

La limpieza de datos (data cleansing) ya no es exclusiva de los analistas. Si usted trabaja con una lista de prospects, usa datos scrapeados en sus procesos o consolida múltiples fuentes, conoce la importancia de un data cleaning eficaz.
Google Sheets y Excel bastan para operaciones sencillas, pero se quedan cortos al consolidar y deduplicar.
En esta guía, aprenderá a usar Datablist, una herramienta online gratuita para limpiar y normalizar sus datos.
Aquí tiene un resumen rápido de las operaciones de limpieza que verá en este artículo:
- Convertir texto a Datetime, Number, Boolean
- Convertir HTML a texto (eliminar etiquetas HTML)
- Eliminar espacios extra de los textos
- Normalizar sus datos
- Eliminar símbolos de los textos
- Separar nombre completo en First Name y Last Name
- Deduplicar elementos
- Extraer emails, URLs, etc. de textos
- Usar Regular Expressions para filtrar y validar datos
- Crear transformaciones personalizadas con JavaScript
- Validar direcciones de Email
Importar desde CSV o copiar y pegar datos
Datablist es una herramienta perfecta para limpiar datos. Es un editor CSV online con funciones de limpieza, edición masiva y enrichments. Y escala hasta millones de items por colección.
Abra Datablist y cargue sus colecciones con fuentes de datos.
Para crear una nueva colección, haga clic en el botón + en la barra lateral. Luego haga clic en "Import CSV/Excel" para cargar su archivo. O use el acceso directo desde la página de inicio para ir directamente al paso de importación de archivos.
Detección automática del formato
El asistente de importación de Datablist detecta automáticamente direcciones de email, Datetimes en ISO 8601, Booleans, Numbers, URLs, etc. cuando están bien formateados.
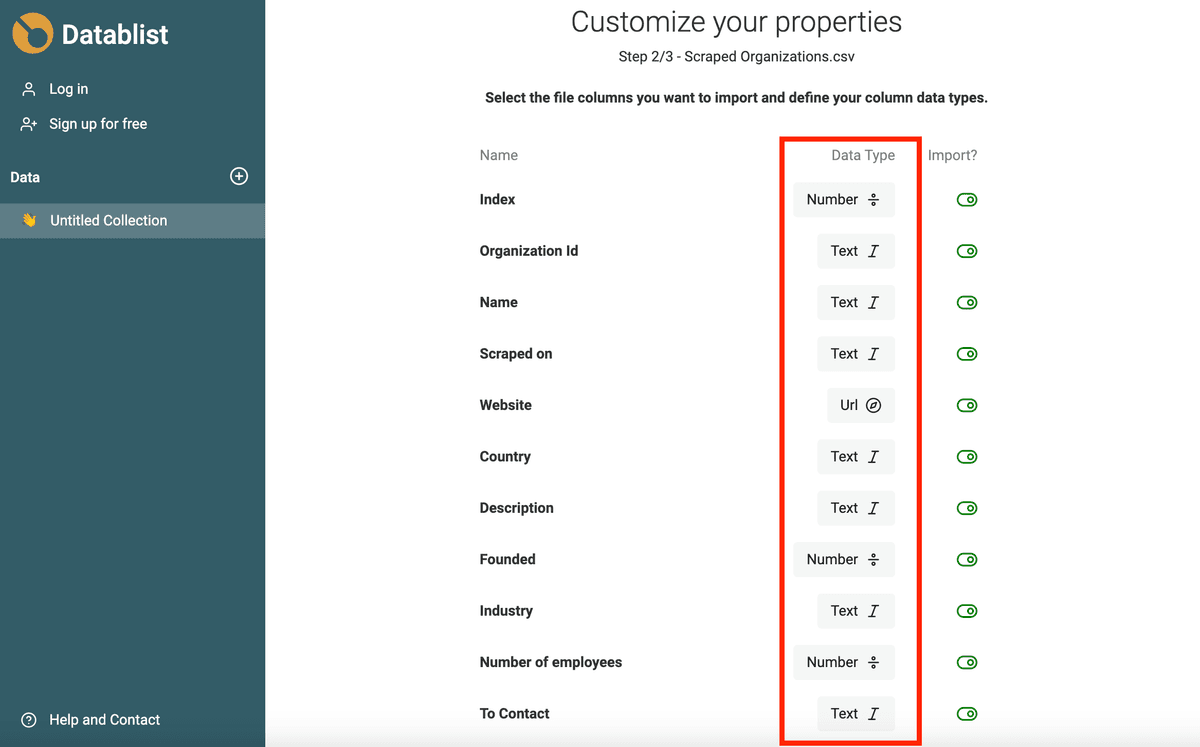
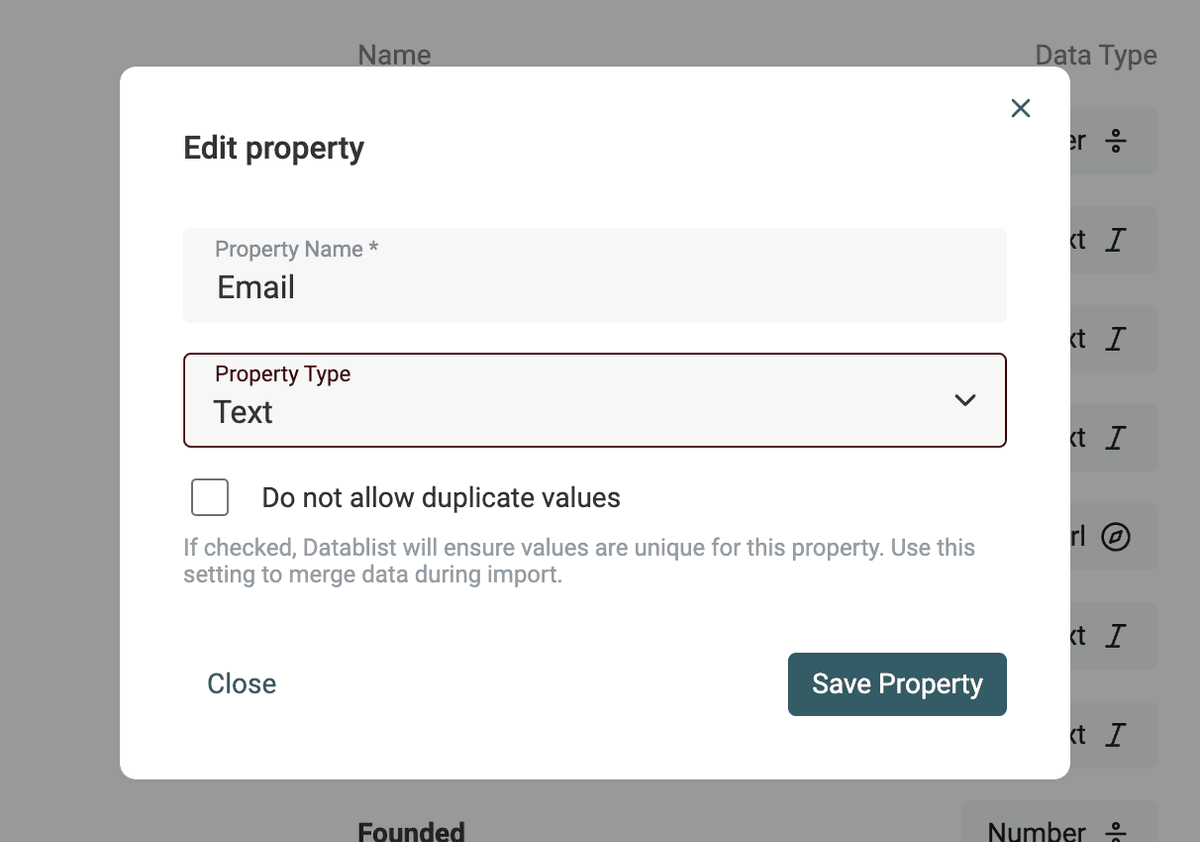
Si sus datos requieren un análisis más complejo (formatos de fecha/hora distintos, errores tipográficos en URLs o emails), impórtelos como propiedad de tipo Text. En la siguiente sección le muestro cómo convertir propiedades de texto a Datetime, Boolean o Number.
Convertir texto a fecha/hora, booleano y número
Marie Kondo dice: «La vida comienza realmente cuando pone su casa en orden». Con sus datos pasa igual: «¡Las ventas empiezan de verdad cuando tiene sus datos en orden!» 😅
Filtrar por una fecha (fecha de creación, de ronda de inversión, etc.), un número (precio, número de empleados) o un booleano es mucho más fácil cuando son objetos nativos y no solo texto.
Abra la herramienta "Text to Datetime, Number, Checkbox" desde el menú "Clean".
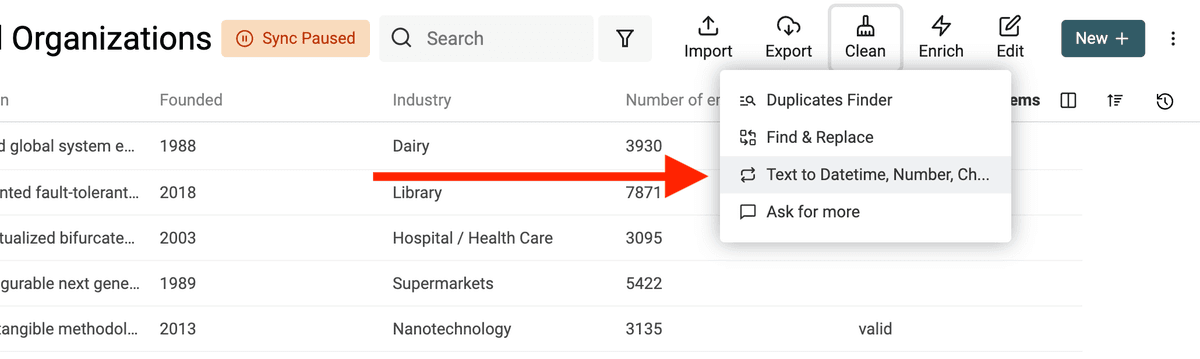
Convertir texto a formato fecha/hora
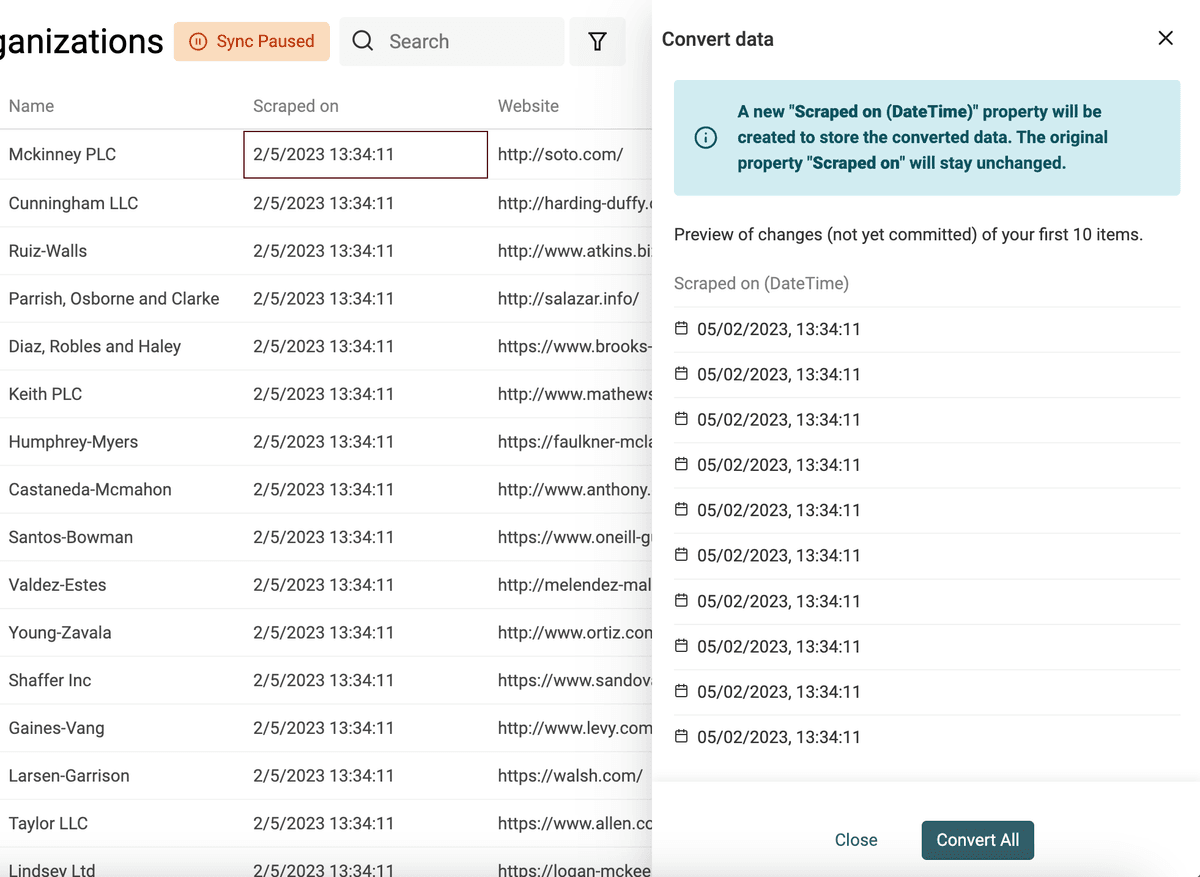
Datetime tiene un formato internacional llamado ISO 8601 con una estructura definida. Si sus datos usan formato ISO 8601, durante la importación se creará automáticamente una propiedad de tipo Datetime para almacenarlos.
Para valores de Date y Datetime en otros formatos, debe indicar el formato utilizado para que Datablist pueda convertirlos a valores estructurados de tipo Datetime.
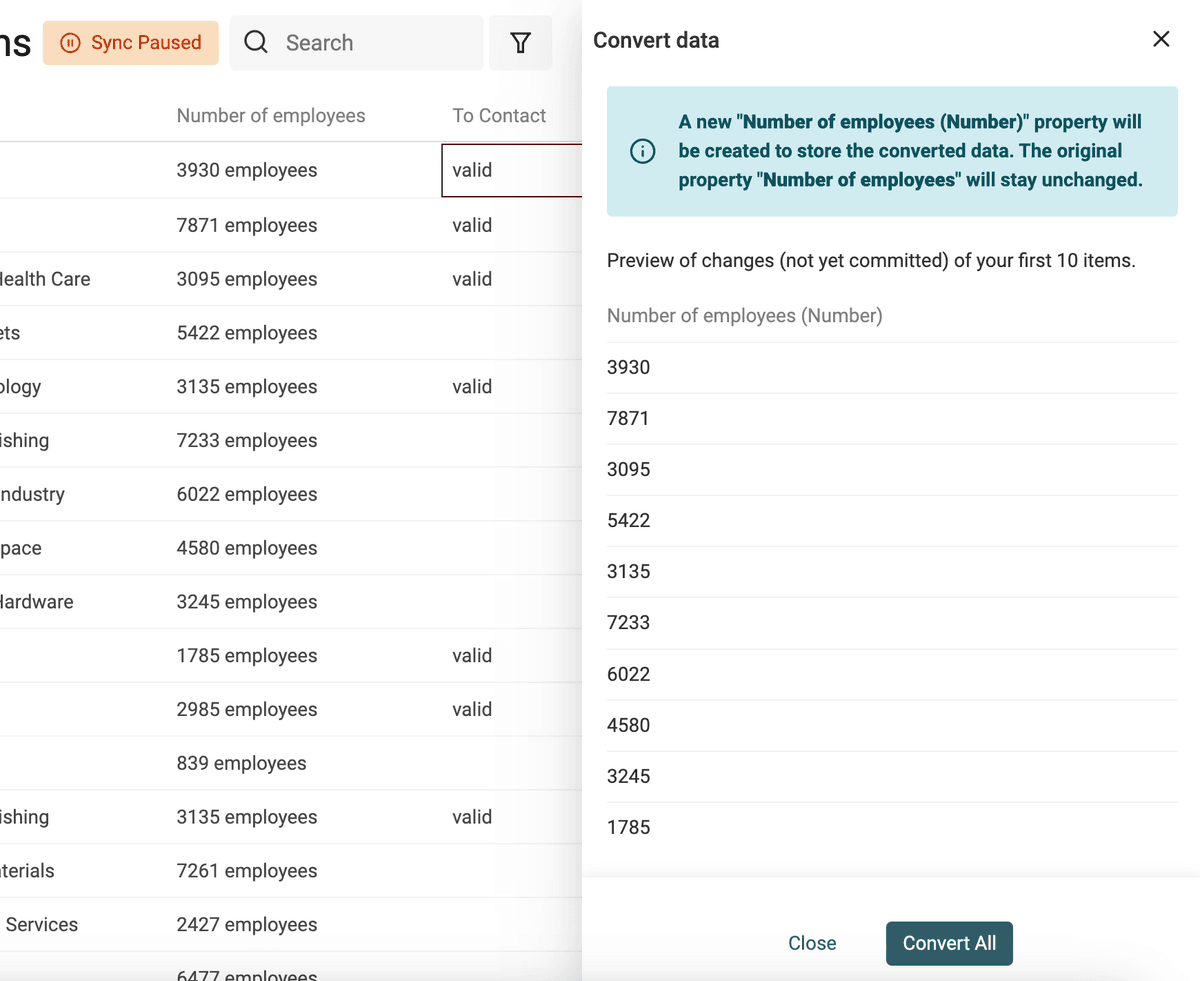
Seleccione la propiedad a convertir y elija "Convert to Datetime".
