

Pipedrive es excelente para gestionar leads y ventas. Sin embargo, como cualquier CRM, con el tiempo se acumulan contactos y organizaciones duplicados.
La herramienta de deduplicación integrada de Pipedrive tiene limitaciones importantes (ver todas las limitaciones del Merge Duplicates de Pipedrive):
- Solo detecta coincidencias exactas usando los nombres de personas/organizaciones. No identifica nombres de empresa con sufijos legales (Google LLC == Google), no hace fuzzy matching ni deduplicación usando website, email, etc.
- No permite fusionar en lote los duplicados.
Si está lidiando con People u Organizations duplicados en Pipedrive, necesita una mejor solución.
Ahí es donde entra Datablist Duplicates Finder para deduplicar sus datos de Pipedrive. En esta guía, le mostraré cómo:
- Importar sus People y/o Organizations de Pipedrive en Datablist
- Detectar y fusionar duplicados con algoritmos avanzados
- Sincronizar las fusiones en lote de vuelta a Pipedrive
- Limitaciones del Merge Duplicates nativo de Pipedrive
Paso 1: Importe sus contactos de Pipedrive
El primer paso para limpiar sus duplicados en Pipedrive es importar sus datos en Datablist. Así podrá usar herramientas de deduplicación avanzadas que Pipedrive no ofrece. Siga estos pasos para importar sus contactos y organizaciones:
1. Cree una nueva colección en Datablist
Una colección en Datablist es como una hoja de cálculo donde guarda y limpia sus datos. Cada colección contendrá sus contactos de Pipedrive (People) o sus empresas (Organizations).
- Si quiere deduplicar People, cree una colección para People.
- Si quiere deduplicar Organizations, cree una colección para Organizations.
- Si necesita limpiar ambos, cree dos colecciones separadas: una para People y otra para Organizations.
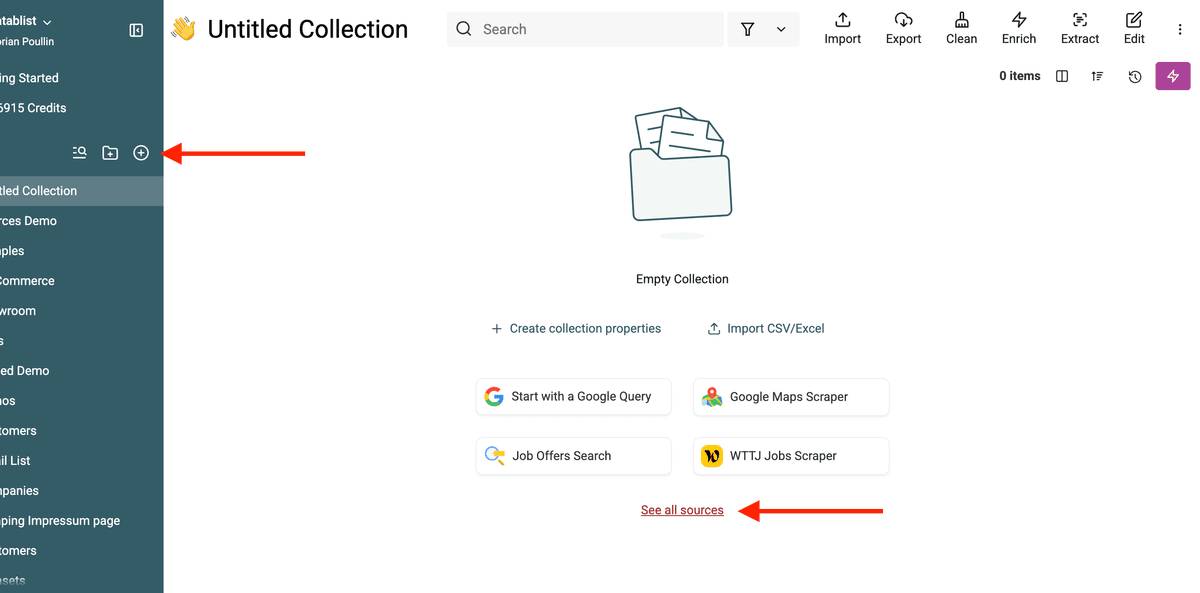
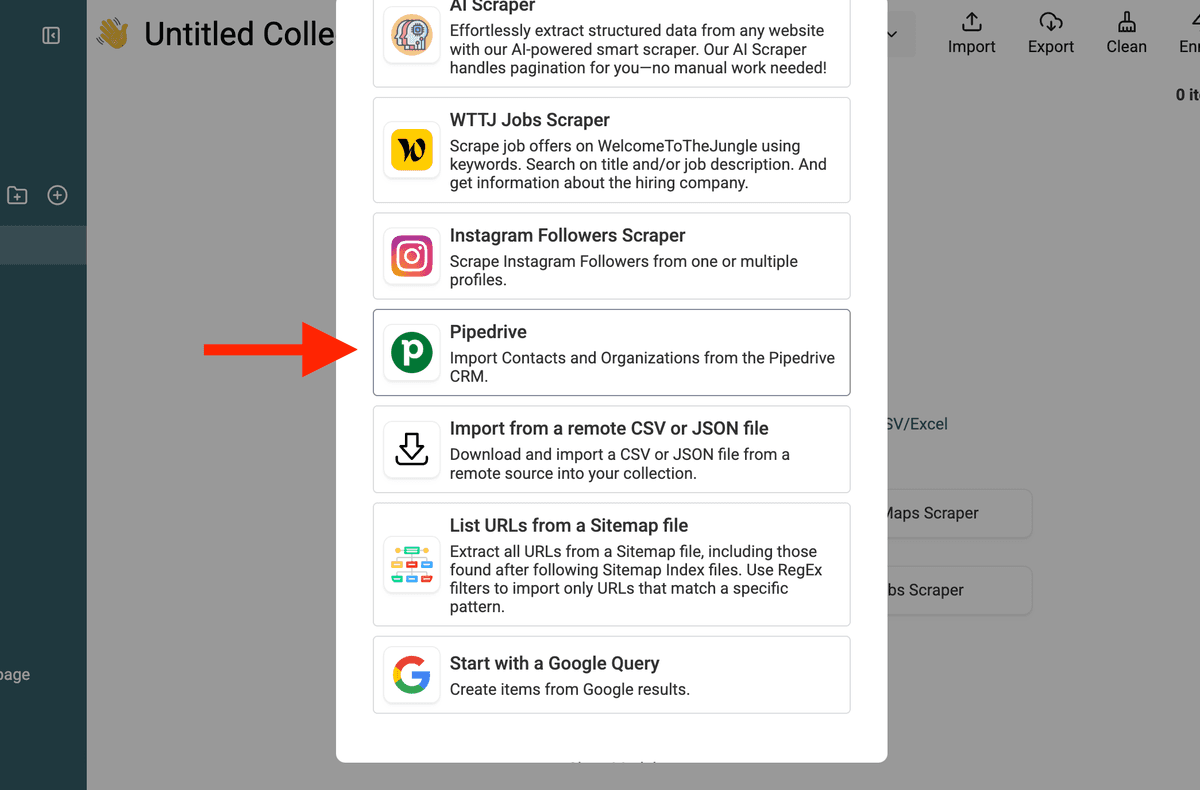
2. Seleccione “Source → Pipedrive”
Datablist se conecta directamente a su cuenta de Pipedrive a través de la API.
En su colección de Datablist, vaya a Import → seleccione Source → elija Pipedrive. O directamente desde el enlace "See all sources" en la pantalla inicial de la colección.
3. Encuentre su Pipedrive API Key
Se le pedirá que introduzca su API key de Pipedrive.
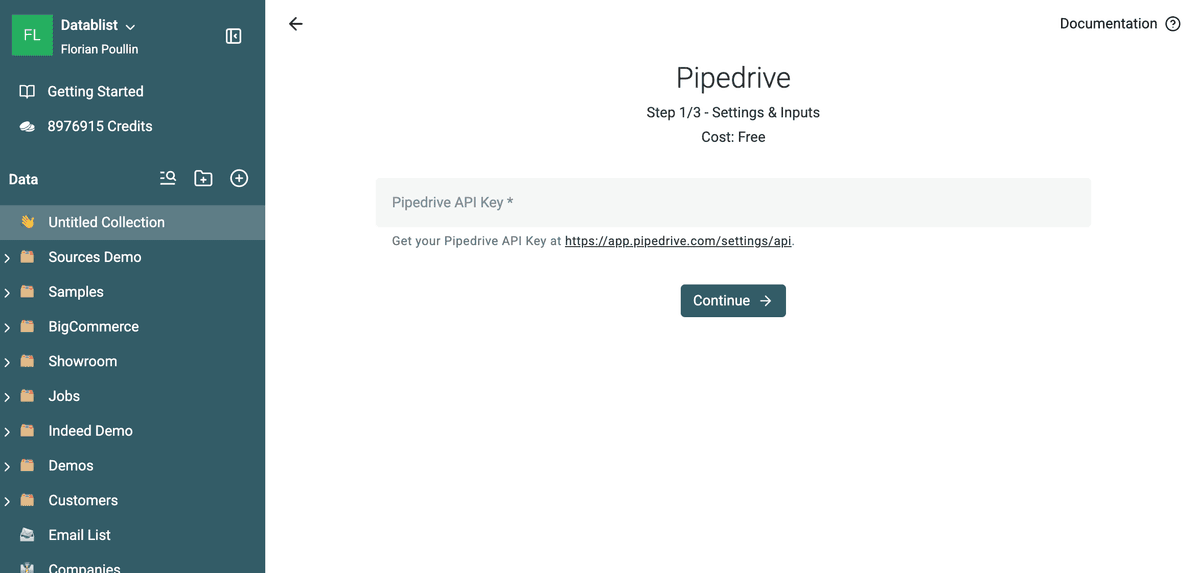
Su Pipedrive API key es necesaria para vincular Datablist con su cuenta de Pipedrive. Vaya a Pipedrive API Settings y copie su API key personal. Péguela en Datablist.
4. Elija People u Organizations
Una vez conectado, decida qué desea importar:
- Si va a limpiar contactos duplicados, seleccione People.
- Si va a limpiar empresas duplicadas, seleccione Organizations.
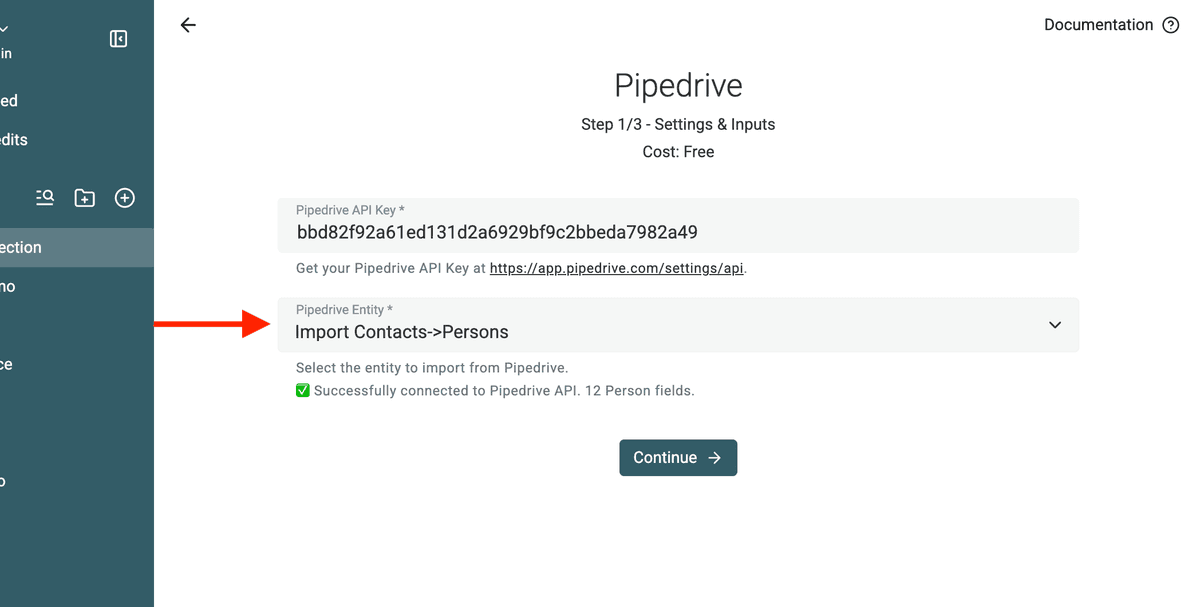
Nota: Si necesita ambos, impórtelos por separado en dos colecciones diferentes.
¿Por qué colecciones separadas? - Pipedrive almacena People y Organizations de forma distinta. No puede deduplicar una mezcla de ambos al mismo tiempo. Mantenerlos separados garantiza resultados precisos.
5. Datablist recupera todos los campos de Pipedrive
Una vez seleccione People u Organizations, Datablist importará:
- Campos estándar de Pipedrive (Name, Email, Phone, Website, etc.).
- Campos personalizados que haya creado en Pipedrive.
