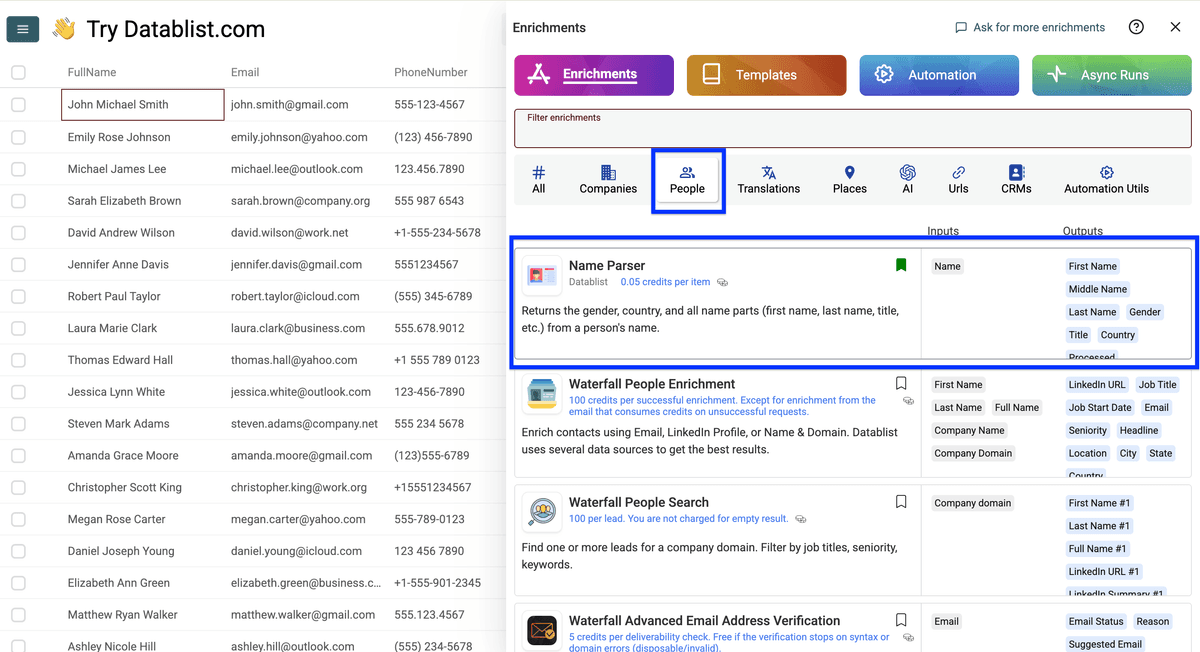
把姓名列 map 为 input property,点击 Continue to outputs configuration。
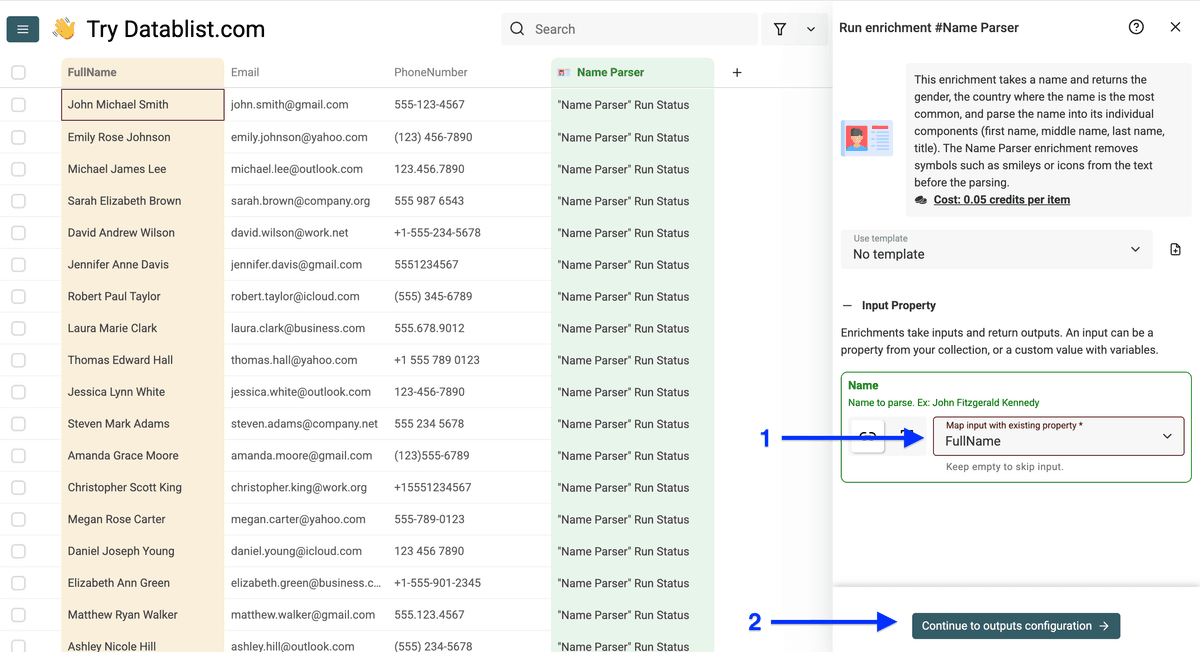
你可以得到这些 outputs:
- First names
- Middle names
- Last names
- Gender
- Title
- Origin country of the name
按需点击 plus (+) 新建输出列,然后点击 Instant Run。
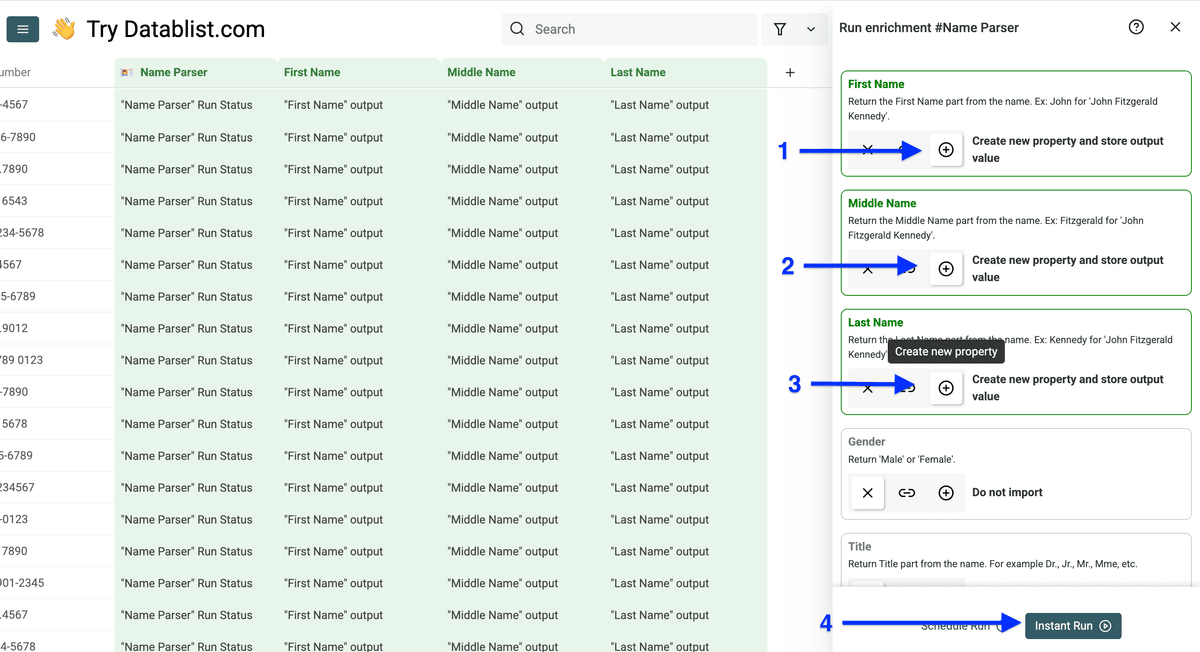
这就是拆分后的效果。
如何从邮箱中提取 Domain
Step 1:提取 Domain
注册 Datablist。
Import CSV 或 Excel。
点击 Extract,选择 Extract domains for email addresses or URLs。
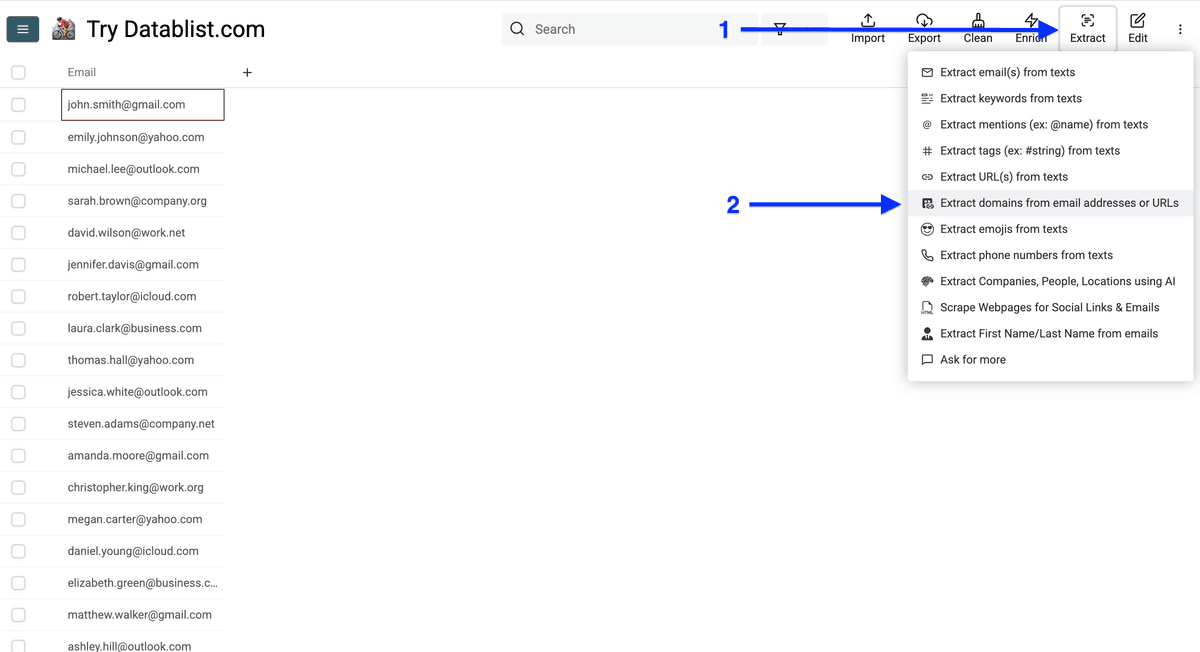
把邮箱列 map 为 input property,点击 Preview extraction。
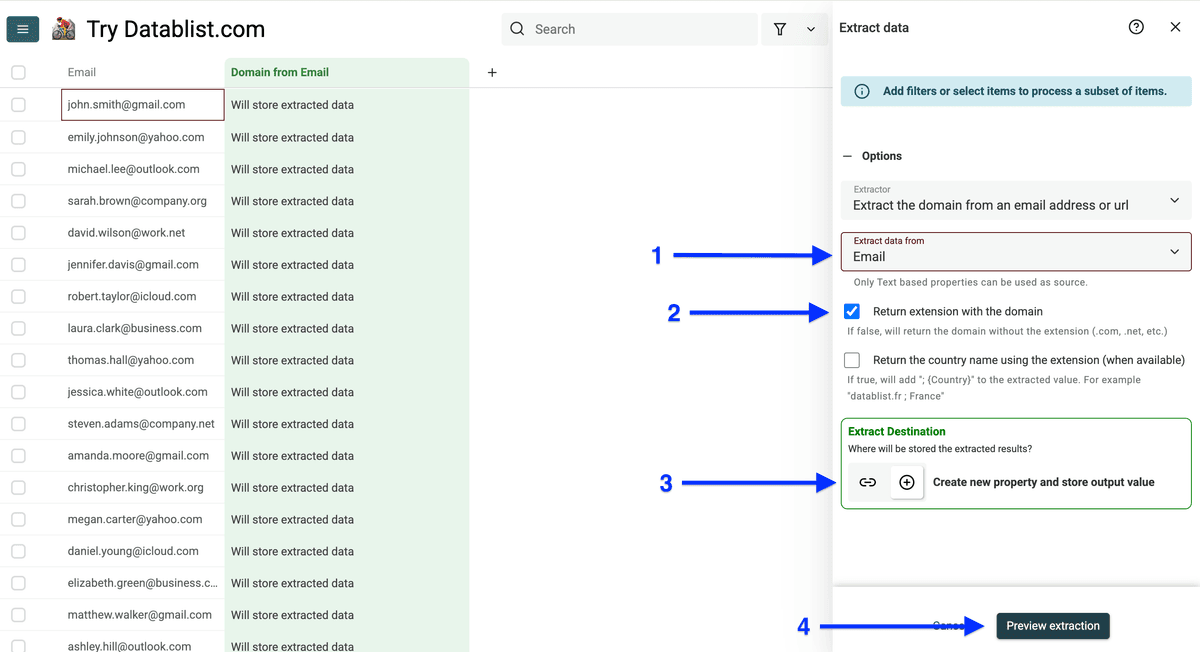
你会先看到前 10 行预览,确认没问题后点击 Extract data。
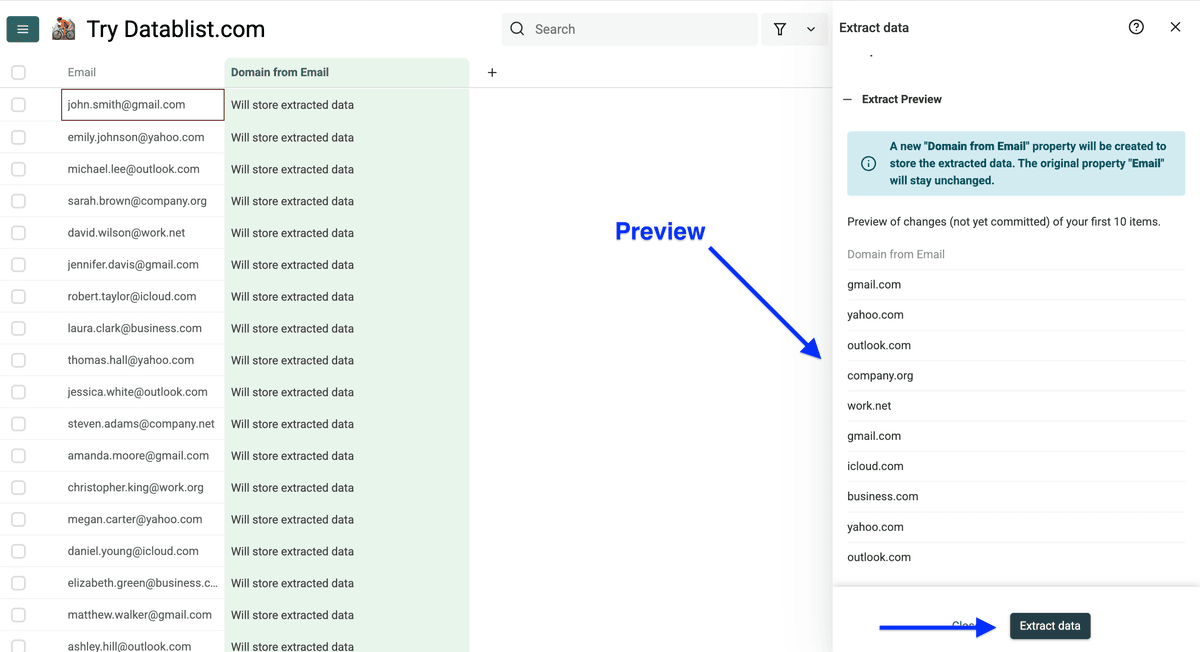
提取后的效果如下:
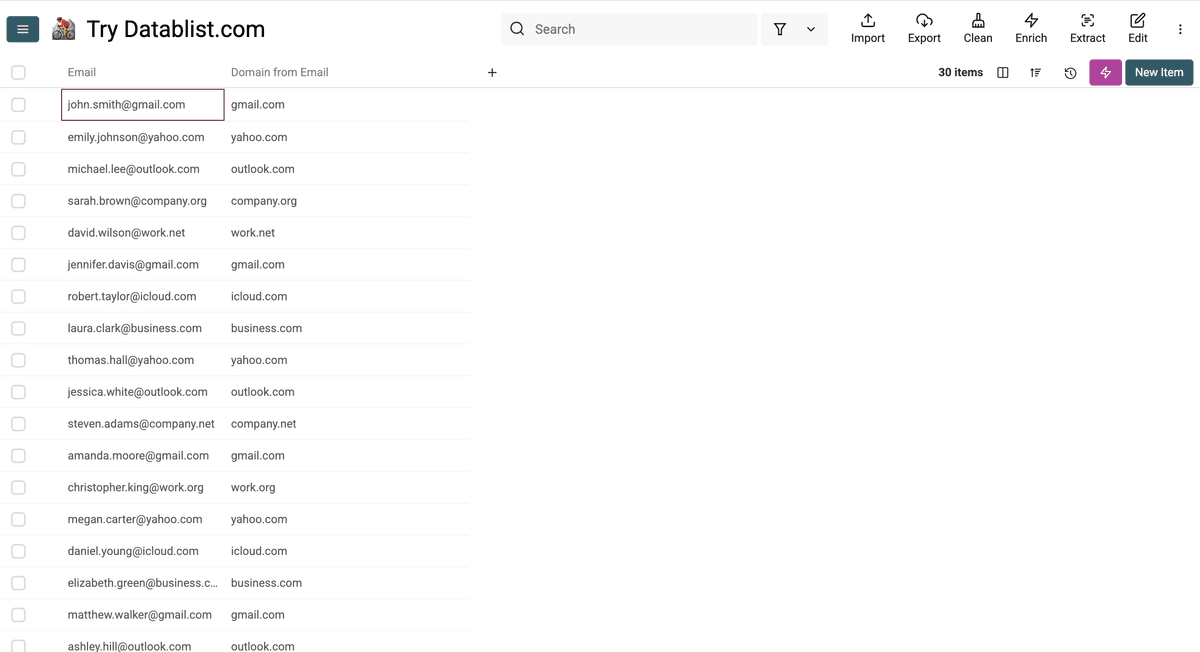
如何为 CRM 清理批量格式化手机号
手机号格式化是我最喜欢的 CRM cleaning 工作流之一,Datablist 在这个任务上特别好用:
- 支持任意国家的手机号
- 同时兼容:
- 国际格式(+XX)
- 本地格式
- 同一个文件里可同时处理多个国家
这个例子里,我的文件包含:
- 美国手机号
- 印尼手机号
- 德国手机号
- 阿尔及利亚手机号
我会一次性把它们全部格式化。
❗ 重要提示
如果同一个文件里有多个国家的手机号,必须包含一个 “Country” 列,用来告诉 Datablist 每条手机号来自哪个国家。
开始!
