Бесплатное удаление дубликатов


Что такое дедупликация данных?
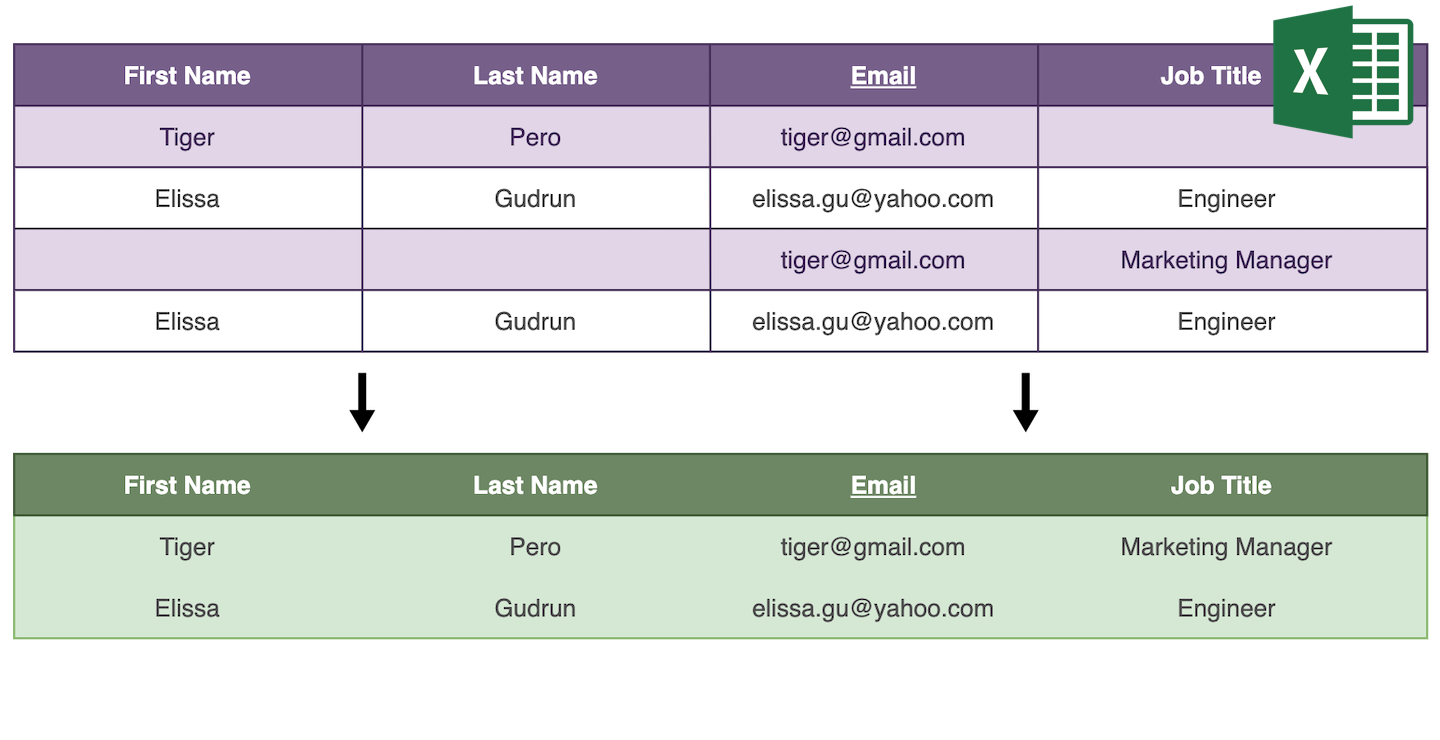
Дедупликация данных, или дедупликация, — это процесс удаления дублирующихся записей из набора данных.
Дедупликация необходима для получения списка уникальных записей. В маркетинге с рассылками, в lead generation или управлении клиентами. И в e-commerce при ведении каталогов товаров. Две записи считаются дубликатами, если они относятся к одной сущности. Например, два leads с одинаковым email-адресом или два товара с одинаковым штрихкодом.
Дубликаты ухудшают качество данных и снижают производительность. Есть два способа избавиться от дублей: удалить их или объединить похожие записи в одну.
Удалять дубликаты просто: алгоритм дедупликации находит повторяющиеся записи и удаляет все, кроме одной. Объединение дубликатов требует анализа записей, чтобы собрать их в единую мастер-запись.


















