New Enrichments Experience
After building strong foundations for dealing with CSV files and data cleaning (deduplication, etc.), it's time to work on enrichments.
The vision is simple: the web is overwhelmed with external services to enrich companies/people, verify email addresses, guess the gender from a name, scrape URLs, etc. But it's a mess to combine all those services.
A way to do it is to use workflow automation tools (Zapier, Make, n8n) on top of spreadsheets. Yet, it is complex, error management is a mess, and it's mostly suited for event-based workflows.
Datablist aims to replace spreadsheet tools for list management (lead generation, lead scoring, product catalogs, customer management, company screening, etc.). A central hub with built-in enrichment integration.
Here are the latest developments to get enrichments as a first-class citizen in Datablist.
Enrichments Listing
Enrichments are listed in a new drawer. The top bar lets you filter between enrichments for "Companies", "People", "Translations", "Places", "AI (Artificial Intelligence)", and "URLs".
For each enrichment, the inputs and output properties are visible. The cost is displayed directly in the listing.
And a bookmark flag moves your favorite enrichments to the top.
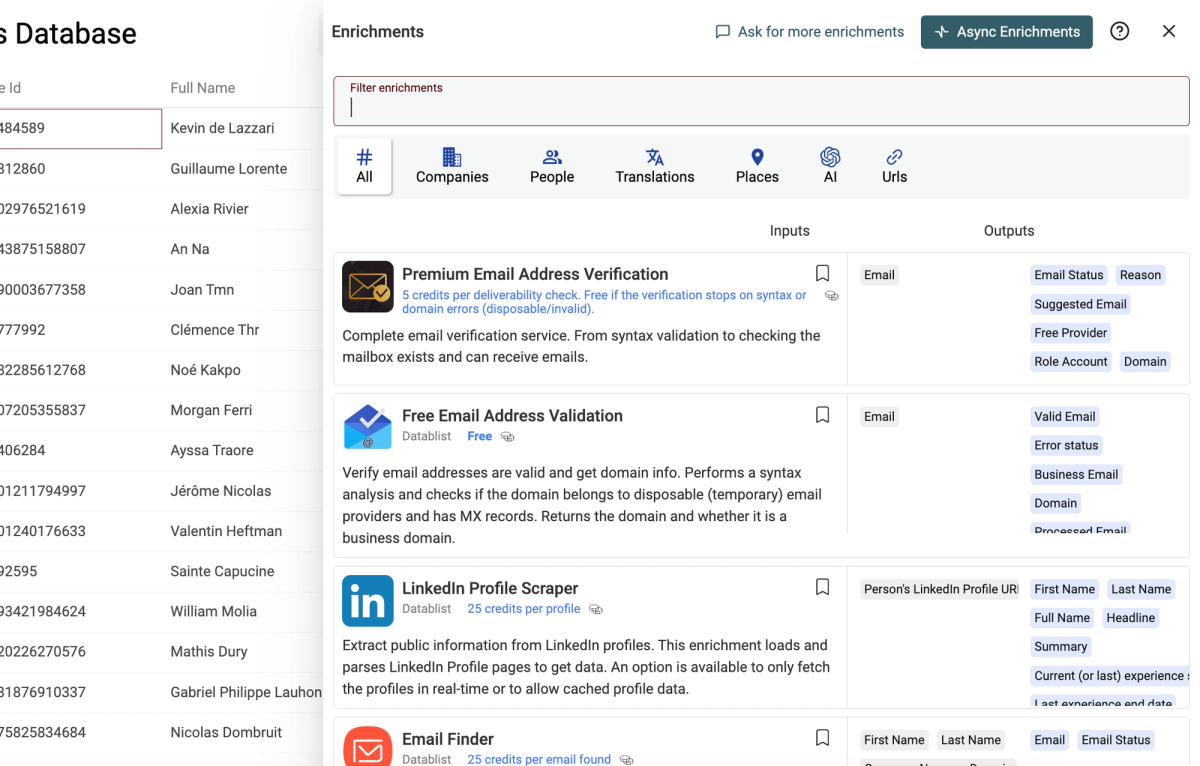
Enrichment Runner
The "Enrichment Runner" is the screen to configure and run an enrichment. I've heard your feedback and the runner has been revamped.
Custom inputs with RichText editor
Imagine you have an enrichment with a "Full Name" input and you have "First Name" and "Last Name" in your collection. That's when you will be happy to use the new "Custom Input" feature.
You can write custom texts with variables from your properties. In the previous example, you would write "{{firstName}} {{lastName}}" to build "Full Name" input values.