Step 1:批量格式化手机号
注册 Datablist.com。
Import CSV 或 Excel。
点击 Enrich。
进入 AI,选择 Phone Number Extractor
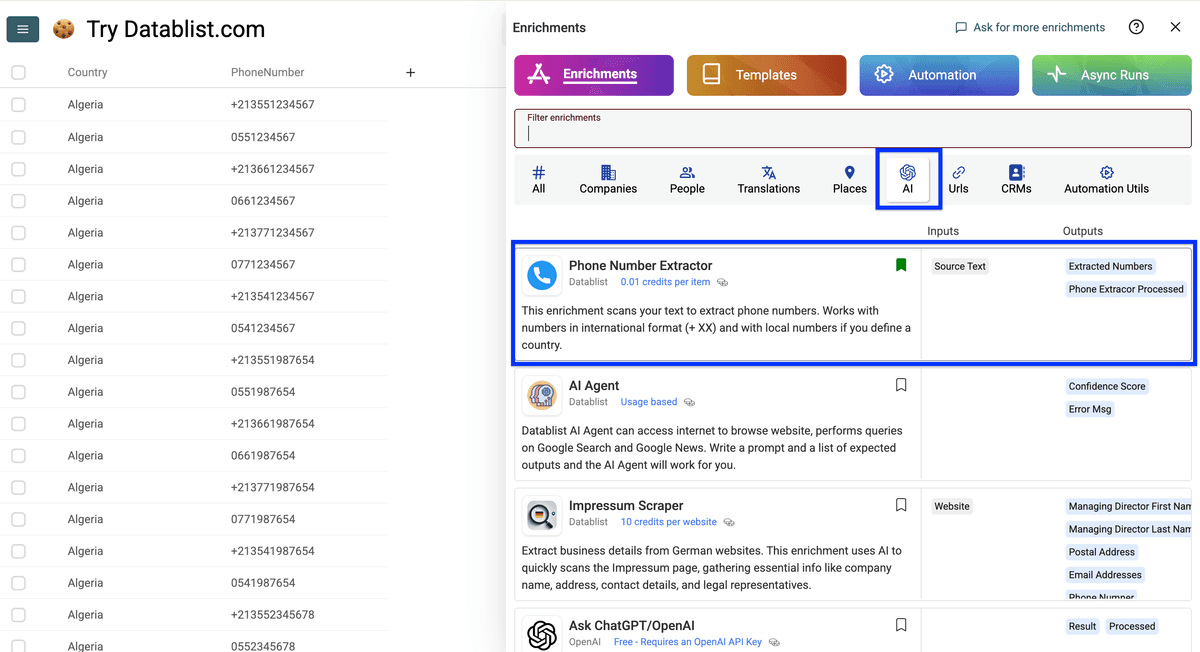
选择你列表里手机号的来源国家,并勾选 Advanced Settings。
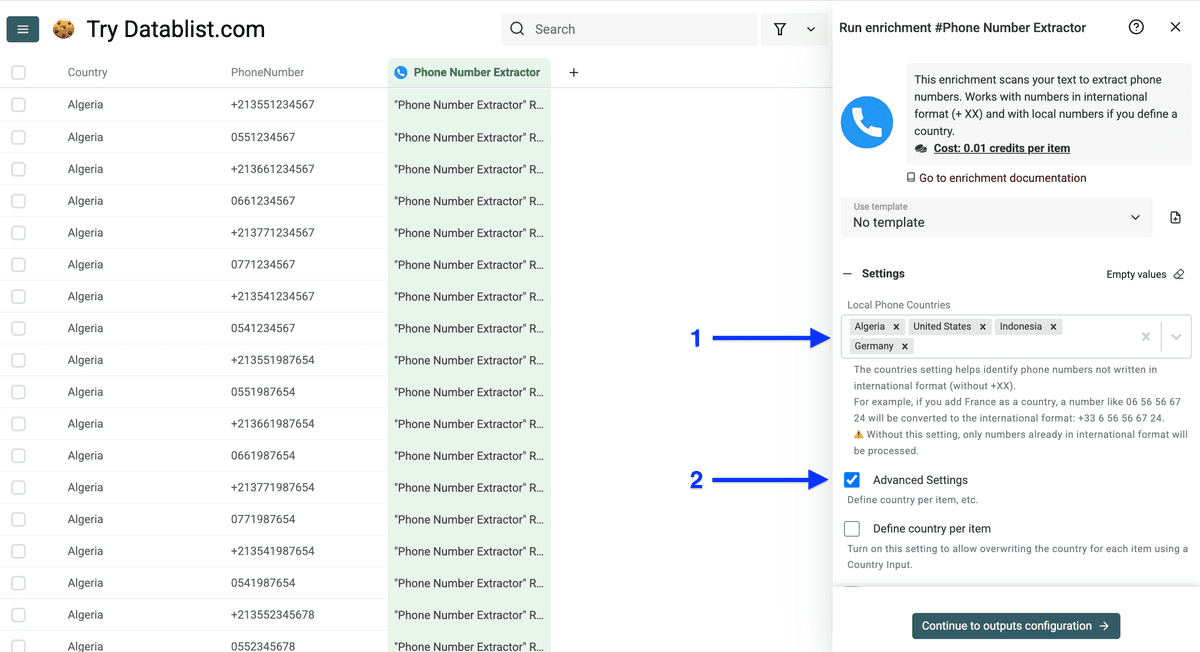
勾选 Define country per Item,启用“按行输入国家”。
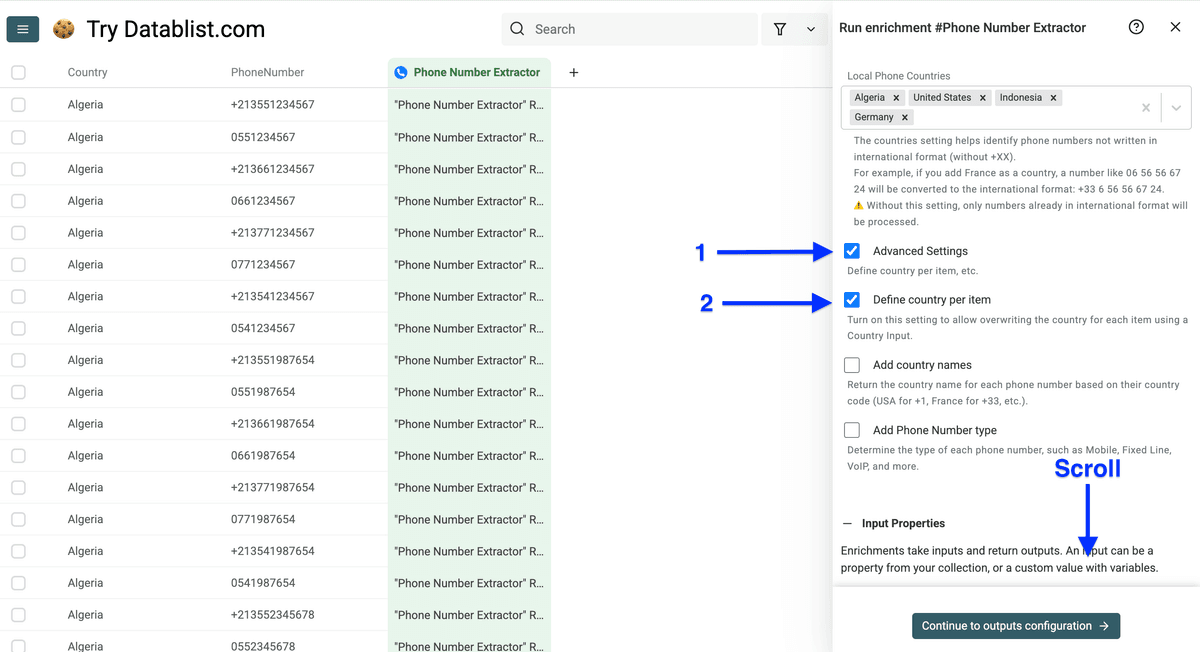
💡 Quick Tip
只有在处理单一国家手机号时,才建议开启 Add phone number type,因为多国家混在一起时准确率会下降。
把手机号列和国家列 map 为 input properties,点击 Continue to outputs configuration。
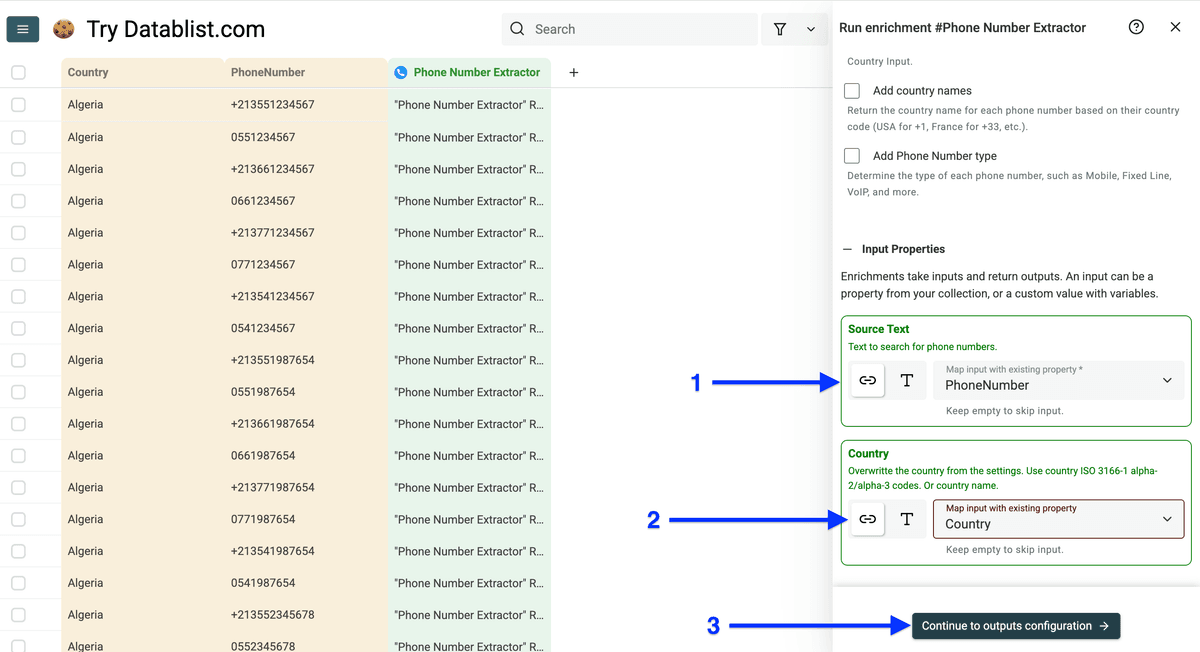
点击 plus icon 新建“格式化后手机号”输出列,然后点击 Instant Run。
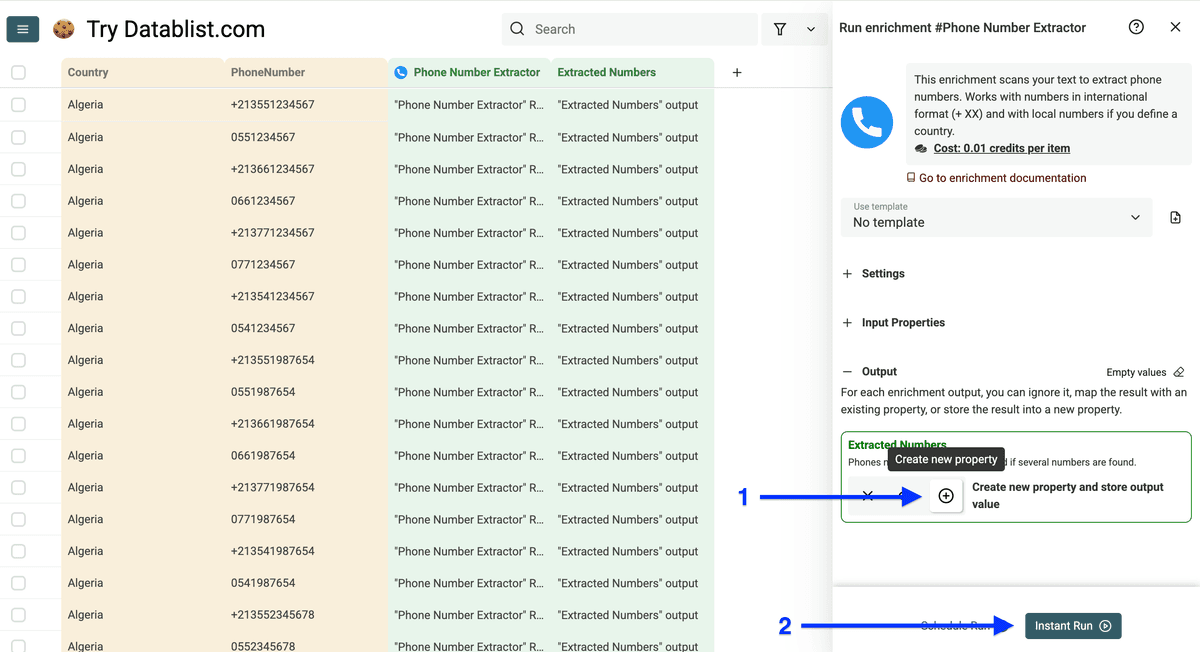
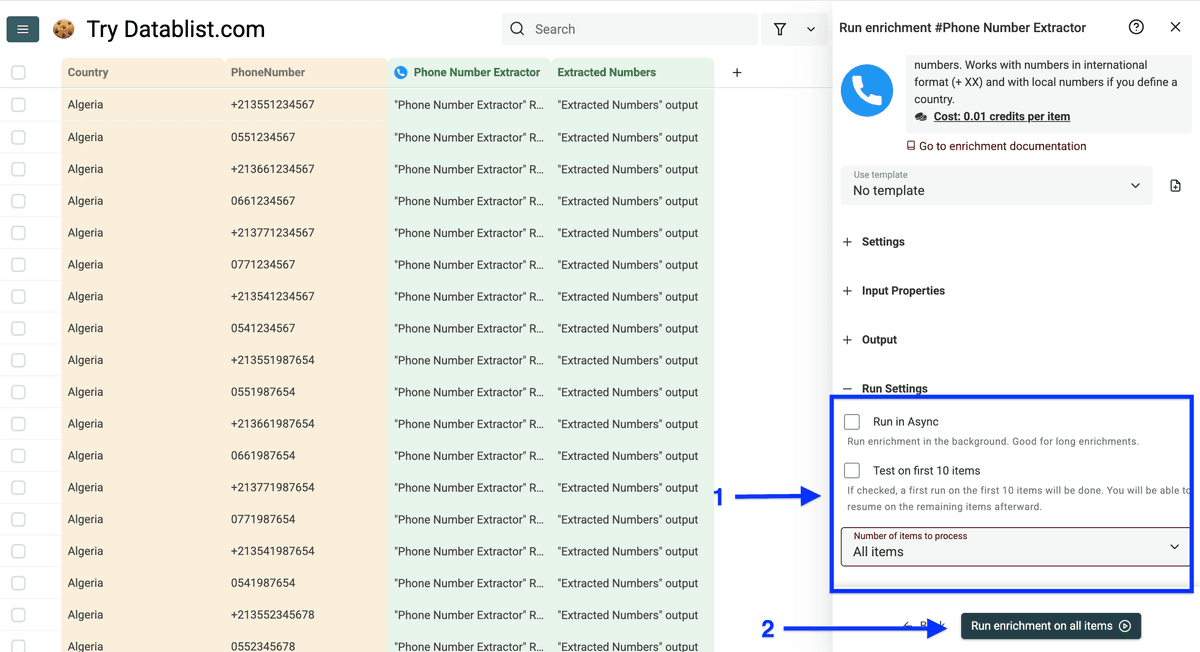
接下来你会看到 Run Settings,可以设置:
- Run in Async(大列表强烈建议)
- Test on the first 10 items
- 选择 number of items to process(10/100/自定义)
配置好后点击 Run enrichment on all items。
这就是格式化后的手机号:
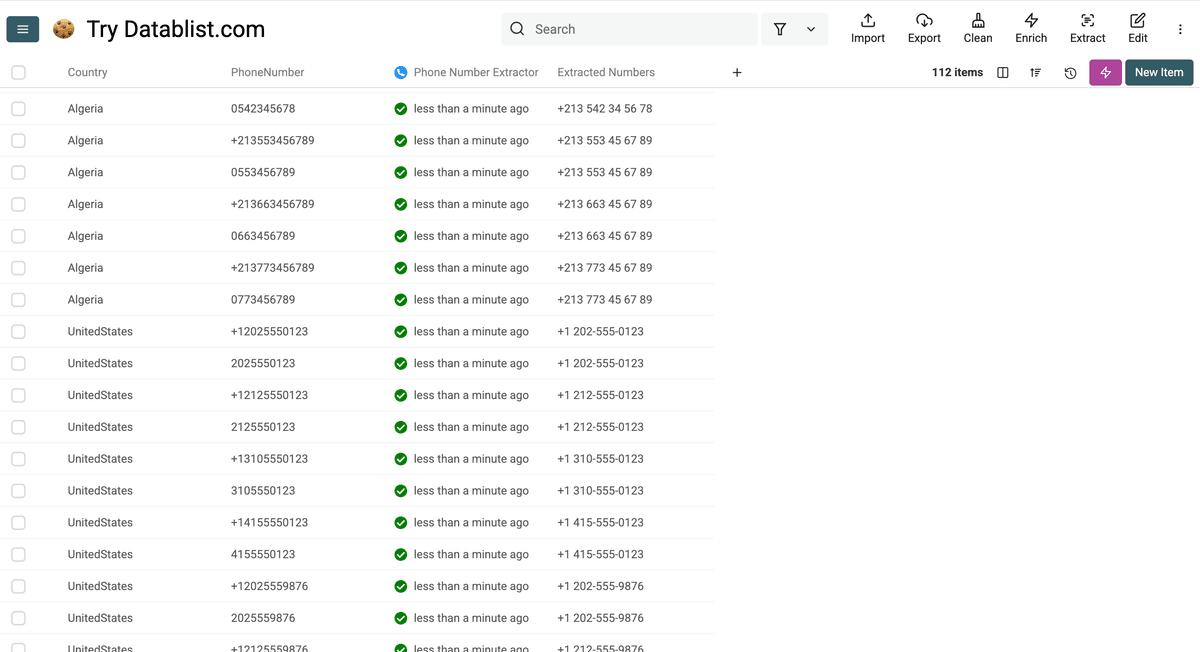
如何更新你的 CRM 数据
让 CRM 数据保持“新鲜”对业务成败非常关键。要高效更新 CRM,你需要掌握这些:
- 如何用公司名找到公司域名
- 如何抓取企业信息与公司详情
- 如何抓取难以找到的公司细节
- 如何抓取 CRM 联系人的 LinkedIn profile
- 如何拿到 verified emails
- 如何找到 verified phone numbers
走起!
