Scrapes agency listings from Clutch.co including company names, ratings, services, pricing, and profile links
Cómo usar este prompt de AI
- Create a New Collection: Comience creando una colección nueva y vacía en Datablist donde se almacenarán los datos. Haga clic en '+ Create new collection' en la barra lateral.
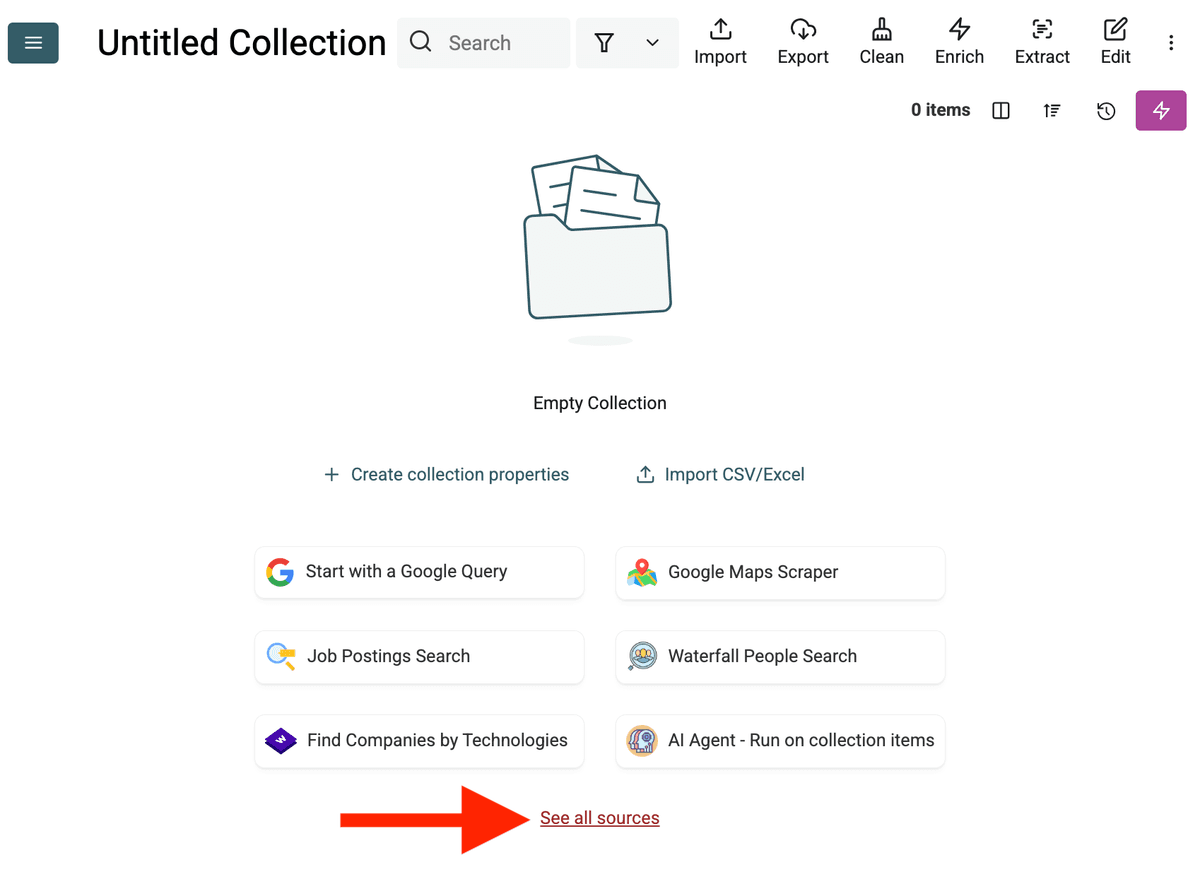
- Select the AI Agent Source: Haga clic en "See all sources" o vaya a "Import" -> "Import From Data Sources". Elija "AI Agent - Site Scraper".
