

El data matching, también llamado record linkage o deduplicación, es el proceso de identificar y vincular registros relacionados a través de múltiples datasets. Es el ingrediente secreto que convierte datos crudos y desordenados en un activo valioso para marketing, ventas o análisis.
La mayoría de las herramientas disponibles son complejas y costosas. Datablist es una aplicación online, compatible con Mac OS, Microsoft Windows y Linux, para hacer data matching de forma rápida. Implementa exact match, phonetic y algoritmos avanzados de fuzzy matching.
En esta guía, aprenderá a desmitificar la complejidad del data matching. Tanto si empieza desde cero como si es un profesional buscando optimizar su proceso, este tutorial le aportará valor.
Aquí tiene un resumen rápido de los puntos sobre Data Matching que encontrará en este artículo:
- Cargar sus conjuntos de datos
- Preparación de datos: limpieza y normalización
- Emparejar registros en una o varias colecciones
- Deduplicar: eliminar o fusionar grupos coincidentes
Empiece a usar nuestra herramienta online de Data Matching en segundos. Sin llamadas de ventas ni presentaciones en PowerPoint.
Paso 1: Cargar sus conjuntos de datos
El primer paso es cargar sus datasets en Datablist. Datablist es una herramienta online para gestión de listas. Puede ver y editar archivos CSV y archivos Excel. Es la herramienta perfecta para gestionar su lista de Leads, limpiar datos de clientes o limpiar datos extraídos de la web.
Para empezar, cree una colección para cargar su primer dataset.

Luego, haga clic en el botón Import.

Una vez importado su primer dataset, puede:
- Importar otros datasets con estructuras de datos comunes en la misma colección.
- Importar datasets con estructuras diferentes en colecciones nuevas.
El Duplicates Finder de Datablist encuentra registros coincidentes dentro de una sola colección o entre colecciones con estructuras de datos distintas.
Paso 2: Limpiar sus datos si es necesario
El segundo paso es la limpieza de datos. Limpiar los datos es un prerrequisito esencial para el data matching: garantiza la precisión y fiabilidad del proceso. Datos sucios o inconsistentes pueden llevar a emparejamientos incorrectos y resultados poco fiables. En esencia, la limpieza de datos allana el camino para un data matching exitoso.
Cuando aparecen en nombres (de personas o empresas), no aportan nada y pueden impedir que el algoritmo de deduplicación detecte duplicados.
Datablist incluye una lista de herramientas de limpieza de datos:
- Remove symbols and punctuation - Textos extraídos pueden contener emojis y símbolos ASCII, o nombres con puntuación. El algoritmo de matching de Datablist los ignora para el emparejamiento, pero pueden impedir la fusión automática durante el proceso de deduplicación.
- Remove extra spaces - Un espacio adicional entre palabras basta para que dos cadenas difieran. Los algoritmos de matching de Datablist preprocesan los textos para quitar espacios extra, pero también pueden impedir la fusión automática durante el proceso de deduplicación.
- Extract email addresses, URLs, etc. from texts - Si su dataset tiene texto no estructurado con emails, URLs, menciones, tags, etc., use nuestro Data Extractor para extraer esas entidades y estructurar sus datos. Con entidades estructuradas, el Data Matching será más sencillo.
- Remove HTML tags - Otra función de limpieza es convertir cadenas con etiquetas HTML a texto plano. Así puede emparejar listas extraídas que contienen HTML con otros datasets.
- Convert text to DateTime, Number, Boolean, etc. - Datablist ofrece estructura de datos real con formatos nativos (DateTime, Number, Boolean, etc.). Un paso importante es convertir texto crudo a formato nativo. DateTime y números nativos son clave para reglas avanzadas de fusión cuando necesita elegir un ítem maestro por comparación de valores (por ejemplo, la fecha más reciente).
- Change text case to get consistent formatting - Cambiar el uso de mayúsculas/minúsculas es simple pero necesario. Datablist incluye varios algoritmos de cambio de case).
- Split o merge properties - Ideal para datos multivalor. Si una propiedad contiene varios emails separados por comas/semicolon/espacios, la herramienta Split Property de Datablist creará varias propiedades con un único email cada una.
- Eliminar o reemplazar valores vacíos - Use las funciones de filtrado de Datablist para filtrar valores vacíos o filas vacías.
Consulte nuestra guía de limpieza de datos para más ejemplos e instrucciones.
Normalizar nombres de personas
Trabajar con datasets de personas es común en la deduplicación de datos. Clientes, Leads y datasets de prospectos son ejemplos de listas de personas. En el mejor de los casos, el matching se basa en identificadores únicos como emails o números de identidad. Sin esos identificadores, o para cruzar personas entre datasets, necesitará usar los nombres en el proceso.
El preprocesamiento de nombres asegura un formato uniforme y reduce errores durante la deduplicación.
Eliminar ruido en los nombres
Los nombres pueden variar mucho. Apodos, abreviaturas, ortografías alternativas y caracteres especiales son habituales.
Use la potente herramienta Find & Replace para eliminar prefijos, sufijos, stop-words, añadidos regionales y otras palabras innecesarias.
Por ejemplo, para quitar títulos de cortesía, use esta expresión regular:
^\s*(mr|mrs|dr|miss|ms|sir|madam|m).?\s
Y reemplácela por una cadena vacía.