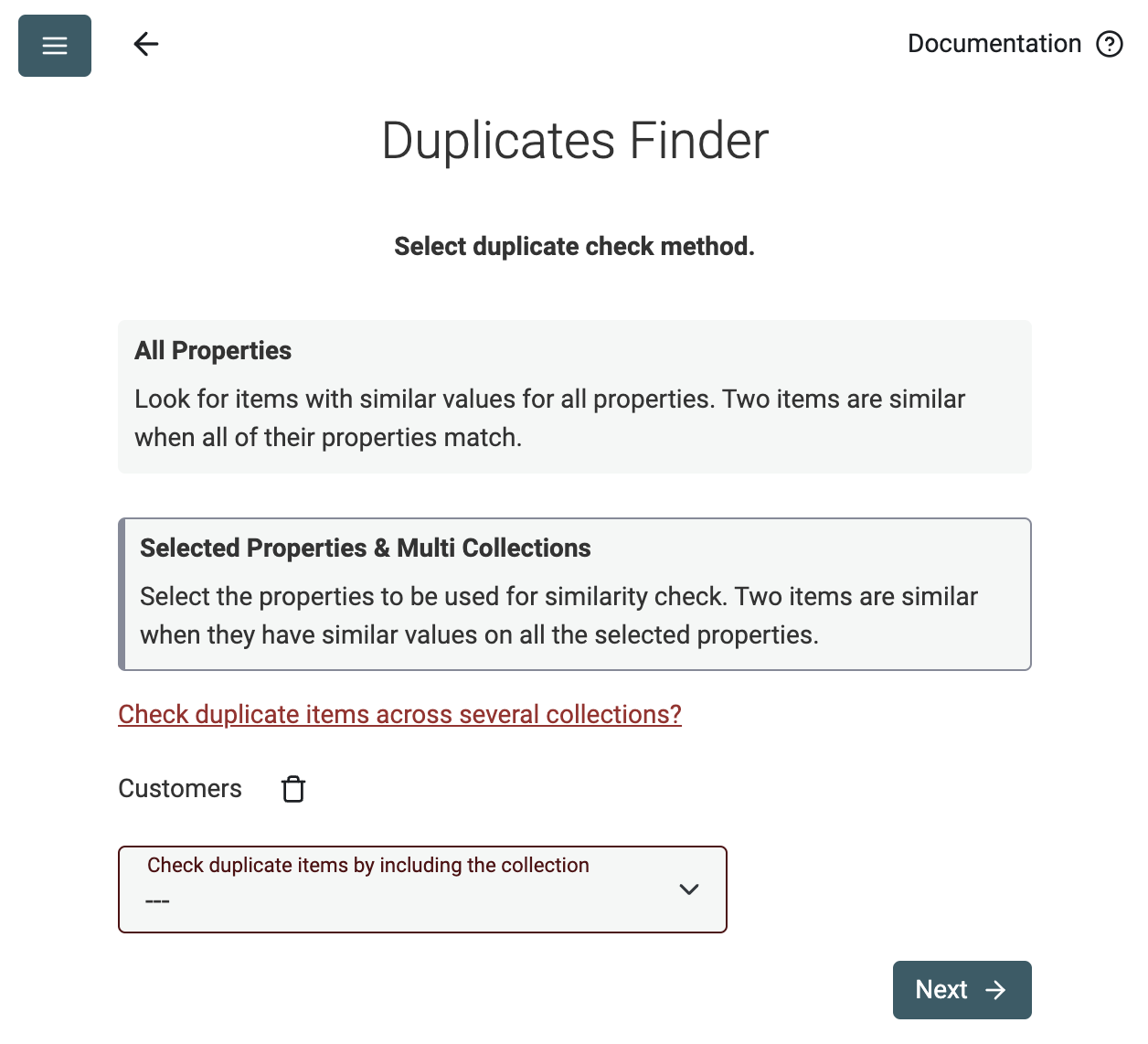
Анализ по всем полям или по выбранным свойствам — в одной или нескольких коллекциях данных
Datablist Duplicates Finder работает как с полным сравнением элементов, так и по выбранным свойствам.
Используйте режим Selected Properties, чтобы находить дубли контактов по их email-адресу или обнаруживать дубликаты в списке компаний по URL их сайта.
