

Scraper Google est l’un des moyens les plus rentables pour constituer une liste de leads. Mais la plupart des utilisateurs se heurtent vite à une limite : Google n’affiche généralement plus de résultats après les 250 à 300 premiers.
Même si des millions de pages correspondent à votre recherche, les pages suivantes finissent simplement par ne plus rien afficher.
Datablist contourne cette limite avec la source "Start with Google Search Queries".
Au lieu de lancer une seule recherche et de récupérer seulement 200 résultats, vous pouvez exécuter des dizaines, voire des centaines de variantes en une seule fois.
Vous pouvez obtenir environ 4�000 résultats pour seulement 1 $.
Ce guide vous montre comment automatiser ce processus pour extraire des milliers de résultats qualifiés sans écrire une seule ligne de code.
📌 Exemples de cas d’usage
- Créer une liste de leads à partir de profils LinkedIn
- Rechercher des profils Instagram avec des mots-clés
- Cibler des entreprises selon des technologies web précises
- Créer des bases d’entreprises locales dans des centaines de villes
Liens rapides vers les sections :
- Comprendre la limite des 300 résultats
- La stratégie multi-requêtes & utiliser l’IA pour créer des variantes de requêtes
- Guide pas à pas pour scraper Google avec Datablist
- Nettoyer et dédupliquer vos données
- Enrichir vos résultats de recherche
- Analyse des coûts : scraper à petit budget
Comprendre la limite des 300 résultats
Google optimise son moteur pour une navigation humaine. La plupart des gens trouvent ce qu’ils cherchent dès la première page.
Google n’a donc aucun intérêt à afficher des milliers de résultats à un seul utilisateur, et cherche aussi à limiter les abus liés au scraping.
Si vous essayez d’aller jusqu’à la page 40, vous verrez souvent un message indiquant que Google a supprimé des résultats similaires, ou bien les pages apparaîtront simplement vides.
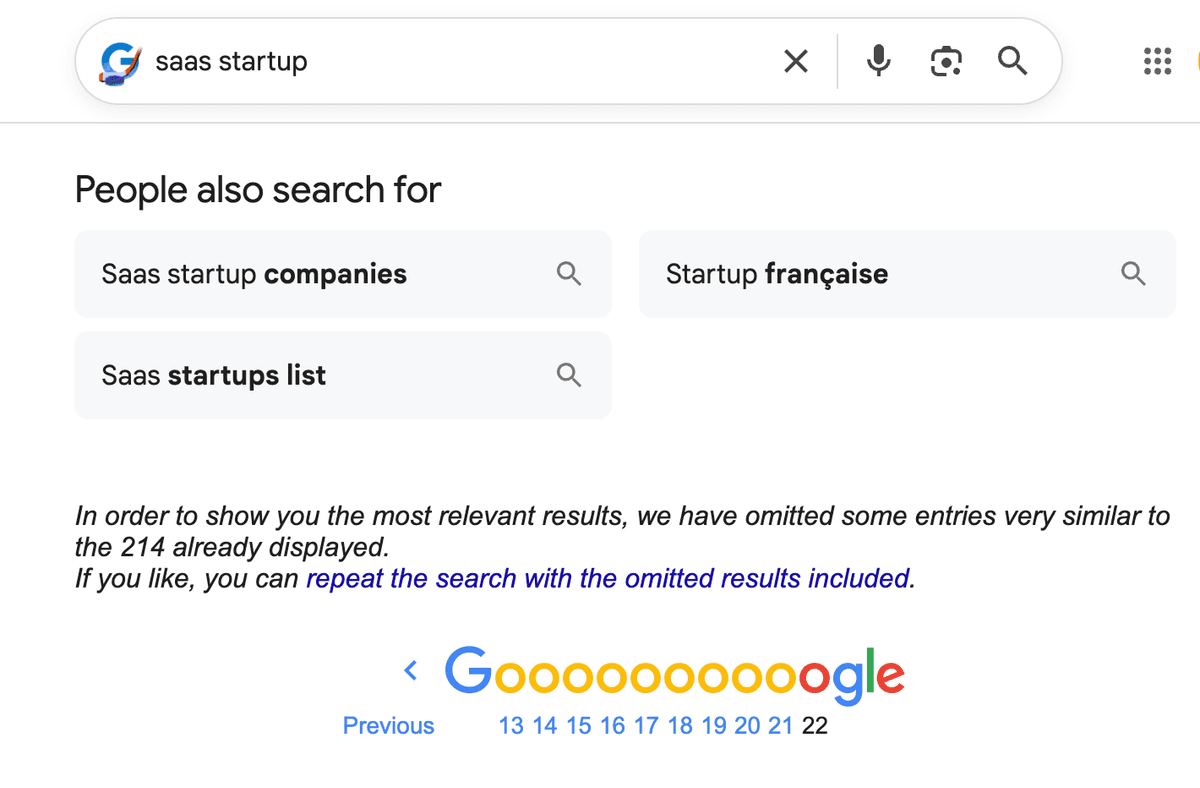
En lead generation, c’est un vrai problème. Si vous recherchez "avocat France", vous trouverez peut-être 250 prospects intéressants. Mais des milliers d’autres restent invisibles, car ils se situent entre les positions 301 et 10�00. Impossible de les atteindre avec un mot-clé trop large.
La seule manière d’accéder à ces résultats cachés consiste à rendre votre recherche plus précise. En réduisant le périmètre, vous poussez Google à afficher les 300 meilleurs résultats d’une niche plus restreinte. En répétant cette approche sur des dizaines de segments, vous reconstruisez progressivement la liste complète.
La stratégie multi-requêtes
Le scraping multi-requêtes consiste à découper une recherche large en une multitude de requêtes plus petites, qui se recoupent partiellement. Au lieu de chercher "avocats en France", vous allez chercher "avocats à Paris", "avocats à Lyon", "avocats à Marseille", "avocats à Toulouse" et "avocats à Nantes".
Chaque recherche locale vous donne un nouveau lot de 200 à 300 résultats. Si vous lancez des recherches sur les 50 plus grandes villes de France, vous pouvez potentiellement collecter 15�00 résultats. Il y aura forcément des recoupements, puisqu’un cabinet peut apparaître sur plusieurs villes ou thématiques proches, mais le volume de résultats uniques reste bien supérieur à celui d’une seule requête générique.
