
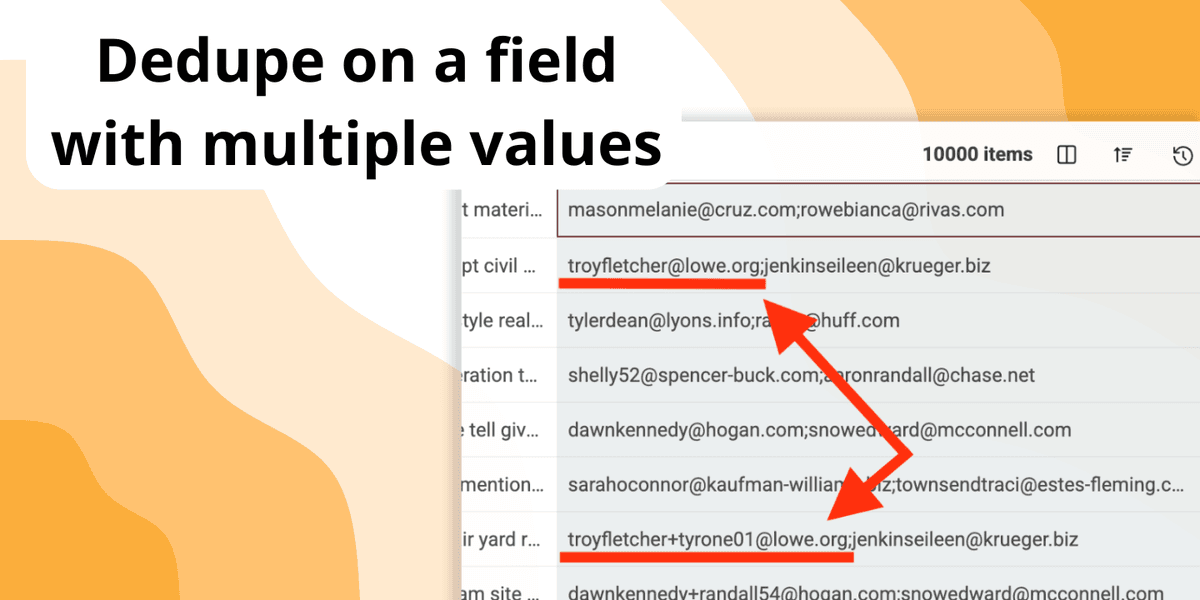
La déduplication devient nettement plus complexe lorsqu'un même champ contient plusieurs valeurs.
Imaginez une liste de contacts où le champ "Emails" contient plusieurs adresses séparées par des virgules, ou une base entreprises où la colonne "URLs" recense plusieurs liens vers des sites ou des réseaux sociaux.
Les outils classiques de déduplication ont généralement du mal à repérer que deux fiches sont des doublons si elles partagent ne serait-ce qu'une seule de ces valeurs multiples.
Datablist propose une solution robuste à ce problème de déduplication avancée.
Dans cet article vous découvrirez comment dédupliquer une liste sur un champ à valeurs multiples :
- Importer vos données pour la déduplication
- Identifier les doublons par recherche de valeurs multiples
- Résoudre les conflits et fusionner les doublons
Étape 1 : Importer et préparer vos données pour la déduplication
La première étape consiste à importer vos données dans Datablist. Cela peut passer par l'import d'un fichier CSV ou Excel, ou une connexion à votre CRM ou à d'autres sources.
