
¡Limpiar duplicados implica mucho más que darle a “delete”!
Algunos registros son idénticos. Otros tienen valores en conflicto. Y muchos son complementarios: no hay que eliminarlos, sino fusionarlos.
Según su workflow, puede que necesite fusionar registros, actualizar un registro “maestro” o simplemente marcar duplicados para revisarlos.
Las herramientas básicas borran filas sin entender prioridades de campos ni reglas de negocio. Ese enfoque se lleva por delante datos útiles.
Una buena deduplicación exige lógica clara: defina cómo elegir el registro maestro, cómo resolver conflictos y qué hacer con los registros secundarios.
En este artículo verá métodos prácticos para fusionar, actualizar y eliminar duplicados en archivos CSV, hojas de Excel y CRMs.
¡Vamos!
📌 Resumen para los que van con prisa
Este artículo cubre todo lo que necesita para deduplicar sus spreadsheets: cómo fusionar, actualizar y eliminar duplicados de la forma correcta.
Problema: Sin entender patrones de priorización y acciones masivas, al trabajar con duplicados terminará perdiendo información importante o conservando los registros equivocados.
Solución: Datablist ofrece tres métodos de dedupe: fusión y eliminación simples, edición con IA para reglas complejas y deduplicación entre varios archivos.
Los métodos de deduplicación que veremos:
En los próximos 10 minutos aprenderá
- Qué es Datablist y por qué podemos hablar de duplicados con autoridad
- Lo que debe saber sobre duplicados antes de depurar/deduplicar su lista
- Las 3 formas más efectivas de eliminar duplicados (paso a paso)
Por qué debería hacernos caso
Datablist es una plataforma para crear workflows de lead generation que ya permite a 26.000 usuarios encontrar, enriquecer y limpiar datos usando más de 60 herramientas distintas: desde AI Agents hasta Email Finders, AI processors, Technology enrichments y mucho más.
Además, Datablist incluye una suite de deduplicación muy completa para fusionar, actualizar, eliminar o marcar duplicados en pocos clics y sin necesidad de programar.
Fundamentos de la deduplicación
Antes de ver cómo deduplicar su lista, conviene entender los principios detrás de las distintas técnicas de deduplicación.
En esta sección veremos:
- Una explicación rápida de los tipos de duplicados
- Fundamentos para deduplicar registros con conflictos
- Preguntas para definir su objetivo más rápido
Lo que necesita entender: fundamentos de la deduplicación
Los siguientes puntos solo aplican a la deduplicación dentro de un solo archivo. Para deduplicación entre varios archivos, solo puede borrar copias de ciertos archivos, y no fusionar ni actualizar. Por eso, estos principios son útiles, aunque no obligatorios.
Por defecto, Datablist intenta fusionar duplicados automáticamente. En la práctica, esto no siempre funciona porque la mayoría de usuarios tiene duplicados con datos en conflicto.
Cuando hay conflictos, el proceso se apoya en dos conceptos:
- Patrones de priorización para elegir el registro maestro dentro de un grupo de duplicados
- Acciones masivas para gestionar los registros secundarios de ese grupo
Tipos de duplicados
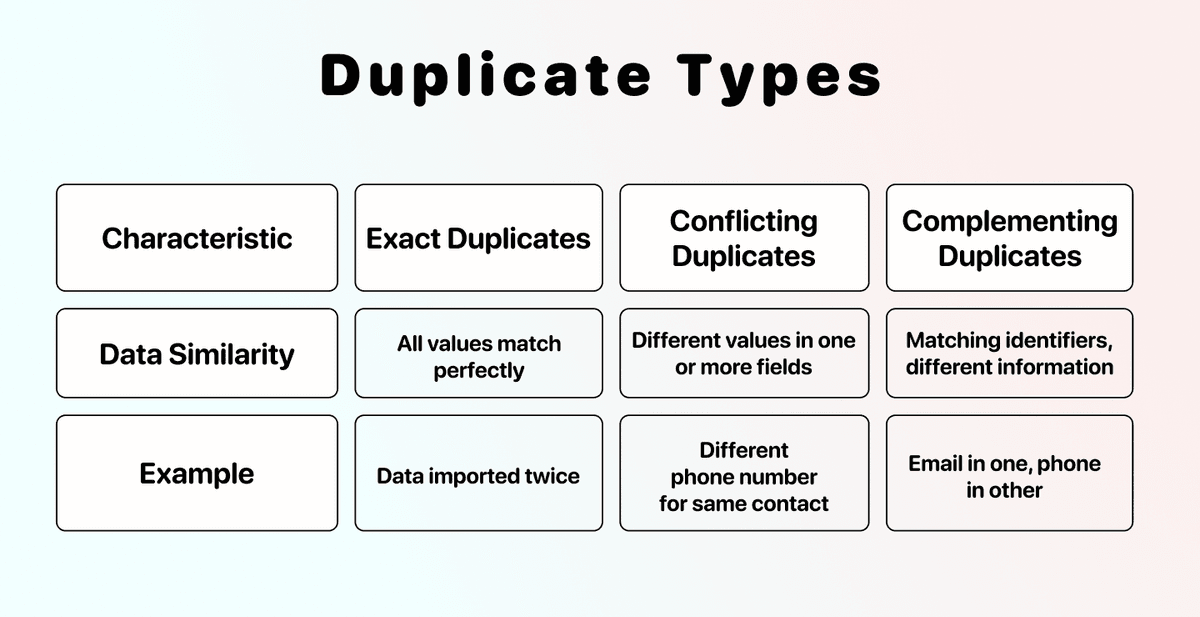
Clasificamos los duplicados según lo parecidos que sean sus campos.
- Duplicados exactos: todas las columnas tienen los mismos valores. Suelen venir de importaciones duplicadas o de un copy-paste accidental.
- Duplicados con conflicto: representan la misma entidad, pero discrepan en algunos campos (teléfono, cargo, revenue, etc.).
- Duplicados complementarios: cada registro tiene información útil distinta que conviene combinar. Por ejemplo, un registro puede tener un email address y su duplicado un teléfono; en ese caso se complementan.
Primero: definir un patrón de priorización
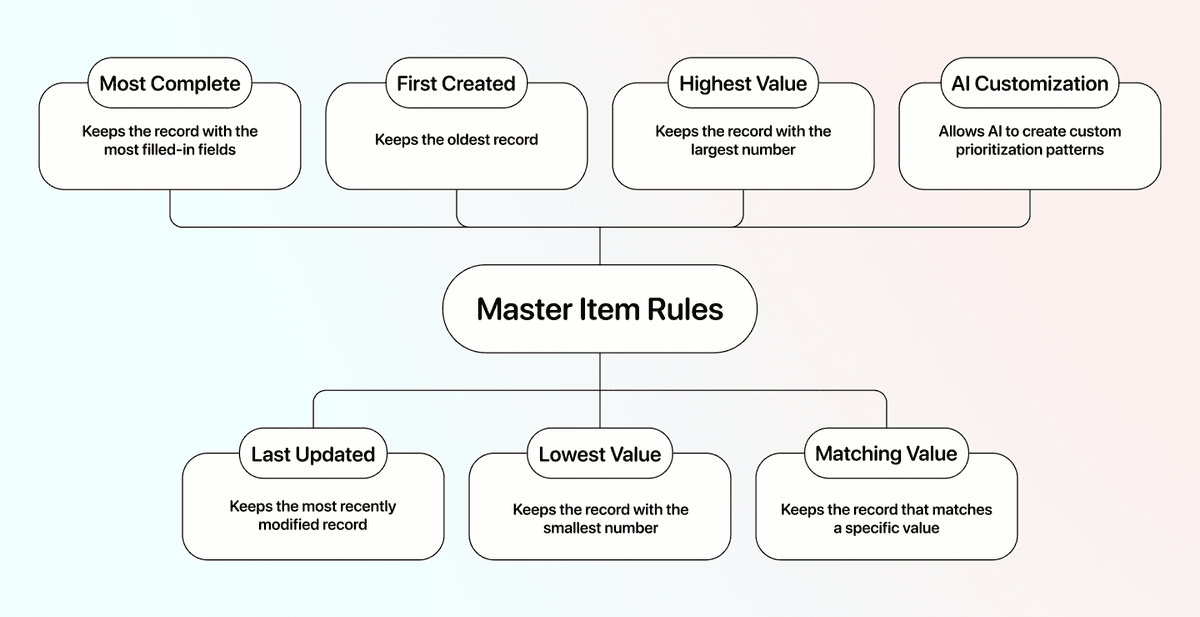
Debe decidir qué registro será el de referencia. A esto lo llamamos la Master Item Rule. Quédese con el término: lo necesitará más adelante.
Ejemplos de patrones / Master Item Rules:
- Most complete: conserva el registro con más campos rellenados
- Last updated: conserva el registro modificado más recientemente
- First created: conserva el registro más antiguo
- Lowest value: conserva el registro con el número más bajo en una columna concreta
- Highest value: conserva el registro con el número más alto en una columna concreta
- Matching value: conserva el registro que coincide con un valor específico en una propiedad que usted define
📘 Master Item Rules
Importante: “Last updated” y “First created” solo tienen sentido si los datos se han gestionado dentro de Datablist a lo largo del tiempo. Si acaba de subir su archivo, estas opciones no funcionarán porque los spreadsheets importados no traen ese metadato.
Si no tiene claro qué Master Item Rule elegir, recomendamos “Most complete” o usar la técnica explicada en la segunda parte de la sección paso a paso.