Cette stratégie fonctionne parce qu’elle modifie l’"intention" de recherche du point de vue de Google. En utilisant des variations géographiques ou d’autres types de segmentation, vous faites remonter des prospects qui étaient en position 5�00 sur une recherche large à la position 1 sur une recherche ciblée.
Utiliser l’IA pour créer des variantes de requêtes
Créer manuellement 100 variantes d’une requête prend du temps. Mais les LLM modernes comme ChatGPT, Gemini ou Claude peuvent le faire instantanément. Il suffit de leur donner un prompt pour obtenir en quelques secondes une liste de recherches parfaitement formatée.
La stratégie par localisation
La localisation est la manière la plus simple de multiplier les résultats. Chaque pays dispose de listes de villes, de départements ou de régions.
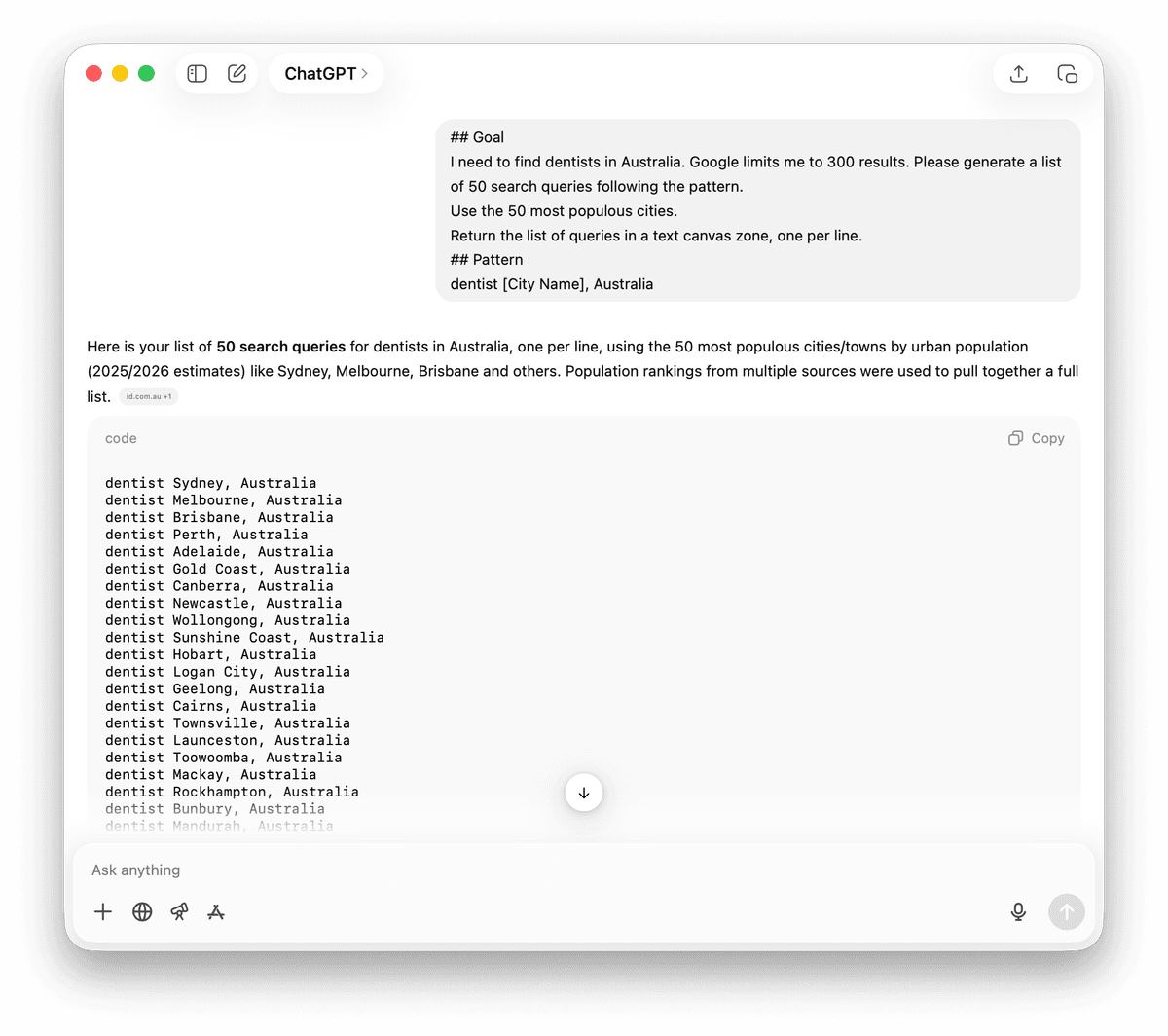
Je cherche des dentistes en France. Google me limite à 300 résultats. Merci de générer une liste de 50 requêtes selon ce modèle.
Utilisez les 50 villes les plus peuplées.
Retournez la liste des requêtes dans une zone de texte, une requête par ligne.