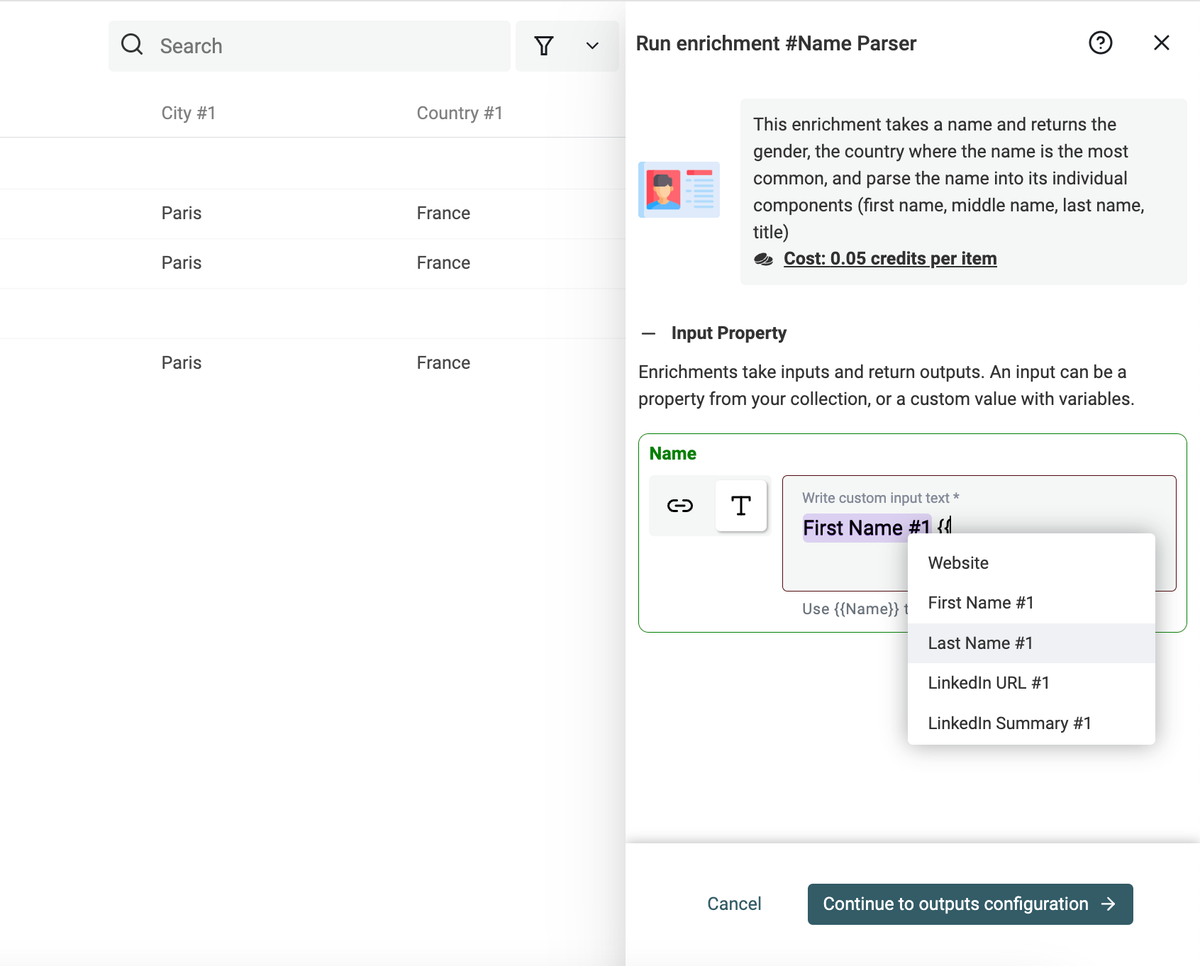
Auto-skip items with existing data
I want the default behavior to be the least risky. So you don't lose or overwrite data. With the new runner, the default behavior is to skip your items when there is already some data in the output properties.
For example, if you use a translation enrichment. You have a "Source" property with the text to translate. And a "Target" property to store the translated text.
When you run the translation, it will translate and populate the "Target" property.
Then, you add new items, etc. The second time you run the translation enrichment, it will skip all the items with a text in the "Target" property. So only the new items will be sent to be translated.
This setting is available in the "Existing Data Rule". Other options are available to only edit data for the empty cells, or to overwrite data.
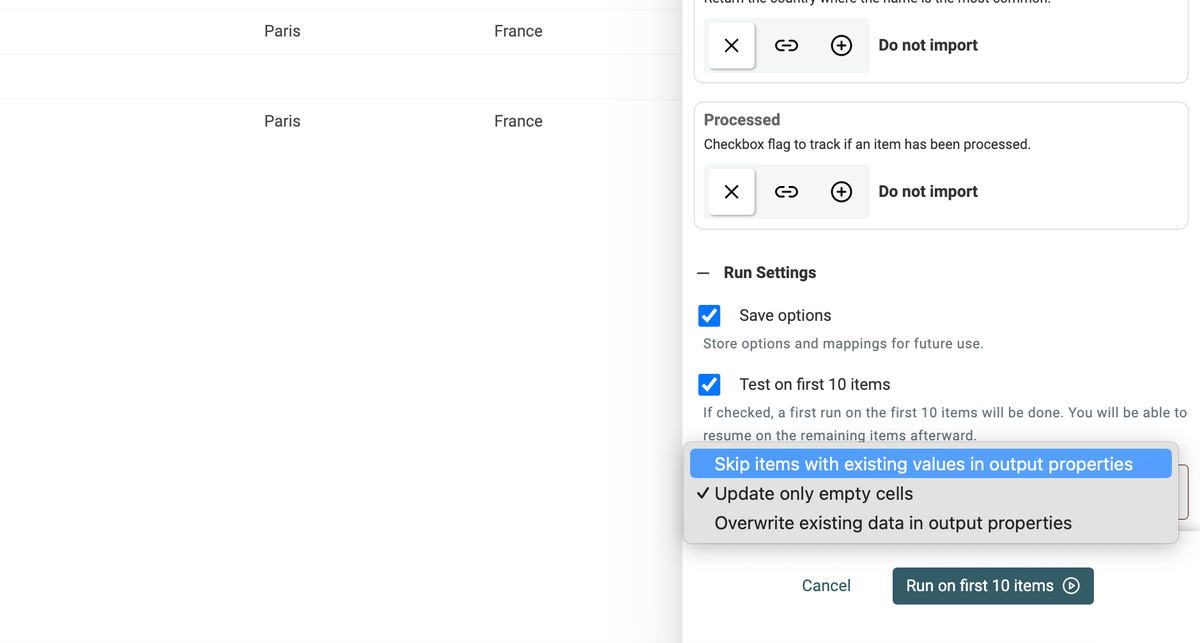
See new properties to be created
It can be complex to understand how the enrichments work. With "Settings", "Inputs", "Outputs", etc.
The outputs section is even more complex. You can ignore an output, map it with an existing property, or create a new property to store the data.
With this new runner UI, I've made some visual changes to better understand what will happen with your enrichment outputs.
New properties are shown in green.
New properties are not created until you run the enrichment. You can change the output configuration without messing with your collection data structure.
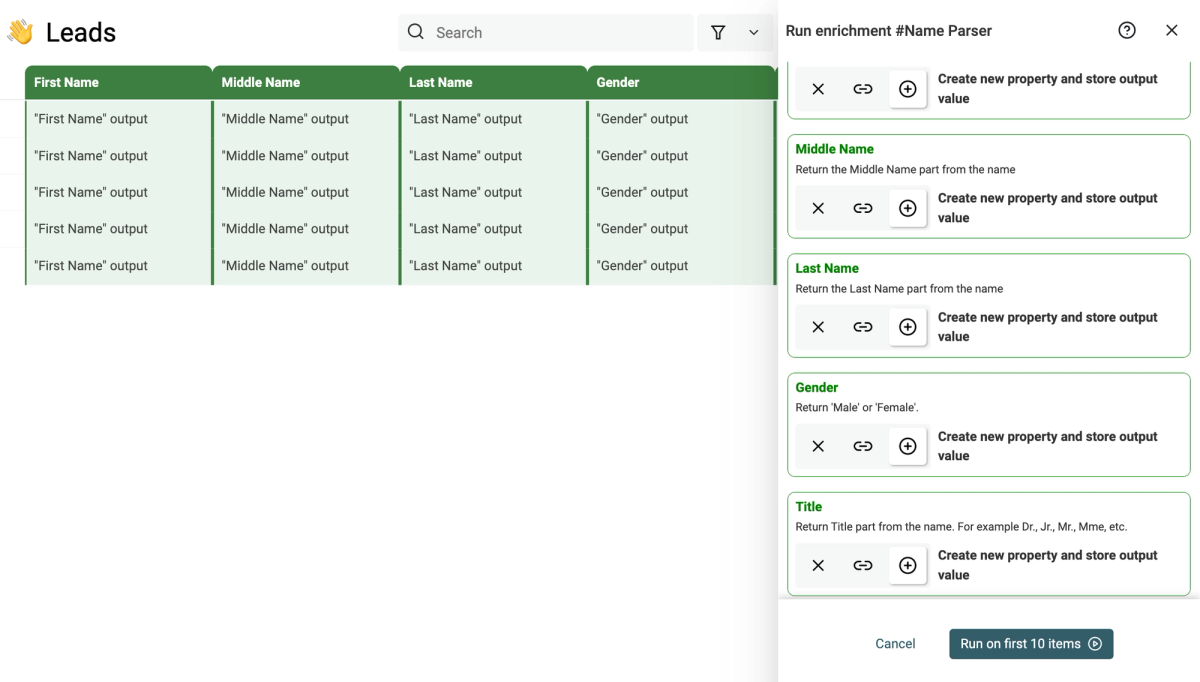
Test on first 10 items
Enrichments can mess with your data and some of them cost credits. You need to be sure the enrichment works like you expect it to do.
Before running on all your current items, the enrichment will be run on the first 10 items. Once you have validated the results, it runs on the remaining items.
Better errors management
Dealing with external APIs can give headaches! You can get server errors (for example throttling errors).
Datablist stops the enrichment when an error occurs. To prevent any collateral damage.
But once you have seen the error message, you might want to retry the enrichment on the remaining items. This is now possible. The runner keeps track of the item IDs that have been processed. A "Retry" button is available after an error happens. On Retry, Datablist will skip the already processed items.
Async Enrichments
Another big release with the asynchronous runner! Previously, enrichments could only run from the browser. This was enough for fast enrichments, or with a small number of items. But you had to keep your browser open to enrich a large collection. This prevented me from adding long-running enrichments such as email finder, email verification, scraping, etc.
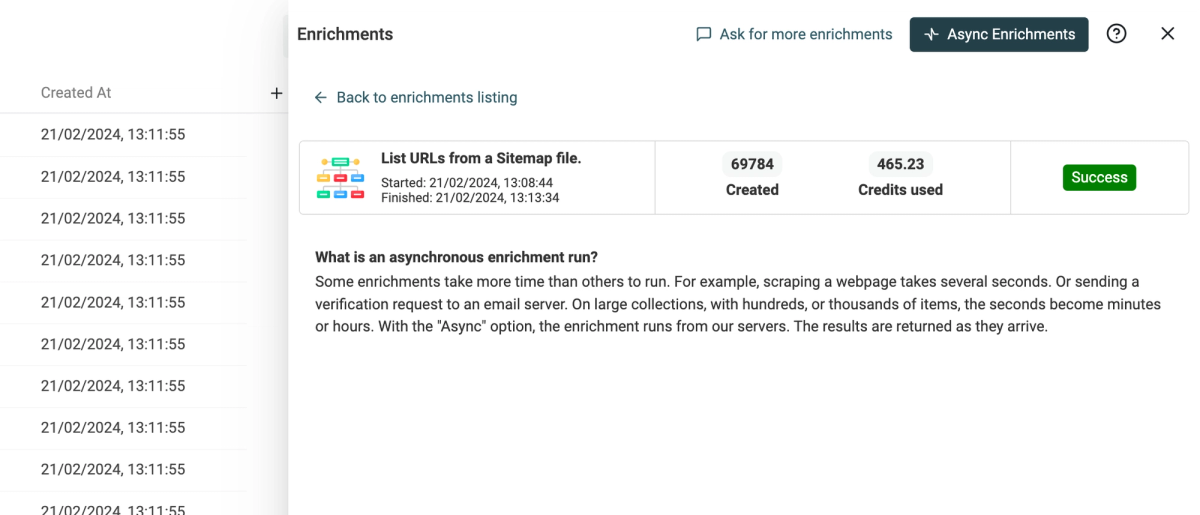
Currently, it is not possible to choose to run a specific enrichment asynchronously. Some enrichments that take a long time to be processed have been configured to run asynchronously, and others are still triggered by the browser. In the coming weeks, you will be able to select how to run the enrichment.
This opens several future possibilities such as workflow building, etc.
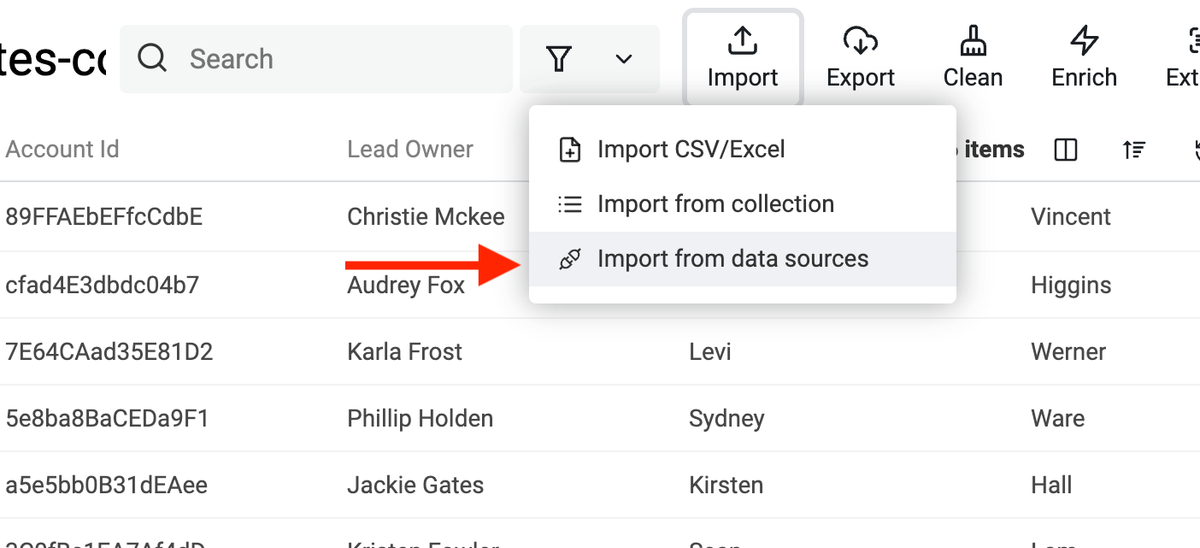
Data Sources for Lead Generation
Data Sources are a new kind of enrichment! Classic enrichments run on each item to provide additional data. Whereas data sources create new items. This is perfect for lead generation.
Data Sources are available from the "Import" menu.
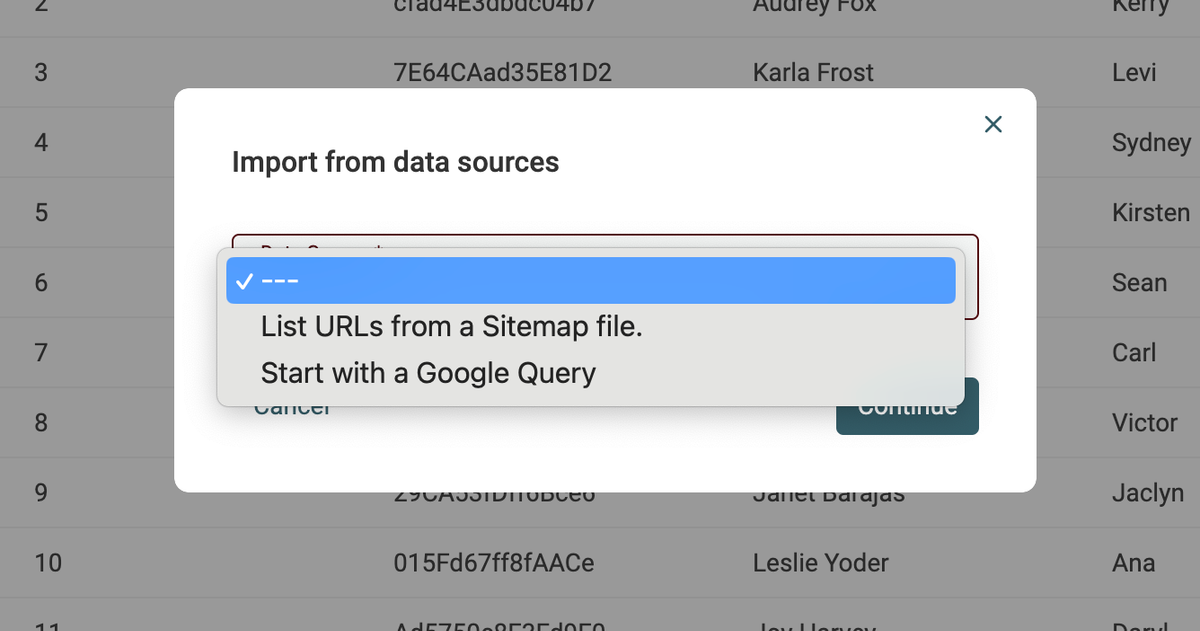
Start from a Google Search query
This one is self-explicit. You write a Google Search query, and it returns the Google results as items. This source can scrape a maximum of 200 results with a free account, and up to 1000 results with the Standard plan.
Google is more powerful than you might think. With operators, it is possible to build complex queries and search on specific websites.
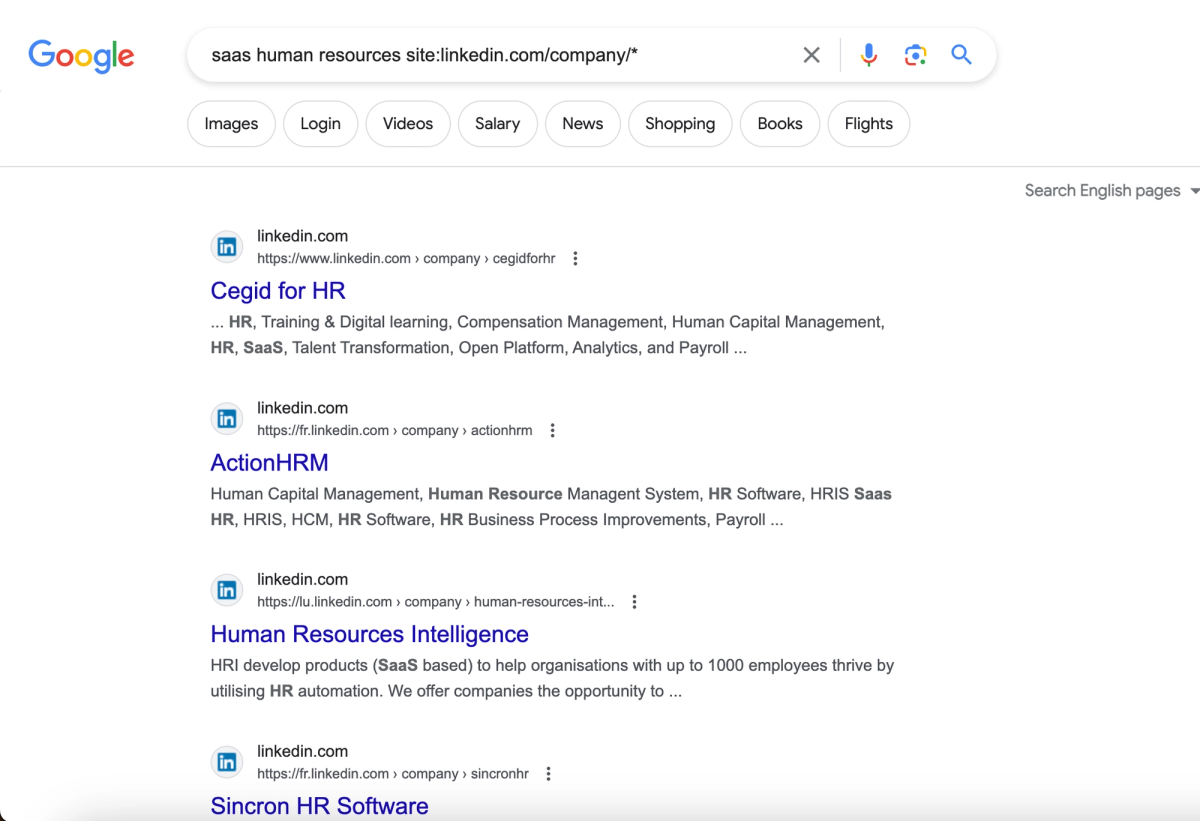
A search such as "saas human resources site:linkedin.com/company/*" will return all SaaS companies in the HR spaces. You can search for LinkedIn profiles, job ads, etc.