Notas Si no está familiarizado con las expresiones regulares, contáctenos y le ayudaremos a limpiar sus datos.
Dividir el nombre completo en partes
Datablist es mucho más que limpieza: también ofrece data enrichment. Ejemplos de enrichment son lead enrichments o traducciones de CSV con Deepl.
El Name Parser es un enrichment perfecto para limpiar nombres de personas. Toma un nombre completo y devuelve sus partes: nombre, segundo nombre y apellido. Además, devuelve el género más probable y el país más común para ese nombre.
Usa datos estadísticos para dividir nombres completos.
Para usarlo, abra el "Enrich Menu" desde los botones superiores.

Luego, seleccione "Name Parser".

Después, seleccione la propiedad con los nombres. Y asigne o cree nuevas propiedades para guardar los resultados. La propiedad de nombre completo no se modificará; solo se escribirán las propiedades de salida con los resultados.

Normalizar nombres de empresas
También puede quitar ruido de los nombres de empresa: prefijos, sufijos, stop-words, añadidos regionales u otros elementos que dificultan el matching.
Un ejemplo típico es eliminar sufijos como "Inc." o "GmbH".
Use esta expresión regular en la herramienta Find & Replace:
,?\s(llc|inc|incorporated|corporation|corp|co|gmbh|ltd).?$
Y reemplácela por una cadena vacía.


Normalizar nombres de empresa y direcciones en todos sus datasets es clave para llevarlos a un formato estándar.
Normalizar nombres de calles
Si realiza Data Matching con direcciones postales, la normalización de nombres de calles es crucial. Las direcciones pueden escribirse con abreviaturas, prefijos direccionales o sufijos numéricos. Sin normalizar, la misma calle puede aparecer con múltiples representaciones, complicando el matching.
Por ejemplo: Main 9 St, Main 9TH St. y Main 9th Street se refieren a la misma calle. O Washington Blvd y Washington Boulevard.
Usar algoritmos fuzzy para estas diferencias no es eficiente. Entre Washington Blvd y Washington Boulevard hay varios cambios de letras; la distancia de similitud calculada por fuzzy-matching será alta.
Una mejor forma es normalizar los nombres de calles. Un formato coherente asegura consistencia.
Datablist ofrece normalización de nombres de calles para formatos en inglés: estandariza abreviaturas, números de calle, etc.
Notas
La normalización de calles funciona con direcciones separadas en campos. La información del nombre de la calle debe estar en una propiedad distinta. Un valor de dirección completa no funcionará.
Haga clic en "Normalize Street Names" desde el menú "Clean".

Luego, seleccione la propiedad con los nombres de calle y elija "Normalize english street names".

Revise la vista previa de los cambios y haga clic en "Run".

Paso 3: Emparejar registros en una o varias colecciones
Con los datos limpios y normalizados, pasamos al data matching. En este paso agruparemos los registros similares.

Datablist ofrece dos formas de comparar registros:
- Selected properties comparison - El modo más usado. Usted define las propiedades a comparar. Este modo es compatible con matching entre varias colecciones.
- All Properties comparison - En este modo, el Duplicates Finder de Datablist identifica y elimina registros exactamente iguales: deben tener los mismos datos en las mismas propiedades. Si una propiedad está vacía, los registros no se emparejarán.

Seleccione propiedades para el matching
Para el resto de la guía usaremos el modo "Selected Properties & Multi Collections".
El siguiente paso es seleccionar las propiedades que se usarán para el matching. Si eligió varias colecciones en el paso anterior, se le pedirá un mapeo de propiedades para cada colección.
Notas
Datablist intentará mapear automáticamente sus propiedades entre colecciones usando sus nombres.