## Modèle
dentiste [Nom de la ville], France
La stratégie par mots-clés
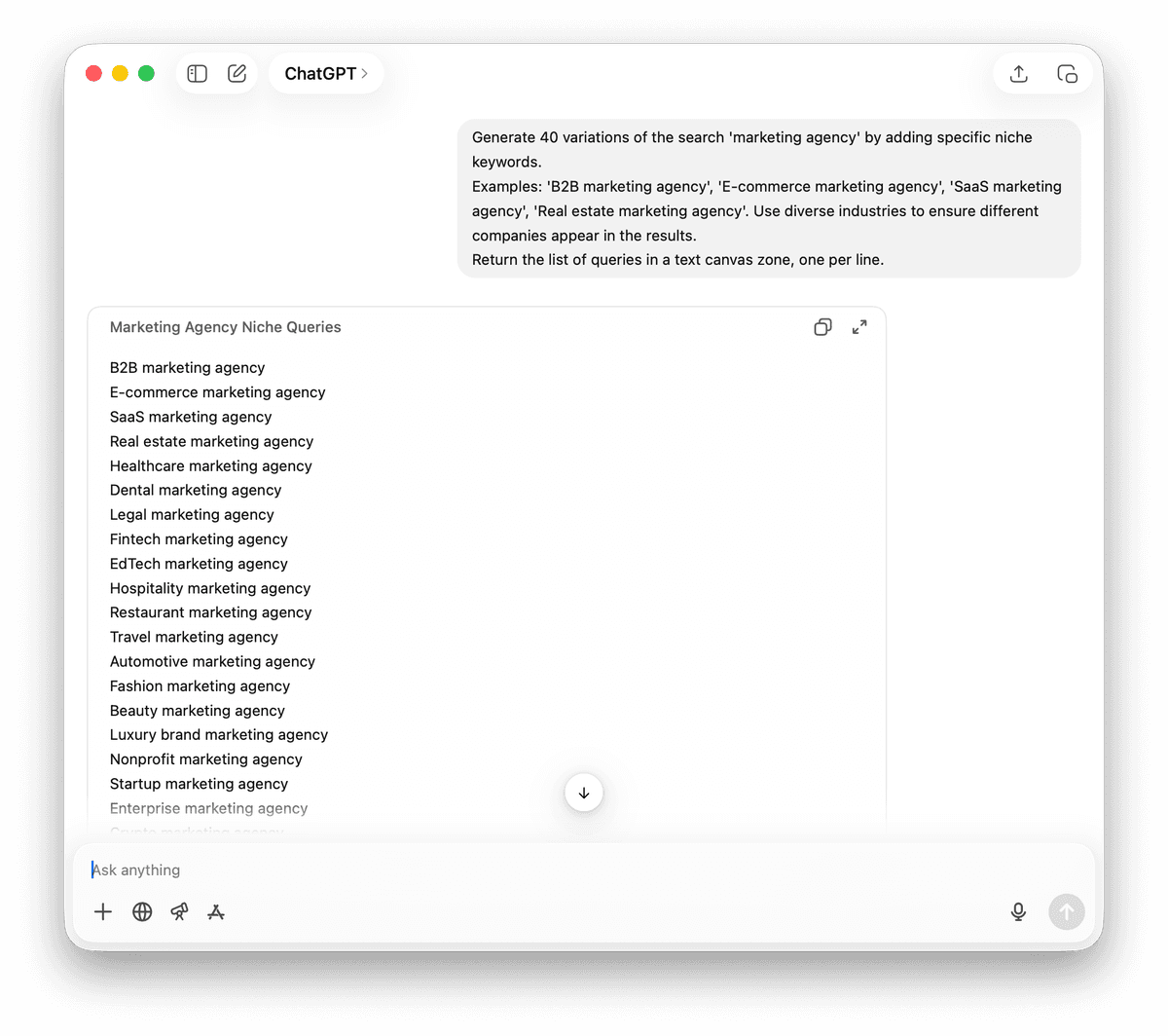
Parfois, la variation géographique n’est pas adaptée. Si vous cherchez par exemple des "agences marketing remote", mieux vaut varier les mots-clés.
Exemples : 'B2B marketing agency', 'E-commerce marketing agency', 'SaaS marketing agency', 'real estate marketing agency'. Utilisez des secteurs variés afin de faire apparaître des entreprises différentes dans les résultats.
Retournez la liste des requêtes dans une zone de texte, une requête par ligne.
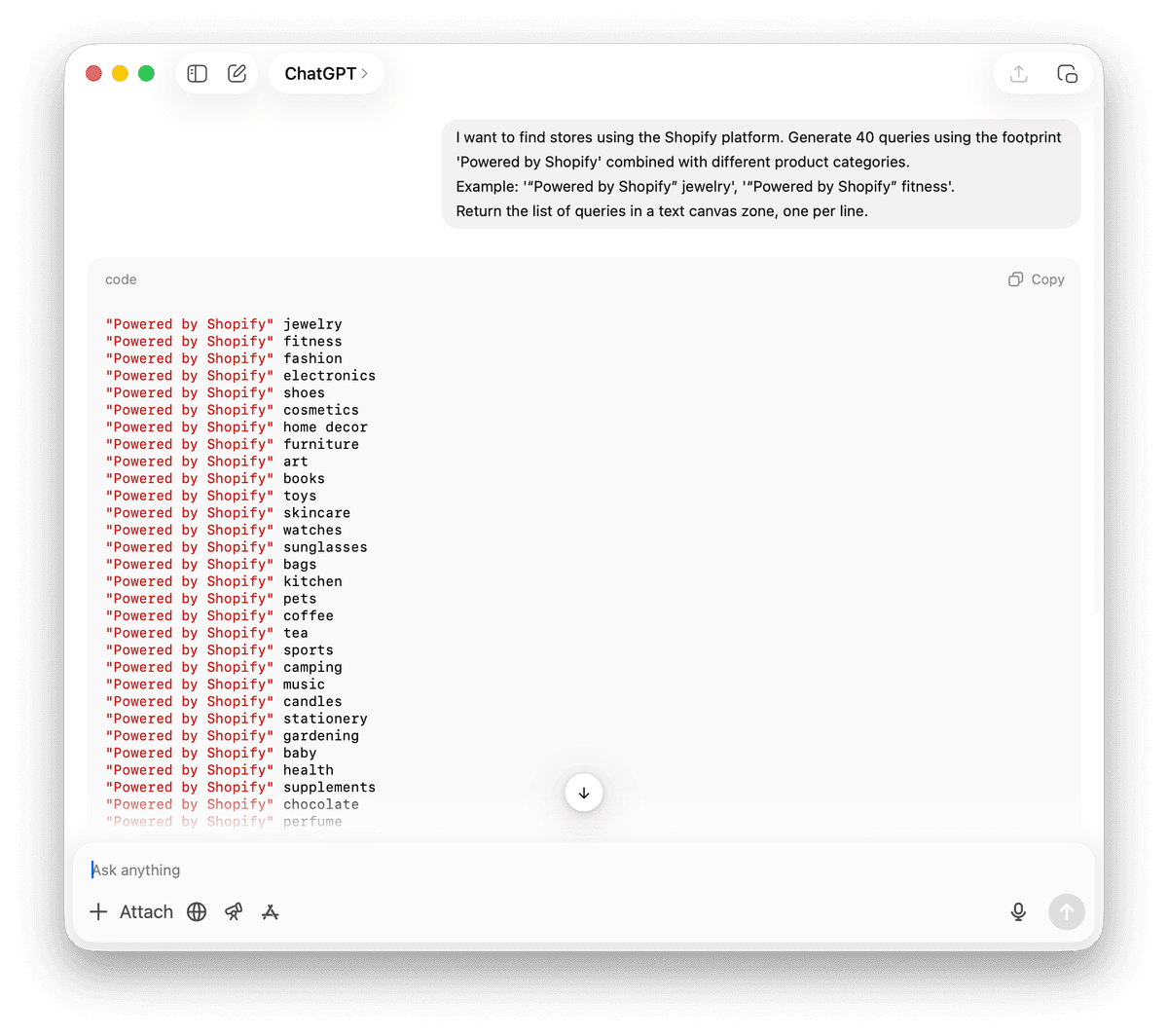
La stratégie des "footprints"
De nombreux sites web utilisent des logiciels spécifiques. Ces outils laissent souvent une trace dans le code HTML ou dans le footer du site. Google indexe ce texte.
Exemple : '“Powered by Shopify” jewelry', '“Powered by Shopify” fitness'.
Retournez la liste des requêtes dans une zone de texte, une requête par ligne.
Guide pas à pas pour scraper Google avec Datablist
Une fois votre liste de requêtes prête, Datablist prend en charge toute la partie technique liée à leur exécution en parallèle. Vous n’avez pas à gérer des proxies rotatifs, des navigateurs headless ou l’extraction de données depuis le HTML.
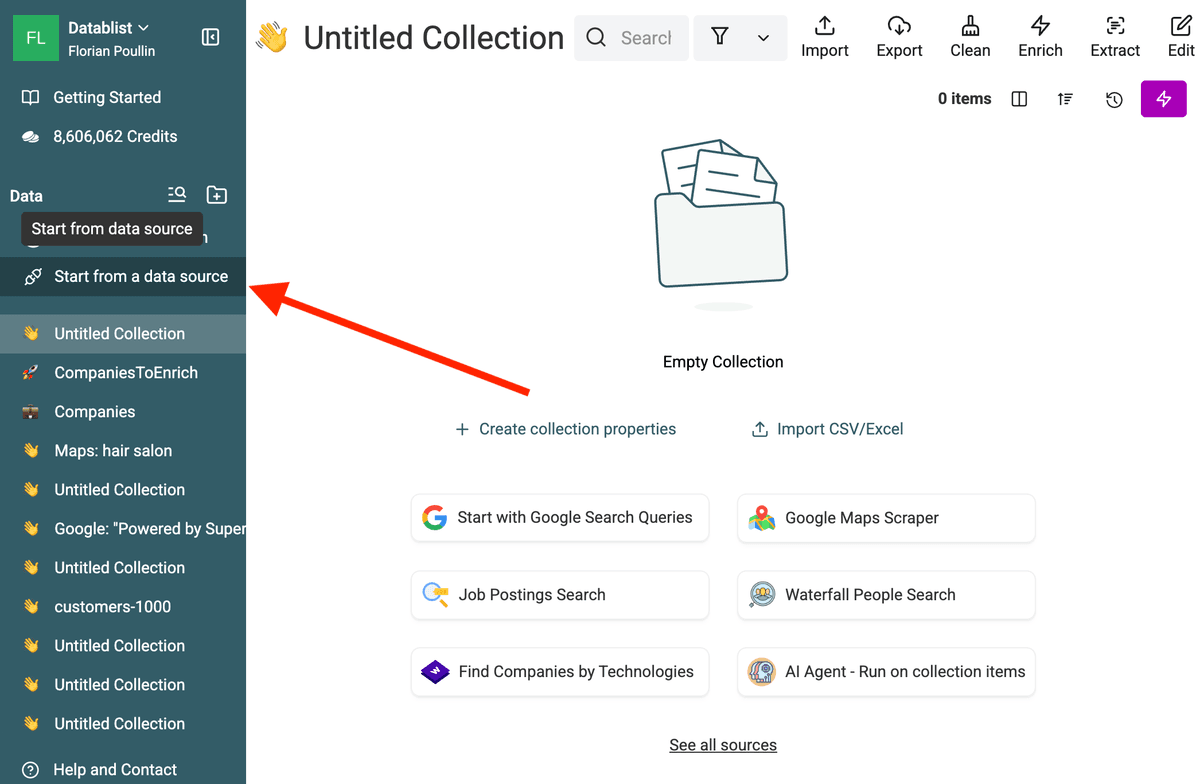
1. Accéder à la source de données
Ouvrez Datablist puis cliquez sur "Start from a data source" dans la barre latérale.
Cherchez la source de données "Start with Google Search Queries". Cette source a été conçue pour l’extraction à grande échelle.
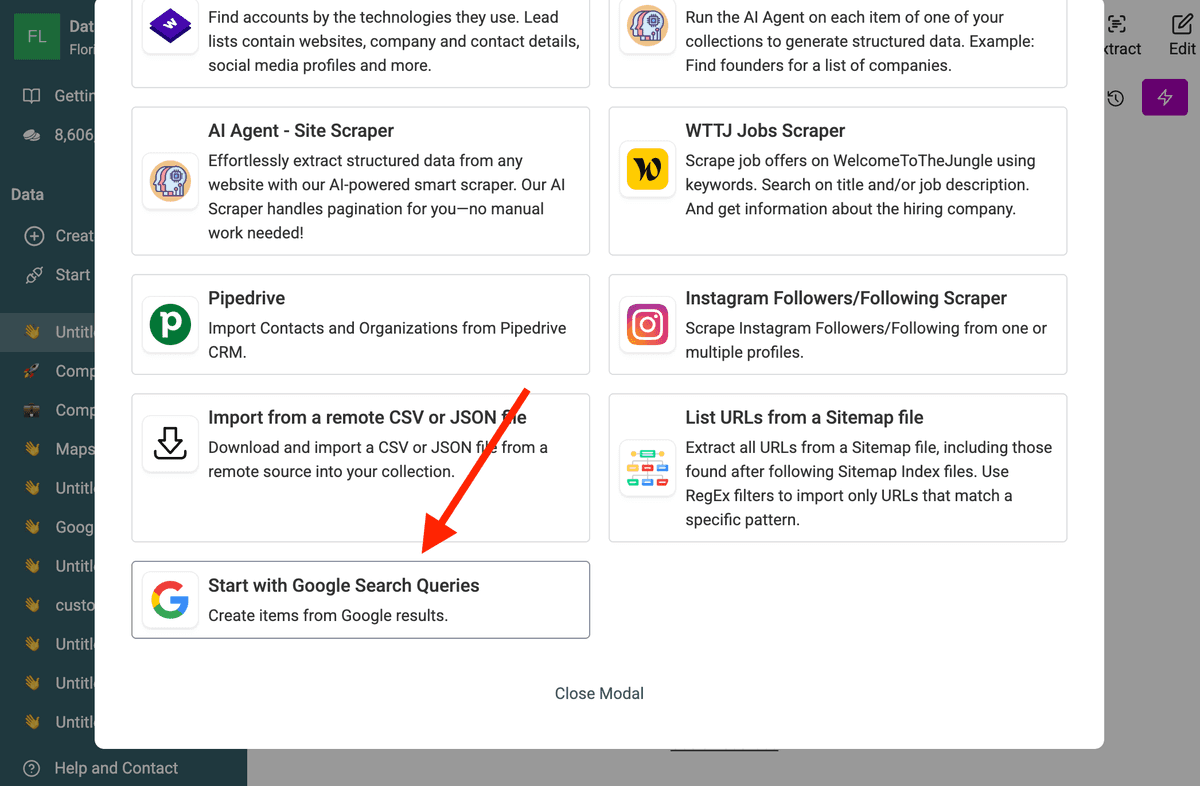
2. Collez vos requêtes et configurez les paramètres de recherche
Copiez la liste de variantes générée par votre IA. Collez-la dans le champ de requêtes de Datablist. Vous pouvez coller des dizaines, voire des centaines de lignes d’un coup.
