Eliminador gratuito de duplicados
¿Qué es la deduplicación de datos?
La deduplicación de datos, o deduping, es el proceso de eliminar registros duplicados de un conjunto de datos.
La deduplicación es necesaria para tener una lista de entradas únicas: en marketing con listas de correo, en lead generation o en la gestión de clientes. O en e-commerce al gestionar catálogos de productos. Dos entradas son duplicadas cuando se refieren a la misma entidad: dos leads con la misma dirección de email, o dos productos con el mismo código de barras.
Los duplicados afectan la calidad de sus datos y reducen su productividad. Existen dos soluciones para deshacerse de los duplicados: eliminarlos o fusionar entradas similares en una sola.
Eliminar duplicados es fácil: el algoritmo de deduplicación encuentra las entradas duplicadas y borra todos los registros excepto uno. Fusionar duplicados requiere analizar las entradas duplicadas para combinarlas en un único registro maestro.


















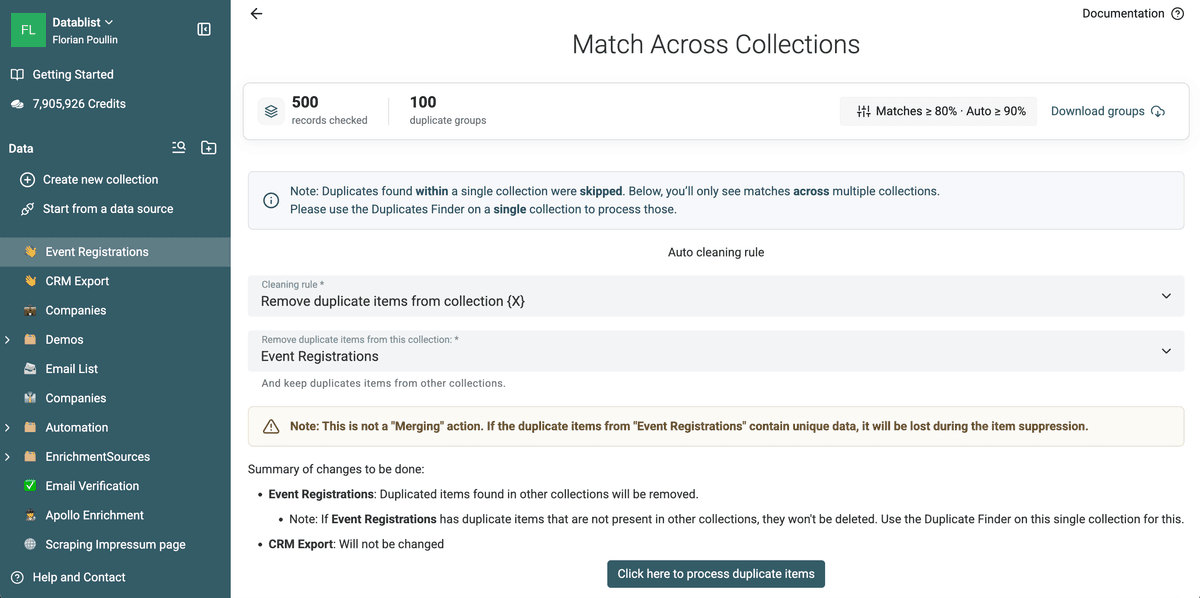
Análisis completo o parcial de elementos, en una o varias colecciones de datos
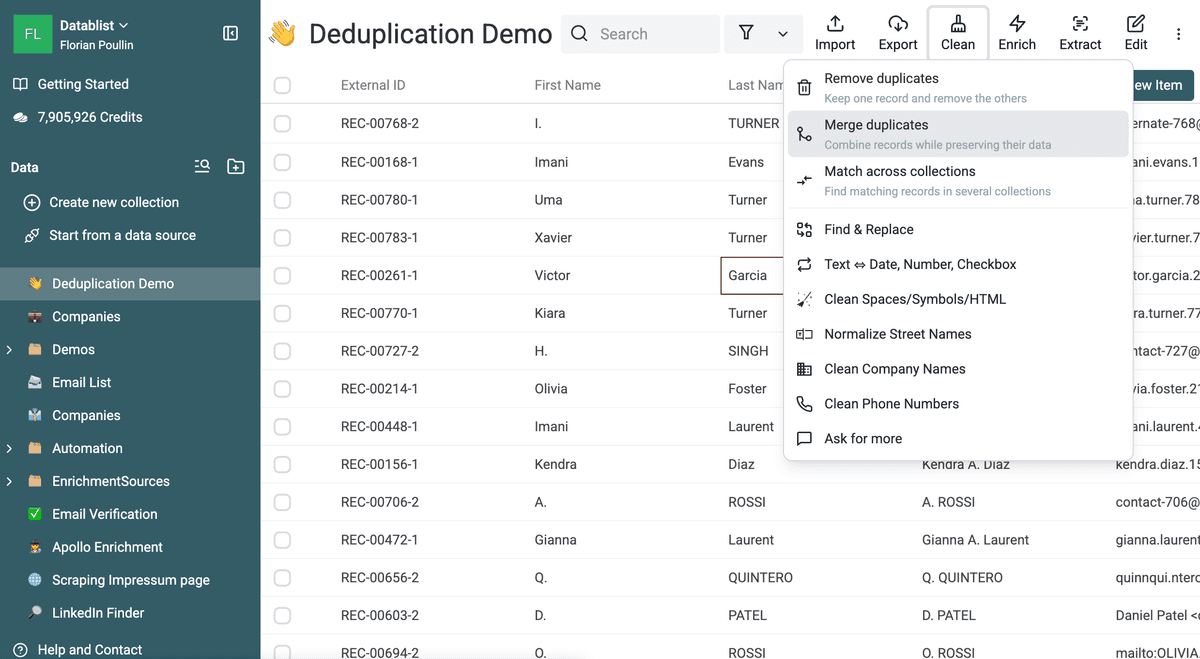
Datablist Duplicates Finder funciona con comparación completa de elementos o con propiedades seleccionadas.
Use el modo Selected Properties para encontrar contactos duplicados basándose en su dirección de email o para detectar duplicados en una lista de empresas usando la URL de su sitio web.
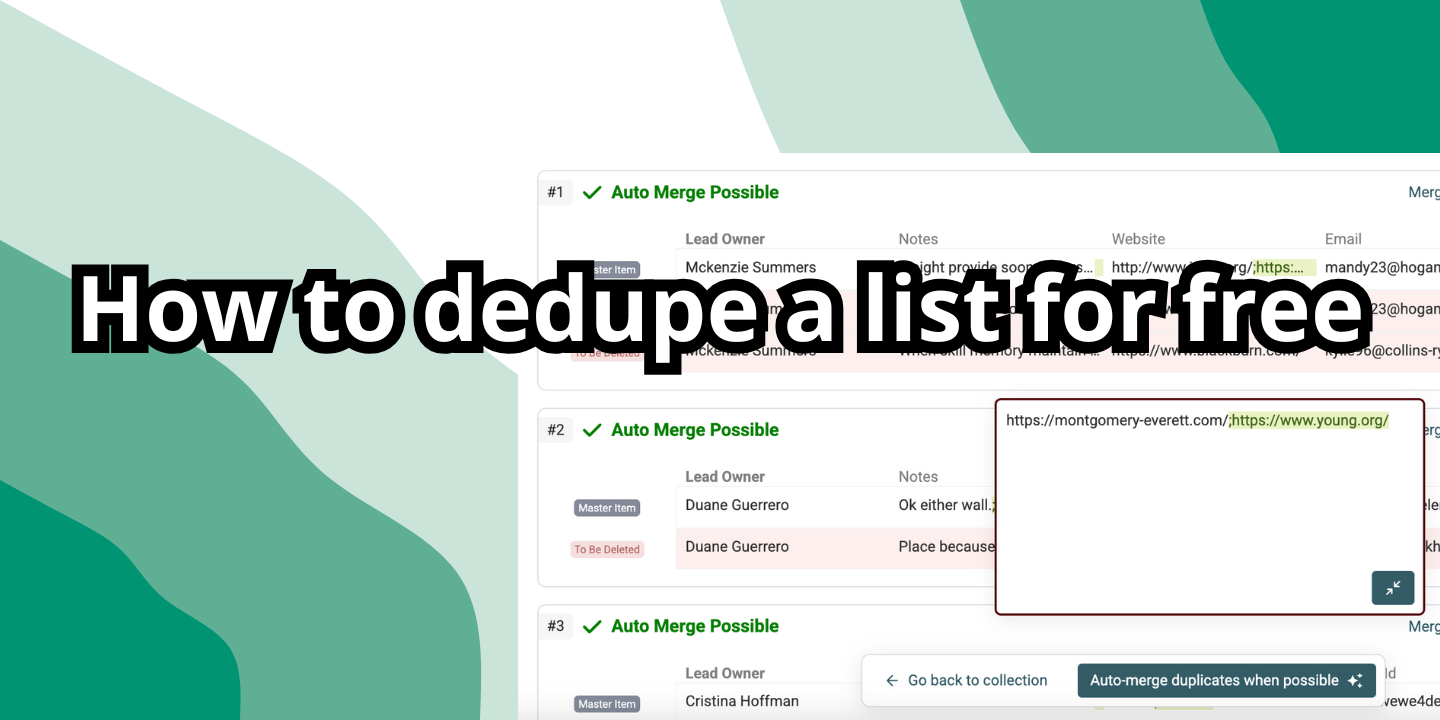
Vista previa de duplicados
Datablist lista los duplicados encontrados para que usted decida qué operación realizar.
Abra los elementos duplicados en el panel de detalles para editar y fusionar información. O simplemente elimine los duplicados.
Eliminar o consolidar duplicados
Fusionar automáticamente los duplicados sin conflictos
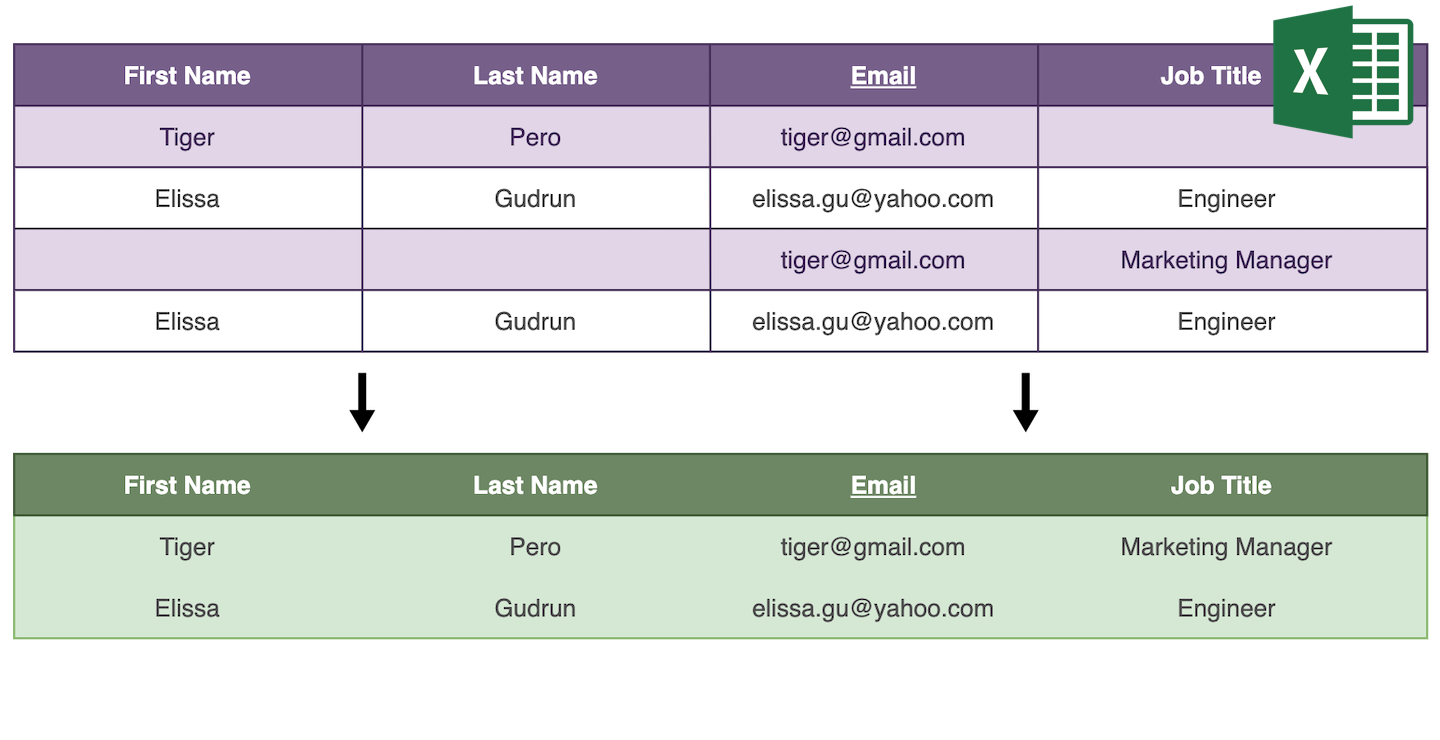
Datablist encuentra automáticamente todos los valores duplicados que pueden fusionarse sin perder información.
- Cuando todos los elementos duplicados tienen los mismos valores de propiedades, solo se mantiene un elemento y los demás se eliminan.
- Si los elementos duplicados son complementarios, el elemento con más información se selecciona como elemento principal y sus valores de propiedades se completan usando los valores de propiedades de los otros elementos. Luego se eliminan todos los elementos excepto el principal.
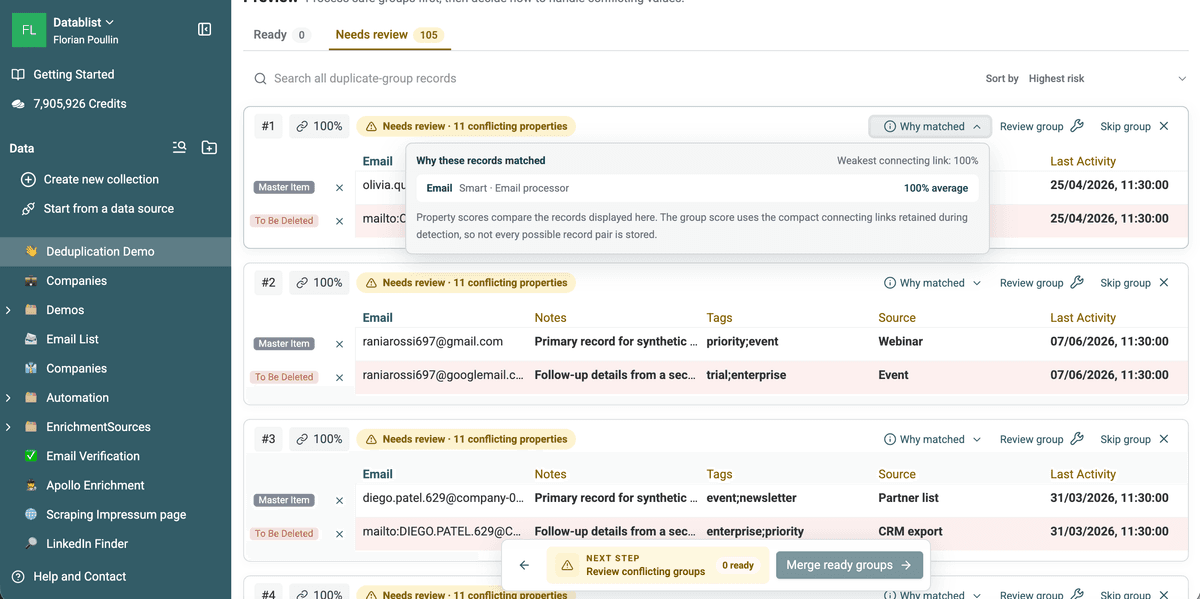
- Si los elementos duplicados tienen valores de propiedades en conflicto, se omiten para la fusión manual.
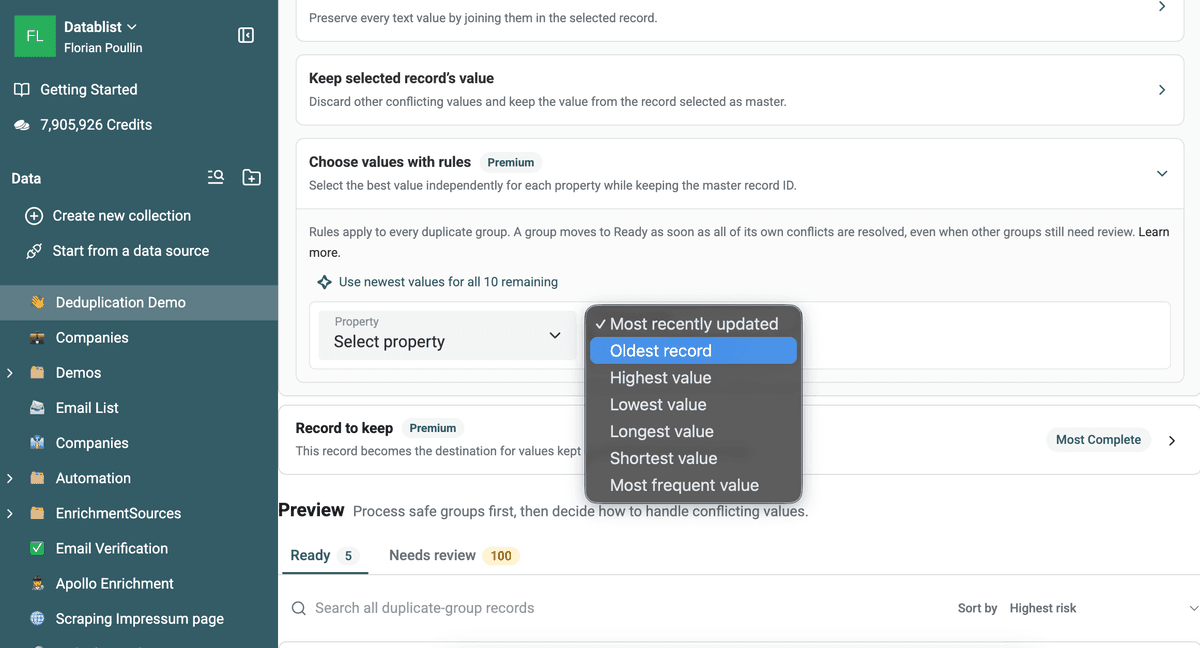
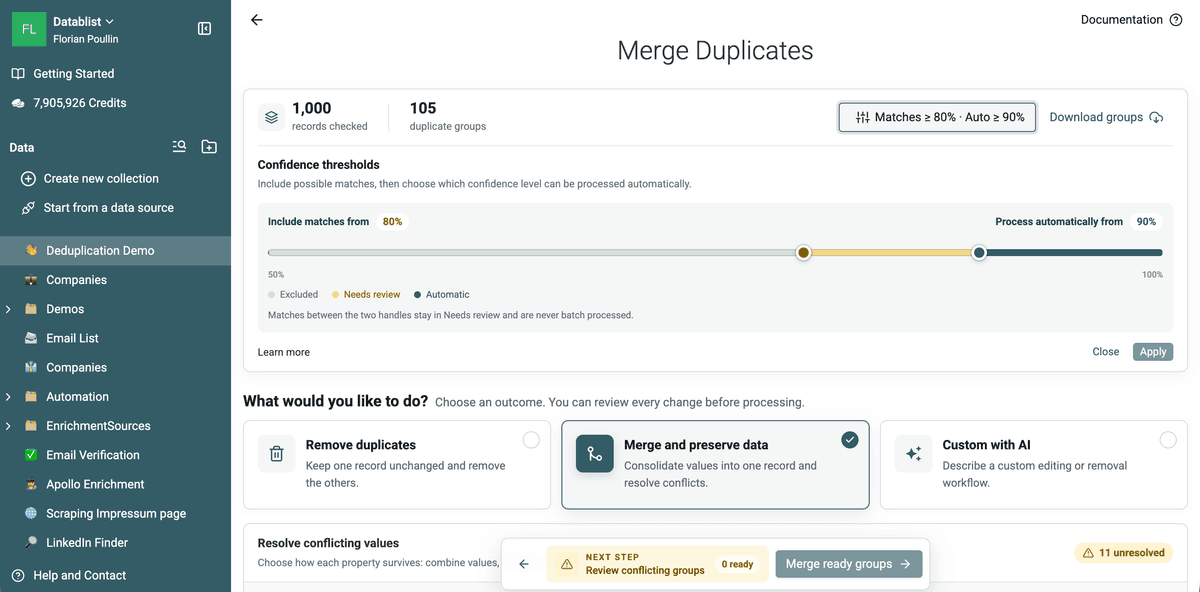
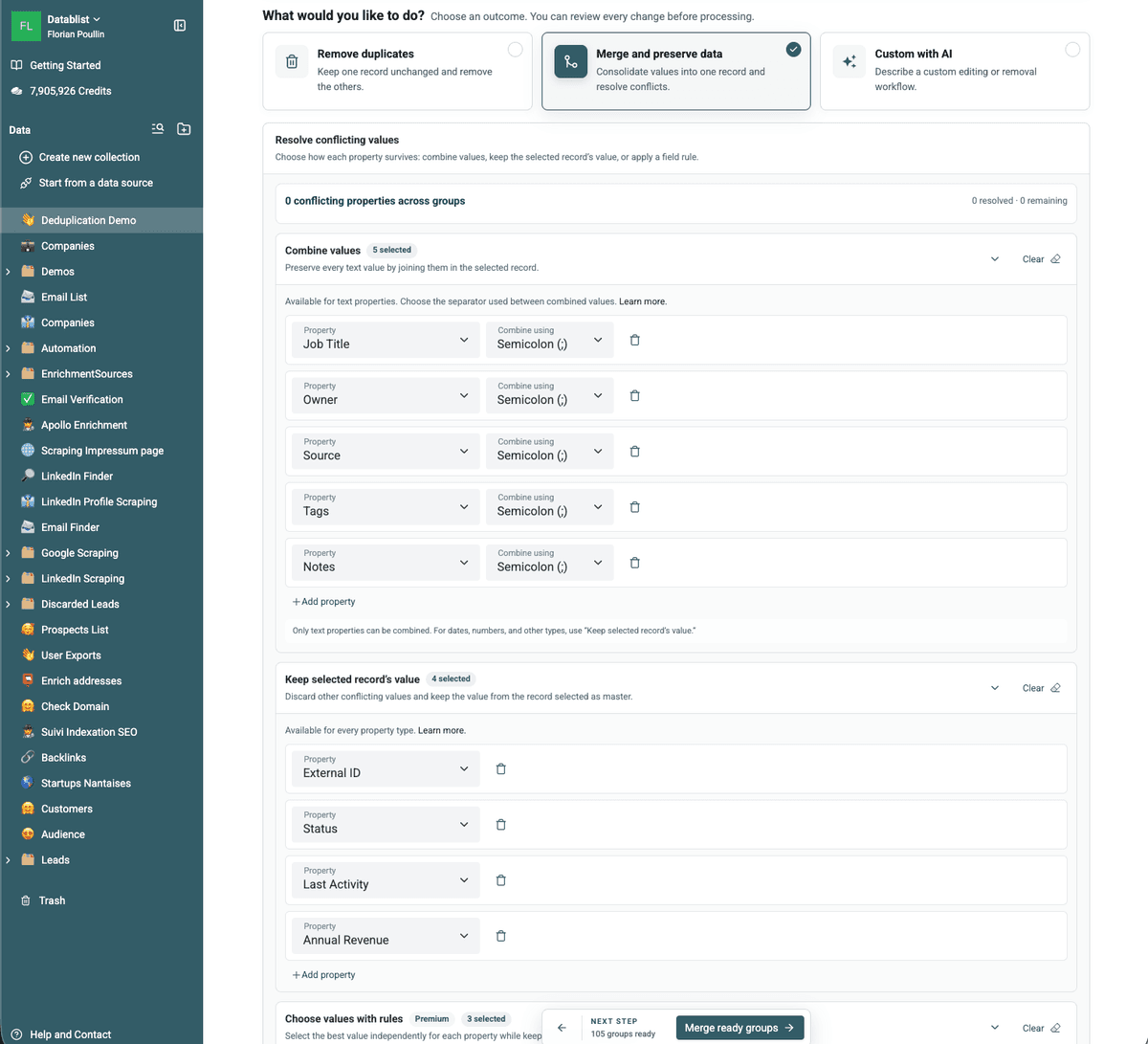
Consolide duplicados para mantener un único registro
Cuando una fusión simple no es suficiente, use las funciones avanzadas: combine o descarte valores duplicados para consolidar sus registros duplicados.
Datablist enumera sus campos en conflicto y le permite elegir cómo tratarlos. Use Combine values para concatenación de datos. Y Drop values para mantener el valor de un registro maestro.
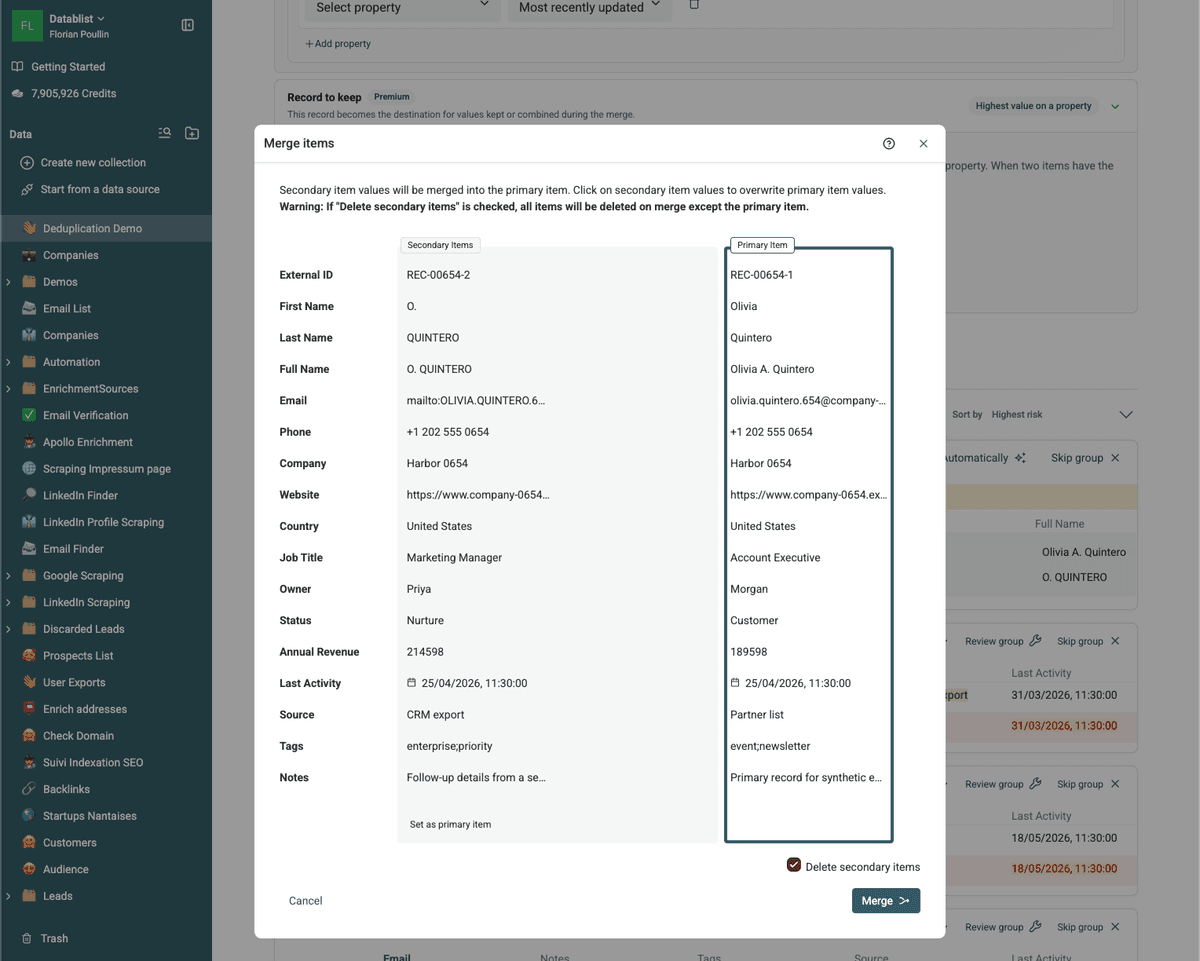
O revise manualmente los valores en conflicto con el asistente de fusión
Cuando la fusión automática no sea posible, use el asistente de fusión de Datablist para seleccionar qué valor conservar y consolidar sus elementos.
El elemento con más información se selecciona como elemento maestro y recibe valores complementarios de los elementos secundarios.
Procesamiento de duplicados con AI
Exportar a archivos CSV o Excel
¿Necesita transferir sus datos a otra aplicación o a una hoja de cálculo?
<0>Sus datos siempre son suyos</0>, simplemente exporte los elementos seleccionados o toda su colección a un archivo CSV o a un archivo de Microsoft Excel.
Los archivos CSV generados son compatibles con Google Sheets y con todas las aplicaciones comunes.
¿Cuándo usar la deduplicación de datos?
- Deduplicación de listas de correo
Con el tiempo, múltiples fuentes alimentarán su lista de correo. Con participantes de webinars, compradores, usuarios freemium, etc., una dirección de email puede aparecer varias veces en su lista.
Las direcciones de email duplicadas impactan sus campañas de marketing con costes extra, comportamiento tipo spam y el riesgo de frustrar a los usuarios si siguen recibiendo emails después de darse de baja de una campaña.- Cómo limpiar una lista de correo
- Deduplicación en Microsoft Excel
Google Sheets, Microsoft Excel y otras herramientas de hojas de cálculo ofrecen funciones básicas de deduplicación. Resaltan los valores duplicados en una columna o los eliminan. Use la fusión automática de Datablist y el Asistente de Fusión manual para tratar registros duplicados complejos.
Datablist abre tanto archivos CSV como Excel.- Cómo deduplicar un archivo de Excel
- Herramienta de deduplicación de leads y prospectos
En marketing B2B, la calidad de su base de datos de prospectos impacta los resultados de sus campañas. Una lista de datos sucia con leads duplicados aumenta el coste de almacenamiento, reduce la eficiencia del seguimiento de leads y genera frustración en su equipo de ventas.
Gestione sus procesos de lead generation con Datablist. O importe sus datos del CRM o listas de leads en Datablist para limpiarlos.- Cómo deduplicar listas de leads
- Deduplicar archivos CSV
Limpiar datos CSV lleva tiempo. Los data engineers usan lenguajes de programación como Python para analizar y limpiar datos CSV. Datablist ofrece una herramienta No-Code para realizar procesos de limpieza de datos con sus archivos CSV para usuarios no técnicos. Abra archivos CSV con cientos de miles de filas y deduplique registros rápidamente.
- Cómo deduplicar un archivo CSV
Preguntas frecuentes
Sí, puede encontrar y fusionar duplicados en línea de forma gratuita. Funciones básicas como la coincidencia exacta y smart matching están disponibles sin una cuenta. Para algoritmos avanzados como fuzzy o phonetic matching, se necesita un plan de pago.
Excel elimina permanentemente las filas duplicadas, lo que le hace perder datos potencialmente valiosos de esas entradas. Datablist fusiona registros, combinando inteligentemente información complementaria de todos los duplicados en un único registro maestro completo. No pierde ningún dato.
Datablist está diseñado para manejar archivos grandes. Puede procesar listas con hasta 1 millón de filas en el plan gratuito y hasta 1,5 millones de filas en nuestros planes de pago, muy por encima de los límites de las herramientas de hojas de cálculo tradicionales.
Absolutamente. Nuestra herramienta usa algoritmos avanzados de fuzzy matching, como Levenshtein y Jaro-Winkler, para identificar registros similares incluso con errores ortográficos, typos o pequeñas diferencias de formato.
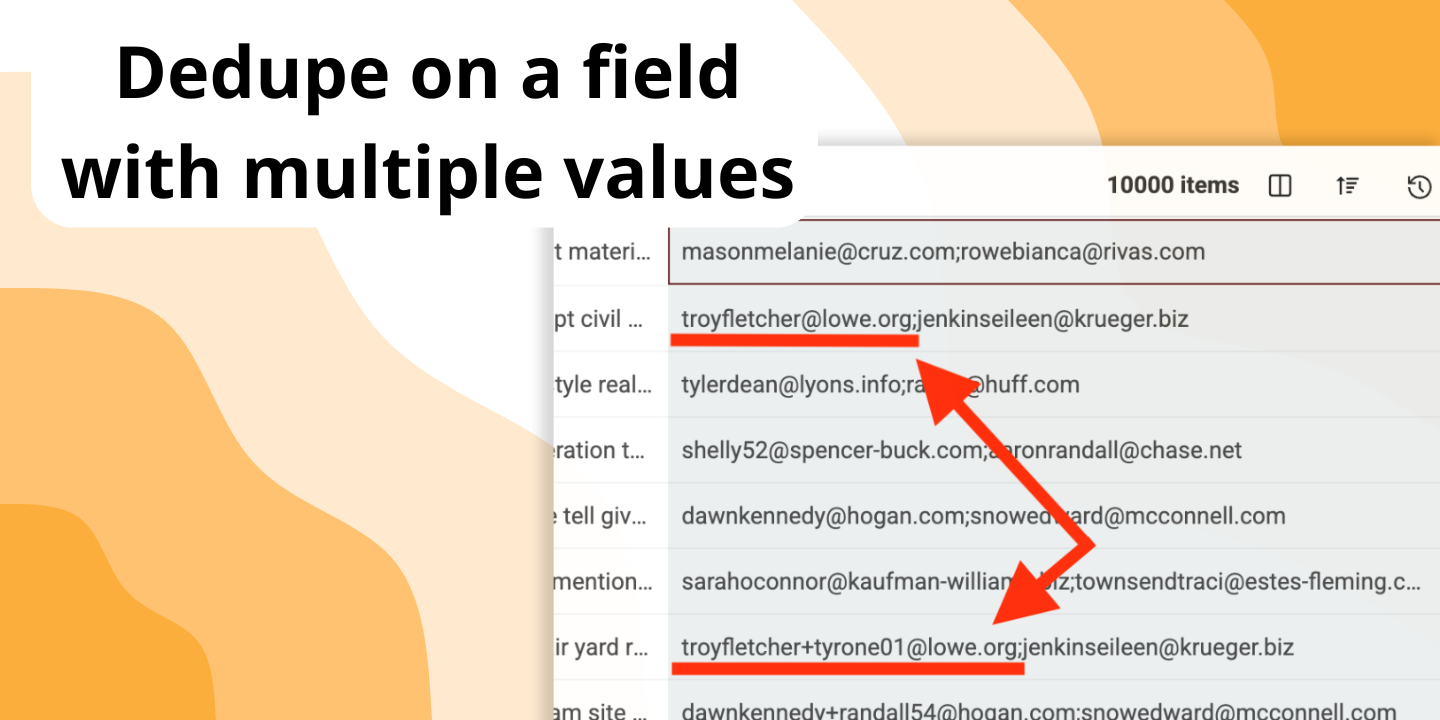
Está diseñado para eso. Puede habilitar "Multiple Value Matching" para tratar cada valor dentro de una celda (separados por punto y coma) como una entrada independiente para la comparación. Encuentra una coincidencia si al menos uno de los valores es un duplicado.