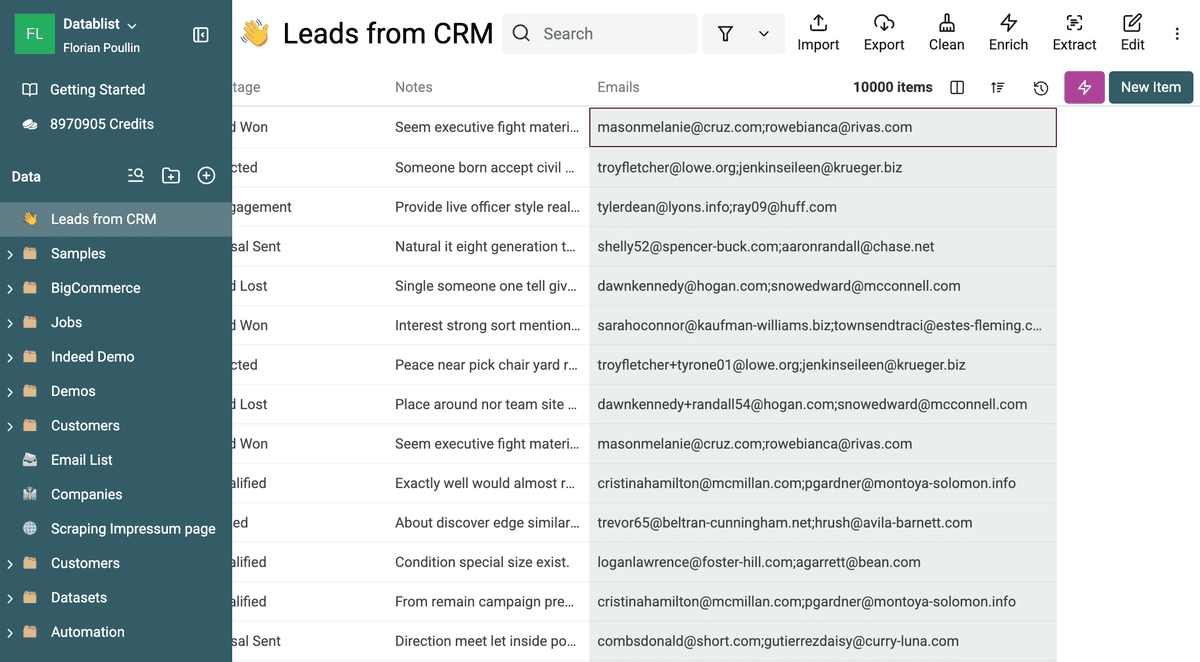
Une fois les données importées, il est important de bien examiner le champ contenant les valeurs multiples. La fonction "Multiple Values" de Datablist fonctionne avec des valeurs séparées par un point-virgule (;).
Exemple :
Imaginez un champ "Emails" dans une liste de contacts. Si les emails sont listés ainsi :
- Enregistrement 1 :
john.doe@example.com; jane.doe@example.com; info@example.com - Enregistrement 2 :
jane.doe@example.com; support@example.com; sales@example.com - Enregistrement 3 :
john.doe@example.com; marketing@example.com
Datablist sera capable de reconnaître que l'Enregistrement 1 et l'Enregistrement 3 comportent "john.doe@example.com", et que l'Enregistrement 1 et l'Enregistrement 2 partagent "jane.doe@example.com", même si tout est dans un seul champ.
Gérer les différents séparateurs :
Si vos valeurs multiples sont séparées par autre chose qu'un point-virgule (par exemple, une virgule, un pipe | ou un espace), il faut normaliser vos données avant d'utiliser le Duplicates Finder. L'outil puissant Find & Replace de Datablist est fait pour cela.
Voici comment utiliser Find & Replace pour standardiser vos séparateurs en point-virgule :
- Accédez à votre collection dans Datablist.
- Sélectionnez la colonne contenant plusieurs valeurs.
- Allez dans le menu "Clean" puis choisissez "Find & Replace".
- Dans le champ "Find", saisissez le séparateur actuel (ex :
,pour valeurs séparées par virgule). - Dans le champ "Replace with", tapez un point-virgule
;. - Cliquez sur "Apply".
En vous assurant que tous vos champs multi-valeurs utilisent un point-virgule comme séparateur, vous permettrez à la fonctionnalité "Multiple Values" de fonctionner précisément.
Étape 2 : Identifier les doublons avec la recherche sur plusieurs valeurs
Votre donnée est importée et les champs multi-valeurs bien formatés (séparateur point-virgule). Vous pouvez passer à la recherche des doublons.