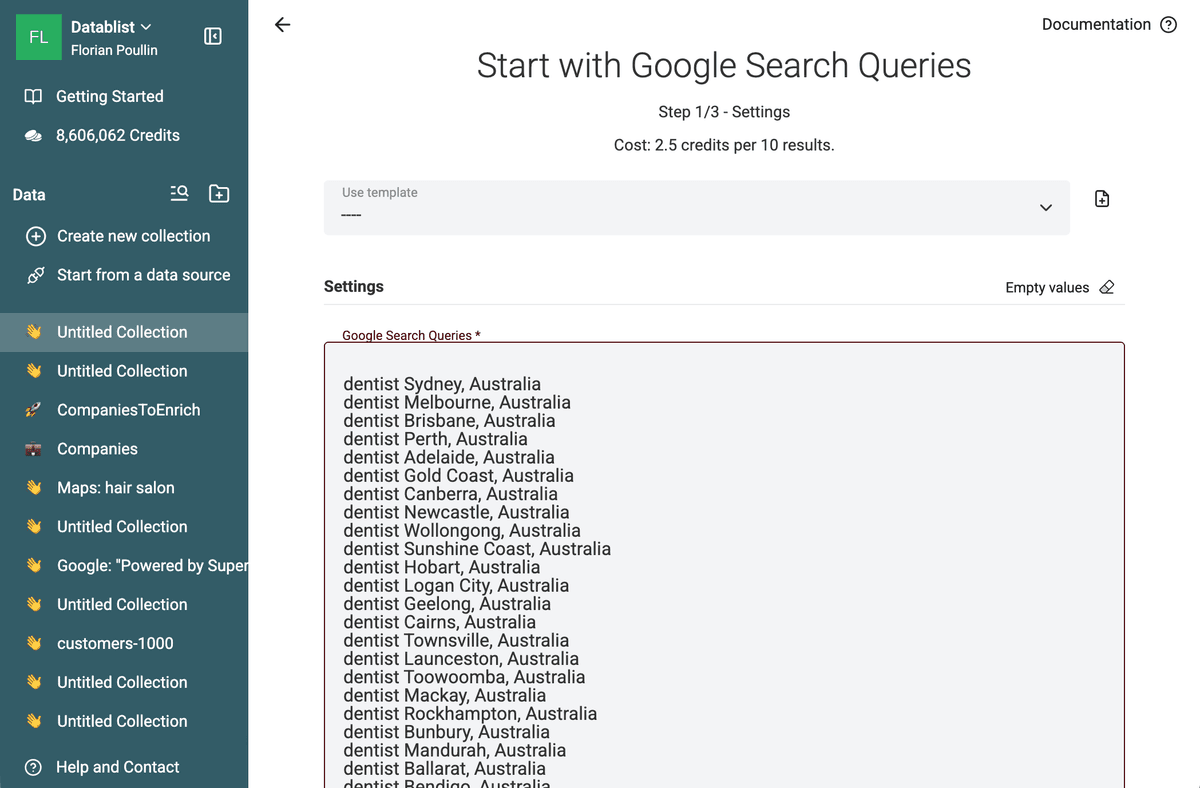
Définissez ensuite le pays et la langue ciblés. C’est indispensable. Si vous recherchez des avocats en France mais que vous définissez les États-Unis comme pays cible, Google retournera des résultats différents, et probablement peu pertinents. Vous pouvez aussi préciser une période si vous ne voulez que des résultats indexés sur le dernier mois ou la dernière année.
4. Lancez l’extraction et patientez
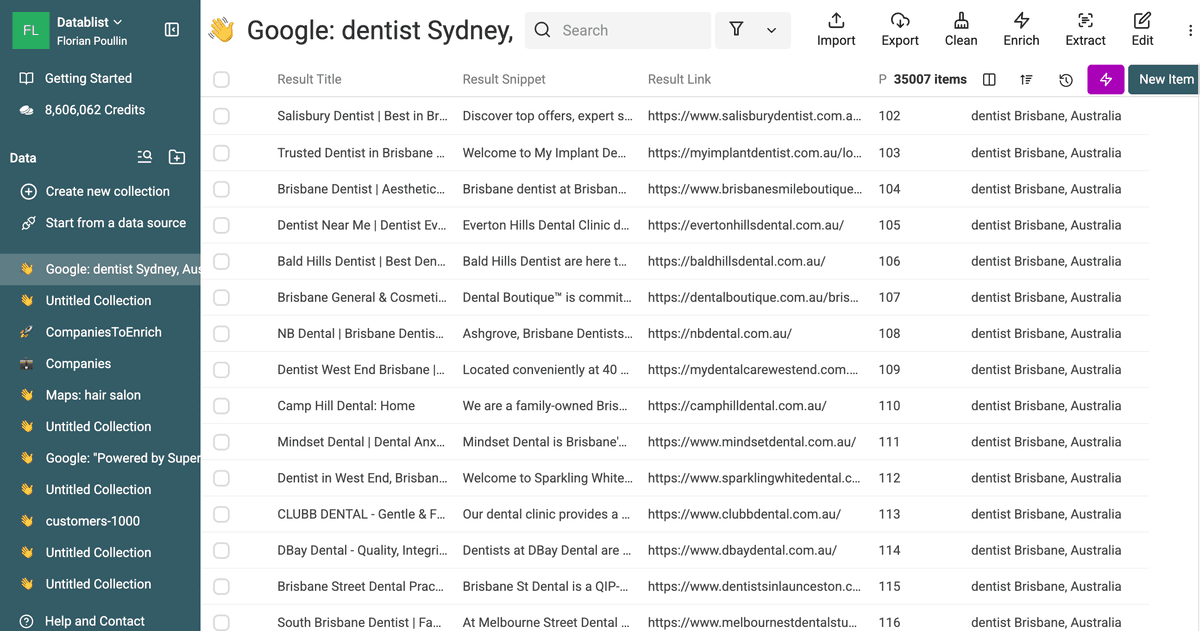
Cliquez sur le bouton de lancement. Datablist traite alors vos requêtes. Comme le scraping Google demande une gestion fine pour éviter les blocages, la plateforme s’occupe du timing pour vous.