Elija el algoritmo de matching
En el paso siguiente, verá las propiedades seleccionadas y deberá configurar los algoritmos de comparación.
Datablist implementa los siguientes algoritmos de matching:
-
Exact - Recomendado para propiedades no textuales como DateTime, Number, Boolean, etc. Para texto, puede decidir si la comparación distingue mayúsculas. El algoritmo exact elimina espacios iniciales y finales.
-
Smart - Preprocesa sus ítems para hacer matching con ligeras variaciones. Empareja URLs con distintos protocolos, y maneja el orden de palabras y la puntuación. "John-Doe" y "Doe John" coincidirán.
-
Phonetic con algoritmo Double Metaphone - Datablist implementa Double Metaphone para matching fonético. Convierte palabras en códigos que representan su pronunciación. Dos palabras con sonido similar obtendrán el mismo código.
-
Fuzzy matching con algoritmos de distancia - También implementa fuzzy matching con las distancias Jaro-Winkler y Levenshtein. Al seleccionarlo, debe definir un umbral de similitud. Cuanto mayor el umbral, menos variación permitida.
Consulte nuestra documentación para más detalles.

Notas
- Smart, Phonetic y los algoritmos fuzzy solo aplican a propiedades basadas en texto (incluyendo Email, Text, LongText).
- Las propiedades URL solo son compatibles con Exact y Smart.
Paso 4: Eliminar o fusionar grupos coincidentes (deduplicación)
El Duplicates Finder de Datablist devuelve los grupos coincidentes en pocos segundos.
Fusión automática para deduplicación en una colección
La herramienta de Data Matching de Datablist incluye un algoritmo avanzado para fusionar duplicados, con dos modos:
- Fusión de ítems sin conflictos de datos (ver abajo)
- Fusión con conflictos usando concatenación o descarte de valores (ver abajo)
Notas:
Esta función solo está disponible en la deduplicación de una sola colección. En deduplicaciones multi-colección la estructura de datos puede variar entre colecciones.
Fusión automática sin conflictos de datos
Datablist detectará automáticamente todos los duplicados que pueden fusionarse sin perder información.
Funciona así:
- Si todos los ítems duplicados tienen los mismos valores en las propiedades, se conservará un único ítem y se eliminarán los demás.
- Si los ítems duplicados son complementarios, se seleccionará como principal el ítem con más información y se rellenarán sus propiedades usando las de los otros ítems. Luego, se eliminarán todos excepto el principal.
- Si los duplicados tienen valores en conflicto, se omitirán para fusión manual.
Fusión automática con resolución de conflictos
Al ejecutar el algoritmo de fusión automática, el Duplicates Finder de Datablist detecta propiedades en conflicto. Un conflicto ocurre cuando dos ítems tienen valores diferentes para una propiedad. Para poder fusionarlos, debe elegir entre dos opciones:
- Combinar valores de propiedades - Permite concatenar valores con un delimitador. Por ejemplo, si dos "Phone" distintos existen para un registro similar, puede concatenarlos con punto y coma. Ideal para emails, teléfonos, notas, etc.
- Descartar valores de propiedades - Para propiedades no textuales, es posible conservar un solo valor y descartar el conflictivo. Si dos DateTime difieren, no tiene sentido concatenarlos: hay que elegir uno. Útil también con identificadores externos (p. ej., IDs de cuenta en su CRM), que deben ser únicos y no una cadena concatenada.
Reglas de limpieza para matching multi-colección
Cuando ejecuta el Data Matching de Datablist sobre varios datasets, la fusión automática no estará disponible. Sus colecciones pueden tener estructuras de datos diferentes.
En su lugar, Datablist ofrece una función de limpieza para eliminar ítems duplicados en todas las colecciones excepto una. Úsela para asegurar unicidad de ítems en sus datasets.

Se muestra una vista previa de los cambios antes de ejecutar el algoritmo de limpieza.

Fusión manual con el Merging Assistant
Para los registros duplicados restantes, hay un asistente de fusión manual.
Para fusionar duplicados, haga clic en el botón "Manual Merging Assistant" a la izquierda de cada grupo.