Para casos complejos, Datablist le permite usar IA para crear patrones de priorización personalizados, por ejemplo: si la columna A contiene “Hello people” y la columna B contiene “of Germany”.
Más sobre esto en la segunda parte de la sección paso a paso.
Segundo: elegir una acción masiva
Una vez elegido el patrón de priorización, el siguiente paso es decidir qué hacer con los registros que no ganan.
Ejemplos de acciones masivas para procesar duplicados:
- Eliminar elementos secundarios
- Fusionar el Master Item con el elemento secundario en un único registro
- Fusionar propiedades seleccionadas del elemento secundario con el Master Item y eliminar el resto
- Actualizar propiedades seleccionadas del Master Item con los valores del elemento secundario
- Marcar duplicados sin eliminarlos (muy útil en organizaciones grandes, donde los registros secundarios pueden ser necesarios por compliance)
- … y cualquier otra variante que se le ocurra
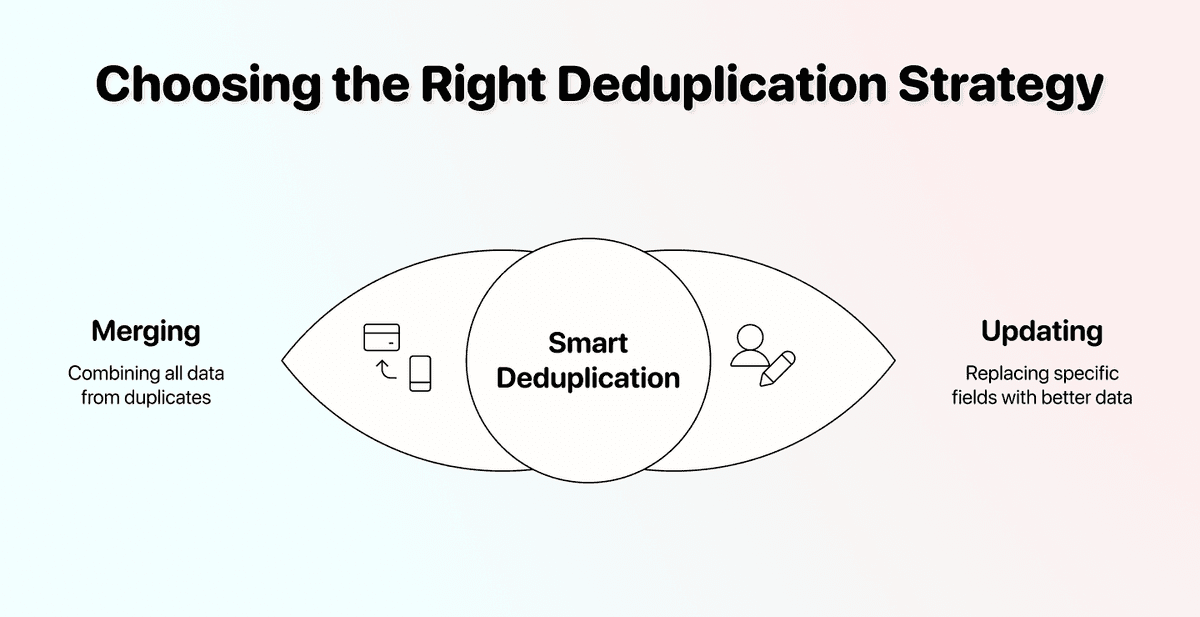
📘 Diferencia entre fusionar duplicados y actualizar duplicados
Fusionar es combinar los valores de ambos registros. Es especialmente útil en contactos duplicados de CRM cuando tiene notas en ambos registros.
Actualizar significa sustituir valores específicos por datos mejores de otra fuente. Úselo cuando cada duplicado tenga algo correcto: por ejemplo, conservar el contacto A, pero corregir su cargo con el dato preciso del contacto B.
Preguntas que debe hacerse antes de deduplicar una lista
Ahora que ya entiende patrones y acciones masivas, use estas preguntas para definir rápidamente su patrón de priorización y qué hacer con el resto.
¿Qué registro debería ser su Master Item?
Esta pregunta le ayuda a determinar su patrón de priorización. Piense qué hace que un duplicado sea “mejor” que otro.
Pregúntese:
- ¿Hay un registro más completo que los demás?
- ¿Alguno viene de una fuente más fiable?
- ¿Hay uno más reciente o actualizado?
- ¿Existe algún valor concreto que lo convierta en la versión “correcta”?
Su respuesta determina la Master Item Rule:
- Si lo más importante es la completitud → use “Most complete”
- Si lo más importante es la recencia → use “Last updated” o “First created”
- Si gana el que tenga un valor específico → use “Matching value”
- Si la lógica es más compleja → use AI Editing (Método 2)
¿Qué debería pasar con los registros que no son el Master?
Esta pregunta le ayuda a determinar su acción masiva. Una vez elegido el ganador, ¿qué quiere hacer con los demás?
Pregúntese:
- ¿Los otros registros tienen datos valiosos que quiera conservar?
- ¿Debería combinar información de varios registros en uno?
- ¿Solo necesito borrar los extras y seguir?
- ¿Necesito marcar duplicados para revisión en lugar de eliminarlos?
Su respuesta determina su acción masiva:
- Si los otros registros no aportan valor → drop all conflicting values/ delete
- Si los otros registros tienen información útil → combine the conflicting values o update el master item
- Si necesita conservar registros por compliance → flag duplicados sin eliminar
- Si necesita seleccionar valores puntuales → use AI Editing (Método 2)
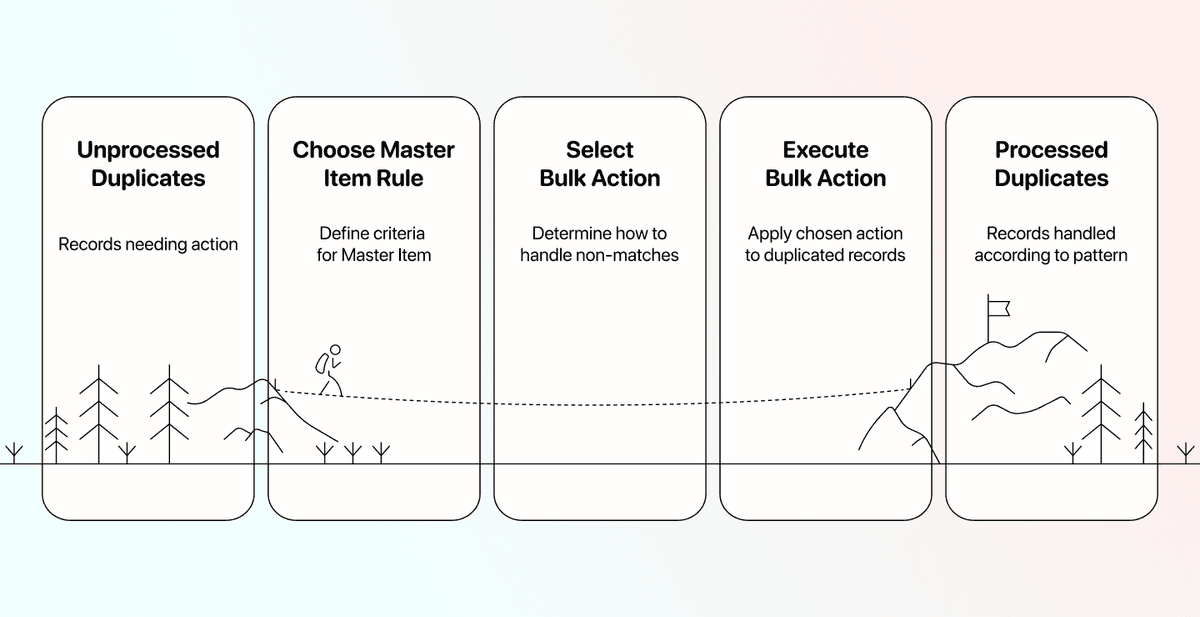
Deduplicación: cómo limpiar registros duplicados de sus datos
Datablist tiene una suite de deduplicación que cubre de todo, desde eliminar duplicados sencillos hasta deduplicación entre varios archivos. Por eso, en esta sección verá 3 workflows distintos:
- Fusionar y eliminar duplicados en un solo archivo con reglas simples
- Actualizar y eliminar duplicados en un solo archivo con reglas complejas
- Eliminar duplicados entre varios archivos; no se puede fusionar
¡Empecemos!
Cómo gestiona Datablist los duplicados (repaso rápido)
Si leyó la sección anterior, puede saltárselo; si no, aquí tiene un resumen para que entienda exactamente qué va a hacer.
- Datablist escanea sus datos y encuentra filas con información coincidente en las columnas que usted indique.
- Cuando detecta duplicados, le permite auto-fusionarlos si son coincidencias exactas.
- Si hay duplicados con conflicto, le pide que elija un patrón para priorizar un registro sobre otro (la “Master Item Rule”).
- Una vez definida la Master Item Rule, puede fusionar, actualizar, marcar o eliminar el segundo registro duplicado.
Fusión y eliminación simple de duplicados en un solo archivo
Esta es la forma más sencilla de quitar duplicados: tiene una lista donde algunas entradas se repiten y quiere conservar una sola copia por registro.