Vous pouvez suivre l’arrivée des résultats dans votre collection en temps réel.
Nettoyer et dédupliquer vos données
Dédupliquer les résultats
Un des principaux effets secondaires d’une campagne de 50 requêtes similaires, c’est la duplication. Un cabinet d’avocats bien référencé peut apparaître pour "avocat Paris", "avocat France" et "avocat droit des affaires". Quand vous fusionnez tous ces résultats dans une seule collection Datablist, vous vous retrouvez avec trois lignes pour la même entreprise.
Vous devez dédupliquer vos données avant de commencer votre outreach. Datablist inclut un puissant outil Duplicates Finder.
- Ouvrez le menu "Clean".
- Sélectionnez "Duplicates Finder".
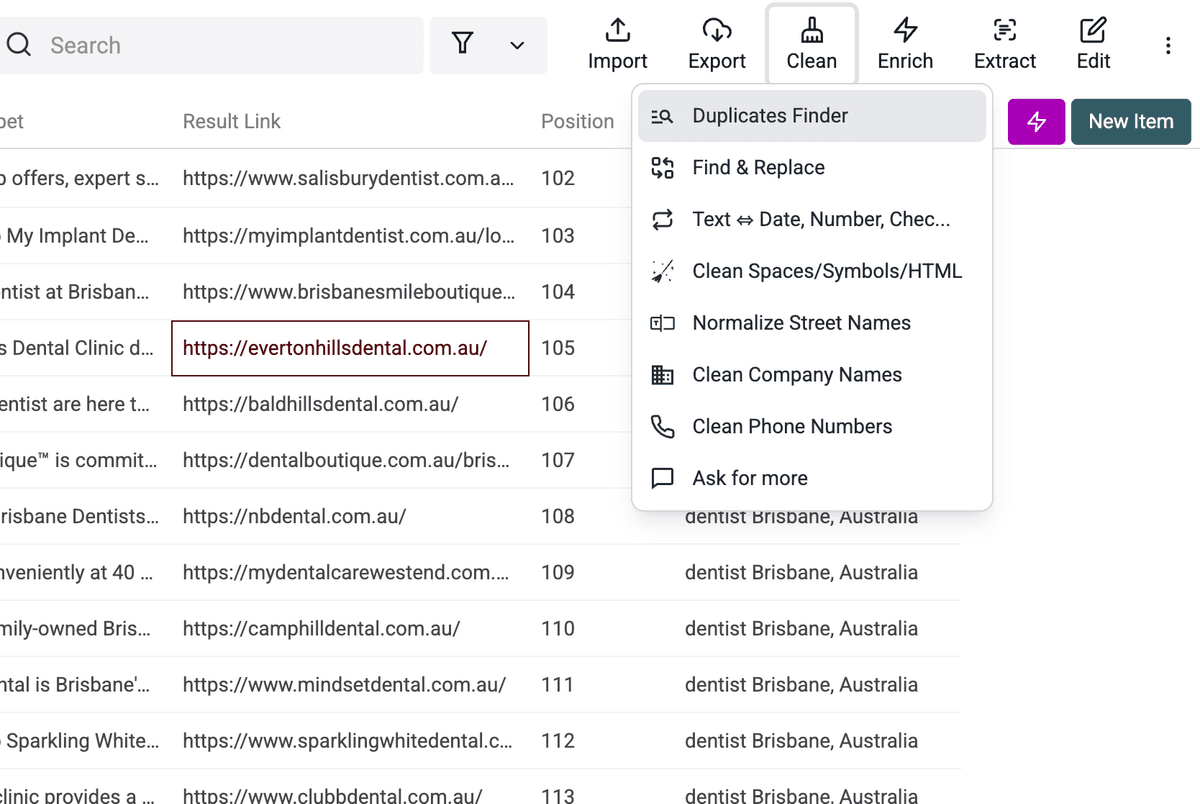
- Choisissez la propriété à comparer. Pour des résultats Google, "Result Link" est le meilleur choix.