Se abrirá la herramienta de fusión. A la derecha verá el "Primary Item" y a la izquierda los duplicados restantes, llamados "Secondary Items". Datablist elige como "Primary item" el que más datos tiene.
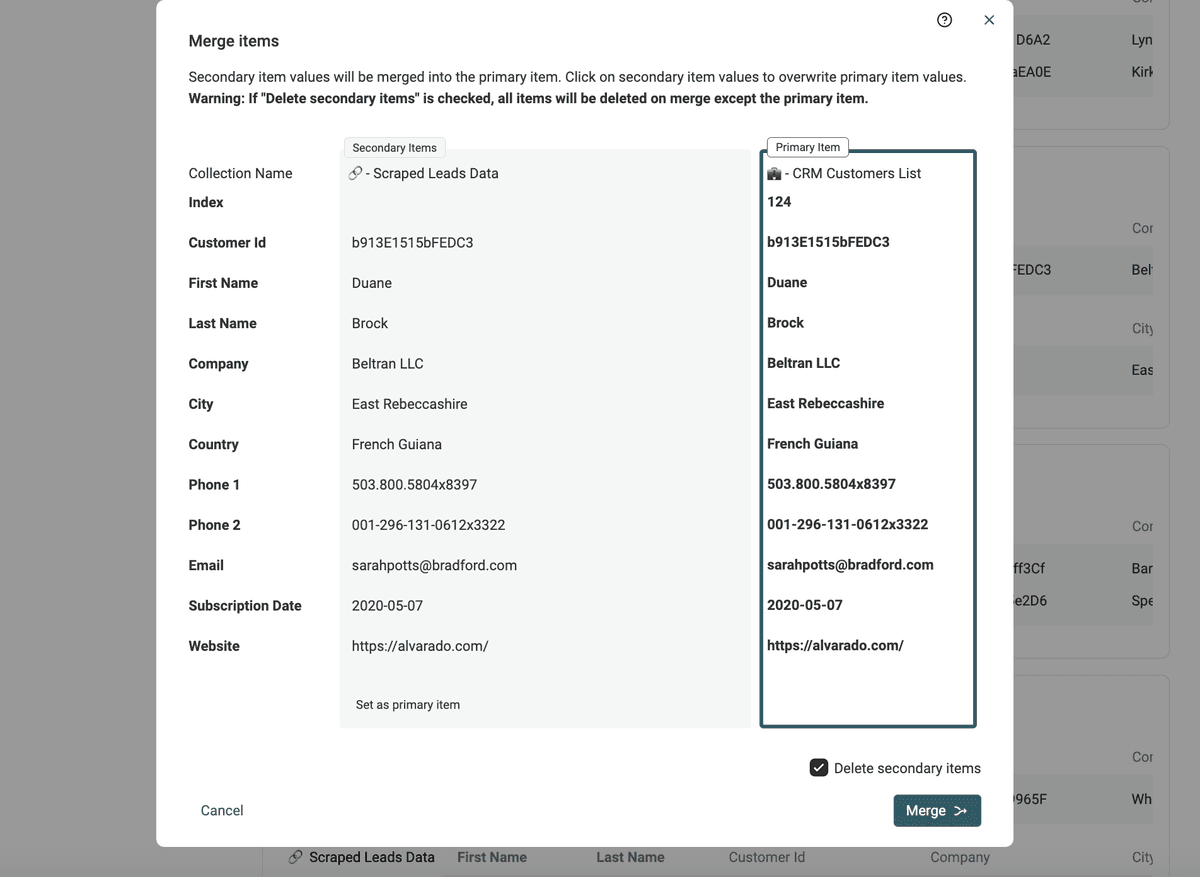
Cuando es posible, los valores de propiedades de los secondary items se seleccionan automáticamente para integrarse en el primary item. Si varios valores entran en conflicto, deberá decidir qué valor conservar.
Si el "Primary item" resultante le convence, haga clic en Merge para confirmar. Todos los secondary items se eliminarán para conservar un único ítem combinado.
Notas El Manual Merging Assistant está disponible en deduplicación multi-colección cuando las colecciones comparten una estructura similar (mismas propiedades).
Descargar grupos duplicados para fusionar con otra herramienta
Por último, la herramienta de Data Matching de Datablist permite exportar los grupos duplicados detectados. Puede exportar un CSV o Excel con todos los ítems duplicados listados consecutivamente.

Use el archivo para limpiar sus registros con otra herramienta (por ejemplo, una hoja de cálculo) o para análisis más complejos.
FAQ
¿Qué es el Data Matching?
El data matching, también conocido como record linkage o deduplicación, es el proceso de identificar y vincular registros relacionados dentro o entre datasets. Su objetivo es mejorar la calidad, precisión y consistencia reconociendo y consolidando entradas duplicadas o similares que representan las mismas entidades, personas u objetos.
Es útil para limpiar datasets que acumulan duplicados con el tiempo o para combinar varios datasets con campos similares o solapados.
El data matching puede usar campos discriminantes como email, URL del sitio web o identificadores; o una combinación de atributos no únicos (nombre, fecha de nacimiento, empresa o ubicación) para generar una puntuación de similitud entre registros.
¿Qué tan rápido es el Data Matching de Datablist?
La herramienta de Data Matching de Datablist carga sus datasets en memoria para analizar coincidencias. Está pensada para datasets de hasta 1 millón de registros y realiza la mayoría de análisis en pocos minutos.
¿Necesito habilidades técnicas para hacer Data Matching?
No. Datablist es una solución no-code para todos: desde analistas de datos hasta equipos de marketing o ventas.
¿Cuándo usar Data Matching?
El data matching tiene aplicaciones en finanzas, salud, marketing y gestión de clientes, donde se requieren datos fiables para tomar decisiones o integrarse con otras herramientas.
Facilita tareas como la detección de fraude, la consolidación de perfiles y el data enrichment desde múltiples fuentes.
¿Qué sigue?
Si le interesa la limpieza de datos, pueden interesarle estas guías: