

Hai una lista piena di duplicati? Che si tratti di contatti clienti, iscritti alla newsletter o inventario prodotti, le voci duplicate vanno eliminate: fanno perdere tempo e denaro. Inviare due volte la stessa email allo stesso contatto non è solo fastidioso: danneggia anche la tua reputazione.
La buona notizia? Puoi deduplicare la tua lista online gratis con Datablist. È uno strumento semplice e potente per rimuovere i duplicati e ripulire i dati in pochi minuti. Niente codice, zero mal di testa.
In questa guida, vedrai come deduplicare una lista in tre passaggi:
Parte 1: Importa la tua lista con duplicati
Il primo passo per deduplicare la tua lista online con Datablist è semplicissimo: caricare i dati sulla piattaforma.
Datablist lavora senza problemi con vari formati (CSV, Excel) e può importare dati anche da fonti esterne come Pipedrive.
Passo 1: Crea una nuova Collection
Pensa a una Collection in Datablist come a un foglio di calcolo. Per iniziare, crea una nuova Collection per la lista che vuoi deduplicare.
Clicca sul pulsante "+" nella sidebar per creare una nuova Collection.
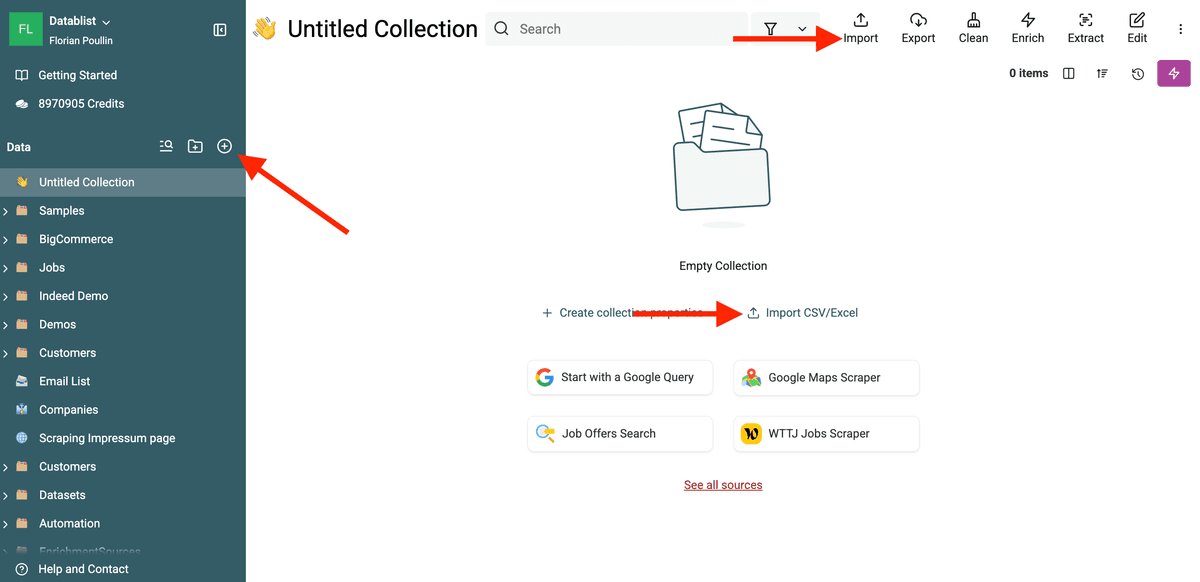
Nella nuova Collection, clicca su "Import CSV/Excel". Oppure su "Sources" per integrazioni avanzate.