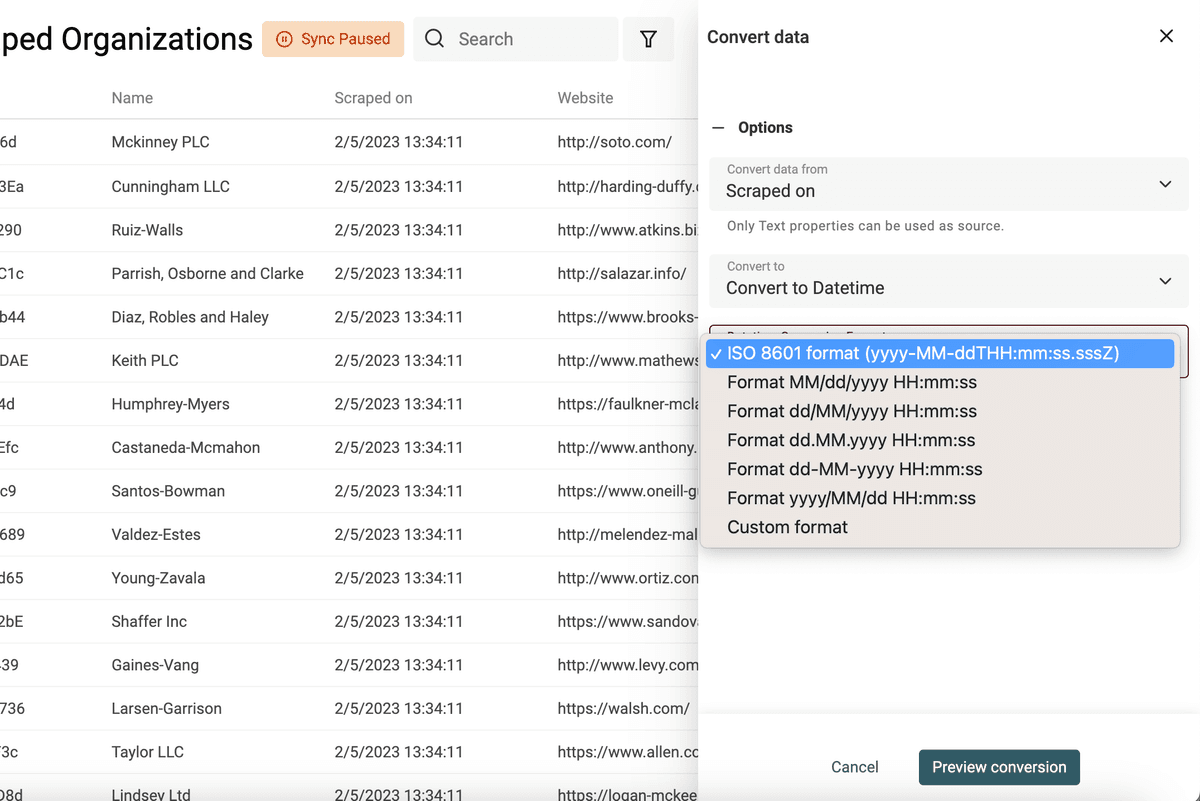
Se listan formatos comunes (los usados por Google Sheets y Excel) o seleccione "Custom format" para definir su propio formato de fecha/hora.
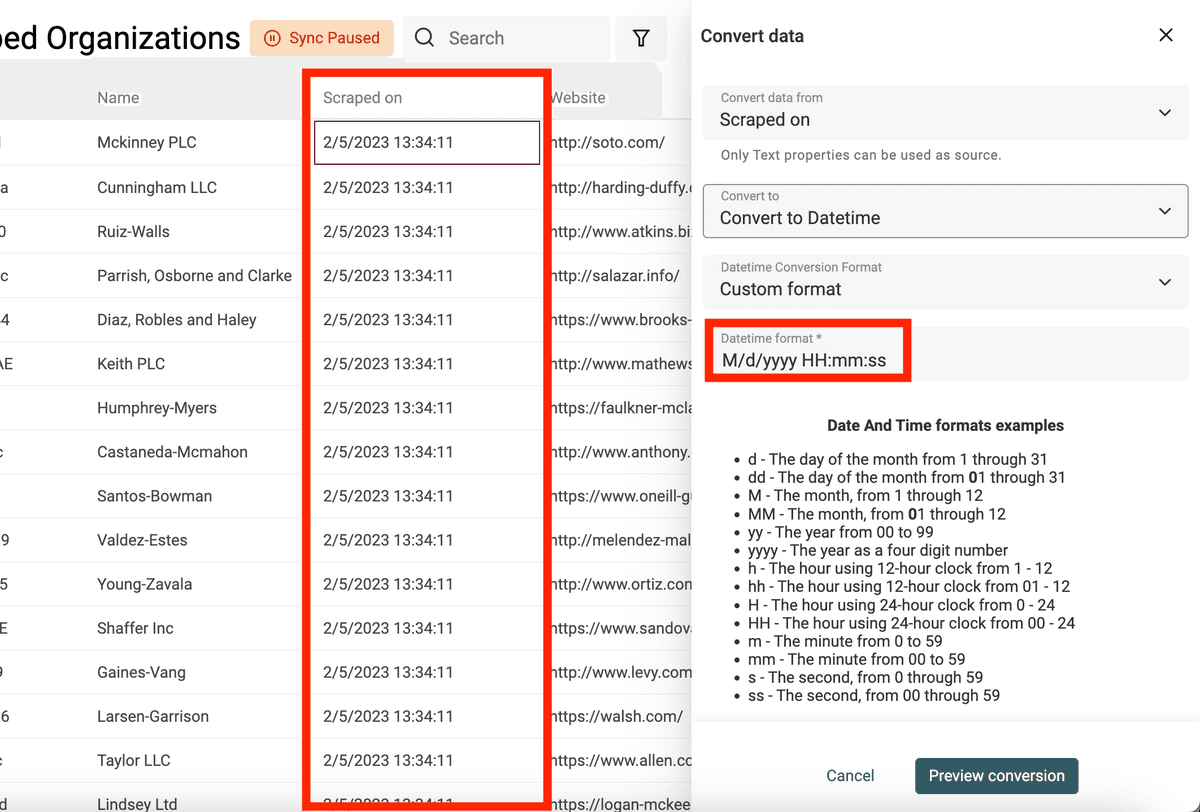
Si tiene fechas y/o datetimes en varios formatos dentro de una sola propiedad, seleccione "Custom or multiple formats" en "Datetime Conversion Format". Luego, introduzca un formato por línea. Datablist probará cada formato empezando por la primera línea hasta devolver una Date válida.
👉 Visite nuestra documentación para saber más sobre formatos de fecha personalizados.
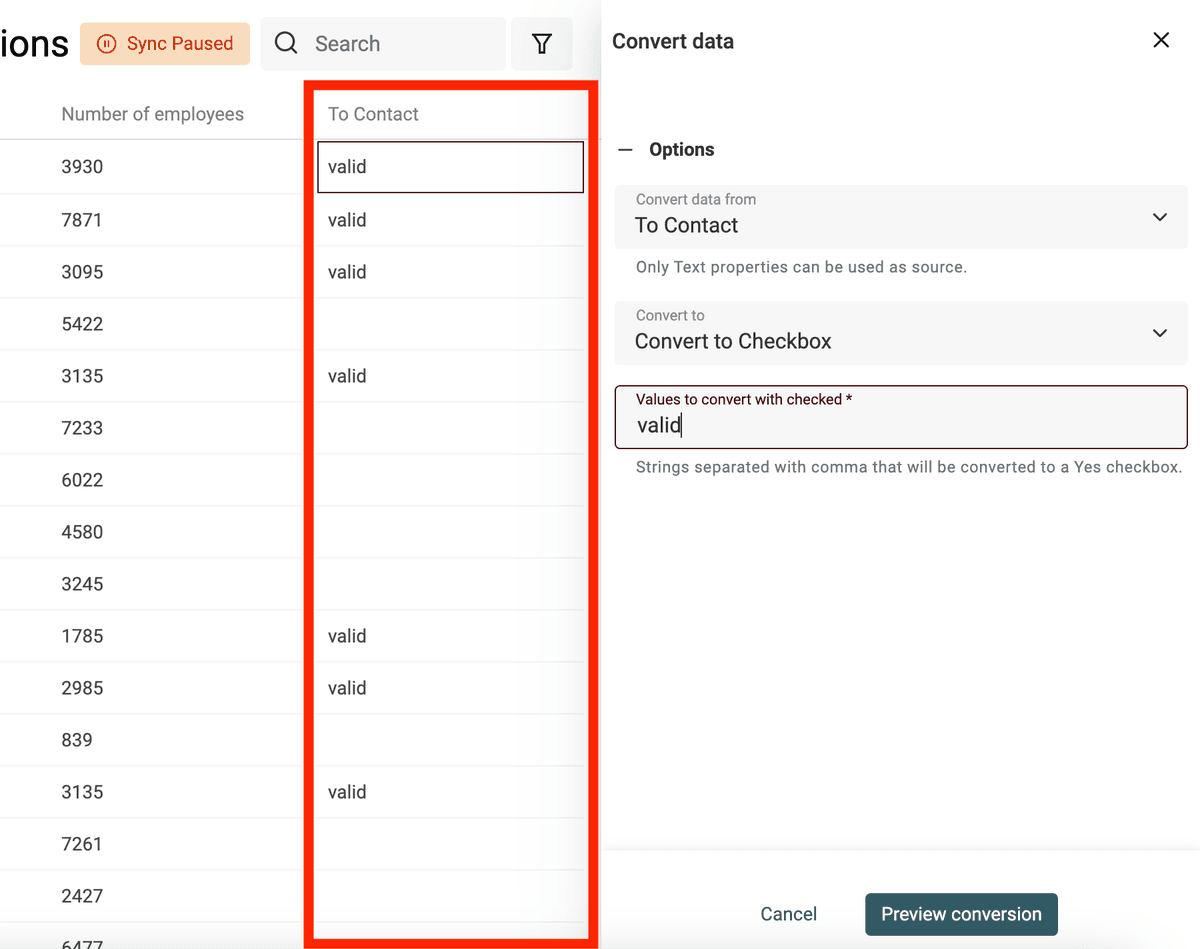
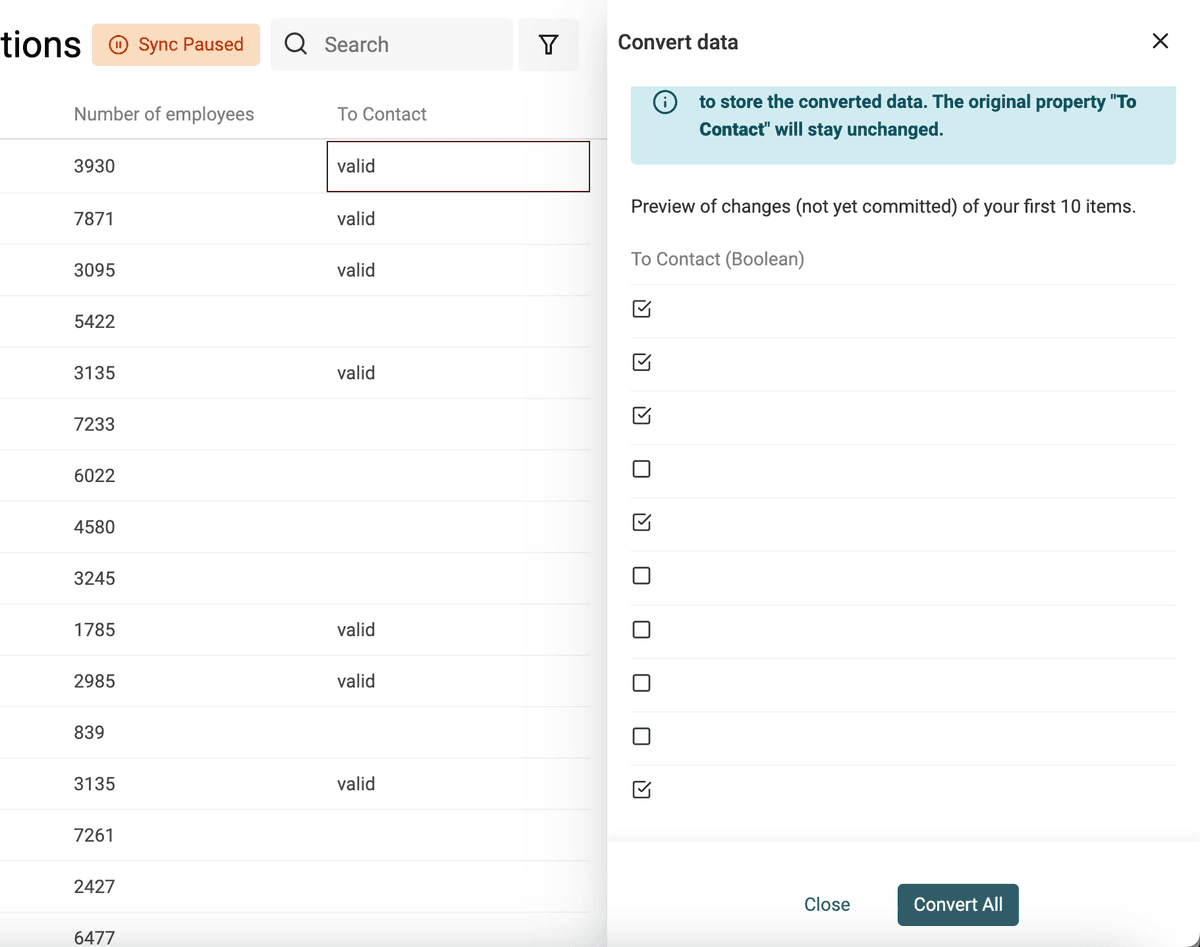
Crear Checkboxes (booleanos) desde texto
Datablist convierte automáticamente columnas con valores como "Yes, No", "TRUE, FALSE", etc., en propiedades de tipo Checkbox al importar. Use el conversor para casos más complejos.
Defina los valores (separados por comas) que se convertirán en un checkbox marcado. Los demás valores quedarán desmarcados.