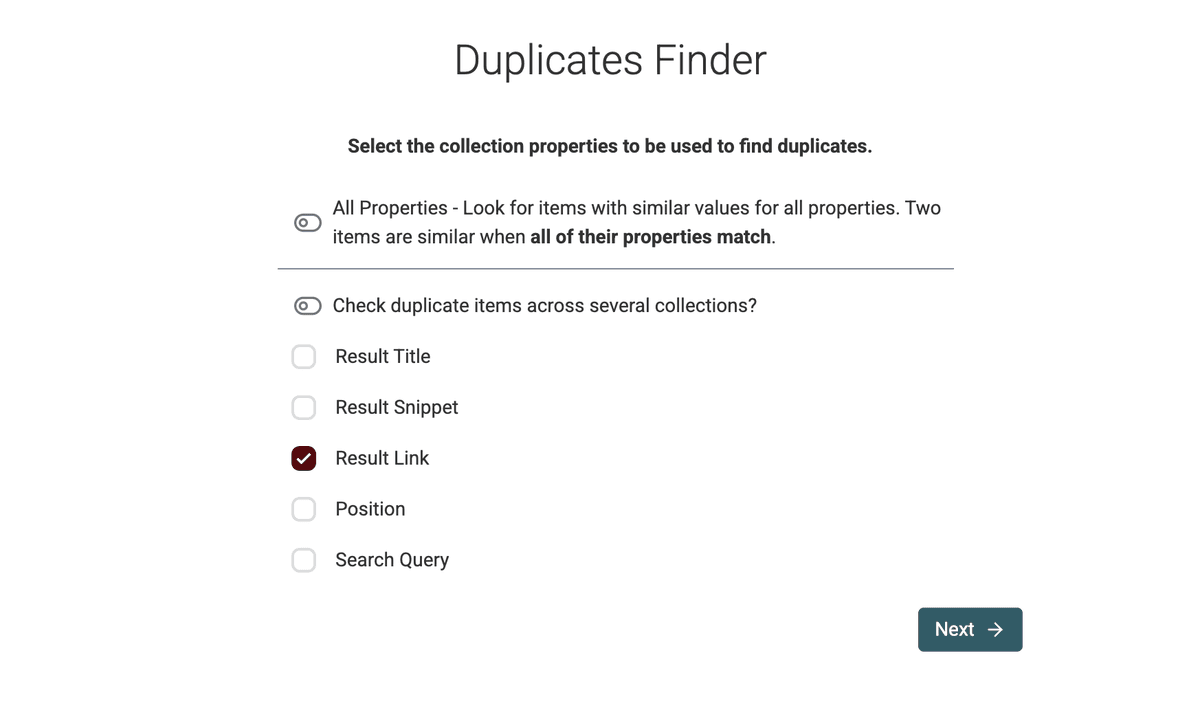
- Sélectionnez le préprocesseur "URL" pour ignorer le chemin, les query params, etc. pendant la déduplication.
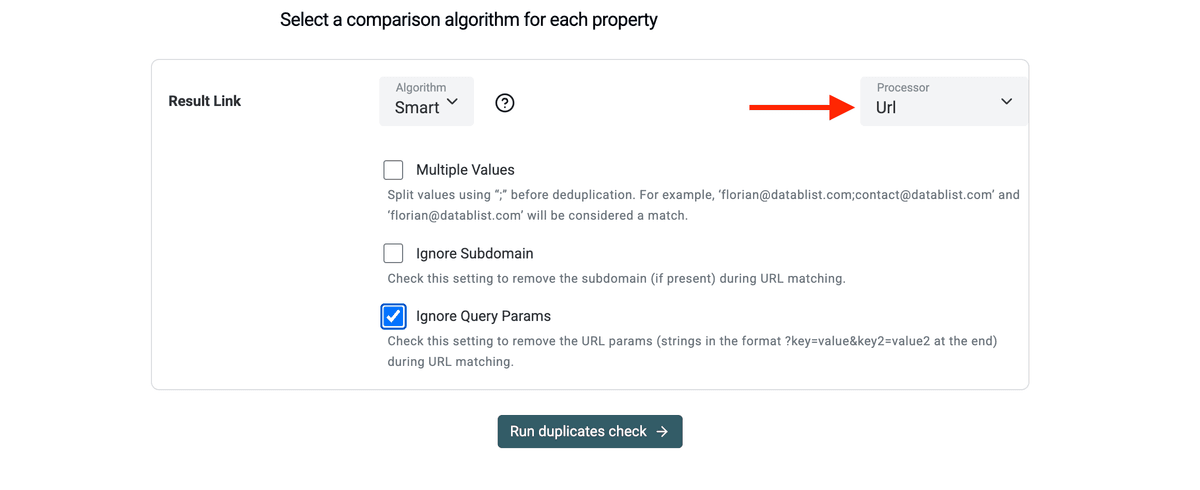
- Laissez l’outil identifier les lignes correspondantes, puis fusionnez-les ou supprimez les doublons.
Supprimer le bruit
Nettoyer les données consiste aussi à éliminer le bruit. Certains résultats Google seront des agrégateurs comme Yelp, PagesJaunes ou Tripadvisor. Dans la plupart des cas, vous voudrez les exclure pour vous concentrer sur les sites directs des entreprises.
Utilisez les fonctions de filtrage pour exclure les domaines d’annuaires les plus courants. Vous trouverez des étapes détaillées pour gérer ce type de fichiers dans ce guide sur le nettoyage de données.
Enrichir vos résultats de recherche
Une URL ou un titre de page ne suffisent généralement pas pour une campagne commerciale. Une fois votre liste de sites uniques obtenue, il vous faut des informations de contact. Datablist agit comme un hub d’enrichment capable d’envoyer vos données scrapées vers d’autres services.
Trouver des emails
-
Récupérer des emails à partir de domaines d’entreprise
Si votre scraping renvoie des domaines d’entreprise, utilisez l’enrichment Datablist "Waterfall People Search". Il identifie les personnes qui travaillent dans ces entreprises et renvoie leurs informations de profil ainsi que des adresses email vérifiées. C’est idéal pour créer des listes de contacts B2B très ciblées. -
Récupérer des emails à partir d’URL de profils LinkedIn
Si votre scraping renvoie des liens de profils LinkedIn, utilisez le Waterfall Email Finder de Datablist. Il retrouve l’adresse email professionnelle à partir de la seule URL du profil LinkedIn. Vous pouvez suivre notre guide pas à pas ici : Trouver une adresse email à partir d’une URL de profil LinkedIn.
Obtenir les pages LinkedIn d’entreprise à partir des domaines
Si vous partez de sites web d’entreprise, vous pouvez les transformer en assets LinkedIn en un clic. Utilisez l’enrichment "LinkedIn Company Page Matcher". Il retrouve la page LinkedIn officielle de chaque entreprise de votre liste.
C’est particulièrement puissant : un simple résultat Google devient un profil entreprise enrichi avec le secteur, la taille et des données d’activité.
Une fois la correspondance trouvée, vous pouvez récupérer des informations détaillées sur l’entreprise via :
Vous passez rapidement d’URLs brutes à une donnée B2B structurée.
Utiliser AI Agent pour visiter les sites web
Parfois, les informations les plus utiles sont cachées sur le site. C’est là que AI Agent devient très utile.
AI Agent visite chaque site à votre place et lit les pages comme le ferait un humain.
Il peut :
- Catégoriser les entreprises selon le contenu de leur site
- Qualifier les leads en "haute priorité" ou "basse priorité"
- Extraire des coordonnées depuis les pages Contact ou À propos
Au lieu d’ouvrir 500 onglets et de les parcourir un par un, vous laissez l’agent faire le travail lourd.