Cuándo es útil
- Importó el mismo CSV dos veces por error
- Su exportación del CRM contiene contactos duplicados
- Datos scrapeados tienen entradas repetidas por errores de paginación
Paso 1: Regístrese y suba sus datos
- Regístrese en Datablist
- Upload su CSV o Excel
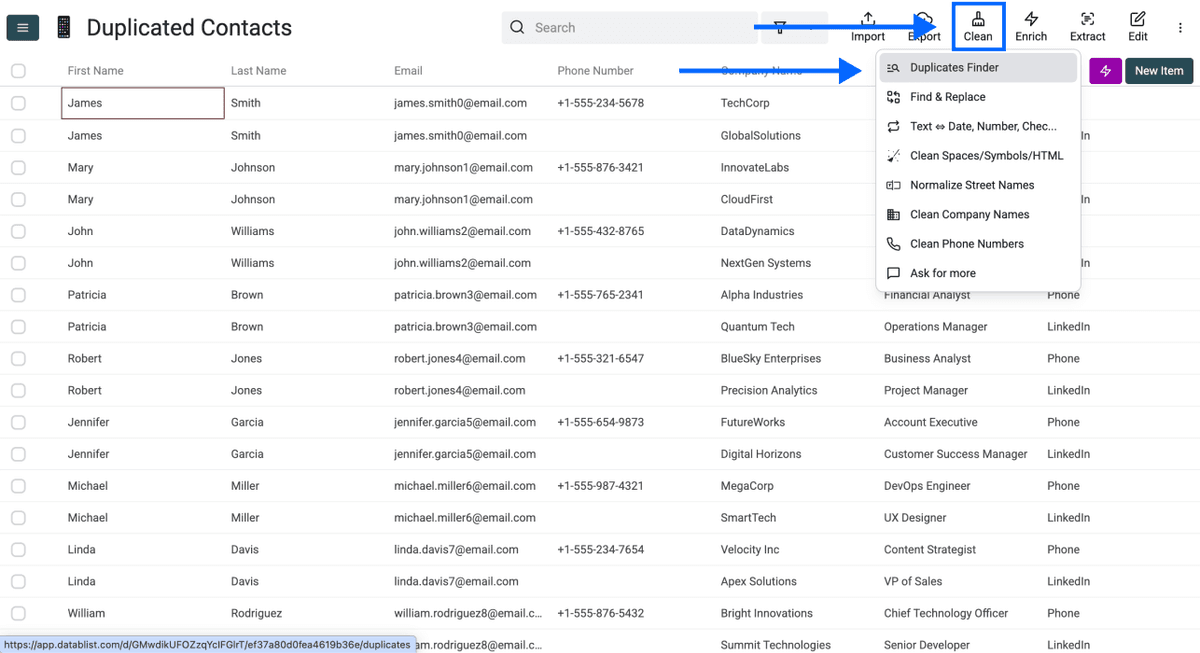
Paso 2: Vaya a Duplicates Finder
Haga clic en Clean en el menú superior y seleccione Duplicates Finder
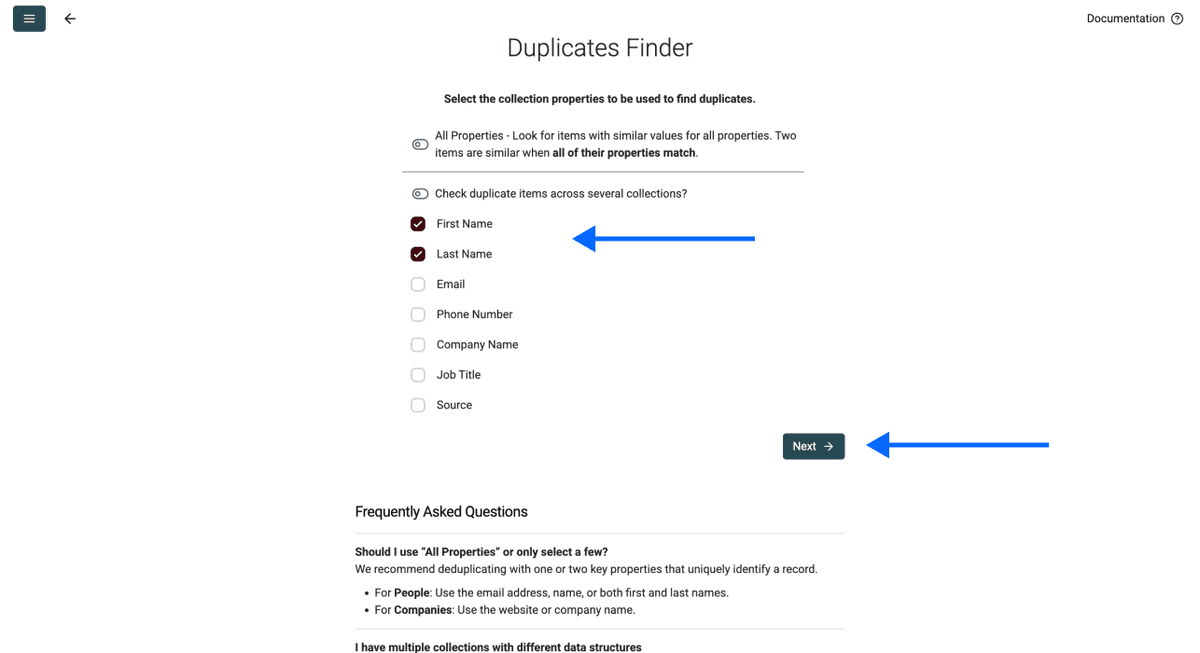
Paso 3: Elija su identificador único
En este paso tendrá dos opciones:
Opción 1: elegir una o varias columnas como identificador único (RECOMENDADO)
Piense en el identificador único como el dato que hace que cada registro sea “distinto”. Por ejemplo:
- Usando una columna: si elige “Email” como identificador único, entonces john@example.com se considerará único aunque todo lo demás coincida
- Usando varias columnas: si elige “First Name” + “Company”, entonces “John” en “Microsoft” es distinto de “John” en “Google”
Cuantas más columnas seleccione, más estricta será la coincidencia. Recomendamos empezar con una o dos columnas que realmente identifiquen registros únicos en sus datos.
Opción 2: deduplicar basándose en todas las propiedades (NO RECOMENDADO)
Esta opción comprueba si cada columna de una fila coincide exactamente con la de otra. Es decir: solo se consideran duplicados cuando todos los datos son idénticos.
Por qué no lo recomendamos: en datos reales, los duplicados rara vez coinciden al 100% en todas las columnas. La misma persona puede tener cargos ligeramente distintos, o una empresa puede aparecer con distinto número de empleados según la fuente. Si usa esta opción, se le escaparán la mayoría de duplicados.
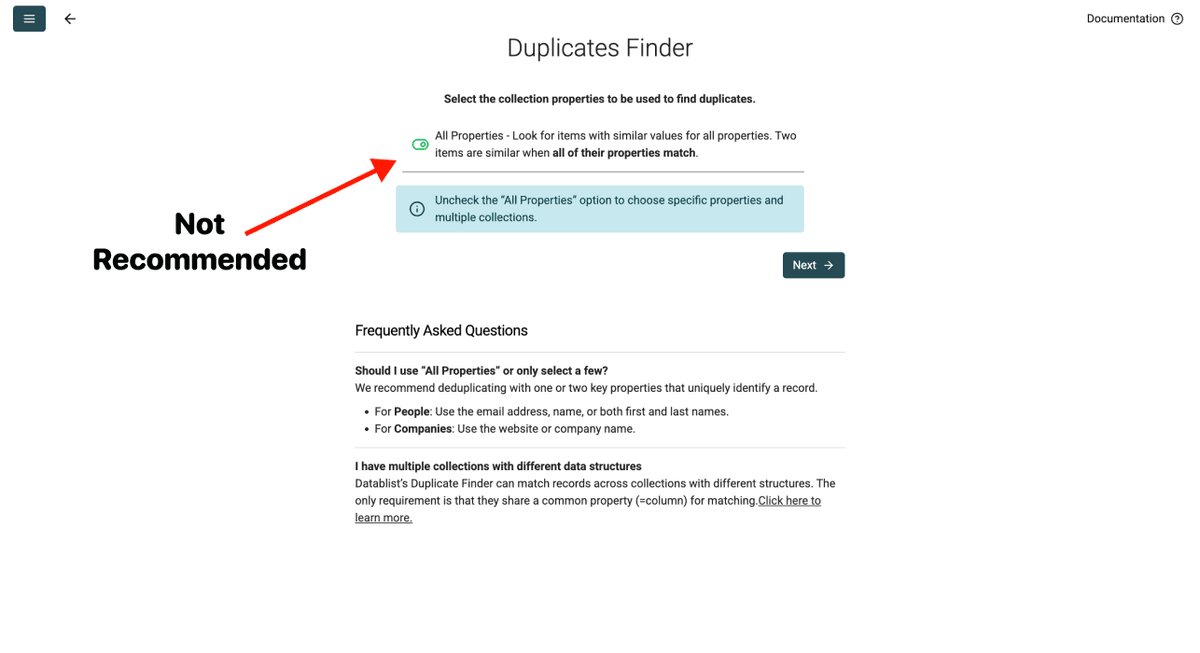
Cuándo podría ser útil la segunda opción: úsela solo si busca filas duplicadas exactas importadas dos veces por accidente, donde literalmente cada campo sea idéntico.
Cuando haya seleccionado las propiedades por las que quiere deduplicar, baje y haga clic en Next
Paso 4: Seleccione el algoritmo de comparación
En este paso debe seleccionar un algoritmo de comparación y un processor para cada propiedad por la que quiera deduplicar. Recomendamos mantener la configuración por defecto salvo en nombres de empresa.