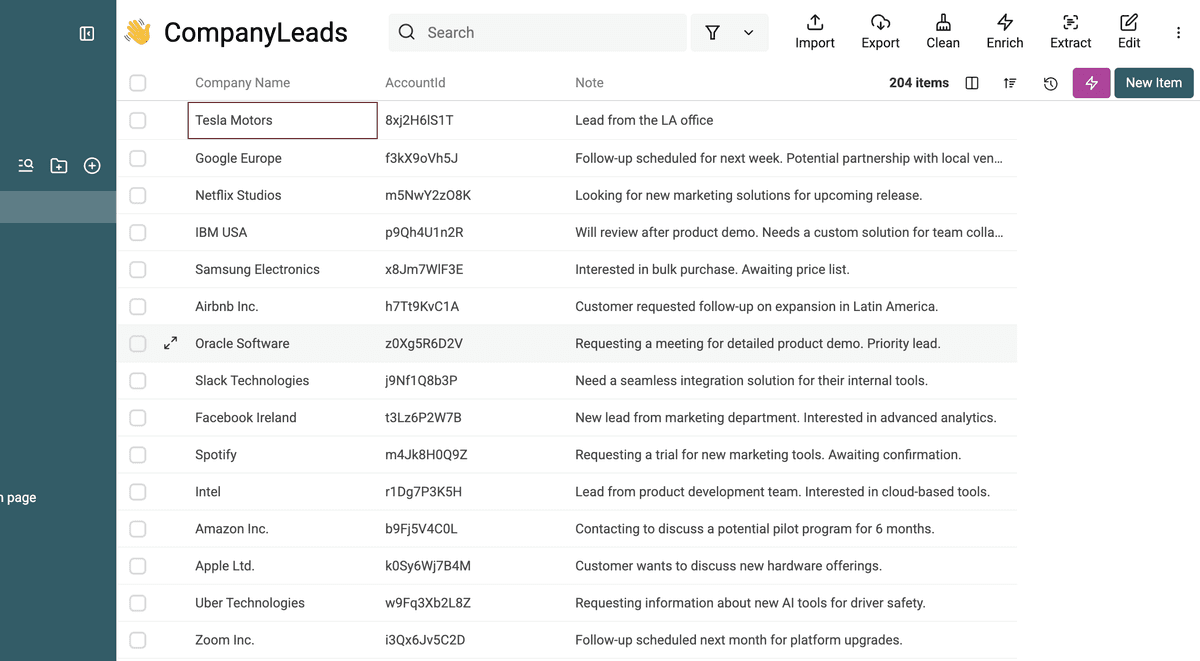
Dopo il caricamento, Datablist mostrerà un'anteprima dei tuoi dati, con colonne (proprietà) e alcune righe. Dai un'occhiata veloce per verificare che tutto sia a posto.
Parte 2: Trova i duplicati nella lista
La tua lista è pronta. Ora andiamo a caccia dei duplicati.
Datablist usa algoritmi avanzati per individuare record probabilmente duplicati, anche quando non sono identici al 100%.
Passo 1: Apri Duplicates Finder
Per iniziare la ricerca, apri il menu "Clean" nella tua Collection e clicca su "Duplicates Finder".
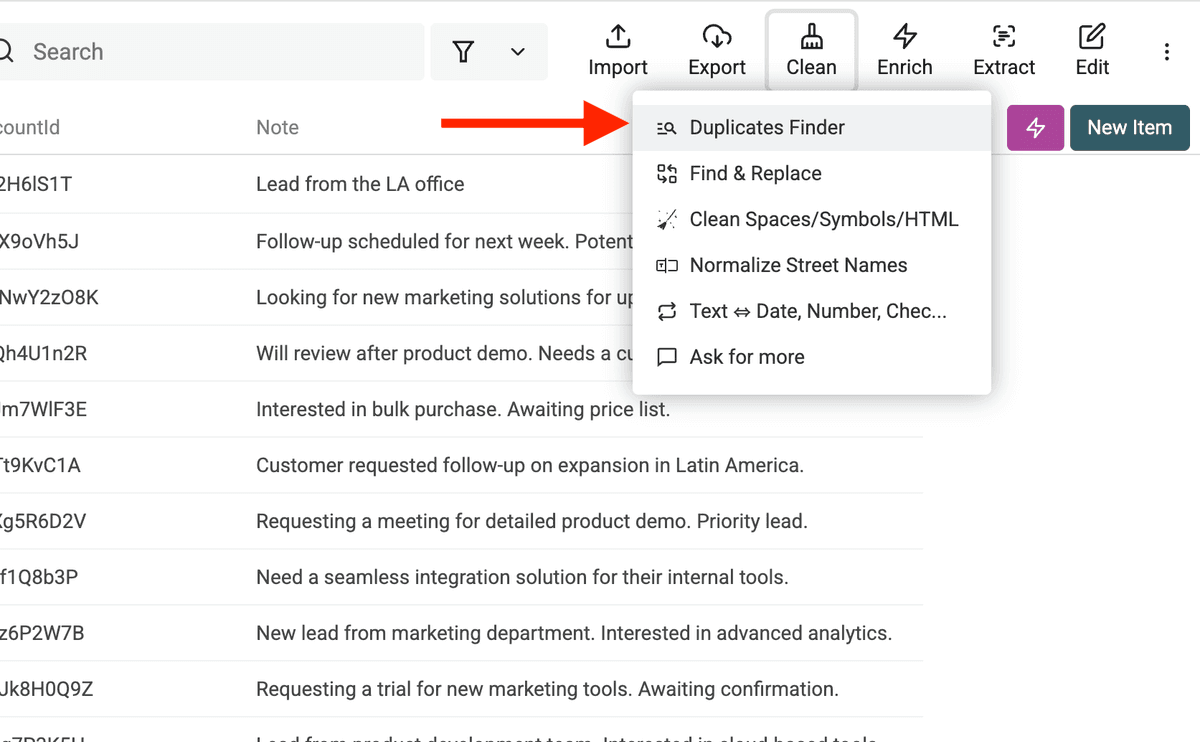
Si aprirà il Duplicates Finder, dove puoi impostare come cercare i duplicati nella tua lista.