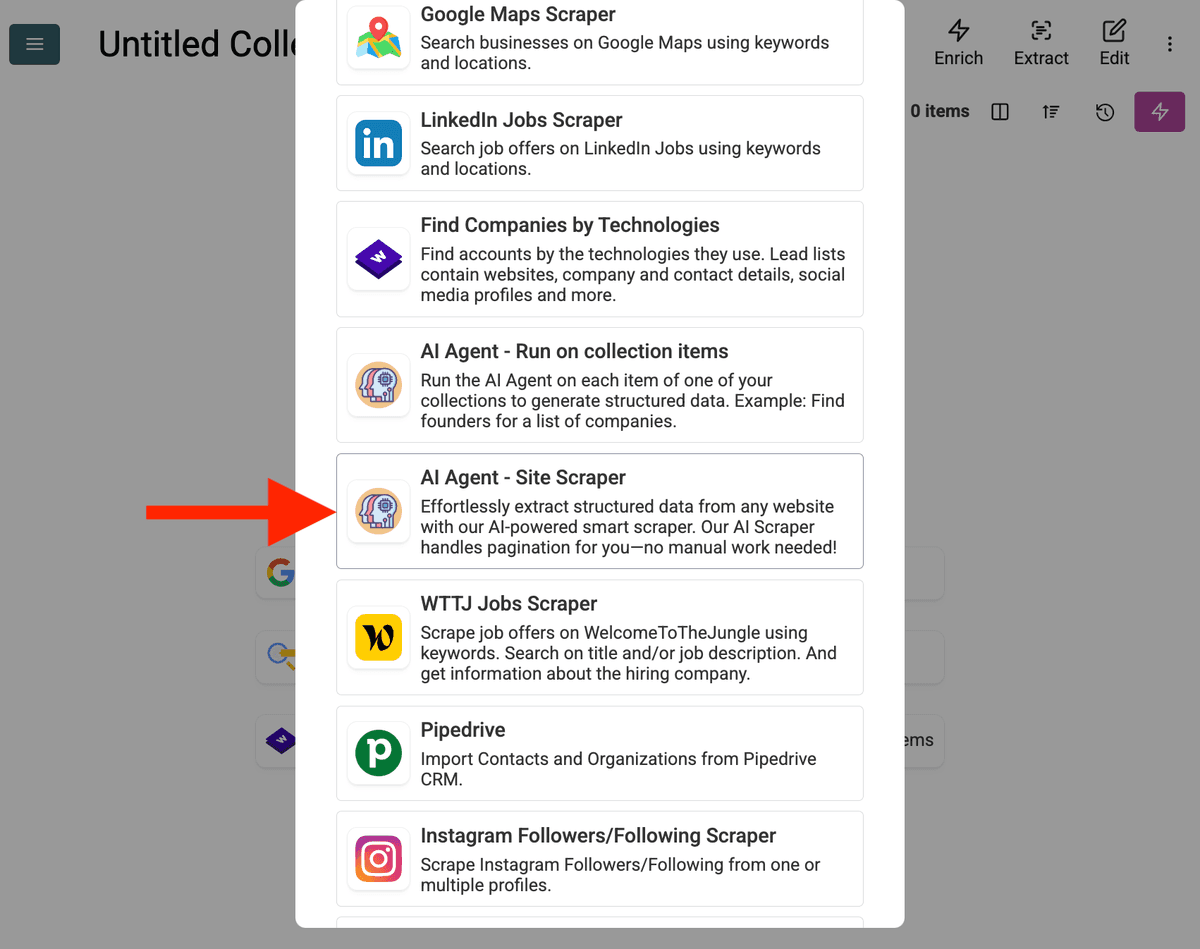
-
Configure the Source:
- Select Template: Busque y elija el prompt en el menú desplegable "Template". El prompt anterior se cargará automáticamente.