-
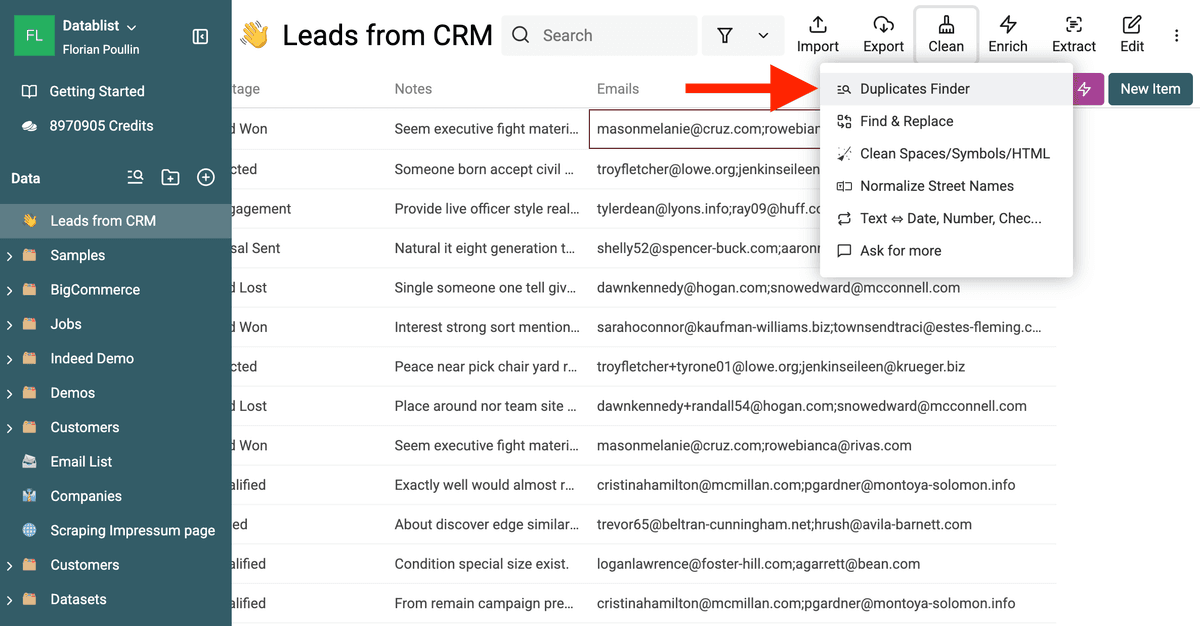
Rendez-vous dans le menu "Clean" et choisissez "Duplicates Finder".
Ouvrir l''outil Duplicates Finder -
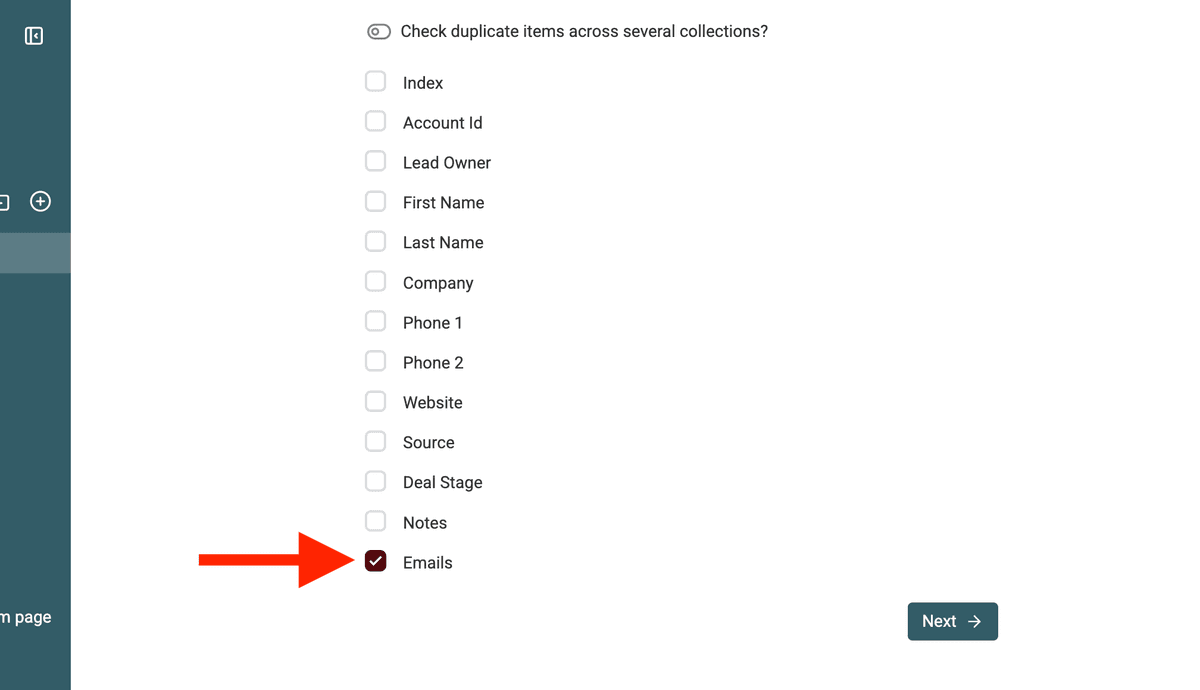
Dans Duplicates Finder, sélectionnez la colonne contenant les valeurs multiples sur laquelle vous souhaitez détecter des doublons. Par exemple, la colonne "Emails".
