

Hace unos meses lanzamos una funcionalidad que no esperábamos que fuera tan potente.
Ahora, esta función está sacudiendo la industria del web scraping No‑Code.
La funcionalidad de la que hablo es nuestra fuente “AI Agent - Site Scraper”. Este agente de AI scraping puede ir a cualquier sitio web para encontrar, procesar y extraer los datos que usted necesita.
Unos meses después, descubrí 3 cosas:
- Toda la industria del No‑Code scraping es una gran mentira
- Construimos el mejor scraper No‑Code sin darnos cuenta
- Los AI scraping agents son más potentes, más fáciles y más rápidos que cualquier herramienta de No‑Code scraping anterior
📌 Resumen para quienes van con prisa
Este artículo le cuenta todo lo necesario sobre el verdadero No‑Code scraping, y demuestra que no requiere APIs, CSS selectors ni conocimientos técnicos. Si está con prisa, aquí va el resumen:
Problema: Las herramientas “No‑Code” de scraping siguen requiriendo conocimientos técnicos, le obligan a entender la estructura del sitio, ver tutoriales, pasar horas configurando y, cuando el sitio cambia un detalle, todo se rompe.
Por qué es un problema: No debería tener que aprender APIs, CSS selectors ni ver horas de tutoriales solo para extraer datos de la web. Eso va contra la idea de “No‑Code”.
Solución: El scraping con AI de Datablist usando instrucciones en lenguaje natural. Usted describe lo que quiere y la IA se encarga del resto.
Qué aprenderá: Este artículo destapa las mentiras del No‑Code scraping, enseña cómo es el No‑Code real y le da casos de uso y consejos de prompting.
Por qué usar Datablist para No‑Code Scraping: 3 razones clave
- Realmente sin código: describa lo que quiere en lenguaje natural
- Maneja webs complejas con JavaScript, paginación y contenido dinámico
- Se adapta a cambios del sitio, a diferencia de los scrapers con CSS selectors frágiles
Qué cubre este artículo
- La industria No‑Code y sus mentiras
- La solución fácil: use palabras, no APIs
- Casos de uso y consejos para AI Scraping
- Preguntas frecuentes sobre No‑Code Scraping
La industria No‑Code y sus mentiras
Esta sección trata de desmontar los mitos y trucos de la industria del No‑Code scraping. La verdad es que la mayoría de herramientas “No‑Code” no son realmente sin código. Simplemente reempaquetan la complejidad técnica en otro formato.
Por qué el código nunca fue el problema
Piénselo un momento: el código nunca fue el problema. Si supiera programar, haría scraping con código y nunca buscaría una solución No‑Code.
Usted busca soluciones No‑Code porque no quiere aprender a programar solo para scrapear un sitio web, pero la gente es lista y le vendieron una solución medio funcional; una solución que sigue implicando:
- Curva de aprendizaje pronunciada
- Ver un montón de tutoriales
- Entender la estructura de los sitios web
Y, a veces, trabajar con conceptos cercanos al código como los CSS selectors.
El problema real nunca fue “código vs. No‑Code”.
El problema real siempre fue la curva de aprendizaje, la complejidad y los dolores de cabeza técnicos.
Lo que intentaron venderle
La industria del No‑Code scraping tiene tres enfoques principales, y ninguno resuelve de verdad la complejidad.
Scrapers basados en API
Estas herramientas dicen ser “No‑Code” porque usted no escribe Python o JavaScript. Pero hay cosas que no le cuentan.
Igual tendrá que lidiar con:
- Estructuras del DOM del sitio
- CSS selectors
- Etiquetas HTML
Técnicamente no está programando, pero está haciendo algo igual de técnico. Está traduciendo necesidades humanas a selectores legibles por máquinas, que es básicamente programar con pasos extra.

Herramientas de apuntar y hacer clic
Este enfoque es más fácil, pero aún le exige entender cómo está construido el sitio. Le facilitan un poco al permitirle hacer clic en elementos, pero no le ahorran los dolores de cabeza.
¿El mayor problema? Si cambia la estructura del sitio, tiene que volver a configurarlo todo desde cero. Esto implica:
- Ver el tutorial otra vez
- Reconfigurar todos sus selectores
- Cruzar los dedos para que esta vez funcione
Extensiones de navegador
Básicamente son herramientas de “apuntar y hacer clic” que operan en su navegador en lugar de una app dedicada. Muchas son gratuitas, como Instant Data Scraper.