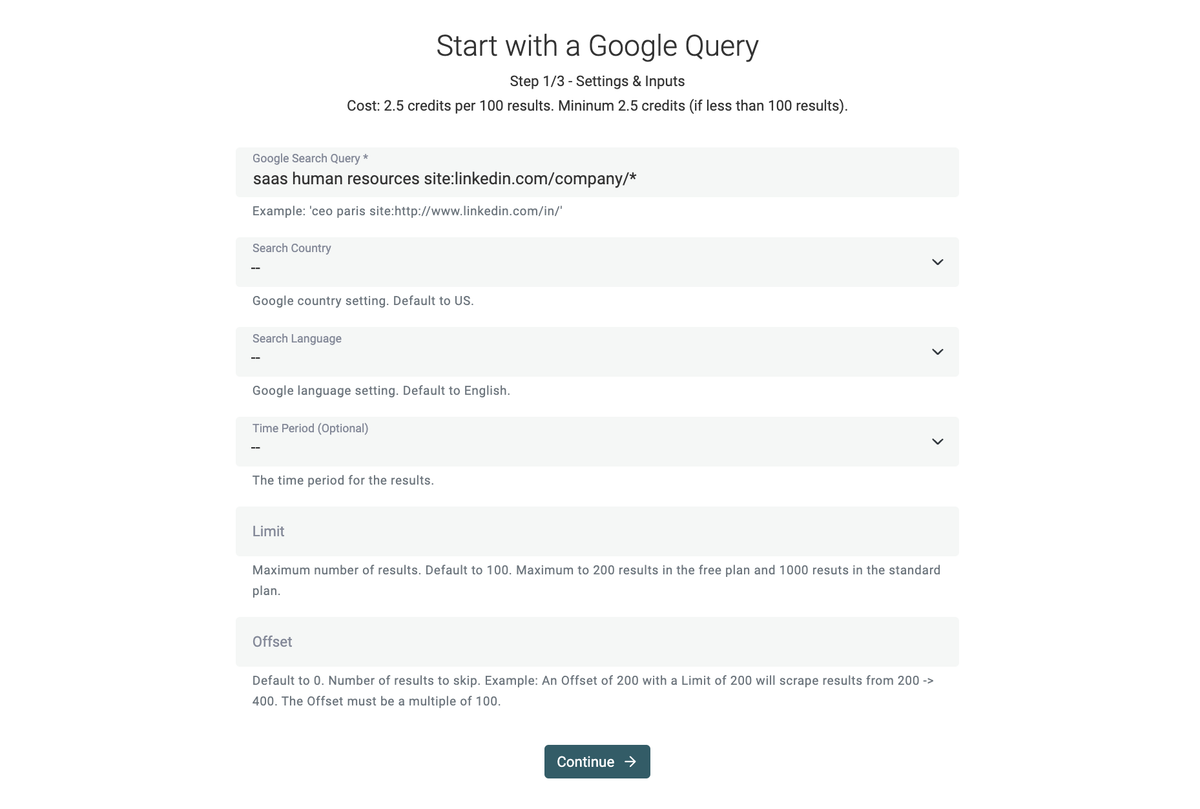
Will scrape and import results items from the following Google query:
Start from a Sitemap URL
This data source is technical but very powerful. Sitemaps are XML files listing all the webpage URLs a website has. For datablist.com, the sitemap lists all guides, blog posts, etc.