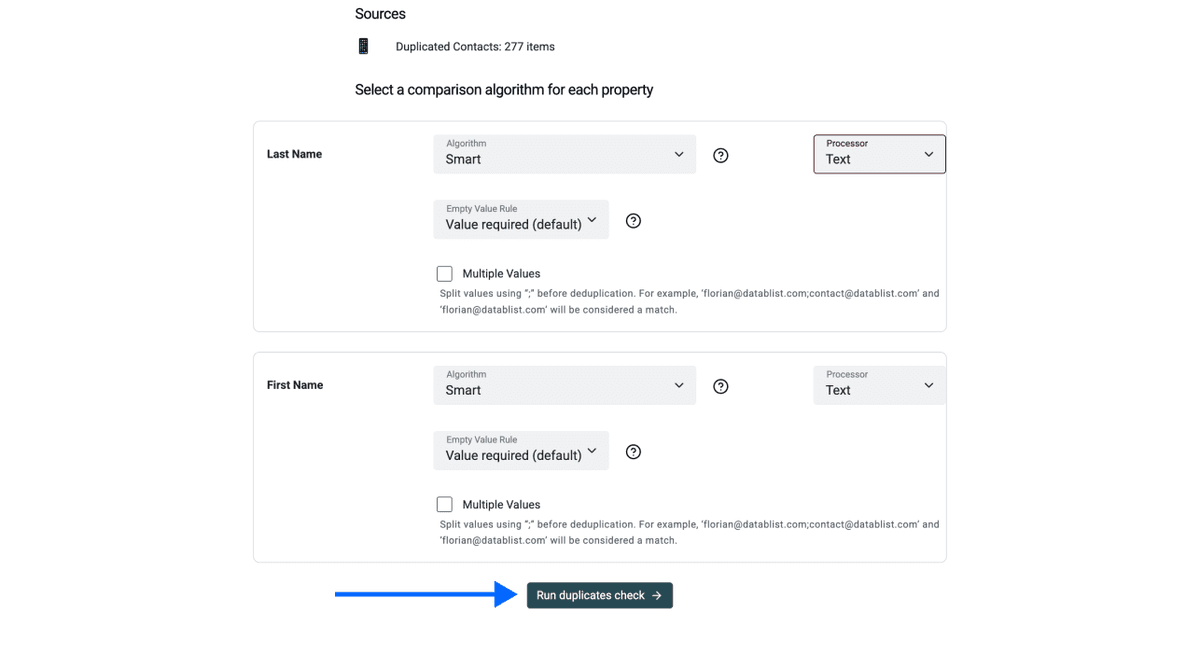
Si deduplica por nombres de empresa: elija el processor de company names, ya que es el único que Datablist no puede detectar automáticamente.
Paso 5: Elija el Master Item, revise y resuelva conflictos
- Elija la master item rule: como se explicó en la primera sección, Datablist siempre le pide especificar una Master Item rule. La regla por defecto es “Most Complete”, pero puede elegir otra.
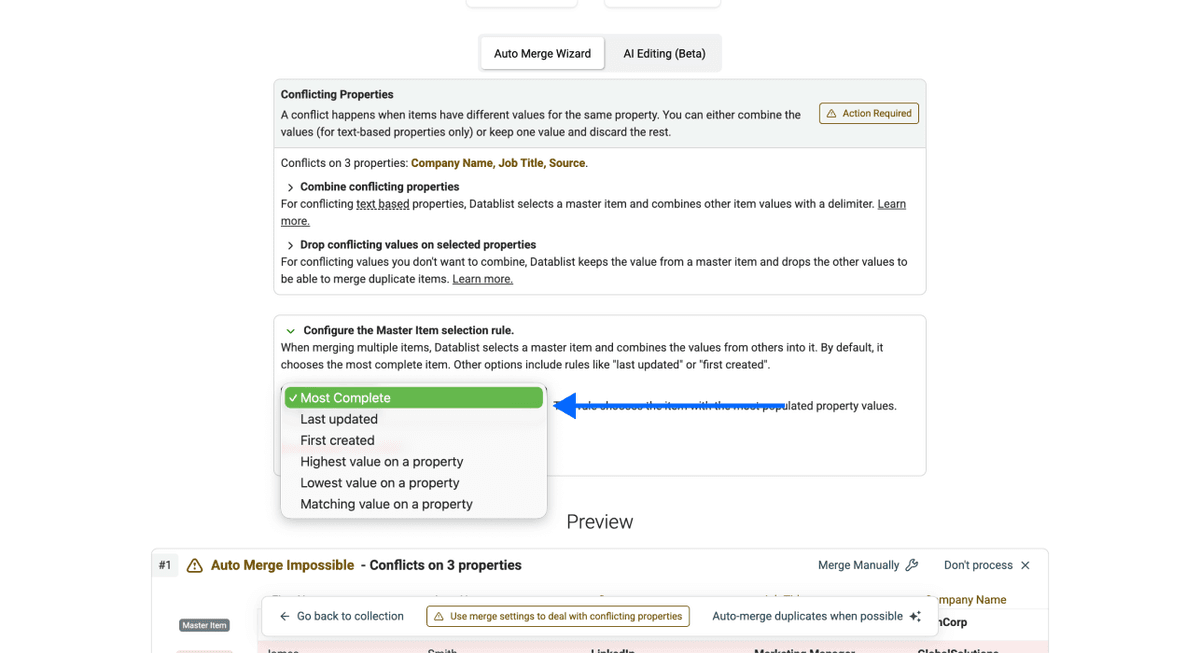
-
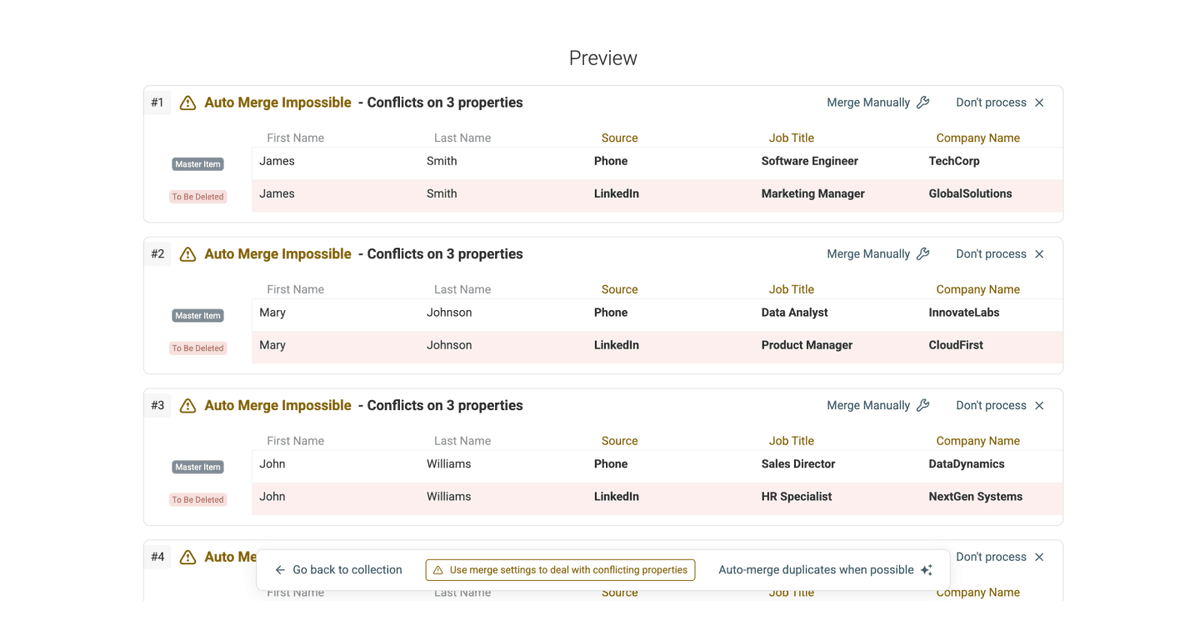
Revise y resuelva conflictos si hace falta: muchas veces los duplicados no coinciden en todas las propiedades. Por eso le pedimos que especifique un master item.
Para resolver conflictos, puede elegir entre combinar o descartar los valores en conflicto. Eso sí: combinar valores solo funciona con propiedades de texto. Si tiene números, fechas/hora, etc., normalmente tendrá que combinar ambas reglas: combinar y descartar.
