
Ogni scraper basato su codice è costruito sulla struttura di un singolo sito. Nel momento in cui punti quello stesso script su un sito diverso, i selector non corrispondono più, la pagina torna vuota e lo script si rompe.
Con un prompt questo non succede. Ti basta descrivere ciò che vuoi in modo semplice, e un agente AI analizza ogni pagina da zero, invece di affidarsi a regole hardcoded per un unico layout.
È proprio questo cambio di approccio che oggi ti permette di fare scraping di qualsiasi sito senza codice, ottenendo dati puliti e strutturati da quasi ogni pagina in pochi minuti invece che in ore.
📌 Riassunto per chi va di fretta
L’idea chiave: non ti serve uno scraper diverso per ogni sito. Gli scraper basati su codice sono vincolati alla struttura di un solo website, mentre un AI scraping agent si adatta a siti diversi partendo da un unico prompt in linguaggio naturale.
In questo articolo ti spiego come oggi un solo tool possa fare scraping di quasi qualsiasi sito e ti mostro, passo dopo passo, come farlo con l’AI Scraping Agent di Datablist.
Cosa ti porterai a casa:
- Una visione chiara del perché gli scraper basati su codice o template si rompono quando cambiano i siti
- Come l’AI scraping si confronta con i metodi no-code più tradizionali
- Una guida step-by-step per fare scraping di qualsiasi sito
Cosa troverai in questa guida
- Cosa significa davvero fare scraping di qualsiasi sito senza codice
- AI scraping vs metodi più vecchi per fare scraping senza codice
- Cosa cercare in un tool per fare scraping di qualsiasi sito
- Guida step-by-step con l’AI Scraping Agent di Datablist
- Domande frequenti
Cosa significa davvero fare scraping di qualsiasi sito
Due anni fa, fare scraping di un sito senza codice significava quasi sempre lavorare su un sito popolare per cui esisteva già un template pronto. Da quando l’AI è diventata accessibile a tutti, lo scenario è cambiato.
Oggi significa esattamente quello che dice: puntare un tool su quasi qualsiasi pagina pubblica e ottenere dati puliti e strutturati, senza scrivere script.
Perché prima per fare web scraping serviva codice
Gli scraper classici sono script mappati sull’HTML di un singolo sito. Si basano su selector specifici, classi CSS e pattern di paginazione presenti in quella pagina precisa.
Funziona finché il target non cambia: se punti lo stesso script su un altro sito e nulla corrisponde, ottieni righe vuote o un errore.
Cosa cambia con un web scraper no-code
Un web scraper no-code elimina del tutto lo script. Invece di scrivere codice, configuri ciò che vuoi tramite un’interfaccia visuale o istruzioni testuali.
È la categoria che la maggior parte delle persone conosce già, ma al suo interno i tool non sono affatto tutti uguali. Per questo conviene dividerli in due sottocategorie:
- Tool point-and-click e template: selezioni i campi su una pagina oppure carichi un template già pronto per un sito popolare.
- AI scraping agent: descrivi i dati in plain English e l’agente capisce come estrarli.
Entrambi eliminano il codice, ma solo uno elimina anche la dipendenza dal fatto che un sito sia popolare o prevedibile.
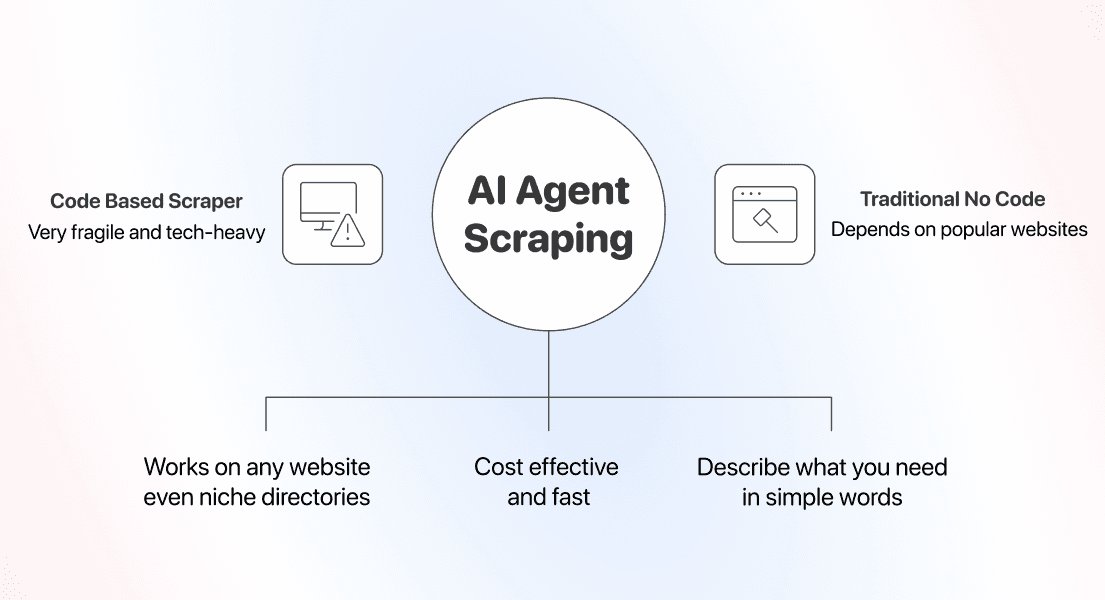
Perché oggi puoi fare scraping di qualsiasi sito senza codice
Il cambiamento nasce dal modo in cui l’AI legge una pagina. Un AI scraping agent analizza il contenuto della pagina insieme al tuo prompt e decide cosa estrarre.