Extraer números de textos
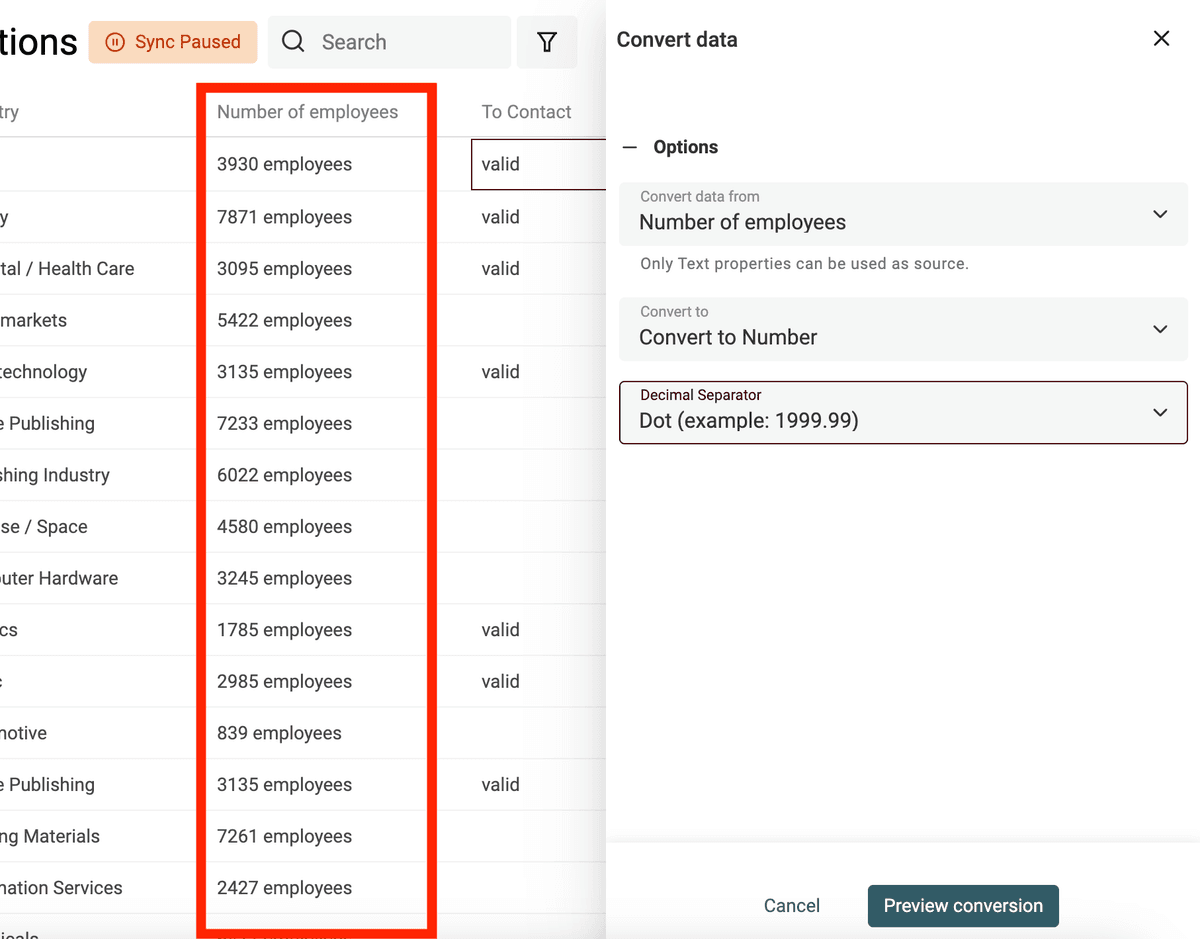
Use el conversor "Text to number" para:
- Normalizar números con separadores de decimales y miles personalizados
- Extraer números de textos con letras
👉 Visite nuestra documentación para aprender más sobre la conversión de números.
Limpiar datos
Convertir HTML a texto
Las herramientas de scraping analizan código HTML y es habitual que aparezcan etiquetas HTML en sus textos.
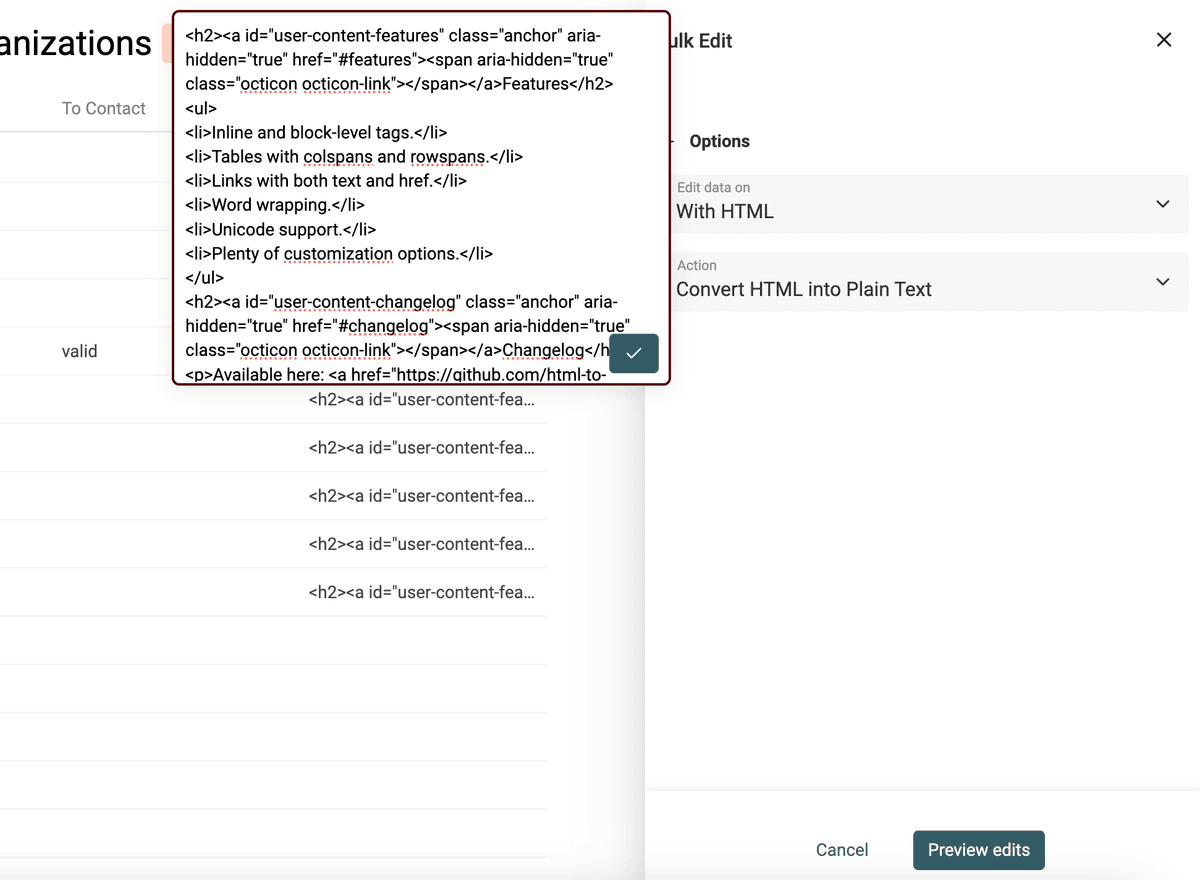
El HTML incluye enlaces, imágenes y listas con viñetas, y está escrito con párrafos y múltiples líneas.
El objetivo es conservar parte del orden que aporta el HTML pero transformar ese código ilegible en texto plano.
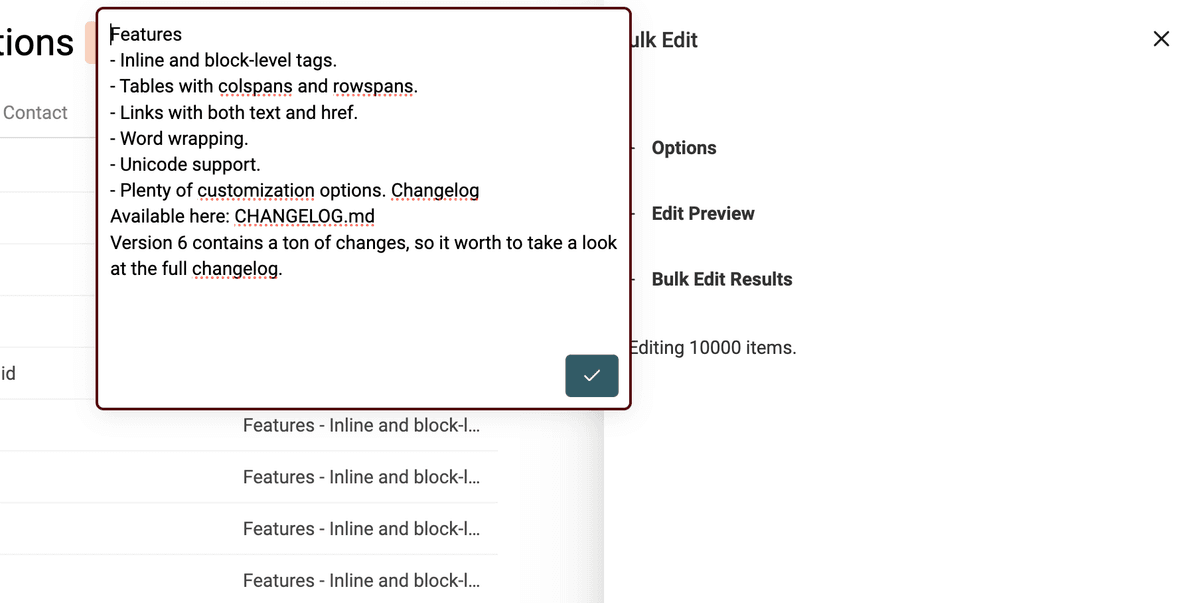
El conversor de HTML a texto de Datablist mantiene los saltos de línea y transforma las viñetas en listas con el prefijo -.
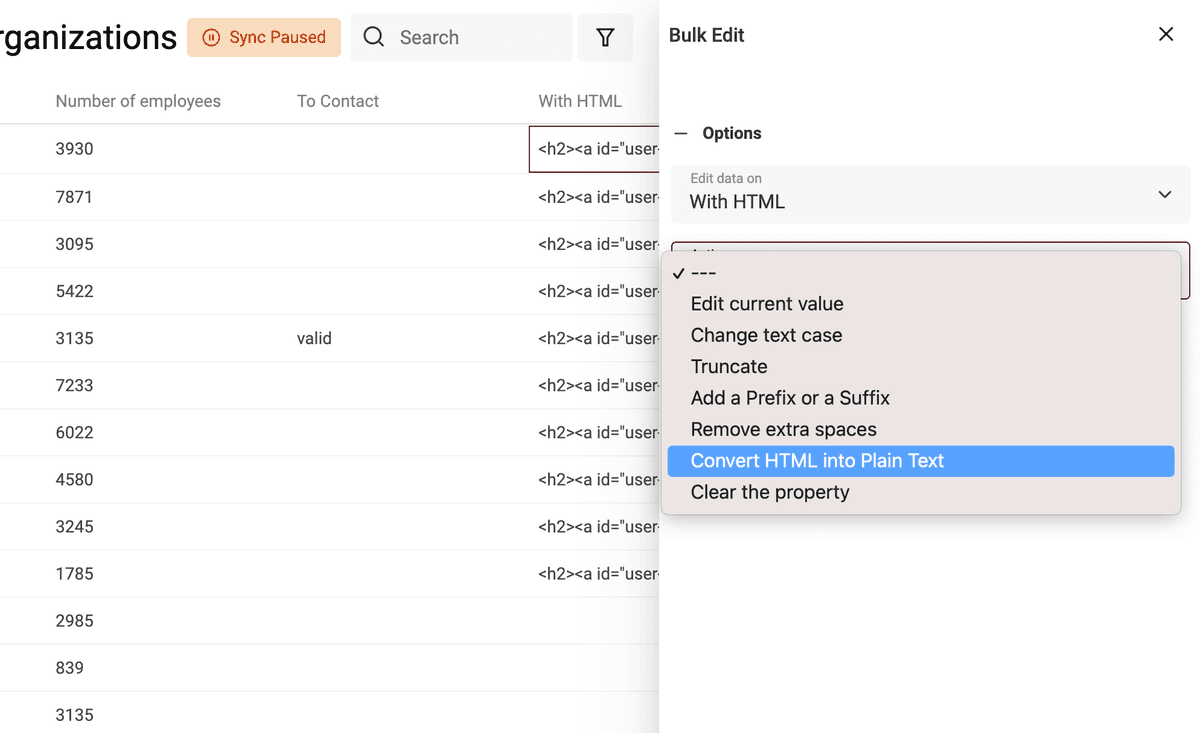
Para convertir su texto con etiquetas HTML en texto plano, abra la herramienta Bulk Edit en el menú Edit.
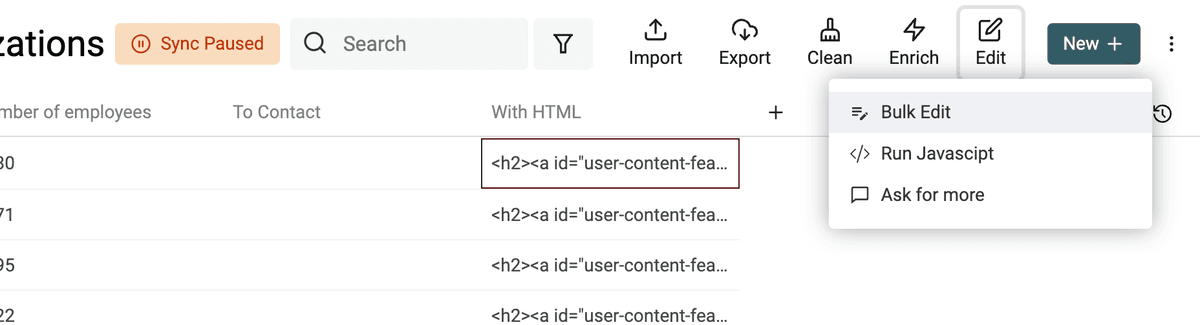
Seleccione su propiedad con etiquetas HTML y elija "Convert HTML into plain text".
Eliminar espacios extra
Otro problema común con datos desordenados son los espacios de más. Los espacios provienen de saltos de línea, de Tab y de otros caracteres que representan espacios en HTML.
Datablist incluye una herramienta de limpieza para eliminar espacios extra.
Tiene dos modos:
- Modo 1: Eliminar todos los espacios. Este modo quita cualquier carácter de espacio. Es ideal para limpiar teléfonos, precios, etc., donde solo necesita letras, dígitos, etc.
- Modo 2: Eliminar solo "espacios extra".
Para el segundo modo, el algoritmo funciona así:
- Elimina espacios duplicados entre palabras
- Elimina líneas vacías
- Elimina espacios al inicio y al final de cada línea
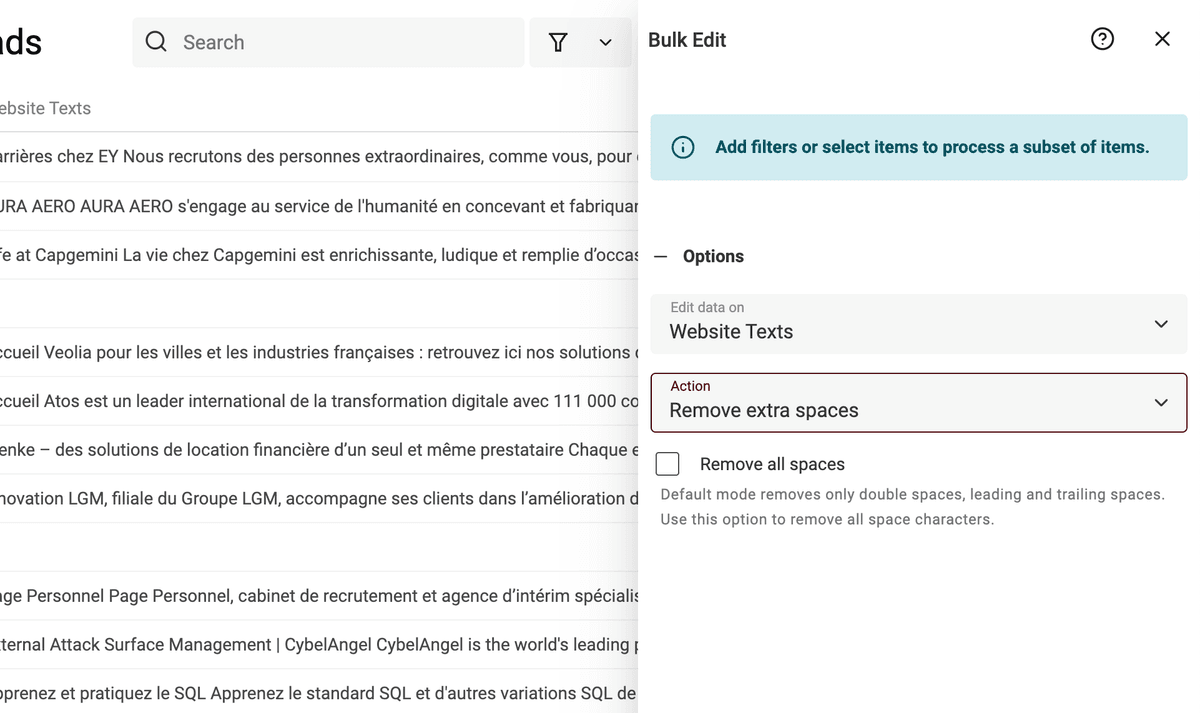
Para quitar espacios extra, vaya a la herramienta "Bulk Edit" del menú "Edit". Seleccione su propiedad y la acción "Remove extra spaces".