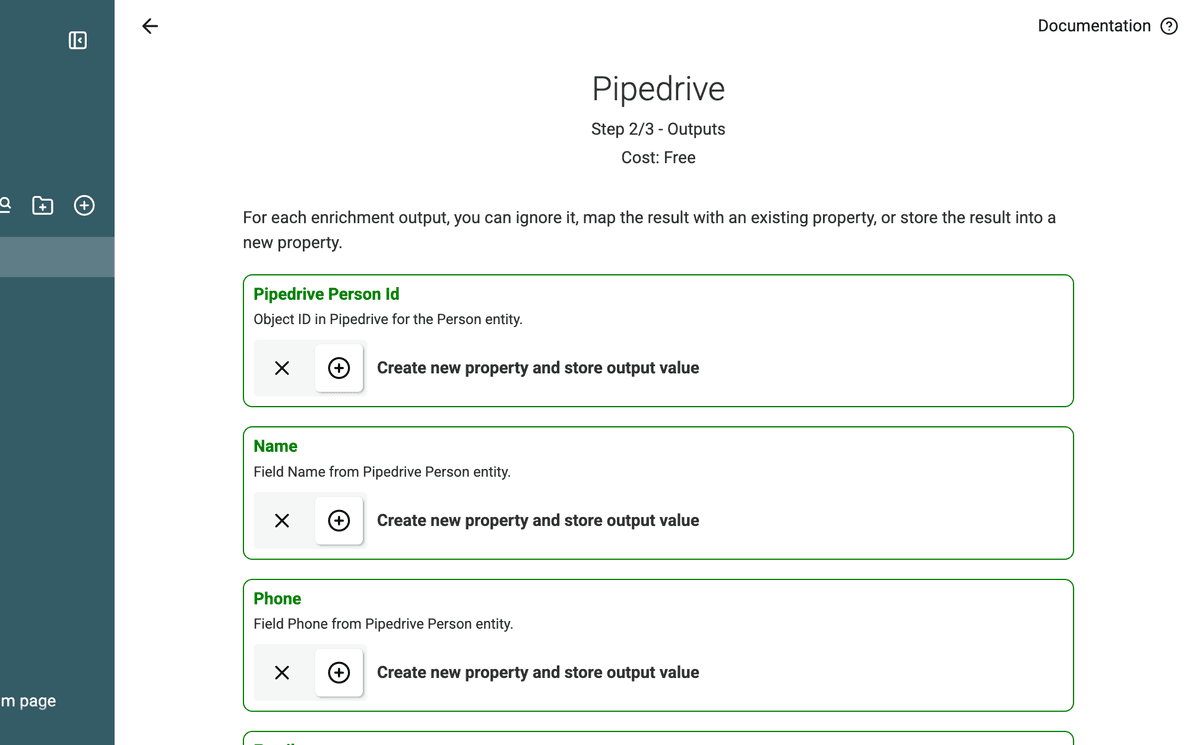
Así se asegura de que todos los datos relevantes estén disponibles para deduplicar.
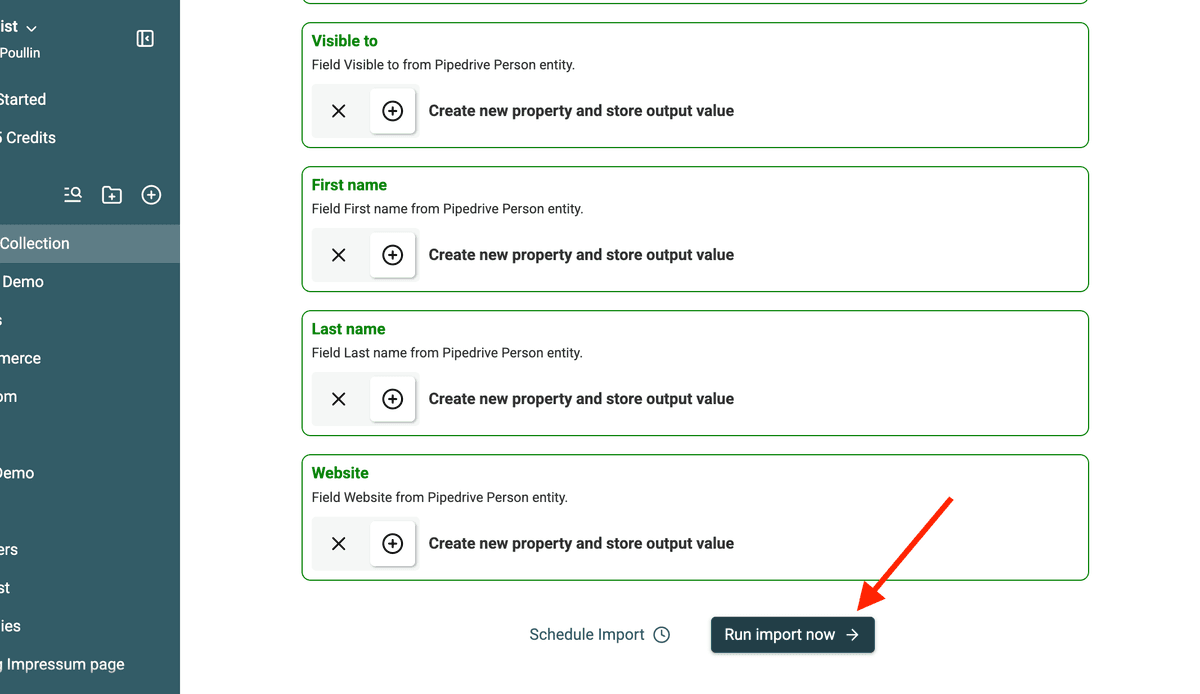
6. Ejecute la importación
Haga clic en Import para comenzar a recuperar sus datos. El tiempo dependerá del número de registros.
Datablist procesa sus contactos y los estructura para la deduplicación.
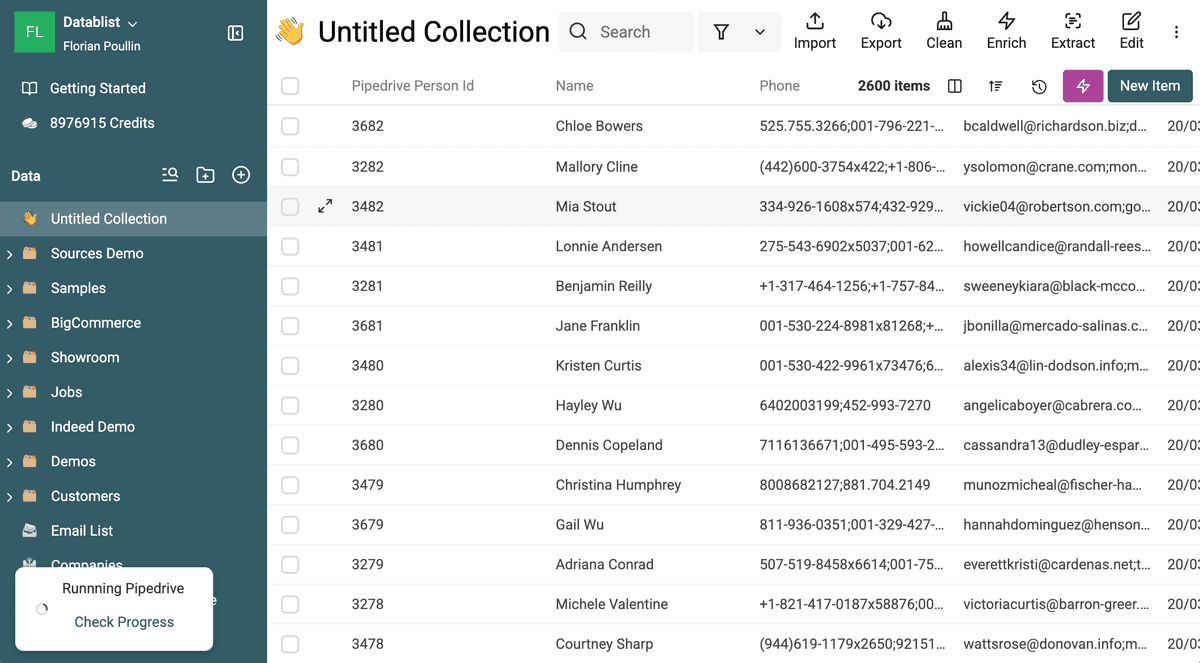
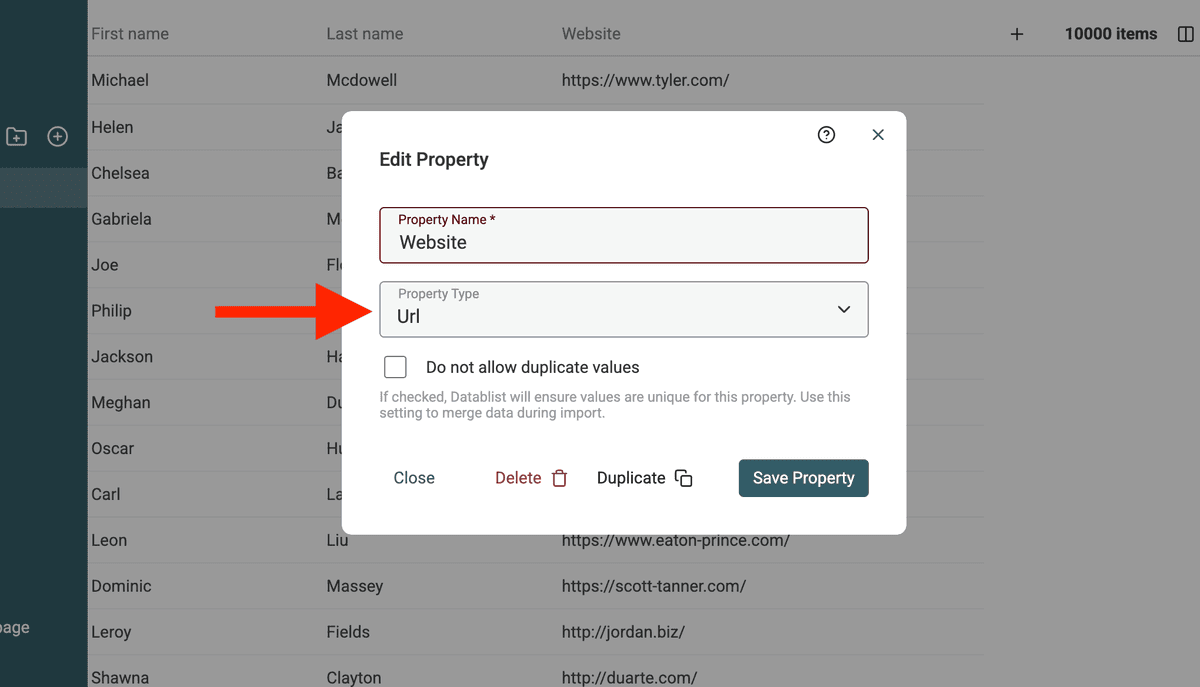
Cambie los tipos de datos para URLs
Datablist Duplicates Finder tiene procesadores especiales para tratar Emails, URLs, etc. Si sus datos incluyen websites, cambie el tipo de la propiedad a URL.
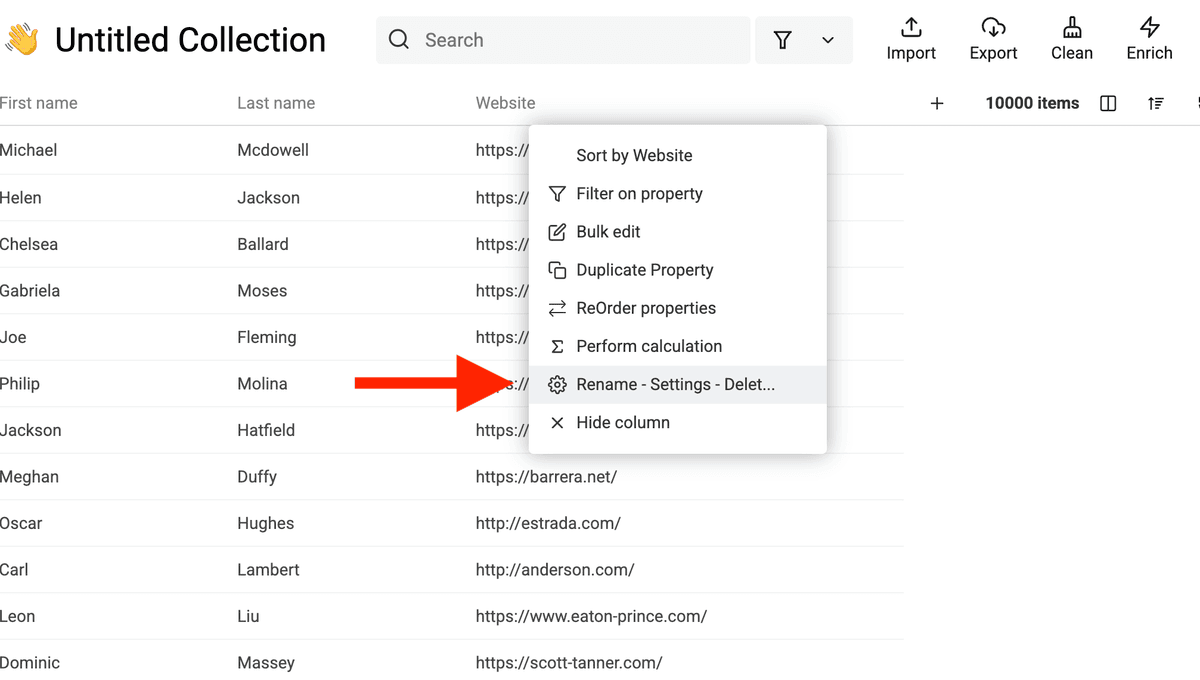
Múltiples direcciones de email y números de teléfono
Si un contacto tiene varios emails o teléfonos en Pipedrive, se concatenan en un único campo separados por punto y coma ;.
Ejemplo:
- John Doe tiene dos emails en Pipedrive:
john@company.comyj.doe@gmail.com. - En Datablist aparece: Email:
john@company.com;j.doe@gmail.com
Esto permite a Datablist manejar correctamente múltiples valores durante la deduplicación.