Questo approccio elimina la dipendenza dai selector hardcoded, ed è proprio qui che sta il suo vantaggio: non c’è una regola fissa che si rompe quando cambia il layout, perché l’agente rilegge la pagina a ogni esecuzione.
AI scraping vs metodi più vecchi per fare scraping senza codice
Il no-code non è una categoria unica, e le differenze tra i vari approcci emergono subito quando un sito è di nicchia o quando una pagina molto usata cambia layout.
Scraper basati su codice: potenti, ma legati a un solo sito
Scrivere il proprio scraper in Python o JavaScript ti dà il massimo controllo. Decidi tu ogni selector, ogni regola di paginazione, ogni retry e ogni timeout.
Ma ogni script è costruito per un solo sito, richiede uno sviluppatore per essere creato e si rompe ogni volta che quel sito cambia struttura. È vero, gli scraper basati su codice costano poco in esecuzione, ma hanno un altro prezzo: uno script per ogni sito, uno sviluppatore sempre disponibile e manutenzione ogni volta che il target aggiorna le pagine.
Per un team che fa scraping da molti siti diversi, questo costo cresce in fretta. Cinque target possono significare cinque script e cinque problemi distinti da sistemare ogni settimana.
Scraper point-and-click e template: facili, finché il sito non è di nicchia
I tool template e point-and-click sono stati i primi veri scraper no-code. Funzionano bene sui siti popolari perché qualcuno ha già creato il template, oppure perché la pagina è abbastanza semplice da configurare a mano.
I problemi veri iniziano quando vuoi fare scraping di pagine meno diffuse, come directory di nicchia, e-commerce regionali o layout insoliti, che spesso non hanno alcun template pronto.
E, come gli scraper basati su codice, continuano comunque a dipendere dalla stabilità della pagina: quando il sito cambia struttura, le selezioni salvate smettono di funzionare, i dati smettono di arrivare e tocca rimetterci mano.
AI scraping: un solo prompt che si adatta a qualsiasi sito
L’AI scraping risolve due problemi:
- Configurazioni infinite
- Scraper che si rompono quando il sito target cambia struttura
Tu descrivi semplicemente i dati che vuoi, passi una URL all’agente e lui restituisce righe strutturate.
Dato che l’agente legge ogni pagina nel momento stesso in cui viene analizzata, lo stesso prompt può funzionare su siti diversi. Una product page, una directory, una listing page: il workflow non cambia.
Ed è proprio qui che entra in gioco l’AI Scraping Agent di Datablist. Prende una URL target e un prompt in plain English, così puoi fare scraping di qualsiasi sito senza codice e completare il lavoro in minuti invece che in ore. Inoltre semplifica molto anche il data cleaning, perché i dati raccolti finiscono direttamente in un foglio dove puoi deduplicare ed enrich immediatamente.
Abbiamo confrontato i metodi di scraping no-code sulle metriche più importanti 👈🏽
Cosa cercare in un tool per fare scraping di qualsiasi sito senza codice
Quando capisci che un AI Scraper è migliore di uno scraper costruito sito per sito, la vera domanda diventa: di quale tool puoi davvero fidarti? Personalmente guardo tre aspetti: copertura, stabilità e facilità d’uso.
Copertura: riesce a gestire siti di nicchia e long-tail?
La copertura è il primo test. Molti tool promettono di fare scraping di qualsiasi sito, ma poi in realtà dipendono da una libreria di template predefiniti valida solo per i siti più popolari.
La domanda più importante è: questo tool riesce a fare scraping di un sito che non ha mai visto prima?
Gli agenti basati su prompt superano questo test perché non si appoggiano ai template. Se tra i tuoi target ci sono directory di nicchia o siti regionali, questo è il criterio più importante.
Un modo rapido per verificarlo: prova il tool sul sito più strano della tua lista e guarda se riesce davvero a estrarne i dati.
Manutenzione: si rompe ogni volta che il sito cambia?
La manutenzione degli scraper è spesso il costo di cui nessuno parla. Selector, regole di paginazione e proxy smettono di funzionare quando il target cambia layout, e qualcuno deve intervenire per sistemarli.