Marque la opción "Remove all spaces" para eliminar todos los espacios. Déjela desactivada para quitar solo los "espacios extra".
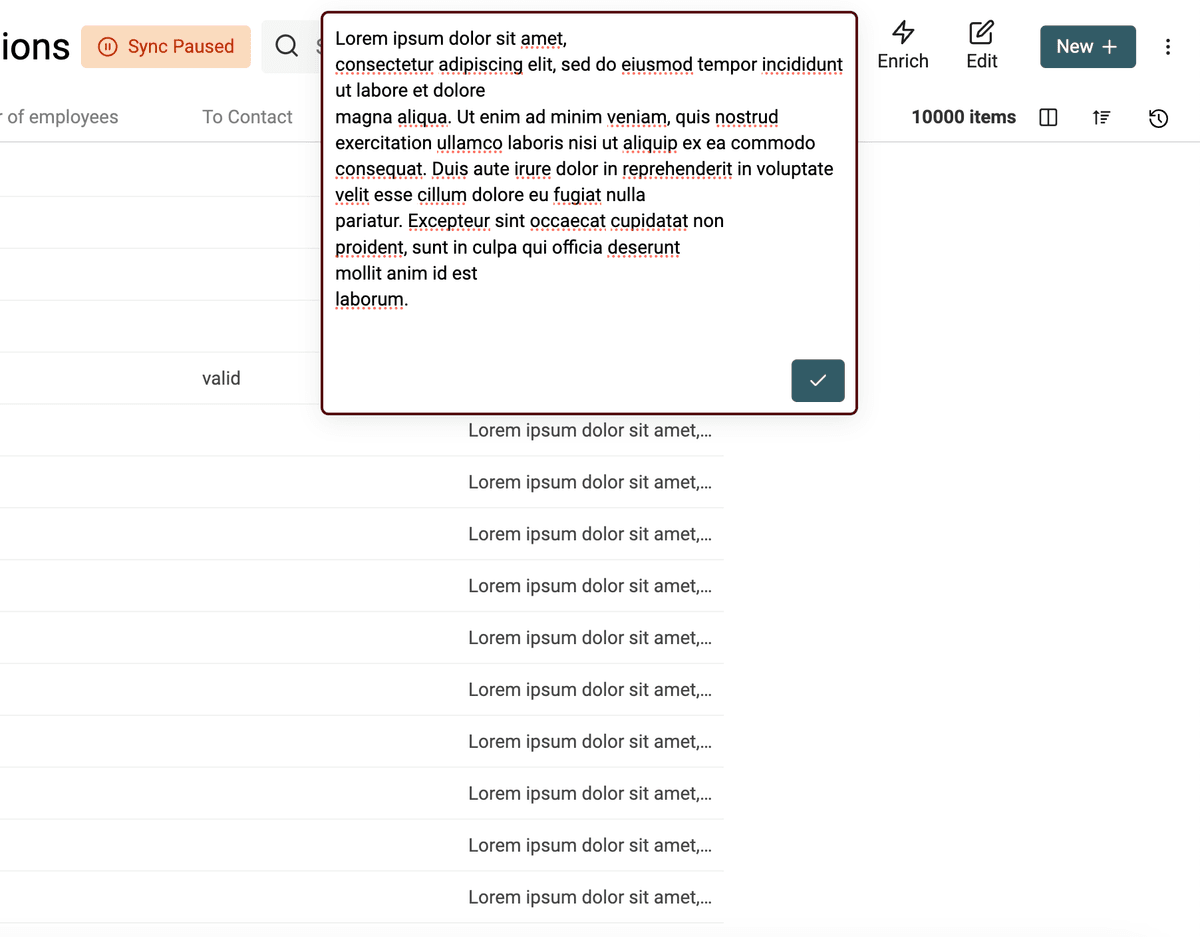
Aquí tiene un ejemplo con el algoritmo eliminando espacios extra:
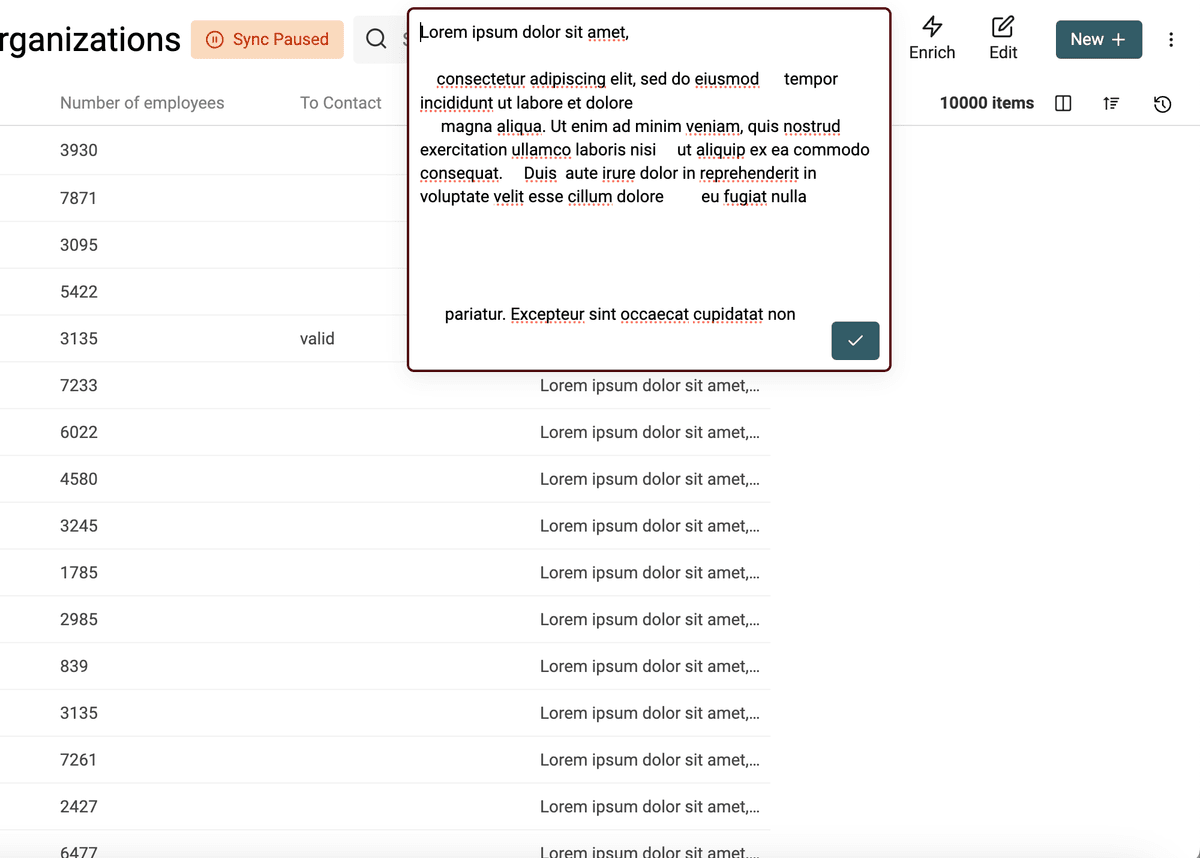
Tras la limpieza, sin los espacios extra:
Cambiar las mayúsculas/minúsculas
Cambiar el case del texto es sencillo. Abra la herramienta "Bulk Edit" en el menú "Edit".
Seleccione la propiedad a procesar y use la acción "Change text case".
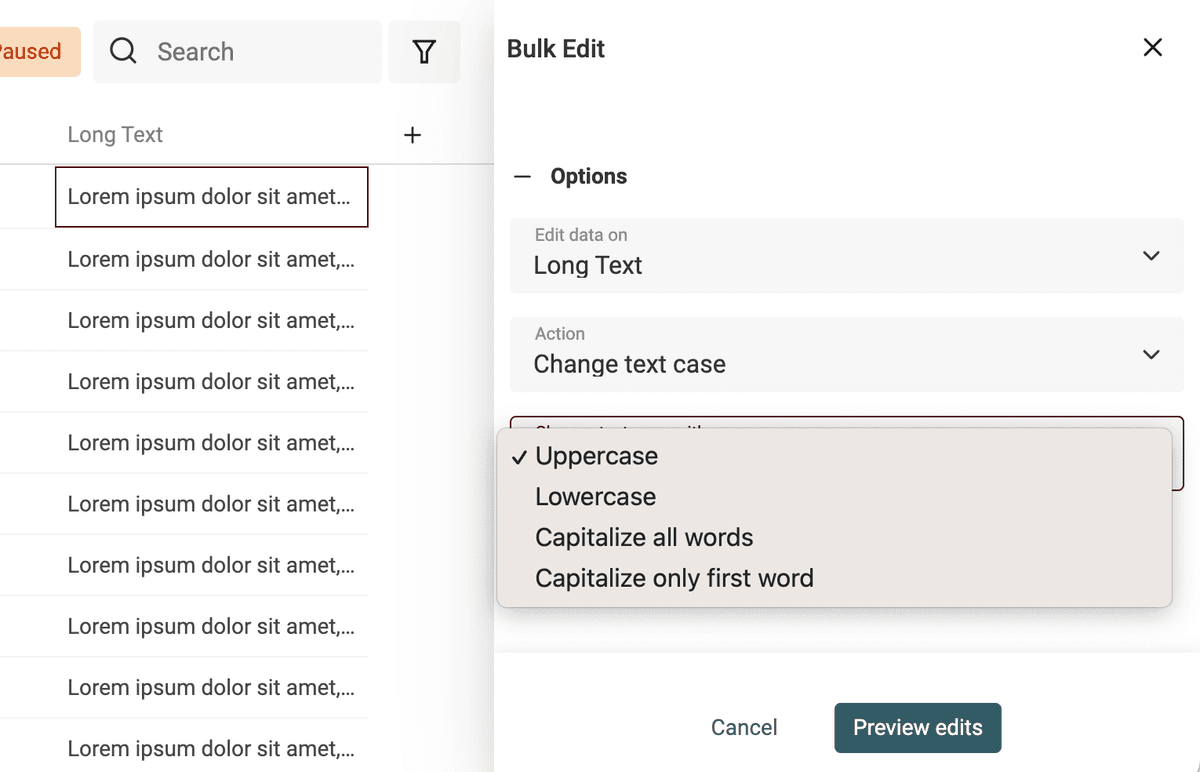
Hay 4 modos disponibles:
- Uppercase: Todas las letras se convierten en mayúsculas. Ej.:
john=>JOHN - Lowercase: Todas las letras se convierten en minúsculas. Ej.:
API=>api - Capitalize: La primera letra de cada palabra va en mayúscula. Ej.:
john is a good man=>John Is A Good Man - Capitalize only the first word: Solo la primera letra de la primera palabra va en mayúscula. Ej.:
john is a good man=>John is a good man
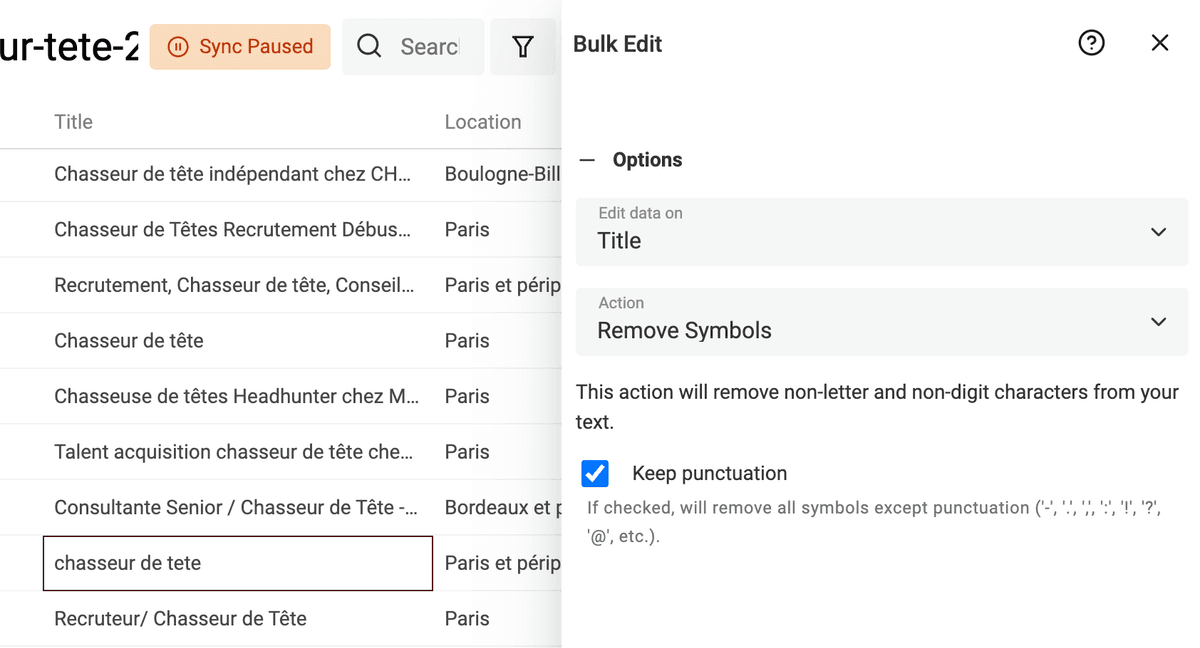
Eliminar símbolos de los textos
Textos extraídos de páginas HTML o con inputs de usuarios (por ejemplo, títulos de perfil de LinkedIn) pueden contener símbolos: emojis y otros caracteres que dificultan el procesamiento de datos. Un simple emoji al final de un nombre puede impedir que un algoritmo de deduplicación lo detecte.
Datablist incorpora un procesador para eliminar cualquier símbolo no textual de sus datos.
Haga clic en "Bulk Edit" desde el menú "Edit", seleccione una propiedad de texto y elija la transformación "Remove symbols".
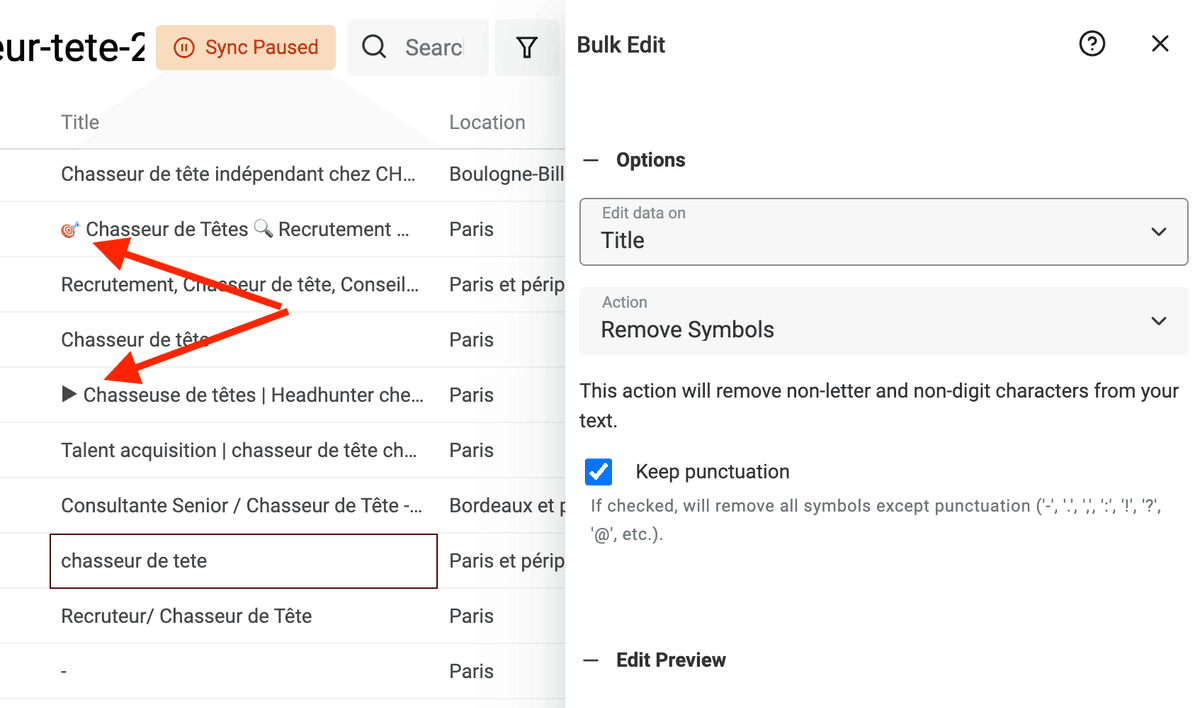
Si la vista previa es correcta, ejecute la transformación para procesar sus items.