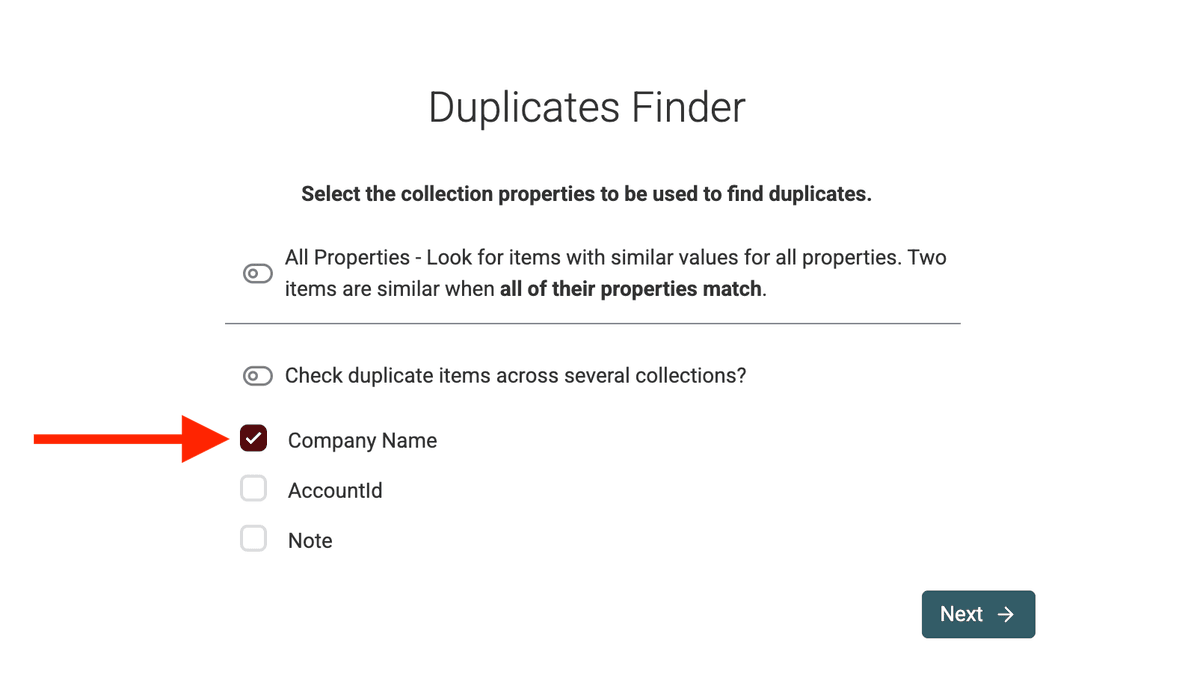
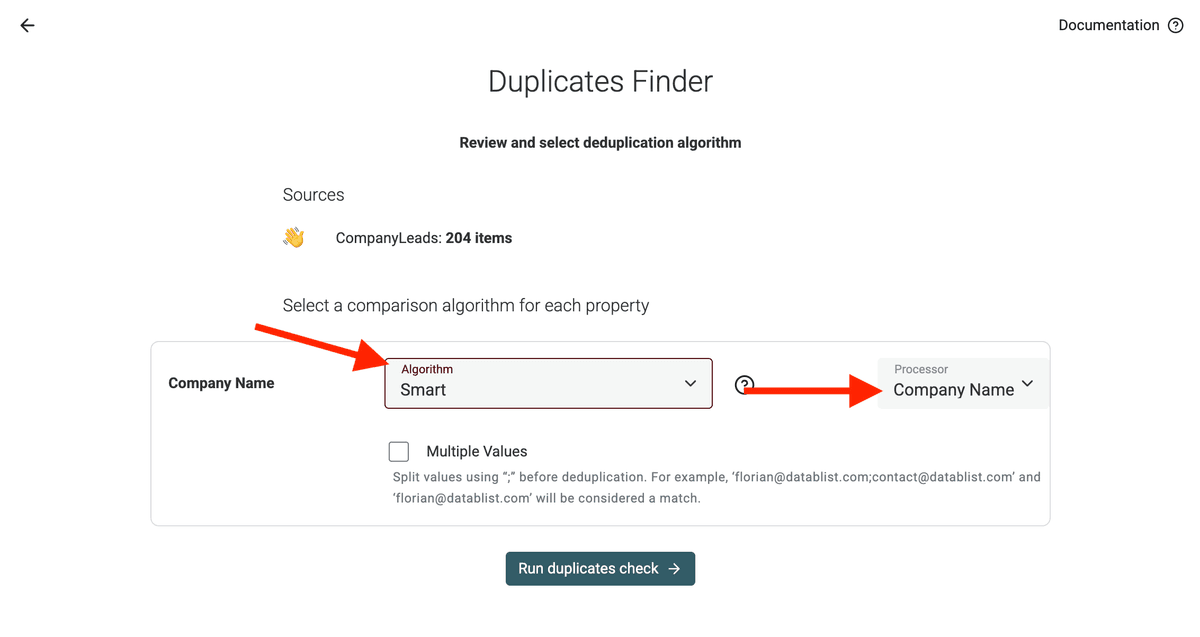
Passo 2: Scegli cosa confrontare: Proprietà di deduplica
Una "proprietà di deduplica" è semplicemente la colonna (o campo) che Datablist userà per confrontare i record e capire se sono duplicati.