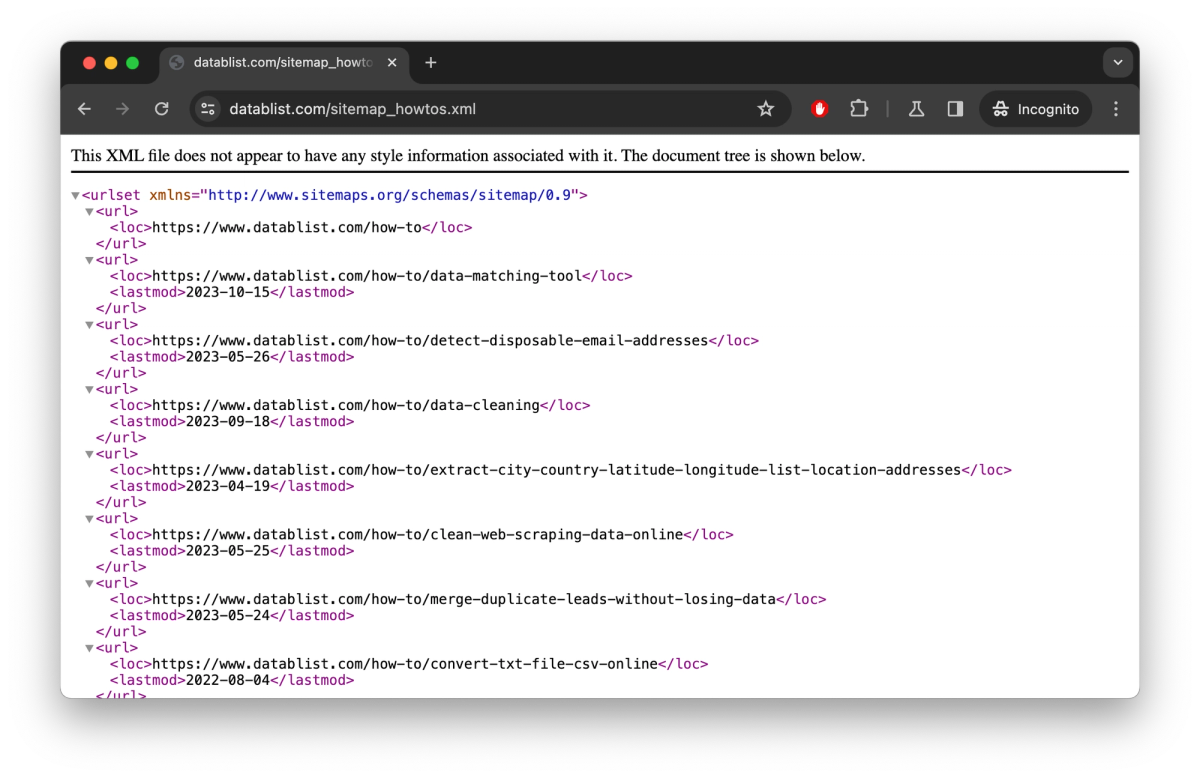
And for companies or people directories, job boards, blogs, etc. you can scrape the pages in a snap using the sitemap and the Bulk Scraper (or Links Scraper).
This data source plays nice with the "Unique value" setting available for a property. With the "Unique value" setting, you can detect a delta between two sitemap imports. Perfect for finding new job ads, newly published companies, or people.
If you need help implementing a Lead Generation workflow using sitemaps, just contact me.
New Enrichments
LinkedIn Profile Scraper
Extract public information from LinkedIn profiles. This enrichment loads and parses LinkedIn Profile pages to get data. An option is available to only fetch the profiles in real-time or to allow cached profile data.
Email Verification Premium
Complete email verification service. From syntax validation to checking the mailbox exists and can receive emails.
Email Finder
Find a professional email address using first name, last name, and company info (name or domain). Email addresses are verified and you pay only for the emails found.
Bulk Scraper
Scrape URLs with CSS selectors. Use the proxy option to scrape protected webpages, and configure multiple selectors to scrape several texts.
Links & Email Addresses Scraper
Apollo People Search
Search one or more profiles using Apollo.io. Define matching Job Titles, Seniority, and company domains and get profiles.
PeopleDataLabs Person Search
Search one or more profiles using PeopleDataLabs powerful ElasticSearch query language. Use variables from your items to build complex queries.
Instagram Profile Scraper
Extract public information from Instagram profiles in bulk. This enrichment loads and scrapes Instagram Profile pages to get data.
Find Company domains from Company names
Return the domain matching the company name. Return the domain with the more traffic when several domains match.
Detect Language from a Text
Return the language code and name by analyzing a text.
Duplicates Finder
Two improvements have been done to the Duplicates Finder.
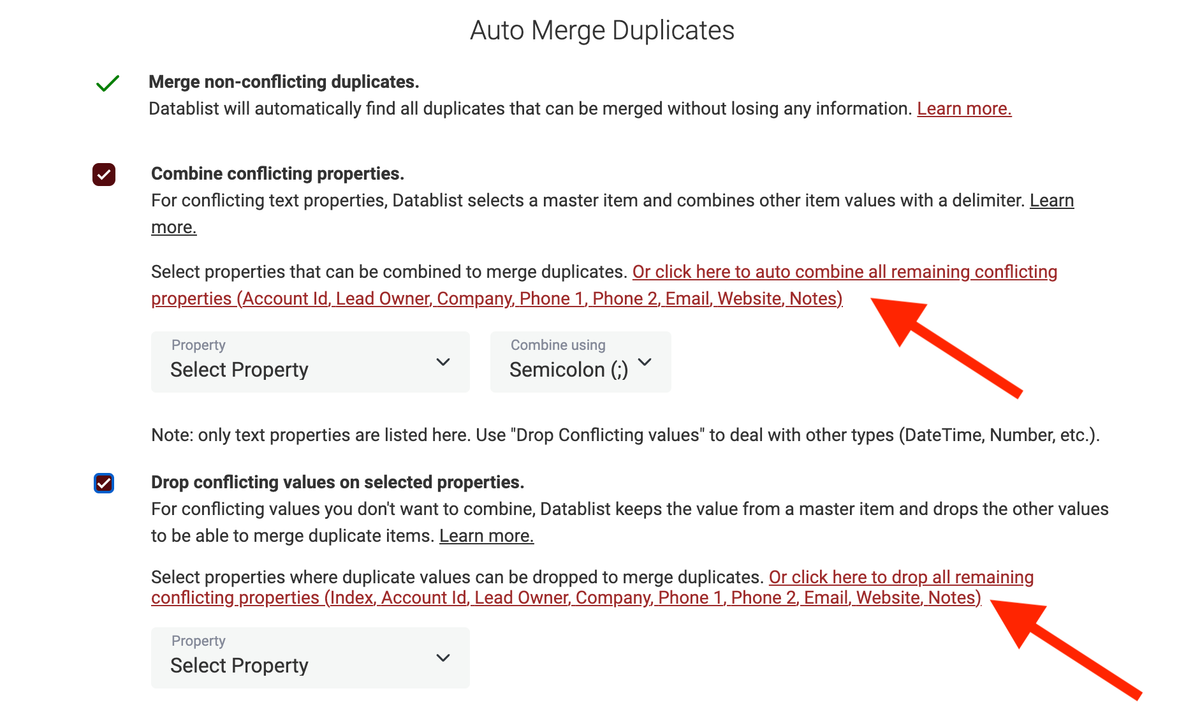
The first is a link to automatically combine or drop the remaining conflicting properties in duplicates finder.
The links are available after a first "Auto-Merge" that returns the conflicting properties.