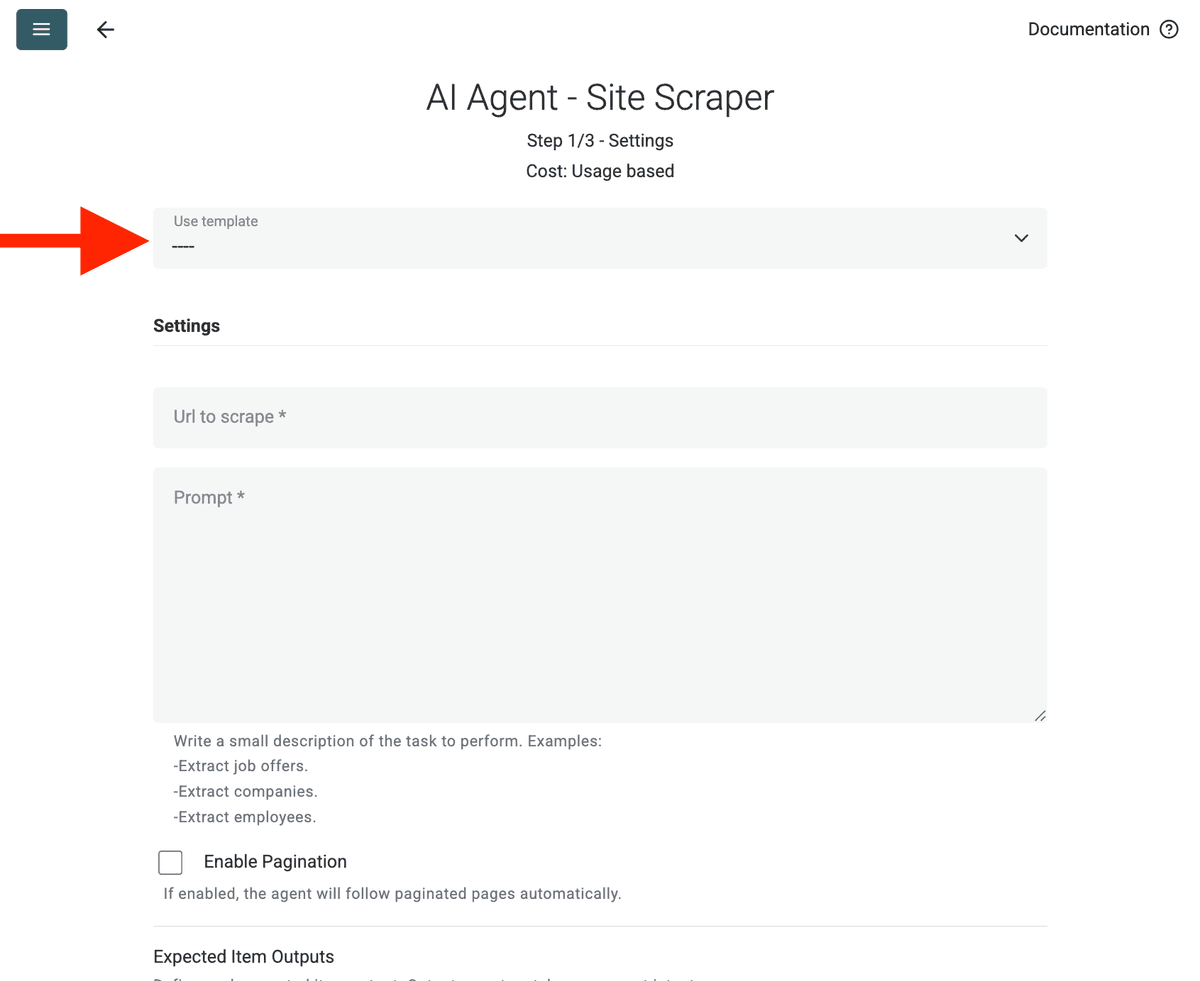
- URL to Scrape: Ingrese su URL para extraer
- Enable Pagination (Optional): Si los resultados están en varias páginas, marque Enable Pagination y defina un límite razonable en Max Pages (p. ej., 10).
- Customize (Optional): Puede ajustar el modelo de AI (p. ej., GPT-4o mini suele ser rentable), editar el prompt para necesidades específicas o modificar los Outputs esperados.