Normalizar con Find and Replace
Para crear segmentos en sus listas de prospects, necesita normalizar sus datos.
- Normalizar job titles
- Normalizar países y ciudades
- Normalizar URL
- Etc.
Su objetivo es reducir una propiedad con texto libre a una con opciones limitadas. O transformar textos en una versión más básica (por ejemplo, una URL con path a un simple dominio).
Datablist incluye una potente herramienta de Find and Replace. Funciona con texto simple y con expresiones regulares.
Las Regular Expressions son complejas, pero muy poderosas.
Aquí tiene algunos ejemplos de uso de RegEx para limpiar datos.
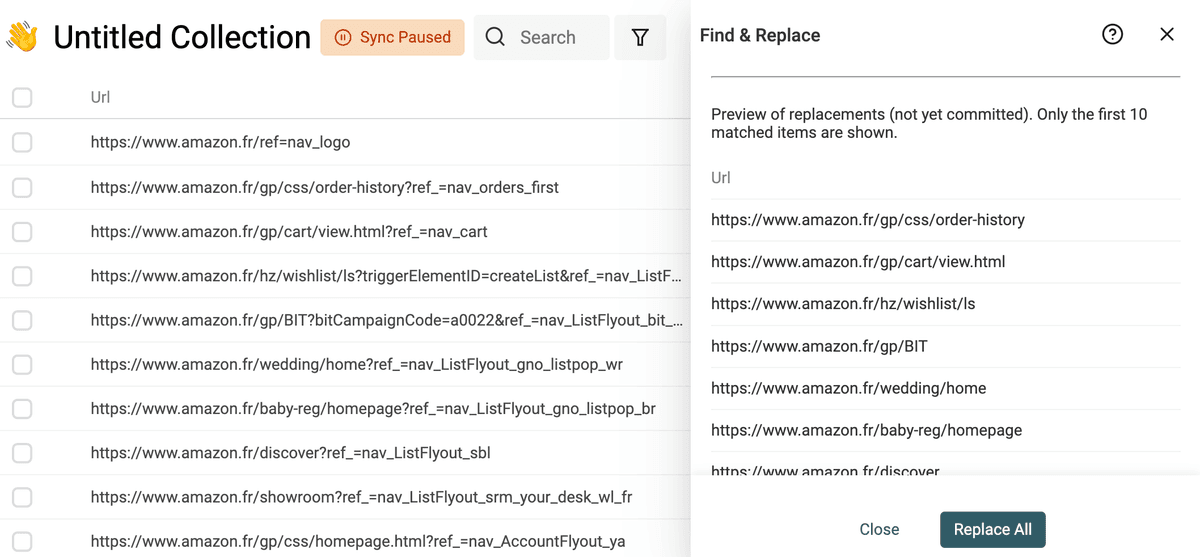
Quitar parámetros de consulta en una URL
Las URLs scrapeadas suelen tener parámetros de tracking o marketing que no sirven. Quitarlos le dará URLs limpias y ayudará a deduplicar al usar la URL para encontrar duplicados.
Para eliminar los query parameters de sus URLs, active la opción "Match using regular expression". Use la siguiente expresión regular con un texto de reemplazo vacío:
\?.*$
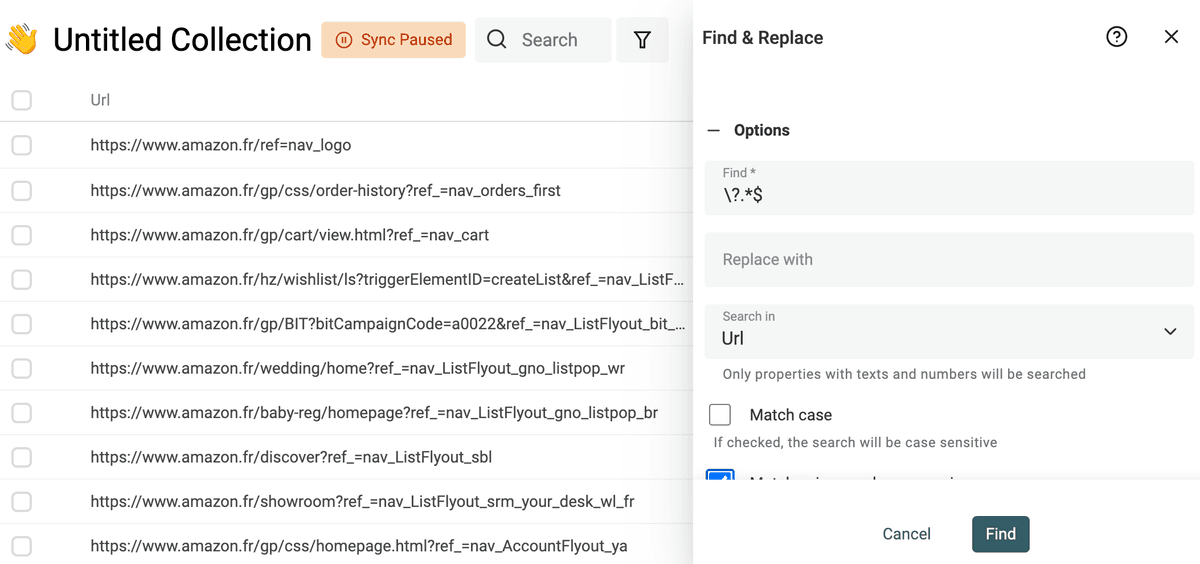
Y aplíquelo a su propiedad de URL.
Obtener dominio desde direcciones de email
Otro uso de Find and Replace con expresiones regulares es extraer el dominio de un email.
Duplique su propiedad de email para preservar los datos originales. Use la siguiente expresión regular con un reemplazo vacío:
^(\w)*@
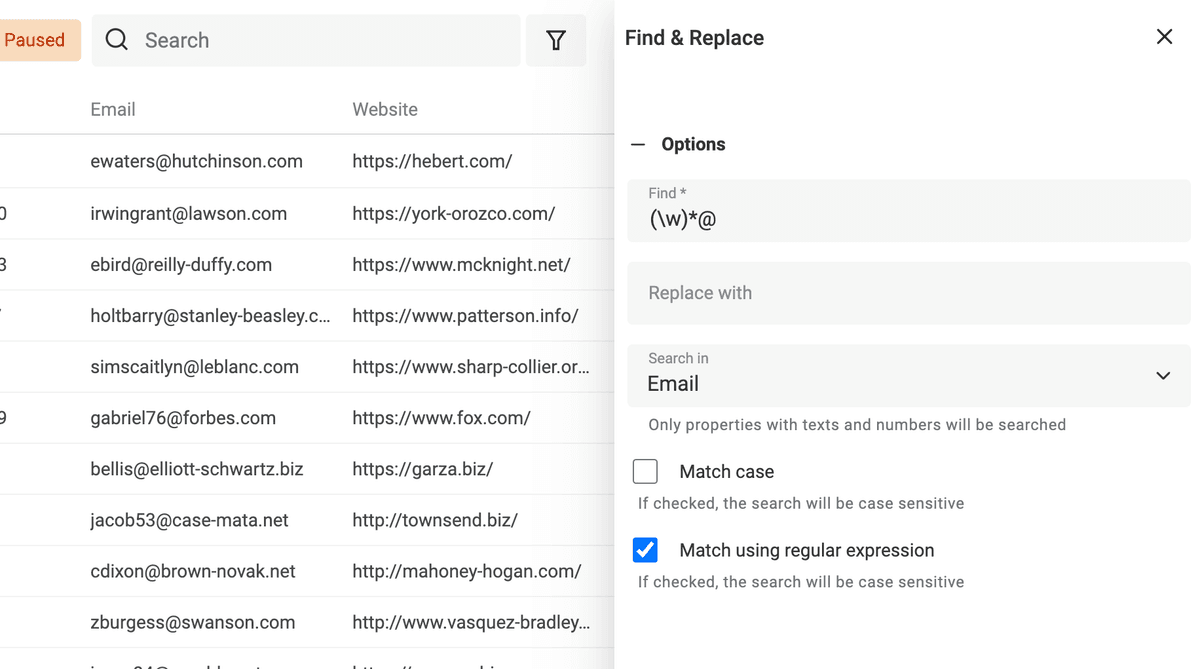
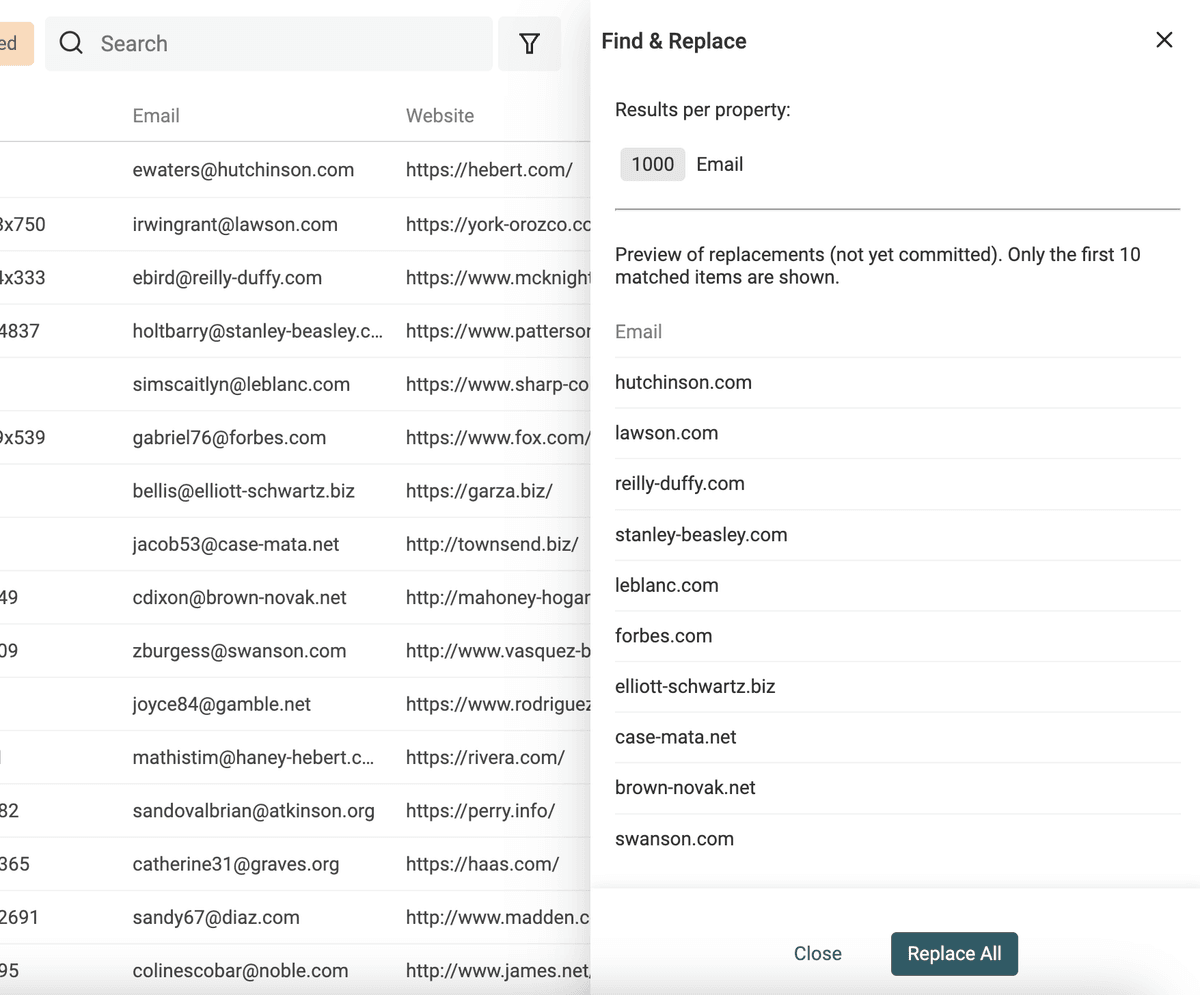
👉 Para saber más, visite la documentación de Find and Replace.
Separar nombre completo en First Name y Last Name
Al hacer scraping de listas de leads, suele obtener el "Full Name" y luego necesita separarlo en "First Name" y "Last Name". Poder dividir el nombre con precisión es un paso clave.
Separar nombre y apellido es útil para personalizar sus campañas de Cold Emailing, encontrar el género del contacto y recuperar el título académico.
Dividir nombres puede ser complejo. Por suerte, Datablist ofrece una herramienta sencilla para separar "Name" en dos valores usando el espacio como delimitador.
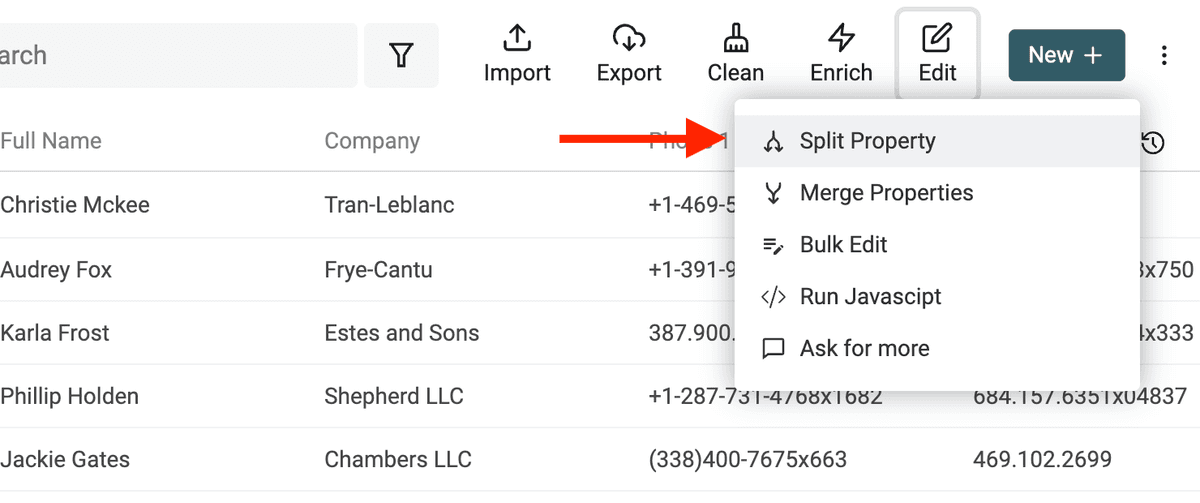
Para empezar, abra la herramienta "Split Property" en el menú "Edit".