Sélectionner la propriété -
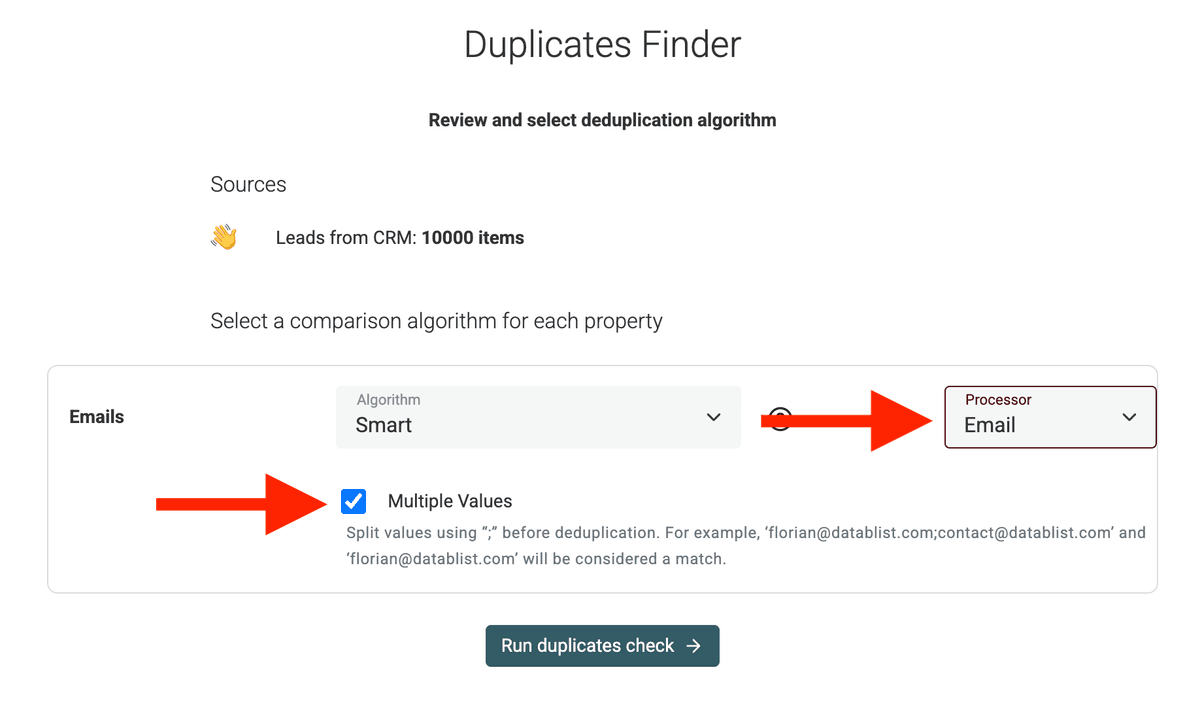
Activez la case à cocher "Multiple Values". Un champ dédié apparaît pour confirmer ou préciser le séparateur. Vérifiez bien qu'il s'agit de
;.Activer l''option Multiple Values -
Choisissez votre algorithme de matching et le Processor
Datablist propose plusieurs algorithmes de déduplication. Les principaux :
- Algorithme Smart : C'est souvent le meilleur point de départ. Il va analyser chaque email individuellement et identifier les doublons dès qu'au moins une adresse est partagée.
- Algorithme Distance : Si vous prévoyez des variantes ou fautes de frappe (ex : "john.doe@exmaple.com" vs. "john.doe@example.com"), ce mode est utile. Réglez le seuil de similarité selon votre tolérance.