Удаляйте или консолидируйте дубликаты

Автоматическое объединение неконфликтующих дубликатов
Datablist автоматически находит все дубликаты, которые можно объединить без потери информации.
- Если у всех дублирующихся элементов одинаковые значения свойств, сохраняется только один элемент, а остальные удаляются.
- Если дубликаты дополняют друг друга, запись с наибольшим количеством информации выбирается как основная, и её значения свойств дополняются значениями из других записей. Затем все записи, кроме основной, удаляются.
- Если у дубликатов конфликтующие значения свойств, такие элементы пропускаются для ручного объединения.
Консолидируйте дубли, чтобы сохранить одну запись
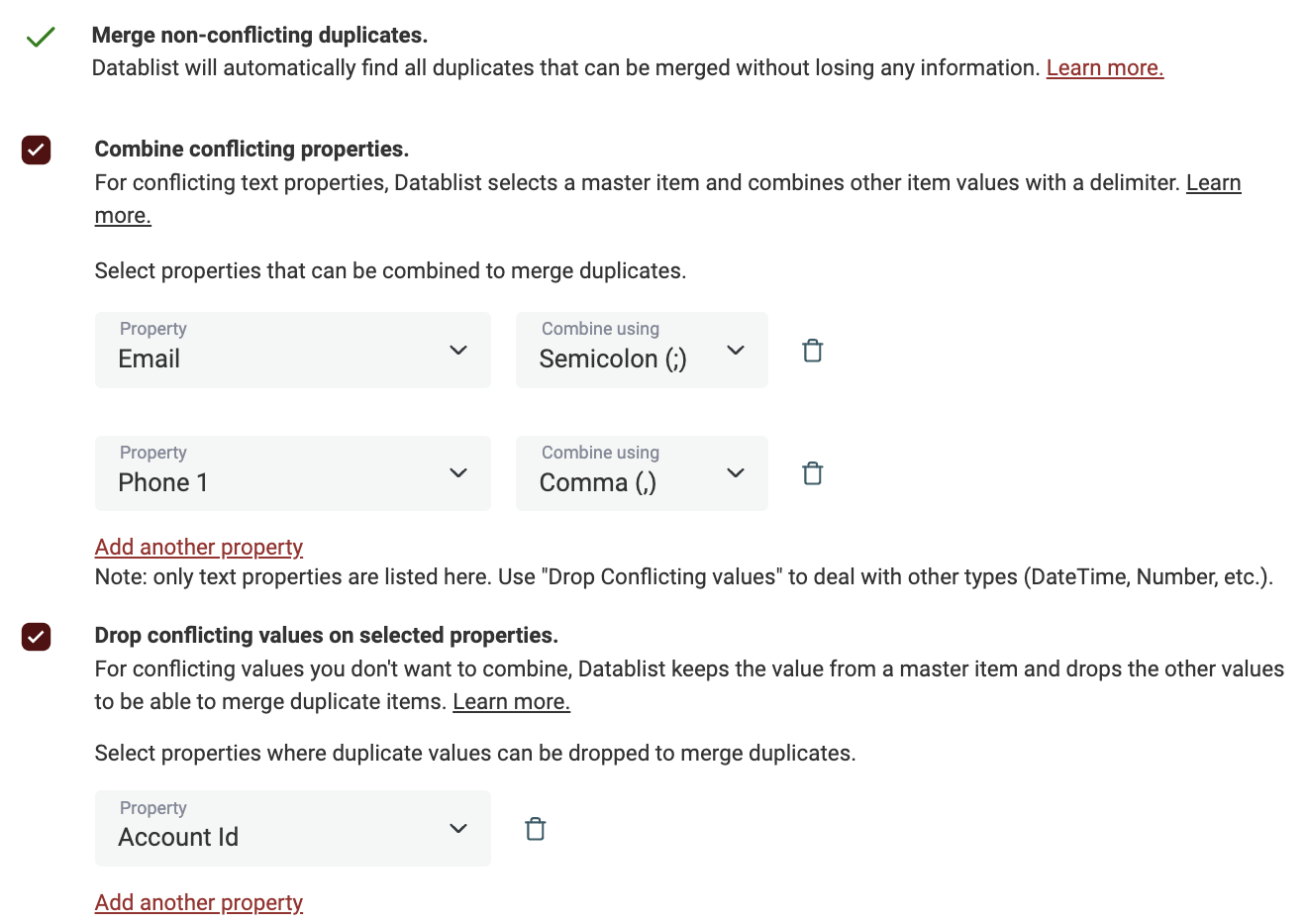
Когда простого объединения недостаточно, используйте расширенные функции: объединяйте или удаляйте дублирующиеся значения, чтобы консолидировать дубликаты записей.