Scegli quella giusta in base al tipo di lista:
Ad esempio:
- Liste di contatti: L’email è spesso il riferimento più affidabile, perché quasi sempre unica. Se non hai l’email per tutti, puoi usare il nome o la combinazione nome + cognome.
- Liste prodotti: Puoi usare il nome prodotto o un ID univoco (EAN, GTIN, SKU).
- Liste aziende: Il company name o la URL del sito sono ottime opzioni.
Nel Duplicates Finder ti verrà chiesto di selezionare una o più proprietà per il matching.
Passo 3: Seleziona algoritmo di matching e Processor
Datablist offre diversi modi di confronto, a seconda di quanto vuoi essere severo:
- Exact: trova solo i record con valore esattamente identico. Perfetto per individuare voci davvero uguali.
- Smart: più tollerante. Riconosce, ad esempio, URL equivalenti con http/https diversi o testi con piccole differenze di punteggiatura.
- Phonetic (Double Metaphone): confronta in base al suono, non solo alla grafia. Utilissimo per i nomi con varianti di spelling ma suono simile.
- Fuzzy Matching (Jaro-Winkler & Levenshtein): calcola la somiglianza tra testi. Puoi impostare la soglia di similarità per intercettare duplicati con refusi, abbreviazioni o piccole differenze.
📝 Note
L’algoritmo Exact è disponibile per utenti anonimi. Lo Smart richiede un account gratuito. Metaphone e Fuzzy Matching sono inclusi solo nei piani a pagamento.
Scegli l’algoritmo più adatto per ciascuna proprietà di deduplica.
Inoltre, imposta il processor migliore per normalizzare i dati prima della deduplica. Così valori simili corrisponderanno anche con piccole differenze.
Processor comuni in Datablist:
- URLs - Rimuove protocolli (http, https), parametri e tracking per far coincidere link equivalenti.
- Esempio: https://example.com?utm_source=newsletter → example.com
- Emails - Ignora alias come +filter negli indirizzi Gmail, così le varianti coincidono.
- Esempio: john+work@gmail.com → john@gmail.com
- Company Names - Rimuove suffissi legali (Inc., LLC), termini business (Partners, Group) e geografici (Europe, USA).
- Esempio: Acme Inc. → Acme
📝 Note
Il processor Company Names è disponibile solo nei piani a pagamento.
🔗 Risorsa
Dedupe fields with several values - Se la tua proprietà di deduplica contiene più valori, usa l’impostazione "Multiple Values".
👉 Importante: deduplica in più passaggi
Per la maggior parte delle liste, è consigliabile iniziare con il matching "Smart" e poi fare un secondo passaggio con "Fuzzy Matching" sulla stessa proprietà o su un’altra (ad esempio il nome se prima hai usato l’email).
I duplicati trovati con l’algoritmo "Smart" sono quasi sempre veri duplicati. Quindi puoi unirli con meno verifiche.
Con gli algoritmi di distanza, invece, possono esserci "falsi positivi". Due nomi che differiscono per una lettera possono o non possono indicare la stessa entità. Serve più attenzione in fase di revisione dei gruppi (vedi sotto).
✅ Consiglio: parti con Smart Matching, poi affina con Distance (Fuzzy) Matching.
Passo 4: Avvia il controllo di deduplica
Dopo aver scelto proprietà e algoritmo(i), clicca su "Run duplicates check" per avviare il processo.
Datablist scansiona la lista e raggruppa i record che considera potenziali duplicati in base alle tue regole.
Passo 5: Verifica i gruppi di duplicati trovati
Al termine, Datablist mostra i "Duplicate Groups".
Ogni gruppo contiene due o più record considerati duplicati.
In ciascun gruppo puoi vedere come combaciano e se ci sono valori in conflitto.
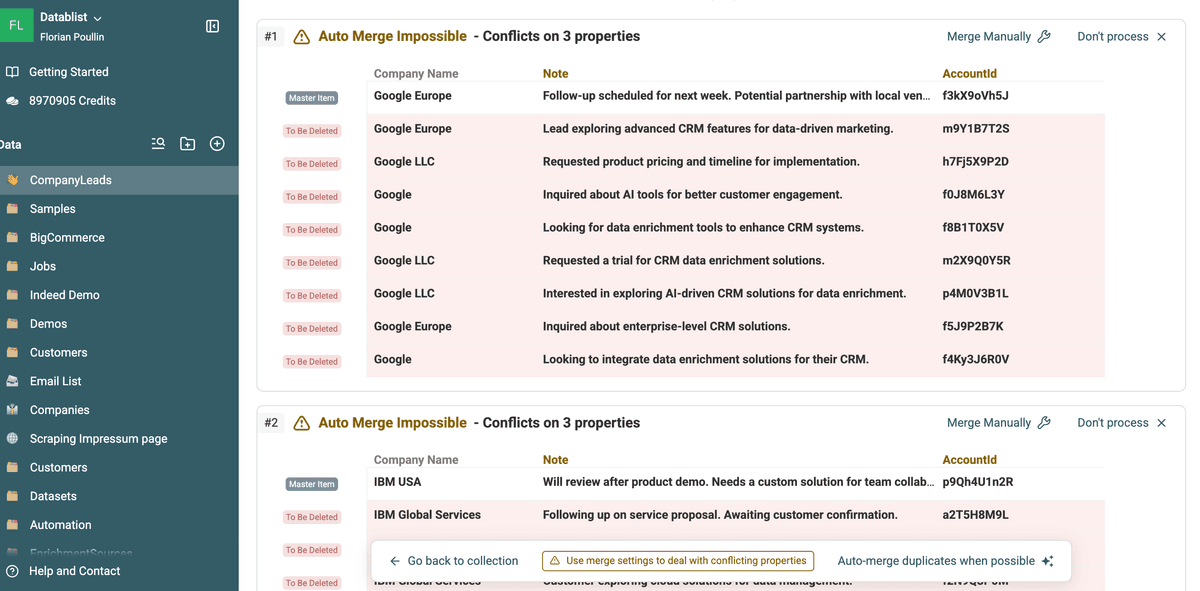
Questo passaggio è importante per confermare il matching ed evitare di raggruppare record che in realtà sono legittimi e distinti.
📝 Note
Se ti serve solo l’elenco dei duplicati, puoi scaricare un file CSV/Excel con i gruppi. Ogni gruppo ha un identificatore univoco. Puoi anche ottenere il conteggio dei duplicati se ti servono solo statistiche.
Parte 3: Risolvi e unisci i duplicati
Hai trovato i duplicati! Ora è il momento di deduplicare la lista unendoli.
Serve decidere come gestire le informazioni in conflitto e poi fondere i record duplicati in una singola voce pulita.
Passo 1: Capire gruppi di duplicati e conflitti
In un gruppo di duplicati, potresti notare differenze tra i vari record: sono i "valori in conflitto".
Per esempio, due contatti duplicati potrebbero condividere la stessa email ma avere numeri di telefono o job title diversi.
Passo 2: Imposta le regole di merge per i valori in conflitto
Datablist ti permette di scegliere come gestire i valori in conflitto durante il merge. Puoi definire regole per indicare quale valore mantenere o come combinarli.
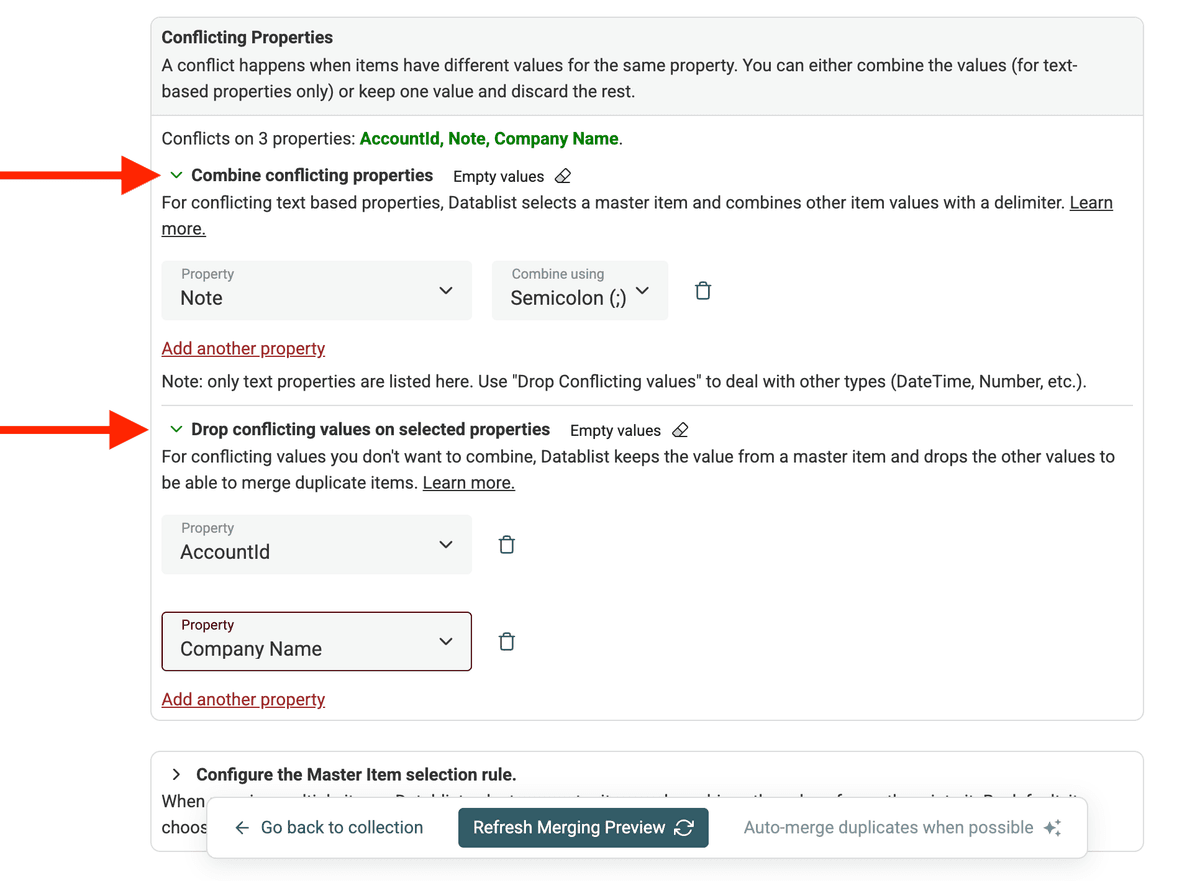
Due opzioni per gestire i conflitti:
- Combine Conflicting Values: se i valori sono complementari (es. più numeri di telefono, note), combinati.
- Drop Conflicting Values: se vuoi tenere il valore di un solo record scartando l’altro, seleziona "Drop conflicting values...".
💡 Suggerimento
Con le opzioni Combine conflicting values e Drop conflicting values hai un link rapido per selezionare automaticamente tutte le proprietà in conflitto.
Esempio di combinazione di valori multipli:
Supponiamo due voci duplicate dello stesso contatto:
Record 1: Email: john.doe@example.com, Phone: 555-1234
Record 2: Email: john.doe@example.com, Phone: 555-5678
Se imposti la regola di merge per la proprietà "Phone" su "Combine values", il record unito sarà:
Record unito: Email: john.doe@example.com, Phone: 555-1234;555-5678
Passo 3: Configura la regola di Master Item
Quando unisci duplicati, Datablist sceglie un record principale e vi fonde dentro le informazioni degli altri.
Puoi controllare come viene scelto il Master Record con queste regole:
- Most Complete: seleziona il record con più campi compilati.
- Last Updated: seleziona il record aggiornato più di recente.
- First Created: seleziona il record più vecchio per data di creazione.
- Highest Value: seleziona il record con il valore più alto in una proprietà scelta. A parità, prevale il più recente.
- Lowest Value: seleziona il record con il valore più basso in una proprietà scelta. A parità, prevale il più recente.
- Matching Value: seleziona il record che contiene un valore specifico in una proprietà. Se nessun record corrisponde, non verranno uniti.
Passo 4: Merge automatico dei duplicati (quando possibile)
Ogni volta che modifichi le impostazioni di merge, clicca su "Refresh Preview" per vedere l’effetto.
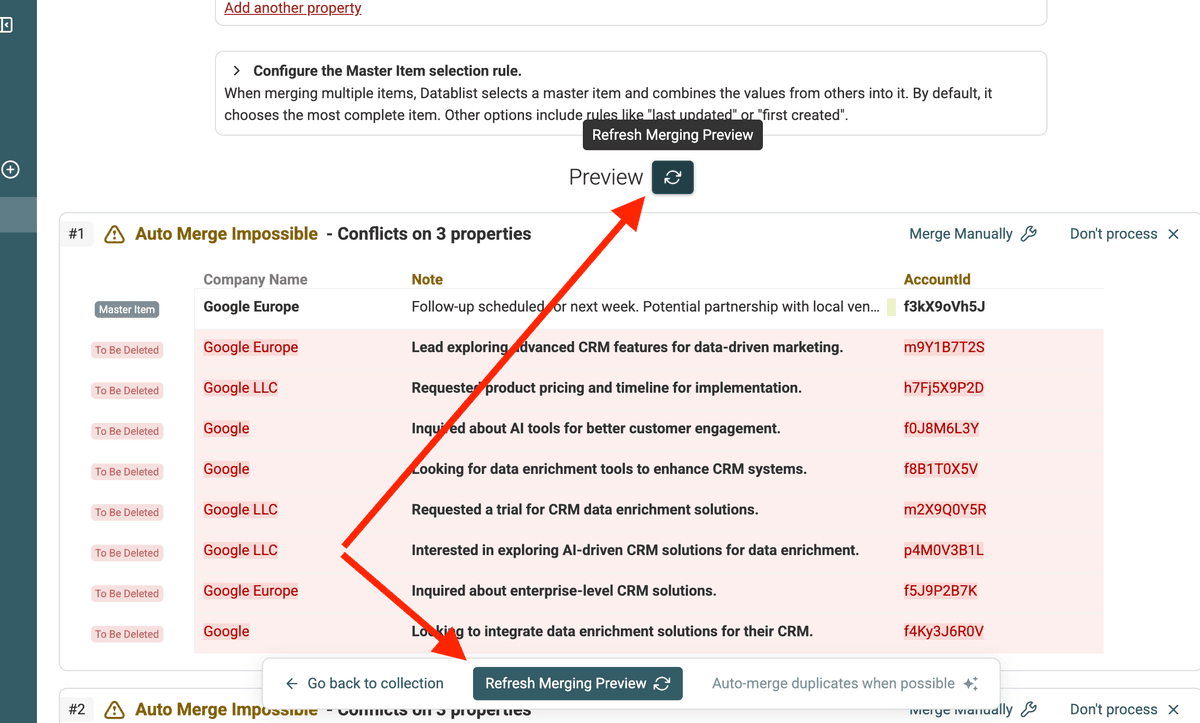
Una volta impostate le regole, Datablist potrà unire automaticamente i gruppi quando non ci sono più valori in conflitto.