如何根据公司名称找到公司 Domain
这是我们最常用的 company enrichment 之一。说白了:没有 domain,很多后续 enrichment 都无从谈起——所以我把它放在第一位(也最符合流程)。
Step 1:用公司名找 Domain
注册 Datablist.com。
Upload 一份包含公司名的列表。
Step 2:运行 Domain Finder
点击 Enrich
进入 URLs,选择 Find company domains from company names
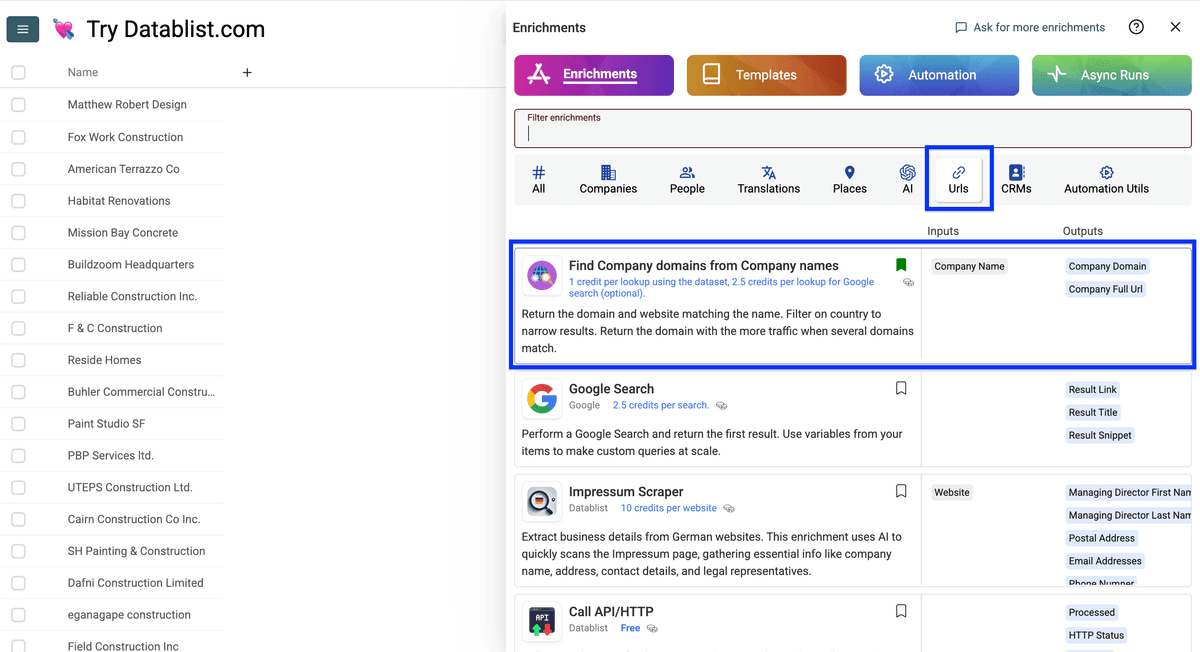
Search Settings 说明 🔍
有两种搜索方式:
-
默认选项:Companies Dataset + Google Fallback
先查数据库(找到则 1 credit)→ 不行再用 Google 兜底(2.5 credits)
-
最便宜选项:Use only Companies Dataset
只查数据库(1 credit)
这些设置用于控制 domain 的匹配方式:
- Target Country:限定国家,通常更准
- Accept non-root websites:允许返回“domain + path”的网站(如
platform.com/company),而不只限主域名(company.com) - Skip following domains:过滤掉 Crunchbase、Northdata 等目录站结果(它们通常不是公司官网)
如果你追求覆盖率最大化, 保持默认搜索选项,选一个国家,其他保持空即可。
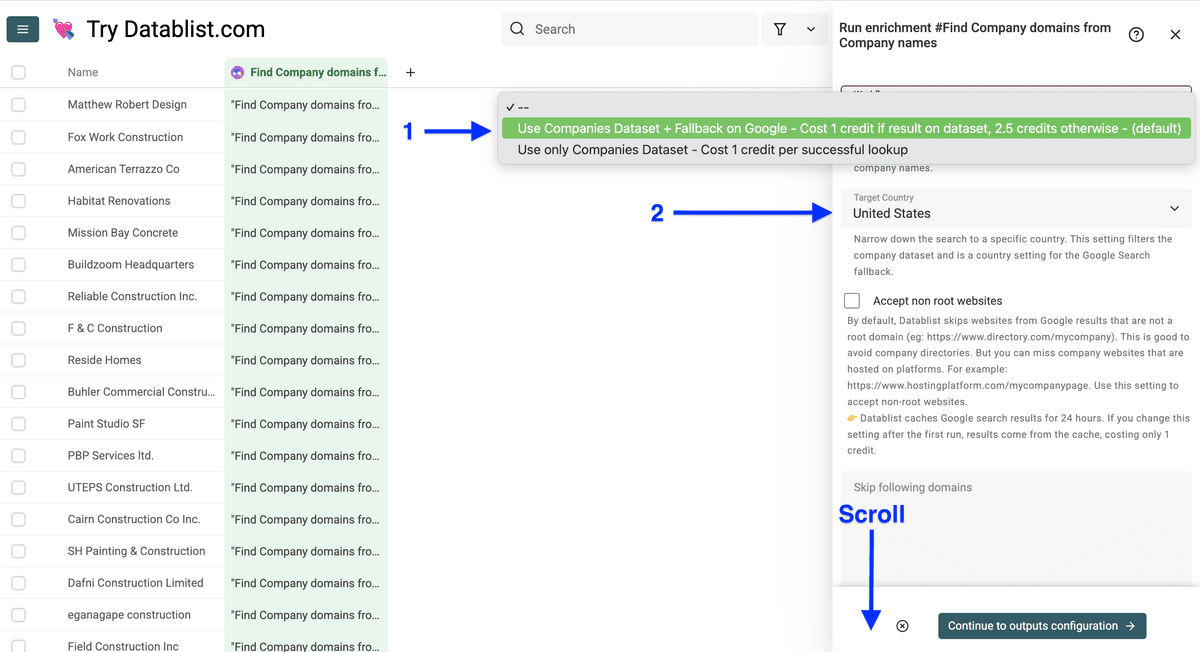
设置好后,向下把公司名列 map 为 input property,点击 Continue to outputs configuration。
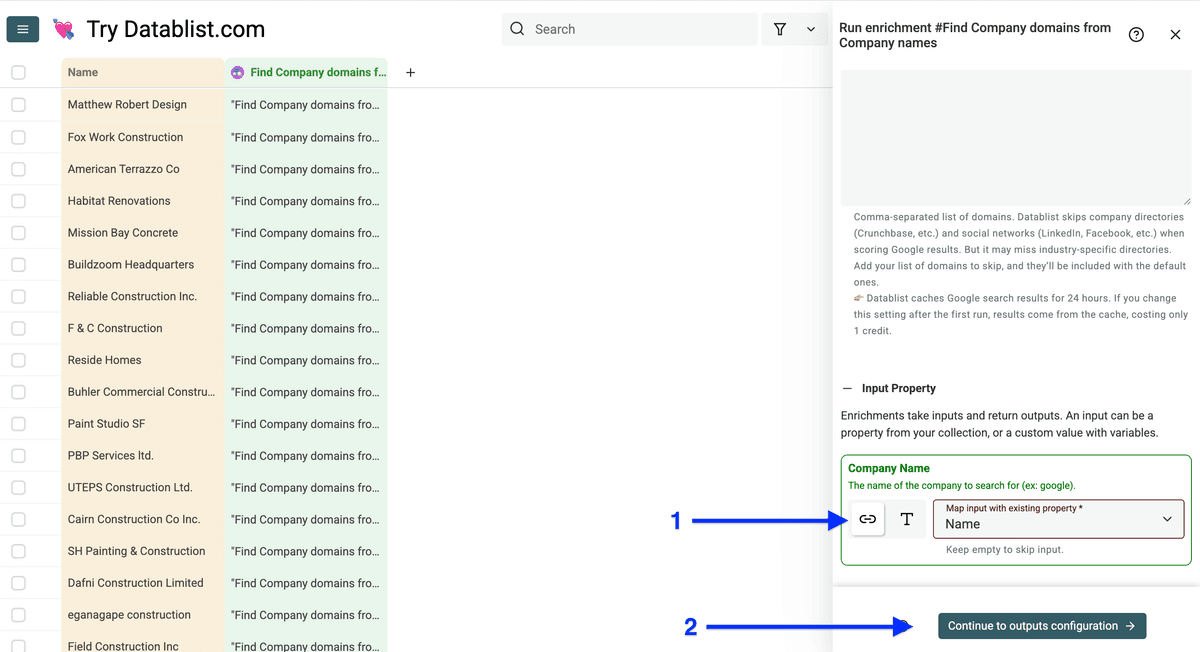
然后你可以创建 “Company URL”“Company Domain” 或两者的输出列(点 plus icons)。我一般只要 company domain。完成后点击 Instant Run。
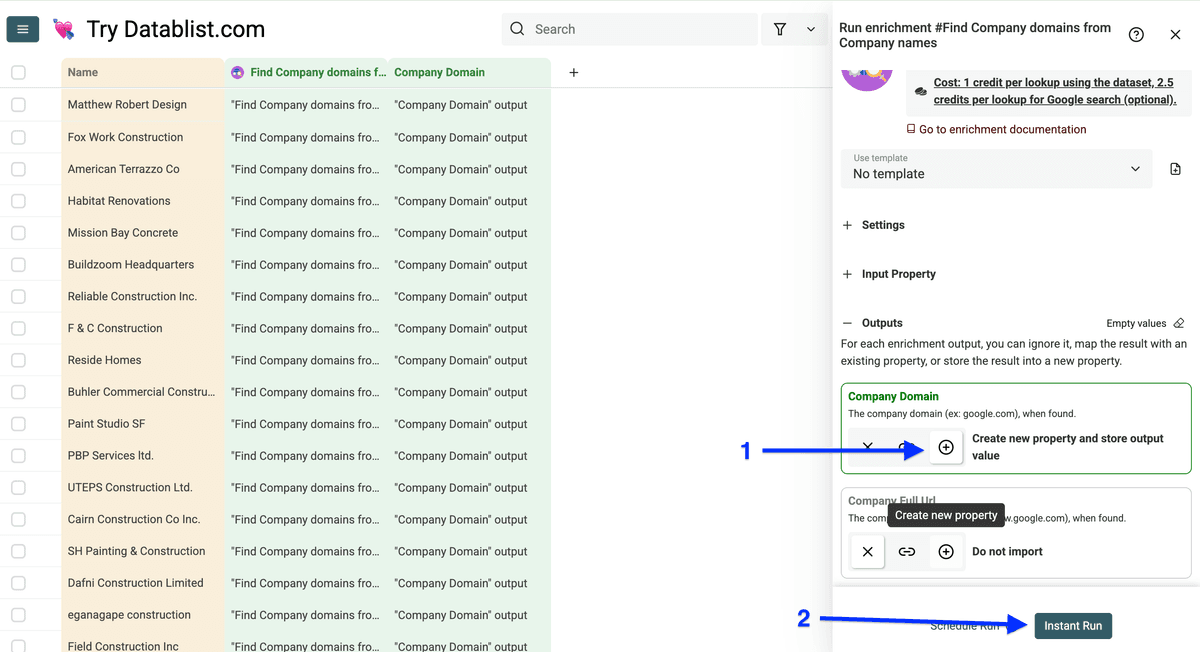
你会看到 Run Settings,可以:
- Run in Async
- 选择 number of items to process(10/100/自定义)
配置后点击 Run enrichment on all items。
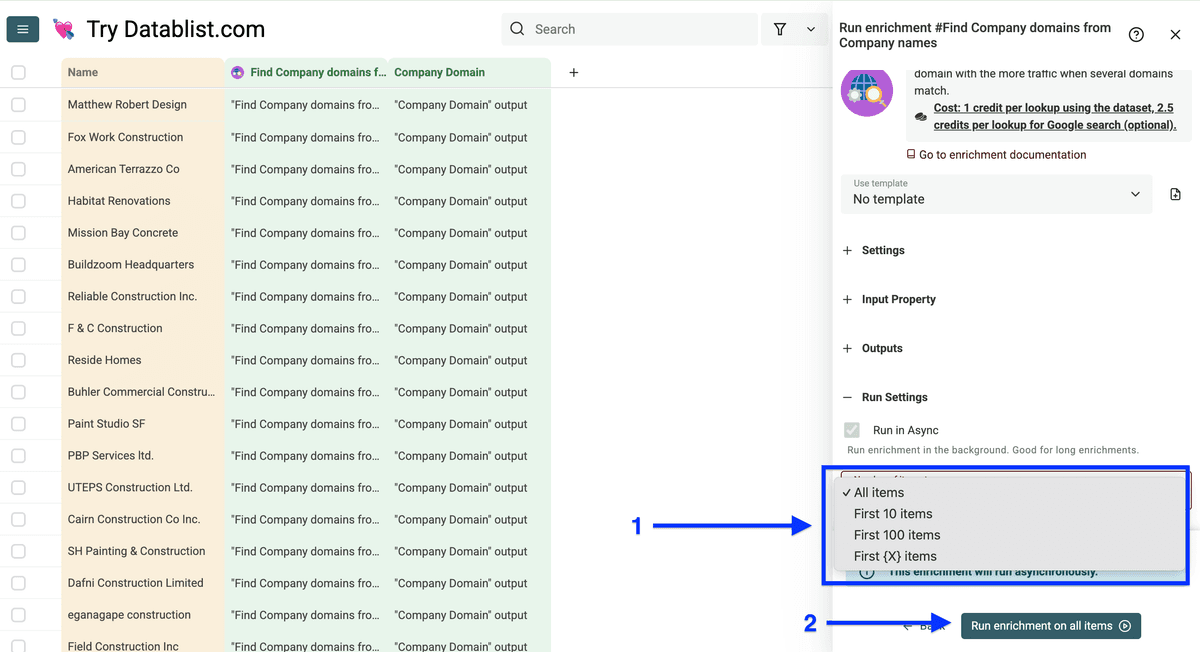
运行后列表会变成这样(成本见下图)。
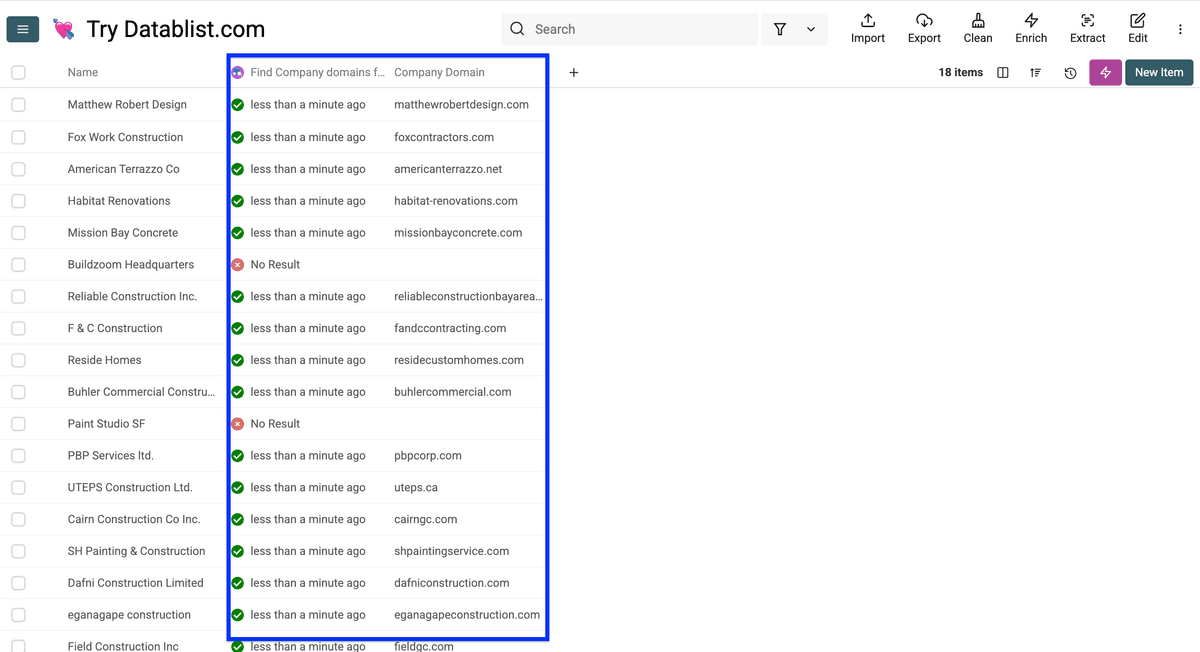
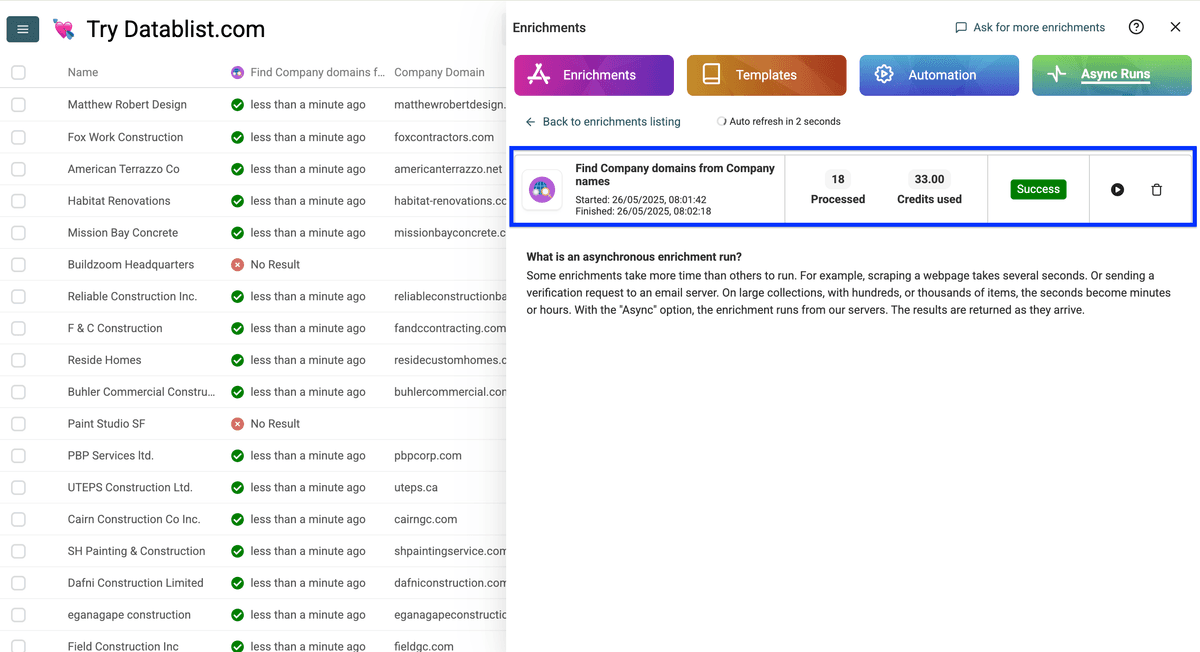
我为 16 个 domains 支付了 33 credits,平均每个 domain 2.06 credits。假设你有 1,000 个 domains,大概只需要 ≈ 2,062 credits = $2.03。
👉 想更深入可以看这篇:finding company websites from company names
如何抓取企业信息与公司详情
这一节我们主要拿一些基础 firmographic data,用来判断某些 accounts 值不值得继续做更深度的 research/enrichment。
这里的 firmographic data 指的是 LinkedIn 常见的公司信息,例如:
- Headcount
- Company Name
- Website
- Company headquarter
- Specialities
- Industry