Datablist propose aussi un "Processor" qui normalise les données avant la recherche de doublons. Si vous travaillez sur des URLs, choisissez
URL, pour les emails, prenezEmails, etc.Ainsi, avec l'Email processor,
john@datablist.comsera considéré comme identique àjohn+spam@datablist.com. -
Lancez la détection des doublons. Datablist traitera chaque email (ou valeur) individuellement pour la comparaison. Les fiches qui partagent au moins une valeur (ou en ont de très proches avec Distance Algorithm) seront groupées comme doublons potentiels.
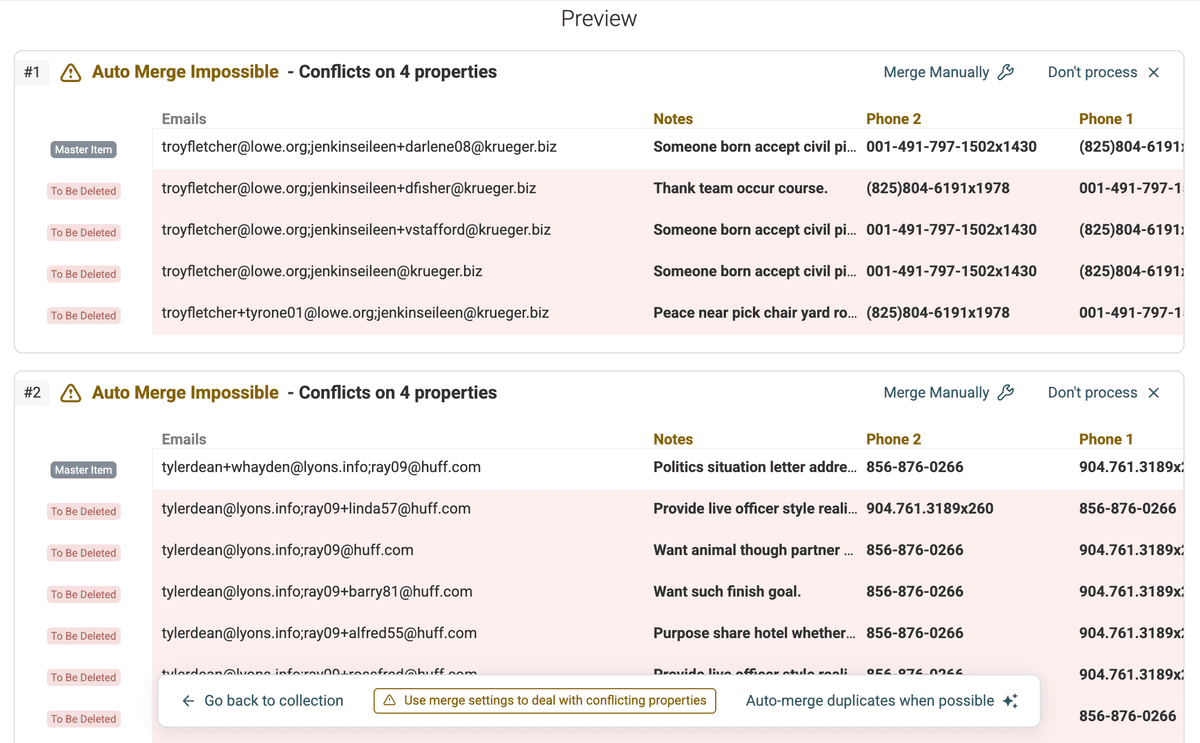
Aperçu des doublons détectés -
Examinez attentivement chaque groupe. Vous verrez précisément comment Datablist groupe vos fiches selon les valeurs partagées dans le champ multi-valeurs. Par exemple, dans notre cas "Emails", les enregistrements 1 et 3 seront probablement groupés grâce à "john.doe@example.com". Les 1 et 2 aussi via "jane.doe@example.com".
Étape 3 : Résoudre les conflits et fusionner les doublons
Après l'identification des groupes de doublons, la prochaine étape consiste à définir comment fusionner ces fiches, notamment pour le champ multi-valeurs et les autres propriétés conflictuelles.
-
Pour chaque groupe, Datablist mettra en évidence les champs en conflit : ce sont les propriétés où les valeurs diffèrent (numéro de téléphone, autres emails si vous aviez dédoublonné sur ce champ, intitulés de poste, etc).
-
Concernant le champ multi-valeurs (ici, "Emails"), vous avez des options de fusion :
-
Combiner les valeurs : Généralement l'option la plus logique. Datablist rassemblera toutes les valeurs uniques dans un seul champ, séparées par le séparateur. Exemple : fusionner l'Enregistrement 1 (
john.doe@example.com; jane.doe@example.com; info@example.com) et le 3 (john.doe@example.com; marketing@example.com) donnera :john.doe@example.com; jane.doe@example.com; info@example.com; marketing@example.com. -
Supprimer les valeurs en conflit : Si l'une des fiches est manifestement plus complète et que vous souhaitez écarter l'autre, choisissez "Drop conflicting values...".
Sélection du master record
Vous pouvez aussi définir comment Datablist désigne la fiche principale. Lors d'une fusion, Datablist conserve un enregistrement, le met à jour, supprime les autres.
Plusieurs règles existent pour ce choix :
- Le plus complet : Fiche comportant le plus de champs renseignés.
- Dernière modification : Fiche la plus récemment modifiée.
- Création la plus ancienne : L’enregistrement le plus ancien.
- Valeur la plus haute : Selon une propriété, et s’il y a égalité, la plus récente.
- Valeur la plus basse : Selon une propriété, s’il y a égalité idem.
- Valeur spécifique : L'enregistrement qui possède une valeur précise dans une propriété. Si aucun ne correspond, il n'y a pas de fusion.
-
-
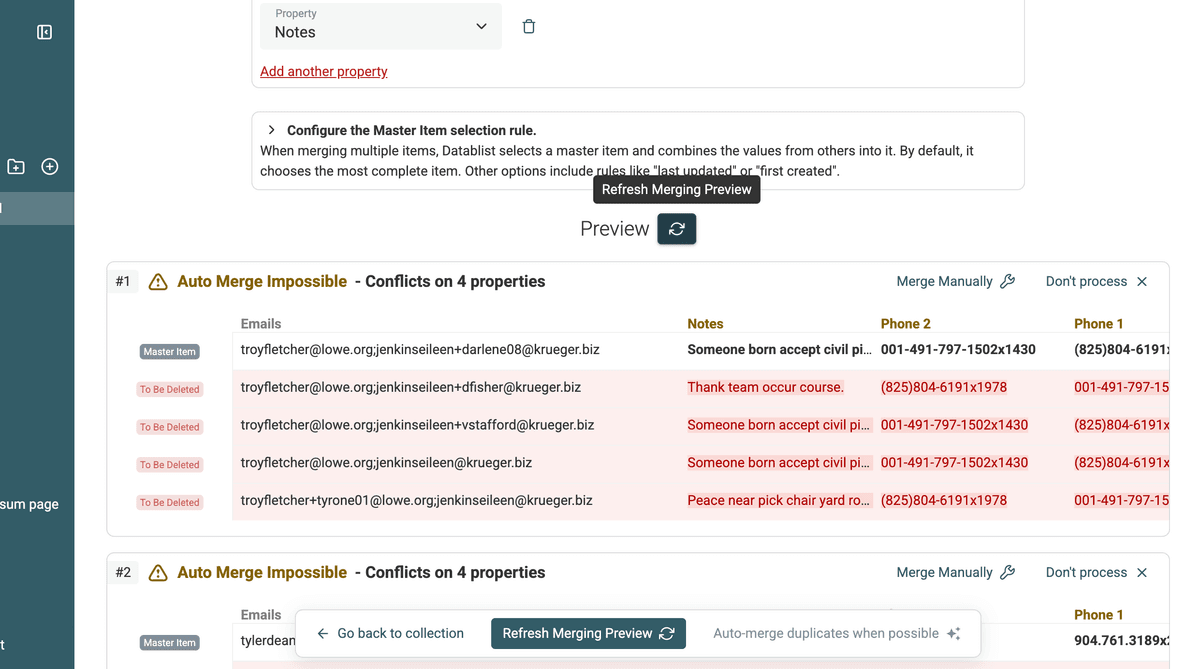
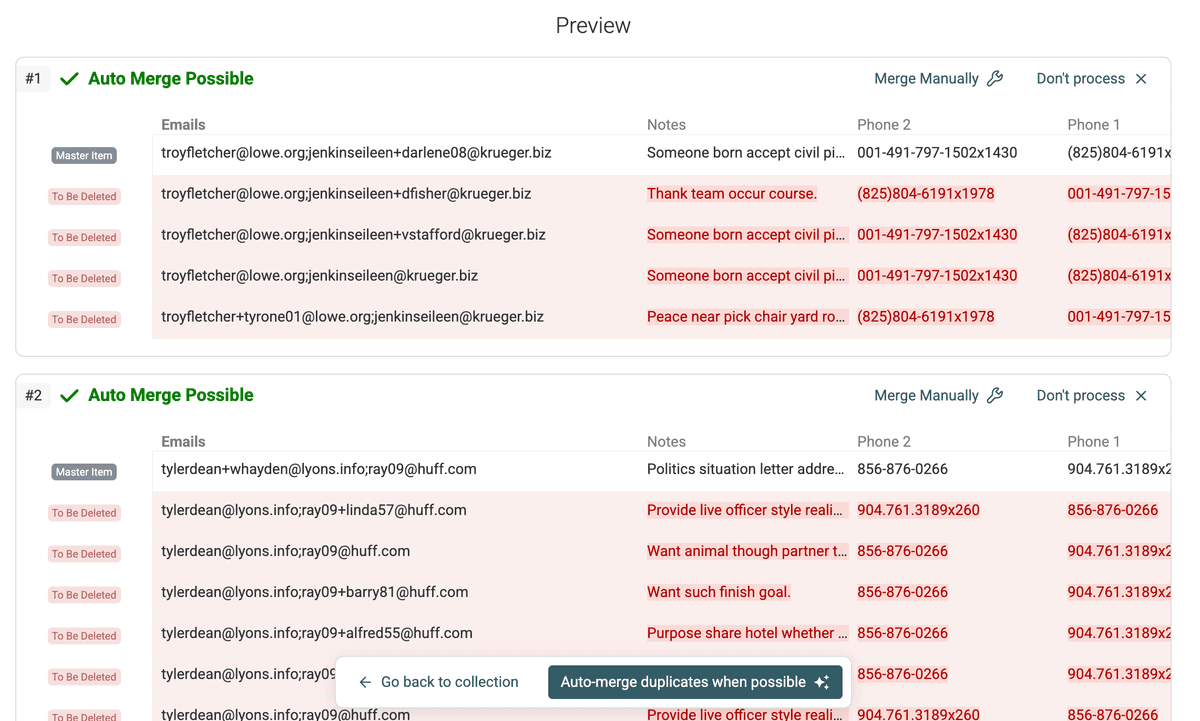
Une fois toutes les règles de fusion décidées, mettez à jour l’aperçu. Vous verrez alors exactement le résultat final de chaque fusion. Vérifiez bien la bonne consolidation des valeurs multiples.
Mise à jour aperçu fusion -
Revoyez cet aperçu attentivement pour valider les résultats. Quand tout est bon, lancez la fusion. Utilisez l'option "Auto-merge duplicates when possible" ou fusionnez manuellement les groupes souhaités.
Aperçu réussite fusion -
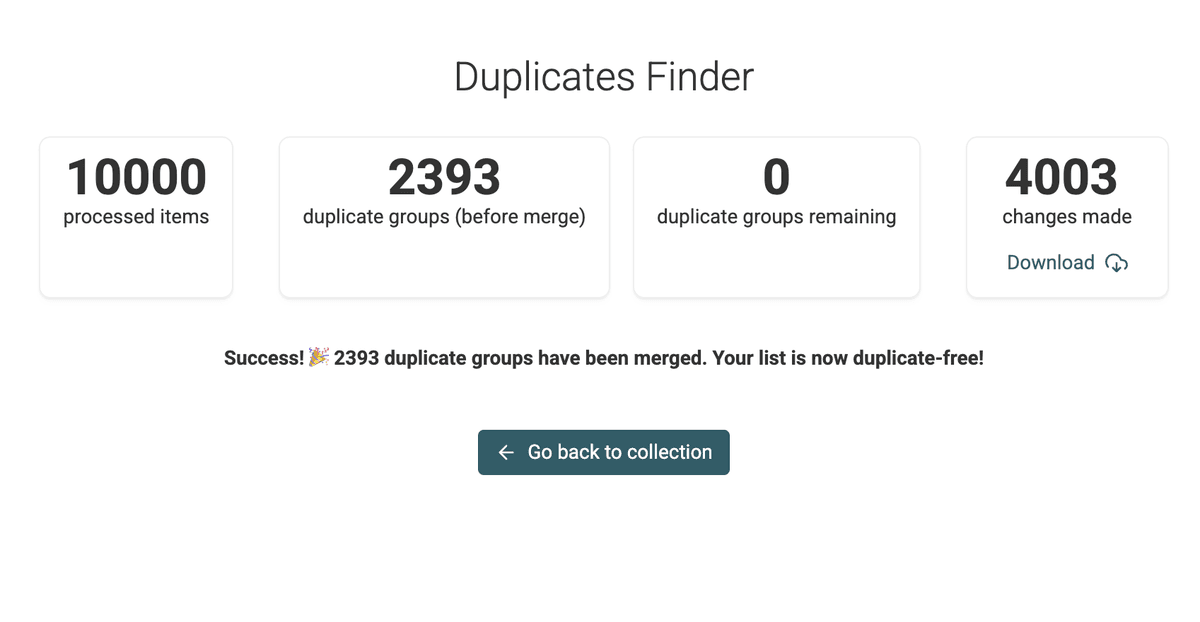
Une fois la fusion terminée, Datablist fournira un résumé des opérations faites.
Écran résultat fusion
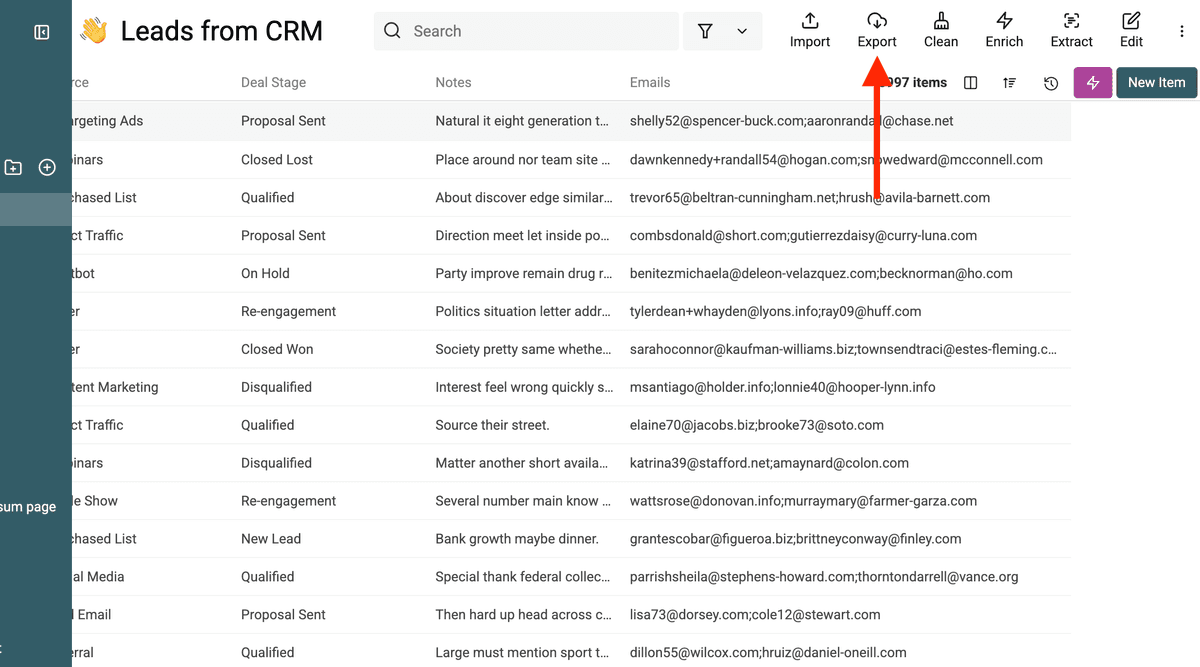
Enfin, vous pouvez exporter votre liste propre et dédupliquée, avec l’information consolidée même pour les champs à valeurs multiples.
En suivant ce pas-à-pas, vous exploitez pleinement la fonction "Multiple Values" de Datablist pour effectuer des déduplications avancées sur des listes où des champs clés comportent plusieurs valeurs. Pensez à standardiser vos séparateurs en point-virgule pour garantir les meilleurs résultats.