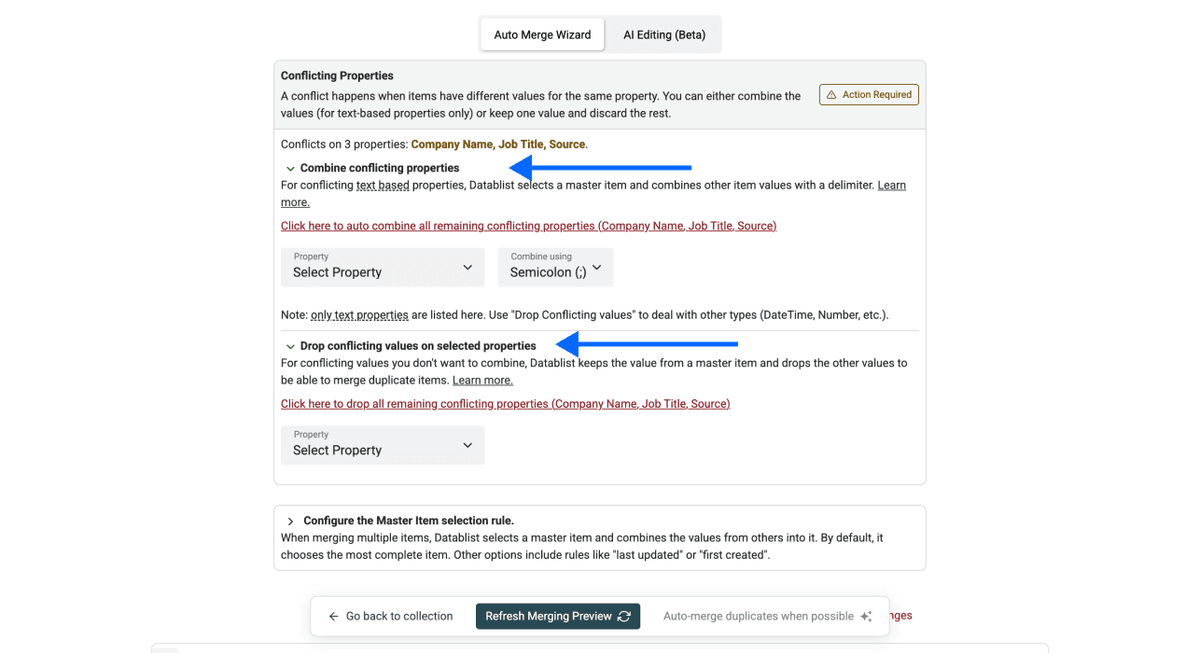
- Haga clic en Refresh Merging Preview para ver los cambios que se aplicarán
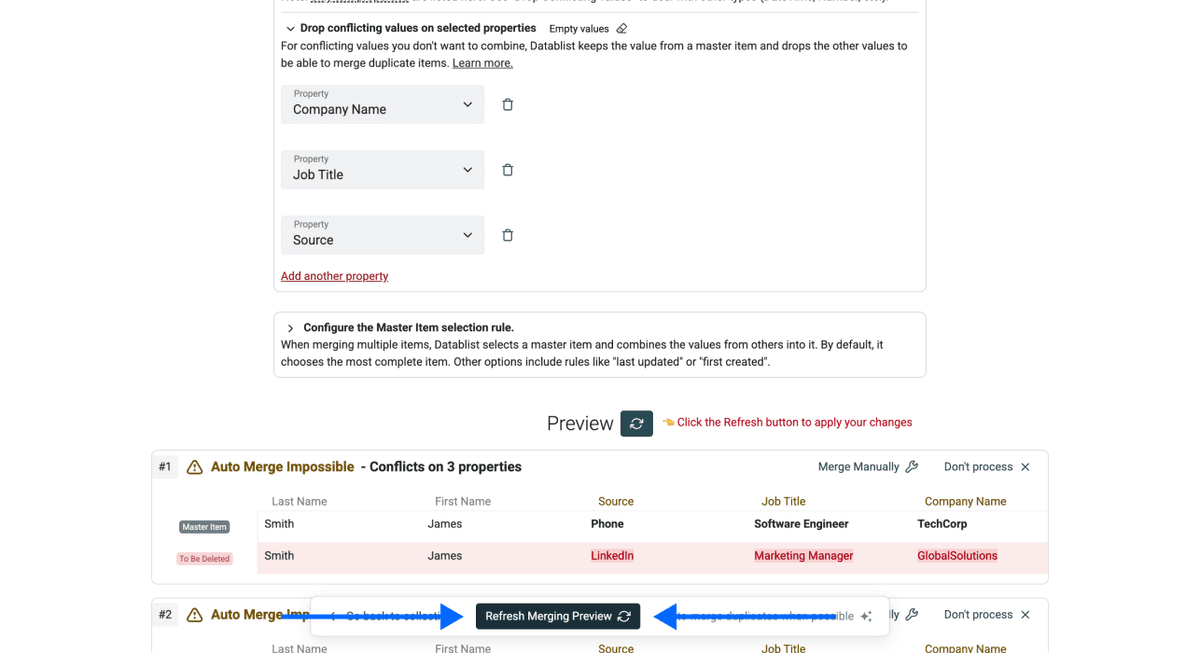
Paso 6: Ejecutar y revisar
Ahora solo tiene que hacer clic en Auto-merge when possible.
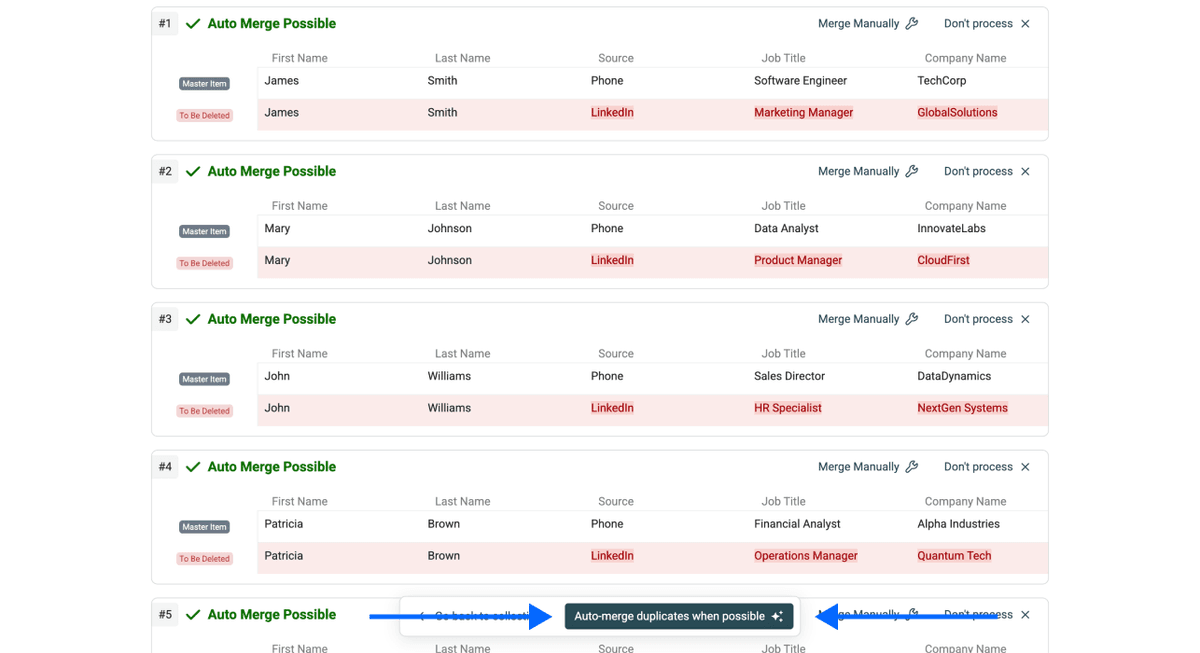
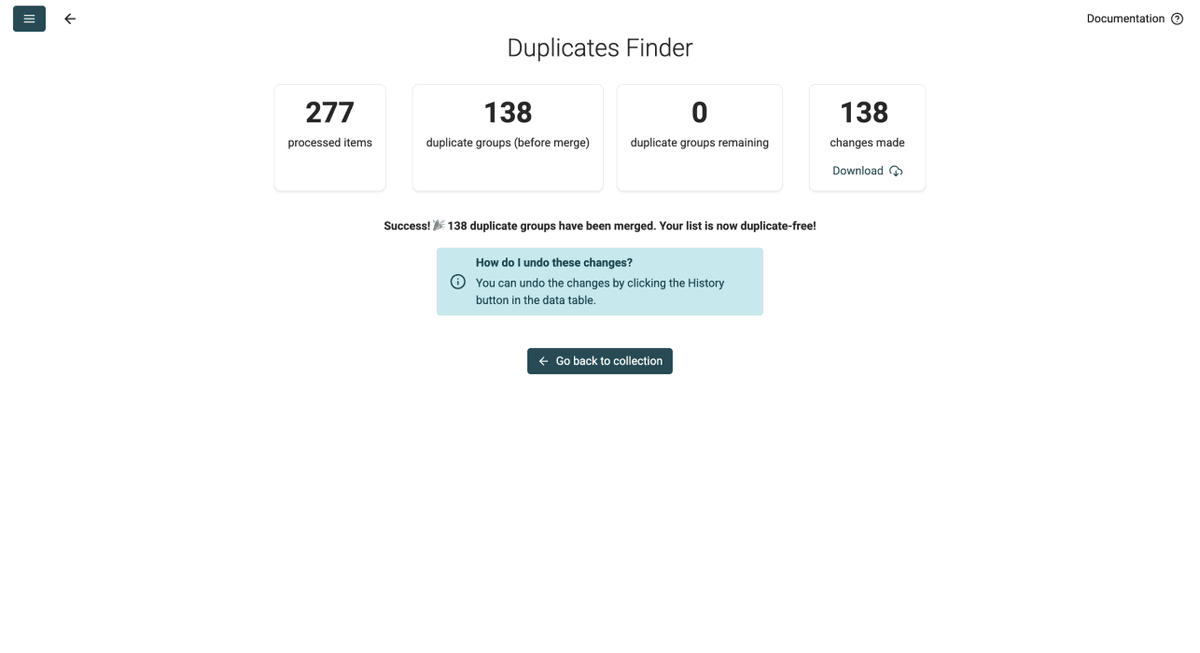
Una vez fusionados los duplicados, Datablist le permitirá descargar los cambios como CSV. El archivo incluirá:
- Todos los duplicados que había en su archivo
- Los registros donde se han fusionado
- Los cambios realizados
- El Datablist record ID
Descargar ese archivo es opcional.