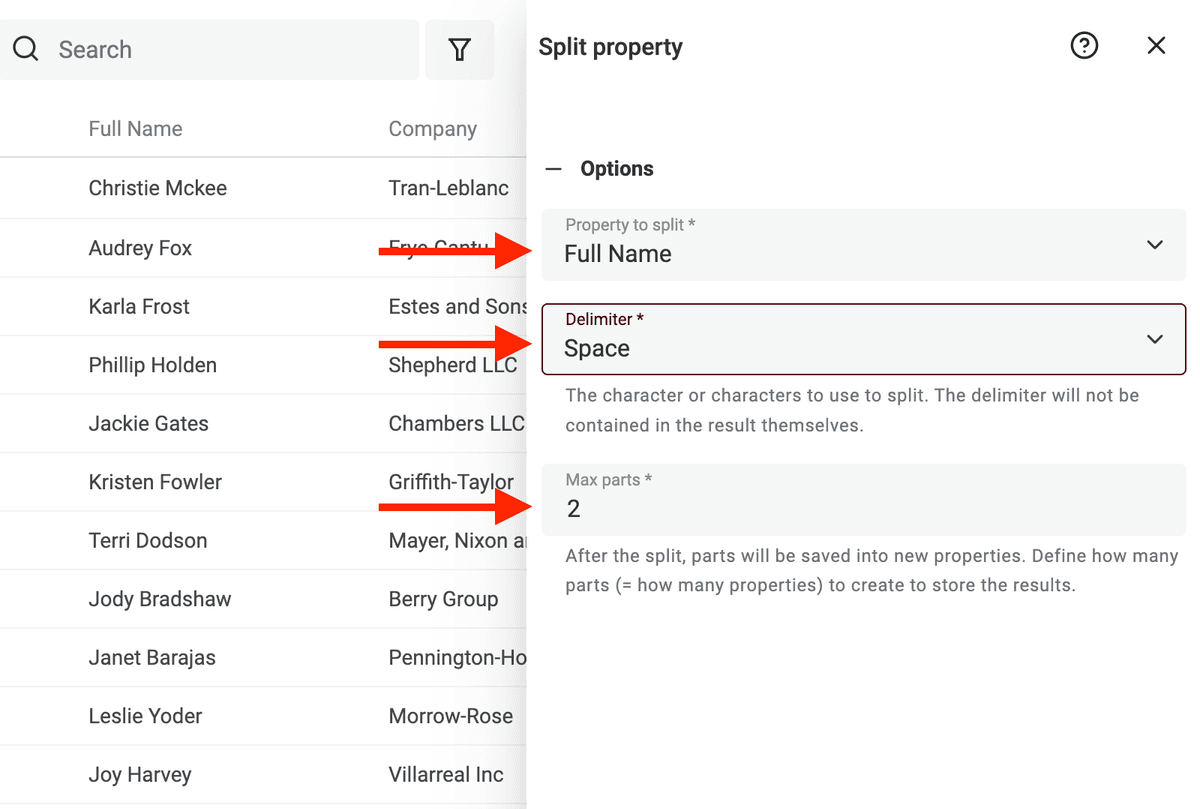
Luego, seleccione la propiedad con los nombres a analizar. Elija Space como delimitador y defina el número máximo de partes en 2.
Ejecute la vista previa. Datablist analizará sus primeros 10 items para generar el preview. Si el resultado es correcto, haga clic en "Split Property" para ejecutar el algoritmo en todos los items actuales.
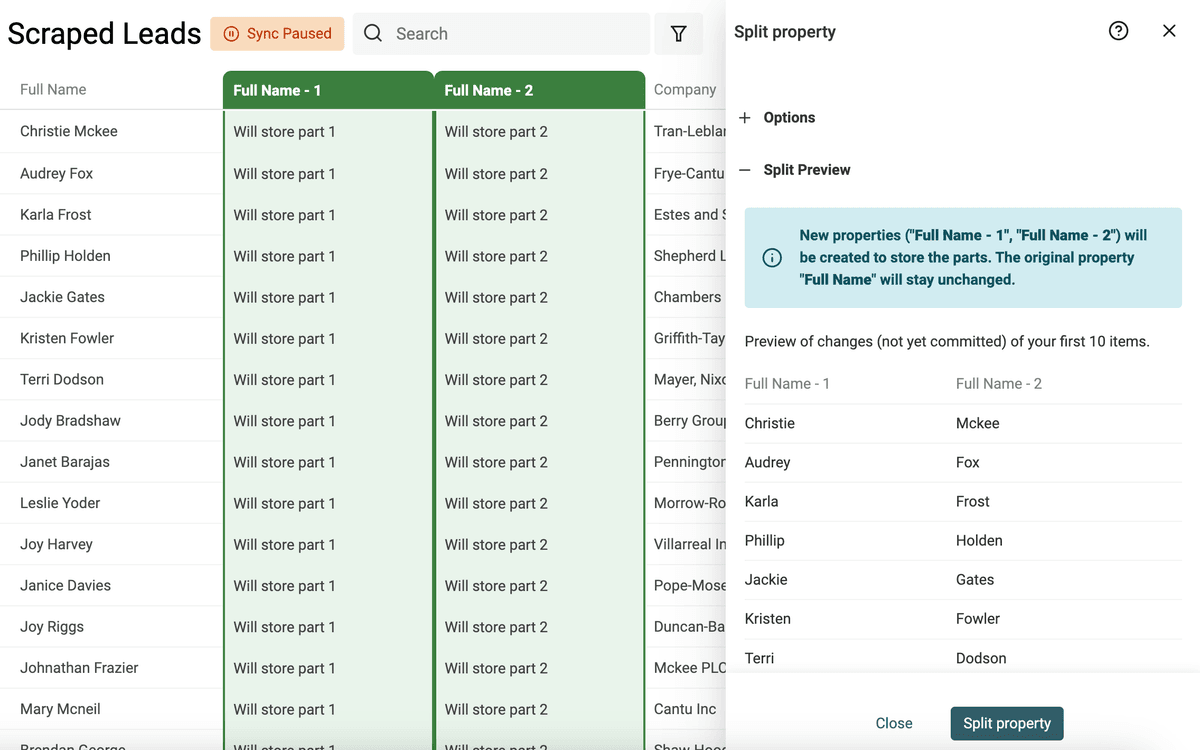
Tras la división, renombre las dos propiedades creadas como "First Name" y "Last Name".
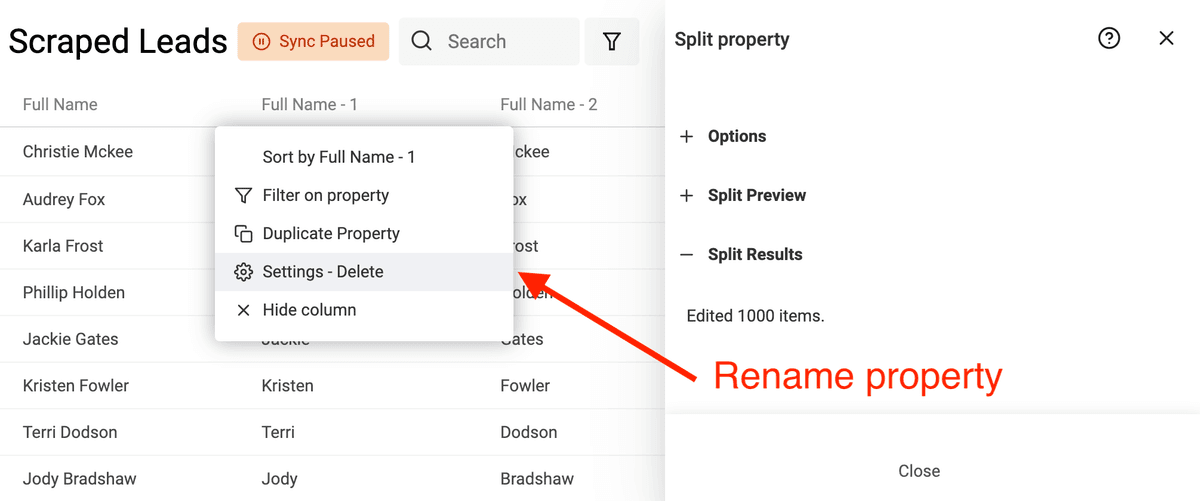
Este ejemplo se centra en el formato occidental, que suele incluir nombre y apellido. Puede complicarse con nombres no occidentales, con múltiples nombres o apellidos, o cuando incluyen títulos o sufijos.
Deduplicación de datos
Datablist tiene un potente algoritmo para dedupe records. Encuentra items similares usando una o varias propiedades y cuenta con un algoritmo automático para fusionarlos sin perder datos.
Para ejecutar la deduplicación, haga clic en "Duplicate Finder" en el menú "Clean".
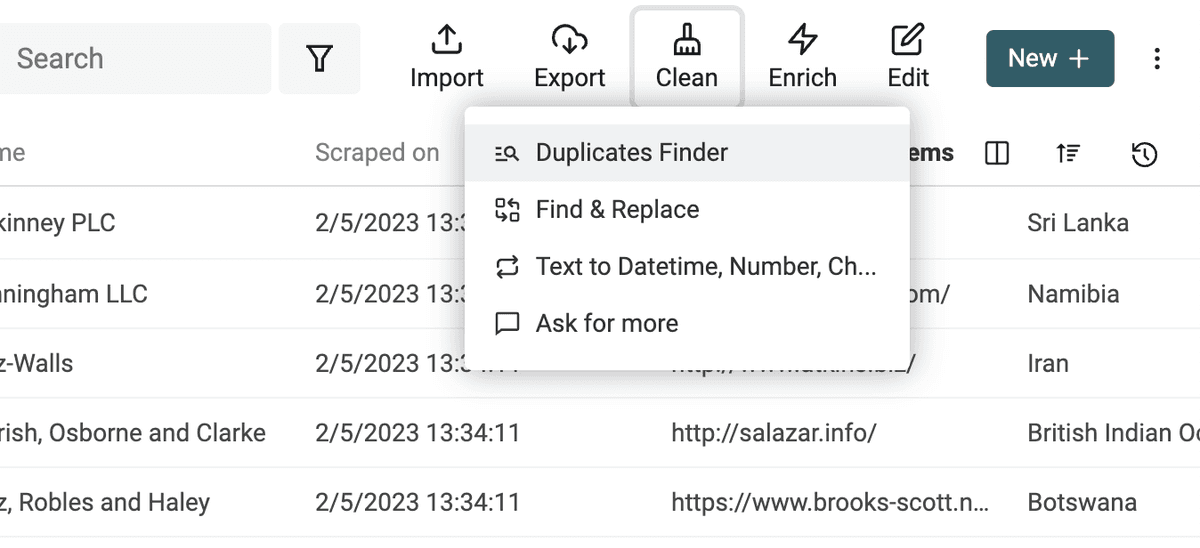
Seleccione las propiedades que se usarán para el matching.
En la página de resultados, ejecute el algoritmo "Auto Merge" una vez, solo con la opción "Merge non-conflicting duplicates". Esto fusionará los duplicados que se puedan unir fácilmente y listará las propiedades con conflictos.
El algoritmo de dedupe ofrece dos opciones para tratar datos en conflicto. Puede "Combine conflicting properties" usando un delimitador, o descartar los valores en conflicto para mantener un único master item.
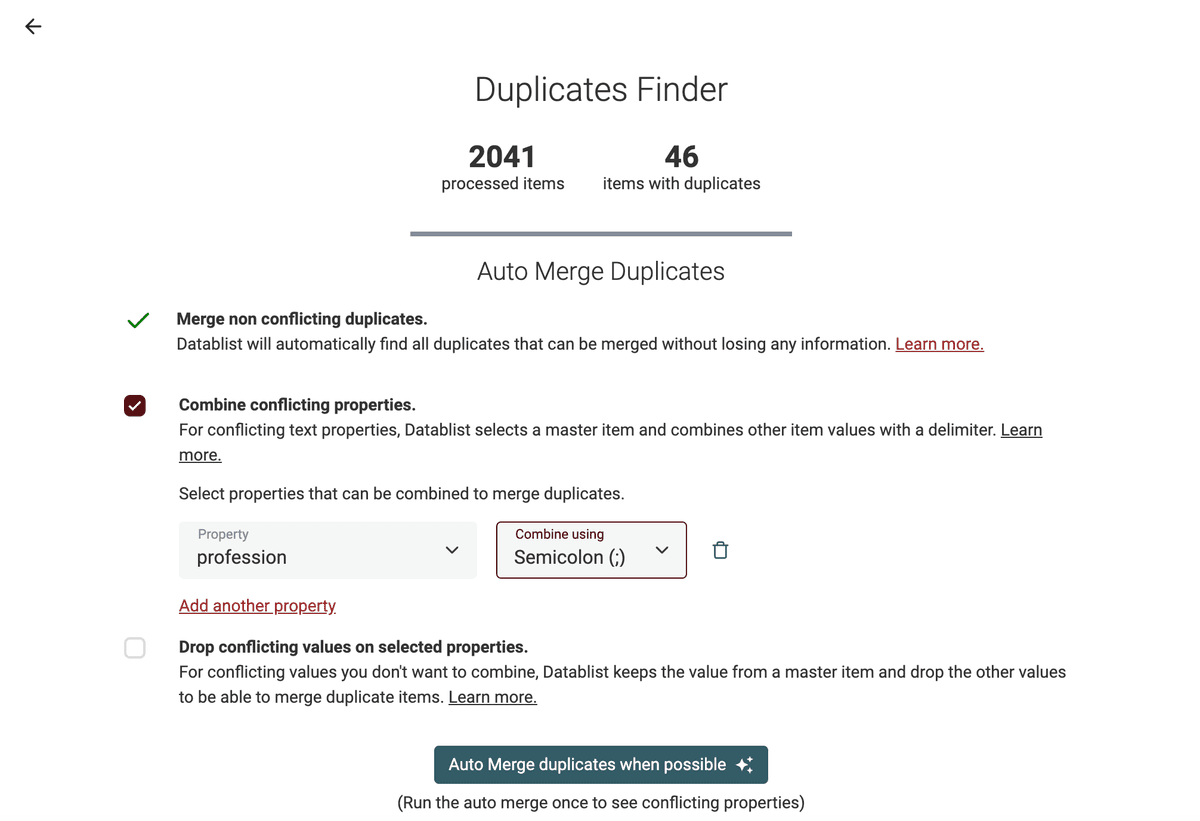
👉 Visite nuestra guía para fusionar duplicados en archivos CSV y nuestra guía para encontrar y fusionar duplicados usando nombres de empresa.
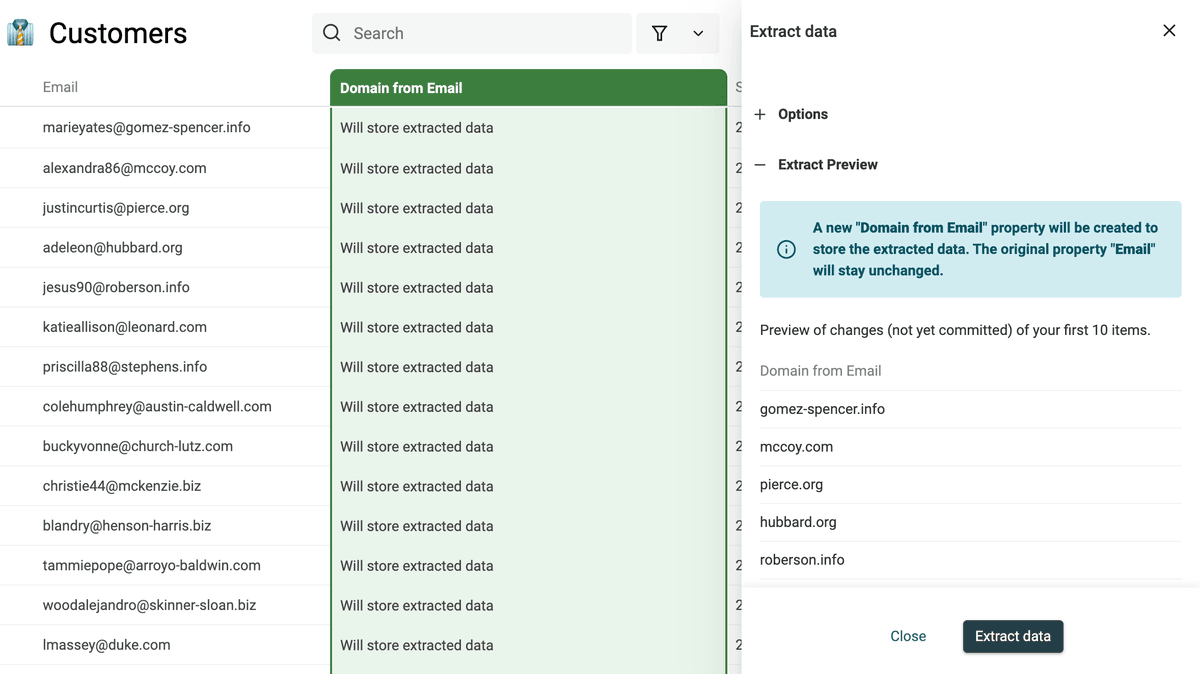
Extraer emails, URLs, etc. de textos
Datablist Data Extractor es una herramienta para analizar textos no estructurados y extraer entidades.