Los grandes problemas de estas herramientas:
- Un cambio en el sitio y toca rehacer todo desde cero
- Funcionalidad y escala limitadas
- Pueden bloquear su IP
📘 El patrón que debe notar
Los tres enfoques le obligan a entender la estructura técnica de los sitios. Han reempaquetado la complejidad en interfaces distintas. Eso no resuelve el problema; solo lo mueve de sitio. AI Scraping
Lo que realmente quiere
Seamos sinceros con lo que busca: usted quiere scraping sin dolores de cabeza, no “sin código” por definición. Esto es lo que “sin dolores de cabeza” significa de verdad:
Sin dolores de cabeza
- No me obligue a entender CSS selectors
- No me haga ver tutoriales de 3 horas
- No se rompa cuando el sitio actualice su diseño
Sin curva de aprendizaje
- Debería poder empezar de inmediato
- No debería tener que aprender una habilidad técnica nueva
En esencia, usted quiere describir su objetivo en lenguaje natural y obtener resultados. Todo lo demás es fricción innecesaria que la industria ha normalizado.
La solución: sustituir el scraping No‑Code por AI Scraping
La solución al problema del No‑Code scraping no es una interfaz de “apuntar y hacer clic” mejor ni una API más limpia. La solución es eliminar por completo la capa técnica y usar lenguaje natural.
Cómo el AI Scraping hace que el No‑Code sea realmente sin código
Como su nombre indica, AI scraping deja que la IA haga el scraping del sitio, no usted. Usted se convierte en el gestor, no en el operador técnico.
Con No‑Code scraping impulsado por IA, simplemente le dice al sistema qué hacer, cómo hacerlo y cuándo hacerlo. La IA gestiona toda la complejidad técnica por detrás.
No necesita entender:
- CSS selectors ni estructura HTML
- Arquitectura del DOM
- Endpoints de API ni documentación técnica
Usted da instrucciones en lenguaje natural y el agente de AI scraping resuelve el resto. Así de fácil debería haber sido el No‑Code scraping desde el principio.
La empresa que le trae la solución: Datablist.com
Como mencioné al principio, no planeábamos destruir la industria No‑Code; lo hicimos por accidente porque un usuario necesitaba scrapear un sitio web y le construimos una solución.
Creamos un AI Agent capaz de:
- Entender instrucciones en lenguaje natural
- Navegar sitios complejos automáticamente
- Manejar páginas con mucho JavaScript
- Controlar la paginación
- Extraer datos de forma inteligente
- …
Y el gran avance no fue construir un scraper “mejor”.
Fue eliminar por completo la necesidad de conocimientos técnicos.
Usted le dice a la IA lo que quiere y ella decide cómo conseguirlo.
Sin CSS selectors. Sin inspeccionar el DOM. Sin tutoriales.
Qué es Datablist
Datablist es una plataforma para automatizar flujos de lead generation, data enrichment y data cleaning, creada para perfiles no técnicos como ventas, marketing y recruiting.
Le permite encontrar, limpiar y enriquecer datos con más de 60 herramientas, desde AI Agents hasta Email Finders, AI processors, Technology enrichments y muchas más.

Además, Datablist le permite crear workflows automatizados que se ejecutan bajo demanda o por programación. Algunos casos de uso prácticos que encantan a los usuarios de Datablist:
- Construir listas de leads
- Personalizar emails con IA
- Limpiar y deduplicar CRMs
- Scrapear ofertas de empleo en 19 portales a la vez
- Scrapear miles de negocios en Páginas Amarillas
- Scrapear búsquedas de LinkedIn Sales Navigator sin arriesgar su cuenta
Creo que el mensaje es claro: si necesita obtener, limpiar o enriquecer datos, o automatizar workflows basados en datos, y lo quiere fácil, rápido y fiable, Datablist es el lugar.
Y además de todo eso, Datablist solucionó por accidente el problema del web scraping No‑Code.
💡 Datablist en 35 palabras
Datablist es una plataforma para automatizar workflows de lead generation, con más de 60 herramientas: AI Agents, Waterfall Enrichment para encontrar emails y teléfonos, utilidades de data cleaning para deduplicación y más.
Por qué elegir Datablist
El enfoque de Datablist para el No‑Code scraping es distinto al del mercado porque nunca vendimos “dolores de cabeza bien empaquetados”; apostamos por AI scraping.
¿Qué significa para usted?
Solución realmente No‑Code
- Cero conocimientos técnicos requeridos
- No necesita entender HTML ni CSS
- Sus automatizaciones no se rompen con cada cambio del sitio
Solo necesita hacer un prompt
- Escriba lo que quiere en lenguaje natural
- La IA entiende el contexto y la intención
Plantillas para muchos scrapers
- Prompts predefinidos para casos comunes
- Plantillas para scrapear directorios
- Plantillas para e‑commerce
- Plantillas para extraer case studies
La forma más fácil de scrapear un directorio
- Funciona en Yellow Pages, Yelp, TripAdvisor, Alibaba
- Gestiona la paginación automáticamente
Sin exportar‑importar entre 10 herramientas
- Los datos van directo a una interfaz tipo hoja de cálculo
- Edite, filtre y enriquezca en un solo lugar
- Acceda a todo un ecosistema de lead generation
Casos de uso y consejos de uso
Usar Datablist para scrapear sitios, directorios o incluso escalar búsquedas con IA es fácil; el enfoque es siempre el mismo: describa lo que quiere con la máxima precisión.