- Description
- Country
- Region
- Founding year
- LinkedIn URL
- Sales Navigator ID
- Followers count
- Slogan
开始!
Step 1:准备公司 domain 或 LinkedIn URL
注册 Datablist.com。
Import 一份列表,包含 CRM 里公司的 domain 或 LinkedIn URL。
Step 2:运行 Company Enrichment
点击 Enrich。
进入 Companies,选择 Company Enrichment。
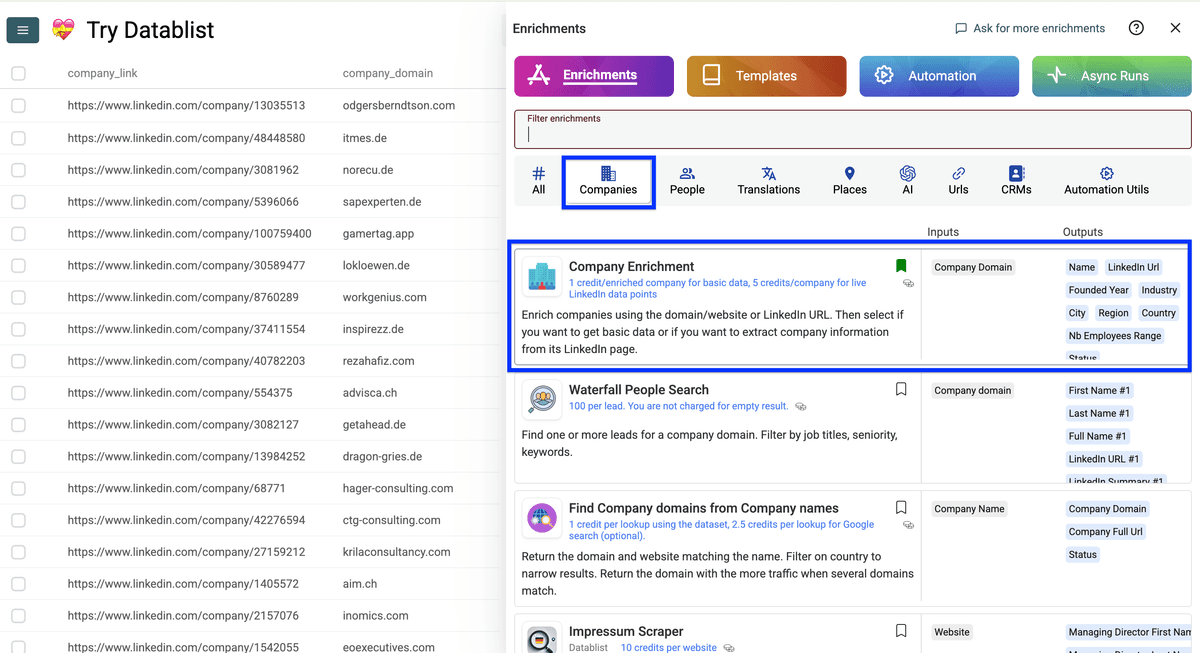
这里有两组关键设置:
1)Data Source Options: enrichment 的输入来源
- Company domain(默认)
- LinkedIn URL
2)Data Return Options & Costs: 返回数据类型与成本
- Basic data(1 credit):行业、地点、员工数、成立年份
- LinkedIn data(5 credits):直接从 LinkedIn 页面拉取实时信息
我建议:如果你有 LinkedIn URL 就用它拿实时 LinkedIn data;没有的话,就用 company domain + basic data。
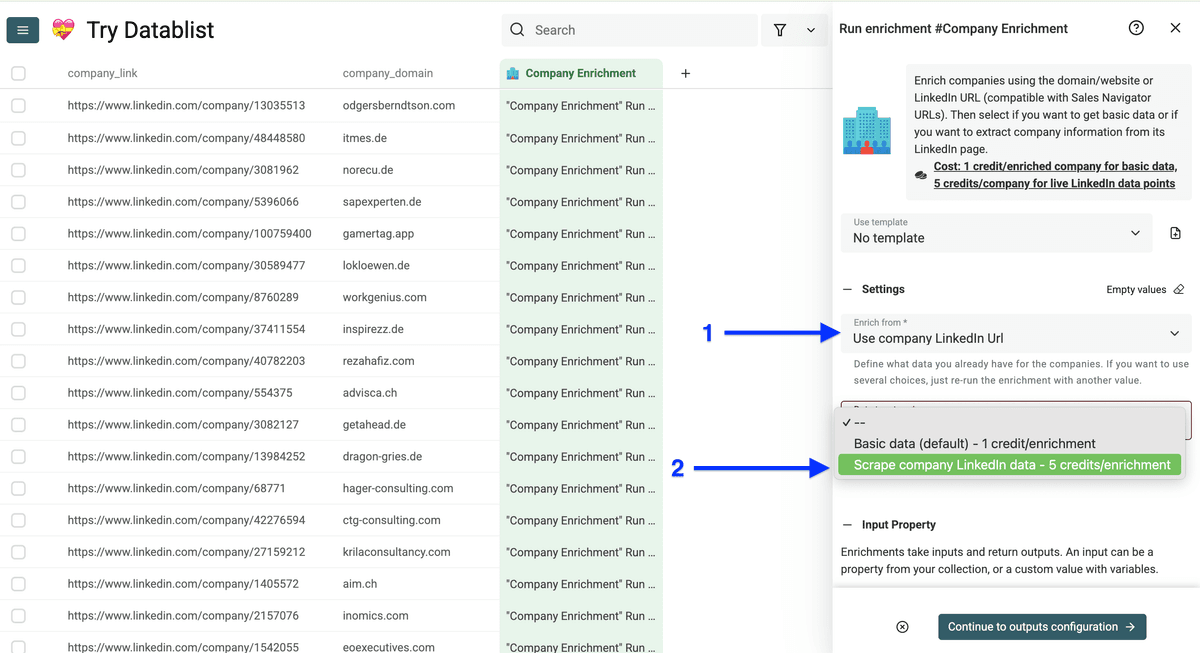
选好设置后,把 LinkedIn URL 列 map 为 input property,点击 Continue to outputs configuration。
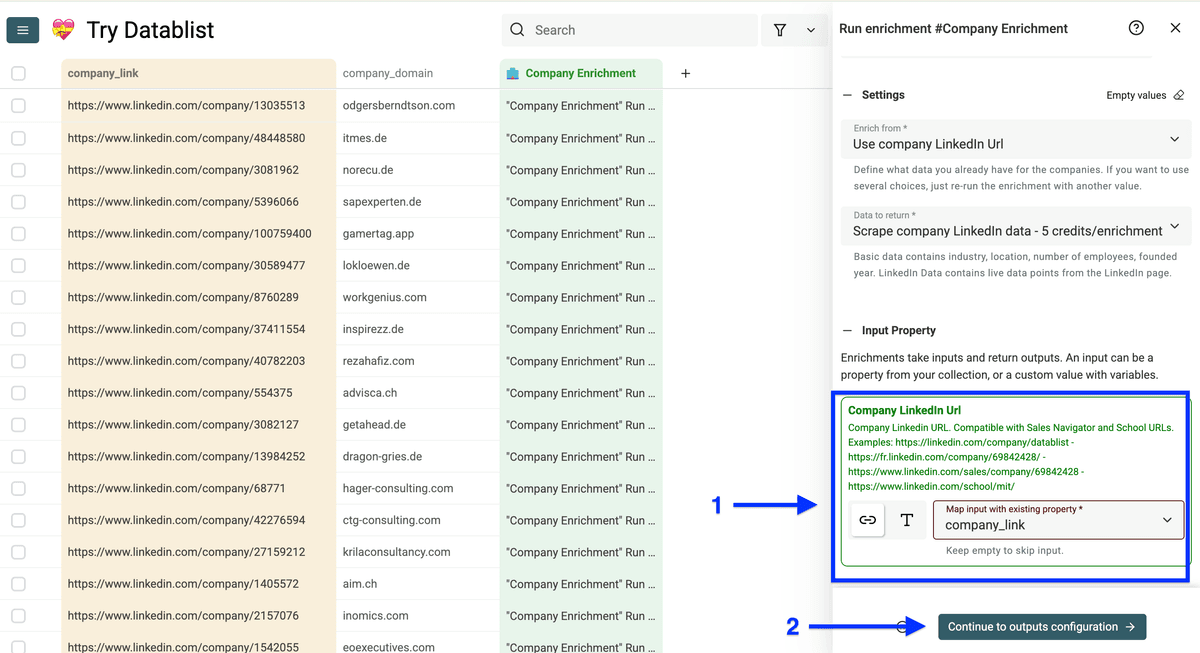
按需点 plus icons 新建输出列,然后点击 Instant Run。
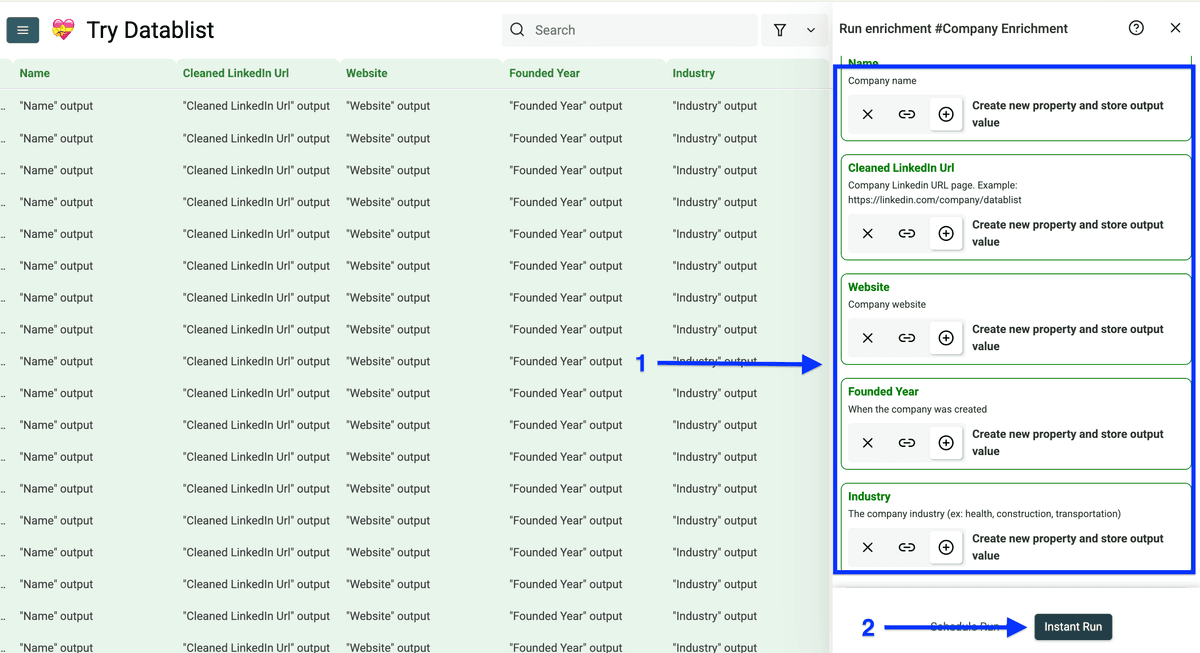
你会看到 Run Settings:
- Run in Async
- 选择 number of items to process(10/100/自定义)
然后点击 Run enrichment on all items。
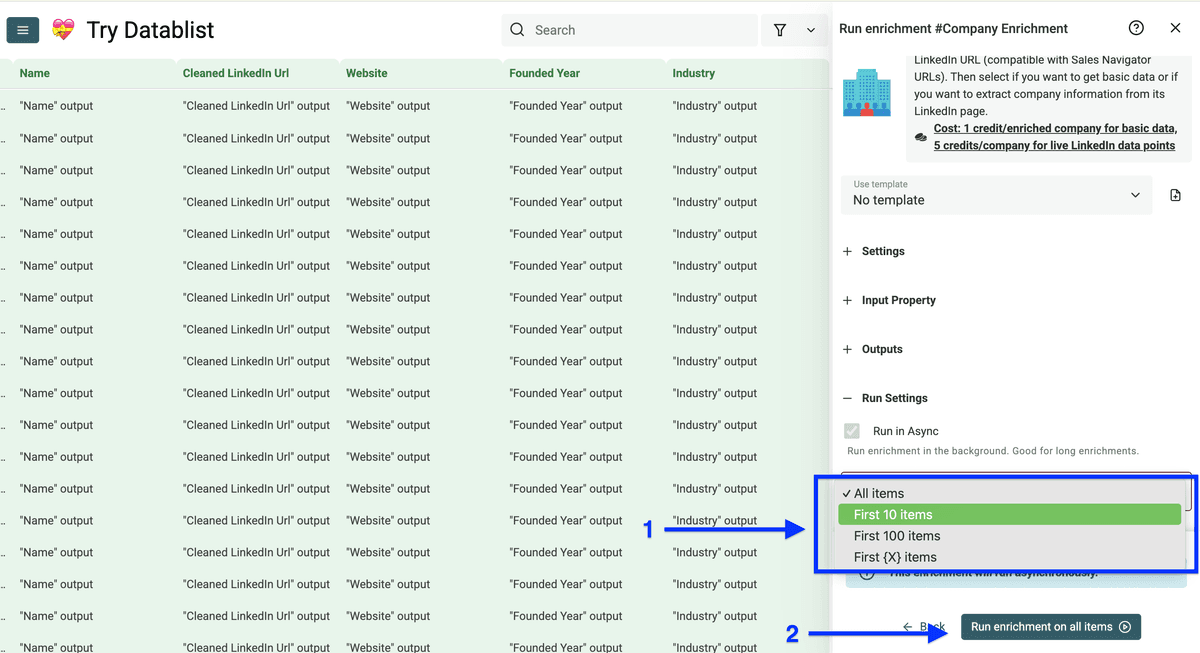
这是我从 LinkedIn 抓到的公司详情结果:
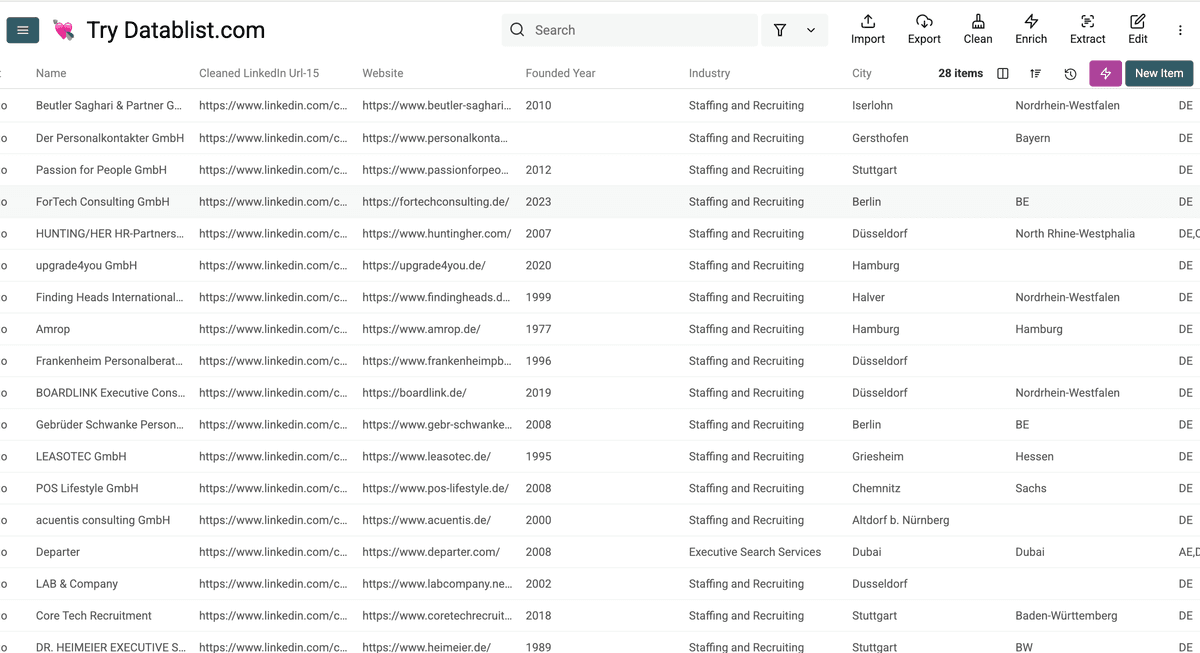
但你可能想要 LinkedIn 上没有的信息——比如那种你手动查每家公司要花几个小时的数据。这个时候 Datablist 的价值就出来了:你可以用 AI agent 把重复性的 research 自动化。
如何抓取难以找到的公司详情
这大概是我最喜欢的一部分(对,我前面也说过,但这次真的不一样)。
因为我会演示:如何用 AI research agent 去挖出 传统数据库经常漏掉的“隐藏公司信息”。
比如制造业公司,可能有多个零售分支、生产基地、细分业务线——这些信息在标准数据库里往往不全。
一些你可能想挖的“隐藏公司信息”例子:
- 专利与知识产权
- 核心高管的过往履历
- 供应链与供应商关系
- 客户成功案例与 case studies
- 研发方向与技术栈
这些数据点通常需要跨官网、新闻稿、行业报告、垂直数据库做深度检索。AI research agent 可以通过分析多个来源并汇总关键信息来完成这件事。
这个例子里,我会演示如何找出:某些企业到底有多少生产基地(production facilities)。
开始!
Step 1:准备公司列表
注册 Datablist.com。
Import 一份公司列表(包含 company domains)。
Step 2:使用 AI Agent 做自动 research