Una vez finalice la importación, sus datos estarán listos para deduplicar. A continuación, encontraremos duplicados con técnicas de matching avanzadas.
Paso 2: Detecte duplicados en People y Organizations de Pipedrive
Ahora que sus contactos u organizaciones de Pipedrive están en Datablist, es hora de encontrar duplicados. A diferencia de la herramienta integrada de Pipedrive, Datablist usa algoritmos avanzados de matching para detectar registros similares, incluso cuando los nombres varían ligeramente o faltan datos de contacto.
Así se hace:
1. Abra Duplicates Finder y elija una propiedad de deduplicación
En su colección de Datablist, vaya a Clean → Duplicates Finder.
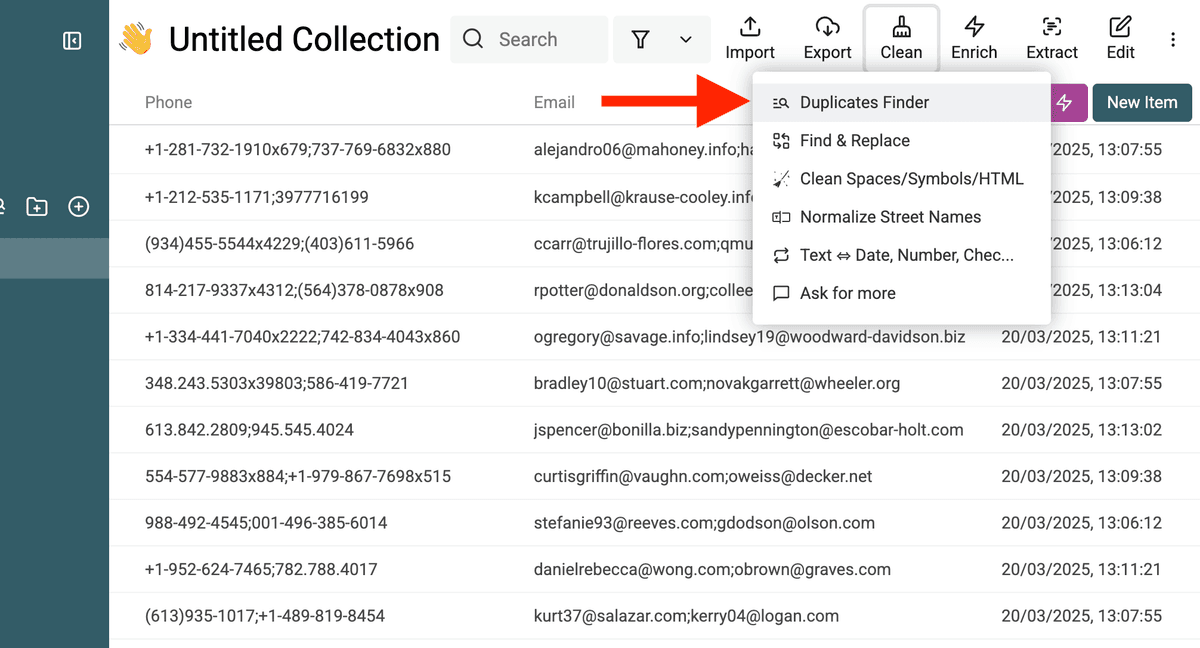
Una propiedad de deduplicación es el campo que Datablist usará para encontrar duplicados. La mejor opción depende del tipo de dato:
- Para People: Use Email (lo más fiable) o Name (si faltan emails o son inconsistentes).
- Para Organizations: Use Website (lo ideal) o Name (si no hay website disponible).
💡 Ejemplo:
- Si "Google" tiene dos registros: uno con
Google LLCy otro conGoogle, Datablist los detectará como duplicados porque sus nombres son similares.
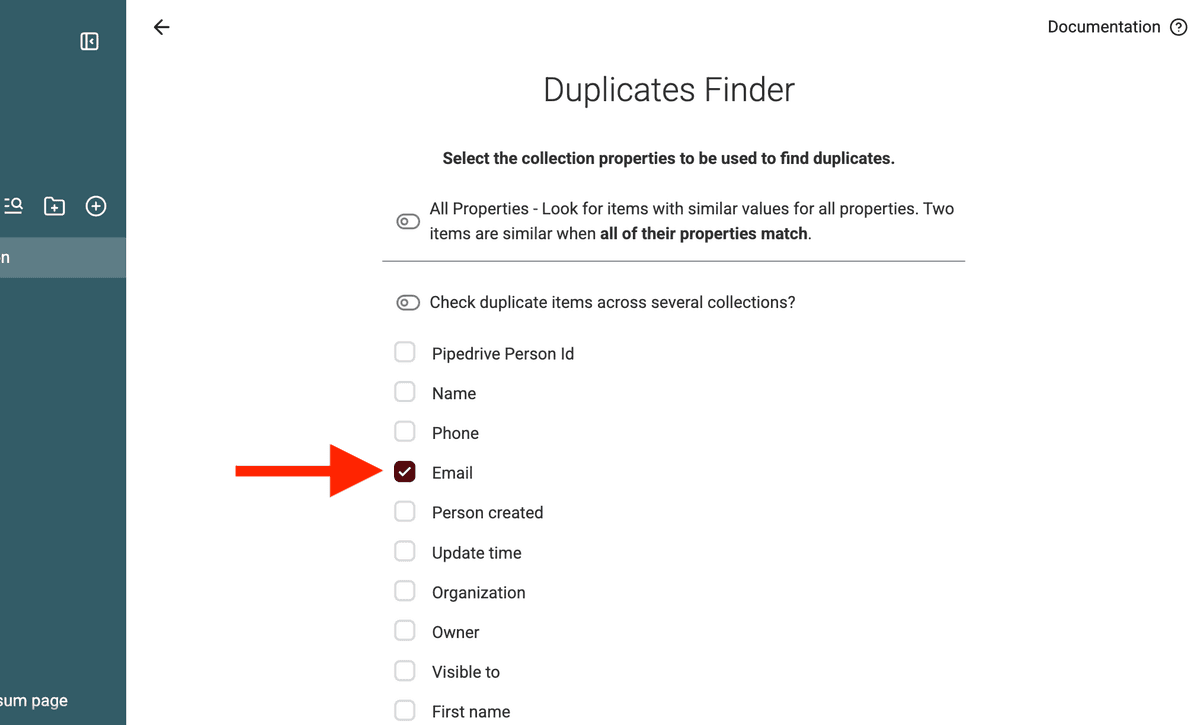
2. Ejecute la deduplicación
Para mejores resultados, no fusione todo de una sola vez. Ejecute la deduplicación en iteraciones:
1️⃣ Primera pasada: Haga matching por Email (People) o Website (Organizations). Así encuentra duplicados claros. 2️⃣ Segunda pasada: Haga matching por Name (People u Organizations) para atrapar duplicados que puedan tener emails distintos pero se refieran a la misma entidad.
🔹 ¿Por qué en dos pasos?
- Si fusiona por Email + Name juntos, pequeñas variaciones en el nombre ("John Doe" vs. "Johnathan Doe") podrían impedir el match.
- Hacer primero una pasada por email garantiza que las coincidencias exactas se resuelvan antes, evitando errores.
Atención con múltiples Emails y nombres de empresa
Algunos campos de Pipedrive incluyen múltiples valores, como Emails y Phones.
Si está deduplicando por campos como Emails o Phones que tienen varios valores (separados por ;), active el modo "Multiple Values" en Datablist. Así, si un contacto tiene john@company.com; j.doe@gmail.com en un registro y solo john@company.com en otro, se hará el match correctamente.
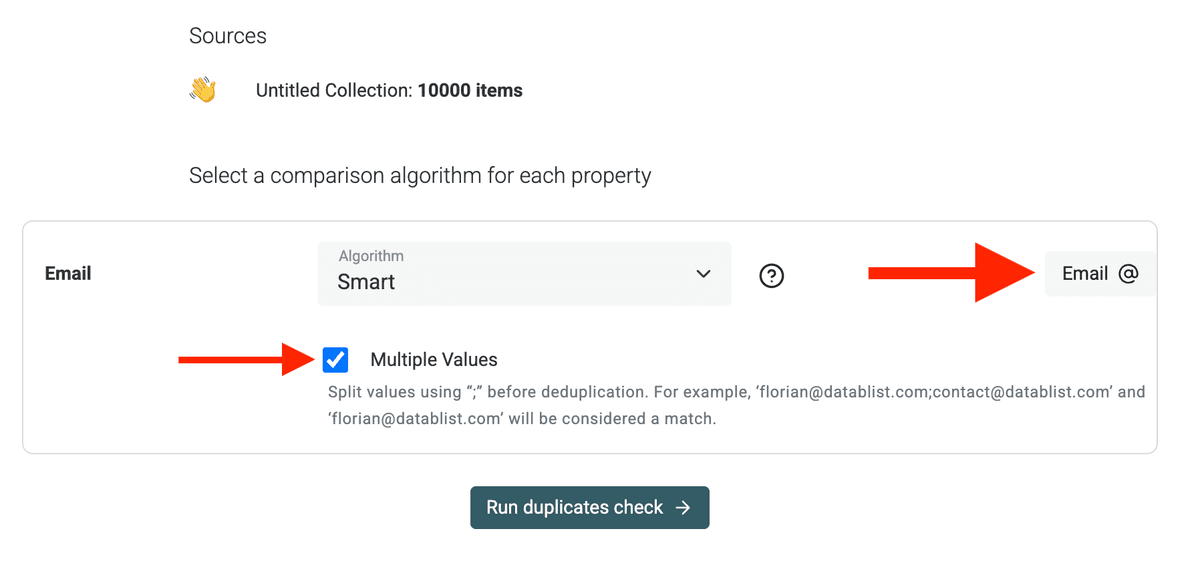
Si está deduplicando por nombres de empresa, Duplicates Finder de Datablist tiene un procesador dedicado para tratar sufijos legales y palabras de relleno.
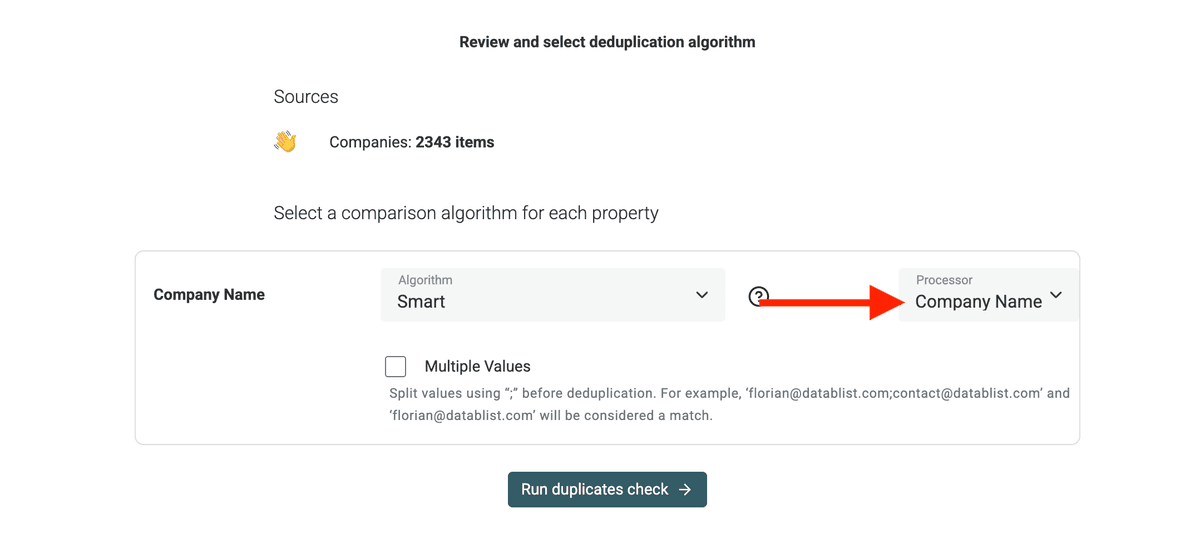
Si está deduplicando por websites, use el procesador
URL.
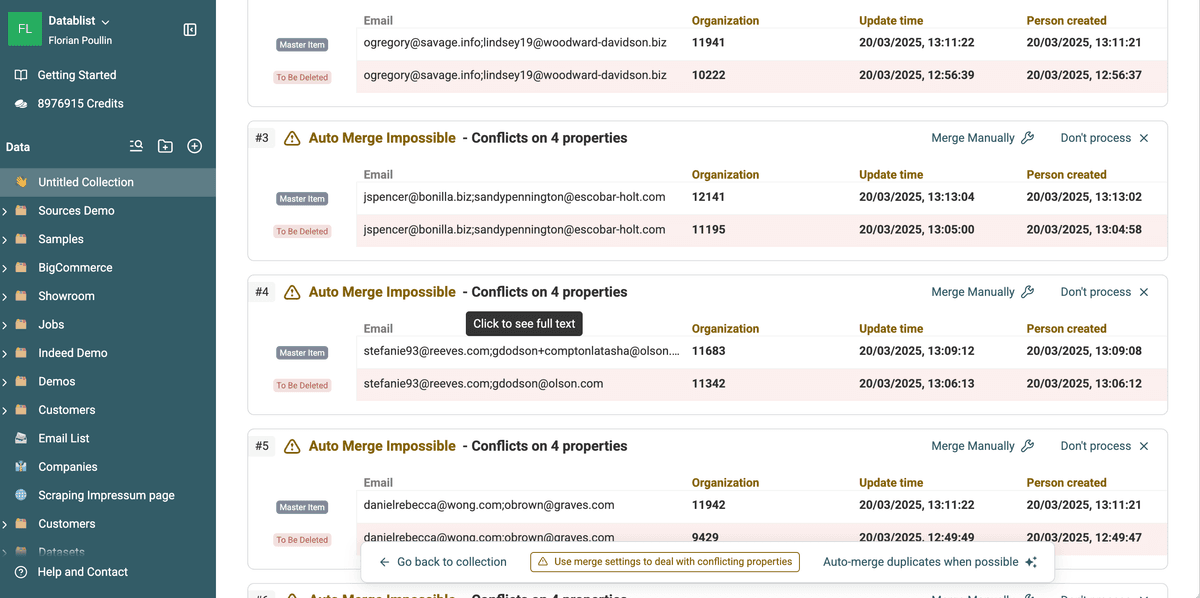
3. Revise los duplicados detectados y los valores en conflicto
Una vez finalizado el escaneo, Datablist agrupa los duplicados.