Un tool legato a regole fisse scarica quel lavoro su di te. Ogni modifica al layout si trasforma in una piccola riparazione, e queste riparazioni non finiscono mai davvero.
Un agente di scraping guidato da prompt evita gran parte di questo problema, perché rilegge la pagina a ogni run invece di fidarsi dei selector di ieri. Il prompt resta lo stesso anche quando la pagina cambia.
Facilità d’uso: come dovrebbe essere un vero web scraper no-code
L’ultimo test è semplice: riesci davvero a usarlo senza uno sviluppatore?
Un tool universale serve a poco a un team recruiting, operations o marketing se per farlo funzionare bisogna coinvolgere un engineer.
Valutalo dal tuo punto di vista. Riesci a scrivere un prompt semplice, mappare qualche campo ed esportare il risultato in autonomia?
È esattamente per questo che è stato progettato l’AI Scraping Agent di Datablist: scrivi un prompt, configuri i campi ed esporti i dati. Niente codice, niente sviluppatore, niente setup specifico per ogni sito.
Se non sai quale tool sia più adatto ai tuoi target, abbiamo confrontato i migliori tool di scraping no-code uno contro l’altro 👈🏽
Guida step-by-step per fare scraping di qualsiasi sito
Passiamo alla parte pratica. Tutto quello che segue si svolge dentro Datablist, la piattaforma di workflow automation pensata per AI scraping e data enrichment.
Tu fornisci una URL target e un prompt semplice, e il sistema restituisce dati strutturati da quasi qualsiasi sito senza codice, in pochi minuti invece che in ore. Niente sviluppatore, niente setup sito per sito.