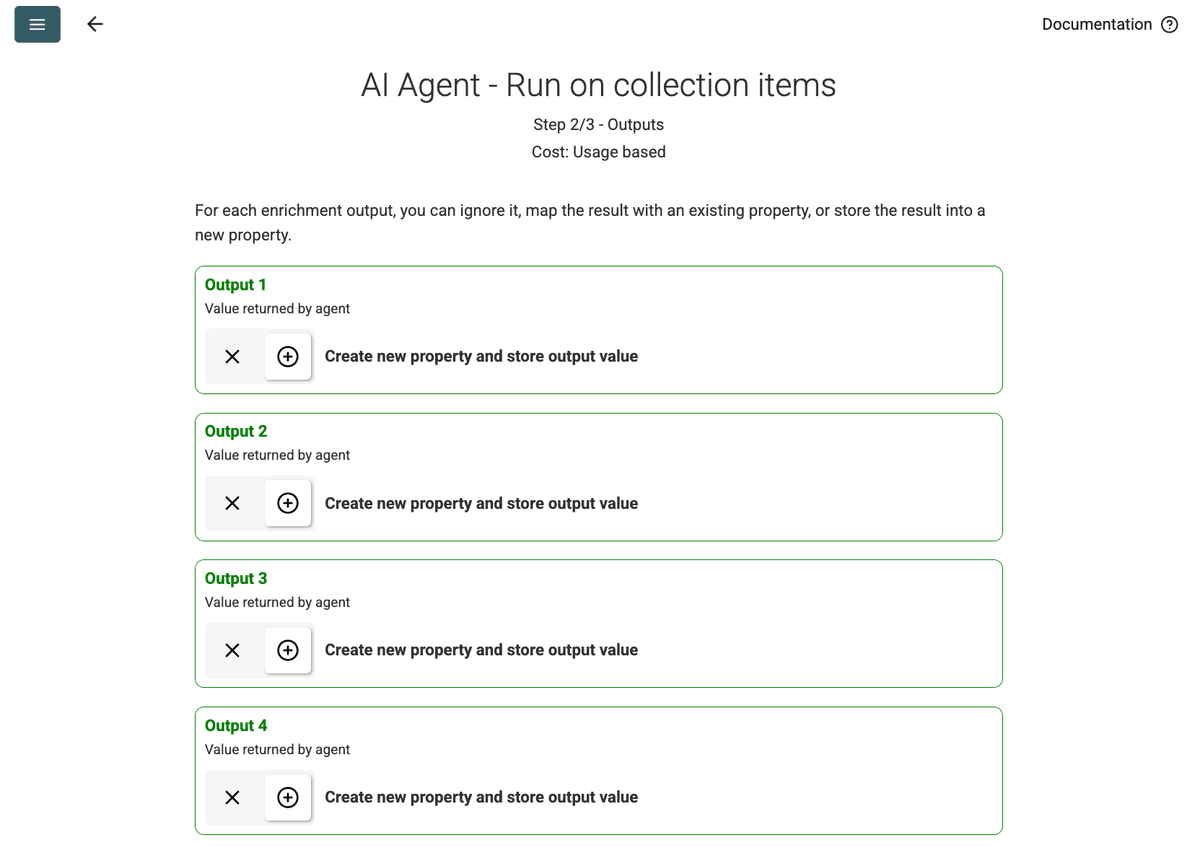
- Review Outputs: Haga clic en Continue. Datablist mostrará los campos de salida definidos en el prompt (Project Name, Client Company Name). Haga clic en el icono + junto a cada uno para crear las propiedades correspondientes (columnas) en su colección.
- Run Import: Haga clic en Run import now. El AI Agent comenzará a hacer scraping del sitio web según el prompt y rellenará su colección.
Precios
Esta fuente de datos usa créditos de Datablist según el uso. El costo depende de la complejidad del sitio web y del número de páginas visitadas.
Pruebe ejecutar primero el AI Agent en una sola página para obtener una estimación del costo.
Preguntas frecuentes
¿Cómo iniciar otra ejecución con la misma configuración?