- Verá grupos de People u Organizations similares. Los llamamos "Duplicate Groups".
- Cada grupo mostrará cómo coinciden (por email, name o website) y si tienen datos en conflicto.
3.a. Comprenda los grupos de duplicados
Cada grupo de duplicados contiene varios registros que se consideran la misma entidad.
- Algunos grupos pueden fusionarse automáticamente porque tienen datos idénticos o complementarios.
- Otros requieren revisión manual porque tienen información en conflicto.
💡 Ejemplo:
- Si dos registros de “John Doe” tienen el mismo email pero teléfonos distintos, Datablist los detectará como duplicados y marcará el teléfono como campo en conflicto.
3.b. Configure las reglas de fusión para valores en conflicto
Entender los conflictos
Los conflictos aparecen cuando los contactos duplicados tienen valores distintos en el mismo campo. Por ejemplo, dos registros con cargos o teléfonos diferentes. Datablist resalta estos conflictos para que elija qué valor mantener.
Cómo resolver los conflictos
Datablist ofrece una interfaz intuitiva para resolver conflictos de forma eficiente y mantener datos limpios y precisos.
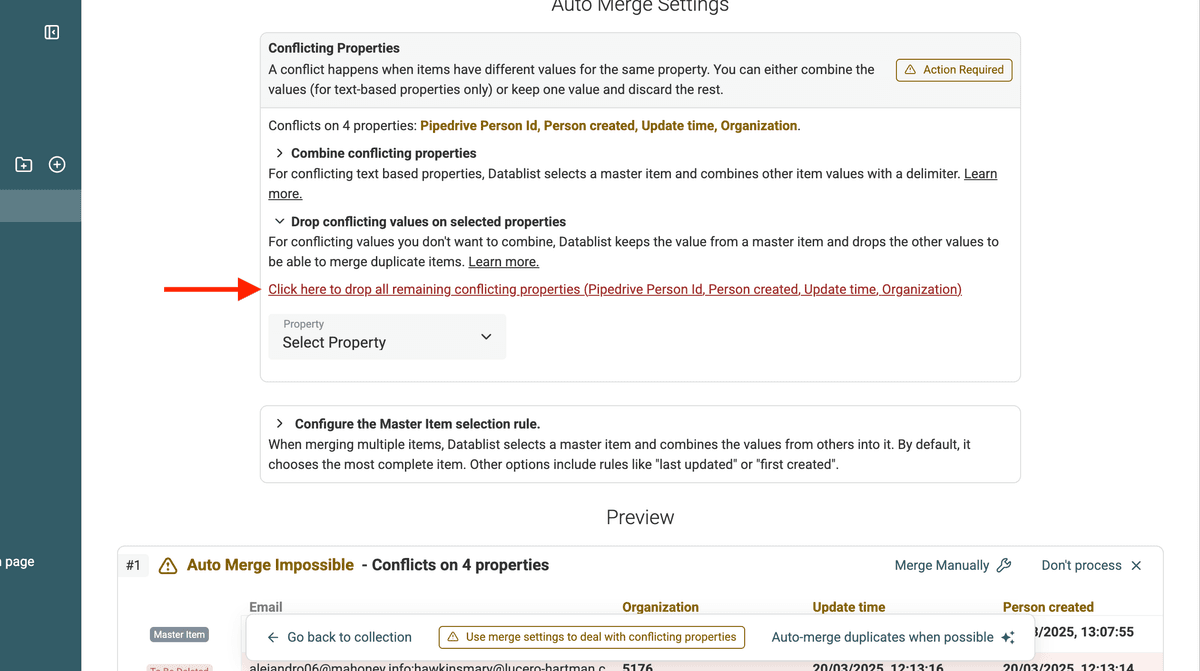
- Combine valores: Si los valores son complementarios (p. ej., varios teléfonos, notas), combínelos.
- Conserve un valor y elimine los demás: Si un contacto está claramente más completo y desea descartar el otro, seleccione "Drop conflicting values...".
Para las opciones Combine conflicting values y Drop conflicting values, tiene un acceso directo para seleccionar automáticamente todas las propiedades en conflicto.
Seleccione un registro maestro
También puede configurar cómo Datablist elige el registro maestro. Al fusionar registros duplicados, Datablist mantiene un registro, actualiza sus campos y elimina los demás para quedarse con uno solo.
Puede controlar cómo Datablist selecciona este Master Record eligiendo entre varias reglas:
- Most Complete: Elige el registro con más campos rellenos.
- Last Updated: Elige el registro modificado más recientemente.
- First Created: Elige el registro más antiguo según la fecha de creación.
- Highest Value: Elige el registro con el valor más alto en una propiedad seleccionada. Si varios tienen el mismo valor, selecciona el más reciente.
- Lowest Value: Elige el registro con el valor más bajo en una propiedad seleccionada. Si varios tienen el mismo valor, selecciona el más reciente.
- Matching Value: Elige el registro que contiene un valor específico en una propiedad seleccionada. Si ninguno coincide, no se fusionarán.
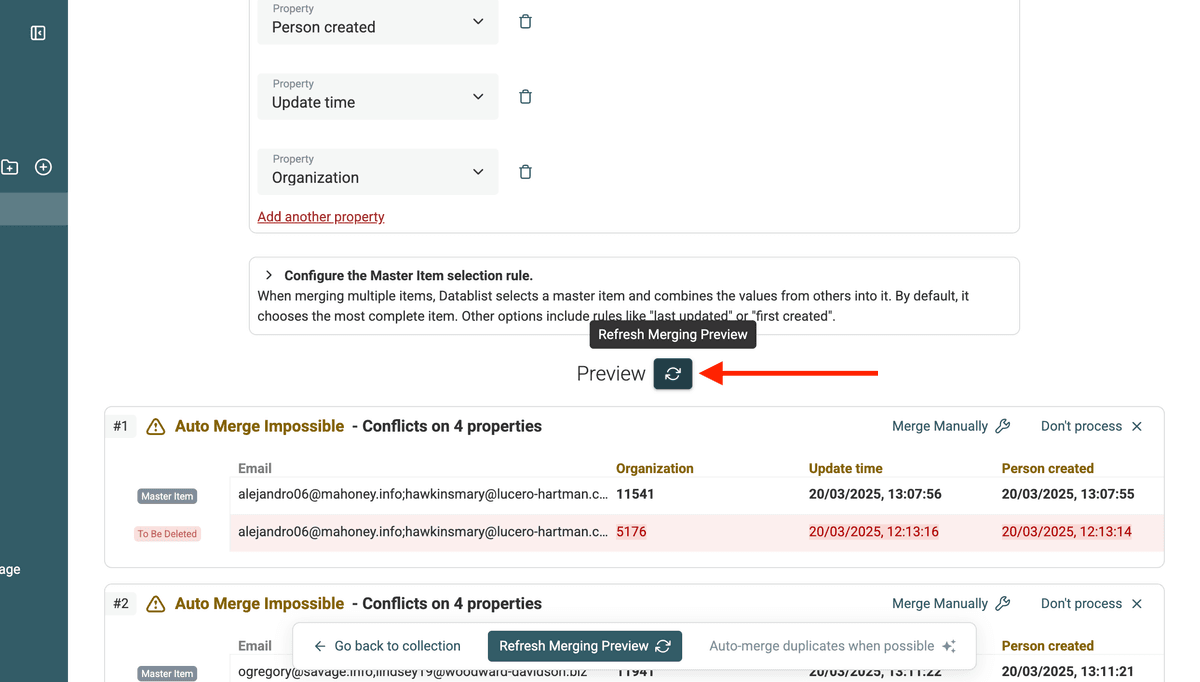
Datablist muestra una vista previa de los cambios que se realizarán. Verá qué registros se eliminarán, qué valores se combinarán, etc.
Haga clic en "Refresh" en la vista previa cuando termine de definir las reglas de fusión.
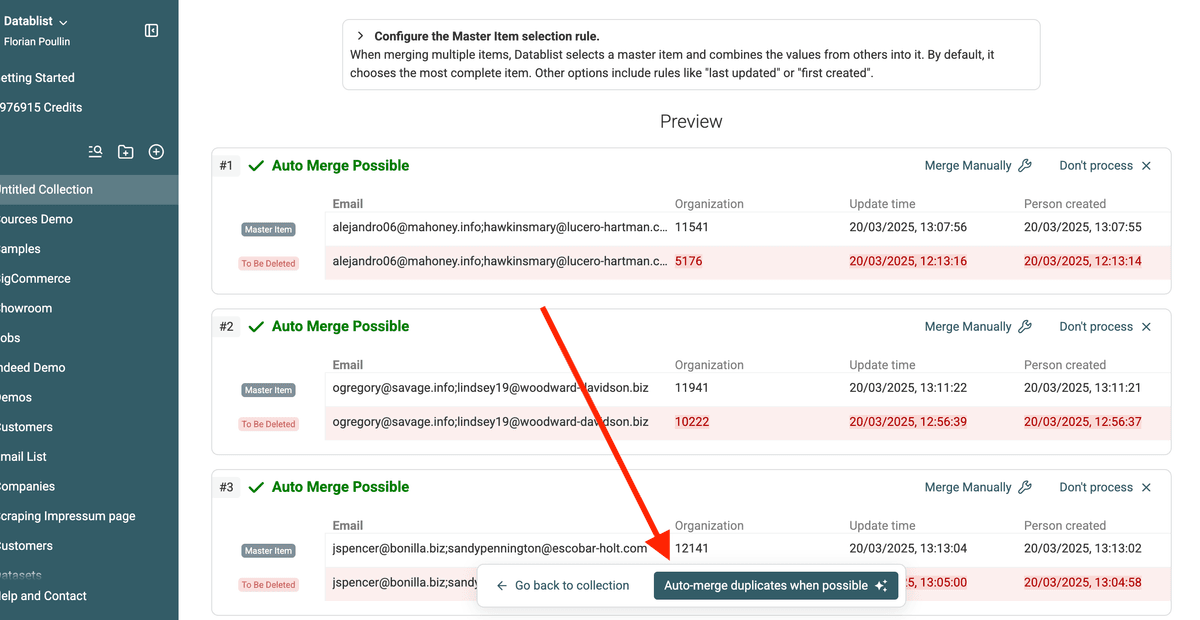
🔹 Ejemplo: Fusionar dos contactos
El siguiente ejemplo muestra el resultado de estas reglas:
- Drop Conflicting values en el campo
Name. - Combine Conflicting values en el campo
Phone.
| Field | Contact 1 | Contact 2 | Merged Result |
|---|---|---|---|
| Name | John Doe | Johnathan Doe | John Doe |
| john@company.com | john@company.com | john@company.com | |
| Phone | 555-1234 | 555-5678 | 555-1234; 555-5678 |
3.c. Fusione duplicados automáticamente
Cuando esté conforme con la vista previa, haga clic en "Auto-merge duplicates when possible" para que Datablist aplique las reglas de fusión en todos los grupos de duplicados.
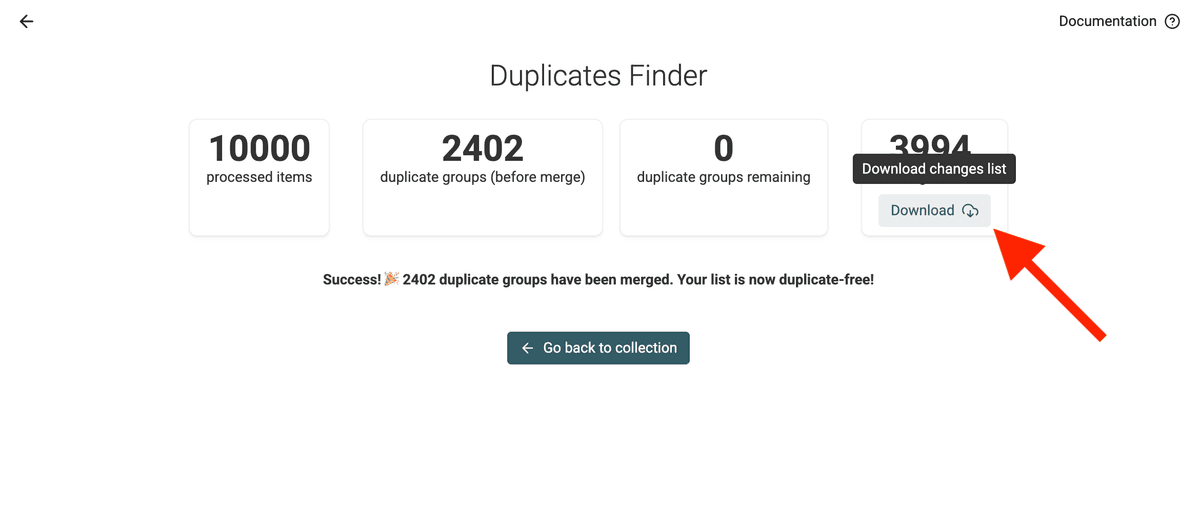
3.d. Descargue el archivo de cambios
⚠️ NECESITA este archivo de cambios para fusionar y actualizar los registros en su Pipedrive CRM.
Paso 3: Sincronice las fusiones en lote de vuelta a Pipedrive
Sus duplicados ya están fusionados en Datablist. El paso final es sincronizar los datos limpios de vuelta a Pipedrive para que su CRM quede actualizado.
Para ello usaremos el archivo de cambios descargado en el paso anterior (consulte 3.d. Descargue el archivo de cambios). Este archivo lista todos los registros fusionados, duplicados eliminados y campos actualizados.
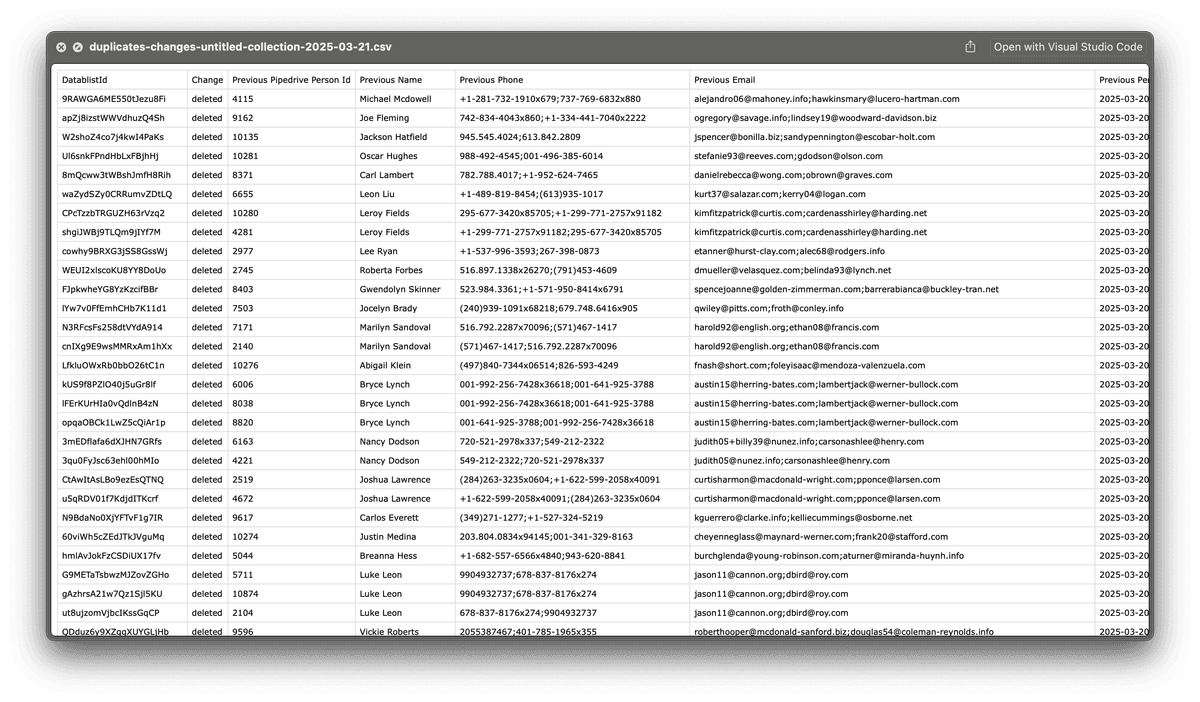
En este archivo Change Log podrá ver:
✅ Updated Records → Contacts u Organizations que se modificaron (p. ej., emails, teléfonos o nombres combinados). Con los datos previos y los nuevos datos actualizados.
✅ Deleted Records → Registros duplicados que se fusionaron en un registro maestro. Con el id del registro eliminado y el id del registro maestro que lo sustituyó. Esos registros deben eliminarse en Pipedrive.
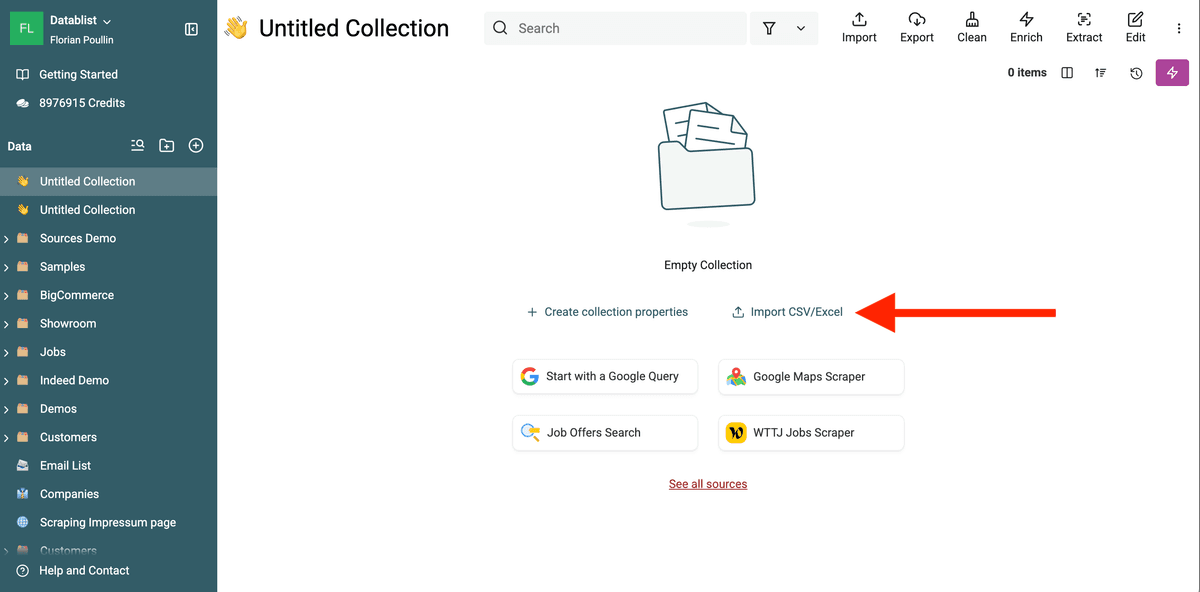
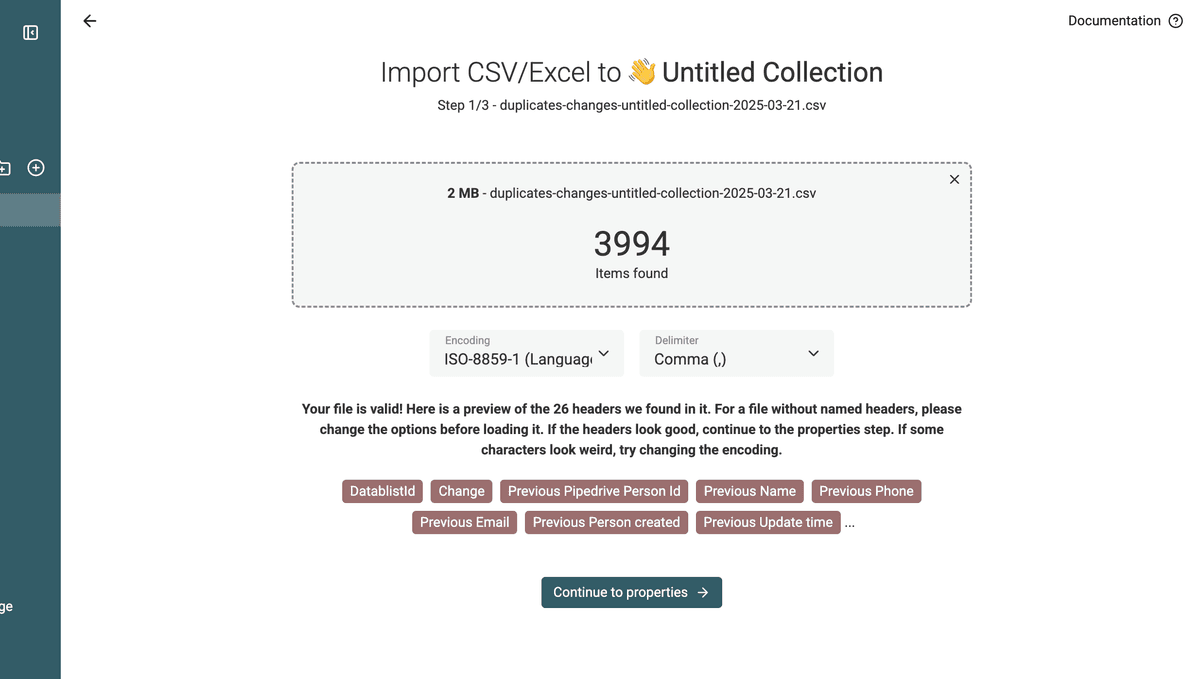
3.a Importe el archivo de cambios de duplicados en una colección nueva
Para aplicar esos cambios en su Pipedrive, cree una nueva colección y cargue el archivo de cambios.
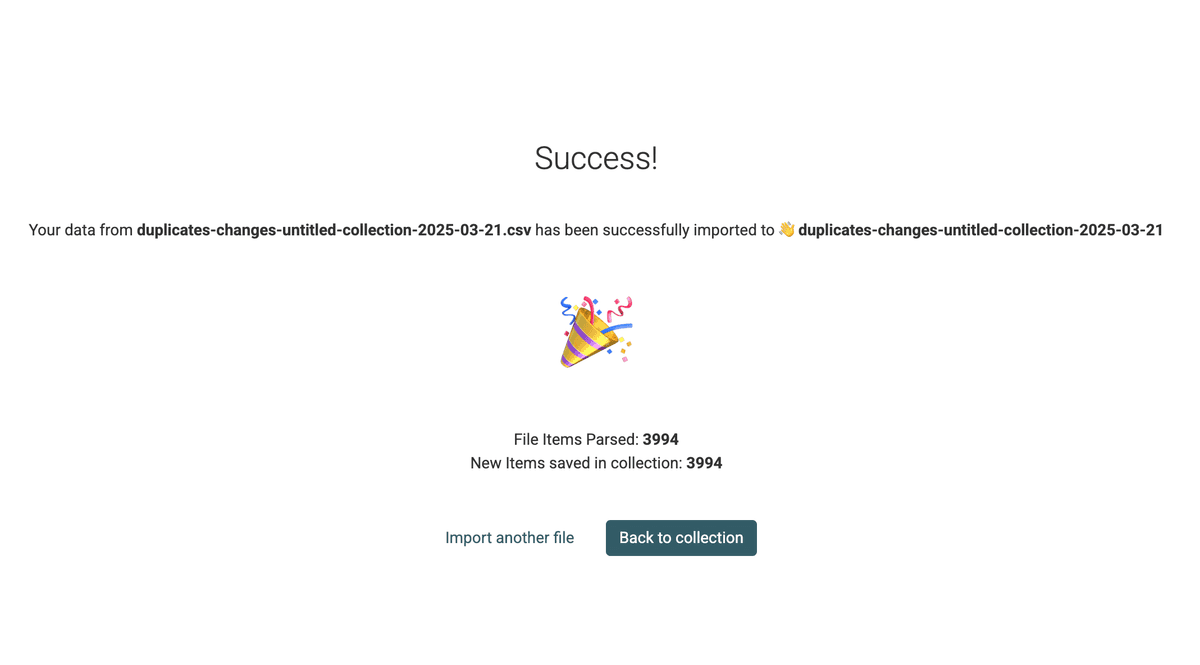
Tendrá una colección con las operaciones de fusión.
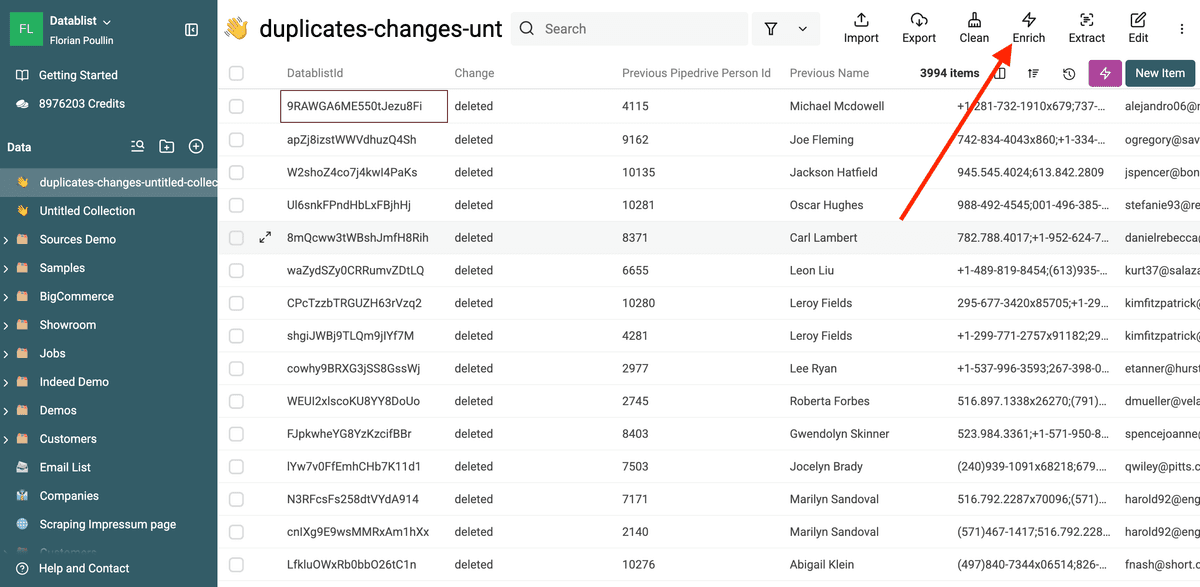
3.b. Fusione y elimine los registros duplicados
El primer paso para aplicar esos cambios en Pipedrive es indicar a Pipedrive que fusione los registros "deleted" con los "master".