Per renderlo concreto, in questa guida faremo due cose:
- Configurare lo scraping ed eseguirlo
- Impostare una proprietà univoca in modo che le esecuzioni ripetute non importino mai due volte la stessa riga
Come fare scraping di qualsiasi sito con l’AI Scraping Agent di Datablist
Per dimostrare questa promessa su un caso reale, useremo l’AI Scraping Agent su una category page di GymShark, ma ogni passaggio funziona allo stesso modo su qualsiasi sito tu voglia analizzare.
Prima di iniziare, assicurati di avere:
- Un account Datablist
- La URL della pagina che vuoi analizzare
- Un elenco chiaro dei campi che vuoi estrarre
- Esempi per ogni campo che potrebbe essere interpretato male
- Un limite approssimativo di pagine da processare
Step 1: registrati e crea una Collection
Per prima cosa, registrati su Datablist.com.
Poi crea una New Collection per ospitare i dati che stai per estrarre.
Step 2: apri AI Agent - Site Scraper
All’interno della tua nuova collection, clicca su See all sources.
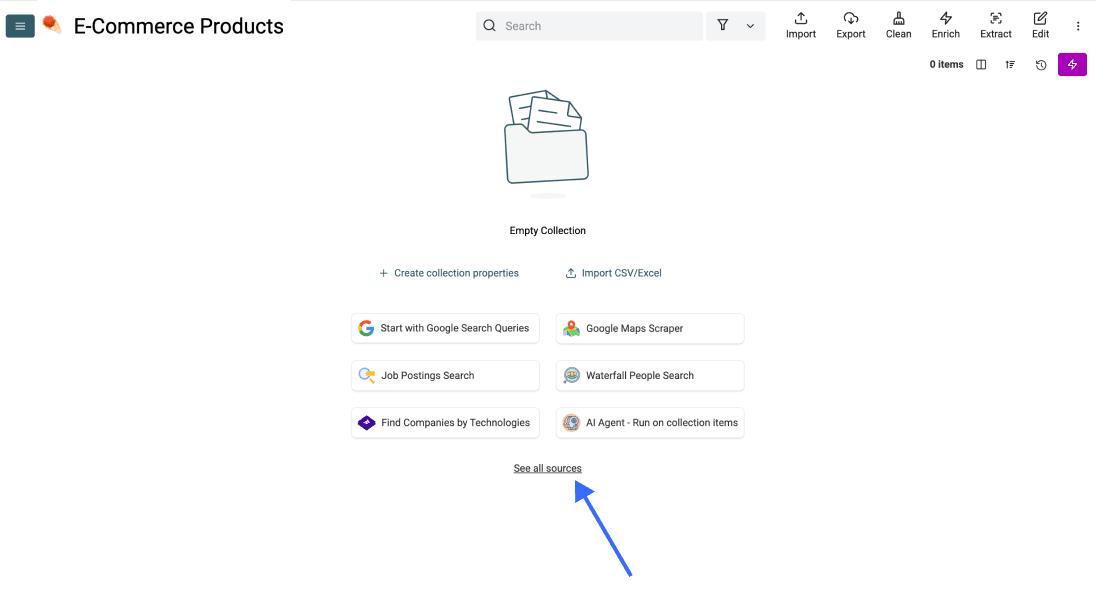
Scorri verso il basso e seleziona AI Agent - Site Scraper
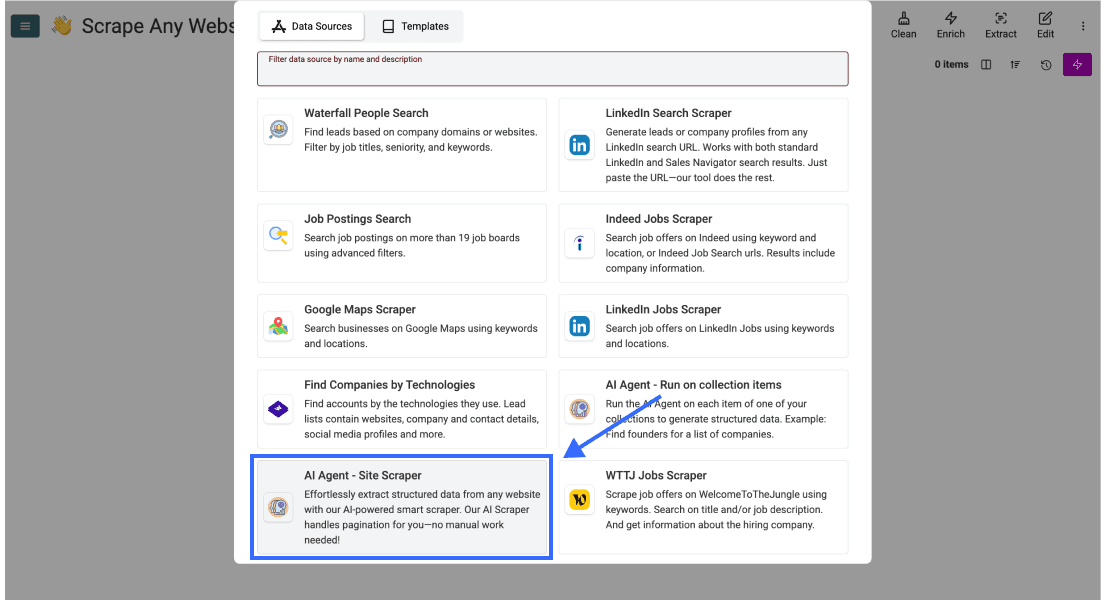
Step 3: scrivi il prompt e configura il task
Incolla la URL target nel primo campo. In questo esempio useremo una category page di GymShark, ma puoi fare scraping di qualsiasi sito.
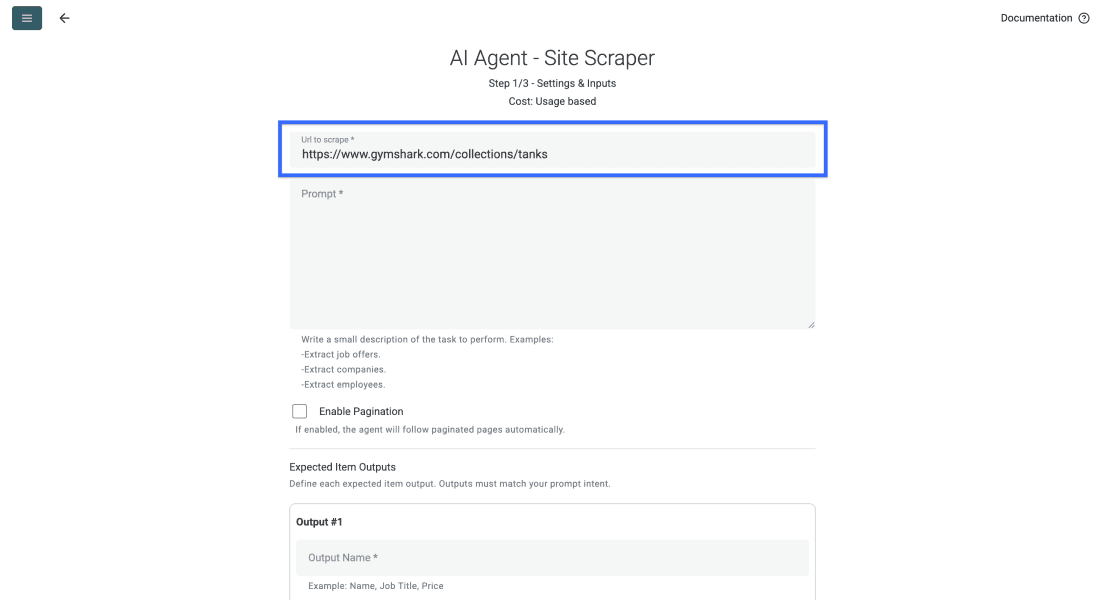
Poi scorri fino al campo del prompt e descrivi cosa deve estrarre l’agente da ogni pagina. Qui sotto trovi anche un prompt di esempio.