Études de cas et cas d’usage
Cas pratique : l’agence ultra-spécialisée
Une agence marketing spécialisée dans les vétérinaires voulait se développer partout en France. Une seule recherche sur "vétérinaire France" ne remontait que 300 résultats. En générant une liste des 500 plus grandes villes françaises et en les lançant dans Datablist, elle a collecté 85�00 résultats bruts.
Après déduplication par domaine, elle disposait de 42�00 cliniques vétérinaires uniques. Elle a ensuite enrichi ces résultats avec des informations de contact.
Cas pratique : le recruteur Tech
Un recruteur devait identifier des CTO de startups à Paris. Il a utilisé la requête :
site:linkedin.com/in/ "CTO" "Paris" "startup"
Il a ensuite créé des variantes en remplaçant "Paris" par d’autres hubs Tech français comme Lyon, Marseille, Toulouse et Nantes. Il a aussi fait varier l’intitulé de poste : "VP Engineering", "Technical Co-founder" et "Head of Development". Avec cette approche multi-angle, il a constitué un vivier de 4�00 profils dirigeants, bien au-delà de ce qu’une recherche LinkedIn standard permettrait.
Cas pratique : trouver des revendeurs en ligne
Le fondateur d’une marque de cosmétiques voulait identifier des boutiques en ligne indépendantes susceptibles de distribuer sa nouvelle gamme d’huiles visage bio. Au lieu de chercher manuellement, il a ciblé le footprint "Powered by Shopify", fréquent chez les retailers indépendants.
Il a utilisé la stratégie "footprint" :
"organic face oil" "powered by shopify"
En utilisant un LLM pour générer des variantes pour chaque catégorie de produits ("natural beauty boutique", "vegan skincare", "botanical serum"), il a identifié plus de 1�00 boutiques en ligne uniques correspondant à son profil de distributeur idéal.
Il a importé les résultats dans Datablist, supprimé les doublons, puis utilisé AI Agent de Datablist pour trouver les coordonnées de contact.
Analyse des coûts : scraper à petit budget
Le web scraping traditionnel coûte cher. Faire appel à un développeur pour créer un scraper sur mesure représente souvent plusieurs milliers d’euros. Et les APIs de scraping dédiées impliquent généralement un abonnement mensuel ainsi qu’un minimum de maîtrise technique pour exploiter les sorties JSON.
Datablist simplifie complètement l’équation. Son système basé sur des crédits signifie que vous ne payez que pour les données effectivement extraites.
- Tarif : 2,5 crédits pour 10 résultats Google.
- Valeur : avec des packs de crédits à partir de 1 $ pour 20�00 crédits, le calcul est simple.
- Résultat : vous obtenez environ 4�00 résultats pour 1 $.
Comparé à l’achat de listes de leads souvent obsolètes auprès de courtiers, parfois facturées 0,50 $ par lead, scraper des données fraîches depuis Google coûte infiniment moins cher. Vous gardez la main sur les filtres, le timing et les niches ciblées.
Conseils : utilisez les opérateurs de recherche Google
Pour améliorer la qualité de vos données scrapées, voici quelques opérateurs Google utiles pour construire vos requêtes.
Ces symboles indiquent à Google exactement où chercher vos mots-clés.
- site: utilisez-le pour scraper les résultats d’une plateforme spécifique. Pour trouver des profils LinkedIn, utilisez
site:linkedin.com/in/. - inurl: recherche des mots à l’intérieur de l’URL. Pour trouver des pages de contact, utilisez
inurl:contact. - intitle: recherche des mots dans le titre de la page.
intitle:"Index of"permet souvent de trouver des répertoires ouverts. - filetype: utile pour trouver des documents.
filetype:pdf "marketing plan"permet par exemple de trouver des documents stratégiques publics. - - (signe moins) : exclut des mots. Si vous cherchez des avocats mais pas des cabinets de recrutement, utilisez
avocat -recrutement.
Combinés au scraping multi-requêtes, ces opérateurs deviennent un outil extrêmement précis. Par exemple :
site:instagram.com "concept store" -inurl:/p/
Cette recherche permet de trouver des pages de profil Instagram de concept stores tout en excluant les publications individuelles (chemin /p/). En la déclinant sur 50 pays ou niches différents, vous pouvez constituer une base mondiale d’influenceurs ou de concurrents.
📘 Consultez notre guide
Découvrez notre article Search and Scrape Instagram Profiles by Category and Keywords pour aller plus loin sur la recherche de profils Instagram via Google.
FAQ
Pourquoi Google limite-t-il les résultats à 300 ?
Google cherche avant tout à offrir la meilleure expérience utilisateur. Le moteur considère que si vous n’avez pas trouvé ce que vous cherchez après 30 pages, les suivantes ont peu de chances d’être utiles. Cela permet aussi de protéger ses serveurs contre les bots qui tenteraient de télécharger l’intégralité du web.
Est-ce légal de scraper Google ?
Le scraping de données publiquement accessibles est généralement autorisé pour des usages business comme la recherche ou la lead generation. En revanche, vous devez respecter les règles de confidentialité, notamment le RGPD, lorsque vous traitez des données personnelles. Vérifiez toujours aussi les conditions d’utilisation des sites que vous visitez via les résultats de recherche.
Puis-je scraper Google Maps avec cet outil ?
La source "Start with Google Search Queries" est conçue pour le moteur de recherche Google classique. Si vous avez besoin de données locales d’entreprise avec les avis, les horaires d’ouverture et les coordonnées cartographiques précises, mieux vaut utiliser un scraper Google Maps dédié. Les résultats Search sont plus adaptés aux sites web et profils digitaux ; les résultats Maps sont plus utiles pour les établissements physiques.
Comment gérer les "CAPTCHAs" ?
Lorsque vous utilisez Datablist, vous n’avez rien à gérer. La plateforme s’occupe des headers de requête et de la rotation des proxies. Si une requête rencontre un challenge, le système gère automatiquement la logique de retry. Vous ne voyez que les données finales dans votre collection.
Puis-je utiliser ces résultats dans mon CRM ?
Oui. Datablist vous permet d’exporter vos données nettoyées et enrichies en CSV ou en fichier Excel. La plupart des CRM comme HubSpot, Salesforce ou Pipedrive permettent d’importer directement ces fichiers. En nettoyant d’abord vos données dans Datablist, vous gardez votre CRM propre, sans doublons ni entrées inutiles.