Pipedrive proporciona una API de merge para consolidar registros duplicados. La usaremos.
Para el perfil técnico, así funciona la API de Pipedrive:
- Use el endpoint
/organizations/:id/mergepara Organizations. - Use el endpoint
/persons/:id/mergepara People. - El registro duplicado se elimina, y sus datos se transfieren al registro maestro.
💡 Ejemplo de petición API:
PUT https://api.pipedrive.com/v1/persons/{duplicate_id}/merge?api_token=YOUR_API_KEY
{
"merge_with_id": "{master_record_id}"
}
🔹 ¿Por qué usar la Merge API?
- Garantiza que todos los deals, actividades y notas vinculados permanezcan asociados al registro maestro.
- Los datos no conflictivos (como teléfonos o emails adicionales) se conservan automáticamente.
No se preocupe - Datablist tiene un enrichment nativo que llama a este endpoint de Pipedrive por usted.
El primer paso es seleccionar solo los elementos con una operación de cambio deleted.
Luego, en el menú Enrich, seleccione Pipedrive Merge Duplicates.
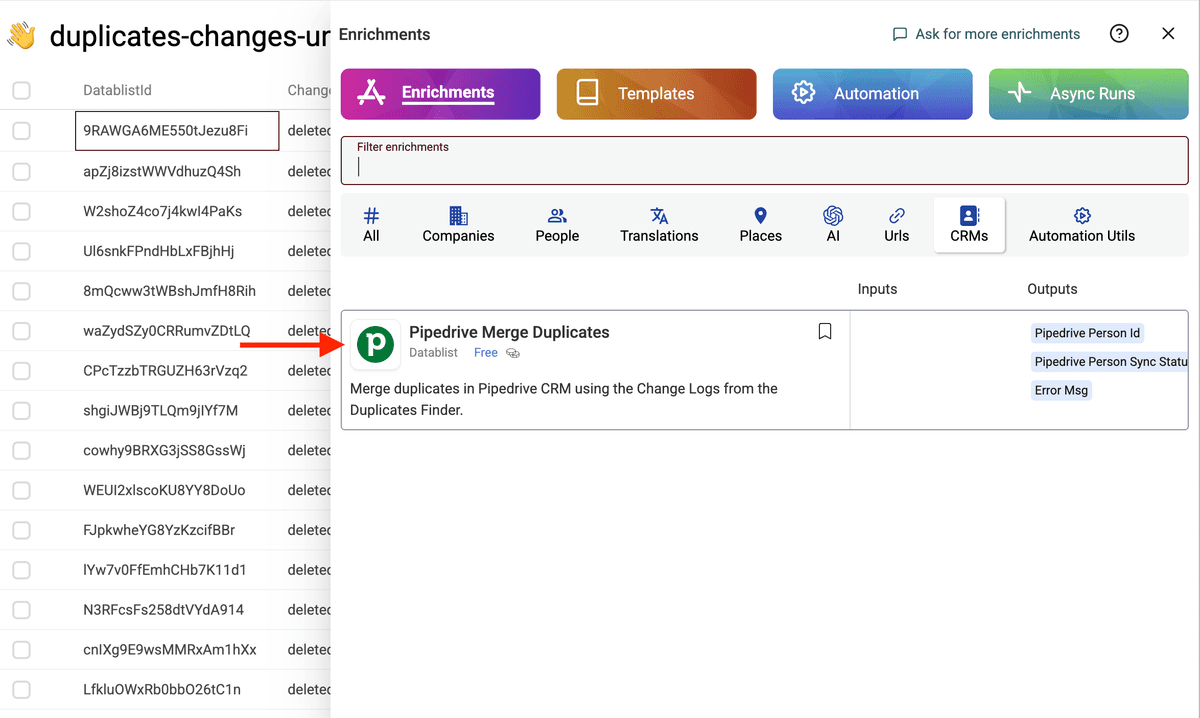
Asegúrese de ver únicamente "deleted" en la columna change antes de ejecutar el enrichment Pipedrive Merge Duplicates.
Introduzca su Pipedrive API key y configure la entidad de Pipedrive que va a fusionar.
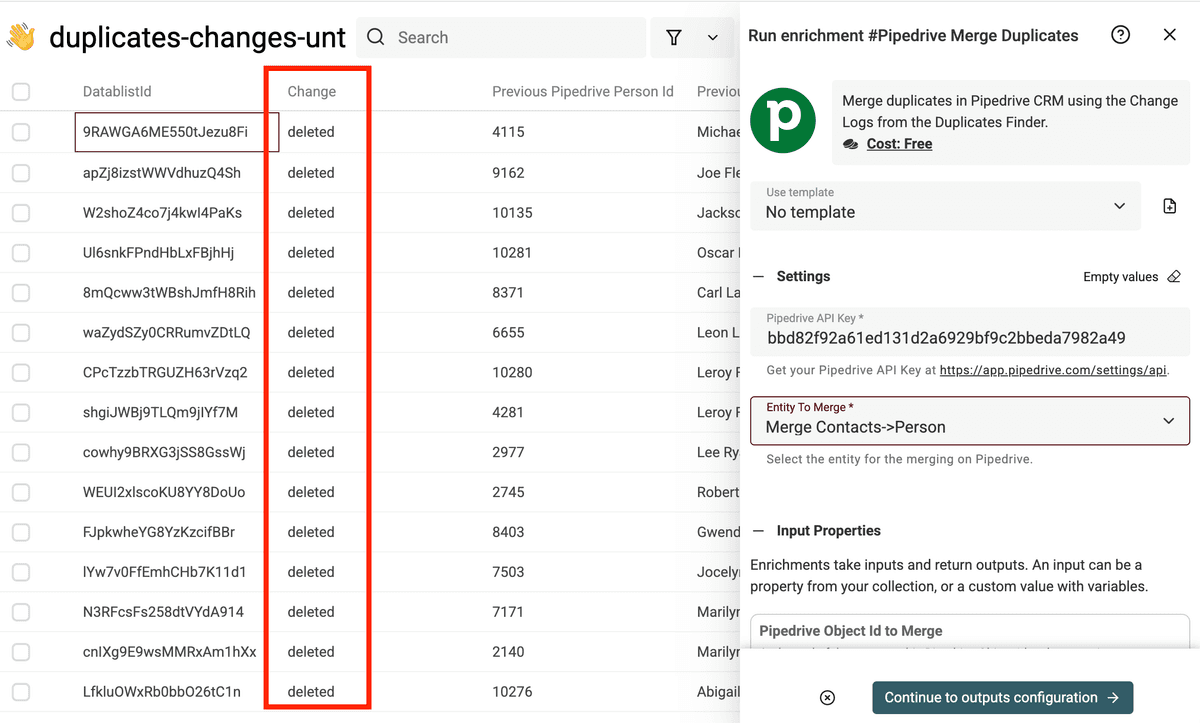
Después, en los inputs, para Pipedrive Object Id to Merge, asigne el campo Previous Pipedrive Person Id.
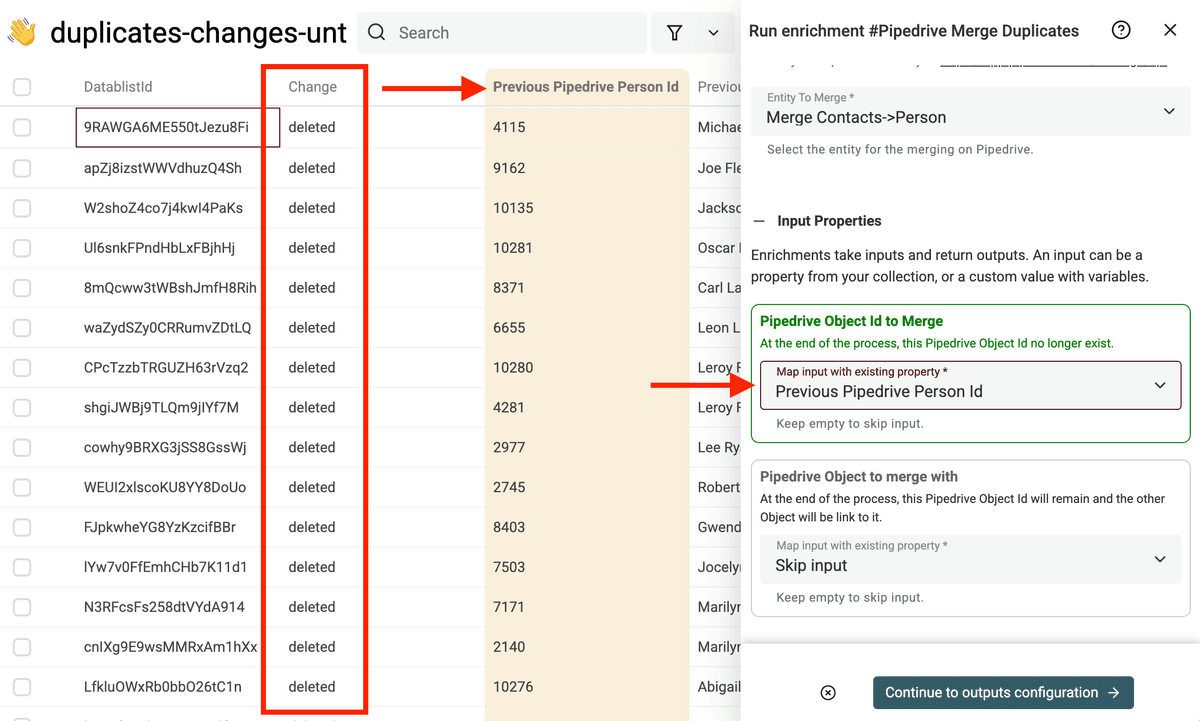
Para Pipedrive Object to merge with, asigne el campo Destination Pipedrive Person Id.
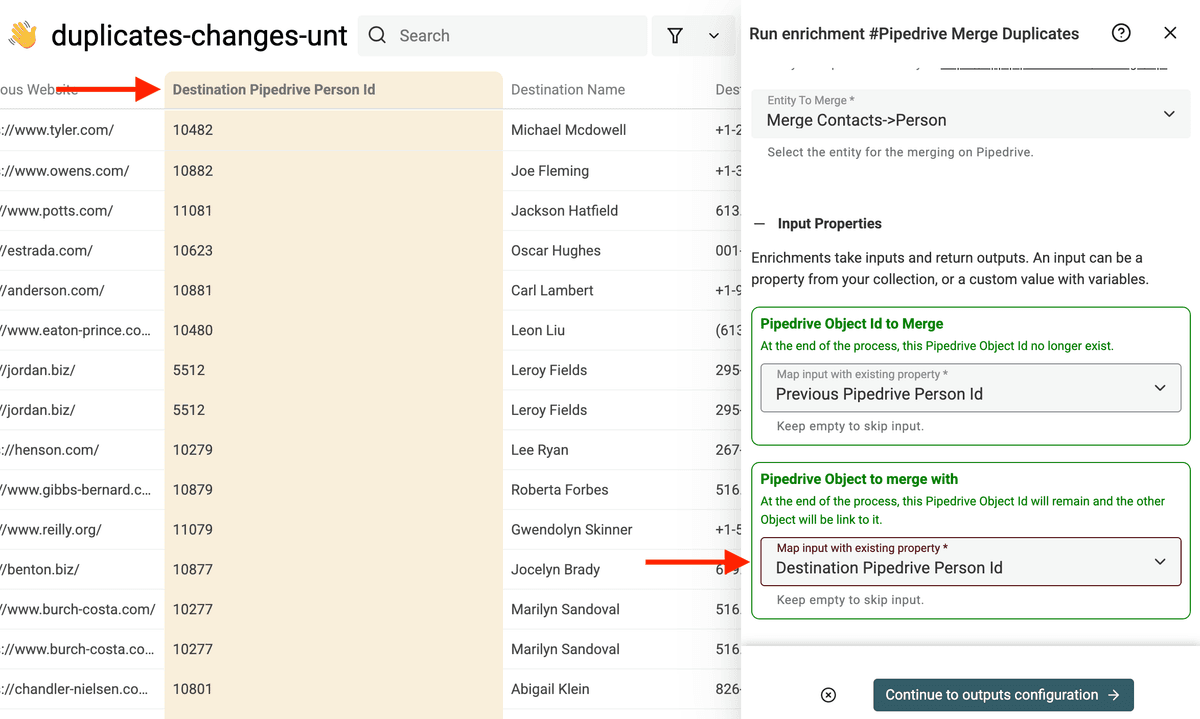
Luego, inicie el proceso de fusión.
Podrá ver el progreso directamente en Datablist.
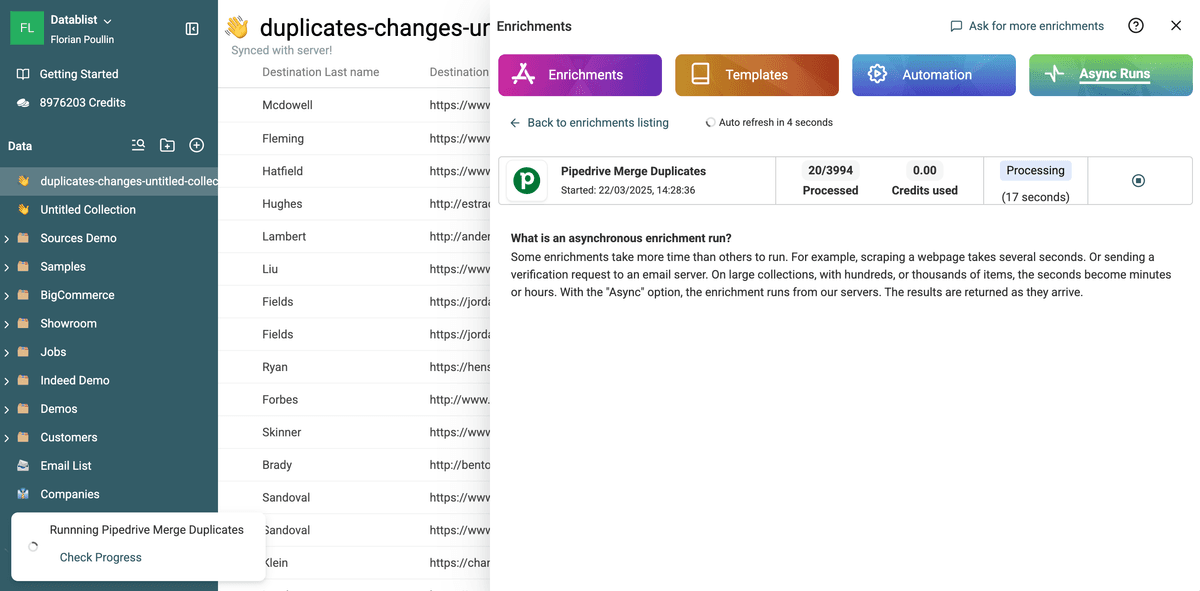
Para cada línea de la colección, verá el estado de la fusión.
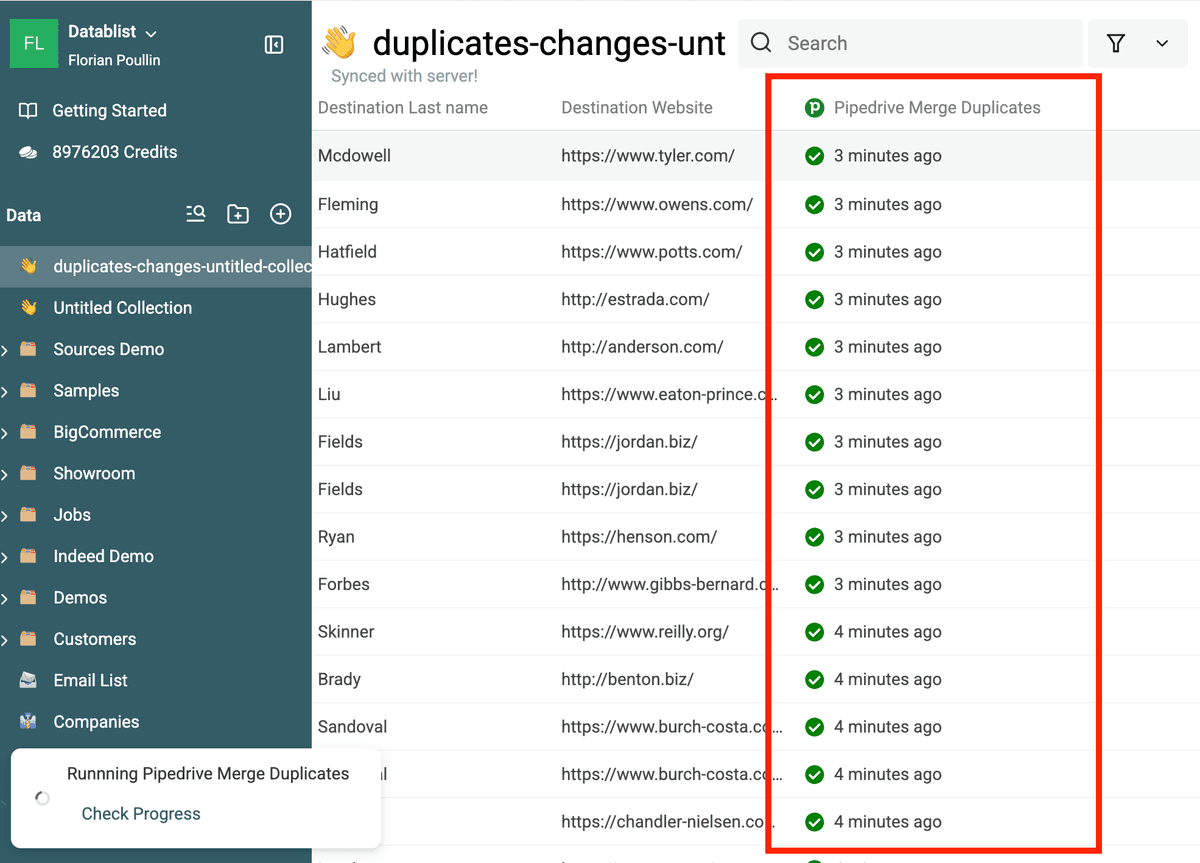
Puede comprobar el registro de Pipedrive que se eliminará. Vaya al registro (para People, la URL es https://app.pipedrive.com/person/:ID). Aparecerá un mensaje en la parte superior de la pantalla.
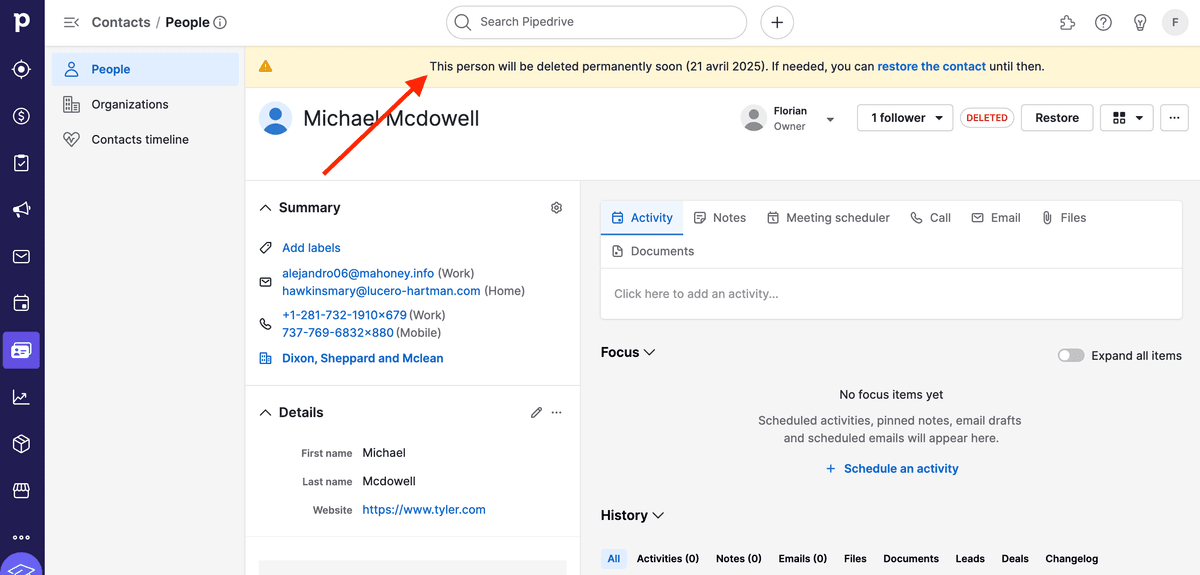
En los registros maestros también verá los datos fusionados.
3.c. Sincronice los registros actualizados en Pipedrive
En el paso anterior usamos la Merge API de Pipedrive para unir los registros duplicados con el maestro.
Por desgracia, durante este proceso de fusión, Pipedrive añade los valores del duplicado al maestro. Podría terminar con websites repetidos, etc.
Para solucionarlo, actualizaremos los registros maestros restantes con los datos limpios que obtuvimos tras la fusión en Datablist.
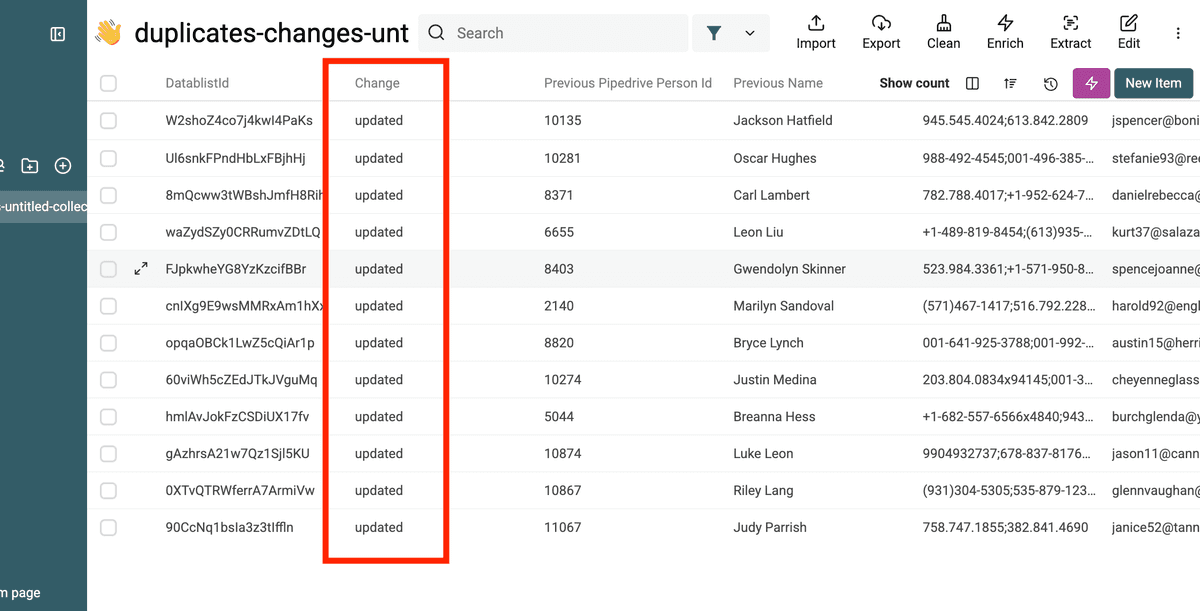
En la misma colección del "archivo de cambios", filtre la columna change para ver solo la operación updated.
Luego haga clic en Export -> Send to external tool.
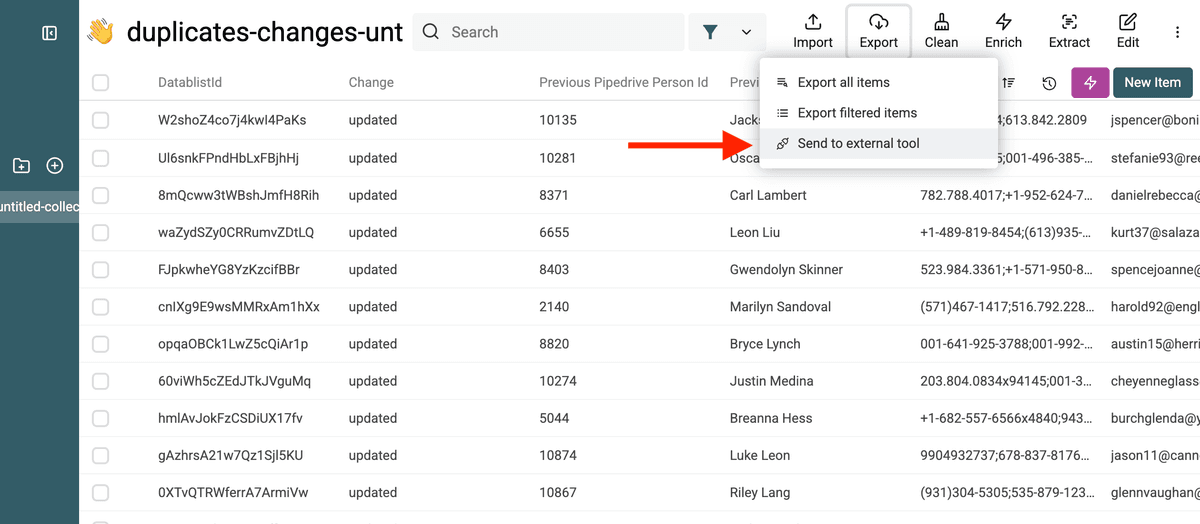
Y seleccione Sync with Persons/Organizations in Pipedrive.
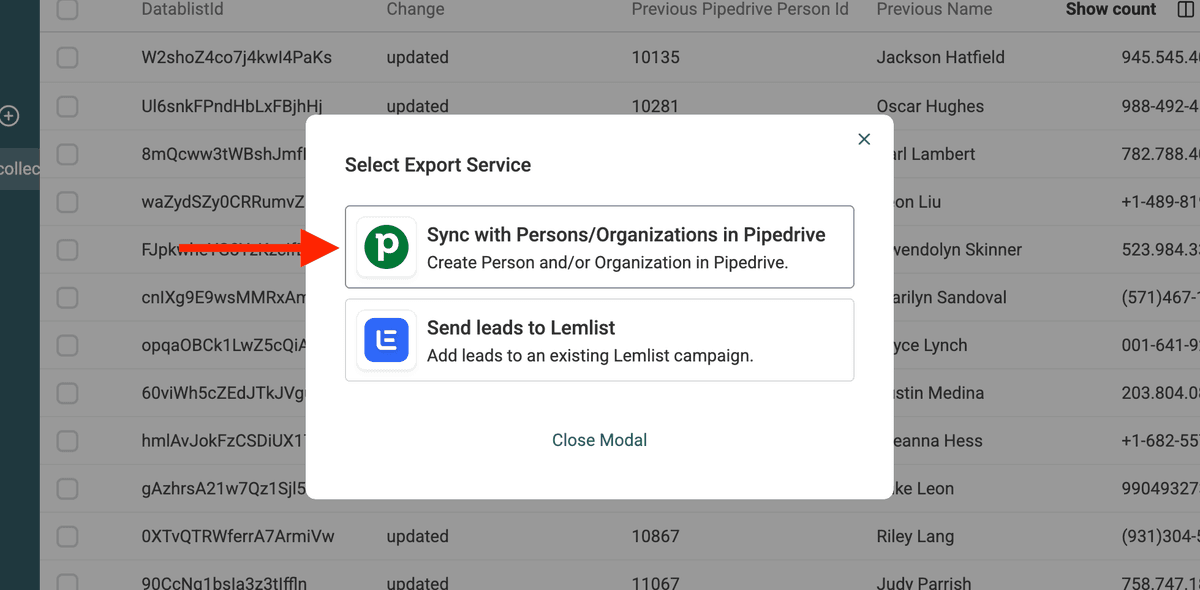
Introduzca su Pipedrive API Key y elija la entidad que va a actualizar (People u Organizations).