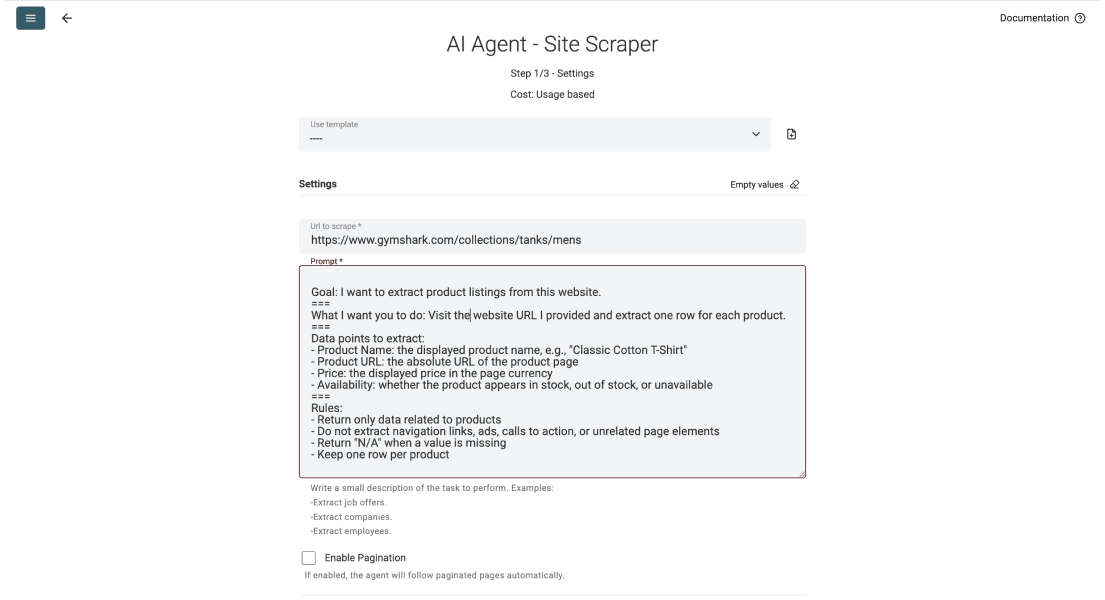
Un buon prompt spiega all’agente cosa estrarre, cosa ignorare e che aspetto deve avere ogni riga. Puoi copiare la struttura qui sotto e sostituire i campi con i tuoi.
Goal: I want to extract product listings from this website.
.===
What I want you to do: Visit the URL I provide and return one row per product.
.===
Data points to extract:
- Product Name (example: "Classic Cotton T-Shirt")
- Product URL: the absolute link to the product page
- Price: the displayed price in the page currency
- Availability: in stock, out of stock, or unavailable
.===
Mistakes to avoid:
- Return only product data; ignore navigation, ads, and call to actions
- Return "N/A" when a value is missing
- Keep one row per product
L’agente segue molto meglio le istruzioni quando il prompt nomina chiaramente ogni campo e include un esempio. I prompt vaghi sono la causa principale dei risultati disordinati.
Segui queste regole per scrivere prompt per AI agent per ottenere risultati più puliti 👈🏽
Una volta finito il prompt, imposta quante pagine vuoi che l’agente analizzi.
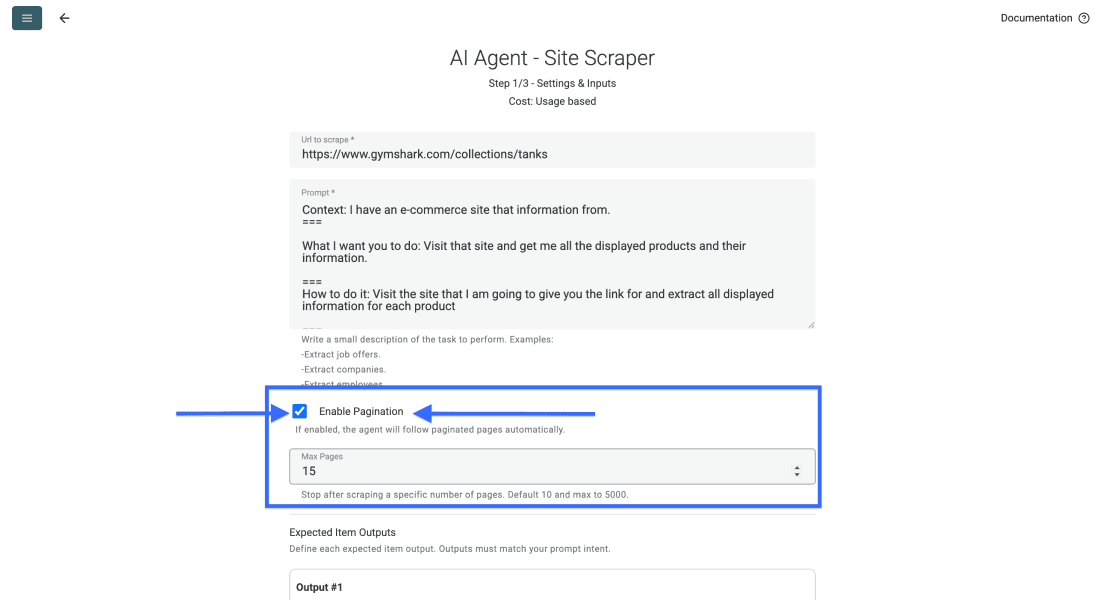
📘 Nota sulla paginazione nelle listing page
La maggior parte delle listing page divide i risultati su più pagine. Imposta il limite in base a quanto del sito vuoi coprire. Datablist supporta fino a 5.000 pagine per run.