Introducción rápida al prompting
Antes de hablar de todos los casos de uso del agente de AI scraping, déjeme mostrarle lo sencillo que es instruirlo.
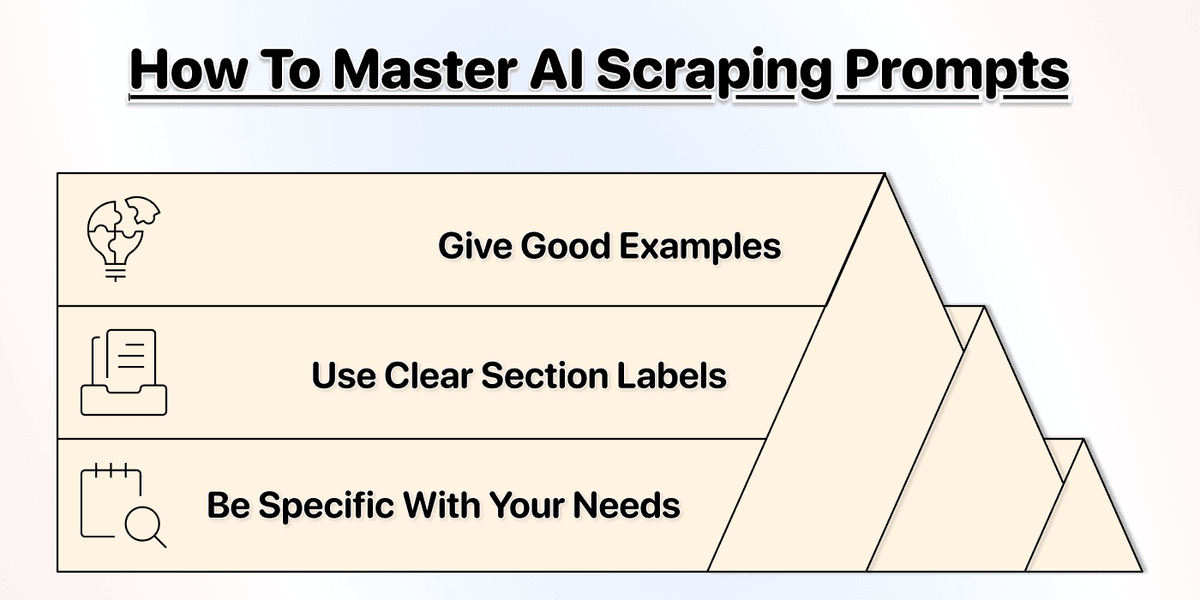
Reglas de prompting:
Un buen prompt es simple. No necesita ser experto. Solo debe ser claro con lo que quiere. Algunos consejos para mejores prompts:
Sea específico {#sea-especifico}
- No diga “obtén información del producto”
- Diga “obtén nombre del producto, precio y estado de disponibilidad”
- Incluya ejemplos cuando sea posible
Así se asegura de obtener los datos que quiere sin que el agente de IA interprete algo mal.
Use etiquetas por sección {#use-etiquetas-por-seccion}
- Organice su prompt con secciones claras
- Goal: qué intenta conseguir
- Data Points: qué información específica necesita
- Format: cómo quiere los datos estructurados
- Constraints: qué evitar o incluir
Las etiquetas ayudan al agente a entender a qué se refiere en cada parte. No es obligatorio; solo hemos visto que mejora mucho la precisión.
Dé ejemplos {#de-ejemplos}
El agente no lo sabe todo. Algunos sitios son muy complejos. Al dar ejemplos evita falsos positivos, mejora la precisión y reduce coste.
Aquí tiene una guía detallada para escribir prompts para un AI agent 👈🏽
💡 Pro Tip: manejo de paginación
El AI Agent de Datablist puede manejar automáticamente contenido paginado. Solo active la paginación en la configuración y defina el máximo de páginas. El agente navegará por todas y extraerá los datos.