Seleccione el campo ID y los campos que quiera actualizar con valores limpios.
Importante - Debe seleccionar el campo
IDpara actualizar los datos y no crear registros nuevos.
En este ejemplo, solo actualizaré el campo website. Así que selecciono ID y Website.
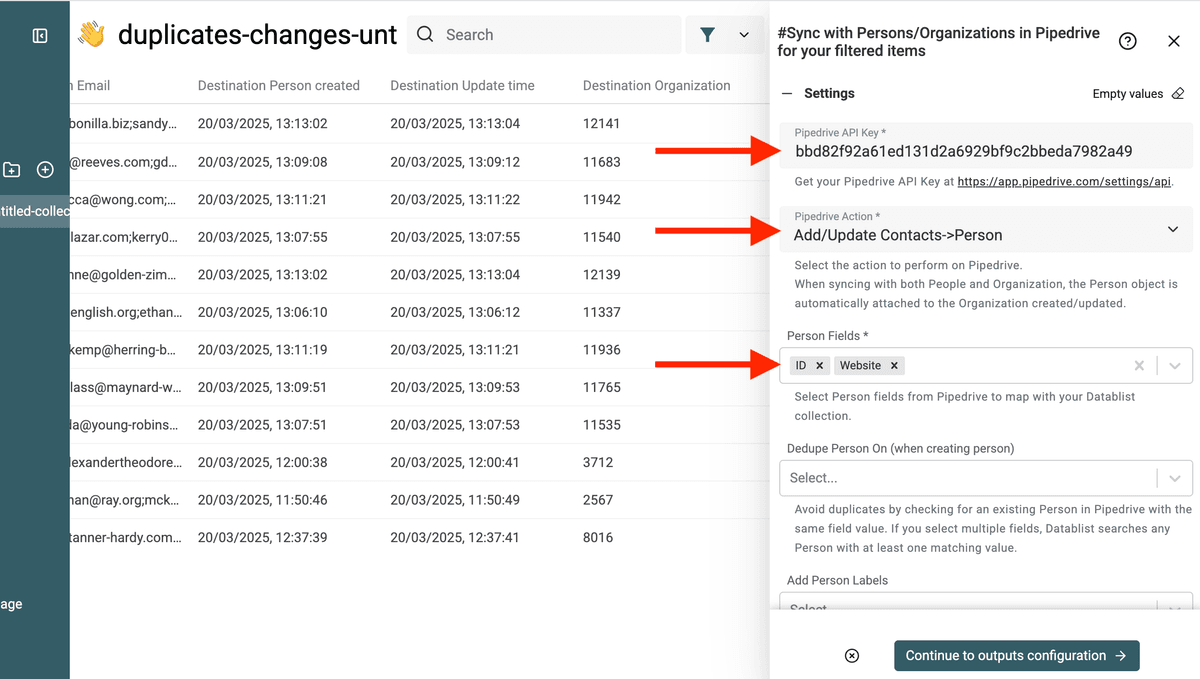
En la sección Inputs, asigne con los campos Destination XX.
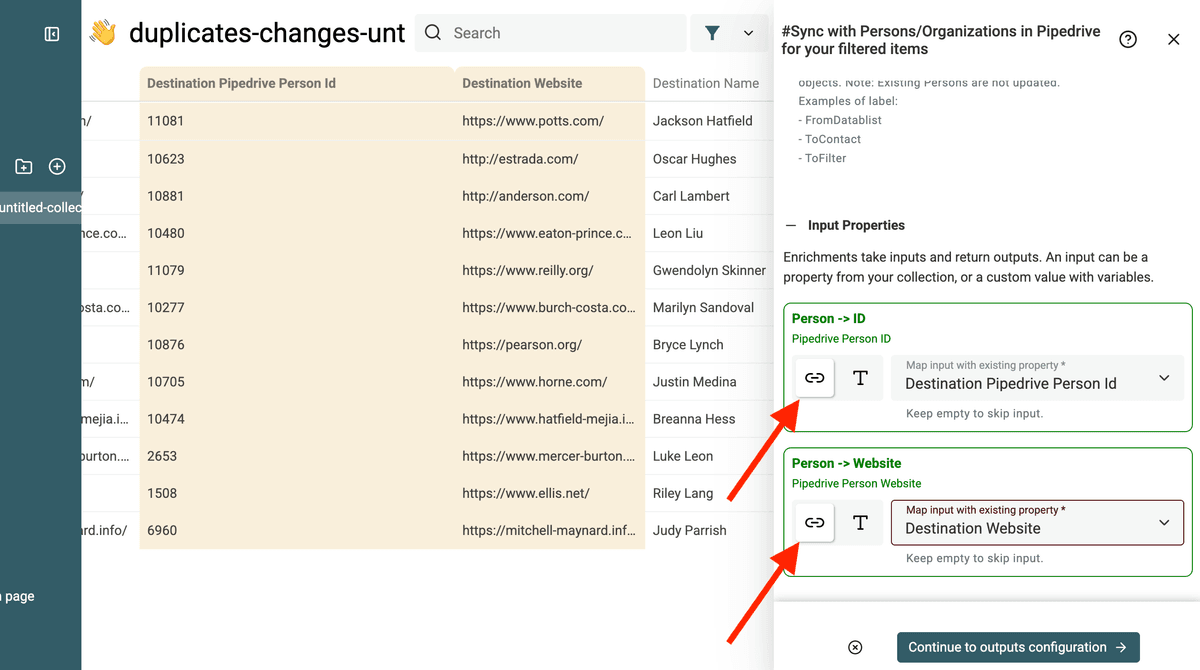
Configure los outputs para ver el estado de la actualización.
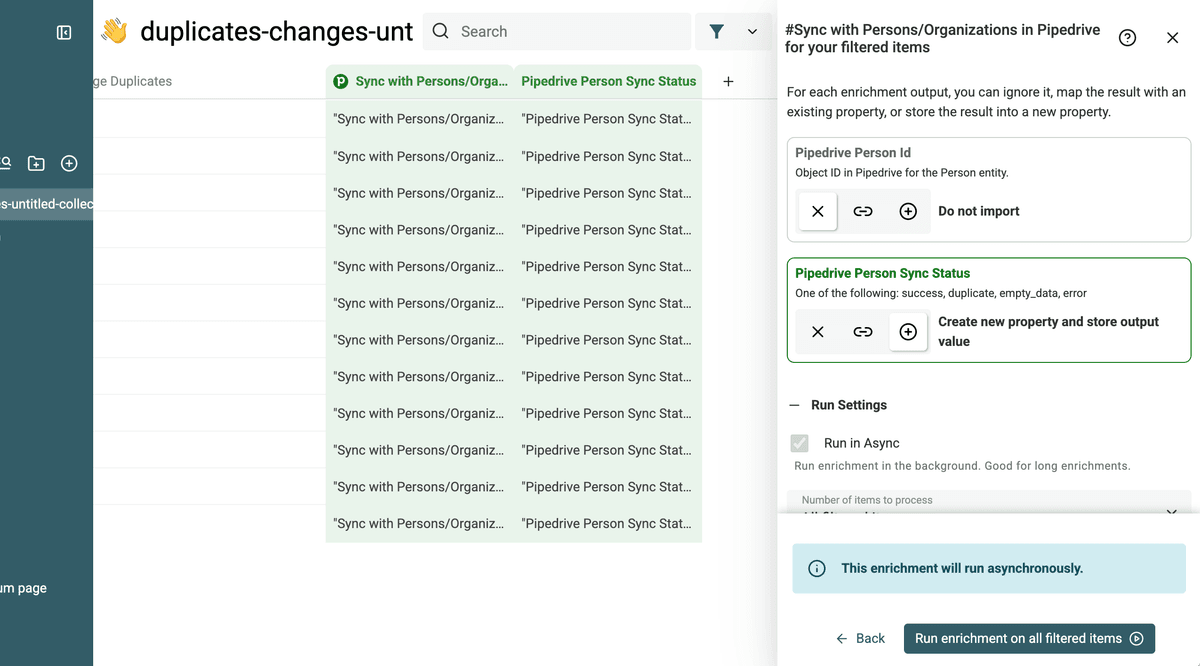
Luego ejecute el proceso.
Puede comprobar el resultado yendo al Changelog del registro en Pipedrive.
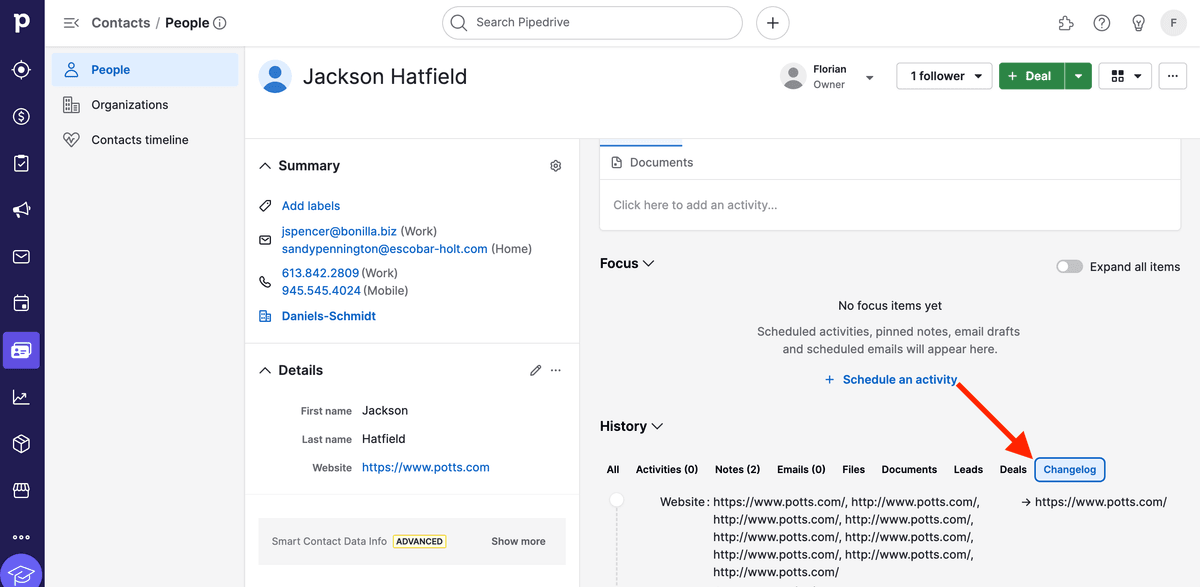
3.d. ¡Listo! Su Pipedrive CRM ya está limpio
¡Eso es todo! Ha conseguido: ✅ Importar datos en Datablist. ✅ Encontrar y fusionar duplicados con algoritmos inteligentes. ✅ Sincronizar los datos limpios de vuelta a Pipedrive.
Su CRM ahora está deduplicado y ordenado, para gestionar sus ventas y contactos con más facilidad. 🚀
Limitaciones del Merge Duplicates nativo de Pipedrive
Pipedrive ofrece una herramienta básica de deduplicación, pero tiene limitaciones serias que pueden dejar su CRM lleno de duplicados. Aquí tiene por qué Datablist es la mejor opción:
1. Pipedrive solo encuentra coincidencias exactas
La detección de duplicados de Pipedrive es demasiado estricta. Solo casa registros con nombres idénticos. Esto significa que:
- "Google LLC" y "Google" no se marcarán como duplicados.
- Emails, teléfonos o websites no se consideran para la deduplicación.
✅ Ventaja de Datablist: Usa fuzzy matching para captar duplicados incluso cuando nombres, emails o websites difieren ligeramente.
2. Sin fusión en lote en Pipedrive
Pipedrive le obliga a fusionar duplicados uno por uno, lo que consume mucho tiempo si tiene cientos de duplicados.
✅ Ventaja de Datablist: Fusión en lote con control total sobre cómo se combinan los campos para asegurar datos limpios y completos.
3. Sin control sobre las reglas de fusión
Al fusionar en Pipedrive:
- No puede elegir qué campos conservar o combinar.
- Parte de la información puede perderse si el sistema elige mal el registro maestro.
✅ Ventaja de Datablist: Defina reglas personalizadas de fusión, combine múltiples valores y asegure que no se pierdan datos importantes.
4. Sin historial de merges ni Change Log
Pipedrive no registra qué se fusionó o qué registros se eliminaron. Si ocurre un error, no hay deshacer.
✅ Ventaja de Datablist: Change Log con el detalle de cada fusión para que siempre sepa qué cambió.
Pipedrive es genial para gestionar ventas, pero en deduplicación, Datablist es la opción más inteligente. ¡Pruébelo hoy y limpie su CRM sin esfuerzo! 🚀