Sí. Puede importar varios archivos a Datablist y ejecutar el Duplicates Finder en todos ellos. Puede hacer coincidir registros basándose en un identificador común, incluso si los archivos tienen columnas o estructuras diferentes.
En absoluto. Datablist es una solución completamente no-code. El Duplicates Finder le guía con un proceso simple, paso a paso, en el que selecciona sus columnas y reglas de coincidencia desde una interfaz fácil de usar.
Nuestra función de AI Editing le da flexibilidad ilimitada. En lugar de reglas de fusión estándar, puede escribir instrucciones en inglés sencillo. Por ejemplo, pídale que sume cifras de ventas de entradas duplicadas o que elija el registro maestro según la fecha más reciente. Convierte la lógica compleja en una solicitud simple.
Datablist consolida sus datos en un único registro maestro. Completa automáticamente la información faltante a partir de otros duplicados y le ofrece opciones para los datos en conflicto: puede combinar texto de diferentes filas o elegir qué valor conservar. Luego, los registros redundantes se eliminan.
Ofrecemos varios algoritmos para diferentes necesidades: 'Exact' para coincidencias idénticas, 'Smart' para variaciones como el orden de las palabras o los protocolos de URL, 'Phonetic' para nombres que suenan igual y 'Fuzzy Matching' para typos y errores ortográficos.
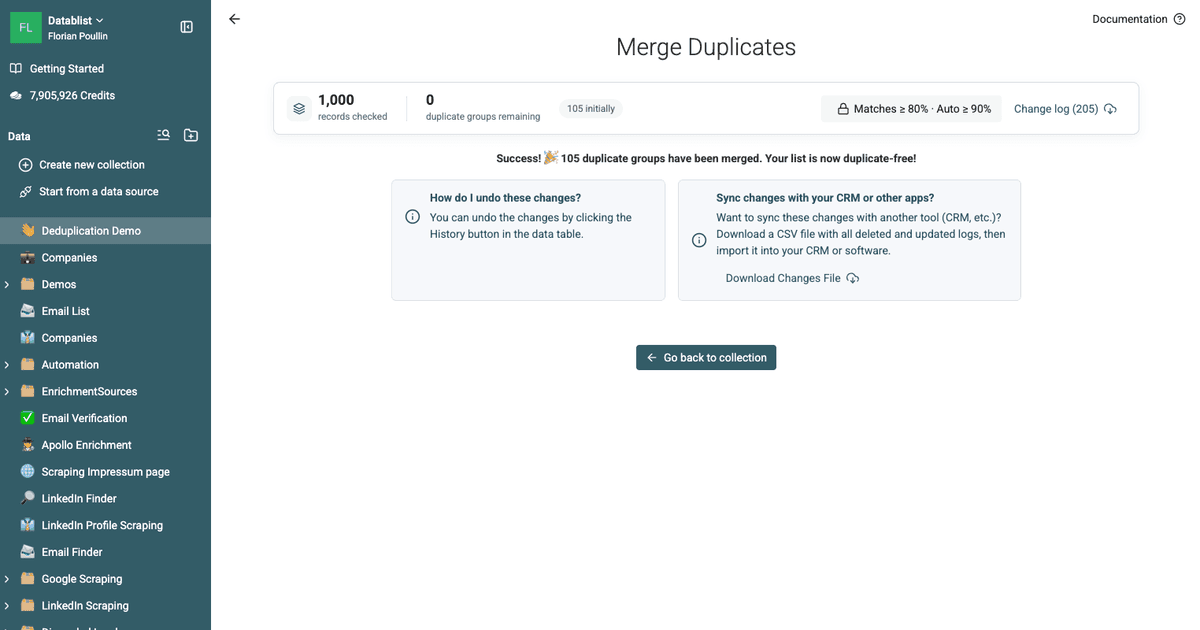
Sí. Después de que Datablist identifique todos los grupos de duplicados, puede exportarlos a un archivo CSV o Excel antes de realizar cualquier cambio. Este archivo lista todos los elementos duplicados de forma consecutiva, con cada grupo listado uno tras otro, lo que facilita revisarlos externamente o procesarlos con otra herramienta.
Una vez que termine de fusionar, Datablist proporciona un 'Changes List' descargable. Este archivo actúa como registro, detallando cada registro que se actualizó o eliminó durante el proceso. Puede usar este archivo para replicar fácilmente los cambios en su sistema externo, como un CRM, garantizando que sus datos queden perfectamente sincronizados.
See Also