💡 Si cometió algún error
También puede revertir los cambios desde el botón de historial y deshacer las acciones al volver a la vista de spreadsheet.
Editar duplicados antes de eliminarlos
A veces las master item rules “simples” no alcanzan. ¿Y si quiere quedarse con el teléfono de un registro, pero el cargo de otro? Ahí es donde entra AI Editing.
Cómo funciona: en lugar de elegir una regla predefinida, usted describe lo que quiere en inglés (o lenguaje natural). La IA de Datablist lee sus instrucciones, genera un script y aplica esa lógica personalizada a cada grupo de duplicados.
Cuándo es útil
- Tiene contactos de varias fuentes (CRM, LinkedIn, listas telefónicas) y quiere combinar lo mejor de cada una
- Sus duplicados tienen campos distintos rellenos y quiere elegir valores concretos
- Necesita lógica personalizada que no encaja con las master item rules estándar
- Quiere actualizar registros antes de borrarlos, no solo elegir un ganador
- Quiere marcar duplicados en lugar de eliminarlos por compliance
Paso 1: Regístrese y suba sus datos
- Regístrese en Datablist
- Upload su CSV o Excel
Paso 2: Vaya a Duplicates Finder
Haga clic en Clean en el menú superior y seleccione Duplicates Finder
Paso 3: Elija su identificador único
Seleccione la(s) columna(s) que usará para hacer match de duplicados. Después, baje y haga clic en Next
Paso 4: Seleccione el algoritmo de comparación
Seleccione un algoritmo de comparación y un processor para cada propiedad por la que quiera deduplicar. Recomendamos dejar los valores por defecto salvo para nombres de empresa.
Paso 5: Abra AI Editing
En lugar de seleccionar una master item rule, haga clic en AI Editing dentro del panel de deduplicación.
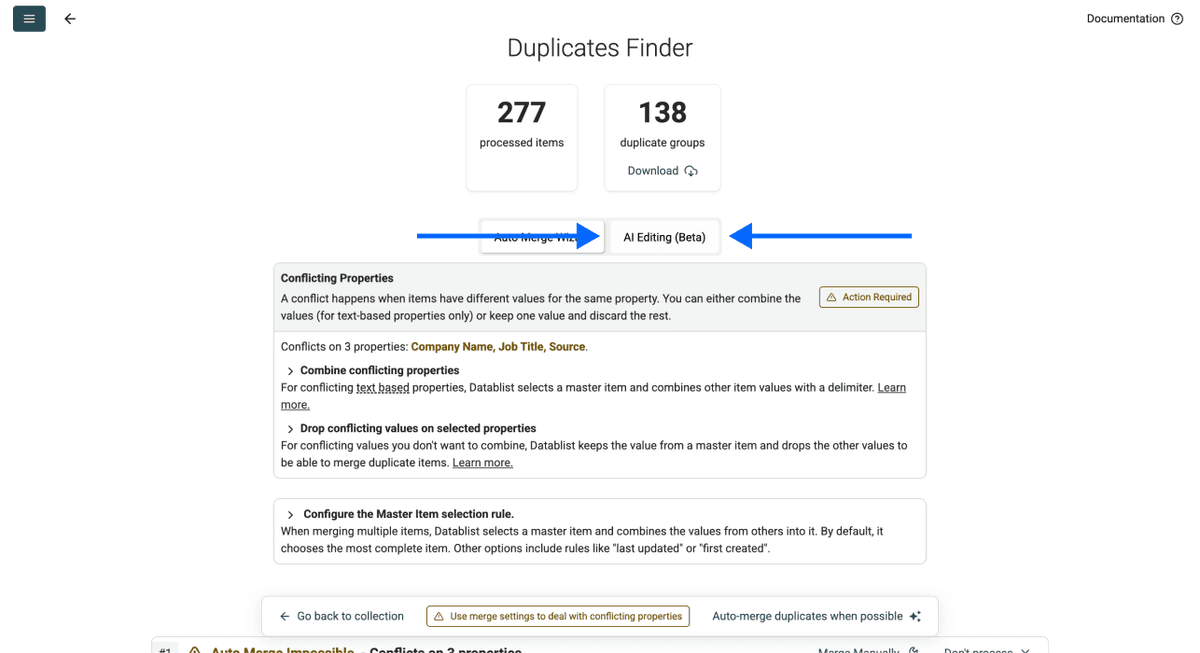
Paso 6: Escriba su prompt
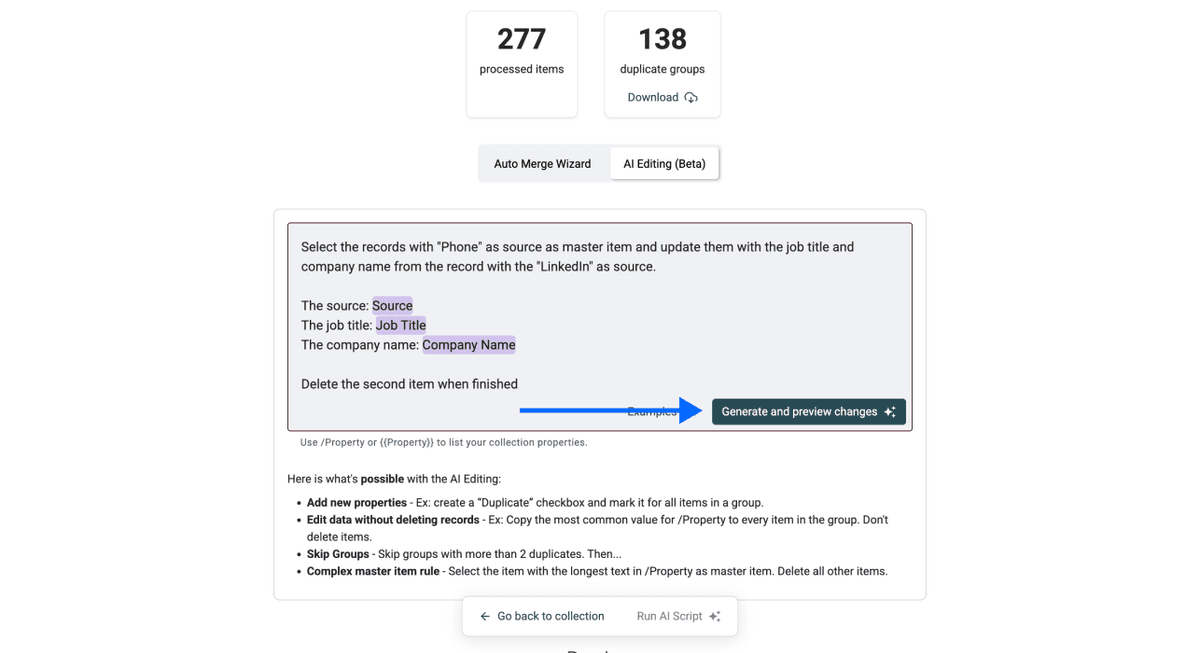
Describa lo que quiere en lenguaje natural. Aquí tiene un ejemplo práctico:
Imagine que tiene datos de contacto de dos fuentes: verificación telefónica y scraping de LinkedIn. Los registros del teléfono tienen números verificados, pero LinkedIn tiene cargos y nombres de empresa más actualizados. Usted quiere mantener como master el registro del teléfono, pero actualizarlo con datos de LinkedIn.
Este es el prompt que usé:
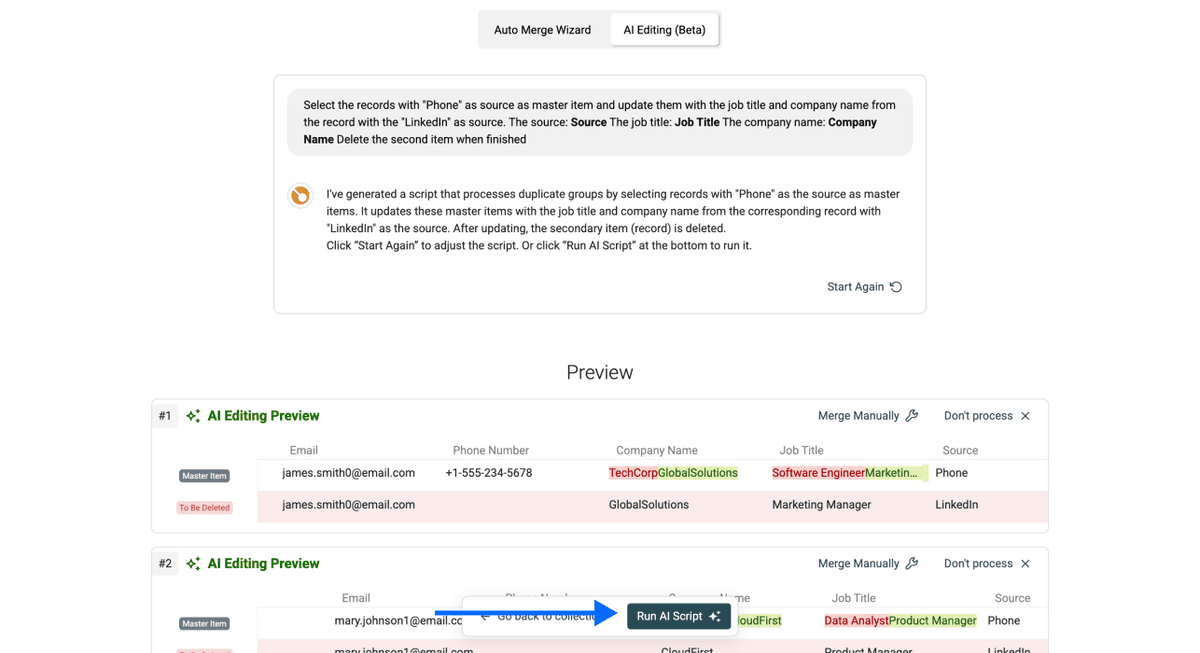
Select the records with "Phone" as source as master item and update them with the job title and company name from the record with the "LinkedIn" as source.