Usa reconocimiento de patrones para detectar:
- Direcciones de email en un texto
- URLs en un texto
- Dominio desde URLs
- Dominio desde emails
- Menciones (p. ej., @name) en un texto
- Tags (p. ej., #tag) en un texto
Data Extractor es perfecto para el análisis y la estructuración de datos. Con emails, URLs, etc. bien formateados, podrá conectar sus datos con otras herramientas y crear flujos automatizados.
Por ejemplo, una vez que obtenga emails, podrá enriquecerlos para encontrar información de contacto. O, usando el dominio de las URLs, puede consultar su ranking de tráfico con, por ejemplo, Similarweb.
Datablist Data Extractor está disponible desde el menú "Edit -> Extract url, email, tag, etc.".
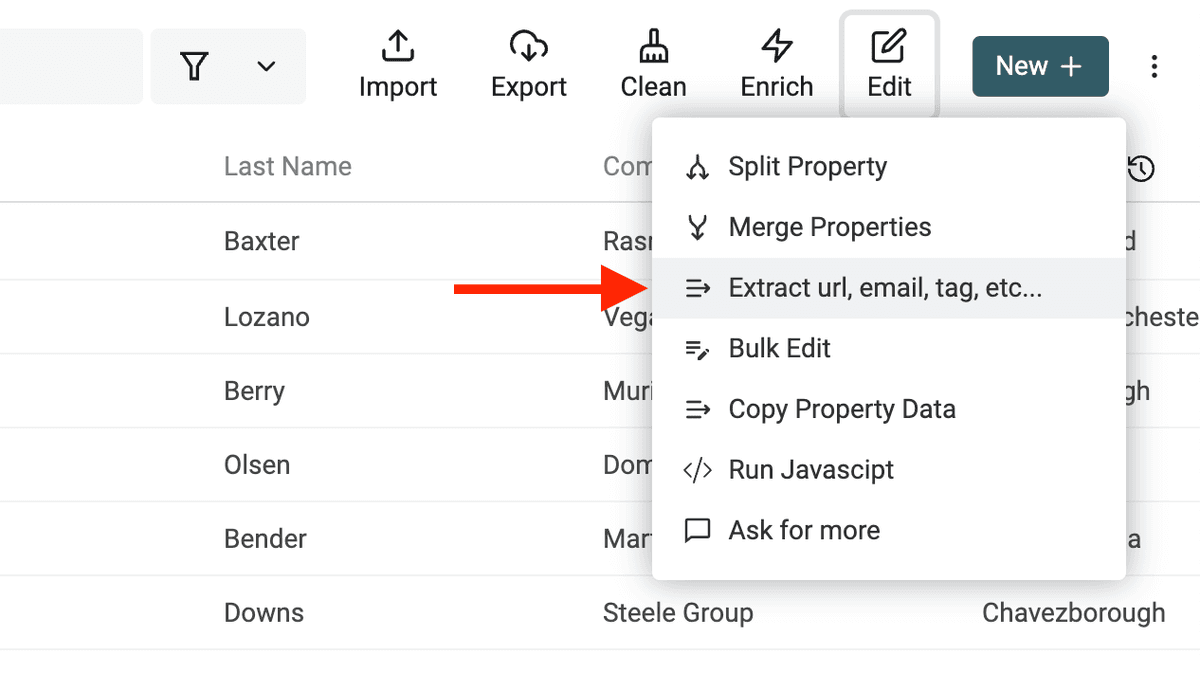
Seleccione la propiedad con texto no estructurado y elija un parser.
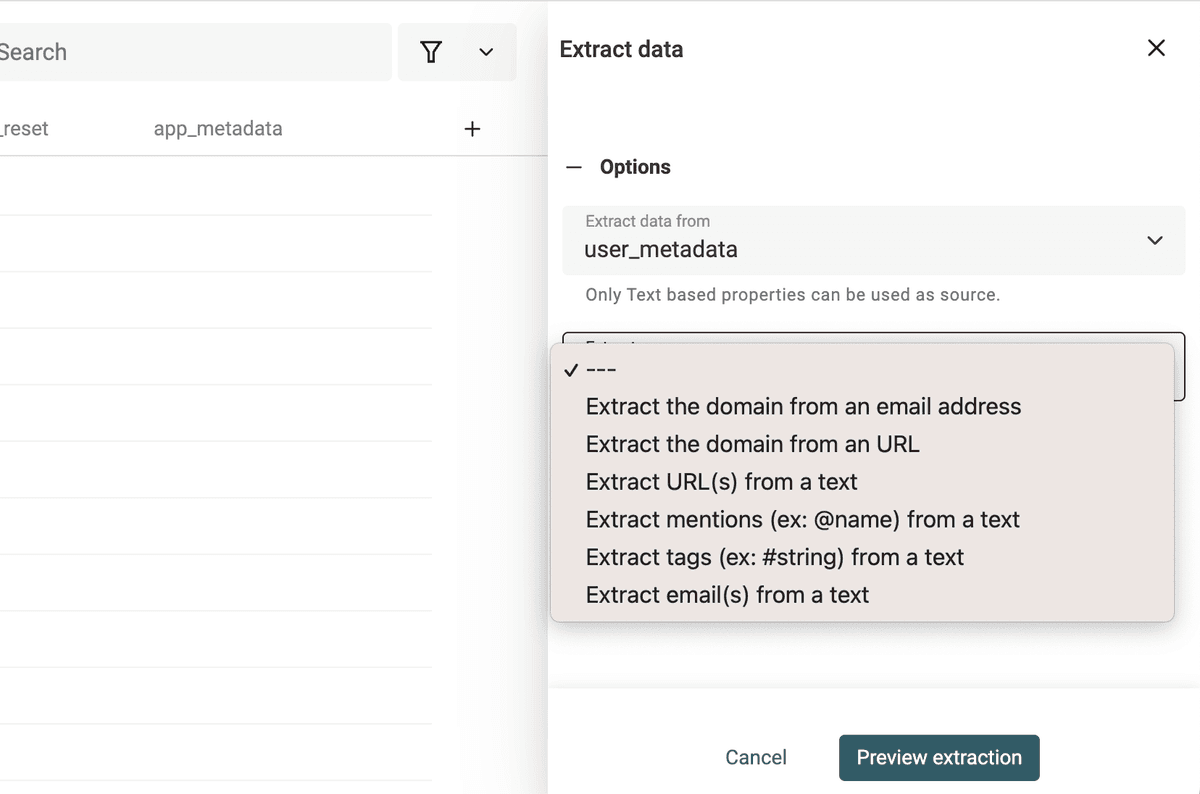
Ejecute el parser para ver una vista previa. Si es correcta, haga clic en "Extract" para procesar sus items.
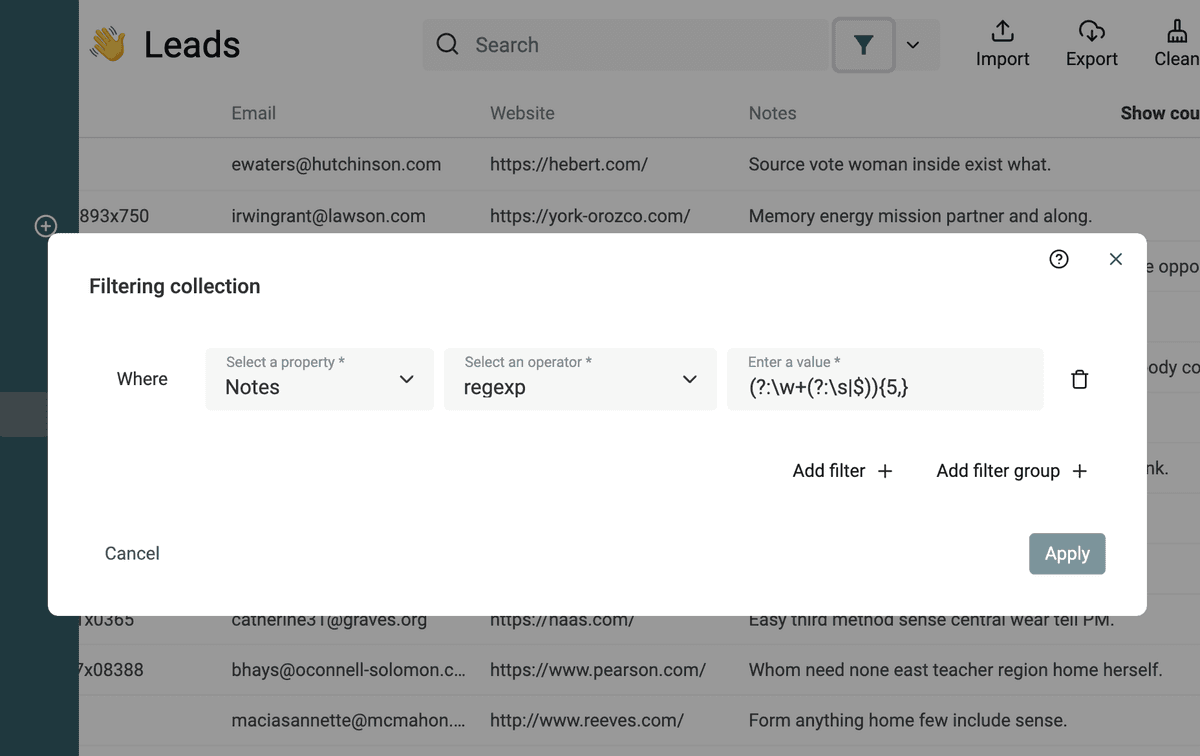
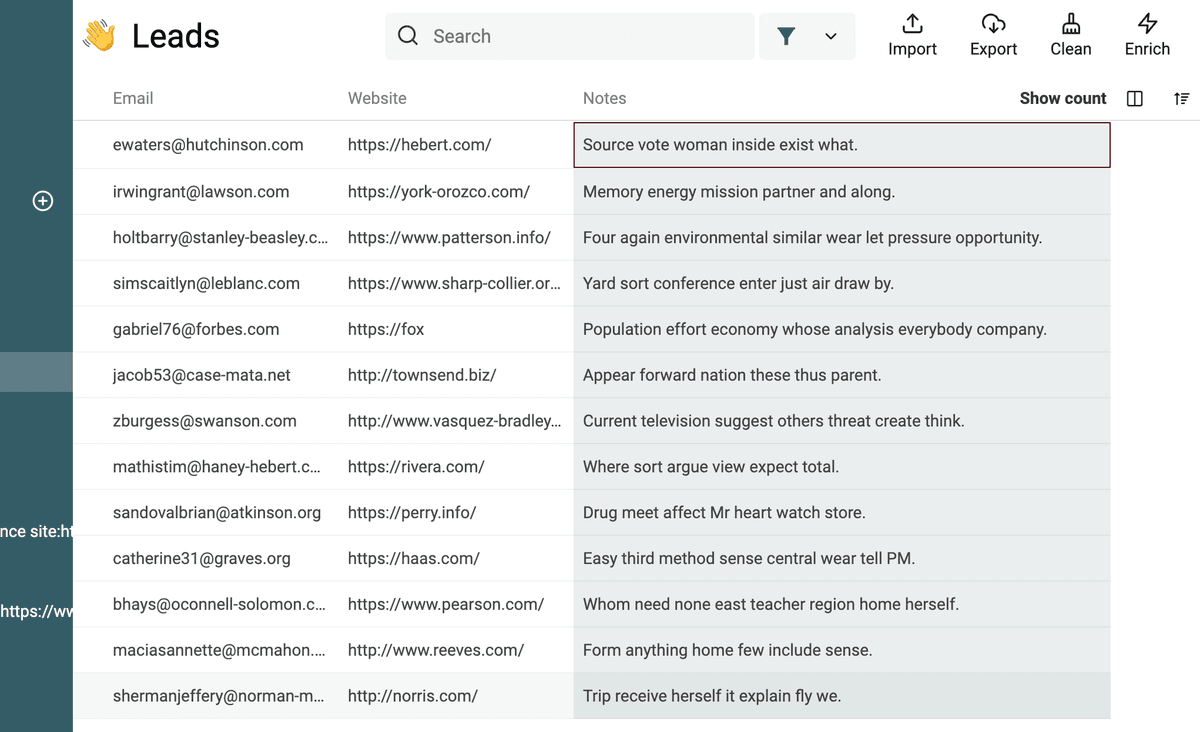
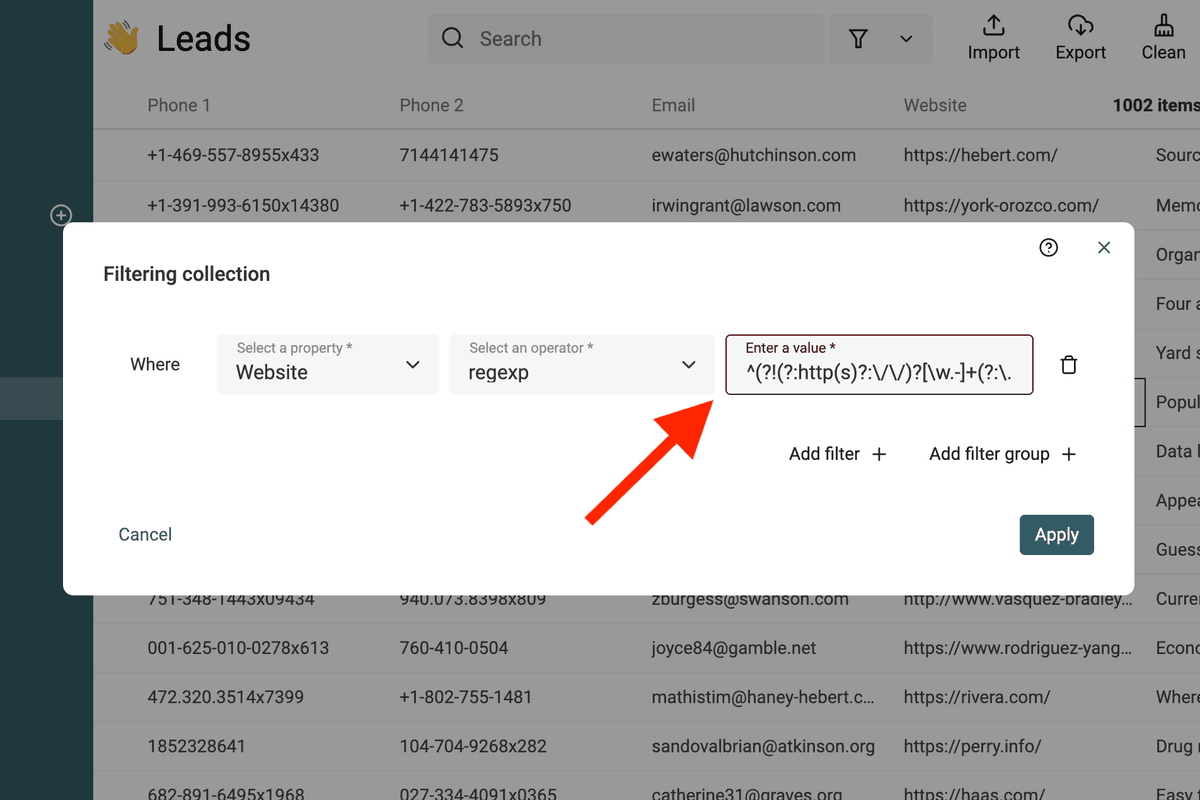
Usar RegEx para filtrar y validar datos
Datablist le permite usar Regular Expression para filtrar datos.