Una volta impostati prompt e limite di pagine, scorri verso il basso per configurare i campi di output.
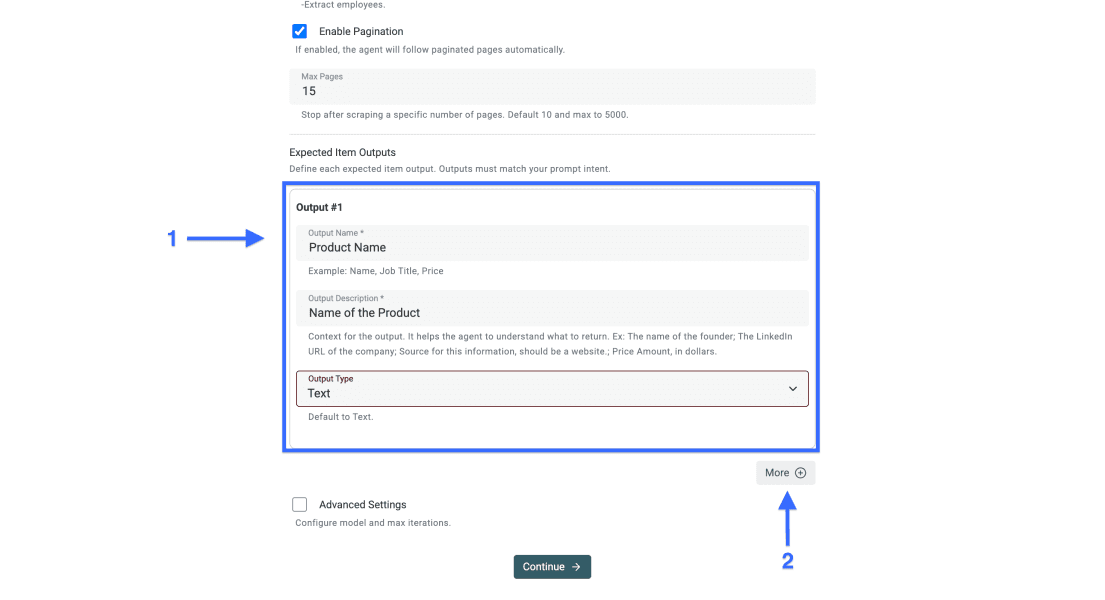
Step 4: definisci i campi di output
Se scrivi tu il prompt, i campi di output dovrebbero rispecchiare i data point richiesti. Una colonna per ogni campo mantiene i dati ordinati e facili da usare.