The source: /source
The job title: /job title
The company name: /company
Delete the second item when finished
Nota: no olvide mapear sus propiedades en el prompt usando /
Cuando esté listo, haga clic en Generate and preview changes
Paso 7: Revise y aplique los cambios
Datablist le mostrará exactamente qué cambios hará la IA antes de aplicarlos. Revise la vista previa para asegurarse de que coincide con lo que espera.
Cuando esté conforme, haga clic en Run AI Script para aplicar los cambios a todos los grupos de duplicados. Después, exporte sus datos ya limpios.
💡 Consejos de prompt para mejores resultados
Sea muy específico con sus expectativas. Cuanto más claro describa lo que debe hacer, mejores serán los resultados.
Con esto también puede
- Marcar duplicados en lugar de borrarlos: escriba un prompt como “Add 'DUPLICATE' to the status column for all non-master items instead of deleting them”
- Combinar campos de texto: “Merge all notes from duplicate records into the master item's notes field, separated by line breaks”
- Priorizar por calidad de fuente: “Use Salesforce records as master when available, otherwise use HubSpot, then spreadsheet imports”
- … o cualquier otra lógica que se le ocurra.
Eliminar duplicados entre dos hojas o más
Si tiene dos archivos CSV distintos y quiere encontrar registros que aparecen en ambos, o deduplicar una nueva lead list contra la exportación existente de su CRM, Datablist lo hace sencillo.
Cómo funciona: a diferencia de la deduplicación dentro de un solo archivo, este workflow compara registros entre varios archivos y elimina duplicados que se repiten en distintas fuentes de datos. Puede seleccionar dos o más archivos, sin límite.
Cuándo es útil
- Está importando nuevos leads y quiere evitar duplicados con sus contactos existentes
- Está uniendo datos de varios proveedores o fuentes
- Necesita encontrar el solapamiento entre dos listas de clientes
- Quiere evitar contactar al mismo prospect dos veces
- Necesita consolidar datos de clientes de varios departamentos o sucursales
- … y muchos otros workflows de data cleaning
📘 Diferencia importante frente a la deduplicación en un solo archivo
Al deduplicar entre varios archivos, Datablist elimina duplicados por completo en lugar de fusionarlos.
Paso 1: Regístrese y suba sus archivos
- Regístrese en Datablist
- Import su primer archivo CSV o Excel
- Import su segundo archivo en otra collection (y cualquier archivo adicional con el que quiera deduplicar)
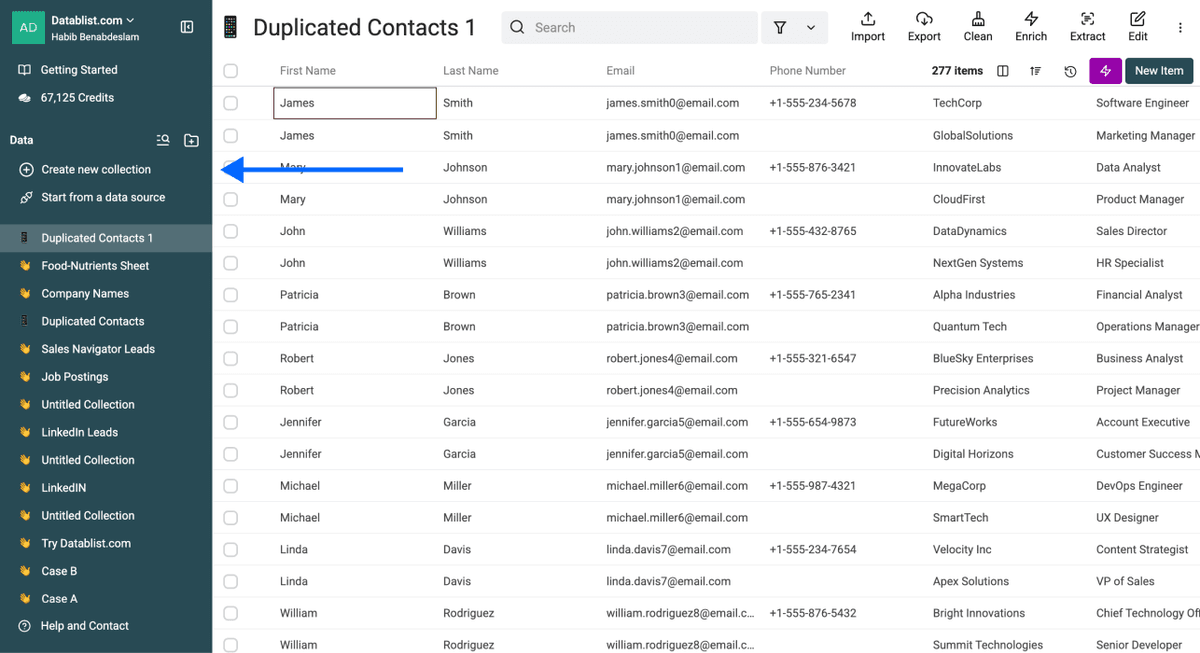
- Asegúrese de tener un identificador único
Antes de seguir, confirme que todos sus archivos comparten al menos una columna común que pueda usarse como identificador único. Por ejemplo:
- Email address
- LinkedIn URL
- Company domain
- Phone number
- Cualquier otro campo que identifique un registro de forma única
Paso 2: Vaya a Duplicates Finder
Haga clic en Clean en el menú superior y seleccione Duplicates Finder
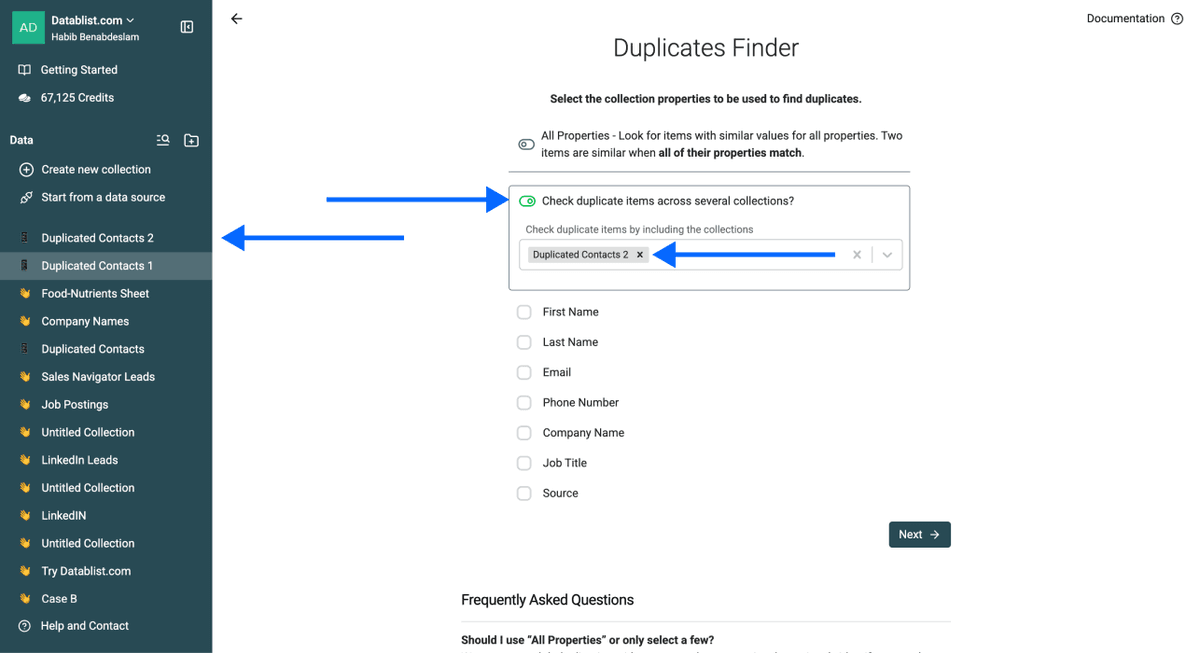
Paso 3: Active la deduplicación entre varias collections
- Marque Check Duplicate Items Across Several Collections
- Seleccione la(s) collection(s) / archivo(s) que acaba de importar
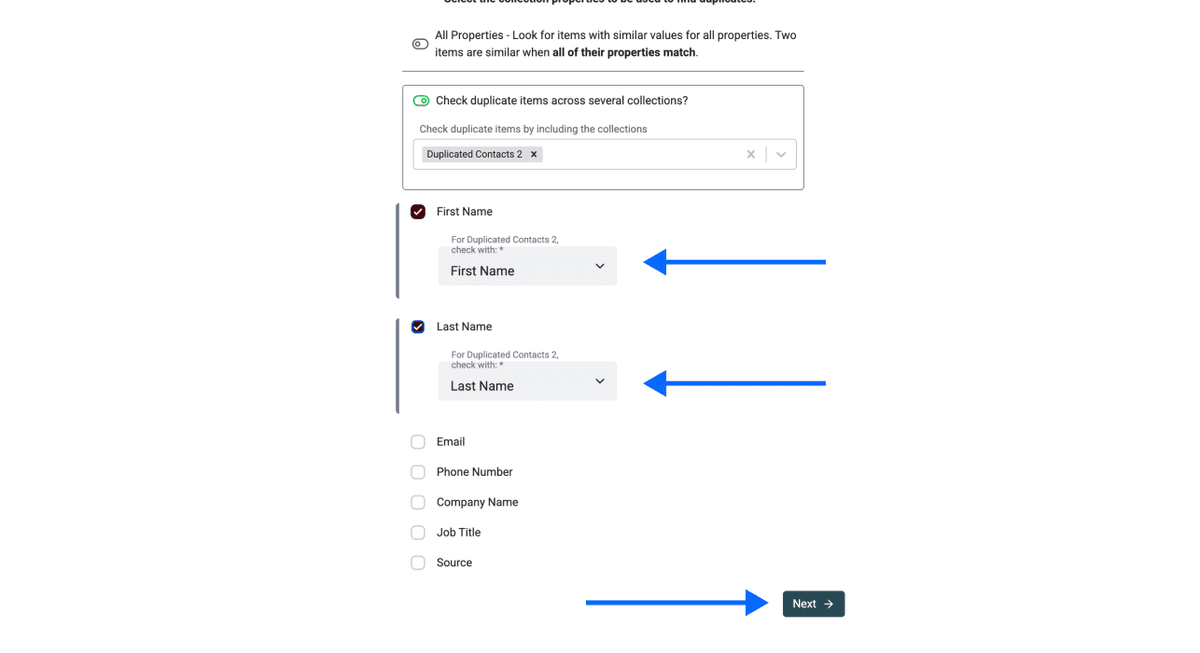
Paso 4: Elija la propiedad de identificador único
Seleccione la propiedad que usará para hacer match de duplicados entre archivos. Puede elegir varias, pero asegúrese de que todos los archivos contengan esas propiedades para que la deduplicación sea precisa.