点击 Enrich。
进入 AI,选择 AI Agent。
你可以自己写 prompt,也可以先用我下面的 prompt 来测试。想更系统地写 prompt,可以看:Learn here how to prompt the AI agent
这个 prompt 做的事是:
- 搜索每家公司有多少生产基地
- 判断是否超过 5 个
- 超过 5 个标记为 “ICP”,否则标记为 “Irrelevant”
- 再搜索这些基地分别在哪里
- 输出完整地点清单
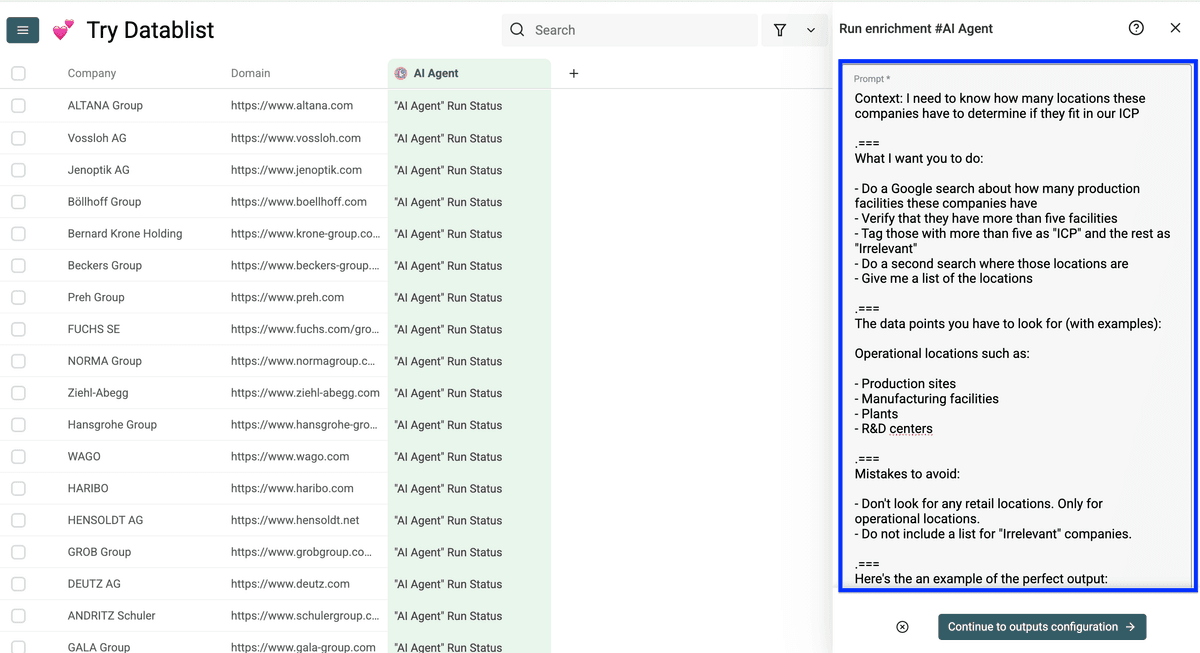
Context: I need to know how many locations these companies have to determine if they fit in our ICP
===What I want you to do:
- Do a Google search about how many production facilities these companies have
- Verify that they have more than five facilities
- Tag those with more than five as "ICP" and the rest as "Irrelevant"
- Do a second search where those locations are
- Give me a complete list of all locations
The data points you have to look for (with examples):
Operational locations such as:
- Production sites
- Manufacturing facilities
- Plants
- R&D centers
Mistakes to avoid: - Don't look for any retail locations. Only for operational locations. - Do not include a list for "Irrelevant" companies.
===Here's the an example of the perfect output:
ICP Status: ICP Locations:
- Bonn, Germany
- Solingen, Germany
- Wilkau-Haßlau, Germany
- Neuss, Germany
- Graz, Austria
- Pontefract, UK
- Castleford, UK
- Wisconsin, USA
Here is the name of the company: /Company
设置好 prompt 后,向下配置 outputs。我这里配置 2 个 outputs:
- ICP Status
- Locations
先配置第一个 output,再点 More 新增第二个(你也可以新增更多)。
然后勾选 Advanced Settings。
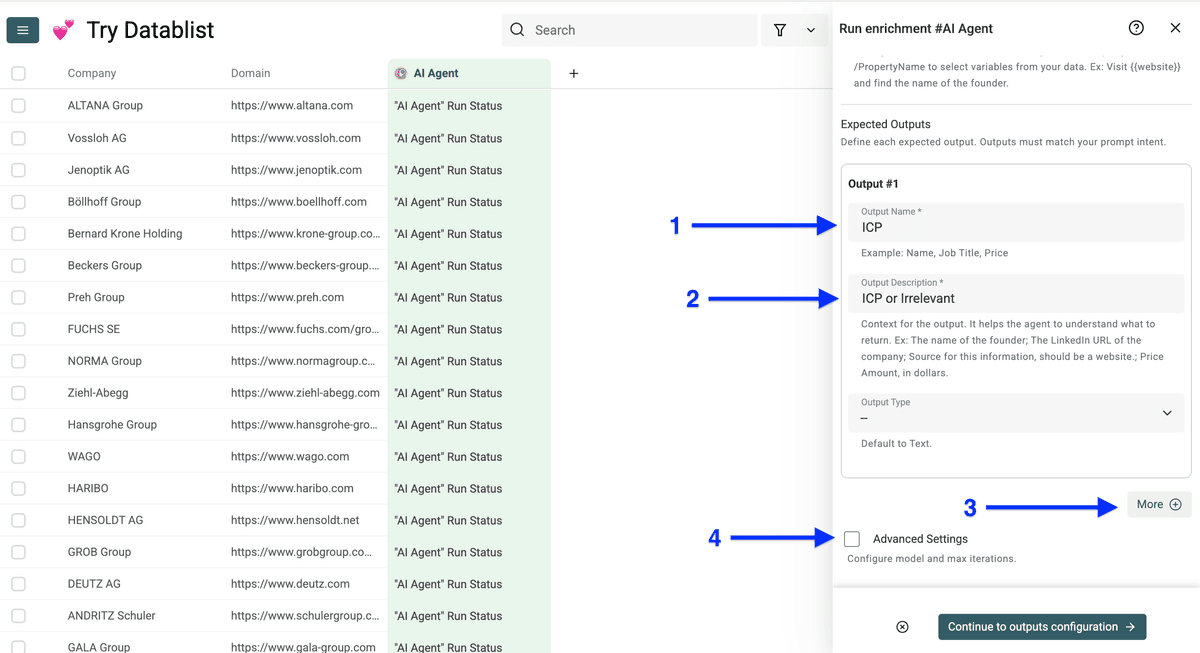
AI Agent 的 advanced settings 允许你:
- 选择要用的 LLM model
- 设置 agent 最大迭代次数(maximum number of iterations)
- 开启 Render HTML,让 agent 可以滚动网页
设置好后点击 Continue to outputs configuration。
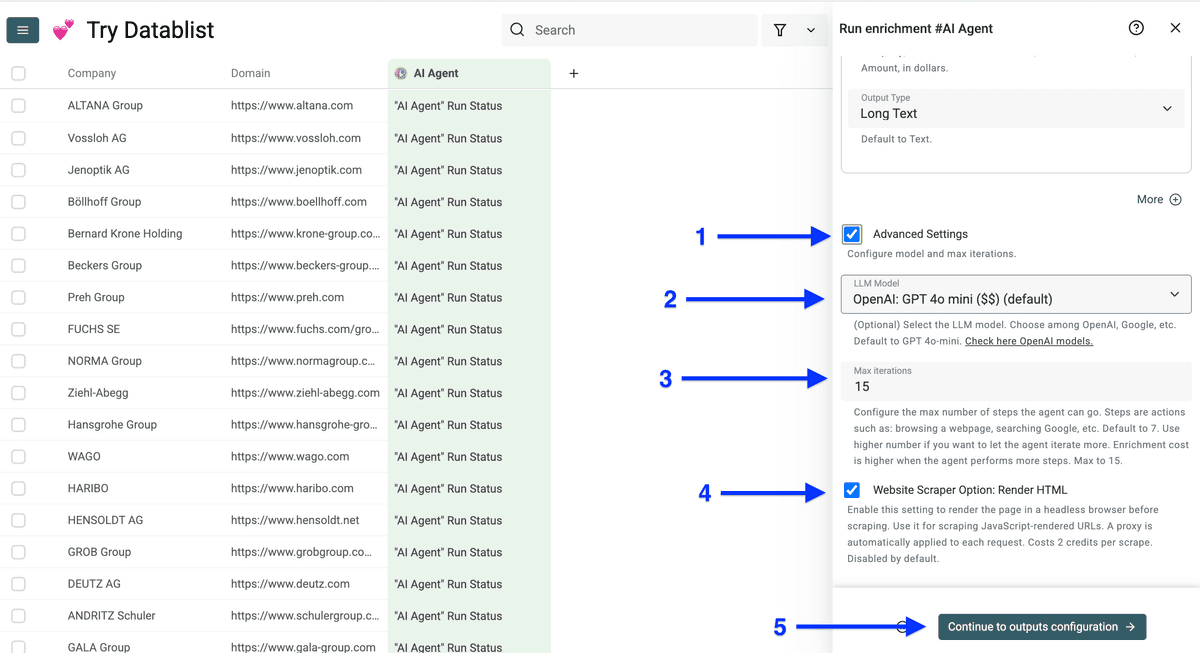