Datablist показывает конфликтующие поля и позволяет выбрать, как с ними поступить. Используйте Объединить значения для конкатенации данных и Отбросить значения, чтобы сохранить значение из одной мастер‑записи.
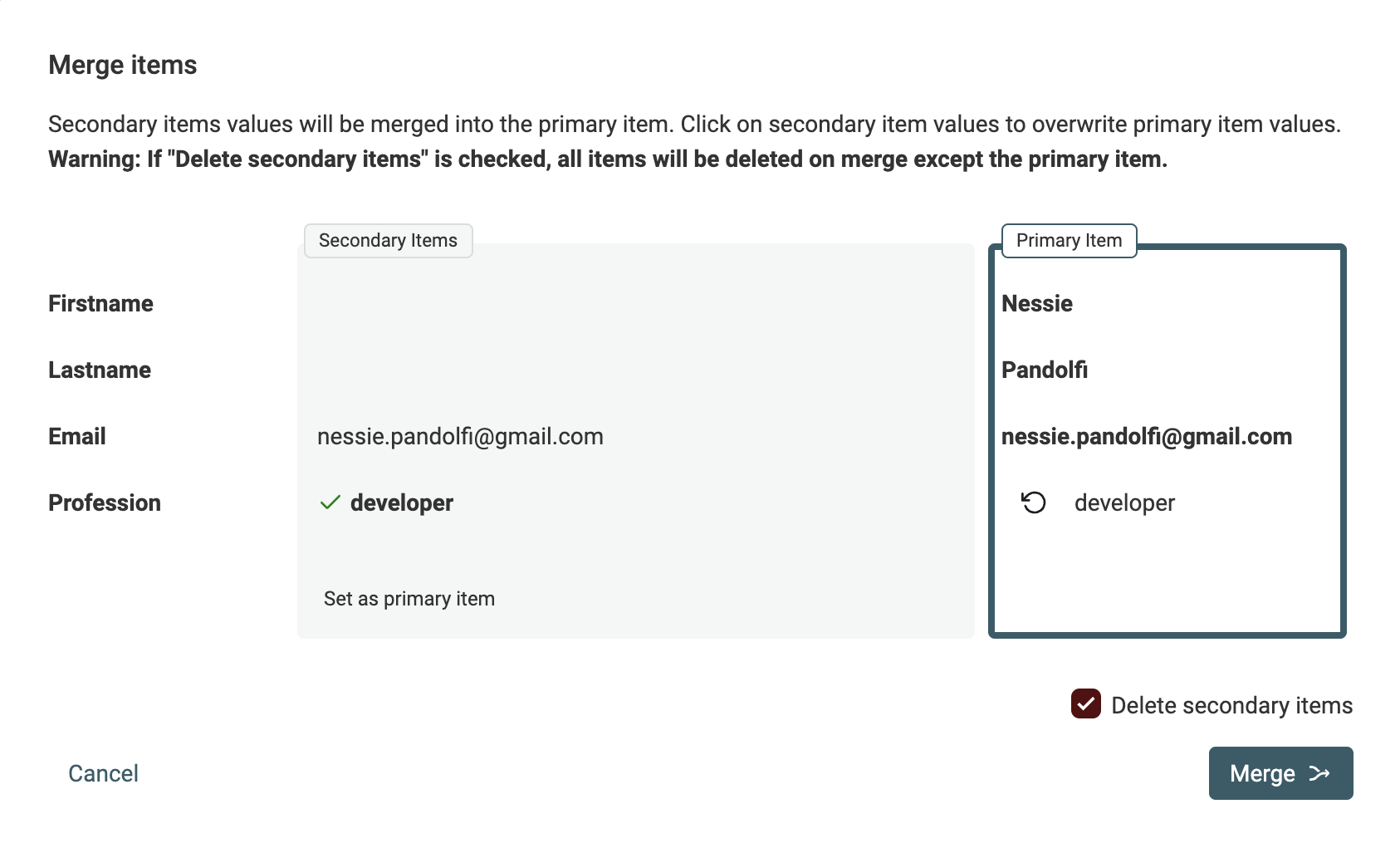
Или проверьте конфликтующие значения вручную с ассистентом объединения
Когда автообъединение невозможно, используйте ассистент объединения Datablist, чтобы выбрать, какое значение сохранить и консолидировать записи.