Paso 5: Seleccione el algoritmo de comparación
Elija el mecanismo de comparación que encaje con sus datos:
- Exact: ideal para URLs, dominios o IDs donde necesita coincidencias exactas
- Smart: ideal para propiedades de texto donde pueden existir pequeñas variaciones
Haga clic en Run duplicates check cuando haya elegido el método.
Paso 6: Configure reglas de limpieza
Elija cómo quiere gestionar los duplicados:
- Remove duplicate items from collection X: elimina duplicados del archivo seleccionado
- Keep duplicate items only in collection X: disponible solo al deduplicar entre 3 o más collections
Haga clic en Process duplicate items para continuar.
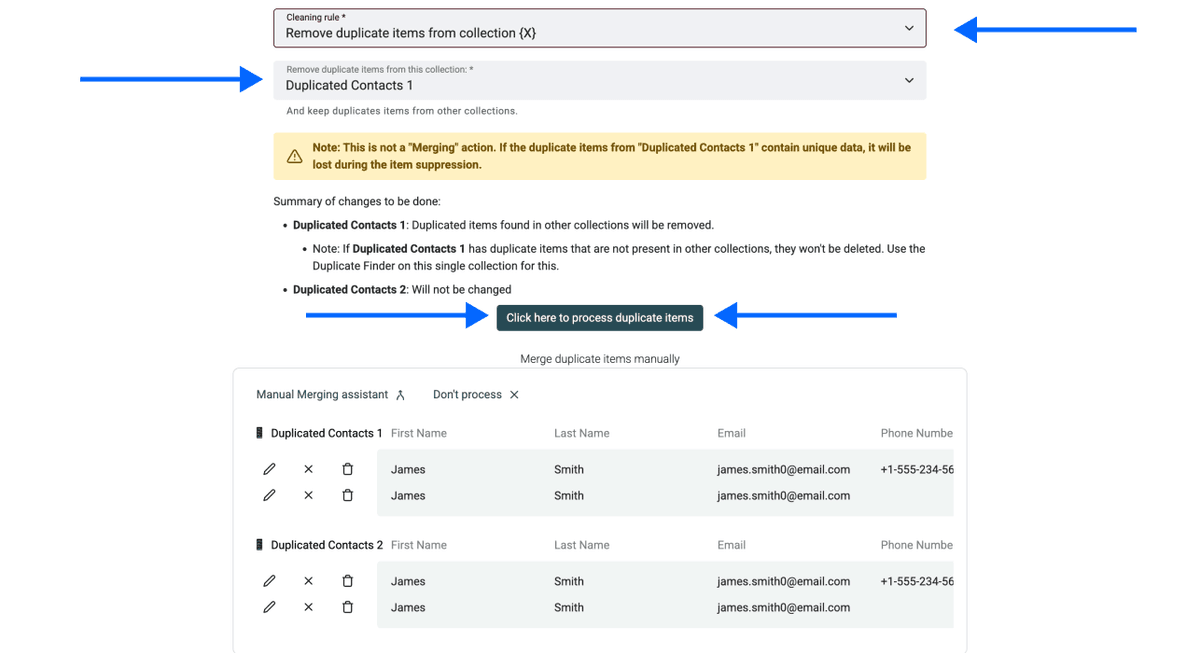
¡Y listo!
Conclusión
Enhorabuena: llegó al final y ahora sabe más de deduplicación que la mayoría. Aquí va un repaso rápido de lo más importante:
- No todos los duplicados son iguales; identificar el tipo cambia totalmente el enfoque
- Elegir bien el Master Item y la acción masiva puede ahorrarle horas de limpieza manual
- A diferencia de otras herramientas que le obligan a trabajar “a su manera”, Datablist le permite manejar duplicados exactamente como usted lo necesita
Ya sea que esté fusionando contactos en un CRM caótico, aplicando lógica personalizada con IA o limpiando nuevos leads contra su base de datos, ahora tiene las herramientas y el criterio para hacerlo bien.
Preguntas frecuentes
¿Cómo decide Datablist qué registro duplicado conservar?
Datablist no lo decide: lo decide usted. Usted elige una Master Item Rule (como “Most complete” o “Last updated”) que le indica a Datablist qué registro priorizar. Si su lógica es más compleja, puede usar AI Editing para definir reglas personalizadas en lenguaje natural (y el asistente de IA se encarga del resto).
¿Qué diferencia la suite de deduplicación y matching de Datablist frente a otros productos?
Tres cosas: flexibilidad, personalización con IA y precio. La mayoría de herramientas solo permite borrar duplicados. Datablist le permite fusionar, actualizar, marcar o eliminar en función de reglas que usted define. AI Editing cubre lógicas complejas que otras herramientas simplemente no pueden. Y el producto comparable más cercano suele costar varios miles de dólares al año (software enterprise).
¿Y si no quiero borrar mis duplicados?
Puede marcarlos en lugar de eliminarlos. Use AI Editing y escriba un prompt tipo: “Add 'DUPLICATE' to the status column for all non-master items instead of deleting them.” Es especialmente útil por compliance o cuando necesita revisar duplicados antes de quitarlos.
¿Qué pasa si las Master Item Rules no encajan con mi caso?
Use AI Editing. En lugar de elegir una regla predefinida, describe su lógica en lenguaje natural y la IA de Datablist crea un script personalizado. Por ejemplo: “Keep the record from Salesforce, but use the job title from LinkedIn.”
¿Puedo crear Master Item Rules personalizadas?
Sí. Con AI Editing puede escribir cualquier regla de priorización que pueda describir. ¿Quiere conservar registros donde la columna A contenga un valor específico? ¿O priorizar con varias condiciones? Escríbalo y la IA se encarga.
¿Qué es un identificador único en deduplicación?
Un identificador único es la columna (o combinación de columnas) que hace que cada registro sea distinto. Por ejemplo, si usa “Email” como identificador único, dos filas con el mismo email se consideran duplicados aunque el resto de campos difieran. También puede combinar columnas como “First Name” + “Company” para un match más estricto.
¿Cómo deduplico una lista con valores en conflicto?
Los duplicados con conflicto ocurren cuando dos registros representan la misma entidad pero tienen valores distintos en algunos campos. Para gestionarlos: (1) elija una Master Item Rule para decidir qué registro gana, (2) decida si quiere combinar, descartar o actualizar los valores en conflicto, (3) use la suite de deduplicación de Datablist para aplicar esas decisiones en bulk. En casos complejos, AI Editing le permite seleccionar valores concretos de distintos registros.
¿Cómo puedo marcar duplicados sin eliminarlos?
Puede hacerlo con AI Editing dentro de la Deduplication and Matching Suite. Solo escriba un prompt como: “Add 'DUPLICATE' to the status column for all non-master items instead of deleting them.” Así deja los duplicados marcados para revisión sin perder datos, ideal para compliance o aprobaciones manuales.
Cómo actualizar registros duplicados sin borrar
Actualizar duplicados significa sustituir valores específicos del registro maestro por datos mejores de otra fuente. Para eso, puede usar AI Editing dentro de la Deduplication and Matching Suite. Solo tiene que describir lo que quiere, por ejemplo: “Keep records from Source A, but update the job title and company name using values from Source B.” La IA aplica su lógica a todos los grupos de duplicados; después puede borrar los extras o dejarlos marcados.