点击 plus icons 为每个 output 新建列,然后点击 Instant Run。
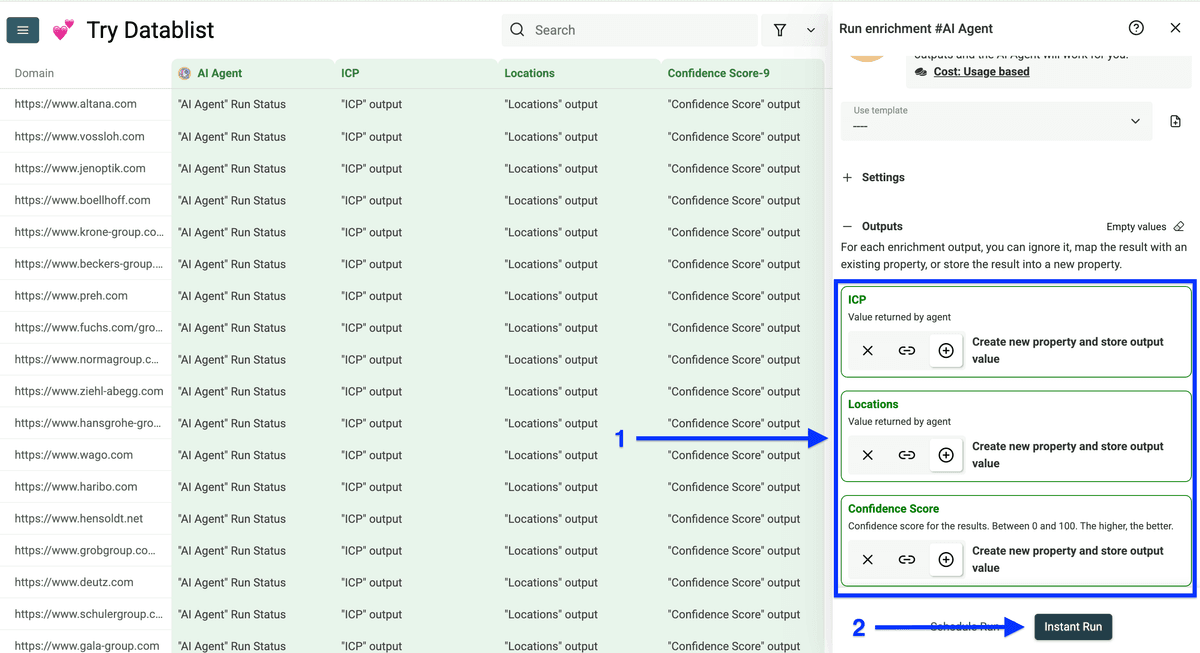
接着配置 Run Settings(选择处理条数),然后点击 Run enrichment on all items 开始执行。
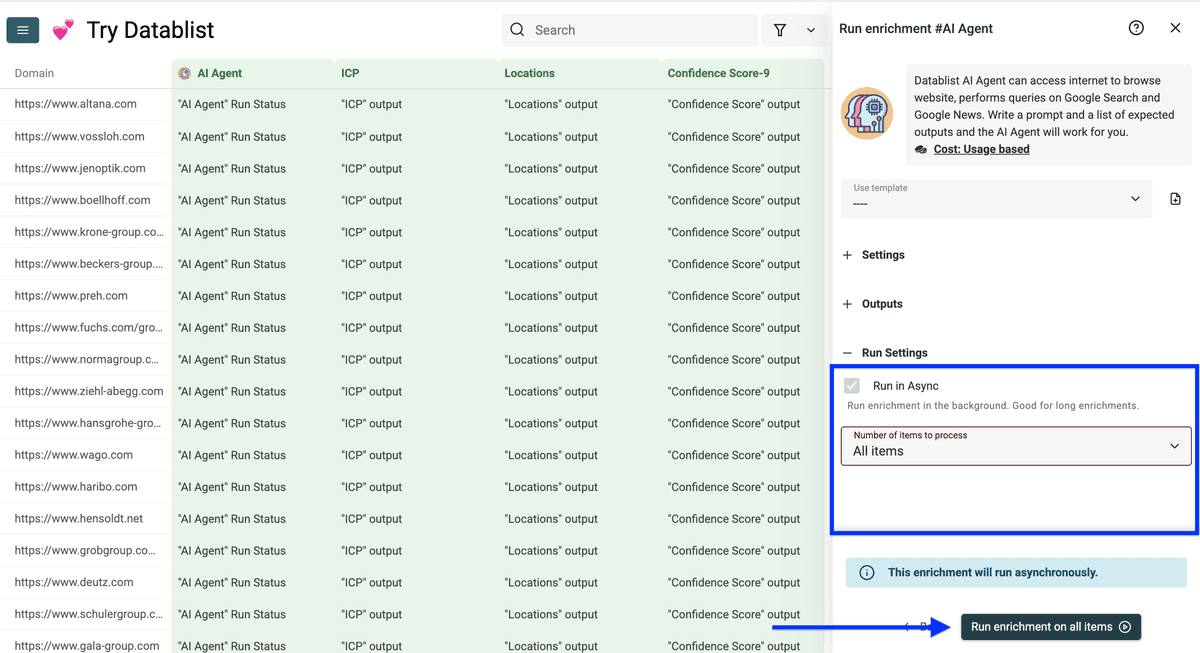
你会发现这些结果远超数据库信息,很多细节是传统数据供应商根本给不到的。
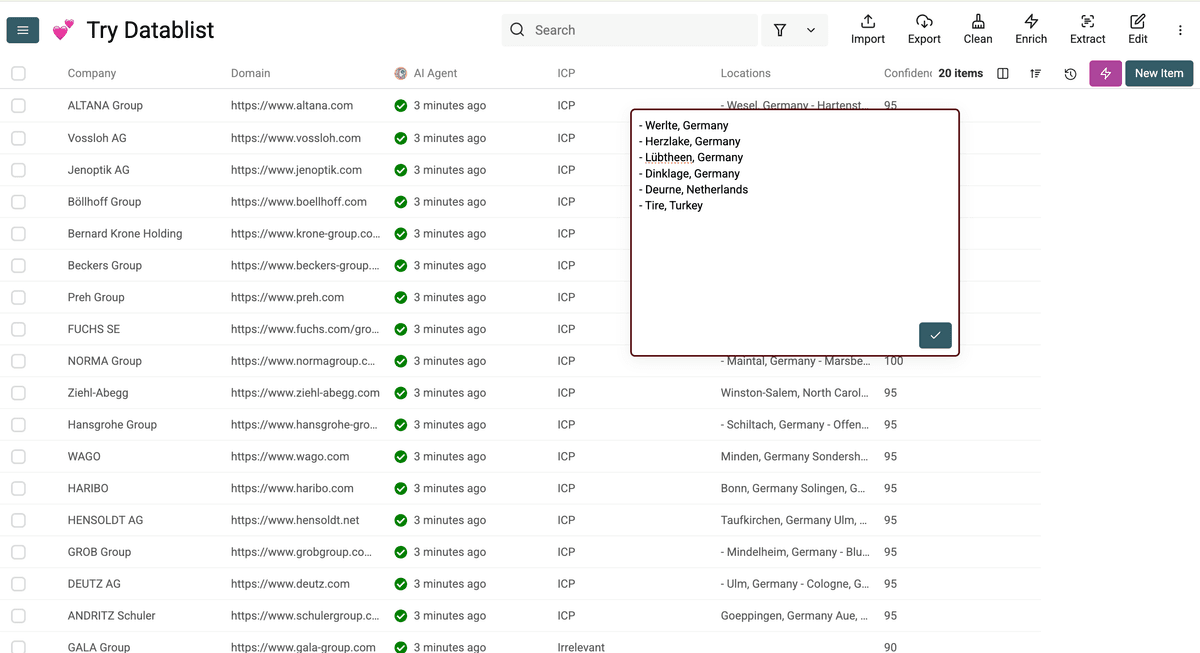
📘 想象力才是上限
这个例子是为了展示 AI agent 能做多强,所以刻意做得“夸张”一点。但你也可以用它判断医院是私立还是公立,或者做任何其他 research(我们也会协助你把 prompt 写好)。
如何抓取潜在客户的 LinkedIn 个人主页
如果你想让 prospecting 更有 human touch(更像真人),个性化(personalization)是关键。
但前提是:你得区分“有温度”和“有相关性”。而要做到这两点,你都需要抓取 LinkedIn profile。
你唯一需要的输入是:LinkedIn profile URL。
Step 1:准备 LinkedIn URLs
Upload 一份包含 prospects LinkedIn URLs 的列表。
Step 2:抓取 LinkedIn profile 数据
点击 Enrich
进入 People,选择 LinkedIn Profile Scraper。
LinkedIn profile scraping 的核心设置:
- Cache vs Real-time: 默认用缓存数据;开 real-time 可拿最新数据(每个 profile 50 credits)
- Work Experience: 返回多少段过往工作经历(默认 3,最多 10)
- Datablist 输入支持 普通 LinkedIn URL(
linkedin.com/in/xxx)以及 Sales Navigator URL
设置好后点击 Continue to outputs configuration。
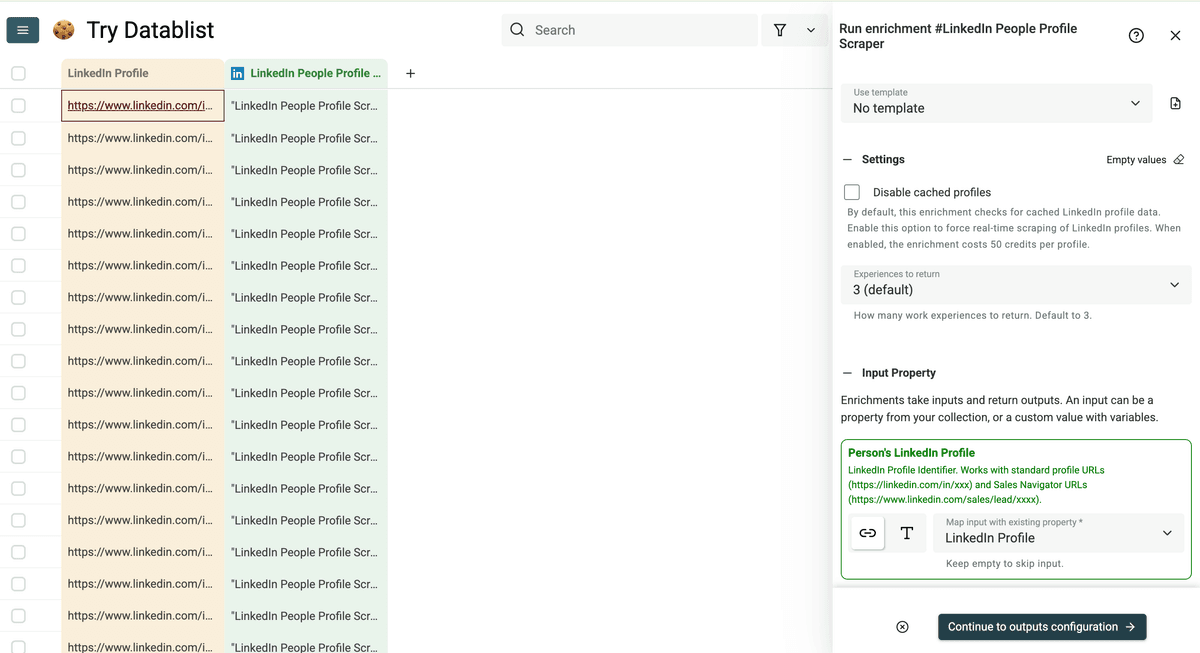
点击 plus icons 添加你需要的输出列。可选数据点包括:
- LinkedIn Profile URL - 标准化 URL(linkedin.com/in/xxx)
- Basic Info - 姓名、headline、summary
- Location - 城市、州/省、国家(code 与全称)
- Current Position - 职位、公司名、时间、公司 URL、官网、行业、规模、简介、地点
- Work History - 前 2 段工作经历
- Additional Info - 语言、connections 数
然后点击 Instant Run。
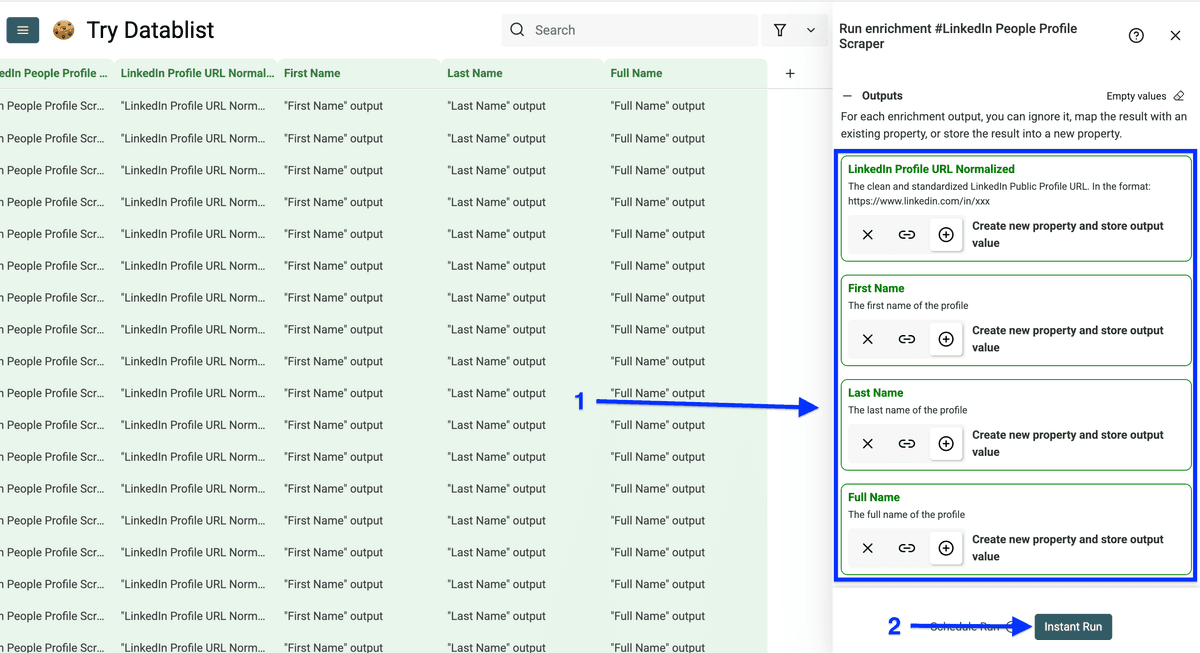
在 Run Settings 里你可以:
- Run in Async
- Test on the first 10 items
- 选择 number of items to process(10/100/自定义)
设置好后,点击 Run enrichment on first X items 开始抓取。
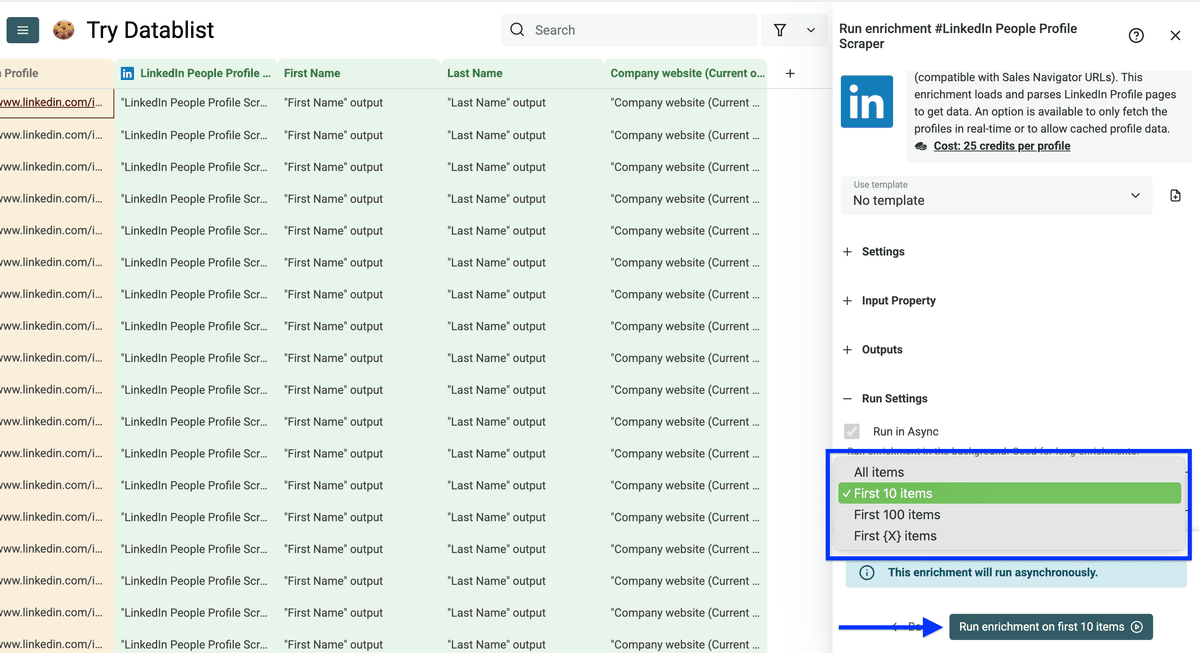
这是结果:
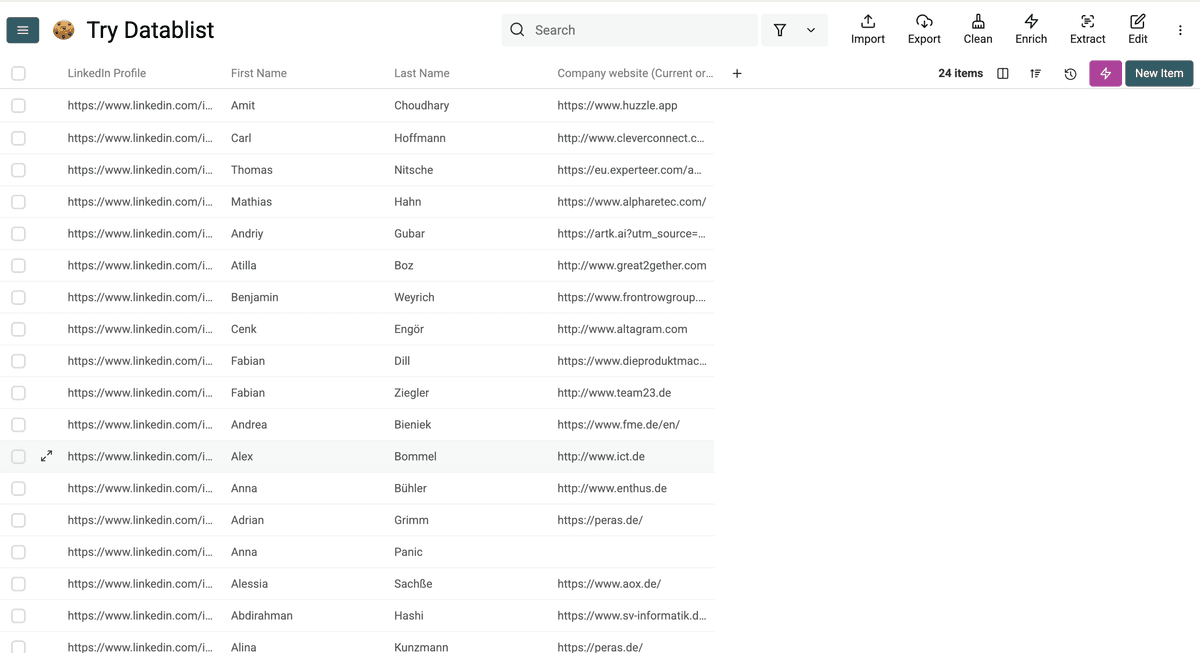
Note: 我这里没有抓取全部字段,因为我只需要姓名和 domain 来找手机号;但如果你需要,完全可以拿到更多数据点。
接下来带你用 verified emails enrich CRM!