Cerca la voce "Auto-merge when possible" per eseguire il merge automatico.
Passo 5: Merge manuale dei duplicati rimasti
Per i gruppi con valori in conflitto che richiedono una scelta, procedi con il merge manuale.
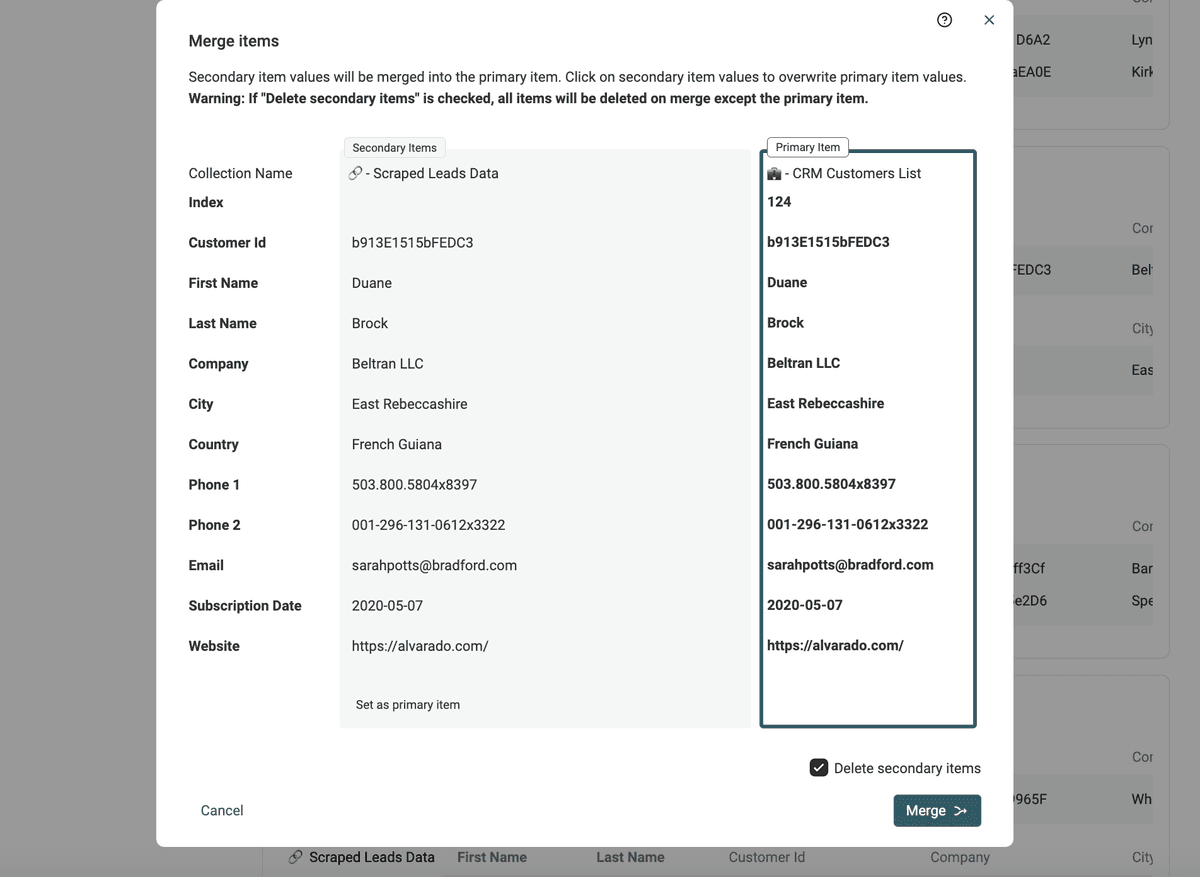
Datablist offre un "Manual Merging Assistant" che mostra i valori in conflitto affiancati, così puoi decidere cosa tenere nel record finale.