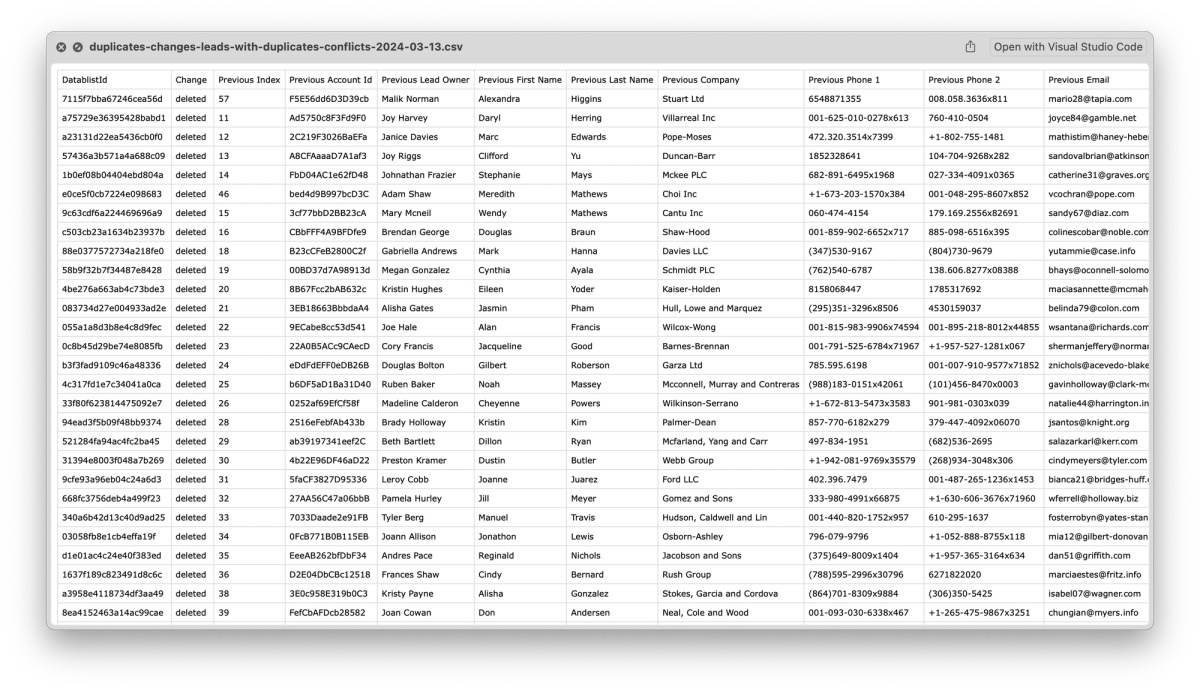
The second improvement is a new button to download the changes list from the duplicates merging. The change list contains the modifications done on each item: updated or deleted. And two columns for each property, "Previous {property name}" and "Destination {property name}".

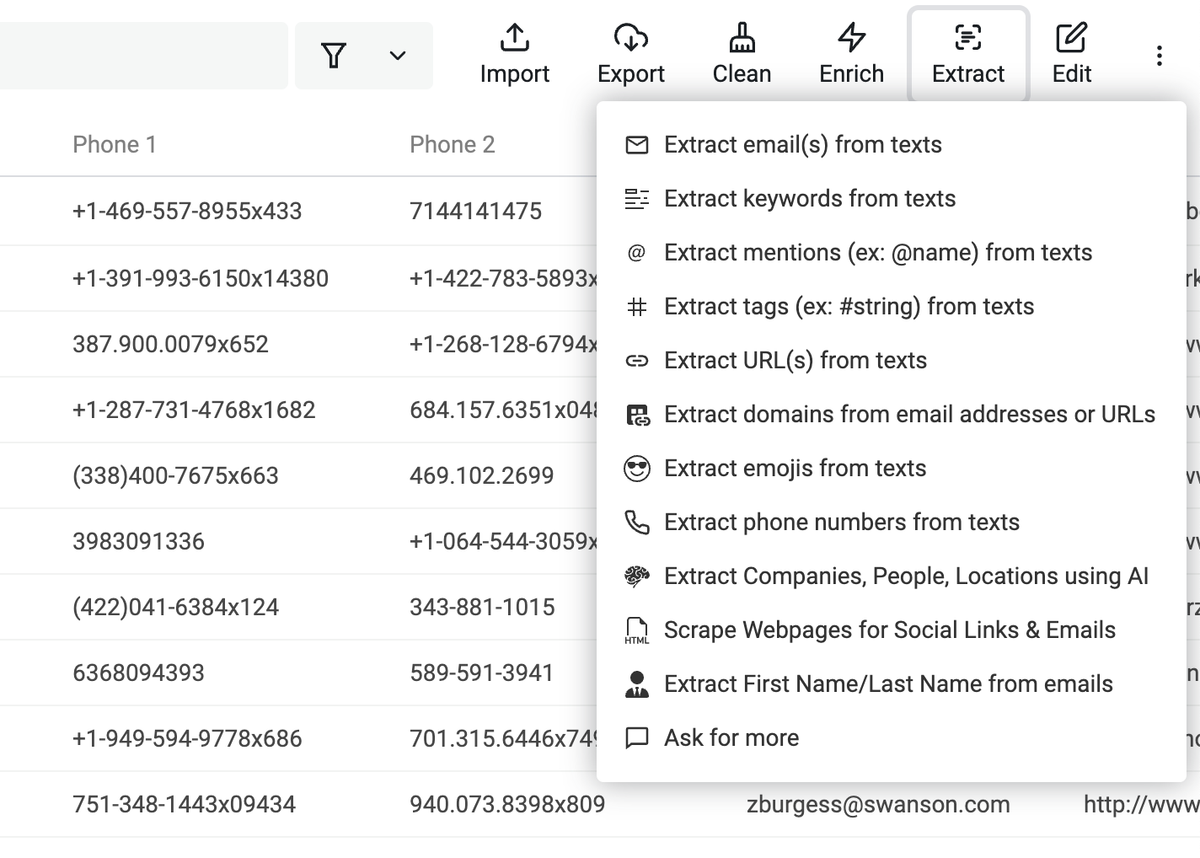
Extract Menu
A new "Extract" menu has been added in the collection header. You can extract email addresses, tags, domains, etc. from texts.