如何为你的 CRM 找到已验证的 Email
没有 verified email,你就像在没有门牌号的城市送信——基本等于碰运气。
要 enrich CRM 并拿到 verified emails,你需要:
- 联系人姓名(必需)
- 公司名或 domain(必需)
- LinkedIn URL(可选)
Step 1:导入联系人列表
注册 Datablist.com。
Import 联系人列表。
Step 2:使用 Waterfall Email Finder
点击 Enrich。
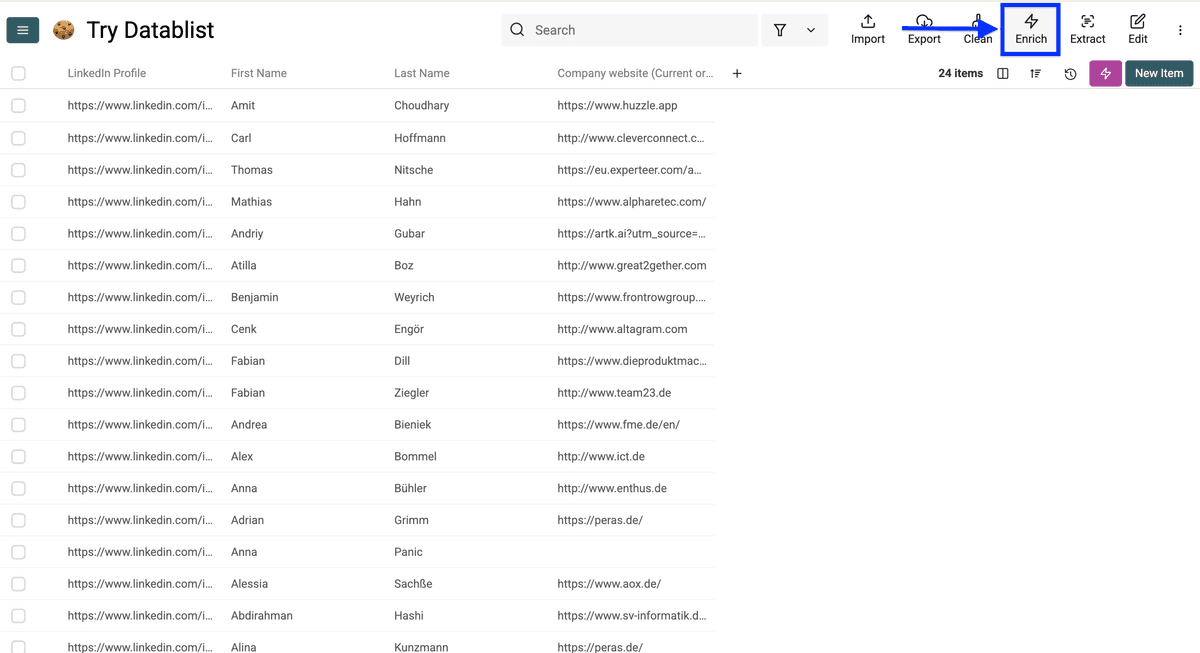
进入 People,使用 Waterfall Email Finder。
它的工作原理很简单:
Datablist 的 Waterfall Email Finder 会串联 15+ 个 email provider 逐个尝试,帮你找到 prospect 的邮箱,而且 只对成功结果收费。很公平,对吧?
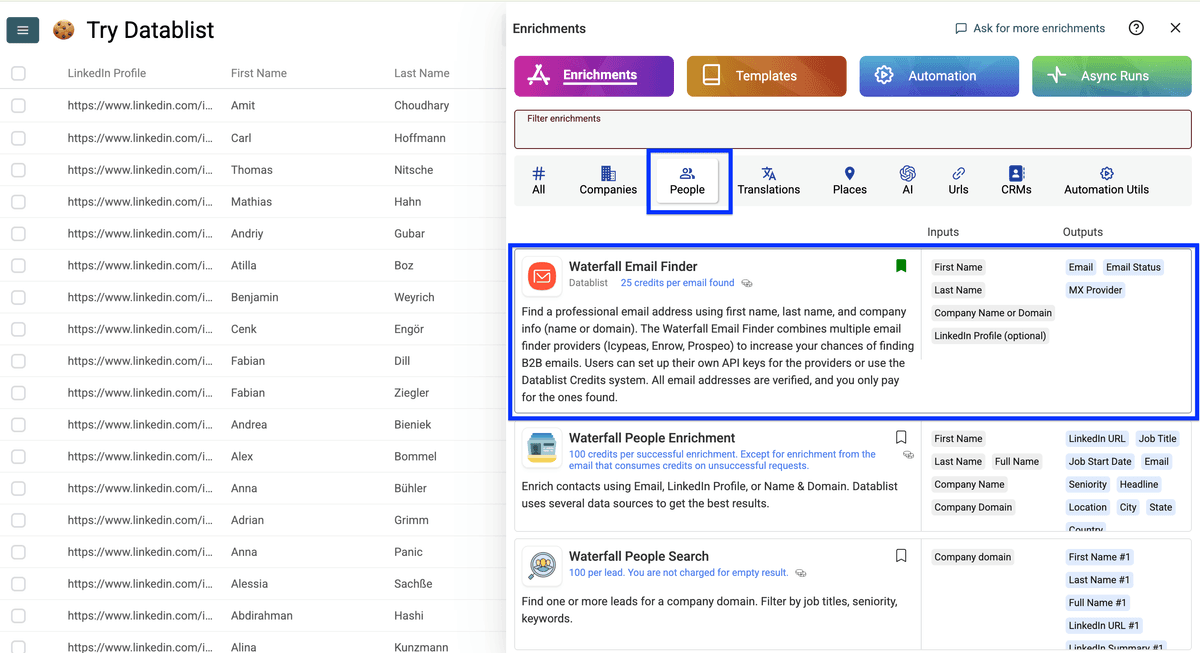
你还可以配置 waterfall,比如:
- 用 full name 替代 first/last
- 选择你偏好的 providers,并使用你自己的 API keys
这些都是可选项。想要覆盖率最大,就保持默认设置。
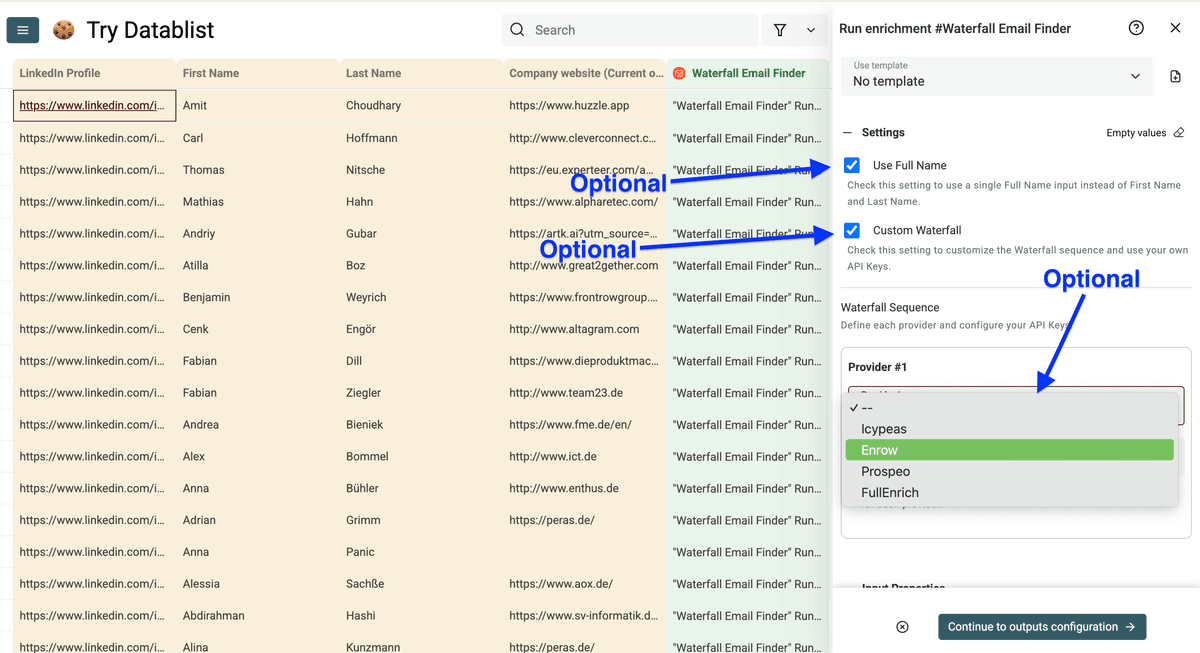
向下 map 输入列,点击 Continue to output configuration。
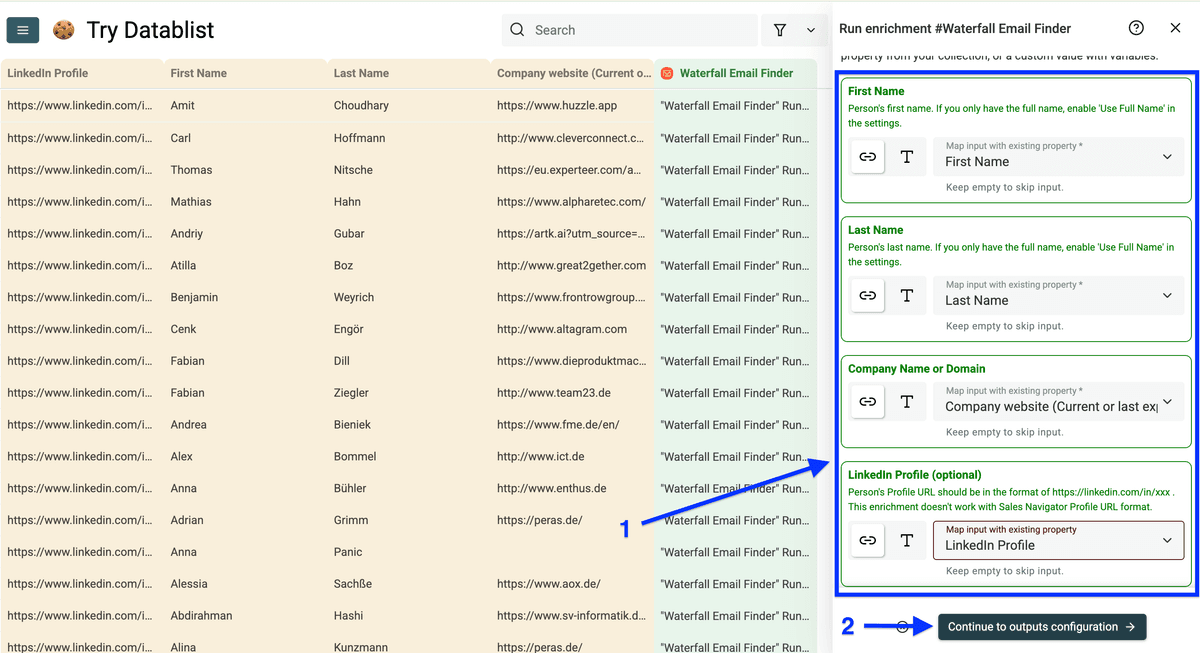
这个 enrichment 会输出 3 个字段:
- Email address
- Email address status
- MX provider
点 plus icons 新建输出列,然后点击 Instant Run。
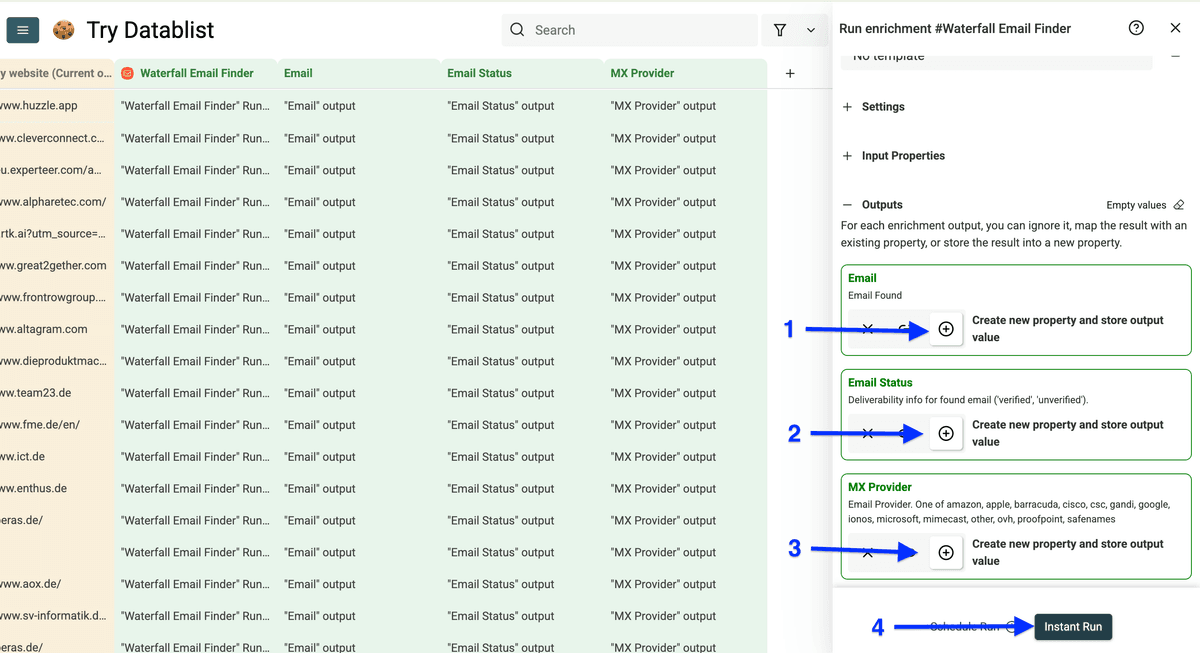
然后在 Run Settings 里选择处理条数,点击 Run enrichment on all items。
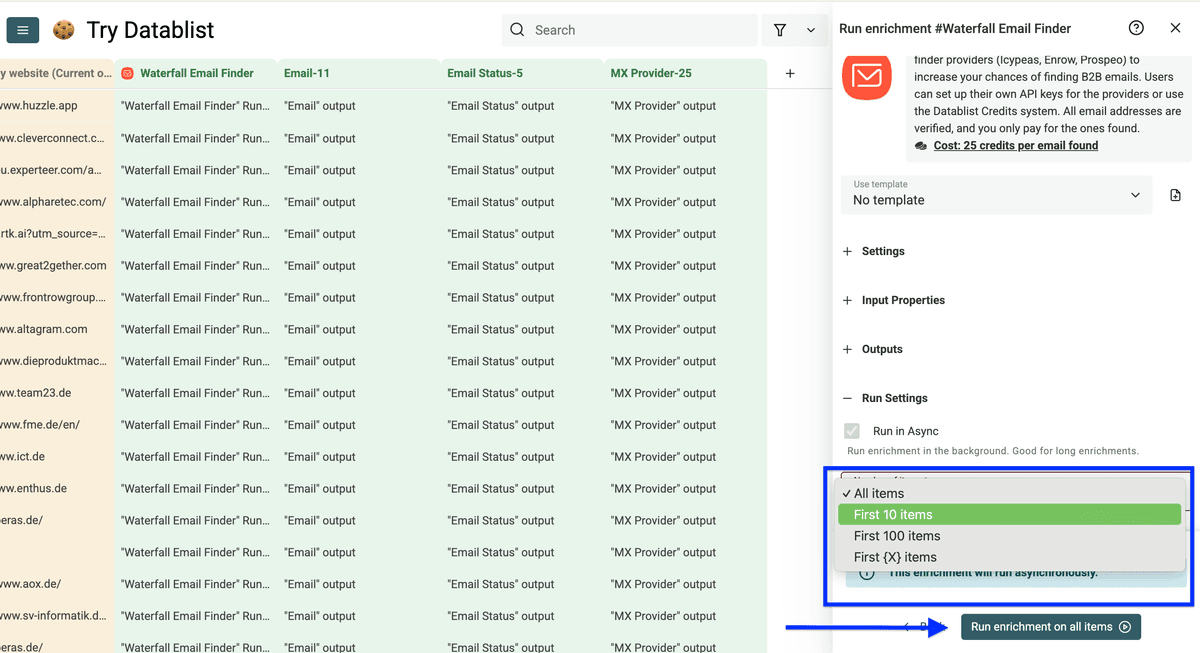
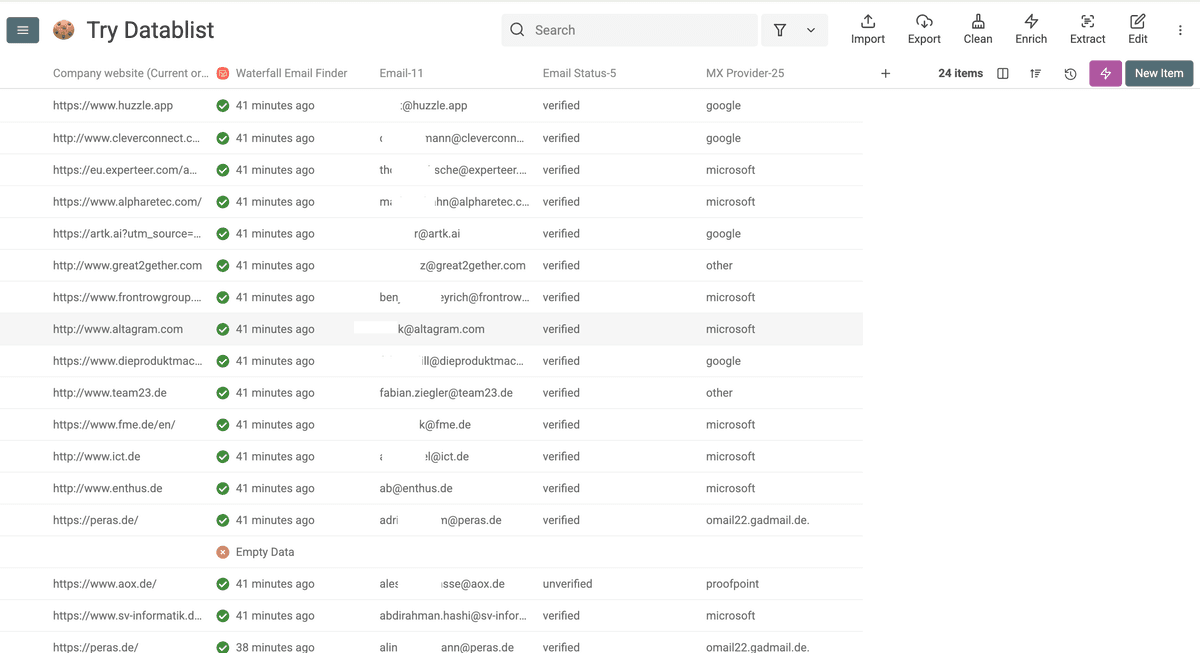
你会看到:只要有数据可用,它就能把邮箱找出来。用 Waterfall Email Finder,你可以很轻松地批量 enrich 成千上万条准确的联系人邮箱。
下面继续:如何找 verified mobile phone numbers!