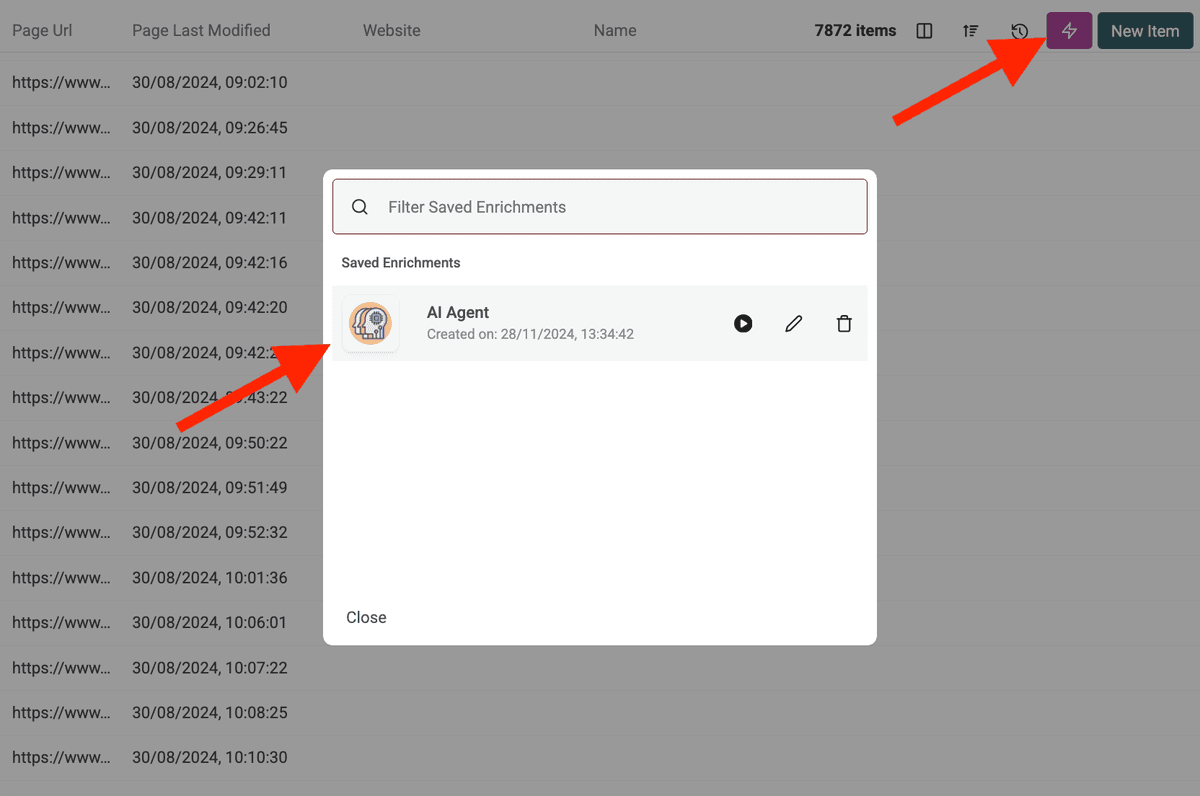
Una vez que ejecute su AI Agent, haga clic en el botón rosa en la parte superior derecha de su tabla de datos para abrirlo nuevamente con su última configuración utilizada.
¿Qué ocurre si el AI Agent intenta acceder a un sitio protegido o es bloqueado?
El AI Agent utiliza automáticamente servidores proxy cuando es necesario para acceder a sitios que puedan tener protecciones de scraping o restricciones geográficas. Esto aumenta las posibilidades de extracción exitosa de datos, aunque los sitios muy protegidos aún pueden presentar desafíos.
¿Cuántos datos puedo procesar con el AI Agent?
Al ejecutar el AI Agent (ya sea como enriquecimiento o como fuente de datos), las colecciones de Datablist pueden procesar hasta 100.000 elementos (filas). Para conjuntos de datos mayores, quizá necesite dividir sus datos en varias colecciones.
¿En qué se diferencia el AI Agent de los enriquecimientos de ChatGPT/Claude/Gemini?
Los enriquecimientos de AI estándar (ChatGPT, Claude, Gemini) procesan datos que ya están en su colección usando el conocimiento existente de la AI. El AI Agent puede interactuar activamente con la web en tiempo real: realizar búsquedas en Google, navegar sitios web y extraer información nueva según su prompt.
¿Qué tan precisos son los resultados?
La precisión depende en gran medida de la claridad y la especificidad de su prompt, así como de la complejidad de la tarea y la información disponible en línea. Proporcionar instrucciones claras, ejemplos y reglas para manejar errores mejora los resultados. Datablist suele proporcionar una puntuación de confianza para las salidas del AI Agent a fin de ayudar a medir la fiabilidad.