Запись с наибольшим количеством информации выбирается как главная и получает дополнительные значения из вторичных записей.
Обработка дубликатов с помощью AI
Когда использовать дедупликацию данных?
- Дедупликация рассылочного списка
Со временем в ваш рассылочный список попадает множество источников. Из‑за участников вебинаров, покупателей, freemium‑пользователей и т. п. один и тот же email-адрес может появляться в списке несколько раз.
Дублирующиеся email-адреса увеличивают затраты маркетинговых кампаний, создают спамоподобное поведение и вызывают раздражение пользователей, если они продолжают получать рассылки после отписки от кампании.- Как очистить рассылочный список
- Дедупликация в Microsoft Excel
Google Sheets, Microsoft Excel и другие табличные инструменты предлагают базовые возможности дедупликации: подсветить дубли в столбце или удалить их. Используйте в Datablist автоматическое объединение и ручной Merging Assistant для работы со сложными дубликатами.
Datablist открывает как CSV, так и Excel файлы.- Как удалить дубликаты в файле Excel
- Инструмент дедупликации leads и потенциальных клиентов
В B2B‑маркетинге качество базы перспективов влияет на результаты кампаний. Грязный список данных с дубликаты leads увеличивает стоимость хранения, снижает эффективность трекинга лидов и приводит к фрустрации вашей команды продаж.
Управляйте процессами генерация лидов с Datablist. Или импортируйте данные из вашего CRM или lead‑листы в Datablist, чтобы очистить их.- Как дедуплицировать lead-листы
- Дедупликация файлов CSV
Очистка данных CSV отнимает много времени. Инженеры по данным используют языки программирования, например Python, чтобы парсить и очищать CSV. Datablist предлагает No-Code инструмент для очистки данных в ваших CSV‑файлах для нетехнических пользователей. Открывайте CSV‑файлы с сотнями тысяч строк и быстро удаляйте дубликаты записей.
- Как удалить дубликаты в CSV‑файле
Часто задаваемые вопросы
Да, вы можете находить и объединять дубликаты онлайн бесплатно. Базовые функции, такие как Exact и Smart matching, доступны без аккаунта. Для продвинутых алгоритмов, таких как fuzzy или phonetic matching, нужен платный план.
Excel безвозвратно удаляет строки‑дубликаты, из‑за чего вы теряете потенциально ценную информацию. Datablist объединяет записи, интеллектуально комбинируя взаимодополняющие данные из всех дублей в единую, полную мастер‑запись. Вы не теряете данные.
Datablist создан для работы с большими файлами. Вы можете обрабатывать списки до 1 млн строк в бесплатном плане и до 1,5 млн строк в платных планах — намного больше, чем позволяют традиционные табличные инструменты.
Да, конечно. Мы используем продвинутые алгоритмы нечеткого сопоставления, такие как расстояния Levenshtein и Jaro‑Winkler, чтобы находить похожие записи даже при опечатках, ошибках или небольших различиях в формате.