Per ogni output:
- Imposta il nome del dato come Output Name
- Aggiungi una Output Description chiara, con un esempio se utile
- Scegli il Output Type corretto, ad esempio testo, numero, URL o email
- Clicca su More per aggiungere altri campi di output
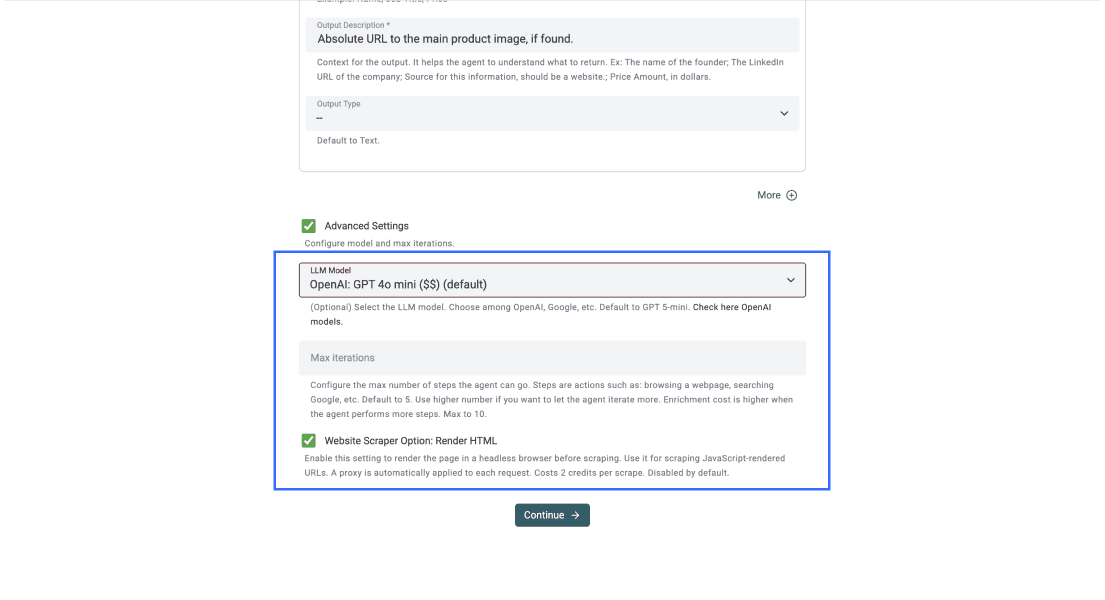
Step 5: configura le impostazioni avanzate
Una volta definiti gli output, spunta la casella accanto a Advanced Settings e applica queste impostazioni:
- LLM: OpenAI GPT-4o mini, per il miglior rapporto performance/prezzo
- Max iterations: 10
- Render HTML: attivo, fondamentale per i siti che caricano contenuti con JavaScript
A questo punto il pannello Advanced Settings dovrebbe apparire così.
Step 6: avvia lo scraping
Quando prompt, output e impostazioni sono pronti, clicca su Continue
Datablist creerà una proprietà per ogni output configurato. A questo punto puoi controllare di non aver dimenticato nulla e cliccare su Run Import Now quando sei pronto per iniziare lo scraping.

Dopo pochi minuti, le righe arriveranno nella tua collection, pronte per essere pulite, enrichite, deduplicate o esportate.
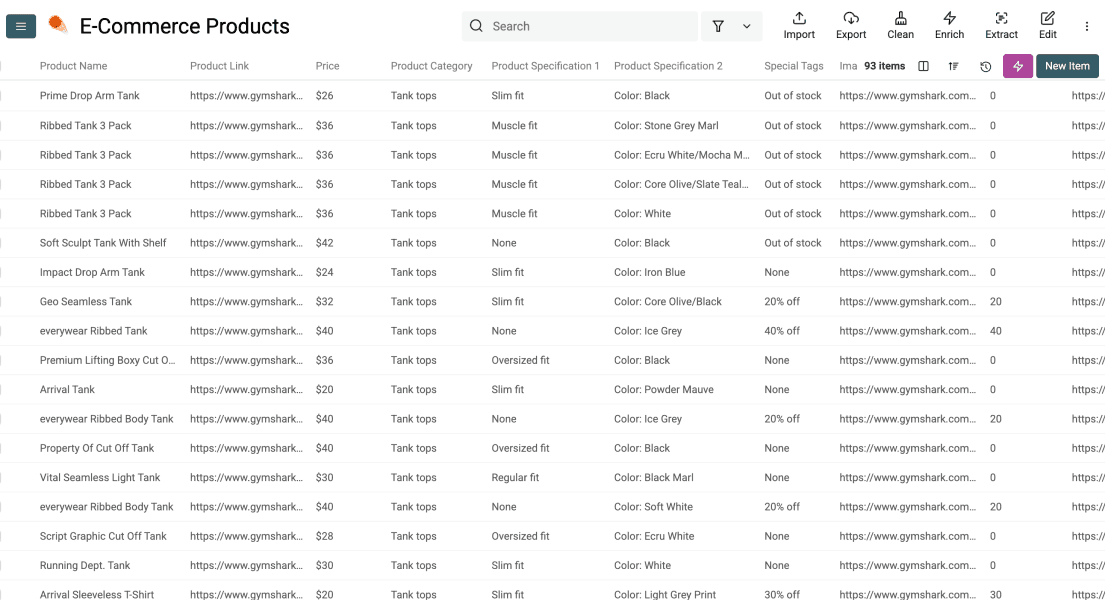
Se prevedi di ripetere questo scraping in futuro, segui la sezione qui sotto per impostare prima una colonna univoca, così non importerai due volte la stessa riga.
Come evitare duplicati nelle attività di scraping ripetute
Ora ti mostro come evitare i duplicati in Datablist impostando un identificatore univoco prima di ripetere un task di scraping.
Step 1: scegli un identificatore univoco
Per prima cosa, scegli la colonna che Datablist dovrà usare per rilevare i duplicati.
Ad esempio, se stai estraendo prodotti, usa un valore stabile come Product URL o Item URL. Se lavori su aziende, usa Company Domain o Business Name.