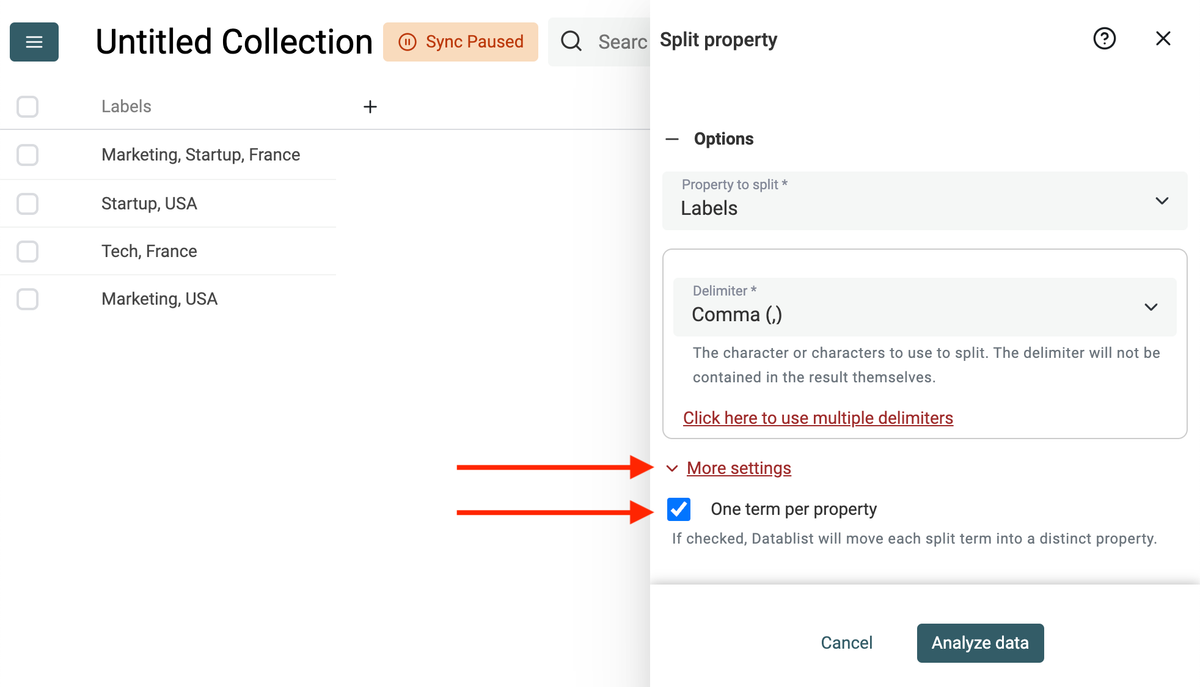
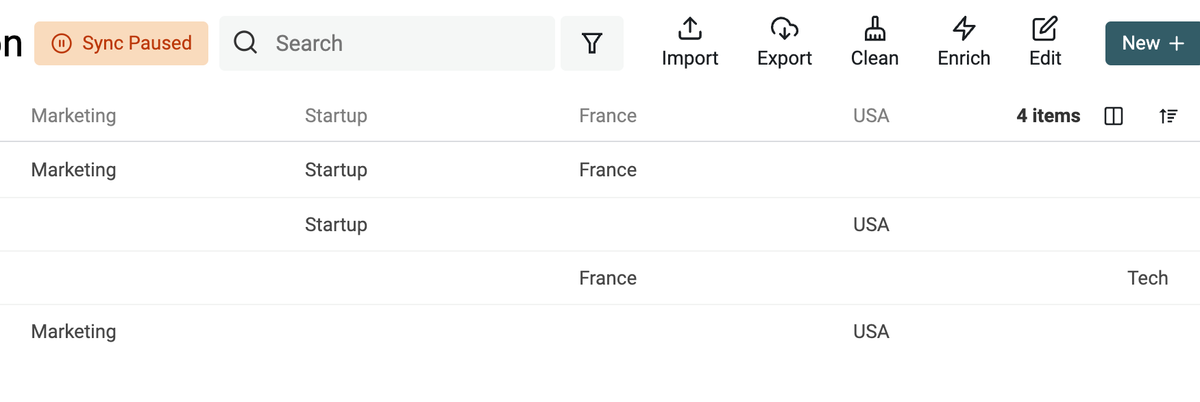
Improved Splitting Property tool
The "Split Property" has been improved.
First, you no longer need to explicitly set the number of properties to create. Now, an "analysis" step scans your first 2000 items to detect the best number of properties to create.
Second, a new option is now available to group split terms by name.
New Filters
Startswith, Endswith, and RegEx filtering on texts
Startswith, Endswith, and RegEx filters are now available on texts.
RegEx expressions are powerful when you master them. Perfect for finding items that match a pattern (phone number validation, URLs).
Check Data Filtering documentation.
Relative filters on DateTime
You can now filter dates by comparing them to the current day.
You define three parts:
- Next or Last
- A number
- A duration term: hours, days, months, years
For example: "Last 2 days".
Map Extract and Convert results into an existing property
Previously, extract and convert tools returned the results into new properties. So, after adding new items, you couldn't re-run the tools on the new items without having to create new properties.
You can now select if the results go to a new property or an existing one. Only compatible properties are available. If you convert Text to DateTime, you can only map the result property to existing DateTime properties.
Misc
- Show a tooltip on the preview cells with text overflow
- Allow Number and Checkbox properties for RichText variables
- Add "Sum" in Calculations
- Create a new property with the keyword shortcut "p" on a collection page
- Shortcuts to filter from the "Distinct Value" calculation
- Convert DateTime to Text
- Handle multiple date formats for Text to DateTime conversion
- Shortcut to BulkEdit from the column menu
- Allow Bulk Edit on DateTime properties
Bug Fixes
- Fix error when editing a collection name and directly switching to another collection
- Fix phone numbers (+XXXX) that were imported as numbers. CSV columns with texts in the format "+XXXXX" (plus sign and digits) with at least 8 digits are kept as Text.
- Fix loading items issue when switching between collections quickly. A "loading" text was displayed and the items didn't load.