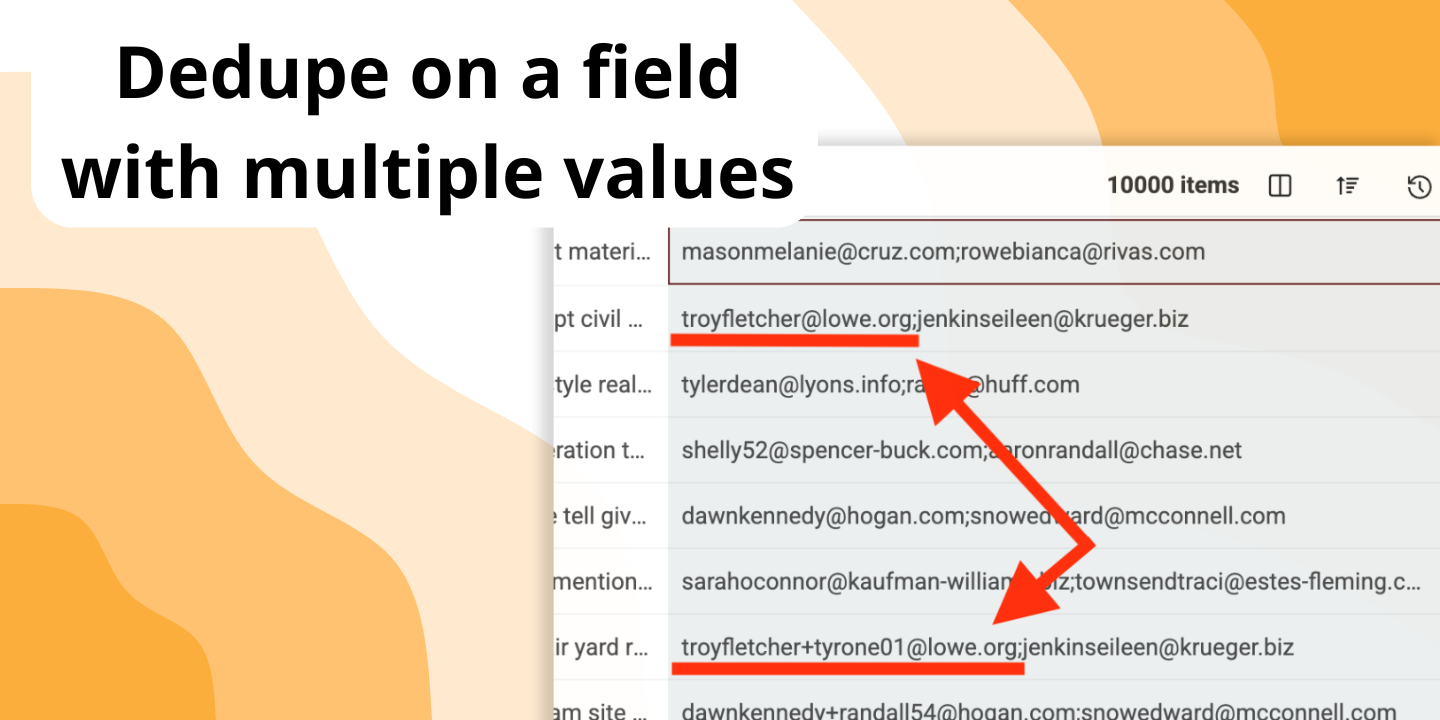
Это предусмотрено. Включите опцию "Multiple Value Matching", чтобы обрабатывать каждое значение в ячейке (разделённое точкой с запятой) как отдельную сущность для сравнения. Совпадение будет найдено, даже если дублируется хотя бы одно из значений.
Да. Вы можете импортировать несколько файлов в Datablist и запустить Duplicates Finder сразу по всем. Инструмент сопоставляет записи по общему идентификатору, даже если у файлов разные столбцы и структуры.
Нет. Datablist — полностью no-code решение. Duplicates Finder проводит вас через простой пошаговый процесс: вы выбираете столбцы и правила сопоставления в удобном интерфейсе.
Наша функция AI Editing даёт неограниченную гибкость. Вместо стандартных правил объединения вы можете писать инструкции простым английским. Например, попросите суммировать показатели продаж из дублирующих записей или выбирать мастер‑запись по самой поздней дате. Сложная логика превращается в простой запрос.
Datablist консолидирует данные в одну мастер‑запись. Он автоматически заполняет недостающую информацию из других дублей и предлагает варианты для конфликтующих данных: вы можете объединять текст из разных строк или выбирать, какое значение сохранить. Избыточные записи затем удаляются.
Мы предлагаем несколько алгоритмов для разных задач: 'Exact' — для идентичных совпадений, 'Smart' — для вариаций вроде порядка слов или протоколов URL, 'Phonetic' — для имён, звучащих похоже, и 'Fuzzy Matching' — для опечаток и ошибок.
Да. После того как Datablist определит все группы дубликатов, вы можете экспортировать их в CSV или Excel до внесения изменений. В этом файле все дублирующиеся элементы идут подряд, группами один за другим, что упрощает внешнюю проверку или обработку в другом инструменте.
После завершения объединения Datablist предоставляет скачиваемый файл 'Changes List'. Это журнал, где перечислены все записи, обновлённые или удалённые в процессе. Используйте его, чтобы легко повторить изменения во внешней системе, например в CRM, и сохранить полную синхронизацию данных.
See Also