💡 Scegli un identificatore stabile
Scegli un valore che appartenga a una sola riga. Product URL, item URL, company domain ed email funzionano quasi sempre meglio dei nomi, perché i nomi possono ripetersi.
Step 2: apri le impostazioni della colonna
Clicca sull’intestazione della colonna che vuoi usare come identificatore univoco.
Poi seleziona Rename - Settings - Delete.

Step 3: impedisci i valori duplicati
Ora seleziona la casella Do not allow duplicate values.
Poi clicca su Save Property.

Step 4: controlla l’icona a forma di chiave
Una volta salvata la colonna, Datablist mostrerà un’icona a forma di chiave accanto al nome della colonna.
Quell’icona conferma che la colonna è ora un identificatore univoco.
Da questo momento, quando esegui di nuovo lo stesso scrape, source o import, Datablist aggiunge solo le righe con nuovi valori univoci. In questo modo mantieni la collection pulita anche quando ripeti lo stesso processo nel tempo.
In sintesi: basta configurare scraper, inizia a usare i prompt
Il vero cambiamento non è un singolo tool. È il fatto che una pagina più un prompt in plain English hanno sostituito il vecchio modello “uno script per ogni sito”, che rendeva il web scraping così fragile. Ed è per questo che oggi lo stesso workflow può fare scraping di qualsiasi sito, che si tratti di una directory, di un marketplace o di uno store di nicchia.
Domande frequenti sul web scraping senza codice
L’AI Scraping Agent di Datablist può fare scraping di qualsiasi sito?
Funziona su quasi qualsiasi sito pubblico. Dal momento che legge ogni pagina tramite un prompt invece di affidarsi a un template fisso, si adatta anche a siti mai visti prima.
Esiste una prova gratuita per il web scraper no-code di Datablist?
Sì. Puoi iniziare gratis, creare una collection e provare gratuitamente l’AI Scraping Agent.
Devo scrivere codice per usare l’AI Scraping Agent di Datablist?
No. Ti basta descrivere ciò che vuoi in plain English, mappare alcuni campi di output e avviare il task. Non c’è nessuno script da scrivere né da riscrivere quando un sito cambia layout. È proprio per questo che Datablist ti aiuta a fare scraping di qualsiasi sito senza codice.
Che tipo di dati può estrarre un AI Scraping Agent da un sito?
Tutto ciò che la pagina mostra e che tu chiedi esplicitamente: nomi prodotto, prezzi, URL, disponibilità, contatti, listing e altro ancora. Definisci tu i campi nel prompt e negli output. Nota: l’AI Scraper di Datablist non può estrarre informazioni backend, come la disponibilità reale di stock, se non sono visibili sul sito pubblico.
Quanto costa fare scraping di siti con Datablist?
Lo scraping funziona con crediti a consumo, quindi paghi in base a ciò che processi. Il modo più economico per verificare tutto prima di uno scrape completo è fare un test su piccola scala.
Posso esportare i dati estratti in CSV o Excel?
Sì. Una volta che le righe arrivano nella tua collection, puoi pulirle, deduplicarle, enrichirle ed esportarle, anche in CSV ed Excel, direttamente da Datablist.
Cosa significa fare scraping di un sito senza codice?
Significa estrarre dati strutturati da una pagina senza scrivere né mantenere uno script. Invece di programmare selector manualmente, configuri un tool oppure descrivi i dati che vuoi raccogliere in plain English tramite prompting.
Si può davvero fare scraping di qualsiasi sito senza codice?
Puoi fare scraping di quasi qualsiasi sito pubblico senza codice se usi un AI Scraping Agent, perché gli agenti AI si adattano a layout diversi partendo da un unico prompt. Login e protezioni anti-bot molto aggressive, però, possono ancora creare attrito su alcuni siti.
Qual è la differenza tra AI scraping e web scraping tradizionale?
Lo scraping tradizionale esegue uno script hardcoded sulla struttura di un singolo sito. L’AI scraping invece legge la pagina con un prompt a ogni run, così lo stesso setup si adatta a molti siti diversi.
Perché gli scraper si rompono quando un sito cambia layout?
Uno scraper si basa su selector specifici e pattern di pagina precisi. Quando il sito cambia questi elementi, lo script non trova più i dati e restituisce risultati vuoti o errori, finché qualcuno non lo riscrive.
Cos’è un web scraper no-code e come funziona?
Un web scraper no-code estrae dati senza programmazione. I tool point-and-click ti permettono di selezionare i campi visivamente, mentre gli AI scraping agent ricevono un prompt in plain English e recuperano i dati per te.
Quanto tempo serve per fare scraping di un sito senza codice?
Dipende dal tool che usi, ma se prendiamo Datablist.com come esempio, bastano pochi minuti: registrazione, prompt, mapping dei campi e avvio. Anche lo scrape in sé di solito si conclude in 5-10 minuti, a seconda del numero di pagine che processi.