Per usarlo, clicca sul pulsante del gruppo interessato.
Vedrai i dati di tutti i record del gruppo e potrai selezionare i valori da mantenere prima di cliccare su "Merge".
Passo 6: Fatto! Revisione e finalizza
Dopo aver unito tutti i gruppi, dai un’ultima occhiata alla lista pulita.
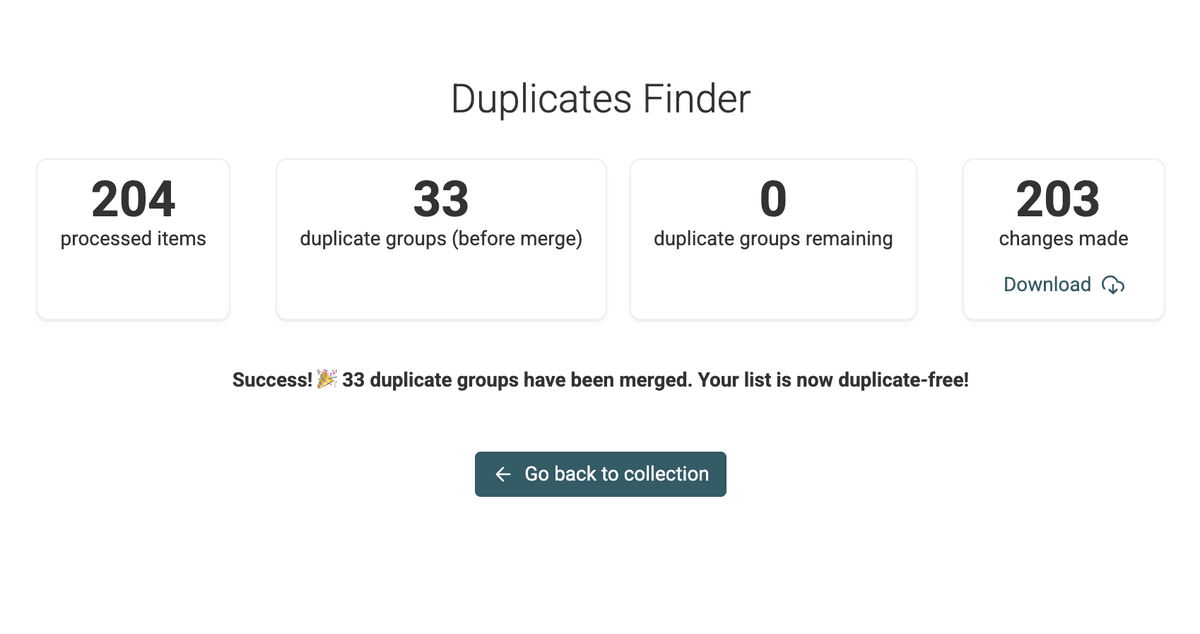
Assicurati che la deduplica abbia funzionato come desideravi e che i dati siano accurati e senza duplicati.
Poi torna alla Collection e clicca su "Export" per scaricare il CSV o l’Excel con i dati puliti.
Prova Datablist per la pulizia dati continua.
Domande frequenti (FAQ)
Datablist è davvero gratis per la deduplica?
Sì! Puoi rimuovere i duplicati online gratis 💰, senza registrazione.
Carica il file e inizia a pulire. Per gli algoritmi avanzati di matching, puoi creare un account gratuito.
Gli unici algoritmi a pagamento sono fuzzy matching e deduplica fonetica.
Datablist gestisce liste grandi con migliaia di record?
Assolutamente! Datablist è progettato per processare liste molto grandi.
Che tu abbia 10.000 o 500.000+ record, il duplicate finder scannerizza e raggruppa velocemente. Niente più spezzare i dati in blocchi: carica e pulisci!
Datablist supporta il fuzzy matching per quasi-duplicati?
Sì! Datablist include algoritmi di fuzzy matching 🔍 come Levenshtein e Jaro-Winkler per intercettare refusi e piccole differenze. Ad esempio, può abbinare:
- "Jon Smith" con "John Smith"
- "Acme Ltd." con "Acme Inc"
Controlli tu il livello di similarità per regolare la soglia e migliorare l’accuratezza.
Posso deduplicare contatti CRM, Lead o dati clienti?
Certo! Esporta i tuoi dati CRM (da HubSpot, Salesforce o qualsiasi altro tool) in CSV, caricali su Datablist e rimuovi i duplicati in pochi minuti. Dopo la pulizia, puoi usare i Change Files generati per applicare gli aggiornamenti nel CRM—senza data entry manuale!
Se usi Pipedrive, offriamo una integrazione diretta per la deduplica massiva.