如何用已验证的手机号 Enrich 你的 CRM
Cold caller 是“猎人”。当其他人都在用自动化消息塞满收件箱时,一通 cold call 反而更容易穿透噪音。
是的,两种方式都有效——但电话往往更有“真人感”。
下面是获取这些高价值手机号的方法。
Step 1:导入 LinkedIn profile URLs
注册 Datablist.com。
Upload 一份包含 LinkedIn profile URLs 的列表。
Step 2:使用 Waterfall Phone Finder
点击 Enrich。
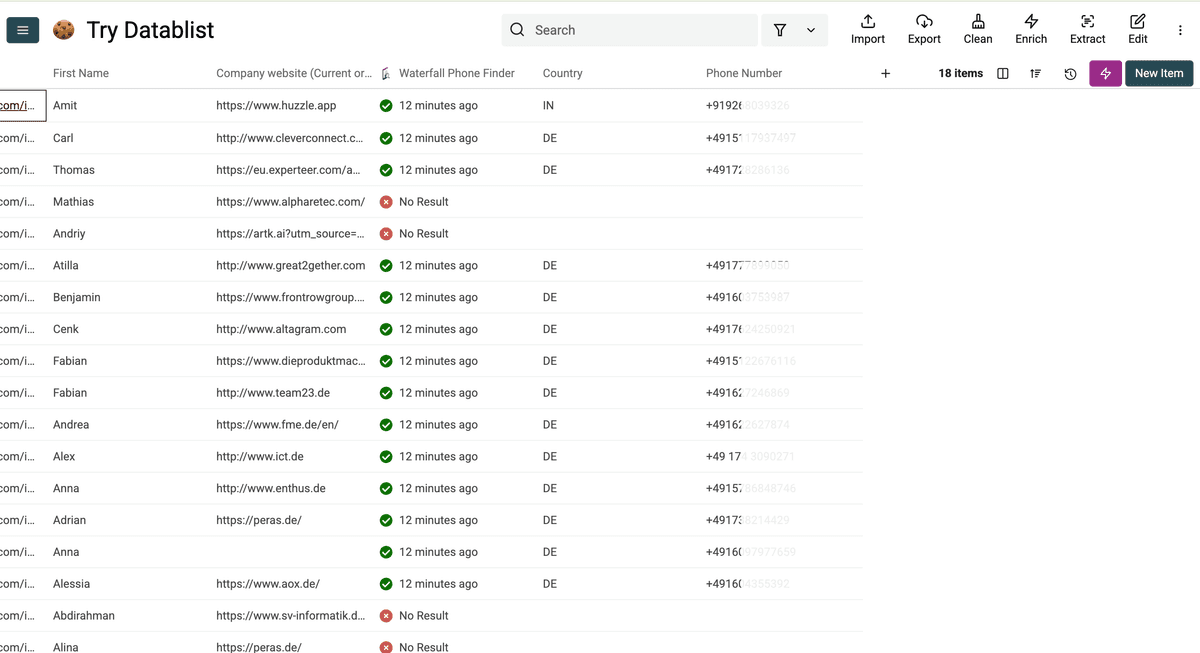
进入 People,选择 Waterfall Phone Finder
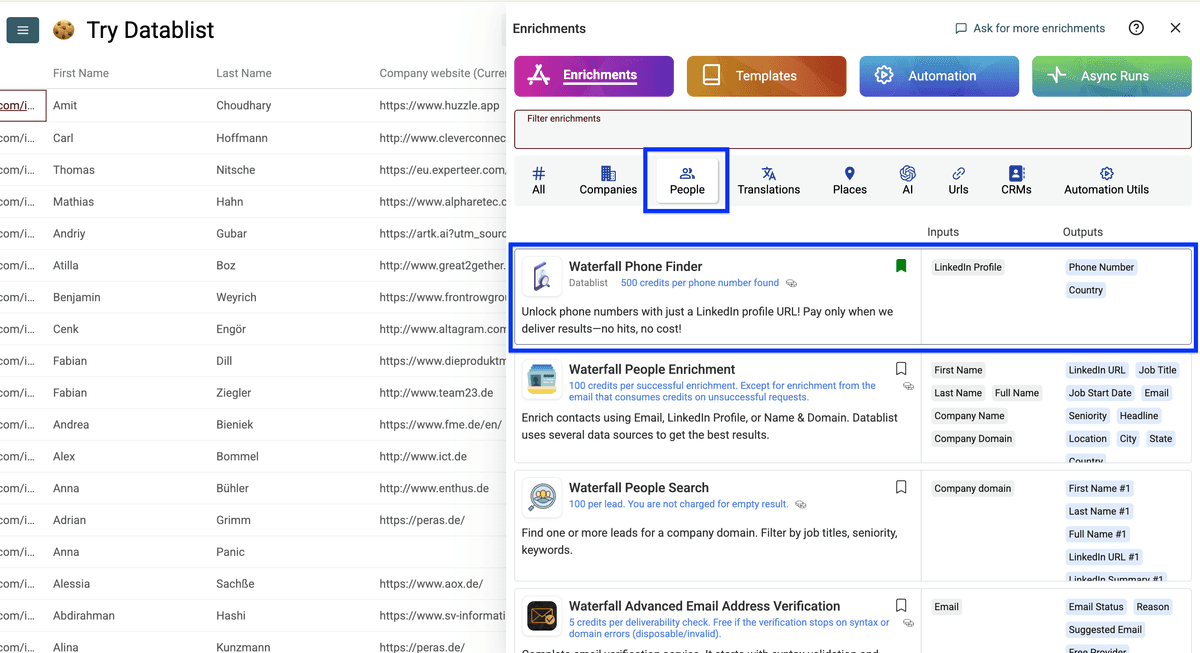
把 LinkedIn profile URL 列 map 为 input property,点击 Continue to outputs configuration。
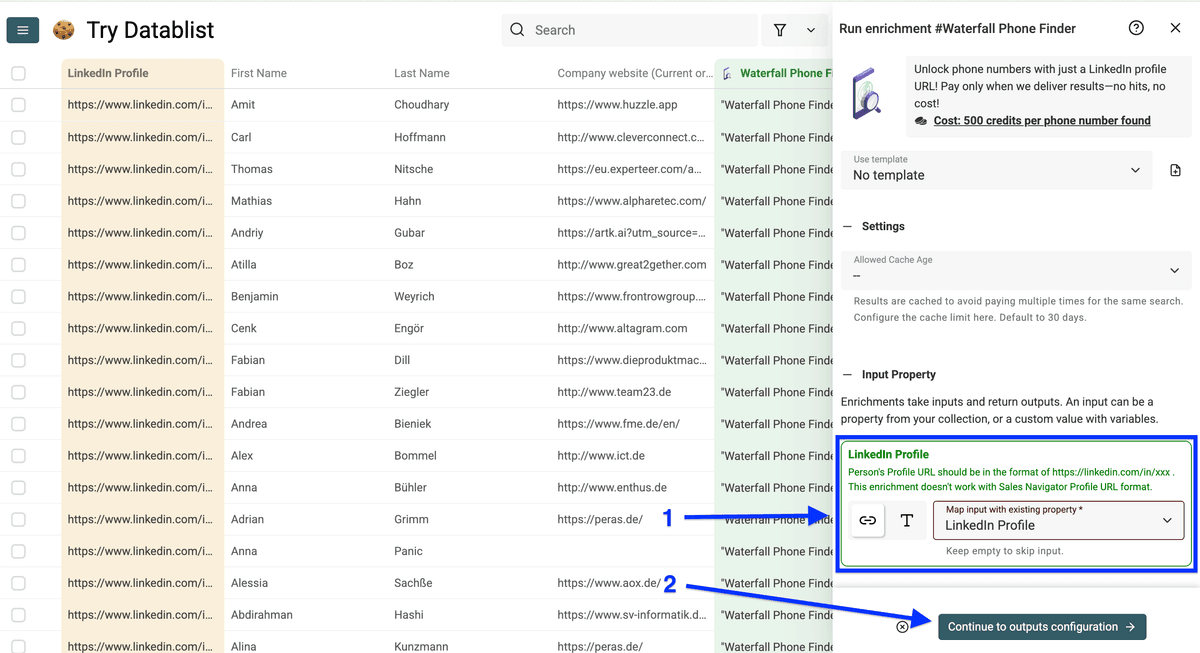
点击 plus icons 添加输出列:
- Phone Number: 返回带国家区号的国际格式(例如 +1-555-0123)
- Country: 返回两位国家代码(例如 US、GB、DE)
然后点击 Instant Run。
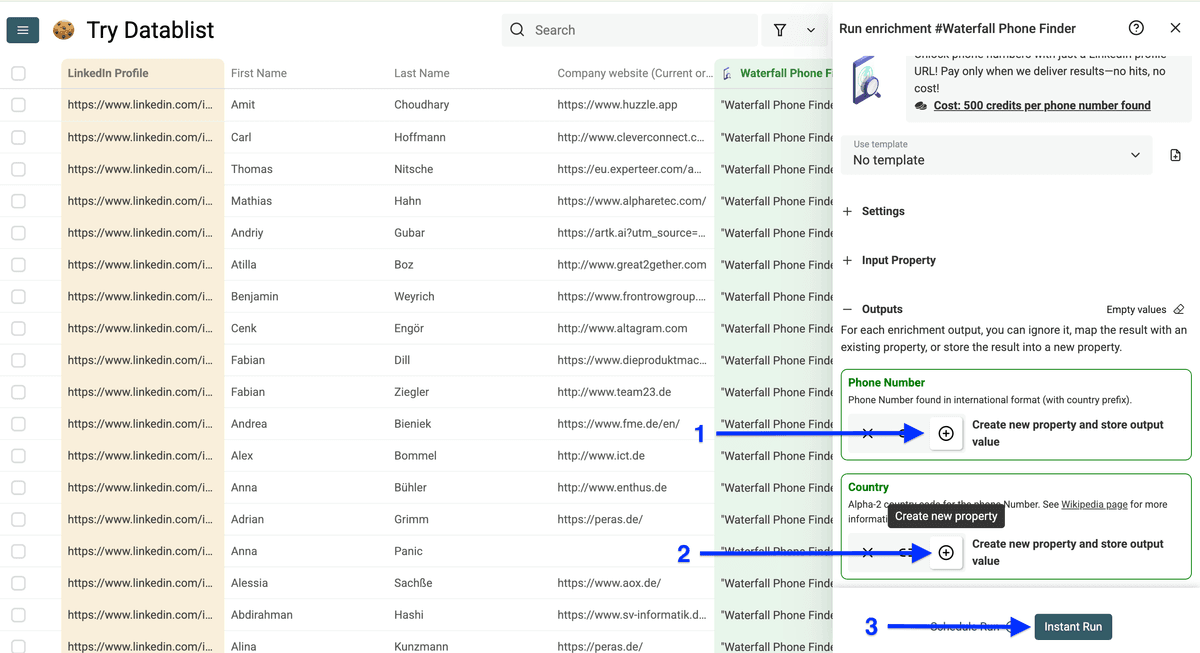
在 Run Settings 里选择处理条数,然后点击 Run enrichment on all items 开始找手机号。
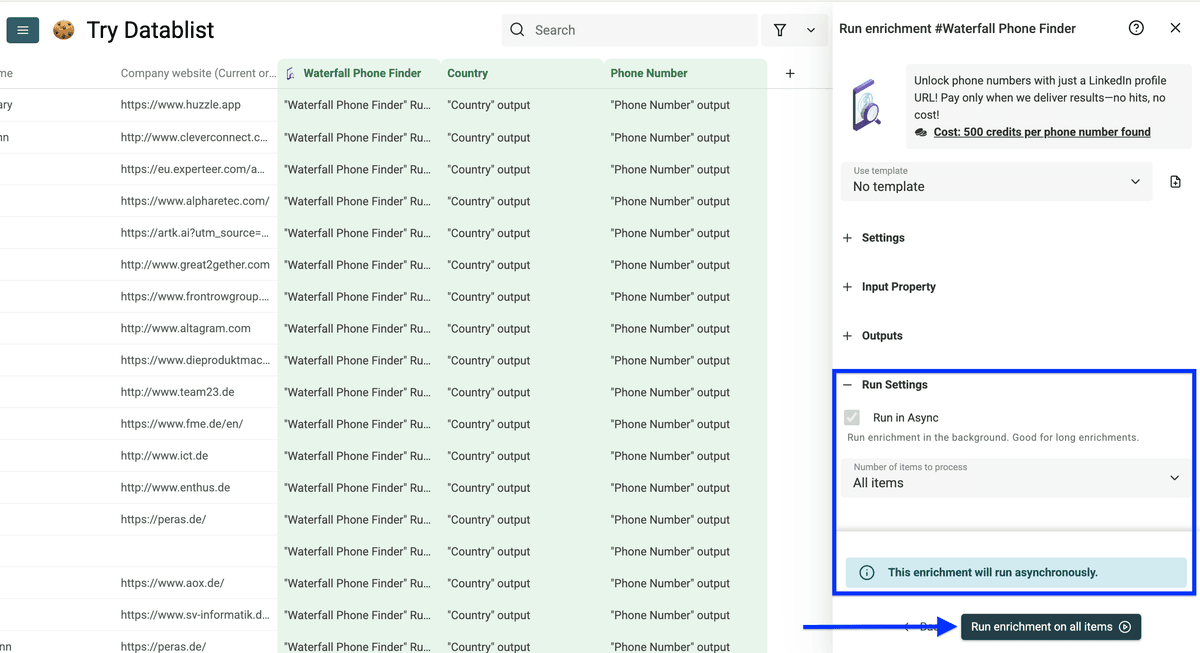
Datablist 几乎帮我找到了所有手机号。你也可以试试。
总结
在节奏越来越快的今天,商业关系变化极快,过期或错误的 CRM 数据会直接拉低成功率,导致机会流失、资源浪费。
定期做数据清理与 enrichment,应该成为优先级任务。
使用 Datablist 这类工具把这些策略落地,你就能持续维护一套高质量 CRM 数据库,从而获得更好的触达体验与更高的转化率。
别忘了:市场、销售和客服的质量,最终都取决于背后的数据质量。把 enrichment 变成 CRM 维护流程的一部分,你才能保持竞争力。
“你如何收集、管理并使用信息,将决定你赢还是输。” - Bill Gates
CRM 清理常见问题 FAQ
CRM 数据每年有多少会过期?
大约每年有 30% 的 CRM 数据会变得过期(obsolete)。包括:
- 15–20% 的邮箱地址会失效
- 18% 的手机号会变更
- 21% 的 CEO 职位会更替
- 25–33% 的人会换工作
糟糕的 CRM 数据会让公司损失多少钱?
糟糕的 CRM 数据平均每条错误记录会造成约 100 美元损失。对于大型组织,这可能意味着每年数百万美元的损失,来源包括:
- 浪费的 marketing 预算
- 生产力损失
- 错过的机会
- 因客户沟通错误带来的品牌信誉损伤
什么是 CRM 清理?
CRM Cleaning 是一套系统化的方法,用于维护并提升客户数据库的数据质量。它由 4 个核心支柱组成:
- Deduplication:删除重复项并合并记录
- Validation:验证已有数据点的准确性,例如 email 与手机号
- Structuring and Formatting:统一数据格式,让信息组织一致
- Data Enrichment:补充新的、相关的数据来完善客户画像
规律性地做 CRM cleaning,可以确保团队一直在用准确、最新的数据做决策与客户触达。
如何保持 CRM 一直干净?
- 定义标准化输入格式——例如统一 call notes 的记录框架
- 限制某些列只能输入特定类型(例如手机号列只允许数字)
- 设定必填字段——例如要求销售必须填写 “Last Contact Date”,确保数据完整
ChatGPT 能做数据清理吗?
ChatGPT 不是为数据清理而生的——做这件事你会有更合适、甚至免费的工具,比如 Datablist。这并不意味着 ChatGPT 完全不能处理数据,但它无法稳定处理大文件;一旦你有 1k+ records,出错概率会非常高。