Filtrar textos por número de palabras
Con esta expresión regular, puede filtrar textos con al menos {n} palabras:
(?:\w+(?:\s|$)){5,} (reemplace el 5 por cualquier número)
Otras variantes:
(?:\w+(?:\s|$)){,5}: Textos con menos de 5 palabras (incluye 5)(?:\w+(?:\s|$)){5,10}: Textos con entre 5 y 10 palabras
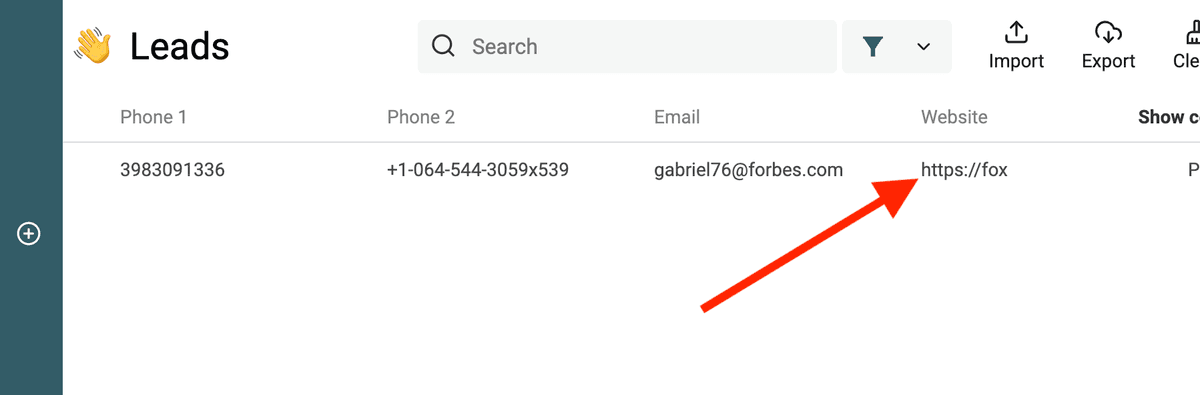
Filtrar URLs no válidas
La siguiente RegEx detecta URLs no válidas:
^(?!(?:http(s)?:\/\/)?[\w.-]+(?:\.[\w\.-]+)+[\w\-\._~:\/?#[\]@!\$&'\(\)\*\+,;=.]+).*$
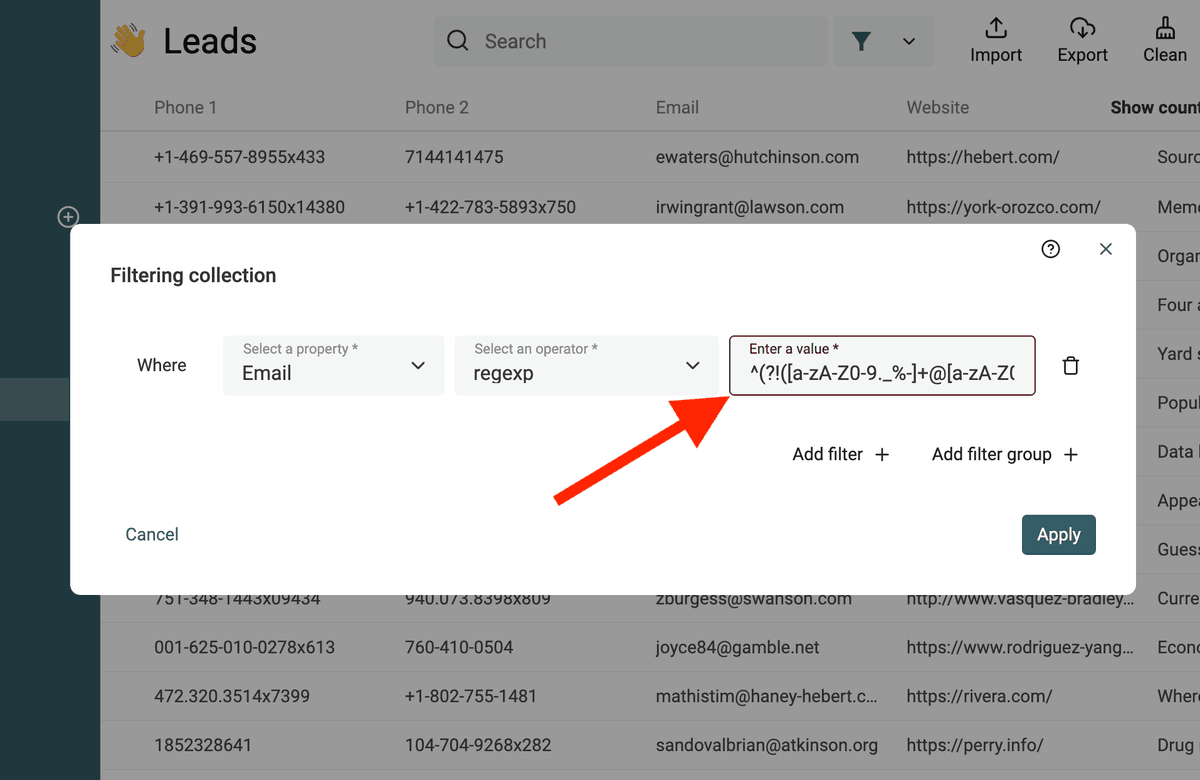
Filtrar emails no válidos
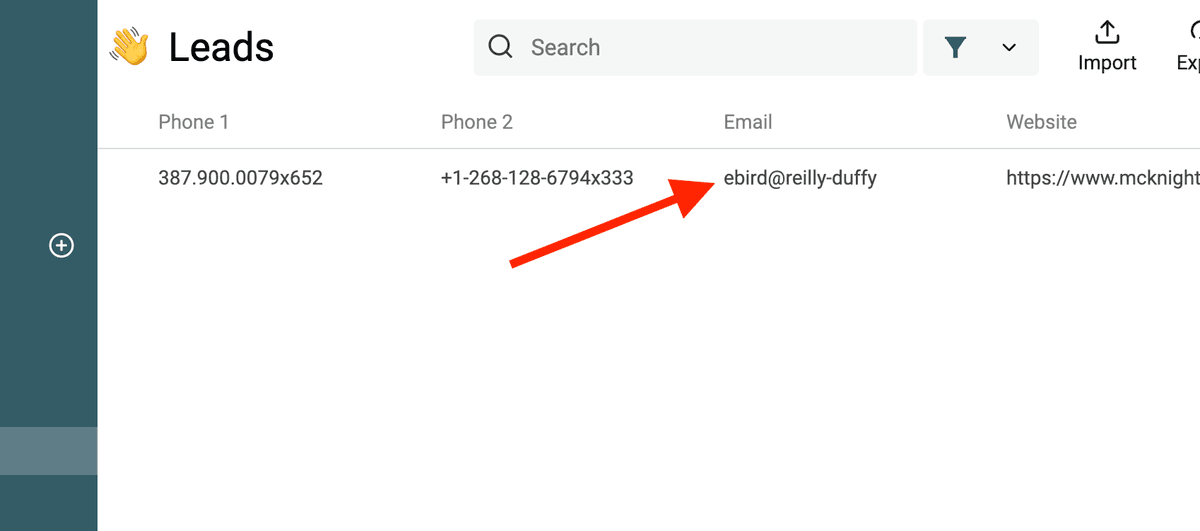
La siguiente RegEx detecta direcciones de email no válidas:
^(?!([a-zA-Z0-9._%-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,})).*$
Crear transformaciones personalizadas con JavaScript
Datablist le permite ejecutar código JavaScript personalizado sobre sus datos. Con esta capacidad, podrá resolver retos únicos, manejar formatos especializados, realizar cálculos complejos y aplicar transformaciones avanzadas.
Esta potente función le permite desplegar toda su creatividad y experiencia en manipulación de datos. Tiene flexibilidad para aplicar lógica a medida, crear bucles, condiciones y usar un amplio abanico de funciones de JavaScript para abordar incluso las tareas de limpieza más complejas.
Abra el editor JavaScript haciendo clic en "Run JavaScript" desde el menú "Edit".
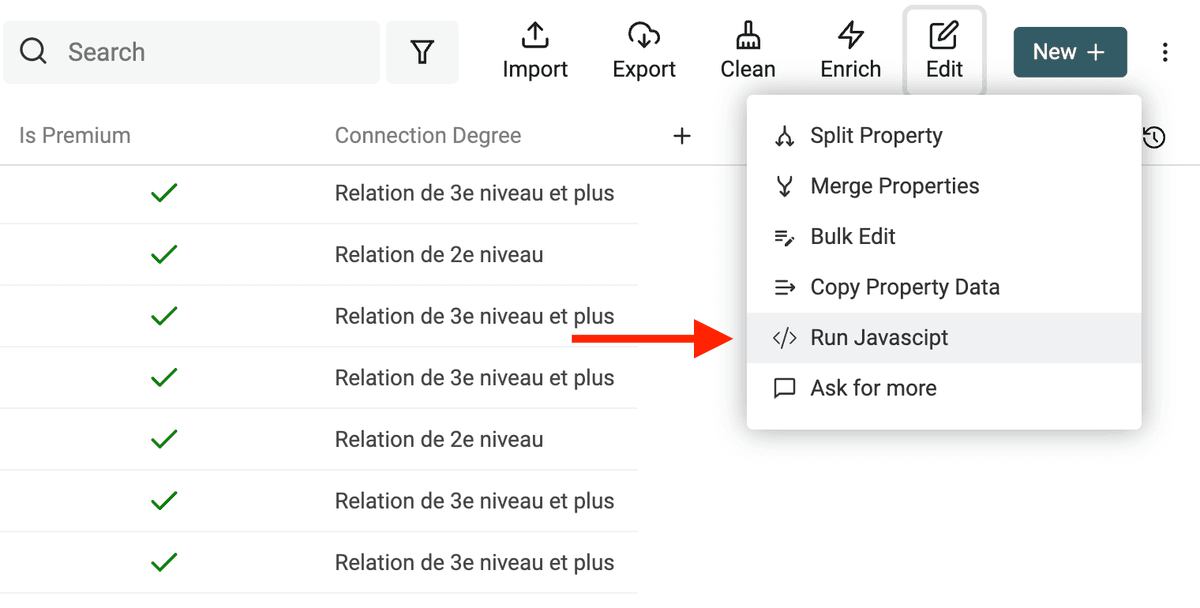
👉 Visite nuestra documentación para saber cómo escribir código JavaScript.
Validar direcciones de email
Los datos obtenidos por scraping pueden ser antiguos, contener typos o ser inválidos. Esto es especialmente cierto con las direcciones de email que vienen del scraping.
Cuando los datos son generados por usuarios, encontrará emails falsos en su base. O direcciones de proveedores desechables.
Datablist tiene una herramienta de validación de email integrada que le permite verificar miles de direcciones.
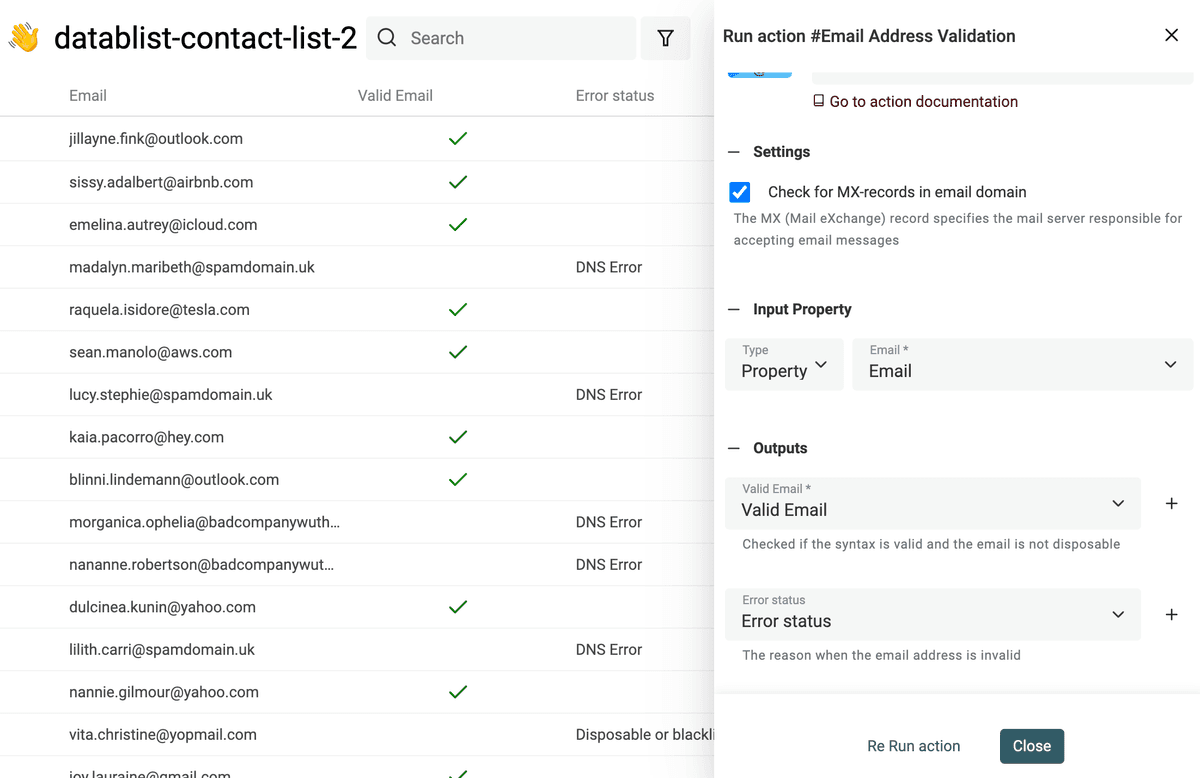
El servicio de verificación ofrece:
- Análisis de sintaxis del email: El primer control asegura que el email cumple el estándar IETF y realiza un análisis sintáctico completo. Esto detecta direcciones sin arroba (@), con dominios inválidos, etc.
- Detección de proveedores desechables: El segundo control identifica emails temporales. Busca dominios de proveedores de Disposable Email Address (DEA) como Mailinator, Temp-Mail, YopMail, etc.
- Verificación de registros MX del dominio: Un email válido debe tener un dominio con registros MX configurados. Esos registros MX indican el servidor que acepta los mensajes para el dominio. Si faltan, la dirección es inválida. Para cada dominio, el servicio consulta los registros DNS y busca los MX. Si el dominio no existe, el email se marca como inválido. Si existe pero sin MX válido, también se marca como inválido.
- Segmentación entre Business y Personal Email: Con prospects de lead magnets o para segmentar su base de usuarios, quizá quiera separar emails corporativos de personales. El servicio entrega esta información para enriquecer sus contactos.
FAQ
¿Qué es la limpieza de datos y por qué es importante?
La limpieza de datos, también llamada data cleansing o data scrubbing, es el proceso de identificar y corregir o eliminar errores, incoherencias e inexactitudes en un dataset. Incluye detectar y resolver problemas como valores faltantes, registros duplicados, errores de formato, outliers e inconsistencias en la representación de datos.
Es un paso crucial en el procesamiento de datos, ya que garantiza que la información sea precisa, confiable y adecuada para el análisis o su uso en distintas aplicaciones.
¿Qué otras herramientas gratuitas hay para Data Cleaning?
El panorama de data cleaning abarca desde herramientas genéricas como las hojas de cálculo hasta aplicaciones especializadas. Aquí tiene algunas alternativas gratuitas, además de Datablist, para sus tareas de limpieza.
OpenRefine
OpenRefine (antes Google Refine) es una herramienta open‑source centrada en explorar, limpiar y transformar datos desordenados e inconsistentes.
OpenRefine es una app de escritorio compatible con archivos tabulares (CSV, TSV), Microsoft Excel y otros formatos estructurados como JSON y XML.
OpenRefine es muy útil para tratar CSV inválidos:
- Gestiona muy bien problemas de encoding
- Ofrece opciones para resolver errores de formato CSV
En sus puntos débiles, OpenRefine tiene una curva de aprendizaje pronunciada y carece de algunas funciones orientadas al negocio. No incluye deduplicación ni flujos sencillos para unir un dataset con otra lista para actualizar o consolidar datos. Tampoco ofrece funciones de colaboración ni enrichments e integraciones de negocio.
Microsoft Excel y Google Sheets
Microsoft Excel y Google Sheets son potentes hojas de cálculo que pueden usarse para limpiar y preparar datos. Aunque tienen diferencias, ambas incluyen funciones útiles para transformar y depurar información.
Puede usar fórmulas para transformar y manipular datos. Y con formato condicional, resaltar valores inválidos que requieran revisión manual.
¿Necesita ayuda con su limpieza de datos?
Siempre busco feedback y casos reales de data cleaning para resolver. Por favor, contácteme y comparta su caso de uso.