===
Data Points que necesito:- Nombre del producto (ejemplo: "Classic T-Shirt")
- Precio (ejemplo: "$29.99")
- URL del producto (enlace completo)
- Disponibilidad (In Stock / Out of Stock)
===
Format:- Devuelva una fila por producto
- Use "N/A" si falta algún dato
===
Constraints:- Omita banners promocionales
- Solo obtenga productos reales, no páginas de categoría
Casos de uso de scraping sin código
Las posibilidades del No‑Code scraping son casi infinitas. Estos son los casos más populares y efectivos que hemos visto con AI scraping:
Directorios
- Scrapear negocios de Páginas Amarillas
- Scrapear datos de restaurantes en Yelp
- Scrapear propiedades de AirBnB
- Scrapear información de hoteles en TripAdvisor
- Scrapear catálogos de proveedores en Alibaba
- Scrapear propiedades en Zillow
- Scrapear Realtors desde Zillow
Sitios e‑commerce
Otros
- Scrapear todos los case studies de un sitio
- Extraer expositores de webs de ferias
📘 Cómo scrapear múltiples sitios
Si tiene muchos sitios similares que scrapear, también puede usar el AI Research Agent de Datablist para scrapear una lista de webs. Este agente además permite ejecutar búsquedas con IA a escala.
Conclusión: el No‑Code Scraping debería renombrarse
El No‑Code scraping debería llamarse “scraping sin dolores técnicos” porque eso es lo que la gente realmente quiere. Usted no busca No‑Code porque no pueda programar; lo busca porque no quiere aprender habilidades técnicas solo para extraer datos.
Así que, si el scraping no es su actividad principal de ingresos, no debería estar obligado a perder horas en ello, y la solución no es una API más bonita ni una interfaz de “apuntar y hacer clic” más limpia.
La solución es eliminar por completo la capa técnica, es decir, AI scraping.
Y con Datablist, puede hacer exactamente eso y además:
- Obtener resultados en minutos, no horas
- Escalar de un sitio a miles
- Describir lo que quiere en lenguaje natural
- Adaptarse automáticamente a cambios del sitio
El problema del No‑Code scraping por fin está resuelto. Y lo hicimos por accidente.

Preguntas frecuentes sobre No‑Code Scraping
¿Puede Datablist scrapear directorios?
Sí, el AI Scraping Agent de Datablist puede scrapear directorios de forma eficiente, y el agente maneja la paginación automáticamente, para extraer miles de fichas sin configuración manual.
Por ejemplo, hemos scrapeado con éxito datos de:
- TripAdvisor: reseñas, hoteles, restaurantes y más
- Listados de negocios en Páginas Amarillas
- Catálogos de propiedades en Airbnb
- Bases de proveedores en Alibaba
- Información de negocios en Yelp
- … y muchos más
¿Puedo scrapear datos de múltiples páginas automáticamente?
Sí, el AI Scraping Agent de Datablist soporta paginación automática. Defina el número máximo de páginas en la configuración y el agente navegará por todas, extrayendo los datos sin intervención manual.
Esto funciona para:
- Catálogos de productos e‑commerce
- Listados de directorios en múltiples páginas
- Resultados de búsqueda paginados
- Archivos de blogs
- …
¿Cuánto cuesta usar el Scraping Agent de Datablist?
La tarificación de los AI agents de Datablist es por uso y varía según la complejidad de la tarea. En directorios como Páginas Amarillas, el coste es menor y scrapear 1000 fichas suele costar entre 800 y 1000 créditos. En sitios con mucho JavaScript, como tiendas Shopify, el coste puede ser mayor.
¿Qué es el No‑Code Scraping?
El No‑Code scraping es extraer datos de sitios web sin escribir código ni usar habilidades técnicas. El verdadero No‑Code significa que puede describir lo que quiere en lenguaje natural y obtener resultados, sin entender HTML, CSS selectors o APIs.
¿Puede Datablist manejar sitios con mucho JavaScript?
Sí, el AI Agent de Datablist puede scrapear sitios con mucho JavaScript. Active la opción "Render HTML" en la configuración avanzada para que el agente espere a que cargue el JavaScript antes de extraer los datos.
Esto es esencial para sitios modernos en React, Vue o Angular que cargan contenido dinámicamente tras la carga inicial.
¿Cuál es la diferencia entre No‑Code Scraping y el scraping tradicional?
El scraping tradicional requiere programar (Python, JavaScript) o conocimientos técnicos (CSS selectors, XPath). El No‑Code elimina ese requisito mediante interfaces visuales o, en el caso de Datablist, entendiendo lenguaje natural.
¿Cómo funciona el AI Scraping frente al scraping basado en CSS selectors?
Los scrapers basados en CSS selectors dependen de la estructura exacta del HTML del sitio. Si el sitio cambia el diseño, el scraper se rompe.
El AI scraping entiende el significado del contenido, no solo su ubicación. Puede identificar “esto es un precio de producto” incluso si cambian las clases HTML. Es más resiliente y no requiere mantenimiento.
¿Es legal el No‑Code Scraping?
La legalidad del scraping depende de qué scrapee y cómo use los datos. Scrapear datos públicos suele ser legal, pero debería:
- Respetar los archivos robots.txt
- Evitar scrapear detrás de muros de login
- Usar los datos de forma ética y cumpliendo las leyes de privacidad
- No sobrecargar los servidores con peticiones excesivas